Python_day22
DAY 22 复习日
复习日
仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。
作业:
自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码
kaggle泰坦里克号人员生还预测
一、Kaggle 基础使用步骤
-
注册与登录
- 访问 Kaggle 官网 ,通过 Google 账号或邮箱注册。
- 验证邮箱后完成账户激活。
-
熟悉界面
- Competitions(竞赛):参与数据科学竞赛,赢取奖金或提升技能。
- Datasets(数据集):搜索或上传公开数据集。
- Notebooks(代码笔记本):基于 Jupyter Notebook 的在线编程环境,支持 Python/R。
- Discussions(论坛):与社区交流问题或分享经验。
-
创建/运行 Notebook
- 点击
New Notebook创建代码环境,支持 GPU/TPU 加速。 - 挂载数据集:通过
Add Data添加数据集到 Notebook。
- 点击
-
提交竞赛结果
- 在竞赛页面下载数据,训练模型后生成预测结果文件(如 CSV)。
- 通过竞赛页面的
Submit Predictions上传结果,查看排名。
二、使用注意点
1. 数据隐私与合规
- 避免敏感数据:上传数据集时,确保不包含个人信息或受版权保护的内容。
- 竞赛数据保密:禁止在竞赛期间将数据集分享到外部平台。
2. 资源限制
- GPU/TPU 使用:免费账户每周有约 30 小时的 GPU 和 20 小时的 TPU 配额,超限后需等待重置。
- 会话时长:Notebook 无操作 20 分钟后会自动停止,需手动重启。
- 存储限制:每个 Notebook 最大存储 20GB(含数据集)。
3. 代码与 Notebook 优化
- 依赖安装:在 Notebook 中通过
!pip install安装库时,建议在代码开头一次性安装。 - 开启 GPU:在 Notebook 设置中手动启用 GPU/TPU,否则默认使用 CPU。
- 数据路径:挂载数据集后,数据路径通常为
/kaggle/input/[数据集名称]/。 - 版本保存:定期点击
Save Version备份代码,避免丢失进度。
4. 竞赛注意事项
- 规则阅读:仔细阅读竞赛规则,避免因提交格式错误或违规被取消资格。
- 团队合作:允许组队参赛,但需在提交前合并团队。
- 公平性:禁止多账号刷分或使用非公开数据。
5. 社区互动
- 提问技巧:在论坛提问时,提供清晰的背景、代码错误信息和尝试过的解决方法。
- 引用来源:使用他人代码或数据时,注明来源并遵守许可证(如 CC0、MIT 等)。
6. 性能与效率
- 大数据处理:使用
pandas时优先选择分块读取(chunksize)或高效格式(如parquet)。 - 内存管理:避免在 Notebook 中加载超大数据,可使用
dtype优化或del释放内存。 - 缓存中间结果:将预处理后的数据保存为文件,减少重复计算。
三、其他实用技巧
- 学习资源:利用 Kaggle Learn(短期免费课程)和公开 Notebook 学习模型构建技巧。
- Kaggle API:通过命令行工具批量下载数据集或提交结果(需生成 API Token)。
- 参与社区活动:关注 Kernels(优质代码)、Datasets 和 Discussions 的 Trending 内容,学习最新方法。
常见问题解决
- 数据集加载失败:检查路径是否正确,或通过
ls /kaggle/input查看已挂载数据。 - GPU 未生效:在 Notebook 设置中确认已开启 GPU,并检查是否安装了 GPU 版本的库(如
tensorflow-gpu)。 - 内存不足:减少批量大小(batch size)或使用更轻量级的模型。
Kaggle 的比赛如何运作
- 加入比赛
阅读挑战赛描述,接受比赛规则并访问比赛数据集。 - 开始工作
下载数据,在本地或 Kaggle Notebooks(我们的免设置、可自定义的 Jupyter Notebooks 环境,带有免费 GPU)上构建模型,并生成预测文件。 - 提交 将您的预测作为提交
上传到 Kaggle 并获得准确率分数。 - 查看排行榜
查看您的模型在我们的排行榜上与其他 Kaggler 的排名。 - 提高你的分数
查看论坛,找到来自其他竞争对手的大量教程和见解。
本次挑战——泰坦尼克号 - 从灾难中学习机器学习
泰坦尼克号的沉没是历史上最臭名昭著的沉船事件之一。
1912 年 4 月 15 日,在她的处女航中,被广泛认为“永不沉没”的 RMS 泰坦尼克号在与冰山相撞后沉没。不幸的是,船上的每个人都没有足够的救生艇,导致 1502 名乘客和船员中有 2224 人死亡。
虽然生存下来有一些运气因素,但似乎某些群体比其他人更有可能生存下来。
在本次挑战赛中,我们要求您构建一个预测模型,使用乘客数据(即姓名、年龄、性别、社会经济阶层等)回答“什么样的人更有可能生存”这个问题。
我将在本次比赛中使用哪些数据?
在本次比赛中,您将可以访问两个类似的数据集,其中包括乘客信息,如姓名、年龄、性别、社会经济阶层等。一个数据集的标题为,另一个数据集的标题为 。train.csvtest.csv
Train.csv将包含机上乘客子集(准确地说是 891 人)的详细信息,重要的是,将揭示他们是否幸存,也称为“基本事实”。
该数据集包含类似的信息,但没有透露每位乘客的 “真实情况”。预测这些结果是你的工作。test.csv
使用您在数据中找到的模式,预测机上其他 418 名乘客(在 中找到)是否幸存下来。train.csvtest.csv
查看 “Data” 选项卡以进一步探索数据集。一旦您认为您已经创建了一个有竞争力的模型,请将其提交给 Kaggle,以查看您的模型在我们的排行榜上与其他 Kaggler 的排名。
数据集描述
概述
数据已分为两组:
- 训练集 (train.csv)
- 测试集 (test.csv)
训练集应用于构建机器学习模型。对于训练集,我们提供每位乘客的结果(也称为“真实值”)。您的模型将基于乘客的性别和舱位等“特征”。您还可以使用特征工程来创建新特征。
应该使用测试集来查看模型在看不见的数据上的表现。对于测试集,我们不会提供每位乘客的 Ground Truth。预测这些结果是你的工作。对于测试集中的每个乘客,使用您训练的模型来预测他们是否在泰坦尼克号沉没后幸存下来。
我们还包括 gender_submission.csv,这是一组假设所有且只有女性乘客幸存的预测,作为提交文件应该是什么样子的示例。
数据字典
| 变量 | 定义 | 钥匙 |
|---|---|---|
| 生存 | 生存 | 0 = 否,1 = 是 |
| p类 | 机票舱位 | 1 = 第 1 个,2 = 第 2 个,3 = 第 3 个 |
| 性 | 性 | |
| 年龄 | 年龄(岁) | |
| 国际生物安全指数 | # 泰坦尼克号上的兄弟姐妹/配偶 | |
| 帕奇 | # 泰坦尼克号上的父母/孩子 | |
| 票 | 票号 | |
| 票价 | 乘客票价 | |
| 舱 | 舱位号 | |
| 登船 | 登船港口 | C = 瑟堡,Q = 皇后镇,S = 南安普敦 |
变量注释
pclass:社会经济地位 (SES)
的代理 1st = 上
2nd = 中
3rd = 下
年龄:如果年龄小于 1,则年龄为分数。如果年龄是估计的,是不是以 xx.5
sibsp 的形式:数据集是这样定义家庭关系的......
兄弟姐妹 = 兄弟、姐妹、继兄弟、继姐妹
配偶 = 丈夫、妻子(情妇和未婚夫被忽略)
parch:数据集以这种方式定义家庭关系......
父母 = 母亲,父亲
孩子 = 女儿、儿子、继女、继子
有些孩子只与保姆一起旅行,因此他们 parch=0。
具体步骤
总览
[加载数据] → [预处理] → [特征工程] → [训练模型]
↓ ↑
[获取已训练预处理器] → [提取特征名称] → [合并分析]
具体代码
1. 环境准备
# ========== 1. 环境准备 ==========
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV, StratifiedKFold
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import OneHotEncoder, RobustScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from imblearn.over_sampling import SMOTE
from imblearn.pipeline import make_pipeline as imb_make_pipeline
import warnings
warnings.filterwarnings('ignore')2. 数据加载与清洗
# ========== 2. 数据加载与清洗 ==========
def load_data(path):"""加载并初步处理数据"""df = pd.read_csv(path)# 删除无关特征 [改进1:增加特征删除说明]df.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)return dftrain = load_data('train.csv')
test = load_data('test.csv')3. 数据预处理管道
# ========== 3. 数据预处理管道 ==========
# [改进2:增加鲁棒缩放器]
cat_features = ['Sex', 'Embarked']
num_features = ['Pclass', 'Age', 'SibSp', 'Parch', 'Fare']preprocessor = ColumnTransformer(transformers=[('num', Pipeline(steps=[('imputer', SimpleImputer(strategy='median')),('scaler', RobustScaler()) # 新增特征缩放]), num_features),('cat', Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('encoder', OneHotEncoder(handle_unknown='ignore'))]), cat_features)])
4. 特征工程增强
# ========== 4. 特征工程增强 ==========
def feature_engineering(df):"""自定义特征工程 [改进3:增加新特征]"""# 基础特征df['FamilySize'] = df['SibSp'] + df['Parch'] + 1df['IsAlone'] = (df['FamilySize'] == 1).astype(int)# 新增票价分段特征df['FareCategory'] = pd.cut(df['Fare'],bins=[0, 10, 50, 100, 600],labels=[0, 1, 2, 3]).astype(float)# 新增年龄分段特征df['AgeGroup'] = pd.cut(df['Age'],bins=[0, 12, 18, 60, 100],labels=['Child', 'Teen', 'Adult', 'Elderly']).astype(object)return dftrain = feature_engineering(train)
test = feature_engineering(test)5. 数据集划分策略优化
# ========== 5. 数据集划分策略优化 ==========
# [改进4:使用分层抽样]
X = train.drop('Survived', axis=1)
y = train['Survived']
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y, # 新增分层抽样random_state=42
)6. 构建增强管道
# ========== 6. 构建增强管道 ==========
# [改进5:优化网格搜索参数]
pipeline = imb_make_pipeline(preprocessor,SMOTE(random_state=42),RandomForestClassifier(random_state=42)
)param_grid = {'randomforestclassifier__n_estimators': [100, 200, 300], # 扩展参数范围'randomforestclassifier__max_depth': [5, 7, 9, None],'randomforestclassifier__min_samples_split': [2, 3, 5],'randomforestclassifier__max_features': ['sqrt', 'log2'], # 新增参数'smote__k_neighbors': [3, 5] # 优化SMOTE参数
}7. 模型训练与调参优化
# ========== 7. 模型训练与调参优化 ==========
# [改进6:使用分层交叉验证]
grid_search = GridSearchCV(estimator=pipeline,param_grid=param_grid,scoring='f1',cv=StratifiedKFold(n_splits=5, shuffle=True, random_state=42), # 优化交叉验证n_jobs=-1,verbose=1 # 新增训练过程显示
)grid_search.fit(X_train, y_train)
8. 模型评估增强
# ========== 8. 模型评估增强 ==========
best_model = grid_search.best_estimator_
val_pred = best_model.predict(X_val)print("\n=== 最优参数 ===")
print(grid_search.best_params_)print("\n=== 验证集评估 ===")
print(f"准确率: {accuracy_score(y_val, val_pred):.2f}")
print(f"精确率: {precision_score(y_val, val_pred):.2f}")
print(f"召回率: {recall_score(y_val, val_pred):.2f}")
print(f"F1分数: {f1_score(y_val, val_pred):.2f}")
9. 测试集处理
# ========== 9. 测试集处理 ==========
# [改进7:确保测试集处理一致性]
test_passenger_ids = pd.read_csv('test.csv')['PassengerId']
test_pred = best_model.predict(test)10. 结果保存与特征分析
# ========== 10. 结果保存与特征分析 ==========
submission = pd.DataFrame({'PassengerId': test_passenger_ids,'Survived': test_pred
})
submission.to_csv('titanic_submission.csv', index=False)# 特征重要性分析(修正版)
try:# 获取训练好的预处理器fitted_preprocessor = best_model.named_steps['columntransformer']# 数值特征(包含新增特征)num_feats = num_features + ['FamilySize', 'IsAlone', 'FareCategory']# 分类特征编码后的名称cat_pipeline = fitted_preprocessor.named_transformers_['cat']encoded_cat_feats = cat_pipeline.named_steps['encoder'].get_feature_names_out(cat_features)# 合并所有特征名称all_feature_names = np.concatenate([num_feats, encoded_cat_feats])# 获取重要性importances = best_model.named_steps['randomforestclassifier'].feature_importances_# 创建DataFrameimportance_df = pd.DataFrame({'Feature': all_feature_names,'Importance': importances}).sort_values('Importance', ascending=False)print("\n=== 特征重要性 Top 10 ===")print(importance_df.head(10))except Exception as e:print(f"特征分析失败: {str(e)}")print("可能原因:")print("- sklearn版本过低(需>=1.0),请升级:pip install --upgrade scikit-learn")print("- 预处理器未正确训练")print("\n=== 提交文件已生成 ===")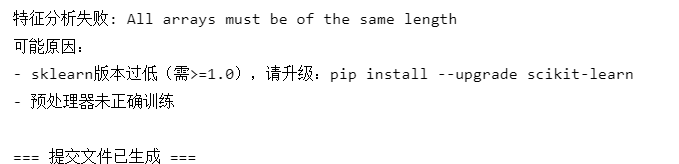
最终提交
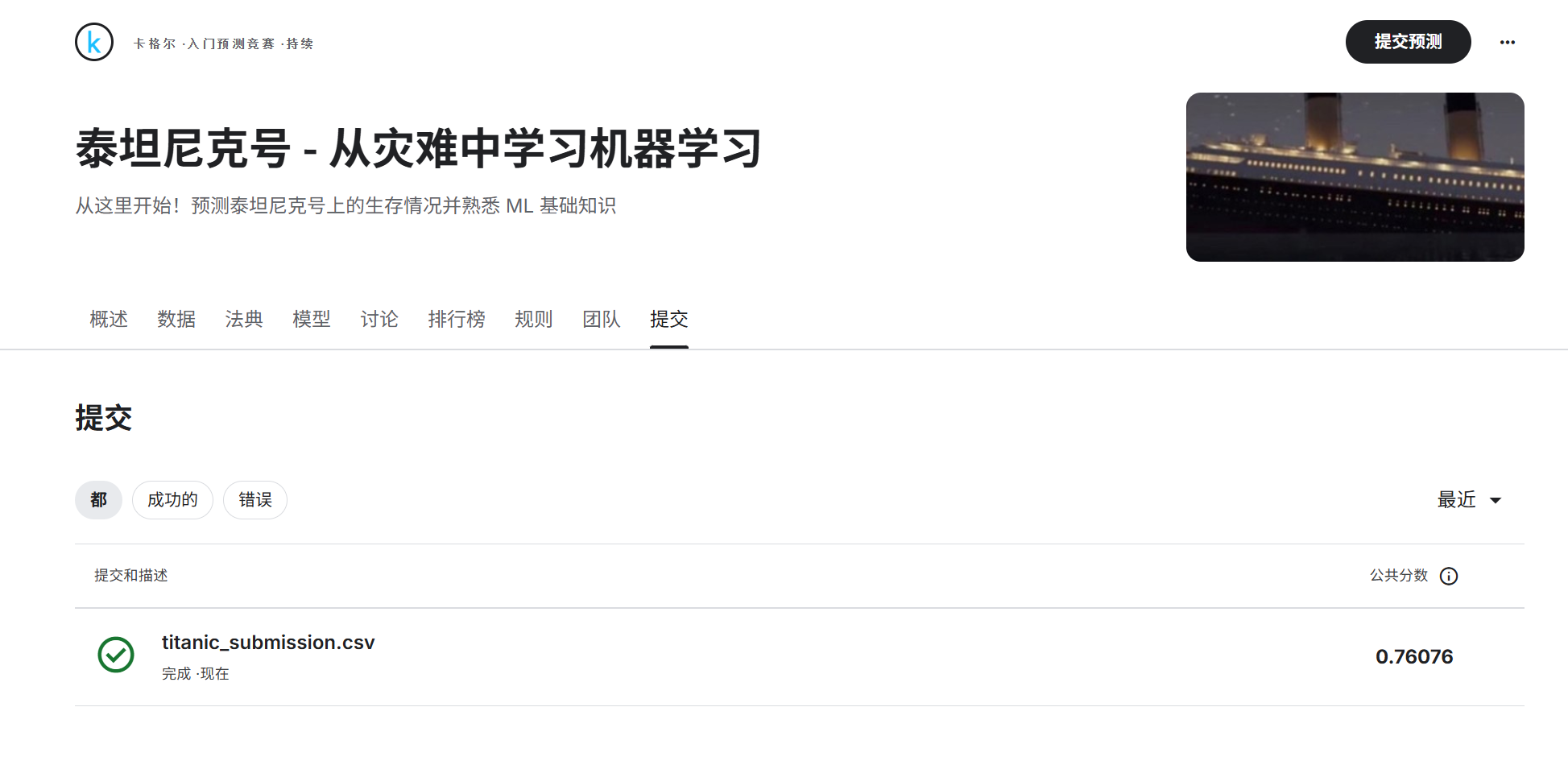
您的提交应为包含 418 行和标题的 CSV 文件。您可以上传 zip/gz/7z 存档。
@浙大疏锦行
相关文章:

Python_day22
DAY 22 复习日 复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 kaggle泰坦里克号人员生还预测 一、Kaggle 基础使用步骤 注册与登录…...

浏览器的B/S架构和C/S架构
浏览器的B/S架构和C/S架构 概述拓展 欢迎来到 Shane 的博客~ 心有猛虎,细嗅蔷薇。 概述 C/S架构? Client/Server架构。但是缺少通用性、系统维护、升级需要重新设计和开发,并且需要开发不同的操作系统,增加了维护和管理的难度。&…...

【C++】内存管理 —— new 和 delete
文章目录 一、C/C 内存分布二、C 语言中动态内存管理方式1. malloc / calloc / realloc / free 三、C 内存管理方式1. new / delete2. operator new 与 operator delete 函数3. new 和 delete 的实现原理(1) new 的原理(2) delete 的原理(3) new T[N] 的原理(4) delete[] 的原理…...

springboot3整合SpringSecurity实现登录校验与权限认证
一:概述 1.1 基本概念 (1)认证 系统判断身份是否合法 (2)会话 为了避免每次操作都进行认证可将用户信息保存在会话中 session认证 服务端有个session,把 session id给前端,每次请求cookie都带着…...

【东枫科技】使用LabVIEW进行深度学习开发
文章目录 DeepLTK LabVIEW深度学习工具包LabVIEW中的深度神经网络**功能与特性****功能亮点:** **支持的网络层****支持的网络架构****参考示例** 授权售价 DeepLTK LabVIEW深度学习工具包 LabVIEW中的深度神经网络 功能亮点: 在 LabVIEW 中创建、配置…...

《智能网联汽车 自动驾驶系统通用技术要求》 GB/T 44721-2024——解读
目录 一、核心框架与适用范围 二、关键技术要求 1. 总体要求 2. 动态驾驶任务执行 3. 动态驾驶任务后援 4. 人机交互(HMI) 5. 说明书要求 三、附录重点 附录A(规范性)——功能安全与预期功能安全 附录B(资料性…...

同一个虚拟环境中conda和pip安装的文件存储位置解析
文章目录 存储位置的基本区别conda安装的包pip安装的包 看似相同实则不同的机制实际路径示例这种差异带来的问题如何检查包安装来源最佳实践建议 总结 存储位置的基本区别 conda安装的包 存储在Anaconda(或Miniconda)目录下的pkgs和envs子目录中: ~/anaconda3/en…...

《Hadoop 权威指南》笔记
Hadoop 基础 MapReduce Hadoop 操作 Hadoop 相关开源项目...

每日一题洛谷P8615 [蓝桥杯 2014 国 C] 拼接平方数c++
P8615 [蓝桥杯 2014 国 C] 拼接平方数 - 洛谷 (luogu.com.cn) #include<iostream> #include<string> #include<cmath> using namespace std; bool jud(int p) {int m sqrt(p);return m * m p; } void solve(int n) {string t to_string(n);//int转换为str…...

【C++】AVL树实现
目录 前言 一、AVL树的概念 二、AVL树的实现 1.基本框架 2.AVL树的插入 三、旋转 1.右单旋 2.左单旋 3.左右双旋 4.右左双旋 四、AVL树的查找 五、AVL树的平衡检测 六、AVL树的删除 总结 前言 本文主要讲解AVL树的插入,AVL树是在二叉搜索树的基础上&a…...

49.EFT测试与静电测试环境和干扰特征分析
EFT测试与静电测试环境和干扰特征分析 1. EFT/B电快速瞬变脉冲群测试及干扰特征分析2. EFT的干扰特征分析与滤波方法3. ESD静电测试及干扰特征分析 1. EFT/B电快速瞬变脉冲群测试及干扰特征分析 EFT测试是模拟在大的感性设备断开瞬间产生的快速瞬变脉冲群对被测设备的影响。 E…...
)
html body 设置heigth 100%,body内元素设置margin-top出滚动条(margin 重叠问题)
今天在用移动端的时候发现个问题,html,body 设置 height:100% 会出现纵向滚动条 <!DOCTYPE html> <html> <head> <title>html5</title> <style> html, body {height: 100%; } * {margin: 0;padding: 0; } </sty…...

1688 API 自动化采集实践:商品详情实时数据接口开发与优化
在电商行业竞争日益激烈的当下,实时获取 1688 平台商品详情数据,能够帮助商家分析市场动态、优化选品策略,也能助力数据分析师洞察行业趋势。通过 API 自动化采集商品详情数据,不仅可以提高数据获取效率,还能保证数据的…...
Transformer Decoder-Only 参数量计算
Transformer 的 Decoder-Only 架构(如 GPT 系列模型)是当前大语言模型的主流架构,其参数量主要由以下几个部分组成: 嵌入层(Embedding Layer)自注意力层(Self-Attention Layers)前馈…...
)
苍穹外卖(数据统计–Excel报表)
数据统计(Excel报表) 工作台 接口设计 今日数据接口 套餐总览接口 菜品总览接口 订单管理接口 编辑代码导入 功能测试 导出运营数据Excel报表 接口设计 代码开发 将模板文件放到项目中 导入Apache POI的maven坐标 在ReportCont…...

如何实现Flask应用程序的安全性
在 Flask 应用中,确保安全性非常关键,尤其是当你将应用部署到公网环境中时。Flask 本身虽然轻量,但通过组合安全策略、扩展库和最佳实践,可以构建一个非常安全的 Web 应用。 一、常见 Flask 安全风险(必须防护…...

【Redis】Redis的主从复制
文章目录 1. 单点问题2. 主从模式2.1 建立复制2.2 断开复制 3. 拓扑结构3.1 三种结构3.2 数据同步3.3 复制流程3.3.1 psync运行流程3.3.2 全量复制3.3.3 部分复制3.3.4 实时复制 1. 单点问题 单点问题:某个服务器程序,只有一个节点(只搞一个…...

趣味编程:四叶草
概述:在万千三叶草中寻觅,只为那一抹独特的四叶草之绿,它象征着幸运与希望。本篇博客主要介绍四叶草的绘制。 1. 效果展示 绘制四叶草的过程是一个动态的过程,因此博客中所展示的为绘制完成的四叶草。 2. 源码展示 #define _CR…...

HTTP 响应状态码总结
一、引言 HTTP 响应状态码是超文本传输协议(HTTP)中服务器对客户端(通常是 Web 浏览器)请求的响应指示。这些状态码是三位数字代码,用于告知客户端请求的结果,包括请求是否成功。响应被分为五个类别&#…...

C语言常见的文件操作函数总结
目录 前言 一、打开和关闭 1.fopen 细节 2.fclos 基本用法示例 二、读写 1.fputc和fgetc 1)fputc 细节 基本用法示例 2)fgetc 细节 基本用法示例 2.fputs和fgets 1)fputs 细节 基本用法示例 2)fgets 细节 基本用法示例 3)puts的使用,以及为什…...

卫宁健康WiNGPT3.0与WiNEX Copilot 2.2:医疗AI创新的双轮驱动分析
引言:医疗AI的双翼时代 在医疗信息化的浪潮中,人工智能技术的深度融入正在重塑整个医疗行业。卫宁健康作为国内医疗健康和卫生领域数字化解决方案的领军企业,持续探索AI技术在医疗场景中的创新应用。2025年5月10日,在第29届中国医院信息网络大会(CHIMA2025)上,卫宁健康…...

【GPT入门】第38课 RAG评估指标概述
这里写自定义目录标题 一、RAG评估指标二、ragas 评估三、trulens 一、RAG评估指标 二、ragas 评估 2.1 ragas介绍 开源地址:https://github.com/explodinggradients/ragas 官方文档:https://docs.ragas.io/en/stable/从文本生成和文本召回两个维度&am…...

深度剖析多模态大模型中的视频编码器算法
写在前面 随着多模态大型语言模型(MLLM)的兴起,AI 理解世界的能力从静态的文本和图像,进一步拓展到了动态的、包含丰富时空信息的视频。视频作为一种承载了动作、交互、场景变化和声音(虽然本文主要聚焦视觉部分)的复杂数据形式,为 MLLM 提供了理解真实世界动态和因果关…...

【递归、搜索与回溯算法】导论
📝前言说明: 本专栏主要记录本人递归、搜索与回溯算法的学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码ÿ…...

《智能网联汽车 自动驾驶功能道路试验方法及要求》 GB/T 44719-2024——解读
目录 1. 适用范围 2. 关键术语 3. 试验条件 3.1 试验道路 3.2 试验车辆 3.3 试验设备 3.4 试验时间 4. 试验方法及要求 4.1 功能激活 4.2 动态驾驶任务执行 4.3 动态驾驶任务后援 4.4 状态提示 5. 附录A(核心环境要素) 6. 实施要点 原文链接…...

path环境变量满了如何处理,分割 PATH 到 Path1 和 Path2
要正确设置 Path1 的值,你需要将现有的 PATH 环境变量 中的部分路径复制到 Path1 和 Path2 中。以下是详细步骤: 步骤 1:获取当前 PATH 的值 打开环境变量窗口: 按 Win R,输入 sysdm.cpl,点击 确定。在 系…...
)
实战项目1(02)
目录 任务场景一 【sw1和sw2的配置如下】 任务场景二 【sw3的配置】 【sw4-6的配置】 任务场景一 某公司有生产、销售、研发、人事、财务等多个部门,这些部门分别连接在两台交换机(SW1和SW2)上,现要求给每个部门划分相应的V…...

m1 安装 Elasticsearch、ik、kibana
一、下载安装ES 1、下载地址 ES|download 2、安装 将下载的安装包解压到 要安装的文件目录 关闭 ES 的安全模式 本地文本编辑器打开elasticsearch.yml配置文件,将红箭头指的地方 改为 false3、启动 ES 启动命令 进入 ES 的安装目录,进入bin文件目…...

游戏引擎学习第273天:动画预览
回顾并为一天的内容定下基调 。目前我们正在编写角色的移动代码,实际上,我们已经在昨天完成了一个简单的角色跳跃的例子。所以今天的重点是,开始更广泛地讨论动画,因为我们希望对现有的动画进行调整,让它看起来更加令…...

JVM中的安全点是什么,作用又是什么?
JVM中的安全点(Safepoint) 是Java虚拟机设计中的一个关键机制,主要用于协调所有线程的执行状态,以便进行全局操作(如垃圾回收、代码反优化等)。它的核心目标是确保在需要暂停所有线程时,每个线程…...

游戏引擎学习第271天:生成可行走的点
回顾并为今天的内容设定背景 我们昨天开始编写一些游戏逻辑相关的内容,虽然这部分不是最喜欢的领域,更偏好底层引擎开发,但如果要独立完成一款游戏,游戏逻辑也必须亲自处理。所以我们继续完善这部分内容。事实上,接下…...

FlySecAgent:——MCP全自动AI Agent的实战利器
最近,出于对人工智能在网络安全领域应用潜力的浓厚兴趣,我利用闲暇时间进行了深入研究,并成功开发了一款小型轻量化的AI Agent安全客户端FlySecAgent。 什么是 FlySecAgent? 这是一个基于大语言模型和MCP(Model-Contr…...

DAMA车轮图
DAMA车轮图是国际数据管理协会(DAMA International)提出的数据管理知识体系(DMBOK)的图形化表示,它以车轮(同心圆)的形式展示了数据管理的核心领域及其相互关系。以下是基于用户提供的关键词对D…...

使用vue3-seamless-scroll实现列表自动滚动播放
vue3-seamless-scroll组件支持上下左右无缝滚动,单步滚动,并且支持复杂图标的无缝滚动。 核心特性 多方向无缝滚动 支持上下、左右四个方向的自动滚动,通过 direction 参数控制(默认 up),适用于新闻轮播、…...

Scrapyd 详解:分布式爬虫部署与管理利器
Scrapyd 是 Scrapy 官方提供的爬虫部署与管理平台,支持分布式爬虫部署、定时任务调度、远程管理爬虫等功能。本文将深入讲解 Scrapyd 的核心功能、安装配置、爬虫部署流程、API 接口使用,以及如何结合 Scrapy-Redis 实现分布式爬虫管理。通过本文&#x…...
)
mac环境配置(homebrew版)
文章目录 【环境配置】HomebrewGitJavaMavenMySQLRedisNacosNode.js 【拓展-mac常见问题】mac文件损坏问题mac必装软件(Java开发版)zsh和bash配置文件区别 【参考资料】 查看每个版本可以用命令brew info xxx ps:每一个环境安装完之后都要关掉…...

19、DeepSeek LLM论文笔记
DeepSeek LLM 1. **引言**2、架构3、多步学习率调度器4、缩放定律1.超参数的缩放定律2. 估计最优模型和数据缩放 5、GQA分组查询注意力汇总deepseekDeepSeek LLM 技术文档总结1. **引言**2. **预训练**3. **扩展法则**4. **对齐(Alignment)**5. **评估*…...

基于LLM的6G空天地一体化网络自进化安全框架
摘要 最近出现的6G空天地一体化网络(SAGINs)整合了卫星、空中网络和地面通信,为各种移动应用提供普遍覆盖。然而,SAGINs的高度动态、开放和异构的性质带来了严重的安全问题。构建SAGINs的防御体系面临两个初步挑战:1)…...

【Mac 从 0 到 1 保姆级配置教程 12】- 安装配置万能的编辑器 VSCode 以及常用插件
文章目录 前言安装 VSCode基础配置常用插件1. 通用开发工具2. 编程语言支持3. 数据库工具4. 主题与界面美化5. 效率工具6. Markdown 工具7. 容器开发8. AI 辅助编程9. 团队协作 最后系列教程 Mac 从 0 到 1 保姆级配置教程目录,点击即可跳转对应文章: 【…...

数据库与SQL核心技术解析:从基础到JDBC编程实战
数据库技术作为现代信息系统的核心,贯穿于数据存储、查询优化、事务管理等关键环节。本文将系统讲解数据库基础知识、SQL语言核心操作、索引与事务机制,并结合Java数据库编程(JDBC)实践,助你构建完整的数据库技术体系。…...
)
JUC并发编程(上)
一、JUC学习准备 核心知识点:进程、线程、并发(共享模型、非共享模型)、并行 预备知识: 基于JDK8,对函数式编程、lambda有一定了解 采用了slf4j打印日志 采用了lombok简化java bean编写 二、进程与线程 进程和线程概念 两者对比…...

postgres--MVCC
PostgreSQL 的 MVCC(Multi-Version Concurrency Control,多版本并发控制) 是其实现高并发和高性能的核心机制,支持多个事务同时读写数据库而无需加锁阻塞。它的核心思想是通过保留数据的多个版本来避免读写冲突,从而提…...

nanodet配置文件分析
以下是针对 NanoDet-Plus-M-1.5x_416 配置文件的逐模块解析,以及调整参数的作用和影响范围: 1. 模型架构(model) Backbone(骨干网络) backbone:name: ShuffleNetV2model_size: 1.5x # 控制网络宽度&…...

【Linux网络】HTTP
应用层协议 HTTP 前置知识 我们上网的所有行为都是在做IO,(我的数据给别人,别人的数据给我)图片。视频,音频,文本等等,都是资源答复前需要先确认我要的资源在哪台服务器上(网络IP&…...
)
Unity中AssetBundle使用整理(一)
一、AssetBundle 概述 AssetBundle 是 Unity 用于存储和加载游戏资源(如模型、纹理、预制体、音频等)的一种文件格式。它允许开发者将游戏资源打包成独立的文件,在运行时动态加载,从而实现资源的按需加载、更新以及减小初始安装包…...

CMOS内存的地址空间在主内存空间中吗?
CMOS内存(即CMOS RAM)的地址空间不位于主内存地址空间(如0x00000-0xFFFFF)内,而是通过独立的I/O端口地址进行访问,具体如下: 1. CMOS内存的物理存储与地址机制 CMOS RAM芯片通常集成在主板…...

大模型应用中常说的Rerank是什么技术?
Rerank技术详解 一、定义与基本原理 Rerank(重排序)是一种在信息检索系统中用于优化搜索结果排序的技术,其核心目标是通过二次评估和排序候选文档,提升结果的相关性和准确性。其运作机制通常分为两阶段: 初步检索:使用传统方法(如BM25关键词匹配或Embedding向量检索)…...

Python-MCPInspector调试
Python-MCPInspector调试 使用FastMCP开发MCPServer,熟悉【McpServer编码过程】【MCPInspector调试方法】-> 可以这样理解:只编写一个McpServer,然后使用MCPInspector作为McpClient进行McpServer的调试 1-核心知识点 1-熟悉【McpServer编…...

C 语言数据结构基石:揭开数组名的面纱与计算数组大小
各类资料学习下载合集 https://pan.quark.cn/s/8c91ccb5a474 在前面的文章中,我们已经学习了 C 语言一维数组的定义和初始化。我们知道数组是用来存储一系列相同类型数据的集合,并通过下标来访问每个元素。但是,除了通过下标访问单个元素,数组名本身在 C 语言中也…...

Java高频面试之并发编程-15
hello啊,各位观众姥爷们!!!本baby今天又来报道了!哈哈哈哈哈嗝🐶 面试官:as-if-serial 是什么?单线程的程序一定是顺序执行的吗? as-if-serial 规则 定义: …...