【C++】内存管理 —— new 和 delete
文章目录
- 一、C/C++ 内存分布
- 二、C 语言中动态内存管理方式
- 1. malloc / calloc / realloc / free
- 三、C++ 内存管理方式
- 1. new / delete
- 2. operator new 与 operator delete 函数
- 3. new 和 delete 的实现原理
- (1) new 的原理
- (2) delete 的原理
- (3) new T[N] 的原理
- (4) delete[] 的原理
- (5) 补充点与注意事项
- 四、定位 new 表达式 (replacement-new)
- 1. 定位 new 表达式的使用
- 2. 应用场景
- 五、malloc / free 与 new / delete 区别总结
一、C/C++ 内存分布
在内存管理中,我们每一个运行起来的程序都会有一个叫进程地址空间的东西,为了更好地管理内存,这里的进程地址空间又进一步地划分为几个区域,分别是:栈、堆、静态区、常量区,用来存储我们的数据。在 C/C++ 中我们所学习到的指针其实就是这样的空间从低地址到高地址以字节为单位的编号。而空指针就是最底下那一个字节 (第 0 个字节) 的地址。
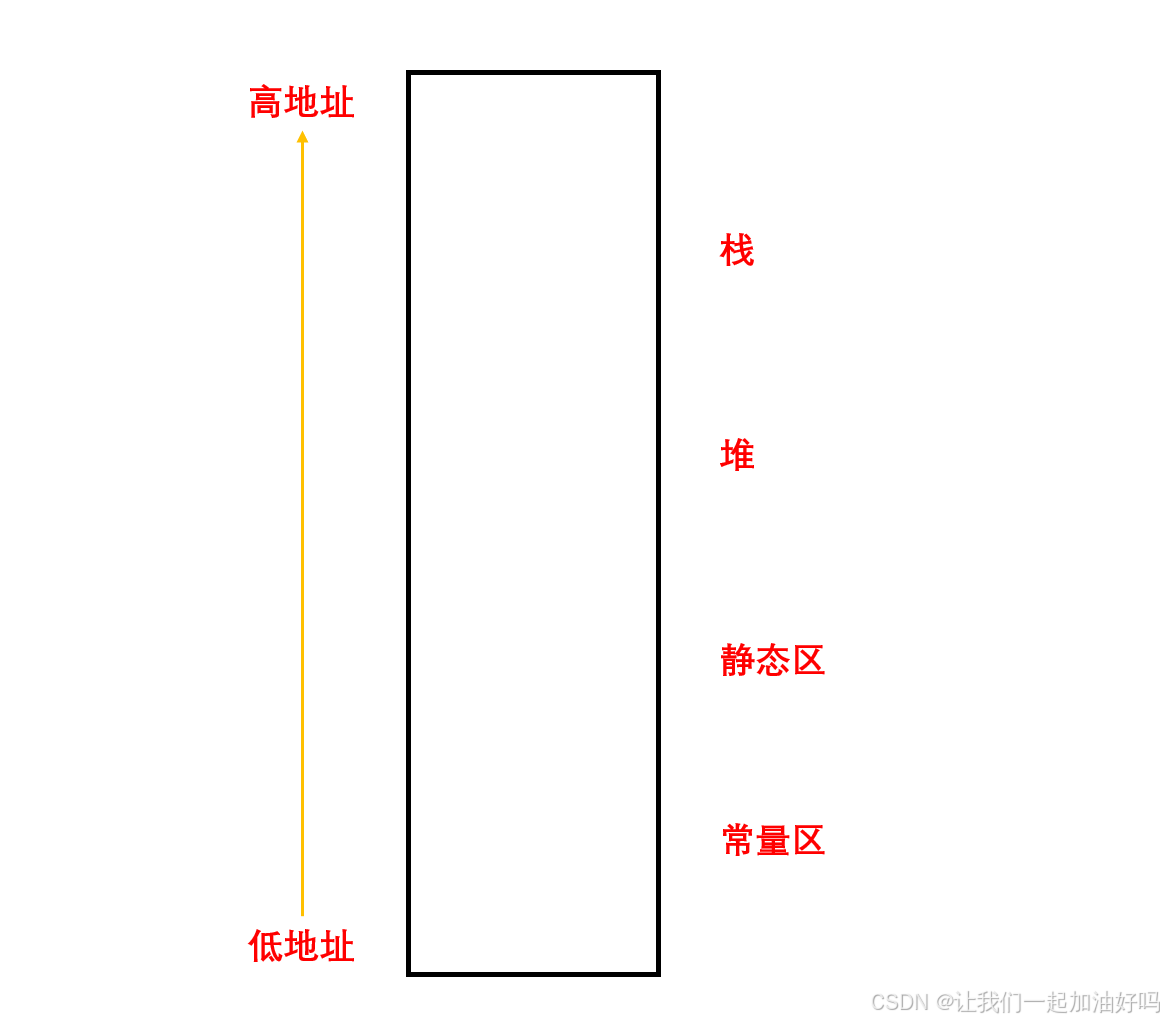
我们所定义的不同类型的数据会存储在不同的区域,下面我们通过一个例题来感受一下。
int globalVar = 1;
static int staticGlobalVar = 1;
void Test()
{static int staticVar = 1;int localVar = 1;const int localVar2 = 2;int num1[10] = { 1, 2, 3, 4 };char char2[] = "abcd";const char* pChar3 = "abcd";int* ptr1 = (int*)malloc(sizeof(int) * 4);int* ptr2 = (int*)calloc(4, sizeof(int));int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);free(ptr1);free(ptr3);
}
选择题:选出对应的变量所存储的区域
A. 栈 B. 堆 C. 静态区(数据段) D. 常量区(代码段)
globalVar:
staticGlobalVar:
staticVar:
localVar:
localVar2:
num1:
char2:
*char2:
pChar3:
*pchar3:
ptr1:
*ptr1:
globalVar 是全局变量,而全局变量存储在静态区,因此选 C。
staticGlobalVar,它是一个全局的静态变量,依旧存储在静态区,选 C。它和普通全局变量的区别就是连接属性不同,普通全局变量所有文件可见,而静态的全局变量只在当前文件可见。
staticVar 是一个局部的静态变量,依旧存储在静态区,选 C。它和全局的静态变量的声明周期都是全局的,但是区别是局部的静态变量初始化要比全局的晚,是第一次执行到该位置的时候才初始化。
localVar 是一个局部变量,存储在 Test 函数的栈帧中,即存储在栈中,选 A。
localVar2 虽然有一个 const 修饰,但是严格来说它是属于一种常变量,一些特殊情况下也是可以修改的,所以它并不存储在常量区,而是存储在栈中,选 A。
nums1 是数组名,数组名又两种含义,一种是代表整个数组,一种是首元素的地址。如果我们对数组进行大小计算 sizeof 的时候,nums1 就代表的是整个数组。如果我们对数组进行一些运算、解引用的时候,数组名就代表的是首元素的地址。无论从哪个角度出发,它都属于一个局部的变量,存储在栈中,选 A。
char2 是一个数组,它是把一个常量的字符串拷贝给了一个数组,char2 本身不是一个常量,因此它和 nums1 一样是一个数组,是一个局部变量,存储在栈中,选 A。
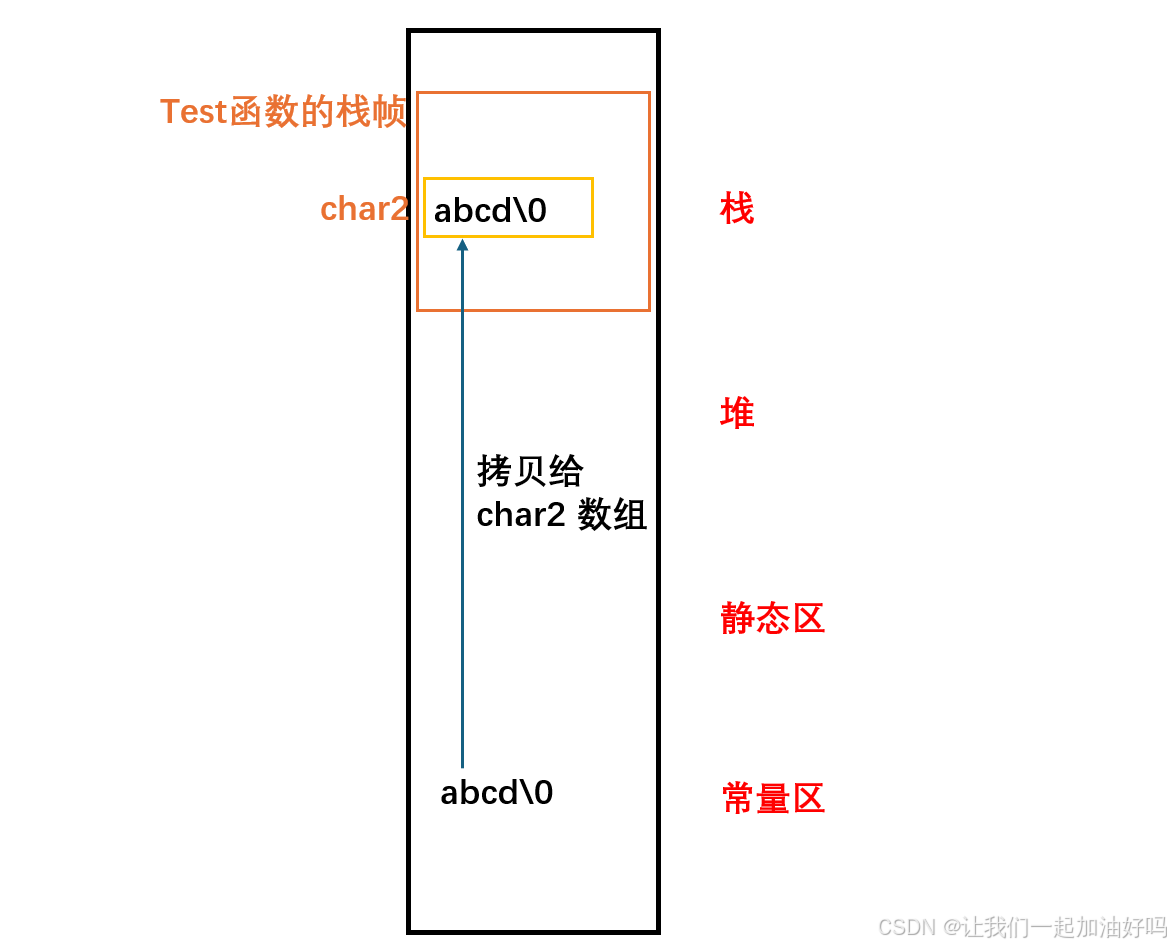
*char2 这里的 char2 代表的是首元素的地址,而再解引用之后就是数组的首元素,即 a 。由上图可知它是也是存储在栈中的,因此选 A。
pchar3 虽然有一个 const 修饰,但是它不属于常量区,并且这里的 const 在 * 的左边,修饰的是指向的内容而不是指针本身,就算是的话那么也不存储在常量区。它依旧是一个局部变量,存储在栈中,选 A。
*pchar3 才存储在常量区,因为这里的 pchar3 本质上是一个指针,这个指针在栈中,只不过它指向了一个常量字符串,这个常量字符串存储在常量区。所以通过解引用之后的内容存储在常量区,选 D。
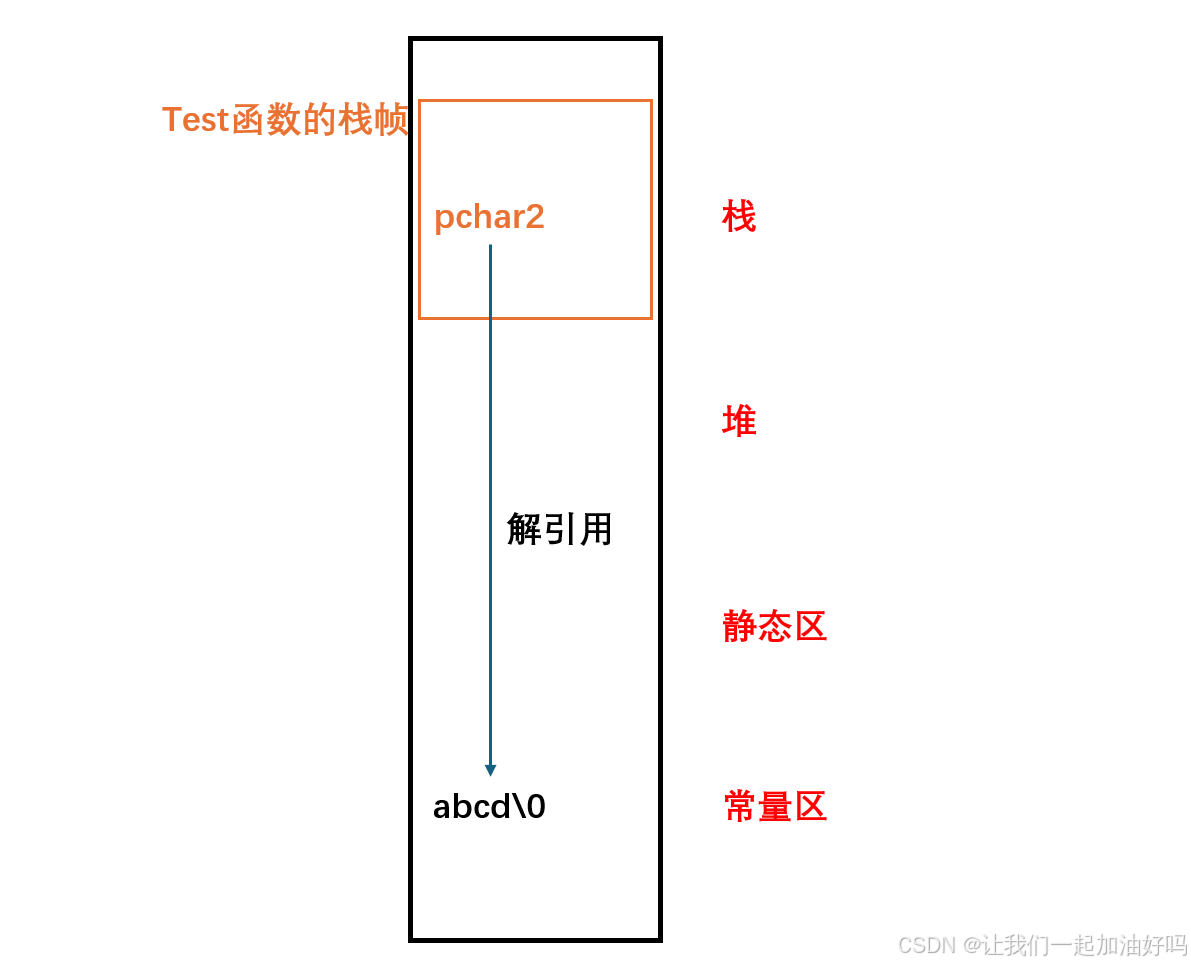
ptr1 同样也是一个指针,属于局部变量,存储在栈中,选 A。
*ptr1 则存储在堆中,因为 ptr1 所指向的内容是 malloc 动态开辟出来的,malloc 出来的数据存储在堆中,选 B。
简单总结一下:
- 栈又叫堆栈,存储非静态局部变量、函数参数、返回值等。并且栈是向下生长的,也就是说后定义的变量的地址要比先定义的变量的地址小。
- 堆用于程序运行时动态内存分配,堆是向上生长的。
- 静态区 (数据段),存储全局数据和静态数据。
- 常量区 (代码段),存储可执行的代码和只读常量。
在这几个区域中,我们需要重点学习堆区域的管理,因为其他区域都是自动管理的,只有堆区域是需要我们手动进行管理的,比如我们要自己开辟空间 (malloc) 和自己释放空间 (free)。
二、C 语言中动态内存管理方式
1. malloc / calloc / realloc / free
在 C 语言中我们学习了相关的动态内存管理的方式,其中包括 malloc、calloc 和 realloc 三种申请空间的方式。
malloc:申请一段空间。
calloc:申请一段空间并且将这些空间按比特位初始化为 0。
realloc:对 malloc、calloc 申请的这些空间进行扩容。扩容分为两种:原地扩容和异地扩容。如果对原来的数组进行扩容,后面的空间没有分配给其他人使用,那么就是原地扩容。如果要扩容的区域分配给其他人使用了,那么就异地扩容:在堆中找一块扩容后大小的没有分配给别人的一块空间,然后把原来的数据拷贝过来,并且把原来的空间 free 掉。
所以以下代码如果是异地扩容那么是不需要释放 ptr2 的,就是因为 realloc 内部已经把这段空间释放掉了。
void Test()
{// 假设此处 realloc 是异地扩容int* ptr2 = (int*)calloc(4, sizeof(int));int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);free(ptr3); // 不需要 free(ptr2)
}
三、C++ 内存管理方式
C 语言中的内存管理方式在 C++ 中可以继续使用,但是有些地方就用不了了,并且使用起来比较麻烦,因此在 C++ 中又提出了自己的内存管理方式。
1. new / delete
在 C++ 中我们可以用 new 和 delete 两个操作符来进行进行动态内存管理。
void Test()
{int* ptr1 = new int; // 动态申请 1 个 int 类型的空间int* ptr2 = new int[10]; // 动态申请 10 个 int 类型的空间delete ptr1; // 释放单个delete[] ptr2; // 释放多个int* ptr3 = new int(10); // 动态申请一个 int 类型的空间并初始化为 10int* ptr4 = new int[10] {1, 2, 3, 4}; // 动态申请 10 个 int 类型的空间并初始化前 4 位delete ptr3;delete[] ptr4;
}
new 和 malloc 的区别就是 malloc 必须要指定你开多少空间,而 new 默认就是开 1 个对应类型的空间,开多个就加一个方括号 [] 即可。并且 new 不需要对返回类型强转,new 的是 int 类型那么自动就返回的是 int*。
当然这些区别都是次要的,一个主要的区别体现在它们为某个类对象开空间时的不同。
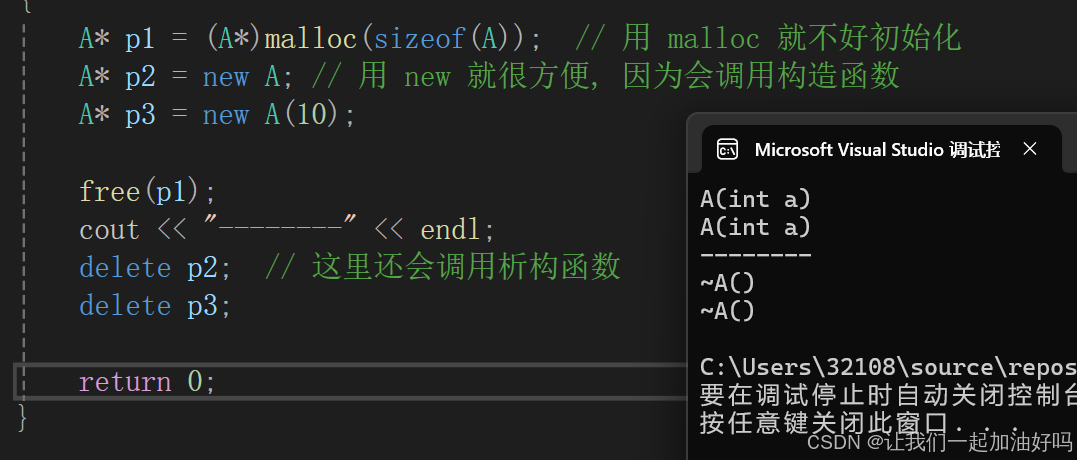
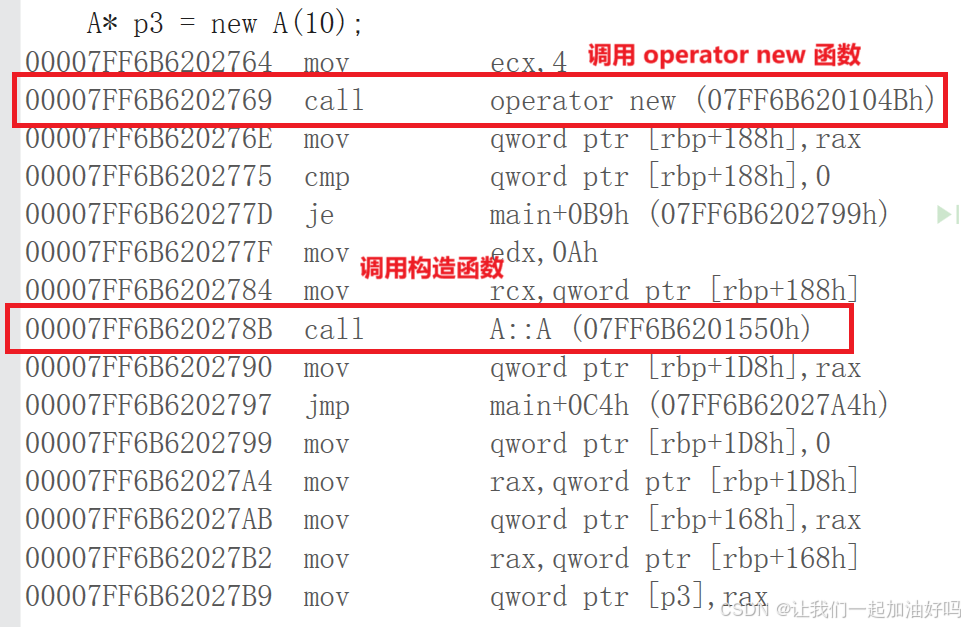
new 和 delete 对于自定义类型除了开空间还会调用构造函数和析构函数。
class A
{
public:A(int a = 1):_a(a){cout << "A(int a)" << endl;}~A(){cout << "~A()" << endl;}private:int _a;
};int main()
{A* p1 = (A*)malloc(sizeof(A)); // 用 malloc 就不好初始化, 它不会调用构造函数A* p2 = new A; // 用 new 就很方便, 因为会调用构造函数A* p3 = new A(10);free(p1); // 不会调用析构函数cout << "--------" << endl;delete p2; // 这里还会调用析构函数delete p3;return 0;
}
除了以上几点之外,new 和 malloc 它们对于申请空间失败情况的处理也不同。
对于 malloc,我们不断申请空间,打印对应的地址并且记录申请的总空间。
int main()
{size_t x = 0;int* ptr1 = nullptr;do {ptr1 = (int*)malloc(10 * 1024 * 1024);if (ptr1)x += 10 * 1024 * 1024; cout << ptr1 << endl;} while (ptr1);cout << x << endl;cout << x / (1024 * 1024) << endl;return 0;
}

可以看到 malloc 不成功的话它会打印一个空地址。
我们再来看看 new 的处理情况。
int main()
{size_t x = 0;int* ptr1 = nullptr;do {ptr1 = new int[10 * 1024 * 1024];if (ptr1)x += 10 * 1024 * 1024 * 4; // 一次 new 四个字节,所以乘以 4cout << ptr1 << endl;} while (ptr1);cout << x << endl;cout << x / (1024 * 1024) << endl;return 0;
}
可以看到 new 申请失败了它并不会打印出空地址,而是转为报错。实际上它的机制是抛异常,如果抛出了异常,我们需要对其进行捕获,如果到 main 函数结束都没有被捕获,就会报错。关于异常的详细内容,我们这里不展开。
2. operator new 与 operator delete 函数
上面我们讲的 new 和 delete 是用户进行动态内存申请和释放的操作符,而 operator new 和 operator delete 是系统提供的全局函数,注意它不是运算符重载函数。new 在底层调用 operator new 全局函数来申请空间,delete 在底层通过 operator delete 全局函数来释放空间。
对于
operator new函数,它实际上是通过 malloc 来申请空间的,只不过除了 malloc,它还有更多的机制。如果 malloc 申请空间成功了就直接返回。如果申请空间失败,那么就尝试执行空间不足的应对措施,如果用户设置了相应的应对措施,则继续申请,否则抛出异常。下面是某版本
operator new的源码:
void *__CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc)
{// try to allocate size bytevoid *p;while ((p = malloc(size)) == 0)if (_callnewh(size) == 0){// report no memory// 如果申请内存失败了,这里会抛出bad_alloc 类型异常static const std::bad_alloc nomem;_RAISE(nomem);}return (p);
}
我们从汇编的角度是可以看到 new 它的底层是调用了 operator new 和析构函数的。
对于
operator delete函数,它最终是通过free来释放空间的。下面是某版本
operator delete的源码:
void operator delete(void *pUserData)
{_CrtMemBlockHeader * pHead;RTCCALLBACK(_RTC_Free_hook, (pUserData, 0));if (pUserData == NULL)return;_mlock(_HEAP_LOCK); /* block other threads */__TRY/* get a pointer to memory block header */pHead = pHdr(pUserData);/* verify block type */_ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse));_free_dbg( pUserData, pHead->nBlockUse ); // 这里其实就是 free()__FINALLY_munlock(_HEAP_LOCK); /* release other threads */__END_TRY_FINALLYreturn;
}// free的实现
#define free(p) _free_dbg(p, _NORMAL_BLOCK)
3. new 和 delete 的实现原理
(1) new 的原理
- 调用
operator new函数申请空间。- 再在申请的空间上调用构造函数,完成对象的构造。
(2) delete 的原理
- 先在空间上执行析构函数,完成对象中资源的清理。
- 再调用
operator delete函数释放对象的空间。
先调用析构函数是因为像 Stack 这样的类,它的成员变量是有一个数组 int* _a 的,这个 _a 本身指向了一块空间,如果你先就调用 operator delete 把 _a 释放掉了,但是 _a 所指向的那块空间并没有释放,就会造成内存泄漏。所以我们要先调用析构函数把 _a 所指向的空间释放掉,再释放 _a。
(3) new T[N] 的原理
- 先调用
operator new[]函数,实际上就是在operator new[]中实际调用多次operator new函数完成 N 个对象空间的申请。- 再在申请的空间上执行 N 次构造函数。
(4) delete[] 的原理
- 在释放的对象空间上先执行 N 次析构函数,完成 N 个对象中资源的清理。
- 再调用
operator delete[]函数释放空间,实际上就是在operator delete[]中调用多次operator delete来释放空间。
(5) 补充点与注意事项
我们先来看看下面这个程序。
class A
{
public:A(int a = 1):_a(a){cout << "A(int a)" << endl;}~A(){_a = 0;cout << "~A()" << endl;}private:int _a;
};int main()
{A* ptr1 = new A[5];delete[] ptr1;return 0;
}
每个 A 对象的大小是 4 个字节,那么开 5 个 A 对象按理来说应该是 20 个字节。但是我们通过汇编的角度观察发现,它开的空间不是 20 个字节而是 24 个字节(16 进制的18对应10进制的24)。而且如果只开一个对象大小的空间就是正常的 4 个字节,不会多出 4 个字节。

为什么 new 多个对象会多开 4 个字节呢?实际上我们开多个空间的时候在开空间的时候会在前面多开 4 个字节来存储我们的数据个数。比如说我们开了 5 个对象大小的空间那么就会在最前面存一个 5,表示有多少个对象。虽然我们在前面多开了 4 个字节,但是实际上 ptr1 指向的是第一个对象的最开始的位置。

而这多开的 4 个字节实际上是给 delete[] 使用的,delete[] 底层是调用多次 delete 和析构函数,delete 的底层是 free,free自己会知道自己要释放多大的空间,那么到底调用多少次析构函数就是由这多存的那个空间中的数所决定的。ptr1 往前偏移 4 个字节把这个值取出来之后 delete[] 就知道要调用多少次析构函数了。
但是如果我们把我们自己写的析构函数屏蔽掉,你会发现它又开的是 20 个字节。
class A
{
public:A(int a = 1):_a(a){cout << "A(int a)" << endl;}private:int _a;
};int main()
{A* ptr1 = new A[5];delete[] ptr1;return 0;
}
16进制的14对应10进制的20。

这是因为如果我们自己没有写析构函数,那么编译器就会自动生成一个析构函数,这个析构函数什么都不会做,那就可以不调用了,因此编译器就会认为前面多存的这个数存了也没什么用,所以就不存了,相当编译器把它优化掉了。
还需要补充讲解的是,如果这个时候我们使用 delete ptr1 这样的不加 [] 的类型的话,是不会报错的,也不会造成内存泄漏。
但是!如果把析构函数重新自己写出来的话用 delete ptr1 就会报错。因为这个时候 ptr1 实际上是指向第一个对象的起始位置,前面还有 4 个字节存储对象个数,相当于指向的是你开出来的空间的中间的一个位置。而释放一段空间是不能从中间开始释放的,释放的空间位置不对那么就会报错,并且它只会调用一次析构函数。
用 delete[] ptr1 才是正确的, ptr1 它会先往前偏移 4 个字节把对象个数取出来,再去释放空间和调用析构函数。
把析构函数删掉用 delete ptr1 不会报错是因为编译器不会开前面的 4 个字节的空间,释放空间的时候是从最开始开始释放的,但是也不要这样用。
所以在释放多个对象的时候,一定要用 delete[] 这样的加方括号的形式,以免出现意外。
四、定位 new 表达式 (replacement-new)
1. 定位 new 表达式的使用
定位 new 表达式是在已分配的原始内存空间中调用构造函数初始化一个对象。
在 C++ 中是不支持直接显式调用构造函数的。
int main()
{A* p1 = new A(1);// p1->A(1); // C++ 不支持这样的显式调用构造函数p1->~A(); // 但是析构可以return 0;
}
但是在特殊条件下我们可以显式地调用构造函数,我们可以显式地调用 operator new 和 operator delete 函数,然后用定位 new 显式调用构造。
int main()
{A* p1 = (A*)operator new(sizeof(A));new(p1)A(10); // 定位 new (replacement new) 显式调用构造函数// 上面两行就相当于 new 的功能p1->~A();operator delete(p1);// 上面两行就相当于 delete 的功能return 0;
}
2. 应用场景
当我们要高频地向系统申请空间的时候,我们的效率就会下降,因此为了提效,我们可以提前找系统申请一大块空间,存储起来,自己来管理,这块空间就是内存池。
而定位new表达式在实际中一般是配合内存池使用。因为内存池分配出的内存没有初始化,所以如果是自定义类型的对象,需要使用定位 new 表达式进行显示调构造函数进行初始化。
五、malloc / free 与 new / delete 区别总结
共同点:
malloc / free 和 new / delete的共同点是:都是从堆上申请空间,并且需要用户手动释放。
不同点:
malloc 和 free 是函数,new 和 delete 是操作符。
malloc 申请的空间不会初始化,new 可以初始化。
malloc 申请空间时,需要手动计算空间大小并传递,new 只需在其后跟上空间的类型即可, 如果是多个对象,[]中指定对象个数即可。
malloc 的返回值为 void, 在使用时必须强转,new 不需要强转,因为 new 后跟的是空间的类型。*
malloc 申请空间失败时,返回的是 NULL,因此使用时必须判空,new 不需要,但是 new 需要捕获异常。
申请自定义类型对象时,malloc / free 只会开辟空间,不会调用构造函数与析构函数,而 new 在申请空间后会调用构造函数完成对象的初始化,delete 在释放空间前会调用析构函数完成空间中资源的清理释放。
相关文章:

【C++】内存管理 —— new 和 delete
文章目录 一、C/C 内存分布二、C 语言中动态内存管理方式1. malloc / calloc / realloc / free 三、C 内存管理方式1. new / delete2. operator new 与 operator delete 函数3. new 和 delete 的实现原理(1) new 的原理(2) delete 的原理(3) new T[N] 的原理(4) delete[] 的原理…...

springboot3整合SpringSecurity实现登录校验与权限认证
一:概述 1.1 基本概念 (1)认证 系统判断身份是否合法 (2)会话 为了避免每次操作都进行认证可将用户信息保存在会话中 session认证 服务端有个session,把 session id给前端,每次请求cookie都带着…...

【东枫科技】使用LabVIEW进行深度学习开发
文章目录 DeepLTK LabVIEW深度学习工具包LabVIEW中的深度神经网络**功能与特性****功能亮点:** **支持的网络层****支持的网络架构****参考示例** 授权售价 DeepLTK LabVIEW深度学习工具包 LabVIEW中的深度神经网络 功能亮点: 在 LabVIEW 中创建、配置…...

《智能网联汽车 自动驾驶系统通用技术要求》 GB/T 44721-2024——解读
目录 一、核心框架与适用范围 二、关键技术要求 1. 总体要求 2. 动态驾驶任务执行 3. 动态驾驶任务后援 4. 人机交互(HMI) 5. 说明书要求 三、附录重点 附录A(规范性)——功能安全与预期功能安全 附录B(资料性…...

同一个虚拟环境中conda和pip安装的文件存储位置解析
文章目录 存储位置的基本区别conda安装的包pip安装的包 看似相同实则不同的机制实际路径示例这种差异带来的问题如何检查包安装来源最佳实践建议 总结 存储位置的基本区别 conda安装的包 存储在Anaconda(或Miniconda)目录下的pkgs和envs子目录中: ~/anaconda3/en…...

《Hadoop 权威指南》笔记
Hadoop 基础 MapReduce Hadoop 操作 Hadoop 相关开源项目...

每日一题洛谷P8615 [蓝桥杯 2014 国 C] 拼接平方数c++
P8615 [蓝桥杯 2014 国 C] 拼接平方数 - 洛谷 (luogu.com.cn) #include<iostream> #include<string> #include<cmath> using namespace std; bool jud(int p) {int m sqrt(p);return m * m p; } void solve(int n) {string t to_string(n);//int转换为str…...

【C++】AVL树实现
目录 前言 一、AVL树的概念 二、AVL树的实现 1.基本框架 2.AVL树的插入 三、旋转 1.右单旋 2.左单旋 3.左右双旋 4.右左双旋 四、AVL树的查找 五、AVL树的平衡检测 六、AVL树的删除 总结 前言 本文主要讲解AVL树的插入,AVL树是在二叉搜索树的基础上&a…...

49.EFT测试与静电测试环境和干扰特征分析
EFT测试与静电测试环境和干扰特征分析 1. EFT/B电快速瞬变脉冲群测试及干扰特征分析2. EFT的干扰特征分析与滤波方法3. ESD静电测试及干扰特征分析 1. EFT/B电快速瞬变脉冲群测试及干扰特征分析 EFT测试是模拟在大的感性设备断开瞬间产生的快速瞬变脉冲群对被测设备的影响。 E…...
)
html body 设置heigth 100%,body内元素设置margin-top出滚动条(margin 重叠问题)
今天在用移动端的时候发现个问题,html,body 设置 height:100% 会出现纵向滚动条 <!DOCTYPE html> <html> <head> <title>html5</title> <style> html, body {height: 100%; } * {margin: 0;padding: 0; } </sty…...

1688 API 自动化采集实践:商品详情实时数据接口开发与优化
在电商行业竞争日益激烈的当下,实时获取 1688 平台商品详情数据,能够帮助商家分析市场动态、优化选品策略,也能助力数据分析师洞察行业趋势。通过 API 自动化采集商品详情数据,不仅可以提高数据获取效率,还能保证数据的…...
Transformer Decoder-Only 参数量计算
Transformer 的 Decoder-Only 架构(如 GPT 系列模型)是当前大语言模型的主流架构,其参数量主要由以下几个部分组成: 嵌入层(Embedding Layer)自注意力层(Self-Attention Layers)前馈…...
)
苍穹外卖(数据统计–Excel报表)
数据统计(Excel报表) 工作台 接口设计 今日数据接口 套餐总览接口 菜品总览接口 订单管理接口 编辑代码导入 功能测试 导出运营数据Excel报表 接口设计 代码开发 将模板文件放到项目中 导入Apache POI的maven坐标 在ReportCont…...

如何实现Flask应用程序的安全性
在 Flask 应用中,确保安全性非常关键,尤其是当你将应用部署到公网环境中时。Flask 本身虽然轻量,但通过组合安全策略、扩展库和最佳实践,可以构建一个非常安全的 Web 应用。 一、常见 Flask 安全风险(必须防护…...

【Redis】Redis的主从复制
文章目录 1. 单点问题2. 主从模式2.1 建立复制2.2 断开复制 3. 拓扑结构3.1 三种结构3.2 数据同步3.3 复制流程3.3.1 psync运行流程3.3.2 全量复制3.3.3 部分复制3.3.4 实时复制 1. 单点问题 单点问题:某个服务器程序,只有一个节点(只搞一个…...

趣味编程:四叶草
概述:在万千三叶草中寻觅,只为那一抹独特的四叶草之绿,它象征着幸运与希望。本篇博客主要介绍四叶草的绘制。 1. 效果展示 绘制四叶草的过程是一个动态的过程,因此博客中所展示的为绘制完成的四叶草。 2. 源码展示 #define _CR…...

HTTP 响应状态码总结
一、引言 HTTP 响应状态码是超文本传输协议(HTTP)中服务器对客户端(通常是 Web 浏览器)请求的响应指示。这些状态码是三位数字代码,用于告知客户端请求的结果,包括请求是否成功。响应被分为五个类别&#…...

C语言常见的文件操作函数总结
目录 前言 一、打开和关闭 1.fopen 细节 2.fclos 基本用法示例 二、读写 1.fputc和fgetc 1)fputc 细节 基本用法示例 2)fgetc 细节 基本用法示例 2.fputs和fgets 1)fputs 细节 基本用法示例 2)fgets 细节 基本用法示例 3)puts的使用,以及为什…...

卫宁健康WiNGPT3.0与WiNEX Copilot 2.2:医疗AI创新的双轮驱动分析
引言:医疗AI的双翼时代 在医疗信息化的浪潮中,人工智能技术的深度融入正在重塑整个医疗行业。卫宁健康作为国内医疗健康和卫生领域数字化解决方案的领军企业,持续探索AI技术在医疗场景中的创新应用。2025年5月10日,在第29届中国医院信息网络大会(CHIMA2025)上,卫宁健康…...

【GPT入门】第38课 RAG评估指标概述
这里写自定义目录标题 一、RAG评估指标二、ragas 评估三、trulens 一、RAG评估指标 二、ragas 评估 2.1 ragas介绍 开源地址:https://github.com/explodinggradients/ragas 官方文档:https://docs.ragas.io/en/stable/从文本生成和文本召回两个维度&am…...

深度剖析多模态大模型中的视频编码器算法
写在前面 随着多模态大型语言模型(MLLM)的兴起,AI 理解世界的能力从静态的文本和图像,进一步拓展到了动态的、包含丰富时空信息的视频。视频作为一种承载了动作、交互、场景变化和声音(虽然本文主要聚焦视觉部分)的复杂数据形式,为 MLLM 提供了理解真实世界动态和因果关…...

【递归、搜索与回溯算法】导论
📝前言说明: 本专栏主要记录本人递归、搜索与回溯算法的学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码ÿ…...

《智能网联汽车 自动驾驶功能道路试验方法及要求》 GB/T 44719-2024——解读
目录 1. 适用范围 2. 关键术语 3. 试验条件 3.1 试验道路 3.2 试验车辆 3.3 试验设备 3.4 试验时间 4. 试验方法及要求 4.1 功能激活 4.2 动态驾驶任务执行 4.3 动态驾驶任务后援 4.4 状态提示 5. 附录A(核心环境要素) 6. 实施要点 原文链接…...

path环境变量满了如何处理,分割 PATH 到 Path1 和 Path2
要正确设置 Path1 的值,你需要将现有的 PATH 环境变量 中的部分路径复制到 Path1 和 Path2 中。以下是详细步骤: 步骤 1:获取当前 PATH 的值 打开环境变量窗口: 按 Win R,输入 sysdm.cpl,点击 确定。在 系…...
)
实战项目1(02)
目录 任务场景一 【sw1和sw2的配置如下】 任务场景二 【sw3的配置】 【sw4-6的配置】 任务场景一 某公司有生产、销售、研发、人事、财务等多个部门,这些部门分别连接在两台交换机(SW1和SW2)上,现要求给每个部门划分相应的V…...

m1 安装 Elasticsearch、ik、kibana
一、下载安装ES 1、下载地址 ES|download 2、安装 将下载的安装包解压到 要安装的文件目录 关闭 ES 的安全模式 本地文本编辑器打开elasticsearch.yml配置文件,将红箭头指的地方 改为 false3、启动 ES 启动命令 进入 ES 的安装目录,进入bin文件目…...

游戏引擎学习第273天:动画预览
回顾并为一天的内容定下基调 。目前我们正在编写角色的移动代码,实际上,我们已经在昨天完成了一个简单的角色跳跃的例子。所以今天的重点是,开始更广泛地讨论动画,因为我们希望对现有的动画进行调整,让它看起来更加令…...

JVM中的安全点是什么,作用又是什么?
JVM中的安全点(Safepoint) 是Java虚拟机设计中的一个关键机制,主要用于协调所有线程的执行状态,以便进行全局操作(如垃圾回收、代码反优化等)。它的核心目标是确保在需要暂停所有线程时,每个线程…...

游戏引擎学习第271天:生成可行走的点
回顾并为今天的内容设定背景 我们昨天开始编写一些游戏逻辑相关的内容,虽然这部分不是最喜欢的领域,更偏好底层引擎开发,但如果要独立完成一款游戏,游戏逻辑也必须亲自处理。所以我们继续完善这部分内容。事实上,接下…...

FlySecAgent:——MCP全自动AI Agent的实战利器
最近,出于对人工智能在网络安全领域应用潜力的浓厚兴趣,我利用闲暇时间进行了深入研究,并成功开发了一款小型轻量化的AI Agent安全客户端FlySecAgent。 什么是 FlySecAgent? 这是一个基于大语言模型和MCP(Model-Contr…...

DAMA车轮图
DAMA车轮图是国际数据管理协会(DAMA International)提出的数据管理知识体系(DMBOK)的图形化表示,它以车轮(同心圆)的形式展示了数据管理的核心领域及其相互关系。以下是基于用户提供的关键词对D…...

使用vue3-seamless-scroll实现列表自动滚动播放
vue3-seamless-scroll组件支持上下左右无缝滚动,单步滚动,并且支持复杂图标的无缝滚动。 核心特性 多方向无缝滚动 支持上下、左右四个方向的自动滚动,通过 direction 参数控制(默认 up),适用于新闻轮播、…...

Scrapyd 详解:分布式爬虫部署与管理利器
Scrapyd 是 Scrapy 官方提供的爬虫部署与管理平台,支持分布式爬虫部署、定时任务调度、远程管理爬虫等功能。本文将深入讲解 Scrapyd 的核心功能、安装配置、爬虫部署流程、API 接口使用,以及如何结合 Scrapy-Redis 实现分布式爬虫管理。通过本文&#x…...
)
mac环境配置(homebrew版)
文章目录 【环境配置】HomebrewGitJavaMavenMySQLRedisNacosNode.js 【拓展-mac常见问题】mac文件损坏问题mac必装软件(Java开发版)zsh和bash配置文件区别 【参考资料】 查看每个版本可以用命令brew info xxx ps:每一个环境安装完之后都要关掉…...

19、DeepSeek LLM论文笔记
DeepSeek LLM 1. **引言**2、架构3、多步学习率调度器4、缩放定律1.超参数的缩放定律2. 估计最优模型和数据缩放 5、GQA分组查询注意力汇总deepseekDeepSeek LLM 技术文档总结1. **引言**2. **预训练**3. **扩展法则**4. **对齐(Alignment)**5. **评估*…...

基于LLM的6G空天地一体化网络自进化安全框架
摘要 最近出现的6G空天地一体化网络(SAGINs)整合了卫星、空中网络和地面通信,为各种移动应用提供普遍覆盖。然而,SAGINs的高度动态、开放和异构的性质带来了严重的安全问题。构建SAGINs的防御体系面临两个初步挑战:1)…...

【Mac 从 0 到 1 保姆级配置教程 12】- 安装配置万能的编辑器 VSCode 以及常用插件
文章目录 前言安装 VSCode基础配置常用插件1. 通用开发工具2. 编程语言支持3. 数据库工具4. 主题与界面美化5. 效率工具6. Markdown 工具7. 容器开发8. AI 辅助编程9. 团队协作 最后系列教程 Mac 从 0 到 1 保姆级配置教程目录,点击即可跳转对应文章: 【…...

数据库与SQL核心技术解析:从基础到JDBC编程实战
数据库技术作为现代信息系统的核心,贯穿于数据存储、查询优化、事务管理等关键环节。本文将系统讲解数据库基础知识、SQL语言核心操作、索引与事务机制,并结合Java数据库编程(JDBC)实践,助你构建完整的数据库技术体系。…...
)
JUC并发编程(上)
一、JUC学习准备 核心知识点:进程、线程、并发(共享模型、非共享模型)、并行 预备知识: 基于JDK8,对函数式编程、lambda有一定了解 采用了slf4j打印日志 采用了lombok简化java bean编写 二、进程与线程 进程和线程概念 两者对比…...

postgres--MVCC
PostgreSQL 的 MVCC(Multi-Version Concurrency Control,多版本并发控制) 是其实现高并发和高性能的核心机制,支持多个事务同时读写数据库而无需加锁阻塞。它的核心思想是通过保留数据的多个版本来避免读写冲突,从而提…...

nanodet配置文件分析
以下是针对 NanoDet-Plus-M-1.5x_416 配置文件的逐模块解析,以及调整参数的作用和影响范围: 1. 模型架构(model) Backbone(骨干网络) backbone:name: ShuffleNetV2model_size: 1.5x # 控制网络宽度&…...

【Linux网络】HTTP
应用层协议 HTTP 前置知识 我们上网的所有行为都是在做IO,(我的数据给别人,别人的数据给我)图片。视频,音频,文本等等,都是资源答复前需要先确认我要的资源在哪台服务器上(网络IP&…...
)
Unity中AssetBundle使用整理(一)
一、AssetBundle 概述 AssetBundle 是 Unity 用于存储和加载游戏资源(如模型、纹理、预制体、音频等)的一种文件格式。它允许开发者将游戏资源打包成独立的文件,在运行时动态加载,从而实现资源的按需加载、更新以及减小初始安装包…...

CMOS内存的地址空间在主内存空间中吗?
CMOS内存(即CMOS RAM)的地址空间不位于主内存地址空间(如0x00000-0xFFFFF)内,而是通过独立的I/O端口地址进行访问,具体如下: 1. CMOS内存的物理存储与地址机制 CMOS RAM芯片通常集成在主板…...

大模型应用中常说的Rerank是什么技术?
Rerank技术详解 一、定义与基本原理 Rerank(重排序)是一种在信息检索系统中用于优化搜索结果排序的技术,其核心目标是通过二次评估和排序候选文档,提升结果的相关性和准确性。其运作机制通常分为两阶段: 初步检索:使用传统方法(如BM25关键词匹配或Embedding向量检索)…...

Python-MCPInspector调试
Python-MCPInspector调试 使用FastMCP开发MCPServer,熟悉【McpServer编码过程】【MCPInspector调试方法】-> 可以这样理解:只编写一个McpServer,然后使用MCPInspector作为McpClient进行McpServer的调试 1-核心知识点 1-熟悉【McpServer编…...

C 语言数据结构基石:揭开数组名的面纱与计算数组大小
各类资料学习下载合集 https://pan.quark.cn/s/8c91ccb5a474 在前面的文章中,我们已经学习了 C 语言一维数组的定义和初始化。我们知道数组是用来存储一系列相同类型数据的集合,并通过下标来访问每个元素。但是,除了通过下标访问单个元素,数组名本身在 C 语言中也…...

Java高频面试之并发编程-15
hello啊,各位观众姥爷们!!!本baby今天又来报道了!哈哈哈哈哈嗝🐶 面试官:as-if-serial 是什么?单线程的程序一定是顺序执行的吗? as-if-serial 规则 定义: …...

MySQL数据库迁移SQL语句指南
MySQL数据库迁移SQL语句指南 一、基础迁移方法 1. 使用mysqldump进行全量迁移 -- 导出源数据库(在命令行执行) mysqldump -u [源用户名] -p[源密码] --single-transaction --routines --triggers --events --master-data2 [数据库名] > migration…...

Vue:生命周期钩子
深入理解 Vue 的钩子函数(生命周期函数) Vue 的钩子函数(生命周期函数)是 Vue 实例在不同阶段自动调用的函数。可以在 Vue 实例的创建、更新、销毁等阶段插入自己的逻辑。 钩子函数的作用 想象一下,Vue 实例的生命周…...