一个关于fsaverage bem文件的说明
MNE文档:基于模板 MRI 的 EEG 前向算子
Head model and forward computation
在了解了脑图谱发展的过程之后,对脑的模版有了更深的认识,所以,对于之前使用的正向的溯源文件,进行一下解析,查看包含的信息,mne的存储格式和nilearn中的格式是否有区别。
本示例中,mne除了fsaverage还有sample,这两个常用。
文章目录
- samaple和fsaverage的对比
- 1. **`fsaverage`:标准模板大脑**
- (1) **来源与定义**
- (2) **数据结构**
- (3) **获取方式**
- 2. **`sample`:示例数据集**
- (1) **来源与定义**
- (2) **数据结构**
- (3) **获取方式**
- 3. **关键区别**
- 4. **何时使用哪一个?**
- (1) **使用 `fsaverage` 的场景**
- (2) **使用 `sample` 的场景**
- 5. **代码示例**
- (1) 加载 `fsaverage` 的 BEM 模型
- (2) 加载 `sample` 的 MEG 数据
- 6. **常见问题**
- (1) **能否将个体数据映射到 `fsaverage` 模板?**
- (2) **`sample` 数据集是否包含 `fsaverage` 数据?**
- (3) **如何切换被试目录?**
- 7. **文档参考**
- 总结
- 几个模版被试的说明
- 1. `fsaverage`
- 2. `fsaverage_sym`
- 3. `morph-maps`
- 4. `sample`
- 总结
- 导入数据
- bem文件的说明
- 计算并可视化 BEM 表面
- bem的surf查看
- 单层的
- 三层的
- BEM模型键值详细分析
- (1) **层 ID 4**(电导率 0.3 S/m)
- (2) **层 ID 3**(电导率 0.006 S/m)
- (3) **层 ID 1**(电导率 0.3 S/m)
- 2. **电导率值的意义**
- 3. **层 ID 的编号问题**
- 使用nilearn进行fsaverage的导入
- 对于src的查看
- 使用 mne.viz.plot_bem
- 生成一个bem文件
samaple和fsaverage的对比
在 MNE-Python 中,sample 和 fsaverage 是两个不同的模板/数据集,但它们的用途和定位有本质区别。以下是详细解释:
1. fsaverage:标准模板大脑
(1) 来源与定义
- 来源:由 FreeSurfer 提供,是一个 标准化的平均大脑模板,基于多被试 MRI 数据配准到 MNI 空间后生成。
- 用途:
- 用于跨被试分析(如组水平统计)。
- 当个体 MRI 数据不可用时,作为替代模板(如源空间、BEM、皮层表面等)。
- 支持脑区标签(如 Brodmann 分区)的标准化映射。
(2) 数据结构
- 包含内容:
- 高分辨率皮层表面(如
white、pial、inflated)。 - 预计算的 BEM 模型(如
fsaverage-5120-5120-5120-bem-sol.fif)。 - 标准源空间(如
fsaverage-ico-5-src.fif)。 - 解剖标签(如
aparc.a2009s分区)。
- 高分辨率皮层表面(如
- 坐标系:MNI 坐标系(标准空间)。
(3) 获取方式
import mne
mne.datasets.fetch_fsaverage(subjects_dir="/path/to/your/subjects_dir")
- 下载后文件存储在
subjects_dir/fsaverage/中。
2. sample:示例数据集
(1) 来源与定义
- 来源:MNE-Python 官方提供的 单被试示例数据集,包含一名真实被试的匿名化数据(EEG/MEG/MRI)。
- 用途:
- 学习 MNE 的入门工具(教程、文档示例)。
- 测试算法或脚本的功能。
- 演示数据预处理、源定位、可视化等完整流程。
(2) 数据结构
- 包含内容:
- 原始 MEG 数据(
.fif文件)。 - MRI 数据(已通过 FreeSurfer 重建的个体大脑)。
- 事件标记、电极位置、噪声协方差矩阵等。
- 预计算的 BEM 模型、源空间、正向模型。
- 原始 MEG 数据(
- 坐标系:个体 MRI 坐标系(未经 MNI 标准化)。
(3) 获取方式
import mne
sample_data_path = mne.datasets.sample.data_path()
subjects_dir = sample_data_path / "subjects"
3. 关键区别
| 特性 | fsaverage | sample |
|---|---|---|
| 类型 | 标准模板(群体平均) | 单被试真实数据(匿名化) |
| 用途 | 跨被试分析、模板化处理 | 学习、测试、演示流程 |
| 坐标系 | MNI 空间 | 个体 MRI 空间 |
| BEM/源空间 | 预生成的模板模型 | 基于个体 MRI 生成的模型 |
| 数据内容 | 仅解剖结构和模板数据 | 完整的 MEG/EEG 数据 + 解剖数据 |
4. 何时使用哪一个?
(1) 使用 fsaverage 的场景
- 你的研究没有个体 MRI 数据,需要标准化分析。
- 进行组水平统计或跨被试比较。
- 需要与文献中的 MNI 坐标结果对齐。
(2) 使用 sample 的场景
- 学习 MNE 的基本操作(如教程中的代码示例)。
- 测试新脚本或算法的兼容性。
- 演示从原始数据到源定位的完整流程。
5. 代码示例
(1) 加载 fsaverage 的 BEM 模型
subjects_dir = "/path/to/subjects_dir"
bem_file = subjects_dir / "fsaverage/bem/fsaverage-5120-5120-5120-bem-sol.fif"
bem_sol = mne.read_bem_solution(bem_file)
(2) 加载 sample 的 MEG 数据
from mne.datasets import sample
data_path = sample.data_path()
raw_file = data_path / "MEG/sample/sample_audvis_raw.fif"
raw = mne.io.read_raw_fif(raw_file, preload=True)
6. 常见问题
(1) 能否将个体数据映射到 fsaverage 模板?
是的!通过 配准(registration) 将个体 MRI 对齐到 fsaverage 的 MNI 空间,使结果可跨被试比较。
工具:
- FreeSurfer 的
recon-all --target fsaverage。 - MNE 的
mne.coregister。
(2) sample 数据集是否包含 fsaverage 数据?
不直接包含,但可单独下载 fsaverage。两者通常分开使用。
(3) 如何切换被试目录?
设置 subjects_dir 环境变量或在代码中指定:
import mne
mne.set_config("SUBJECTS_DIR", "/path/to/your/subjects_dir")
7. 文档参考
fsaverage文档:
MNE: FreeSurfer’s fsaveragesample数据集文档:
Sample Dataset Tutorial
总结
fsaverage是标准模板大脑,用于跨被试分析和标准化处理。sample是单被试示例数据集,用于学习和测试。- 根据研究需求选择:需要模板化分析 →
fsaverage;需要真实数据示例 →sample。
几个模版被试的说明
你提到的四个文件夹 (fsaverage, fsaverage_sym, morph-maps, 和 sample) 在神经影像学和脑电图(EEG)/脑磁图(MEG)数据处理中扮演着不同的角色,它们分别对应不同的模板或功能。下面我将详细解释每个文件夹及其内容的区别:
1. fsaverage
- 描述:
fsaverage是一个标准的大脑模板,由 FreeSurfer 提供,并广泛用于神经影像研究中。它是一个平均化的、对称的大脑模型,基于多个大脑扫描结果构建而成。 - 用途:
- 作为解剖参考框架,用于标准化不同被试的大脑数据。
- 在 MNE-Python 中,常用于源定位分析,提供了一个通用的源空间和 BEM 模型。
- 特点:高分辨率,包含详细的皮层结构信息。
2. fsaverage_sym
- 描述:
fsaverage_sym是fsaverage的一个变体,特别强调左右半球的对称性。这个模板在创建时进行了额外的处理,以确保两个半球尽可能对称。 - 用途:
- 当需要进行严格对称性分析时使用,例如在研究左右半球功能差异时。
- 对于某些特定的统计分析或可视化任务,可能更倾向于使用对称模板。
- 特点:左右半球高度对称,适用于需要严格对称性的研究。
3. morph-maps
- 描述:
morph-maps文件夹通常包含形态映射(morphing maps),这些映射用于将一个被试的数据转换到另一个被试或模板上。 - 用途:
- 在多被试研究中,用于将个体数据标准化到共同的空间框架下,便于跨被试比较和群体分析。
- 可以将单个被试的源估计结果映射到
fsaverage或其他模板上,以便进行群体水平的统计分析。
- 特点:包含从个体到模板或其他个体的映射关系,是实现数据标准化和群体分析的关键工具。
4. sample
- 描述:
sample通常指的是一个示例被试的数据集,包括 EEG/MEG 数据、MRI 扫描结果等。MNE-Python 提供了一个名为sample的示例数据集,用于演示和教学目的。 - 用途:
- 作为学习和测试 MNE-Python 功能的示例数据。
- 研究人员可以使用
sample数据集来熟悉各种数据处理和分析流程。
- 特点:包含完整的实验数据和相关文件,适合初学者和开发者用来学习和调试代码。
总结
fsaverage和fsaverage_sym:都是标准大脑模板,但后者更强调左右半球的对称性。morph-maps:包含用于数据标准化和群体分析的形态映射。sample:是一个示例数据集,用于学习和测试 MNE-Python 的功能。
在实际应用中,根据你的具体需求选择合适的模板和工具非常重要。如果你正在进行多被试研究,可能需要使用 morph-maps 来标准化数据;如果专注于单个被试的详细分析,则可以直接使用 fsaverage 或 fsaverage_sym 作为参考框架。
导入数据
import numpy as npimport mne
from mne.datasets import eegbci, fetch_fsaverage# Download fsaverage files
fs_dir = fetch_fsaverage(verbose=True)
subjects_dir = fs_dir.parent# The files live in:
subject = "fsaverage"
trans = "fsaverage" # MNE has a built-in fsaverage transformation
src = fs_dir / "bem" / "fsaverage-ico-5-src.fif"
bem = fs_dir / "bem" / "fsaverage-5120-5120-5120-bem-sol.fif"
我们获取fsaverage 的存储文件夹。
之前文件中有过一定的描述,下面进行更加详细的记录。
第一个文件fsaverage-ico-4-src.fif中的“src”可能代表“source
space”,即源空间。源空间定义了大脑中可能产生信号的源的位置,通常是皮层表面。ico-4可能指的是四阶的Icosahedron(二十面体)细分,用于生成源空间的网格。Ico-4的细分级别决定了源的数量,细分级别越高,源点越多,计算量也越大。用户可能需要这个文件来进行源定位分析,比如计算逆解。第二个文件fsaverage-5120-5120-5120-bem-sol.fif中的“bem”代表边界元模型(Boundary
Element
Model),用于正向计算中的电磁场模拟。BEM模型需要不同组织的边界,如头皮、颅骨、脑脊液和大脑等。文件名中的5120可能指的是每个边界面(如头皮、颅骨、大脑)的三角形数量,例如5120个三角形。而“sol”可能表示解文件,即已经计算好的BEM模型的解,用于快速计算导联场或正向解。用户在进行EEG/MEG的正向计算时会用到这个文件。
先继续插入可视化的代码,对于raw,需要的可能是布局文件,
(raw_fname,) = eegbci.load_data(subjects=1, runs=[6])
raw = mne.io.read_raw_edf(raw_fname, preload=True)# Clean channel names to be able to use a standard 1005 montage
eegbci.standardize(raw)# Read and set the EEG electrode locations, which are already in fsaverage's
# space (MNI space) for standard_1020:
montage = mne.channels.make_standard_montage("standard_1005")
raw.set_montage(montage)
raw.set_eeg_reference(projection=True) # needed for inverse modeling# Check that the locations of EEG electrodes is correct with respect to MRI
mne.viz.plot_alignment(raw.info,src=src,eeg=["original", "projected"],trans=trans,show_axes=True,mri_fiducials=True,dig="fiducials",
)
bem文件的说明
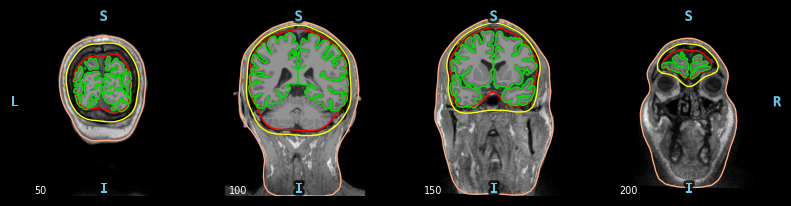
BEM 表面是不同组织之间界面三角剖分,用于前向计算。这些表面例如包括内颅骨表面、外颅骨表面和皮肤外表面,即头皮表面。
计算并可视化 BEM 表面
计算 BEM 表面需要使用 FreeSurfer,并使用命令行工具 mne watershed_bem 或 mne flash_bem,或者相关的函数 mne.bem.make_watershed_bem() 或 mne.bem.make_flash_bem()。
这里我们假设它已经计算过了。每个受试者需要几分钟。
对于脑电图(EEG),我们使用 3 层(内颅骨、外颅骨和皮肤),而对于脑磁图(MEG),只需要 1 层(内颅骨)就足够了。
bem.keys()
dict_keys([‘solution’, ‘bem_method’, ‘surfs’, ‘solver’, ‘is_sphere’,
‘nsol’, ‘sigma’, ‘source_mult’, ‘field_mult’, ‘gamma’])
bem的surf查看
如果要生成一个新的bem,应该需要,这几个层的surf文件
此处需要使用的就是,inner_skull.surf,outer_skull.surf,outer_skin.surf
Using surface:
C:\Users\maten\mne_data\MNE-fsaverage-data\fsaverage\bem\inner_skull.surf
Using surface:
C:\Users\maten\mne_data\MNE-fsaverage-data\fsaverage\bem\outer_skull.surf
Using surface:
C:\Users\maten\mne_data\MNE-fsaverage-data\fsaverage\bem\outer_skin.surf
显示一下,这个的样子
单层的
# 说明,使用pyvista,需要使用不同的绘图格式,表面的点需要转为数量,加上坐标的形式,并构成一维数组。
from mne import read_surface
import numpy as np
import pyvista as pv
import numpy as np
outer_skin_coords, outer_skin_faces = read_surface('C:/Users/maten/mne_data/MNE-fsaverage-data/fsaverage/bem/outer_skin.surf')
faces_pyvista = np.hstack((3 * np.ones((outer_skin_faces.shape[0], 1), dtype=outer_skin_faces.dtype), outer_skin_faces))
surf = pv.PolyData(outer_skin_coords, faces_pyvista.ravel())
surf.plot()
对于
outer skin CM is -0.21 -19.38 -0.23 mm
outer skull CM is -0.19 -19.34 -0.49 mm
inner skull CM is -0.53 -21.10 6.21 mm
这个对应的是质心的坐标。

三层的
from mne import read_surface
import pyvista as pv
import numpy as npdef create_polydata_from_mne_coords_faces(coords, faces):"""Convert coordinates and faces from MNE format to PyVista format."""# 在每个面的前面添加数字 3(因为是三角形)faces_pyvista = np.hstack((3 * np.ones((faces.shape[0], 1), dtype=faces.dtype), faces))return pv.PolyData(coords, faces_pyvista.ravel())# 定义表面文件路径
subjects_dir = 'C:/Users/maten/mne_data/MNE-fsaverage-data/fsaverage/bem/'
surfaces = [('inner_skull', subjects_dir + 'inner_skull.surf', 'blue'),('outer_skull', subjects_dir + 'outer_skull.surf', 'green'),('outer_skin', subjects_dir + 'outer_skin.surf', 'red')
]# 创建PyVista Plotter对象
plotter = pv.Plotter()# 循环遍历每个表面文件并添加到绘图器中
for name, path, color in surfaces:coords, faces = read_surface(path)polydata = create_polydata_from_mne_coords_faces(coords, faces)plotter.add_mesh(polydata, color=color, opacity=0.5, smooth_shading=True)# 显示图形
plotter.show()
BEM模型键值详细分析
BEM (边界元素法) 模型中的键值具有以下含义:
-
solution:BEM求解矩阵,包含了边界面之间的电位关系,用于计算头部不同组织界面上的电位分布。
-
bem_method:使用的BEM方法类型,常见的有"linear collocation"(线性搭配法)或"linear Galerkin"(线性伽辽金法)。
-
surfs:包含头模型中使用的表面信息,通常包括内颅骨、颅骨和头皮三个表面的几何描述(点、面等)。
-
solver:用于求解BEM方程的算法类型。
-
is_sphere:布尔值,表示该BEM模型是否基于球形模型(True)或真实头部形状(False)。
-
nsol:解决方案的维度或自由度数量。
-
sigma:组织电导率值列表,单位通常为S/m(西门子/米),分别对应脑组织、颅骨和头皮的电导率。
-
source_mult:源乘数,与源强度计算相关的系数。
-
field_mult:场乘数,与电场计算相关的系数。
-
gamma:BEM公式中的γ系数矩阵,用于描述不同表面之间的电位关系。
这些参数共同构成了完整的BEM解决方案,用于在MEG/EEG分析中进行正向计算,即从已知的源活动推算出在传感器位置处产生的场分布。
for layer in bem["surfs"]:print(f"层 ID: {layer['id']}")print(f"顶点数: {len(layer['rr'])}, 三角面片数: {len(layer['tris'])}")print(f"电导率 (σ): {layer['sigma']} S/m")
ID: 4 顶点数: 2562, 三角面片数: 5120 电导率 (σ): 0.30000001192092896 S/m
ID:3 顶点数: 2562, 三角面片数: 5120 电导率 (σ): 0.006000000052154064 S/m
ID: 1 顶点数: 2562, 三角面片数: 5120 电导率 (σ): 0.30000001192092896 S/m
(1) 层 ID 4(电导率 0.3 S/m)
- 解剖结构:头皮(Scalp)
- 最外层,包裹颅骨和脑组织。
- 电导率较高(约 0.3 S/m),反映头皮组织(皮肤、肌肉、脂肪)的导电性。
- 作用:
- 在 EEG 中,头皮是电流的最终传导层,直接影响电极测量的电势分布。
- 在 MEG 中,对磁场影响较小(因磁场穿透性强)。
(2) 层 ID 3(电导率 0.006 S/m)
- 解剖结构:颅骨(Skull)
- 中间层,分隔头皮和脑内结构。
- 电导率极低(约 0.006 S/m),反映颅骨的低导电性(骨组织导电性差)。
- 作用:
- 在 EEG 中,颅骨会显著衰减脑内电流的传播,导致头皮电势分布模糊化。
- 是影响 EEG 空间分辨率的主要因素。
(3) 层 ID 1(电导率 0.3 S/m)
- 解剖结构:脑壳(Brain)
- 最内层,包裹脑实质(灰质、白质)和脑脊液(CSF)。
- 电导率较高(约 0.3 S/m),反映脑组织和脑脊液的导电性。
- 作用:
- 直接承载神经元活动产生的电流,是 EEG/MEG 信号的主要源头。
- 在 BEM 模型中,通常与脑脊液合并为一层(尤其在简化模型中)。
2. 电导率值的意义
- 头皮和脑壳(0.3 S/m):
高导电性允许电流自由流动,对 EEG 信号的空间分布起主导作用。 - 颅骨(0.006 S/m):
低导电性导致电流在穿过颅骨时被强烈衰减,是 EEG 信号空间模糊化的主要原因。
注意:颅骨电导率的值存在争议,一些研究建议使用 0.01–0.015 S/m [1],但 MNE 默认使用 0.006 S/m。
默认值:头皮 0.3 S/m,颅骨 0.006 S/m,脑壳 0.3 S/m。
3. 层 ID 的编号问题
你提供的层 ID(4、3、1)与常规 FreeSurfer/MNE 标准 不一致。
- 标准标识(FreeSurfer 惯例):
3:脑壳(Brain)4:颅骨(Skull)5:头皮(Scalp)
- 可能原因:
- 数据生成时使用了非标准标签(如自定义 BEM 模型)。
- 文件可能来自旧版本 MNE 或特定数据集(如
fsaverage模板的某些变体)。 - 需进一步检查数据来源或通过可视化验证(见下文)。
import mne# 绘制 BEM 模型,叠加白质表面
mne.viz.plot_bem(subject="sample",subjects_dir="/path/to/subjects_dir",brain_surfaces="white", # 指定表面类型orientation="coronal",slices=[100, 120, 140], # 切片位置show=True
)
brain_surfaces的类型说明:
[“white”, “pial”]可以叠加显示多个
‘white’ 表面适合检查源空间与解剖的对齐。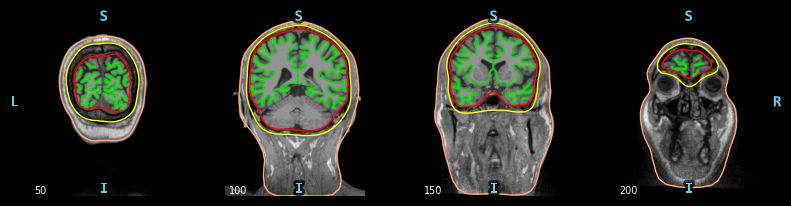
“pail”
‘inflated’ 表面适合观察功能激活的拓扑模式。
“sphere”
‘head’ 或 ‘skull’ 和’brain’用于验证 BEM 模型的几何闭合性。
并不存在,没有对应的文件。

使用nilearn进行fsaverage的导入
from nilearn import datasets, plotting
from nilearn.surface import load_surf_data, load_surf_meshfsaverage = datasets.fetch_surf_fsaverage()
fsaverage#字典
我们可以看到这个文件是上面不同层的
其中pial_left的文件也是由两部分组成的coordinates和face。
作为一个表面模型,有三维坐标点和,构成一个三角面的三维索引坐标。
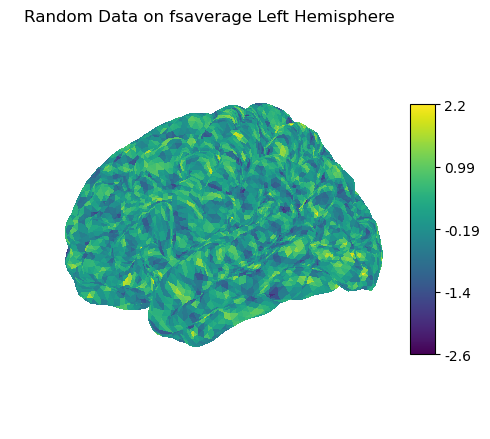
# Step 2: 加载左半球网格并查看顶点数量
mesh = load_surf_mesh(fsaverage['pial_left']) # 返回 (vertices, faces)
n_vertices = mesh[0].shape[0] # vertices 是 (n_vertices, 3) 的坐标数组print(f"左半球顶点数量:{n_vertices}")# Step 3: 生成与顶点数量相同的随机数据
random_data = np.random.randn(n_vertic
plotting.plot_surf(surf_mesh=fsaverage['pial_left'], # 表面网格surf_map=random_data, # 表面数据hemi='left', # 半球view='lateral', # 视角:外侧colorbar=True, # 显示颜色条title='Left Hemisphere Activation'
)
plotting.show()
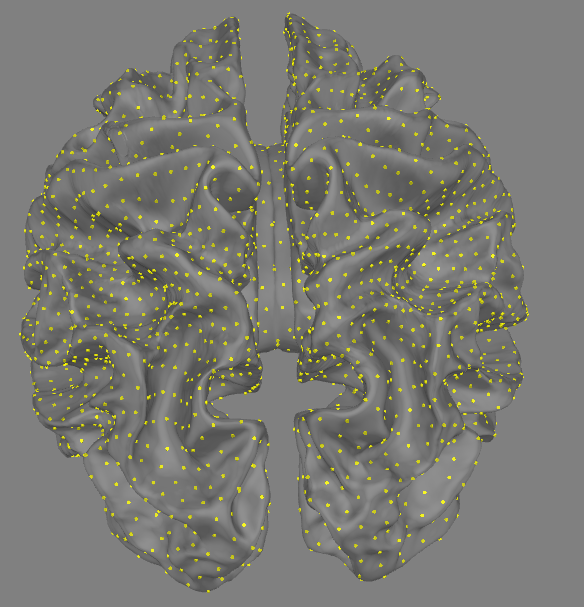
对于src的查看
import os.path as op
import numpy as np
import os
import mne
from mne.datasets import fetch_fsaverage# Download fsaverage files
fs_dir = fetch_fsaverage(verbose=True)
subjects_dir = op.dirname(fs_dir)# The files live in:
subject = "fsaverage"
trans = "fsaverage" # MNE has a built-in fsaverage transformation
#说明ico-5-src.fif文件是源空间文件,bem-sol.fif文件是 bem 文件,用于解决 bem 问题。、
#ico-5的数据太大,无法计算,使用ico-4进行尝试
src = op.join(fs_dir, "bem", "fsaverage-ico-4-src.fif")
bem = op.join(fs_dir, "bem", "fsaverage-5120-5120-5120-bem-sol.fif")
src = mne.read_source_spaces(src)
src.plot()src = mne.read_source_spaces(src)
src.plot()
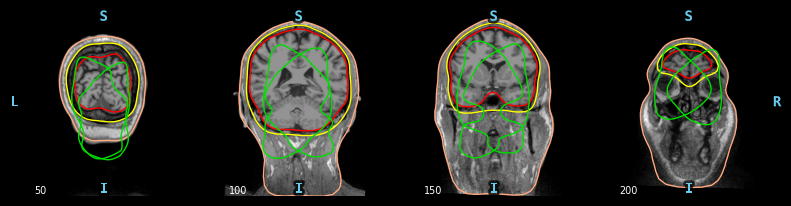
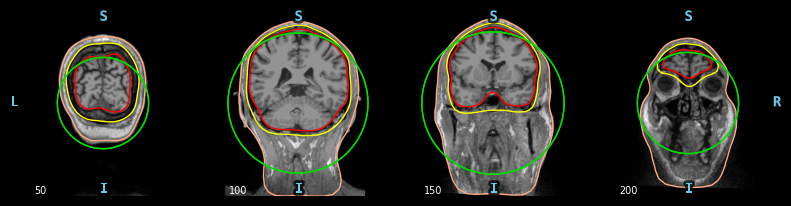
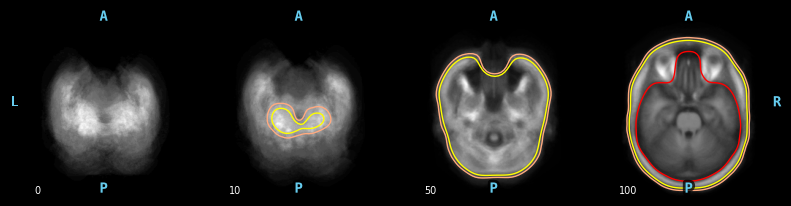
使用 mne.viz.plot_bem
对于bem的可视化,查看的是T1.mgz的图像。
fs_dir:这个是放置模版的文件夹
src:是roi文件或者对应的类似的
subject:是在fs_dir中,在加一个路径。
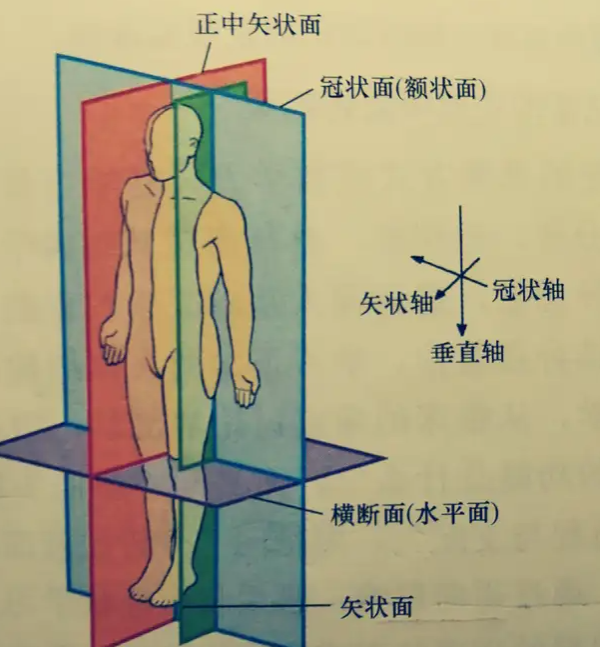
orientation有三种视图’coronal’, ‘axial’, and ‘sagittal’
冠状面(coronal plane)和矢状面(sagittal plane) ,横断面(axial)
slices:时间的切片
mne.viz.plot_bem(subject='fsaverage', subjects_dir=fs_dir, src=None, orientation='axial',slices=[0,10,50,100],show=True)
图示一下这三个面
把有效的溯源点,使用一些数据映射到头图像上,有些不均匀。
对于ico-4进行前向分解的左右脑,因为生理约束,有的点在头皮之外,无法作为有效的点。
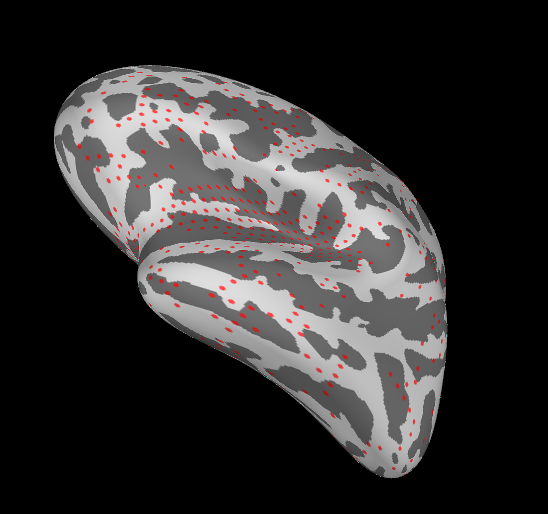
生成一个bem文件
生成失败了, 目前还没找到原因
import mne
subjects_dir = r"D:\系统数据\git仓库\MNE-Cookbook\mne_data\MNE-sample-data\subjects"
conductivity = (0.3, 0.006, 0.3) # 标准导电率值 (S/m) for [脑脊液, 颅骨, 头皮]
model = mne.make_bem_model(subject='fsaverage', ico=4, conductivity=conductivity,subjects_dir=subjects_dir)
bem_sol = mne.make_bem_solution(model)
mne.write_bem_solution('fsaverage-bem-sol.fif', bem_sol)
主要使用的应该是那三个suf文件
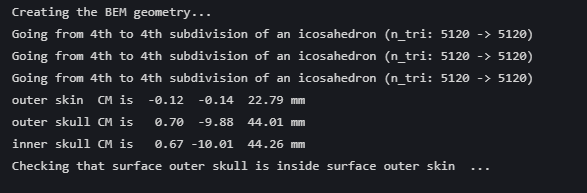
理论上,看之前可视化也没什么问题,但是生成的时候报错了。

目前还找不到什么原因。
相关文章:

一个关于fsaverage bem文件的说明
MNE文档:基于模板 MRI 的 EEG 前向算子 Head model and forward computation 在了解了脑图谱发展的过程之后,对脑的模版有了更深的认识,所以,对于之前使用的正向的溯源文件,进行一下解析,查看包含的信息&a…...

如何解决Kafka集群中Broker磁盘IO瓶颈?
针对Kafka集群Broker磁盘IO瓶颈问题,这里从实际运维场景出发给出解决方案: 1. 分区负载均衡优化 分区迁移策略 # 查看Topic分区分布(识别热点Broker) kafka-topics --bootstrap-server broker1:9092 --describe --topic high_t…...

42 python http之urllib库
作为办公室牛马,日常工作中总少不了和网络数据打交道。比如从公司内部系统抓取数据做报表。Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理 一、Urllib 基础入门 urllib 是 Python 内置的一个强大的处理 URL 和网络请求的库,它包含了多个模块,每个模块都有…...
)
如何把阿里云a账号下面的oss迁移到阿里云b账号下面(同区域)
1.登录a账号进入bucket选择同区域复制 2.登录b账号进入bucket选择bucket授权策略,选择接受复制对象,手动输入,然后是a账号的id和角色名字即可。 3.然后在去a账号保存下同步任务,开始同步了就。...

cuda多维线程的实例
1、注意:在多维中的变化时与平常的不一样,如下图所示,横向变换x,纵向变换y 2、cuda内置变量: 1、thread(线程): 一个线程可作为一个运算单元,多个thread可组成一个block(…...

哈希表的设计
1. 哈希表的基本原理 哈希表是一种通过 哈希函数 将元素的键(Key)映射到存储位置的数据结构。 哈希函数 的作用:通过键值计算存储位置,公式一般为 index hash(key) % capacity。 哈希冲突:不同的键可能被映射到同一…...

前端取经路——入门取经:初出师门的九个CSS修行
大家好,我是老十三,一名前端开发工程师。CSS就像前端修行路上的第一道关卡,看似简单,实则暗藏玄机。在今天的文章中,我将带你一起应对九大CSS难题,从Flexbox布局到响应式设计,从选择器优先级到B…...

网络安全等级保护有关工作事项[2025]
公安部发布公网安〔2025〕1846号文件,关于对网络安全等级保护有关共工作事项的进一步说明 一、备案相关问题 1、如何执行系统备案动态更新工作? 全面梳理与重新填报: 答复:运营者需**全面梳理已备案系统**的情况,对于已完成定…...

柯西不等式应用题
第一种方法是作两个相似三角形ABC和CDE,求出AE长度为3。那么BD最大长度为3。 方法二:柯西不等式(a+b)(c+d)≥(ac+bd) (1√(5-2x&…...

聚焦多种检测场景,华大基因推出全流程本地化检测综合解决方案
“从毫米到微米,神秘的微观世界被发现;从微米到纳米,生命的本源被不断认知。”在时代背景及战略机遇的多重影响下,精准医学已成为新兴的发展趋势,对医学模式的发展具有重要的意义。一直以来,华大基因都致力…...

职场口语之名词从句
目录 一、主语从句 二、宾语从句 三、表语从句 四、同位语从句 一、主语从句 1. Who will win the game is uncertain. 谁将赢得这场比赛还不确定。 2. Why he was late isnt clear. 他为什么迟到还不清楚。 3. What we should do next is important. 我们接下来应该做什么…...

DVWA靶场保姆级通关教程--03CSRF跨站请求伪造
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 目录 文章目录 前言 一、low级别的源码分析 二、medium级别源码分析 安全性分析 增加了一层 Referer 验证: 关键点是:在真实的网络环境中&a…...

LangChain:大语言模型应用的“瑞士军刀”入门指南
LanChain入门指南 什么是LangChain?LangChain的核心价值1. 模块化设计 - AI界的"乐高积木"2. 典型应用场景 快速入门实战环境准备(5分钟)第一个示例:公司命名生成器(10分钟)进阶功能:…...

Mac电脑,idea突然文件都展示成了文本格式,导致ts,tsx文件都不能正常加载或提示异常,解决方案详细说明如下
有一天使用clean my mac软件清理电脑 突然发现idea出现了文件都以文本格式展示,如图所示 然后就卸载,计划重新安装,安装了好几个版本,并且setting->file types怎么设置都展示不对,考虑是否idea没卸载干净ÿ…...
)
如何将本地 Jar 包安装到 Maven 仓库(以 Aspose 为例)
在实际开发中,我们经常会遇到一些第三方库(如商业库 Aspose)无法通过 Maven 仓库直接引入的情况。这时,我们可以手动将 jar 包安装到本地 Maven 仓库,然后像普通依赖一样使用它。 本文以 Aspose.Slides 和 Aspose.Wor…...
充分理解线程库)
[Linux]多线程(一)充分理解线程库
标题:[Linux]多线程 水墨不写bug 文章目录 一、线程的概念1、一句话总结区分进程和线程2、如何理解?3、那么进程和线程的对比?4、Linux为什么要这样设计进程和线程,难道不乱吗?5、从CPU的角度看待执行流?-…...

Mysql order by 用法
ORDER BY 是 SQL 里用于对查询结果进行排序的子句,它能够让查询结果按照指定的列或表达式进行升序或者降序排列,使数据呈现出更有规律的顺序,方便用户查看和分析。下面详细阐述其作用和用法 作用 ORDER BY 的主要作用是对查询结果集进行排序…...

嵌入式学习--江协51单片机day1
今天学习了led灯的相关操作以及独立按键对于led灯的控制。 led灯的相关操作 led灯的相关操作包括点亮,闪烁,流水灯以及流水灯plus 点亮 开发板的led灯是低电平有效,也就是当我们设置0时亮,1时灭。 P2是开发板的led灯模块的8位…...

uniapp开发11-v-for动态渲染list列表数据
uniapp开发11-v-for动态渲染list列表数据!下面是一个简单的动态渲染list列表数据的案例。我们现在还未对接真正的后台接口,所以我们直接在页面组件内部,返回一个json数组,模拟从服务器远程获取到的新闻列表信息。来达到渲染输出的…...

qt国际化翻译功能用法
文章目录 [toc]1 概述2 设置待翻译文本3 生成ts翻译源文件4 编辑ts翻译源文件5 生成qm翻译二进制文件6 加载qm翻译文件进行翻译 更多精彩内容👉内容导航 👈👉Qt开发经验 👈 1 概述 在 Qt 中,ts 文件和 qm 文件是用于国…...
)
nut-list和nut-swipe搭配:nut-cell侧滑定义无法冒泡打开及bug(含代码、案例、截图)
nut-list和nut-swipe搭配:nut-cell侧滑定义无法冒泡打开及bug(含代码、案例、截图) Nut-UI 官方文档: swipe侧滑手势: https://nutui.jd.com/h5/vue/4x/#/zh-CN/component/swipelist 虚拟列表: https://nutui.jd.com/h5/vue/4x/#/zh-CN/component/list疑问+bug+解决方式:…...

WebRTC并非万能:RTMP与RTSP的工程级价值再认识
不是所有低延迟场景都需要WebRTC:RTMP/RTSP的技术硬实力解析 ——来自大牛直播SDK的实战分析与底层技术对比 一、WebRTC是热潮,但不是银弹 近年来,WebRTC频频出现在技术选型会议上: “浏览器直连,免插件”;…...

Factorio 异星工厂 [DLC 解锁] [Steam] [Windows SteamOS]
Factorio 异星工厂 [DLC 解锁] [Steam] [Windows & SteamOS] 注意 这个符号表示 可打开折叠内容 需要有游戏正版基础本体,安装路径不能带有中文,或其它非常规拉丁字符;请务必阅读 使用说明 (最新以网站说明为准)…...

LLM的min_p 参数详
min_p 参数详解 min-p采样,源自论文"Min P Sampling: Balancing Creativity and Coherence at High Temperature"。在大语言模型(LLM)中,min_p 通常是指在生成文本时的最小概率阈值(Minimum Probability),用于控制输出 token 的选择,特别是在核采样(Nucleus…...

C语言_可变参数_LOG宏
LOG宏一般处理,没有参数,只有字符串参数,字符串格式和一个参数,多个参数的场合。以下是针对常见的应用场合举例说明,可便参数的使用。 代码 #include <stdio.h>#define LOG(format, ...) printf("[%s][%…...

19.第二阶段x64游戏实战-vector容器
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:18.第二阶段x64游戏实战-MFC列表框 vector是一个封装了动态大小数组的顺序容器…...
)
第九节:图像处理基础-图像几何变换 (缩放、旋转、平移、翻转)
引言 在计算机视觉和图像处理领域,几何变换是最基础且应用最广泛的技术之一。通过改变图像的几何结构,我们可以实现图像缩放以适应不同分辨率设备,旋转图像以校正方向偏差,平移目标物体进行位置对齐,或通过翻转操作增…...

jmeter 执行顺序和组件作用域
本章节主要讲解“JMeter执行顺序与作用域”的内容,类似于运算符或操作符的优先级,当JMeter测试中包含多个不同的元素时,哪些元素先执行,哪些元素后执行,并不是严格按照它们出现的先后顺序依次有序执行的,而…...

mvc-review
review: 1.最初的做法:一个请求对应一个servlet,这样存在的问题是servlet太多了 2.改动:把一系列请求都对应一个servlet, IndexServlet / AddServlet / DelServlet / UpdateServlet ...-> 合并成FruitServlet 通过一个oper…...

基于ResNet50的手写符号识别系统
基于ResNet50的手写符号识别系统 项目概述 本项目实现了两个手写符号识别模型: ABCD字母识别模型:用于识别手写的A、B、C、D四个字母✓符号识别模型:用于识别手写的对勾(✓)和叉号() 两个模型均基于ResNet50预训练模型,采用迁…...

SpringBoot教学管理平台源码设计开发
概述 基于SpringBoot框架开发的教学管理平台完整项目,帮助开发者快速搭建在线教育平台。该系统包含学生端、教师端和管理后台,实现了课程管理、随堂测试、作业提交等核心功能,是学习SpringBoot开发的优质案例。 主要内容 1. 系统架…...

C++负载均衡远程调用学习之集成测试与自动启动脚本
目录 01 Lars-LbAgentV0.7-route_lb获取路由全部主机信息 02 Lars-LbAgentV0.7-API模块注册功能实现和测试工 03 Lars-LbAgentV0.7-项目构建工具 04 Lars-LbAgentV0.7-启动工具脚本实现 05 Lars-有关fd泄露的调试办法 06 Lars-qps性能测试 07 git企业开发基本流程 01 Lar…...
)
双ISP(双互联网服务提供商)
目录 核心作用 适用场景 实现方式 优缺点 假设一家外贸公司 双ISP(双互联网服务提供商) 是指用户同时接入两个不同的网络服务提供商(Internet Service Provider),通过冗余设计或负载均衡技术,提升网络…...

网工实验——静态路由与BFD联动
网络拓扑图 实验目的: PC与Server通信的时候主要走上面,当主用电路失效的时候走下面 设备: 一台PC主机 一台Server服务器 两台Router路由器 一台S3700交换机 配置 1.配置PC和Server的IP地址 PC Server 2.配置路由器 R3配置对应接口…...

谷歌在即将举行的I/O大会之前,意外泄露了其全新设计语言“Material 3 Expressive”的细节
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

【网络原理】IP协议
目录 编辑 一. IP协议的作用 二. IP协议报头 三. 拆包和组包 四. 地址管理 1)动态分配IP地址 2)NAT机制(网络地址映射) 3) IPV6 五. IP转换 1)客户端到服务器 2)服务器到客户端 六…...

【Python 文件I/O】
Python 的文件 I/O 操作是数据处理的基础技能,涉及文件的读写、路径管理、异常处理等核心功能。以下是文件 I/O 的核心知识点: 一、基础文件操作 1. 打开文件 # 通用模式:r(读)/w(写)/a(追加) b(二进制)/t(文本,默认) f open(…...

torchrun单机多卡运行
torchrun命令使用 torchrun示例 export CUDA_VISIBLE_DEVICES0,1,2 nohup torchrun \--nproc_per_node3 \--nnodes1 \--node_rank0 \--master_addr"127.0.0.1" \--master_port1225 \/data/train.py \--batch_size 32 \--size 320运行如上sh命令发现,即 …...

数据管理平台是什么?企业应如何做好数据化管理?
目录 一、数据管理是什么? 二、数据管理平台有哪些作用? 1. 数据采集与整合 2. 数据清洗与预处理 3. 数据分析与挖掘 4. 数据共享与协作 三、企业应如何做好数据化管理? 1. 建立数据管理战略 2. 完善数据管理制度 3. 培养数据管理人…...

GuassDB如何创建兼容MySQL语法的数据库
GaussDB简介 GaussDB是由华为推出的一款全面支持OLTP和OLAP的分布式关系型数据库管理系统。它采用了分布式架构和高可靠性设计,可以满足大规模数据存储和处理的需求。GaussDB具有高性能、高可靠性和可扩展性等特点,适用于各种复杂的业务场景,…...

Qt国际化实战--精通Qt Linguist工具链
概述 在全球化的今天,软件产品需要支持多种语言和地区,以满足来自世界各地用户的需求。Qt框架提供了一套完整的工具集来帮助开发者实现应用程序的国际化(i18n)和本地化(l10n),其中最核心的就是Qt Linguist工具链 关于国际化与本地化 国际化(i18n): 指的是设计和开发…...

C++内联函数
总结:内联函数是把函数变成一个代码块直接塞入源程序中,省去了一些参数传递和栈操作(省时间),但是同时又增加了代码的大小(因为原本的函数只有会使用指针指向该函数,但是内联函数是直接塞入&…...

26届秋招收割offer指南
26届暑期实习已经陆续启动,这也意味着对于26届的同学们来说,“找工作”已经提上了日程。为了帮助大家更好地准备暑期实习和秋招,本期主要从时间线、学习路线、核心知识点及投递几方面给大家介绍,希望能为大家提供一些实用的建议和…...

Python之内省与反射应用
Python之内省与反射应用 Python作为一门动态语言,具备了强大的内省(Introspection)与反射(Reflection)机制。这两个概念在运行时查看对象的属性、类型、方法等信息,甚至可以动态调用方法或修改对象的属性。…...
)
第三章:langchain加载word文档构建RAG检索教程(基于FAISS库为例)
文章目录 前言一、载入文档(word)1、文档载入代码2、文档载入数据解读(Docx2txtLoader方法)输入数据输出文本内容 3、Docx2txtLoader底层代码文档读取解读Docx2txtLoader底层源码示例文档读取输出结果 二、文本分割1、文本分割代码…...

球速最快的是哪种球类运动·棒球1号位
在体育运动中,球速最快的项目与棒球结合来看,可以分两个角度解读: 一、球速最快的运动项目 羽毛球以426公里/小时(吉尼斯纪录)的杀球速度位列榜首,远超棒球投球速度。其极速源于: 羽毛球拍甜区…...

TVM中Python如何和C++联调?
1. 编译 Debug 版本 # 在项目根目录下创建构建目录(若尚未创建) mkdir -p build && cd build# 配置 Debug 构建 cmake -DCMAKE_BUILD_TYPEDebug ..# 编译(根据 CPU 核心数调整 -j 参数) make -j$(nproc)2. 获取 Python 进…...
从零实现基于Transformer的英译汉任务
1. model.py(用的是上一篇文章的代码:从0搭建Transformer-CSDN博客) import torch import torch.nn as nn import mathclass PositionalEncoding(nn.Module):def __init__ (self, d_model, dropout, max_len5000):super(PositionalEncoding,…...

在 PyTorch 中借助 GloVe 词嵌入完成情感分析
一. Glove 词嵌入原理 GloVe是一种学习词嵌入的方法,它希望拟合给定上下文单词i时单词j出现的次数。使用的误差函数为: 其中N是词汇表大小,是线性层参数, 是词嵌入。f(x)是权重项,用于平衡不同频率的单词对误差的影响…...

大数据应用开发和项目实战-电商双11美妆数据分析
数据初步了解 (head出现,意味着只出现前5行,如果只出现后面几行就是tail) info shape describe 数据清洗 重复值处理 这个重复值是否去掉要看实际情况,比如说:昨天卖了5瓶七喜,今天卖了5瓶七…...