《Python星球日记》 第55天:迁移学习与预训练模型
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、迁移学习基础
- 1. 什么是迁移学习?
- 2. 迁移学习的优势
- 3. 迁移学习的应用场景
- 二、预训练模型详解
- 1. 预训练模型的基本概念
- 2. 常用的预训练模型
- a) VGG系列
- b) ResNet系列
- c) EfficientNet系列
- 三、冻结层与微调技巧
- 1. 模型迁移的两种主要策略
- 2. 如何实现层冻结
- 3. 微调的最佳实践
- 四、超参数调优方法
- 1. 超参数调优的重要性
- 2. 网格搜索(Grid Search)
- 3. 随机搜索(Random Search)
- 4. 早停法(Early Stopping)
- 五、基于ResNet的图像分类实战
- 1. 项目概述与数据准备
- 2. 构建迁移学习模型
- 3. 分两阶段训练模型
- 4. 评估模型并可视化结果
- 5. 模型部署与应用
- 六、总结与进阶方向
- 1. 知识回顾
- 2. 进阶方向
- 3. 实践建议
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第54天:卷积神经网络进阶
欢迎来到Python星球的第55天!🪐
今天我们将探索深度学习中的一项重要技术——迁移学习,以及如何利用预训练模型来提升我们的模型性能。无论你是想节省训练时间,还是面临数据量不足的挑战,这些技术都将帮助你构建更强大的神经网络。
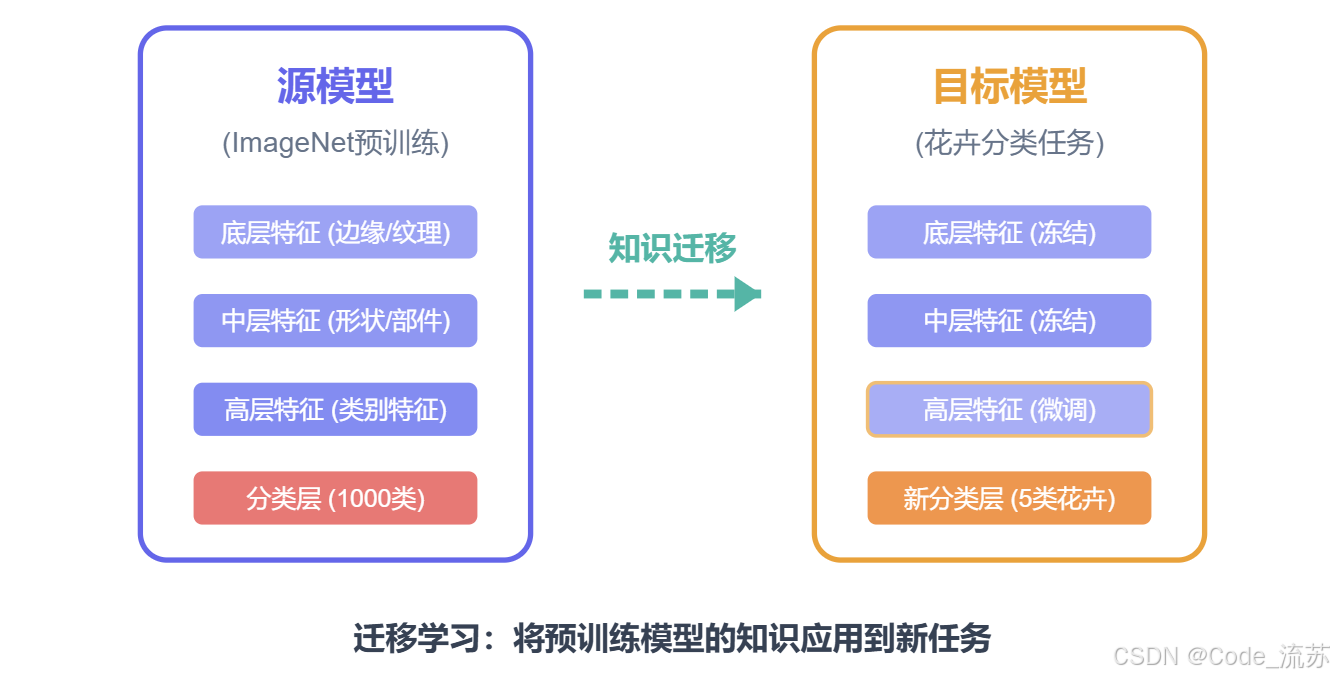
一、迁移学习基础
1. 什么是迁移学习?
迁移学习是一种机器学习方法,它允许我们将从一个任务中学到的知识应用到另一个相关任务中。简单来说,就是让模型"借鉴"已有经验来解决新问题,而不是从零开始学习。
想象一下:如果你已经会骑自行车,那么学习骑摩托车就会容易得多,因为你已经掌握了平衡和方向控制的基本技能。迁移学习在深度学习中的原理也是如此!
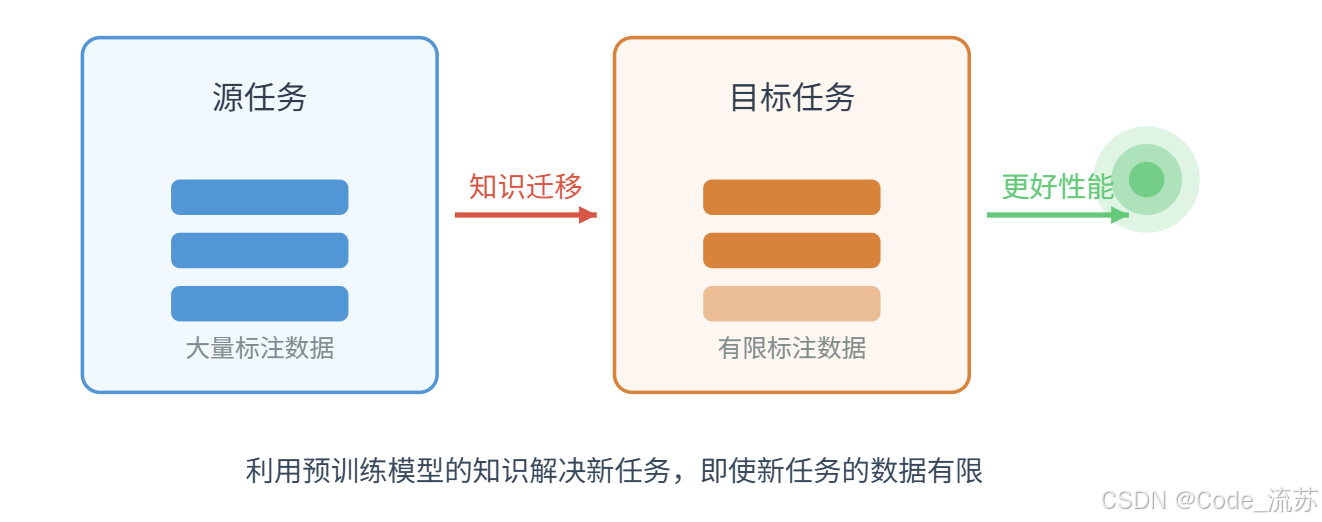
2. 迁移学习的优势
在深度学习世界中,迁移学习具有以下显著优势:
- 减少训练数据需求:当我们的目标任务数据有限时,迁移学习能够大幅降低对大规模标注数据的依赖
- 缩短训练时间:从预训练模型开始,通常能比从随机权重开始训练更快地收敛
- 提高模型性能:尤其在数据有限的情况下,迁移学习通常能获得更好的准确率和泛化能力
- 降低计算资源需求:不需要从头训练大型模型,节省GPU资源和电力消耗
3. 迁移学习的应用场景
迁移学习特别适用于以下场景:
- 目标任务的标注数据量不足
- 源任务和目标任务存在相关性
- 需要快速构建模型原型
- 计算资源有限
二、预训练模型详解
1. 预训练模型的基本概念
预训练模型是指在大规模数据集(如ImageNet,包含上百万张图片)上训练过的神经网络模型。这些模型已经学习了丰富的视觉特征和模式,可以被迁移到其他计算机视觉任务中。
预训练模型的底层卷积层通常捕获通用的特征(如边缘、纹理、简单形状),而高层则捕获更复杂、更特定于任务的特征。这种分层特征提取的能力是迁移学习能够成功的关键原因。
2. 常用的预训练模型
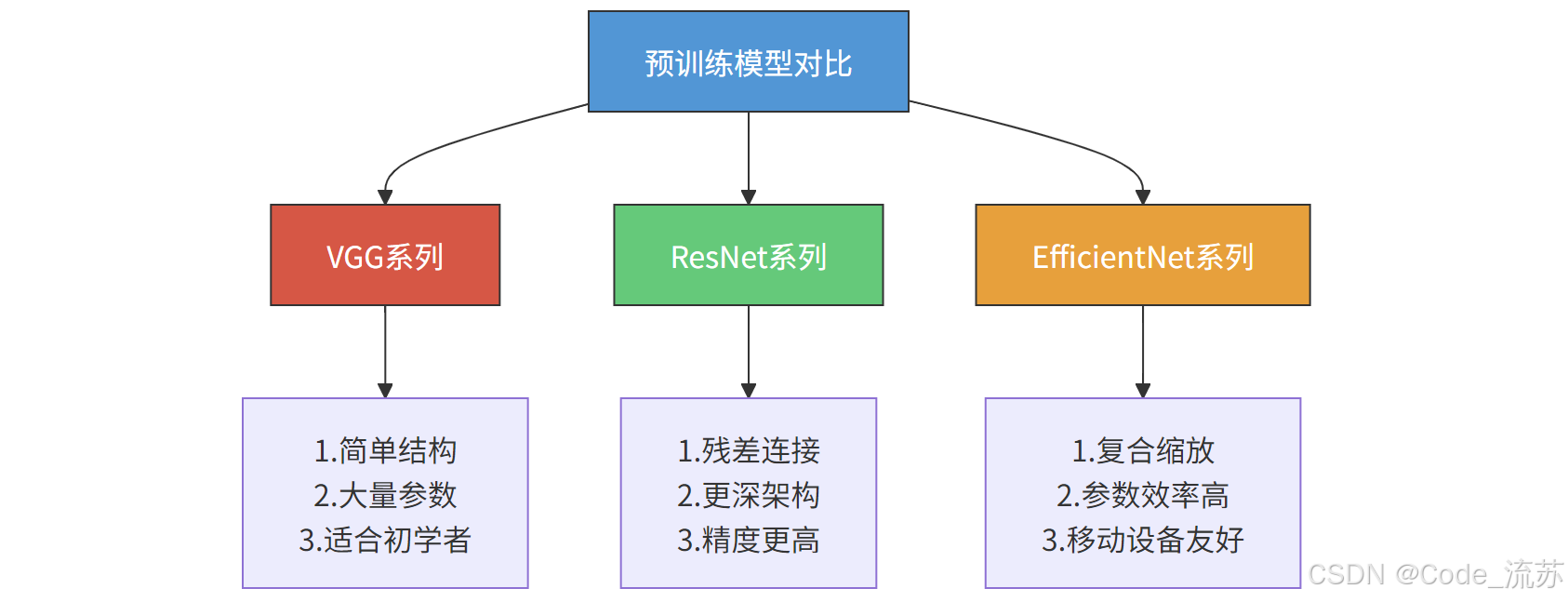
在计算机视觉领域,有几种广泛使用的预训练模型:
a) VGG系列
VGG16/VGG19是由牛津大学Visual Geometry Group开发的模型。
- 特点:结构简单、易于理解,使用3×3卷积堆叠而成
- 参数量:VGG16约有1.38亿参数,VGG19约有1.44亿参数
- 优缺点:结构规整清晰,但参数量大,推理速度相对较慢
- 适用场景:初学者学习CNN架构,较简单的图像分类任务
# 导入VGG16预训练模型
from tensorflow.keras.applications import VGG16# 加载不含顶层(全连接层)的VGG16模型
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
b) ResNet系列
ResNet(残差网络)由微软研究院提出,通过引入残差连接解决了深层网络训练困难的问题。
- 特点:引入跳跃连接(skip connection),允许信息直接从前层传到后层
- 变体:ResNet18、ResNet50、ResNet101、ResNet152等
- 优势:能够构建更深的网络而不导致梯度消失/爆炸问题
- 使用场景:复杂图像分类、目标检测、图像分割等
# 导入ResNet50预训练模型
from tensorflow.keras.applications import ResNet50# 加载预训练的ResNet50
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
c) EfficientNet系列
EfficientNet由Google研究团队开发,通过复合缩放方法在准确率和效率之间取得优异平衡。
- 特点:同时缩放网络的宽度、深度和分辨率
- 变体:EfficientNetB0到EfficientNetB7(复杂度递增)
- 优势:参数量少但性能高,FLOPS效率极佳
- 适用场景:资源受限设备、需要高效推理的应用
# 导入EfficientNetB0预训练模型
from tensorflow.keras.applications import EfficientNetB0# 加载预训练的EfficientNetB0
base_model = EfficientNetB0(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
预训练模型对比:
三、冻结层与微调技巧
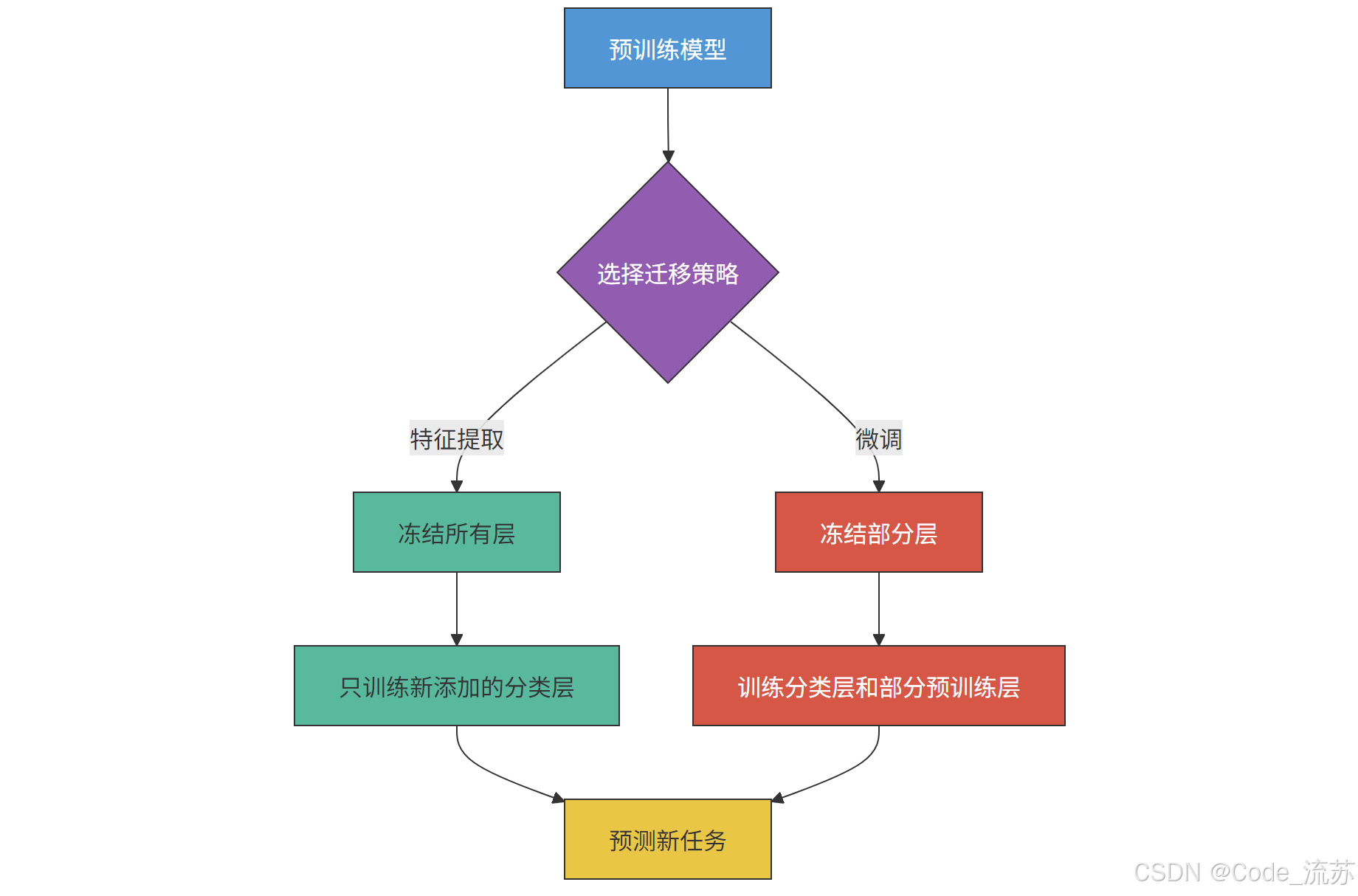
1. 模型迁移的两种主要策略
在迁移学习中,我们主要有两种策略来利用预训练模型:特征提取和微调。
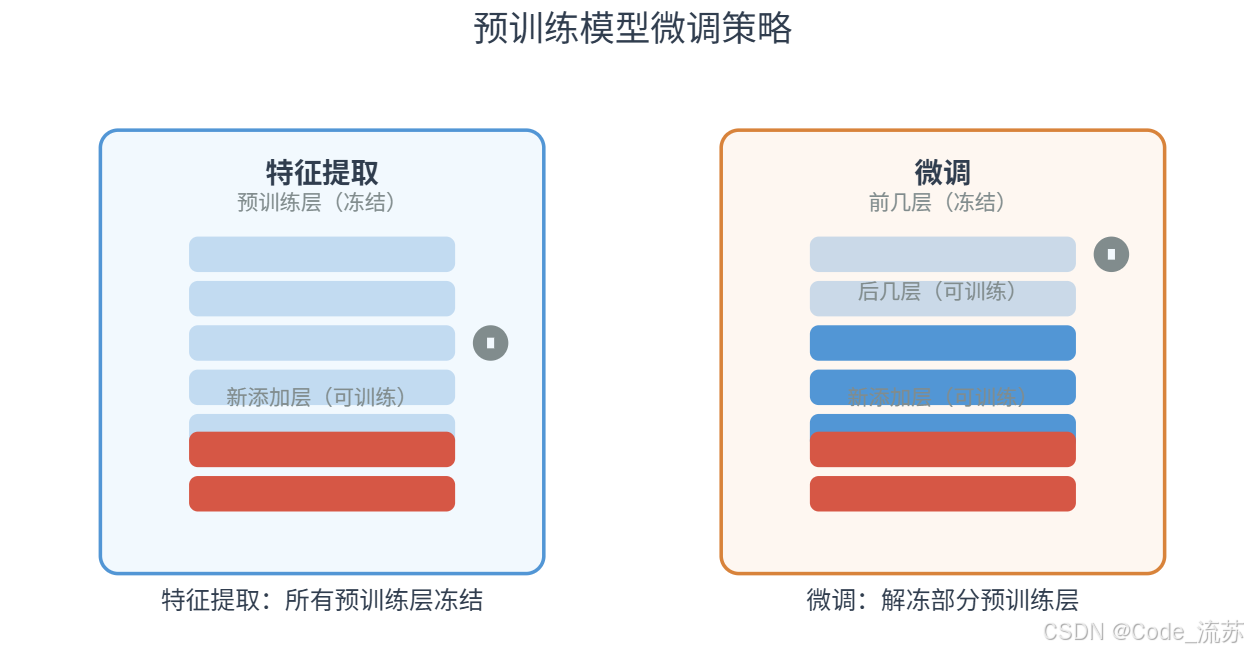
特征提取(Feature Extraction):
在这种策略中,我们将预训练模型视为固定的特征提取器,只训练新添加的层。
- 我们冻结(freeze)预训练模型的所有层,使其权重在训练过程中不更新
- 然后添加自定义的分类层(通常是全连接层),只训练这些新添加的层
- 这种方法适用于新任务与预训练模型的原始任务非常相似的情况,或数据量非常小的情况
微调(Fine-tuning):
在微调策略中,除了训练新添加的层外,我们还会更新预训练模型的部分层。
- 通常冻结预训练模型的前几层(捕获通用特征的层)
- 允许后面的层(捕获更特定任务特征的层)与新添加的分类层一起训练
- 这种方法适用于新任务与原始任务有一定差异,且有足够数据的情况
2. 如何实现层冻结
在TensorFlow/Keras中,冻结层非常简单:
# 冻结预训练模型的所有层
base_model = ResNet50(weights='imagenet', include_top=False)
base_model.trainable = False # 整个模型不可训练# 或者选择性地冻结特定层
base_model = ResNet50(weights='imagenet', include_top=False)
# 冻结前面的层,只训练后面的层
for layer in base_model.layers[:-10]: # 除了最后10层外都冻结layer.trainable = False
3. 微调的最佳实践
微调是一门既需要理论知识又需要经验的艺术,以下是一些最佳实践:
- 分阶段训练:先冻结预训练模型训练几个epoch,然后解冻部分层进行微调
- 较小的学习率:微调时使用比从头训练小10-100倍的学习率,避免破坏预训练权重
- 逐层解冻:从顶层开始逐渐解冻更多层,而不是一次性解冻所有层
- 数据增强:对训练数据应用增强技术,帮助模型更好泛化
- 早停法:使用早停法防止过拟合
四、超参数调优方法
1. 超参数调优的重要性
超参数是在模型训练开始前需要设置的参数,如学习率、批量大小、正则化强度等。在迁移学习中,合适的超参数设置对模型性能至关重要。
与模型权重不同,超参数不能通过梯度下降自动学习,需要我们手动调整或使用自动化方法寻找最佳值。优化超参数可以:
- 提高模型准确率
- 加速训练收敛
- 防止过拟合
- 提升模型泛化能力
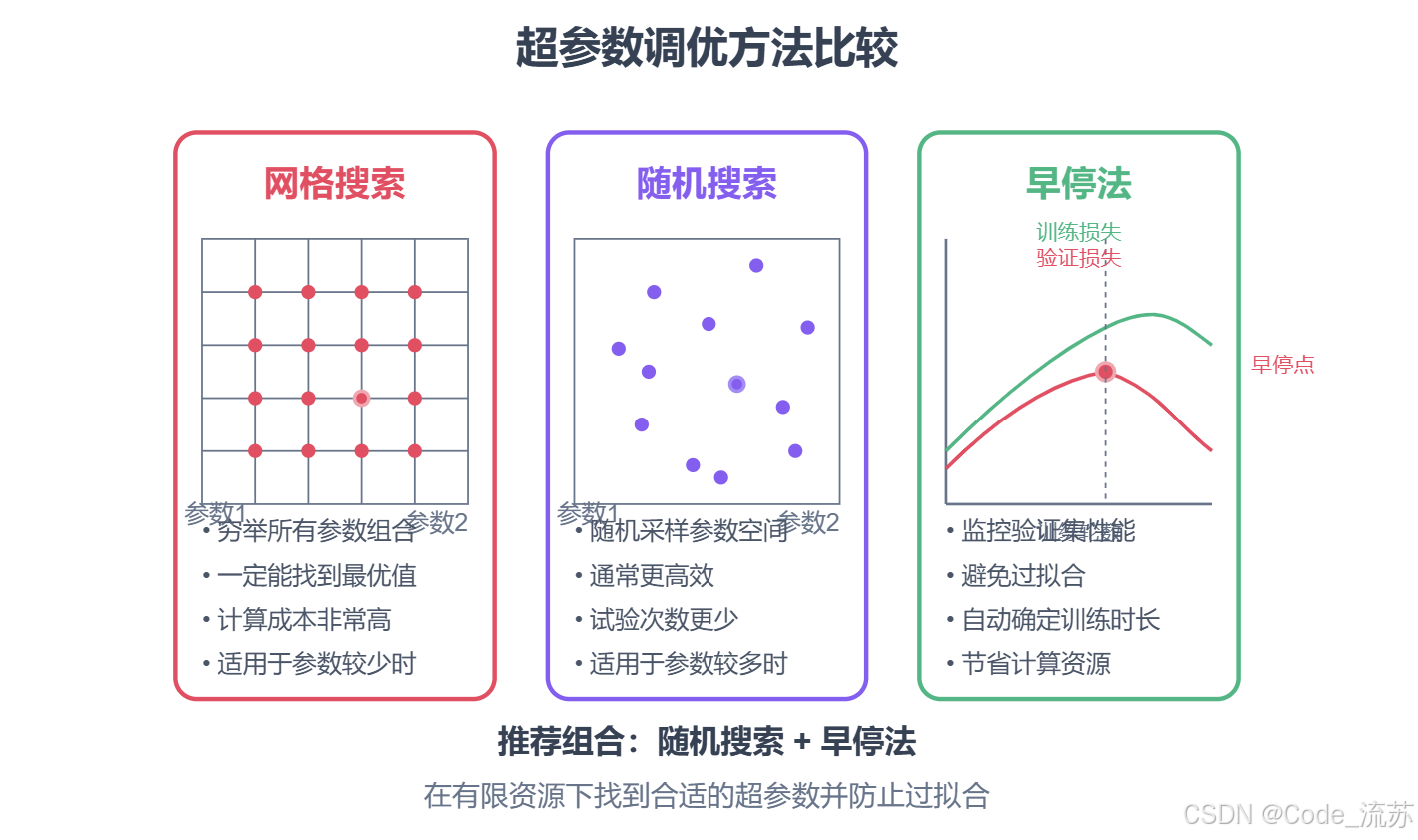
2. 网格搜索(Grid Search)
网格搜索是一种穷举搜索方法,它会尝试超参数空间中所有可能的组合。
- 原理:为每个超参数定义一组离散值,然后尝试所有可能的组合
- 优点:简单、易于理解,一定能找到预定义空间中的最佳组合
- 缺点:计算成本高,参数数量增加时组合数量呈指数增长
- 适用场景:超参数较少,计算资源充足
from sklearn.model_selection import GridSearchCV
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten# 定义一个创建模型的函数
def create_model(learning_rate=0.001):model = Sequential([base_model,Flatten(),Dense(256, activation='relu'),Dense(num_classes, activation='softmax')])model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),loss='categorical_crossentropy',metrics=['accuracy'])return model# 创建包装的模型
model = KerasClassifier(build_fn=create_model, verbose=0)# 定义超参数网格
param_grid = {'learning_rate': [0.001, 0.01, 0.1],'batch_size': [32, 64, 128],'epochs': [10, 20]
}# 创建网格搜索
grid = GridSearchCV(estimator=model, param_grid=param_grid, cv=3)
grid_result = grid.fit(X_train, y_train)# 打印最佳结果
print(f"最佳准确率: {grid_result.best_score_:.4f}")
print(f"最佳参数: {grid_result.best_params_}")
3. 随机搜索(Random Search)
随机搜索不会尝试所有组合,而是随机采样超参数空间中的点。
- 原理:为每个超参数定义一个分布,然后随机采样
- 优点:比网格搜索更高效,通常能以更少的试验次数找到良好的超参数
- 缺点:不保证找到全局最优解
- 适用场景:超参数较多,计算资源有限
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform, randint# 定义超参数分布
param_dist = {'learning_rate': uniform(0.0001, 0.1), # 均匀分布'batch_size': randint(16, 256), # 随机整数'epochs': randint(5, 30)
}# 创建随机搜索
random_search = RandomizedSearchCV(estimator=model, param_distributions=param_dist,n_iter=20, # 尝试20次随机组合cv=3
)random_result = random_search.fit(X_train, y_train)print(f"最佳准确率: {random_result.best_score_:.4f}")
print(f"最佳参数: {random_result.best_params_}")
4. 早停法(Early Stopping)
早停法不是寻找最佳超参数的方法,而是一种防止过拟合的技术。它通过监控验证集性能,在性能开始下降时提前结束训练。
- 原理:在每个epoch后评估验证集性能,如果连续多个epoch没有改善,则停止训练
- 优点:自动确定合适的训练轮数,防止过拟合,节省计算资源
- 缺点:需要单独的验证集,可能过早停止导致欠拟合
- 实现方式:在Keras中使用
EarlyStopping回调函数
from tensorflow.keras.callbacks import EarlyStopping# 定义早停回调
early_stopping = EarlyStopping(monitor='val_loss', # 监控验证集损失patience=5, # 容忍5个epoch没有改善min_delta=0.001, # 最小改善阈值restore_best_weights=True # 恢复最佳权重
)# 在模型训练中使用
history = model.fit(train_generator,validation_data=validation_generator,epochs=100, # 设置较大的epochs,让早停决定何时结束callbacks=[early_stopping]
)
五、基于ResNet的图像分类实战
1. 项目概述与数据准备
现在,让我们将所学的知识应用到实际项目中!我们将使用ResNet50预训练模型来解决一个图像分类任务。在本例中,我们将构建一个能识别5种不同花卉的分类器。
首先,我们需要准备数据和环境:
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint# 设置随机种子,确保结果可复现
tf.random.set_seed(42)# 数据路径
train_dir = 'flowers/train'
valid_dir = 'flowers/validation'
test_dir = 'flowers/test'# 图像尺寸
img_height, img_width = 224, 224 # ResNet50要求的输入尺寸
batch_size = 32# 数据增强与预处理
train_datagen = ImageDataGenerator(rescale=1./255, # 像素值缩放到0-1范围rotation_range=20, # 随机旋转±20度width_shift_range=0.1, # 水平平移±10%height_shift_range=0.1, # 垂直平移±10%shear_range=0.1, # 剪切变换zoom_range=0.1, # 随机缩放±10%horizontal_flip=True, # 随机水平翻转fill_mode='nearest' # 填充模式
)# 验证集只进行缩放,不做增强
valid_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)# 创建数据生成器
train_generator = train_datagen.flow_from_directory(train_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='categorical'
)valid_generator = valid_datagen.flow_from_directory(valid_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='categorical'
)test_generator = test_datagen.flow_from_directory(test_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='categorical'
)# 获取类别数量
num_classes = train_generator.num_classes
print(f"分类任务目标: {num_classes}类花卉")
2. 构建迁移学习模型
接下来,我们创建一个基于ResNet50的迁移学习模型:
# 加载预训练的ResNet50模型,不包括顶层
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(img_height, img_width, 3))# 添加自定义的顶层
x = base_model.output
x = GlobalAveragePooling2D()(x) # 全局平均池化降维
x = Dense(256, activation='relu')(x) # 全连接层
predictions = Dense(num_classes, activation='softmax')(x) # 输出层# 创建最终模型
model = Model(inputs=base_model.input, outputs=predictions)# 冻结ResNet50所有层
for layer in base_model.layers:layer.trainable = False# 打印模型结构
model.summary()
3. 分两阶段训练模型
我们采用两阶段训练策略:先训练新添加的层,然后进行微调。
# 阶段1: 训练新添加的层
model.compile(optimizer=Adam(learning_rate=0.001),loss='categorical_crossentropy',metrics=['accuracy']
)# 设置回调函数
callbacks = [EarlyStopping(monitor='val_accuracy', patience=5, restore_best_weights=True),ModelCheckpoint('best_model_stage1.h5', monitor='val_accuracy',save_best_only=True)
]# 开始训练
print("阶段1: 训练新添加的层...")
history_stage1 = model.fit(train_generator,steps_per_epoch=train_generator.samples // batch_size,validation_data=valid_generator,validation_steps=valid_generator.samples // batch_size,epochs=20,callbacks=callbacks
)# 阶段2: 微调 - 解冻部分ResNet50层
print("阶段2: 微调部分预训练层...")# 解冻ResNet50的最后15层
for layer in model.layers[0].layers[-15:]:layer.trainable = True# 使用更小的学习率重新编译模型
model.compile(optimizer=Adam(learning_rate=0.0001), # 学习率降低10倍loss='categorical_crossentropy',metrics=['accuracy']
)# 更新回调函数
callbacks = [EarlyStopping(monitor='val_accuracy', patience=7, restore_best_weights=True),ModelCheckpoint('best_model_stage2.h5', monitor='val_accuracy',save_best_only=True)
]# 进一步训练
history_stage2 = model.fit(train_generator,steps_per_epoch=train_generator.samples // batch_size,validation_data=valid_generator,validation_steps=valid_generator.samples // batch_size,epochs=30,callbacks=callbacks
)
4. 评估模型并可视化结果
最后,我们评估模型性能并可视化训练过程:
# 在测试集上评估模型
test_loss, test_acc = model.evaluate(test_generator)
print(f'测试集准确率: {test_acc:.4f}')# 可视化训练过程
import matplotlib.pyplot as plt# 绘制准确率曲线
plt.figure(figsize=(12, 4))# 阶段1的曲线
plt.subplot(1, 2, 1)
plt.plot(history_stage1.history['accuracy'], label='训练准确率(阶段1)')
plt.plot(history_stage1.history['val_accuracy'], label='验证准确率(阶段1)')
# 阶段2的曲线
epochs_stage1 = len(history_stage1.history['accuracy'])
plt.plot(range(epochs_stage1, epochs_stage1 + len(history_stage2.history['accuracy'])),history_stage2.history['accuracy'],label='训练准确率(阶段2)'
)
plt.plot(range(epochs_stage1, epochs_stage1 + len(history_stage2.history['val_accuracy'])),history_stage2.history['val_accuracy'],label='验证准确率(阶段2)'
)plt.title('模型准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.legend()# 绘制损失曲线
plt.subplot(1, 2, 2)
plt.plot(history_stage1.history['loss'], label='训练损失(阶段1)')
plt.plot(history_stage1.history['val_loss'], label='验证损失(阶段1)')
# 阶段2的曲线
plt.plot(range(epochs_stage1, epochs_stage1 + len(history_stage2.history['loss'])),history_stage2.history['loss'],label='训练损失(阶段2)'
)
plt.plot(range(epochs_stage1, epochs_stage1 + len(history_stage2.history['val_loss'])),history_stage2.history['val_loss'],label='验证损失(阶段2)'
)plt.title('模型损失')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.legend()plt.tight_layout()
plt.show()# 可视化预测结果
import numpy as np
from tensorflow.keras.preprocessing.image import load_img, img_to_array# 获取类别名称
class_names = list(train_generator.class_indices.keys())# 随机选择测试图像
import os
import randomdef predict_and_visualize(image_path):# 加载并预处理图像img = load_img(image_path, target_size=(img_height, img_width))img_array = img_to_array(img) / 255.0img_array = np.expand_dims(img_array, axis=0)# 预测predictions = model.predict(img_array)predicted_class = np.argmax(predictions[0])confidence = predictions[0][predicted_class]# 显示结果plt.figure(figsize=(6, 6))plt.imshow(img)plt.title(f'预测: {class_names[predicted_class]} ({confidence:.2f})')plt.axis('off')plt.show()# 打印所有类别的置信度for i, class_name in enumerate(class_names):print(f"{class_name}: {predictions[0][i]:.4f}")# 随机选择几张测试图像进行预测
test_images = []
for class_dir in os.listdir(test_dir):class_path = os.path.join(test_dir, class_dir)if os.path.isdir(class_path):images = os.listdir(class_path)if images:random_image = random.choice(images)test_images.append(os.path.join(class_path, random_image))# 展示3张随机图像的预测结果
for img_path in test_images[:3]:predict_and_visualize(img_path)
5. 模型部署与应用
将训练好的模型保存为TensorFlow SavedModel格式,便于部署:
# 保存整个模型
model.save('flower_classifier_resnet50.h5')# 转换为TensorFlow Lite格式(适用于移动设备)
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()# 保存TFLite模型
with open('flower_classifier_resnet50.tflite', 'wb') as f:f.write(tflite_model)print("模型已保存为标准格式和TFLite格式,可用于部署!")
恭喜你!你已经成功构建了一个使用迁移学习的图像分类模型。这种技术不仅能在小数据集上获得良好性能,还大大减少了训练时间和计算资源需求。
六、总结与进阶方向
1. 知识回顾
在本文中,我们学习了:
- 迁移学习的基本概念与优势
- 常用预训练模型的特点与适用场景
- 冻结层与微调的策略和最佳实践
- 三种超参数调优方法(网格搜索、随机搜索、早停法)
- 如何使用ResNet50构建实际的图像分类应用
2. 进阶方向
如果你希望进一步探索迁移学习和预训练模型,可以考虑以下方向:
- 更多预训练模型探索:尝试MobileNet(适用于移动设备)、DenseNet(密集连接)等架构
- 领域适应(Domain Adaptation):解决源域和目标域分布不同的问题
- 知识蒸馏(Knowledge Distillation):将大型预训练模型的知识迁移到小型模型
- 跨模态迁移学习:如图像到文本、文本到图像的知识迁移
- 多任务迁移学习:同时学习多个相关任务
3. 实践建议
- 从简单开始:先使用特征提取,再尝试微调
- 数据质量很重要:即使是迁移学习,高质量的数据集仍然是成功的关键
- 充分实验:尝试不同的预训练模型、不同的冻结策略、不同的超参数
- 关注新动态:深度学习领域发展迅速,新的预训练模型和迁移学习技术不断涌现
通过掌握迁移学习和预训练模型,你可以以更少的数据和计算资源构建强大的深度学习应用。这些技术不仅在学术研究中广泛应用,也在工业界产品开发中扮演着重要角色。
📌 今日学习打卡
学习了迁移学习与预训练模型的基本概念
掌握了模型冻结与微调的最佳实践
了解了超参数调优的三种方法
实现了基于ResNet的图像分类案例
明天我们将进入循环神经网络的学习!
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:

《Python星球日记》 第55天:迁移学习与预训练模型
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、迁移学习基础1. 什么是迁移学习?2. 迁移学习的优势3. 迁移学习的…...
)
Python项目75:PyInstaller+Tkinter+subprocess打包工具1.0(安排 !!)
这个打包工具包含以下功能: 1.主要功能:选择Python脚本文件,设置打包选项(单文件打包、无控制台窗口),自定义程序图标,指定输出目录,实时显示打包日志。 2.自适应布局改进ÿ…...

互联网大厂Java面试实录:从基础到微服务的深度考察
互联网大厂Java面试实录:从基础到微服务的深度考察 面试场景 面试官:风清扬(严肃且技术深厚) 求职者:令狐冲(技术扎实但偶尔含糊) 第一轮:Java基础与框架 风清扬:令狐…...

学习黑客5 分钟深入浅出理解Linux进程管理
5 分钟深入浅出理解Linux进程管理 🖥️ 大家好!今天我们将探索Linux系统中的进程管理——这是理解系统运行机制和进行安全分析的基础知识。在TryHackMe平台上进行网络安全学习时,了解进程如何工作以及如何监控和控制它们,对于识别…...

Kubernetes应用发布方式完整流程指南
Kubernetes(K8s)作为容器编排领域的核心工具,其应用发布流程体现了自动化、弹性和可观测性的优势。本文将通过一个Tomcat应用的示例,详细讲解从配置编写到高级发布的完整流程,帮助开发者掌握Kubernetes应用部署的核心步…...

JVM——即时编译器的中间表达形式
中间表达形式(IR):编译器的核心抽象层 1. IR的本质与作用 在编译原理的体系中,中间表达形式(Intermediate Representation, IR)是连接编译器前端与后端的桥梁。前端负责将源代码转换为IR,而后…...

Js 判断浏览器cookie 是否启用
验证时 google浏览器 135.0.7049.117 不生效 cookie.html <!DOCTYPE html> <html lang"zh"> <head><meta charset"UTF-8"><title>Cookie 检测</title> </head> <body><h1>检测是否启用 Cookie<…...

数字相机的快门结构
数字相机(DC/DSLR等)的快门结构和传统相机有所不同,除了机械快门以外,还存在电子快门,实际上是二者的混合体。我写这篇文章大概介绍一下数字相机的快门结构,希望能抛砖引玉。 要讨论数字相机的快门结构,首先先要了解一下数字相机的结构分类,根据成像原理不同,数字相机大…...

LeetCode --- 448 周赛
题目列表 3536. 两个数字的最大乘积 3537. 填充特殊网格 3538. 合并得到最小旅行时间 3539. 魔法序列的数组乘积之和 一、两个数字的最大乘积 由于数据都是正数,所以乘积最大的两个数,本质就是找数组中最大的两个数即可,可以排序后直接找到…...

添加物体.
在cesium中我们可以添加物体进入地图.我们以广州塔为例 //生成广州塔的位置var position2 Cesium.Cartesian3.fromDegrees(113.3191,23.109,100)viewer.camera.setView({//指定相机位置destination: position2, 运行后如图 我们使用cesium官网提供的代码为广州塔在地图上标点…...

ABB电机控制和保护单元与Profibus DP主站转Modbus TCP网关快速通讯案例
ABB电机控制和保护单元与Profibus DP主站转Modbus TCP网关快速通讯案例 在现代工业自动化系统中,设备之间的互联互通至关重要。Profibus DP和Modbus TCP是两种常见的通信协议,分别应用于不同的场景。为了实现这两种协议的相互转换,Profibus …...

Yocto中`${S}`和`${WORKDIR}`的联系与区别
在Yocto项目中,${S}和${WORKDIR}是构建过程中两个核心路径变量,它们的关系及用途如下: 定义与层级关系${WORKDIR}(工作目录) 是Recipe所有任务执行的基础目录,路径结构为: build/tmp/work/<arch>/<recipe-name>/<version>/。 该目录包含源码解压后的所…...

CDGP历次主观题真题回忆
(一)【论述】 1如何设计企业的数据安全体系?活动+方法+DSMM 2如何管理公司混乱的数据质量?活动+遵循原则+建立质量维度+质量改进生命周期+高阶指标。...

Java学习手册:Spring Cloud 组件详解
一、服务发现组件 - Eureka 核心概念 :Eureka 是一个服务发现组件,包含 Eureka Server 和 Eureka Client 两部分。Eureka Server 作为服务注册中心,负责维护服务实例的注册信息;Eureka Client 则是集成在应用中的客户端࿰…...

【大模型】使用 LLaMA-Factory 进行大模型微调:从入门到精通
使用 LLaMA-Factory 进行模型微调:从入门到精通 一、环境搭建:奠定微调基础(一)安装依赖工具(二)创建 conda 环境(三)克隆仓库并安装依赖 二、数据准备:微调的基石&#…...

sensitive-word-admin v2.0.0 全新 ui 版本发布!vue+前后端分离
前言 sensitive-word-admin 最初的定位是让大家知道如何使用 sensitive-word,所以开始想做个简单的例子。 不过秉持着把一个工具做好的原则,也收到很多小伙伴的建议。 v2.0.0 在 ruoyi-vue(也非常感谢若依作者多年来的无私奉献)…...

HTML属性
HTML(HyperText Markup Language)是网页开发的基石,而属性(Attribute)则是HTML元素的重要组成部分。它们为标签提供附加信息,控制元素的行为、样式或功能。本文将从基础到进阶,全面解析HTML属性…...
)
计算机网络 4-1 网络层(网络层的功能)
【考纲内容】 (一)网络层的功能 异构网络互连;路由与转发;SDN基本概念;拥塞控制 (二)路由算法 静态路由与动态路由;距离-向量路由算法;链路状态路由算法;层…...
》阅读笔记:p17-p27)
《算法导论(第4版)》阅读笔记:p17-p27
《算法导论(第4版)》学习第 10 天,p17-p27 总结,总计 11 页。 一、技术总结 1. insertion sort (1)keys The numbers to be sorted are also known as the keys(要排序的数称为key)。 第 n 次看插入排序,这次有两个地方感触比较深&#…...

C++中线程安全的对多个锁同时加锁
C中线程安全的对多个锁同时加锁 C中线程安全的对两个锁同时加锁 C中线程安全的对两个锁同时加锁 参考文档:https://llfc.club/articlepage?id2UVOC0CihIdfguQFmv220vs5hAG 如果我们现在有一个需要互斥访问的变量 big_object,它的定义如下: …...
一维前缀和, 蓝桥杯)
子串简写(JAVA)一维前缀和, 蓝桥杯
这个题用前缀和,开两个数组,一个存前n个字符数据的c1的数字个数,另一个前n个字符c2的数字个数,然后遍历一次加起来,有一个测试点没过去,把那个存最后数的换成long,应该是这题数据范围给的不对&a…...

数据库故障排查全攻略:从实战案例到体系化解决方案
一、引言:数据库故障为何是技术人必须攻克的 "心腹大患" 在数字化时代,数据库作为企业核心数据资产的载体,其稳定性直接决定业务连续性。据 Gartner 统计,企业每小时数据库 downtime 平均损失高达 56 万美元࿰…...

vllm笔记
目录 vllm简介vllm解决了哪些问题?1. **瓶颈:KV 缓存内存管理低效**2. **瓶颈:并行采样和束搜索中的内存冗余**3. **瓶颈:批处理请求中的内存碎片化** 快速开始安装vllm开始使用离线推理启动 vLLM 服务器 支持的模型文本语言模型生…...

“AI+城市治理”智能化解决方案
目录 一、建设背景 二、需求分析 三、系统设计 四、系统功能 五、应用场景 六、方案优势 七、客户价值 八、典型案例 一、建设背景 当前我国城市化率已突破65%,传统治理模式面临前所未有的挑战。一方面,城市规模扩大带来治理复杂度呈指数级增长,全国城市管理案件年…...

《医疗AI的透明革命:破解黑箱困境与算法偏见的治理之路》
医疗AI透明度困境 黑箱问题对医生和患者信任的影响:在医疗领域,AI模型往往表现为难以理解的“黑箱”,这会直接影响医生和患者对其诊断建议的信任度 。医生如果无法理解AI给出诊断的依据,就难以判断模型是否存在偏见或错误&#x…...

【论文阅读】Efficient and secure federated learning against backdoor attacks
Efficient and secure federated learning against backdoor attacks -- 高效且安全的可抵御后门攻击的联邦学习 论文来源问题背景TLDR系统及威胁模型实体威胁模型 方法展开服务器初始化本地更新本地压缩高斯噪声与自适应扰动聚合与解压缩总体算法 总结优点缺点 论文来源 名称…...
)
21、DeepSeekMath论文笔记(GRPO)
DeepSeekMath论文笔记 0、研究背景与目标1、GRPO结构GRPO结构PPO知识点**1. PPO的网络模型结构****2. GAE(广义优势估计)原理****1. 优势函数的定义**2.GAE(广义优势估计) 2、关键技术与方法3、核心实验结果4、结论与未来方向关键…...

深入解析:如何基于开源p-net快速开发Profinet从站服务
一、Profinet协议与软协议栈技术解析 1.1 工业通信的"高速公路" Profinet作为工业以太网协议三巨头之一,采用IEEE 802.3标准实现实时通信,具有: 实时分级:支持RT(实时)和IRT(等时实时)通信模式拓扑灵活:支持星型、树型、环型等多种网络结构对象模型:基于…...

腾讯多模态定制化视频生成框架:HunyuanCustom
HunyuanCustom 速读 一、引言 HunyuanCustom 是由腾讯团队提出的一款多模态定制化视频生成框架。该框架旨在解决现有视频生成方法在身份一致性(identity consistency)和输入模态有限性方面的不足。通过支持图像、音频、视频和文本等多种条件输入,HunyuanCustom 能…...

警惕C#版本差异多线程中的foreach陷阱
警惕C#版本差异多线程中的foreach陷阱 同样的代码,不同的结果闭包捕获的“时间差”问题绕过闭包陷阱的三种方法Lambda立即捕获(代码简洁)显式传递参数(兼容性最佳)使用Parallel.ForEach(官方推荐)注意事项:版本兼容性指南警惕多线程中的foreach陷阱:C#版本差异引发的…...

2024年AI发展趋势全面解析:从多模态到AGI的突破
2024年AI发展五大核心趋势 1. 多模态AI的爆发式增长 GPT-4V、Gemini等模型实现文本/图像/视频的跨模态理解应用场景扩展至智能客服、内容创作、工业质检等领域 2. 小型化与边缘AI的崛起 手机端LLM(如Phi-2)实现本地化部署隐私保护与实时响应的双重优…...
)
高精度之加减乘除之多解总结(加与减篇)
开篇总述:精度计算的教学比较杂乱,无系统的学习,且存在同法多线的方式进行同一种运算,所以我写此篇的目的只是为了直指本质,不走教科书方式,步骤冗杂。 一,加法 我在此讲两种方法: …...
)
Arduino 开源按键库大合集(单击/双击/长按实现)
2025.5.10 22:25更新:增加了Button2 2025.5.10 13:13更新:增加了superButton 虽然Arduino自带按键中断attachInterrupt(button1.PIN, isr, FALLING);,但是要是要实现去抖,双击检测,长按检测等等就略微麻烦些࿰…...

相机Camera日志分析之八:高通Camx HAL架构opencamera三级日志详解及关键字
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:相机Camera日志分析之七:高通Camx HAL架构opencamera二级日志详解及关键字 这一篇我们开始讲: 相机Camera日志分析之八:高通Camx HAL架构opencamera三级日志详解及关键字 目录 【关注我,后续持续…...

Java零组件实现配置热更新
在某些场景下,我们需要实现配置的热更新,但是又要实现软件即插即用的需求,这就使我们不能引入过多复杂的插件,而nacos等配置中心在分布式业务场景下对配置的管理起着很重要作用,为此需要想一些办法去代替它们而完成同样…...

Kotlin高阶函数多态场景条件判断与子逻辑
Kotlin高阶函数多态场景条件判断与子逻辑 fun main() {var somefun: (Int, Float) -> Longval a 4val b 5fsomefun multi()//if 某条件println(somefun.invoke(a, b))//if 某条件somefun add()println(somefun.invoke(a, b)) }fun multi(): (Int, Float) -> Long {re…...

Ethercat转Profinet网关如何用“协议翻译术“打通自动化产线任督二脉
Ethercat转Profinet网关如何用"协议翻译术"打通自动化产线任督二脉 将遗留的Profinet设备(如传感器)接入现代EtherCAT主站(如Codesys控制器)避免全面更换硬件。 作为一名电气工程师,我最近面临的一个挑战&a…...

每日算法刷题Day1 5.9:leetcode数组3道题,用时1h
1.LC寻找数组的中心索引(简单) 数组和字符串 - LeetBook - 力扣(LeetCode)全球极客挚爱的技术成长平台 思想: 计算总和和左侧和,要让左侧和等于右侧和,即左侧和总和-左侧和-当前数字 代码 c代码: class Solution { public:i…...

MySQL的视图
一、MySQL视图的介绍和作用 MySQL视图,加油兄弟们,孰能生巧,完整代码在最后!!! 视图是一个虚拟的表,并不是真是存在的,视图其实并没有真实的数据,他只是根据一个sql语句…...

旅游推荐数据分析可视化系统算法
旅游推荐数据分析可视化系统算法 本文档详细介绍了旅游推荐数据分析可视化系统中使用的各种算法,包括推荐算法、数据分析算法和可视化算法。 目录 推荐算法 基于用户的协同过滤推荐基于浏览历史的推荐主题推荐算法 亲子游推荐算法文化游推荐算法自然风光推荐算法…...

Pandas:数据处理与分析
目录 一、Pandas 简介 二、Pandas 的安装与导入 三、Pandas 的核心数据结构 (一)Series (二)DataFrame 四、Pandas 数据读取与写入 (一)读取数据 (二)写入数据 五、数据清洗…...

非阻塞式IO-Java NIO
一、NIO简介 Java NIO是Java1.4引入的一种新的IO API,它提供了非阻塞式IO,选择器、通道、缓冲区等新的概念和机制。相比传统的IO,多出的N不单纯是新的,更表现在Non-blocking非阻塞,NIO具有更高的并发性、可扩展性以及…...

tryhackme——Enumerating Active Directory
文章目录 一、凭据注入1.1 RUNAS1.2 SYSVOL1.3 IP和主机名 二、通过Microsoft Management Console枚举AD三、通过命令行net命令枚举四、通过powershell枚举 一、凭据注入 1.1 RUNAS 当获得AD凭证<用户名>:<密码>但无法登录域内机器时,runas.exe可帮助…...
Linux下基本指令 2)
(二)Linux下基本指令 2
【知识预告】 16. date 指令 17. cal 指令 18. find 指令 19. which指令 20. whereis 指令 21. alias 指令 22. grep 指令 23. zip/unzip 指令 24. tar 指令 25. bc 指令 26. uname ‒r 指令 27. 重要的⼏个热键 28. 关机 16 date 指令 指定格式显⽰时间:date %Y-…...

[ctfshow web入门] web70
信息收集 使用cinclude("php://filter/convert.base64-encode/resourceindex.php");读取的index.php error_reporting和ini_set被禁用了,不必管他 error_reporting(0); ini_set(display_errors, 0); // 你们在炫技吗? if(isset($_POST[c])){…...

第三章 Freertos智能小车遥控控制
本文基于小车APP,通过与蓝牙模块进行连接,发送特定信号给小车主控,实现对小车的模式切换、灯光控制、前进、后退、左右控制。目前还未加入电机控制,具体的电机控制效果还不能实现,但是可以进行模式切换与灯光控制。 …...

Spring 6.x 详解介绍
Spring 6.x 是 Spring Framework 的最新主版本,于2022年11月正式发布,标志着对 Java 17 和 Jakarta EE 9 的全面支持,同时引入了多项革新性特性,旨在优化性能、简化开发并拥抱现代技术趋势。 一、核心特性与架构调整 Java 17 与 J…...

阿里云OSS+CDN自动添加文章图片水印配置指南
文章目录 一、环境准备二、OSS水印样式配置三、CDN关键配置四、Handsome主题自动化配置五、水印效果验证六、常见问题排查 一、环境准备 资源清单 阿里云OSS Bucket(绑定自定义域名 static.example.com)阿里云CDN加速域名,回源为Bucket的域名…...

hot100-子串-JS
一、560.和为k的子串 560. 和为 K 的子数组 提示 给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。 子数组是数组中元素的连续非空序列。 示例 1: 输入:nums [1,1,1], k 2 输出:2示例 2…...
)
LeetCode 270:在二叉搜索树中寻找最接近的值(Swift 实战解析)
文章目录 摘要描述题解答案题解代码分析示例测试及结果时间复杂度空间复杂度总结 摘要 在日常开发中,我们经常需要在一组有序的数据中快速找到最接近某个目标值的元素。LeetCode 第 270 题“Closest Binary Search Tree Value”正是这样一个问题。本文将深入解析该…...