Data Mining|缺省值补全实验
- 实验内容任务描述
利用sklearn完成缺省值补全,完成4种以上缺失值补全,并完整地进行模型训练与测试。
四种缺失值补全方法:众数插补、均值插补、K-邻近填充、迭代插补(极大似然估计)
采用模型:随机森林RandomForestClassifier( )
- 实验数据描述
数据集:sklearn的手写数字数据集sklearn.datasets.load_digits()
数据来源:这个数据集来源于美国国家标准与技术研究院(NIST)收集整理的手写数字数据库,经过了一定的预处理后被整合到 scikit-learn 库中。
数据条数:1797张手写数字图像
数据特征:64个(本质上就是将 8×8 像素的手写数字图像按行展开得到的)
在该 8×8 像素的手写数字图像中,不同手写数字在不同像素点会呈现出不同灰度值,因而我们可以通过不同手写数字具有的灰度值特征来进行预测。
说明:由于sklearn.datasets.load_digits() 中并没有缺省值,故在数据处理时人为随机制造缺失值。
- 方法描述
- 众数插补原理
众数是一组数据中出现次数最多的数值。众数插补的基本原理就是利用数据集中已有的完整数据信息,找到每个特征下出现频率最高的那个值,然后用这个众数来填补该特征对应的缺失值。
其背后的逻辑在于,众数在一定程度上反映了该特征最常出现、最具代表性的取值情况,所以当出现缺失值时,用众数来填补可以让数据整体在该特征维度上保持与大部分数据相似的特征表现,维持数据的基本分布结构和特征规律。
| from sklearn.impute import SimpleImputer #创建 SimpleImputer 并指定策略为众数插补 simple_imputer = SimpleImputer(strategy='most_frequent') df_imputed = simple_imputer.fit_transform(df) #对数据集进行拟合并转换(插补缺失值) print(df_imputed) |
众数插补方法简单直观,在很多情况下能有效地处理缺失值问题,不过它也有一定局限性,比如当数据分布较为均匀、不存在明显众数或者众数不能很好代表缺失值合理取值时,插补效果可能不太理想。
- 均值插补原理
均值是一组数据的平均水平的体现,通过计算某一特征所有非缺失值的平均值,用这个平均值来填补该特征对应的缺失值。
其核心思想在于认为数据整体在这个特征维度上具有一定的集中趋势,缺失值的出现只是偶然情况,使用均值进行填补可以让数据在该特征上恢复到整体的平均水平表现,使得数据分布在一定程度上保持相对完整和连贯,从而便于后续的数据分析。
| simple_imputer = SimpleImputer(strategy='mean') #与众数插补非常类似,只是SimpleImputer的策略发生了更改,变为“mean” |
但是,若数据中有异常值,会干扰均值的计算,进而影响插补效果,或者当数据本身分布差异较大时,就要使用其他方法。
- K-邻近填充原理
K - 邻近填充的核心原理是基于这样一个假设:在特征空间中,数据点之间的距离能够反映它们的相似性,距离相近的数据点往往具有相似的属性特征。
换言之,如果一个数据点的某些属性值是缺失的,那么可以通过寻找与其在特征空间中距离最近的K个完整数据点(非缺失值的数据点),利用这K个近邻点对应特征的取值情况来推测该缺失值。
| from sklearn.impute import KNNImputer #用 sklearn 库的 KNNImputer 类来实现K -邻近填充 knn_imputer = KNNImputer(n_neighbors=3) #n_neighbors的值可以调整 df_imputed = knn_imputer.fit_transform(df) # 对数据集进行拟合并转换(填充缺失值) print(df_imputed) |
K - 邻近填充要注意的是n_neighbors的取值,n_neighbors要选取合适的值,数据量一增大,模型对n_neighbors的取值就会变得敏感。可以使用网格搜索、K折交叉验证进行超参数调优,以找到合适的n_neighbors。
- 迭代插补(极大似然估计)原理
迭代插补的核心原理是通过构建一个预测模型,利用数据集中其他非缺失值的特征来预测含有缺失值的特征,并且这个过程会进行多次迭代,不断更新预测结果,使得填补的缺失值更加合理准确。它基于这样一种假设:数据集中的各个特征之间是存在相互关联和依赖关系的,通过挖掘这些关系,可以基于完整的数据部分对缺失部分进行合理推测。
| from sklearn.experimental import enable_iterative_imputer from sklearn.impute import IterativeImputer # 创建IterativeImputer对象,指定基础预测模型以及迭代次数等参数 iterative_imputer = IterativeImputer( estimator=xxxxx, # 可以选择不同的合适的估计器 max_iter=xx, # 设置迭代次数,可根据数据情况调整 random_state=xx) # 设置随机数种子,常用42 df_imputed = iterative_imputer.fit_transform(df) # 对数据集进行拟合并转换 print(df_imputed) |
- 主成分分析(PCA)
主成分分析目的在于对数据降维处理,在尽量保留原始数据中主要信息的前提下,将高维数据投影到低维空间中,使得新的数据表示更加简洁且易于分析和处理。
PCA 试图找到一组新的相互正交(线性无关)的坐标轴(主成分),这些坐标轴按照能够解释原始数据方差的大小进行排序,第一个主成分(轴)能解释原始数据最大的方差,第二个主成分在与第一个主成分正交的前提下,解释次大的方差,以此类推。通过选择前几个方差解释比例较大的主成分,就可以用它们来近似表示原始数据,从而实现降维。
PCA实现方法:可直接调用sklearn 库中的 PCA 类来对数据进行主成分分析。
- 数据可视化方法
本次实验使用了直方图、热力图、混淆矩阵。
均可使用matplotlib库的方法,直接呈现数据的分布特征、缺失值补全效果对比、分类器分类效果等。
- 实验结果

原始手写数字展示0~9
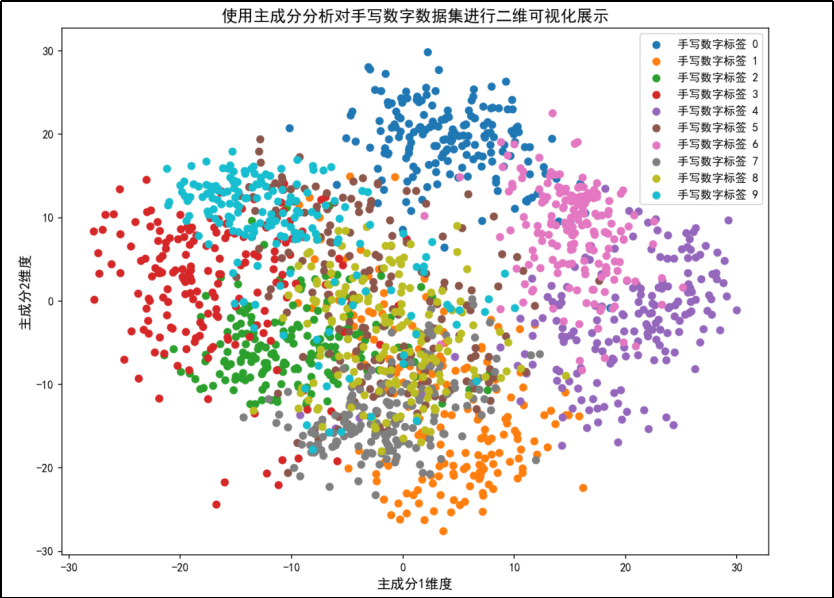
原手写数字数据集二维可视化
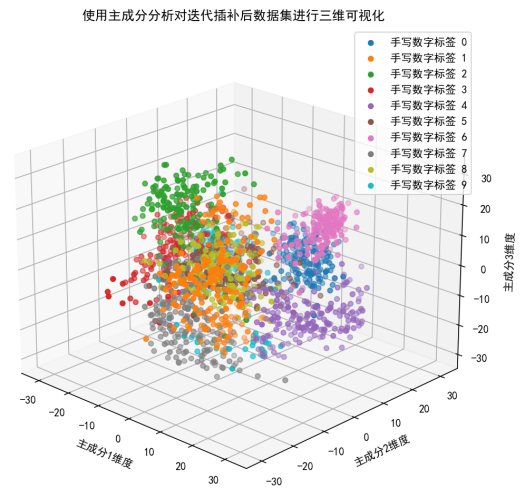
二维可视化结果来看:每个数字标签自形成一个聚类。表明不同手写数字标签的样本在主成分空间中有一定的聚集性。
·手写数字标签 0(蓝色)的样本主要集中在图的右上角,形成一个较为紧密的聚类。
·手写数字标签 1(橙色)的样本分布在图的左侧,形成一个相对分散的聚类。
·手写数字标签 2(绿色)的样本分布在图的中间偏左位置,形成一个较为分散的聚类。
·手写数字标签 3(红色)的样本分布在图的中间偏右位置,形成一个较为紧密的聚类。
·手写数字标签 4(紫色)的样本分布在图的中间偏下位置,形成一个较为分散的聚类。
·手写数字标签 5(青色)的样本分布在图的中间偏左位置,形成一个较为分散的聚类。
·手写数字标签 6(黄色)的样本分布在图的右下角,形成一个较为紧密的聚类。
·手写数字标签 7(灰色)的样本分布在图的中间偏上位置,形成一个较为分散的聚类。
·手写数字标签 8(浅绿色)的样本分布在图的右上角,与标签 0 的样本有一定的重叠。
·手写数字标签 9(深蓝色)的样本分布在图的右侧,形成一个较为紧密的聚类。
- 均值插补方法
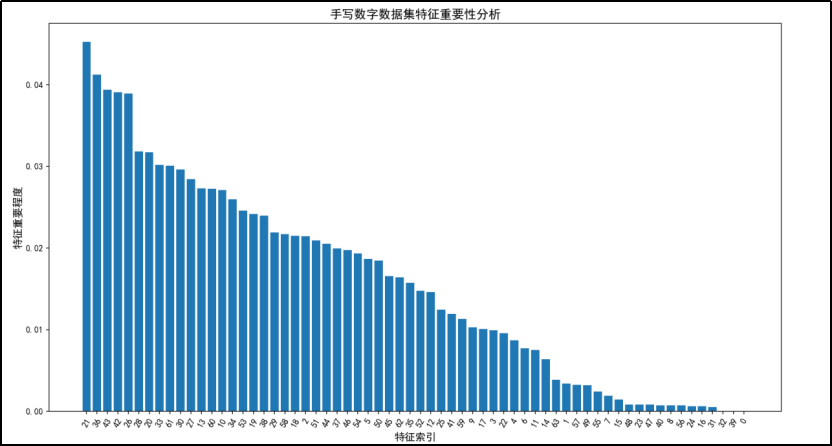
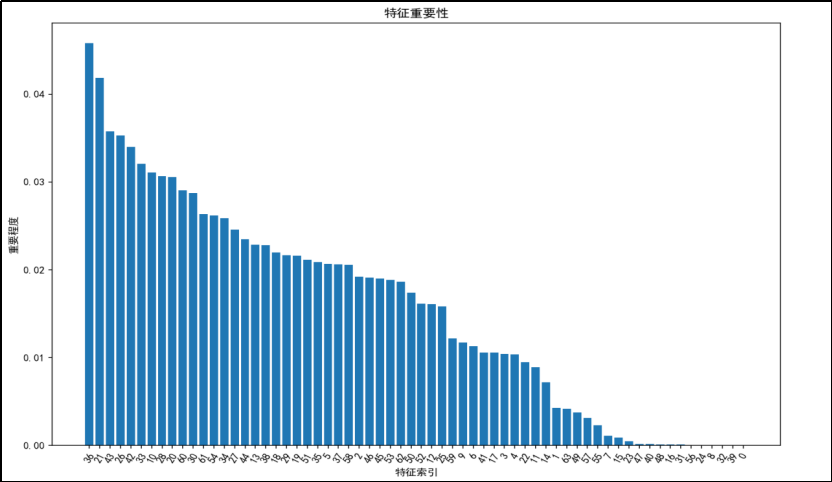
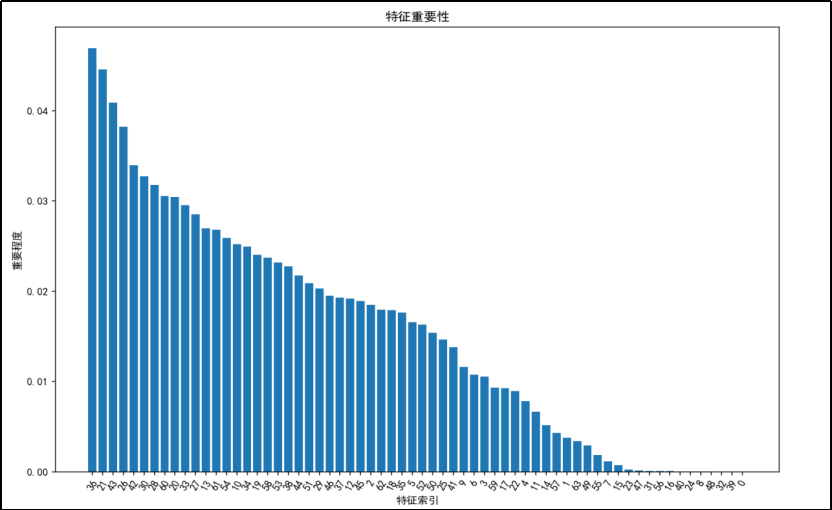
由特征重要性分析可得:
手写数字数据集的特征重要性呈现出明显的递减趋势,前几个特征对模型的贡献最大,而后面的特征重要性逐渐降低。对于手写数字数据集,如果要进行特征选择,可以优先考虑保留前几个特征,因为它们的重要性较高。对于特征重要性较低的特征(如特征索引大于 40 的特征),可以考虑舍弃,以减少模型的复杂度和计算量,同时避免过拟合。

原始手写数字集缺失值矩阵
可以看到在原始数据集中,存在较多的缺失值,黑色条纹较为明显且不规则,表明缺失值在各个特征维度上分布不均匀。

均值插补后的缺失值矩阵
均值插补前后对比表明:
均值插补方法在处理手写数字数据集中的缺失值方面非常有效。通过将缺失值替换为对应特征的均值,能够显著减少数据集中的缺失值数量,使数据更加完整,有助于提高数据分析和模型训练的准确性和可靠性。
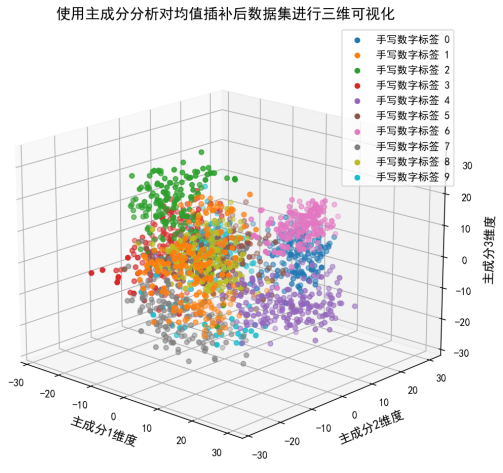
之前的均值插补分析表明,均值插补能够有效减少数据集中的缺失值,使数据更加完整。从三维图来看,经过均值插补后的数据可以进行有效的主成分分析,表明数据的完整性得到了保障,适合进行进一步的数据分析和可视化。
同时,不同手写数字标签之间存在一定的重叠,例如手写数字标签 0 和 8 有一定程度的重叠,这与之前二维可视化的结果一致,说明这些数字在特征空间中的相似性较高。
使用均值插补后的分类结果:
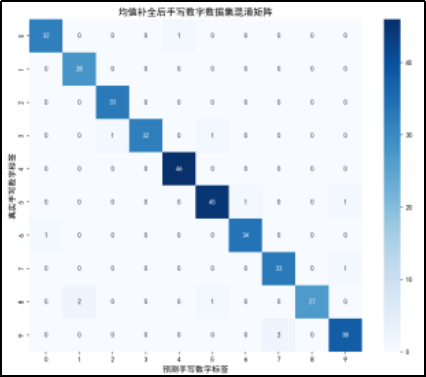
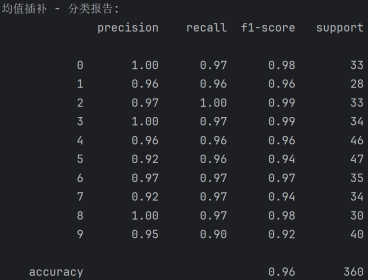
混淆矩阵分析
对角线元素:
·混淆矩阵的对角线元素表示预测正确的样本数量。例如,真实标签为 0 且预测标签也为 0 的样本数量是 32,真实标签为 1 且预测标签也为 1 的样本数量是 23,以此类推。
·从对角线元素来看,大部分数字的预测准确率较高,但也有一些数字的预测准确率较低,如数字 1(23 个正确预测)和数字 9(38 个正确预测)。
非对角线元素:
·非对角线元素表示预测错误的样本数量。例如,真实标签为 0 但被预测为 1 的样本数量是 0,真实标签为 0 但被预测为 2 的样本数量是 0,以此类推。
·可以看到一些数字之间存在混淆。例如,数字 4 有 46 个样本被正确预测,但有部分样本被错误预测为其他数字,数字 5 有 47 个样本被正确预测,但也有部分样本被错误预测为其他数字。
分类报告分析
·Precision(精确率)
精确率表示在所有预测为正的样本中,真正为正的样本比例。例如,数字 0 的精确率为 1.00,数字 1 的精确率为 0.96,数字 2 的精确率为 0.97,以此类推。
大部分数字的精确率较高,但数字 5(0.92)和数字 7(0.92)的精确率相对较低。
·Recall(召回率)
召回率表示在所有真正为正的样本中,被预测为正的样本比例。例如,数字 0 的召回率为 0.97,数字 1 的召回率为 0.96,数字 2 的召回率为 1.00,以此类推。
数字 2 的召回率为 1.00,表示所有真实标签为 2 的样本都被正确预测。数字 9 的召回率为 0.90,相对较低。
·Accuracy(准确率)
整体准确率为 0.96,表示在所有样本中,被正确预测的样本比例为 96%。这表明模型在均值补全后的手写数字数据集上有较好的分类性能。
- 众数插补方法
说明:由于不同方法是在不同py文件中实现的,同时缺省值是由random随机产生,所以不同缺省值处理方法所对应的特征重要性直方图有所不同。


众数插补前后对比表明:
黑色条纹几乎消失,表明在众数插补后,数据集中的缺失值得到了很好的填充。众数插补通过计算每个特征的众数,并将缺失值替换为该众数,使得数据集中的缺失值大幅减少,数据的完整性得到了极大提升,有助于提高数据分析和模型训练的准确性和可靠性。
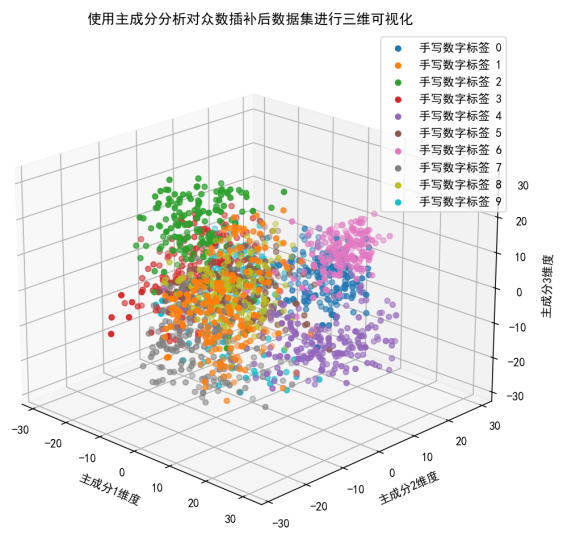
图中不同颜色的点在三维空间中形成了多个聚类,这与之前的均值插补后的可视化结果类似。每个聚类代表一个手写数字标签,说明不同数字在主成分空间中有一定的区分度。
手写数字标签 0(蓝色)的样本主要集中在图的右上角,手写数字标签 1(橙色)的样本分布在图的左侧,手写数字标签 2(绿色)的样本分布在图的中间偏左位置,以此类推。这种分布特征与之前的可视化结果相呼应,进一步验证了数据的内在结构。
使用众数插补后的分类结果:
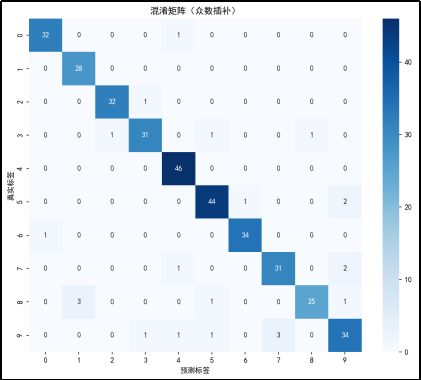
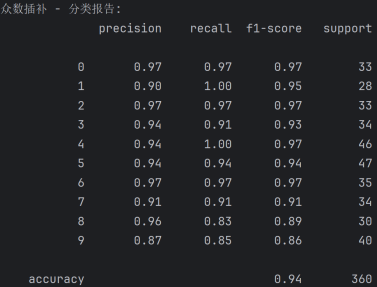
混淆矩阵分析
对角线元素:混淆矩阵的对角线元素表示预测正确的样本数量。例如,真实标签为 0 且预测标签也为 0 的样本数量是 32,真实标签为 1 且预测标签也为 1 的样本数量是 28,以此类推。
从对角线元素来看,大部分数字的预测准确率较高,但也有一些数字的预测准确率较低,如数字 1(28 个正确预测)和数字 9(34 个正确预测)。
非对角线元素:非对角线元素表示预测错误的样本数量。例如,真实标签为 0 但被预测为 1 的样本数量是 0,真实标签为 0 但被预测为 2 的样本数量是 0,以此类推。
可以看到一些数字之间存在混淆。例如,数字 4 有 46 个样本被正确预测,但有部分样本被错误预测为其他数字,数字 5 有 47 个样本被正确预测,但也有部分样本被错误预测为其他数字。
分类报告分析
·Precision(精确率)
精确率表示在所有预测为正的样本中,真正为正的样本比例。例如,数字 0 的精确率为 0.97,数字 1 的精确率为 0.90,数字 2 的精确率为 0.97,以此类推。
大部分数字的精确率较高,但数字 1(0.90)和数字 9(0.87)的精确率相对较低。
·Recall(召回率)
召回率表示在所有真正为正的样本中,被预测为正的样本比例。例如,数字 0 的召回率为 0.97,数字 1 的召回率为 1.00,数字 2 的召回率为 0.97,以此类推。
数字 1 的召回率为 1.00,表示所有真实标签为 1 的样本都被正确预测。数字 8 的召回率为 0.83,相对较低。
·Accuracy(准确率)
整体准确率为 0.94,表示在所有样本中,被正确预测的样本比例为 94%。这表明模型在众数插补后的手写数字数据集上有较好的分类性能,但略低于均值插补后的准确率(0.96)。
- K-邻近填充方法
直方图呈现该情况与前两种原因相同,不再赘述。

K-邻近填充前后对比表明:
右侧的黑色条纹几乎消失,表明在 K - 邻近填充后,数据集中的缺失值得到了很好的填充。K - 邻近填充通过寻找每个缺失值的 K 个最近邻,并根据这些近邻的值来填充缺失值,使得数据集中的缺失值大幅减少,整体数据变得更加完整。
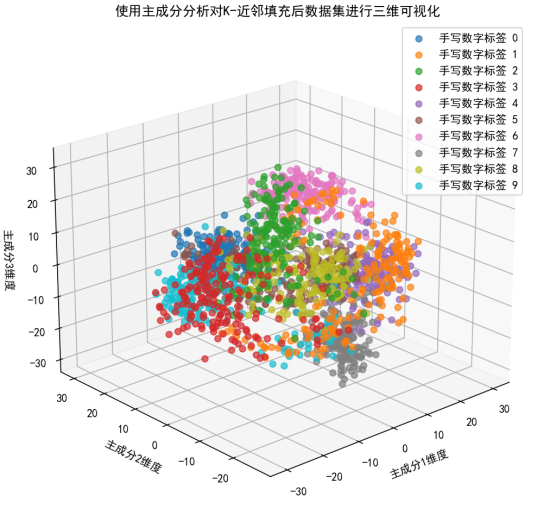
图中不同颜色的点在三维空间中形成了多个聚类,这与之前其他插补方法(如均值插补、众数插补)后的可视化结果类似。每个聚类代表一个手写数字标签,说明不同数字在主成分空间中有一定的区分度。主成分分析能够在三维空间中较好地展示不同手写数字标签的数据分布特征,尽管存在一定的重叠,但总体上能够区分不同的数字。
使用K-邻近填充后的分类结果:
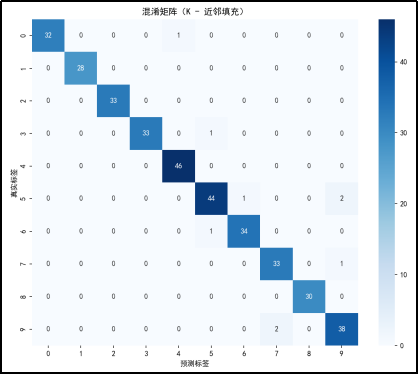
混淆矩阵分析
对角线元素:混淆矩阵的对角线元素表示预测正确的样本数量。例如,真实标签为 0 且预测标签也为 0 的样本数量是 32,真实标签为 1 且预测标签也为 1 的样本数量是 28,以此类推。从对角线元素来看,大部分数字的预测准确率较高,但也有一些数字的预测准确率较低,如数字 9(38 个正确预测)。
非对角线元素:非对角线元素表示预测错误的样本数量。例如,真实标签为 0 但被预测为 1 的样本数量是 0,真实标签为 0 但被预测为 2 的样本数量是 0,以此类推。可以看到一些数字之间存在混淆。例如,数字 4 有 46 个样本被正确预测,但有部分样本被错误预测为其他数字,数字 5 有 47 个样本被正确预测,但也有部分样本被错误预测为其他数字。
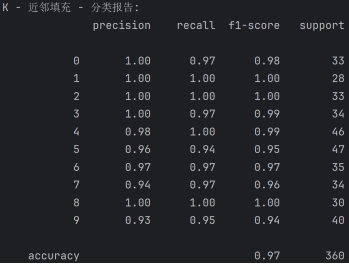
分类报告分析
·Precision(精确率)
精确率表示在所有预测为正的样本中,真正为正的样本比例。例如,数字 0 的精确率为 1.00,数字 1 的精确率为 1.00,数字 2 的精确率为 1.00,以此类推。
大部分数字的精确率较高,但数字 9(0.93)的精确率相对较低。
·Recall(召回率)
召回率表示在所有真正为正的样本中,被预测为正的样本比例。例如,数字 0 的召回率为 0.97,数字 1 的召回率为 1.00,数字 2 的召回率为 1.00,以此类推。
数字 1、2 和 8 的召回率为 1.00,表示所有真实标签为 1、2 和 8 的样本都被正确预测。数字 9 的召回率为 0.95,相对较低。
·Accuracy(准确率)
整体准确率为 0.97,表示在所有样本中,被正确预测的样本比例为 97%。这表明模型在 K - 近邻填充后的手写数字数据集上有较好的分类性能,且比均值插补(0.96)和众数插补(0.94)后的准确率更高。
- 迭代插补方法
直方图呈现该情况与前两种原因相同,不再赘述。

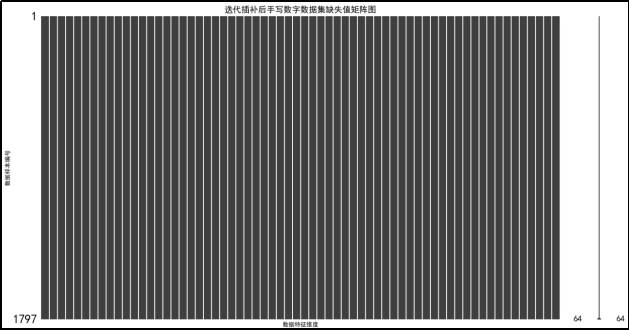
迭代插补前后对比表明:
迭代插补方法在处理该数据集中的缺失值方面非常有效。通过多次迭代和预测,能够显著减少数据集中的缺失值数量,数据的完整性得到了极大提升,有助于提高数据分析和模型训练的准确性和可靠性。
使用迭代插补后的结果:
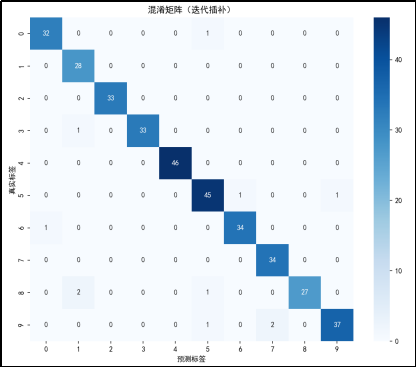
矩阵分析
对角线元素:混淆矩阵的对角线元素表示预测正确的样本数量。例如,真实标签为 0 且预测标签也为 0 的样本数量是 32,真实标签为 1 且预测标签也为 1 的样本数量是 28,以此类推。从对角线元素来看,大部分数字的预测准确率较高,但也有一些数字的预测准确率较低,如数字 1(28 个正确预测)和数字 9(37 个正确预测)。
非对角线元素:非对角线元素表示预测错误的样本数量。例如,真实标签为 0 但被预测为 1 的样本数量是 0,真实标签为 0 但被预测为 2 的样本数量是 0,以此类推。可以看到一些数字之间存在混淆。例如,数字 4 有 46 个样本被正确预测,但有部分样本被错误预测为其他数字,数字 5 有 47 个样本被正确预测,但也有部分样本被错误预测为其他数字。
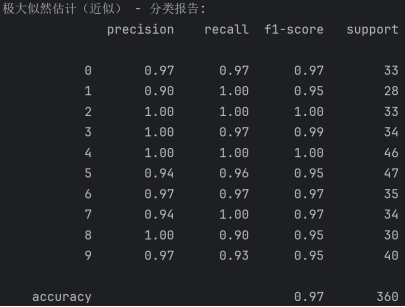
分类报告分析
·Precision(精确率):精确率表示在所有预测为正的样本中,真正为正的样本比例。例如,数字 0 的精确率为 0.97,数字 1 的精确率为 0.90,数字 2 的精确率为 1.00,以此类推。大部分数字的精确率较高,但数字 1(0.90)和数字 9(0.97)的精确率相对较低。
·Recall(召回率):召回率表示在所有真正为正的样本中,被预测为正的样本比例。例如,数字 0 的召回率为 0.97,数字 1 的召回率为 1.00,数字 2 的召回率为 1.00,以此类推。数字 2 和 4 的召回率为 1.00,表示所有真实标签为 2 和 4 的样本都被正确预测。数字 8 的召回率为 0.90,相对较低。
·Accuracy(准确率):整体准确率为 0.97,表示在所有样本中,被正确预测的样本比例为 97%。这表明模型在迭代插补后的手写数字数据集上有较好的分类性能,与 K - 近邻填充后的准确率相同。
- 实验结果分析与结论
(一)四种缺失值处理方法的回顾
1、均值插补
缺失值矩阵对比:原始数据集中存在较多且不均匀分布的缺失值,经过均值插补后,数据集中的缺失值得到了很好的填充,右侧的黑色条纹(代表缺失值)几乎消失。
分类结果:整体准确率达到 96%。不同数字的精确率、召回率和 F1 - score 有一定差异,但整体表现较好。
2、众数插补
缺失值矩阵对比:原始数据集中有较多缺失值,众数插补后数据集中的缺失值大幅减少,黑色条纹几乎消失。
分类结果:整体准确率为 94%。部分数字的精确率、召回率或 F1 - score 相对较低。
3、K - 邻近填充
缺失值矩阵对比:原始数据集存在较多缺失值,K - 邻近填充后缺失值得到很好填充,黑色条纹几乎消失。
分类结果:整体准确率为 97%。在所有插补方法中准确率最高,但数字 9 的精确率、召回率或 F1 - score 相对较低。
4、迭代插补
缺失值矩阵对比:原始数据集缺失值较多且分布不均匀,迭代插补后缺失值大幅减少,黑色条纹几乎消失。
分类结果:整体准确率为 97%,与 K - 邻近填充相同。部分数字(如 1、8、9)的精确率、召回率或 F1 - score 相对较低。
(二)综合结论
缺失值处理效果;
四种方法(均值插补、众数插补、K - 邻近填充、迭代插补)在处理手写数字数据集中的缺失值时,都能有效地减少缺失值数量,从缺失值矩阵图来看,原始数据集中明显的缺失值在处理后都得到了很好的填充,数据完整性得到了显著提升。
对分类准确率的影响;
K - 邻近填充和迭代插补:这两种方法在分类准确率上表现最佳,整体准确率都达到了 97%。它们能够更好地利用数据的内在结构来填充缺失值,进而在后续的分类任务中取得较好的结果。
均值插补:其整体准确率为 96%,略低于 K - 邻近填充和迭代插补,但仍然是一种有效的缺失值处理方法,计算成本相对较低。
众数插补:整体准确率为 94%,在四种方法中最低。虽然它能处理缺失值,但可能由于众数不能很好地代表某些特征的中心趋势,导致在分类任务中的表现相对较弱。
不同数字的分类表现:
在所有方法中,都存在部分数字(如数字 9)的精确率、召回率或 F1 - score 相对较低的情况。这表明这些数字在特征空间中的区分难度较大,无论采用哪种缺失值处理方法,都需要进一步优化模型或者进行针对性的数据增强来提高对这些数字的分类能力。
计算成本和复杂度:
均值插补和众数插补:计算简单,复杂度低,适合大规模数据和对计算资源有限的场景。
K - 邻近填充和迭代插补:计算相对复杂,尤其是在处理大规模数据集时,可能会消耗较多的计算资源和时间。它们通常需要对一些参数(如 K - 邻近填充中的 K 值、迭代插补中的迭代次数等)进行调优,以达到最佳的填充和分类效果。
相关文章:

Data Mining|缺省值补全实验
实验内容任务描述 利用sklearn完成缺省值补全,完成4种以上缺失值补全,并完整地进行模型训练与测试。 四种缺失值补全方法:众数插补、均值插补、K-邻近填充、迭代插补(极大似然估计) 采用模型:随机森林RandomForestClassifier( …...
)
RabbitMQ 快速上手:安装配置与 HelloWorld 实践(一)
一、引言 在当今分布式系统大行其道的技术浪潮下,各个服务之间的通信与协同变得愈发复杂。想象一下,一个电商系统在大促期间,订单服务、库存服务、支付服务、物流服务等众多模块需要紧密配合。如果没有一种高效的通信机制,系统很容…...

适配华为昇腾 NPU 的交互式监控工具
适配华为昇腾 NPU 的交互式监控工具 在人工智能开发的过程中,我们常常希望能够实时了解计算设备的使用情况。对于使用华为昇腾 NPU 的团队来说,传统上只能通过命令行工具(如 npu-smi)来查询性能指标。但这些命令输出的信息分散且…...
上的适配现状与技术展望)
HarmonyOS NEXT~React Native在鸿蒙系统(HarmonyOS)上的适配现状与技术展望
HarmonyOS NEXT~React Native在鸿蒙系统(HarmonyOS)上的适配现状与技术展望 一、背景与现状 鸿蒙系统(HarmonyOS)作为华为自主研发的分布式操作系统,自2019年发布以来已经迭代多个版本。最新的HarmonyOS NEXT更是明确将仅支持原生应用[5],这…...

匿名函数lambda、STL与正则表达式
一、匿名函数lambda 重点: 怎么传递参数。 传引用还是传 1. 匿名函数的基本语法 [捕获列表](参数列表) mutable(可选) 异常属性 -> 返回类型 {// 函数体 } 语法规则:lambda表达式可以看成是一般函数的函数名被略去,返回值使用了一个 -…...

ssti模板注入学习
ssti模板注入原理 ssti模板注入是一种基于服务器的模板引擎的特性和漏洞产生的一种漏洞,通过将而已代码注入模板中实现的服务器的攻击 模板引擎 为什么要有模板引擎 在web开发中,为了使用户界面与业务数据(内容)分离而产生的&…...
的架构差异)
存储扇区分配表:NAND Flash与SD NAND(贴片式SD卡)的架构差异
NAND Flash 和 SD 卡(SD NAND)的存储扇区分配表在原理上有相似之处,但由于二者的结构和应用场景不同,也存在一些差异。 相同点: 基本功能:NAND Flash 和 SD 卡(SD NAND)的存储扇区分…...

FreeRTOS队列原理讲解
继续更新freertos,讲解的是队列,队列是先进先出的一种数据结构,有入队和出队操作,今天主要讲解向队列发送消息源码/从队列取出消息源码。 先讲解入队函数,FreeRTOS中入队操作分为后向入队/前入/覆写,但无论…...

C——俄罗斯方块
前言 编译器选择:VS2022。需要掌握控制台操作、颜色设置、随机数生成、键盘事件、文件操作、二维数组操作等知识。运用语言:C语言。 一、游戏背景 1. 游戏概述 俄罗斯方块是一款经典的益智游戏,主要功能包括: 显示游戏界面 随…...

什么是 Shadow Testing?
Shadow Testing(影子测试)是一种在生产环境中对比验证新旧系统行为一致性的重要测试方法。它被广泛应用于系统迁移、架构重构、模型上线、A/B测试前的数据验证、灰度发布等场景,尤其在保障线上稳定性和数据正确性方面具有关键作用。 一、什么…...

【操作系统期末速成】①操作系统概述
——————2025.5.14————— 操作系统主要考点:操作系统概述、进程管理、内存管理、文件系统、设备管理(前三个重点,第二三个是重中之重) 操作系统概念(OS):(本质上是一个软件…...

关于vue学习的经常性错误
目录 常见问题: 1关于引用本地下载es6模块文件,报404错误 2 使用createApp函数后没有调用mount函数挂载到浏览器 3 在mount函数中,忘记引用插值表达式所在标签的定位符如 标签选择器,类选择器等 4在直接使用Vue3函数时&#…...

使用泛型加载保存数据
文章速览 泛型泛型概述定义优点 实例加载数据保存数据 一个赞,专属于你的足迹! 泛型 泛型概述 泛型(Generics)是 C# 中一种重要的编程特性,它允许程序员编写灵活且类型安全的代码。通过使用泛型,可以创建…...

火山引擎实时音视频 高代码跑通日志
实时音视频 SDK 概览--实时音视频-火山引擎 什么是实时音视频 火山引擎实时音视频(Volcengine Real Time Communication,veRTC)提供全球范围内高可靠、高并发、低延时的实时音视频通信能力,实现多种类型的实时交流和互动。 通…...

ubuntu清除缓存
pip pip cache purgeconda conda clean -a -yapt apt cleanapt-get apt-get cleanmodelscope modelscope clear-cachehuggingface rm -rf ~/.cache/huggingface/*...

Flink SQL 将kafka topic的数据写到另外一个topic里面
-- 创建源表,使用 RAW 格式接收原始 JSON 数据 CREATE TABLE source_kafka ( id STRING, data STRING ) WITH ( connector kafka, topic source_kafka-topic, properties.bootstrap.servers master01:9092, properties.group.id flink-kafka-group, scan.startu…...

【C++重载操作符与转换】纯虚函数
目录 一、纯虚函数的基本概念 1.1 定义与语法 1.2 抽象类 1.3 派生类的实现要求 二、纯虚函数的使用场景 2.1 定义接口 2.2 实现多态 2.3 设计框架 三、纯虚函数的特性 3.1 纯虚函数可以有实现 3.2 抽象类的构造函数和析构函数 3.3 纯虚函数与接口继承 四、纯虚函…...
综述)
面向具身智能的视觉-语言-动作模型(VLA)综述
具身智能被广泛认为是通用人工智能(AGI)的关键要素,因为它涉及控制具身智能体在物理世界中执行任务。在大语言模型和视觉语言模型成功的基础上,一种新的多模态模型——视觉语言动作模型(VLA)已经出现&#…...

车用CAN接口芯片:汽车神经系统的沉默构建者
车用CAN接口芯片:汽车神经系统的沉默构建者 在汽车电子系统的复杂架构中,CAN总线如同人体的神经系统,而CAN接口芯片则扮演着神经突触的角色。这些指甲盖大小的芯片,默默承担着整车超过70%的通信任务,却鲜少成为技…...

AI日报 · 2025年5月14日|Android 生态大型更新与多端 Gemini 集成
1、Google “Android Show: I/O Edition” 汇总:设计、安全、Gemini 三线并进 北京时间 5 月 14 日凌晨(原文标注 5 月 13 日 PDT),Google 在 I/O 前夕举办的 Android Show 一口气公布四大方向更新:① Mater…...

QT+opencv实现卡尺工具找圆、拟合圆
QT Opencv 实现卡尺工具找圆 找圆工具是自己从其他项目里面单独整理出来,可直接引用到新项目中。 程序中提供了函数接口,其他文件直接传入参数就能获取圆心和半径信息。次工具全采用QT和opencv,全部源码可随需求更改。 以下是实现效果&am…...

养生:拥抱健康生活的实用之道
在忙碌的现代生活中,养生逐渐成为人们追求健康的重要方式。从饮食、运动到睡眠与心态,各个养生环节相辅相成,共同构建起健康生活的大厦。以下为你详细介绍养生的关键要点,助你开启健康生活之旅。 饮食养生:科学搭配&a…...

Llama:开源的急先锋
Llama:开源的急先锋 Llama1:开放、高效的基础语言模型 Llama1使用了完全开源的数据,性能媲美GPT-3,可以在社区研究开源使用,只是不能商用。 Llama1提出的Scaling Law 业内普遍认为如果要达到同一个性能指标,训练更…...
)
使用大语言模型从零构建知识图谱(中)
从零到一:大语言模型在知识图谱构建中的实操指南 ©作者|Ninja Geek 来源|神州问学 还没有看过上篇的读者可以阅读《使用大语言模型从零构建知识图谱(上)》了解整个系列的内容 通过创建一个自定义流程来自动上传业务数据 在这一节&#…...

深度强化学习 | 图文详细推导软性演员-评论家SAC算法原理
目录 0 专栏介绍1 最大熵贝尔曼方程2 SAC算法原理推导2.1 参数化动作-价值函数2.2 参数化策略2.3 参数化温度 3 算法流程 0 专栏介绍 本专栏以贝尔曼最优方程等数学原理为根基,结合PyTorch框架逐层拆解DRL的核心算法(如DQN、PPO、SAC)逻辑。针对机器人运动规划场景…...

大数据开发 hadoop集群 3.Hadoop运行环境搭建
一、配置虚拟机 1.1 下载VMware虚拟机 1.下载地址:VMware Workstation下载_VMware Workstation官方免费下载_2024最新版_华军软件园 1.2 创建虚拟机 简易安装信息 1.3. 命名虚拟机 标题一 指定磁盘容量大小(推荐大小) 1.4. 语言和时区设…...

【HTTPS基础概念与原理】HTTPS vs HTTP:为什么现代网站必须用HTTPS?
以下是关于 HTTPS vs HTTP 的详细对比分析,涵盖安全性、性能差异及SEO影响,帮助您全面理解为何现代网站必须采用HTTPS: 一、安全性对比:HTTPS 如何解决 HTTP 的致命缺陷 1. HTTP 的安全隐患 • 明文传输:HTTP 数据以明…...
】Eureka单个服务端的搭建(含源代码)(三))
【springcloud学习(dalston.sr1)】Eureka单个服务端的搭建(含源代码)(三)
该系列项目整体介绍及源代码请参照前面写的一篇文章【springcloud学习(dalston.sr1)】项目整体介绍(含源代码)(一) 这篇文章主要介绍单个eureka服务端的集群环境是如何搭建的。 通过前面的文章【springcloud学习(dalston.sr1)】…...

榕壹云打车系统:基于Spring Boot+MySQL+UniApp的开源网约车解决方案
传统出租车行业的数字化痛点与破局 近年来,随着网约车市场的爆发式增长,传统出租车企业面临数字化转型的迫切需求。传统出租车行业存在以下核心痛点: 1. 运营效率低下:手工调度、纸质单据导致资源浪费。 2. 乘客体验不足:无法实时查看车辆位置、支付不便。 3. 安全监管…...

第5章 运算符、表达式和语句
目录 5.1 循环简介5.2 基本运算符5.3 其他运算符5.4 表达式和语句5.5 类型转换5.6 带有参数的函数5.7 一个实例程序5.11 编程练习 5.1 循环简介 5.2 基本运算符 赋值运算符: 几个术语:数据对象、左值、右值和操作数 数据对象:泛指数据存储区…...

全流量解析:让安全防御从“被动挨打”升级为“主动狩猎”
在网络安全领域,攻击者就像“隐形小偷”,总想悄无声息地入侵你的网络。而全流量解析,就是一套能“看清每一辆网络货车里装了什么”的技术。它通过采集并分析网络中的全部原始流量数据,帮助安全团队发现威胁、溯源攻击,…...

bfs-最小步数问题
最小步长模型 特征: 主要是解决权值为1且状态为字符串类型的最短路问题,实质上是有向图的最短路问题,可以简化为bfs求最短路问题。 代表题目: acwing 845 八数码问题: 八数码题中由于每次交换的状态是由x进行上下左右…...

机器学习 Day17 朴素贝叶斯算法-----概率论知识
1.简介 朴素贝叶斯(Naive Bayes)是一类基于贝叶斯定理(之后讲)并假设特征之间相互独立的概率分类算法 ,是机器学习中应用广泛的分类模型。以下为您详细介绍: 核心原理 贝叶斯定理:描述后验概…...
)
Selenium-Java版(环境安装)
Selenium自动化环境安装 前言 安装 安装客户端库 安装Chrome浏览器 安装Chrome浏览器驱动 安装Edge浏览器驱动 配置环境变量 示例 前言 参考教材:Python Selenium Web自动化 2024版 - 自动化测试 爬虫_哔哩哔哩_bilibili 安装 安装客户端库 <dep…...

【华为HCIP | 华为数通工程师】821—多选解析—第二十四页
980、以下关于BGP路由等价负载分担的描述,正确的是哪些项? A、公网中到达同一目的地的IBGP和EBGP路由不能形成负载分担。 B、在设备上使能BGP负载分担功能后,只有满足条件的多条BGP路由才会成为等价路由,进行负载分担。 C、默认情况下设备只会对AS Path长度相同的路由进…...

如何用Jsoup库提取商品名称和价格?
使用 Jsoup 库提取商品名称和价格是一个常见的任务,尤其是在爬取电商网站的商品详情时。Jsoup 是一个非常强大的 HTML 解析库,可以方便地从 HTML 文档中提取数据。以下是如何使用 Jsoup 提取商品名称和价格的详细步骤和代码示例。 一、环境准备 确保你…...

一文掌握六个空转数据库
写在前面 在实际的空转分析,尤其是细胞注释环节中,我们需要依赖大量的文献/数据库来对结果进行参考、校验,此时空间转录数据库能够快速帮助我们找到合适的参考数据集/信息。此外,现存的很多空转数据库收集了大量可供挖掘的数据&a…...

基于Qt的OSG三维建模
以下是一个基于Qt和OpenSceneGraph(OSG)实现三维模型交互的示例代码,包含模型高亮、文本标注等功能。代码采用Qt5和OSG 3.6版本开发。 一、核心类设计(C) 1. 主窗口类(继承QMainWindow) #inc…...

Spring Cloud:构建云原生微服务架构的最佳工具和实践
🌥️ 1. 引言 一、背景介绍:为什么需要微服务? 随着互联网技术的发展,企业级应用的功能日益复杂,传统的单体架构(Monolithic Architecture)逐渐暴露出一系列问题: 项目庞大&#…...

云图库和黑马点评的项目学习经验
捷优商超 我这个项目我主要实现了三个点,第一个是博主推送,就是用户进行消息的推送,拱用户进行商品的评价。第二个就是用户的签到。第三个就是优惠券秒杀了。 首先是博主推送,我们获取到前端信息以后直接把消息放到数据库里面&…...

苍穹外卖 - Day02 学习笔记
一、核心功能:新增员工 在实现新增员工功能时,有几个关键的技术点和设计考量需要我们掌握。 1.1 数据传输对象 (DTO) 的应用 核心概念: 数据传输对象(Data Transfer Object, DTO)是在应用程序不同分层之间传递数据的…...
——创建型模式之工厂方法)
设计模式(9)——创建型模式之工厂方法
设计模式(9)——创建型模式之工厂方法 工厂方法作用结构伪代码适用场景工厂方法 作用 工厂方法是一种创建型设计模式,其在父类中提供一个创建对象的方法,允许子类决定实例化对象的类型。 结构 产品(Product)将会对接口进行声明。对于所有由创建者及其子类构建的对象,…...

机器学习基础课程-6-课程实验
目录 6.1 实验介绍 实验准备 贷款审批结果预测 6.2 数据读取 6.3 数据处理 6.4 特征处理 有序型特征处理 类别型特征处理 数值型特征归一化 6.5 建立机器学习模型 建立测试模型 结果可视化 6.1 实验介绍 贷款审批结果预测 银行的放贷审批,核心要素为风险控制。因此&…...

IP SSL怎么签发使用
IP证书的签发首先是需要有一个可供绑定的IP地址,作为常用数字证书之一,IP证书也因为其广泛的应用范围而深得用户的青睐和喜欢。 部署IP证书后,可以实现该IP地址的https访问,过程和域名证书相差不多。 IP证书和域名证书的区别 很…...
(理论部分))
QMK键盘编码器(Encoder)(理论部分)
QMK键盘编码器(Encoder)(理论部分) 前言 作为一名深耕机械键盘DIY多年的老司机,我发现很多键盘爱好者对QMK编码器的配置总是一知半解。今天我就把多年积累的经验毫无保留地分享给大家,从硬件接线到软件配置,从基础应用到高阶玩法,一文全搞定!保证看完就能让你的编码…...

AI编程:使用Trae + Claude生成原型图,提示词分享
最近在学习AI编程相关的东西,看到了有人分享的提示词,做了两个APP原型图,分享给大家。 成果 第一个是依据B站的 探索者-子默 的视频,照着生成的AI改写原型图 第二个是我修改了一下提示词让AI生成做视频解析链接的APP原型图。 整体…...
详细讲解进程的组成与特性,状态与转换)
计算机操作系统(七)详细讲解进程的组成与特性,状态与转换
计算机操作系统(七)进程的组成与特性,状态与转换 前言一、进程的组成1. 什么是“进程”?2. 进程的三个核心组成部分2.1 PCB(进程控制块)—— 进程的“身份证户口本”2.2 程序段—— 进程的“任务清单”2.3 …...
)
【2025.5.12】视觉语言模型 (更好、更快、更强)
【2025.5.12】Vision Language Models (Better, Faster, Stronger): https://huggingface.co/blog/vlms-2025 【2024.4.11】Vision Language Models Explained【先了解视觉语言模型是什么】: https://huggingface.co/blog/vlms nanoVLM: https://github.…...

数据清洗ETL
ETL介绍 “ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL一词较常用在数据仓库,…...
详解)
STM32 实时时钟(RTC)详解
一、RTC 简介 RTC(Real Time Clock)即实时时钟,本质上是一个 32 位的秒级计数器: 最大计数值为 4294967295 秒,约合 136 年: 复制编辑 4294967295 / 60 / 60 / 24 / 365 ≈ 136 年 RTC 初始化时&#x…...