Redis+Caffeine构建高性能二级缓存

大家好,我是摘星。今天为大家带来的是Redis+Caffeine构建高性能二级缓存,废话不多说直接开始~
目录
二级缓存架构的技术背景
1. 基础缓存架构
2. 架构演进动因
3. 二级缓存解决方案
为什么选择本地缓存?
1. 极速访问
2. 减少网络IO
3. 降低远程缓存和数据库压力
4. 提升系统吞吐量
5. 功能灵活
本地内存具备的功能
1. 基本读写
2. 缓存淘汰策略
3. 过期时间控制
4. 缓存加载与刷新
5. 并发控制
6. 统计与监控
7. 持久化
8. 事件监听
本地缓存方案选型
1. ConcurrentHashMap
2. Guava Cache
3. Caffeine
4. Encache
方案对比
本地缓存问题及解决
1. 数据一致性
1.1. 解决方案1: 失效广播机制
1.2. 解决方案2:版本号控制
2. 内存管理问题
2.1. 解决方案1:分层缓存架构
2.2. 解决方案2:智能淘汰策略
3. GC压力
3.1. GC压力问题的产生原因
3.2. 解决方案1:堆外缓存(Off-Heap Cache)
3.3. 方案2:分区域缓存
总结
二级缓存架构的技术背景
1. 基础缓存架构
在现代分布式系统设计中,缓存是优化服务性能的核心组件。标准实现方案采用远程缓存(如Redis/Memcached)作为数据库前置层,通过以下机制提升性能:
- 读写策略:遵循Cache-Aside模式,仅当缓存未命中时查询数据库
- 核心价值:
-
- 将平均响应时间从数据库的10-100ms级别降至1-10ms
- 降低数据库负载50%-80%(根据命中率变化)
2. 架构演进动因
当系统面临以下场景时,纯远程缓存方案显现局限性:
| 问题类型 | 表现特征 | 典型案例 |
| 超高并发读取 | Redis带宽成为瓶颈 | 热点商品详情页访问 |
| 超低延迟要求 | 网络往返耗时不可忽略 | 金融行情数据推送 |
| 成本控制需求 | 高频访问导致Redis扩容 | 用户基础信息查询 |
3. 二级缓存解决方案
引入本地缓存构建两级缓存体系:
- 一级缓存:Caffeine(高性能本地缓存)
- 二级缓存:Redis Cluster(高可用远程缓存)
- 协同机制:
-
- 本地缓存设置短TTL(秒级)
- 远程缓存设置长TTL(分钟级)
- 通过PubSub实现跨节点失效
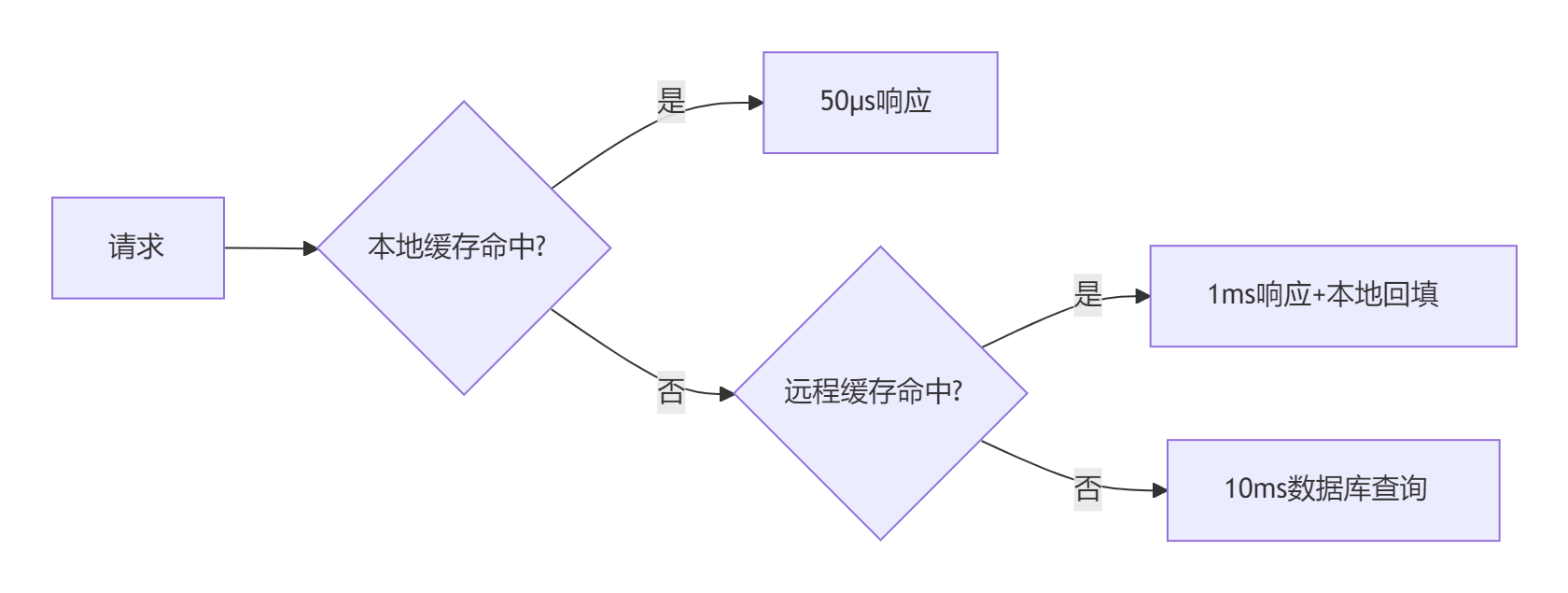
为什么选择本地缓存?
1. 极速访问
内存级响应:本地缓存直接存储在应用进程的内存中(如Java堆内),访问速度通常在纳秒级(如Caffeine的读写性能可达每秒千万次),而远程缓存(如Redis)需要网络通信,延迟在毫秒级。
| 技术选型 | 响应时长 |
| 本地缓存 |
|
| Redis远程缓存 |
|
| 数据库查询 |
|
2. 减少网络IO
避免远程调用:每次访问Redis都需要经过网络I/O(序列化、传输、反序列化),本地缓存完全绕过这一过程。
适用场景:高频访问的热点数据(如商品详情、用户基础信息),通过本地缓存可减少90%以上的Redis请求。
3. 降低远程缓存和数据库压力
保护Redis:大量请求直接命中本地缓存,避免Redis成为瓶颈(尤其在高并发场景下,如秒杀、热点查询)。
减少穿透风险:本地缓存可设置短期过期时间,避免缓存失效时大量请求直接冲击数据库。
4. 提升系统吞吐量
减少线程阻塞:远程缓存访问会阻塞线程(如Redis的同步调用),本地缓存无此问题,尤其适合高并发服务。
案例:某电商系统引入Caffeine后,QPS从1万提升到5万,Redis负载下降60%。
5. 功能灵活
本地缓存支持丰富的特性,满足不同业务需求:
- 淘汰策略:LRU(最近最少使用)、LFU(最不经常使用)、FIFO等。
- 过期控制:支持基于时间(写入后过期、访问后过期)或容量触发淘汰。
- 原子操作:如
get-if-absent-compute(查不到时自动加载),避免并发重复查询。
本地内存具备的功能
1. 基本读写
功能:基础的键值存储与原子操作。
Cache<String, String> cache = Caffeine.newBuilder().build();// 写入缓存
cache.put("user:1", "Alice");// 读取缓存(若不存在则自动计算)
String value = cache.get("user:1", key -> fetchFromDB(key));2. 缓存淘汰策略
功能:限制缓存大小并淘汰数据。
| 算法 | 描述 | 适用场景 | 代码示例(Caffeine) |
| LRU | 淘汰最久未访问的数据 | 热点数据分布不均匀 |
|
| LFU | 淘汰访问频率最低的数据 | 长期稳定的热点数据 |
(W-TinyLFU) |
| FIFO | 按写入顺序淘汰 | 数据顺序敏感的场景 | 需自定义实现 |
3. 过期时间控制
功能:自动清理过期数据。
Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES) // 写入后10分钟过期
.expireAfterAccess(5, TimeUnit.MINUTES) // 访问后5分钟过期
.build();
4. 缓存加载与刷新
功能:自动加载数据并支持后台刷新。
AsyncLoadingCache<String, String> cache = Caffeine.newBuilder()
.refreshAfterWrite(1, TimeUnit.MINUTES) // 1分钟后后台刷新
.buildAsync(key -> fetchFromDB(key));// 获取数据(若需刷新,不会阻塞请求)
CompletableFuture<String> future = cache.get("user:1");5. 并发控制
功能:线程安全与击穿保护。
// 自动合并并发请求(同一key仅一次加载)
LoadingCache<String, String> cache = Caffeine.newBuilder().build(key -> {System.out.println("仅执行一次: " + key);return fetchFromDB(key);});// 并发测试(输出1次日志)
IntStream.range(0, 100).parallel().forEach(i -> cache.get("user:1")
);
6. 统计与监控
功能:记录命中率等指标。
Cache<String, String> cache = Caffeine.newBuilder()
.recordStats() // 开启统计
.build();cache.get("user:1");
CacheStats stats = cache.stats();
System.out.println("命中率: " + stats.hitRate());7. 持久化
功能:缓存数据持久化到磁盘。
// 使用Caffeine + RocksDB(需额外依赖)
Cache<String, byte[]> cache = Caffeine.newBuilder().maximumSize(100).writer(new CacheWriter<String, byte[]>() {@Override public void write(String key, byte[] value) {rocksDB.put(key.getBytes(), value); // 同步写入磁盘}@Override public void delete(String key, byte[] value, RemovalCause cause) {rocksDB.delete(key.getBytes());}}).build();8. 事件监听
功能:监听缓存变更事件。
Cache<String, String> cache = Caffeine.newBuilder().removalListener((key, value, cause) -> System.out.println("移除事件: " + key + " -> " + cause)).evictionListener((key, value, cause) -> System.out.println("驱逐事件: " + key + " -> " + cause)).build();本地缓存方案选型
1. ConcurrentHashMap
ConcurrentHashMap是Java集合框架中提供的线程安全哈希表实现,首次出现在JDK1.5中。它采用分段锁技术(JDK8后改为CAS+synchronized优化),通过将数据分成多个段(segment),每个段独立加锁,实现了高并发的读写能力。作为JUC(java.util.concurrent)包的核心组件,它被广泛应用于需要线程安全哈希表的场景。
- 原生JDK支持,零外部依赖
- 读写性能接近非同步的HashMap
- 完全线程安全,支持高并发
- 提供原子性复合操作(如computeIfAbsent)
import java.util.concurrent.*;
import java.util.function.Function;public class CHMCache<K,V> {private final ConcurrentHashMap<K,V> map = new ConcurrentHashMap<>(16, 0.75f, 32);private final ScheduledExecutorService cleaner = Executors.newSingleThreadScheduledExecutor();// 基础操作public void put(K key, V value) {map.put(key, value);}// 带TTL的putpublic void put(K key, V value, long ttl, TimeUnit unit) {map.put(key, value);cleaner.schedule(() -> map.remove(key), ttl, unit);}// 自动加载public V get(K key, Function<K,V> loader) {return map.computeIfAbsent(key, loader);}// 批量操作public void putAll(Map<? extends K, ? extends V> m) {map.putAll(m);}// 清空缓存public void clear() {map.clear();}
}2. Guava Cache
Guava Cache是Google Guava库中的缓存组件,诞生于2011年。作为ConcurrentHashMap的增强版,它添加了缓存特有的特性。Guava项目本身是Google内部Java开发的标准库,经过大规模生产环境验证,稳定性和性能都有保障。Guava Cache广泛应用于各种需要本地缓存的Java项目中。
- Google背书,质量有保证
- 丰富的缓存特性
- 良好的API设计
- 完善的文档和社区支持
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>31.1-jre</version>
</dependency>import com.google.common.cache.*;
import java.util.concurrent.TimeUnit;public class GuavaCacheDemo {public static void main(String[] args) {LoadingCache<String, String> cache = CacheBuilder.newBuilder().maximumSize(1000) // 最大条目数.expireAfterWrite(10, TimeUnit.MINUTES) // 写入后过期时间.expireAfterAccess(30, TimeUnit.MINUTES) // 访问后过期时间.concurrencyLevel(8) // 并发级别.recordStats() // 开启统计.removalListener(notification -> System.out.println("Removed: " + notification.getKey())).build(new CacheLoader<String, String>() {@Overridepublic String load(String key) throws Exception {return loadFromDB(key);}});try {// 自动加载String value = cache.get("user:1001");// 手动操作cache.put("config:timeout", "5000");cache.invalidate("user:1001");// 打印统计System.out.println(cache.stats());} catch (ExecutionException e) {e.printStackTrace();}}private static String loadFromDB(String key) {// 模拟数据库查询return "DB_Result_" + key;}
}3. Caffeine
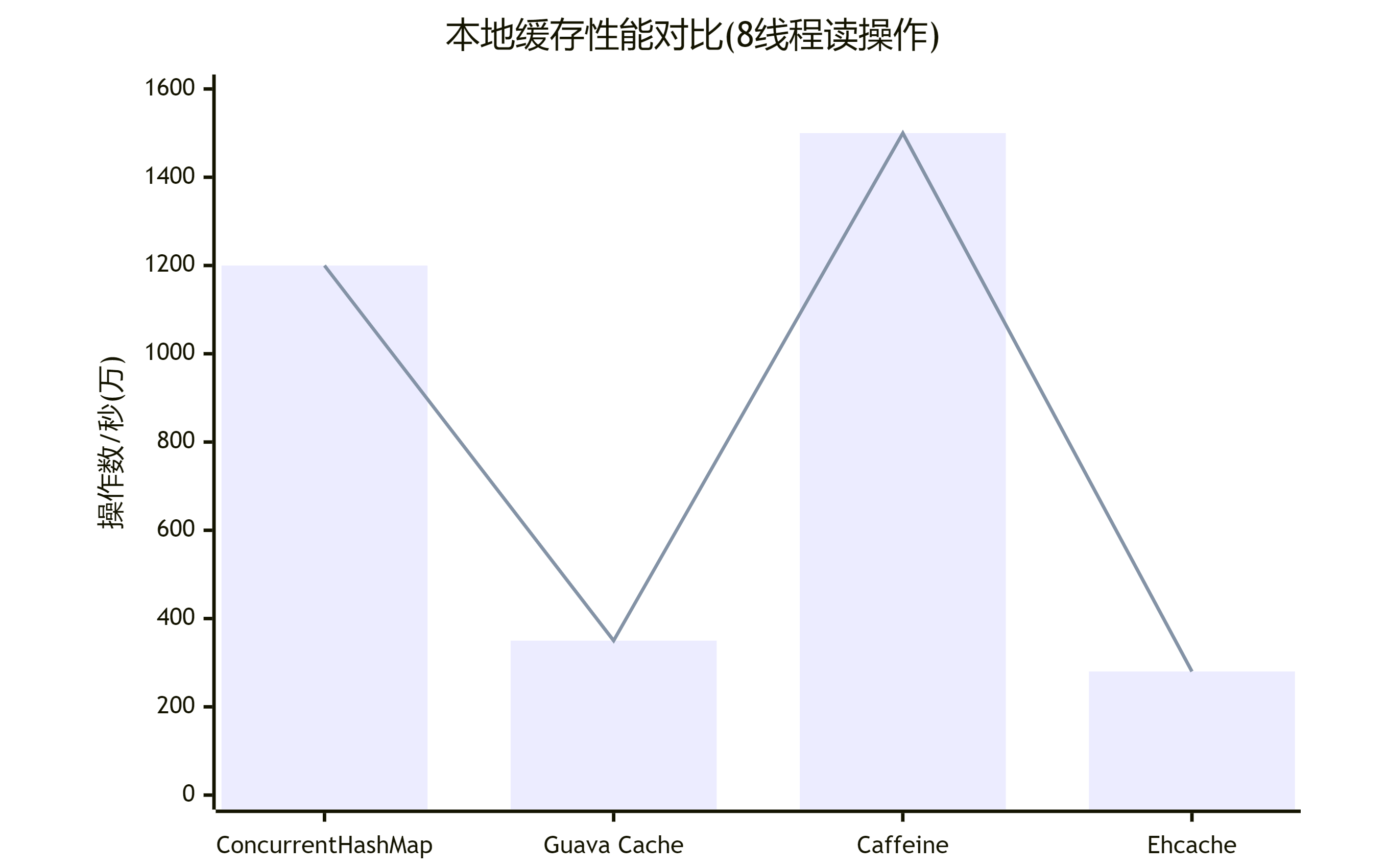
Caffeine是Guava Cache作者的新作品,发布于2015年。它专为现代Java应用设计,采用Window-TinyLFU淘汰算法,相比传统LRU有更高的命中率。Caffeine充分利用Java 8特性(如CompletableFuture),在性能上大幅超越Guava Cache(3-5倍提升),是目前性能最强的Java本地缓存库。
- 超高性能
- 更高的缓存命中率
- 异步刷新机制
- 精细的内存控制
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>2.9.3</version>
</dependency>import com.github.benmanes.caffeine.cache.*;
import java.util.concurrent.TimeUnit;public class CaffeineDemo {public static void main(String[] args) {// 同步缓存Cache<String, Data> cache = Caffeine.newBuilder().maximumSize(10_000).expireAfterWrite(5, TimeUnit.MINUTES).expireAfterAccess(10, TimeUnit.MINUTES).refreshAfterWrite(1, TimeUnit.MINUTES).recordStats().build();// 异步加载缓存AsyncLoadingCache<String, Data> asyncCache = Caffeine.newBuilder().maximumWeight(100_000).weigher((String key, Data data) -> data.size()).expireAfterWrite(10, TimeUnit.MINUTES).buildAsync(key -> loadFromDB(key));// 使用示例Data data = cache.getIfPresent("key1");CompletableFuture<Data> future = asyncCache.get("key1");// 打印统计System.out.println(cache.stats());}static class Data {int size() { return 1; }}private static Data loadFromDB(String key) {// 模拟数据库加载return new Data();}
}4. Encache
EEhcache是Terracotta公司开发的企业级缓存框架,始于2003年。它是JSR-107标准实现之一,支持从本地缓存扩展到分布式缓存。Ehcache的特色在于支持多级存储(堆内/堆外/磁盘),适合需要缓存持久化的企业级应用。最新版本Ehcache 3.x完全重构,提供了更现代的API设计。
- 企业级功能支持
- 多级存储架构
- 完善的监控管理
- 良好的扩展性
<dependency><groupId>org.ehcache</groupId><artifactId>ehcache</artifactId><version>3.9.7</version>
</dependency>import org.ehcache.*;
import org.ehcache.config.*;
import org.ehcache.config.builders.*;
import java.time.Duration;public class EhcacheDemo {public static void main(String[] args) {// 1. 配置缓存管理器CacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder().with(CacheManagerBuilder.persistence("/tmp/ehcache-data")).build();cacheManager.init();// 2. 配置缓存CacheConfiguration<String, String> config = CacheConfigurationBuilder.newCacheConfigurationBuilder(String.class, String.class,ResourcePoolsBuilder.newResourcePoolsBuilder().heap(1000, EntryUnit.ENTRIES) // 堆内.offheap(100, MemoryUnit.MB) // 堆外.disk(1, MemoryUnit.GB, true) // 磁盘).withExpiry(ExpiryPolicyBuilder.timeToLiveExpiration(Duration.ofMinutes(10))).build();// 3. 创建缓存Cache<String, String> cache = cacheManager.createCache("myCache", config);// 4. 使用缓存cache.put("key1", "value1");String value = cache.get("key1");System.out.println(value);// 5. 关闭cacheManager.close();}
}方案对比
| 特性 | ConcurrentHashMap | Guava Cache | Caffeine | Ehcache |
| 基本缓存功能 | ✓ | ✓ | ✓ | ✓ |
| 过期策略 | ✗ | ✓ | ✓ | ✓ |
| 淘汰算法 | ✗ | LRU | W-TinyLFU | LRU/LFU |
| 自动加载 | ✗ | ✓ | ✓ | ✓ |
| 异步加载 | ✗ | ✗ | ✓ | ✗ |
| 持久化支持 | ✗ | ✗ | ✗ | ✓ |
| 多级存储 | ✗ | ✗ | ✗ | ✓ |
| 命中率统计 | ✗ | 基本 | 详细 | 详细 |
| 分布式支持 | ✗ | ✗ | ✗ | ✓ |
| 内存占用 | 低 | 中 | 中 | 高 |
本地缓存问题及解决
1. 数据一致性
两级缓存与数据库的数据要保持一致,一旦数据发生了修改,在修改数据库的同时,本地缓存、远程缓存应该同步更新。
1.1. 解决方案1: 失效广播机制
通过Redis PubSub或Rabbit MQ等消息中间件实现跨节点通知
- 优点:实时性较好,能快速同步变更
- 缺点:增加了系统复杂度,网络分区时可能失效
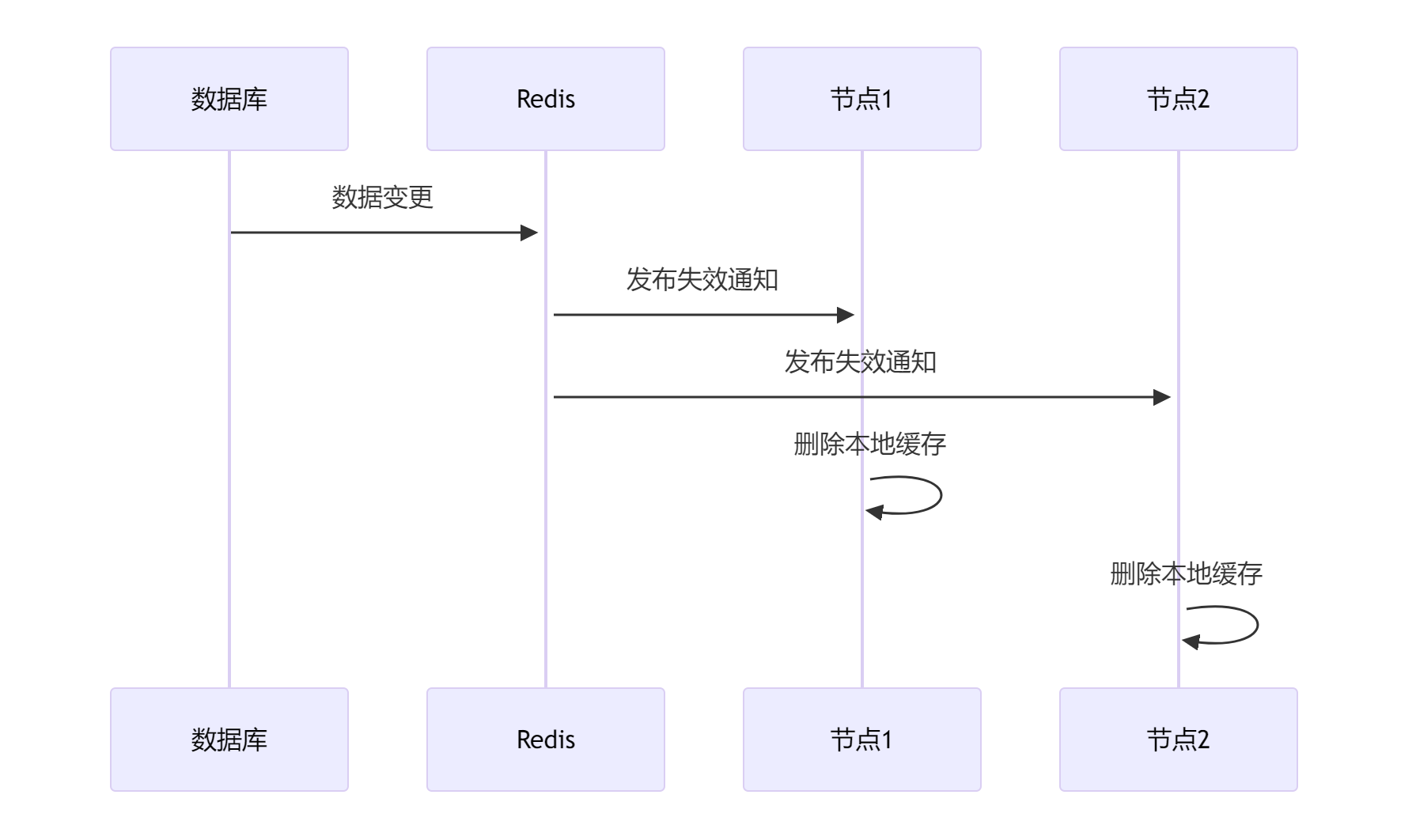
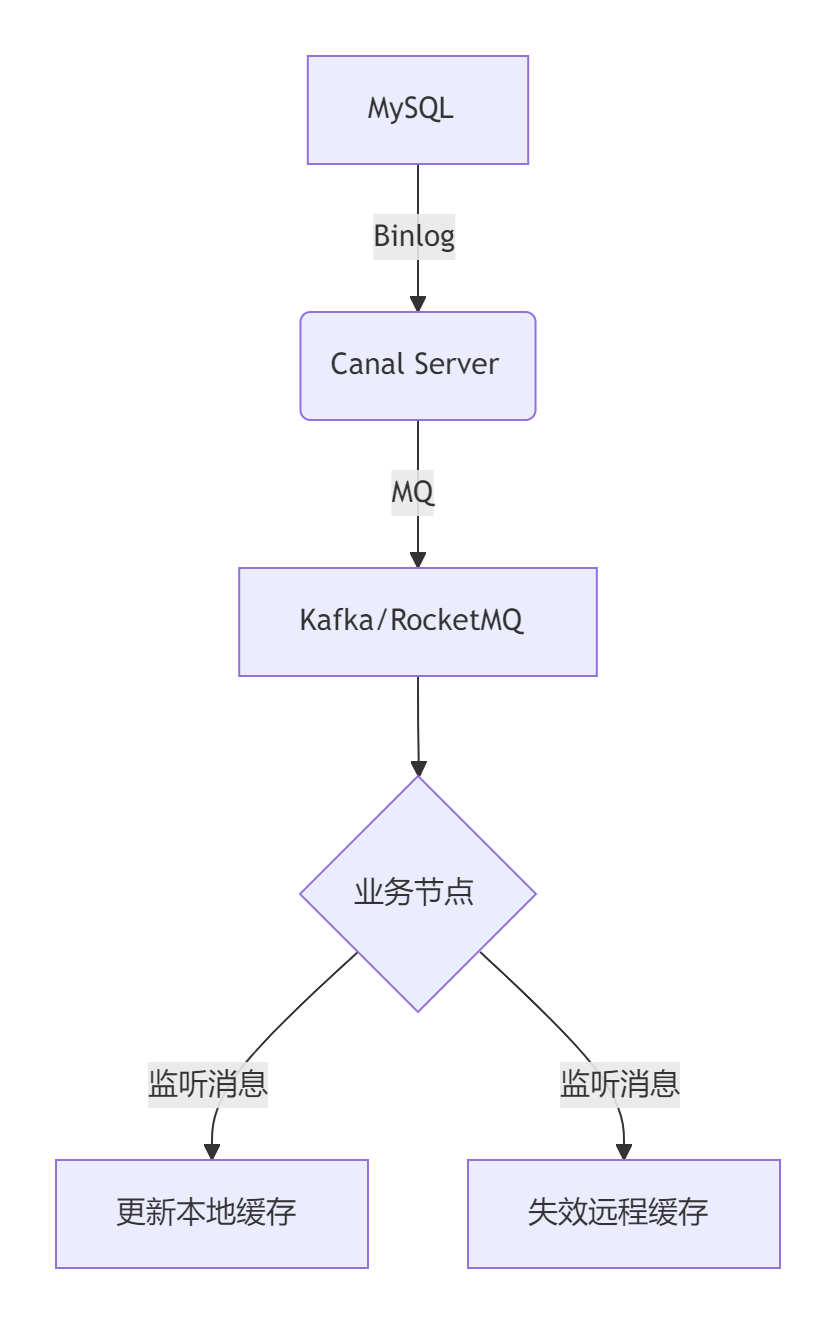
如果你不想在你的业务代码发送MQ消息,还可以适用近几年比较流行的方法:订阅数据库变更日志,再操作缓存。Canal 订阅Mysql的 Binlog日志,当发生变化时向MQ发送消息,进而也实现数据一致性。
1.2. 解决方案2:版本号控制
- 实现原理:
-
- 在数据库表中增加版本号字段(version)
- 缓存数据时同时存储版本号
- 查询时比较缓存版本与数据库版本
// 版本号校验示例
public Product getProduct(long id) {
CacheEntry entry = localCache.get(id);
if (entry != null) {int dbVersion = db.query("SELECT version FROM products WHERE id=?", id);if (entry.version == dbVersion) {return entry.product; // 版本一致,返回缓存}
}
// 版本不一致或缓存不存在,从数据库加载
Product product = db.loadProduct(id);
localCache.put(id, new CacheEntry(product, product.getVersion()));
return product;
}2. 内存管理问题
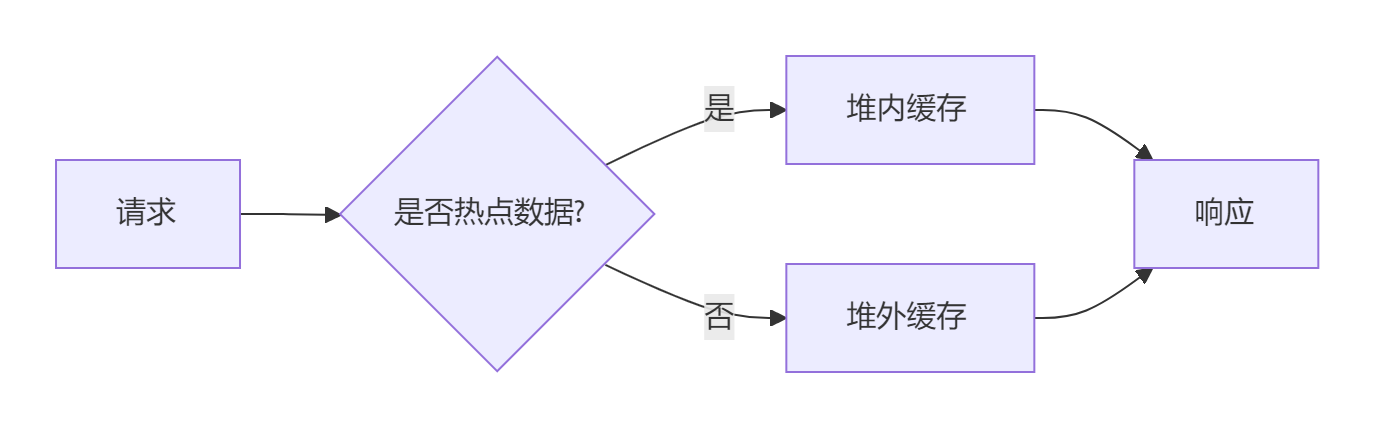
2.1. 解决方案1:分层缓存架构
// 组合堆内与堆外缓存
Cache<String, Object> multiLevelCache = Caffeine.newBuilder()
.maximumSize(10_000) // 一级缓存(堆内)
.buildAsync(key -> {Object value = offHeapCache.get(key); // 二级缓存(堆外)if(value == null) value = loadFromDB(key);return value;
});- 使用
Window-TinyLFU算法自动识别热点 - 对TOP 1%的热点数据单独配置更大容量
2.2. 解决方案2:智能淘汰策略
| 策略类型 | 适用场景 | 配置示例 |
| 基于大小 | 固定数量的小对象 |
|
| 基于权重 | 大小差异显著的对象 |
|
| 基于时间 | 时效性强的数据 |
|
| 基于引用 | 非核心数据 |
|
3. GC压力
3.1. GC压力问题的产生原因
缓存对象生命周期特征:
- 本地缓存通常持有大量长期存活对象(如商品信息、配置数据)
- 与传统短期对象(如HTTP请求作用域对象)不同,这些对象会持续晋升到老年代
- 示例:1GB的本地缓存意味着老年代常驻1GB可达对象
内存结构影响:
// 典型缓存数据结构带来的内存开销
ConcurrentHashMap<String, Product> cache = new ConcurrentHashMap<>();
// 实际内存占用 = 键对象 + 值对象 + 哈希表Entry对象(约额外增加40%开销)GC行为变化表现:
- Full GC频率上升:从2次/天 → 15次/天(如问题描述)
- 停顿时间增长:STW时间从120ms → 可能达到秒级(取决于堆大小)
- 晋升失败风险:当缓存大小接近老年代容量时,容易触发Concurrent Mode Failure
3.2. 解决方案1:堆外缓存(Off-Heap Cache)
// 使用OHC(Off-Heap Cache)示例
OHCache<String, Product> ohCache = OHCacheBuilder.newBuilder()
.keySerializer(new StringSerializer())
.valueSerializer(new ProductSerializer())
.capacity(1, Unit.GB)
.build();优势:
- 完全绕过JVM堆内存管理
- 不受GC影响,内存由操作系统直接管理
- 可突破JVM堆大小限制(如缓存50GB数据)
代价:
- 需要手动实现序列化/反序列化
- 读取时存在内存拷贝开销(比堆内缓存慢约20-30%)
3.3. 方案2:分区域缓存
// 按业务划分独立缓存实例
public class CacheRegistry {private static LoadingCache<String, Product> productCache = ...; // 商品专用private static LoadingCache<Integer, UserProfile> userCache = ...; // 用户专用// 独立配置各缓存参数static {productCache = Caffeine.newBuilder().maximumSize(10_000).build(...);userCache = Caffeine.newBuilder().maximumWeight(100MB).weigher(...).build(...);}
}效果:
- 避免单一超大缓存域导致全局GC压力
- 可针对不同业务设置差异化淘汰策略
总结
通过以上的分析和实现,可以通过Redis+Caffeine实现高性能二级缓存实现。
相关文章:

Redis+Caffeine构建高性能二级缓存
大家好,我是摘星。今天为大家带来的是RedisCaffeine构建高性能二级缓存,废话不多说直接开始~ 目录 二级缓存架构的技术背景 1. 基础缓存架构 2. 架构演进动因 3. 二级缓存解决方案 为什么选择本地缓存? 1. 极速访问 2. 减少网络IO 3…...

【机器人】复现 UniGoal 具身导航 | 通用零样本目标导航 CVPR 2025
UniGoal的提出了一个通用的零样本目标导航框架,能够统一处理多种类型的导航任务。 支持 对象类别导航、实例图像目标导航和文本目标导航,而无需针对特定任务进行训练或微调。 本文分享UniGoal复现和模型推理的过程~ 查找沙发,模…...

LeetCode 373 查找和最小的 K 对数字题解
LeetCode 373 查找和最小的 K 对数字题解 题目描述 给定两个以升序排列的整数数组 nums1 和 nums2,以及一个整数 k。定义一对值 (u,v),其中第一个元素来自 nums1,第二个元素来自 nums2。请找到和最小的 k 个数对。 解题思路 最小堆优化法…...

搜索二维矩阵 II 算法讲解
搜索二维矩阵 II 算法讲解 一、问题描述 给定一个 m x n 的二维矩阵 matrix ,需要在其中搜索一个目标值 target 。该矩阵具有以下特性: 每行的元素从左到右升序排列。每列的元素从上到下升序排列。要求编写一个高效的算法来完成搜索任务。 二、解题思路 方法一:暴力枚举 …...

三层交换机,单臂路由(用DHCP自动配置ip+互通+ACL
三层交换机,单臂路由(用DHCP自动配置ip互通ACL 任务 1.用DHCP自动配置ip 2.三层交换机SVI、 3.单臂路由 4.互通 5.ACL三层交换机SVI 交换机 Switch>en Switch#conf t Enter configuration commands, one per line. End with CNTL/Z. Switch(conf…...
操作的一个函数 flip())
OpenCV CUDA 模块中在 GPU 上对图像或矩阵进行 翻转(镜像)操作的一个函数 flip()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::flip 是 OpenCV 的 CUDA 模块中的一个函数,用于在 GPU 上对图像或矩阵进行 翻转(镜像)操作。它类似…...

链表面试题7之相交链表
来了来了,这道题才是值得我们奇思妙想的题,链接在下面。 160. 相交链表 - 力扣(LeetCode) 看完题目一脸懵吗,没关系,我们还得看示例 还是一脸懵怎么办?? 两个链表相交的方式有几种?…...

Excel-to-JSON插件专业版功能详解:让Excel数据转换更灵活
前言 在数据处理和系统集成过程中,Excel和JSON格式的转换是一个常见需求。Excel-to-JSON插件提供了一套强大的专业版功能,能够满足各种复杂的数据转换场景。本文将详细介绍这些专业版功能的应用场景和使用方法。 订阅说明 在介绍具体功能之前…...

【C++】”如虎添翼“:模板初阶
泛型编程: C中一种使用模板来实现代码重用和类型安全的编程范式。它允许程序员编写与数据类型无关的代码,从而可以用相同的代码逻辑处理不同的数据类型。模板是泛型编程的基础 模板分为两类: 函数模板:代表了一个函数家族&#x…...

【K8S学习之探针】详细了解就绪探针 readinessProbe 和存活探针 livenessProbe 的配置
参考 Pod健康检查 Kubernetes 学习笔记Kubernetes 就绪探针(Readiness Probe) - 人艰不拆_zmc - 博客园Kubernetes存活探针(Liveness Probe) - 人艰不拆_zmc - 博客园 Pod健康检查 Pod的健康状态由两类探针来检查:…...

WSL 安装 Debian 12 后,Linux 如何安装 redis ?
在 WSL 的 Debian 12 上安装 Redis 的步骤如下: 1. 更新系统包列表 sudo apt update && sudo apt upgrade -y2. 安装 Redis sudo apt install redis-server -y3. 启动 Redis 服务 sudo systemctl start redis4. 设置开机自启 sudo systemctl enable red…...

python打卡day22
复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 kaggle泰坦里克号人员生还预测 就是很简单很草率地走了一遍机器学习的经典流程&am…...

国产化Excel处理控件Spire.XLS系列教程:如何通过 C# 删除 Excel 工作表中的筛选器
在 Excel 文件中,筛选器(Filter)是一个常用的数据处理工具,可以帮助用户快速按条件筛选数据行。但在数据整理完成、导出、共享或打印之前,往往需要 删除 Excel 工作表中的筛选器,移除列标题中的下拉筛选按钮…...

使用 DMM 测试 TDR
TDR(时域反射计)可能是实验室中上升时间最快的仪器,但您可以使用直流欧姆表测试其准确性。 TDR 测量什么 在所有高速通道中,反射都很糟糕。我们尝试设计一个通道来减少反射,这些反射都会导致符号间干扰 (…...
)
基于卡尔曼滤波的传感器融合技术的多传感器融合技术(附战场环境模拟可视化代码及应用说明)
基于卡尔曼滤波的传感器融合技术的多传感器融合技术(附战场环境模拟可视化代码及应用说明) 1 目标运动状态空间建模1.1 状态向量定义1.2 状态转移方程1.3 观测模型构建2 卡尔曼滤波核心算法实现2.1 初始化2.2 预测步骤2.3 更新步骤3 多传感器融合仿真验证3.1 传感器模型模拟3…...

M8040A/M8199助力数据中心收发信机测试
随着数字通信和大数据的不断发展,误码率测试变得越来越重要。高性能误码率测试仪作为一种关键的测试设备,可以对数字信号进行高速、高精度的误码率测试,广泛应用于通信、数据中心、半导体等行业。 M8040A误码仪系统当前不仅在上游IP和顶层芯…...

傲云源墅:以五傲价值重构北京主城别墅格局
在高端别墅市场中,产品自身的品质与特色是吸引客户的关键。北京傲云源墅以其独特的 “五傲” 价值,重新定义了北京主城别墅的标准。 首先是低密之傲,傲云源墅的容积率低至约 0.9,与市场上 1.0 以上容积率的别墅相比,为…...
:创业阶段的划分与精益数据分析实践)
精益数据分析(56/126):创业阶段的划分与精益数据分析实践
精益数据分析(56/126):创业阶段的划分与精益数据分析实践 在创业和数据分析的探索之旅中,理解创业阶段的划分以及与之对应的精益数据分析方法至关重要。今天,依旧怀揣着与大家共同进步的心态,深入研读《精…...

[redis进阶六]详解redis作为缓存分布式锁
目录 一 什么是缓存 缓存总结板书: 二 使⽤Redis作为缓存 三 缓存的更新策略 1) 定期⽣成 2) 实时⽣成 四 面试重点:缓存预热,缓存穿透,缓存雪崩 和缓存击穿 1)缓存预热 2)缓存穿透 3)缓存雪崩 4)缓存击穿 五 分布式锁 板书: 1)什么是分布式锁 2)分布式锁的基…...
和HAProxy负载均衡)
【RabbitMQ】应用问题、仲裁队列(Raft算法)和HAProxy负载均衡
🔥个人主页: 中草药 🔥专栏:【中间件】企业级中间件剖析 一、幂等性保障 什么是幂等性? 幂等性是指对一个系统进行重复调用(相同参数),无论同一操作执行多少次,这些请求…...

国产密码新时代!华测国密 SSL 证书解锁安全新高度
在数字安全被提升到国家战略高度的今天,国产密码算法成为筑牢网络安全防线的关键力量。华测国密SSL证书凭借其强大性能与贴心服务,为企业网络安全保驾护航,成为符合国家安全要求的不二之选! 智能兼容,告别浏览器适配…...
)
【Linux篇章】Linux 进程信号2:解锁系统高效运作的 “隐藏指令”,开启性能飞跃新征程(精讲捕捉信号及OS运行机制)
本篇文章将以一个小白视角,通俗易懂带你了解信号在产生,保存之后如何进行捕捉;以及在信号这个话题中;OS扮演的角色及背后是如何进行操作的;如何理解用户态内核态;还有一些可以引出的其他知识点;…...

C# 基础 try-catch代码块
try-catch代码块是C#中用于异常处理的核心机制。异常是在程序执行过程中可能出现的错误,而try-catch代码块允许您在执行代码时捕获并处理这些异常。 一、基础结构 try {//可能抛出异常的代码 } catch (ArgumentException ex) {//处理特定异常 } catch (Excepti…...

为什么 mac os .bashrc 没有自动加载?
原因说明 在macOS中,默认情况下,终端使用的是Bash或Zsh作为shell。对于较新版本的macOS(从Catalina开始),默认的shell已经切换为Zsh。因此,如果你正在使用Zsh,.bashrc文件不会自动生效…...
)
【HarmonyOS Next之旅】DevEco Studio使用指南(二十二)
目录 1 -> 开发静态共享包 1.1 -> 创建库模块 1.2 -> 编译库模块 2 -> 开发动态共享包 2.1 -> 使用约束 2.2 -> 开发动态共享包 2.2.1 -> 创建HSP模块 2.2.2 -> 编译HSP模块 3 -> 发布共享包 1 -> 开发静态共享包 HAR(Harmony Archive…...

QT6.8安装教程
官网下载 链接: Index of /official_releases/online_installers 这个比较慢 建议去 清华大学开源软件镜像站:Index of /qt/archive/online_installers/4.9/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 根据自己什么系统选择 点击打开…...

【Rust泛型】Rust泛型使用详解与应用场景
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

一周学完计算机网络之三:1、数据链路层概述
简单的概述 数据链路层是计算机网络体系结构中的第二层,它在物理层提供的基本服务基础上,负责将数据从一个节点可靠地传输到相邻节点。可以将其想象成一个负责在两个相邻的网络设备之间进行数据 “搬运” 和 “整理” 的 “快递中转站”。 几个重要概念…...

配置ssh无密登录
在root下有一个.ssh文件夹,它的下面有一个known_hosts文件,这个里面记录了哪些其他的主机通过ssh访问过当前的主机。 免密登录原理 (2)生成公钥和私钥 具体操作: 1. 进入 hadoop1001 2. 运行命令:ssh-keyg…...

南京邮电大学金工实习答案
一、金工实习的定义 金工实习是机械类专业学生一项重要的实践课程,它绝非仅仅只是理论知识在操作层面的简单验证,而是一个全方位培养学生综合实践能力与职业素养的系统工程。从本质上而言,金工实习是学生走出教室,亲身踏入机械加…...

无偿帮写毕业论文
以下教程教你如何利用相关网站和AI免费帮你写一个毕业论文。毕竟毕业论文只要过就行,脱产学习这么多年,终于熬出头了,完成毕设后有空就去多看看亲人好友,祝好! 一、找一个论文模板(最好是overleaf) 废话不多说&#…...

【高数上册笔记01】:从集合映射到区间函数
【参考资料】 同济大学《高等数学》教材樊顺厚老师B站《高等数学精讲》系列课程 (注:本笔记为个人数学复习资料,旨在通过系统化整理替代厚重教材,便于随时查阅与巩固知识要点) 仅用于个人数学复习,因为课…...

大数据从专家到小白
文章目录 数据湖技术Apache Iceberg FlinkHiveHadoopHDFS 数据湖技术 Apache Iceberg Iceberg是一个通用的表格式(数据组织格式),它可以适配Presto,Spark等引擎提供高性能的读写和元数据管理功能。 Flink Hive Hadoop HDFS...

特励达力科LeCroy推出Xena Freya Z800 800GE高性能的800G以太网测试平台
Xena Freya Z800 800GE 是由全球领先的测试与测量解决方案提供商特励达力科公司(Teledyne LeCroy)开发的高性能以太网测试平台,专为满足从10GE到800GE数据中心互连速度的需求而设计。特励达力科公司在网络测试领域拥有超过50年的技术积累&…...

LeetCode 热题 100 98. 验证二叉搜索树
LeetCode 热题 100 | 98. 验证二叉搜索树 大家好,今天我们来解决一道经典的二叉树问题——验证二叉搜索树。这道题在 LeetCode 上被标记为中等难度,要求判断给定的二叉树是否是一个有效的二叉搜索树(BST)。 问题描述 给你一个二…...

Linux文件编程——open函数
在 Linux 系统中,文件操作不仅仅通过高级语言的标准库进行,底层的文件操作是通过 系统调用 来实现的。系统调用 是用户空间与操作系统内核之间的接口,允许程序请求操作系统提供的服务,包括文件读写、内存管理、进程控制等。本文将…...

Linux-Ext系列文件系统
1.理解硬件 1.1磁盘 机械磁盘是计算机中唯⼀的⼀个机械设备 磁盘---外设 慢 容量⼤,价格便宜 1.2磁盘的物理结构 1.3磁盘的存储结构 扇区:是磁盘存储数据的基本单位,512字节,块设备 如何定位⼀个扇区呢? 可以先定…...
)
Multisim14使用教程详尽版--(2025最新版)
一、Multisim14前言 1.1、主流电路仿真软件 1. Multisim:NI开发的SPICE标准仿真工具,支持模拟/数字电路混合仿真,内置丰富的元件库和虚拟仪器(示波器、频谱仪等),适合教学和竞赛设计。官网:艾…...

C——猜数字游戏
前面我们已经学习了C语言常见概念,数据类型和变量以及分置于循环的内容,现在我们可以将这些内容结合起来写一个有趣的小游戏。下面正式开始我们今天的主题——猜数字游戏的实现。 猜数字游戏的要求: 1.电脑自动生成1~100的随机数。 2.玩家…...

【iOS】SDWebImage源码学习
SDWebImage源码学习 文章目录 SDWebImage源码学习前言SDWebImage缓存流程sd_setImageWithURL(UIImageViewWebCache层)sd_internalSetImageWithURL(UIViewWebCache层)loadImageWithURL(SDWebManger层)queryCacheOperationForKey(SDImageCache层)删除缓存 callDownloadProcessFor…...

.Net HttpClient 处理响应数据
HttpClient 处理响应数据 1、初始化及全局设置 //初始化:必须先执行一次 #!import ./ini.ipynb2、处理响应状态 //判断响应码:正常 {var response await SharedClient.GetAsync("api/Normal/GetAccount?id1");if(response.StatusCode Sy…...

【心海资源】【最新话费盗u】【未测】提币对方官方波场+没有任何加密+无后门+前端VUE
提笔接口请使用官方提笔,第三方提笔都有风险 后门你们也扫扫,这种源码风险大,自己玩玩学习进行了 重要的事情说三遍 !!!!!!!!!&…...

Python中的标识、相等性与别名:深入理解对象引用机制
在Python编程中,理解变量如何引用对象以及对象之间的比较方式是至关重要的基础概念。本文将通过Lewis Carroll的笔名示例,深入探讨Python中的对象标识、相等性判断以及别名机制。 别名现象:变量共享同一对象 >>> charles {name: …...
)
Java 1.8(也称为Java 8)
Java 1.8(也称为Java 8)是Oracle于2014年发布的一个重要版本,引入了许多新特性和改进,极大地提升了Java语言的表达力和开发效率。以下是Java 1.8的主要新特性: ### 1. Lambda表达式 Lambda表达式是Java 1.8最具革命性…...

LVGL简易计算器实战
文章目录 📁 文件结构建议🔹 eval.h 表达式求值头文件🔹 eval.c 表达式求值实现文件(带详细注释)🔹 ui.h 界面头文件🔹 ui.c 界面实现文件🔹 main.c 主函数入口✅ 总结 项目效果&…...
)
Linux | Uboot-Logo 修改文档(第十七天)
01 Uboot 修改 首先我们在 home 目录下新建一个文件夹 imx6ull,然后打开 i.MX6ULL 终结者光盘资料\05_uboot linux源码,在 window 下解压下图箭头所指的压缩包,解压后分别得到 linux-imx-rel_imx_4.1.15_2.1.0_ga_20200323.tar.gz 和 uboot-imx-rel_imx_4.1.15_2.1.0_…...

数字孪生概念
数字孪生(Digital Twin) 是指通过数字技术对物理实体(如设备、系统、流程或环境)进行高保真建模和实时动态映射,实现虚实交互、仿真预测和优化决策的技术体系。它是工业4.0、智慧城市和数字化转型的核心技术之一。 1. …...

c++STL-string的使用
这里写自定义目录标题 string的使用string写成类模板的原因string的版本举例构造、析构函数和赋值重载构造函数和析构函数operator Iterators迭代器begin和endrbegin和rendcbegin和cend,crbegin和crend(c11) capacity容量有关函数不同编译器下…...

总结C/C++中程序内存区域划分
C/C程序内存分配的⼏个区域 1..栈区(stack):在执⾏函数时,函数内局部变量的存储单元都可以在栈上创建,函数执⾏结束时 这些存储单元⾃动被释放。栈内存分配运算内置于处理器的指令集中,效率很⾼,…...
)
C# 方法(方法重载)
本章内容: 方法的结构 方法体内部的代码执行 局部变量 局部常量 控制流 方法调用 返回值 返回语句和void方法 局部函数 参数 值参数 引用参数 引用类型作为值参数和引用参数 输出参数 参数数组 参数类型总结 方法重载 命名参数 可选参数 栈帧 递归 方法重载 一个类中可以有多个…...