CUDA编程——性能优化基本技巧
本文主要介绍下面三种技巧:
- 使用
__restrict__让编译器放心地优化指针访存 - 想办法让同一个 Warp 中的线程的访存 Pattern 尽可能连续,以利用 Memory coalescing
- 使用 Shared memory
0. 弄清Kernael函数是Compute-bound 还是 Memory-bound
先摆出一个知识点,一般来说,Compute-bound 的 Kernel 不太常见,常见的 Compute-bound 的 Kernel 可能只有矩阵乘法与卷积核比较大的卷积,大多数都是Memory-bound,所以下面我们主要关注如何优化访存。
在经典的冯诺依曼架构下,ALU (Arithmetic Logic Unit,计算逻辑单元,可以简单理解为加法器、乘法器等) 要从内存中取操作数,进行对应的计算(如乘法),并写回内存。所以,计算速度会受到两个因素的限制:ALU 进行计算的速度,与内存的存取速度。如果一个程序的运行速度瓶颈在于前者,那么称其为 Compute-bound 的;如果瓶颈在于后者,那么称其为 Memory-bound 的。
由于 CPU 中运算单元较少,且 CPU 具有多级缓存,所以空间连续性、时间连续性较好的程序在 CPU 上一般是 Compute-bound 的。而 GPU 则恰恰相反:GPU 的核心的规模一般很大,比如 RTX 4090 可以在一秒内做 82.58T 次 float16 运算(暂不考虑 Tensor core),但其内存带宽只有 1TB/s,每秒只能传输 0.5T 个 float16。这便导致 GPU 上的操作更可能会受到内存带宽的限制,成为 Memory-bound。
如何估测一个 CUDA Kernel 是 Compute-bound 还是 Memory-bound 呢?我们可以计算它的 “算存比”,也即,
算存比 = 计算次数/访存次数
并将其与 GPU 的 每秒能做的运算次数/每秒能做的访存次数做比较。
例子:
__global__ void pointwise_add_kernel(int* C, const int* A, const int* B, int n) {for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < n; i += blockDim.x * gridDim.x)C[i] = A[i] + B[i];
}对于上面的 pointwise_add_kernel,其需要访问 3N 次内存(读取A[i]、读取B[i]、写入C[i]),同时做 N次加法,所以其存算比为 N/3N=1/3
对于RTX 4090 可以在一秒内做 82.58T 次 float16 运算(暂不考虑 Tensor core),但其内存带宽只有 1TB/s,每秒只能传输 0.5T 个 float16。起存算比为 82.58/0.5=165.16
因此这个 pointwise_add_kernel为 Memory-bound。
1. __restrict__
restrict关键字用于修饰指针。通过加上restrict关键字,编程者可提示编译器:在该指针的生命周期内,其指向的对象不会被别的指针所引用。
大家还记得什么是 Pointer aliasing 嘛?简单来说,下面两段代码并不是等价的:
void f1(int* x, int* y) {*x += *y;*x += *y;
}
void f2(int* x, int* y) {*x += 2*(*y);
}
这是因为,x 和 y 两个指针可能指向相同的内存。考虑 f(x, x),第一段代码将把 *x 变为 4(*x),而第二段代码则会把 *x 变为 3(*x)。
Pointer aliasing 可能会抑制编译器做出某些优化。比如在上面的代码中,f1() 需要 5 次访存而 f2() 仅需三次,后者更优。但由于编译器并不能假设 x 和 y ,它不敢做这个优化。
所以,我们需要 “显式地” 告诉编译器,两个指针不会指向相同的内存地址(准确来说,应该是 “改变一个指针指向的地址的数据,不会影响到通过其他指针读取的数据”),从而让编译器“放心地” 做出优化。nvcc 支持一个关键字,叫做 __restrict__,加上它,编译器就可以放心地把指针指向的值存在寄存器里,而不是一次又一次地访存,进而提高了性能。
我们可以对比一下示例代码中的 gemm_gpu_mult_block_no_restrict.cu 与 gemm_gpu_mult_block.cu 的性能。在 4090 上,前者平均耗时 40420.75,后者平均耗时 3988.38。可以看出,性能提升幅度不容小觑。
为了验证性能下降确实是由于没有了 __restrict__ 关键字后的额外访存带来的,我们可以对比 gemm_gpu_mult_block.cu 与 gemm_gpu_mult_block_no_restrict_reg.cu 的性能。后者虽然没有使用 __restrict__ 关键字,但它把中间的累加结果存在了变量中,而不是每一次都写回 C 数组。在 4090 上,二者的性能非常相似。这说明,在缺少 __restrict__ 关键字的时候,代码需要进行许多不必要的访存,进而拖慢了速度。
2. Memory Coalescing内存合并
Memory Coalescing主要目的就是:充分利用内存带宽。
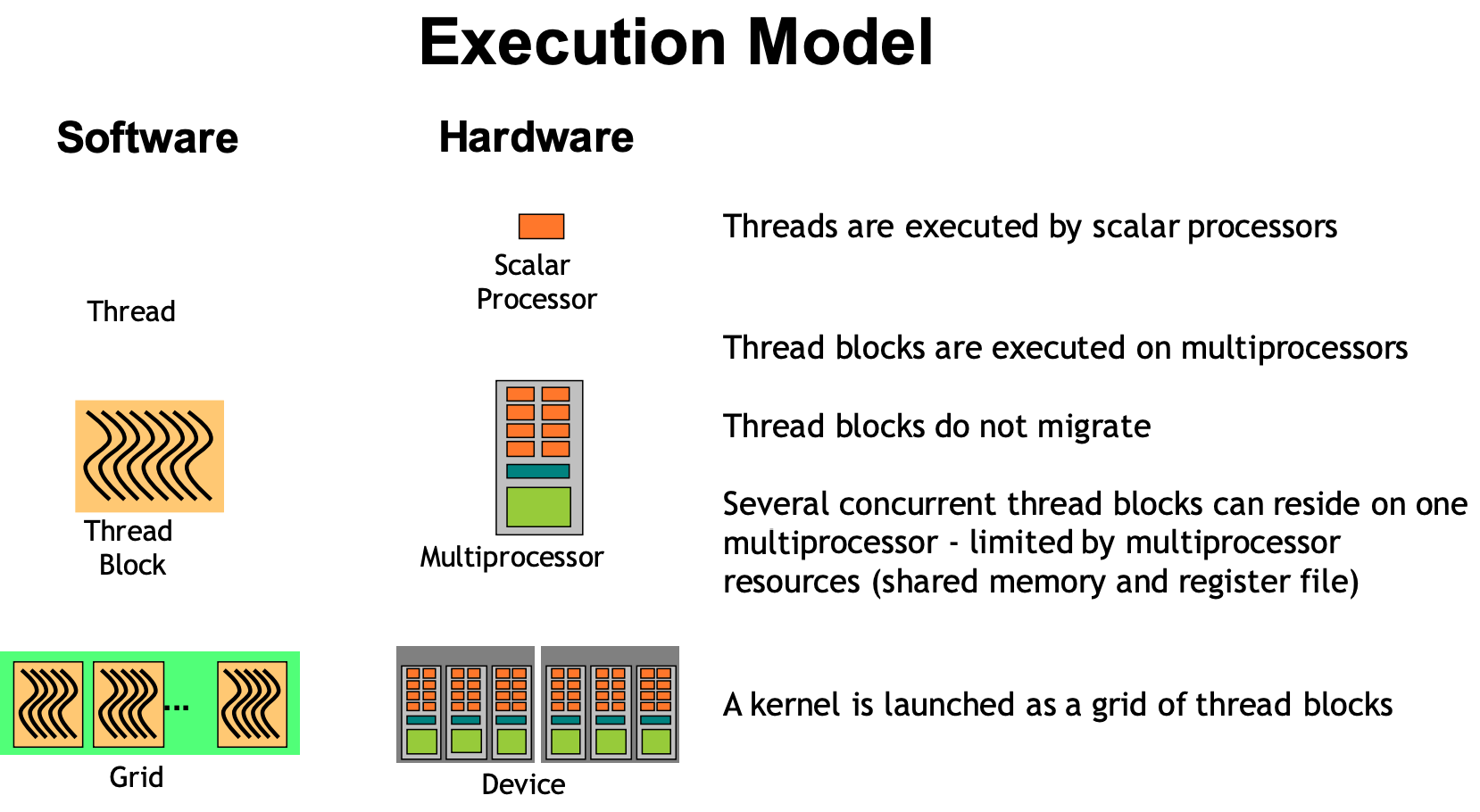
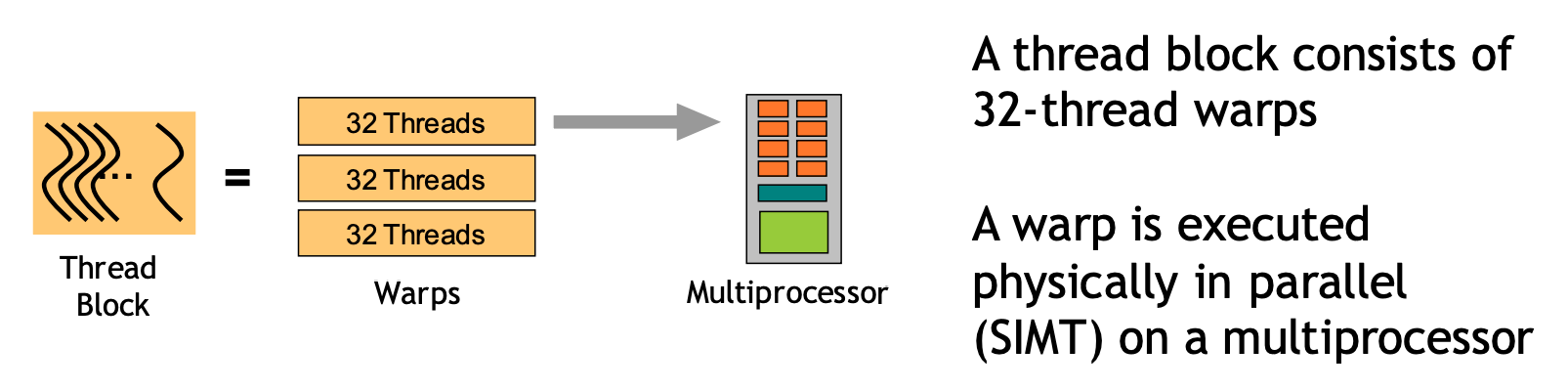
我们先来了解GPU的调度方式。Grid 里包含若干 Thread block,每个 Thread block 则又包含若干 Thread,那么这些 Thread 是如何被调度的呢?它们被按编号分成了若干组,每一组中有 32 个 Thread(即,线程 0 ~ 31 为第一组,32 ~ 63 为第二组,依次类推),这样的 “组” 便被叫做 Warp。
GPU 的调度是以 Warp 作为基本单位的。每个时钟周期内,同一个 Warp 中的所有线程都会执行相同的指令。
(注意,thread, block, grid是软件概念,warp是硬件概念,如以下示意图所示)
(1)Transaction 的基本要求
-
长度为 32 个 Byte:在 GPU 的内存访问中,每个事务(Transaction)的大小被固定为 32 字节。这是硬件设计上的一种规定,用于优化内存访问的效率。
-
开始地址是 32 的倍数:事务(Transaction)的起始地址必须是 32 字节对齐的。也就是说,如果事务的起始地址是 A,那么 Amod32=0。这种对齐要求可以简化硬件设计,并提高内存访问的效率。
(2)Warp 中线程的内存访问模式
-
Warp:在 GPU 中,线程(Thread)是以 Warp 为单位进行调度的。一个 Warp 通常包含多个线程(例如 32 个线程)。
-
线程的内存访问范围:
-
如果一个 Warp 中的第 i 个线程要访问地址范围为 4i∼4i+3 的内存,这意味着每个线程访问 4 字节的数据。
-
由于每个事务(Transaction)的大小是 32 字节,而每个线程访问 4 字节,因此一个 Warp 中的 32 个线程总共需要 4 个事务来完成所有线程的内存访问。因为 32×4 字节 = 128 字节,而 128 字节正好可以分成 4 个 32 字节的事务。
-
然而,内存带宽是有上限的,且每一个 Transaction 的大小都是 32 Byte,这注定了每一秒 GPU 核心可以发起的 Transaction 数量是有上限的。
接下来请阅读 CUDA Best Practices,了解 Memory coalescing 在一个具体的例子中的优化效果。
总之,我们需要尽量保证同一个 Warp 中每一个 Thread 的访存是 coalesced 的,以充分利用内存带宽。
3. Shared Memory
Share memory 既可以用来在同一个 Thread block 的不同 Thread 之间共享数据(最常见的用法是 Reduction),也可以用来优化访存性能。我们现在主要关注后者。
在学习 Shared memory 之前,我们需要先了解一下 CUDA 的内存模型:
CUDA 中大致有这几种内存:
- Global Memory:俗称显存,位于 GPU 核心外部,很大(比如 A100 有 80GB),但是带宽很有限
- L2 Cache:位于 GPU 核心内部,是显存的缓存,程序不能直接使用
- Register:寄存器,位于 GPU 核心内部,Thread 可以直接调用
- Shared memory:位于 GPU 核心内部,每个 Thread block 中的所有 Thread 共用同一块 Shared memory(因此,Shared memory 可以用来在同一个 Thread block 的不同 Thread 之间共享数据),并且带宽极高(因此,Shared memory 可以用来优化性能)。
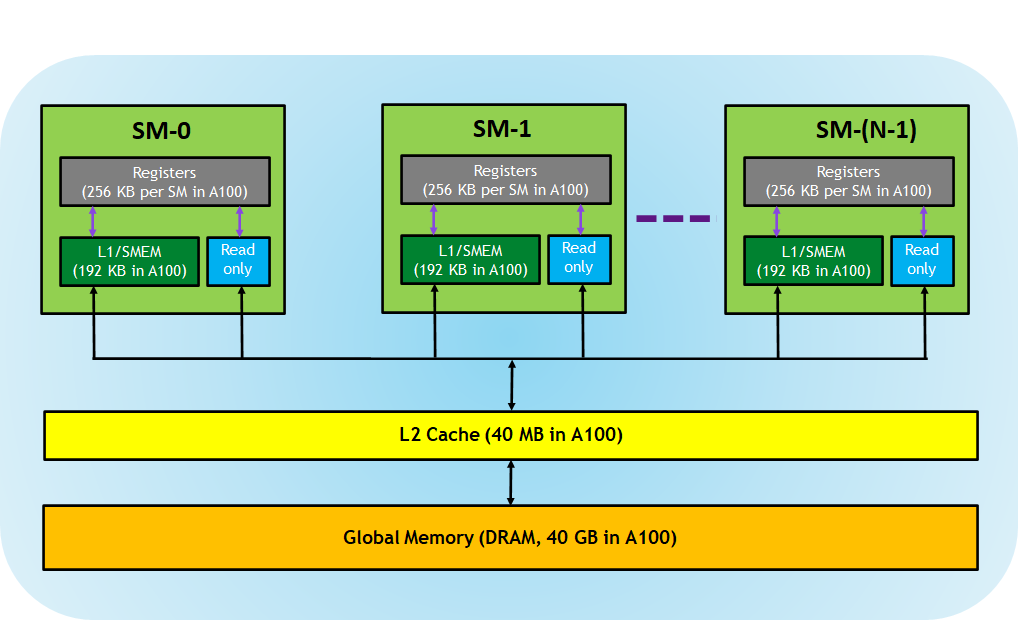
我们还是以矩阵乘法为例。在上面的 gemm_gpu_mult_block.cu 中,为了计算大小分别为 n×k 与 k×m的两个矩阵乘法,我们一共访问了大约 2nmk次内存。这十分不合算,因为三个矩阵加起来也就只有 nk+km+nm个元素。
Tiling
我们尝试使用 Shared memory 来优化矩阵乘法。具体的,我们使用一种叫做 Tiling 的技术。
Tiling 是一种将矩阵划分为小块(Tile)的技术,每个线程块处理一个 Tile。通过这种方式,可以将矩阵的子块加载到 Shared Memory 中,减少全局内存的访问次数,并提高内存访问的局部性。
接下来请阅读这篇文章Tiled Matrix Multiplication(里面有可视化图片)。
在阅读上面那篇文章之后,请阅读示例代码中的 gemm_gpu_tiling.cu,看看我如何实现 Tiling 版本的矩阵乘法。在 4090 上,gemm_gpu_mult_block 耗时 3988.38 us,gemm_gpu_tiling 耗时 311.38 us,性能提升约 10 倍。
#include "gemm_gpu_tiling.h"#include <cassert>#include <cuda_runtime_api.h>constexpr int TILE_SIZE = 32;// gemm_gpu_tiling - GEMM on GPU, using tiling & shared memory to optimize
// global memory accesses
__global__
void gemm_gpu_tiling_kernel(int* __restrict__ C, // [n, m], on gpuconst int* __restrict__ A, // [n, k], on gpuconst int* __restrict__ B, // [k, m], on gpuconst int n,const int m,const int k
) {// We copy the tile from a/b into shared memory, and then do the calculation__shared__ int a_tile[TILE_SIZE][TILE_SIZE];__shared__ int b_tile[TILE_SIZE][TILE_SIZE];int my_c_result = 0;for (int tile_index = 0; tile_index < k/TILE_SIZE; ++tile_index) {// Step 1. Load the tile from a/b into a/b_tilea_tile[threadIdx.y][threadIdx.x] = A[(blockIdx.x*TILE_SIZE + threadIdx.y)*k + (tile_index*TILE_SIZE + threadIdx.x)];b_tile[threadIdx.y][threadIdx.x] = B[(tile_index*TILE_SIZE + threadIdx.y)*m + (blockIdx.y*TILE_SIZE + threadIdx.x)];__syncthreads();// Step 2. Calculate the contribution to my_c_resultfor (int i = 0; i < TILE_SIZE; ++i) {my_c_result += a_tile[threadIdx.y][i] * b_tile[i][threadIdx.x];}__syncthreads();}// Step 3. Store my_c_resultC[(blockIdx.x*TILE_SIZE + threadIdx.y)*m + (blockIdx.y*TILE_SIZE + threadIdx.x)] = my_c_result;
}void gemm_gpu_tiling(int* __restrict__ C, // [n, m], on gpuconst int* __restrict__ A, // [n, k], on gpuconst int* __restrict__ B, // [k, m], on gpuconst int n,const int m,const int k
) {assert (n % TILE_SIZE == 0);assert (m % TILE_SIZE == 0);assert (k % TILE_SIZE == 0);dim3 grid_dim = dim3(n / TILE_SIZE, m / TILE_SIZE);dim3 block_dim = dim3(TILE_SIZE, TILE_SIZE);gemm_gpu_tiling_kernel<<<grid_dim, block_dim>>>(C, A, B, n, m, k);
}
参考资料:
主要参考:CUDA 编程入门 - HPC Wiki
https://github.com/interestingLSY/CUDA-From-Correctness-To-Performance-Code
https://zhuanlan.zhihu.com/p/349726808
https://hackmd.io/@yaohsiaopid/ryHNKkxTr
相关文章:

CUDA编程——性能优化基本技巧
本文主要介绍下面三种技巧: 使用 __restrict__ 让编译器放心地优化指针访存想办法让同一个 Warp 中的线程的访存 Pattern 尽可能连续,以利用 Memory coalescing使用 Shared memory 0. 弄清Kernael函数是Compute-bound 还是 Memory-bound 先摆出一个知…...

图像卷积初识
目录 一、卷积的概念 1、常见卷积核示例 二、使用 OpenCV 实现卷积操作 1、代码说明 2、运行说明 一、卷积的概念 在图像处理中,卷积是一种通过滑动窗口(卷积核)对图像进行局部计算的操作。卷积核是一个小的矩阵,它在图像上…...

K8S服务的请求访问转发原理
开启 K8s 服务异常排障过程前,须对 K8s 服务的访问路径有一个全面的了解,下面我们先介绍目前常用的 K8s 服务访问方式(不同云原生平台实现方式可能基于部署方案、性能优化等情况会存在一些差异,但是如要运维 K8s 服务,…...

VSCode-插件:codegeex:ai coding assistant / 清华智普 AI 插件
一、官网 https://codegeex.cn/ 二、vscode 安装插件 点击安装即可,无需复杂操作,国内软件,无需科学上网,非常友好 三、智能注释 输入 // 或者 空格---后边自动出现注释信息,,按下 Tab 键,进…...
:Secret高级使用模式与安全实践指南)
Kubernetes生产实战(十四):Secret高级使用模式与安全实践指南
一、Secret核心类型解析 类型使用场景自动管理机制典型字段Opaque (默认)自定义敏感数据需手动创建data字段存储键值对kubernetes.io/dockerconfigjson私有镜像仓库认证kubelet自动更新.dockerconfigjsonkubernetes.io/tlsTLS证书管理Cert-Manager可自动化tls.crt/tls.keykube…...

【验证码】⭐️集成图形验证码实现安全校验
💥💥✈️✈️欢迎阅读本文章❤️❤️💥💥 🏆本篇文章阅读大约耗时5分钟。 ⛳️motto:不积跬步、无以千里 📋📋📋本文目录如下:🎁🎁&am…...
)
iOS瀑布流布局的实现(swift)
在iOS开发中,瀑布流布局(Waterfall Flow)是一种常见的多列不等高布局方式,适用于图片、商品展示等场景。以下是基于UICollectionView实现瀑布流布局的核心步骤和优化方法: 一、实现原理 瀑布流的核心在于动态计算每个…...

TGRS | FSVLM: 用于遥感农田分割的视觉语言模型
论文介绍 题目:FSVLM: A Vision-Language Model for Remote Sensing Farmland Segmentation 期刊:IEEE Transactions on Geoscience and Remote Sensing 论文:https://ieeexplore.ieee.org/document/10851315 年份:2025 单位…...
优惠券秒杀)
#Redis黑马点评#(四)优惠券秒杀
目录 一 生成全局id 二 添加优惠券 三 实现秒杀下单 方案一(会出现超卖问题) 方案二(解决了超卖但是错误率较高) 方案三(解决了错误率较高和超卖但是会出现一人抢多张问题) 方案四(解决一人抢多张问题“非分布式…...

https,http1,http2,http3的一些知识
温故知新,突然有人问我项目中🤔有使用http3么,一下不知从何说起,就有了这篇文章的出现。 https加密传输,ssltls https 验证身份 提供加密,混合加密 : 对称加密 非对称加密 原理:…...

《设计数据密集型应用》——阅读小记
设计数据密集型应用 这本书非常推荐看英语版,如果考过了CET-6就可以很轻松的阅读这本书。 当前计算机软件已经不是单体的时代了,分布式系统,微服务现在是服务端开发的主流,如果没有读过这本书,则强力建议读这本书。 …...

SpringCloud之Gateway基础认识-服务网关
0、Gateway基本知识 Gateway 是在 Spring 生态系统之上构建的 API 网关服务,基于 Spring ,Spring Boot 和 Project Reactor 等技术。 Gateway 旨在提供一种简单而有效的方式来对 API 进行路由,以及提供一些强大的过滤器功能,例如…...
:日志管理详解 —— 从排错到恢复的核心利器)
MySQL 从入门到精通(三):日志管理详解 —— 从排错到恢复的核心利器
在 MySQL 数据库的日常运维中,日志是定位问题、优化性能、数据恢复的核心工具。无论是排查服务器启动异常,还是分析慢查询瓶颈,亦或是通过二进制日志恢复误删数据,日志都扮演着 “数据库黑匣子” 的角色。本文将深入解析 MySQL 的…...

单脉冲前视成像多目标分辨算法——论文阅读
单脉冲前视成像多目标分辨算法 1. 论文的研究目标及实际意义1.1 研究目标1.2 实际问题与产业意义2. 论文的创新方法及公式解析2.1 核心思路2.2 关键公式与模型2.2.1 单脉冲雷达信号模型2.2.2 匹配滤波输出模型2.2.3 多目标联合观测模型2.2.4 对数似然函数与优化2.2.5 MDL准则目…...

SpringBoot项目容器化进行部署,meven的docker插件远程构建docker镜像
需求:将Spring Boot项目使用容器化进行部署 前提 默认其他环境,如mysql,redis等已经通过docker部署完毕, 这里只讨论,如何制作springboot项目的镜像 要将Spring Boot项目使用docker容器进行部署,就需要将Spring Boot项目构建成一个docker镜像 一、手动…...

【金仓数据库征文】政府项目数据库迁移:从MySQL 5.7到KingbaseES的蜕变之路
摘要:本文详细阐述了政府项目中将 MySQL 5.7 数据库迁移至 KingbaseES 的全过程,涵盖迁移前的环境评估、数据梳理和工具准备,迁移实战中的数据源与目标库连接配置、迁移任务详细设定、执行迁移与过程监控,以及迁移后的质量验证、系…...

C++GO语言微服务和服务发现②
01 创建go-micro项目-查看生成的 proto文件 02 创建go-micro项目-查看生成的main文件和handler ## 创建 micro 服务 命令:micro new --type srv test66 框架默认自带服务发现:mdns。 使用consul服务发现: 1. 初始consul服务发现&…...
)
手机银行怎么打印流水账单(已解决)
一、中国银行 登录中国银行手机银行APP。 在首页点击“更多”,向左滑动找到并点击“助手”。 在助手页面选择“交易流水打印”。 点击“立即申请”,选择需要打印的账户和时间段。 输入接收流水账单的电子邮箱地址。 提交申请后,在“申请…...

单片机-STM32部分:10-2、逻辑分析仪
飞书文档https://x509p6c8to.feishu.cn/wiki/VrdkwVzOnifH8xktu3Bcuc4Enie 安装包如下:根据自己的系统选择,目前这个工具只有window版本哦 安装方法比较简单,都按默认下一步即可,注意不要安装到中文路径哦。 其余部分参考飞书文档…...

Scala与Go的异同教程
当瑞士军刀遇到电锯:Scala vs Go的相爱相杀之旅 各位准备秃头的程序猿们(放心,用Go和Scala不会加重你的发际线问题),今天我们来聊聊编程界的"冰与火之歌"——Scala和Go的异同。准备好瓜子饮料,我…...

【算法-哈希表】常见算法题的哈希表套路拆解
算法相关知识点可以通过点击以下链接进行学习一起加油!双指针滑动窗口二分查找前缀和位运算模拟链表 在刷题的过程中,我们会频繁遇到一些“高频套路”——而哈希表正是其中最常用也最高效的工具之一。它能帮助我们在 O(1) 的时间复杂度内完成查找、插入与…...

前端取经路——现代API探索:沙僧的通灵法术
大家好,我是老十三,一名前端开发工程师。在现代Web开发中,各种强大的API就像沙僧的通灵法术,让我们的应用具备了超乎想象的能力。本文将带你探索从离线应用到实时通信,从多线程处理到3D渲染的九大现代Web API,让你的应用获得"通灵"般的超能力。 在前端取经的第…...

深入了解 ArkTS:HarmonyOS 开发的关键语言与应用实践
随着 HarmonyOS(鸿蒙操作系统)的推出,华为为开发者提供了一套全新的开发工具和编程语言,使得跨设备、跨平台的应用开发成为可能。在这些工具中,ArkTS(Ark TypeScript)作为一种专为 HarmonyOS 设…...

Flask 调试的时候进入main函数两次
在 Flask 开启 Debug 模式时,程序会因为自动重载(reloader)的机制而启动两个进程,导致if __name__ __main__底层的程序代码被执行两次。以下说明其原理与常见解法。 Flask Debug 模式下自动重载机制 Flask 使用的底层服务器 Wer…...

Git 时光机:修改Commit信息
前言 列位看官都知道,Git 的每一次 git commit,其中会包含作者(Author)和提交者(Committer)的姓名与邮箱。有时可能会因为配置错误、切换了开发环境,或者只是单纯的手滑,导致 commi…...

DAY 21 常见的降维算法
知识点回顾: LDA线性判别PCA主成分分析t-sne降维 还有一些其他的降维方式,也就是最重要的词向量的加工,我们未来再说 作业: 自由作业:探索下什么时候用到降维?降维的主要应用?或者让ai给你出题&…...

Docker使用小结
概念 镜像( Image ) :相当于一个 root 文件系统;镜像构建时,分层存储、层层构建;容器( Container ) :镜像是静态的定义,容器是镜像运行时的实体;…...

kubectl top 查询pod连接数
在 Kubernetes 中,kubectl top 命令默认仅支持查看 Pod 或节点的 CPU/内存资源使用情况,并不直接提供 TCP 连接数的统计功能。若要获取 Pod 的 TCP 连接数,需结合其他工具和方法。以下是具体实现方案: 1. 直接进入容器查看 TCP 连…...
:负载均衡流量分发管理实战指南)
Kubernetes生产实战(十七):负载均衡流量分发管理实战指南
在Kubernetes集群中,负载均衡是保障应用高可用、高性能的核心机制。本文将从生产环境视角,深入解析Kubernetes负载均衡的实现方式、最佳实践及常见问题解决方案。 一、Kubernetes负载均衡的三大核心组件 1)Service资源:集群内流…...

Git 分支指南
什么是 Git 分支? Git 分支是仓库内的独立开发线,你可以把它想象成一个单独的工作空间,在这里你可以进行修改,而不会影响主分支(或 默认分支)。分支允许开发者在不影响项目实际版本的情况下,开…...

自动泊车技术—相机模型
一、相机分类及特性 传感器类型深度感知原理有效工作范围环境适应性功耗水平典型成本区间数据丰富度单目相机运动视差/几何先验1m~∞光照敏感1-2W5−5−502D纹理中双目相机立体匹配 (SGM/SGBM算法)0.3m~20m纹理依赖3-5W50−50−3002D稀疏深度多摄像头系统多视角三角测量0.1m~5…...

程序代码篇---esp32视频流处理
文章目录 前言一、ESP32摄像头设置1.HTTP视频流(最常见)2.RTSP视频流3.MJPEG流 二、使用OpenCV读取视频流1. 读取HTTP视频流2. 读取RTSP视频流 三、使用requests库读取MJPEG流四、处理常见问题1. 连接不稳定或断流2. 提高视频流性能2.1降低分辨率2.2跳过…...

数据结构与算法分析实验12 实现二叉查找树
实现二叉查找树 1、二叉查找树介绍2.上机要求3.上机环境4.程序清单(写明运行结果及结果分析)4.1 程序清单4.1.1 头文件 TreeMap.h 内容如下:4.1.2 实现文件 TreeMap.cpp 文件内容如下:4.1.3 源文件 main.cpp 文件内容如下: 4.2 实现展效果示5…...

深入浅出之STL源码分析2_类模版
1.引言 我在上面的文章中讲解了vector的基本操作,然后提出了几个问题。 STL之vector基本操作-CSDN博客 1.刚才我提到了我的编译器版本是g 11.4.0,而我们要讲解的是STL(标准模板库),那么二者之间的关系是什么&#x…...

Docker、Docker-compose、K8s、Docker swarm之间的区别
1.Docker docker是一个运行于主流linux/windows系统上的应用容器引擎,通过docker中的镜像(image)可以在docker中构建一个独立的容器(container)来运行镜像对应的服务; 例如可以通过mysql镜像构建一个运行mysql的容器,既可以直接进入该容器命…...

【Linux】线程的同步与互斥
目录 1. 整体学习思维导图 2. 线程的互斥 2.1 互斥的概念 2.2 见一见数据不一致的情况 2.3 引入锁Mutex(互斥锁/互斥量) 2.3.1 接口认识 2.3.2 Mutex锁的理解 2.3.3 互斥量的封装 3. 线程同步 3.1 条件变量概念 3.2 引入条件变量Cond 3.2.1 接口认识 3.2.2 同步的…...

C++发起Https连接请求
需要下载安装openssl //stdafx.h #pragma once #include<iostream> #include <openssl/ssl.h> #include <openssl/err.h> #include <iostream> #include <string>#pragma comment(lib, "libssl.lib") #pragma comment(lib, "lib…...

Linux 内核链表宏的详细解释
🔧 Linux 内核链表结构概览 Linux 内核中的链表结构定义在头文件 <linux/list.h> 中。核心结构是: struct list_head {struct list_head *next, *prev; }; 它表示一个双向循环链表的节点。链表的所有操作都围绕这个结构体展开。 🧩 …...
)
[架构之美]Spring Boot集成MyBatis-Plus高效开发(十七)
[架构之美]Spring Boot集成MyBatis-Plus高效开发(十七) 摘要:本文通过图文代码实战,详细讲解Spring Boot整合MyBatis-Plus全流程,涵盖代码生成器、条件构造器、分页插件等核心功能,助你减少90%的SQL编写量…...

游戏引擎学习第270天:生成可行走的点
回顾并为今天的内容定下基调 今天的计划虽然还不完全确定,可能会做一些内存分析,也有可能暂时不做,因为目前并没有特别迫切的需求。最终我们会根据当下的状态随性决定,重点是持续推动项目的进展,无论是 memory 方面还…...

批量统计PDF页数,统计图像属性
软件介绍: 1、支持批量统计PDF、doc\docx、xls\xlsx页数 2、支持统计指定格式文件数量(不填格式就是全部) 3、支持统计JPG、JPEG、PNG图像属性 4、支持统计多页TIF页数、属性 5、支持统计PDF、JPG画幅 统计图像属性 「托马斯的文件助手」…...

QT Creator配置Kit
0、背景:qt5.12.12vs2022 记得先增加vs2017编译器 一、症状: 你是否有以下症状? 1、用qt新建的工程,用qmake,可惜能看见的只有一个pro文件? 2、安装QT Creator后,使用MSVC编译显示no c com…...
)
[架构之美]IntelliJ IDEA创建Maven项目全流程(十四)
[架构之美]IntelliJ IDEA创建Maven项目全流程(十四) 摘要:本文将通过图文结合的方式,详细讲解如何使用IntelliJ IDEA快速创建Maven项目,涵盖环境配置、项目初始化、依赖管理及常见问题解决方案。适用于Java开发新手及…...
 , SpringBoot项目的创建(IDEA2024版本))
SpringBoot学习(上) , SpringBoot项目的创建(IDEA2024版本)
目录 1. SpringBoot介绍 SpringBoot特点 2. SpringBoot入门 2.1 创建SpringBoot项目 Spring Initialize 第一步: 选择创建项目 第二步: 选择起步依赖 第三步: 查看启动类 2.2 springboot父项目 2.3 测试案例 2.3.1 数据库 2.3.2 生成代码 1. SpringBoot介绍 Spring B…...

《Python星球日记》 第51天:神经网络基础
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、引言:走进神经网络的世界二、神经元与激活函数1. 神经元&#x…...

MindSpore框架学习项目-ResNet药物分类-模型评估
目录 4.模型评估 4.1模型预测 4.1.1加载模型 4.1.2通过传入图片路径进行推理 单张图片推理代码解释 4.2图片推理 4.2.1构造可视化推理结果函数 可视化推理结果函数代码解释 4.2.2进行单张推理 参考内容: 昇思MindSpore | 全场景AI框架 | 昇思MindSpore社区…...

Visual Studio Code 前端项目开发规范合集【推荐插件】
文章目录 前言代码格式化工具(Prettier)1、下载 prettier 相关依赖:2、安装 Vscode 插件(Prettier):3、配置 Prettier(.prettierrc.cjs): 代码规范工具(ESLin…...

uniapp-商城-48-后台 分类数据添加修改弹窗bug
在第47章的操作中,涉及到分类的添加、删除和更新功能,但发现uni-popup组件存在bug。该组件的函数接口错误导致在小程序中出现以下问题:1. 点击修改肉类名称时,回调显示为空,并报错“setVal is not defined”࿰…...

OpenLayers 精确经过三个点的曲线绘制
OpenLayers 精确经过三个点的曲线绘制 根据您的需求,我将提供一个使用 OpenLayers 绘制精确经过三个指定点的曲线解决方案。对于三个点的情况,我们可以使用 二次贝塞尔曲线 或 三次样条插值,确保曲线精确通过所有控制点。 实现方案 下面是…...

uniapp小程序中实现无缝衔接滚动效果
组件滚动通知只能实现简单的滚动效果,不能实现滚动内容中的字进行不同颜色的更改,下面实现一个无缝衔接的滚动动画,可以根据自己的需要进行艺术化的更改需要滚动的内容,也可以自定义更改滚动速度。 <template><view cla…...