在 PyTorch 中借助 GloVe 词嵌入完成情感分析
一. Glove 词嵌入原理
GloVe是一种学习词嵌入的方法,它希望拟合给定上下文单词i时单词j出现的次数。使用的误差函数为:
其中N是词汇表大小,是线性层参数,
是词嵌入。f(x)是权重项,用于平衡不同频率的单词对误差的影响,并消除log0时式子不成立情况。
GloVe作者提供了官方的预训练词嵌入(https://nlp.stanford.edu/projects/glove/ )。预训练的GloVe有好几个版本,按数据来源,可以分成:
- 维基百科+gigaword(6B)
- 爬虫(42B)
- 爬虫(840B)
- 推特(27B)
按照词嵌入向量的大小分,又可以分成50维,100维,200维等不同维度。
预训练GloVe的文件格式非常简明,一行代表一个单词向量,每行先是一个单词,再是若干个浮点数,表示该单词向量的每一个元素。
在Pytorch里,我们不必自己去下载解析GloVe,而是可以直接调用Pytorch库自动下载解析GloVe。首先我们要安装Pytorch的NLP库-- torchtext。
如上所述,GloVe版本可以由其数据来源和向量维数确定,在构建GloVe类时,要提供这两个参数,我们选择的是6B token,维度100的GloVe
调用glove.get_vecs_by_tokens,我们能够把token转换成GloVe里的向量。
import torch
from torchtext.vocab import GloVe
glove = GloVe(name='6B', dim=100)
# Get vectors
tensor = glove.get_vecs_by_tokens(['', '1998', '199999998', ',', 'cat'], True)
print(tensor)
PyTorch提供的这个函数非常方便。如果token不在GloVe里的话,该函数会返回一个全0向量。如果你运行上面的代码,可以观察到一些有趣的事:空字符串和199999998这样的不常见数字不在词汇表里,而1998这种常见的数字以及标点符号都在词汇表里。
GloVe类内部维护了一个矩阵,即每个单词向量的数组。因此,GloVe需要一个映射表来把单词映射成向量数组的下标。glove.itos和glove.stoi完成了下标与单词字符串的相互映射。比如用下面的代码,我们可以知道词汇表的大小,并访问词汇表的前几个单词:
myvocab = glove.itos
print(len(myvocab))
print(myvocab[0], myvocab[1], myvocab[2], myvocab[3])最后,我们来通过一个实际的例子认识一下词嵌入的意义。词嵌入就是向量,向量的关系常常与语义关系对应。利用词嵌入的相对关系,我们能够回答“x1之于y1,相当于x2之于谁?”这种问题。比如,男人之于女人,相当于国王之于王后。设我们要找的向量为y2,我们想让x1-y1=x2-y2,即找出一个和x2-(x1-y1)最相近的向量y2出来。这一过程可以用如下的代码描述:
def get_counterpart(x1, y1, x2):x1_id = glove.stoi[x1]y1_id = glove.stoi[y1]x2_id = glove.stoi[x2]#print("x1:",x1,"y1:",y1,"x2:",x2)x1, y1, x2 = glove.get_vecs_by_tokens([x1, y1, x2],True)#print("x1:",x1,"y1:",y1,"x2:",x2)target = x2 - x1 + y1max_sim =0 max_id = -1for i in range(len(myvocab)):vector = glove.get_vecs_by_tokens([myvocab[i]],True)[0]cossim = torch.dot(target, vector)if cossim > max_sim and i not in {x1_id, y1_id, x2_id}:max_sim = cossimmax_id = ireturn myvocab[max_id]
print(get_counterpart('man', 'woman', 'king'))
print(get_counterpart('more', 'less', 'long'))
print(get_counterpart('apple', 'red', 'banana'))
运行结果:
queen
short
yellow
二.基于GloVe的情感分析
情感分析任务与数据集
和猫狗分类类似,情感分析任务是一种比较简单的二分类NLP任务:给定一段话,输出这段话的情感是积极的还是消极的。
比如下面这段话:
I went and saw this movie last night after being coaxed to by a few friends of mine. I'll admit that I was reluctant to see it because from what I knew of Ashton Kutcher he was only able to do comedy. I was wrong. Kutcher played the character of Jake Fischer very well, and Kevin Costner played Ben Randall with such professionalism. ......
这是一段影评,大意说,这个观众本来不太想去看电影,因为他认为演员Kutcher只能演好喜剧。但是,看完后,他发现他错了,所有演员都演得非常好。这是一段积极的评论。
1. 读取数据集:
import os
from torchtext.data import get_tokenizerdef read_imdb(dir='aclImdb', split = 'pos', is_train=True):subdir = 'train' if is_train else 'test'dir = os.path.join(dir, subdir, split)lines = []for file in os.listdir(dir):with open(os.path.join(dir, file), 'rb') as f:line = f.read().decode('utf-8')lines.append(line)return lineslines = read_imdb()
print('Length of the file:', len(lines))
print('lines[0]:', lines[0])
tokenizer = get_tokenizer('basic_english')
tokens = tokenizer(lines[0])
print('lines[0] tokens:', tokens)output:

2.获取经GloVe预处理的数据
在这个作业里,模型其实很简单,输入序列经过词嵌入,送入单层RNN,之后输出结果。作业最难的是如何把token转换成GloVe词嵌入。
torchtext其实还提供了一些更方便的NLP工具类(Field,Vectors),用于管理向量。但是,这些工具需要一定的学习成本,后续学习pytorch时再学习。
Pytorch通常用nn.Embedding来表示词嵌入层。nn.Embedding其实就是一个矩阵,每一行都是一个词嵌入,每一个token都是整型索引,表示该token再词汇表里的序号。有了索引,有了矩阵就可以得到token的词嵌入了。但是有些token在词汇表中并不存在,我们得对输入做处理,把词汇表里没有的token转换成<unk>这个表示未知字符的特殊token。同时为了对齐序列的长度,我们还得添加<pad>这个特殊字符。而用glove直接生成的nn.Embedding里没有<unk>和<pad>字符。如果使用nn.Embedding的话,我们要编写非常复杂的预处理逻辑。
为此,我们可以用GloVe类的get_vecs_by_tokens直接获取token的词嵌入,以代替nn.Embedding。回忆一下前文提到的get_vecs_by_tokens的使用结果,所有没有出现的token都会被转换成零向量。这样,我们就不必操心数据预处理的事了。get_vecs_by_tokens应该发生在数据读取之后,可以直接被写在Dataset的读取逻辑里
from torch.utils.data import DataLoader, Dataset
from torchtext.data import get_tokenizer
from torchtext.vocab import GloVeclass IMDBDataset(Dataset):def __init__(self, is_train=True, dir = 'aclImdb'):super().__init__()self.tokenizer = get_tokenizer('basic_english')pos_lines = read_imdb(dir, 'pos', is_train)neg_lines = read_imdb(dir, 'neg', is_train)self.pos_length = len(pos_lines)self.neg_length = len(neg_lines)self.lines = pos_lines+neg_linesdef __len__(self):return self.pos_length + self.neg_lengthdef __getitem__(self, index):sentence = self.tokenizer(self.lines[index])x = glove.get_vecs_by_tokens(sentence)label = 1 if index < self.pos_length else 0return x, label数据预处理的逻辑都在__getitem__里。每一段字符串会先被token化,之后由GLOVE.get_vecs_by_tokens得到词嵌入数组。
3.对齐输入
使用一个batch的序列数据时常常会碰到序列不等长的问题。实际上利用Pytorch Dataloader的collate_fn机制有更简洁的实现方法。
from torch.nn.utils.rnn import pad_sequencedef get_dataloader(dir='aclImdb'):def collate_fn(batch):x, y = zip(*batch)x_pad = pad_sequence(x, batch_first=True)y = torch.Tensor(y)return x_pad, ytrain_dataloader = DataLoader(IMDBDataset(True, dir),batch_size=32,shuffle=True,collate_fn=collate_fn)test_dataloader = DataLoader(IMDBDataset(False, dir),batch_size=32,shuffle=True,collate_fn=collate_fn)return train_dataloader, test_dataloaderPyTorch DataLoader在获取Dataset的一个batch的数据时,实际上会先吊用Dataset.__getitem__获取若干个样本,再把所有样本拼接成一个batch,比如用__getitem__获取四个[4,3,10,10]这一个batch,可是序列数据通常长度不等,__getitem__可能会获得[10, 100], [15, 100]这样不等长的词嵌入数组。
为了解决这个问题,我们要手动编写把所有张量拼成一个batch的函数。这个函数就是DataLoader的collate_fn函数。我们的collate_fn应该这样编写:
def collate_fn(batch):x, y = zip(*batch)x_pad = pad_sequence(x, batch_first=True)y = torch.Tensor(y)return x_pad, ycollate_fn的输入batch是每次__getitem__的结果的数组。比如在我们这个项目中,第一次获取了一个长度为10的积极的句子,__getitem__返回(Tensor[10, 100], 1);第二次获取了一个长度为15的消极的句子,__getitem__返回(Tensor[15, 100], 0)。那么,输入batch的内容就是:
[(Tensor[10, 100], 1), (Tensor[15, 100], 0)]我们可以用x, y = zip(*batch)把它巧妙地转换成两个元组:
x = (Tensor[10, 100], Tensor[15, 100])
y = (1, 0)之后,PyTorch的pad_sequence可以把不等长序列的数组按最大长度填充成一整个batch张量。也就是说,经过这个函数后,x_pad变成了:
x_pad = Tensor[2, 15, 100]
pad_sequence的batch_first决定了batch是否在第一维。如果它为False,则结果张量的形状是[15, 2, 100]。
pad_sequence还可以决定填充内容,默认填充0。在我们这个项目中,被填充的序列已经是词嵌入了,直接用全零向量表示<pad>没问题。
有了collate_fn,构建DataLoader就很轻松了:
DataLoader(IMDBDataset(True, dir),batch_size=32,shuffle=True,collate_fn=collate_fn)注意,使用shuffle=True可以令DataLoader随机取数据构成batch。由于我们的Dataset十分工整,前一半的标签是1,后一半是0,必须得用随机的方式去取数据以提高训练效率。
4.模型
import torch.nn as nn
GLOVE_DIM = 100
GLOVE = GloVe(name = '6B', dim=GLOVE_DIM)
class RNN(torch.nn.Module):def __init__(self, hidden_units=64, dropout_rate = 0.5):super().__init__()self.drop = nn.Dropout(dropout_rate)self.rnn = nn.GRU(GLOVE_DIM, hidden_units, 1, batch_first=True)self.linear = nn.Linear(hidden_units,1)self.sigmoid = nn.Sigmoid()def forward(self, x:torch.Tensor):# x: [batch, max_word_length, embedding_length]emb = self.drop(x)output,_ = self.rnn(emb)output = output[:, -1]output = self.linear(output)output = self.sigmoid(output)return output这里要注意一下,PyTorch的RNN会返回整个序列的输出。而在预测分类概率时,我们只需要用到最后一轮RNN计算的输出。因此,要用output[:, -1]取最后一次的输出。
5. 训练、测试、推理
train_dataloader, test_dataloader = get_dataloader()
model = RNN()optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
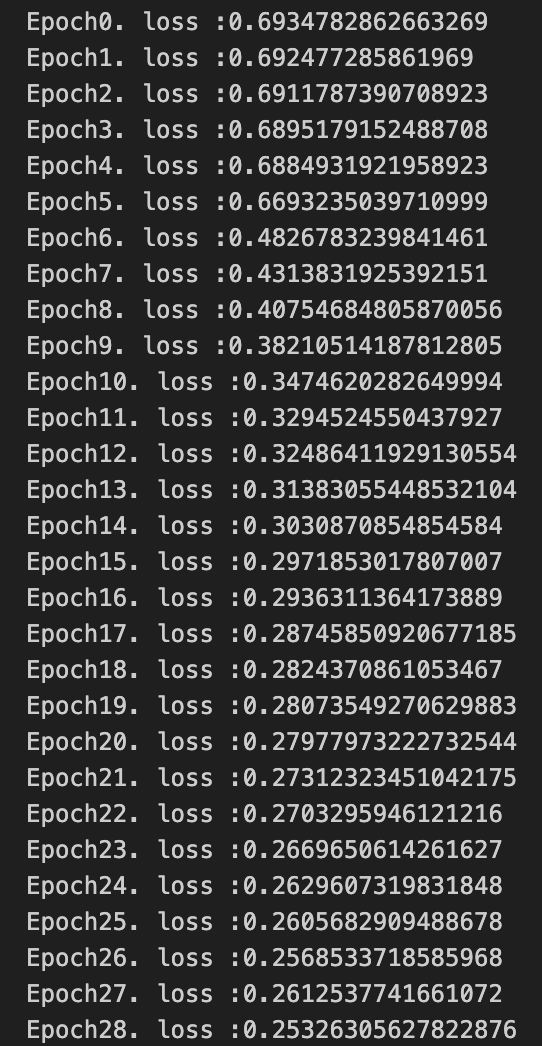
citerion = torch.nn.BCELoss()for epoch in range(100):loss_sum = 0dataset_len = len(train_dataloader.dataset)for x, y in train_dataloader:batchsize = y.shape[0]hat_y = model(x)hat_y = hat_y.squeeze(-1)loss = citerion(hat_y, y)optimizer.zero_grad()loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)optimizer.step()loss_sum += loss * batchsizeprint(f'Epoch{epoch}. loss :{loss_sum/dataset_len}')torch.save(model.state_dict(),'rnn.pth')output:
model.load_state_dict(torch.load('rnn.pth'))
accuracy = 0
dataset_len = len(test_dataloader.dataset)
model.eval()
for x, y in test_dataloader:with torch.no_grad():hat_y = model(x)hat_y.squeeze_(1)predictions = torch.where(hat_y>0.5,1,0)score = torch.sum(torch.where(predictions==y,1,0))accuracy += score.item()
accuracy /= dataset_lenprint(f'Accuracy:{accuracy}') Accuracy:0.90516
tokenizer = get_tokenizer('basic_english')
article = "U.S. stock indexes fell Tuesday, driven by expectations for tighter Federal Reserve policy and an energy crisis in Europe. Stocks around the globe have come under pressure in recent weeks as worries about tighter monetary policy in the U.S. and a darkening economic outlook in Europe have led investors to sell riskier assets."x = GLOVE.get_vecs_by_tokens(tokenizer(article)).unsqueeze(0)
with torch.no_grad():hat_y = model(x)
hat_y = hat_y.squeeze_().item()
result = 'positive' if hat_y > 0.5 else 'negative'
print(result)negative
相关文章:

在 PyTorch 中借助 GloVe 词嵌入完成情感分析
一. Glove 词嵌入原理 GloVe是一种学习词嵌入的方法,它希望拟合给定上下文单词i时单词j出现的次数。使用的误差函数为: 其中N是词汇表大小,是线性层参数, 是词嵌入。f(x)是权重项,用于平衡不同频率的单词对误差的影响…...

大数据应用开发和项目实战-电商双11美妆数据分析
数据初步了解 (head出现,意味着只出现前5行,如果只出现后面几行就是tail) info shape describe 数据清洗 重复值处理 这个重复值是否去掉要看实际情况,比如说:昨天卖了5瓶七喜,今天卖了5瓶七…...

web服务
一、nginx的安装与启用 nginx的安装 开源版本的Nginx官网:http://nginx.org Nginx在安装的过程中可以选择源码安装也可以选择使用软件包安装 源码安装下载相应的源码压缩包解压后编译完成安装 软件安装包可以使用rpm或者apt命令进行安装,也可以使用dnf…...
 或分片集群 (Sharded Cluster)?)
在Spring Boot 中如何配置MongoDB的副本集 (Replica Set) 或分片集群 (Sharded Cluster)?
在 Spring Boot 中配置 MongoDB 副本集 (Replica Set) 或分片集群 (Sharded Cluster) 非常相似,主要区别在于连接字符串 (URI) 中提供的主机列表和一些特定选项。 最常的方式是使用 spring.data.mongodb.uri 属性配置连接字符串。 1. 连接到 MongoDB 副本集 (Repl…...

Oracle中游标和集合的定义查询及取值
在 Oracle 存储过程中,使用游标处理自定义数据行类型时,可以通过 定义记录类型(RECORD) 和 游标(CURSOR) 结合实现。 1. 定义自定义记录类型 使用 TYPE … IS RECORD 定义自定义行数据类型: DE…...

Python企业级MySQL数据库开发实战指南
简介 Python与MySQL的完美结合是现代Web应用和数据分析系统的基石,能够创建高效稳定的企业级数据库解决方案。本文将从零开始,全面介绍如何使用Python连接MySQL数据库,设计健壮的表结构,实现CRUD操作,并掌握连接池管理、事务处理、批量操作和防止SQL注入等企业级开发核心…...

【LLM】Open WebUI 使用指南:详细图文教程
Open WebUI 是一个开源的、可扩展且用户友好的自托管 AI 平台,专为生成式人工智能模型交互而设计。 Open WebUI 旨在为用户提供一个简单易用、功能强大且高度定制化的界面,使其能够轻松与各种 AI 模型(如文本生成、图像生成、语音识别等)进行交互。 一、安装与初始化配置 扩…...

前端封装框架依赖管理全攻略:构建轻量可维护的私有框架
前端封装框架依赖管理全攻略:构建轻量可维护的私有框架 前言 在自研前端框架的开发中,依赖管理是决定框架可用性的关键因素。不合理的依赖设计会导致: 项目体积膨胀:重复依赖使最终打包体积增加30%版本地狱:不同项目…...

Listremove数据时报错:Caused by: java.lang.UnsupportedOperationException
看了二哥的foreach陷阱后,自己也遇见了需要循环删除元素的情况,立马想到了当时自己阴差阳错的避开所有坑的解决方式:先倒序遍历,再删除。之前好使,但是这次不好使了,报错Caused by: java.lang.UnsupportedO…...

互联网大厂Java求职面试:云原生与AI融合下的系统设计挑战-1
互联网大厂Java求职面试:云原生与AI融合下的系统设计挑战-1 在当今云计算和人工智能迅猛发展的背景下,互联网大厂对Java工程师的要求已从传统的单体架构和业务逻辑处理,转向了更复杂的云原生架构设计、AI模型集成以及高并发系统的性能优化能…...
:屏障(Barrier))
并发设计模式实战系列(16):屏障(Barrier)
🌟 大家好,我是摘星! 🌟 今天为大家带来的是并发设计模式实战系列,第十六章屏障(Barrier),废话不多说直接开始~ 目录 一、核心原理深度拆解 1. 屏障的同步机制 2. 关键参数 二…...

pywinauto通过图片定位怎么更加精准的识别图片?
pywinauto通过图片定位怎么更加精准的识别图片? 可以使用置信度的配置,添加了对比图片相似程度达到多少就可以认为是合适的定位图片 import time from time import sleep from pywinauto.application import Application from pywinauto.keyboard impo…...
)
Spring Cloud Stream集成RocketMQ(kafka/rabbitMQ通用)
什么是Spring Cloud Stream Spring Cloud Stream 是 Spring 生态系统中的一个框架,用于简化构建消息驱动微服务的开发和集成。它通过抽象化的方式将消息中间件(如 RabbitMQ、Kafka、RocketMQ 等)的复杂通信逻辑封装成简单的编程模型…...

基于docker使用showdoc搭建API开发文档服务器
以下是基于 Docker 快速搭建 ShowDoc API 文档服务器的完整指南,包含优化配置和常见问题解决方案: 1. 快速部署方案 # 创建数据目录(确保权限) mkdir -p /showdoc_data/html && chmod 777 -R /showdoc_data# 一键启动容器…...
 视觉语言模型的技术背景、应用场景和商业前景(Grok3 DeepSearch模式回答))
Vision-Language Models (VLMs) 视觉语言模型的技术背景、应用场景和商业前景(Grok3 DeepSearch模式回答)
prompt: 你是一位文笔精湛、十分专业的技术博客作者,你将从技术背景、应用场景和商业前景等多个维度去向读者介绍Vision-Language Models 关键要点 研究表明,视觉语言模型(VLMs)是多模态AI系统,能同时处理视觉和文本数…...

OpenAI大变革!继续与微软等,以非营利模式冲击AGI
今天凌晨2点,OpenAI宣布,将继续由非营利组织控制;现有的营利性实体将转变为一家公共利益公司;非营利组织将控制该公共利益公司,并成为其重要的持股方。 这也就是说OpenAI曾在去年提到的由非营利性转变成营利性公司&am…...

Ubuntu打开中文文本乱码
文章目录 中文乱码问题修复乱码系统字符编码修改文本编码修改vim乱码 utf-8编码原理特点应用场景与其他编码的转换 iso-8859-1基本信息字符涵盖应用场景与其他编码的关系 ubuntu打开文本出现乱码,可能是编码没设置对。 中文乱码问题 使用vim打开文本,或…...

车载通信网络安全:挑战与解决方案
1. 简介 当今时代见证了车载汽车技术的巨大发展,因为现代智能汽车可以被视为具有出色外部基础设施连接能力的信息物理系统 [ 1 ]。车载技术支持的现代智能汽车不应被视为类似于机械系统,而是由数百万行复杂代码组成的集成架构,可为车内乘客提…...

【Linux系统】读写锁
读者写者问题 重点 读者写者问题是并发编程中的经典问题,主要研究多个进程或线程对共享数据进行读和写操作时如何实现同步和互斥,以保证数据的一致性和操作的正确性 。 问题核心要点 同步与互斥:需要确保多个读者可以同时读共享数据&#…...

springBoot中自定义一个validation注解,实现指定枚举值校验
缘由 在后台写接口的时候,经常会出现dto某个属性是映射到一个枚举的情况。有时候还会出现只能映射到枚举类中部分枚举值的情况。以前都是在service里面自行判断,很多地方代码冗余,所以就想着弄一个自定义的validation注解来实现。 例如下面某…...

【Python】--装饰器
装饰器(Decorator)本质上是一个返回函数的函数 主要作用是:在不修改原函数代码的前提下,给函数增加额外的功能 比如:增加业务,日志记录、权限验证、执行时间统计、缓存等场景 my_decorator def func():pas…...

排序算法——堆排序
一、介绍 「堆排序heapsort」是一种基于堆数据结构实现的高效排序算法。我们可以利用已经学过的“建堆操作”和“元素出堆操作”实现堆排序。 1. 输入数组并建立小顶堆,此时最小元素位于堆顶。 2. 不断执行出堆操作,依次记录出堆元素,即可得…...

Day111 | 灵神 | 二叉树 | 验证二叉搜索树
Day111 | 灵神 | 二叉树 | 验证二叉搜索树 98.验证二叉搜索树 98. 验证二叉搜索树 - 力扣(LeetCode) 方法一:前序遍历 递归函数传入合法的左右边界,只有当前结点是合法的边界,才是二叉搜索树,否则就返回…...

软考-软件设计师中级备考 13、刷题 数据结构
倒计时17天时间不多了,数据库、UML、等知识点有基础直接略过,法律全靠考前的一两天刷题,英语直接放弃。 一、数据结构:链表、栈、队列、数组、哈希表、树、图 1、关于链表操作,说法正确的是: A)新增一个头…...

【5G通信】天线调整
在天线工程中,机械下倾角、电子下倾角和数字下倾角是调整天线波束指向的不同技术手段,其核心区别在于实现方式和灵活性: 1. 机械下倾角(Mechanical Downtilt) 定义:通过物理调整天线的安装角度,…...

Kafka的Log Compaction原理是什么?
Kafka的Log Compaction(日志压缩)是一种独特的数据保留策略,其核心原理是保留每个key的最新有效记录。以下是关键原理分点说明: 1. 键值保留机制 通过扫描所有消息的key,仅保留每个key对应的最新value值。例如&#…...
·内存管理机制、优先级继承机制以及优先级翻转)
嵌入式面试八股文(十四)·内存管理机制、优先级继承机制以及优先级翻转
目录 1. 内存管理算法(五种内存管理机制) 1.1 heap_1.c 1.2 heap_2.c 1.3 heap_3.c 1.4 heap_4.c 1.5 heap_5.c 1.6 总结 2. STM32通知寄存器有哪些? 2.1 核心寄存器组(Cortex-M) 2.2 特殊功能寄存…...

深度剖析:可视化如何重塑驾驶舱信息交互模式
为什么你开车时总觉得“信息太多却抓不住重点”? 今天的汽车早已不是单纯的交通工具,而是一个高度集成的信息终端。从导航、油耗、胎压到自动驾驶提示,各种数据不断涌进驾驶舱。 但问题也随之而来: 关键信息被淹没在一堆图标里…...

app根据蓝牙名字不同,匹配不同的产品型号,显示对应的UI界面
在开发一个 App 时,如果希望根据蓝牙设备名称(Bluetooth Name)的不同,自动匹配不同的产品型号,并显示对应的 UI 界面,可以按照以下思路来实现: ✅ 功能目标 扫描并连接蓝牙设备;获取…...

数据结构 --- 栈
1.栈的初始化 2.入栈 3.出栈 4.取出栈顶元素 5.获取栈中有效元素个数 6.栈的销毁 栈:⼀种特殊的线性表,其只允许在固定的⼀端进⾏插⼊和删除元素操作。进⾏数据插⼊和删除操作 的⼀端称为栈顶,另⼀端称为栈底。栈中的数据元素遵守后进先…...
-第三十七天)
37-算法打卡-栈与队列-滑动窗口最大值-leetcode(239)-第三十七天
1 题目地址 239. 滑动窗口最大值 - 力扣(LeetCode)239. 滑动窗口最大值 - 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。返回 滑…...

【原创分享】魔音变声器内含超多语音包实时变声
魔音变声器,一款专业的调音变声器软件 亲测可使用所有功能[真棒] 去除所有广告 ————————————【下 载 地 址】———————————— 【获取方法1】:https://pan.xunlei.com/s/VOP_TXtKNlevTgYvIlxmmJquA1?pwd8vpi# ————————————【下 …...
——线性表的顺序表示和实现)
数据结构(一)——线性表的顺序表示和实现
一、线性表的定义 由n(n>0)个数据特性相同的元素构成的有限序列称为线性表,(n0)的时候被称为空表。 一个数据元素可以是简单的一个数据,一个符号,也可以是复杂的若干个数据项的组合。 二、线性表的类型定义 s线性表是由n(n≥0)个相同类…...
)
Winform(12.控件讲解)
ChildForm窗口: ChildForm代码: using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms; namespac…...
》)
Python 10天冲刺 《元编程(Meta-programming)》
Python 的元编程(Meta-programming)是指在程序运行期间动态生成、修改或操作代码的技术。它允许开发者通过代码控制代码的行为,从而实现灵活、可扩展和抽象化的编程模式。Python 提供了多种元编程工具,包括装饰器、元类、动态导入…...

Android开发-创建、运行、调试App工程
在移动应用开发的世界里,Android平台凭借其开放性和广泛的设备支持,成为了许多开发者的选择。而要成为一名合格的Android开发者,掌握如何创建、运行以及调试应用程序是必不可少的基础技能。本文将详细介绍如何使用Android Studio完成这些任务…...
:通过读取PE文件获取EXE或者DLL的依赖)
系统级编程(二):通过读取PE文件获取EXE或者DLL的依赖
PE文件 Windows的PE文件(Portable Executable)是一种专为Windows操作系统设计的标准可执行文件格式,用于存储和管理可执行程序、动态链接库(DLL)、驱动程序等二进制文件。PE文件格式自Windows NT 3.1引入以来,已成为Windows平台上所有可执行文件的标准格式,并广泛应用于…...

Linux主机时间设置操作指南及时间异常影响
一、Linux主机时间设置命令操作指南 1. 查看当前系统时间与时区 查看当前时间与时区:timedatectl # 显示详细时间与时区信息(systemd系统适用) date # 查看当前系统时间 hwclock --show # 查看硬件时…...

GPS定位方案
目录 一、常用的GPS定位方案包括: 二、主流品牌及热销型号 三、常用GPS算法及核心逻辑: 一、基础定位算法 二、高精度算法 三、辅助优化算法 四、信号处理底层算法 四、基本原理(想自己写算法的琢磨一下原理) 一、常用的GP…...

应对联网汽车带来的网络安全挑战
数字化加速正在彻底改变全球各行各业,而汽车行业更是走在了前列。目前,全球自动驾驶汽车保有量约为4860万辆,预计到2024年将增长至5420万辆。 智能汽车的崛起无疑令人兴奋,但也带来了一系列问题。为了保护客户免受新的威胁,汽车行业必须做出一系列考量:针对自动驾驶、网…...

人工智能与生命科学的深度融合:破解生物医学难题,引领未来科技革命
引言 随着人工智能技术的飞速发展,生命科学领域迎来了前所未有的变革。从药物研发到疾病预测,从个性化医疗到基因组学,AI的深度融入不仅加速了生物医学的进步,还在多个领域打破了传统科学研究的局限,开创了新的医学前沿…...
:4326和3857两种坐标系有什么区别?各自用途是什么?)
DeepSeek智能时空数据分析(七):4326和3857两种坐标系有什么区别?各自用途是什么?
序言:时空数据分析很有用,但是GIS/时空数据库技术门槛太高 时空数据分析在优化业务运营中至关重要,然而,三大挑战仍制约其发展:技术门槛高,需融合GIS理论、SQL开发与时空数据库等多领域知识;空…...

Qt/C++面试【速通笔记七】—Qt中为什么new QWidget不需要手动调用delete?
在Qt的开发中,管理内存是一个非常重要的话题,特别是在使用QWidget这类窗口组件时,很多开发者会遇到一个问题:“为什么我使用new QWidget创建的窗口对象不需要手动调用delete进行销毁?”。 1. 父子关系机制:…...

Super-vlan
Super VLAN(VLAN聚合)的理论与配置 1. 基本概念 Super VLAN(超级VLAN)是一种VLAN聚合技术,主要用于解决传统VLAN划分中IP地址浪费的问题。其核心思想是将多个Sub VLAN(子VLAN)聚合到一个Super …...

C——函数
一、函数的概念 数学中我们其实就⻅过函数的概念,⽐如:⼀次函数 y kx b ,k和b都是常数,给⼀个任意的 x,就得到⼀个y值。 其实在C语⾔也引⼊函数(function)的概念,有些翻译为&…...

5.6刷题并查集
P1551 亲戚 #include<bits/stdc.h> using namespace std; const int N 5010; int f[N]; int find(int x){if(f[x] x)return x;return f[x] find(f[x]); } void solve(){int n, m, p; cin >> n >> m >> p;for(int i 1; i < n; i)f[i] i;for(in…...

pcl平面投影
// 创建一个系数为XY0,Z1的平面pcl::ModelCoefficients::Ptr coefficients (new pcl::ModelCoefficients ());coefficients->values.resize (4);coefficients->values[0] coefficients->values[1] 0;coefficients->values[2] 1.0;coefficients->values[3] 0…...

Linux远程管理
如何查看ip 如何使用vim编辑器 如何设置网络信息 远程访问 一:网络管理 (1)获取计算机的网络信息 基本语法: windows ipconfig ifconfig enS33: f1agS4163<UP,BR0ADCAST,RUNNING,MULTICAST> mtu 1500 inet…...

如何添加或删除极狐GitLab 项目成员?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 项目成员 (BASIC ALL) 成员是有权访问您的项目的用户和群组。 每个成员都有一个角色,这决定了他们在项目中可以…...

2025年服务器技术全景解析:量子计算、液冷革命与未来生态构建
2025年服务器技术全景解析:量子计算、液冷革命与未来生态构建 一、量子计算:从实验室到产业化的跨越 1. 中国量子计算产业化突破 • 本源量子“悟空”超导计算机: 搭载72位自主超导量子芯片“悟空芯”,支持198个量子比特…...