缓存(5):常见 缓存数据淘汰算法/缓存清空策略
主要的三种缓存数据淘汰算法
FIFO(first in first out):先进先出策略,最先进入缓存的数据在缓存空间不够的情况下(超出最大元素限制)会被优先被清除掉,以腾出新的空间接受新的数据。策略算法主要比较缓存元素的创建时间。在数据实效性要求场景下可选择该类策略,优先保障最新数据可用。
LFU(less frequently used):最少使用策略,无论是否过期,根据元素的被使用次数判断,清除使用次数较少的元素释放空间。策略算法主要比较元素的hitCount(命中次数)。在保证高频数据有效性场景下,可选择这类策略。
LRU(least recently used):最近最少使用策略,无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。策略算法主要比较元素最近一次被get使用时间。在热点数据场景下较适用,优先保证热点数据的有效性。
其他的一些简单策略比如:
- 根据过期时间判断,清理过期时间最长的元素;
- 根据过期时间判断,清理最近要过期的元素;
- 随机清理;
- 根据关键字(或元素内容)长短清理等。
FIFO
算法:最先进来的数据,被认为在未来被访问的概率也是最低的,因此,当规定空间用尽且需要放入新数据的时候,会优先淘汰最早进来的数据
优点:最简单、最公平的一种数据淘汰算法,逻辑简单清晰,易于实现
缺点:这种算法逻辑设计所实现的缓存的命中率是比较低的,因为没有任何额外逻辑能够尽可能的保证常用数据不被淘汰掉
LRU-时间 (适用局部突发流量场景)
算法:如果一个数据最近很少被访问到,那么被认为在未来被访问的概率也是最低的,当规定空间用尽且需要放入新数据的时候,会优先淘汰最久未被访问的数据
优点:
- LRU 实现简单,在一般情况下能够表现出很好的命中率,是一个“性价比”很高的算法。
- LRU可以
有效的对访问比较频繁的数据进行保护,也就是针对热点数据的命中率提高有明显的效果。 - LRU局部突发流量场景,对
突发性的稀疏流量(sparse bursts)表现很好。
缺点:
- 在存在 周期性的局部热点 数据场景,有大概率可能造成缓存污染。
- 最近访问的数据,并不一定是周期性数据,比如把全量的数据做一次迭代,那么LRU 会产生较大的缓存污染,因为周期性的局部热点数据,可能会被淘汰。
LRU-K
算法:LRU中的K是指数据被访问K次,传统LRU与此对比则可以认为传统LRU是LRU-1
LRU-K有两个队列,新来的元素先进入到历史访问队列中,该队列用于记录元素的访问次数,采用的淘汰策略是LRU或者FIFO,- 当
历史队列中的元素访问次数达到K的时候,才会进入缓存队列
Two Queues
Two Queues与LRU-K相比,他也同样是两个队列,不同之处在于,他的队列一个是缓存队列,一个是FIFO队列,
当新元素进来的时候,首先进入FIFO队列,当该队列中的元素被访问的时候,会进入LRU队列
LFU-频率 (适用局部周期性流量场景)
算法:如果一个数据在一定时间内被访问的次数很低,那么被认为在未来被访问的概率也是最低的,当规定空间用尽且需要放入新数据的时候,会优先淘汰时间段内访问次数最低的数据
优点:
- LFU
适用于 局部周期性流量场景,在这个场景下,比LRU有更好的缓存命中率。 - 在 局部周期性流量场景下,
LFU是以次数为基准,所以更加准确,自然能有效的保证和提高命中率
缺点:
- 因为LFU
需要记录数据的访问频率,因此需要额外的空间; - 它需要给每个记录项维护频率信息,每次访问都需要更新,这是个巨大的开销;
- 在**
存在 局部突发流量场景下,有大概率可能造成缓存污染, 算法命中率会急剧下降,这也是他最大弊端。** 所以,LFU 对突发性的稀疏流量(sparse bursts)是无效的。
LFU 按照访问次数或者访问频率取胜,这个次数有一个累计的长周期, 导致前期经常访问的数据,访问次数很大,或者说权重很高
新来的缓存数据, 哪怕他是突发热点,但是,新数据的访问次数累计的时间太短老的记录已经占用了缓存,过去的一些大量被访问的记录,在将来不一定会继续是热点数据,但是就一直把“坑”占着了,而那些偶然的突破热点数据,不太可能会被保留下来,而是被淘汰- 所以,
存在突发性的稀疏流量下,LFU中的偶然的、稀疏的突发流量在访问频率上,不占优势,很容易被淘汰,造成缓存污染和未来缓存命中率下降
TinyLFU
概述
TinyLFU 就是其中一个优化算法,专门为了解决 LFU 上的三个问题而被设计出来的。
LFU 上的三个问题如下
- 如何减少访问频率的保存,所带来的空间开销
- 如何减少访问记录的更新,所带来的时间开销
- 如果提升对局部热点数据的 算法命中率
解决第1个问题/第2个问题是采用了 Count–Min Sketch 算法
Count-Min Sketch算法
将一个hash操作,扩增为多个hash,这样原来hash冲突的概率就降低了几个等级,且当多个hash取得数据的时候,取最低值,也就是Count Min的含义所在。
Count–Min Sketch 的原理跟 Bloom Filter 一样,只不过Bloom Filter 只有 0 和 1的值,可以把 Count–Min Sketch 看作是“数值”版的 Bloom Filter。
解决第三个问题是让老的访问记录,尽量降低“新鲜度”
Count–Min Sketch 算法
工作原理
ount-Min Sketch算法简单的工作原理:
- 假设有四个hash函数,每当元素被访问时,将进行次数加1;
- 此时会按照约定好的四个hash函数进行hash计算找到对应的位置,相应的位置进行+1操作;
当获取元素的频率时,同样根据hash计算找到4个索引位置;取得四个位置的频率信息,然后根据Count Min取得最低值作为本次元素的频率值返回,即Min(Count);
空间开销
Count-Min Sketch访问次数的空间开销?
-
用4个hash函数会存访问次数,那空间就是4倍
-
解决:
- 访问次数超过15次其实是很热的数据了,没必要存太大的数字。所以我们用4位就可以存到15
一个访问次数占4个位,一个long有64位,可以存 16个访问次数,4个访问一次一组的话, 一个long 可以分为4组- 一个 key 对应到 4个hash 值, 也就是 4个 访问次数,一个long 可以分为存储 4个Key的 访问 次数
最终:一个long对应的数组大小其实是容量的4倍(本来一个long是一个key的,但是现在可以存4个key)
降鲜机制
提升对局部热点数据的 算法命中率
让缓存降低“新鲜度”,剔除掉过往频率很高,但之后不经常的缓存
Caffeine 有一个 Freshness Mechanism。
做法:当整体的统计计数(当前所有记录的频率统计之和,这个数值内部维护)达到某一个值时,那么所有记录的频率统计除以 2。
TinyLFU 的算法流程
当缓存空间不够的时候,TinyLFU 找到 要淘汰的元素 (the cache victim),也就是使用频率最小的元素 ,
然后 TinyLFU 决定 将新元素放入缓存,替代 将 要淘汰的元素 (the cache victim)
W-TinyLFU
演进
TinyLFU 在面对突发性的稀疏流量(sparse bursts)时表现很差
新的记录(new items)还没来得及建立足够的频率就被剔除出去了,这就使得命中率下降
W-TinyLFU是 LFU 的变种,也是TinyLFU的变种
W-TinyLFU是如何演进:W-TinyLFU = LRU + LFU
LRU能很好的 处理 局部突发流量LFU能很好的 处理 局部周期流量
W-TinyLFU(Window Tiny Least Frequently Used)是对TinyLFU的的优化和加强,加入 LRU 以应对局部突发流量, 从而实现缓存命中率的最优。
W-TinyLFU 在空间效率和访问命中率之间达到了显著平衡,成为现代缓存库(如 Caffeine)的核心算法。
数据结构
W-TinyLFU增加了一个 W-LRU窗口队列 的组件
- 当一个数据进来的时候,会进行筛选比较,进入W-LRU窗口队列
- 经过淘汰后进入Count-Min Sketch算法过滤器,
通过访问访问频率判决, 是否进入缓存
作用:如果一个数据最近被访问的次数很低,那么被认为在未来被访问的概率也是最低的,当规定空间用尽的时候,会优先淘汰最近访问次数很低的数据
W-LRU窗口队列 用于应 对 局部突发流量TinyLFU 用于 应对 局部周期流量
存储空间结构
W-TinyLFU将缓存存储空间分为两个大的区域:Window Cache和Main Cache
-
Window Cache:是一个标准的LRU Cache -
Main Cache:是一个SLRU(Segmemted LRU)cache,划分为Protected Cache(保护区)和Probation Cache(考察区)两个区域,这两个区域都是基于LRU的Cache。- 精细化淘汰:使用 TinyLFU 算法(基于概率型频率统计)结合 SLRU(Segmented LRU,分段LRU)策略,区分高频和低频条目。
- 长期频率管理:存储经过 Window Cache 筛选的高频访问条目,基于访问频率决定保留优先级。
Protected 是一个受保护的区域,该区域中的缓存项不会被淘汰- 存储长期高频访问的条目(“热数据”)。
- 占比约 80%,使用 LRU 淘汰策略。
- Probation Region(观察区)
- 存储候选条目,与 Window Cache 淘汰的条目竞争。
- 占比约 20%,使用 TinyLFU 比较频率决定去留。
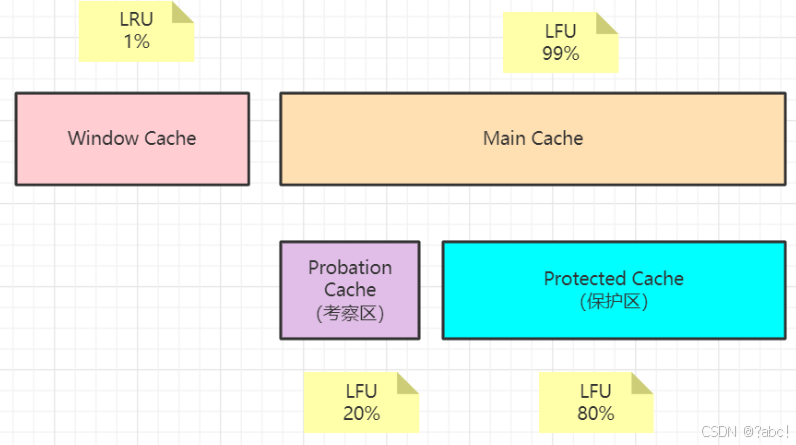
空间最优选:当 window 区配置为总容量的 1%,剩余的 99%当中的 80%分给 protected 区,20%分给 probation 区时,这时整体性能和命中率表现得最好,所以 Caffeine 默认的比例设置就是这个。
- 这个比例 Caffeine 会在运行时根据统计数据(statistics)去动态调整,如果你的
应用程序的缓存随着时间变化比较快的话,或者说具备的突发特点数据多,那么增加 window 区的比例可以提高命中率 - 如果
周期性热地数据多,缓存都是比较固定不变的话,增加 Main Cache 区(protected 区 +probation 区)的比例会有较好的效果。
W-TinyLFU的算法流程
写入机制
第一步:当有新的缓存项写入缓存时,会先写入Window Cache区域,当Window Cache空间满时,最旧的缓存项会被移出Window Cache
第二步:将移出Window Cache的缓存移动到Main Cache
- 如果Probation Cache未满,从Window Cache移出的缓存项会直接写入Probation Cache
- 如果Probation Cache已满,则会根据
TinyLFU算法确定从Window Cache移出的缓存项是丢弃(淘汰)还是写入Probation Cache
第三步:Probation Cache中的缓存项如果访问频率达到一定次数,会提升到Protected Cache
- 如果Protected Cache也满了,最旧的缓存项也会移出Protected Cache,然后
根据TinyLFU算法确定是丢弃(淘汰)还是写入Probation Cache。
淘汰机制为
从Window Cache或Protected Cache移出的缓存项称为Candidate,Probation Cache中最旧的缓存项称为Victim。
如果Candidate缓存项的访问频率大于Victim缓存项的访问频率,则淘汰掉Victim。
如果Candidate小于或等于Victim的频率,
- 那么如果Candidate的频率小于5,则淘汰掉Candidate;
- 否则,则在Candidate和Victim两者之中随机地淘汰一个。
总结
caffeine综合了LFU和LRU的优势,将不同特性的缓存项存入不同的缓存区域,
- 最近刚产生的缓存项进入Window区,不会被淘汰
- 访问频率高的缓存项进入Protected区,也不会淘汰
- 介于这两者之间的缓存项存在Probation区,当缓存空间满了时,Probation区的缓存项会根据访问频率判断是保留还是淘汰;
优点:
- 很好的平衡了访问频率和访问时间新鲜程度两个维度因素,尽量将新鲜的访问频率高的缓存项保留在缓存中
- 同时在维护缓存项访问频率时,引入计数器饱和和衰减机制,即节省了存储资源,也能较好的处理稀疏流量、短时超热点流量等传统LRU和LFU无法很好处理的场景
- 使用Count-Min Sketch算法存储访问频率,极大的节省空间;
- TinyLFU会 定期进行新鲜度 衰减操作,应对访问模式变化;、
- 并且使用W-LRU机制能够尽可能避免缓存污染的发生,在过滤器内部会进行筛选处理,避免低频数据置换高频数据
W-TinyLFU的缺点:目前已知应用于Caffeine Cache组件里,应用不是很多。
相关文章:
:常见 缓存数据淘汰算法/缓存清空策略)
缓存(5):常见 缓存数据淘汰算法/缓存清空策略
主要的三种缓存数据淘汰算法 FIFO(first in first out):先进先出策略,最先进入缓存的数据在缓存空间不够的情况下(超出最大元素限制)会被优先被清除掉,以腾出新的空间接受新的数据。策略算法主要比较缓存元素的创建时…...

深入了解linux系统—— 自定义shell
shell的原理 我们知道,我们程序启动时创建的进程,它的父进程都是bash也就是shell命令行解释器; 那bash都做了哪些工作呢? 根据已有的知识,我们可以简单理解为: 输出命令行提示符获取并解析我们输入的指令…...

【通讯录教程】如何将号码快速导入手机通讯录,支持苹果和安卓手机,一次性导入大量号码进入手机通讯录,基于WPF的解决方案
以下是一个基于WPF的解决方案,用于将大量号码快速导入苹果和安卓手机通讯录: 项目应用场景 企业员工通讯录批量导入:HR需要将数百名员工的联系方式快速导入公司手机客户关系管理:销售人员需要将大量客户信息导入…...

Git初始化相关配置
Git配置 在Git安装完成后,windows操作系统上会多出一个Git Bash的软件,如果是linux或者是macOS,那么直接打开终端,在终端中敲击命令即可 # 检查git版本 git -v # 或 git --version在使用git时,需要配置一下用户名和邮…...

n8n中订阅MQTT数据
第一步:创建mqtt登录证证 第二步:创建mqtt trigger组件,并配置凭证和订阅主题 第三步:创建Code节点,编写格式转换代码 第四步:创建转发MQTT节点,并配置MQTT凭证 第五步:启用工作流 整…...

Docker、ECS 与 K8s 网段冲突:解决跨服务通信中的路由问题
🧩 问题背景 在阿里云的项目中,在项目初期搭建过程中遇到了一个让人头疼的网络冲突问题:同一个 VPC 中的 Docker 容器和 Kubernetes 集群由于使用相同的网段,导致k8s pod连接ECS容器之间的网络连接失败。 背景环境: …...

《智能网联汽车 自动驾驶系统设计运行条件》 GB/T 45312-2025——解读
目录 1. 标准概述 2. 核心概念 3. 标准核心内容 3.1 一般要求 3.2 ODC基础元素层级 3.3 ODC元素具体要求 3.4 附录A(ODC示例) 4. 技术挑战与实施建议 5. 标准意义 原文链接:国家标准|GB/T 45312-2025 (发布:2…...
详解)
AARRR用户增长模型(海盗指标)详解
目录 一、模型起源与概述二、五大阶段详解1. 获取(Acquisition)1.1 定义1.2 关键指标 2. 激活(Activation)2.1 定义2.2 关键指标 3. 留存(Retention)3.1 定义3.2 关键指标3.3 提升留存手段案例3.4 互联网留…...

CSS专题之自定义属性
前言 石匠敲击石头的第 12 次 CSS 自定义属性是现代 CSS 的一个强大特性,可以说是前端开发需知、必会的知识点,本篇文章就来好好梳理一下,如果哪里写的有问题欢迎指出。 什么是 CSS 自定义属性 CSS 自定义属性英文全称是 CSS Custom Proper…...

JVM——Java字节码基础
引入 Java字节码(Java Bytecode)是Java技术体系的核心枢纽,所有Java源码经过编译器处理后,最终都会转化为.class文件中的字节码指令。这些指令不依赖于具体的硬件架构和操作系统,而是由Java虚拟机(JVM&…...

【React中useRef钩子详解】
一、useRef的核心特性 useRef是React提供的Hook,用于在函数组件中创建可变的持久化引用,具有以下核心特性: 持久化存储 返回的ref对象在组件整个生命周期内保持不变,即使组件重新渲染,current属性的值也不会丢失。无触发渲染 修改ref.current的值不会导致组件重新渲染,适…...

《AI大模型应知应会100篇》第58篇:Semantic Kernel:微软的大模型应用框架
第58篇:Semantic Kernel:微软的大模型应用框架 ——用C#和Python构建下一代AI应用的统一编程范式 📌 摘要 随着大模型(LLM)技术的快速发展,如何将这些强大的语言模型与传统代码系统进行无缝集成ÿ…...

ssh -T git@github.com 测试失败解决方案:修改hosts文件
问题描述 通过SSH方式测试,使用该方法测试连接可能会遇到连接超时、端口占用的情况,原因是因为DNS配置及其解析的问题 ssh -T gitgithub.com我们可以详细看看建立 ssh 连接的过程中发生了什么,可以使用 ssh -v命令,-v表示 verbo…...

c++面向对象:接口设计
一、什么是接口(Interface)? 在面向对象编程中,接口可以理解为一种“规范”或“约定”。 更具体一点: 它定义了“某个对象”应该具备哪些功能(方法、行为)但不关心这些功能的具体实现细节 用…...

[Java][Leetcode middle] 80. 删除有序数组中的重复项 II
删除重复元素,最多只保留两个 1. 计数法 第一个元素直接加入当与前一个元素相同时,计数器1,不同时计数器恢复1; 只有计数器小于2时,记录元素; public int removeDuplicates2(int[] nums) {int cnt 1;in…...

【Bluedroid】蓝牙HID DEVICE断开连接流程源码分析
蓝牙HID(Human Interface Device)的断开连接流程涉及从应用层到协议栈的多层交互。本文通过剖析Android Bluetooth协议栈代码,梳理从上层调用disconnect()到最终物理链路断开的完整流程,涵盖状态检查、消息传递、L2CAP通道关闭、资…...

嵌入式硬件篇---陀螺仪|PID
文章目录 前言1. 硬件准备主控芯片陀螺仪模块电机驱动电源其他 2. 硬件连接3. 软件实现步骤(1) MPU6050初始化与数据读取(2) 姿态解算(互补滤波或DMP)(3) PID控制器设计(4) 麦克纳姆轮协同控制 4. 主程序逻辑5. 关键优化与调试技巧(1) 传感器校准(2) PID…...
)
redis数据结构-07(SADD、SREM、SMEMBERS)
Redis Sets 简介:SADD、SREM、SMEMBERS Redis 集合是一种基础数据结构,可用于存储一组唯一且无序的元素。了解如何管理集合对于各种应用至关重要,从跟踪唯一访客到管理用户权限。本课将全面介绍 Redis 集合,重点介绍核心命令 SAD…...

嵌入式硬件篇---TOF|PID
文章目录 前言1. 硬件准备主控芯片ToF模块1.VL53L0X2.TFmini 执行机构:电机舵机其他 2. 硬件连接(1) VL53L0X(IC接口)(2) TFmini(串口通信) 3. ToF模块初始化与数据读取(1) VL53L0X(基于HAL库)(…...

# Anaconda3 常用命令
Anaconda3 常用命令及沙箱环境管理指南 Anaconda3 是一个强大的 Python 发行版,广泛用于数据科学、机器学习和科学计算。其核心优势在于通过 沙箱环境(Conda Environment) 实现项目隔离,避免依赖冲突。本文将介绍 Anaconda3 的常…...

嵌入式硬件篇---无线通信模块
文章目录 前言一、四种无线串口模块深度对比二、模块优缺点分析1. 蓝牙模块(HC-05)优点缺点 2. WiFi模块(ESP8266)优点缺点 3. 2.4G射频(NRF24L01)优点缺点 4. LoRa模块(SX1278)优点…...
)
MySQL 索引(二)
文章目录 索引理解MySQL对page做管理page的概念单个page多个page 页目录单页情况(提高page内部的查找的效率)多页情况(提高page间的查找效率)复盘一下为什么选择B树,不选择其他数据结构呢聚簇索引 VS 非聚簇索引 索引操…...

代码随想录算法训练营第六十天| 图论7—卡码网53. 寻宝
图论第七天,prim和kruskal算法,说实话都没看的很懂,有点抽象难理解,只能照着题解理解一下了。 53. 寻宝(prim) 53. 寻宝(第七期模拟笔试) 复制一下网站上的prim算法的结论 prim算…...

「OC」源码学习—— 消息发送、动态方法解析和消息转发
「OC」源码学习—— 消息发送、动态方法解析和消息转发 前言 前面我们在学习alloc源码的时候,就在callAlloc源码之中简单的探究过,类初始化缓存的问题,我们知道在一个类第一次被实例化的时候,会调用objc_msgSend去二次调用alloc…...

MySQL数据库下篇
#作者:允砸儿 #日期:乙巳青蛇年 四月十四 今天笔者将会把MySQL数据库的知识完结,再者笔者会浅写一下sql注入的内容。在后面笔者会逐渐的将网安世界徐徐展开。 php与mysql联动 编程接口 笔者在前面的文章写了php的内容,现在我…...

Linux之进程概念
目录 一、冯诺依曼体系结构 二、操作系统(Operator System) 2.1、概念 2.2、设计OS的目的 2.3、系统调用和库函数概念 三、进程 3.1、基本概念 3.1.1、描述进程-PCB 3.1.2、task_struct 3.1.3、查看进程 3.1.4、通过系统调用获取进程标识符 3.1.5、两种杀掉进程的方…...

numpy模块综合使用
一、numpy模块的综合使用方法 # 使用矩阵的好处,矩阵对于python中列表,字典等数据类型一个一个拿来计算是会方便计算很多的,底层使用的是c语言 # 在数据分析和数据处理的时候也经常常用 import numpy as np array np.array([[1,2,3],[2,3,4…...

嵌入式硬件篇---SPI
文章目录 前言1. SPI协议基础1.1 物理层特性四线制(标准SPI)SCKMOSIMISONSS/CS 三线制(半双工模式)通信模式 1.2 通信时序(时钟极性CPOL和相位CPHA)常用模式Mode 0Mode 3 1.3 典型通信流程 2. STM32F103RCT…...

【大模型】AI智能体Coze 知识库从使用到实战详解
目录 一、前言 二、知识库介绍 2.1 coze 知识库功能介绍 2.2 coze 知识库应用场景 2.3 coze 知识库类型 2.4 coze 知识库权限说明 2.5 coze 知识库与记忆对比 2.6 知识库的使用流程 三、知识库创建与使用 3.1 创建知识库入口 3.2 创建文本知识库 3.2.1 上传文件 3.…...
)
深度学习:系统性学习策略(二)
深度学习的系统性学习策略 基于《认知觉醒》与《认知驱动》的核心方法论,结合深度学习的研究实践,从认知与技能双重维度总结以下系统性学习策略: 一、认知觉醒:构建深度学习的思维操作系统 三重脑区协同法则 遵循**本能脑(舒适区)-情绪脑(拉伸区)-理智脑(困难区)**的…...

TikTok 推广干货:AI 加持推广效能
TikTok 推广是提升账号影响力、吸引更多关注的关键一环。其中,巧妙利用热门话题标签是增加视频曝光的有效捷径。运营者需要密切关注当下流行趋势,搜索与账号定位紧密相关的热门标签。例如,对于美妆账号而言,带上 “# 美妆教程 #热…...

滑动窗口——将x减到0的最小操作数
题目: 这个题如果我们直接去思考方法是很困难的,因为我们不知道下一步是在数组的左还是右操作才能使其最小。正难则反,思考一下,无论是怎么样的,最终这个数组都会分成三个部分左中右,而左右的组合就是我们…...

无侵入式弹窗体验_探索 Chrome 的 Close Watcher API
1. 引言 在网页开发中,弹窗(Popup)是一种常见的交互方式,用于提示用户进行操作、确认信息或展示关键内容。然而,传统的 JavaScript 弹窗方法如 alert()、confirm() 和 prompt() 存在诸多问题,包括阻塞主线程、样式不可定制等。 为了解决这些问题,Chrome 浏览器引入了 …...

牛客周赛 Round 92 题解 Java
目录 A 小红的签到题 B 小红的模拟题 C 小红的方神题 D 小红的数学题 E 小红的 ds 题 F 小红的小苯题 A 小红的签到题 直接构造类似于 a_aaaa,a_aaaaaaaa 这种 即可 // github https://github.com/Dddddduo // github https://github.com/Dddddduo/acm-java…...

DAY 17 训练
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 DAY 17 训练 聚类算法聚类评估指标介绍1. 轮廓系数 (Silhouette Score)2. CH 指数 (Calinski-Harabasz Index)3. DB 指数 (Davies-Bouldin Index) 1. KMeans 聚类算法原理确定…...
)
多源最短路径(Floyed)
#include <iostream> #include <vector> #include <stack> using namespace std; class Graph{ private: int vertex; //顶点数 //int** matrix; //有向图关系矩阵 int** path; //存储关系矩阵 int** pre; //存储中间节点k public: con…...

基于去中心化与AI智能服务的web3钱包的应用开发的背景描述
Web3代表了下一代互联网模式,其核心特征包括去中心化、数据主权、智能合约和区块链技术的广泛应用。根据大数据调查显示,用户希望拥有自己的数据控制权,并希望在去中心化网络中享受类似Web2的便捷体验。DeFi(去中心化金融) 生态日趋成熟的背景…...

LabVIEW车牌自动识别系统
在智能交通快速发展的时代,车牌自动识别系统成为提升交通管理效率的关键技术。本案例详细介绍了基于 LabVIEW 平台,搭配大恒品牌相机构建的车牌自动识别系统,该系统在多个场景中发挥着重要作用,为交通管理提供了高效、精准的解决方…...

C# Newtonsoft.Json 使用指南
Newtonsoft.Json (也称为 Json.NET) 是一种适用于 .NET 的常用高性能 JSON 框架,用于处理 JSON 数据。它提供了高性能的 JSON 序列化和反序列化功能。 安装 通过 NuGet 安装 基本用法 1. 序列化对象为 JSON 字符串 using Newtonsoft.Json;var product new Prod…...

Python_day22
DAY 22 复习日 复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 kaggle泰坦里克号人员生还预测 一、Kaggle 基础使用步骤 注册与登录…...

浏览器的B/S架构和C/S架构
浏览器的B/S架构和C/S架构 概述拓展 欢迎来到 Shane 的博客~ 心有猛虎,细嗅蔷薇。 概述 C/S架构? Client/Server架构。但是缺少通用性、系统维护、升级需要重新设计和开发,并且需要开发不同的操作系统,增加了维护和管理的难度。&…...

【C++】内存管理 —— new 和 delete
文章目录 一、C/C 内存分布二、C 语言中动态内存管理方式1. malloc / calloc / realloc / free 三、C 内存管理方式1. new / delete2. operator new 与 operator delete 函数3. new 和 delete 的实现原理(1) new 的原理(2) delete 的原理(3) new T[N] 的原理(4) delete[] 的原理…...

springboot3整合SpringSecurity实现登录校验与权限认证
一:概述 1.1 基本概念 (1)认证 系统判断身份是否合法 (2)会话 为了避免每次操作都进行认证可将用户信息保存在会话中 session认证 服务端有个session,把 session id给前端,每次请求cookie都带着…...

【东枫科技】使用LabVIEW进行深度学习开发
文章目录 DeepLTK LabVIEW深度学习工具包LabVIEW中的深度神经网络**功能与特性****功能亮点:** **支持的网络层****支持的网络架构****参考示例** 授权售价 DeepLTK LabVIEW深度学习工具包 LabVIEW中的深度神经网络 功能亮点: 在 LabVIEW 中创建、配置…...

《智能网联汽车 自动驾驶系统通用技术要求》 GB/T 44721-2024——解读
目录 一、核心框架与适用范围 二、关键技术要求 1. 总体要求 2. 动态驾驶任务执行 3. 动态驾驶任务后援 4. 人机交互(HMI) 5. 说明书要求 三、附录重点 附录A(规范性)——功能安全与预期功能安全 附录B(资料性…...

同一个虚拟环境中conda和pip安装的文件存储位置解析
文章目录 存储位置的基本区别conda安装的包pip安装的包 看似相同实则不同的机制实际路径示例这种差异带来的问题如何检查包安装来源最佳实践建议 总结 存储位置的基本区别 conda安装的包 存储在Anaconda(或Miniconda)目录下的pkgs和envs子目录中: ~/anaconda3/en…...

《Hadoop 权威指南》笔记
Hadoop 基础 MapReduce Hadoop 操作 Hadoop 相关开源项目...

每日一题洛谷P8615 [蓝桥杯 2014 国 C] 拼接平方数c++
P8615 [蓝桥杯 2014 国 C] 拼接平方数 - 洛谷 (luogu.com.cn) #include<iostream> #include<string> #include<cmath> using namespace std; bool jud(int p) {int m sqrt(p);return m * m p; } void solve(int n) {string t to_string(n);//int转换为str…...

【C++】AVL树实现
目录 前言 一、AVL树的概念 二、AVL树的实现 1.基本框架 2.AVL树的插入 三、旋转 1.右单旋 2.左单旋 3.左右双旋 4.右左双旋 四、AVL树的查找 五、AVL树的平衡检测 六、AVL树的删除 总结 前言 本文主要讲解AVL树的插入,AVL树是在二叉搜索树的基础上&a…...

49.EFT测试与静电测试环境和干扰特征分析
EFT测试与静电测试环境和干扰特征分析 1. EFT/B电快速瞬变脉冲群测试及干扰特征分析2. EFT的干扰特征分析与滤波方法3. ESD静电测试及干扰特征分析 1. EFT/B电快速瞬变脉冲群测试及干扰特征分析 EFT测试是模拟在大的感性设备断开瞬间产生的快速瞬变脉冲群对被测设备的影响。 E…...