Linux之进程概念
目录
一、冯诺依曼体系结构
二、操作系统(Operator System)
2.1、概念
2.2、设计OS的目的
2.3、系统调用和库函数概念
三、进程
3.1、基本概念
3.1.1、描述进程-PCB
3.1.2、task_struct
3.1.3、查看进程
3.1.4、通过系统调用获取进程标识符
3.1.5、两种杀掉进程的方式
3.1.6、理解cwd,exe
3.1.7、通过系统调用创建进程—fork
3.2、进程状态
3.2.1、操作系统的阻塞和挂起状态
3.2.2、Linux内核源代码
3.2.3、进程状态查看
3.2.4、Z(zombie)-僵⼫进程
3.2.5、僵尸进程的危害
3.2.6、孤儿进程
3.3、进程优先级
3.3.1、基本概念
3.3.2、查看进程优先级
3.3.3、PRI and NI
3.3.4、PRI vs NI
3.3.5、查看进程优先级的命令
3.3.6、竞争、独⽴、并⾏、并发
3.4、进程切换
3.4.1、优先级
3.4.2、活动队列
3.4.3、过期队列
3.4.4、active指针和expired指针
3.5.5、进程饥饿问题
3.4.6、总结
3.4.7、补充知识
四、环境变量
4.1、命令行参数
4.2、基本概念
4.3、常见环境变量
4.3.1、查看环境变量方法
4.4、和环境变量相关的命令
4.5、环境变量的组织方式
4.6、通过代码如何获取环境变量
4.7、通过系统调用获取或设置环境变量
4.8、环境变量的全局属性
五、程序地址空间
5.1、研究平台
5.2、程序地址空间回顾
5.3、进程地址空间
5.4、虚拟内存管理
5.5、为什么要有虚拟地址空间
一、冯诺依曼体系结构
我们常⻅的计算机,如笔记本。我们不常⻅的计算机,如服务器,⼤部分都遵守冯诺依曼体系。
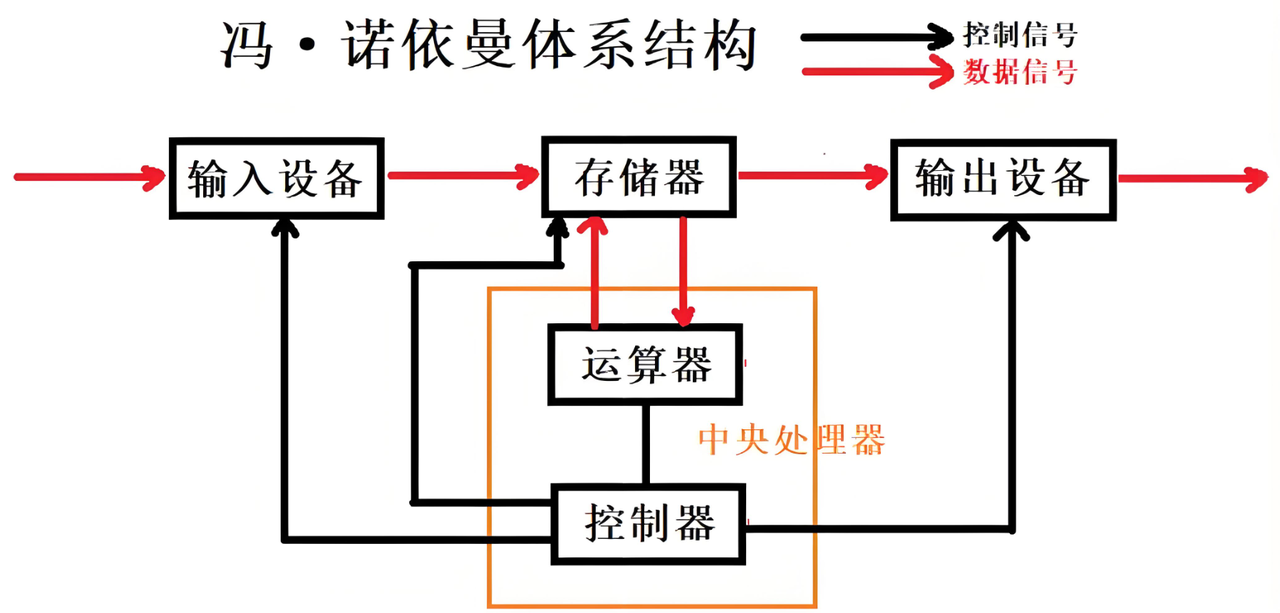
截⾄⽬前,我们所认识的计算机,都是由⼀个个的硬件组件组成。
- 输⼊单元:包括键盘,⿏标,扫描仪,写板等。
- 中央处理器(CPU):含有运算器和控制器等。
- 输出单元:显⽰器,打印机等。
关于冯诺依曼,必须强调⼏点:
- 这⾥的存储器指的是内存。
- 不考虑缓存情况,这⾥的CPU能且只能对内存进⾏读写,不能访问外设(输⼊或输出设备),这里的不能访问指的是数据层面,它不能直接从输入设备读数据,也不能直接向输出设备写入数据,这两个操作都需要内存作为中间媒介来完成。但是它可以直接向输入和输出设备发送控制信号。
- 外设(输⼊或输出设备)要输⼊或者输出数据,也只能写⼊内存或者从内存中读取。
- ⼀句话,所有设备都只能直接和内存打交道。
二、操作系统(Operator System)
2.1、概念
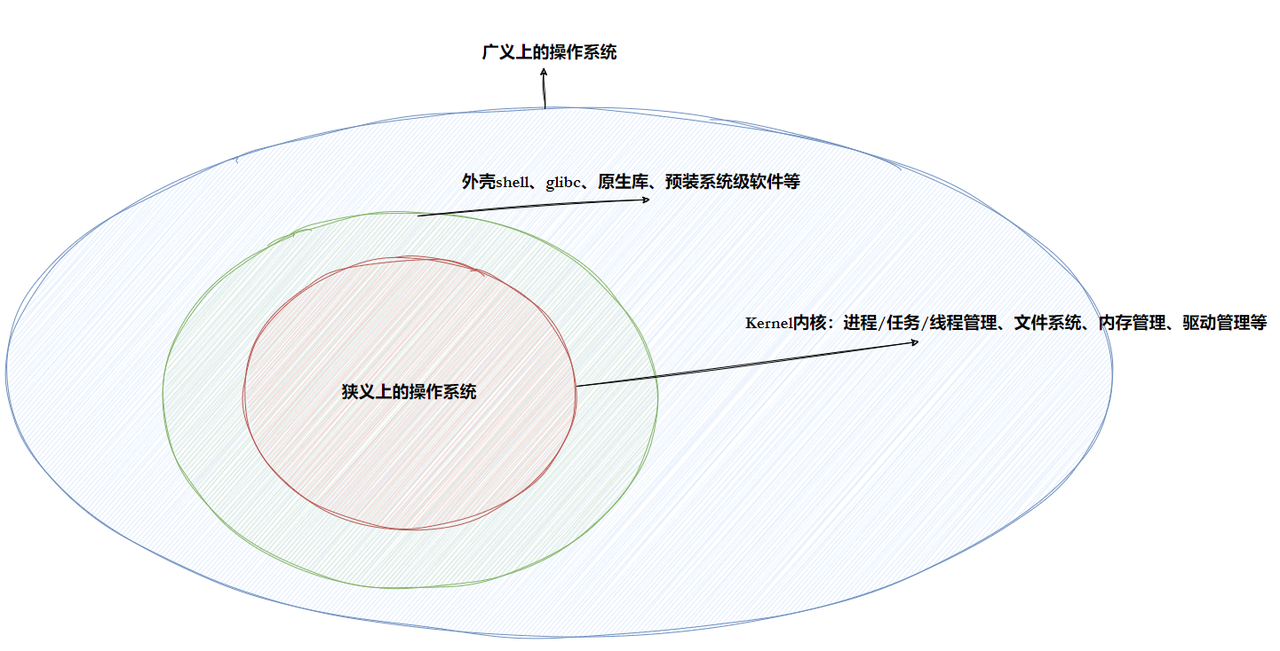
任何计算机系统都包含⼀个基本的程序集合,称为操作系统(OS)。笼统的理解,操作系统包括:
- 内核(进程管理,内存管理,⽂件管理,驱动管理)。
- 其他程序(例如函数库,shell程序等等)。
2.2、设计OS的目的
- 对下,与硬件交互,管理所有的软硬件资源。
- 对上,为用户程序(应⽤程序)提供⼀个良好的执⾏环境。
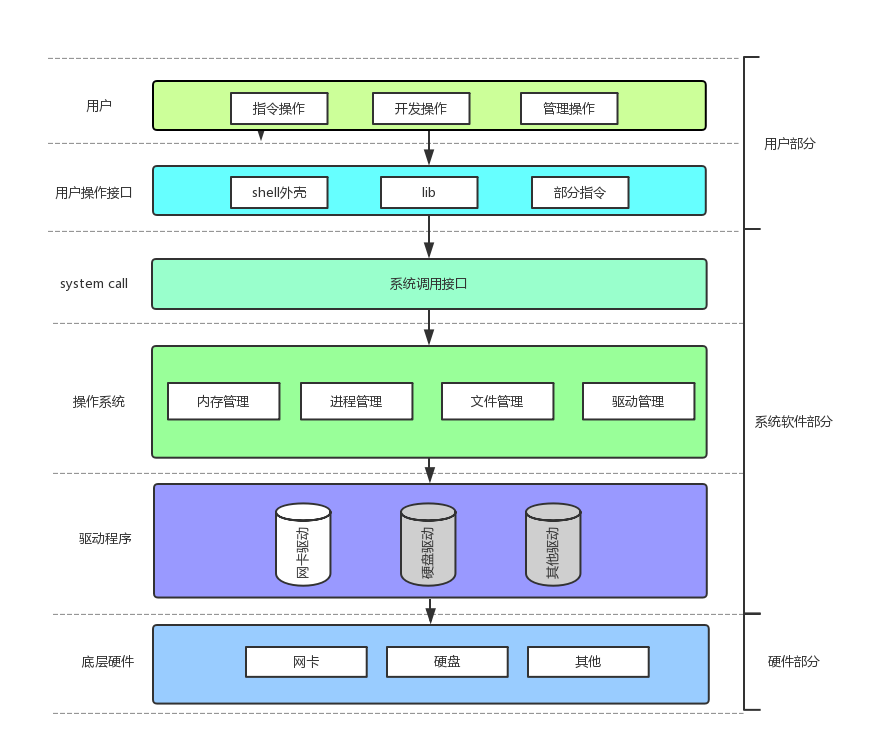
操作系统是如何管理硬件的呢?
首先,在操作系统中维护着一种结构体类型,该结构体中封装了所有硬件的相关信息。然后,将该结构体对象以链表的形式连接起来,这样对底层硬件的管理就变成了对链表的增删查改。这种管理方式叫做"先描述,在组织"。任何计算机对象,管理的思路都遵循该原则。
核心功能:在整个计算机软硬件架构中,操作系统的定位是:⼀款纯正的“搞管理”的软件。
2.3、系统调用和库函数概念
- 在开发⻆度,操作系统对外会表现为⼀个整体,但是会暴露⾃⼰的部分接⼝,供上层开发使⽤, 这部分由操作系统提供的接⼝,叫做系统调⽤。
- 系统调⽤在使⽤上,功能⽐较基础,对用户的要求相对也⽐较⾼,所以,有⼼的开发者可以对部分系统调⽤进⾏适度封装,从⽽形成库,有了库,就很有利于更上层用户或者开发者进⾏⼆次开发。
三、进程
3.1、基本概念
- 课本概念:程序的⼀个执⾏实例,正在执⾏的程序等。
- 内核观点:担当分配系统资源(CPU时间,内存)的实体。
- 进程管理方式—"先描述,在组织"。(进程的管理会被转化为对某种数据结构的管理)
- 进程 = 内核数据结构(进程控制块) + 程序的代码和数据。
3.1.1、描述进程-PCB
基本概念:
- 进程信息被放在⼀个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
- 课本上称之为PCB(process control block),Linux操作系统下的PCB是:task_struct。
task_struct—PCB的一种:
- 在Linux中描述进程的结构体叫做task_struct。
- task_struct是Linux内核的⼀种数据结构,它会被装载到RAM(内存)⾥并且包含着进程的信息。
3.1.2、task_struct
内容分类:
- 标⽰符: 描述本进程的唯⼀标⽰符,⽤来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执⾏的下⼀条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
- 上下⽂数据: 进程执⾏时处理器的寄存器中的数据。
- I/O状态信息: 包括显⽰的I/O请求,分配给进程的I/O设备和被进程使⽤的⽂件列表。
- 记账信息: 可能包括处理器时间总和,使⽤的时钟数总和,时间限制,记账号等。
- 其他信息.....。
标示符详解:当我们启动一个进程后,操作系统会为它生成一个唯一的编号用来标识它,这个唯一的编号就叫做PID。另外,同一个程序在不同的时间点启动,它的PID是会不同的。但在一次启动过程中,只要不退出,它的进程PID是不变的。
组织进程:
可以在内核源代码⾥找到它。所有运⾏在系统⾥的进程都以task_struct链表的形式存在内核⾥。
3.1.3、查看进程
1. 进程的信息可以通过 /proc 系统⽂件夹查看。
如:要获取PID为1的进程信息,你需要查看 /proc/1 这个⽂件夹。

解释:当我们启动一个进程的时候,系统会自动为我们创建一个以当前进程PID为名称的目录,且该目录在/proc目录下;当某一个进程结束后,系统会自动删除它在/proc目录下对应的文件夹。
2. ⼤多数进程信息同样可以使⽤top和ps这些用户级⼯具来获取。如下图:

解释:上图中我们通过 ps -axj 命令查询所有进程信息,命令中分号前面的作用是将查到的进程信息的头部部分,即属性名称筛选出来,方便查看每个值分别对应是什么,分号后面是将所有进程信息中和myproc相关的筛选出来,这里查到两个,但只有第一个是我们运行的myproc程序,第二个是我们在查找时使用了grep命令,而grep命令一旦运行就也变成了一个进程,又因为它查找含有myproc名称的进程信息,所以它的命令中含有myproc字段,所以查的时候就将自己进程的信息也过滤出来了。如果不想要grep进程的信息也可以,只需要在反向过滤一下就可以了。
如下图:

注意:一行中想执行多条指令可以使用分号隔开,也可以使用 && 符号。
3.1.4、通过系统调用获取进程标识符
- 进程id(PID)
- ⽗进程id(PPID)
系统调用:
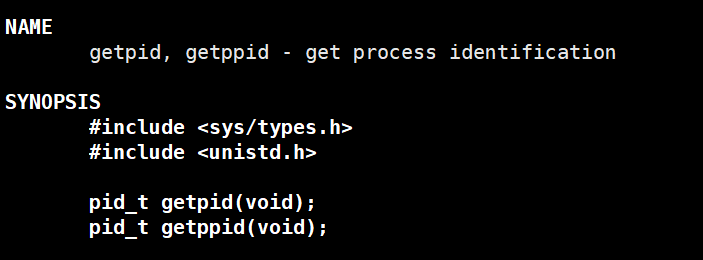
解释:在我们想要获取进程标识符(PID)的程序中调用该接口即可,该方法不需要传入参数,返回值类型是 pid_t 类型,使用时需要包含图中展示的头文件。
示例代码:
1 #include<stdio.h>2 #include<unistd.h>3 #include<sys/types.h>4 5 int main()6 {7 pid_t id = getpid();8 while(1)9 {10 printf("hello,bit, I am a process, pid:%d\n",id);11 sleep(1);12 }13 14 return 0;15 } 效果:

获取父进程PID同理,示例代码:
1 #include<stdio.h>2 #include<unistd.h>3 #include<sys/types.h>4 5 int main()6 {7 // chdir("/home/swb");8 9 // FILE* fp = fopen("log.txt","w");10 11 // if(fp == NULL)12 // {13 // perror("fopen fail:");14 // }15 16 pid_t id = getpid();17 pid_t ppid = getppid();18 while(1)19 {20 printf("hello,bit, I am a process, pid:%d,ppid:%d\n",id,ppid); 21 sleep(1);22 }23 24 return 0;25 }
效果:
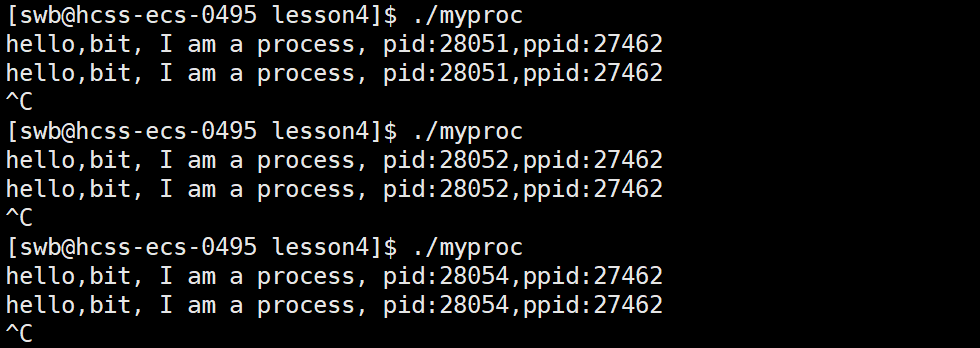
解释:首先,我们需要知道是在Linux系统中,新创建任何进程的时候,都是由该进程自己的父进程创建的。从上面代码运行效果可以看到,这个进程的父进程一直是同一个,那么它的父进程是谁呢?我们查一下这个父进程的PID看一下,如下图:

从上图我们可以看出,这个PID代表的进程是bash,即命令行解释器。由此,我们可以得到结论:命令行中,执行命令或者执行程序,本质是bash进程创建了一个子进程,再由子进程执行我们的代码。
3.1.5、两种杀掉进程的方式
1. Ctrl + c
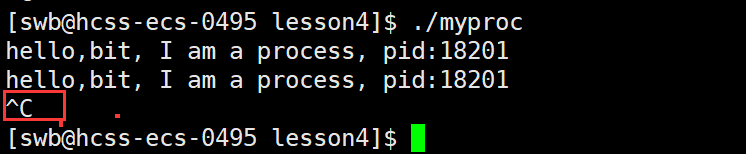
2. 指令:kill -9 进程PID

解释:上图开启了两个shell,以红色竖线作为分隔,我们可以看到当右边shell输入命令后,左侧进程终止。
3.1.6、理解cwd,exe
cwd (current work dir -> 即当前工作路径):指向进程的当前工作目录(即进程运行时所在的路径)。
当我们在代码中进行文件操作的时候,如果我们没有指定路径,而是只写了一个文件名,这时代码在执行的时候就会将cwd中存储的路径拼接到文件名中,作为该文件的路径。
示例代码:
1 #include<stdio.h>2 #include<unistd.h>3 #include<sys/types.h>4 5 int main()6 {7 FILE* fp = fopen("log.txt","w");8 9 pid_t id = getpid(); 10 while(1)11 {12 printf("hello,bit, I am a process, pid:%d\n",id);13 sleep(1);14 }15 16 return 0;17 }
效果:
启动进程前:

启动进程后:

我们可以看到,代码中我们没有指定打开文件的路径,所以这里自动以cwd作为默认路径了。
通过/proc的方法查看进程信息:

验证cwd的作用:
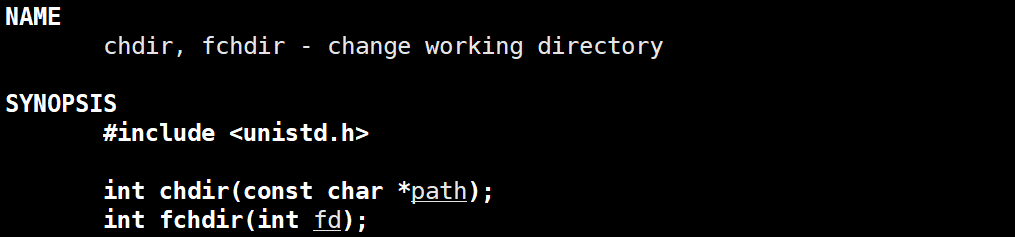
上面图片中的接口可以更改调用该接口的进程的cwd。
示例代码:
1 #include<stdio.h>2 #include<unistd.h>3 #include<sys/types.h>4 5 int main()6 {7 chdir("/home/swb");8 9 FILE* fp = fopen("log.txt","w");10 11 if(fp == NULL)12 {13 perror("fopen fail:");14 }15 16 pid_t id = getpid();17 while(1)18 {19 printf("hello,bit, I am a process, pid:%d\n",id);20 sleep(1);21 }22 23 return 0;24 } 效果:
启动进程前:

启动进程后:

从上面代码和结果中我们可以验证出:当我们进行文件操作时,如果不指定路径,cwd所表示的路径会被当做默认路径拼接上去。
通过/proc的方法查看进程信息:

exe:指向进程对应的可执行文件的路径。
3.1.7、通过系统调用创建进程—fork
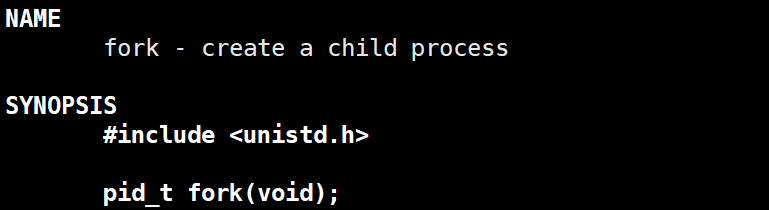
- fork有两个返回值。如果创建子进程成功,给父进程返回子进程PID,给子进程返回0。
- ⽗⼦进程代码共享,数据各⾃开辟空间,私有⼀份(采⽤写时拷⻉)。
- fork 之后通常要⽤ if 进⾏分流。
示例代码:
1 #include<stdio.h>2 #include<unistd.h>3 #include<sys/types.h>4 5 int main()6 {7 printf("I am a process,pid:%d,ppid:%d\n",getpid(),getppid());8 9 pid_t id = fork();10 (void)id;11 printf("I am a 分支,pid:%d,ppid:%d\n",getpid(),getppid());12 sleep(1);13 14 15 return 0;16 }
效果:

在Linux中,一个父进程可以有多个子进程,一个子进程只能有一个父进程,所以在Linux中进程也是树形结构。
验证fork的两个返回值:
1 #include<stdio.h>2 #include<unistd.h>3 #include<sys/types.h>4 5 int main()6 {7 printf("I am a process,pid:%d,ppid:%d\n",getpid(),getppid());8 9 pid_t id = fork();10 if(id > 0)11 {12 while(1)13 {14 printf("我是父进程,pid:%d,ppid:%d,ret id:%d\n",getpid(),getppid(),id);15 sleep(1);16 }17 }18 else if(id == 0)19 {20 while(1)21 {22 printf("我是子进程,pid:%d,ppid:%d,ret id:%d\n"getpid(),getppid(),id);23 sleep();24 }25 }2627 return 0;28 }效果:

首先,从上面图中可以看出,对于父进程确实返回的是子进程的PID,子进程返回的是0,为什么是这样返回呢?这是因为父进程与子进程是一对多的关系,父进程需要子进程的PID对子进程进行管理,而子进程只有一个父进程,所以返回0证明创建成功就可以了。其次,我们发现一段代码中,if 和 else if 都执行了,这是为什么呢?这是因为父进程的创建的时候,相应的代码和数据会从磁盘中被调到内存中,但是父进程创建子进程的时候,只为子进程创建了对应的PCB,但没有新的代码从磁盘中加载到内存了,所以父子进程是共享同一份代码的,对于父进程去执行这份代码,if 判断成立。对于子进程去执行这份代码,else if 判断成立。所以 if 和 else if 都执行了。
验证数据独立:
1 #include<stdio.h>2 #include<unistd.h>3 #include<sys/types.h>4 5 int gval = 0;6 7 int main()8 {9 printf("I am a process,pid:%d, ppid:%d\n",getpid(),getppid());10 11 pid_t id = fork();12 if(id > 0)13 {14 while(1)15 {16 printf("我是父进程,pid: %d, ppid: %d, ret id: %d, gval: %d\n",getpid(),getppid(),id,gval);17 sleep(1);18 }19 }20 else if(id == 0)21 {22 while(1)23 {24 printf("我是子进程,pid: %d, ppid: %d, ret id: %d, gval: %d\n",getpid(),getppid(),id,gval);25 gval++;26 sleep(1); 27 }28 }29 return 0;30 } 效果:
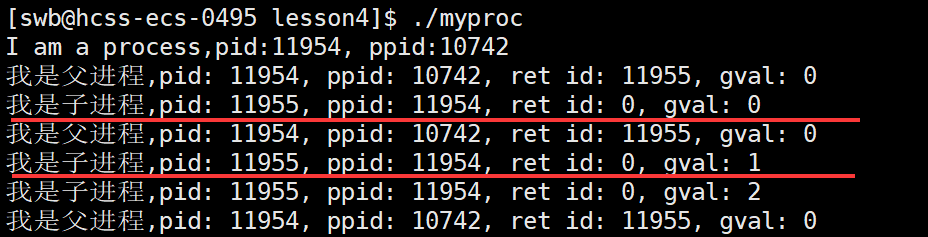
结论:进程具有很强的独立性,多个进程之间,运行时,互不影响,即便是父子。对于代码而言,它们是只读的,对于数据而言,它们各自私有一份。也正是因为数据各自私有,上面代码中,接受fork返回值的变量(id)只有一份,但父子进程使用起来却是不同的值。
进一步理解为什么fork会有两返回值:
首先,fork也是一个函数,它会将父进程的task_struct拷贝一份,并对部分属性进行修改作为子进程的task_struct,然后将子进程的task_struct链入进程列表中,此时,子进程在内核中就已经存在了,当执行到 return 语句时,说明该函数的主要功能已经全部完成,即父子进程已经运行了,所以 return 语句被父子进程各执行了一次,这也就是为什么一个函数会有两个返回值。
3.2、进程状态
3.2.1、操作系统的阻塞和挂起状态
阻塞状态:
当一个进程运行期间需要和外设打交道时,但此时外设上数据还没有准备就绪,这时该进程就会被挂载到对应外设的阻塞队列中,等待数据就绪(例如等待键盘输入),这个等待的过程就处于阻塞状态。所以阻塞的本质就是进程连入目标外部设备,CPU不对该进程进行调度。
挂起状态:
挂起状态需要在内存严重不足时才会产生。当内存不足时,某些等待外设数据就绪的进程(即处于阻塞状态的进程)可能会被操作系统将该进程的代码和数据换出到磁盘中,当数据就绪后,再将该进程的代码和数据换入。这种状态也叫做阻塞挂起状态。这种方式属于使用时间换空间,因为代码和数据换出和换入的过程本质是在和磁盘做IO操作,大量进行该操作是比较消耗时间的。(磁盘中有一个swap分区专门用来存储换出的代码和数据)
3.2.2、Linux内核源代码
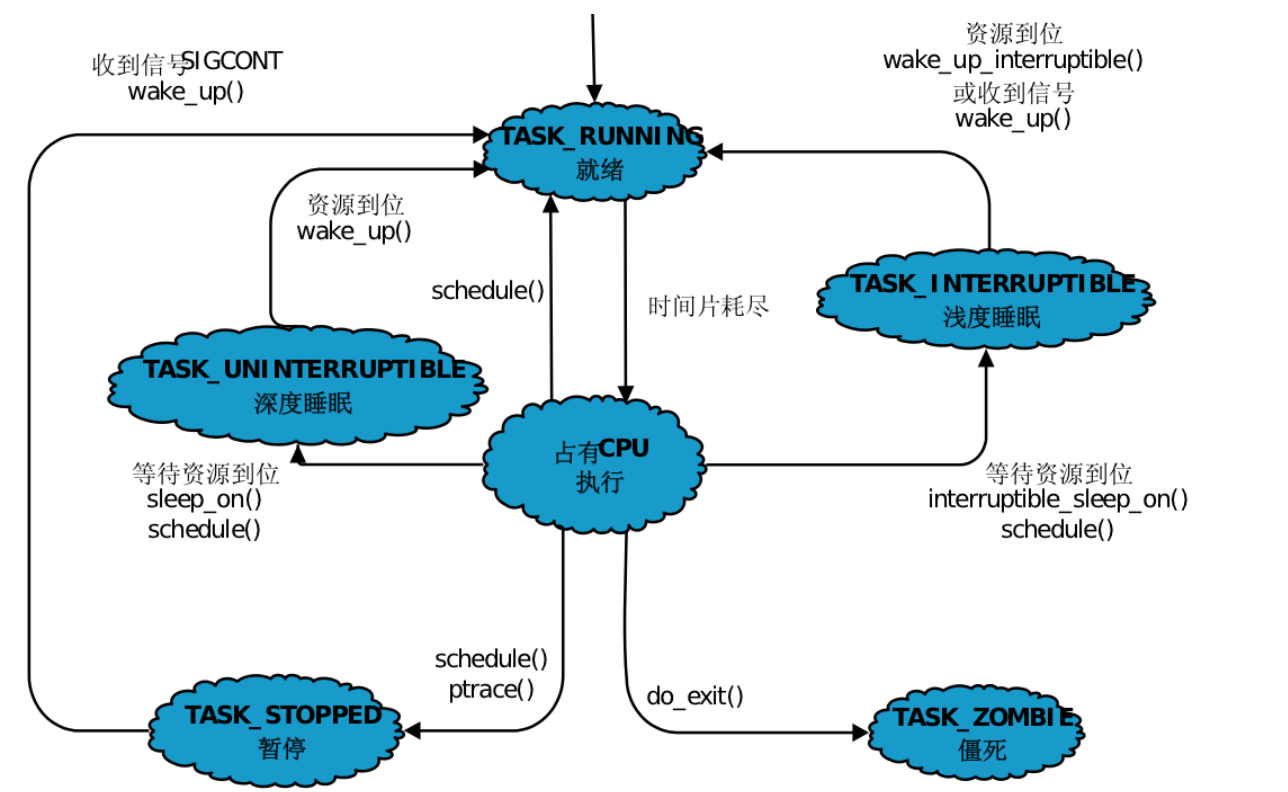
为了弄明⽩正在运⾏的进程是什么意思,我们需要知道进程的不同状态。⼀个进程可以有⼏个状 态(在Linux内核⾥,进程有时候也叫做任务)。
下⾯的状态在kernel源代码⾥定义:
/* *The task state array is a strange "bitmap" of *reasons to sleep. Thus "running" is zero, and *you can test for combinations of others with *simple bit tests. */
static const char *const task_state_array[] = {
"R (running)", /*0 */
"S (sleeping)", /*1 */
"D (disk sleep)", /*2 */
"T (stopped)", /*4 */
"t (tracing stop)", /*8 */
"X (dead)", /*16 */
"Z (zombie)", /*32 */
};
- R运⾏状态(running):并不意味着进程⼀定在运⾏中,它表明进程要么是在运⾏中要么在运⾏队列⾥。
- S睡眠状态(sleeping):意味着进程在等待事件完成,如等待IO操作(如键盘输入)。S状态是阻塞等待状态的一种。(这⾥的睡眠有时候也叫做可中断睡眠 (interruptible sleep),可中断睡眠是指在S状态时可以通过某种方式 ( 如 kill 命令 ) 杀掉该进程)。
- D磁盘休眠状态(Disk sleep),即因等待磁盘级IO操作而处于阻塞等待的状态,有时候也叫不可中断睡眠状态(uninterruptible sleep),在这个状态的进程通常会等待IO的结束,这里的不可中断睡眠是指不可以被操作系统以任何形式杀掉该进程,D状态也是阻塞等待状态的一种。
- T停⽌状态(stopped):可以通过发送 SIGSTOP 信号(kill -19)给进程来停⽌(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号(kill -18)让进程继续运⾏。当一个进程做了非法但不致命的错误,就会被操作系统暂停。
- t追踪停止状态(tracing stop):当一个进程处于被追踪/调试的时候,因为断点而停下,此时进程状态就是t。
- X死亡状态(dead):这个状态只是⼀个返回状态,你不会在任务列表⾥看到这个状态。我们可以通过echo $? 命令来打印最近一个进程退出时的退出信息。
3.2.3、进程状态查看
ps aux / ps axj 命令
- a:显⽰⼀个终端所有的进程,包括其他用户的进程。
- x:显⽰没有控制终端的进程,例如后台运⾏的守护进程。
- j:显⽰进程归属的进程组ID、会话ID、⽗进程ID,以及与作业控制相关的信息。
- u:以用户为中⼼的格式显⽰进程信息,提供进程的详细信息,如用户、CPU和内存使⽤情况等。
3.2.4、Z(zombie)-僵⼫进程
- 僵死状态(Zombies)是⼀个⽐较特殊的状态。当进程退出并且⽗进程(使⽤wait()系统调⽤)没有读取到⼦进程退出的返回代码时就会产⽣僵死(⼫)进程。
- 僵死进程会以终⽌状态保持在进程表中,并且会⼀直在等待⽗进程读取退出状态代码。
- 所以,只要⼦进程退出,⽗进程还在运⾏,但⽗进程没有读取⼦进程状态,⼦进程进⼊Z状态。
如下是⼀个僵尸进程例⼦:
#include <stdio.h>
#include <unistd.h>int main()
{printf("父进程运行: pid: %d, ppid:%d\n", getpid(), getppid());pid_t id = fork();if(id == 0){// 子进程int cnt = 10;while(cnt > 0){printf("我是子进程,我的pid: %d, ppid: %d, cnt: %d\n", getpid(), getppid(), cnt);sleep(1);cnt--;}}else{// 父进程while(1){printf("我是父进程,我的pid: %d, ppid: %d\n", getpid(), getppid());sleep(1);}}return 0;
}
结果:

从上图可以看到,当我们的父进程没有回收子进程的退出信息时,子进程会一直处于Z状态。
3.2.5、僵尸进程的危害
- 进程的退出状态必须被维持下去,因为他要告诉关⼼它的进程(⽗进程),你交给我的任务,我 办的怎么样了。可⽗进程如果⼀直不读取,那⼦进程就⼀直处于Z状态? 是的!
- 维护退出状态本⾝就是要⽤数据维护,也属于进程基本信息,所以保存在task_struct(PCB)中, 换句话说,Z状态⼀直不退出,PCB⼀直都要维护? 是的!
- 那⼀个⽗进程创建了很多⼦进程,就是不回收,是不是就会造成内存资源的浪费? 是的! 因为数据结构对象本⾝就要占⽤内存,想想C中定义⼀个结构体变量(对象),是要在内存的某个位置进⾏开辟空间!
- 会造成内存泄漏? 是的!
3.2.6、孤儿进程
⽗进程如果提前退出,那么⼦进程后退出,进⼊Z之后,那该如何处理呢?
- ⽗进程先退出,⼦进程就称之为“孤⼉进程”
- 孤⼉进程会被1号initd(系统)进程领养,当然也就会由initd进程回收。
3.3、进程优先级
3.3.1、基本概念
- cpu资源分配的先后顺序,就是指进程的优先权(priority)。
- 优先权⾼的进程有优先执⾏权利。配置进程优先权对多任务环境的linux很有⽤,可以改善系统性能。
- 还可以把进程运⾏到指定的CPU上,这样⼀来,把不重要的进程安排到某个CPU,可以⼤改善系统整体性能。
3.3.2、查看进程优先级
在linux或者unix系统中,⽤ps ‒l命令则会类似输出以下⼏个内容:(还可以通过加-a选项显示所有进程)

我们很容易注意到其中的⼏个重要信息,有下:
- UID:代表执⾏者的⾝份。
- PID:代表这个进程的代号。
- PPID:代表这个进程是由哪个进程发展衍⽣⽽来的,亦即⽗进程的代号。
- PRI:代表这个进程可被执⾏的优先级,其值越⼩越早被执⾏。
- NI:代表这个进程的nice值。
3.3.3、PRI and NI
- PRI也还是⽐较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执⾏的先后顺序,此值越⼩进程的优先级别越⾼。
- 那NI呢?就是我们所要说的nice值了,其表⽰进程可被执⾏的优先级的修正数值。
- PRI值越⼩越快被执⾏,那么加⼊nice值后,将会使得PRI变为:PRI(new)=PRI(80)+nice。这里每次修改优先级时,新的优先级都等于默认的优先级数值(80)+ nice值。和上次的PRI值无关。
- 这样,当nice值为负值的时候,那么该程序将会优先级值将变⼩,即其优先级会变⾼,则其越快被执⾏。
- 所以,调整进程优先级,在Linux下,就是调整进程nice值。
- nice其取值范围是-20⾄19,⼀共40个级别。
3.3.4、PRI vs NI
- 进程的nice值不是进程的优先级,他们不是⼀个概念,但是进程nice值会影响到进程的优先级变化。
- 可以理解nice值是进程优先级的修正修正数据。
3.3.5、查看进程优先级的命令
⽤top命令更改已存在进程的nice:
- top
- 进⼊top后按“r”‒>输⼊进程PID‒>输⼊nice值
注意:
- 其他调整优先级的命令:nice,renice。还有一些系统函数也可以。
- OS不允许我们频繁修改优先级,如果我们频繁进行修改可能前几次成功,后面就会失败。
3.3.6、竞争、独⽴、并⾏、并发
- 竞争性:系统进程数⽬众多,⽽CPU资源只有少量,甚⾄1个,所以进程之间是具有竞争属性的。为了⾼效完成任务,更合理竞争相关资源,便具有了优先级
- 独⽴性:多进程运⾏,需要独享各种资源,多进程运⾏期间互不⼲扰。
- 并⾏:多个进程在多个CPU下分别,同时进⾏运⾏,这称之为并⾏。
- 并发:多个进程在⼀个CPU下采⽤进程切换的⽅式,在⼀段时间之内,让多个进程都得以推进,称之为并发。
3.4、进程切换
CPU上下⽂切换:其实际含义是任务切换,或者CPU寄存器切换。当多任务内核决定运⾏另外的任务时,它保存正在运⾏任务的当前状态,也就是CPU寄存器中的全部内容。这些内容被保存在任务⾃⼰的堆栈中,⼊栈⼯作完成后就把下⼀个将要运⾏的任务的当前状况从该任务的栈中重新装⼊CPU寄存器, 并开始下⼀个任务的运⾏,这⼀过程就是context switch。
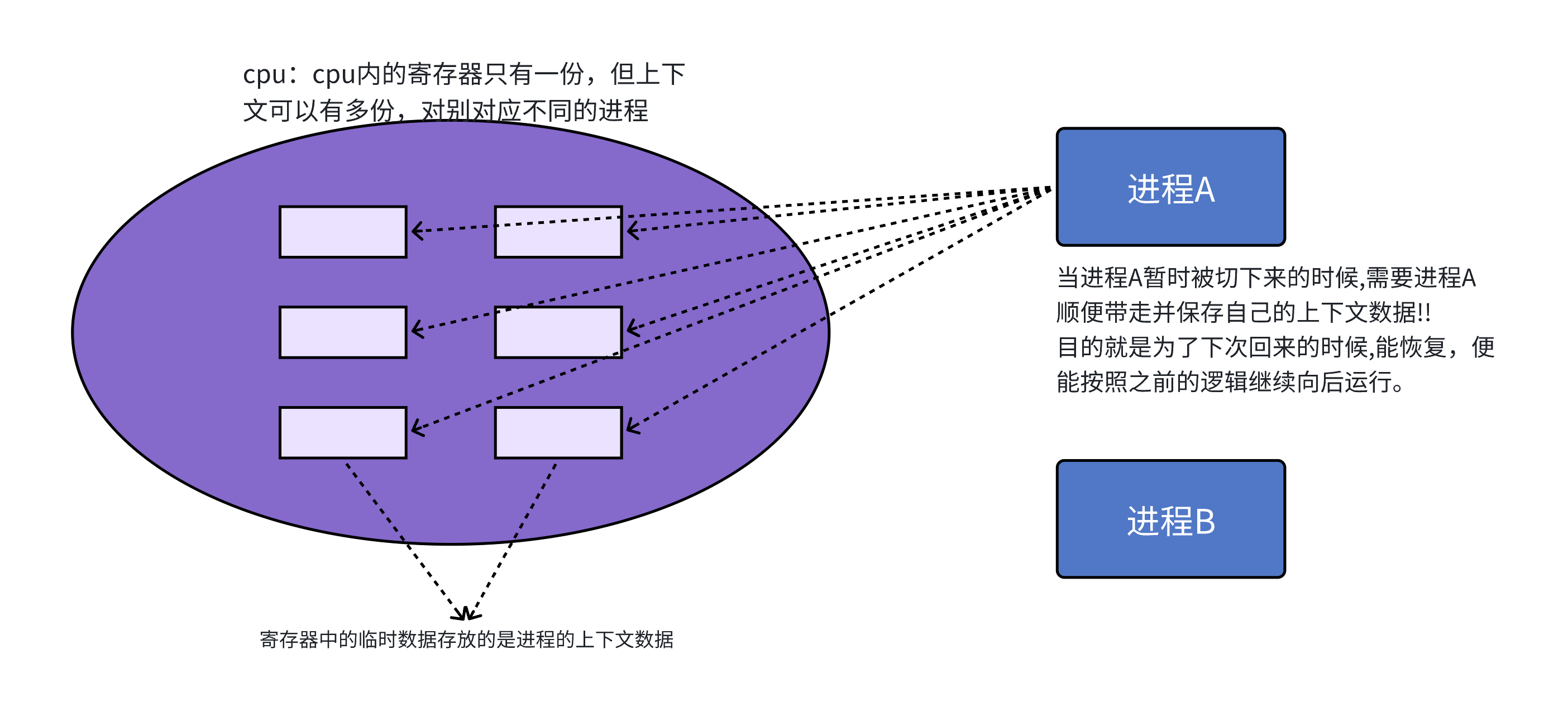
参考⼀下Linux内核0.11代码:

注意:
时间⽚:当代计算机都是分时操作系统,每个进程都有它合适的时间⽚(其实就是⼀个计数 器)。时间⽚到达,进程就被操作系统从CPU中剥离下来。
Linux2.6内核进程O(1)调度队列:
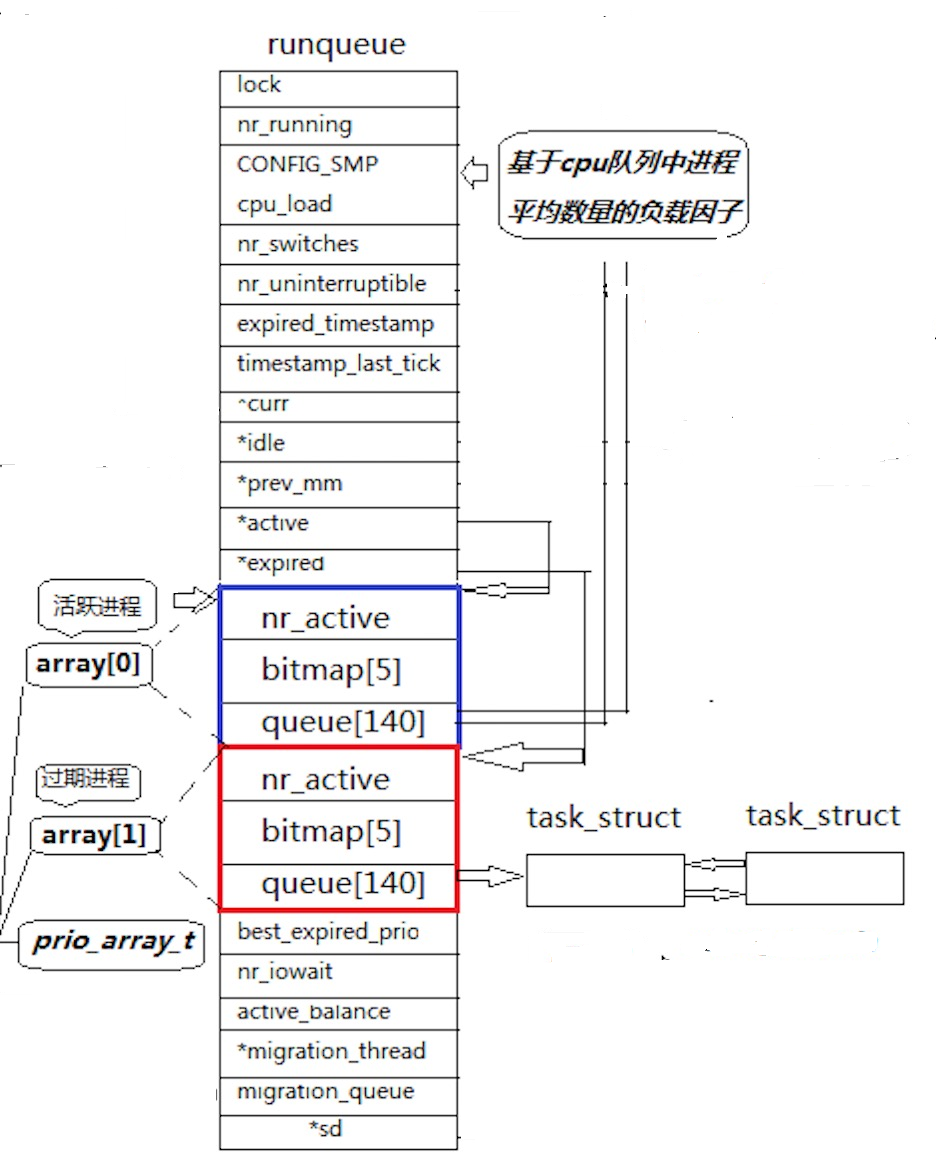
上图是Linux2.6内核中进程队列的数据结构,之间关系也已经给⼤家画出来,⽅便⼤家理解。
注意:⼀个CPU只拥有⼀个runqueue,如果有多个CPU就要考虑进程个数的负载均衡问题。
3.4.1、优先级
- 普通优先级:100〜139(我们都是普通的优先级,想想nice值的取值范围,可与之对应!)
- 实时优先级:0〜99(不关⼼)
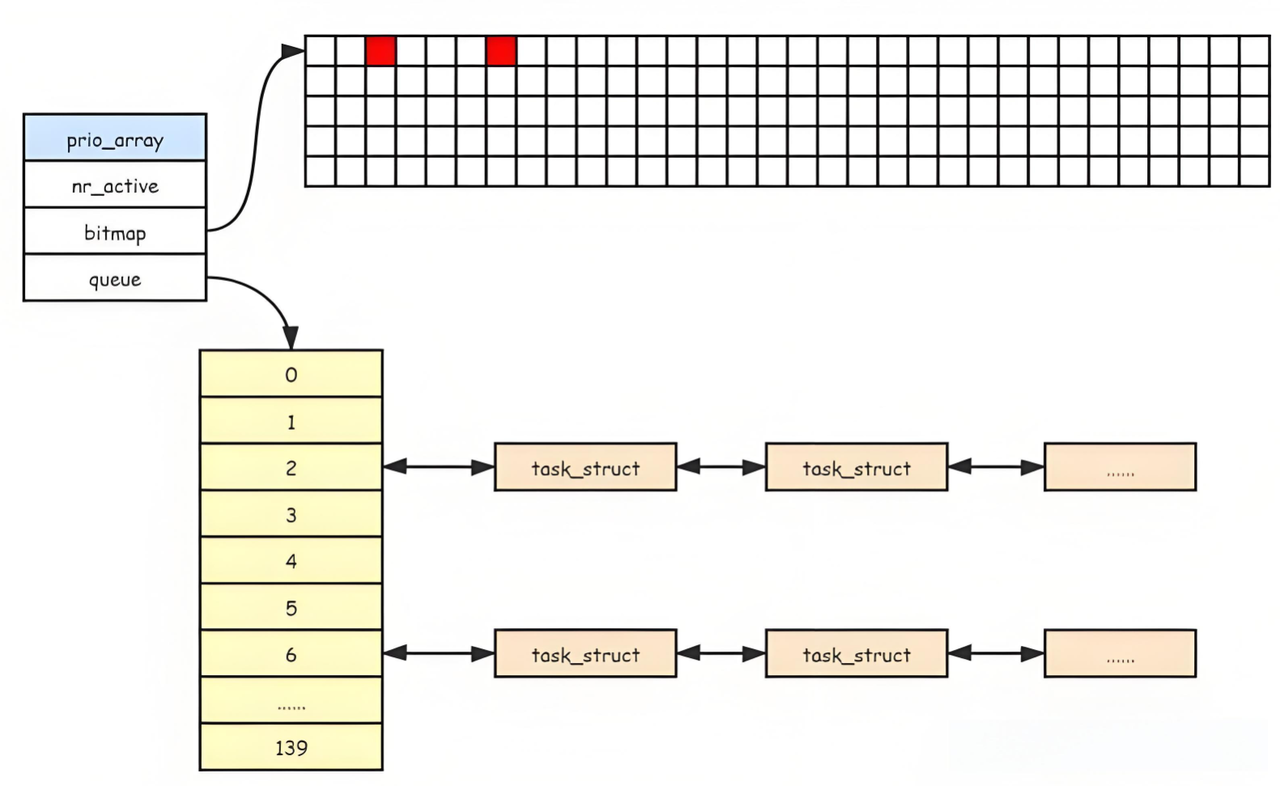
3.4.2、活动队列
- 时间⽚还没有结束的所有进程都按照优先级放在该队列。
- nr_active:表示总共有多少个运⾏状态的进程。当它为0时,就会交换active和expired指针。
- queue[140]:⼀个元素就是⼀个进程队列,相同优先级的进程按照FIFO规则进⾏排队调度,所以, 数组下标就是优先级!(其实就是一个哈希桶)
- 从该结构中,选择⼀个最合适的进程,过程是怎么的呢?
- 1.从0下表开始遍历queue[140]。
- 2.找到第⼀个⾮空队列,该队列必定为优先级最⾼的队列。
- 3.拿到选中队列的第⼀个进程,开始运⾏,调度完成!
- 4.遍历queue[140]时间复杂度是常数!但还是太低效了!
- bitmap[5]:bitmap数组是一个整型数组,它可以解决遍历queue数组效率低的问题。它本质其实就是一个位图,⼀共140个优先级,⼀共140个进程队列,为了提⾼查找⾮空队列的效率,就可以⽤ 5*32(160)个⽐特位表⽰队列是否为空,160个比特位刚好可以覆盖140个进程队列,这样,便可以很⼤提⾼查找效率!
bitmap查找示例代码:
for(int i = 0; i < 5; i++)
{if(bitmap[i] == 0) continue;//一次就可以检测32个位置else{//找32个比特位中不为0的那一个}
}解释:使用该位图查找,我们可以先依次遍历数组中五个整形变量,找第一个不为0的,如果为0,这个整型变量代表的32个比特位都不用检测了,这样就可以达到一次检测32个比特位的效果,找到第一个不为0的后,最多只需要遍历32次就可以找到哪个是第一个不为0的位置。5和32都是常数,这样就将算法优化到了O(1)的级别。
3.4.3、过期队列
- 过期队列和活动队列结构⼀模⼀样。
- 过期队列上放置的进程,是时间⽚耗尽的进程和新产生的进程。
- 当活动队列上的进程都被处理完毕之后,对过期队列的进程进⾏时间⽚重新计算。
3.4.4、active指针和expired指针
- active指针永远指向活动队列。
- expired指针永远指向过期队列。
- 可是活动队列上的进程会越来越少,过期队列上的进程会越来越多,因为进程时间⽚到期时⼀直都存在的。
- 不过没关系,在合适的时候,只要能够交换active指针和expired指针的内容,就相当于有具有了⼀批新的活动进程!
3.5.5、进程饥饿问题
首先,调度器在调度进程时要保证均衡地进行调度,其次还要考虑优先级的问题,这时就会带来一个问题,如果不断有新的进程产生,且优先级都很高,这时如果将这些新的进程插入active指向的活动队列,这些进程一定会插入在前面,执行时也会优先执行,那么如果一直插入这些优先级高的进程就会导致优先级低的进程始终得不到调度,所以对于新产生的进程会被放到expired指向的过期队列,另外,时间片用完的进程如果放回active指向的队列,那么下次调度还会执行它,这是因为每次调度都会从优先级高向低调度,那么又会导致优先级低的始终得不到调度,所以时间片用完的进程也会被放到expired指向的过期队列。这样active队列永远是一个存量进程竞争的情况,即active队列中进程只会越来越少,不会增多。当active队列所有进程都调度完了,就交换active指针和expired指针,继续调度,这样就可以在保证优先级的情况下,进行均衡调度了。
3.4.6、总结
在系统当中查找⼀个最合适调度的进程的时间复杂度是⼀个常数,不随着进程增多⽽导致时间成 本增加,我们称之为进程调度O(1)算法!
3.4.7、补充知识
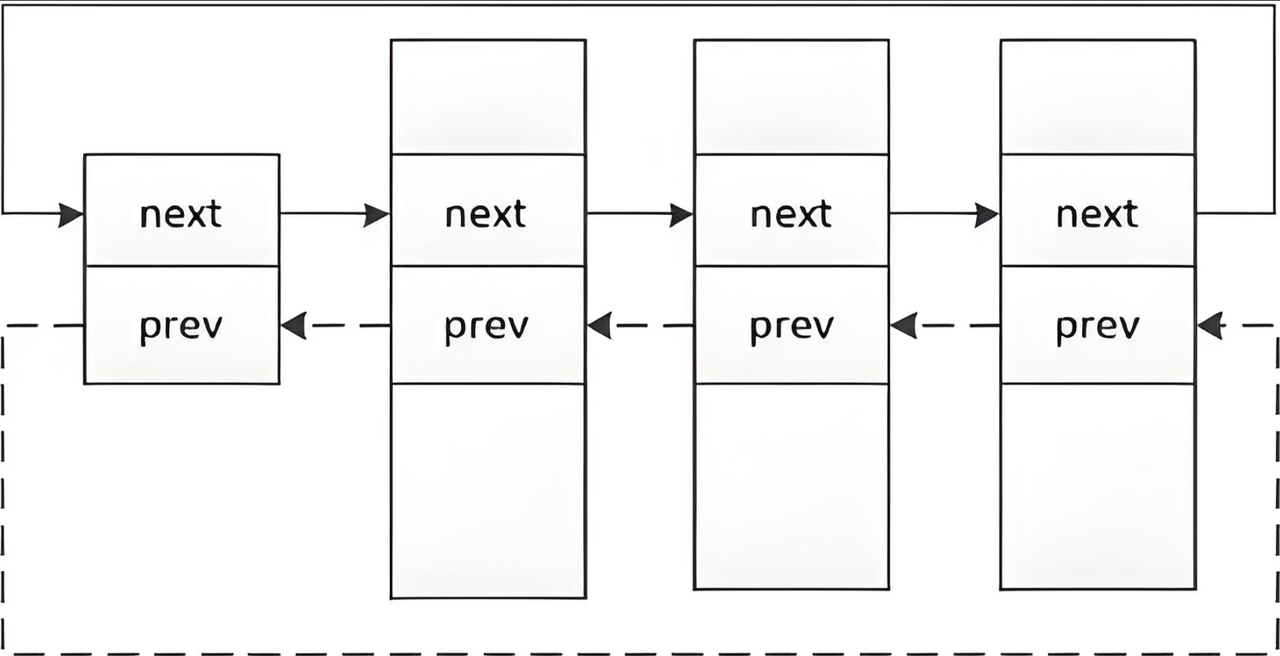
所有进程都要以链表形式连接起来。那么在Linux系统中,它是如何链接的呢?
首先,PCB是以双链表的形式连接起来的,但是,它和我们数据结构里面那种双链表不同,数据结构中学的双链表是一个节点中既有数据域也有指针域。如图:

但在Linux进程这里,它是单独创建了一个结构体类型,该结构体中没有属性字段,只有连接字段。然后在task_struct中封装这种结构体对象,通过这种结构体的相互链接来完成task_struct的连接。如图:
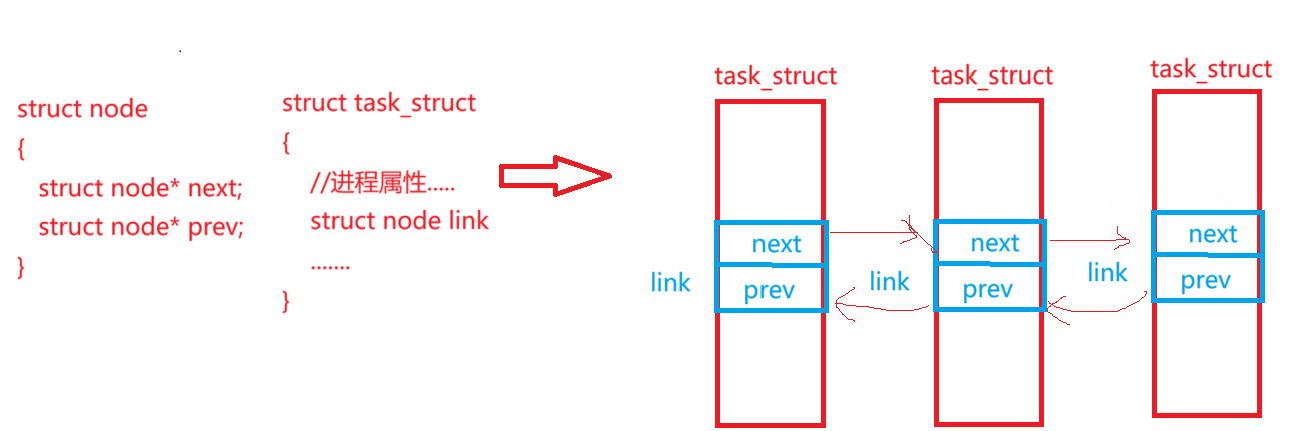
这样做的意义:

原理:通过这种方式连接,我们该如何访问进程的其他属性呢。首先我们要知道,在一个结构体变量中,它的地址分配是从低到高分配的,如下图:
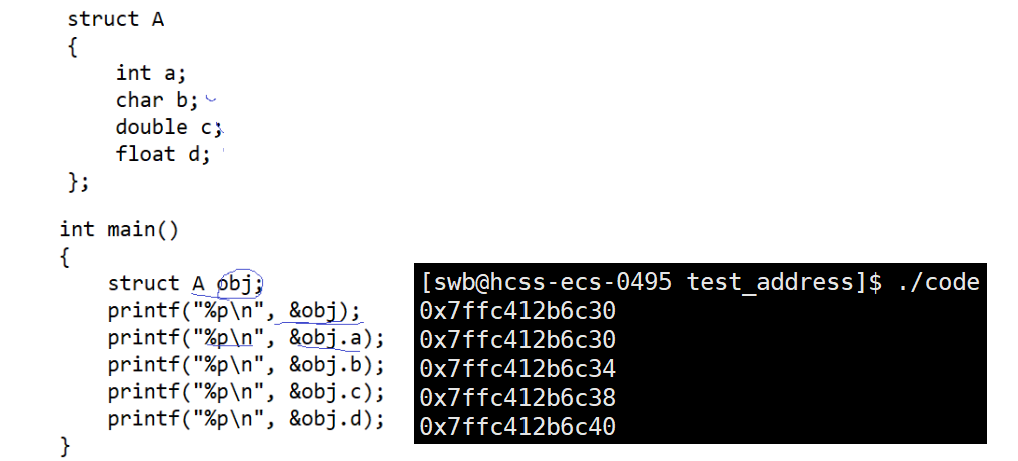
在知道这个后,如果我们只知道变量 c 的地址,如何访问其他变量呢?首先我们需要假设在零地址处有一个当前结构体类型的对象,然后我们访问它的 c 变量,取出 c 变量的地址,因为该结构体起始地址是零,且结构体中的成员是从低到高分配地址的,所以对于这个假设的结构体对象,c 的地址就是 c 相对于结构体起始位置的偏移量。如下图:
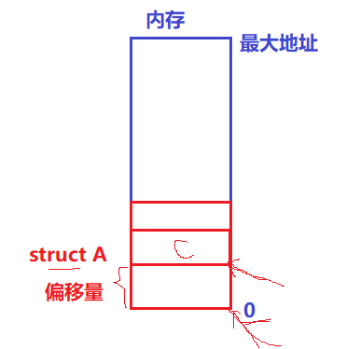
接下来我们想访问其他成员就只需要将我们实际知道的 c 的地址减去相对于起始位置的偏移量,进而得到该结构体对象的起始地址,然后对起始地址做强制类型转换就可以访问所有成员了。如下图:

对于进程这里同理,我们也是使用这个方法就可以通过只有连接字段的结构体中存储的地址对整个进程相关信息进行访问了。
注意:零地址处的这个结构体变量并不存在,它只是我们假设的,用来获取 c 变量相对于结构体对象起始位置的偏移量,只有知道偏移量,我们才能通过 c变量算出整个结构体对象的起始位置。 这样在通过强制类型转换就可以访问其他成员了。
四、环境变量
4.1、命令行参数
示例代码:
1 #include<stdio.h>2 3 int main(int argc, char* argv[])4 {5 printf("argc: %d\n",argc);6 7 for(int i = 0; i < argc; i++)8 {9 printf("argv[%d]: %s\n", i, argv[i]);10 }11 12 return 0;13 } 效果:
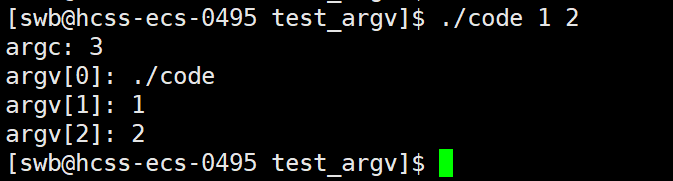
解释:上面代码中,main函数的参数叫做命令行参数列表,其中,argc是参数的个数,argv[]是参数的清单。命令行参数列表的作用就是使同一个程序,能够根据命令行参数的不同,表现出不同的功能,比如:指令中选项的实现。
4.2、基本概念
- 环境变量(environment variables)⼀般是指在操作系统中⽤来指定操作系统运⾏环境的⼀些参数。
- 如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪 ⾥,但是照样可以链接成功,⽣成可执⾏程序,原因就是有相关环境变量帮助编译器进⾏查找。
- 环境变量通常具有某些特殊⽤途,还有在系统当中通常具有全局特性。
4.3、常见环境变量
- PATH:指定命令的搜索路径。
- HOME:指定用户的主⼯作⽬录(即用户登陆到Linux系统中时,默认的⽬录)。
- SHELL:当前Shell,它的值通常是/bin/bash。
- PWD:保存当前进程工作路径。
- USER:表明当前正在使用系统的用户是谁。
为什么系统知道命令在/user/bin路径下?这是因为PATH环境变量,它告诉了shell应该去哪个路径下查找。我们可以通过echo $PATH 命令来查看PATH的内容。如图:

从上图可以看出,PATH是一个以冒号为分隔的路径集合,当我们执行命令时,就会依次从这些路径中查找,如果我们执行自己写的程序时不想带路径,有两种方法:
1. 将我们的程序拷贝到这些路径的某一个中(一般是/user/bin)。
2. 将我们自己程序的路径添加到PATH中。
添加方法如下:

我们现在查看和修改的这个PATH其实是内存级别的,只要退出当前登录后再重新登录,shell就会重新加载一个环境变量。我们之前对它做过的修改就会消失。
那么,PATH最开始的内容是从哪里来的呢?其实,环境变量开始都是在系统的配置文件中的,当我们登录时,会启动一个shell程序,shell程序会读取用户和系统相关的环境变量的配置文件,形成自己的环境变量表。然后shell进程和它所创建的子进程都是可以看见这个环境变量表的。
4.3.1、查看环境变量方法
echo $NAME //NAME:你的环境变量名称

4.4、和环境变量相关的命令
- echo:显⽰某个环境变量值。
- export:设置⼀个新的环境变量。
- env:显⽰所有环境变量。
- unset:清除环境变量。
- set:显⽰本地定义的shell变量和环境变量。
在shell中,除了有环境变量还有本地变量,我们可以直接 "变量名=值" 的形式定义本地变量,如下:
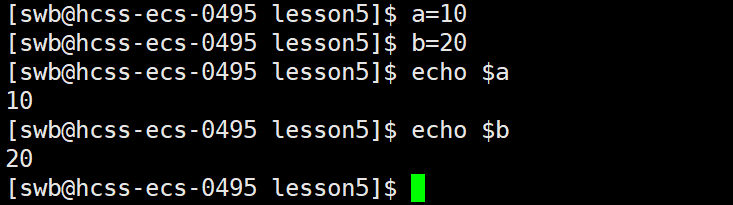
我们定义好的本地变量会被放到一个存储本地变量的表中,它也是内存级别的,我们可以通过set命令来查看我们定义的所有本地变量和环境变量,如图。
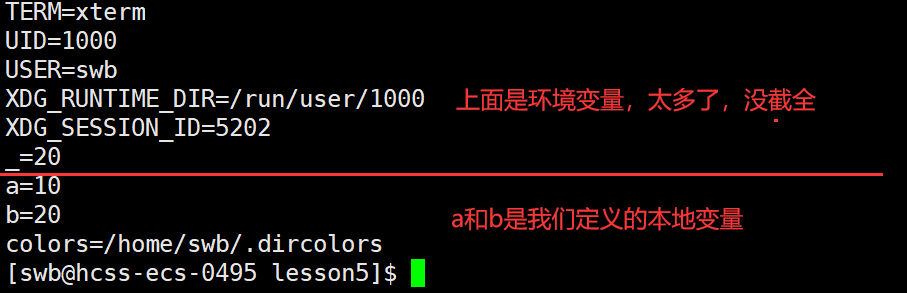
这时我们访问环境变量的表是没有本地变量的,如果我们想将本地变量放到环境变量中,需要使用export来将本地变量导入环境变量中,如图:
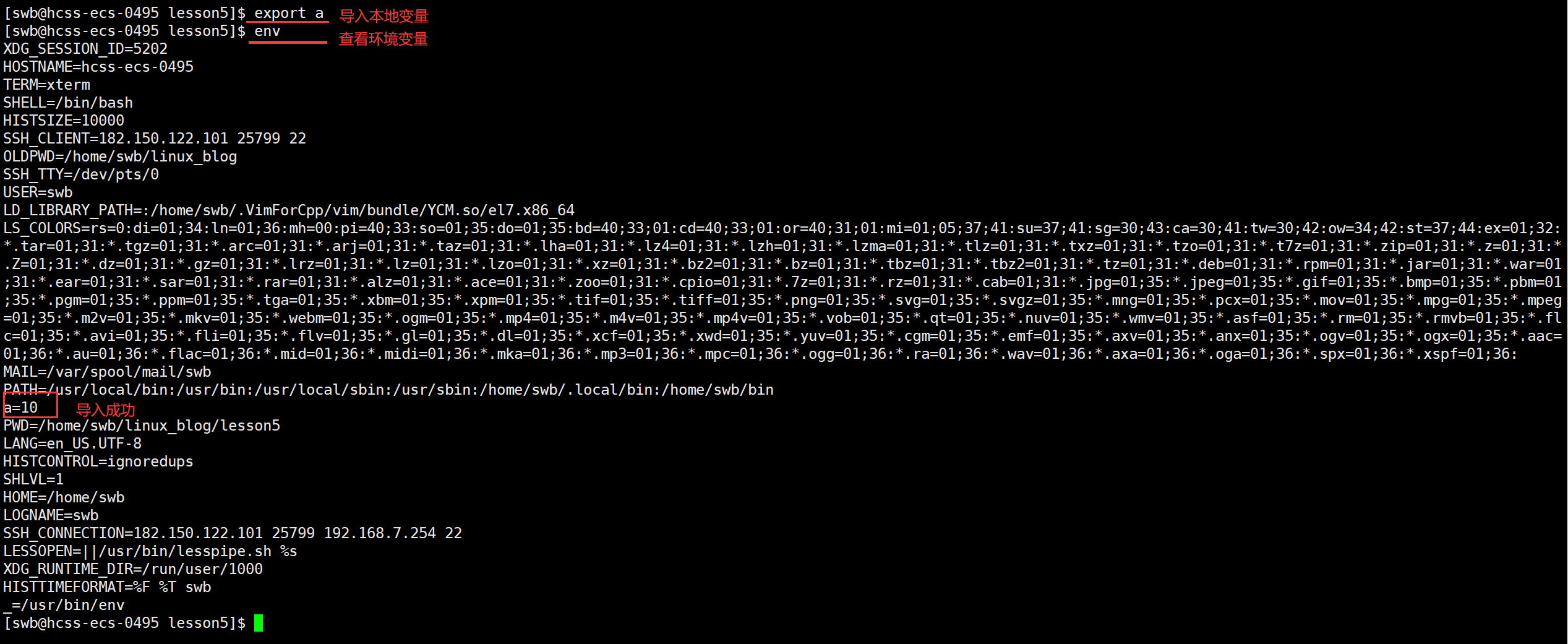
当我们不需要时可以通过unset命令来清楚本地变量,直接 "unset+本地变量名" 就可以。
注意:环境变量可以被子进程继承下去,而本地变量不能!
4.5、环境变量的组织方式
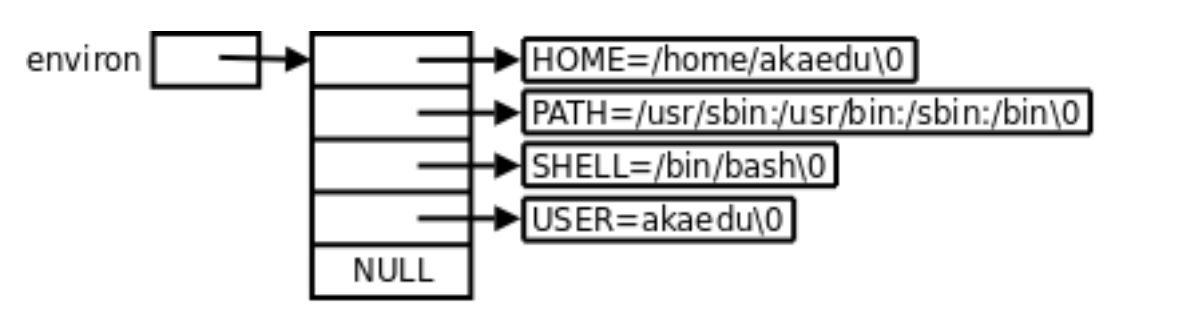
每个程序都会收到⼀张环境表,环境表是⼀个字符指针数组,每个指针指向⼀个以’\0’结尾的环境 字符串。
4.6、通过代码如何获取环境变量
- 命令⾏第三个参数
其实在main函数中,不止有argc和argv两个形参,还有第三个形参,即环境变量,代码:
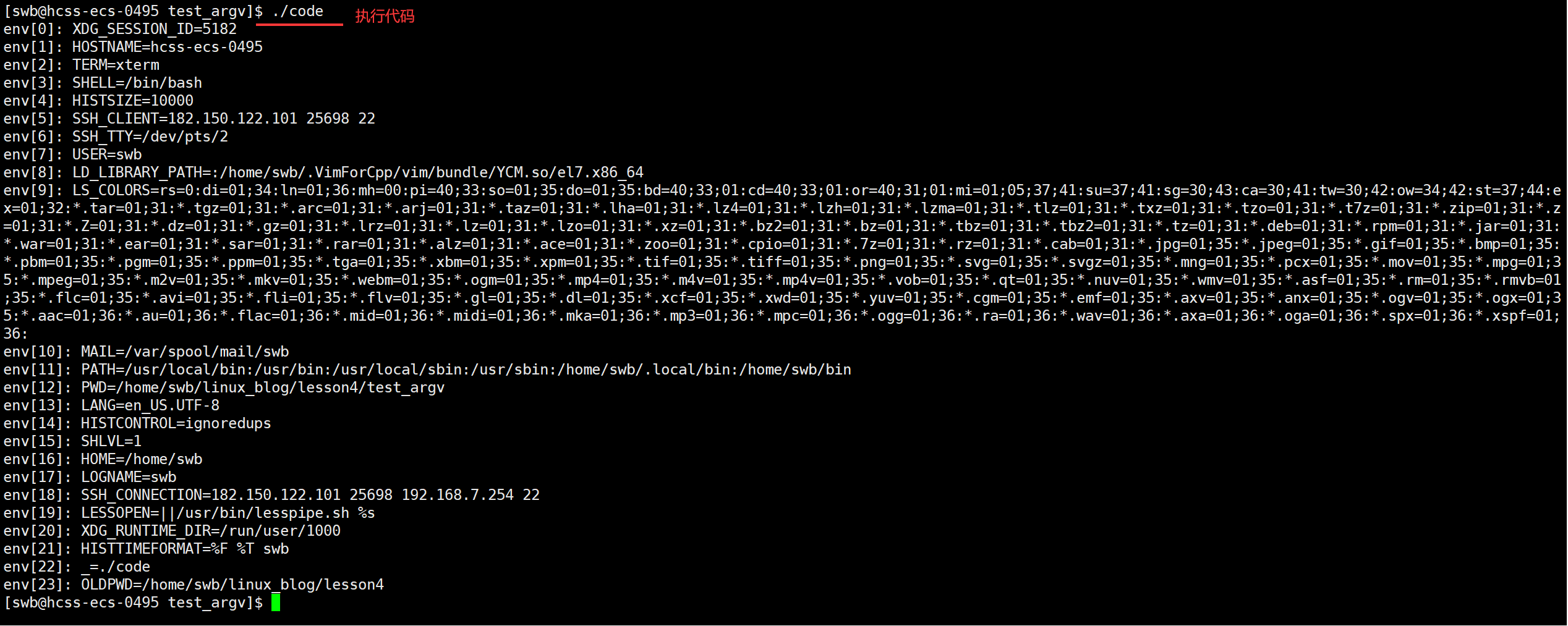
1 #include<stdio.h>2 3 int main(int argc, char* argv[], char* env[])4 {5 6 for(int i = 0; env[i]; i++)7 {8 printf("env[%d]: %s\n",i,env[i]);9 } 10 11 return 0;12 }
效果:
- 通过第三⽅变量environ获取
libc中定义的全局变量environ指向环境变量表,environ没有包含在任何头⽂件中,所以在使⽤时要⽤ extern声明。
示例代码:
#include<stdio.h>
extern char **environ;int main()
{for(int i = 0; environ[i]; i++){printf("%s\n", environ[i]);}return 0;
}4.7、通过系统调用获取或设置环境变量
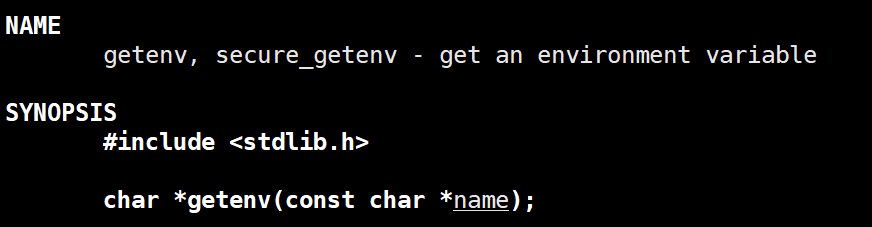
- getenv
- putenv
常⽤getenv和putenv函数来访问特定的环境变量。
示例代码:
1 #include<stdio.h>2 #include<stdlib.h>3 4 int main()5 {6 const char* who = getenv("USER");7 printf("USER: %s\n",who);8 printf("PWD: %s\n",getenv("PWD"));9 10 return 0;11 }效果:

4.8、环境变量的全局属性
为什么环境变量具有全局属性:
首先我们要知道,环境变量是可以被子进程继承的,bash创建的子进程可以看到环境变量,而bash的子进程又会作为父进程将环境变量传递给它的的子进程,依次类推,环境变量可以被所有bash之后的进程全部看到,所以,环境变量具有 "全局属性"。
意义:
- 系统的配置信息,尤其是具有 "指导性" 的配置信息,是所有进程都需要拿到的,它也是系统配置起效的一种表现。
- 进程具有独立性,环境变量可以用来进程间传递信息(只读数据)。
五、程序地址空间
5.1、研究平台
- kernel 2.6.32
- 32位平台
5.2、程序地址空间回顾
在C语言中,我们了解过这样的空间布局图:
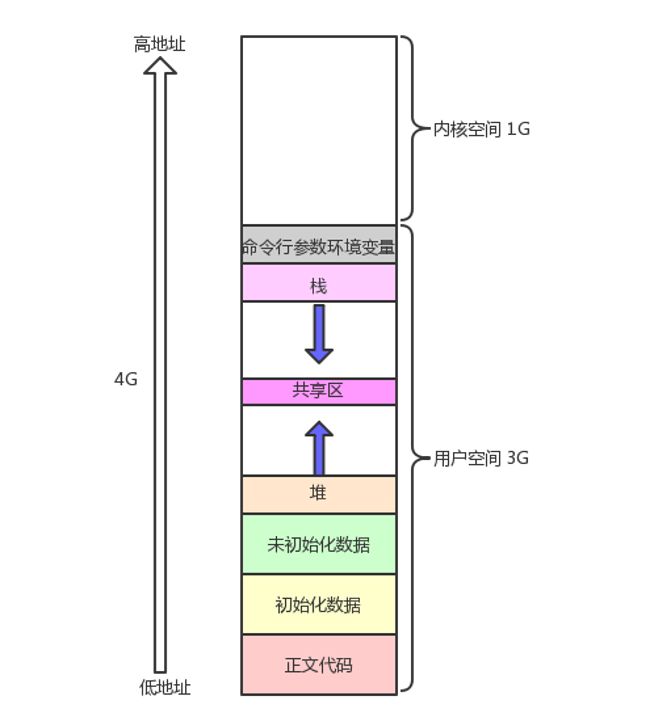
实际上这并不是程序地址空间,而是进程地址空间。我们看下面示例代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>int unval;
int gval = 100;int main()
{printf("我是一个进程, pid: %d, ppid: %d\n", getpid(), getppid());pid_t id = fork();if(id == 0){// childwhile(1){printf("我是子进程, pid : %d, ppid : %d, gval: %d, &gval: %p\n", getpid(), getppid(), gval, &gval);gval++;sleep(1);}}else{//parentwhile(1){printf("我是父进程, pid : %d, ppid : %d, gval: %d, &gval: %p\n", getpid(), getppid(), gval, &gval);sleep(1);}}
}效果:
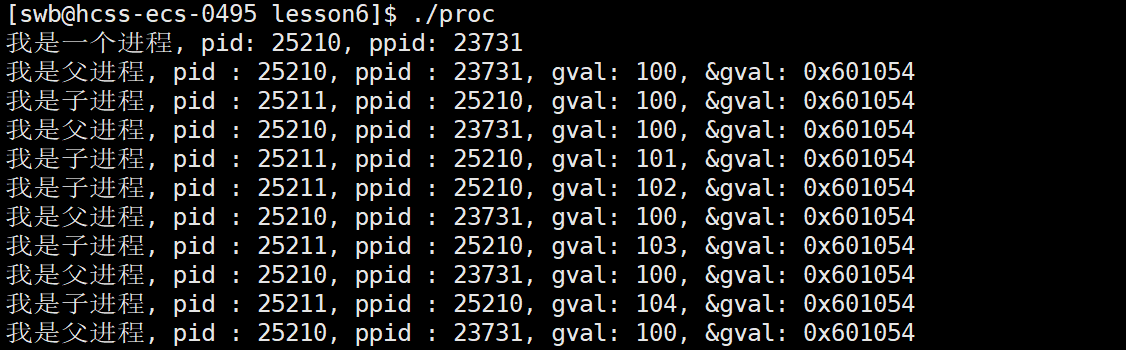
我们发现,⽗⼦进程,输出地址是⼀致的,但是变量内容不⼀样!能得出如下结论:
- 变量内容不⼀样,所以⽗⼦进程输出的变量绝对不是同⼀个变量。
- 但地址值是⼀样的,说明,该地址绝对不是物理地址!
- 在Linux地址下,这种地址叫做虚拟地址。
- 我们在⽤C/C++语⾔所看到的地址,全部都是虚拟地址!物理地址,用户⼀概看不到,由OS统⼀管理。
- OS让每一个进程都认为自己是独占系统物理内存大小,进程彼此之间不知道,不关心对方的存在,从而实现一定程度的隔离。
- 如何管理虚拟地址呢?答案是 "先描述,在组织",所谓的进程虚拟地址空间,本质是一个内核数据结构对象。(类似PCB)
注意:OS必须负责将虚拟地址转化成物理地址 。
5.3、进程地址空间
所以之前说‘程序的地址空间’是不准确的,准确的应该说成 进程地址空间 ,那该如何理解呢?看 图:分⻚&虚拟地址空间
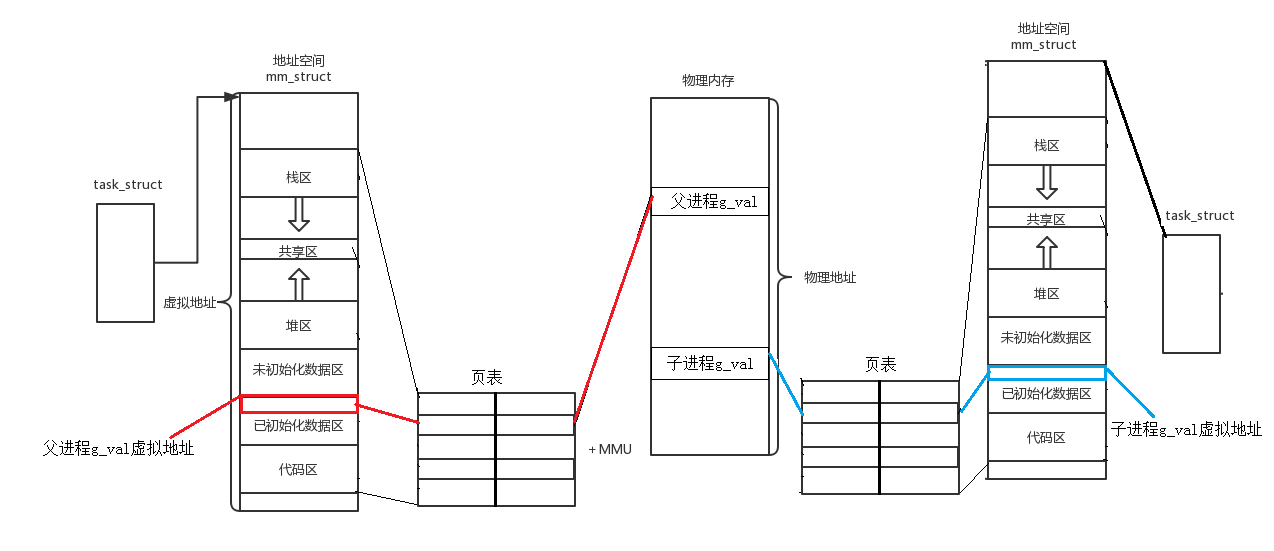
说明:
- 上⾯的图就⾜矣说明问题,同⼀个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映射到了不同的物理地址!
- 对于进程地址空间的划分,本质其实就是在结构体中定义出每个区域的开始和结束位置。
- 父进程创建子进程时,子进程的task_struct是将父进程的task_struct拷贝后再修改个别属性后得到的,同样的,子进程的 mm_struct 和 页表 也是从父进程那里拷贝来的,因为拷贝后完全相同,所以父子进程通过页表映射到同样的代码内存区域,所以父子代码共享,同理,不修改变量时,数据其实也是共享的,但是当我们修改变量时,OS就会自动再开辟一块区域,将要被修改的变量拷贝到这块区域中,再修改子进程页表的映射关系,将这个变量的虚拟地址映射的物理地址改为新开的这块区域的地址。修改变量时,OS的这种机制叫做写实拷贝机制,这个过程完全是由OS自主完成的。
- 之所以命令行参数和环境变量可以被子进程继承也是因为子进程的mm_struct和页表是直接拷贝自父进程的,所以经过映射后,父子进程代码和数据共享,子进程可以看到父进程的命令行参数和环境变量。
补充问题:
- 关于变量和地址:其实变量就是地址,在编译器将我们的语言翻译成汇编后,变量就都是地址了。
- 重新理解进程独立性:进程 = 内核数据结构 + 代码和数据。而每个进程的内核数据结构都是各自一份的,代码和数据也都是独立的,所以进程具有独立性。
5.4、虚拟内存管理
描述linux下进程的地址空间的所有的信息的结构体是 mm_struct (内存描述符)。每个进程只有⼀个mm_struct结构,在每个进程的task_struct结构中,有⼀个指向该进程的结构。
struct task_struct
{
/*...*/
struct mm_struct *mm; //对于普通的用户进程来说该字段指向他的虚拟地址空间的用户空间部分,对于内核线程来说这部分为NULL。
struct mm_struct *active_mm; // 该字段是内核线程使⽤的。当该进程是内核线程时,它的mm字段为NULL,表⽰没有内存地址空间,可也并不是真正的没有,这是因为所有进程关于内核的映射都是⼀样的,内核线程可以使⽤任意进程的地址空间。
/*...*/
}
可以说,mm_struct结构是对整个用户空间的描述。每⼀个进程都会有⾃⼰独⽴的mm_struct,这样每⼀个进程都会有⾃⼰独⽴的地址空间才能互不⼲扰。先来看看由task_struct到mm_struct,进程的地址空间的分布情况:
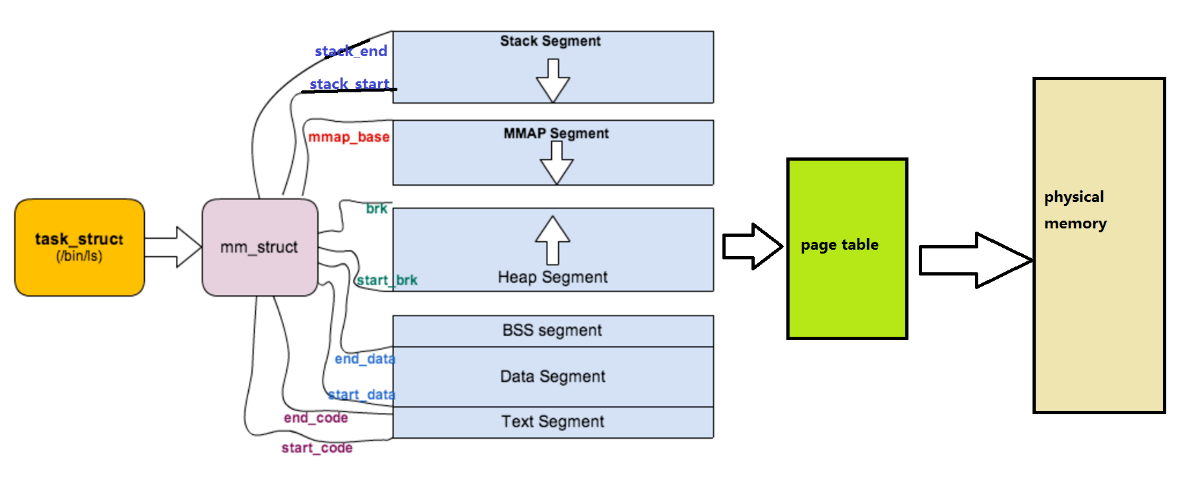
定位mm_struct⽂件所在位置和task_struct所在路径是⼀样的,不过他们所在⽂件是不⼀样的, mm_struct所在的⽂件是mm_types.h。
struct mm_struct
{
/*...*/
struct vm_area_struct *mmap; /* 指向虚拟区间(VMA)链表 */
struct rb_root mm_rb; /* red_black树 */
unsigned long task_size; /*具有该结构体的进程的虚拟地址空间的⼤⼩*/
/*...*/
// 代码段、数据段、堆栈段、参数段及环境段的起始和结束地址。
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
/*...*/
}
那既然每⼀个进程都会有⾃⼰独⽴的mm_struct,操作系统肯定是要将这么多进程的mm_struct组织起来的!虚拟空间的组织⽅式有两种:
- 当虚拟区较少时采取单链表,由mmap指针指向这个链表;
- 当虚拟区间多时采取红⿊树进⾏管理,由mm_rb指向这棵树。
linux内核使⽤ vm_area_struct 结构来表⽰⼀个独⽴的虚拟内存区域(VMA),由于每个不同质的虚 拟内存区域功能和内部机制都不同,因此⼀个进程使⽤多个vm_area_struct结构来分别表⽰不同类型的虚拟内存区域。上⾯提到的两种组织⽅式使⽤的就是vm_area_struct结构来连接各个VMA,⽅便进程快速访问。
struct vm_area_struct {
unsigned long vm_start; //虚存区起始
unsigned long vm_end; / /虚存区结束
struct vm_area_struct *vm_next, *vm_prev; //前后指针
struct rb_node vm_rb; //红⿊树中的位置
unsigned long rb_subtree_gap;
struct mm_struct *vm_mm; //所属的 mm_struct
pgprot_t vm_page_prot;
unsigned long vm_flags; //标志位
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
struct list_head anon_vma_chain;
struct anon_vma *anon_vma;
const struct vm_operations_struct *vm_ops; //vma对应的实际操作
unsigned long vm_pgoff; //⽂件映射偏移量
struct file * vm_file; //映射的⽂件
void * vm_private_data; //私有数据
atomic_long_t swap_readahead_info;
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;
所以我们可以对上图在进⾏更细致的描述,如下图所⽰:
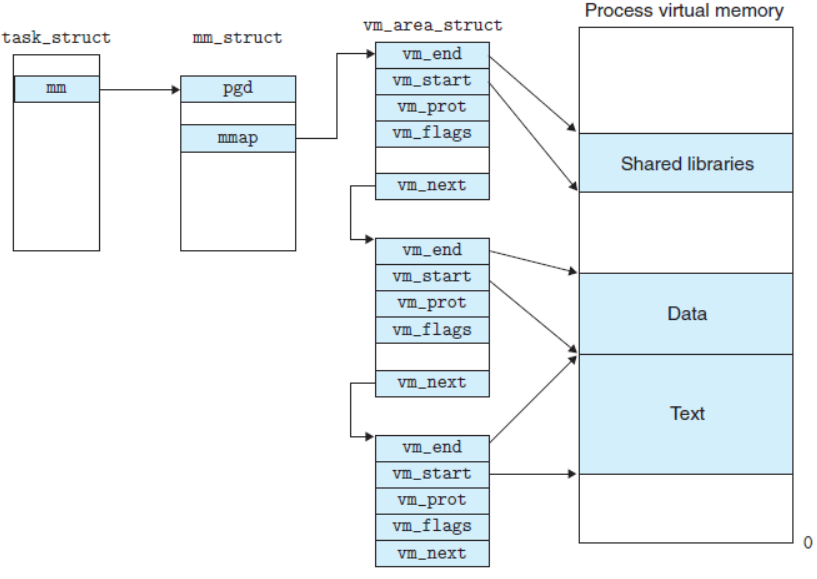
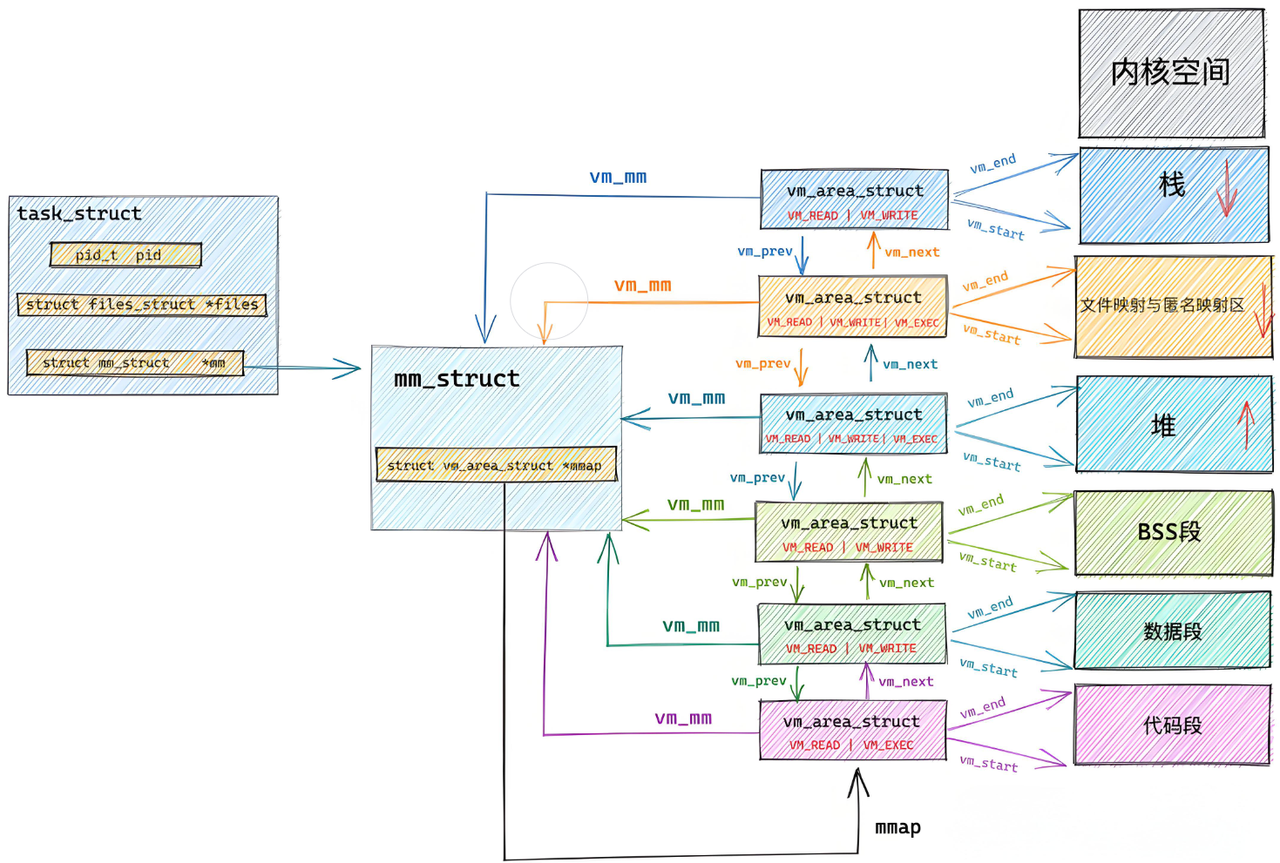
补充知识:
- 关于页表:页表中除了有虚拟地址和物理地址的映射关系外,还有标记位。如标识当前目标内容的权限的标记位->r,w,x。如果一段代码对只读数据进行写入操作,通过这些标记位就可以检测到问题,进而终止进程;还有检测当前代码或数据是否在物理内存中存在的标记位(isexists),因为一个进程的代码和数据并不是一次性全部导入到物理内存中的,而是会分批加载,而且还要考虑挂起等状态,所以需要检测当前目标资源是否在物理内容中存在。
- 关于地址空间:mm_struct是一个结构体变量,所以在使用前必须进行初始化,那么它是如何进行初始化的呢?其实,可执行程序在编译的时候,各个区域的大小信息就已经有了,所以mm_struct也是根据这些信息进行初始化的,还有一部分是OS自动动态创建的。
5.5、为什么要有虚拟地址空间
这个问题其实可以转化为:如果程序直接可以操作物理内存会造成什么问题?
在早期的计算机中,要运⾏⼀个程序,会把这些程序全都装⼊内存,程序都是直接运⾏在内存上的, 也就是说程序中访问的内存地址都是实际的物理内存地址。当计算机同时运⾏多个程序时,必须保证这些程序⽤到的内存总量要⼩于计算机实际物理内存的⼤⼩。
那当程序同时运⾏多个程序时,操作系统是如何为这些程序分配内存的呢?例如某台计算机总的内存⼤⼩是128M,现在同时运⾏两个程序A和B,A需占⽤内存10M,B需占⽤内存110。计算机在给程序分 配内存时会采取这样的⽅法:先将内存中的前10M分配给程序A,接着再从内存中剩余的118M中划分出110M分配给程序B。
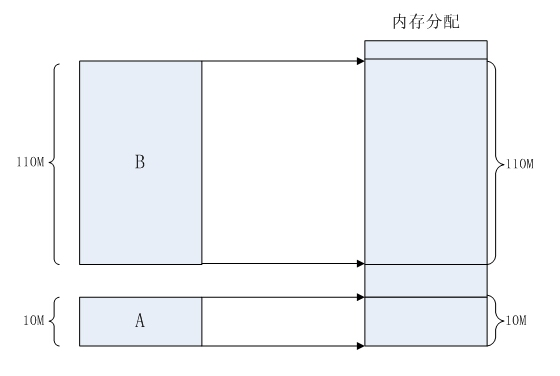
这种分配⽅法可以保证程序A和程序B都能运⾏,但是这种简单的内存分配策略问题很多。
- 安全⻛险
- 每个进程都可以访问任意的内存空间,这也就意味着任意⼀个进程都能够去读写系统相关内存区域,如果是⼀个⽊⻢病毒,那么他就能随意的修改内存空间,让设备直接瘫痪。
- 地址不确定
- 众所周知,编译完成后的程序是存放在硬盘上的,当运⾏的时候,需要将程序搬到内存当中去运⾏,如果直接使⽤物理地址的话,我们⽆法确定内存现在使⽤到哪⾥了,也就是说拷⻉的实际内存地址每⼀次运⾏都是不确定的,⽐如:第⼀次执⾏a.out时候,内存当中⼀个进程都没有运⾏,所以搬移到内存地址是0x00000000,但是第⼆次的时候,内存已经有10个进程在运⾏了,那执⾏a.out的时候,内存地址就不⼀定了。
- 效率低下
- 如果直接使⽤物理内存的话,⼀个进程就是作为⼀个整体(内存块)操作的,如果出现物理内存不够⽤的时候,我们⼀般的办法是将不常⽤的进程拷⻉到磁盘的交换分区中,好腾出内存,但是如果是物理地址的话,就需要将整个进程⼀起拷⾛,这样,在内存和磁盘之间拷⻉ 时间太⻓,效率较低。
存在这么多问题,有了虚拟地址空间和分⻚机制就能解决了吗?当然!
- 地址空间和⻚表是OS创建并维护的!是不是也就意味着,凡是想使⽤地址空间和⻚表进⾏映射, 也⼀定要在OS的监管之下来进⾏访问!!也顺便保护了物理内存中的所有的合法数据,包括各个进程以及内核的相关有效数据!
- 因为有地址空间的存在和⻚表的映射的存在,我们的物理内存中可以对未来的数据进⾏任意位置的加载!物理内存的分配 和 进程的管理就可以做到没有关系,进程管理模块和内存管理模块就完成了解耦合。
- 因为有地址空间的存在,所以我们在C、C++语⾔上new, malloc空间的时候,其实是在地址空间上申请的,物理内存可以甚⾄⼀个字节都不给你。⽽当你真正进⾏对物理地址空间访问的时候,才执⾏内存的相关管理算法,帮你申请内存,构建⻚表映射关系(延迟分配),这是由操作系统⾃动完成,用户包括进程完全0感知!!
- 因为⻚表的映射的存在,程序在物理内存中理论上就可以任意位置加载。它可以将地址空间上的 虚拟地址和物理地址进⾏映射,在进程视⻆所有的内存分布都可以是有序的。
相关文章:

Linux之进程概念
目录 一、冯诺依曼体系结构 二、操作系统(Operator System) 2.1、概念 2.2、设计OS的目的 2.3、系统调用和库函数概念 三、进程 3.1、基本概念 3.1.1、描述进程-PCB 3.1.2、task_struct 3.1.3、查看进程 3.1.4、通过系统调用获取进程标识符 3.1.5、两种杀掉进程的方…...

numpy模块综合使用
一、numpy模块的综合使用方法 # 使用矩阵的好处,矩阵对于python中列表,字典等数据类型一个一个拿来计算是会方便计算很多的,底层使用的是c语言 # 在数据分析和数据处理的时候也经常常用 import numpy as np array np.array([[1,2,3],[2,3,4…...

嵌入式硬件篇---SPI
文章目录 前言1. SPI协议基础1.1 物理层特性四线制(标准SPI)SCKMOSIMISONSS/CS 三线制(半双工模式)通信模式 1.2 通信时序(时钟极性CPOL和相位CPHA)常用模式Mode 0Mode 3 1.3 典型通信流程 2. STM32F103RCT…...

【大模型】AI智能体Coze 知识库从使用到实战详解
目录 一、前言 二、知识库介绍 2.1 coze 知识库功能介绍 2.2 coze 知识库应用场景 2.3 coze 知识库类型 2.4 coze 知识库权限说明 2.5 coze 知识库与记忆对比 2.6 知识库的使用流程 三、知识库创建与使用 3.1 创建知识库入口 3.2 创建文本知识库 3.2.1 上传文件 3.…...
)
深度学习:系统性学习策略(二)
深度学习的系统性学习策略 基于《认知觉醒》与《认知驱动》的核心方法论,结合深度学习的研究实践,从认知与技能双重维度总结以下系统性学习策略: 一、认知觉醒:构建深度学习的思维操作系统 三重脑区协同法则 遵循**本能脑(舒适区)-情绪脑(拉伸区)-理智脑(困难区)**的…...

TikTok 推广干货:AI 加持推广效能
TikTok 推广是提升账号影响力、吸引更多关注的关键一环。其中,巧妙利用热门话题标签是增加视频曝光的有效捷径。运营者需要密切关注当下流行趋势,搜索与账号定位紧密相关的热门标签。例如,对于美妆账号而言,带上 “# 美妆教程 #热…...

滑动窗口——将x减到0的最小操作数
题目: 这个题如果我们直接去思考方法是很困难的,因为我们不知道下一步是在数组的左还是右操作才能使其最小。正难则反,思考一下,无论是怎么样的,最终这个数组都会分成三个部分左中右,而左右的组合就是我们…...

无侵入式弹窗体验_探索 Chrome 的 Close Watcher API
1. 引言 在网页开发中,弹窗(Popup)是一种常见的交互方式,用于提示用户进行操作、确认信息或展示关键内容。然而,传统的 JavaScript 弹窗方法如 alert()、confirm() 和 prompt() 存在诸多问题,包括阻塞主线程、样式不可定制等。 为了解决这些问题,Chrome 浏览器引入了 …...

牛客周赛 Round 92 题解 Java
目录 A 小红的签到题 B 小红的模拟题 C 小红的方神题 D 小红的数学题 E 小红的 ds 题 F 小红的小苯题 A 小红的签到题 直接构造类似于 a_aaaa,a_aaaaaaaa 这种 即可 // github https://github.com/Dddddduo // github https://github.com/Dddddduo/acm-java…...

DAY 17 训练
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 DAY 17 训练 聚类算法聚类评估指标介绍1. 轮廓系数 (Silhouette Score)2. CH 指数 (Calinski-Harabasz Index)3. DB 指数 (Davies-Bouldin Index) 1. KMeans 聚类算法原理确定…...
)
多源最短路径(Floyed)
#include <iostream> #include <vector> #include <stack> using namespace std; class Graph{ private: int vertex; //顶点数 //int** matrix; //有向图关系矩阵 int** path; //存储关系矩阵 int** pre; //存储中间节点k public: con…...

基于去中心化与AI智能服务的web3钱包的应用开发的背景描述
Web3代表了下一代互联网模式,其核心特征包括去中心化、数据主权、智能合约和区块链技术的广泛应用。根据大数据调查显示,用户希望拥有自己的数据控制权,并希望在去中心化网络中享受类似Web2的便捷体验。DeFi(去中心化金融) 生态日趋成熟的背景…...

LabVIEW车牌自动识别系统
在智能交通快速发展的时代,车牌自动识别系统成为提升交通管理效率的关键技术。本案例详细介绍了基于 LabVIEW 平台,搭配大恒品牌相机构建的车牌自动识别系统,该系统在多个场景中发挥着重要作用,为交通管理提供了高效、精准的解决方…...

C# Newtonsoft.Json 使用指南
Newtonsoft.Json (也称为 Json.NET) 是一种适用于 .NET 的常用高性能 JSON 框架,用于处理 JSON 数据。它提供了高性能的 JSON 序列化和反序列化功能。 安装 通过 NuGet 安装 基本用法 1. 序列化对象为 JSON 字符串 using Newtonsoft.Json;var product new Prod…...

Python_day22
DAY 22 复习日 复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 kaggle泰坦里克号人员生还预测 一、Kaggle 基础使用步骤 注册与登录…...

浏览器的B/S架构和C/S架构
浏览器的B/S架构和C/S架构 概述拓展 欢迎来到 Shane 的博客~ 心有猛虎,细嗅蔷薇。 概述 C/S架构? Client/Server架构。但是缺少通用性、系统维护、升级需要重新设计和开发,并且需要开发不同的操作系统,增加了维护和管理的难度。&…...

【C++】内存管理 —— new 和 delete
文章目录 一、C/C 内存分布二、C 语言中动态内存管理方式1. malloc / calloc / realloc / free 三、C 内存管理方式1. new / delete2. operator new 与 operator delete 函数3. new 和 delete 的实现原理(1) new 的原理(2) delete 的原理(3) new T[N] 的原理(4) delete[] 的原理…...

springboot3整合SpringSecurity实现登录校验与权限认证
一:概述 1.1 基本概念 (1)认证 系统判断身份是否合法 (2)会话 为了避免每次操作都进行认证可将用户信息保存在会话中 session认证 服务端有个session,把 session id给前端,每次请求cookie都带着…...

【东枫科技】使用LabVIEW进行深度学习开发
文章目录 DeepLTK LabVIEW深度学习工具包LabVIEW中的深度神经网络**功能与特性****功能亮点:** **支持的网络层****支持的网络架构****参考示例** 授权售价 DeepLTK LabVIEW深度学习工具包 LabVIEW中的深度神经网络 功能亮点: 在 LabVIEW 中创建、配置…...

《智能网联汽车 自动驾驶系统通用技术要求》 GB/T 44721-2024——解读
目录 一、核心框架与适用范围 二、关键技术要求 1. 总体要求 2. 动态驾驶任务执行 3. 动态驾驶任务后援 4. 人机交互(HMI) 5. 说明书要求 三、附录重点 附录A(规范性)——功能安全与预期功能安全 附录B(资料性…...

同一个虚拟环境中conda和pip安装的文件存储位置解析
文章目录 存储位置的基本区别conda安装的包pip安装的包 看似相同实则不同的机制实际路径示例这种差异带来的问题如何检查包安装来源最佳实践建议 总结 存储位置的基本区别 conda安装的包 存储在Anaconda(或Miniconda)目录下的pkgs和envs子目录中: ~/anaconda3/en…...

《Hadoop 权威指南》笔记
Hadoop 基础 MapReduce Hadoop 操作 Hadoop 相关开源项目...

每日一题洛谷P8615 [蓝桥杯 2014 国 C] 拼接平方数c++
P8615 [蓝桥杯 2014 国 C] 拼接平方数 - 洛谷 (luogu.com.cn) #include<iostream> #include<string> #include<cmath> using namespace std; bool jud(int p) {int m sqrt(p);return m * m p; } void solve(int n) {string t to_string(n);//int转换为str…...

【C++】AVL树实现
目录 前言 一、AVL树的概念 二、AVL树的实现 1.基本框架 2.AVL树的插入 三、旋转 1.右单旋 2.左单旋 3.左右双旋 4.右左双旋 四、AVL树的查找 五、AVL树的平衡检测 六、AVL树的删除 总结 前言 本文主要讲解AVL树的插入,AVL树是在二叉搜索树的基础上&a…...

49.EFT测试与静电测试环境和干扰特征分析
EFT测试与静电测试环境和干扰特征分析 1. EFT/B电快速瞬变脉冲群测试及干扰特征分析2. EFT的干扰特征分析与滤波方法3. ESD静电测试及干扰特征分析 1. EFT/B电快速瞬变脉冲群测试及干扰特征分析 EFT测试是模拟在大的感性设备断开瞬间产生的快速瞬变脉冲群对被测设备的影响。 E…...
)
html body 设置heigth 100%,body内元素设置margin-top出滚动条(margin 重叠问题)
今天在用移动端的时候发现个问题,html,body 设置 height:100% 会出现纵向滚动条 <!DOCTYPE html> <html> <head> <title>html5</title> <style> html, body {height: 100%; } * {margin: 0;padding: 0; } </sty…...

1688 API 自动化采集实践:商品详情实时数据接口开发与优化
在电商行业竞争日益激烈的当下,实时获取 1688 平台商品详情数据,能够帮助商家分析市场动态、优化选品策略,也能助力数据分析师洞察行业趋势。通过 API 自动化采集商品详情数据,不仅可以提高数据获取效率,还能保证数据的…...
Transformer Decoder-Only 参数量计算
Transformer 的 Decoder-Only 架构(如 GPT 系列模型)是当前大语言模型的主流架构,其参数量主要由以下几个部分组成: 嵌入层(Embedding Layer)自注意力层(Self-Attention Layers)前馈…...
)
苍穹外卖(数据统计–Excel报表)
数据统计(Excel报表) 工作台 接口设计 今日数据接口 套餐总览接口 菜品总览接口 订单管理接口 编辑代码导入 功能测试 导出运营数据Excel报表 接口设计 代码开发 将模板文件放到项目中 导入Apache POI的maven坐标 在ReportCont…...

如何实现Flask应用程序的安全性
在 Flask 应用中,确保安全性非常关键,尤其是当你将应用部署到公网环境中时。Flask 本身虽然轻量,但通过组合安全策略、扩展库和最佳实践,可以构建一个非常安全的 Web 应用。 一、常见 Flask 安全风险(必须防护…...

【Redis】Redis的主从复制
文章目录 1. 单点问题2. 主从模式2.1 建立复制2.2 断开复制 3. 拓扑结构3.1 三种结构3.2 数据同步3.3 复制流程3.3.1 psync运行流程3.3.2 全量复制3.3.3 部分复制3.3.4 实时复制 1. 单点问题 单点问题:某个服务器程序,只有一个节点(只搞一个…...

趣味编程:四叶草
概述:在万千三叶草中寻觅,只为那一抹独特的四叶草之绿,它象征着幸运与希望。本篇博客主要介绍四叶草的绘制。 1. 效果展示 绘制四叶草的过程是一个动态的过程,因此博客中所展示的为绘制完成的四叶草。 2. 源码展示 #define _CR…...

HTTP 响应状态码总结
一、引言 HTTP 响应状态码是超文本传输协议(HTTP)中服务器对客户端(通常是 Web 浏览器)请求的响应指示。这些状态码是三位数字代码,用于告知客户端请求的结果,包括请求是否成功。响应被分为五个类别&#…...

C语言常见的文件操作函数总结
目录 前言 一、打开和关闭 1.fopen 细节 2.fclos 基本用法示例 二、读写 1.fputc和fgetc 1)fputc 细节 基本用法示例 2)fgetc 细节 基本用法示例 2.fputs和fgets 1)fputs 细节 基本用法示例 2)fgets 细节 基本用法示例 3)puts的使用,以及为什…...

卫宁健康WiNGPT3.0与WiNEX Copilot 2.2:医疗AI创新的双轮驱动分析
引言:医疗AI的双翼时代 在医疗信息化的浪潮中,人工智能技术的深度融入正在重塑整个医疗行业。卫宁健康作为国内医疗健康和卫生领域数字化解决方案的领军企业,持续探索AI技术在医疗场景中的创新应用。2025年5月10日,在第29届中国医院信息网络大会(CHIMA2025)上,卫宁健康…...

【GPT入门】第38课 RAG评估指标概述
这里写自定义目录标题 一、RAG评估指标二、ragas 评估三、trulens 一、RAG评估指标 二、ragas 评估 2.1 ragas介绍 开源地址:https://github.com/explodinggradients/ragas 官方文档:https://docs.ragas.io/en/stable/从文本生成和文本召回两个维度&am…...

深度剖析多模态大模型中的视频编码器算法
写在前面 随着多模态大型语言模型(MLLM)的兴起,AI 理解世界的能力从静态的文本和图像,进一步拓展到了动态的、包含丰富时空信息的视频。视频作为一种承载了动作、交互、场景变化和声音(虽然本文主要聚焦视觉部分)的复杂数据形式,为 MLLM 提供了理解真实世界动态和因果关…...

【递归、搜索与回溯算法】导论
📝前言说明: 本专栏主要记录本人递归、搜索与回溯算法的学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码ÿ…...

《智能网联汽车 自动驾驶功能道路试验方法及要求》 GB/T 44719-2024——解读
目录 1. 适用范围 2. 关键术语 3. 试验条件 3.1 试验道路 3.2 试验车辆 3.3 试验设备 3.4 试验时间 4. 试验方法及要求 4.1 功能激活 4.2 动态驾驶任务执行 4.3 动态驾驶任务后援 4.4 状态提示 5. 附录A(核心环境要素) 6. 实施要点 原文链接…...

path环境变量满了如何处理,分割 PATH 到 Path1 和 Path2
要正确设置 Path1 的值,你需要将现有的 PATH 环境变量 中的部分路径复制到 Path1 和 Path2 中。以下是详细步骤: 步骤 1:获取当前 PATH 的值 打开环境变量窗口: 按 Win R,输入 sysdm.cpl,点击 确定。在 系…...
)
实战项目1(02)
目录 任务场景一 【sw1和sw2的配置如下】 任务场景二 【sw3的配置】 【sw4-6的配置】 任务场景一 某公司有生产、销售、研发、人事、财务等多个部门,这些部门分别连接在两台交换机(SW1和SW2)上,现要求给每个部门划分相应的V…...

m1 安装 Elasticsearch、ik、kibana
一、下载安装ES 1、下载地址 ES|download 2、安装 将下载的安装包解压到 要安装的文件目录 关闭 ES 的安全模式 本地文本编辑器打开elasticsearch.yml配置文件,将红箭头指的地方 改为 false3、启动 ES 启动命令 进入 ES 的安装目录,进入bin文件目…...

游戏引擎学习第273天:动画预览
回顾并为一天的内容定下基调 。目前我们正在编写角色的移动代码,实际上,我们已经在昨天完成了一个简单的角色跳跃的例子。所以今天的重点是,开始更广泛地讨论动画,因为我们希望对现有的动画进行调整,让它看起来更加令…...

JVM中的安全点是什么,作用又是什么?
JVM中的安全点(Safepoint) 是Java虚拟机设计中的一个关键机制,主要用于协调所有线程的执行状态,以便进行全局操作(如垃圾回收、代码反优化等)。它的核心目标是确保在需要暂停所有线程时,每个线程…...

游戏引擎学习第271天:生成可行走的点
回顾并为今天的内容设定背景 我们昨天开始编写一些游戏逻辑相关的内容,虽然这部分不是最喜欢的领域,更偏好底层引擎开发,但如果要独立完成一款游戏,游戏逻辑也必须亲自处理。所以我们继续完善这部分内容。事实上,接下…...

FlySecAgent:——MCP全自动AI Agent的实战利器
最近,出于对人工智能在网络安全领域应用潜力的浓厚兴趣,我利用闲暇时间进行了深入研究,并成功开发了一款小型轻量化的AI Agent安全客户端FlySecAgent。 什么是 FlySecAgent? 这是一个基于大语言模型和MCP(Model-Contr…...

DAMA车轮图
DAMA车轮图是国际数据管理协会(DAMA International)提出的数据管理知识体系(DMBOK)的图形化表示,它以车轮(同心圆)的形式展示了数据管理的核心领域及其相互关系。以下是基于用户提供的关键词对D…...

使用vue3-seamless-scroll实现列表自动滚动播放
vue3-seamless-scroll组件支持上下左右无缝滚动,单步滚动,并且支持复杂图标的无缝滚动。 核心特性 多方向无缝滚动 支持上下、左右四个方向的自动滚动,通过 direction 参数控制(默认 up),适用于新闻轮播、…...

Scrapyd 详解:分布式爬虫部署与管理利器
Scrapyd 是 Scrapy 官方提供的爬虫部署与管理平台,支持分布式爬虫部署、定时任务调度、远程管理爬虫等功能。本文将深入讲解 Scrapyd 的核心功能、安装配置、爬虫部署流程、API 接口使用,以及如何结合 Scrapy-Redis 实现分布式爬虫管理。通过本文&#x…...
)
mac环境配置(homebrew版)
文章目录 【环境配置】HomebrewGitJavaMavenMySQLRedisNacosNode.js 【拓展-mac常见问题】mac文件损坏问题mac必装软件(Java开发版)zsh和bash配置文件区别 【参考资料】 查看每个版本可以用命令brew info xxx ps:每一个环境安装完之后都要关掉…...