python打卡day22
复习日
仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。
作业:
自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码
kaggle泰坦里克号人员生还预测
就是很简单很草率地走了一遍机器学习的经典流程,其实数据还可以提取新特征,但懒得搞了,特征也少不需要降维。就是这个项目本身就分了训练集和测试集,需要注意一下数据预处理跟之前不太一样
# 导入相关库
import pandas as pd
import numpy as npimport seaborn as sns
import matplotlib.pyplot as pltimport warnings
warnings.filterwarnings("ignore")plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsefrom sklearn.ensemble import RandomForestClassifier
from skopt import BayesSearchCV
from skopt.space import Integer, Categorical
import time
import shap# 读取数据
train_data = pd.read_csv('/kaggle/input/titanic/train.csv')
test_data = pd.read_csv('/kaggle/input/titanic/test.csv')分别执行吧,就不放结果图了
train_data.head()train_data.info()train_data.isnull().sum()test_data.isnull().sum()train_data.describe() # 看看数值型数据的分布train_data.describe(include=['O']) # 看看对象型数据的分布train_data.groupby(['Sex'], as_index=False)['Survived'].mean() # 很显然性别跟存活率有关train_data.groupby(['Pclass'], as_index=False)['Survived'].mean() # 票价等级越高存活率越高train_data.groupby(['Age'], as_index=False)['Survived'].mean()# 年龄这个不太好看,还是画图吧
sns.histplot(train_data, x='Age',hue='Survived', multiple='dodge') # 婴儿、80岁左右老年人和年轻人存活率高点可以看看每个特征与最后标签的相关性来确定是否需要去除,这里只看了几个特征,最后直接根据特征的含义评判了,数据探索还可以再多一点数据可视化一下更明确,这里的处理其实蛮粗糙的,比如名字还可以看出头衔阶层啥的对吧,和幸存率可能还是有关系的(
- Age、Sex 年龄性别特征肯定与幸存相关;
- Pclass 票价等级也和幸存有关
- Embarked 登船港口可能与幸存或其他重要特征相关;
- Ticket 票号包含较高重复率(22%),并且和幸存之间可能没有相关性,因此可能会从我们的分析中删除;
- Cabin 客舱号可能被丢弃,因为它在训练和测试集中缺失值过多(数据高度不完整);
- PassengerId 乘客编号可能会从训练数据集中删除,因为它对幸存没有作用;
- Name 名字特征比较不规范,可能也对幸存没有直接贡献,因此可能会被丢弃。
下面是数据预处理
PassengerId = test_data["PassengerId"] # 保存ID便于提交# 清除无用特征
cols_to_drop = ['PassengerId', 'Name', 'Ticket', 'Cabin']
train_data = train_data.drop([col for col in cols_to_drop if col in train_data.columns], axis=1)
test_data = test_data.drop([col for col in cols_to_drop if col in test_data.columns], axis=1)# 缺失值处理一下
train_data['Embarked'].fillna(train_data['Embarked'].mode()[0], inplace=True)
train_data['Age'].fillna(train_data['Age'].median(), inplace=True)
test_data['Age'].fillna(test_data['Age'].median(), inplace=True)
test_data['Fare'].fillna(test_data['Fare'].median(), inplace=True)# 离散变量编码
train_data = pd.get_dummies(train_data, columns=['Embarked'])
train_data2 = pd.read_csv('/kaggle/input/titanic/train.csv')
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in train_data.columns:if i not in train_data2.columns:list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:train_data[i] = train_data[i].astype(int) # 这里的i就是独热编码后的特征名test_data = pd.get_dummies(test_data, columns=['Embarked'])
test_data2 = pd.read_csv('/kaggle/input/titanic/test.csv')
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in test_data.columns:if i not in test_data2.columns:list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:test_data[i] = test_data[i].astype(int) # 这里的i就是独热编码后的特征名sex_mapping = {'male':1,'female':0,
}
train_data['Sex'] = train_data['Sex'].map(sex_mapping)
test_data['Sex'] = test_data['Sex'].map(sex_mapping)数据集不用划分,直接训练
X_train = train_data.drop(['Survived'], axis=1) # 特征,axis=1表示按列删除
y_train = train_data['Survived'] # 标签X_test = test_data.copy() # 特征# --- 1. 默认参数的随机森林 ---
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
acc_rf = round(rf_model.score(X_train, y_train) * 100, 2) # 看不了测试集的评估指标那就看看训练集的
print(f'训练集分类准确率:{acc_rf}')# --- 2. 贝叶斯优化调参的随机森林 ---
print("--- 2. 贝叶斯优化调参的随机森林 (训练集 -> 测试集) ---")param_space = {'n_estimators': (50, 500), # 树的数量(50~500)'max_depth': (3, 15), # 树的最大深度(3~15)'min_samples_split': (2, 10), # 分裂所需最小样本数(2~10)'min_samples_leaf': (1, 5), # 叶节点最小样本数(1~5)'max_features': ['sqrt', 'log2'], # 特征选择方式'bootstrap': [True, False] # 是否使用bootstrap采样
}
# 定义优化器(迭代50次)
opt = BayesSearchCV(estimator=RandomForestClassifier(random_state=42),search_spaces=param_space,n_iter=50, # 迭代次数cv=5, # 5折交叉验证scoring='accuracy', # 优化目标(准确率)random_state=42,n_jobs=-1 # 使用所有CPU核心
)start_time = time.time()
opt.fit(X_train, y_train) # 执行贝叶斯优化best_rf = opt.best_estimator_
rf_pred_opt = best_rf.predict(X_test)end_time = time.time()print(f"贝叶斯优化耗时: {end_time - start_time:.2f} 秒")
print(f"最佳参数: {opt.best_params_}")
acc_rf_opt = round(best_rf.score(X_train, y_train) * 100, 2)
print(f'优化后训练集准确率: {acc_rf_opt}%')最后还是用shap看看吧
# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(rf_model)
shap_values = explainer.shap_values(X_test)
shap_values# --- 1. SHAP 特征重要性条形图 (Summary Plot - Bar) ---
print("--- 1. SHAP 特征重要性条形图 ---")
shap.summary_plot(shap_values[0], X_test, plot_type="bar",show=False)
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()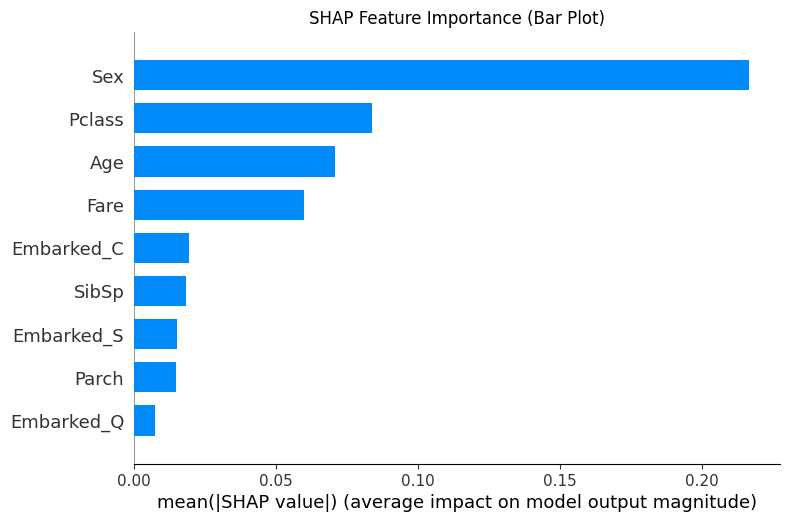
# --- 2. SHAP 特征重要性蜂巢图 (Summary Plot - Violin) ---
print("--- 2. SHAP 特征重要性蜂巢图 ---")
shap.summary_plot(shap_values[0], X_test,plot_type="violin",show=False,max_display=10)
plt.title("SHAP Feature Importance (Violin Plot)")
plt.show()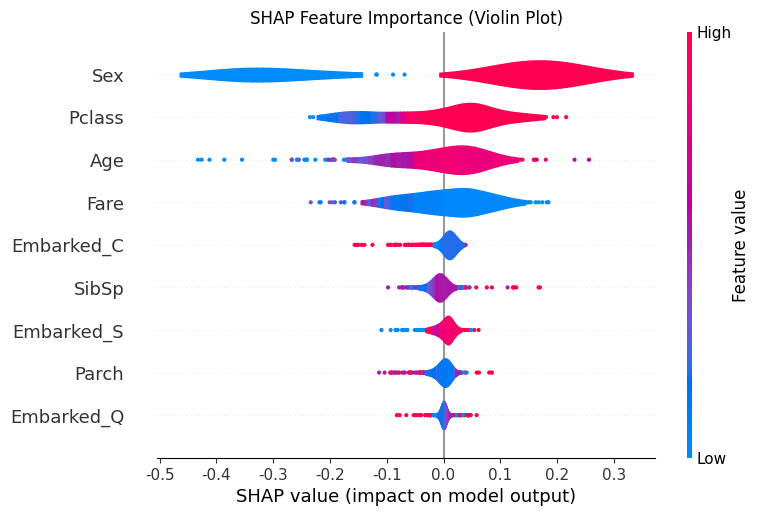
保存csv文件,调参谦和调参后都提交了一下做对比,还是贝叶斯优化后准确率高点
submission = pd.DataFrame({"PassengerId": PassengerId,"Survived": rf_pred})
submission.to_csv('./submission.csv', index=False)
print("Your submission was successfully saved!")submission2 = pd.DataFrame({"PassengerId": PassengerId,"Survived": rf_pred_opt})
submission2.to_csv('./submission2.csv', index=False)
print("Your submission was successfully saved!")@浙大疏锦行
相关文章:

python打卡day22
复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 kaggle泰坦里克号人员生还预测 就是很简单很草率地走了一遍机器学习的经典流程&am…...

国产化Excel处理控件Spire.XLS系列教程:如何通过 C# 删除 Excel 工作表中的筛选器
在 Excel 文件中,筛选器(Filter)是一个常用的数据处理工具,可以帮助用户快速按条件筛选数据行。但在数据整理完成、导出、共享或打印之前,往往需要 删除 Excel 工作表中的筛选器,移除列标题中的下拉筛选按钮…...

使用 DMM 测试 TDR
TDR(时域反射计)可能是实验室中上升时间最快的仪器,但您可以使用直流欧姆表测试其准确性。 TDR 测量什么 在所有高速通道中,反射都很糟糕。我们尝试设计一个通道来减少反射,这些反射都会导致符号间干扰 (…...
)
基于卡尔曼滤波的传感器融合技术的多传感器融合技术(附战场环境模拟可视化代码及应用说明)
基于卡尔曼滤波的传感器融合技术的多传感器融合技术(附战场环境模拟可视化代码及应用说明) 1 目标运动状态空间建模1.1 状态向量定义1.2 状态转移方程1.3 观测模型构建2 卡尔曼滤波核心算法实现2.1 初始化2.2 预测步骤2.3 更新步骤3 多传感器融合仿真验证3.1 传感器模型模拟3…...

M8040A/M8199助力数据中心收发信机测试
随着数字通信和大数据的不断发展,误码率测试变得越来越重要。高性能误码率测试仪作为一种关键的测试设备,可以对数字信号进行高速、高精度的误码率测试,广泛应用于通信、数据中心、半导体等行业。 M8040A误码仪系统当前不仅在上游IP和顶层芯…...

傲云源墅:以五傲价值重构北京主城别墅格局
在高端别墅市场中,产品自身的品质与特色是吸引客户的关键。北京傲云源墅以其独特的 “五傲” 价值,重新定义了北京主城别墅的标准。 首先是低密之傲,傲云源墅的容积率低至约 0.9,与市场上 1.0 以上容积率的别墅相比,为…...
:创业阶段的划分与精益数据分析实践)
精益数据分析(56/126):创业阶段的划分与精益数据分析实践
精益数据分析(56/126):创业阶段的划分与精益数据分析实践 在创业和数据分析的探索之旅中,理解创业阶段的划分以及与之对应的精益数据分析方法至关重要。今天,依旧怀揣着与大家共同进步的心态,深入研读《精…...

[redis进阶六]详解redis作为缓存分布式锁
目录 一 什么是缓存 缓存总结板书: 二 使⽤Redis作为缓存 三 缓存的更新策略 1) 定期⽣成 2) 实时⽣成 四 面试重点:缓存预热,缓存穿透,缓存雪崩 和缓存击穿 1)缓存预热 2)缓存穿透 3)缓存雪崩 4)缓存击穿 五 分布式锁 板书: 1)什么是分布式锁 2)分布式锁的基…...
和HAProxy负载均衡)
【RabbitMQ】应用问题、仲裁队列(Raft算法)和HAProxy负载均衡
🔥个人主页: 中草药 🔥专栏:【中间件】企业级中间件剖析 一、幂等性保障 什么是幂等性? 幂等性是指对一个系统进行重复调用(相同参数),无论同一操作执行多少次,这些请求…...

国产密码新时代!华测国密 SSL 证书解锁安全新高度
在数字安全被提升到国家战略高度的今天,国产密码算法成为筑牢网络安全防线的关键力量。华测国密SSL证书凭借其强大性能与贴心服务,为企业网络安全保驾护航,成为符合国家安全要求的不二之选! 智能兼容,告别浏览器适配…...
)
【Linux篇章】Linux 进程信号2:解锁系统高效运作的 “隐藏指令”,开启性能飞跃新征程(精讲捕捉信号及OS运行机制)
本篇文章将以一个小白视角,通俗易懂带你了解信号在产生,保存之后如何进行捕捉;以及在信号这个话题中;OS扮演的角色及背后是如何进行操作的;如何理解用户态内核态;还有一些可以引出的其他知识点;…...

C# 基础 try-catch代码块
try-catch代码块是C#中用于异常处理的核心机制。异常是在程序执行过程中可能出现的错误,而try-catch代码块允许您在执行代码时捕获并处理这些异常。 一、基础结构 try {//可能抛出异常的代码 } catch (ArgumentException ex) {//处理特定异常 } catch (Excepti…...

为什么 mac os .bashrc 没有自动加载?
原因说明 在macOS中,默认情况下,终端使用的是Bash或Zsh作为shell。对于较新版本的macOS(从Catalina开始),默认的shell已经切换为Zsh。因此,如果你正在使用Zsh,.bashrc文件不会自动生效…...
)
【HarmonyOS Next之旅】DevEco Studio使用指南(二十二)
目录 1 -> 开发静态共享包 1.1 -> 创建库模块 1.2 -> 编译库模块 2 -> 开发动态共享包 2.1 -> 使用约束 2.2 -> 开发动态共享包 2.2.1 -> 创建HSP模块 2.2.2 -> 编译HSP模块 3 -> 发布共享包 1 -> 开发静态共享包 HAR(Harmony Archive…...

QT6.8安装教程
官网下载 链接: Index of /official_releases/online_installers 这个比较慢 建议去 清华大学开源软件镜像站:Index of /qt/archive/online_installers/4.9/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 根据自己什么系统选择 点击打开…...

【Rust泛型】Rust泛型使用详解与应用场景
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

一周学完计算机网络之三:1、数据链路层概述
简单的概述 数据链路层是计算机网络体系结构中的第二层,它在物理层提供的基本服务基础上,负责将数据从一个节点可靠地传输到相邻节点。可以将其想象成一个负责在两个相邻的网络设备之间进行数据 “搬运” 和 “整理” 的 “快递中转站”。 几个重要概念…...

配置ssh无密登录
在root下有一个.ssh文件夹,它的下面有一个known_hosts文件,这个里面记录了哪些其他的主机通过ssh访问过当前的主机。 免密登录原理 (2)生成公钥和私钥 具体操作: 1. 进入 hadoop1001 2. 运行命令:ssh-keyg…...

南京邮电大学金工实习答案
一、金工实习的定义 金工实习是机械类专业学生一项重要的实践课程,它绝非仅仅只是理论知识在操作层面的简单验证,而是一个全方位培养学生综合实践能力与职业素养的系统工程。从本质上而言,金工实习是学生走出教室,亲身踏入机械加…...

无偿帮写毕业论文
以下教程教你如何利用相关网站和AI免费帮你写一个毕业论文。毕竟毕业论文只要过就行,脱产学习这么多年,终于熬出头了,完成毕设后有空就去多看看亲人好友,祝好! 一、找一个论文模板(最好是overleaf) 废话不多说&#…...

【高数上册笔记01】:从集合映射到区间函数
【参考资料】 同济大学《高等数学》教材樊顺厚老师B站《高等数学精讲》系列课程 (注:本笔记为个人数学复习资料,旨在通过系统化整理替代厚重教材,便于随时查阅与巩固知识要点) 仅用于个人数学复习,因为课…...

大数据从专家到小白
文章目录 数据湖技术Apache Iceberg FlinkHiveHadoopHDFS 数据湖技术 Apache Iceberg Iceberg是一个通用的表格式(数据组织格式),它可以适配Presto,Spark等引擎提供高性能的读写和元数据管理功能。 Flink Hive Hadoop HDFS...

特励达力科LeCroy推出Xena Freya Z800 800GE高性能的800G以太网测试平台
Xena Freya Z800 800GE 是由全球领先的测试与测量解决方案提供商特励达力科公司(Teledyne LeCroy)开发的高性能以太网测试平台,专为满足从10GE到800GE数据中心互连速度的需求而设计。特励达力科公司在网络测试领域拥有超过50年的技术积累&…...

LeetCode 热题 100 98. 验证二叉搜索树
LeetCode 热题 100 | 98. 验证二叉搜索树 大家好,今天我们来解决一道经典的二叉树问题——验证二叉搜索树。这道题在 LeetCode 上被标记为中等难度,要求判断给定的二叉树是否是一个有效的二叉搜索树(BST)。 问题描述 给你一个二…...

Linux文件编程——open函数
在 Linux 系统中,文件操作不仅仅通过高级语言的标准库进行,底层的文件操作是通过 系统调用 来实现的。系统调用 是用户空间与操作系统内核之间的接口,允许程序请求操作系统提供的服务,包括文件读写、内存管理、进程控制等。本文将…...

Linux-Ext系列文件系统
1.理解硬件 1.1磁盘 机械磁盘是计算机中唯⼀的⼀个机械设备 磁盘---外设 慢 容量⼤,价格便宜 1.2磁盘的物理结构 1.3磁盘的存储结构 扇区:是磁盘存储数据的基本单位,512字节,块设备 如何定位⼀个扇区呢? 可以先定…...
)
Multisim14使用教程详尽版--(2025最新版)
一、Multisim14前言 1.1、主流电路仿真软件 1. Multisim:NI开发的SPICE标准仿真工具,支持模拟/数字电路混合仿真,内置丰富的元件库和虚拟仪器(示波器、频谱仪等),适合教学和竞赛设计。官网:艾…...

C——猜数字游戏
前面我们已经学习了C语言常见概念,数据类型和变量以及分置于循环的内容,现在我们可以将这些内容结合起来写一个有趣的小游戏。下面正式开始我们今天的主题——猜数字游戏的实现。 猜数字游戏的要求: 1.电脑自动生成1~100的随机数。 2.玩家…...

【iOS】SDWebImage源码学习
SDWebImage源码学习 文章目录 SDWebImage源码学习前言SDWebImage缓存流程sd_setImageWithURL(UIImageViewWebCache层)sd_internalSetImageWithURL(UIViewWebCache层)loadImageWithURL(SDWebManger层)queryCacheOperationForKey(SDImageCache层)删除缓存 callDownloadProcessFor…...

.Net HttpClient 处理响应数据
HttpClient 处理响应数据 1、初始化及全局设置 //初始化:必须先执行一次 #!import ./ini.ipynb2、处理响应状态 //判断响应码:正常 {var response await SharedClient.GetAsync("api/Normal/GetAccount?id1");if(response.StatusCode Sy…...

【心海资源】【最新话费盗u】【未测】提币对方官方波场+没有任何加密+无后门+前端VUE
提笔接口请使用官方提笔,第三方提笔都有风险 后门你们也扫扫,这种源码风险大,自己玩玩学习进行了 重要的事情说三遍 !!!!!!!!!&…...

Python中的标识、相等性与别名:深入理解对象引用机制
在Python编程中,理解变量如何引用对象以及对象之间的比较方式是至关重要的基础概念。本文将通过Lewis Carroll的笔名示例,深入探讨Python中的对象标识、相等性判断以及别名机制。 别名现象:变量共享同一对象 >>> charles {name: …...
)
Java 1.8(也称为Java 8)
Java 1.8(也称为Java 8)是Oracle于2014年发布的一个重要版本,引入了许多新特性和改进,极大地提升了Java语言的表达力和开发效率。以下是Java 1.8的主要新特性: ### 1. Lambda表达式 Lambda表达式是Java 1.8最具革命性…...

LVGL简易计算器实战
文章目录 📁 文件结构建议🔹 eval.h 表达式求值头文件🔹 eval.c 表达式求值实现文件(带详细注释)🔹 ui.h 界面头文件🔹 ui.c 界面实现文件🔹 main.c 主函数入口✅ 总结 项目效果&…...
)
Linux | Uboot-Logo 修改文档(第十七天)
01 Uboot 修改 首先我们在 home 目录下新建一个文件夹 imx6ull,然后打开 i.MX6ULL 终结者光盘资料\05_uboot linux源码,在 window 下解压下图箭头所指的压缩包,解压后分别得到 linux-imx-rel_imx_4.1.15_2.1.0_ga_20200323.tar.gz 和 uboot-imx-rel_imx_4.1.15_2.1.0_…...

数字孪生概念
数字孪生(Digital Twin) 是指通过数字技术对物理实体(如设备、系统、流程或环境)进行高保真建模和实时动态映射,实现虚实交互、仿真预测和优化决策的技术体系。它是工业4.0、智慧城市和数字化转型的核心技术之一。 1. …...

c++STL-string的使用
这里写自定义目录标题 string的使用string写成类模板的原因string的版本举例构造、析构函数和赋值重载构造函数和析构函数operator Iterators迭代器begin和endrbegin和rendcbegin和cend,crbegin和crend(c11) capacity容量有关函数不同编译器下…...

总结C/C++中程序内存区域划分
C/C程序内存分配的⼏个区域 1..栈区(stack):在执⾏函数时,函数内局部变量的存储单元都可以在栈上创建,函数执⾏结束时 这些存储单元⾃动被释放。栈内存分配运算内置于处理器的指令集中,效率很⾼,…...
)
C# 方法(方法重载)
本章内容: 方法的结构 方法体内部的代码执行 局部变量 局部常量 控制流 方法调用 返回值 返回语句和void方法 局部函数 参数 值参数 引用参数 引用类型作为值参数和引用参数 输出参数 参数数组 参数类型总结 方法重载 命名参数 可选参数 栈帧 递归 方法重载 一个类中可以有多个…...

Dockerfile 完全指南:从入门到最佳实践
Dockerfile 完全指南:从入门到最佳实践 1. Dockerfile 简介与作用 Dockerfile 是一个文本文件,包含了一系列用于构建 Docker 镜像的指令。它允许开发者通过简单的指令定义镜像的构建过程,实现自动化、可重复的镜像构建。 主要作用…...
)
DEEPPOLAR:通过深度学习发明非线性大核极坐标码(2)
目录 2.问题的提出和背景 2.1 信道编码 2.2.极化码 极坐标编码 极坐标解码 原文:《DEEPPOLAR: Inventing Nonlinear Large-Kernel Polar Codes via Deep Learning》 2.问题的提出和背景 2.1 信道编码 信道编码是一种为传输添加冗余的技术,使其对…...
)
ESP32-S3 学习笔记(1)
ESP32-S3 学习笔记(1) 背景环境添加工程文件材料准备轻触开关的正负极 背景 闲来无事,看到立创论坛上有许多大佬开源的项目,甚是厉害,于是决定自己也来搞一搞,同时可以做一些技术积累,看了很…...

Python Cookbook-7.9 访问 MySQL 数据库
任务 想访问一个 MySQL 数据库。 解决方案 MySQLdb 模块正是为这种任务而设计的: import MySQLdb #创建一个连接对象,再用它创建游标 con = MySQLdb.connect(host = "127.0.0.1", port = 3306, user = "joe",<...

docker安装superset实践
1、拉取docker镜像 docker pull apache/superset:latest 2、安装superset容器 mkdir /usr/local/develop/docker/superset/ -p touch /usr/local/develop/docker/superset/superset_config.py superset_config.py配置文件如下: SQLALCHEMY_DATABASE_URI mysql:…...

Web开发—Vue工程化
文章目录 前言 Vue工程化 一、介绍 二、环境准备 1.介绍create-vue 2.NodeJS安装 3.npm介绍 三,Vue项目创建 四,项目结构 五,启动项目 六,Vue项目开发流程 七,API风格 前言 Vue工程化 前面我们在介绍Vue的时候&#…...

什么是硬件中断请求号?什么是中断向量号?
一、硬件中断请求号(IRQ,Interrupt Request Number) 定义: 硬件中断请求号(IRQ)是硬件设备向CPU发送中断请求时使用的唯一标识符,用于区分不同的中断源。例如,键盘、硬盘等外设…...
)
[Java实战]Spring Boot 定时任务(十五)
[Java实战]Spring Boot 定时任务(十五) 一、定时任务的应用场景 数据同步:每日凌晨同步第三方数据状态检查:每5分钟扫描订单超时未支付资源清理:每小时清理临时文件报表生成:每月1号生成财务统计报表通知…...

OpenWrt开发第7篇:OpenWrt配置支持Web界面
文/指尖动听知识库-谷谷 文章为付费内容,商业行为,禁止私自转载及抄袭,违者必究!!! 文章专栏:Openwrt开发-基于Raspberry Pi 4B开发板 OpenWrt的luci是一个基于Web的图形化管理界面,为用户提供了直观的操作方式,无需命令行即可完成大部分功能的配置。 1.在终端输入ma…...

【多模态】IMAGEBIND论文阅读
every blog every motto: Although the world is full of suffering, it is full also of the overcoming of it 0. 前言 IMAGEBIND 多模态论文梗概 IMAGEBIND是一种夸模态的神经网络,以图片为中心,联合六中模态的网络(图片、文…...

【C语言干货】二维数组传参本质
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、二维数组的内存布局 1.二维数组的实质2.二维数组的地址关系 二、二维数组传参的本质 1.参数传递的退化机制2.三种等效的函数声明方式 总结 前言 提示&#…...