进阶 DFS 学习笔记
字数:12017字。
文章盗的图注明了出处,全部出自 y 总的算法提高课。
不知道为啥这个时候才开始学这个东西,好像是很多同龄人都已经学完了。
进阶 DFS 具体来说好几个东西,所以可能内容有一些些多。
默认 DFS 和 BFS 已经掌握了,且对最短路有了解,而且知道 DFS 该如何剪枝。否则建议出门左转。
直接进入正题。
双向广搜
BFS 显然没有 DFS 那么多变(DFS 可以大力剪枝),但是也是有一些优化方法的。
其中比较常用的,就是双向广搜,和 A-star 算法这两个东西,其中 A-star 也可以被称作 A*。
首先来讲双向广搜。
先剧透一下:双向广搜的名字很好理解,但是使用场景有一个约束:最终需要到达的状态必须不能很多。
双向广搜可以把时间复杂度弄到大约是开根号的一个级别。
双向广搜顾名思义啊,就是从两个方向同时进行广搜,而不是从一个方向搜到另外一个方向。
双向广搜实际上和 Meet-in-the-middle 是两个差不多的东西。只不过前者是双向的 BFS,后者可以是双向的 DFS 也可以是双向的 BFS。
为什么要这么做呢?因为有些 BFS 的状态可能会多到爆炸,连 O ( n ) O(n) O(n) 的算法也无法治疗。
例如经典的八数码问题,一共是 9 9 9 个格子,那么就是 9 ! 9! 9! 级别的状态,有一些大,但是还是可以治疗一下。
但是如果扩展到十五数码问题,一共是 15 15 15 个格子,那么就直接废了。
例如 Acwing 190. 字串变换 这道题,显然可以想到使用 BFS 来跑,对于每一个状态向可以到达的状态连一条边。但是每一个字符串的长度最多有 20 20 20 个(相对于来讲有些巨多),而规则一共只有 6 6 6 个,而我们只需要搜 10 10 10 步。
显然可以算出来这里的状态数量为 6 10 6^{10} 610 个,时间和空间都不太吃得消。
所以要优化。
优化的这个时候就有了一个很常用的方式:从起点和终点同时开始搜,这样就可以得出双向广搜。
就有点像走迷宫的时候,有时候采用一边从起点走迷宫,一边从终点逆推的方法会快一些。
考虑到每一层的状态数都是成指数增加的,但是,发现字串变换那道题,最终达到的状态需要考虑的只有一个!
偷一张 y 总的图:
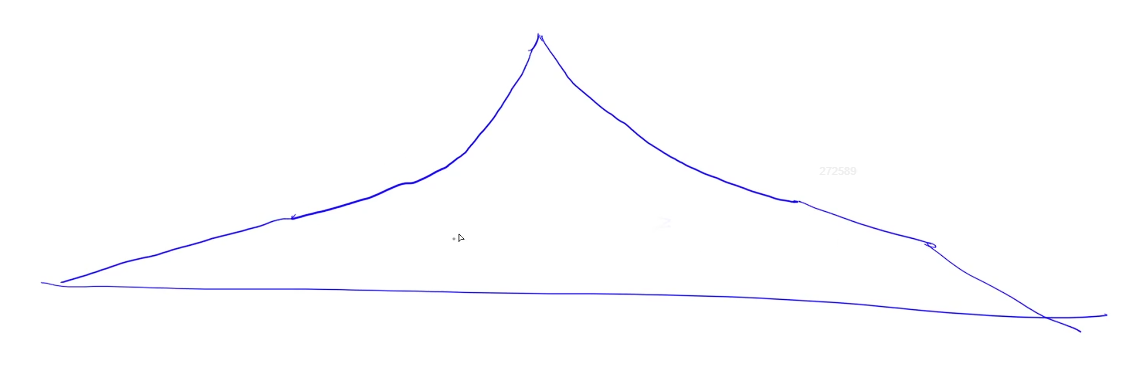
最上面的那个点就是起点,而每一次的状态都在疯狂增加,最终会形成一个宽边帽的形式。
但是,如果从终点同时往回搜,就会成为这个样子:
显然,面积小了很多!!对应的,状态数量也小了很多!
而且在搜到中间层的时候,就会相遇了。字串变换的那道题很友好地告诉我们:**我们只需要搜 10 10 10 步即可。**所以如果从起点和终点共同出发,相遇的地方就是两者都走了 5 5 5 步的时候,也就是对应 6 5 × 2 6^5 \times 2 65×2,整整把复杂度开了个平方!
但是考虑如何判断相遇的时候,可以直接使用 map 往上莽即可,看一下对于一个状态在对面有没有相同的状态。最终还会多一个 log \log log 但是无伤大雅。可见双向广搜的优化效果是很优秀的。
于是这道题就做完了,双向广搜也就同时讲完了。
最终还有一些尾巴,也就是双向广搜的一个小优化。
首先有一个不那么聪明的做法,就是直接先跑完两边的,或者是左边扩展一步,再右边扩展一步。
但是还有一点优化常数的做法。为了节省时间,我们可以在每一次需要扩展的时候看一下是左边的队列元素少还是右边的队列元素少。
可以感性理解,想想为什么。
#include <bits/stdc++.h>
using namespace std;
typedef unordered_map<string, int> um;//使用 typedef 来简化代码
string s, t;
string a[10], b[10];
int n = 1;int ex(queue<string> &q, um &mp1, um &mp2, string a[], string b[]) {//扩展string t = q.front();q.pop();for (int i = 1; i <= n; i++)for (int j = 0; j + a[i].size() <= t.size(); j++)if (t.substr(j, a[i].size()) == a[i]) {//找有没有可以替换的地方string to = t.substr(0, j) + b[i] + t.substr(j + a[i].size());if (mp2.count(to))return mp1[t] + mp2[to] + 1;if (mp1.count(to))continue;q.push(to), mp1[to] = mp1[t] + 1;}return 11;//没有找到
}int bfs(string s, string t) {queue<string> q1, q2;um mp1, mp2;q1.push(s), q2.push(t);mp1[s] = 0, mp2[t] = 0;while (!q1.empty() && !q2.empty()) {int x;if (q1.size() <= q2.size())x = ex(q1, mp1, mp2, a, b);elsex = ex(q2, mp2, mp1, b, a);if (x <= 10)//找到答案直接返回return x;}return 11;
}int main() {cin >> s >> t;while ((cin >> a[n] >> b[n]))n++;n--;if (s == t) {//特判!!cout << "0\n";return 0;}int x = bfs(s, t);if (x <= 10)cout << x << endl;elsecout << "NO ANSWER!";return 0;
}代码跑得飞快,即使在 Acwing 老爷机的情况下也跑了 20ms。可见其优化效果显著。
A-star 算法
我们也将迎来第一个重头戏。
这个名字非常高级,把一个优化 BFS 的名字写得冠冕堂皇,我也不知道为什么,但是这个算法是真的有点用。
这个算法需要改进的 BFS 的不足,和双向 BFS 改进的一样。都是在浩瀚如海的状态下找到一个状态到另一个状态的最短路径。
不过 A-star 算法和双向广搜的处理方法不同,A-star 算法在原有 BFS 的基础下加了一个启发函数(人类智慧)。梦回启发式合并
那么这个启发函数是干嘛的呢?大家先不用管这个东西是什么,先想想这个东西要有什么作用。
实际上这个东西的作用是这样的:**充分发扬人类智慧,得出启发函数,使得起点只需要走很少个点就可以搜到终点。**上面这句话也可以说是 A-star 算法的核心思想。
A-star 算法的使用场景:状态很多,而且状态之间的边权可以为负数,但是不能出现负环。
我们来了解一下算法的流程。
首先,我们会将 BFS 中的队列换成优先队列。队列是小根堆。每一个元素包含两个要素:一个是从起点到当前点的真实距离,一个是从当前点到终点的估价距离。
(众所周知,当看到“估价”的字眼的时候,我们就已经猜到这个东西是人类智慧了。)
而且还有一个更加奇怪的点:优先队列按照真实距离和估价距离的和来排序(其实很好理解,就是估计的起点到终点的距离,但是这个不确定性实在是有点无法忍受)。这是什么玩意?
然后就是比较容易理解的部分:对于每一条路径,挑一个和最小的点来扩展。这也是为什么这个东西是小根堆。
注意,A-star 算法不需要在搜索的时候判重。
当发现终点出队的时候,没错,这个和就是答案。
其实我上面讲的 A-star 算法的使用场景的内容还漏掉了一个点:A-star 算法不一定什么时候都是正确的。
实际上有一个结论:只要对于每一个状态状态到终点的估价函数都 ≤ \le ≤ 状态到终点的实际距离,而且每一个估价函数都必须要非负数(否则错得更加离谱),A-star 算法就是正确的。
(再插叙一条对下面的内容有帮助的结论:状态到终点估价函数和实际距离越接近越好,显然估价函数可以取 0 0 0 但是这样就退化为 dijkstra 算法了。)
考虑如何证明。考虑使用反证法:如果满足对于每一个状态状态到终点的估价函数都 ≤ \le ≤ 状态到终点的实际距离,但是终点第一次出队时得到的答案并不是最优的。
接下来找矛盾点即可。
设终点为 T T T,起点为 S S S。
记 f x f_x fx 表示状态为 x x x 的时候 x → T x \to T x→T 的估价函数, g x g_x gx 表示状态为 x x x 的时候 x → T x \to T x→T 实际距离, d x d_x dx 表示起点 S → x S \to x S→x 的实际距离,而 a n s x ans_x ansx 表示 d x + f x d_x + f_x dx+fx。显然 f x ≤ g x f_x \le g_x fx≤gx,而且优先队列是按照 a n s x ans_x ansx 来排序的。
设终点 T T T 时算出起点到 T T T 的距离时 a n s T = d T ans_T=d_T ansT=dT,而应该算出来的答案为 d 最优 = a n s 最优 d_{最优} = ans_{最优} d最优=ans最优。显然 d T > d 最优 d_T > d_{最优} dT>d最优。设这个最优答案属于的点为 u u u。
则 d u + f u ≤ d u + g u = d 最优 d_u + f_u \le d_u + g_u = d_{最优} du+fu≤du+gu=d最优,可以得出 d T > d 最优 ≥ d u + f u = a n s u d_T > d_{最优} \ge d_u + f_u = ans_u dT>d最优≥du+fu=ansu,于是,观察式子可以发现 a n s T > a n s u ans_T > ans_u ansT>ansu,那么并不应该是 T T T 为第一个终点出队的点啊!而是 u u u!
找到了矛盾点。所以得证这个结论是正确的。
注意,A-star 算法只能求出全局最小值,并不能求出局部最小值。这点需要特别注意。话说这东西思想没啥却咋这么多规矩
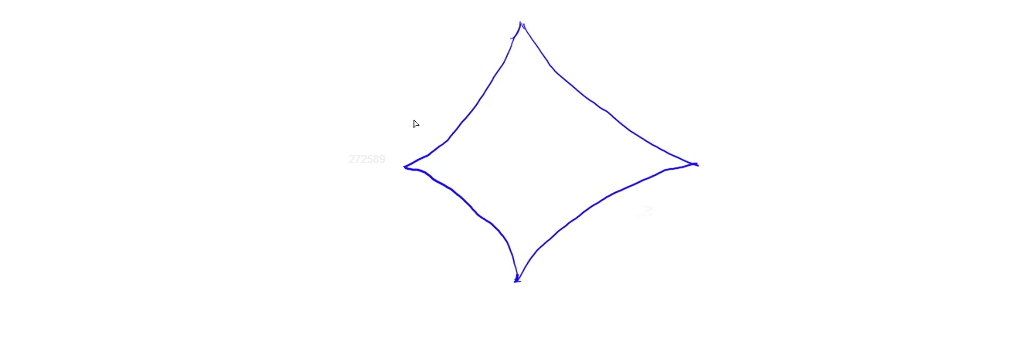
很容易找到一个反例:
欸,我再盗一张图:

注意看一下中间的那个交点,其如果是正常跑 A-star 的话它会从上面的一条路走过来,得到局部“最优解”是 6 6 6。但实际上它可以从下面的点走过来,这样的答案原本是 < 6 <6 <6 的。所以这个东西不能求出局部最小值。
这也是《算法竞赛进阶指南》中写错的一个点。
估价函数还是 A-star 算法中比较重要的一个点,但是估价函数的优秀的构造方法一般都很人类智慧,很难自己想到。
所以我们只好借鉴前人的思想,因为 A-star 算法的题目实在不多,所以把每一种题型的估价函数构造方法都弄熟练即可。
当然如果你考试时遇到了你不会的模型,你只能听天由命,或者猜一个了。
这需要你的想象力。
Acwing 179. 八数码
我们来看一道 A-star 算法的练手题。
对于八数码问题有一个快速判断是否无解的充要条件:
如果将输入的序列里面去掉那个叫做
x的项,如果这个序列的逆序对的数量是偶数则有解,否则无解。
这里就不证了,好像很难证。大约是和哈密顿回路有关系。
考虑找出估价函数。
不妨设估价函数为当前状态中每个数与它的目标位置的曼哈顿距离之和。
这是可能的最优情况(也就是每一轮都有一个数可以向目标位置移一格,显然这是最好的情况),可以证明不管实际情况的答案有多么优秀,一定都不小于这个值。
于是就这么简单地得出来了策略。
#include <bits/stdc++.h>
using namespace std;
const string fin = "12345678x";int dx[] = {0, 1, 0, -1};int dy[] = {1, 0, -1, 0};
string op = "rdlu";//操作,便于还原方案inline int get(string s) {//估价函数int x = 0;for (int i = 0; i < 9; i++)if (s[i] != 'x') {int a = s[i] - '1';//注意这里是 1 而不是 0!!!笔者这里卡了好久!!警钟长鸣!x += abs(i / 3 - a / 3) + abs(i % 3 - a % 3);}return x;
}
typedef pair<int, string> pis;//简化一下代码
inline void bfs(string st) {unordered_map<string, int> dep;//每一个点的步数unordered_map<string, pair<string, char> > pre;//每一个点的前驱,用来还原方案priority_queue<pis, vector<pis>, greater<pis> > q;q.push({get(st), st});dep[st] = 0;while (!q.empty()) {//首先队列非空string st = q.top().second;q.pop();int dp = dep[st];if (st == fin)//碰到终点直接退出break;int px, py;for (int i = 0; i < 9; i++)if (st[i] == 'x')px = i / 3, py = i % 3;//找 'x' 的位置string nw = st;for (int i = 0; i < 4; i++) {//尝试移动 'x'int x = px + dx[i], y = py + dy[i];if (x < 0 || x > 2 || y < 0 || y > 2)continue;//判断是否越界swap(st[x * 3 + y], st[px * 3 + py]);//移动if (!dep.count(st) || dep[st] > dp + 1) {//首先如果没有被访问到肯定可以加入队列,其次如果被访问到了但是从这里走会更优也可以重新加入队列dep[st] = dp + 1;pre[st] = {nw, op[i]};//记录前驱q.push({dep[st] + get(st), st});//加入队列}swap(st[x * 3 + y], st[px * 3 + py]);//还原}}string nw = fin, opr;while (nw != st) {//找出方案opr += pre[nw].second;nw = pre[nw].first;}reverse(opr.begin(), opr.end());//这里需要反转一下,因为是倒着走的cout << opr << endl;
}int main() {string s, x;char c;while (cin >> c) {//cin>>c 是一个友好的东西,可以帮我们过滤掉空格s += c;if (c != 'x')x += c;}int cnt = 0;for (int i = 0; i < 8; i++)for (int j = i + 1; j < 8; j++)cnt += (x[i] > x[j]);//算逆序对if (cnt & 1)//逆序对为奇数的时候则无解cout << "unsolvable";elsebfs(s);return 0;
}Acwing 178. 第 K 短路
感谢 这篇博客 把我一句话点醒了,大家快去点赞!
这句话就是:
我们知道在 BFS 中,第一次搜索到达终点的路径就是到终点的最短路,那么第 k k k 次到达终点的路径当然就是到终点的第 k k k 短路了。
我学了三年的算法竞赛怎么就没想到呢.jpg
而这里的 k ≤ 1000 k \le 1000 k≤1000,允许我们一次一次地到达终点。
但是这里需要注意的是:因为允许多次访问一个点(终点就是一个例子),所以每一个点走相邻地点时,不能再像 dijkstra 一样看相邻的结点走过了就不走了,而是必须要走所有相邻的结点。
所以我们就有了暴力的做法,感觉这种方法的复杂度比较玄学,但是肯定不能过。
但是根据数学直觉发现状态数量会非常庞大(每一个点都会走 k k k 次左右),于是考虑 A-star 算法。
这里需要注意一个点,想到了就谈一下:这个时候 A-star 算法依旧不能求出局部最小值,所以也不能求出除了终点之外的点的第 k k k 短路径。
A-star 算法就只需要思考两个东西:无解情况 和 估价函数。
首先考虑估价函数。显然有一个可能的构造方法就是:每一个点的估价函数都是这个点到终点的最短路径。这是有一些显然的,这样一定是小于等于实际情况的。
显然可以通过建反边跑最短路来求估价函数。
考虑再把估价函数再放大一点(这样可以节省时间),但是现实已经不允许我们再优化了。例如如果 k = 1 k=1 k=1 的话,对于某一些结点,它的估价函数就是恰好等于实际情况。所以这样是最大的可能的值。
考虑无解情况,就是当终点不能到达起点的时候显然不可以(路径的数量为 0 0 0)。剩下的无解情况就直接交给 A-star 算法看一下能不能熬到 k k k 次到达终点即可。
实际上也可以通过拓扑排序 + DAG 上 DP 来搞,这样就可以完全判断所有的无解情况,但是这样太复杂了。
代码有一点点难写。。
感觉搜索和 dp 在代码复杂度上面很像反义词。搜索是思路不难,但是代码并不好写。而 dp 是思路有些恶心,而代码相比搜索来说算短的(那些十几个转移方程和需要科技来优化的除外)。
但是这道题不需要上一道题一样使用 unordered_map 来记录每一个状态的步数了(这样有点难搞),直接加入状态。具体地,每一个状态记录:起点到这个点的距离和这个点的估价函数的和,起点到这个点的距离 和 这个点的编号。
这道题有一些些坑,在代码里面会体现出来。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int n, m;
const int N = 1010;
int f[N];
bool vis[N];
int s, t, k;
typedef pair<int, int> pii;
typedef pair<int, pii> piii;
vector<pii> v[N], fv[N];void dijkstra(int s) {for (int i = 1; i <= n; i++)f[i] = 1e15;f[s] = 0;priority_queue<pii, vector<pii>, greater<pii> > q;q.push({0, s});while (!q.empty()) {int u = q.top().second;q.pop();if (!vis[u])vis[u] = 1;elsecontinue;for (auto [to, w] : fv[u])if (f[to] > f[u] + w && !vis[to]) {f[to] = f[u] + w;q.push({f[to], to});}}
}
int cnt[N];int bfs() {priority_queue<piii, vector<piii>, greater<piii> > q;q.push({f[s], {0, s}});while (!q.empty()) {int u = q.top().second.second, dis = q.top().second.first;q.pop();cnt[u]++;if (cnt[t] == k)return dis;for (auto [to, w] : v[u])if (cnt[to] < k)//坑二,需要判断是否走了 <k 次,要不然就走了也没用q.push({dis + w + f[to], {dis + w, to}});}return -1;
}signed main() {cin >> n >> m;for (int i = 1; i <= m; i++) {int x, y, w;cin >> x >> y >> w;v[x].push_back({y, w});fv[y].push_back({x, w});}cin >> s >> t >> k;if (s == t)//坑一k++;dijkstra(t);if (f[s] == 1e15) {cout << "-1\n";return 0;}cout << bfs() << endl;return 0;
}迭代加深搜索
乍一看这些搜索名字好像都挺高级的,实际上并不难。
迭代加深搜索的英文名是 IDDFS,也就是加上了 Iterative Deepening(迭代加深) 的 DFS。
通过名字可以知道这是一种和深度有密切关系的 DFS 优化算法。
在搜索的时候,可能会有这样的情况发生:搜索树太高了,以至于每一次搜索一个分岔,返回都要很长时间。但是你要搜的答案在很浅层的位置。
而你如果按照普通的 DFS 来跑的话,你就需要在很多地方白跑一趟那么长的距离。然后你又发现你的答案不需要你跑那么远,好长的一段时间都白费了,就问你气不气?
但是,我们可以从搜索树的根结点开始,每一次迭代加深搜索树的深度,找这一层的结点里面是否有答案并计算答案。
显然,这样的效率会高很多。因为你找到答案你就直接输出了,没有必要再到所有更深的深度的结点里面里面去搜。
于是 IDDFS 的思想就是那么简单。
显然 IDDFS 不会劣于暴力 DFS,因为 DFS 遍历到的状态 IDDFS 最多也只会遍历到一次,而 DFS 没有遍历到的状态 IDDFS 就更不可能遍历到了。
然后就有人会问了:那这不是和 BFS 一模一样的吗,都是逐渐增加深度?
注意,BFS 的空间复杂度和迭代加深搜索不同。
BFS 的主体结构是一个队列,每一次访问一层也要记录下上一层的结点(这样的复杂度是指数级别的,比较浪费空间)。
而迭代加深搜索只会记录路径上的信息,所以它的时间空间复杂度是 O ( n ) O(n) O(n) 的(也就是和答案所在的深度成正比),比 BFS 更加优秀。
但是于是我们会发现迭代加深搜索有时候可能会比 BFS 更加优秀,但是 BFS 好写啊!
而且,迭代加深搜索相比于 BFS 有一个独门绝技。BFS 有 A-star 的优化算法,而迭代加深搜索有一个 IDA-star 算法,是前面的 A* 的优化版本。
可能有些人还会问:那么这个东西会不会效率太低呢?
等比数列求和公式告诉我们,这样的效率并不是太低的。
在最坏的情况下,设搜索树是二叉树,在第 n n n 层的点数为 2 n 2^n 2n,而前 n − 1 n-1 n−1 层的点数为 2 0 + 2 1 + ⋯ + 2 n − 1 = 2 n − 1 < 2 n 2^0+2^1 + \cdots + 2^{n-1} = 2^n - 1<2^n 20+21+⋯+2n−1=2n−1<2n,发现前 n − 1 n-1 n−1 层在最坏情况下相对于第 n n n 层单单一层的点数可以忽略不计!(算上的话也只是多了一个常数)。如果树的叉数更多,或者是情况不是最坏的,那就更可以忽略不计了!
那有些人就又会问:那么如果这个二叉树不是满二叉树呢?
不妨仔细思考一下。如果第 x x x 层相比于前 x − 1 x-1 x−1 层的结点数并不多的话,那么这棵树就不是爆炸式增长的了,直接暴力也可以,何况 IDDFS 比暴力 DFS 更快呢。
所以这样优化是毋庸置疑的,很高效。想想你搜完前几层的 x x x 个点就搜到了答案就退出了,而普通的 DFS 必须要辛辛苦苦地全部搜一遍。
170. 加成序列
不妨来看一道 IDDFS 地练手题。
这道题要求我们构造一个数列满足题面中的要求,还要长度最小,且整个数列的值域 ≤ 100 \le 100 ≤100。
长度最小,就很容易想到使用 IDDFS 了。
其次,发现最终的答案可以是这样子的: 1 , 2 , 4 , 8 , 16 , 32 , 64 , 128 1,2,4,8,16,32,64,128 1,2,4,8,16,32,64,128,可以发现长度为 8 8 8 的数列就已经可以使最后一个数 > 100 >100 >100 了,所以可以证明最终的答案的长度不会大于 8 8 8。
于是就更加 IDDFS 了:答案的长度,也就是答案状态的深度不会超过 8 8 8。
显然可以加几个剪枝来优化一下时间:
剪枝一:优先枚举较大的数
这是显然的。这样可以尽可能地减小答案的长度。
剪枝二:排除等效的冗余
可能会有人不懂这是什么意思,实际上这个东西的含义很简单:就是排除相同的序列。
例如 1 , 2 , 3 , 4 , □ 1,2,3,4,\square 1,2,3,4,□,这个序列。很容易发现 □ \square □ 可以等于 1 + 4 = 2 + 3 = 5 1+4=2+3=5 1+4=2+3=5,所以这两种情况最终都会得出来一个相同的序列。
所以可以使用桶来搞。
剪枝三:使用性质
这个性质就是:每一个数至多是上一个数的两倍。
所以如果一个数即使每一次翻一倍都不能达到目标的话,那就直接 return 得了。
代码比较好写。就是直接枚举答案的长度,并 dfs 判断即可。
#include <bits/stdc++.h>
using namespace std;
const int N = 210;
int p[N];
int n;bool dfs(int nw, int d) {if (nw > d)return 0;if (p[nw - 1] == n)//找到序列return 1;if (p[nw - 1] * (1 << (d - nw + 1)) < n)//剪枝三return 0;bool f[N] = {0};//初始化!!!for (int i = 0; i < nw; i++)for (int j = 0; j <= i; j++) {int sum = p[i] + p[j];if (sum > n || sum <= p[nw - 1]/*剪枝二*/ || f[sum])continue;f[sum] = 1, p[nw] = sum;if (dfs(nw + 1, d))return 1;}return 0;
}int main() {p[0] = 1;while (1) {cin >> n;if (!n)return 0;int d = 1;while (!dfs(1, d))//迭代加深搜索d++;for (int i = 0; i < d; i++)//输出答案cout << p[i] << " ";cout << endl;}return 0;
}IDA-star 算法
根据前面的 IDDFS 和 A-star 算法的启发,世界上诞生了一个叫做 IDA-star 算法,也就是迭代加深 A 星算法。
迭代加深只有在状态呈指数级增长时才有较好的效果,而 A* 就是为了防止状态呈指数级增长的,所以强强联手变成更强的东西。
众所周知 DFS 加上一个 ID 就可以优化很多,所以 A-star 加上一个 ID 也可以优化很多。这里的 ID 是一个很强的优化。
IDA-star 就是比较朴素的 dfs 加上一个估价函数,时间复杂度有些玄学,其他的和 A-star 算法没有啥共同点。
优化就是这个东西:
一开始先指定一个 d d d(要迭代加深的深度),然后就是一个非常强的剪枝:
- 如果一个点到答案的预估函数怎么样都会 > d >d >d 的话,那么就直接不搜这个点了。
这就是 IDA* 的思想。
180. 排书
显然每一次的决策可以有 15 × 14 + 14 × 13 + 13 × 12 + ⋯ + 2 × 1 2 = 560 \frac{15 \times 14 + 14\times 13 + 13\times 12 +\cdots + 2\times 1}{2} = 560 215×14+14×13+13×12+⋯+2×1=560 种,要爆搜的话显然最终的时间复杂度就是 O ( 56 0 4 ) = O ( 爆炸 ) O(560^4) = O(爆炸) O(5604)=O(爆炸)。
但是显然可以使用双向广搜把它变成 O ( 56 0 2 ) O(560^2) O(5602) 的,这样就可以过了。
考虑使用 IDA-star 来做这道题。
IDA-star 和 A-star 相同,还是需要思考如何设计估价函数。
显然最终排好序的序列一定是这样子的: 1 , 2 , 3 , ⋯ , n 1,2,3,\cdots,n 1,2,3,⋯,n。
**考虑相邻两个元素之间的关系。**显然,最终排好序的序列,后一个数的值是前一个数的值 + 1 + \ 1 + 1。
考虑将 [ l , r ] [l,r] [l,r] 从序列中删除,并移到另一个位置。再次将眼光放到相邻关系上面。发现最多会改变三个相邻关系。
所以,设要排序的序列是 a 1 , a 2 , a 3 , ⋯ , a n a_1,a_2,a_3,\cdots,a_n a1,a2,a3,⋯,an,设 ∑ i = 1 n − 1 ( a i + 1 − a i ≠ 1 ) = t o t \sum_{i=1}^{n-1} (a_{i+1}-a_i \not = 1) = tot ∑i=1n−1(ai+1−ai=1)=tot(也就是算相邻关系不对的数对数量),而每一次最多会纠正 3 3 3 个相邻关系。
所以最终一个序列的估价函数就是 ⌈ t o t 3 ⌉ = ⌊ t o t + 2 3 ⌋ \lceil \frac{tot}{3} \rceil = \lfloor \frac{tot+2}{3} \rfloor ⌈3tot⌉=⌊3tot+2⌋。可以证明,这是可能达到的最大值。
感觉这个思路太妙了,出题人真是个天才!!!
#include <bits/stdc++.h>
using namespace std;
const int N = 16;
int n;
int b[N], a[5][N];int f() {//估价函数int res = 0;for (int i = 0; i < n - 1; i++)if (b[i + 1] != b[i] + 1)res++;return (res + 2) / 3;
}bool get() {for (int i = 0; i < n; i++)if (b[i] != i + 1)return 0;return 1;
}bool dfs(int d, int mx) {//直接大力 dfsif (d + f() > mx)return 0;if (get())return 1;for (int l = 0; l < n; l++)for (int r = l; r < n; r++)for (int k = r + 1; k < n; k++) {memcpy(a[d], b, sizeof b);int x, y;for (x = r + 1, y = l; x <= k; x++, y++)b[y] = a[d][x];for (x = l; x <= r; x++, y++)b[y] = a[d][x];if (dfs(d + 1, mx))return 1;memcpy(b, a[d], sizeof b);}return 0;
}int main() {int T;cin >> T;while (T--) {cin >> n;for (int i = 0; i < n; i++)cin >> b[i];int d = 0;while (d < 5 && !dfs(0, d))d++;if (d >= 5)cout << "5 or more" << endl;elsecout << d << endl;}return 0;
}
相关文章:

进阶 DFS 学习笔记
字数:12017字。 文章盗的图注明了出处,全部出自 y 总的算法提高课。 不知道为啥这个时候才开始学这个东西,好像是很多同龄人都已经学完了。 进阶 DFS 具体来说好几个东西,所以可能内容有一些些多。 默认 DFS 和 BFS 已经掌握了…...

计算机设计大赛山东省赛区软件开发赛道线上答辩复盘
流程回顾: 1.抽签顺序: 抽签顺序并不一定代表是最终顺序,要注意看通知不要遗漏。 2.答辩形式: 线上答辩,加入腾讯会议,进会议时自己的备注是作品编号,等轮到自己组答辩时主持人会把人拉进来…...

第7次课 栈A
课堂学习 栈(stack) 是一种遵循先入后出逻辑的线性数据结构。 我们可以将栈类比为桌面上的一摞盘子,如果想取出底部的盘子,则需要先将上面的盘子依次移走。我们将盘子替换为各种类型的元素(如整数、字符、对象等&…...

TXT编码转换工具iconv
iconv.exe是实现TXT编码转换的命令行工具,支持几百种编码格式的转换,利用它可以在自主开发程序上实现TXT文档编码的自动转换。 一、命令参数格式 Usage: iconv [-c] [-s] [-f fromcode] [-t tocode] [file ...] or: iconv -l 二、转换的示例 将UTF-8…...

基于Spring Boot + Vue的高校心理教育辅导系统
一、项目背景介绍 随着高校对学生心理健康教育的重视,传统的人工心理辅导与测评模式已经难以满足广大师生的个性化需求。为了提高心理服务的效率、便捷度和覆盖范围,本项目开发了一个高校心理教育辅导系统,集成心理评测、辅导预约、留言交流…...
丢失MFA的解决方案)
关于甲骨文(oracle cloud)丢失MFA的解决方案
前两年,申请了一个招商的多币种信用卡,然后就从网上撸了一个oracle的免费1h1g的服务器。 用了一段时间,人家要启用MFA验证。 啥叫MFA验证,类似与短信验证吧,就是绑定一个手机,然后下载一个app,每…...

Linux系统管理与编程17:自动化部署ftp服务
兰生幽谷,不为莫服而不芳; 君子行义,不为莫知而止休。 #virtual用户管理:passerbyA、captain和admin三个虚拟用户 # passerbyA只能看,captain可看读写上传,但不能删除。admin全部权限 [rootshell shell]…...

C++STL——stack,queue
stack与queue 前言容器适配器deque 前言 本篇主要讲解stack与queue的底层,但并不会进行实现,stack的接口 queue的接口 ,关于stack与queue的接口在这里不做讲解,因为通过前面的对STL的学习,这些接口都是大同小异的。 …...

HC-SR04超声波测距传感器
1.基本信息 供电电压5v,测量范围2cm~400cm,测量精度正负3mm,超声波频率40khz 2.连接引脚: 3.工作原理 TRIG引脚发送至少10us的高电平信号,ECHO引脚负责接受信号; 接受方式:计算测量高电平持续的时间,从一…...

内存安全暗战:从 CVE-2025-21298 看 C 语言防御体系的范式革命
引言 2025 年 3 月,美国 CERT 发布的《年度漏洞报告》揭示了触目惊心的数据:C/C 相关漏洞占全年高危漏洞的 68%,其中内存安全问题贡献了 92% 的远程代码执行风险。当 CVE-2025-21298 漏洞在某工业控制软件中被利用,导致欧洲某核电…...

Linux笔记---System V共享内存
1. System V共享内存简介 System V共享内存是一种在Linux系统中用于进程间通信的机制。顾名思义,就是申请一段可供多个进程共享的内存,以用于进程间通信,相对于管道机制要更加直接。 1.1 原理 System V共享内存通过创建和使用一个特定的IP…...

MySQL 1366 - Incorrect string value:错误
MySQL 1366 - Incorrect string value:错误 错误如何发生发生原因: 解决方法第一种尝试第二种尝试 错误 如何发生 在给MySQL添加数据的时候发生了下面的错误 insert into sys_dept values(100, 0, 0, 若依科技, 0, 若依, 15888888888, ryqq.com, 0,…...

慈缘基金会“蝴蝶飞”助西藏女孩白玛卓嘎“折翼重生”
历经六个月、178天的艰难治疗,来自西藏拉萨的15岁女孩白玛卓嘎,终于在4月底挺直脊梁,带着自信的笑容踏上了回家的路。这场跨越雪域高原与首都北京的“生命蜕变之旅”,不仅改写了这位藏族少女的人生轨迹,更见证了公益力…...

【生存技能】ubuntu 24.04 如何pip install
目录 原因解决方案说明 在接手一个新项目需要安装python库时弹出了以下提示: 原因 这个报错是因为在ubuntu中尝试直接使用 pip 安装 Python 包到系统环境中,ubuntu 系统 出于稳定性考虑禁止了这种操作 这里的kali是因为这台机器的用户起名叫kali,我也不知道为什么…...

TDengine 在智能制造中的核心价值
简介 智能制造与数据库技术的深度融合,已成为现代工业技术进步的一个重要里程碑。随着信息技术的飞速发展,智能制造已经成为推动工业转型升级的关键动力。在这一进程中,数据库技术扮演着不可或缺的角色,它不仅承载着海量的生产数…...
)
代码随想录第41天:图论2(岛屿系列)
一、岛屿数量(Kamacoder 99) 深度优先搜索: # 定义四个方向:右、下、左、上,用于 DFS 中四向遍历 direction [[0, 1], [1, 0], [0, -1], [-1, 0]]def dfs(grid, visited, x, y):"""对一块陆地进行深度…...

C语言复习--柔性数组
柔性数组是C99中提出的一个概念.结构体中的最后⼀个元素允许是未知大小的数组,这就叫做柔性数组成员。 格式大概如下 struct S { int a; char b; int arr[];//柔性数组 }; 也可以写成 struct S { int a; char b; int arr[0];//柔性数组 }; …...

《Python星球日记》 第55天:迁移学习与预训练模型
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、迁移学习基础1. 什么是迁移学习?2. 迁移学习的优势3. 迁移学习的…...
)
Python项目75:PyInstaller+Tkinter+subprocess打包工具1.0(安排 !!)
这个打包工具包含以下功能: 1.主要功能:选择Python脚本文件,设置打包选项(单文件打包、无控制台窗口),自定义程序图标,指定输出目录,实时显示打包日志。 2.自适应布局改进ÿ…...

互联网大厂Java面试实录:从基础到微服务的深度考察
互联网大厂Java面试实录:从基础到微服务的深度考察 面试场景 面试官:风清扬(严肃且技术深厚) 求职者:令狐冲(技术扎实但偶尔含糊) 第一轮:Java基础与框架 风清扬:令狐…...

学习黑客5 分钟深入浅出理解Linux进程管理
5 分钟深入浅出理解Linux进程管理 🖥️ 大家好!今天我们将探索Linux系统中的进程管理——这是理解系统运行机制和进行安全分析的基础知识。在TryHackMe平台上进行网络安全学习时,了解进程如何工作以及如何监控和控制它们,对于识别…...

Kubernetes应用发布方式完整流程指南
Kubernetes(K8s)作为容器编排领域的核心工具,其应用发布流程体现了自动化、弹性和可观测性的优势。本文将通过一个Tomcat应用的示例,详细讲解从配置编写到高级发布的完整流程,帮助开发者掌握Kubernetes应用部署的核心步…...

JVM——即时编译器的中间表达形式
中间表达形式(IR):编译器的核心抽象层 1. IR的本质与作用 在编译原理的体系中,中间表达形式(Intermediate Representation, IR)是连接编译器前端与后端的桥梁。前端负责将源代码转换为IR,而后…...

Js 判断浏览器cookie 是否启用
验证时 google浏览器 135.0.7049.117 不生效 cookie.html <!DOCTYPE html> <html lang"zh"> <head><meta charset"UTF-8"><title>Cookie 检测</title> </head> <body><h1>检测是否启用 Cookie<…...

数字相机的快门结构
数字相机(DC/DSLR等)的快门结构和传统相机有所不同,除了机械快门以外,还存在电子快门,实际上是二者的混合体。我写这篇文章大概介绍一下数字相机的快门结构,希望能抛砖引玉。 要讨论数字相机的快门结构,首先先要了解一下数字相机的结构分类,根据成像原理不同,数字相机大…...

LeetCode --- 448 周赛
题目列表 3536. 两个数字的最大乘积 3537. 填充特殊网格 3538. 合并得到最小旅行时间 3539. 魔法序列的数组乘积之和 一、两个数字的最大乘积 由于数据都是正数,所以乘积最大的两个数,本质就是找数组中最大的两个数即可,可以排序后直接找到…...

添加物体.
在cesium中我们可以添加物体进入地图.我们以广州塔为例 //生成广州塔的位置var position2 Cesium.Cartesian3.fromDegrees(113.3191,23.109,100)viewer.camera.setView({//指定相机位置destination: position2, 运行后如图 我们使用cesium官网提供的代码为广州塔在地图上标点…...

ABB电机控制和保护单元与Profibus DP主站转Modbus TCP网关快速通讯案例
ABB电机控制和保护单元与Profibus DP主站转Modbus TCP网关快速通讯案例 在现代工业自动化系统中,设备之间的互联互通至关重要。Profibus DP和Modbus TCP是两种常见的通信协议,分别应用于不同的场景。为了实现这两种协议的相互转换,Profibus …...

Yocto中`${S}`和`${WORKDIR}`的联系与区别
在Yocto项目中,${S}和${WORKDIR}是构建过程中两个核心路径变量,它们的关系及用途如下: 定义与层级关系${WORKDIR}(工作目录) 是Recipe所有任务执行的基础目录,路径结构为: build/tmp/work/<arch>/<recipe-name>/<version>/。 该目录包含源码解压后的所…...

CDGP历次主观题真题回忆
(一)【论述】 1如何设计企业的数据安全体系?活动+方法+DSMM 2如何管理公司混乱的数据质量?活动+遵循原则+建立质量维度+质量改进生命周期+高阶指标。...

Java学习手册:Spring Cloud 组件详解
一、服务发现组件 - Eureka 核心概念 :Eureka 是一个服务发现组件,包含 Eureka Server 和 Eureka Client 两部分。Eureka Server 作为服务注册中心,负责维护服务实例的注册信息;Eureka Client 则是集成在应用中的客户端࿰…...

【大模型】使用 LLaMA-Factory 进行大模型微调:从入门到精通
使用 LLaMA-Factory 进行模型微调:从入门到精通 一、环境搭建:奠定微调基础(一)安装依赖工具(二)创建 conda 环境(三)克隆仓库并安装依赖 二、数据准备:微调的基石&#…...

sensitive-word-admin v2.0.0 全新 ui 版本发布!vue+前后端分离
前言 sensitive-word-admin 最初的定位是让大家知道如何使用 sensitive-word,所以开始想做个简单的例子。 不过秉持着把一个工具做好的原则,也收到很多小伙伴的建议。 v2.0.0 在 ruoyi-vue(也非常感谢若依作者多年来的无私奉献)…...

HTML属性
HTML(HyperText Markup Language)是网页开发的基石,而属性(Attribute)则是HTML元素的重要组成部分。它们为标签提供附加信息,控制元素的行为、样式或功能。本文将从基础到进阶,全面解析HTML属性…...
)
计算机网络 4-1 网络层(网络层的功能)
【考纲内容】 (一)网络层的功能 异构网络互连;路由与转发;SDN基本概念;拥塞控制 (二)路由算法 静态路由与动态路由;距离-向量路由算法;链路状态路由算法;层…...
》阅读笔记:p17-p27)
《算法导论(第4版)》阅读笔记:p17-p27
《算法导论(第4版)》学习第 10 天,p17-p27 总结,总计 11 页。 一、技术总结 1. insertion sort (1)keys The numbers to be sorted are also known as the keys(要排序的数称为key)。 第 n 次看插入排序,这次有两个地方感触比较深&#…...

C++中线程安全的对多个锁同时加锁
C中线程安全的对多个锁同时加锁 C中线程安全的对两个锁同时加锁 C中线程安全的对两个锁同时加锁 参考文档:https://llfc.club/articlepage?id2UVOC0CihIdfguQFmv220vs5hAG 如果我们现在有一个需要互斥访问的变量 big_object,它的定义如下: …...
一维前缀和, 蓝桥杯)
子串简写(JAVA)一维前缀和, 蓝桥杯
这个题用前缀和,开两个数组,一个存前n个字符数据的c1的数字个数,另一个前n个字符c2的数字个数,然后遍历一次加起来,有一个测试点没过去,把那个存最后数的换成long,应该是这题数据范围给的不对&a…...

数据库故障排查全攻略:从实战案例到体系化解决方案
一、引言:数据库故障为何是技术人必须攻克的 "心腹大患" 在数字化时代,数据库作为企业核心数据资产的载体,其稳定性直接决定业务连续性。据 Gartner 统计,企业每小时数据库 downtime 平均损失高达 56 万美元࿰…...

vllm笔记
目录 vllm简介vllm解决了哪些问题?1. **瓶颈:KV 缓存内存管理低效**2. **瓶颈:并行采样和束搜索中的内存冗余**3. **瓶颈:批处理请求中的内存碎片化** 快速开始安装vllm开始使用离线推理启动 vLLM 服务器 支持的模型文本语言模型生…...

“AI+城市治理”智能化解决方案
目录 一、建设背景 二、需求分析 三、系统设计 四、系统功能 五、应用场景 六、方案优势 七、客户价值 八、典型案例 一、建设背景 当前我国城市化率已突破65%,传统治理模式面临前所未有的挑战。一方面,城市规模扩大带来治理复杂度呈指数级增长,全国城市管理案件年…...

《医疗AI的透明革命:破解黑箱困境与算法偏见的治理之路》
医疗AI透明度困境 黑箱问题对医生和患者信任的影响:在医疗领域,AI模型往往表现为难以理解的“黑箱”,这会直接影响医生和患者对其诊断建议的信任度 。医生如果无法理解AI给出诊断的依据,就难以判断模型是否存在偏见或错误&#x…...

【论文阅读】Efficient and secure federated learning against backdoor attacks
Efficient and secure federated learning against backdoor attacks -- 高效且安全的可抵御后门攻击的联邦学习 论文来源问题背景TLDR系统及威胁模型实体威胁模型 方法展开服务器初始化本地更新本地压缩高斯噪声与自适应扰动聚合与解压缩总体算法 总结优点缺点 论文来源 名称…...
)
21、DeepSeekMath论文笔记(GRPO)
DeepSeekMath论文笔记 0、研究背景与目标1、GRPO结构GRPO结构PPO知识点**1. PPO的网络模型结构****2. GAE(广义优势估计)原理****1. 优势函数的定义**2.GAE(广义优势估计) 2、关键技术与方法3、核心实验结果4、结论与未来方向关键…...

深入解析:如何基于开源p-net快速开发Profinet从站服务
一、Profinet协议与软协议栈技术解析 1.1 工业通信的"高速公路" Profinet作为工业以太网协议三巨头之一,采用IEEE 802.3标准实现实时通信,具有: 实时分级:支持RT(实时)和IRT(等时实时)通信模式拓扑灵活:支持星型、树型、环型等多种网络结构对象模型:基于…...

腾讯多模态定制化视频生成框架:HunyuanCustom
HunyuanCustom 速读 一、引言 HunyuanCustom 是由腾讯团队提出的一款多模态定制化视频生成框架。该框架旨在解决现有视频生成方法在身份一致性(identity consistency)和输入模态有限性方面的不足。通过支持图像、音频、视频和文本等多种条件输入,HunyuanCustom 能…...

警惕C#版本差异多线程中的foreach陷阱
警惕C#版本差异多线程中的foreach陷阱 同样的代码,不同的结果闭包捕获的“时间差”问题绕过闭包陷阱的三种方法Lambda立即捕获(代码简洁)显式传递参数(兼容性最佳)使用Parallel.ForEach(官方推荐)注意事项:版本兼容性指南警惕多线程中的foreach陷阱:C#版本差异引发的…...

2024年AI发展趋势全面解析:从多模态到AGI的突破
2024年AI发展五大核心趋势 1. 多模态AI的爆发式增长 GPT-4V、Gemini等模型实现文本/图像/视频的跨模态理解应用场景扩展至智能客服、内容创作、工业质检等领域 2. 小型化与边缘AI的崛起 手机端LLM(如Phi-2)实现本地化部署隐私保护与实时响应的双重优…...
)
高精度之加减乘除之多解总结(加与减篇)
开篇总述:精度计算的教学比较杂乱,无系统的学习,且存在同法多线的方式进行同一种运算,所以我写此篇的目的只是为了直指本质,不走教科书方式,步骤冗杂。 一,加法 我在此讲两种方法: …...
)
Arduino 开源按键库大合集(单击/双击/长按实现)
2025.5.10 22:25更新:增加了Button2 2025.5.10 13:13更新:增加了superButton 虽然Arduino自带按键中断attachInterrupt(button1.PIN, isr, FALLING);,但是要是要实现去抖,双击检测,长按检测等等就略微麻烦些࿰…...