机器学习基础课程-6-课程实验
目录
6.1 实验介绍
实验准备
贷款审批结果预测
6.2 数据读取
6.3 数据处理
6.4 特征处理
有序型特征处理
类别型特征处理
数值型特征归一化
6.5 建立机器学习模型
建立测试模型
结果可视化
6.1 实验介绍
贷款审批结果预测
银行的放贷审批,核心要素为风险控制。因此,对于申请人的审查关注的要点为违约可能性。而违约可能性通常由申请人收入情况、稳定性、贷款数额及偿还年限等因素来衡量。该项目根据申请人条件,进一步细化得到各个变量对于违约评估的影响,从而预测银行是否会批准贷款申请。在项目实现过程中使用了经典的机器学习算法,对申请贷款客户进行科学归类,从而帮助金融机构提高对贷款信用风险的控制能力。
6.2 数据读取
数据读取
import pandas as pd
file = './data/loan_records.csv'
loan_df = pd.read_csv(file)
数据预览
print('数据集一共有{}行,{}列'.format(loan_df.shape[0], loan_df.shape[1]))
数据集一共有614行,13列
loan_df.head()

从贷款数据样本中,可以观察得到数据的特征
- Loan_ID:样本标号
- 性别:贷款人性别
- 已婚:是否结婚 (Y/N)
- 家属:供养人数
- 教育: 受教育程度(研究生/非研究生)
- Self_Employed:是否自雇 (Y/N)
- 申请人收入:申请人收入
- 共同申请人收入:联合申请人收入
- 贷款金额:贷款金额(单位:千)
- Loan_Amount_Term:贷款期限(单位:月)
- Credit_History:历史信用是否达标(0/1)
- Property_Area:居住地区(城市/半城市/农村)
- Loan_Status:是否批准(Y/N)
在我们即将构建的机器学习模型当中,Loan_Status将是模型训练的目标列
数据统计信息
loan_df.describe()
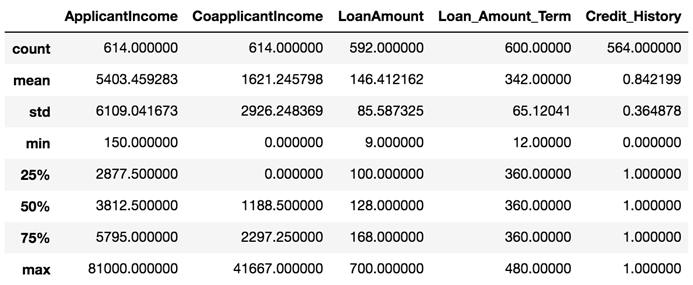
观察数据情况可以得知:
- LoanAmount、Loan_Amount_Term、Credit_History有明显的缺失值,需要进行空值处理
6.3 数据处理
重复值处理
if loan_df[loan_df['Loan_ID'].duplicated()].shape[0] > 0:
print('数据集存在重复样本')
else:
print('数据集不存在重复样本')
数据集不存在重复样本
缺失值处理
cols = loan_df.columns.tolist()
for col in cols:
empty_count = loan_df[col].isnull().sum()
print('{} 空记录数为:{}'.format(col, empty_count))
Loan_ID 空记录数为:0
Gender 空记录数为:13
Married 空记录数为:3
Dependents 空记录数为:15
Education 空记录数为:0
Self_Employed 空记录数为:32
ApplicantIncome 空记录数为:0
CoapplicantIncome 空记录数为:0
LoanAmount 空记录数为:22
Loan_Amount_Term 空记录数为:14
Credit_History 空记录数为:50
Property_Area 空记录数为:0
Loan_Status 空记录数为:0
# 将存在空值的样本删除
clean_loan_df = loan_df.dropna()
print('原始样本数为{},清理后的样本数为{}'.format(loan_df.shape[0], clean_loan_df.shape[0]))
原始样本数为614,清理后的样本数为480
特殊值处理
数值列Dependents包含3+,将其全部转换为3
# 可忽略SettingWithCopyWarning
clean_loan_df.loc[clean_loan_df['Dependents'] == '3+', 'Dependents'] = 3
特征数据和标签数据提取
在该数据集中,共有以下三种特征列
- 数值型特征列
-
- 家属:供养人数
- 申请人收入:申请人收入
- 共同申请人收入:联合申请人收入
- 贷款金额:贷款金额(单位:千)
- Loan_Amount_Term:贷款期限(单位:月)
- 有序型特征
-
- 教育: 受教育程度(研究生/非研究生)
- Credit_History:历史信用是否达标(0/1)
- 类别型特征
-
- 性别:贷款人性别
- 已婚:是否结婚 (Y/N)
- Self_Employed:是否自雇 (Y/N)
- Property_Area:居住地区(城市/半城市/农村)
# 按数据类型指定特征列
# 1. 数值型特征列
num_cols = ['Dependents', 'ApplicantIncome', 'CoapplicantIncome', 'LoanAmount', 'Loan_Amount_Term']
# 2. 有序型特征
ord_cols = ['Education', 'Credit_History']
# 3. 类别型特征
cat_cols = ['Gender', 'Married', 'Self_Employed', 'Property_Area']
feat_cols = num_cols + ord_cols + cat_cols
# 特征数据
feat_df = clean_loan_df[feat_cols]
#################################################################
# TODO
# 将标签Y转换为1,标签N转换为0
# 并将结果保存至labels变量中
labels = clean_loan_df['Loan_Status'].copy()
labels.loc[clean_loan_df['Loan_Status'] == 'Y'] = 1
labels.loc[clean_loan_df['Loan_Status'] == 'N'] = 0
#################################################################
现在我们需要划分数据集为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(feat_df, labels, random_state=10, test_size=1/4)
print('训练集有{}条记录,测试集有{}条记录'.format(X_train.shape[0], X_test.shape[0]))
训练集有360条记录,测试集有120条记录
6.4 特征处理
有序型特征处理
有序型特征中Credit_History已经是数值,只需要转换教育列就即可:将Graduate转为1,Not Graduate转为0
# 可忽略SettingWithCopyWarning# 在训练集上做处理X_train.loc[X_train['Education'] == 'Graduate', 'Education'] = 1X_train.loc[X_train['Education'] == 'Not Graduate', 'Education'] = 0# 在测试集上做处理X_test.loc[X_test['Education'] == 'Graduate', 'Education'] = 1X_test.loc[X_test['Education'] == 'Not Graduate', 'Education'] = 0# 获取有序型特征处理结果train_ord_feats = X_train[ord_cols].valuestest_ord_feats = X_test[ord_cols].values类别型特征处理
from sklearn.preprocessing import LabelEncoder, OneHotEncoderimport numpy as npdef encode_cat_feats(train_df, test_df, col_name): """ 对某列类别型数据进行编码 """ # 类别型数据 train_cat_feat = X_train[col_name].values test_cat_feat = X_test[col_name].values label_enc = LabelEncoder() onehot_enc = OneHotEncoder(sparse=False) # 在训练集上处理 proc_train_cat_feat = label_enc.fit_transform(train_cat_feat).reshape(-1, 1) proc_train_cat_feat = onehot_enc.fit_transform(proc_train_cat_feat) # 在测试集上处理 proc_test_cat_feat = label_enc.transform(test_cat_feat).reshape(-1, 1) proc_test_cat_feat = onehot_enc.transform(proc_test_cat_feat) return proc_train_cat_feat, proc_test_cat_feat# 初始化编码处理后的特征enc_train_cat_feats = Noneenc_test_cat_feats = None# 对每个类别型特征进行编码处理for cat_col in cat_cols: enc_train_cat_feat, enc_test_cat_feat = encode_cat_feats(X_train, X_test, cat_col) # 在训练数据上合并特征 if enc_train_cat_feats is None: enc_train_cat_feats = enc_train_cat_feat else: enc_train_cat_feats = np.hstack((enc_train_cat_feats, enc_train_cat_feat)) # 在测试数据上合并特征 if enc_test_cat_feats is None: enc_test_cat_feats = enc_test_cat_feat else: enc_test_cat_feats = np.hstack((enc_test_cat_feats, enc_test_cat_feat))数值型特征归一化
将所有特征进行合并,然后进行范围归一化。
from sklearn.preprocessing import MinMaxScaler# 获取数值型特征train_num_feats = X_train[num_cols].valuestest_num_feats = X_test[num_cols].values# 合并序列型特征、类别型特征、数值型特征all_train_feats = np.hstack((train_ord_feats, enc_train_cat_feats, train_num_feats))all_test_feats = np.hstack((test_ord_feats, enc_test_cat_feats, test_num_feats))################################################################## TODO# 数值归一化到0-1# 将处理后的训练特征保存到变量all_proc_train_feats中# 将处理后的测试特征保存到变量all_proc_test_feats中scaler = MinMaxScaler(feature_range=(0, 1))all_proc_train_feats = scaler.fit_transform(all_train_feats)all_proc_test_feats = scaler.transform(all_test_feats)#################################################################print('处理后的特征维度为', all_proc_train_feats.shape[1])处理后的特征维度为 166.5 建立机器学习模型
建立测试模型
使用网格搜索(GridSearchCV)来调整模型的重要参数
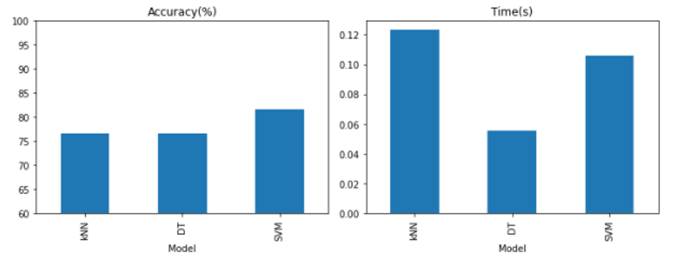
from sklearn.linear_model import LogisticRegressionfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.svm import SVCfrom sklearn.model_selection import GridSearchCVimport timedef train_test_model(X_train, y_train, X_test, y_test, model_name, model, param_range): """ 训练并测试模型 model_name: kNN kNN模型,对应参数为 n_neighbors LR 逻辑回归模型,对应参数为 C SVM 支持向量机,对应参数为 C DT 决策树,对应参数为 max_depth Stacking 将kNN, SVM, DT集成的Stacking模型, meta分类器为LR AdaBoost AdaBoost模型,对应参数为 n_estimators GBDT GBDT模型,对应参数为 learning_rate RF 随机森林模型,对应参数为 n_estimators 根据给定的参数训练模型,并返回 1. 最优模型 2. 平均训练耗时 3. 准确率 """ print('训练{}...'.format(model_name)) ################################################################# # TODO # 初始化网格搜索方法进行模型训练,使用5折交叉验证,保存到变量clf中 clf = GridSearchCV(estimator=model, param_grid=param_range, cv=5, scoring='accuracy', refit=True) start = time.time() clf.fit(X_train, y_train) ################################################################# start = time.time() clf.fit(X_train, y_train) # 计时 end = time.time() duration = end - start print('耗时{:.4f}s'.format(duration)) # 验证模型 train_score = clf.score(X_train, y_train) print('训练准确率:{:.3f}%'.format(train_score * 100)) test_score = clf.score(X_test, y_test) print('测试准确率:{:.3f}%'.format(test_score * 100)) print('训练模型耗时: {:.4f}s'.format(duration)) y_pred = clf.predict(X_test) return clf, test_score, duration################################################################## TODO# 在model_name_param_dict中添加逻辑回归和SVM分类器,并指定相应的超参数及搜索范围model_name_param_dict = {'kNN': (KNeighborsClassifier(), {'n_neighbors': [1, 5, 15]}), 'DT': (DecisionTreeClassifier(), {'max_depth': [10, 50, 100]}), 'SVM': (SVC(kernel='linear'), {'C': [0.01, 1, 100]}), 'DT': (DecisionTreeClassifier(), {'max_depth': [10, 50, 100]}) }################################################################## 比较结果的DataFrameresults_df = pd.DataFrame(columns=['Accuracy (%)', 'Time (s)'], index=list(model_name_param_dict.keys()))results_df.index.name = 'Model'for model_name, (model, param_range) in model_name_param_dict.items(): _, best_acc, mean_duration = train_test_model(all_proc_train_feats, y_train.astype('int'), all_proc_test_feats, y_test.astype('int'), model_name, model, param_range) results_df.loc[model_name, 'Accuracy (%)'] = best_acc * 100 results_df.loc[model_name, 'Time (s)'] = mean_duration训练kNN...耗时0.0661s训练准确率:80.556%测试准确率:76.667%训练模型耗时: 0.0661s训练DT...耗时0.0442s训练准确率:91.111%测试准确率:76.667%训练模型耗时: 0.0442s训练SVM...耗时0.1124s训练准确率:80.556%测试准确率:81.667%训练模型耗时: 0.1124s结果可视化
现在对比一下各个模型的效率和他们的准确率吧!
# 结果可视化import matplotlib.pyplot as plt%matplotlib inlineplt.figure(figsize=(10, 4))ax1 = plt.subplot(1, 2, 1)results_df.plot(y=['Accuracy (%)'], kind='bar', ylim=[60, 100], ax=ax1, title='Accuracy(%)', legend=False)ax2 = plt.subplot(1, 2, 2)results_df.plot(y=['Time (s)'], kind='bar', ax=ax2, title='Time(s)', legend=False)plt.tight_layout()plt.show()
相关文章:

机器学习基础课程-6-课程实验
目录 6.1 实验介绍 实验准备 贷款审批结果预测 6.2 数据读取 6.3 数据处理 6.4 特征处理 有序型特征处理 类别型特征处理 数值型特征归一化 6.5 建立机器学习模型 建立测试模型 结果可视化 6.1 实验介绍 贷款审批结果预测 银行的放贷审批,核心要素为风险控制。因此&…...

IP SSL怎么签发使用
IP证书的签发首先是需要有一个可供绑定的IP地址,作为常用数字证书之一,IP证书也因为其广泛的应用范围而深得用户的青睐和喜欢。 部署IP证书后,可以实现该IP地址的https访问,过程和域名证书相差不多。 IP证书和域名证书的区别 很…...
(理论部分))
QMK键盘编码器(Encoder)(理论部分)
QMK键盘编码器(Encoder)(理论部分) 前言 作为一名深耕机械键盘DIY多年的老司机,我发现很多键盘爱好者对QMK编码器的配置总是一知半解。今天我就把多年积累的经验毫无保留地分享给大家,从硬件接线到软件配置,从基础应用到高阶玩法,一文全搞定!保证看完就能让你的编码…...

AI编程:使用Trae + Claude生成原型图,提示词分享
最近在学习AI编程相关的东西,看到了有人分享的提示词,做了两个APP原型图,分享给大家。 成果 第一个是依据B站的 探索者-子默 的视频,照着生成的AI改写原型图 第二个是我修改了一下提示词让AI生成做视频解析链接的APP原型图。 整体…...
详细讲解进程的组成与特性,状态与转换)
计算机操作系统(七)详细讲解进程的组成与特性,状态与转换
计算机操作系统(七)进程的组成与特性,状态与转换 前言一、进程的组成1. 什么是“进程”?2. 进程的三个核心组成部分2.1 PCB(进程控制块)—— 进程的“身份证户口本”2.2 程序段—— 进程的“任务清单”2.3 …...
)
【2025.5.12】视觉语言模型 (更好、更快、更强)
【2025.5.12】Vision Language Models (Better, Faster, Stronger): https://huggingface.co/blog/vlms-2025 【2024.4.11】Vision Language Models Explained【先了解视觉语言模型是什么】: https://huggingface.co/blog/vlms nanoVLM: https://github.…...

数据清洗ETL
ETL介绍 “ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL一词较常用在数据仓库,…...
详解)
STM32 实时时钟(RTC)详解
一、RTC 简介 RTC(Real Time Clock)即实时时钟,本质上是一个 32 位的秒级计数器: 最大计数值为 4294967295 秒,约合 136 年: 复制编辑 4294967295 / 60 / 60 / 24 / 365 ≈ 136 年 RTC 初始化时&#x…...

Java中的异常机制
目录 Error(错误) Exception(异常) 受检异常(Checked Exception) 非受检异常(Unchecked Exception) 图示总结: 异常处理机制 try-catch-finally throws关键字 图…...

计算机网络:怎么理解调制解调器的数字调制技术?
数字调制技术详解 数字调制技术是将数字比特流转换为适合在物理信道(如电缆、光纤、无线信道)传输的模拟信号的核心技术。通过改变载波(通常是正弦波)的幅度、频率或相位(或组合),将二进制数据映射到模拟波形上。其目标是高效利用频谱资源、提升抗干扰能力,并适应不同…...

【MySQL】自适应哈希详解:作用、配置以及如何查看
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

【sql】按照数据的日期/天 ,对入库数据做数量分类
我今天写SQL,发现我的时间的写法是“年-月-日 时:分:秒 ”, 我想要按照“年-月-日”分类,看看我每一天的入库数据量是多少,然后做出一个报表出来。 sql对时间的处理: SELECT DATE(update_time) AS date_only,COUNT(*…...

【PostgreSQL数据分析实战:从数据清洗到可视化全流程】附录-A. PostgreSQL常用函数速查表
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL常用函数速查表:从数据清洗到分析的全场景工具集引言一、字符串处理函数1.1 基础操作函数1.2 模式匹配函数(正则表达式) 二、数…...
)
【软件测试】:推荐一些接口与自动化测试学习练习网站(API测试与自动化学习全攻略)
一、API测试练习平台 Postman Learning Center (https://learning.postman.com/) 特点:Postman官方学习中心,提供API测试完整教程(含视频、文档、沙盒环境) 练习场景:请求构造、环境变量、自动…...

iOS Safari调试教程
iOS Safari调试 本教程将指导您如何使用WebDebugX调试iOS设备上的Safari浏览器。通过本教程,您将学习如何连接iOS设备、调试Safari中的网页、分析性能问题以及解决常见的调试挑战。 准备工作 在开始调试iOS Safari之前,请确保您已经: 安装…...

Java 大视界——Java 大数据在智慧交通智能停车诱导系统中的数据融合与实时更新
面对城市停车资源错配导致的30%以上交通拥堵问题,本文以某新一线城市智慧交通项目为蓝本,深度解析Java大数据技术如何实现多源停车数据融合、动态路径规划与诱导策略优化。通过构建“感知-计算-决策”全链路系统,实现车位状态更新延迟<200…...

KUKA库卡焊接机器人智能气阀
在工业焊接的大舞台上,成本把控与环保考量愈发重要。KUKA 库卡焊接机器人智能气阀,作为前沿科技结晶,成为实现库卡焊接机器人节气的关键 “利器”,助力企业在降本增效与绿色发展之路上大步迈进。 智能气阀融合先进传感与智能调…...

react中安装依赖时的问题 【集合】
目录 依赖升级/更新 1、 npm install --save-dev 与 npm install 的区别 1. 安装位置(依赖类型) 2. package.json 中的区别 3. 示例 4. 何时使用哪种方式 2、npm install 和 yarn add 有什么不一样吗 命令语法: …...

【网络实验】-BGP-EBGP的基本配置
实验拓扑 实验要求: 使用两种方式建立不同AS号的BGP邻居,不同AS号路由器之间建立的邻居称为EBGP邻居 实验目的: 熟悉使用物理口和环回口建立邻居的方式 IP地址规划: 路由器接口IP地址AR1G0/0/012.1.1.1/24AR1Loopback 01.1.1…...

【嵌入式开发-按键扫描】
嵌入式开发-按键扫描 ■ 1. 按键■ 按键队列发送后在读取队列处理■ 定时器30ms扫描一次,并通过MsgAdd(msg); 发送出去。 ■ 2. 触摸屏处理■■ ■ 1. 按键 ■ 按键队列发送后在读取队列处理 // key queue #define KEY_QUEUE_MAX 5typedef enum {KEY_TYPE_IR 0,K…...

NineData 社区版 V4.1.0 正式发布,新增 4 条迁移链路,本地化数据管理能力再升级
NineData 社区版 V4.1.0 正式更新发布。本次通过新增 4 条迁移链路扩展、国产数据库深度适配、敏感数据保护增强等升级,进一步巩固了其作为高效、安全、易用的数据管理工具的定位。无论是开发测试、数据迁移,还是多环境的数据管理,NineData…...

TypeScript装饰器:从入门到精通
TypeScript装饰器:从入门到精通 什么是装饰器? 装饰器(Decorator)是TypeScript中一个非常酷的特性,它允许我们在不修改原有代码的情况下,给类、方法、属性等添加额外的功能。想象一下装饰器就像给你的代码…...

R语言学习--Day02--实战经验反馈
最近在做需要用R语言做数据清洗的项目,在网上看再多的技巧与语法,都不如在项目中实战学习的快,下面是我通过实战得来的经验。 判断Rstudio是否卡死 很多时候,我们在运行R语言代码时,即使只是运行框选的几行代码&#…...

《AI驱动的智能推荐系统:原理、应用与未来》
一、引言 在当今信息爆炸的时代,用户面临着海量的信息选择,从购物平台上的商品推荐到流媒体服务中的影视推荐,智能推荐系统已经成为我们日常生活中不可或缺的一部分。AI驱动的智能推荐系统通过分析用户的行为和偏好,为用户提供个性…...

AR禁毒:科技赋能,筑牢防毒新防线
过去,传统禁毒宣传教育方式对普及禁毒知识、提高禁毒意识意义重大。但随着时代和社会环境变化,其困境逐渐显现。传统宣传方式单一,主要依靠讲座、发传单、办展览。讲座形式枯燥,对青少年吸引力不足;发传单易被丢弃&…...

Ubuntu摄像头打开失败
如果遇见上面Ubuntu连接摄像头但无法打开如以上 先安装cheese apt install cheese 打开终端控制台,输入以下命令 ls /dev/video* 出现以上有设备的情况,我们采用以下解决 : 1、点击虚拟机->点击设置 2、 进入设置界面点击USB控制器&a…...
AclConcreteGraph:capture_begin)
Ascend的aclgraph(七)AclConcreteGraph:capture_begin
1 回顾 在上一章Ascend的aclgraph(六)AclConcreteGraph中提到了capture_begin和capture_end两个函数,这2个函数是pybind形式,调用到torch_npu中去执行。 大概流程图如下: def __enter__(self):# Free as much memory as we can…...

JT/T 808 各版本协议字段级别对比与解析适配建议
文章目录 一、概述二、字段级对比表(以核心消息为例)三、版本文档结构差异分析四、Java 协议解析适配建议4.1、协议版本识别策略:4.2、可扩展消息体结构设计:4.3、字段兼容处理建议:4.4、推荐使用解析库或框架…...

Kafka 消费者组进度监控方法解析
#作者:张桐瑞 文章目录 前言一、使用 Kafka 自带命令行工具 kafka-consumer-groups 脚本二、使用 Kafka Java Consumer API 编程三、使用 Kafka 自带的 JMX 监控指标 前言 在 Kafka 消息队列系统中,对于 Kafka 消费者而言,监控其消费进度&a…...

国产大模型 “五强争霸”,决战 AGI
中国 AI 大模型市场正经历一场史无前例的洗牌!曾经 “百模混战” 的局面已落幕,字节、阿里、阶跃星辰、智谱和 DeepSeek 五大巨头强势崛起,形成 “基模五强” 新格局。这场竞争不仅是技术实力的较量,更是资源、人才与生态的全面博…...
)
lesson01-PyTorch初见(理论+代码实战)
一、初识PyTorch 二、同类框架 PyTorchVSTensorFlow 三、参数 对比 四、PyTorch生态 四、常用的网络层 五、代码分析 import torch from torch import autogradx torch.tensor(1.) a torch.tensor(1., requires_gradTrue) b torch.tensor(2., requires_gradTrue) c tor…...

几种运放典型应用电路
运算放大器简称:OP、OPA、OPAMP、运放。 一、电压跟随器 电压跟随器顾名思义运放的输入端电压与运放的输出电压相等 这个电路一般应用目的是增加电压驱动能力: 比如说有个3V电源,借一个负载,随着负载电流变大,3V就会变小说明3V电源带负载能力小,驱动能力弱,这个时候…...

Mybatis——动态sql
<if> 实现方式 动态标签 <if> 条件判断,进行sql语句拼接 成立则拼接 <where> 进行条件子句拼接,防止and重复 if案例 crtl alt L 格式化 <foreach>——用于批量操作(删除) <include>...

技术社区集锦
推荐地址 社区汇总地址 https://juejin.cn/post/7468935497799286834 社区 项目ValueValueGitHubgithub.com-----Giteegitee.com-----StackOverflowstackoverflow.com全球知名的技术问答网站博客园www.cnblogs.com开发者的知识分享社区稀土掘金juejin.cn技术内容分享与交流平…...

【Elasticsearch】DSL 篇
Elasticsearch 之 DSL 篇 介绍 Elasticsearch 提供了基于 JSON 的 DSL 语句来定义查询条件,其 JavaAPI 就是在组织 DSL 条件。 先学习 DSL 的查询语法,然后再基于 DSL 来对照学习 JavaAPI,就会事半功倍 json 格式,好理解&#…...

常见 RPC 协议类别对比
RPC(Remote Procedure Call,远程过程调用)协议是分布式系统中实现跨进程通信的核心机制之一。它允许客户端像调用本地函数一样调用远端服务器上的函数。 根据通信方式、数据编码方式和平台兼容性不同,常见的 RPC 协议分为以下几类…...
)
React系列——nvm、node、npm、yarn(MAC)
nvm,node,npm之间的区别 1、nvm:nodejs版本管理工具。nvm 可以管理很多 node 版本和 npm 版本。 2、nodejs:在项目开发时的所需要的代码库 3、npm:nodejs包管理工具。nvm、nodejs、npm的关系 nvm 管理 nodejs 和 npm…...

LeetCode 热题 100 230. 二叉搜索树中第 K 小的元素
LeetCode 热题 100 | 230. 二叉搜索树中第 K 小的元素 大家好,今天我们来解决一道经典的二叉搜索树问题——二叉搜索树中第 K 小的元素。这道题在 LeetCode 上被标记为中等难度,要求查找二叉搜索树中的第 K 小的元素。 问题描述 给定一个二叉搜索树的根…...

vscode - 笔记
1 IDE就用vscode,安装Remote-SSH插件通过SSH访问树莓派里的文件夹 写在开始:阿尔法Linux开发板学习开始 - 银色的音色 - 博客园 2 VSCode之Linux C/C开发和调试 VSCode之Linux C/C开发和调试 CMake代码编译 json配置_哔哩哔哩_bilibili 3 VS Code 凭…...

使用VSCode编辑Markdown+PlantUml
vscode :https://code.visualstudio.com/ 什么是markdown: Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档。 Markdown 编写的文档可以导出 HTML 、Word、图像、PDF、Epub 等多种格式的文档。 在vscode上安装MarkDown相关…...

关于 Golang GC 机制的一些细节:什么是根对象?GC 机制的触发时机?
文章目录 关于 Golang GC 机制的一些细节:什么是根对象?GC 机制的触发时机?简要回顾 Golang GC 三色标记法的工作流程什么是根对象?GC 的触发时机? 关于 Golang GC 机制的一些细节:什么是根对象?…...
是什么?)
内存虚拟盘(RAMDisk)是什么?
内存虚拟盘(RAMDisk)是一种通过软件将计算机的部分物理内存(RAM)模拟为硬盘驱动器的技术,利用内存的高速读写特性显著提升数据访问效率。以下从原理、优势、实现方式及应用场景等方面详细解析: 1. 技术原…...
的工作原理与应用场景)
深入浅出入侵检测系统(IDS)的工作原理与应用场景
网络安全界的“火眼金睛”:入侵检测系统IDS 一、IDS简介:网络安全界的“火眼金睛” 在计算机安全领域,有一个“火眼金睛”的角色,它能在网络世界中识破各种“妖魔鬼怪”的伪装,及时发出警报,保护我们的数…...

AISBench benchmark评测工具实操-精度评测场景-采用命令行指定模型和数据集的方式
一、环境信息 1.1.硬件设备 昇腾Atlas800 I A2:910A 01:00.0 Processing accelerators: Huawei Technologies Co., Ltd. Device d801 (rev 20) 1.2.软件信息 1.2.1模型: DeepSeek-R1-Distill-Qwen-1.5B 1.2.2.物理机系统: NAME="EulerOS" VERSION="2.0 …...

HTTP GET报文解读
考虑当浏览器发送一个HTTP GET报文时,通过Wireshark 俘获到下列ASCII字符串: GET /cs453/index.html HTTP/1.1 Host: gaia.cs.umass.edu User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.2) Gecko/20040804 Netscape/7.2 (ax) Acc…...

南审计院考研分享会 经验总结
汪学长 – 中科大 计科专硕 初试准备 数学先做真题,模拟题刷的越多分越高;408真题最重要,模拟题辅助;英语只做真题;政治9月份开始背 代码能力在低年级培养的重要性和路径 考研不选择机构原因 因为机构里面学习的框…...
)
Android多媒体——媒体解码流程分析(十四)
NuPlayer 的解码模块相对比较简单,统一使用了一个基类 NuPlayerDecoderBase 管理,该类中包含了一个 MediaCodec 的对象,实际解码工作全靠 MediaCodec。 一、解码器创建 解码器创建的入口在 NuPlayer 的 NuPlayer::instantiateDecoder() 函数调用时。NuPlayer 在执行 start(…...

学习threejs,使用Physijs物理引擎,通过控制重力,实现多米诺骨牌效果
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️Physijs 物理引擎1.1.1 ☘️…...
)
自由学习记录(60)
Lecture 16 Ray Tracing 4_哔哩哔哩_bilibili 老师说的“高频采样”问题是什么? 现在考虑一个特殊情况: ❗ 一个像素内,图像信号变化很剧烈(高频): 比如: 细网格纹理 马赛克背景 很高频的…...

Gartner《分布式和微服务架构中数据架构》学习心得
一、简介 随着信息技术的不断发展,软件架构也在持续演变以适应不断变化的业务需求。从传统的单体架构向分布式和微服务架构转变,给数据的管理带来了新的挑战和机遇。《Working With Data in Distributed and Microservices Architectures》研究针对在分布式和微服务架构中处…...