5月12日复盘-RNN
5月12日复盘
二、RNN 模型
1.先导
1.1 为什么需要循环神经网络 RNN
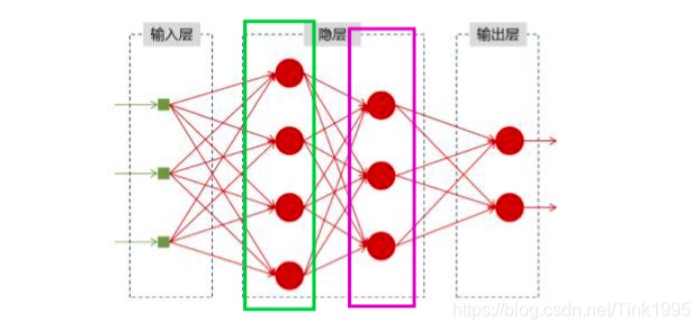
上图是一幅全连接神经网络图,我们可以看到输入层-隐藏层-输出层,他们每一层之间是相互独立地,(框框里面代表同一层),每一次输入生成一个节点,同一层中每个节点之间又相互独立的话,那么我们每一次的输入其实跟前面的输入是没有关系地。这样在某一些任务中便不能很好的处理序列信息。
1.2 时序数据
对于不同类型的数据和任务,理解数据的顺序和前后关系的重要性是至关重要的。对于图像识别这样的任务来说,图片的前后顺序并不会影响识别结果,因为图片中的像素是独立且无序的。但是,当涉及到文本、股票、天气、语音等具有时间顺序或逻辑顺序的数据时,顺序的变化会对结果产生显著影响。

举例来说,对于一句话"我吃苹果",如果改变顺序为"苹果吃我",意思完全变了。这种语言的表达方式对顺序和词语的关联有着极高的敏感性。而对于股票和天气数据,先后顺序也具有重要意义,因为后续的数据可能受到之前数据的影响,如股票市场的走势或天气的变化趋势。
在文本理解方面,顺序也至关重要。例如,对于经典的古诗"床前明月光,疑是地上霜。举头望明月,低头思故乡。“,如果改变了诗句的顺序,那么整首诗的意境和情感也将随之改变,这就是所谓的"蝴蝶效应”。一个微小的改变可能会导致整体结果的巨大变化。
因此,在处理具有时间或逻辑顺序的数据时,我们必须考虑到顺序的重要性,并设计相应的模型来充分利用数据的前后关系,以获得更准确和有意义的结果。这也是循环神经网络(RNN)等模型在这些任务中被广泛使用的原因之一,因为它们能够捕捉到数据的顺序信息,并根据前面的输入来预测后续的输出。
2. RNN 原理
2.1 概述
循环神经网络(Recurrent Neural Network,RNN)是一种神经网络结构,专门用于处理序列数据。与传统的前馈神经网络不同,RNN 在内部具有反馈连接,允许信息在网络内部传递。这种结构使得 RNN 能够对序列数据的历史信息进行建模,并在一定程度上具有记忆能力。
在自然语言处理领域,RNN 被广泛应用于语言建模、机器翻译、情感分析等任务。通过捕捉单词之间的上下文信息,RNN 能够更好地理解语言的含义和结构。
同时,RNN 也在时间序列预测领域发挥着重要作用,比如股票价格预测、天气预测等。通过学习序列数据的模式和趋势,RNN 能够提供有用的预测信息,帮助人们做出决策。
然而,传统的 RNN 存在一些问题,例如难以处理长期依赖关系、梯度消失或梯度爆炸等。为了解决这些问题,出现了一些改进的 RNN 变种,如长短期记忆网络(LSTM)和门控循环单元(GRU)。这些变种结构能够更有效地捕捉长期依赖关系,并且在训练过程中更加稳定。
2.2 模型架构
循环神经网络(RNN)是深度学习中的一种架构,专门设计来处理序列数据,例如时间序列数据或自然语言文本。RNN的核心特征在于它能够在处理序列的每个元素时保留一个内部状态(记忆),这个内部状态能够捕捉到之前元素的信息。这种设计使得RNN特别适合处理那些当前输出依赖于之前信息的任务。
常见的RNN架构如下图两种:
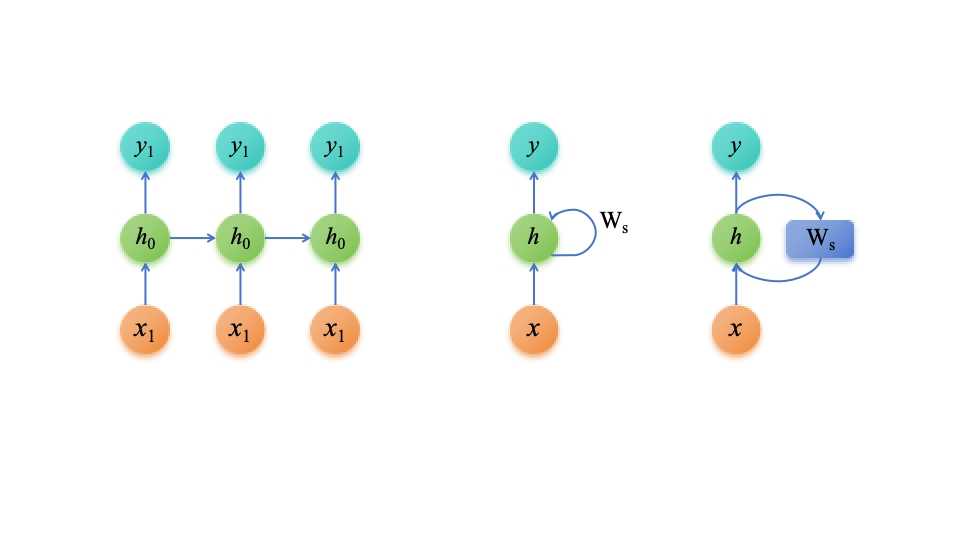
左图可以理解为,先将每一层的网络简化,再将网络旋转90度得到的简化图
而右边两种类型,可以理解为,再将左图继续进行简化
在RNN的经典架构中,网络通过一个特殊的循环结构将信息从一个处理步骤传递到下一个。这个循环结构通常被称为“隐藏层状态”或简单地称为“隐藏状态”。隐藏状态是RNN的记忆部分,它能够捕获并存储关于已处理序列元素的信息。
当RNN处理一个序列时,它会在每个时间步接受一个输入,并更新其隐藏状态。这个更新过程依赖于当前的输入和之前的隐藏状态,从而使得网络能够“记住”并利用过去的信息。这个过程可以通过以下数学公式简化表达:
s t = f ( U ⋅ x t + W ⋅ s t − 1 ) s_t=f(\mathbf{U}·x_t+\mathbf{W}·s_{t-1}) st=f(U⋅xt+W⋅st−1)
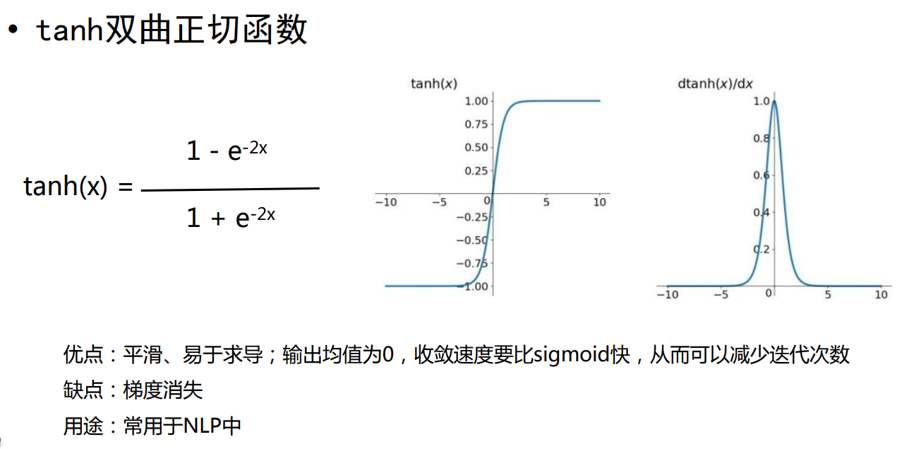
在这个公式中, S t {S}_{t} St表示在时间步t的隐藏状态, x t {x}_{t} xt是当前时间步的输入,U 和 W分别是输入到隐藏状态和隐藏状态到隐藏状态的权重矩阵。函数f通常是一个非线性函数,如tanh或ReLU,用于引入非线性特性并帮助网络学习复杂的模式。
RNN的输出在每个时间步也可以计算出来,这依赖于当前的隐藏状态:
- O t {O}_{t} Ot = g(V s t {s}_{t} st)
其中 O t {O}_{t} Ot是时间步t的输出,V是从隐藏状态到输出层的权重矩阵,g是另一个非线性函数,常用于输出层。
RNN也是传统的神经网络架构,但是他里面包含了一个“盒子”,这个盒子里记录了输入时网络的状态,在下一次输入时,必须要考虑“盒子”。随着不断的输入,盒子里也会更新,那么这个盒子就是“隐藏态”
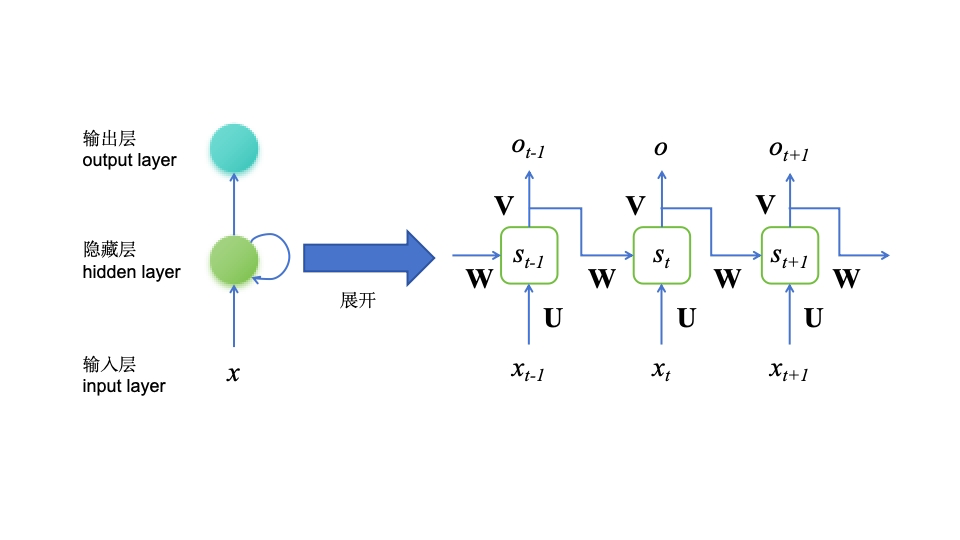
假设为一个包含三个单词的句子,将模型展开,即为一个三层的网络结构
可以理解为, x t − 1 {x}_{t-1} xt−1为第一个词, x t {x}_{t} xt为第二个词, x t + 1 {x}_{t+1} xt+1为第三个词
图中参数含义:
-
x t {x}_{t} xt表示第t步的输入。比如 x 1 {x}_{1} x1为第二个词的词向量( x 0 {x}_{0} x0为第一个词);
-
H t {H}_{t} Ht为隐藏层的第t步的状态,它是网络的记忆单元。
-
H t {H}_{t} Ht根据当前输入层的输出与上一时刻隐藏层的状态 H t − 1 {H}_{t-1} Ht−1进行计算,如下所示。
H t = f ( U ⋅ x t + W ⋅ H t − 1 ) H_t=f(\mathbf{U}·x_t+\mathbf{W}·H_{t-1}) Ht=f(U⋅xt+W⋅Ht−1) -
其中,U是输入层的连接矩阵,W是上一时刻隐含层到下一时刻隐含层的权重矩阵,f(·)一般是非线性的激活函数,如tanh或ReLU。
-
-
O t {O}_{t} Ot是第t步的输出。输出层是全连接层,即它的每个节点和隐含层的每个节点都互相连接,V是输出层的连接矩阵,g(·)一是激活函数。
-
o t = g ( V ⋅ s t ) o_t=g(\mathbf{V}·s_t) ot=g(V⋅st)
-
带入可以得到
H t = f ( W i n X t + W s H t − 1 + b t ) = f ( W i n X t + W s f ( W i n X t − 1 + W s H t − 2 + b t − 1 ) + b t ) = f ( W i n X t + W s f ( W i n X t − 1 + W s f ( W i n X t − 2 + W s H t − 3 + b t − 2 ) + b t − 1 ) + b t ) = f ( W i n X t + W s f ( W i n X t − 1 + W s f ( W i n X t − 2 + W s ( . . . ) ) + b t − 2 ) + b t − 1 ) + b t ) \begin{align} H_t&=f(\mathbf{W}_{in}X_t+\mathbf{W}_{s}H_{t-1}+b_t)\\ &=f(\mathbf{W}_{in}X_t+\mathbf{W}_{s}f(\mathbf{W}_{in}X_{t-1}+\mathbf{W}_{s}H_{t-2}+b_{t-1})+b_{t})\\ &=f(\mathbf{W}_{in}X_t+\mathbf{W}_{s}f(\mathbf{W}_{in}X_{t-1}+\mathbf{W}_{s}f(\mathbf{W}_{in}X_{t-2}+\mathbf{W}_{s}H_{t-3}+b_{t-2})+b_{t-1})+b_t)\\ &=f(\mathbf{W}_{in}X_t+\mathbf{W}_{s}f(\mathbf{W}_{in}X_{t-1}+\mathbf{W}_{s}f(\mathbf{W}_{in}X_{t-2}+\mathbf{W}_{s}(...))+b_{t-2})+b_{t-1})+b_t) \end{align} Ht=f(WinXt+WsHt−1+bt)=f(WinXt+Wsf(WinXt−1+WsHt−2+bt−1)+bt)=f(WinXt+Wsf(WinXt−1+Wsf(WinXt−2+WsHt−3+bt−2)+bt−1)+bt)=f(WinXt+Wsf(WinXt−1+Wsf(WinXt−2+Ws(...))+bt−2)+bt−1)+bt)
-
通过这种逐步处理序列并在每一步更新隐藏状态的方式,RNN能够在其内部维持一个随时间变化的“记忆”。这使得它能够对之前序列元素的信息做出响应,并据此影响后续的输出。这种特性对于诸如语言模型、文本生成、语音识别等许多序列处理任务至关重要。
2.3 RNN的内部结构
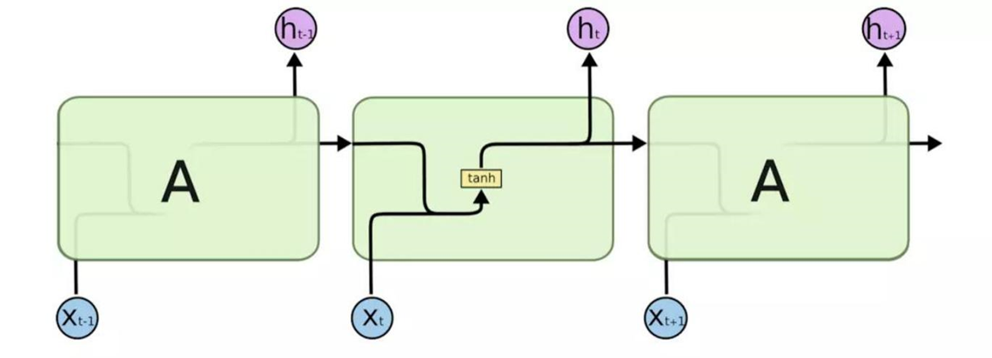
2.4 RNN模型输入输出关系对应模式
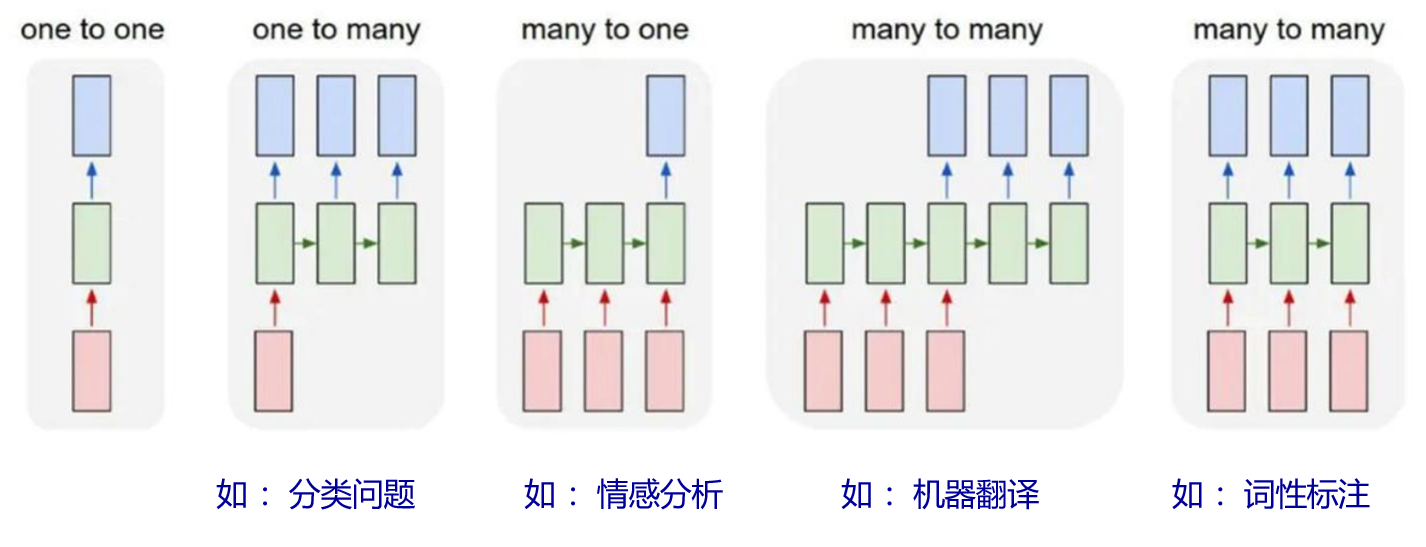
通过改变RNN的结构,即调整其输入和输出的数量和形式,可以让它适应各种不同的任务。以下是几种常见的RNN结构调整示例,以及它们各自适用的任务类型:
- 一对多(One-to-Many):这种结构的RNN接受单个输入并产生一系列输出。这种模式常用于“看图说话”的任务,即给定一张图片(单个输入),RNN生成一段描述该图片的文本(一系列输出)。在这种情况下,RNN的结构被调整为首先对输入图片进行编码,然后根据这个编码连续生成文本序列中的词语。
- 多对一(Many-to-One):与一对多相反,多对一的RNN结构接受一系列输入并产生单个输出。这种结构适用于如文本分类和情感分析等任务,其中模型需要阅读和理解整个文本(一系列输入),然后决定文本属于哪个类别(单个输出)。在图片生成的上下文中,这种结构可以通过分析一系列的特征或指令来生成单个图片输出。
- 多对多(Many-to-Many):这种结构的RNN既接受一系列输入,也产生一系列输出。这在需要输入和输出均为序列的任务中非常有用,例如机器翻译,其中模型需要读取一个语言的文本(一系列输入),然后生成另一种语言的对应文本(一系列输出)。另一个例子是小说生成,其中RNN可以基于给定的开头或主题(一系列输入),连续生成故事的后续内容(一系列输出)。
3. RNN 代码实现
重要参数含义
-
Batch Size (批量大小):
- Batch size指的是在一次前向传播或反向传播过程中同时处理的样本数量。
- 例如,在文本处理中,如果一批数据包含100个句子,那么batch size就是100。
-
Sequence Length (序列长度):
- Sequence length是指输入数据中每个样本的连续时间步(或词、字符)的数量。
- 例如,在一个句子级别的任务中,一个句子可能包含10个单词,那么序列长度就是10。
-
Input Size (输入大小):
- Input size是指每个时间步输入向量的特征维度。
- 在处理文本时,如果每个词都被表示为一个固定维度的向量,那么input size就是这个词向量的维度。
- 如在情感分析任务中,每个词可能被嵌入为一个100维的向量,那么input size就是100。
-
Hidden Size (隐藏层大小):
- Hidden size是指RNN单元内部隐藏状态(Hidden State)的维度。
- 在每个时间步,RNN都会根据当前输入和上一时间步的隐藏状态来计算新的隐藏状态,新隐藏状态的维度就是hidden size。
- 例如,如果我们设置hidden size为256,那么每个时间步产生的隐藏状态就是一个256维的向量。
- 根据实验和模型复杂度的要求自由选择隐藏层大小,它并不是通过特定计算得出的数值。
- 隐藏层大小的选择会影响到模型的学习能力和表示能力,同时也影响到模型的计算资源消耗。
- 实践中,较小的隐藏层大小可能会限制模型的表达能力,而过大的隐藏层大小则可能导致过拟合、训练时间增加等问题。
- 在决定隐藏层大小时,通常需要结合具体任务的特点、数据集规模、计算资源等因素进行合理选择,并通过交叉验证、网格搜索等方式进行超参数调优,以找到最优的隐藏层大小以及其他超参数组合。
-
Output Size (输出大小):
-
Output size通常与特定任务相关。
-
对于一般的RNN,每个时间步的输出大小与hidden size相同,即输出也是一个隐藏状态维度的向量。
-
在分类任务中,最后一层可能通过一个全连接层映射到类别数目,这时最后一个时间步的输出大小可能是类别数目的维度。
-
如果是多层或双向RNN,输出也可能经过额外的处理(如拼接、池化等),最终的输出大小会根据具体应用需求来确定。
-
在最简单的单向单层循环神经网络(RNN)中,输出大小(output size)的计算通常比较直接:
- 如果目的是为了获取每个时间步(time step)的隐藏状态表示,并且不进行额外的转换操作,那么每个时间步的输出大小(output size)就等于您设定的隐藏层大小(hidden size)。
例如,如果设置的隐藏层大小(hidden size)是256,那么在每个时间步,RNN的输出也将是一个256维的向量。
-
如果在RNN之后添加了其他层(如全连接层或分类层)来进行进一步的处理,比如进行分类任务,那么输出大小取决于这些后续层的设计。例如,如果您接下来是一个Softmax层用于做多分类,且类别数是10,则输出大小将会是10,表示每个样本的概率分布。
-
如果是在做序列到序列(Sequence-to-Sequence)的任务,比如机器翻译,最后的时间步的隐藏状态通常会通过一个线性层映射到目标词汇表大小,这样输出大小就会是目标词汇表的大小。
-
具体的单层单向RNN示例来说明维度变换过程:
假设正在处理一个文本分类任务,每个单词已经被嵌入为一个100维的向量,我们的序列长度(sequence length)是50(即最长句子有50个单词),批量大小(batch size)是32(一次处理32个句子),我们设定的隐藏层大小(hidden size)是128。
-
输入维度(input size): 每个时间步(每个单词)的输入向量维度是100,所以整个输入张量的维度是
(batch size, sequence length, input size),即(32, 50, 100)。 -
隐藏层计算: RNN会对每个时间步的输入进行处理,并基于上一时间步的隐藏状态生成当前时间步的隐藏状态。隐藏状态的维度由我们设定,这里是128维,所以每个时间步的隐藏状态和输出的维度都是
(batch size, hidden size),即(32, 128)。 -
输出维度(output size): 因为这里我们假设没有在RNN后添加额外的层(例如分类层),所以每个时间步的输出大小就等于隐藏层大小,也就是128维。但是,由于输出是针对每一个时间步的,所以整个输出序列的维度为
(batch size, sequence length, hidden size),即(32, 50, 128)。
如果后续需要进行分类,比如这是一个二分类问题,我们会把最后一个时间步的隐藏状态(128维)通过一个全连接层(Dense Layer)映射到类别数目的维度,如2维,此时输出大小将变为 (32, 2),表示32个样本的二维概率分布。
3.1 原生代码
import numpy as np
# 原始数据 一句话 3个单词 每个2个维度
x = np.random.rand(3,2)# RNN参数
input_size = 2
hidden_size = 3
# 词表大小是输出维度 6
output_size = 6# 初始化权重矩阵
# 输入权重矩阵
Wx = np.random.rand(input_size, hidden_size)
# 隐藏权重矩阵
Wh = np.random.rand(hidden_size, hidden_size)
# 输出权重矩阵
Wout = np.random.rand(hidden_size, output_size)# 偏置
bh = np.zeros((hidden_size,))
bout = np.zeros((output_size,))# 激活函数
def tanh(x):return np.tanh(x)# 初始化隐藏状态
H_prev = np.zeros((hidden_size,))# 前向传播
# 时间步1 第一个单词
x1 = x[0,:]
H1 = tanh(np.dot(x1,Wx) + np.dot(H_prev,Wh)+bh)
Y = np.dot(H1,Wout)+bout# 时间步2 第二个单词
x2 = x[1,:]
H2 = tanh(np.dot(x2,Wx) + np.dot(H1,Wh)+bh)
Y2 = np.dot(H2,Wout)+bout# 时间步3 第三个单词
x3 = x[2,:]
H3 = tanh(np.dot(x3,Wx) + np.dot(H2,Wh)+bh)
Y3 = np.dot(H3,Wout)+bout# 输出结果
print("时间步1的隐藏状态:",H1)
print("时间步2的隐藏状态:",H2)
print("时间步3的隐藏状态:",H3)
print("时间步1的输出结果:",Y)
print("时间步2的输出结果:",Y2)
print("时间步3的输出结果:",Y3)
np.dot 是 NumPy 库中用于计算两个数组的点积(dot product)的函数。它的行为取决于输入数组的维度:
-
对于二维数组,
np.dot计算的是矩阵乘积。这意味着如果 A 是一个 m×n 矩阵,B 是一个 n×p 矩阵,那么np.dot(A, B)的结果将是一个 m×p 矩阵,其中每个元素由 A 中的行与 B 中的列之间的点积计算得出。 -
对于一维数组,
np.dot计算的是向量的内积(inner product)。即,如果 a 和 b 是长度相同的两个一维数组,那么np.dot(a, b)就是 a 和 b 对应元素相乘之后的结果之和。 -
A是一维数组(shape 为(n,)),B是二维数组(shape 为(n, m)),相当于:👉 将
A视为一个行向量(1×n),与矩阵B(n×m)相乘,得到一个 1×m 的结果(即 shape 为(m,)的一维数组)。
3.2 基于 RNNCell 代码实现
import torch
from torch import nn# 创建数据 词嵌入之后的维度
x = torch.randn(10,6,5)# 模型参数
hidden_size = 8# 利用rnncell创建RNN模型
class RNN(nn.Module):def __init__(self,batch_size,hidden_size,batch_flag=True):super(RNN, self).__init__()# nn.RNNCell 返回的是隐藏状态 参数 第一个参数是输入维度(词嵌入之后的维度) 第二个是隐藏状态维度self.rnncell = nn.RNNCell(input_size=5, hidden_size=hidden_size)# self.fc = nn.Linear(20, 10)self.batch_size = batch_sizeself.hidden_size = hidden_size# 标识符 类型是布尔类型self.batch_flag = batch_flag# 初始化隐藏状态def intialize_hidden(self):self.h_prev = torch.zeros(self.batch_size, self.hidden_size)return self.h_prevdef forward(self, x, h_prev=None):"""注意传递进来的数据格式 一般经过词嵌入格式(B,S,D)但是在rnn中 需要数据格式 (S,B,D)词数开头:param x: 如果说self.batch_flag是ture就代表传入的数据格式是(B,S,D):return:"""if self.batch_flag:batch_size, seq_len, dim = x.size(0), x.size(1), x.size(2)# 数据处理为(S,B,D)x = x.permute(1, 0, 2)else:batch_size, seq_len, dim = x.size(0), x.size(1), x.size(2)hiddens = []if h_prev is None:init_hidden = self.intialize_hidden()else:init_hidden = h_prev# 循环遍历每个时间步for t in range(seq_len):# 输入数据x_t = x[t]# 在t时刻获取隐藏状态 封装的是H1 = tanh(np.dot(x1,Wx) + np.dot(H_prev,Wh)+bh)# 初始化隐藏状态可以省略 init_hiddenhidden_t = self.rnncell(x_t, init_hidden)hiddens.append(hidden_t)# 所有时间步堆叠成新的张量output = torch.stack(hiddens)# 处理数据if self.batch_flag:output = output.permute(1,0,2)return outputmodel = RNN(10,hidden_size)
output = model(x)
print(output.shape)
nn.RNNCell 本质上只返回隐藏状态,它没有单独的输出结果。一般在 RNN 中,隐藏状态既可以被视为输出,也可以通过一个线性层将隐藏状态转化为实际的输出。
3.3 基于 pytorch API 代码实现
官方代码细节:https://pytorch.org/docs/stable/_modules/torch/nn/modules/rnn.html#RNN
官方文档解释:https://pytorch.org/docs/stable/generated/torch.nn.RNN.html#rnn
import torch
from torch import nn# 初始数据
x = torch.randn(10, 6, 5)# 模型设置参数
hidden_size = 8
batch_size = 10
sen_len = 6
input_size = 5# 初始化隐藏状态 (1, batch_size, hidden_size)
h_prev = torch.zeros(batch_size, hidden_size)# RNN调用
rnn = nn.RNN(input_size, hidden_size, batch_first=True)# h_prev 可以不传
out, h_last = rnn(x,h_prev.unsqueeze(0))
print(out.shape)
print(h_last.shape)
input是一个形状为(batch_size, sequence_length, input_size)的张量,表示一批包含T个时间步长的序列,每个时间步长的输入特征维度为input_size。h_prev是所有序列共享的初始隐含状态,形状为(batch_size, hidden_size)。h_prev.unsqueeze(0)将h_prev的批量维度增加一层,因为PyTorch RNN期望隐含状态作为一个元组(num_layers, batch_size, hidden_size),在这里我们只有一个隐藏层,所以增加了一维使得形状变为(1, batch_size, hidden_size)。rnn(input, h_prev.unsqueeze(0))执行RNN的前向传播,得到的rnn_output是整个序列的输出结果,形状为(batch_size, sequence_length, hidden_size),而state_final是最后一个时间步的隐含状态,形状为(num_layers, batch_size, hidden_size)。- 两个返回值
rnn_output和state_final代表着循环神经网络在当前时间步的输出和最终的隐藏状态。rnn_output:代表当前时间步的 RNN 输出。对于很多序列模型而言,每个时间步都会有一个输出。这个输出可能会被用于下一时间步的计算,或者作为模型的最终输出。state_final:代表 RNN 模型在最后一个时间步的隐藏状态。这个隐藏状态通常被认为是对整个序列的编码或总结,它可能会被用于某些任务的最终预测或输出。
3.3.1 单向、单层RNN
-
定义一个单层循环神经网络(RNN)实例:
signle_rnn = nn.RNN(4, 3, 1, batch_first=True)这行代码创建了一个RNN层,其参数含义如下:
4表示输入序列的特征维度(feature size),即每个时间步的输入向量长度为4。3表示隐藏状态(hidden state)的维度,即RNN单元内部记忆的向量长度为3。1表示RNN层的数量,这里仅为单层。batch_first=True指定输入张量的第一个维度代表批次(batch),第二个维度代表时间步(sequence length),这对于处理批次数据时更容易理解。
-
创建输入数据张量:
input = torch.randn(1, 2, 4)这行代码生成了一个随机张量作为RNN的输入,它的形状为
(batch_size, sequence_length, feature_size),具体到这里的值是:1表示批大小(batch size),即本次输入的数据样本数量。2表示序列长度(sequence length),即每个样本的输入序列包含两个时间步。4是每个时间步输入向量的特征维度,与RNN层设置一致。
-
对输入数据进行前向传播:
output, h_n = signle_rnn(input)这行代码将之前创建的随机输入数据送入RNN层进行前向计算。执行后得到两个输出:
output是经过RNN处理后的输出序列,其形状通常为(batch_size, sequence_length, num_directions * hidden_size)。在这个例子中,因为没有指定双向RNN,所以num_directions=1。因此,output的尺寸将是(1, 2, 3),对应每个批次中的每个时间步输出一个维度为3的向量。h_n是最后一个时间步的隐藏状态(hidden state),它通常是最终时间步的隐藏状态或者是所有时间步隐藏状态的某种聚合(取决于RNN类型)。在这里,h_n的形状是(num_layers * num_directions, batch_size, hidden_size),但由于只有一层并且是无方向的RNN,所以形状会简化为(1, 1, 3),即单一隐藏状态向量。这个隐藏状态可以用于下个时间步的预测或者作为整个序列的编码。
3.3.2 双向、单层RNN
双向单层RNN(Recurrent Neural Network)是一种特殊类型的循环神经网络,它能够在两个方向上处理序列数据,即正向和反向。这使得网络在预测当前输出时,能够同时考虑到输入序列中当前元素之前的信息和之后的信息。双向单层RNN由两个独立的单层RNN组成,一个负责处理正向序列(从开始到结束),另一个负责处理反向序列(从结束到开始)。
主要特点
- 双向处理: 最显著的特点是双向结构,使得模型能够同时学习到序列中某一点前后的上下文信息,这对于很多序列任务来说是非常有价值的,比如自然语言处理中的文本理解、语音识别等。
- 单层结构: “单层”指的是在每个方向上,网络结构只有一层RNN,即每个方向上只有一层循环单元(如LSTM单元或GRU单元)。虽然是单层的,但由于其双向特性,实际上每个时间点都有两个循环单元对信息进行处理。
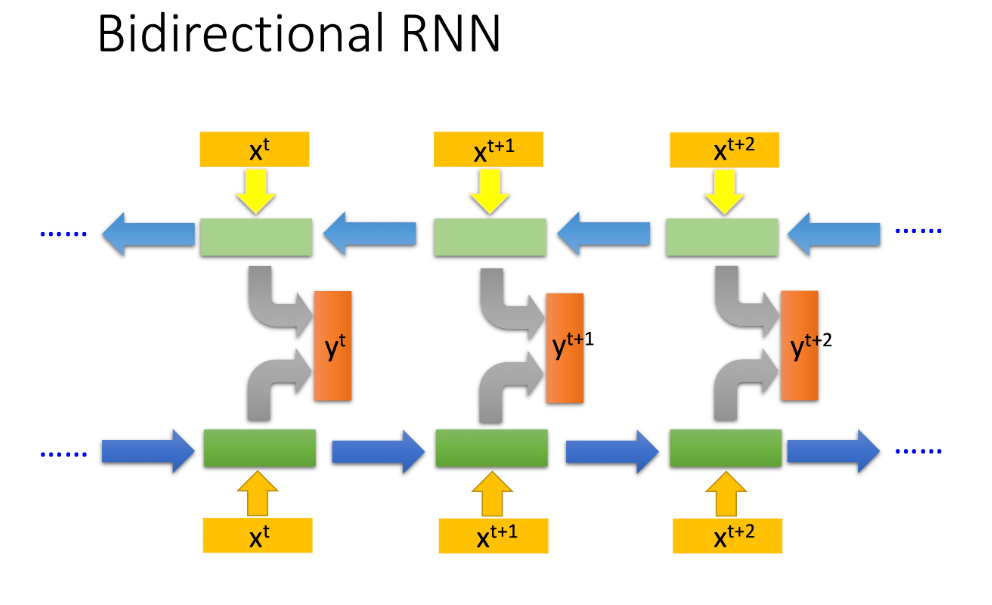
-
定义一个双向循环神经网络(Bi-RNN)实例:
bi_rnn = nn.RNN(4, 3, 1, batch_first=True, bidirectional=True)这行代码创建了一个具有双向连接的RNN层,参数含义如下:
4依然是输入序列的特征维度(每个时间步长的输入向量有4个元素)。3表示的是单向隐藏状态(hidden state)的维度;由于设置了bidirectional=True,实际上模型会同时维护正向和反向两个隐藏状态,因此总的隐藏状态维度将是2 * 3。1表示RNN层的数量,这里也是单层。batch_first=True保持输入张量的批量维度在最前面。bidirectional=True指定该RNN为双向的,这意味着对于每个时间步,除了向前传递的信息外,还会考虑向后传递的信息,从而能够捕捉序列中前后依赖关系。
-
创建输入数据张量:
input = torch.randn(1, 2, 4)这行代码生成了一个随机张量作为双向RNN的输入,其形状仍为
(batch_size, sequence_length, feature_size),即(1, 2, 4)。这表示有一个样本(batch_size=1),序列长度为2,每个时间步有4个特征。 -
对输入数据进行前向传播:
output, h_n = bi_rnn(input)将随机输入数据传入双向RNN进行前向计算。执行后获取的结果与单向RNN有所不同:
-
output现在包含了正向和反向两个方向的输出,其形状为(batch_size, sequence_length, num_directions * hidden_size),在本例中为(1, 2, 2 * 3),即每个时间步有两个方向上的隐藏状态输出拼接而成的向量。 -
h_n包含了最后时间步的正向和反向隐藏状态,形状为(num_layers * num_directions, batch_size, hidden_size),在本例中实际为(2, 1, 3),分别对应正向和反向隐藏状态各一个。每个隐藏状态向量都是相应方向上整个序列信息的汇总。
-
相关文章:

5月12日复盘-RNN
5月12日复盘 二、RNN 模型 1.先导 1.1 为什么需要循环神经网络 RNN 上图是一幅全连接神经网络图,我们可以看到输入层-隐藏层-输出层,他们每一层之间是相互独立地,(框框里面代表同一层),每一次输入生成一个节点,同…...
docker卸载navidrome)
linux小主机搭建自己的nas(二)docker卸载navidrome
测试的时候安装了一个音乐播放器在root下面,现在先给他删掉 停止并删除容器 docker ps -a | grep navidrome# 停止并删除容器(替换 YOUR_CONTAINER_NAME 为实际名称) docker stop YOUR_CONTAINER_NAME && docker rm YOUR_CONTAINER…...

.NET 在鸿蒙系统上的适配现状
目录 .NET 在鸿蒙系统上的适配现状 鸿蒙系统对虚拟机的限制与.NET的适配挑战 NativeAOT 在鸿蒙系统中的适配原理与实现方式 已知问题与解决方案:鸿蒙系统中的 syscall 限制 鸿蒙系统适配中的技术难点与解决方案 跨平台编译的挑战与应对策略 依赖库管理与兼容…...

01-centos离线升级至almalinux
官网链接官方代码调整: 1. vi repositories/system_upgrade/common/actors/targetuserspacecreator/libraries/userspacegen.py with mounting.BindMount(sourceuserspace_dir, targetos.path.join(context.base_dir, install_root_dir.lstrip(/))):_restore_persi…...

Python 处理图像并生成 JSONL 元数据文件 - 固定text版本
Python 处理图像并生成 JSONL 元数据文件 - 固定text版本 flyfish JSONL(JSON Lines)简介 JSONL(JSON Lines,也称为 newline-delimited JSON)是一种轻量级的数据序列化格式,由一系列独立的 JSON 对象组成…...

uniapp使用npm下载
uniapp的项目在使用HBuilder X创建时是不会有node_modules文件夹的,如下图所示: 但是uni-app不管基于哪个框架,它内部一定是有node.js的,否则没有办法去实现框架层面的一些东西,只是说它略微有点差异。具体差异表现在…...

前端面试每日三题 - Day 31
这是我为准备前端/全栈开发工程师面试整理的第30天每日三题练习: ✅ 题目1:WebAssembly前端深度实践指南 核心优势对比 维度JavaScriptWebAssembly解析速度需要解析编译预编译二进制执行性能动态类型较慢静态类型接近原生内存管理自动垃圾回收手动内存…...

通义千问席卷日本!开源界“卷王”阿里通义千问成为日本AI发展新基石
据日本经济新闻(NIKKEI)报道,通义千问已成为日本AI开发的新基础,其影响力正逐步扩大,深刻改变着日本AI产业的格局。 同时,日本经济新闻将通义千问Qwen2.5-Max列为全球AI模型综合评测第六名,不仅…...

01 安装CANoe
文章目录 0、Introduction1、Install CANoe1.1、Unlock Package1.2、Kick autorun1.3、Install CANoe1.4、Wait Download1.5、Restart application1.6、Vector CANoe Installation1.7、Installation Successfully1.8、Open CANoe 2、Install Drivers2.1、Unlock Package2.2、Ki…...

AutoDL租用服务器教程
在跑ai模型的时候,容易遇到算力不够的情况。此时便需要租用服务器。autodl是个较为便宜的服务器租用平台,h20仅需七点几元每小时。下面是简单的介绍。 打开网站AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL,并登录账号 登录后ÿ…...

【人工智能-agent】--Dify中MCP工具存数据到MySQL
本文记录的工作如下: 自定义MCP工具,爬取我的钢铁网数据爬取的数据插值处理自定义MCP工具,把爬取到的数据(str)存入本地excel表格中自定义MCP工具,把爬取到的数据(str)存入本地MySQ…...

ctfshow——web入门351~356
SSRF没有出网的部分 web入门351 $ch curl_init($url); 作用:初始化一个 cURL 会话,并设置目标 URL。解释: curl_init($url) 创建一个新的 cURL 资源,并将其与 $url 关联。这里的 $url 是用户提供的,因此目标地址完全…...
)
堆复习(C语言版)
目录 1.树的相关概念: 2.堆的实现 3.TopK问题 4.总结 1.树的相关概念: 1.结点的度:一个结点含有的子树(孩子)个数。 A的度为6 2.叶结点or终端结点:度为0的结点。 J、K、L、H、I 都是叶子结点 3.非终端结…...

解决LangChain4j报错HTTP/1.1 header parser received no bytes
问题描述 当使用langchain4j-open-ai调用自己部署的大模型服务时报错: public static void main(String[] args) {OpenAiChatModel model OpenAiChatModel.builder().apiKey("none").modelName("qwen2.5-instruct").baseUrl("http://19…...
:案例与实战技巧)
深入解析MySQL联合查询(UNION):案例与实战技巧
在数据库操作中,查询是最常用的操作之一。MySQL提供了强大的查询功能,联合查询(UNION)是其中非常有用的一项操作。联合查询可以将多个查询结果合并成一个结果集,使得从不同来源的数据整合变得更加简单高效。本文将详细…...

[计算机科学#14]:数据结构
【核知坊】:释放青春想象,码动全新视野。 我们希望使用精简的信息传达知识的骨架,启发创造者开启创造之路!!! 内容摘要:数据结构是计算机科学中的核心概念,用于…...

【计算机网络】HTTP 协议
HTTP是什么? HTTP 全称是“超文本传输协议”,是互联网上应用最广泛的应用层协议,用于客户端和服务器之间的通信。 HTTP 的实现在 HTTP 3.0之前都是基于传输层的 TCP 实现的, HTTP 3.0 改为了基于 UDP 实现,但是现在市…...

原生的 XMLHttpRequest 和基于 jQuery 的 $.ajax 方法的异同之处以及使用场景
近期参与一个项目的开发,发现项目中的ajax请求有两种不同的写法,查询了下两种写法的异同之处以及使用场景。 下面将从以下两段简单代码进行异同之处的分析及使用场景的介绍: // 写法一: var xhr new XMLHttpRequest(); xhr.open…...
)
横向移动(上)
横向移动(上) 横向移动指的是攻击者在内网中获得初始访问权限之后,通过相关技术扩大敏感数据和高价值资产权限的行为 常见的横向移动的方式 1.通过web漏洞 2.通过远程桌面 3.通过账号密码 4.通过不安全的配置 5.通过系统漏洞 利用远控…...

关于 js:7. 模块化、构建与工具链
一、模块系统:CommonJS、ESM、UMD 模块系统的目标: 将代码拆分为独立的逻辑单元(模块),实现封装、复用、依赖管理。 在 Web 前端/Node 中,因为 JavaScript 起初没有模块机制,因此出现了多个模…...
)
一次IPA被破解后的教训(附Ipa Guard等混淆工具实测)
一行代码的疏忽,一个默认的类名,一个未混淆的资源路径,都可能成为攻击者入侵的入口。 背景:一次“不值一提”的上线,成了代价惨重的经验 故事的起点很简单:我们给销售部门做了一款小型内部演示 App&#x…...

麒麟系统安装.net core环境变量
本文主要记录在麒麟系统上安装.net core的运行环境,这里使用的是麒麟V10桌面版,后续测试服务器到了之后再使用服务器版进行安装测试。 环境安装 下载 这里由于是桌面版,我直接使用浏览器下的包,下完之后在终端中安装。 安装 1…...

如何使用 React Hooks 替代类组件的生命周期方法?
文章目录 1. 引言2. useEffect 概述3. 模拟类组件的生命周期方法3.1 模拟 componentDidMount3.2 模拟 componentDidUpdate3.3 模拟 componentWillUnmount 4. 多个 useEffect 的使用5. 注意事项6. 总结 1. 引言 在 React 16.8 版本之前,开发者主要通过类组件&#x…...

windows 在安装 Ubuntu-20.04 显示操作超时解决办法
1. 问题概述与原因分析 在我们用下面命令安装 Ubuntu-20.04 时系统显示操作超时: wsl --install -d Ubuntu-20.04大概率是没打开 Windows 虚拟机监控程序平台,可以在控制面板–>程序和功能里面打开 2. 解决办法与步骤 解决方式如下: 我…...

Spring Boot中Redis序列化配置详解
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 引言 在使用Spring Boot集成Redis时,序列化方式的选择直接影响数据存储的效率和系统兼容性。默认的JDK序列化存在可读性差、存储空间大等问题&am…...

OpenCV进阶操作:光流估计
文章目录 前言一、光流估计1、光流估计是什么?2、光流估计的前提?1)亮度恒定2)小运动3)空间一致 3、OpenCV中的经典光流算法1)Lucas-Kanade方法(稀疏光流)2) Farneback方…...
)
2025年渗透测试面试题总结-渗透测试红队面试八(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 渗透测试红队面试八 二百一十一、常见中间件解析漏洞利用方式 二百一十二、MySQL用户密码存储与加密 …...

前端面试高频50个问题,解答
以下是前端面试中常见的50个高频问题及其简要解答: HTML HTML5 有哪些新特性? 语义化标签(如 <header>、<footer>)、多媒体支持(如 <audio>、<video>)、本地存储(如 l…...

Elasticsearch架构原理
1、Elasticsearch的节点类型 1.1 Master节点 在Elasticsearch启动时,会选举出来一个Master节点。当某个节点启动后,然后 使用Zen Discovery机制找到集群中的其他节点,并建立连接。 discovery.seed_hosts: ["192.168.21.130", &qu…...

前端面试宝典---webpack面试题
webpack 的 tree shaking 的原理 Webpack 的 Tree Shaking 过程主要包含以下步骤: 模块依赖分析:Webpack 首先构建一个完整的模块依赖图,确定每个模块之间的依赖关系。导出值分析:通过分析模块之间的 import 和 exportÿ…...

Vue 2 项目中配置 Tailwind CSS 和 Font Awesome 的最佳实践
Vue 2 项目中配置 Tailwind CSS 和 Font Awesome 的最佳实践 一、Tailwind CSS 配置 1. 安装依赖 npm install tailwindcssnpm:tailwindcss/postcss7-compat tailwindcss/postcss7-compat postcss^7 autoprefixer^92. 创建配置文件 npx tailwindcss init3. 创建样式文件 在…...

hiveserver2与beeline进行远程连接hive配置及遇到的问题
1、hiveserver2 参与用户模拟功能,因为开启后才能保证各用户之间的权限隔离。 1.1、配置 $HADOOP_HOME/etc/hadoop/core-site.xml <!--配置所有节点的root用户都可作为代理用户--> <property><name>hadoop.proxyuser.root.hosts</name>&…...

单词短语0512
当然可以,下面是“opportunity”在考研英语中的常用意思和高频短语,采用大字体展示,便于记忆: ✅ opportunity 的考研常用意思: 👉 机会,良机 表示有利的时机或条件,尤指成功的可能…...
)
c++刷题便捷函数(类似于stoi的小函数)
标题 stoi(字符串转整形)map和set都有count成员函数,返回值是该key的个数,可以用来查是否存在该元素。bool is_sorted(nums.begin(), nums.end() 检验是否有序INT_MAX,INT_MIN分别是整形最大和最小初始化二维矩阵 vector<vector\<int>> mart…...

想实现一个基于MCP的pptx生成系统架构图【初版实现】
技术栈:Python + MCP协议 + python-pptx + FastMCP 核心创新点:通过MCP协议实现PPTX元素的动态化生成与标准化模板管理 当前还是个半成品,后续持续更新。 主要先介绍一下思路。 一、MCP协议与系统设计原理 1.1 为什么选择MCP? 标准化工具调用:通过MCP将PPTX元素生成逻辑封…...

jwt学习
基于token的鉴权机制也是无状态的(类似于http协议),不需要保在服务端保留用户的认证或会话信息。 构成 jwt由三部分构成:头部、payload、签名,中间用.隔开 头部(header) 包含两部分信息:声明类型、声明加密的算法 例如:…...

pth的模型格式怎么变成SafeTensors了?
文章目录 背景传统模型格式的安全隐患效率与资源瓶颈跨框架兼容性限制Hugging Face 的解决方案:SafeTensors行业与社区的推动SafeTensors 的意义总结 背景 最近要找一些适合embedding的模型,在huggingface模型库上看到一些排名比较靠前的,准…...

如何判断IP是否被平台标记
一、基础检测:连通性与黑名单筛查 网络连通性测试 Ping与Traceroute:通过命令测试延迟和路由路径,若延迟>50ms或存在异常节点(如某跳延迟>200ms),可能影响可用性。示例命令: bash ping 8.…...

【c++】异常详解
目录 C语言处理错误的局限性异常的定义异常的具体使用细则异常的抛出与捕获在函数调用链中异常栈展开匹配原则异常的重新抛出异常规范throw(类型)noexcept 成熟的异常体系c自己的异常体系异常的优缺点优点缺点 异常安全 C语言处理错误的局限性 C语言处理错误常常会用到assert和…...

从模型加密到授权交付,CodeMeter赋能3D打印商业化全流程
引言 在数字化制造快速演进的当下,3D 打印(增材制造)作为具备高度灵活性与创新潜力的制造方式,正重塑备件供应链与产品生命周期管理。然而,随着应用场景不断扩展,企业面临的知识产权保护、数字资产商业化与…...

ESP32开发之freeRTOS的事件组
什么是事件组事件组的应用场景事件组的API函数事件组应用举例总结什么是事件组 概念:事件组就是一个整数,高8位给内核使用,其他位用来表示事件。在ESP32的IDF freeRTOS中,这个整数是32位的,低24位用来供事件组使用。 举一个生活中的例子: 你在等快递,有三个包裹来自不…...

K8S中构建双架构镜像-从零到成功
背景介绍 公司一个客户的项目使用的全信创的环境,服务器采用arm64的机器,而我们的应用全部是amd64的,于是需要对现在公司流水线进行arm64版本的同步镜像生成。本文介绍从最开始到最终生成双架构的全部过程,以及其中使用的相关配置…...

腾讯怎样基于DeepSeek搭建企业应用?怎样私有化部署满血版DS?直播:腾讯云X DeepSeek!
2025新春,DeepSeek横空出世,震撼全球! 通过算法优化,DeepSeek将训练与推理成本降低至国际同类模型的1/10,极大的降低了AI应用开发的门槛。 可以预见,2025年,是AI应用落地爆发之年! ✔…...

【论信息系统项目的质量管理】
论信息系统项目的质量管理 前言一、抓好质量管理规划工作,为质量管理和确认提供指南和方向。二、做好管理质量相关工作,促进质量过程改进。三、抓好控制质量,确保实现质量目标四、综合协调质量与成本、进度、范围的关系总结 前言 为解决日常出…...

SpringAI框架中的RAG模块详解及应用示例
SpringAI框架中的RAG模块详解及应用示例 RAG(Retrieval-Augmented Generation)可以通过检索知识库,克服大模型训练完成后参数冻结的局限性,携带知识让大模型根据知识进行回答。SpringAI框架提供了模块化的API来支持RAG࿰…...

图像增强技术
一、目的 通过本实验加深对数字图像增强操作的理解,熟悉MATLAB中的有关函数;了解直方图均衡化和卷积滤波的原理;熟悉低通和高通滤波模板的构造方法。 二、实验内容与设计思想 1、观察实验结果可看出, 原图像 I的对比度较低&…...

【Java学习笔记】多态参数
多态参数 应用:方法定义的形参类型为父类类型,实参允许为子类类型 // 父类 package polyparemeter;public class employee {private String name;private double salary;//构造器public employee(){}public employee(String name, double salary) {thi…...

计算机网络核心技术解析:从基础架构到应用实践
计算机网络作为现代信息社会的基石,承载着全球数据交换与资源共享的核心功能。本文将从网络基础架构、核心协议、分层模型到实际应用场景,全面解析计算机网络的核心技术,并结合行业最新趋势,为读者构建系统的知识体系。 一、计算机…...

LiveData:Android响应式编程的核心利器
LiveData是一种可观察的数据持有类,用于在Android应用中实现数据的响应式编程。它具有以下特点和作用: 特点 生命周期感知:LiveData能够感知与其关联的组件(如Activity、Fragment)的生命周期状态。只有当组件处于活跃状态(如Activity处于RESUMED状态)时,LiveData才会将…...

【LeeCode】1.两数之和
文章目录 1. 暴力求解2. 哈希表具体过程1. nums [2, 7, 11, 15],target 9:2. nums [11, 15, 2, 7], target 9 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数ÿ…...