面向具身智能的视觉-语言-动作模型(VLA)综述
具身智能被广泛认为是通用人工智能(AGI)的关键要素,因为它涉及控制具身智能体在物理世界中执行任务。在大语言模型和视觉语言模型成功的基础上,一种新的多模态模型——视觉语言动作模型(VLA)已经出现,通过利用它们独特的生成动作的能力来解决具身智能中的语言条件机器人任务。
近年来,业内开发了各类VLA,文章提出了第一个关于具身人工智能的VLA的调查。这项工作提供了VLA的详细分类,分为三条主要的研究路线。第一条线关注VLA的各个组件、第二条线致力于开发擅长预测低级动作的控制策略、第三条线包括能够将长期任务分解成子任务序列的高级任务规划器,从而引导VLA遵循更通用的用户指令。此外,文章还提供了相关资源的广泛摘要,包括数据集、模拟器和基准。最后,我们-讨论了VLA面临的挑战,并概述了具身智能的未来方向。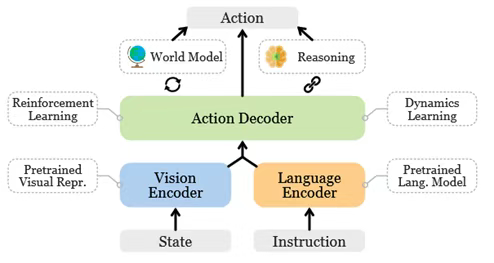
图1:视觉-语言-动作模型的一般架构。重要的相关组件显示在虚线框中。视觉-语言-动作模型(VLA)代表一类旨在处理多模态输入的模型,结合视觉、语言和动作模态的信息。该术语最先由RT-2 提出。VLA模型被开发用于解决具身智能中的指令跟随任务。与以ChatGPT为代表的聊天AI不同,具身智能需要控制物理实体并与环境交互。机器人是具身智能最突出的领域。在语言为条件的机器人任务中,策略必须具备1)理解语言指令、2)视觉感知环境、3)生成适当动作的能力,这就需要VLA的多模态能力。相比于早期的深度强化学习方法,基于VLA的策略在复杂环境中表现出更优越的多样性、灵活性和泛化性。这使得VLA不仅适用于像工厂这样的受控环境,还适用于日常生活任务。视觉-语言-动作模型 (VLA)是处理视觉和语言的多模态输入并输出机器人动作以完成具身任务的模型。它们是具身智能领域在机器人策略指令跟随的基石。这些模型依赖于强大的视觉编码器、语言编码器和动作解码器。在大型VLM的成功基础上,VLA模型已经展示了其在应对复杂任务挑战方面的潜力,如图1所示。与VLM类似,VLA利用视觉基础模型作为视觉编码器来获得当前环境状态的预训练视觉表示,例如对象类别、姿态和几何形状。VLA使用其大语言模型的令牌嵌入(token embeddings)对指令进行编码,并采用各种策略来调整视觉和语言嵌入,包括BLIP-2和LLaVA等方法。通过对机器人数据进行微调,大语言模型可以充当解码器来预测动作和执行语言条件机器人任务。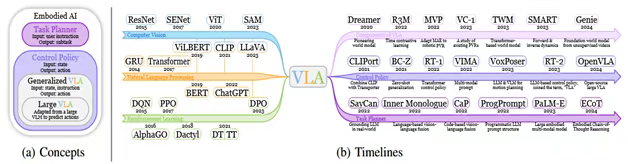
图2:(a)概述本文讨论的具身智能主要概念的维恩图。(b)追踪从单模态模型到视觉-语言-动作模型演变的时间线。VLA与三条工作线密切相关,如图2b中的时间线和图3中的分类法所示。一些方法侧重于VLAs(III-A)的单个组件,如预训练的视觉表示、动力学学习(dynamics learning)、世界模型和推理。与此同时,大量的研究致力于低级控制策略(III-B)。在这一类别中,语言指令和视觉感知被输入到控制策略中,然后控制策略生成低级动作,如平移和旋转,从而使VLAs成为控制策略的理想选择。相比之下,另一类模型充当高级任务规划器,负责任务分解(§IV)。这些模型将长期任务分解为一系列子任务,这些子任务反过来引导VLAs实现总体目标,如图4所示。当前大多数机器人系统都采用这样的分层框架,因为高级任务规划器可以利用具有高容量的模型,而低级控制策略可以专注于速度和精度,类似于分层强化学习。为了更全面地概述具身智能的当前进展,提出了“VLA”的广义定义,如图2a所示。将VLA定义为任何能够处理来自视觉和语言的多模态输入以产生完成具体化任务的机器人动作的模型,通常遵循图1中的架构。VLA的最初概念是指一种使VLM适应机器人任务的模型[2]。类似于大语言模型和更通用的语言模型之间的区别,我们将原始VLAs指定为“大型VLAs”(LVLAs),因为它们基于大语言模型或大型VLM。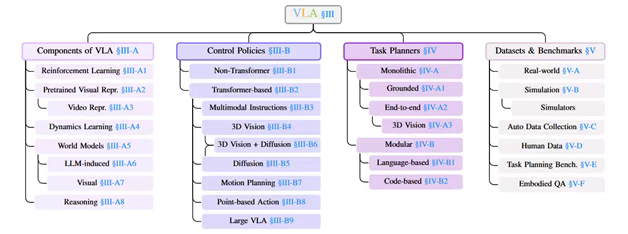
图3:VLA模型的分类。VLA的组成部分视觉语言具身智能(Vision-Language-Action, VLA)模型的发展依赖于多个关键组件的协同优化。这些组件从感知、决策到世界建模和推理,共同推动了具身智能的进步。以下是各核心组件的详细介绍:强化学习(Reinforcement Learning, RL)强化学习在VLA模型中扮演关键角色,其状态-动作-奖励序列与序列建模问题高度契合,使得Transformer能够有效处理RL任务。Decision Transformer(DT)和Trajectory Transformer(TT)率先将RL问题转化为序列预测任务,利用Transformer的自回归特性优化策略学习。Gato进一步扩展了这一范式,支持多模态输入和跨任务泛化。此外,基于人类反馈的强化学习(RLHF)已成为大语言模型(LLM)训练的重要组成部分,例如SEED通过结合技能RL和人类反馈解决长周期任务的稀疏奖励问题。Reflexion则创新性地用语言反馈替代传统RL的权重更新机制,使模型能够通过自然语言交互优化策略。预训练视觉表征(Pretrained Visual Representations, PVRs)视觉编码器的质量直接影响VLA模型的性能,因为它决定了机器人对环境的理解能力。CLIP通过大规模图像-文本对比学习训练,成为机器人领域广泛采用的视觉编码器。R3M提出时间对比学习和视频-语言对齐两个目标,分别增强时序一致性和语义相关性。MVP借鉴计算机视觉中的掩码自编码(MAE)方法,在机器人数据集上进行视觉重建预训练。Voltron在MAE基础上引入语言条件生成,提升视觉与语言模态的对齐能力。DINOv2采用自蒸馏框架,结合多裁剪增强策略,在像素和图像级别同时学习表征。I-JEPA通过联合嵌入预测架构,专注于局部图像特征的建模。Theia则通过蒸馏多个视觉基础模型(如分割、深度估计)构建轻量且高性能的单一模型。视频表征(Video Representations)视频数据不仅包含单帧图像信息,还蕴含丰富的时序和3D结构信息。传统方法通过逐帧提取PVRs拼接成视频表征,但新兴技术如NeRF和3D高斯泼溅(3D-GS)能够直接从视频中重建3D场景,为机器人提供更丰富的环境理解。例如,F3RM和3D-LLM利用NeRF提取3D几何信息,而PhysGaussian和UniGS则基于3D高斯泼溅实现动态场景建模。此外,视频中的音频信息(如环境声音)也可作为机器人策略的重要输入,增强多模态感知能力。动力学学习(Dynamics Learning)动力学学习旨在让模型掌握环境的状态转移规律,包括前向动力学(预测下一状态)和逆向动力学(预测动作)。Vi-PRoM通过对比学习和伪标签分类预训练视频模型,提升时序动态建模能力。MIDAS专注于逆向动力学预测,将观测序列转化为动作序列。SMART结合前向、逆向动力学和随机掩码 hindsight 控制,同时建模局部和全局时序依赖。MaskDP采用掩码决策预测任务,联合学习状态和动作的重建。PACT通过自回归预测状态-动作序列,构建通用动力学模型,适用于导航等下游任务。VPT利用半监督模仿学习,基于少量标注数据预训练Minecraft基础模型,最终实现人类水平性能。世界模型(World Models)世界模型能够编码常识知识并预测未来状态,支持基于模型的规划和想象训练。Dreamer系列工作通过潜在动力学模型(包含状态编码、转移和奖励预测模块)实现高效想象优化。IRIS采用类似GPT的自回归Transformer作为世界模型基础,结合VQ-VAE视觉编码器生成想象轨迹。TWM探索了纯Transformer架构在世界建模中的应用。这些模型使机器人能够在执行真实动作前,通过内部模拟搜索最优策略。LLM诱导的世界模型(LLM-induced World Models)大语言模型(LLM)蕴含丰富的常识知识,可被转化为符号化世界模型。DECKARD利用LLM生成抽象世界模型(AWM),指导Minecraft中的物品合成任务。LLM-DM将LLM转化为规划域定义语言(PDDL)的生成器,构建符号化仿真器辅助规划。RAP将LLM同时作为策略和世界模型,结合蒙特卡洛树搜索(MCTS)实现结构化推理。LLM-MCTS进一步扩展至部分可观测环境(POMDPs),利用LLM的常识知识缩小搜索空间。视觉世界模型(Visual World Models)与文本世界模型不同,视觉世界模型能够生成未来状态的图像、视频或3D场景。Genie提出生成式交互环境框架,通过无监督视频训练实现帧级交互模拟。3D-VLA利用扩散模型生成目标图像或点云,指导机器人完成任务。UniSim基于真实交互视频构建生成模型,模拟高低层级动作的视觉结果。这些模型能够生成逼真的环境交互数据,为机器人提供丰富的训练经验。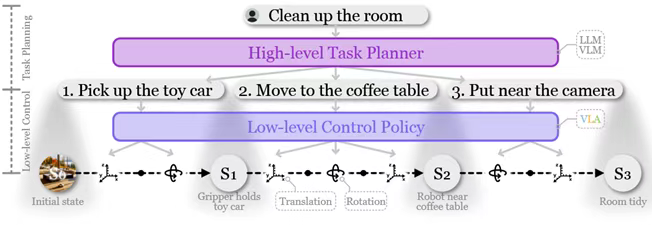
图4:分层机器人策略的图示。高级任务规划器将用户指令分解为子任务,然后由低级控制策略逐步执行。低层控制策略(Low-level Control Policies)非Transformer控制策略在Transformer架构普及之前,研究者们已经探索了多种基于传统神经网络架构的低层控制策略。CLIPort是这一时期的代表性工作,它创造性地将CLIP的视觉语言编码能力与Transporter网络的空间推理能力相结合,形成了一个双流处理架构。其中语义流通过CLIP提取图像的高级语义特征,空间流则利用Transporter网络处理RGB-D数据以精确定位物体空间位置。这种分离处理的方式使得系统能够同时理解"要操作什么"和"在哪里操作",最终输出精确的抓取和放置位姿。BC-Z则采用了不同的技术路线,通过FiLM(Feature-wise Linear Modulation)层实现语言指令与视觉特征的深度融合,这种条件调节机制使模型能够将抽象的语言指令转化为具体的动作策略,展现出强大的零样本泛化能力。MCIL突破了传统任务ID或目标图像的条件限制,开创性地支持自由形式的自然语言指令输入,其关键创新在于设计了一个共享的编码空间,使得语言目标和视觉目标可以相互转换,从而能够充分利用大量未标注的演示数据。HULC系列工作则提出了更为复杂的层次化架构,将高层规划与底层控制解耦,其中顶层的Transformer负责长时程任务分解,底层网络处理即时动作生成,同时引入视觉语言对比学习损失来增强多模态对齐。这些早期探索为后续Transformer-based控制策略的发展奠定了重要基础。Transformer-based控制策略随着Transformer在序列建模中的优势得到验证,控制策略设计逐渐向Transformer架构收敛。Interactive Language系统展示了语言实时引导的强大能力,其核心在于构建了规模空前多样的语言指令数据集,使Transformer策略能够精准理解并执行复杂的长时程重排列任务。Hiveformer则进一步强调了多视角观测和历史信息的重要性,相比传统单帧输入的方法,其设计的时空注意力机制能够更好地捕捉场景动态变化。Gato作为里程碑式的工作,首次实现了单一模型在Atari游戏、图像描述和积木堆叠等多个领域的通用控制,其突破点在于设计了统一的分词方案,将不同模态和任务的输入输出都转化为标准化的token序列。RoboCat在Gato基础上引入了自我改进机制,通过迭代式微调和自动数据生成,仅需100条演示就能快速适应新任务,其创新的未来观测预测目标显著提升了样本效率。RT-1对BC-Z架构进行了全面升级,采用更高效的EfficientNet视觉编码器,并将MLP动作解码器替换为Transformer解码器,通过注意力机制整合历史观测,在真实机器人任务中展现出卓越性能。Q-Transformer则开创性地将Q-learning引入Transformer策略,通过自回归Q函数和保守正则化,能够同时利用成功和失败的演示数据。RT-Trajectory提出了轨迹草图条件控制的新范式,将传统语言指令扩展为直观的空间轨迹指导,大幅提升了新物体和新任务的泛化能力。ACT及其改进版本MT-ACT采用条件VAE框架,通过动作分块预测和时间集成技术增强动作序列的连贯性。RoboFlamingo则证明已有视觉语言大模型(如Flamingo)只需添加简单的LSTM策略头就能有效迁移到机器人控制任务。多模态指令控制策略多模态指令控制策略突破了纯文本指令的限制,开创了更丰富的人机交互方式。VIMA系统是这一方向的先驱,它设计了包括物体操作、视觉目标达成、新概念理解、单次视频模仿等在内的多模态提示体系,通过专门的VIMA-Bench评测平台系统评估了模型在位置泛化、组合泛化、新物体泛化和新任务泛化四个层级的表现。其核心创新在于构建了统一的提示编码器,能够同时处理语言、图像、视频等多种形式的任务描述。MOO在RT-1基础上扩展了多模态指令处理能力,通过集成OWLViT图像编码器,系统能够理解基于指向动作、GUI点击等非语言形式的指令输入。这类方法的关键挑战在于建立跨模态的共享表征空间,使得不同形式的指令都能映射到统一的控制策略空间。最新研究还探索了如何将触觉反馈、语音指令等更多模态融入控制系统,进一步丰富人机交互的维度。3D视觉控制策略3D视觉控制策略致力于利用三维场景表征提升控制精度和鲁棒性。PerAct是该领域的突破性工作,它采用3D体素作为统一表征,通过多视角RGB-D重建构建场景的立体几何结构,将动作预测转化为目标体素选择问题,这种显式的结构先验使模型仅需少量演示就能学会复杂操作。Act3D则提出连续分辨率3D特征场,通过自适应分辨率平衡计算效率和表征精度。RoboUniView通过UVFormer模块将多视角图像转化为3D占据信息,显著提升了抓取成功率。VER在视觉语言导航任务中验证了由粗到细的体素化策略的有效性。RVT系列工作另辟蹊径,采用虚拟重渲染技术从场景点云生成新颖视角图像,避免了直接处理3D数据的复杂性。这些方法共同面临的挑战是如何在计算开销和表征丰富度之间取得平衡,以及如何处理动态场景的实时更新问题。最新趋势是将神经辐射场(NeRF)和3D高斯泼溅等先进三维重建技术融入控制框架,以获取更精确的场景几何和语义信息。扩散控制策略扩散控制策略将图像生成领域的扩散模型成功迁移到动作预测领域。Diffusion Policy是开创性工作,它将机器人策略建模为去噪扩散过程,采用DDPM框架并结合滚动时域控制、视觉条件化和时序扩散Transformer等技术,有效解决了多模态动作分布、高维动作空间的挑战。SUDD构建了LLM引导的数据生成和蒸馏框架,通过组合基础机器人原语(如抓取采样器和运动规划器)生成高质量训练数据,再蒸馏到扩散策略中。Octo设计了模块化的Transformer扩散架构,支持灵活接入不同任务编码器和观测编码器,在Open X-Embodiment大规模数据集上验证了跨机器人的知识迁移能力。MDT将视觉领域的DiT模型引入动作预测,配合掩码生成预测和对比潜在对齐两个辅助目标,性能超越传统U-Net架构。RDT-1B专注于双手操作任务,通过统一动作格式实现跨机器人数据集预训练,其10亿参数规模的模型展现出强大的零样本泛化能力。这些方法的核心优势在于能够自然地表征多峰动作分布,但实时推理速度仍是实际部署的主要瓶颈。运动规划控制策略运动规划控制策略专注于将高层任务分解为满足约束的可行轨迹。Language Costs提出基于语言代价函数的规划框架,通过将自然语言指令转化为代价图来指导运动规划,支持用户通过语言交互实时修正目标。VoxPoser创新性地将LLM的编程能力与VLM的感知能力结合,无需训练即可生成满足语言指令的可行轨迹,其核心是构建3D体素化的操作可行域和约束域表示。RoboTAP通过TAPIR算法从演示视频中提取关键点轨迹,构建分阶段的视觉伺服控制策略。这类方法的关键挑战在于如何将抽象的语言约束准确转化为数学形式的运动约束,以及如何处理复杂环境下的实时规划问题。最新进展探索如何将基于采样的传统规划算法与学习型策略相结合,在保证安全性的同时提升规划效率。基于点的控制策略基于点的控制策略探索轻量化的动作表征方式。PIVOT将机器人任务重构为视觉问答问题,通过VLM在图像关键点上进行迭代选择,大幅降低了动作预测的复杂度。RoboPoint通过微调VLM实现空间可行域预测,将2D图像点映射为3D动作。ReKep提出基于3D关键点的约束优化框架,将复杂任务分解为一系列关键点约束的求解问题。这些方法的优势在于能够直接复用现有视觉语言模型,实现零样本或少样本的控制策略生成,但通常需要额外的运动规划模块来实现精确控制。当前研究重点是如何提升点预测的精度和稳定性,以及如何将离散点选择与连续动作优化更好地结合。大规模视觉语言动作模型大规模视觉语言动作模型(LVLA)代表了当前最前沿的研究方向。RT-2通过联合微调互联网规模VQA数据和机器人数据,使模型涌现出符号推理和语义理解等高级能力。RT-H引入语言动作中间层,构建"指令-语言动作-底层动作"的三层架构,既改善了任务间的知识共享,又支持语言级错误修正。RT-X系列通过Open X-Embodiment大规模数据集训练,验证了跨机器人知识迁移的可行性。OpenVLA作为开源替代方案,探索了LoRA和量化等高效微调技术。π-0采用流匹配架构将预训练VLM扩展为VLA,通过混合专家框架平衡通用知识和专业技能。这些大型模型虽然展现出惊人的泛化能力,但也面临计算成本高、推理延迟大等实际挑战,催生了TinyVLA等轻量化解决方案的研究。未来发展方向包括更高效的架构设计、更灵活的任务适应机制,以及更可靠的安全保障体系。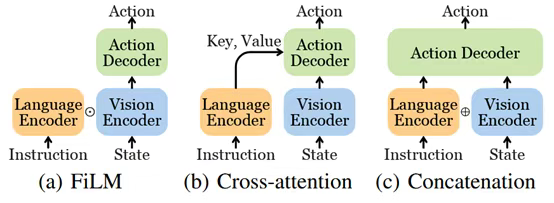
图5:基于Transformer的控制策略的三种常见视觉语言融合方法。FiLM层(Hadamard product⊙)用于RT-1模型中。有人利用交叉注意力来调节指令。级联(⊕)是LVLAs中的主要方法。任务规划器(Task Planners)整体式任务规划器(Monolithic Task Planners):单个大语言模型或多模态大语言模型(MLLM)通常可以通过采用定制的框架或通过对包含的数据集进行微调来生成任务计划。我们将这些称为整体模型。基于落地的任务规划器(Grounded Task Planners)基于落地的任务规划器专注于将抽象任务分解为可执行子任务,同时考虑低层控制策略的实际可行性。SayCan提出了开创性的任务落地框架,通过结合LLM的语义规划能力("说"出可能技能)和低层策略的可行性评估("能"执行程度),实现了高层指令到具体动作的可靠转换。Translated ⟨LM⟩采用独特的双阶段规划机制,先由生成式LLM产生自然语言动作描述,再通过掩码语言模型将其映射为具体可执行动作,并创新性地引入"重新提示"策略来处理执行过程中的前提条件错误。(SL)³算法通过分段、标记和参数更新的迭代学习过程,从稀疏语言标注中自动发现可重用技能模块,构建了层次化的策略表示。这类方法的核心价值在于建立了语义规划与物理执行之间的可靠桥梁,其技术挑战主要来自动态环境下可行性评估的准确性,以及多步任务分解的长期一致性维护。端到端任务规划器(End-to-end Task Planners)端到端任务规划器利用大规模多模态语言模型的涌现能力,直接实现从指令到计划的端到端生成。PaLM-E通过深度融合ViT视觉编码器和PaLM语言模型,构建了统一的多模态推理架构,既能处理常规的视觉问答任务,又能生成可指导机器人执行的详细计划,并具备根据环境观测实时调整的动态重规划能力。EmbodiedGPT创新设计了具身变形器模块,通过联合优化视觉特征提取和规划信息生成,输出包含空间上下文的任务实例特征,为低层策略提供丰富的执行上下文。这类方法的显著优势是避免了传统流水线式系统的信息损失,但其成功高度依赖互联网规模的多模态预训练数据,且存在计算成本高、决策过程可解释性弱等实际问题。当前研究前沿集中在模型轻量化、物理约束注入和可解释性增强等方向。支持3D视觉的端到端规划器(End-to-end Task Planners with 3D Vision)支持3D视觉的端到端规划器通过扩展传统视觉语言模型架构,显著提升了空间理解和三维交互能力。LEO采用创新的两阶段训练范式,先通过3D视觉语言对齐学习建立几何理解基础,再经指令微调阶段获得精确的动作规划能力,在复杂操作和导航任务中展现出卓越表现。3D-LLM构建了灵活的多模态3D特征接口,支持点云、神经辐射场等多种三维表征的融合处理,使语言模型首次具备真正的三维空间推理能力。MultiPLY突破性地将感知模态扩展到触觉、音频等物理交互信号,建立了以物体为中心的具身认知框架。ShapeLLM则通过创新的ReCon++编码器架构,实现了从多视角视觉教师到点云表征的知识蒸馏,在其提出的3D MM-Vet基准测试中刷新了性能记录。这些技术的突破性在于将离散的语言指令与连续的三维动作空间建立了直接关联,但面临3D数据获取成本高、实时计算负载大等工程挑战,未来发展重点包括高效3D表征学习、跨模态对齐优化和增量式场景理解等技术方向。模块化任务规划器(Modular Task Planners):在嵌入数据上微调端到端模型可能是昂贵的,并且有一些方法通过将现成的大语言模型和VLM组装到任务规划器中来采用模块化设计。基于语言的任务规划器(Language-based Task Planners)基于语言的模块化任务规划器通过自然语言描述实现多模态信息交换,构建了灵活可扩展的规划系统。Inner Monologue创新性地在高层指令和低层策略间建立闭环规划机制,利用LLM生成可执行语言指令并根据策略反馈动态调整,其反馈系统整合了任务成功状态、物体场景变化和人工输入等多源信息,全部以文本形式实现无需额外训练。ReAct采用类似的交替执行推理与动作的框架,通过语言空间实现多模态对齐。LLM-Planner进一步提出分层规划架构,高层LLM生成自然语言计划后由低层规划器转化为原始动作,并引入动态重规划机制解决执行卡顿问题。LID通过主动数据收集(ADG)和事后重标记技术最大化利用失败轨迹数据,其语言模型策略展现出强大的组合泛化能力。Socratic Models突破性地构建了无需微调的模块化系统,通过多模态提示技术实现预训练模型间的即插即用协作,将非语言输入统一转化为语言描述进行规划,在机器人感知和规划任务中表现出独特优势。这些方法的共同特点是通过自然语言这一通用接口降低模块间耦合度,但需要精心设计提示工程来确保生成计划与低层策略的兼容性。基于代码的任务规划器(Code-based Task Planners)基于代码的任务规划器充分利用大模型的程序生成能力,将任务规划转化为可执行代码的编写过程。ProgPrompt开创性地采用类程序规范提示LLM生成家务任务计划,通过程序断言机制整合环境反馈,实现少量示例引导的规划。ChatGPT for Robotics构建了"用户在环"的控制范式,通过定义物体检测、抓取等API接口,引导模型生成可调试的控制代码,结合仿真环境和用户反馈迭代优化。Code as Policies(CaP)深入挖掘GPT-3和Codex的代码生成潜力,创建可直接调用感知模块和控制原语的策略代码,在空间几何推理和新指令泛化方面表现突出,其升级版COME-robot通过GPT-4V的多模态能力消除了独立感知API的需求。DEPS提出"描述-解释-规划-选择"四步框架,不仅生成计划还能对失败进行自我解释式重规划,并创新性地引入可训练的子目标选择器优化执行路径。ConceptGraphs将观测序列转化为开放词汇的3D场景图,通过2D分割模型和VLM标注构建富含语义空间关系的JSON描述,为代码生成提供结构化环境表征。这类方法的核心价值在于将规划过程程序化,既保留了传统代码的精确可控优势,又获得了LLM的语义理解能力,但性能受限于模型编程能力且需要预先封装完备的API文档体系。技术特性与权衡模块化任务规划器通过组合现成LLM和VLM构建,相比整体式规划器具有更低部署成本。基于语言的方案天然适配大模型的文本处理优势,Inner Monologue和ReAct等通过精巧的反馈机制实现闭环规划,但需要额外转换层对接低层策略。基于代码的方案如ProgPrompt和CaP虽然需要预先封装API,但能直接生成可调试的执行代码,DEPS的自我解释机制进一步提升了系统可靠性。ConceptGraphs创新的3D场景图表示弥补了纯文本描述的空间信息缺失。当前挑战集中在如何平衡模块化带来的灵活性损失,以及如何构建更高效的跨模态接口。最新趋势是结合语言和代码的双重优势,如COME-robot通过多模态大模型消除独立感知模块,或探索视觉程序生成等混合表征方式。未来突破可能来自动态模块组合机制和神经符号结合的新型架构。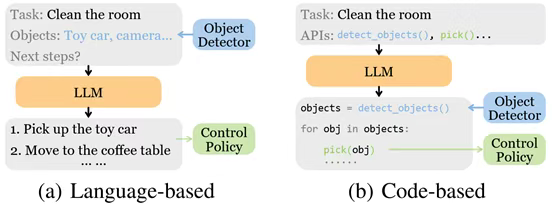
图6:在模块化任务规划器中将大语言模型连接到多模态模块的不同方法。数据集与基准测试(Datasets and Benchmarks)真实机器人数据集与基准测试真实世界机器人数据收集面临三重核心挑战:硬件成本与时间投入构成第一道门槛,从机器人设备采购到专家演示数据采集需要大量资源投入;跨平台异构性带来第二重障碍,不同机器人的传感器配置、控制模式和末端执行器差异导致数据难以统一;6D位姿标注与实验可复现性则是第三大技术瓶颈。当前主流数据集如Bridge V2和RT-1-X通过多机器人协作缓解数据规模问题,而Open X-Embodiment通过标准化数据格式促进跨平台知识迁移。值得注意的是,真实场景评估必须依赖人工评判,这导致评测成本居高不下,MetaWorld等基准通过定义细粒度任务分解指标部分缓解该问题,但动态环境中的长期任务评估仍具挑战性。
仿真环境与模拟数据集仿真技术通过虚拟环境突破物理限制,Gazebo和Isaac Sim等平台支持大规模并行数据采集,但仿真与现实间的领域差距形成显著障碍。该差距源自三重因素:图形渲染保真度不足导致视觉域差异,物理引擎精度限制影响动力学建模,以及物体参数化建模误差引入系统偏差。为解决这些问题,NVIDIA Omniverse等平台采用实时光线追踪提升视觉真实度,PyBullet则通过GPU加速提高物理仿真精度。TDW和ThreeDWorld创新性地引入非刚性物体模拟能力,而SAPIEN专注于可操作物体的精确物理特性建模。仿真基准测试如BEHAVIOR和VirtualHome的优势在于提供自动化评估指标,支持精确的实验复现和公平比较,但如何建立有效的仿真到现实迁移评估体系仍是开放问题。自动化数据收集技术自动化数据采集系统通过算法生成替代人工干预,RoboGen采用生成式仿真范式自动设计训练课程,其三步循环包含技能提案、环境生成和策略优化,显著提升数据多样性。AutoRT构建LLM驱动的机器人编排框架,通过任务生成、可行性过滤和混合执行(自主策略与人工遥操作结合)实现闭环数据生产。DIAL专注于语言指令增强,利用VLM对现有数据集进行语义扩展,而RoboPoint通过程序化生成随机3D场景解决特定任务数据匮乏问题。这些技术的共同突破是建立了数据生产的自主进化机制,但生成数据的质量监控和偏差控制仍需深入研究。人类行为数据集人类演示数据因其灵巧性和多样性成为重要补充,但存在三大应用瓶颈:运动捕捉系统难以精确转换人体 kinematics 到机器人形态,Kinect等设备采集的第三方视角数据与机器人第一视角存在表征差异,且原始数据包含大量无关动作需要清洗。UMI通过手持式夹爪设备采集人体操作数据,在保持演示自然性的同时解决形态差异问题。大规模数据集如Something-Something和Epic-Kitchens提供丰富的日常活动记录,但需要复杂的预处理才能转化为可用训练数据。当前研究前沿集中在运动重定向算法开发和跨形态技能迁移技术上。任务规划基准测试任务规划评估体系呈现多维度发展趋势,EgoPlan-Bench通过人工标注实现真实场景细粒度评估,但扩展性受限。PlanBench创新性地建立多维评估框架,从成本最优性、计划验证到动态重规划能力进行全面测评。LoTa-Bench将规划执行环节纳入评估,通过模拟器运行生成计划计算成功率,而EAI提出模块化接口标准,支持对LLM决策过程的细粒度诊断。这些基准共同推动规划系统从静态评估向闭环验证演进,但如何平衡评估复杂度和可扩展性仍是挑战。具身问答基准测试具身问答(EQA)基准测试开创性地将主动探索引入评估体系,EmbodiedQA和IQUAD奠定基础框架,要求智能体在回答前通过导航探索环境。MT-EQA扩展至多目标复合问题,MP3D-EQA将视觉输入升级为点云数据以测试3D推理能力。EgoVQA和EgoTaskQA聚焦第一人称视角,分别强化时空推理和因果关系理解。EQA-MX突破性地引入非语言模态(如视线注视和指向手势),OpenEQA则构建七维评估体系涵盖从功能推理到世界知识的全面测评。这类基准的核心价值在于评估物理常识和空间推理等基础能力,但当前仍受限于模拟器环境,真实场景的主动探索评估体系尚待建立。总结当前,视觉语言动作(VLA)模型在具身智能领域取得了显著进展,但仍面临诸多关键挑战。安全性始终是机器人系统的核心考量,需要结合常识推理、风险评估和人机交互协议构建可靠的安全保障体系。数据集与基准测试的扩展性、多样性以及细粒度评估能力仍需提升,以支持更全面的模型诊断与优化。基础模型的泛化能力仍落后于NLP领域的LLMs,如何构建适应多样化任务、环境和具身形态的通用机器人基础模型(RFM)是未来重要方向。多模态融合技术虽已取得突破,但如何高效对齐视觉、语言、触觉、音频等模态,并实现动态环境下的自适应推理仍待探索。长时程任务的端到端规划框架、实时响应能力的优化、多智能体协作系统的通信与调度机制,以及伦理与社会影响的规范化研究,都是推动VLA技术落地的关键课题。未来,随着医疗护理、工业自动化等新应用场景的拓展,VLA模型需结合领域知识(如医学图像分析)和隐私保护技术(如联邦学习),构建更安全、可靠、高效的智能系统。跨学科协作与技术创新将共同推动具身智能从实验室走向现实世界,最终实现与人类社会的无缝融合。论文:Ma, Y.; Song, Z.; Zhuang, Y.; Hao, J.; King, I. A Survey on Vision-Language-Action Models for Embodied AI. arXiv March 4, 2025. https://doi.org/10.48550/arXiv.2405.14093.原文链接:https://arxiv.org/pdf/2405.14093v3
相关文章:
综述)
面向具身智能的视觉-语言-动作模型(VLA)综述
具身智能被广泛认为是通用人工智能(AGI)的关键要素,因为它涉及控制具身智能体在物理世界中执行任务。在大语言模型和视觉语言模型成功的基础上,一种新的多模态模型——视觉语言动作模型(VLA)已经出现&#…...

车用CAN接口芯片:汽车神经系统的沉默构建者
车用CAN接口芯片:汽车神经系统的沉默构建者 在汽车电子系统的复杂架构中,CAN总线如同人体的神经系统,而CAN接口芯片则扮演着神经突触的角色。这些指甲盖大小的芯片,默默承担着整车超过70%的通信任务,却鲜少成为技…...

AI日报 · 2025年5月14日|Android 生态大型更新与多端 Gemini 集成
1、Google “Android Show: I/O Edition” 汇总:设计、安全、Gemini 三线并进 北京时间 5 月 14 日凌晨(原文标注 5 月 13 日 PDT),Google 在 I/O 前夕举办的 Android Show 一口气公布四大方向更新:① Mater…...

QT+opencv实现卡尺工具找圆、拟合圆
QT Opencv 实现卡尺工具找圆 找圆工具是自己从其他项目里面单独整理出来,可直接引用到新项目中。 程序中提供了函数接口,其他文件直接传入参数就能获取圆心和半径信息。次工具全采用QT和opencv,全部源码可随需求更改。 以下是实现效果&am…...

养生:拥抱健康生活的实用之道
在忙碌的现代生活中,养生逐渐成为人们追求健康的重要方式。从饮食、运动到睡眠与心态,各个养生环节相辅相成,共同构建起健康生活的大厦。以下为你详细介绍养生的关键要点,助你开启健康生活之旅。 饮食养生:科学搭配&a…...

Llama:开源的急先锋
Llama:开源的急先锋 Llama1:开放、高效的基础语言模型 Llama1使用了完全开源的数据,性能媲美GPT-3,可以在社区研究开源使用,只是不能商用。 Llama1提出的Scaling Law 业内普遍认为如果要达到同一个性能指标,训练更…...
)
使用大语言模型从零构建知识图谱(中)
从零到一:大语言模型在知识图谱构建中的实操指南 ©作者|Ninja Geek 来源|神州问学 还没有看过上篇的读者可以阅读《使用大语言模型从零构建知识图谱(上)》了解整个系列的内容 通过创建一个自定义流程来自动上传业务数据 在这一节&#…...

深度强化学习 | 图文详细推导软性演员-评论家SAC算法原理
目录 0 专栏介绍1 最大熵贝尔曼方程2 SAC算法原理推导2.1 参数化动作-价值函数2.2 参数化策略2.3 参数化温度 3 算法流程 0 专栏介绍 本专栏以贝尔曼最优方程等数学原理为根基,结合PyTorch框架逐层拆解DRL的核心算法(如DQN、PPO、SAC)逻辑。针对机器人运动规划场景…...

大数据开发 hadoop集群 3.Hadoop运行环境搭建
一、配置虚拟机 1.1 下载VMware虚拟机 1.下载地址:VMware Workstation下载_VMware Workstation官方免费下载_2024最新版_华军软件园 1.2 创建虚拟机 简易安装信息 1.3. 命名虚拟机 标题一 指定磁盘容量大小(推荐大小) 1.4. 语言和时区设…...

【HTTPS基础概念与原理】HTTPS vs HTTP:为什么现代网站必须用HTTPS?
以下是关于 HTTPS vs HTTP 的详细对比分析,涵盖安全性、性能差异及SEO影响,帮助您全面理解为何现代网站必须采用HTTPS: 一、安全性对比:HTTPS 如何解决 HTTP 的致命缺陷 1. HTTP 的安全隐患 • 明文传输:HTTP 数据以明…...
】Eureka单个服务端的搭建(含源代码)(三))
【springcloud学习(dalston.sr1)】Eureka单个服务端的搭建(含源代码)(三)
该系列项目整体介绍及源代码请参照前面写的一篇文章【springcloud学习(dalston.sr1)】项目整体介绍(含源代码)(一) 这篇文章主要介绍单个eureka服务端的集群环境是如何搭建的。 通过前面的文章【springcloud学习(dalston.sr1)】…...

榕壹云打车系统:基于Spring Boot+MySQL+UniApp的开源网约车解决方案
传统出租车行业的数字化痛点与破局 近年来,随着网约车市场的爆发式增长,传统出租车企业面临数字化转型的迫切需求。传统出租车行业存在以下核心痛点: 1. 运营效率低下:手工调度、纸质单据导致资源浪费。 2. 乘客体验不足:无法实时查看车辆位置、支付不便。 3. 安全监管…...

第5章 运算符、表达式和语句
目录 5.1 循环简介5.2 基本运算符5.3 其他运算符5.4 表达式和语句5.5 类型转换5.6 带有参数的函数5.7 一个实例程序5.11 编程练习 5.1 循环简介 5.2 基本运算符 赋值运算符: 几个术语:数据对象、左值、右值和操作数 数据对象:泛指数据存储区…...

全流量解析:让安全防御从“被动挨打”升级为“主动狩猎”
在网络安全领域,攻击者就像“隐形小偷”,总想悄无声息地入侵你的网络。而全流量解析,就是一套能“看清每一辆网络货车里装了什么”的技术。它通过采集并分析网络中的全部原始流量数据,帮助安全团队发现威胁、溯源攻击,…...

bfs-最小步数问题
最小步长模型 特征: 主要是解决权值为1且状态为字符串类型的最短路问题,实质上是有向图的最短路问题,可以简化为bfs求最短路问题。 代表题目: acwing 845 八数码问题: 八数码题中由于每次交换的状态是由x进行上下左右…...

机器学习 Day17 朴素贝叶斯算法-----概率论知识
1.简介 朴素贝叶斯(Naive Bayes)是一类基于贝叶斯定理(之后讲)并假设特征之间相互独立的概率分类算法 ,是机器学习中应用广泛的分类模型。以下为您详细介绍: 核心原理 贝叶斯定理:描述后验概…...
)
Selenium-Java版(环境安装)
Selenium自动化环境安装 前言 安装 安装客户端库 安装Chrome浏览器 安装Chrome浏览器驱动 安装Edge浏览器驱动 配置环境变量 示例 前言 参考教材:Python Selenium Web自动化 2024版 - 自动化测试 爬虫_哔哩哔哩_bilibili 安装 安装客户端库 <dep…...

【华为HCIP | 华为数通工程师】821—多选解析—第二十四页
980、以下关于BGP路由等价负载分担的描述,正确的是哪些项? A、公网中到达同一目的地的IBGP和EBGP路由不能形成负载分担。 B、在设备上使能BGP负载分担功能后,只有满足条件的多条BGP路由才会成为等价路由,进行负载分担。 C、默认情况下设备只会对AS Path长度相同的路由进…...

如何用Jsoup库提取商品名称和价格?
使用 Jsoup 库提取商品名称和价格是一个常见的任务,尤其是在爬取电商网站的商品详情时。Jsoup 是一个非常强大的 HTML 解析库,可以方便地从 HTML 文档中提取数据。以下是如何使用 Jsoup 提取商品名称和价格的详细步骤和代码示例。 一、环境准备 确保你…...

一文掌握六个空转数据库
写在前面 在实际的空转分析,尤其是细胞注释环节中,我们需要依赖大量的文献/数据库来对结果进行参考、校验,此时空间转录数据库能够快速帮助我们找到合适的参考数据集/信息。此外,现存的很多空转数据库收集了大量可供挖掘的数据&a…...

基于Qt的OSG三维建模
以下是一个基于Qt和OpenSceneGraph(OSG)实现三维模型交互的示例代码,包含模型高亮、文本标注等功能。代码采用Qt5和OSG 3.6版本开发。 一、核心类设计(C) 1. 主窗口类(继承QMainWindow) #inc…...

Spring Cloud:构建云原生微服务架构的最佳工具和实践
🌥️ 1. 引言 一、背景介绍:为什么需要微服务? 随着互联网技术的发展,企业级应用的功能日益复杂,传统的单体架构(Monolithic Architecture)逐渐暴露出一系列问题: 项目庞大&#…...

云图库和黑马点评的项目学习经验
捷优商超 我这个项目我主要实现了三个点,第一个是博主推送,就是用户进行消息的推送,拱用户进行商品的评价。第二个就是用户的签到。第三个就是优惠券秒杀了。 首先是博主推送,我们获取到前端信息以后直接把消息放到数据库里面&…...

苍穹外卖 - Day02 学习笔记
一、核心功能:新增员工 在实现新增员工功能时,有几个关键的技术点和设计考量需要我们掌握。 1.1 数据传输对象 (DTO) 的应用 核心概念: 数据传输对象(Data Transfer Object, DTO)是在应用程序不同分层之间传递数据的…...
——创建型模式之工厂方法)
设计模式(9)——创建型模式之工厂方法
设计模式(9)——创建型模式之工厂方法 工厂方法作用结构伪代码适用场景工厂方法 作用 工厂方法是一种创建型设计模式,其在父类中提供一个创建对象的方法,允许子类决定实例化对象的类型。 结构 产品(Product)将会对接口进行声明。对于所有由创建者及其子类构建的对象,…...

机器学习基础课程-6-课程实验
目录 6.1 实验介绍 实验准备 贷款审批结果预测 6.2 数据读取 6.3 数据处理 6.4 特征处理 有序型特征处理 类别型特征处理 数值型特征归一化 6.5 建立机器学习模型 建立测试模型 结果可视化 6.1 实验介绍 贷款审批结果预测 银行的放贷审批,核心要素为风险控制。因此&…...

IP SSL怎么签发使用
IP证书的签发首先是需要有一个可供绑定的IP地址,作为常用数字证书之一,IP证书也因为其广泛的应用范围而深得用户的青睐和喜欢。 部署IP证书后,可以实现该IP地址的https访问,过程和域名证书相差不多。 IP证书和域名证书的区别 很…...
(理论部分))
QMK键盘编码器(Encoder)(理论部分)
QMK键盘编码器(Encoder)(理论部分) 前言 作为一名深耕机械键盘DIY多年的老司机,我发现很多键盘爱好者对QMK编码器的配置总是一知半解。今天我就把多年积累的经验毫无保留地分享给大家,从硬件接线到软件配置,从基础应用到高阶玩法,一文全搞定!保证看完就能让你的编码…...

AI编程:使用Trae + Claude生成原型图,提示词分享
最近在学习AI编程相关的东西,看到了有人分享的提示词,做了两个APP原型图,分享给大家。 成果 第一个是依据B站的 探索者-子默 的视频,照着生成的AI改写原型图 第二个是我修改了一下提示词让AI生成做视频解析链接的APP原型图。 整体…...
详细讲解进程的组成与特性,状态与转换)
计算机操作系统(七)详细讲解进程的组成与特性,状态与转换
计算机操作系统(七)进程的组成与特性,状态与转换 前言一、进程的组成1. 什么是“进程”?2. 进程的三个核心组成部分2.1 PCB(进程控制块)—— 进程的“身份证户口本”2.2 程序段—— 进程的“任务清单”2.3 …...
)
【2025.5.12】视觉语言模型 (更好、更快、更强)
【2025.5.12】Vision Language Models (Better, Faster, Stronger): https://huggingface.co/blog/vlms-2025 【2024.4.11】Vision Language Models Explained【先了解视觉语言模型是什么】: https://huggingface.co/blog/vlms nanoVLM: https://github.…...

数据清洗ETL
ETL介绍 “ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL一词较常用在数据仓库,…...
详解)
STM32 实时时钟(RTC)详解
一、RTC 简介 RTC(Real Time Clock)即实时时钟,本质上是一个 32 位的秒级计数器: 最大计数值为 4294967295 秒,约合 136 年: 复制编辑 4294967295 / 60 / 60 / 24 / 365 ≈ 136 年 RTC 初始化时&#x…...

Java中的异常机制
目录 Error(错误) Exception(异常) 受检异常(Checked Exception) 非受检异常(Unchecked Exception) 图示总结: 异常处理机制 try-catch-finally throws关键字 图…...

计算机网络:怎么理解调制解调器的数字调制技术?
数字调制技术详解 数字调制技术是将数字比特流转换为适合在物理信道(如电缆、光纤、无线信道)传输的模拟信号的核心技术。通过改变载波(通常是正弦波)的幅度、频率或相位(或组合),将二进制数据映射到模拟波形上。其目标是高效利用频谱资源、提升抗干扰能力,并适应不同…...

【MySQL】自适应哈希详解:作用、配置以及如何查看
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

【sql】按照数据的日期/天 ,对入库数据做数量分类
我今天写SQL,发现我的时间的写法是“年-月-日 时:分:秒 ”, 我想要按照“年-月-日”分类,看看我每一天的入库数据量是多少,然后做出一个报表出来。 sql对时间的处理: SELECT DATE(update_time) AS date_only,COUNT(*…...

【PostgreSQL数据分析实战:从数据清洗到可视化全流程】附录-A. PostgreSQL常用函数速查表
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL常用函数速查表:从数据清洗到分析的全场景工具集引言一、字符串处理函数1.1 基础操作函数1.2 模式匹配函数(正则表达式) 二、数…...
)
【软件测试】:推荐一些接口与自动化测试学习练习网站(API测试与自动化学习全攻略)
一、API测试练习平台 Postman Learning Center (https://learning.postman.com/) 特点:Postman官方学习中心,提供API测试完整教程(含视频、文档、沙盒环境) 练习场景:请求构造、环境变量、自动…...

iOS Safari调试教程
iOS Safari调试 本教程将指导您如何使用WebDebugX调试iOS设备上的Safari浏览器。通过本教程,您将学习如何连接iOS设备、调试Safari中的网页、分析性能问题以及解决常见的调试挑战。 准备工作 在开始调试iOS Safari之前,请确保您已经: 安装…...

Java 大视界——Java 大数据在智慧交通智能停车诱导系统中的数据融合与实时更新
面对城市停车资源错配导致的30%以上交通拥堵问题,本文以某新一线城市智慧交通项目为蓝本,深度解析Java大数据技术如何实现多源停车数据融合、动态路径规划与诱导策略优化。通过构建“感知-计算-决策”全链路系统,实现车位状态更新延迟<200…...

KUKA库卡焊接机器人智能气阀
在工业焊接的大舞台上,成本把控与环保考量愈发重要。KUKA 库卡焊接机器人智能气阀,作为前沿科技结晶,成为实现库卡焊接机器人节气的关键 “利器”,助力企业在降本增效与绿色发展之路上大步迈进。 智能气阀融合先进传感与智能调…...

react中安装依赖时的问题 【集合】
目录 依赖升级/更新 1、 npm install --save-dev 与 npm install 的区别 1. 安装位置(依赖类型) 2. package.json 中的区别 3. 示例 4. 何时使用哪种方式 2、npm install 和 yarn add 有什么不一样吗 命令语法: …...

【网络实验】-BGP-EBGP的基本配置
实验拓扑 实验要求: 使用两种方式建立不同AS号的BGP邻居,不同AS号路由器之间建立的邻居称为EBGP邻居 实验目的: 熟悉使用物理口和环回口建立邻居的方式 IP地址规划: 路由器接口IP地址AR1G0/0/012.1.1.1/24AR1Loopback 01.1.1…...

【嵌入式开发-按键扫描】
嵌入式开发-按键扫描 ■ 1. 按键■ 按键队列发送后在读取队列处理■ 定时器30ms扫描一次,并通过MsgAdd(msg); 发送出去。 ■ 2. 触摸屏处理■■ ■ 1. 按键 ■ 按键队列发送后在读取队列处理 // key queue #define KEY_QUEUE_MAX 5typedef enum {KEY_TYPE_IR 0,K…...

NineData 社区版 V4.1.0 正式发布,新增 4 条迁移链路,本地化数据管理能力再升级
NineData 社区版 V4.1.0 正式更新发布。本次通过新增 4 条迁移链路扩展、国产数据库深度适配、敏感数据保护增强等升级,进一步巩固了其作为高效、安全、易用的数据管理工具的定位。无论是开发测试、数据迁移,还是多环境的数据管理,NineData…...

TypeScript装饰器:从入门到精通
TypeScript装饰器:从入门到精通 什么是装饰器? 装饰器(Decorator)是TypeScript中一个非常酷的特性,它允许我们在不修改原有代码的情况下,给类、方法、属性等添加额外的功能。想象一下装饰器就像给你的代码…...

R语言学习--Day02--实战经验反馈
最近在做需要用R语言做数据清洗的项目,在网上看再多的技巧与语法,都不如在项目中实战学习的快,下面是我通过实战得来的经验。 判断Rstudio是否卡死 很多时候,我们在运行R语言代码时,即使只是运行框选的几行代码&#…...

《AI驱动的智能推荐系统:原理、应用与未来》
一、引言 在当今信息爆炸的时代,用户面临着海量的信息选择,从购物平台上的商品推荐到流媒体服务中的影视推荐,智能推荐系统已经成为我们日常生活中不可或缺的一部分。AI驱动的智能推荐系统通过分析用户的行为和偏好,为用户提供个性…...

AR禁毒:科技赋能,筑牢防毒新防线
过去,传统禁毒宣传教育方式对普及禁毒知识、提高禁毒意识意义重大。但随着时代和社会环境变化,其困境逐渐显现。传统宣传方式单一,主要依靠讲座、发传单、办展览。讲座形式枯燥,对青少年吸引力不足;发传单易被丢弃&…...