DAY 21 常见的降维算法
- LDA线性判别
- PCA主成分分析
- t-sne降维
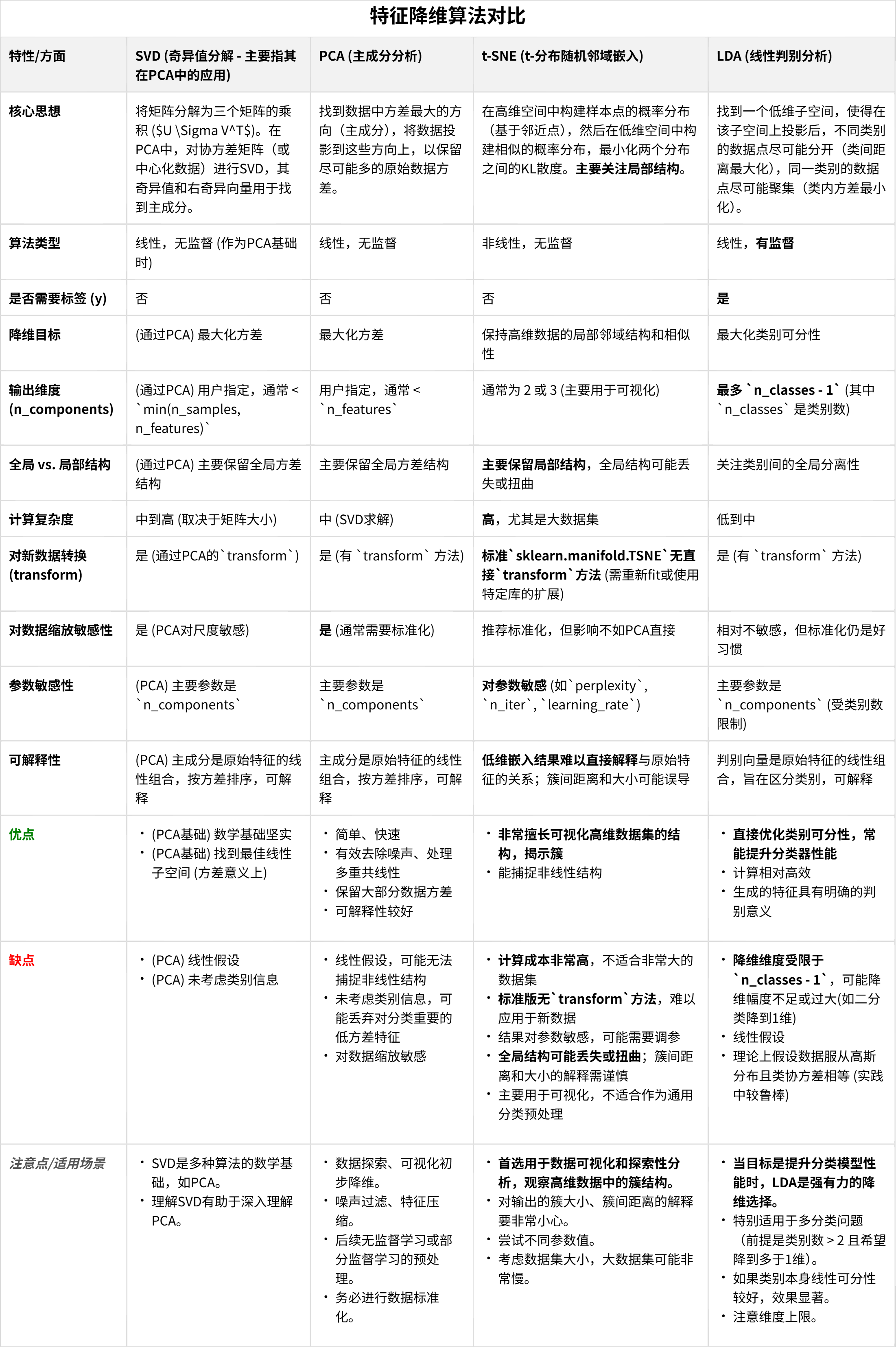
还有一些其他的降维方式,也就是最重要的词向量的加工,我们未来再说
作业:
自由作业:探索下什么时候用到降维?降维的主要应用?或者让ai给你出题,群里的同学互相学习下。可以考虑对比下在某些特定数据集上t-sne的可视化和pca可视化的区别。
什么时候用到降维
数据特征过多:当数据集中特征数量非常庞大时,可能会导致“维度灾难”,增加计算复杂度和训练时间,还可能引发过拟合问题。降维可以减少特征数量,降低计算成本,提高模型训练效率。
数据可视化困难:人类通常只能直观理解二维或三维的数据。当数据维度超过三维时,很难直接进行可视化分析。通过降维将数据映射到二维或三维空间,能帮助我们直观地观察数据分布、聚类情况等。
数据存在冗余特征:数据集中可能存在一些高度相关或冗余的特征,这些特征对模型的贡献有限,反而会增加计算负担。降维可以去除这些冗余特征,保留最具代表性的信息。
模型性能不佳:如果模型在训练过程中表现不佳,如训练时间过长、过拟合严重等,可能是因为数据维度太高。降维可以简化数据结构,提高模型的泛化能力和性能。
降维的主要应用
数据可视化:在生物信息学中,基因表达数据通常具有高维度。通过主成分分析(PCA)或 t - 分布随机邻域嵌入(t - SNE)等降维方法,将基因表达数据降维到二维或三维空间,研究人员可以直观地观察不同样本之间的关系,发现潜在的生物模式。
机器学习:在图像识别任务中,原始图像数据维度很高,降维可以减少计算量,提高模型训练速度和性能。例如,使用线性判别分析(LDA)对图像特征进行降维,然后输入到分类模型中进行训练和预测。
数据压缩:在存储和传输大量数据时,降维可以减少数据的存储空间和传输带宽。例如,在视频压缩中,通过降维技术去除视频帧中的冗余信息,实现数据的高效压缩。
特征选择:在数据分析和建模过程中,降维可以帮助我们筛选出最具代表性的特征,去除无关或冗余的特征。例如,在信用风险评估中,通过降维方法选择与信用风险相关性最高的特征,提高评估模型的准确性。
输入:
## 预处理流程回顾
#1. 导入库
import pandas as pd
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号#2. 读取数据查看数据信息--理解数据
data = pd.read_csv(r'heart.csv') #读取数据
print("数据基本信息:")
data.info()
print("\n数据前5行预览:")
print(data.head())#3. 缺失值处理
# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
print("\n离散变量:")
print(discrete_features)
# 依次查看内容
for feature in discrete_features:print(f"\n{feature}的唯一值:")print(data[feature].value_counts())
#本数据集中不纯在离散变量
# thal 标签编码
thal_mapping = {1: 1,2: 2,3: 3,
}
data['thal'] = data['thal'].map(thal_mapping)
# slope的独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['slope'])
data2 = pd.read_csv(r"heart.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:if i not in data2.columns:
list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:
data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名
print(list_final) # 打印出来的就是独热编码后的特征名
# 布尔矩阵显示缺失值,这个方法返回一个布尔矩阵
print(data.isnull())
print(data.isnull().sum()) # 统计每一列缺失值的数量
#填补缺失值
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表
print("\n连续变量:")
print(continuous_features)for feature in continuous_features:
mode_value = data[feature].mode()[0] #获取该列的众数。
data[feature] = data[feature].fillna(mode_value) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。
print(data.isnull().sum()) # 统计每一列缺失值的数量
# 4. 异常值处理
#异常值一般不处理,或者结合对照试验处理和不处理都尝试下,但是论文中要写这个,作为个工作量
#此数据集无缺失值data.info() # 查看数据集的信息,包括数据类型和缺失值情况from sklearn.model_selection import train_test_split
X = data.drop('target', axis=1) # 特征
y = data['target'] # 目标变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 划分训练集和测试集,test_size表示测试集占比,random_state表示随机种子,保证每次划分结果一致。
print(f"训练集形状: {X_train.shape}")
print(f"测试集形状: {X_test.shape}")from sklearn.ensemble import RandomForestClassifier #随机森林分类器from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
# --- 1. 默认参数的随机森林 ---
# 评估基准模型,这里确实不需要验证集
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time # 这里介绍一个新的库,time库,主要用于时间相关的操作,因为调参需要很长时间,记录下会帮助后人知道大概的时长
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))import time
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler # 特征缩放
from sklearn.decomposition import PCA # 主成分分析
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA # 线性判别分析
# UMAP 需要单独安装: pip install umap-learn
import umap # 如果安装了 umap-learn,可以这样导入from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import warnings
warnings.filterwarnings("ignore") # 忽略所有警告信息# 假设 X_train, X_test, y_train, y_test 已经准备好了print(f"\n--- 2. PCA 降维 + 随机森林 (不使用 Pipeline) ---")
# 步骤 1: 特征缩放
scaler_pca = StandardScaler()
X_train_scaled_pca = scaler_pca.fit_transform(X_train)
X_test_scaled_pca = scaler_pca.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: PCA降维
# 选择降到10维,或者你可以根据解释方差来选择,例如:
pca_expl = PCA(random_state=42)
pca_expl.fit(X_train_scaled_pca)
cumsum_variance = np.cumsum(pca_expl.explained_variance_ratio_)
n_components_to_keep_95_var = np.argmax(cumsum_variance >= 0.95) + 1
print(f"为了保留95%的方差,需要的主成分数量: {n_components_to_keep_95_var}")# 我们测试下降低到10维的效果
pca = PCA(n_components=10, random_state=42)
X_train_pca = pca.fit_transform(X_train_scaled_pca)
X_test_pca = pca.transform(X_test_scaled_pca) # 使用训练集上的PCA模型# 步骤 3: 训练随机森林分类器
rf_model_pca = RandomForestClassifier(random_state=42)
rf_model_pca.fit(X_train_pca, y_train) # 在降维后的训练集上训练
rf_pred_pca = rf_model_pca.predict(X_test_pca) # 在降维后的测试集上预测print("\nPCA降维 + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_pca))
print("PCA降维 + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_pca))# 假设 X_train, X_test, y_train, y_test 已经准备好了
# 并且你的 X_train, X_test 是DataFrame或Numpy Arrayprint(f"\n--- 3. t-SNE 降维 + 随机森林 ---")
print(" 标准 t-SNE 主要用于可视化,直接用于分类器输入可能效果不佳。")# 步骤 1: 特征缩放
scaler_tsne = StandardScaler()
X_train_scaled_tsne = scaler_tsne.fit_transform(X_train)
X_test_scaled_tsne = scaler_tsne.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: t-SNE 降维
# 我们将降维到与PCA相同的维度(例如10维)或者一个适合分类的较低维度。
# t-SNE通常用于2D/3D可视化,但也可以降到更高维度。
# 然而,降到与PCA一样的维度(比如10维)对于t-SNE来说可能不是其优势所在,
# 并且计算成本会显著增加,因为高维t-SNE的优化更困难。
# 为了与PCA的 n_components=10 对比,我们这里也尝试降到10维。
# 但请注意,这可能非常耗时,且效果不一定好。
# 通常如果用t-SNE做分类的预处理(不常见),可能会选择非常低的维度(如2或3)。# n_components_tsne = 10 # 与PCA的例子保持一致,但计算量会很大
n_components_tsne = 2 # 更典型的t-SNE用于分类的维度,如果想快速看到结果# 如果你想严格对比PCA的10维,可以将这里改为10,但会很慢
from sklearn.manifold import TSNE # 新增导入 TSNE 类
# 对训练集进行 fit_transform
tsne_model_train = TSNE(n_components=n_components_tsne,
perplexity=30, # 常用的困惑度值
n_iter=1000, # 足够的迭代次数
init='pca', # 使用PCA初始化,通常更稳定
learning_rate='auto', # 自动学习率 (sklearn >= 1.2)
random_state=42, # 保证结果可复现
n_jobs=-1) # 使用所有CPU核心
print("正在对训练集进行 t-SNE fit_transform...")
start_tsne_fit_train = time.time()
X_train_tsne = tsne_model_train.fit_transform(X_train_scaled_tsne)
end_tsne_fit_train = time.time()
print(f"训练集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_train - start_tsne_fit_train:.2f} 秒")# 对测试集进行 fit_transform
# 再次强调:这是独立于训练集的变换
tsne_model_test = TSNE(n_components=n_components_tsne,
perplexity=30,
n_iter=1000,
init='pca',
learning_rate='auto',
random_state=42, # 保持参数一致,但数据不同,结果也不同
n_jobs=-1)
print("正在对测试集进行 t-SNE fit_transform...")
start_tsne_fit_test = time.time()
X_test_tsne = tsne_model_test.fit_transform(X_test_scaled_tsne) # 注意这里是 X_test_scaled_tsne
end_tsne_fit_test = time.time()
print(f"测试集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_test - start_tsne_fit_test:.2f} 秒")# 步骤 3: 训练随机森林分类器
rf_model_tsne = RandomForestClassifier(random_state=42)
rf_model_tsne.fit(X_train_tsne, y_train) # 在降维后的训练集上训练
rf_pred_tsne = rf_model_tsne.predict(X_test_tsne) # 在降维后的测试集上预测print("\nt-SNE降维 + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_tsne))
print("t-SNE降维 + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_tsne))# 假设 X_train, X_test, y_train, y_test 已经准备好了
# 并且你的 X_train, X_test 是DataFrame或Numpy Arrayprint(f"\n--- 4. LDA 降维 + 随机森林 ---")
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA # 线性判别分析
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis # 再次导入# 步骤 1: 特征缩放
scaler_lda = StandardScaler()
X_train_scaled_lda = scaler_lda.fit_transform(X_train)
X_test_scaled_lda = scaler_lda.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: LDA 降维
n_features = X_train_scaled_lda.shape[1]
if hasattr(y_train, 'nunique'):
n_classes = y_train.nunique()
elif isinstance(y_train, np.ndarray):
n_classes = len(np.unique(y_train))
else:
n_classes = len(set(y_train))max_lda_components = min(n_features, n_classes - 1)# 设置目标降维维度
n_components_lda_target = 10if max_lda_components < 1:print(f"LDA 不适用,因为类别数 ({n_classes}) 太少,无法产生至少1个判别组件。")
X_train_lda = X_train_scaled_lda.copy() # 使用缩放后的原始特征
X_test_lda = X_test_scaled_lda.copy() # 使用缩放后的原始特征
actual_n_components_lda = n_featuresprint("将使用缩放后的原始特征进行后续操作。")
else:# 实际使用的组件数不能超过LDA的上限,也不能超过我们的目标(如果目标更小)
actual_n_components_lda = min(n_components_lda_target, max_lda_components)if actual_n_components_lda < 1: # 这种情况理论上不会发生,因为上面已经检查了 max_lda_components < 1print(f"计算得到的实际LDA组件数 ({actual_n_components_lda}) 小于1,LDA不适用。")
X_train_lda = X_train_scaled_lda.copy()
X_test_lda = X_test_scaled_lda.copy()
actual_n_components_lda = n_featuresprint("将使用缩放后的原始特征进行后续操作。")else:print(f"原始特征数: {n_features}, 类别数: {n_classes}")print(f"LDA 最多可降至 {max_lda_components} 维。")print(f"目标降维维度: {n_components_lda_target} 维。")print(f"本次 LDA 将实际降至 {actual_n_components_lda} 维。") lda_manual = LinearDiscriminantAnalysis(n_components=actual_n_components_lda, solver='svd')
X_train_lda = lda_manual.fit_transform(X_train_scaled_lda, y_train)
X_test_lda = lda_manual.transform(X_test_scaled_lda)print(f"LDA降维后,训练集形状: {X_train_lda.shape}, 测试集形状: {X_test_lda.shape}")start_time_lda_rf = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_lda = RandomForestClassifier(random_state=42)
rf_model_lda.fit(X_train_lda, y_train) # 在降维后的训练集上训练
rf_pred_lda = rf_model_lda.predict(X_test_lda) # 在降维后的测试集上预测print("\nLDA降维 + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_lda))
print("LDA降维 + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_lda))
输出:
Data columns (total 16 columns):# Column Non-Null Count Dtype
--- ------ -------------- -----0 age 303 non-null int641 sex 303 non-null int642 cp 303 non-null int643 trestbps 303 non-null int644 chol 303 non-null int645 fbs 303 non-null int646 restecg 303 non-null int647 thalach 303 non-null int648 exang 303 non-null int649 oldpeak 303 non-null float6410 ca 303 non-null int6411 thal 303 non-null float6412 target 303 non-null int6413 slope_0 303 non-null int6414 slope_1 303 non-null int6415 slope_2 303 non-null int64
dtypes: float64(2), int64(14)
memory usage: 38.0 KB
训练集形状: (242, 15)
测试集形状: (61, 15)
--- 1. 默认参数随机森林 (训练集 -> 测试集) ---
训练与预测耗时: 0.0828 秒默认随机森林 在测试集上的分类报告:
precision recall f1-score support0 0.89 0.83 0.86 291 0.85 0.91 0.88 32 accuracy 0.87 61
macro avg 0.87 0.87 0.87 61
weighted avg 0.87 0.87 0.87 61默认随机森林 在测试集上的混淆矩阵:
[[24 5][ 3 29]]--- 2. PCA 降维 + 随机森林 (不使用 Pipeline) ---
为了保留95%的方差,需要的主成分数量: 13PCA降维 + 随机森林 在测试集上的分类报告:
precision recall f1-score support0 0.84 0.93 0.89 291 0.93 0.84 0.89 32 accuracy 0.89 61
macro avg 0.89 0.89 0.89 61
weighted avg 0.89 0.89 0.89 61PCA降维 + 随机森林 在测试集上的混淆矩阵:
[[27 2][ 5 27]]--- 3. t-SNE 降维 + 随机森林 ---
标准 t-SNE 主要用于可视化,直接用于分类器输入可能效果不佳。
正在对训练集进行 t-SNE fit_transform...
训练集 t-SNE fit_transform 完成,耗时: 1.83 秒
正在对测试集进行 t-SNE fit_transform...
测试集 t-SNE fit_transform 完成,耗时: 0.18 秒t-SNE降维 + 随机森林 在测试集上的分类报告:
precision recall f1-score support0 0.67 0.21 0.32 291 0.56 0.91 0.69 32 accuracy 0.57 61
macro avg 0.61 0.56 0.50 61
weighted avg 0.61 0.57 0.51 61t-SNE降维 + 随机森林 在测试集上的混淆矩阵:
[[ 6 23][ 3 29]]--- 4. LDA 降维 + 随机森林 ---
原始特征数: 15, 类别数: 2
LDA 最多可降至 1 维。
目标降维维度: 10 维。
本次 LDA 将实际降至 1 维。
LDA降维后,训练集形状: (242, 1), 测试集形状: (61, 1)LDA降维 + 随机森林 在测试集上的分类报告:
precision recall f1-score support0 0.76 0.90 0.83 291 0.89 0.75 0.81 32 accuracy 0.82 61
macro avg 0.83 0.82 0.82 61
weighted avg 0.83 0.82 0.82 61LDA降维 + 随机森林 在测试集上的混淆矩阵:
[[26 3][ 8 24]]
相关文章:

DAY 21 常见的降维算法
知识点回顾: LDA线性判别PCA主成分分析t-sne降维 还有一些其他的降维方式,也就是最重要的词向量的加工,我们未来再说 作业: 自由作业:探索下什么时候用到降维?降维的主要应用?或者让ai给你出题&…...

Docker使用小结
概念 镜像( Image ) :相当于一个 root 文件系统;镜像构建时,分层存储、层层构建;容器( Container ) :镜像是静态的定义,容器是镜像运行时的实体;…...

kubectl top 查询pod连接数
在 Kubernetes 中,kubectl top 命令默认仅支持查看 Pod 或节点的 CPU/内存资源使用情况,并不直接提供 TCP 连接数的统计功能。若要获取 Pod 的 TCP 连接数,需结合其他工具和方法。以下是具体实现方案: 1. 直接进入容器查看 TCP 连…...
:负载均衡流量分发管理实战指南)
Kubernetes生产实战(十七):负载均衡流量分发管理实战指南
在Kubernetes集群中,负载均衡是保障应用高可用、高性能的核心机制。本文将从生产环境视角,深入解析Kubernetes负载均衡的实现方式、最佳实践及常见问题解决方案。 一、Kubernetes负载均衡的三大核心组件 1)Service资源:集群内流…...

Git 分支指南
什么是 Git 分支? Git 分支是仓库内的独立开发线,你可以把它想象成一个单独的工作空间,在这里你可以进行修改,而不会影响主分支(或 默认分支)。分支允许开发者在不影响项目实际版本的情况下,开…...

自动泊车技术—相机模型
一、相机分类及特性 传感器类型深度感知原理有效工作范围环境适应性功耗水平典型成本区间数据丰富度单目相机运动视差/几何先验1m~∞光照敏感1-2W5−5−502D纹理中双目相机立体匹配 (SGM/SGBM算法)0.3m~20m纹理依赖3-5W50−50−3002D稀疏深度多摄像头系统多视角三角测量0.1m~5…...

程序代码篇---esp32视频流处理
文章目录 前言一、ESP32摄像头设置1.HTTP视频流(最常见)2.RTSP视频流3.MJPEG流 二、使用OpenCV读取视频流1. 读取HTTP视频流2. 读取RTSP视频流 三、使用requests库读取MJPEG流四、处理常见问题1. 连接不稳定或断流2. 提高视频流性能2.1降低分辨率2.2跳过…...

数据结构与算法分析实验12 实现二叉查找树
实现二叉查找树 1、二叉查找树介绍2.上机要求3.上机环境4.程序清单(写明运行结果及结果分析)4.1 程序清单4.1.1 头文件 TreeMap.h 内容如下:4.1.2 实现文件 TreeMap.cpp 文件内容如下:4.1.3 源文件 main.cpp 文件内容如下: 4.2 实现展效果示5…...

深入浅出之STL源码分析2_类模版
1.引言 我在上面的文章中讲解了vector的基本操作,然后提出了几个问题。 STL之vector基本操作-CSDN博客 1.刚才我提到了我的编译器版本是g 11.4.0,而我们要讲解的是STL(标准模板库),那么二者之间的关系是什么&#x…...

Docker、Docker-compose、K8s、Docker swarm之间的区别
1.Docker docker是一个运行于主流linux/windows系统上的应用容器引擎,通过docker中的镜像(image)可以在docker中构建一个独立的容器(container)来运行镜像对应的服务; 例如可以通过mysql镜像构建一个运行mysql的容器,既可以直接进入该容器命…...

【Linux】线程的同步与互斥
目录 1. 整体学习思维导图 2. 线程的互斥 2.1 互斥的概念 2.2 见一见数据不一致的情况 2.3 引入锁Mutex(互斥锁/互斥量) 2.3.1 接口认识 2.3.2 Mutex锁的理解 2.3.3 互斥量的封装 3. 线程同步 3.1 条件变量概念 3.2 引入条件变量Cond 3.2.1 接口认识 3.2.2 同步的…...

C++发起Https连接请求
需要下载安装openssl //stdafx.h #pragma once #include<iostream> #include <openssl/ssl.h> #include <openssl/err.h> #include <iostream> #include <string>#pragma comment(lib, "libssl.lib") #pragma comment(lib, "lib…...

Linux 内核链表宏的详细解释
🔧 Linux 内核链表结构概览 Linux 内核中的链表结构定义在头文件 <linux/list.h> 中。核心结构是: struct list_head {struct list_head *next, *prev; }; 它表示一个双向循环链表的节点。链表的所有操作都围绕这个结构体展开。 🧩 …...
)
[架构之美]Spring Boot集成MyBatis-Plus高效开发(十七)
[架构之美]Spring Boot集成MyBatis-Plus高效开发(十七) 摘要:本文通过图文代码实战,详细讲解Spring Boot整合MyBatis-Plus全流程,涵盖代码生成器、条件构造器、分页插件等核心功能,助你减少90%的SQL编写量…...

游戏引擎学习第270天:生成可行走的点
回顾并为今天的内容定下基调 今天的计划虽然还不完全确定,可能会做一些内存分析,也有可能暂时不做,因为目前并没有特别迫切的需求。最终我们会根据当下的状态随性决定,重点是持续推动项目的进展,无论是 memory 方面还…...

批量统计PDF页数,统计图像属性
软件介绍: 1、支持批量统计PDF、doc\docx、xls\xlsx页数 2、支持统计指定格式文件数量(不填格式就是全部) 3、支持统计JPG、JPEG、PNG图像属性 4、支持统计多页TIF页数、属性 5、支持统计PDF、JPG画幅 统计图像属性 「托马斯的文件助手」…...

QT Creator配置Kit
0、背景:qt5.12.12vs2022 记得先增加vs2017编译器 一、症状: 你是否有以下症状? 1、用qt新建的工程,用qmake,可惜能看见的只有一个pro文件? 2、安装QT Creator后,使用MSVC编译显示no c com…...
)
[架构之美]IntelliJ IDEA创建Maven项目全流程(十四)
[架构之美]IntelliJ IDEA创建Maven项目全流程(十四) 摘要:本文将通过图文结合的方式,详细讲解如何使用IntelliJ IDEA快速创建Maven项目,涵盖环境配置、项目初始化、依赖管理及常见问题解决方案。适用于Java开发新手及…...
 , SpringBoot项目的创建(IDEA2024版本))
SpringBoot学习(上) , SpringBoot项目的创建(IDEA2024版本)
目录 1. SpringBoot介绍 SpringBoot特点 2. SpringBoot入门 2.1 创建SpringBoot项目 Spring Initialize 第一步: 选择创建项目 第二步: 选择起步依赖 第三步: 查看启动类 2.2 springboot父项目 2.3 测试案例 2.3.1 数据库 2.3.2 生成代码 1. SpringBoot介绍 Spring B…...

《Python星球日记》 第51天:神经网络基础
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、引言:走进神经网络的世界二、神经元与激活函数1. 神经元&#x…...

MindSpore框架学习项目-ResNet药物分类-模型评估
目录 4.模型评估 4.1模型预测 4.1.1加载模型 4.1.2通过传入图片路径进行推理 单张图片推理代码解释 4.2图片推理 4.2.1构造可视化推理结果函数 可视化推理结果函数代码解释 4.2.2进行单张推理 参考内容: 昇思MindSpore | 全场景AI框架 | 昇思MindSpore社区…...

Visual Studio Code 前端项目开发规范合集【推荐插件】
文章目录 前言代码格式化工具(Prettier)1、下载 prettier 相关依赖:2、安装 Vscode 插件(Prettier):3、配置 Prettier(.prettierrc.cjs): 代码规范工具(ESLin…...

uniapp-商城-48-后台 分类数据添加修改弹窗bug
在第47章的操作中,涉及到分类的添加、删除和更新功能,但发现uni-popup组件存在bug。该组件的函数接口错误导致在小程序中出现以下问题:1. 点击修改肉类名称时,回调显示为空,并报错“setVal is not defined”࿰…...

OpenLayers 精确经过三个点的曲线绘制
OpenLayers 精确经过三个点的曲线绘制 根据您的需求,我将提供一个使用 OpenLayers 绘制精确经过三个指定点的曲线解决方案。对于三个点的情况,我们可以使用 二次贝塞尔曲线 或 三次样条插值,确保曲线精确通过所有控制点。 实现方案 下面是…...

uniapp小程序中实现无缝衔接滚动效果
组件滚动通知只能实现简单的滚动效果,不能实现滚动内容中的字进行不同颜色的更改,下面实现一个无缝衔接的滚动动画,可以根据自己的需要进行艺术化的更改需要滚动的内容,也可以自定义更改滚动速度。 <template><view cla…...

【Docker 新手入门指南】第四章:镜像加速
【Docker 新手入门指南】系列文章目录 【Docker 新手入门指南】第一章:前言【Docker 新手入门指南】第二章:架构概述【Docker 新手入门指南】第三章:快速安装【Docker 新手入门指南】第四章:镜像加速 文章目录 🚀【Doc…...

k8s删除pv和pvc后,vg存储没释放分析
原因是pv对应的lvm没删除 pv如下: local-068e2cac-22de-40f3-af90-efd151d043c8 100Gi RWO Retain Released sase-ops/alertmanager-kube-prometheus-stack-alertmanager-db-alertmanager-kube-prometheus-stack-alertmanager-0 …...
使用 Docker 安装 Zipkin 和 Skywalking)
Ubuntu 22.04(WSL2)使用 Docker 安装 Zipkin 和 Skywalking
Ubuntu 22.04(WSL2)使用 Docker 安装 Zipkin 和 Skywalking 分布式追踪工具在现代微服务架构中至关重要,它们帮助开发者监控请求在多个服务之间的流动,识别性能瓶颈和潜在错误。本文将指导您在 Ubuntu 22.04(WSL2 环境…...

【DLF】基于语言的多模态情感分析
作者提出的不足 模态平等处理导致冗余与冲突 问题:现有MSA方法对所有模态(语言、视觉、音频)平等处理,忽略模态间贡献差异(如语言为主导模态)。后果:跨模态交互引入冗余信息(如视觉和音频中与情感无关的噪声),甚至模态对间双向信息传递(…...

window 显示驱动开发-线性伸缩空间段
线性伸缩空间段类似于线性内存空间段。 但是,伸缩空间段只是地址空间,不能容纳位。 若要保存位,必须分配系统内存页,并且必须重定向地址空间范围以引用这些页面。 内核模式显示微型端口驱动程序(KMD)必须实…...

[Linux网络_71] NAT技术 | 正反代理 | 网络协议总结 | 五种IO模型
目录 1.NAT技术 NAPT 2.NAT和代理服务器 3.网线通信各层协议总结 补充说明 4.五种 IO 模型 1.什么是IO?什么是高效的IO? 2.有那些IO的方式?这么多的方式,有那些是高效的? 异步 IO 🎣 关键缺陷类比…...

免费5个 AI 文字转语音工具网站!
一个爱代码的设计师在运营,不定时分享干货、学习方法、效率工具和AIGC趋势发展。个人网站:tomda.top 分享几个好用的文字转语音、语音转文字的在线工具,麻烦需要的朋友保存。 01. ChatTTS 中英文智能转换,语音自然流畅,在线免费…...

【入门】数字走向II
描述 输入整数N,输出相应方阵。 输入描述 一个整数N。( 0 < n < 10 ) 输出描述 一个方阵,每个数字的场宽为3。 #include <bits/stdc.h> using namespace std; int main() {int n;cin>>n;for(int in;i>1;i--){for(…...
)
Linux基础(文件权限和用户管理)
1.文件管理 1.1 文件权限 文件的权限总共有三种:r(可读),w(可写),x(可执行),其中r是read,w是write,x是execute的缩写。 我们…...

【BYD_DM-i技术解析】
关键词:构型、能量流、DM-i 一、发展历史:从DM1到DM5的技术跃迁 比亚迪DM(Dual Mode)技术始于2008年,其发展历程可划分为五代,核心目标始终围绕“油电协同”与“高效节能”展开: DM1…...

React Hooks 精要:从入门到精通的进阶之路
Hooks 是 React 16.8 引入的革命性特性,它让函数组件拥有了类组件的能力。以下是 React Hooks 的详细使用指南。 一、基础 Hooks 1. useState - 状态管理 import { useState } from react;function Counter() {const [count, setCount] = useState(0); // 初始值为0return …...

为什么选择 FastAPI、React 和 MongoDB?
在技术日新月异的今天,全栈开发需要兼顾效率、性能和可扩展性。FastAPI、React 和 MongoDB 这三者的组合,恰好构成了一个覆盖前后端与数据库的技术黄金三角。它们各自解决了开发中的核心痛点,同时以轻量化的设计和强大的生态系统,成为现代 Web 开发的首选方案。以下将从架构…...

01背包类问题
文章目录 [模版]01背包1. 第一问: 背包不一定能装满(1) 状态表示(2) 状态转移方程(3) 初始化(4) 填表顺序(5) 返回值 2. 第二问: 背包恰好装满3. 空间优化 416.分割等和子集1. 状态表示2. 状态转移方程3. 初始化4. 填表顺序5. 返回值 [494. 目标和](https://leetcode.cn/proble…...

重复的子字符串
28. 找出字符串中第一个匹配项的下标 给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。 示例 1&#…...

Spark MLlib网页长青
一、实验目的 1.掌握Spark SQL中用户自定义函数的编写。 2. 掌握特征工程的OneHotEncoder、VectorAssembler。 3. 熟悉决策树算法原理,能够使用Spark MLlib库编写程序 4. 掌握二分类问题评估方法 5. 能够使用TrainValidation和crossValidation交叉验证找出最佳模型。 6…...

详解多协议通信控制器
详解多协议通信控制器 在上文中,我们使用Verilog代码实现了完整的多协议通信控制器,只是讲解了具体原理与各个模块的实现代码,但是为什么这么写?这么写有什么用?模块与模块之间又是怎么连接相互作用的?今天我们就来处理这些问题。 为什么不能直接用 FPGA 内部时钟给外设?…...

JavaWeb基础
七、JavaWeb基础 javaWeb:完整技术体系,掌握之后能够实现基于B/S架构的系统 1. C/S和B/S 1.1 C/S(Client/server) C/S:客户端与服务器 本质:本地上有代码(程序在本机上)优点&#…...

localStorage和sessionStorage
localStorage和sessionStorage localStorage是指在用户浏览器中存储数据的方式,允许Web应用程序将少量的数据保存在用户设备上,便于页面之间、关闭浏览器后的数据持久化,他不会随着HTTP请求发送道服务器,减少带宽消耗,…...

c++类【高潮】
类继承 和直接复制源代码修改相比,继承的好处是减少测试。 基类:原始类, 派生类:继承类,基于基类丰富更多内容的类。 继承一般用公有继承,class 派生类名 : public 基类名{……}; 公有继承&…...

C++进阶--AVL树的实现续
文章目录 C进阶--AVL树的实现双旋AVL树的查找AVL树的检验结语 很高兴和搭大家见面,给生活加点impetus,开启今天的比编程之路!! 今天我们来完善AVL树的操作,为后续红黑树奠定基础!! 作者&#x…...

1 2 3 4 5顺序插入,形成一个红黑树
红黑树的特性与优点 红黑树是一种自平衡的二叉搜索树,通过额外的颜色标记和平衡性约束,确保树的高度始终保持在 O(log n)。其核心特性如下: 每个节点要么是红色,要么是黑色。根节点和叶子节点(NIL节点)是…...

Telnetlib三种异常处理方案
1. socket.timeout 异常 触发场景 网络延迟高或设备响应缓慢,导致连接或读取超时。 示例代码 import telnetlib import socketdef telnet_connect_with_timeout(host, port23, timeout2):try:# 设置超时时间(故意设置较短时间模拟超时)tn…...

Linux:进程间通信---消息队列信号量
文章目录 1.消息队列1.1 消息队列的原理1.2 消息队列的系统接口 2. 信号量2.1 信号量的系统调用接口 3. 浅谈进程间通信3.1 IPC在内核中数据结构设计3.2 共享内存的缺点3.3 理解信号量 序:在上一章中,我们引出了命名管道和共享内存的概念,了解…...

暗物质卯引力挂载技术
1、物体质量以及其所受到的引力约束(暗物质压力差) 自然界的所有物体,其本身都是没有质量的。我们所理解的质量,其实是物体球周空间的暗物质对物体的挤压,压力差。 对于宇宙空间中的单个星球而言,它的球周各处压力是相同的,所以,它处于平衡状态,漂浮在宇宙中。 对于星…...
连接)
JMeter 中实现 双 WebSocket(双WS)连接
在 JMeter 中实现 双 WebSocket(双WS)连接 的测试场景(例如同时连接两个不同的 WebSocket 服务或同一服务的两个独立会话),可以通过以下步骤配置: 1. 场景需求 两个独立的 WebSocket 连接(例如 …...