21、DeepSeekMath论文笔记(GRPO)
DeepSeekMath论文笔记
- 0、研究背景与目标
- 1、GRPO结构
- GRPO结构
- PPO知识点
- **1. PPO的网络模型结构**
- **2. GAE(广义优势估计)原理**
- **1. 优势函数的定义**
- 2.GAE(广义优势估计)
- 2、关键技术与方法
- 3、核心实验结果
- 4、结论与未来方向
- 关键问题与答案
- 1. **DeepSeekMath在数据处理上的核心创新点是什么?**
- 2. **GRPO算法相比传统PPO有何优势?**
- 3. **代码预训练对数学推理能力的影响如何?**
0、研究背景与目标
- 挑战与现状:
- 数学推理因结构化和复杂性对语言模型构成挑战,主流闭源模型(如GPT-4、Gemini-Ultra)未开源,而开源模型在MATH等基准测试中性能显著落后。
- 目标:通过数据优化和算法创新,提升开源模型数学推理能力,逼近闭源模型水平。


1、GRPO结构
GRPO结构
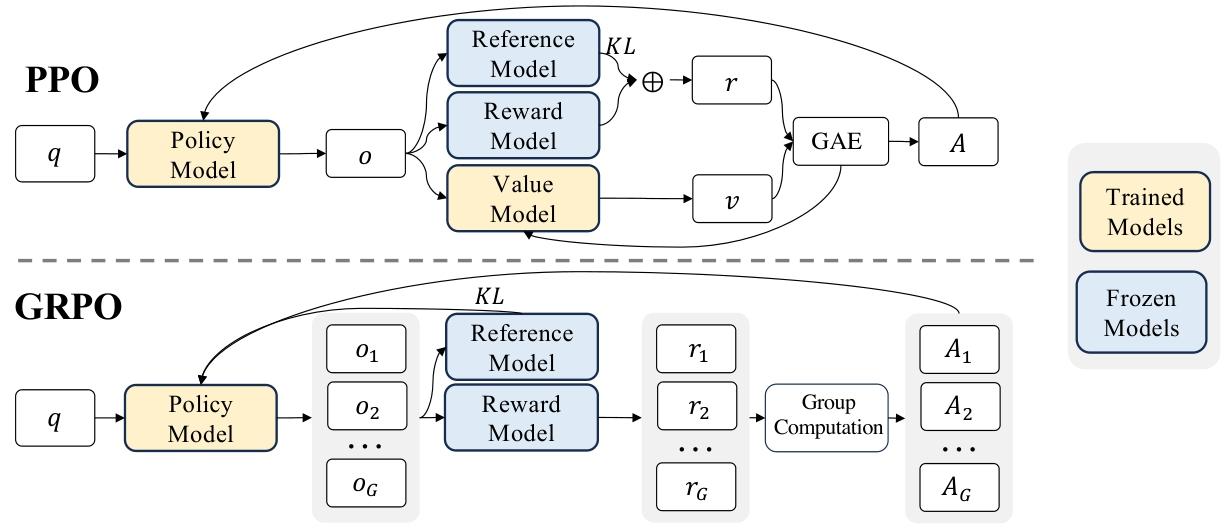
图 4 |PPO 和我们的 GRPO 示范。GRPO 放弃了价值模型,而是根据组分数估计基线,从而显著减少了训练资源。
近端策略优化(PPO)(舒尔曼等人,2017年)是一种演员 - 评论家强化学习算法,在大语言模型(LLMs)的强化学习微调阶段得到了广泛应用(欧阳等人,2022年)。具体来说,它通过最大化以下替代目标来优化大语言模型:
J P P O ( θ ) = E [ q ∼ P ( Q ) , o ∼ π θ o l d ( O ∣ q ) ] 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ min [ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t , clip ( π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) , 1 − ε , 1 + ε ) A t ] ( 1 ) \mathcal{J}_{PPO}(\theta)=\mathbb{E}\left[q \sim P(Q), o \sim \pi_{\theta_{old }}(O | q)\right] \frac{1}{|o|} \sum_{t = 1}^{|o|} \min \left[\frac{\pi_{\theta}\left(o_{t} | q, o_{<t}\right)}{\pi_{\theta_{old }}\left(o_{t} | q, o_{<t}\right)} A_{t}, \text{clip}\left(\frac{\pi_{\theta}\left(o_{t} | q, o_{<t}\right)}{\pi_{\theta_{old }}\left(o_{t} | q, o_{<t}\right)}, 1 - \varepsilon, 1 + \varepsilon\right) A_{t}\right] (1) JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)]∣o∣1t=1∑∣o∣min[πθold(ot∣q,o<t)πθ(ot∣q,o<t)At,clip(πθold(ot∣q,o<t)πθ(ot∣q,o<t),1−ε,1+ε)At](1)
其中, π θ \pi_{\theta} πθ和 π θ o l d \pi_{\theta_{old}} πθold分别是当前策略模型和旧策略模型, q q q和 o o o分别是从问题数据集和旧策略 π θ o l d \pi_{\theta_{old}} πθold中采样得到的问题和输出。 ε \varepsilon ε是PPO中引入的与裁剪相关的超参数,用于稳定训练。 A t A_{t} At是优势值,通过应用广义优势估计(GAE)(舒尔曼等人,2015年)计算得出,该估计基于奖励值 { r ≥ t } \{r_{\geq t}\} {r≥t}和学习到的价值函数 V ψ V_{\psi} Vψ 。因此,在PPO中,价值函数需要与策略模型一起训练。为了减轻奖励模型的过度优化问题,标准做法是在每个令牌的奖励中添加来自参考模型的每个令牌的KL散度惩罚项(欧阳等人,2022年),即:
r t = r φ ( q , o ≤ t ) − β log π θ ( o t ∣ q , o < t ) π r e f ( o t ∣ q , o < t ) r_{t}=r_{\varphi}\left(q, o_{\leq t}\right)-\beta \log\frac{\pi_{\theta}\left(o_{t} | q, o_{<t}\right)}{\pi_{ref}\left(o_{t} | q, o_{<t}\right)} rt=rφ(q,o≤t)−βlogπref(ot∣q,o<t)πθ(ot∣q,o<t)
其中, r φ r_{\varphi} rφ是奖励模型, π r e f \pi_{ref} πref是参考模型,通常是初始的监督微调(SFT)模型, β \beta β是KL散度惩罚项的系数。
由于PPO中使用的价值函数通常与策略模型规模相当,这会带来巨大的内存和计算负担。此外,在强化学习训练过程中,价值函数在优势值计算中被用作基线以减少方差。而在大语言模型的环境中,奖励模型通常只给最后一个令牌分配奖励分数,这可能会使精确到每个令牌的价值函数的训练变得复杂。
为了解决这个问题,如图4所示,我们提出了组相对策略优化(GRPO)。它无需像PPO那样进行额外的价值函数近似,而是使用针对同一问题产生的多个采样输出的平均奖励作为基线。更具体地说,对于每个问题 q q q,GRPO从旧策略 π θ o l d \pi_{\theta_{old}} πθold中采样一组输出 { o 1 , o 2 , ⋯ , o G } \{o_{1}, o_{2}, \cdots, o_{G}\} {o1,o2,⋯,oG},然后通过最大化以下目标来优化策略模型:
J G R P O ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ o l d ( O ∣ q ) ] 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min [ π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) A ^ i , t , clip ( π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) , 1 − ε , 1 + ε ) A ^ i , t ] − β D K L [ π θ ∣ ∣ π r e f ] } (3) \begin{aligned} \mathcal{J}_{GRPO}(\theta) & =\mathbb{E}\left[q \sim P(Q),\left\{o_{i}\right\}_{i = 1}^{G} \sim \pi_{\theta_{old}}(O | q)\right] \\ & \frac{1}{G} \sum_{i = 1}^{G} \frac{1}{|o_{i}|} \sum_{t = 1}^{|o_{i}|}\left\{\min \left[\frac{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}{\pi_{\theta_{old}}\left(o_{i, t} | q, o_{i,<t}\right)}\hat{A}_{i, t}, \text{clip}\left(\frac{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}{\pi_{\theta_{old}}\left(o_{i, t} | q, o_{i,<t}\right)}, 1 - \varepsilon, 1 + \varepsilon\right) \hat{A}_{i, t}\right]-\beta \mathbb{D}_{KL}\left[\pi_{\theta}|| \pi_{ref}\right]\right\} \end{aligned} \tag{3} JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βDKL[πθ∣∣πref]}(3)
其中, ε \varepsilon ε和 β \beta β是超参数, A ^ i , t \hat{A}_{i, t} A^i,t是仅基于每组内输出的相对奖励计算得到的优势值,将在以下小节中详细介绍。GRPO利用组相对的方式计算优势值,这与奖励模型的比较性质非常契合,因为奖励模型通常是在同一问题的输出之间的比较数据集上进行训练的。还需注意的是,GRPO不是在奖励中添加KL散度惩罚项,而是通过直接将训练后的策略与参考策略之间的KL散度添加到损失中来进行正则化,避免了 A ^ i , t \hat{A}_{i, t} A^i,t计算的复杂化。并且,与公式(2)中使用的KL散度惩罚项不同,我们使用以下无偏估计器(舒尔曼,2020年)来估计KL散度:
D K L [ π θ ∥ π r e f ] = π r e f ( o i , r ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − log π r e f ( o i , r ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − 1 \mathbb{D}_{KL}\left[\pi_{\theta} \| \pi_{ref}\right]=\frac{\pi_{ref}\left(o_{i, r} | q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}-\log\frac{\pi_{ref}\left(o_{i, r} | q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}-1 DKL[πθ∥πref]=πθ(oi,t∣q,oi,<t)πref(oi,r∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,r∣q,oi,<t)−1
该估计值保证为正。
算法流程:

PPO知识点
强化学习全面知识点参考:https://blog.csdn.net/weixin_44986037/article/details/147685319
https://blog.csdn.net/weixin_44986037/category_12959317.html
PPO的网络模型结构(优势估计)
若使用在策略与价值函数之间共享参数的神经网络架构,则需使用一个结合了策略替代项与价值函数误差项的损失函数。
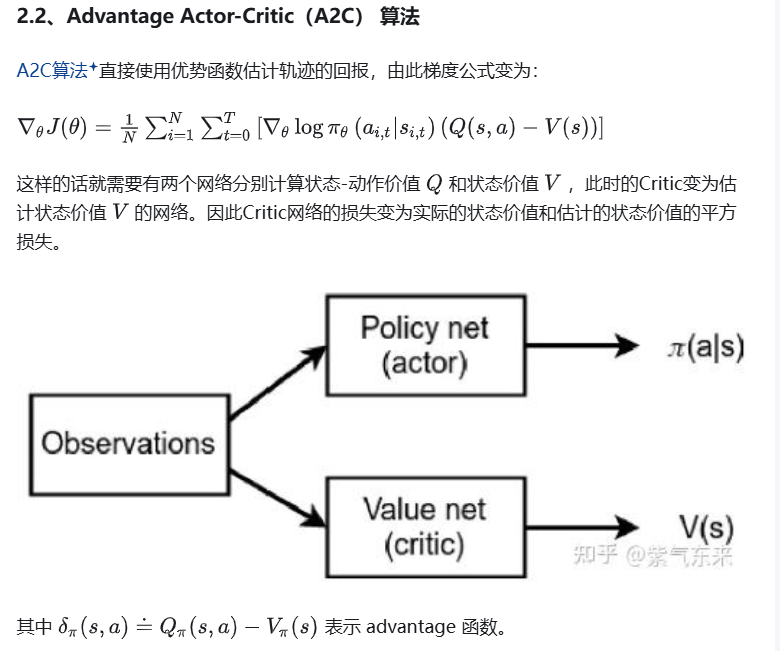
在PPO(Proximal Policy Optimization)算法中,网络模型的数量为两个,分别是 Actor网络 和 Critic网络。而 GAE(Generalized Advantage Estimation) 是一种用于计算优势函数(Advantage Function)的方法,并不引入额外的网络模型。以下是详细说明:
1. PPO的网络模型结构
PPO基于 Actor-Critic 架构,包含以下两个核心网络:
-
Actor网络(策略网络)
• 功能:生成动作概率分布 π ( a ∣ s ) \pi(a|s) π(a∣s),指导智能体行为。
• 结构:多层感知机(MLP)或Transformer,输出层为动作空间的概率分布。- 输入:当前状态 s s s。
- 输出:动作概率分布(离散动作空间)或动作分布参数(连续动作空间,如高斯分布的均值和方差)。
- 作用:决定智能体在特定状态下选择动作的策略(策略优化的核心)。
-
Critic网络(价值网络)
• 功能:估计状态价值函数 V ( s ) V(s) V(s),用于计算优势函数 A t A_t At。
• 结构:与Actor类似,但输出层为标量值(状态价值)。- 输入:当前状态 s s s。
- 输出:状态价值 V ( s ) V(s) V(s),即从当前状态开始预期的累积回报。
- 作用:评估状态的好坏,辅助Actor网络更新策略(通过优势函数的计算)。
-
变体与优化
• 共享参数:部分实现中,Actor和Critic共享底层特征提取层以减少参数量。
• GRPO变体:如DeepSeek提出的GRPO算法,去除Critic网络,通过组内奖励归一化简化计算,但标准PPO仍保留双网络结构。
共享编码层:
在实际实现中,Actor和Critic网络的底层特征提取层(如卷积层、Transformer层等)可能共享参数,以减少计算量并提高特征复用效率。例如,在图像输入场景中,共享的CNN层可以提取通用的视觉特征,然后分别输出到Actor和Critic的分支。
PPO基于 Actor-Critic 架构,A2C网络结构:
参考:https://zhuanlan.zhihu.com/p/450690041
GRPO和PPO网络结构:
图 4 |PPO 和我们的 GRPO 示范。GRPO 放弃了价值模型,而是根据组分数估计基线,从而显著减少了训练资源。
由于PPO中使用的价值函数通常与策略模型规模相当,这会带来巨大的内存和计算负担。此外,在强化学习训练过程中,价值函数在优势值计算中被用作基线以减少方差。而在大语言模型的环境中,奖励模型通常只给最后一个令牌分配奖励分数,这可能会使精确到每个令牌的价值函数的训练变得复杂。
为了解决这个问题,如图4所示,我们提出了组相对策略优化(GRPO)。它无需像PPO那样进行额外的价值函数近似,而是使用针对同一问题产生的多个采样输出的平均奖励作为基线。
2. GAE(广义优势估计)原理
1. 优势函数的定义
优势函数 A ( s , a ) A(s, a) A(s,a) 的数学表达式为:
A π ( s , a ) = Q π ( s , a ) − V π ( s ) A^\pi(s, a) = Q^\pi(s, a) - V^\pi(s) Aπ(s,a)=Qπ(s,a)−Vπ(s)
- Q π ( s , a ) Q^\pi(s, a) Qπ(s,a):动作值函数,表示在状态 s s s 下执行动作 a a a 后,遵循策略 π \pi π 所能获得的期望累积奖励。
- V π ( s ) V^\pi(s) Vπ(s):状态值函数,表示在状态 s s s 下,遵循策略 π \pi π 所能获得的期望累积奖励(不指定具体动作)。
- 意义:若 A ( s , a ) > 0 A(s, a) > 0 A(s,a)>0,说明执行动作 a a a 相比于当前策略的平均表现更优;若 A ( s , a ) < 0 A(s, a) < 0 A(s,a)<0,则说明该动作不如当前策略的平均水平。
2.GAE(广义优势估计)
GAE是PPO中用于估计优势函数的核心技术,通过平衡偏差与方差优化策略梯度更新。其核心结构包括以下要点:
-
多步优势加权
GAE通过指数衰减加权不同步长的优势估计(如TD残差)构建综合优势值,公式为:
A t GAE = ∑ l = 0 ∞ ( γ λ ) l δ t + l A_t^{\text{GAE}} = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l} AtGAE=l=0∑∞(γλ)lδt+l
其中, δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st)为时序差分误差。 γ \gamma γ(折扣因子)控制长期回报衰减, λ \lambda λ(GAE参数)调节偏差-方差权衡。 -
偏差-方差平衡机制
• λ ≈ 0 \lambda \approx 0 λ≈0:退化为单步TD残差(高偏差、低方差)• λ ≈ 1 \lambda \approx 1 λ≈1:接近蒙特卡洛估计(低偏差、高方差)
通过调节 λ \lambda λ,GAE在两者间取得最优折衷。
-
与TD-λ的区别
GAE将TD-λ的资格迹思想引入策略梯度框架,直接服务于优势函数计算,而非传统的价值函数更新。
参考:https://blog.csdn.net/animate1/article/details/146100100

2、关键技术与方法
-
大规模数学语料构建(DeepSeekMath Corpus):
- 数据来源:从Common Crawl中通过迭代筛选获取,以OpenWebMath为种子数据,用fastText分类器识别数学网页,经4轮筛选得到 35.5M网页、120B tokens,含英/中多语言内容,规模是Minerva所用数学数据的7倍、OpenWebMath的9倍。
- 去污染:过滤含基准测试题的文本(10-gram精确匹配),避免数据泄露。
- 质量验证:在8个数学基准测试中,基于该语料训练的模型性能显著优于MathPile、OpenWebMath等现有语料,证明其高质量和多语言优势。
-
模型训练流程:
- 预训练:
- 基于代码模型 DeepSeek-Coder-Base-v1.5 7B 初始化,训练数据含 56%数学语料、20%代码、10%自然语言 等,总 500B tokens。
- 基准表现:MATH基准 36.2%(超越Minerva 540B的35%),GSM8K 64.2%。
- 监督微调(SFT):
- 使用 776K数学指令数据(链思维CoT、程序思维PoT、工具推理),训练后模型在MATH达 46.8%,超越同规模开源模型。
- 强化学习(RL):Group Relative Policy Optimization (GRPO):
- 创新点:无需独立价值函数,通过组内样本平均奖励估计基线,减少内存消耗,支持过程监督和迭代RL。
- 效果:MATH准确率提升至 51.7%,GSM8K从82.9%提升至88.2%,CMATH从84.6%提升至88.8%,超越7B-70B开源模型及多数闭源模型(如Inflection-2、Gemini Pro)。
- 预训练:
3、核心实验结果
-
数学推理性能:
基准测试 DeepSeekMath-Base 7B DeepSeekMath-Instruct 7B DeepSeekMath-RL 7B GPT-4 Gemini Ultra MATH (Top1) 36.2% 46.8% 51.7% 52.9% 53.2% GSM8K (CoT) 64.2% 82.9% 88.2% 92.0% 94.4% CMATH (中文) - 84.6% 88.8% - - - 关键优势:在不依赖外部工具和投票技术的情况下,成为首个在MATH基准突破50%的开源模型,自一致性方法(64样本)可提升至60.9%。
-
泛化与代码能力:
- 通用推理:MMLU基准得分 54.9%,BBH 59.5%,均优于同类开源模型。
- 代码任务:HumanEval(零样本)和MBPP(少样本)表现与代码模型DeepSeek-Coder-Base-v1.5相当,证明代码预训练对数学推理的促进作用。
4、结论与未来方向
-
核心贡献:
- 证明公开网络数据可构建高质量数学语料,小模型(7B)通过优质数据和高效算法可超越大模型(如Minerva 540B)。
- 提出GRPO算法,在减少训练资源的同时显著提升数学推理能力,为RL优化提供统一范式。
- 验证代码预训练对数学推理的积极影响,填补“代码是否提升推理能力”的研究空白。
-
局限:
- 几何推理和定理证明能力弱于闭源模型,少样本学习能力不足(与GPT-4存在差距)。
- arXiv论文数据对数学推理提升无显著效果,需进一步探索特定任务适配。
-
未来工作:
- 优化数据筛选流程,构建更全面的数学语料(如几何、定理证明)。
- 探索更高效的RL算法,结合过程监督和迭代优化,提升模型泛化能力。
关键问题与答案
1. DeepSeekMath在数据处理上的核心创新点是什么?
答案:通过 迭代筛选+多语言数据 构建高质量数学语料。以OpenWebMath为种子,用fastText分类器从Common Crawl中筛选数学网页,经4轮迭代获得120B tokens,涵盖英/中多语言内容,规模远超现有数学语料(如OpenWebMath的9倍),且通过严格去污染避免基准测试数据泄露。
2. GRPO算法相比传统PPO有何优势?
答案:GRPO通过 组内相对奖励估计基线 替代独立价值函数,显著减少训练资源消耗。无需额外训练价值模型,直接利用同一问题的多个样本平均奖励计算优势函数,同时支持过程监督(分步奖励)和迭代RL,在MATH基准上比PPO更高效,准确率提升5.9%(46.8%→51.7%)且内存使用更优。
3. 代码预训练对数学推理能力的影响如何?
答案:代码预训练能 显著提升数学推理能力,无论是工具使用(如Python编程解题)还是纯文本推理。实验表明,基于代码模型初始化的DeepSeekMath-Base在GSM8K+Python任务中得分66.9%,远超非代码模型(如Mistral 7B的48.5%),且代码与数学混合训练可缓解灾难性遗忘,证明代码中的逻辑结构和形式化推理对数学任务有迁移优势。
相关文章:
)
21、DeepSeekMath论文笔记(GRPO)
DeepSeekMath论文笔记 0、研究背景与目标1、GRPO结构GRPO结构PPO知识点**1. PPO的网络模型结构****2. GAE(广义优势估计)原理****1. 优势函数的定义**2.GAE(广义优势估计) 2、关键技术与方法3、核心实验结果4、结论与未来方向关键…...

深入解析:如何基于开源p-net快速开发Profinet从站服务
一、Profinet协议与软协议栈技术解析 1.1 工业通信的"高速公路" Profinet作为工业以太网协议三巨头之一,采用IEEE 802.3标准实现实时通信,具有: 实时分级:支持RT(实时)和IRT(等时实时)通信模式拓扑灵活:支持星型、树型、环型等多种网络结构对象模型:基于…...

腾讯多模态定制化视频生成框架:HunyuanCustom
HunyuanCustom 速读 一、引言 HunyuanCustom 是由腾讯团队提出的一款多模态定制化视频生成框架。该框架旨在解决现有视频生成方法在身份一致性(identity consistency)和输入模态有限性方面的不足。通过支持图像、音频、视频和文本等多种条件输入,HunyuanCustom 能…...

警惕C#版本差异多线程中的foreach陷阱
警惕C#版本差异多线程中的foreach陷阱 同样的代码,不同的结果闭包捕获的“时间差”问题绕过闭包陷阱的三种方法Lambda立即捕获(代码简洁)显式传递参数(兼容性最佳)使用Parallel.ForEach(官方推荐)注意事项:版本兼容性指南警惕多线程中的foreach陷阱:C#版本差异引发的…...

2024年AI发展趋势全面解析:从多模态到AGI的突破
2024年AI发展五大核心趋势 1. 多模态AI的爆发式增长 GPT-4V、Gemini等模型实现文本/图像/视频的跨模态理解应用场景扩展至智能客服、内容创作、工业质检等领域 2. 小型化与边缘AI的崛起 手机端LLM(如Phi-2)实现本地化部署隐私保护与实时响应的双重优…...
)
高精度之加减乘除之多解总结(加与减篇)
开篇总述:精度计算的教学比较杂乱,无系统的学习,且存在同法多线的方式进行同一种运算,所以我写此篇的目的只是为了直指本质,不走教科书方式,步骤冗杂。 一,加法 我在此讲两种方法: …...
)
Arduino 开源按键库大合集(单击/双击/长按实现)
2025.5.10 22:25更新:增加了Button2 2025.5.10 13:13更新:增加了superButton 虽然Arduino自带按键中断attachInterrupt(button1.PIN, isr, FALLING);,但是要是要实现去抖,双击检测,长按检测等等就略微麻烦些࿰…...

相机Camera日志分析之八:高通Camx HAL架构opencamera三级日志详解及关键字
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:相机Camera日志分析之七:高通Camx HAL架构opencamera二级日志详解及关键字 这一篇我们开始讲: 相机Camera日志分析之八:高通Camx HAL架构opencamera三级日志详解及关键字 目录 【关注我,后续持续…...

Java零组件实现配置热更新
在某些场景下,我们需要实现配置的热更新,但是又要实现软件即插即用的需求,这就使我们不能引入过多复杂的插件,而nacos等配置中心在分布式业务场景下对配置的管理起着很重要作用,为此需要想一些办法去代替它们而完成同样…...

Kotlin高阶函数多态场景条件判断与子逻辑
Kotlin高阶函数多态场景条件判断与子逻辑 fun main() {var somefun: (Int, Float) -> Longval a 4val b 5fsomefun multi()//if 某条件println(somefun.invoke(a, b))//if 某条件somefun add()println(somefun.invoke(a, b)) }fun multi(): (Int, Float) -> Long {re…...

Ethercat转Profinet网关如何用“协议翻译术“打通自动化产线任督二脉
Ethercat转Profinet网关如何用"协议翻译术"打通自动化产线任督二脉 将遗留的Profinet设备(如传感器)接入现代EtherCAT主站(如Codesys控制器)避免全面更换硬件。 作为一名电气工程师,我最近面临的一个挑战&a…...

每日算法刷题Day1 5.9:leetcode数组3道题,用时1h
1.LC寻找数组的中心索引(简单) 数组和字符串 - LeetBook - 力扣(LeetCode)全球极客挚爱的技术成长平台 思想: 计算总和和左侧和,要让左侧和等于右侧和,即左侧和总和-左侧和-当前数字 代码 c代码: class Solution { public:i…...

MySQL的视图
一、MySQL视图的介绍和作用 MySQL视图,加油兄弟们,孰能生巧,完整代码在最后!!! 视图是一个虚拟的表,并不是真是存在的,视图其实并没有真实的数据,他只是根据一个sql语句…...

旅游推荐数据分析可视化系统算法
旅游推荐数据分析可视化系统算法 本文档详细介绍了旅游推荐数据分析可视化系统中使用的各种算法,包括推荐算法、数据分析算法和可视化算法。 目录 推荐算法 基于用户的协同过滤推荐基于浏览历史的推荐主题推荐算法 亲子游推荐算法文化游推荐算法自然风光推荐算法…...

Pandas:数据处理与分析
目录 一、Pandas 简介 二、Pandas 的安装与导入 三、Pandas 的核心数据结构 (一)Series (二)DataFrame 四、Pandas 数据读取与写入 (一)读取数据 (二)写入数据 五、数据清洗…...

非阻塞式IO-Java NIO
一、NIO简介 Java NIO是Java1.4引入的一种新的IO API,它提供了非阻塞式IO,选择器、通道、缓冲区等新的概念和机制。相比传统的IO,多出的N不单纯是新的,更表现在Non-blocking非阻塞,NIO具有更高的并发性、可扩展性以及…...

tryhackme——Enumerating Active Directory
文章目录 一、凭据注入1.1 RUNAS1.2 SYSVOL1.3 IP和主机名 二、通过Microsoft Management Console枚举AD三、通过命令行net命令枚举四、通过powershell枚举 一、凭据注入 1.1 RUNAS 当获得AD凭证<用户名>:<密码>但无法登录域内机器时,runas.exe可帮助…...
Linux下基本指令 2)
(二)Linux下基本指令 2
【知识预告】 16. date 指令 17. cal 指令 18. find 指令 19. which指令 20. whereis 指令 21. alias 指令 22. grep 指令 23. zip/unzip 指令 24. tar 指令 25. bc 指令 26. uname ‒r 指令 27. 重要的⼏个热键 28. 关机 16 date 指令 指定格式显⽰时间:date %Y-…...

[ctfshow web入门] web70
信息收集 使用cinclude("php://filter/convert.base64-encode/resourceindex.php");读取的index.php error_reporting和ini_set被禁用了,不必管他 error_reporting(0); ini_set(display_errors, 0); // 你们在炫技吗? if(isset($_POST[c])){…...

第三章 Freertos智能小车遥控控制
本文基于小车APP,通过与蓝牙模块进行连接,发送特定信号给小车主控,实现对小车的模式切换、灯光控制、前进、后退、左右控制。目前还未加入电机控制,具体的电机控制效果还不能实现,但是可以进行模式切换与灯光控制。 …...

Spring 6.x 详解介绍
Spring 6.x 是 Spring Framework 的最新主版本,于2022年11月正式发布,标志着对 Java 17 和 Jakarta EE 9 的全面支持,同时引入了多项革新性特性,旨在优化性能、简化开发并拥抱现代技术趋势。 一、核心特性与架构调整 Java 17 与 J…...

阿里云OSS+CDN自动添加文章图片水印配置指南
文章目录 一、环境准备二、OSS水印样式配置三、CDN关键配置四、Handsome主题自动化配置五、水印效果验证六、常见问题排查 一、环境准备 资源清单 阿里云OSS Bucket(绑定自定义域名 static.example.com)阿里云CDN加速域名,回源为Bucket的域名…...

hot100-子串-JS
一、560.和为k的子串 560. 和为 K 的子数组 提示 给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。 子数组是数组中元素的连续非空序列。 示例 1: 输入:nums [1,1,1], k 2 输出:2示例 2…...
)
LeetCode 270:在二叉搜索树中寻找最接近的值(Swift 实战解析)
文章目录 摘要描述题解答案题解代码分析示例测试及结果时间复杂度空间复杂度总结 摘要 在日常开发中,我们经常需要在一组有序的数据中快速找到最接近某个目标值的元素。LeetCode 第 270 题“Closest Binary Search Tree Value”正是这样一个问题。本文将深入解析该…...

《操作系统真象还原》第十三章——编写硬盘驱动程序
文章目录 前言硬盘及分区表创建从盘及获取安装的磁盘数创建磁盘分区表硬盘分区表浅析 编写硬盘驱动程序硬盘初始化修改interrupt.c编写ide.h编写ide.c 实现thread_yield和idle线程修改thread.c 实现简单的休眠函数修改timer.c 完善硬盘驱动程序继续编写ide.c 获取硬盘信息&…...

DNS服务实验
该文章将介绍DNS服务的正向和反向解析实验、主从实验、转发服务器实验以及Web解析实验 正向解析实验:将域名解析为对应的IP地址 反向解析实验:将IP地址解析为对应的域名 主从实验:主服务器区域数据文件发送给从服务器,从服务器…...

SierraNet M1288网络损伤功能显著助力GPU互联网络的测试验证,包含包喷洒,LLR等复杂特性的验证测试
SierraNet M1288 以太网协议分析仪 产品概述 SierraNet M1288 是一款兼具高性价比与全面功能的以太网和光纤通道数据捕获及协议验证系统。它能够以全线路速率 100% 记录所有流量,并借助 InFusion™ 工具实现高级错误注入和流量破坏功能,为开发人员和协议…...

HunyuanCustom:文生视频框架论文速读
《HunyuanCustom: A Multimodal-Driven Architecture for Customized Video Generation》论文讲解 一、引言 本文提出了 HunyuanCustom,这是一个基于多模态驱动的定制化视频生成框架。该框架旨在解决现有视频生成模型在身份一致性(identity consistenc…...

HTTP、HTTPS、SSH区别以及如何使用ssh-keygen生成密钥对
HTTP、HTTPS、SSH区别以及如何使用ssh-keygen生成密钥对 HTTP (HyperText Transfer Protocol) 定义:应用层协议,用于通过Web传输数据(如网页、文件)默认端口:80机制:客户端发送Get请求,服务器…...

如何启动vue项目及vue语法组件化不同标签应对的作用说明
如何启动vue项目及vue语法组件化不同标签应对的作用说明 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是node.js和vue的使用。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】&…...

Ubuntu22.04安装显卡驱动/卸载显卡驱动
报错 今日输入nvidia-smi报错,在安装了535和550,包括560都没办法解决,但是又怕乱搞导致环境损坏,打算把显卡卸载然后重新安装系统默认推荐版本的显卡驱动 qinqin:~$ nvidia-smi Failed to initialize NVML: Driver/library version mismatch NVML library version: 560.35卸载…...

【桌面】【输入法】常见问题汇总
目录 一、麒麟桌面系统输入法概述 1、输入法介绍 2、输入法相关组件与服务 3、输入法调试相关命令 3.1、输入法诊断命令 3.2、输入法配置重新加载命令 3.3、启动fcitx输入法 3.4、查看输入法有哪些版本,并安装指定版本 3.5、重启输入法 3.6、查看fcitx进程…...

Web3 初学者学习路线图
目录 🌟 Web3 初学者学习路线图 🧩 第一步:搞懂 Web3 是什么 ✅ 学什么? 🔧 推荐工具: 🎥 推荐学习: 🛠️ 第二步:了解智能合约和 Solidity(核心技能) ✅ 学什么? 🔧 工具: 📘 推荐课程: 🌐 第三步:连接前端和区块链,创建简单 DApp ✅ 学…...

python打卡day21
常见的降维算法 知识点回顾: LDA线性判别PCA主成分分析t-sne降维 之前学了特征降维的两个思路,特征筛选(如树模型重要性、方差筛选)和特征组合(如SVD/PCA)。 现在引入特征降维的另一种分类:无/有…...
投稿经验分享)
KNOWLEDGE-BASED SYSTEMS(KBS期刊)投稿经验分享
期刊介绍: KBS是计算机一区,CCF-c期刊,(只看大类分区,小类不用看,速度很快,桌拒比较多,能送审就机会很大!) 具体时间流程: 7月初投稿…...

vue使用rules实现表单校验——校验用户名和密码
编写校验规则 常规校验 const rules {username: [{ required: true, message: 请输入用户名, trigger: blur },{ min: 5, max: 16, message: 长度在 5 到 16 个字符, trigger: blur }],password: [{ required: true, message: 请输入密码, trigger: blur },{ min: 5, max: 1…...

[CANN] 安装软件依赖
环境 昊算平台910b NPUdocker容器 安装步骤 安装依赖-安装CANN(物理机场景)-软件安装-开发文档-昇腾社区 apt安装miniconda安装 Apt 首先进行换源,参考昇腾NPU容器内 apt 换源 Miniconda 安装miniconda mkdir -p ~/miniconda3 wget …...

代码随想录算法训练营第三十七天
LeetCode题目: 300. 最长递增子序列674. 最长连续递增序列718. 最长重复子数组2918. 数组的最小相等和(每日一题) 其他: 今日总结 往期打卡 300. 最长递增子序列 跳转: 300. 最长递增子序列 学习: 代码随想录公开讲解 问题: 给你一个整数数组 nums ,找到其中最长…...
)
Qt开发经验 --- 避坑指南(11)
文章目录 [toc]1 QtCreator同时运行多个程序2 刚安装的Qt编译报错cannot find -lGL: No such file or directory3 ubuntu下Qt无法输入中文4 Qt版本发行说明5 Qt6.6 VS2022报cdb.exe无法定位dbghelp.dll输入点6 Qt Creator13.0对msvc-qmake-jom.exe支持有问题7 银河麒麟系统中ud…...

vue 组件函数式调用实战:以身份验证弹窗为例
通常我们在 Vue 中使用组件,是像这样在模板中写标签: <MyComponent :prop"value" event"handleEvent" />而函数式调用,则是让我们像调用一个普通 JavaScript 函数一样来使用这个组件,例如:…...
)
青藏高原东北部祁连山地区250m分辨率多年冻土空间分带指数图(2023)
时间分辨率:10年 < x < 100年空间分辨率:100m - 1km共享方式:开放获取数据大小:24.38 MB数据时间范围:近50年来元数据更新时间:2023-10-08 数据集摘要 多年冻土目前正在经历大规模的退化,…...
)
[6-2] 定时器定时中断定时器外部时钟 江协科技学习笔记(41个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 V 30 31 32 33 34 35 36 37 38 39 40 41...

抖音视频去水印怎么操作
在抖音上保存或分享视频时,水印通常会自动添加。如果想去除水印,可以尝试以下方法,但请注意尊重原创作者的版权,仅限个人合理使用。 方法 1:使用第三方去水印工具(手机/电脑均可) 复制视频链接 …...

Java并发编程
Java并发编程的核心挑战 线程安全与数据竞争 线程安全的概念及其重要性数据竞争的产生原因及常见场景如何通过同步机制(如锁、原子类)避免数据竞争 // 示例:使用synchronized关键字实现线程安全 public class Counter {private int count …...

【ospf综合实验】
拓扑图:...

NVMe控制器之仿真平台搭建
本设计采用Verilog HDL语言进行实现并编写测试激励,仿真工具使用Mentor公司的QuestaSim 10.6c软件完成对关键模块的仿真验证工作,由于是基于Xilinx公司的Kintex UltraScale系列FPGA器件实现的,因此使用Xilinx公司的Vivado2019.1设计套件工具进…...

深入探究 InnoDB 的写失效问题
在 MySQL 数据库的世界中,InnoDB 存储引擎凭借其卓越的性能和可靠性,成为众多应用的首选。然而,如同任何复杂的系统一样,InnoDB 也面临着一些挑战,其中写失效问题便是一个值得深入探讨的关键议题。本文将带您全面了解 …...

边缘计算从专家到小白
“云-边-端”架构 “云” :传统云计算的中心节点,是边缘计算的管控端。汇集所有边缘的感知数据、业务数据以及互联网数据,完成对行业以及跨行业的态势感知和分析。 “边” :云计算的边缘侧,分为基础设施边缘和设备边缘…...

智能商品推荐系统技术路线图
智能商品推荐系统技术路线图 系统架构图 --------------------------------------------------------------------------------------------------------------- | 用户交互层 (Presentation Layer) …...

SpringMVC面试内容
SpringMVC运行流程 SpringMVC的运行流程SpringBoot Vue交互流程HTTP 的 GET 和 POST 区别跨域请求是什么?有什么问题?怎么解决?浏览器访问资源没有响应,怎么排查Cookie的理解Session的理解 Cookie和Session的区别 SpringMVC的运行流程 1、域名解析…...