[Linux网络_71] NAT技术 | 正反代理 | 网络协议总结 | 五种IO模型
目录
1.NAT技术
NAPT
2.NAT和代理服务器
3.网线通信各层协议总结
补充说明
4.五种 IO 模型
1.什么是IO?什么是高效的IO?
2.有那些IO的方式?这么多的方式,有那些是高效的?
异步 IO
🎣 关键缺陷类比
📝 具体技术缺陷
⚠️ 实践中的坑
多路复用,引入了对多个文件的同时等待,那么对这多个文件的管理,就又可以引入我们的数据结构啦
1.NAT技术
NAT技术背景
之前我们讨论了, IPv4协议中, IP地址数量不充足的问题
NAT技术当前解决IP地址不够用的主要手段, 是路由器的一个重要功能;
- NAT能够将私有IP对外通信时转为全局IP. 也就是就是一种将私有IP和全局IP相互转化的技术方法:
- 很多学校, 家庭, 公司内部采用每个终端设置私有IP, 而在路由器或必要的服务器上设置全局IP;
- 全局IP要求唯一, 但是私有IP不需要; 在不同的局域网中出现相同的私有IP是完全不影响的;
NAT IP转换过程
之前说过,当进行数据跨网络传输时,构建一个报文向下交付,到网络层后要经过路由选择,发现要去目标主机和我并不再同一个子网,所以向下交付封装MAC帧交付给出口路由器 ,家用路由器的IP地址肯定知道因为你连接过路由器,如果不知道MAC地址就做ARP。
- 然后出口路由器经过同样的策略交给下一跳路由器直到交给目标主机。
- 在整个交付过程中,路由器不仅仅是把报文交给下一跳。
- 更重要的在交付的时候把源IP地址不断的做替换。
- 每一个路由器不仅有LAN口IP,还要WAN口IP,当做数据包转发时,是把源IP替换成路由器的WAN口IP。
一路替换然后数据包经过目的主机处理然后返回接下来怎么走呢?
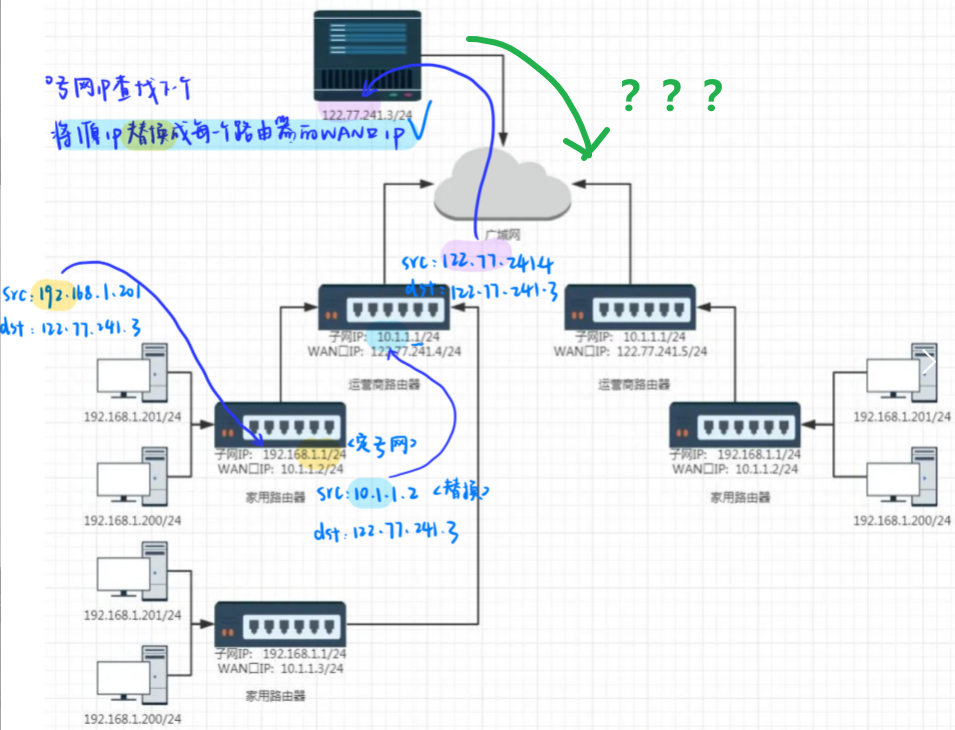
下面我们具体说一下整个过程。
- 客户端A、B、C都有自己的私有IP,每台主机我们要透过现象看本质,每台机器都有TCP/IP协议栈。
- 客户端A将数据经过路由器发送给服务器。
- 其中路由器本质天然的就包含了NAT地址转化的功能,所以在数据在刚开始转发时源IP地址是它自己私有IP,然后经过路由选择发现要去路由器,到路由器之后就把当前IP报头中源地址替换成路由器自己的WAN口IP,然后让路由替这个主机发起网络请求,最终经过内网和公网转发这个数据到了服务器。
- 服务器处理好了根据得到的源IP构建响应返回给NAT路由器,那此时NAT路由器中报文中目的IP目前是202.244.174.37,接下来问题是怎么从这个路由器回到主机。
有人可能说转化时建立一个映射关系,然后回到NAT路由器在把目的IP转化一次变成源IP地址不就可以了吗,但如果是一个局域网主机都访问同于一个服务器呢?
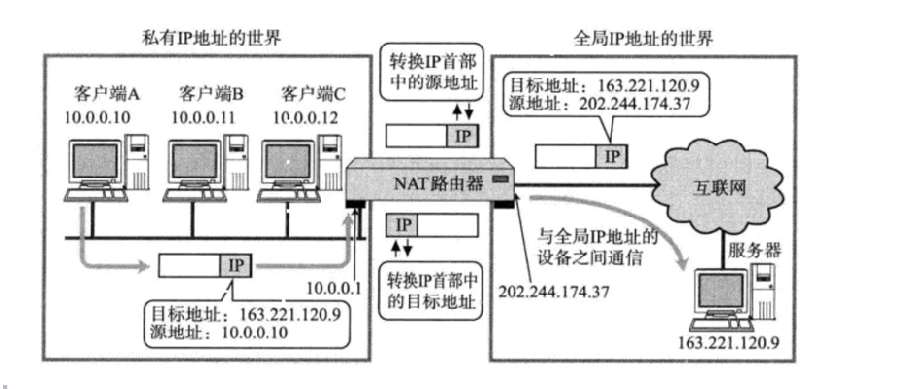
NAPT
那么问题来了, 如果局域网内, 有多个主机都访问同一个外网服务器, 那么对于服务器返回的数据中, 目的IP都是相同的. 那么NAT路由器如何判定将这个数据包转发给哪个局域网的主机?
- 这时候NAPT来解决这个问题了. 使用IP+port来建立这个关联关系
- (还是 我们之前提到的,一层区分不了,那就再加一层😋
- 当数据包回到NAT路由器的时候,目前并不能确认这个报文应该转给主机A、B、C当中哪一个。
- 但我们要求它必须分清楚,是谁的数据就给谁返回,就决定了当前路由器就必须自己维护从外网到内网之间数据包和主机之间的对应关系。
- 学了这么久实际上我们知道主机A、B、C三台主机IP地址是不一样的,所以对应每台主机都会有特定的标识符来告诉NAT路由器我们各自是谁。
- 可是有一个细节我们从开始到现在一直没说,实际上通信的并不全是客户端A、B、C这些主机,其实本质是户端A、B、C上特定的进程和服务器上某个特定的进程在通信,而进程都是自己的端口号的。并且同时可能会存在一台主机上有不同进程可能都要去访问外网。
所以NAT路由器除了要区分客户端A、B、C之间差别,也要有能力区分同一台主机不同的进程!
- 说白了就是NAT路由器不仅仅要区分客户端A、B、C,然后把响应报文要转给不同的主机。
- 还有同一台主机不同进程发给其他服务器,服务器处理之后把响应报文都发到NAT路由器,NAT路由器要把响应给同一台主机的不同进程,所以还需要端口号来区分同一台主机不同进程!
所以数据包在经过NAT路由器进行转发出去的时候,不仅要考虑源IP地址替换的问题,源端口号也要被替换。
因此路由器还要在自身内部维护一张NAT转换表! 其实这张转换表是KV式的转换表。
(于是 又回到了我们的算法问题上面
- 公网IP肯定是不一样的,局域网内不同主机IP地址也是不一样的。
- 可能是同一台主机不同进程发送请求,也有可能是不同主机但是端口号相同的进行发送请求
但是因为有IP和端口号的存在这个组成四元组的请求在局域网内一定是唯一四元组。
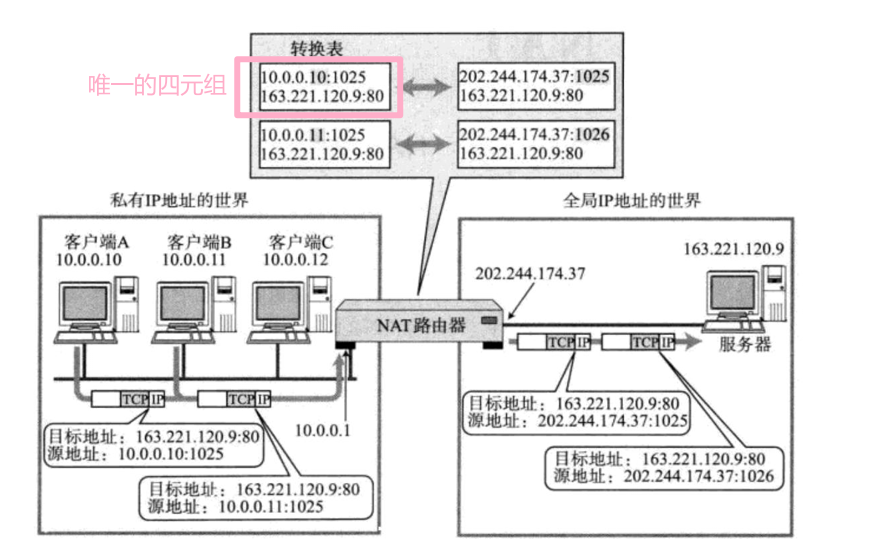
(☺️理解:虽然客户端发的可能是去 同一个主机+port,但因为是不同客户端发的,我们之后可能还涉及到了一个应答的问题,所以在 nat 转发的时候,替换为相同的 转发的源 ip 地址时,port 端口要设置的不同
- 把请求报文经过NAT路由器源IP地址的转换,源port也可能转换(可能一台主机不同进程都访问外网)。
- 替换之后这个四元组请求在公网内也是唯一的。
所以NAT路由表做了源IP替换和可能源port的替换之后变成了新的源IP和或者新的源port,因为一个是私网IP一个是公网IP,这两种IP一定是不一样的,也就是说替换完了之后两个四元组的源IP一定是不一样的 - 就注定了这两个唯一的四元组合起来整体一定是不一样的并且是唯一的。
所以在NAT路由器中就构建了互为键值的映射表 并且都是唯一的。
也就是说从左到右,左侧的值是具有唯一性的,从右到左,右侧的值也是具有唯一性的。
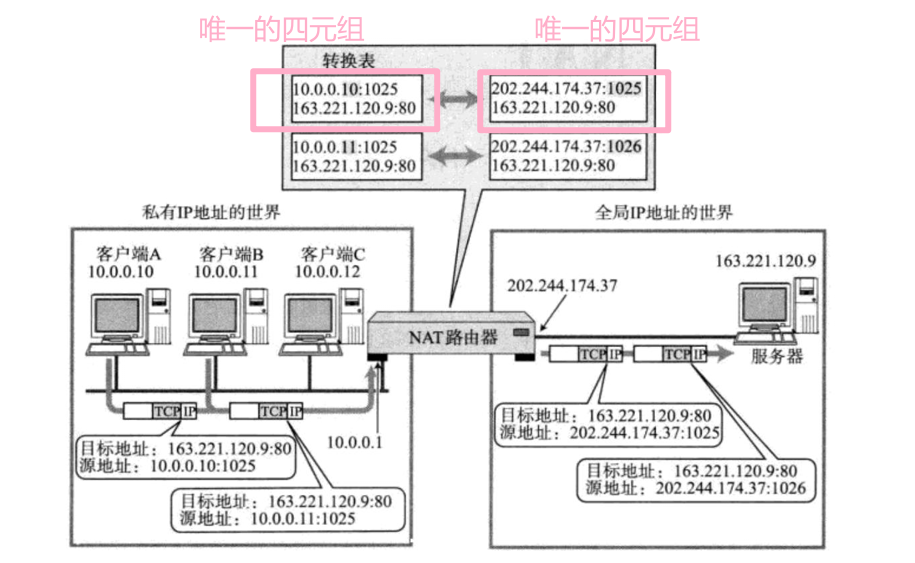
所以数据包回来到NAT路由器后,虽然NAT路由器看到目的IP都是一样的,但是曾经端口号可能做了替换,因此看到的整体一定是不一样的。
- 然后再根据映射,所以最终就可以区分出那个数据包是那个主机的进程的。
- 所以不用担心数据包回来的问题,因为路上的路由器都会建立NAT转换表。这个NAT转换表可以从左到右查,也可以从右到左查。(有不同的端口,可以实现来区分返回)
- 经过刚才的分析,如果主机上从来没有访问外网,那外网能不能之间通过路由器访问这台主机呢?
不能!因为路上的路由器并没有建立对应的映射关系。 - 所以也不能把数据反向的从外网推送给该主机。除非该主机访问外网然后路上路由器记录对应的映射关系,外网才能访问该主机。
这种互为映射的关联关系也是由NAT路由器自动维护的.
- 例如在TCP的情况下, 建立连接时, 就会生成这个表项;
- 在断开连接后, 就会删除这个表项
所以有NAT这种技术的存在可以让我们构建各自各样的子网,然后通过转发访问公网 - 只要保证最终的出口路由器(连接公网的路由器)它所面对公网的IP地址是唯一的就可以了,内网环境可以使用NAT进行各自转发。
NAT技术的缺陷
由于NAT依赖这个转换表, 所以有诸多限制:
- 无法从NAT外部向内部服务器建立连接; (NAT 只能从内向外)
- 转换表的生成和销毁都需要额外开销;
- 通信过程中一旦NAT设备异常, 即使存在热备, 所有的TCP连接也都会断开;(这是一个很危险的事情)
2.NAT和代理服务器
代理服务器又分为正向代理和反向代理.
举个例子
花王尿不湿是一个很经典的尿不湿品牌, 产自日本.
我自己去日本买尿不湿比较不方便, 但是可以让我在日本工作的表姐去超市买了快递给我. 此时超市看到的买家是我表姐, 我的表姐就是 “反向代理”;(代表的是日本超市)
就好比我自己在访问时看不到真正服务器,我只知道要什么东西就找这个代理服务器要。这就是反向代理。
后来找我表姐买尿不湿的人太多了, 我表姐觉得天天去超市太麻烦, 干脆去超市买了一大批尿不湿屯在国内家里, 如果有人来找她代购, 就直接把屯在国内家里的货发出去, 而不必再去超市. 此时我表姐就是 "正向代理(代表的是客户)
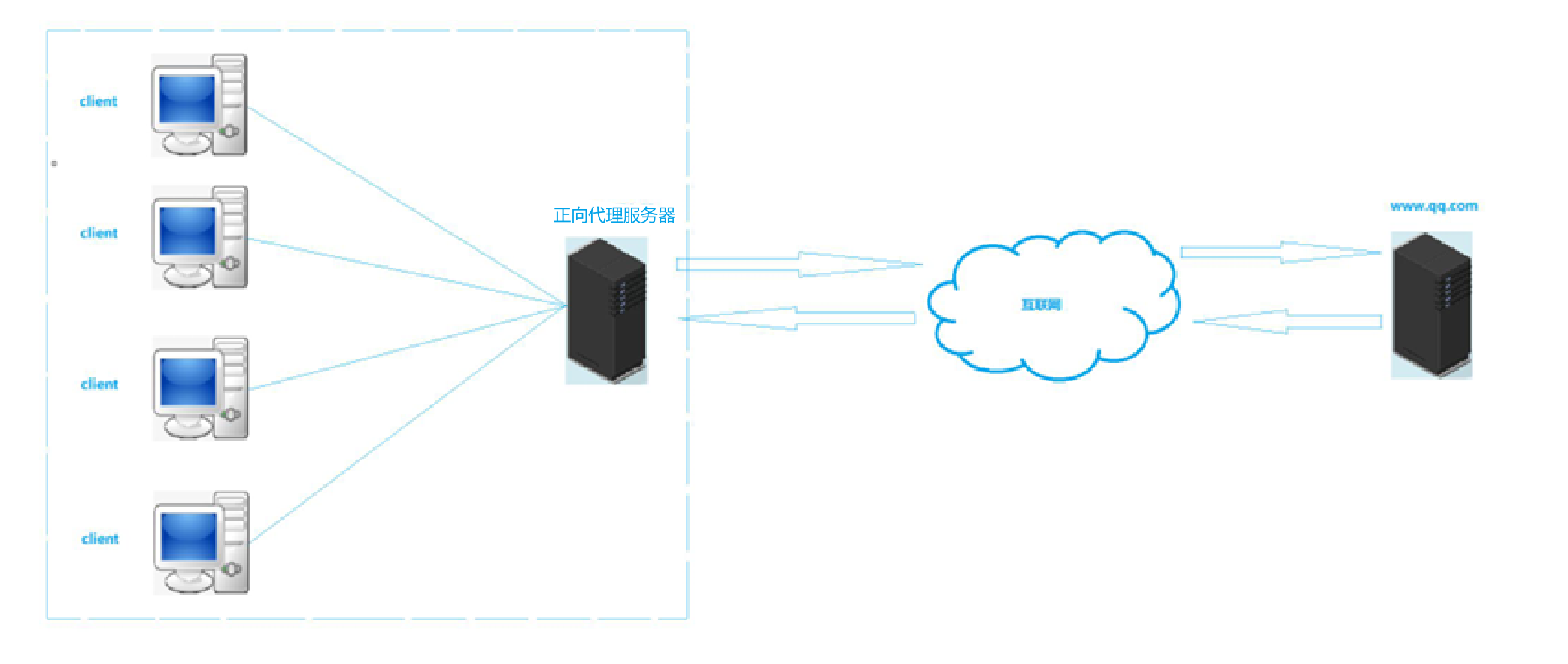
代理客户端的是 正向代理
代理服务端的是 反向代理
(相当于 这个正 是以客户为正)
一般我们在公司层面,现在有很多机器,这些机器通过网络访问公司内部的服务器。
- 公司内部一定是有多种服务器的,可是有这么多服务器都暴露在公网里面, 每一台服务器也都得有自己公网IP的话,那么最终我们应该访问那一台服务器呢?其实是比较尴尬的。
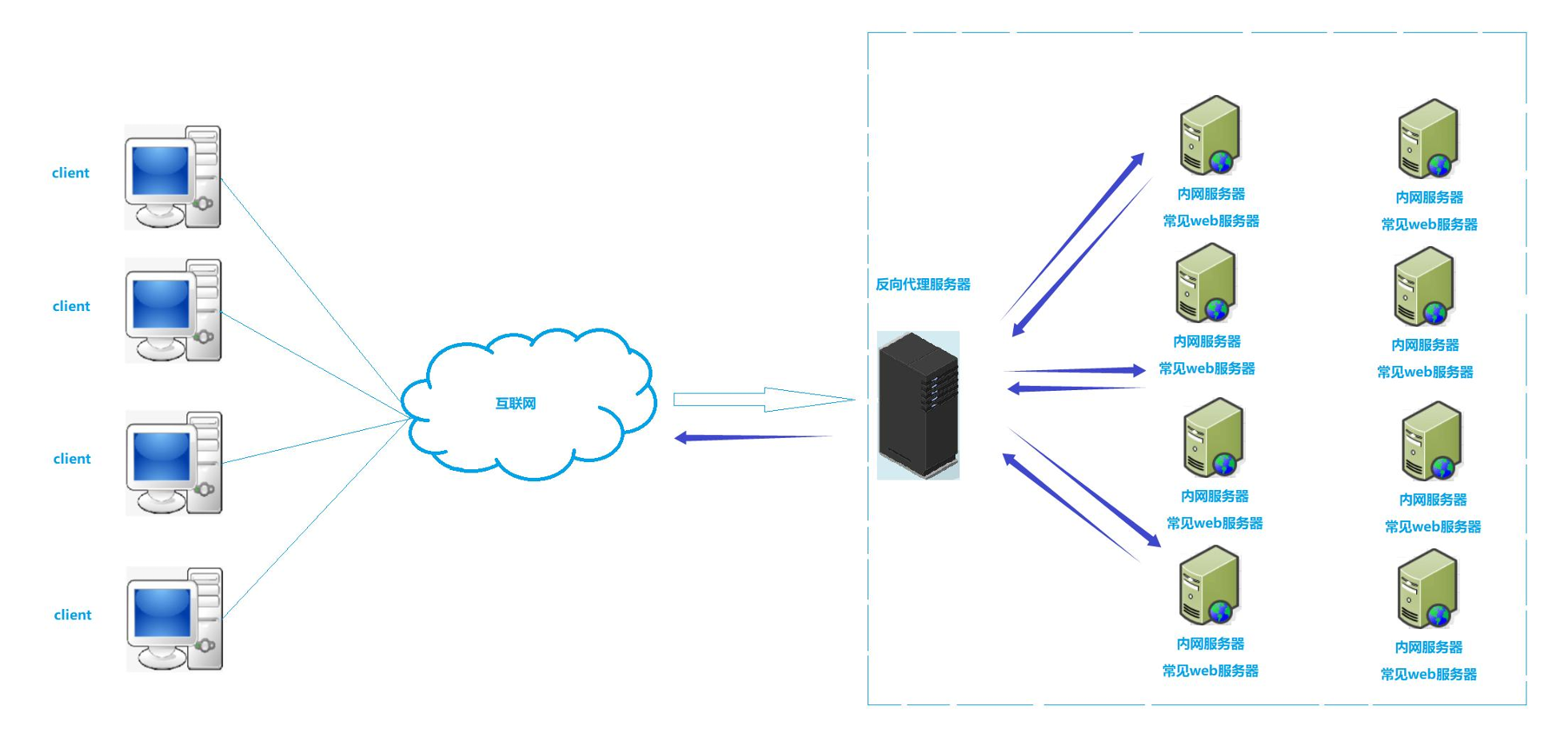
- 所以提供服务的一方呢,可能会给我们提供一个入口服务器。这个入口服务器一般会部署某些网络服务,现在就变成了只有这一台入口服务器有自己的公网IP,暴露在公网里,所有人都访问这台入口路由器,那么这一台机器最终就可以把所有人请求转发到它内网中某台服务器来对外提供服务。
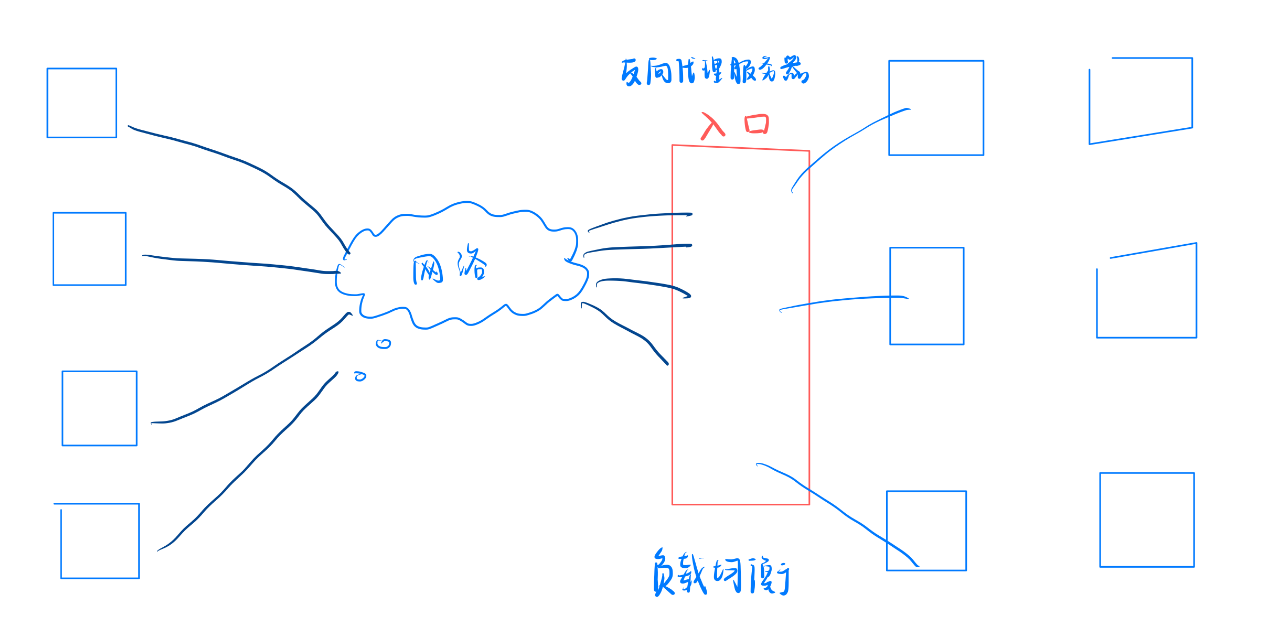
我们就把这台入口机器称之为代理服务器严格来说称之为反向代理服务器。
- 假设现在有4千万个客户端,有大量的请求都过来的,反向代理服务器收到大量的请求,如果它内部没有做任何处理,把请求全都给一台机器或者少量几台机器
- 最终会导致这几台机器压力非常大,其他机器很闲,最终导致这个集群承受压力能力变得非常低。
- 所以反向代理为了解决这个问题,在自己内部中当有请求到来它内部有策略的把请求均衡的分散到整个集群所有主机上,这种策略我们称之为负载均衡
-
一般作为反向代理服务器配置都比较高,上面通常充当反向代理服务的一般有一些软件服务,比如说Nginx,它是一款web服务器也可以充当代理服务器。 - 一般把结果返回给客户端有两种做法,一种是把对应的处理结果返回给代理,然后由代理通过网络转发给客户端。
另一种把对应的处理结果由内网机器直接通过网络访问客户端。
反向代理通常作为机房入口机器,来实现分发和负载均衡
反向代理服务器在学校网络环境中的应用
- 分发和负载均衡:反向代理通常作为机房或网络入口,用于实现流量的分发和负载均衡,优化资源使用并提高访问效率。
- 访问控制与缓存:当学生尝试通过校园网访问外网时,实际上请求首先发送到学校的反向代理服务器。学校可以通过这道“门”限制学生的访问,例如阻止访问某些不被允许的内容。此外,如果多个用户请求相同的内容(如观看同一部电影),服务器可以缓存这些内容,并在后续请求中直接提供缓存版本,减少重复的公网访问,提高响应速度。
- 禁止访问:对于不允许访问的公网资源,学校可以直接在反向代理服务器上丢弃这些请求,从而阻止学生访问特定的外网内容。
- 上网认证与收费:为了管理校园网资源,学校可能会要求学生通过登录页面进行身份验证和缴费确认后才能上网。所有网络请求都需经过这台服务器,确保只有通过认证且付费的用户才能获得公网访问权限。这种方式不仅帮助学校管理网络资源,还能保证用户的身份安全和服务质量。
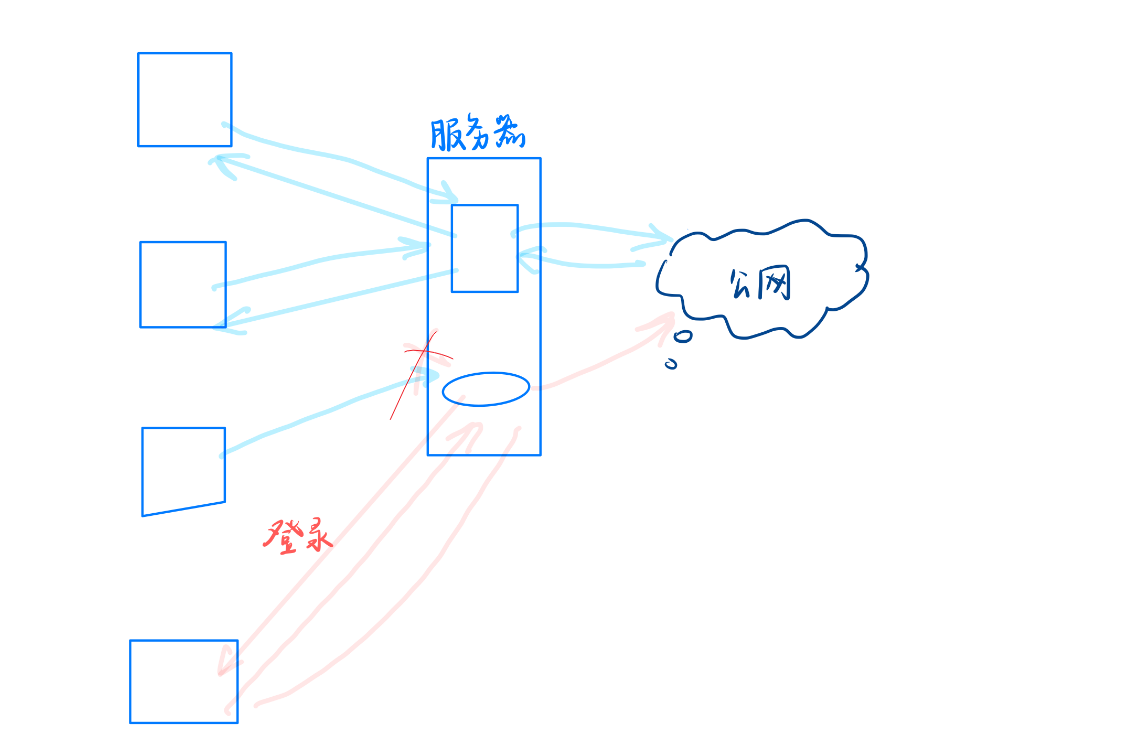
- 像这种服务器替用户去访问我们称之为正向代理。它可以缓存资源,然后从学校层面可以根据正向代理服务器对学生所访问的各种资源进行限定,同理也可以对学生做入网许可的管理,这就是正向代理。正向代理服务器归根结底其实就是把所有请求收集在一起方便对请求本身做管理。
上面内容好像和刚才说的NAT有些类似,NAT是在做由路由器替用户去进行请求,这不就是正向代理,那么是不是这样呢?
- 路由器往往都具备NAT设备的功能, 通过NAT设备进行中转, 完成子网设备和其他子网设备的通信过程.
- 代理服务器看起来和NAT设备有一点像. 客户端像代理服务器发送请求, 代理服务器将请求转发给真正要请求的服务器; 服务器返回结果后, 代理服务器又把结果回传给客户端.
- 看起来它们俩工作原理好像有一点像,但其他它们俩是不同的东西。
那么NAT和代理服务器的区别有哪些呢?
(即 如何理解 NAT 的转发,和代理服务器的转发 之间的区别
从应用上讲,
- NAT设备是网络基础设备之一, 解决的是IP不足的问题.
- 代理服务器则是更贴近具体应用, 比如通过代理服务器进行翻墙, 另外像迅游这样的加速器, 也是使用代理服务器.
从底层实现上讲,
- NAT是工作在网络层, 直接对IP地址进行替换.
- 代理服务器往往工作在应用层.
从使用范围上讲,
- NAT一般在局域网的出口部署,
- 代理服务器可以在局域网做, 也可以在广域网做, 也可以跨网.
从部署位置上看,
- NAT一般集成在防火墙, 路由器等硬件设备上,
- 代理服务器则是一个软件程序, 需要部署在服务器上.代理服务器是一种应用比较广的技术.
- 翻墙: 广域网中的代理.
- 负载均衡: 局域网中的代理.
3.网线通信各层协议总结
以下是对网络通信各层协议的整理表格,按层级结构分类展示关键知识点:
| 协议层级 | 核心协议/概念 | 主要特点 | 关键知识点 |
| 数据链路层 | 以太网(Ethernet) | 实现同一局域网内设备间的直接通信 | ▪ 包含物理层规范(拓扑结构、传输速率) |
| ARP协议 | 动态维护IP地址与MAC地址映射关系 | ▪ 通过广播请求获取目标MAC | |
| 网络层 | IP协议(IPv4/IPv6) | 实现跨网络的数据路由与寻址 | ▪ IP地址逻辑标识设备 |
| ICMP协议 | 网络状态诊断与控制 | ▪ Ping命令基于ICMP回显请求 | |
| 路由协议(如OSPF、BGP) | 动态选择最优传输路径 | ▪ 路由表维护目标网络与下一跳关系 | |
| 传输层 | TCP协议 | 提供可靠、面向连接的端到端传输 | ▪ 三次握手建立连接/四次挥手断开 |
| UDP协议 | 提供高效、无连接的简单传输服务 | ▪ 无连接、不可靠但延迟低 | |
| 应用层 | HTTP/HTTPS | 万维网数据通信基础 | ▪ 请求-响应模型(GET/POST等) |
| DNS协议 | 域名与IP地址的映射系统 | ▪ 分层解析(根域名→顶级→权威) | |
| 自定义应用协议 | 满足特定业务需求 | ▪ 需明确定义报文格式(头部+载荷) |
补充说明
- 层级关联:
▪ 数据链路层MAC地址用于局域网通信 → 网络层IP地址实现跨网寻址 → 传输层端口号定位具体应用 → 应用层协议处理具体业务数据 - 典型交互流程:

- 协议设计原则:
▪ 下层为上层提供服务(如IP层依赖数据链路层传输)
▪ 协议开销与效率的平衡(TCP可靠性 vs UDP高效率)
▪ 安全性分层实现(链路层加密/WiFi WPA2、传输层TLS、应用层HTTPS)
4.五种 IO 模型
1.什么是IO?什么是高效的IO?
在之前我们都知道的input,output不就是IO吗
- 站在冯诺依曼体系角度我们知道从外设把数据搬到内存这不就是Input吗
- 把数据从内存拷贝到外设中这不就是output吗。
这不就是传说中的IO吗。没错,但是这种理解还不够深刻!
- 当我们在网络中发送数据的时候是使用write发生,read读取。
- 当我们在进行write写入的时候曾经说过,我们在应用层调用write本质并不是把数据发送到网络中,其实只是把数据从应用层拷贝到传输层的发送缓冲区,所有write本质就是拷贝。
- 当我们调用read读取数据时,其实并不是从网络中读取,而是从传输层的接收缓冲区中把数据从内核中拷贝到应用层,所以read也是拷贝函数。可是你想拷贝就能给你拷贝吗?
你想write,有没有可能发送缓冲区因为流量控制的问题发送缓冲区已经被写满了数据,你想write但当前缓冲区没有空间让你write了。
- 那么此时write操作默认就是阻塞在哪里,直到缓冲区有空间了
- write我们写代码到现在见到很少。但是当我们read读取数据的时候,我们被阻塞的情况是非常常见的。
以读为例,说读取就是拷贝这句话没错,但是当你想拷贝就能拷贝吗?
万一人家接收缓冲区就没有数据呢?你的read只能阻塞住。所以要记住read、write本质就是拷贝,但是拷贝是有条件的。
所以不用考虑操作系统,就站在read接口使用角度,调用read/recv… 有两种情况
- 没有数据,就会阻塞住
- 有数据,read/recv… 会在拷贝完成之后进行返回
这个阻塞不就是在等待资源就绪吗。
所以不能简单认为read/recv… 只有拷贝。这是不全面的认识。
read/recv… 读取的本质应用要分成两种东西。
- 站在我们角度read/recv…就是input。
- 读取也是同样如此要风两种东西,write/send…就是output。
IO本质:
IO = 等 + 数据拷贝
在系统层面和网络层面IO都叫数据拷贝,就比如写文件的时候,把数据写到文件的过程我们根本不知道,调用write也只是把文件写到操作系统里,然后由操作系统把数据刷新到文件里。
- 同理,我们也没有资格把数据直接写到网络里,只是把数据交给了操作系统,由操作系统帮我们发送。
- 所以我们发现系统和网络在IO的处理上是一至的。
- 在系统的时候我们不说IO=等+数据拷贝,是因为在系统层面等这个事情不直观,访问一个本地文件很快就写完成,很快就读完成了。
- 看不到等。其实有没有等呢?一定要等!今天就知道了,你要读取数据,但数据可能并不在内存中,你必须要等,因为操作系统首先要把数据从外设(磁盘)搬到内存里。
- 而磁盘是外设,所以操作系统要给磁盘下达指令把数据从磁盘中拷贝到内存等工作做完了,然后你才把数据从操作系统拷贝到用户,只不过这个过程太快了,你感受不到。
今天就不一样,在网络通信距离变长了,还要流量控制、拥塞控制等,所以距离一长等的比重就显得明显了,就能感觉到IO=等+数据拷贝了。
什么是高效的IO?
你经常会听别人说我们要高效的IO,凭什么?你IO高效的提高究竟是在做哪方面的提高?
- 首先数据拷贝这件事情,它的效率是固定的。
- 因为数据拷贝的的本质是从硬件到硬件,该花多少时间就花多少时间,要么就是由你主机上的总线的位宽决定的,要么就是由你网络的带宽决定的。
- 所以这个东西本身就是确定的,只要你能保证你在拷贝的时候它在100%一直在拷贝,它的效率就已经到达上限了。
既然IO = 等 + 数据拷贝,那什么叫做高效IO呢?
其实,只要减少 等待 的比重,即可!
- 想象一下调用read只花1秒,可是其中有99%的时间都在等待,等待的事件永远是主要矛盾,那么只有1%的时间花在拷贝上,拷贝本身就是从操作系统拷贝到用户,它是从内核到用户。
- 站在硬件角度上就是从内存到内存,这个时间本身就是一个固定时间,站在操作系统角度把数据从外设搬到内存,把硬件上速度拉满它能拷贝多少就是多少。
- 可是在IO大部分时间在等,如果把等和数据拷贝时间反过了,99%在拷贝,1%在等
- 我调用read很快就能够或者等的比重降的非常低,一调用read就直接返回,那这就叫做高效IO。
而在 等待 这件事情上,我们是需要从软件策略完成的。
read/recv它们策略很简单粗暴,没有数据就等,有数据就拷贝。
2.有那些IO的方式?这么多的方式,有那些是高效的?
下面讲个小故事理解IO的过程。
我们可能见过别人钓鱼或者自己钓鱼,那么把钓鱼步骤化繁为简,钓鱼分两步
钓鱼 = 等 + 钓

钓鱼:
- 张三:专注死盯鱼漂,不达目的不罢休 → 阻塞IO
- 李四:三心二意,频繁查看鱼漂 → 非阻塞IO
- 王五:挂铃铛通知,轻松做其他事 → 信号驱动IO
- 赵六:百竿齐发,来回巡检 → 多路复用(select/epoll)
- 田七:完全委托小王,自己专注工作 → 异步IO
效率分析:
- 直观效率:赵六 > 王五 > 张三 > 李四 > 田七(但田七实现了零等待)
- 理论极限:田七的异步模式效率最高(系统代为完成所有操作)
- 现实折中:赵六的多路复用是性价比最高的方案
关键对应关系:
| 故事元素 | 计算机概念 | 性能瓶颈 |
|---------------|-----------------------|----------------------|
| 鱼漂动静 | 数据就绪事件 | 事件检测延迟 |
| 100根鱼竿 | 多文件描述符 | 系统监控上限 |
| 来回巡检 | select轮询 | O(n)时间复杂度 |
| 铃铛响动 | SIGIO信号 | 信号处理延迟 |
| 小王代劳 | aio_read异步调用 | 系统回调机制 | 现实工程启示:
- 阻塞IO:简单但浪费线程资源(如传统socket编程)
- 非阻塞IO:CPU空转严重(需配合超时机制)
- 信号驱动:适用于低频事件(如串口通信)
- 多路复用:高并发基石(nginx/epoll模型)(可以一次等待多个)
- 异步IO:未来方向但实现复杂(如Windows IOCP)
💡 在Linux中,
epoll_wait就是赵六的"巡检优化版",用红黑树管理鱼竿(文件描述符),事件通知复杂度降为O(1)
所以,钓鱼的人,等的比重比较低,单位时间,钓鱼的效率就高!
- 其次,张三,李四,王五,赵六,田七(小王)谁钓鱼效率最高?
- 首先张三、李四、王五、田七(小王)它们只有一人一竿,只有赵六是一人多竿。鱼竿多就是了不起。假设赵六100条竿,加上其他的人4条竿。
- 站在鱼的角度头顶上有着104个诱饵,咬到任何一个诱饵概率是一样的,要是咬的话,赵六钓鱼成功概率就是100/104,其他人只是1/104,所以赵六钓鱼时任一鱼竿就绪概率概率就100/104。
- 所以单位时间内任何一个鱼竿就绪概率就是比其他人大。所以站在旁观者看赵六就可能一直有鱼咬竿的事情。
- 所以单位时间内,赵六这种钓鱼方式等的比重比较低,所以赵六钓鱼的效率比较高。
我们把这种一次可以等待多个鱼竿的钓鱼方式叫做多路转接/多路复用
张三 ------> 阻塞IO
李四 ------> 非阻塞IO
王五 ------> 信号驱动式IO(还没有钓鱼就知道铃铛响了,鱼就咬钩了)
赵六 ------> 多路转接/多路复用
田七 (小王) ------> 异步IO
- 张三、李四,王五、赵六、田七 ----> 进程/线程
小王 ----> OS
鱼 ----> 数据
河 ----> 内核空间
鱼鳔 ----> 数据就绪的事件
鱼竿 ----> 文件描述符
钓鱼的动作 ----> read/recv…钓鱼
理解:
- 当张三这个进程去读数据时,只要底层数据没有就绪,就要一直等待将自己挂起。只有数据就绪了,才会被唤醒然后读到数据在返回。
- 李四这个进程去读数据时,当底层数据没有就绪,李四并不会因为read/recv…而被阻塞,而是立马返回,在自己的while循环中去做其他事情。然后再去读(可以设定询问间隔时间)。
- 王五这个进程在进行IO之前,一旦IO了操作系统会给进程推送SIGIO信号(需要特定接口去设置),王五在进行调用recv之前,他只是注册一下SIGIO的方法,然后王五继续向后执行做自己的事情,一旦有IO就绪了,王五的信号捕捉方法里直接调用recv,然后把数据从内核拷贝到用户空间,这叫做信号驱动。
- 赵六这个进程拿着多个文件描述符,一次等待多个,具体怎么等后面说。
- 田七这个进程,通过异步IO的接口直接将数据读取的工作交给操作系统,除了把任务交给操作系统同时他还给了操作系统一个缓冲区(鱼桶),以及给了操作系统一个通知(电话),比如是某些回调方法或者某些回调策略。
- 让操作系统在读取数据时直接把数据全部从内核中读取到缓冲区,然后用告诉操作系统的方法,来告知田七数据准备好了让田七直接用就好了,这就叫做异步IO。
所以我们把上面对IO的方式,我们称之为五种IO模型。所有IO都隶属于上面模型,目前大部分使用的文件接口用的是阻塞IO。
而多路转接/多路复用是比较高效的
对比五种IO模型的差别
张三、李四、王五在效率上有差别吗?
没有!因为他们在整个IO过程,该等多少时间就等了多少时间。效率上是没有差别的。都只有一个鱼竿,而鱼钓上来的概率是一样的。
但是在其他方面有差别!阻塞式什么事都不干,只进行IO,所以其他方面没有优势。
- 而非阻塞式IO,它可以轮询式的方法检测底层数据是否就绪,在检测没有数据就绪时还可以在等的时间做其他事情。
- 信号驱动也是一样的,在等待数据就绪时,也同样在等的时间做其他事情。
- 所以张三、李四、王五在IO上效率是一样的,但是整体上李四,王五可以做其他事情,表现上他们好像多做了事情然后更高效一点,但是这高效没有体现在IO上。
王五(信号驱动)究竟有没有等待呢?
他一定等了,要不然王五早就走了,为什么还要待在岸边呢?所以本质上还是等了。
只不过等的方式有些差别,别人是主动去检测,而他变成了你好了,你来叫我。信号驱动是采用回调的方式来进行等待的。
- 张三、李四、王五、赵六他们其实每一个人都等了,当鱼咬钩时每一个人都钓了。每一个人都参与了IO的过程,我们把他们都可以称之为同步IO。
- 田七并没有等鱼咬钩,也没有当鱼咬钩时把鱼钓上来,他连河边都没有去过,他把任务交给小王,并没有参与IO的两个阶段中的任何一个阶段,我们把他称之为异步IO。
- (他都没有进行 IO,直接拿到了结果,我们之前写的 rpc 就是一个异步 IO,但是谨记,没有银弹,异步有时容易造成混乱,所以我们有时会采用协程)
阻塞式IO和非阻塞式IO有什么差别呢?
共同点:钓
不同点:等的方式不同!
异步这里好理解,但是同步这里就有一个问题了,我们曾经学过一个线程同步的概念。
- 现在又学了一个同步IO,那这两个同步是一样的吗?
它们之间的关系就和老婆和老婆饼一样,没有任何关系!当我们在网络中搜索同步的概念时一定要加前提条件。线程同步是让多线程执行具有一定的顺序性。还是说IO的同步允许参与IO的过程!
为什么多路转接/多路复用是高效的代名词?
因为 IO = 等 + 数据拷贝,多路转接/多路复用可以减少等的比重
同样等,但是一次可以等待多个文件描述符至少有一个就绪。调用read等的比重降低了,未来效率就高了。
异步 IO
异步I/O的一个缺点是在某些情况下可能会导致更多的上下文切换和更高的开销,因为操作系统需要频繁地在多个任务之间进行调度。
用之前钓鱼故事中的「田七委托小王」场景来解释异步IO的缺点:
🎣 关键缺陷类比
田七(应用程序) 小王(操作系统)│ ││ 委托钓鱼任务 ││─────────────────────────>││ ├─ 需要准备鱼竿、鱼饵、水桶...│ ├─ 必须完全信任小王的钓鱼能力│ ├─ 无法实时查看钓鱼进度│ │(突然下暴雨也不知道)│ ││ ←─── 桶满才通知 ──── │📝 具体技术缺陷
- 开发复杂度剧增
-
- 需要设计复杂的回调机制(如同田七要给小王写详细钓鱼指南)
- 状态管理困难(无法直观看到鱼竿的实时状态)
- 示例代码复杂度对比:
// 同步模式(张三式)
fish = wait_and_catch(); // 简单直观// 异步模式(田七式)
start_async_catch(callback_func);
while(1){ /* 处理其他事但需维护回调状态 */ }- 系统支持碎片化
| 操作系统 | 实现方式 | 如同... |
| Linux | libaio/epoll | 小王只会传统钓鱼法 |
| Windows | IOCP | 小王会用智能钓鱼机器人 |
| macOS | kqueue | 小王擅长海钓 |
- 调试噩梦
-
- 回调链断裂时难以追溯(如小王钓到鱼但忘记打电话)
- 多线程+异步的竞态条件(多个小王同时操作鱼桶)
- 资源隐性消耗
-
- 每个异步操作需要维护上下文(如同每个鱼竿要配记录本)
- 事件循环本身消耗CPU(田七频繁看手机是否收到通知)
- 所以他哪怕去干别的事了,只等结果,但是他等的也不安心..(异步IO 存在的问题)
- 不适用场景
┌───────────────┬───────────────┐
│ 适合场景 │ 如同... │
├───────────────┼───────────────┤
│ 大规模并发请求 │ 赵六式百竿监控 │(多路复用)
├───────────────┼───────────────┤
│ 简单串行任务 │ 张三式专注单竿 │
└───────────────┴───────────────┘
⚠️ 实践中的坑
- 缓冲区管理失控:如同小王钓的鱼太多,桶溢出导致鱼逃跑(内存泄漏)
- 超时机制缺失:若小王永远钓不满桶,田七会永久等待(死锁)
- 优先级反转:紧急钓鱼需求可能被普通请求阻塞
建议在需要处理 10,000+ 并发连接 的场景(如高频交易系统)才考虑纯异步方案,其他情况可结合多路复用(赵六模式)+线程池优化。
下篇文章我们将继续详细讲解代码实现~
相关文章:

[Linux网络_71] NAT技术 | 正反代理 | 网络协议总结 | 五种IO模型
目录 1.NAT技术 NAPT 2.NAT和代理服务器 3.网线通信各层协议总结 补充说明 4.五种 IO 模型 1.什么是IO?什么是高效的IO? 2.有那些IO的方式?这么多的方式,有那些是高效的? 异步 IO 🎣 关键缺陷类比…...

免费5个 AI 文字转语音工具网站!
一个爱代码的设计师在运营,不定时分享干货、学习方法、效率工具和AIGC趋势发展。个人网站:tomda.top 分享几个好用的文字转语音、语音转文字的在线工具,麻烦需要的朋友保存。 01. ChatTTS 中英文智能转换,语音自然流畅,在线免费…...

【入门】数字走向II
描述 输入整数N,输出相应方阵。 输入描述 一个整数N。( 0 < n < 10 ) 输出描述 一个方阵,每个数字的场宽为3。 #include <bits/stdc.h> using namespace std; int main() {int n;cin>>n;for(int in;i>1;i--){for(…...
)
Linux基础(文件权限和用户管理)
1.文件管理 1.1 文件权限 文件的权限总共有三种:r(可读),w(可写),x(可执行),其中r是read,w是write,x是execute的缩写。 我们…...

【BYD_DM-i技术解析】
关键词:构型、能量流、DM-i 一、发展历史:从DM1到DM5的技术跃迁 比亚迪DM(Dual Mode)技术始于2008年,其发展历程可划分为五代,核心目标始终围绕“油电协同”与“高效节能”展开: DM1…...

React Hooks 精要:从入门到精通的进阶之路
Hooks 是 React 16.8 引入的革命性特性,它让函数组件拥有了类组件的能力。以下是 React Hooks 的详细使用指南。 一、基础 Hooks 1. useState - 状态管理 import { useState } from react;function Counter() {const [count, setCount] = useState(0); // 初始值为0return …...

为什么选择 FastAPI、React 和 MongoDB?
在技术日新月异的今天,全栈开发需要兼顾效率、性能和可扩展性。FastAPI、React 和 MongoDB 这三者的组合,恰好构成了一个覆盖前后端与数据库的技术黄金三角。它们各自解决了开发中的核心痛点,同时以轻量化的设计和强大的生态系统,成为现代 Web 开发的首选方案。以下将从架构…...

01背包类问题
文章目录 [模版]01背包1. 第一问: 背包不一定能装满(1) 状态表示(2) 状态转移方程(3) 初始化(4) 填表顺序(5) 返回值 2. 第二问: 背包恰好装满3. 空间优化 416.分割等和子集1. 状态表示2. 状态转移方程3. 初始化4. 填表顺序5. 返回值 [494. 目标和](https://leetcode.cn/proble…...

重复的子字符串
28. 找出字符串中第一个匹配项的下标 给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。 示例 1&#…...

Spark MLlib网页长青
一、实验目的 1.掌握Spark SQL中用户自定义函数的编写。 2. 掌握特征工程的OneHotEncoder、VectorAssembler。 3. 熟悉决策树算法原理,能够使用Spark MLlib库编写程序 4. 掌握二分类问题评估方法 5. 能够使用TrainValidation和crossValidation交叉验证找出最佳模型。 6…...

详解多协议通信控制器
详解多协议通信控制器 在上文中,我们使用Verilog代码实现了完整的多协议通信控制器,只是讲解了具体原理与各个模块的实现代码,但是为什么这么写?这么写有什么用?模块与模块之间又是怎么连接相互作用的?今天我们就来处理这些问题。 为什么不能直接用 FPGA 内部时钟给外设?…...

JavaWeb基础
七、JavaWeb基础 javaWeb:完整技术体系,掌握之后能够实现基于B/S架构的系统 1. C/S和B/S 1.1 C/S(Client/server) C/S:客户端与服务器 本质:本地上有代码(程序在本机上)优点&#…...

localStorage和sessionStorage
localStorage和sessionStorage localStorage是指在用户浏览器中存储数据的方式,允许Web应用程序将少量的数据保存在用户设备上,便于页面之间、关闭浏览器后的数据持久化,他不会随着HTTP请求发送道服务器,减少带宽消耗,…...

c++类【高潮】
类继承 和直接复制源代码修改相比,继承的好处是减少测试。 基类:原始类, 派生类:继承类,基于基类丰富更多内容的类。 继承一般用公有继承,class 派生类名 : public 基类名{……}; 公有继承&…...

C++进阶--AVL树的实现续
文章目录 C进阶--AVL树的实现双旋AVL树的查找AVL树的检验结语 很高兴和搭大家见面,给生活加点impetus,开启今天的比编程之路!! 今天我们来完善AVL树的操作,为后续红黑树奠定基础!! 作者&#x…...

1 2 3 4 5顺序插入,形成一个红黑树
红黑树的特性与优点 红黑树是一种自平衡的二叉搜索树,通过额外的颜色标记和平衡性约束,确保树的高度始终保持在 O(log n)。其核心特性如下: 每个节点要么是红色,要么是黑色。根节点和叶子节点(NIL节点)是…...

Telnetlib三种异常处理方案
1. socket.timeout 异常 触发场景 网络延迟高或设备响应缓慢,导致连接或读取超时。 示例代码 import telnetlib import socketdef telnet_connect_with_timeout(host, port23, timeout2):try:# 设置超时时间(故意设置较短时间模拟超时)tn…...

Linux:进程间通信---消息队列信号量
文章目录 1.消息队列1.1 消息队列的原理1.2 消息队列的系统接口 2. 信号量2.1 信号量的系统调用接口 3. 浅谈进程间通信3.1 IPC在内核中数据结构设计3.2 共享内存的缺点3.3 理解信号量 序:在上一章中,我们引出了命名管道和共享内存的概念,了解…...

暗物质卯引力挂载技术
1、物体质量以及其所受到的引力约束(暗物质压力差) 自然界的所有物体,其本身都是没有质量的。我们所理解的质量,其实是物体球周空间的暗物质对物体的挤压,压力差。 对于宇宙空间中的单个星球而言,它的球周各处压力是相同的,所以,它处于平衡状态,漂浮在宇宙中。 对于星…...
连接)
JMeter 中实现 双 WebSocket(双WS)连接
在 JMeter 中实现 双 WebSocket(双WS)连接 的测试场景(例如同时连接两个不同的 WebSocket 服务或同一服务的两个独立会话),可以通过以下步骤配置: 1. 场景需求 两个独立的 WebSocket 连接(例如 …...

卡尔曼滤波算法简介与 Kotlin 实现
一、引言 卡尔曼滤波(Kalman Filter)是一种基于线性系统状态空间模型的最优递归估计算法,由鲁道夫・E・卡尔曼于 1960 年提出。其核心思想是通过融合系统动态模型预测值与传感器观测值,在最小均方误差准则下实现对系统状态的实时…...

【比赛真题解析】混合可乐
这次给大家分享一道比赛题:混合可乐。 洛谷链接:U561549 混合可乐 【题目描述】 Jimmy 最近沉迷于可乐中无法自拔。 为了调配出他心目中最完美的可乐,Jimmy买来了三瓶不同品牌的可乐,然后立马喝掉了一些(他实在是忍不住了),所以 第一瓶可口可乐最大容量为 a 升,剩余 …...

[论文阅读]BadPrompt: Backdoor Attacks on Continuous Prompts
BadPrompt: Backdoor Attacks on Continuous Prompts BadPrompt | Proceedings of the 36th International Conference on Neural Information Processing Systems 36th Conference on Neural Information Processing Systems (NeurIPS 2022) 如图1a,关注的是连续…...

DeepSeek 实现趣味心理测试应用开发教程
一、趣味心理测试应用简介 趣味心理测试是一种通过简单的问题或互动,为用户提供心理特征分析的方式。它通常包含以下功能: 测试题目展示:以问答形式呈现心理测试题。用户行为分析:根据用户的回答或选择,分析心理特征…...

计算机网络八股文--day1
从浏览器输入url到显示主页的过程? 1. 浏览器查询域名的IP地址 2. 浏览器和服务器TCP三次握手 3. 浏览器向服务器发送一个HTTP请求 4. 服务器处理请求,返回HTTP响应 5. 浏览器解析并且渲染页面 6. 断开连接 其中使用到的协议有DNS协议(…...

【计算机视觉】OpenCV实战项目:FunnyMirrors:基于OpenCV的实时哈哈镜效果实现技术解析
FunnyMirrors:基于OpenCV的实时哈哈镜效果实现技术解析 1. 项目概述2. 技术原理2.1 图像变形基础2.2 常见的哈哈镜变形算法2.2.1 凸透镜效果2.2.2 凹透镜效果2.2.3 波浪效果 3. 项目实现细节3.1 核心代码结构3.2 主要功能实现3.2.1 图像采集3.2.2 变形映射生成3.2.3…...

量子机器学习:下一代AI的算力革命与算法范式迁移——从量子神经网络到混合量子-经典架构的产业落地
一、引言:当AI遇见量子力学 2025年,全球量子计算市场规模突破200亿美元,而量子机器学习(QML)正以370%的年复合增长率(数据来源:Gartner 2024)成为最受关注的技术融合领域。传统深度…...

【数据结构】——栈
一、栈的概念和结构 栈其实就是一种特殊的顺序表,其只允许在一端进出,就是栈的数据的插入和删除只能在一端进行,进行数据的插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的元素遵循先进后出LIFO(Last InFirst O…...

Octave 绘图快速入门指南
目录 1. 基本的 2D 绘图 2. 自定义图形样式 3. 绘制散点图 4. 绘制柱状图 5. 绘制直方图 6. 3D 绘图 6.6.1 3D 曲面图 6.6.2 3D 散点图 7. 绘制极坐标 8. 多子图绘制 总结 Octave 是一个类似于 MATLAB 的开源数学软件,广泛用于数值计算和数据分析。它提供…...

RabbitMQ深入学习
继续上一节的学习,上一节学习了RabbitMQ的基本内容,本节学习RabbitMQ的高级特性。 RocketMQ的高级特性学习见这篇博客 目录 1.消息可靠性1.1生产者消息确认1.2消息持久化1.3消费者消息确认1.4消费失败重试机制1.5消息可靠性保证总结 2.什么是死信交换机…...

数据结构中的栈与队列:原理、实现与应用
前言:栈和队列是计算机科学中两种最基础的线性数据结构,它们的独特操作规则和广泛的应用场景使其成为每一位开发者必须掌握的核心知识。本文将通过生活案例、代码实现和实际应用场景,带您深入理解这两种数据结构的精髓。 1.栈(Sta…...

Android 13 默认打开 使用屏幕键盘
原生设置里,系统-语言和输入法-实体键盘-使用屏幕键盘 选项, 关闭时,外接物理键盘,如USB键盘,输入时不会弹出软键盘。 打开时,外接物理键盘,如USB键盘,输入时会弹出软键盘。 这个选…...

C++GO语言微服务之图片、短信验证码生成及存储
目录 01 session的处理 02 获取网页图片验证码ID 03 测试图片验证码 04 图片验证码模块集成 05 图片验证码功能移植微服务 06 图片验证码功能对接微服务的web实现 07 对接微服务的web实现步骤小结 08 Redis数据库基本操作回顾 09 go语言操作Redis数据库API介绍 10 go语…...

视觉革命来袭!ComfyUI-LTXVideo 让视频创作更高效
探索LTX-Video 支持的ComfyUI 在数字化视频创作领域,视频制作效果的提升对创作者来说无疑是一项重要的突破。LTX-Video支持的ComfyUI便是这样一款提供自定义节点的工具集,它专为改善视频质量、提升生成速度而开发。接下来,我们将详细介绍其功…...
)
MySQL 索引(一)
文章目录 索引(重点)硬件理解磁盘盘片和扇区定位扇区磁盘的随机访问和连续访问 软件方面的理解建立共识索引的理解 索引(重点) 索引可以提高数据库的性能,它的价值,在于提高一个海量数据的检索速度。 案例…...

认识 Linux 内存构成:Linux 内存调优之内存分配机制和换页行为认知
写在前面 博文内容涉及 Linux 中内存分配和换页机制的基本认知理解不足小伙伴帮忙指正 😃,生活加油99%的焦虑都来自于虚度时间和没有好好做事,所以唯一的解决办法就是行动起来,认真做完事情,战胜焦虑,战胜那些心里空荡荡的时刻,而不是选择逃避。不要站在原地想象困难,行…...

uniapp-商城-50-后台 商家信息
本文介绍了如何在后台管理系统中添加和展示商家信息,包括商家logo、名称、电话、地址和介绍等内容,并支持后期上传营业许可等文件。通过使用uni-app的uni-forms组件,可以方便地实现表单的创建、校验和管理操作。文章详细说明了组件的引入、页…...

汇编语言的温度魔法:单总线温度采集与显示的奇幻之旅
在嵌入式系统的奇妙世界中,汇编语言与硬件的结合总是充满了无限可能。今天,我将带你走进一场充满乐趣的实验:如何用汇编语言在单片机上实现单总线温度采集与显示。这不仅是一次技术探索,更是一场点亮创意与灵感的奇幻之旅…...

2025盘古石初赛WP
来不及做,还有n道题待填坑 文章目录 手机取证 Mobile Forensics分析安卓手机检材,手机的IMSI是? [答案格式:660336842291717]养鱼诈骗投资1000,五天后收益是? [答案格式:123]分析苹果手机检材&a…...

巡检机器人数据处理技术的创新与实践
摘要 随着科技的飞速发展,巡检机器人在各行业中逐渐取代人工巡检,展现出高效、精准、安全等显著优势。当前,巡检机器人已从单纯的数据采集阶段迈向对采集数据进行深度分析的新阶段。本文探讨了巡检机器人替代人工巡检的现状及优势,…...

MySQL的Order by与Group by优化详解!
目录 前言核心思想:让索引帮你“排好序”或“分好组”Part 1: ORDER BY 优化详解1.1 什么是 Filesort?为什么它慢?1.2 如何避免 Filesort?—— 利用索引的有序性1.3 EXPLAIN 示例 (ORDER BY) Part 2: GROUP BY 优化详解2.1 什么是…...
压缩7倍)
使用小丸工具箱(视频压缩教学)压缩7倍
我们日常经常会遇见视频录制或者剪辑视频生成之后,视频文件非常占用存储空间,那么这款开源工具可以帮助我们压缩7倍,而且视频质量依然清晰。 软件下载 ①:可以通过我分享的CSDN资源下载:https://download.csdn.net/d…...
)
ui组件二次封装(vue)
组件二次封装的意义 保证一个系统中ui风格和功能的一致性便于维护 从属性、事件、插槽、ref这几方面考虑 属性和事件的处理:ui组件上绑定$attrs(v-model本质也是一个属性加一个事件,所以也在其列) 在自定义组件中打印$attrs&am…...

利用大型语言模型有效识别网络威胁情报报告中的攻击技术
摘要 本研究评估了网络威胁情报(CTI)提取方法在识别来自网络威胁报告中的攻击技术方面的性能,这些报告可从网络上获取,并使用了 MITRE ATT&CK 框架。我们分析了四种配置,这些配置利用了最先进的工具,包…...

笔试模拟 day4
观前提醒: 笔试所有系列文章均是记录本人的笔试题思路与代码,从中得到的启发和从别人题解的学习到的地方,所以关于题目的解答,只是以本人能读懂为目标,如果大家觉得看不懂,那是正常的。如果对本文的某些知…...

TCP的连接管理
三次握手 什么是三次握手? 1. 第一次握手(客户端 → 服务器) 客户端发送一个 SYN 报文,请求建立连接。 报文中包含一个初始序列号 SEQ x。 表示:我想和你建立连接,我的序列号是 x。 2. 第二次握手&a…...

ffmpeg 写入avpacket时候,即av_interleaved_write_frame方法是如何不需要 业务层释放avpacket的 逻辑分析
我们在通过 av_interleaved_write_frame方法 写入 avpacket的时候,通常不需要关心 avpacket的生命周期。 本文分析一下内部实现的部分。 ----> 代表一个内部实现。 A(){ B(); C(); } B(){ D(); } 表示为: A ---->B(); ---->D(); ---->C(); int…...

【MyBatis-7】深入理解MyBatis二级缓存:提升应用性能的利器
在现代应用开发中,数据库访问往往是性能瓶颈之一。作为Java生态中广泛使用的ORM框架,MyBatis提供了一级缓存和二级缓存机制来优化数据库访问性能。本文将深入探讨MyBatis二级缓存的工作原理、配置方式、使用场景以及最佳实践,帮助开发者充分利…...

扫雷革命:矩阵拓扑与安全扩散的数学之美
目录 扫雷革命:矩阵拓扑与安全扩散的数学之美引言第一章 雷区生成算法1.1 组合概率模型1.2 矩阵编码体系第二章 数字计算系统2.1 卷积核运算2.2 边缘处理第三章 安全扩散机制3.1 广度优先扩散3.2 记忆化加速第四章 玩家推理模型4.1 线性方程组构建4.2 概率决策模型第五章 高级…...

通俗的桥接模式
桥接模式(Bridge Pattern) 就像一座桥,把两个原本独立变化的东西连接起来,让它们可以各自自由变化,互不干扰。简单来说,就是 “把抽象和实现分开,用组合代替继承”。 一句话理解桥接模式 假设你…...