第三章:langchain加载word文档构建RAG检索教程(基于FAISS库为例)
文章目录
- 前言
- 一、载入文档(word)
- 1、文档载入代码
- 2、文档载入数据解读(Docx2txtLoader方法)
- 输入数据
- 输出文本内容
- 3、Docx2txtLoader底层代码文档读取解读
- Docx2txtLoader底层源码示例文档读取
- 输出结果
- 二、文本分割
- 1、文本分割代码
- 2、底层代码
- 1、文档输入内容
- 2、split_documents函数源码解读
- 3、create_documents函数源码解读
- split_text函数源码解读
- _split_text_with_regex函数源码解读
- _merge_splits函数源码解读
- 三、文本向量化存储(以faiss库示例)
- 1、使用faiss实现本地向量化代码
- 2、faiss类源码解读
- FAISS类注释翻译
- FAISS类的示意结构
- FAISS类结构示意图
- 3、VectorStore类源码解读
- 四、构建一个完整RAG实现检索的代码Demo
前言
如果你已有了向量embed模型,该如何构建一个检索方法呢?本节就是一个完整的构建教程,使用word文档载入到分块再到向量化,并利用数据库进行检索。我们使用FAISS库来实现这个功能,依然使用langchain款就爱来完成。该代码实现是比较简单的,但这仅仅是给初学者学习的。我们会进一步从底层源码进行解读,给出更深入讲解。
一、载入文档(word)
构建rag需要将现有知识知识转向量化。在此之前需要载入文档,这里将使用word作为列子来载入。而后期你想载入不同模态数据,需要使用不同方式来实现。
1、文档载入代码
我们给出了word文档载入内容,其代码如下:
# 加载Word文档
from langchain_community.document_loaders import Docx2txtLoader
def load_word_document(file_path):# 创建一个Docx2txtLoader对象,用于加载指定路径的Word文档loader = Docx2txtLoader(file_path)# 调用loader对象的load方法,加载文档内容并返回return loader.load()
使用上面代码即可完成。
2、文档载入数据解读(Docx2txtLoader方法)
输入数据
输入数据包含文字,图片,公式以及文档嵌入的公式与页眉。我们需要了解langchain自带文档库Docx2txtLoader解析。我们重点关注其有回车键地方与有公式地方。
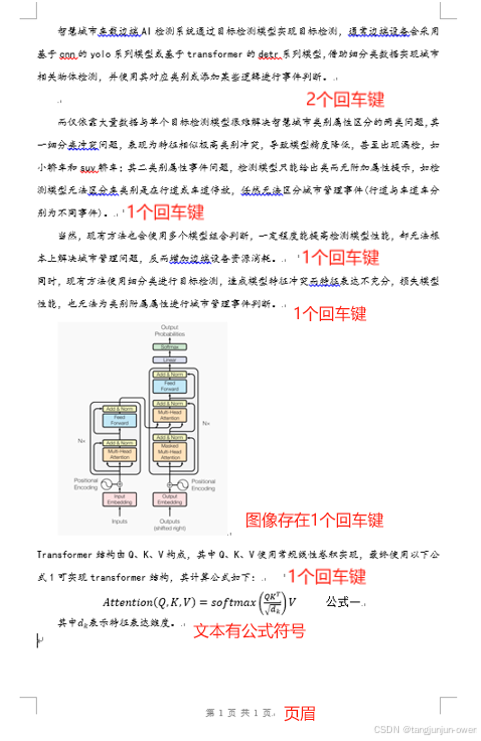
输出文本内容
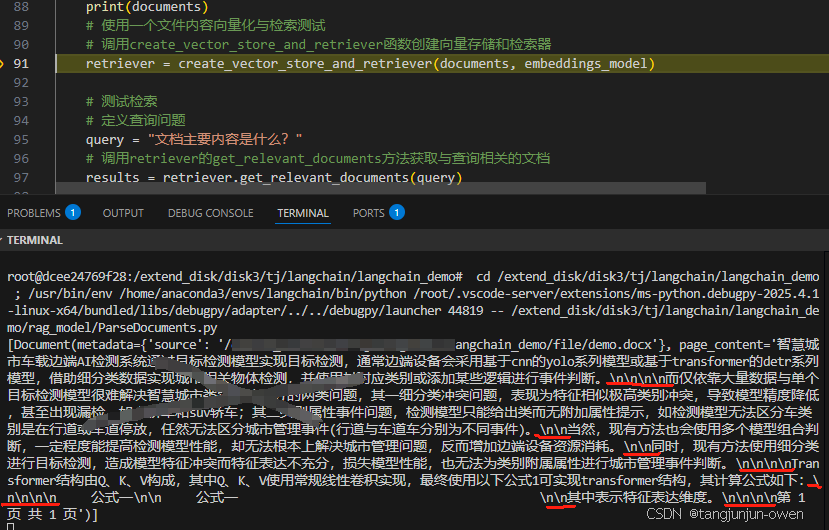
以下就是文本输出内容,我们可以发现,每一个回车键就会有个/n/n表示,所以多少个回车键就有多少个,而且我们可以发现这个不能
3、Docx2txtLoader底层代码文档读取解读
随后,我们根据from langchain_community.document_loaders import Docx2txtLoader其源码不断挖掘,深入到底层逻辑,我们将其源码重要内容摘出来构建了一个示例代码。
Docx2txtLoader底层源码示例文档读取
你会发现实际是用python自带方法进行解析的,而且是xml方式来解析。我将其代码构成了一个示例,如下代码:
import argparse
import re
import xml.etree.ElementTree as ET
import zipfile
import os
import sysnsmap = {'w': 'http://schemas.openxmlformats.org/wordprocessingml/2006/main'}
def qn(tag):"""Stands for 'qualified name', a utility function to turn a namespaceprefixed tag name into a Clark-notation qualified tag name for lxml. Forexample, ``qn('p:cSld')`` returns ``'{http://schemas.../main}cSld'``.Source: https://github.com/python-openxml/python-docx/"""prefix, tagroot = tag.split(':')uri = nsmap[prefix]return '{{{}}}{}'.format(uri, tagroot)def xml2text(xml):"""A string representing the textual content of this run, with contentchild elements like ``<w:tab/>`` translated to their Pythonequivalent.Adapted from: https://github.com/python-openxml/python-docx/"""text = u''root = ET.fromstring(xml)for child in root.iter():if child.tag == qn('w:t'):t_text = child.texttext += t_text if t_text is not None else ''elif child.tag == qn('w:tab'):text += '\t'elif child.tag in (qn('w:br'), qn('w:cr')):text += '\n'elif child.tag == qn("w:p"):text += '\n\n'return textdef process(docx, img_dir=None):text = u''# unzip the docx in memoryzipf = zipfile.ZipFile(docx)filelist = zipf.namelist()# get header text# there can be 3 header files in the zipheader_xmls = 'word/header[0-9]*.xml'for fname in filelist:if re.match(header_xmls, fname):text += xml2text(zipf.read(fname))# get main textdoc_xml = 'word/document.xml'text += xml2text(zipf.read(doc_xml))# get footer text# there can be 3 footer files in the zipfooter_xmls = 'word/footer[0-9]*.xml'for fname in filelist:if re.match(footer_xmls, fname):text += xml2text(zipf.read(fname))if img_dir is not None:# extract imagesfor fname in filelist:_, extension = os.path.splitext(fname)if extension in [".jpg", ".jpeg", ".png", ".bmp"]:dst_fname = os.path.join(img_dir, os.path.basename(fname))with open(dst_fname, "wb") as dst_f:dst_f.write(zipf.read(fname))zipf.close()return text.strip()if __name__ == '__main__':text = process("/extend_disk/disk3/tj/langchain/langchain_demo/file/demo.docx")# sys.stdout.write(text.encode('utf-8'))print(text)pass而源码真正底层位置如下图:
注:之所以摘出来,是告诉读者,你可以任意修改!并给出word本质内容。
输出结果
使用上面代码得到输出结果如下,这个结果和Docx2txtLoader是一样的,如下:
'智慧城市车载边端AI检测系统通过目标检测模型实现目标检测,通常边端设备会采用基于cnn的yolo系列模型或基于transformer的detr系列模型,借助细分类数据实现城市相关物体检测,并使用其对应类别或添加某些逻辑进行事件判断。\n\n\n\n而仅依靠大量数据与单个目标检测模型很难解决智慧城市类别属性区分的两类问题,其一细分类冲突问题,表现为特征相似极高类别冲突,导致模型精度降低,甚至出现漏检,如小轿车和suv轿车;其二类别属性事件问题,检测模型只能给出类而无附加属性提示,如检测模型无法区分车类别是在行道或车道停放,任然无法区分城市管理事件(行道与车道车分别为不同事件)。\n\n当然,现有方法也会使用多个模型组合判断,一定程度能提高检测模型性能,却无法根本上解决城市管理问题,反而增加边端设备资源消耗。\n\n同时,现有方法使用细分类进行目标检测,造成模型特征冲突而特征表达不充分,损失模型性能,也无法为类别附属属性进行城市管理事件判断。\n\n\n\nTransformer结构由Q、K、V构成,其中Q、K、V使用常规线性卷积实现,最终使用以下公式1可实现transformer结构,其计算公式如下:\n\n\n\n 公式一\n\n 公式一 \n\n其中表示特征表达维度。\n\n\n\n第 1 页 共 1 页'
二、文本分割
对于读取的文档,转成了text格式内容,我们需要进行文本分割。也就是将一个大文本切分成不同小块的文本,这样才能更方便的存入数据库中。大多情况都是纯文本进行分割。
1、文本分割代码
我们采用别人方法来调用分割文本split。我们给出了from langchain.text_splitter import CharacterTextSplitter方法的文本分割方法,其代码如下:
from langchain.text_splitter import CharacterTextSplitter
# 初始化文本分割器
def init_text_splitter(**kwargs):# separator="\n", chunk_size=1000, chunk_overlap=200separator,chunk_size,chunk_overlap = kwargs.get("separator","\n"),kwargs.get("chunk_size",1000),kwargs.get("chunk_overlap",200)text_splitter = CharacterTextSplitter(separator=separator, chunk_size=chunk_size, chunk_overlap=chunk_overlap)return text_splitter# 创建向量存储并初始化检索器
def get_texts_split(documents, **kwargs):# 定义一个函数,用于将文档列表分割成文本片段# 参数documents是一个包含多个文档的列表# 参数kwargs是一个关键字参数字典,用于传递给文本分割器的初始化函数text_splitter = init_text_splitter(**kwargs)# 调用init_text_splitter函数,传入kwargs参数字典,初始化一个文本分割器对象split_texts = text_splitter.split_documents(documents)# split_documents方法的具体实现也不在当前代码中,它可能是用于将文档分割成多个文本片段的方法return split_texts
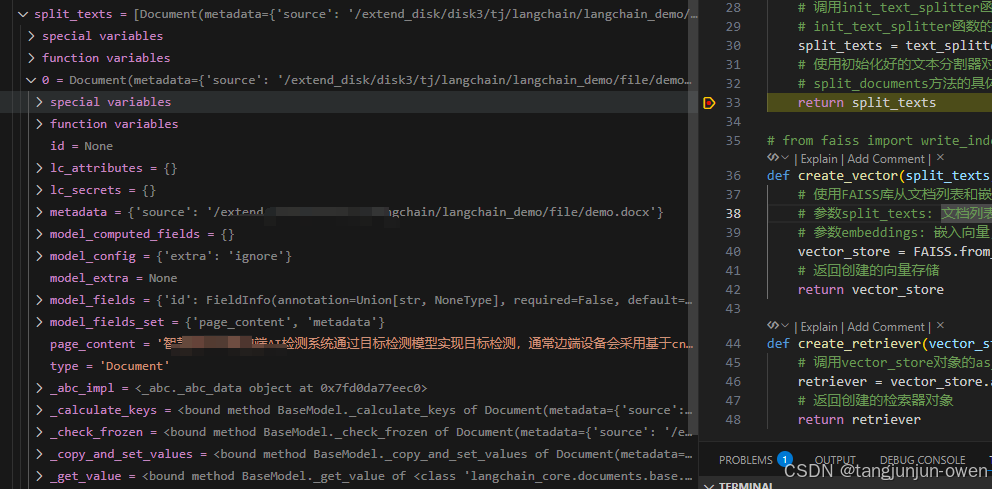
自然结果也是列表,每个元素是Document的类,最主要是包含metadata与page_content内容,其结果如下:
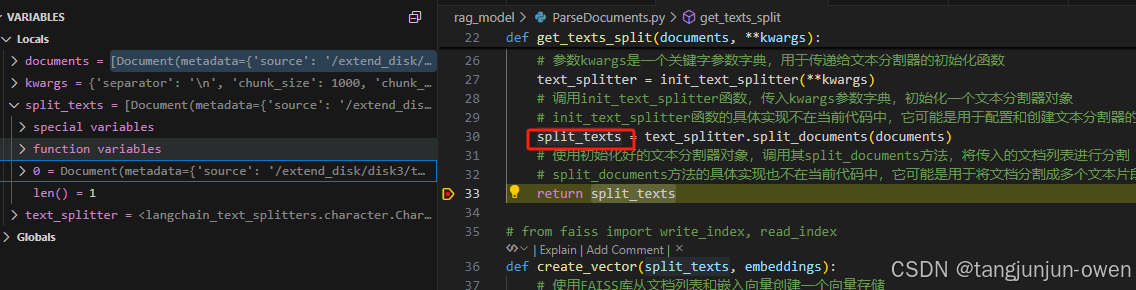
而元素内容如下:
2、底层代码
上面代码给出了文本分割内容,紧接着我们从底层代码来讲解其运行机理。我们看到text_splitter.split_documents(documents)调用,我们来解释split_documents方法。
1、文档输入内容
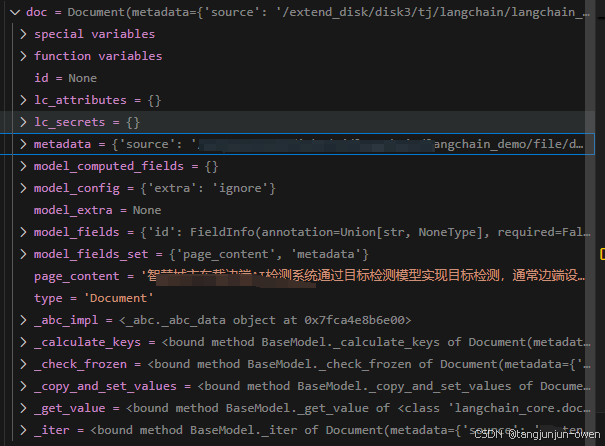
我们首先知道documents输入是一个列表,而列表的元素是Document类(如下源码所示)。显然metadata与page_content很重要,前者是个字典,主要附加来源等信息,后这是内容。
class BaseMedia(Serializable):id: Optional[str] = Nonemetadata: dict = Field(default_factory=dict)"""Arbitrary metadata associated with the content."""@field_validator("id", mode="before")def cast_id_to_str(cls, id_value: Any) -> Optional[str]:if id_value is not None:return str(id_value)else:return id_valueclass Document(BaseMedia):page_content: str"""String text."""type: Literal["Document"] = "Document"def __init__(self, page_content: str, **kwargs: Any) -> None:super().__init__(page_content=page_content, **kwargs) # type: ignore[call-arg]@classmethoddef is_lc_serializable(cls) -> bool:"""Return whether this class is serializable."""return True@classmethoddef get_lc_namespace(cls) -> list[str]:"""Get the namespace of the langchain object."""return ["langchain", "schema", "document"]def __str__(self) -> str:if self.metadata:return f"page_content='{self.page_content}' metadata={self.metadata}"else:return f"page_content='{self.page_content}'"
page_content内容如下:
'智慧城市车载边端AI检测系统通过目标检测模型实现目标检测,通常边端设备会采用基于cnn的yolo系列模型或基于transformer的detr系列模型,借助细分类数据实现城市相关物体检测,并使用其对应类别或添加某些逻辑进行事件判断。\n\n\n\n而仅依靠大量数据与单个目标检测模型很难解决智慧城市类别属性区分的两类问题,其一细分类冲突问题,表现为特征相似极高类别冲突,导致模型精度降低,甚至出现漏检,如小轿车和suv轿车;其二类别属性事件问题,检测模型只能给出类而无附加属性提示,如检测模型无法区分车类别是在行道或车道停放,任然无法区分城市管理事件(行道与车道车分别为不同事件)。\n\n当然,现有方法也会使用多个模型组合判断,一定程度能提高检测模型性能,却无法根本上解决城市管理问题,反而增加边端设备资源消耗。\n\n同时,现有方法使用细分类进行目标检测,造成模型特征冲突而特征表达不充分,损失模型性能,也无法为类别附属属性进行城市管理事件判断。\n\n\n\nTransformer结构由Q、K、V构成,其中Q、K、V使用常规线性卷积实现,最终使用以下公式1可实现transformer结构,其计算公式如下:\n\n\n\n 公式一\n\n 公式一 \n\n其中表示特征表达维度。\n\n\n\n第 1 页 共 1 页'
metadata内容如下:
{'source': '/langchain_demo/file/demo.docx'}
具体而言,如下图:
2、split_documents函数源码解读
documents经过下面函数将其内容给到texts, metadatas列表,保存内容如上所示。然后进入self.create_documents(texts, metadatas=metadatas)代码。
def split_documents(self, documents: Iterable[Document]) -> List[Document]:"""Split documents."""texts, metadatas = [], []for doc in documents:texts.append(doc.page_content)metadatas.append(doc.metadata)return self.create_documents(texts, metadatas=metadatas)
3、create_documents函数源码解读
随后定义了一个documents空列表,再进行text循环,首先是进入split_text函数,该函数是一个切割再合并方式。切割是基于某个字符标志进行,一般以/n作为切割,可以将一个文本切割多个文本列表;合并是将切割列表按照chunk size作为依据进行合并,一般若未超过chunk size则合并成一整段文本,而合并连接是使用separate变量内容,而超过chunk size则进行文本分段,可能返回为多个元素的列表。最后,返回chunk size会被保存到Document类中,若被切割就会依次保存,再将所有内容都会保存到documents列表中(其代码)。其代码如下:
def create_documents(self, texts: List[str], metadatas: Optional[List[dict]] = None
) -> List[Document]:"""Create documents from a list of texts."""_metadatas = metadatas or [{}] * len(texts)documents = []for i, text in enumerate(texts):index = 0previous_chunk_len = 0for chunk in self.split_text(text):metadata = copy.deepcopy(_metadatas[i])if self._add_start_index:offset = index + previous_chunk_len - self._chunk_overlapindex = text.find(chunk, max(0, offset))metadata["start_index"] = indexprevious_chunk_len = len(chunk)new_doc = Document(page_content=chunk, metadata=metadata)documents.append(new_doc)return documents
注:使用了2个for循环,第一个是texts文本的,第二个是条件chunk size进行的切割for循环。
split_text函数源码解读
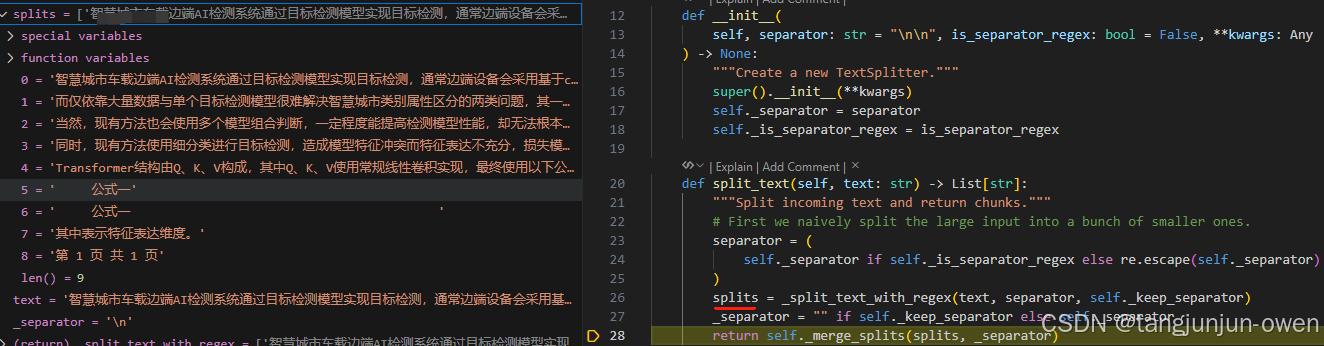
这个函数主要是对每个text元素进行分割,首先使用separator的分割符号进行分割,这里默认是/n符号,这个再初始化地方设置。
def split_text(self, text: str) -> List[str]:"""Split incoming text and return chunks."""# First we naively split the large input into a bunch of smaller ones.separator = (self._separator if self._is_separator_regex else re.escape(self._separator))splits = _split_text_with_regex(text, separator, self._keep_separator)_separator = "" if self._keep_separator else self._separatorreturn self._merge_splits(splits, _separator)
使用分割符号分割结果如下:
_split_text_with_regex函数源码解读
不说了,这个是separator符号来切割的,而实现这个功能就是下面代码,如下:
def _split_text_with_regex(text: str, separator: str, keep_separator: Union[bool, Literal["start", "end"]]
) -> List[str]:# Now that we have the separator, split the textif separator:if keep_separator:# The parentheses in the pattern keep the delimiters in the result._splits = re.split(f"({separator})", text)splits = (([_splits[i] + _splits[i + 1] for i in range(0, len(_splits) - 1, 2)])if keep_separator == "end"else ([_splits[i] + _splits[i + 1] for i in range(1, len(_splits), 2)]))if len(_splits) % 2 == 0:splits += _splits[-1:]splits = ((splits + [_splits[-1]])if keep_separator == "end"else ([_splits[0]] + splits))else:splits = re.split(separator, text)else:splits = list(text)return [s for s in splits if s != ""]
_merge_splits函数源码解读
这个函数我看了半天,不是特别明白。但大致逻辑是对splits列表文本进行合并,但超过既定的chunk_size尺寸,就会被切割。而合并句子使用separator作为连接符号,该代码如下所示:
def _merge_splits(self, splits: Iterable[str], separator: str) -> List[str]:# We now want to combine these smaller pieces into medium size# chunks to send to the LLM.separator_len = self._length_function(separator)docs = []current_doc: List[str] = []total = 0for d in splits:_len = self._length_function(d)if (total + _len + (separator_len if len(current_doc) > 0 else 0)> self._chunk_size):if total > self._chunk_size:logger.warning(f"Created a chunk of size {total}, "f"which is longer than the specified {self._chunk_size}")if len(current_doc) > 0:doc = self._join_docs(current_doc, separator)if doc is not None:docs.append(doc)# Keep on popping if:# - we have a larger chunk than in the chunk overlap# - or if we still have any chunks and the length is longwhile total > self._chunk_overlap or (total + _len + (separator_len if len(current_doc) > 0 else 0)> self._chunk_sizeand total > 0):total -= self._length_function(current_doc[0]) + (separator_len if len(current_doc) > 1 else 0)current_doc = current_doc[1:]current_doc.append(d)total += _len + (separator_len if len(current_doc) > 1 else 0)doc = self._join_docs(current_doc, separator)if doc is not None:docs.append(doc)return docs
三、文本向量化存储(以faiss库示例)
FAISS类源码位置:home > anaconda3 > envs > langchain > lib > python3.10 > site-packages > langchain_community > vectorstores > .faiss.py > FAISS
vectorstores类源码位置: home > anaconda3 > envs > langchain > lib > python3.10 > site-packages > langchain_core > vectorstores > .base.py > VectorStore
1、使用faiss实现本地向量化代码
我们看到,这个用库实际是比较简单的,而split_texts的元素是document类,内容也是这样做了处理的。
其完整代码如下:
def create_vector(split_texts, embeddings):# 使用FAISS库从文档列表和嵌入向量创建一个向量存储# 参数split_texts: 文档列表,每个文档已经被分割成单独的文本片段# 参数embeddings: 嵌入向量,用于将文本片段转换为向量表示vector_store = FAISS.from_documents(split_texts, embeddings)# 返回创建的向量存储return vector_storedef create_retriever(vector_store): # 调用vector_store对象的as_retriever方法,将vector_store转换为一个检索器retriever = vector_store.as_retriever()# 返回创建的检索器对象return retriever
使用上面方法就可以实现向量本地化方法。然而,这样的调用并不能让我们理解其内部原理。为此,我接下来就是对这个进行解释。
2、faiss类源码解读
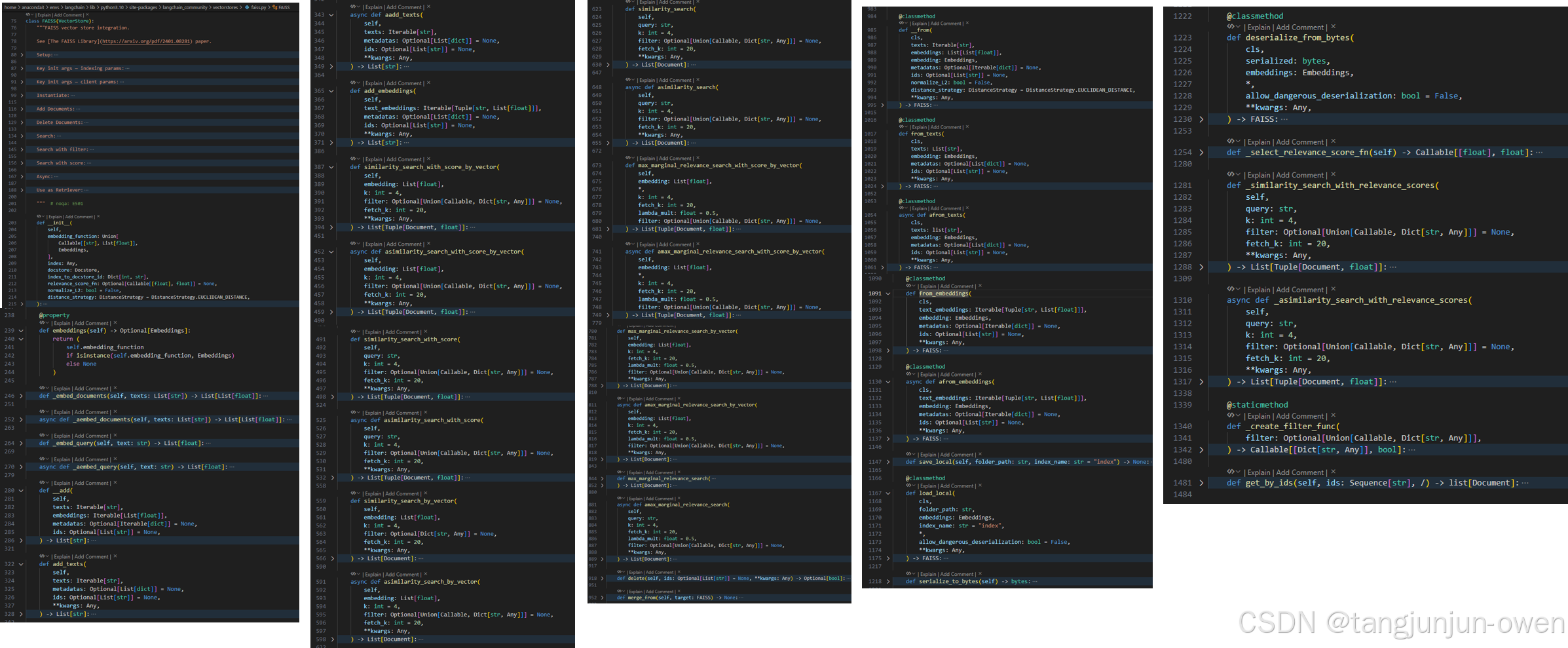
首先我给出faiss类的源码示意结构,尽管内容有些多,但你想明白更深原理,可以大致看一下。这个类有实现各种方法的原理。如何embed、查询等内容,基本囊括了向量所有操作内容。而该方法是继承VectorStore,我也会给出讲解。现在我想给出FAISS类的解释,然后在给出源码示意。
FAISS类注释翻译
这部分来源faiss的注解,翻译成中文如下:
FAISS 向量存储集成。参见 [FAISS 库](https://arxiv.org/pdf/2401.08281) 论文。安装:安装 ``langchain_community`` 和 ``faiss-cpu`` Python 包。.. code-block:: bashpip install -qU langchain_community faiss-cpu主要初始化参数 —— 索引参数:embedding_function: Embeddings使用的嵌入函数。主要初始化参数 —— 客户端参数:index: Any使用的 FAISS 索引。docstore: Docstore使用的文档存储。index_to_docstore_id: Dict[int, str]索引到文档存储 ID 的映射。初始化:.. code-block:: pythonimport faissfrom langchain_community.vectorstores import FAISSfrom langchain_community.docstore.in_memory import InMemoryDocstorefrom langchain_openai import OpenAIEmbeddingsindex = faiss.IndexFlatL2(len(OpenAIEmbeddings().embed_query("hello world")))vector_store = FAISS(embedding_function=OpenAIEmbeddings(),index=index,docstore=InMemoryDocstore(),index_to_docstore_id={})添加文档:.. code-block:: pythonfrom langchain_core.documents import Documentdocument_1 = Document(page_content="foo", metadata={"baz": "bar"})document_2 = Document(page_content="thud", metadata={"bar": "baz"})document_3 = Document(page_content="我将被删除 :(")documents = [document_1, document_2, document_3]ids = ["1", "2", "3"]vector_store.add_documents(documents=documents, ids=ids)删除文档:.. code-block:: pythonvector_store.delete(ids=["3"])搜索:.. code-block:: pythonresults = vector_store.similarity_search(query="thud", k=1)for doc in results:print(f"* {doc.page_content} [{doc.metadata}]").. code-block:: python* thud [{'bar': 'baz'}]带过滤条件的搜索:.. code-block:: pythonresults = vector_store.similarity_search(query="thud", k=1, filter={"bar": "baz"})for doc in results:print(f"* {doc.page_content} [{doc.metadata}]").. code-block:: python* thud [{'bar': 'baz'}]带分数的搜索:.. code-block:: pythonresults = vector_store.similarity_search_with_score(query="qux", k=1)for doc, score in results:print(f"* [SIM={score:3f}] {doc.page_content} [{doc.metadata}]").. code-block:: python* [SIM=0.335304] foo [{'baz': 'bar'}]异步操作:.. code-block:: python# 添加文档# await vector_store.aadd_documents(documents=documents, ids=ids)# 删除文档# await vector_store.adelete(ids=["3"])# 搜索# results = vector_store.asimilarity_search(query="thud", k=1)# 带分数的搜索results = await vector_store.asimilarity_search_with_score(query="qux", k=1)for doc, score in results:print(f"* [SIM={score:3f}] {doc.page_content} [{doc.metadata}]").. code-block:: python* [SIM=0.335304] foo [{'baz': 'bar'}]用作检索器:.. code-block:: pythonretriever = vector_store.as_retriever(search_type="mmr",search_kwargs={"k": 1, "fetch_k": 2, "lambda_mult": 0.5},)retriever.invoke("thud").. code-block:: python[Document(metadata={'bar': 'baz'}, page_content='thud')]
FAISS类的示意结构
特别关注FAISS继承了VectorStore类。
class FAISS(VectorStore):def __init__(self,embedding_function: Union[Callable[[str], List[float]],Embeddings,],index: Any,docstore: Docstore,index_to_docstore_id: Dict[int, str],relevance_score_fn: Optional[Callable[[float], float]] = None,normalize_L2: bool = False,distance_strategy: DistanceStrategy = DistanceStrategy.EUCLIDEAN_DISTANCE,):...@propertydef embeddings(self) -> Optional[Embeddings]:...def _embed_documents(self, texts: List[str]) -> List[List[float]]:...async def _aembed_documents(self, texts: List[str]) -> List[List[float]]:...def _embed_query(self, text: str) -> List[float]:...def __add(self,texts: Iterable[str],embeddings: Iterable[List[float]],metadatas: Optional[Iterable[dict]] = None,ids: Optional[List[str]] = None,) -> List[str]:...def add_texts(self,texts: Iterable[str],metadatas: Optional[List[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> List[str]:...async def aadd_texts(self,texts: Iterable[str],metadatas: Optional[List[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> List[str]:...def add_embeddings(self,text_embeddings: Iterable[Tuple[str, List[float]]],metadatas: Optional[List[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> List[str]:...def similarity_search_with_score_by_vector(self,embedding: List[float],k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:...async def asimilarity_search_with_score_by_vector(self,embedding: List[float],k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:...def similarity_search_with_score(self,query: str,k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:...async def asimilarity_search_with_score(self,query: str,k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:...def similarity_search_by_vector(self,embedding: List[float],k: int = 4,filter: Optional[Dict[str, Any]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Document]:...async def asimilarity_search_by_vector(self,embedding: List[float],k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Document]:...def similarity_search(self,query: str,k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Document]:...async def asimilarity_search(self,query: str,k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Document]:...def max_marginal_relevance_search_with_score_by_vector(self,embedding: List[float],*,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,filter: Optional[Union[Callable, Dict[str, Any]]] = None,) -> List[Tuple[Document, float]]:...async def amax_marginal_relevance_search_with_score_by_vector(self,embedding: List[float],*,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,filter: Optional[Union[Callable, Dict[str, Any]]] = None,) -> List[Tuple[Document, float]]:...def max_marginal_relevance_search_by_vector(self,embedding: List[float],k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,filter: Optional[Union[Callable, Dict[str, Any]]] = None,**kwargs: Any,) -> List[Document]:...async def amax_marginal_relevance_search_by_vector(self,embedding: List[float],k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,filter: Optional[Union[Callable, Dict[str, Any]]] = None,**kwargs: Any,) -> List[Document]:...def max_marginal_relevance_search(self,query: str,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,filter: Optional[Union[Callable, Dict[str, Any]]] = None,**kwargs: Any,) -> List[Document]:...async def amax_marginal_relevance_search(self,query: str,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,filter: Optional[Union[Callable, Dict[str, Any]]] = None,**kwargs: Any,) -> List[Document]:...def delete(self, ids: Optional[List[str]] = None, **kwargs: Any) -> Optional[bool]:...def merge_from(self, target: FAISS) -> None:...@classmethoddef __from(cls,texts: Iterable[str],embeddings: List[List[float]],embedding: Embeddings,metadatas: Optional[Iterable[dict]] = None,ids: Optional[List[str]] = None,normalize_L2: bool = False,distance_strategy: DistanceStrategy = DistanceStrategy.EUCLIDEAN_DISTANCE,**kwargs: Any,) -> FAISS:...@classmethoddef from_texts(cls,texts: List[str],embedding: Embeddings,metadatas: Optional[List[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> FAISS:...@classmethodasync def afrom_texts(cls,texts: list[str],embedding: Embeddings,metadatas: Optional[List[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> FAISS:...@classmethoddef from_embeddings(cls,text_embeddings: Iterable[Tuple[str, List[float]]],embedding: Embeddings,metadatas: Optional[Iterable[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> FAISS:...@classmethodasync def afrom_embeddings(cls,text_embeddings: Iterable[Tuple[str, List[float]]],embedding: Embeddings,metadatas: Optional[Iterable[dict]] = None,ids: Optional[List[str]] = None,**kwargs: Any,) -> FAISS:...def save_local(self, folder_path: str, index_name: str = "index") -> None:...@classmethoddef load_local(cls,folder_path: str,embeddings: Embeddings,index_name: str = "index",*,allow_dangerous_deserialization: bool = False,**kwargs: Any,) -> FAISS:...def serialize_to_bytes(self) -> bytes:"""Serialize FAISS index, docstore, and index_to_docstore_id to bytes."""return pickle.dumps((self.index, self.docstore, self.index_to_docstore_id))@classmethoddef deserialize_from_bytes(cls,serialized: bytes,embeddings: Embeddings,*,allow_dangerous_deserialization: bool = False,**kwargs: Any,) -> FAISS:...def _select_relevance_score_fn(self) -> Callable[[float], float]:...def _similarity_search_with_relevance_scores(self,query: str,k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:...async def _asimilarity_search_with_relevance_scores(self,query: str,k: int = 4,filter: Optional[Union[Callable, Dict[str, Any]]] = None,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:...@staticmethoddef _create_filter_func(filter: Optional[Union[Callable, Dict[str, Any]]],) -> Callable[[Dict[str, Any]], bool]:...def filter_func_cond(field: str, condition: Union[Dict[str, Any], List[Any], Any]) -> Callable[[Dict[str, Any]], bool]:...def filter_func(filter: Dict[str, Any]) -> Callable[[Dict[str, Any]], bool]:...def get_by_ids(self, ids: Sequence[str], /) -> list[Document]:docs = [self.docstore.search(id_) for id_ in ids]return [doc for doc in docs if isinstance(doc, Document)]
FAISS类结构示意图
home > anaconda3 > envs > langchain > lib > python3.10 > site-packages > langchain_community > vectorstores > .faiss.py > FAISS
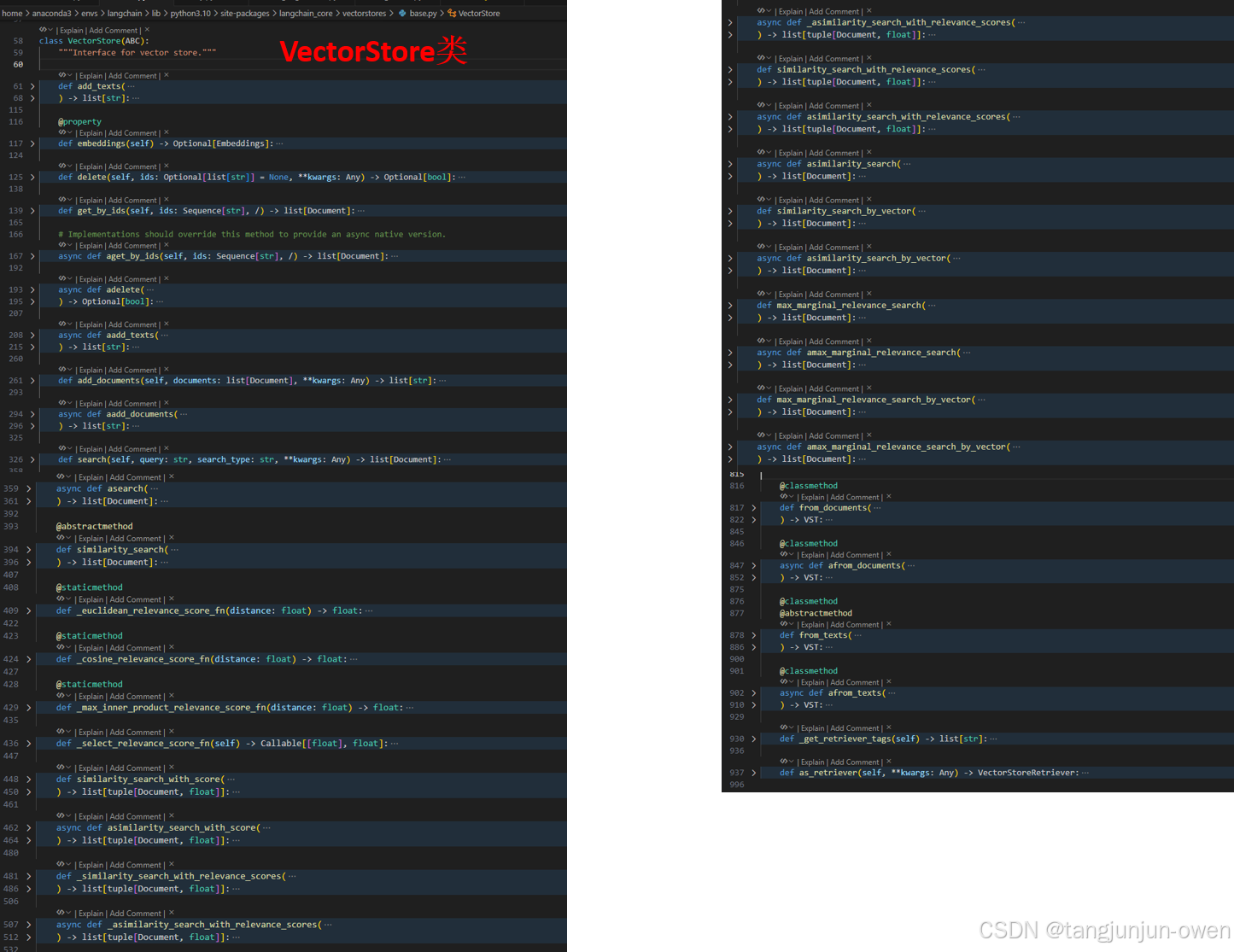
3、VectorStore类源码解读
这是向量相关的基类,我们可以大致了解其基类的方法。这个也很重要。其代码示意结构如下:
class VectorStore(ABC):"""Interface for vector store."""def add_texts(self,texts: Iterable[str],metadatas: Optional[list[dict]] = None,*,ids: Optional[list[str]] = None,**kwargs: Any,) -> list[str]:@propertydef embeddings(self) -> Optional[Embeddings]:def delete(self, ids: Optional[list[str]] = None, **kwargs: Any) -> Optional[bool]:def get_by_ids(self, ids: Sequence[str], /) -> list[Document]:async def aget_by_ids(self, ids: Sequence[str], /) -> list[Document]:async def adelete(self, ids: Optional[list[str]] = None, **kwargs: Any) -> Optional[bool]:async def aadd_texts(self,texts: Iterable[str],metadatas: Optional[list[dict]] = None,*,ids: Optional[list[str]] = None,**kwargs: Any,) -> list[str]:def add_documents(self, documents: list[Document], **kwargs: Any) -> list[str]:async def aadd_documents(self, documents: list[Document], **kwargs: Any) -> list[str]:def search(self, query: str, search_type: str, **kwargs: Any) -> list[Document]:async def asearch(self, query: str, search_type: str, **kwargs: Any) -> list[Document]:@abstractmethoddef similarity_search(self, query: str, k: int = 4, **kwargs: Any) -> list[Document]:@staticmethoddef _euclidean_relevance_score_fn(distance: float) -> float:@staticmethoddef _cosine_relevance_score_fn(distance: float) -> float:"""Normalize the distance to a score on a scale [0, 1]."""return 1.0 - distance@staticmethoddef _max_inner_product_relevance_score_fn(distance: float) -> float:def _select_relevance_score_fn(self) -> Callable[[float], float]:def similarity_search_with_score(self, *args: Any, **kwargs: Any) -> list[tuple[Document, float]]:async def asimilarity_search_with_score(self, *args: Any, **kwargs: Any) -> list[tuple[Document, float]]:def _similarity_search_with_relevance_scores(self,query: str,k: int = 4,**kwargs: Any,) -> list[tuple[Document, float]]:async def _asimilarity_search_with_relevance_scores(self,query: str,k: int = 4,**kwargs: Any,) -> list[tuple[Document, float]]:def similarity_search_with_relevance_scores(self,query: str,k: int = 4,**kwargs: Any,) -> list[tuple[Document, float]]:async def asimilarity_search_with_relevance_scores(self,query: str,k: int = 4,**kwargs: Any,) -> list[tuple[Document, float]]:async def asimilarity_search(self, query: str, k: int = 4, **kwargs: Any) -> list[Document]:def similarity_search_by_vector(self, embedding: list[float], k: int = 4, **kwargs: Any) -> list[Document]: async def asimilarity_search_by_vector(self, embedding: list[float], k: int = 4, **kwargs: Any) -> list[Document]:def max_marginal_relevance_search(self,query: str,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,**kwargs: Any,) -> list[Document]: async def amax_marginal_relevance_search(self,query: str,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,**kwargs: Any,) -> list[Document]:def max_marginal_relevance_search_by_vector(self,embedding: list[float],k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,**kwargs: Any,) -> list[Document]:async def amax_marginal_relevance_search_by_vector(self,embedding: list[float],k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5,**kwargs: Any,) -> list[Document]:@classmethoddef from_documents(cls: type[VST],documents: list[Document],embedding: Embeddings,**kwargs: Any,) -> VST:@classmethodasync def afrom_documents(cls: type[VST],documents: list[Document],embedding: Embeddings,**kwargs: Any,) -> VST:@classmethod@abstractmethoddef from_texts(cls: type[VST],texts: list[str],embedding: Embeddings,metadatas: Optional[list[dict]] = None,*,ids: Optional[list[str]] = None,**kwargs: Any,) -> VST:@classmethodasync def afrom_texts(cls: type[VST],texts: list[str],embedding: Embeddings,metadatas: Optional[list[dict]] = None,*,ids: Optional[list[str]] = None,**kwargs: Any,) -> VST:def _get_retriever_tags(self) -> list[str]:"""Get tags for retriever.""" def as_retriever(self, **kwargs: Any) -> VectorStoreRetriever:
其图像示意结构如下:
四、构建一个完整RAG实现检索的代码Demo
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import Docx2txtLoader
from langchain_community.vectorstores import FAISS# 加载Word文档
def load_word_document(file_path):# 创建一个Docx2txtLoader对象,用于加载指定路径的Word文档loader = Docx2txtLoader(file_path)# 调用loader对象的load方法,加载文档内容并返回return loader.load()# 初始化文本分割器
def init_text_splitter(**kwargs):# separator="\n", chunk_size=1000, chunk_overlap=200separator,chunk_size,chunk_overlap = kwargs.get("separator","\n"),kwargs.get("chunk_size",1000),kwargs.get("chunk_overlap",200)text_splitter = CharacterTextSplitter(separator=separator, chunk_size=chunk_size, chunk_overlap=chunk_overlap)return text_splitter# 创建向量存储并初始化检索器
def get_texts_split(documents, **kwargs):# 定义一个函数,用于将文档列表分割成文本片段# 参数documents是一个包含多个文档的列表# 参数kwargs是一个关键字参数字典,用于传递给文本分割器的初始化函数text_splitter = init_text_splitter(**kwargs)# 调用init_text_splitter函数,传入kwargs参数字典,初始化一个文本分割器对象# init_text_splitter函数的具体实现不在当前代码中,它可能是用于配置和创建文本分割器的函数split_texts = text_splitter.split_documents(documents)# 使用初始化好的文本分割器对象,调用其split_documents方法,将传入的文档列表进行分割# split_documents方法的具体实现也不在当前代码中,它可能是用于将文档分割成多个文本片段的方法return split_texts# from faiss import write_index, read_index
def create_vector(split_texts, embeddings):# 使用FAISS库从文档列表和嵌入向量创建一个向量存储# 参数split_texts: 文档列表,每个文档已经被分割成单独的文本片段# 参数embeddings: 嵌入向量,用于将文本片段转换为向量表示vector_store = FAISS.from_documents(split_texts, embeddings)# 返回创建的向量存储return vector_storedef create_retriever(vector_store): # 调用vector_store对象的as_retriever方法,将vector_store转换为一个检索器retriever = vector_store.as_retriever()# 返回创建的检索器对象return retriever
def save_vector_store(vector_store,save_path):# save_path = "path/to/your/index.faiss"vector_store.save_local(save_path)return save_path
def load_vector_store(save_path,embeddings):# 注释:定义一个函数load_vector_store,用于加载向量存储# 参数save_path:字符串类型,表示向量存储文件的路径# 参数embeddings:嵌入对象,用于向量存储的检索和索引# 注释:注释掉的代码,原本用于指示用户设置向量存储文件的路径# load_path = "path/to/your/index.faiss"# 注释:使用FAISS库的load_local方法加载本地向量存储# save_path:向量存储文件的路径# embeddings:嵌入对象,用于向量存储的检索和索引vector_store = FAISS.load_local(save_path, embeddings)# 注释:返回加载的向量存储对象return vector_storedef create_vector_store_and_retriever(documents, embeddings_model):# 测试一个文件向量化与检索# 定义文本分割的参数kwargs = {"separator":"\n","chunk_size":1000,"chunk_overlap":200}# 调用get_texts_split函数,将文档分割成小块文本split_texts = get_texts_split(documents, **kwargs)# 调用create_vector函数,将分割后的文本转换为向量存储vector_store = create_vector(split_texts, embeddings_model)# 调用create_retriever函数,创建一个检索器,用于从向量存储中检索信息retriever = create_retriever(vector_store)# 返回创建好的检索器return retriever# 写一个检索demo
def retriever_demo(embeddings_model):# 定义Word文档的路径word_file_path = "/langchain/langchain_demo/file/demo.docx"# 调用load_word_document函数加载Word文档内容documents = load_word_document(word_file_path)print(documents)# 使用一个文件内容向量化与检索测试# 调用create_vector_store_and_retriever函数创建向量存储和检索器retriever = create_vector_store_and_retriever(documents, embeddings_model)# 测试检索# 定义查询问题query = "文档主要内容是什么?"# 调用retriever的get_relevant_documents方法获取与查询相关的文档results = retriever.get_relevant_documents(query)# 返回检索结果return results# 主函数
if __name__ == "__main__":# 使用一个文件内容向量化与检索测试word_file_path = "/langchain/langchain_demo/file/demo.docx" # 替换为你的Word文件路径from EmbedModelOpenAI import load_embed_model_localembeddings_model = load_embed_model_local() # 加载embed模型,这个再我之前章节有介绍res = retriever_demo(embeddings_model)print(res)# documents = load_word_document(word_file_path)# retriever = create_vector_store_and_retriever(documents, embeddings_model)相关文章:
)
第三章:langchain加载word文档构建RAG检索教程(基于FAISS库为例)
文章目录 前言一、载入文档(word)1、文档载入代码2、文档载入数据解读(Docx2txtLoader方法)输入数据输出文本内容 3、Docx2txtLoader底层代码文档读取解读Docx2txtLoader底层源码示例文档读取输出结果 二、文本分割1、文本分割代码…...

球速最快的是哪种球类运动·棒球1号位
在体育运动中,球速最快的项目与棒球结合来看,可以分两个角度解读: 一、球速最快的运动项目 羽毛球以426公里/小时(吉尼斯纪录)的杀球速度位列榜首,远超棒球投球速度。其极速源于: 羽毛球拍甜区…...

TVM中Python如何和C++联调?
1. 编译 Debug 版本 # 在项目根目录下创建构建目录(若尚未创建) mkdir -p build && cd build# 配置 Debug 构建 cmake -DCMAKE_BUILD_TYPEDebug ..# 编译(根据 CPU 核心数调整 -j 参数) make -j$(nproc)2. 获取 Python 进…...
从零实现基于Transformer的英译汉任务
1. model.py(用的是上一篇文章的代码:从0搭建Transformer-CSDN博客) import torch import torch.nn as nn import mathclass PositionalEncoding(nn.Module):def __init__ (self, d_model, dropout, max_len5000):super(PositionalEncoding,…...

在 PyTorch 中借助 GloVe 词嵌入完成情感分析
一. Glove 词嵌入原理 GloVe是一种学习词嵌入的方法,它希望拟合给定上下文单词i时单词j出现的次数。使用的误差函数为: 其中N是词汇表大小,是线性层参数, 是词嵌入。f(x)是权重项,用于平衡不同频率的单词对误差的影响…...

大数据应用开发和项目实战-电商双11美妆数据分析
数据初步了解 (head出现,意味着只出现前5行,如果只出现后面几行就是tail) info shape describe 数据清洗 重复值处理 这个重复值是否去掉要看实际情况,比如说:昨天卖了5瓶七喜,今天卖了5瓶七…...

web服务
一、nginx的安装与启用 nginx的安装 开源版本的Nginx官网:http://nginx.org Nginx在安装的过程中可以选择源码安装也可以选择使用软件包安装 源码安装下载相应的源码压缩包解压后编译完成安装 软件安装包可以使用rpm或者apt命令进行安装,也可以使用dnf…...
 或分片集群 (Sharded Cluster)?)
在Spring Boot 中如何配置MongoDB的副本集 (Replica Set) 或分片集群 (Sharded Cluster)?
在 Spring Boot 中配置 MongoDB 副本集 (Replica Set) 或分片集群 (Sharded Cluster) 非常相似,主要区别在于连接字符串 (URI) 中提供的主机列表和一些特定选项。 最常的方式是使用 spring.data.mongodb.uri 属性配置连接字符串。 1. 连接到 MongoDB 副本集 (Repl…...

Oracle中游标和集合的定义查询及取值
在 Oracle 存储过程中,使用游标处理自定义数据行类型时,可以通过 定义记录类型(RECORD) 和 游标(CURSOR) 结合实现。 1. 定义自定义记录类型 使用 TYPE … IS RECORD 定义自定义行数据类型: DE…...

Python企业级MySQL数据库开发实战指南
简介 Python与MySQL的完美结合是现代Web应用和数据分析系统的基石,能够创建高效稳定的企业级数据库解决方案。本文将从零开始,全面介绍如何使用Python连接MySQL数据库,设计健壮的表结构,实现CRUD操作,并掌握连接池管理、事务处理、批量操作和防止SQL注入等企业级开发核心…...

【LLM】Open WebUI 使用指南:详细图文教程
Open WebUI 是一个开源的、可扩展且用户友好的自托管 AI 平台,专为生成式人工智能模型交互而设计。 Open WebUI 旨在为用户提供一个简单易用、功能强大且高度定制化的界面,使其能够轻松与各种 AI 模型(如文本生成、图像生成、语音识别等)进行交互。 一、安装与初始化配置 扩…...

前端封装框架依赖管理全攻略:构建轻量可维护的私有框架
前端封装框架依赖管理全攻略:构建轻量可维护的私有框架 前言 在自研前端框架的开发中,依赖管理是决定框架可用性的关键因素。不合理的依赖设计会导致: 项目体积膨胀:重复依赖使最终打包体积增加30%版本地狱:不同项目…...

Listremove数据时报错:Caused by: java.lang.UnsupportedOperationException
看了二哥的foreach陷阱后,自己也遇见了需要循环删除元素的情况,立马想到了当时自己阴差阳错的避开所有坑的解决方式:先倒序遍历,再删除。之前好使,但是这次不好使了,报错Caused by: java.lang.UnsupportedO…...

互联网大厂Java求职面试:云原生与AI融合下的系统设计挑战-1
互联网大厂Java求职面试:云原生与AI融合下的系统设计挑战-1 在当今云计算和人工智能迅猛发展的背景下,互联网大厂对Java工程师的要求已从传统的单体架构和业务逻辑处理,转向了更复杂的云原生架构设计、AI模型集成以及高并发系统的性能优化能…...
:屏障(Barrier))
并发设计模式实战系列(16):屏障(Barrier)
🌟 大家好,我是摘星! 🌟 今天为大家带来的是并发设计模式实战系列,第十六章屏障(Barrier),废话不多说直接开始~ 目录 一、核心原理深度拆解 1. 屏障的同步机制 2. 关键参数 二…...

pywinauto通过图片定位怎么更加精准的识别图片?
pywinauto通过图片定位怎么更加精准的识别图片? 可以使用置信度的配置,添加了对比图片相似程度达到多少就可以认为是合适的定位图片 import time from time import sleep from pywinauto.application import Application from pywinauto.keyboard impo…...
)
Spring Cloud Stream集成RocketMQ(kafka/rabbitMQ通用)
什么是Spring Cloud Stream Spring Cloud Stream 是 Spring 生态系统中的一个框架,用于简化构建消息驱动微服务的开发和集成。它通过抽象化的方式将消息中间件(如 RabbitMQ、Kafka、RocketMQ 等)的复杂通信逻辑封装成简单的编程模型…...

基于docker使用showdoc搭建API开发文档服务器
以下是基于 Docker 快速搭建 ShowDoc API 文档服务器的完整指南,包含优化配置和常见问题解决方案: 1. 快速部署方案 # 创建数据目录(确保权限) mkdir -p /showdoc_data/html && chmod 777 -R /showdoc_data# 一键启动容器…...
 视觉语言模型的技术背景、应用场景和商业前景(Grok3 DeepSearch模式回答))
Vision-Language Models (VLMs) 视觉语言模型的技术背景、应用场景和商业前景(Grok3 DeepSearch模式回答)
prompt: 你是一位文笔精湛、十分专业的技术博客作者,你将从技术背景、应用场景和商业前景等多个维度去向读者介绍Vision-Language Models 关键要点 研究表明,视觉语言模型(VLMs)是多模态AI系统,能同时处理视觉和文本数…...

OpenAI大变革!继续与微软等,以非营利模式冲击AGI
今天凌晨2点,OpenAI宣布,将继续由非营利组织控制;现有的营利性实体将转变为一家公共利益公司;非营利组织将控制该公共利益公司,并成为其重要的持股方。 这也就是说OpenAI曾在去年提到的由非营利性转变成营利性公司&am…...

Ubuntu打开中文文本乱码
文章目录 中文乱码问题修复乱码系统字符编码修改文本编码修改vim乱码 utf-8编码原理特点应用场景与其他编码的转换 iso-8859-1基本信息字符涵盖应用场景与其他编码的关系 ubuntu打开文本出现乱码,可能是编码没设置对。 中文乱码问题 使用vim打开文本,或…...

车载通信网络安全:挑战与解决方案
1. 简介 当今时代见证了车载汽车技术的巨大发展,因为现代智能汽车可以被视为具有出色外部基础设施连接能力的信息物理系统 [ 1 ]。车载技术支持的现代智能汽车不应被视为类似于机械系统,而是由数百万行复杂代码组成的集成架构,可为车内乘客提…...

【Linux系统】读写锁
读者写者问题 重点 读者写者问题是并发编程中的经典问题,主要研究多个进程或线程对共享数据进行读和写操作时如何实现同步和互斥,以保证数据的一致性和操作的正确性 。 问题核心要点 同步与互斥:需要确保多个读者可以同时读共享数据&#…...

springBoot中自定义一个validation注解,实现指定枚举值校验
缘由 在后台写接口的时候,经常会出现dto某个属性是映射到一个枚举的情况。有时候还会出现只能映射到枚举类中部分枚举值的情况。以前都是在service里面自行判断,很多地方代码冗余,所以就想着弄一个自定义的validation注解来实现。 例如下面某…...

【Python】--装饰器
装饰器(Decorator)本质上是一个返回函数的函数 主要作用是:在不修改原函数代码的前提下,给函数增加额外的功能 比如:增加业务,日志记录、权限验证、执行时间统计、缓存等场景 my_decorator def func():pas…...

排序算法——堆排序
一、介绍 「堆排序heapsort」是一种基于堆数据结构实现的高效排序算法。我们可以利用已经学过的“建堆操作”和“元素出堆操作”实现堆排序。 1. 输入数组并建立小顶堆,此时最小元素位于堆顶。 2. 不断执行出堆操作,依次记录出堆元素,即可得…...

Day111 | 灵神 | 二叉树 | 验证二叉搜索树
Day111 | 灵神 | 二叉树 | 验证二叉搜索树 98.验证二叉搜索树 98. 验证二叉搜索树 - 力扣(LeetCode) 方法一:前序遍历 递归函数传入合法的左右边界,只有当前结点是合法的边界,才是二叉搜索树,否则就返回…...

软考-软件设计师中级备考 13、刷题 数据结构
倒计时17天时间不多了,数据库、UML、等知识点有基础直接略过,法律全靠考前的一两天刷题,英语直接放弃。 一、数据结构:链表、栈、队列、数组、哈希表、树、图 1、关于链表操作,说法正确的是: A)新增一个头…...

【5G通信】天线调整
在天线工程中,机械下倾角、电子下倾角和数字下倾角是调整天线波束指向的不同技术手段,其核心区别在于实现方式和灵活性: 1. 机械下倾角(Mechanical Downtilt) 定义:通过物理调整天线的安装角度,…...

Kafka的Log Compaction原理是什么?
Kafka的Log Compaction(日志压缩)是一种独特的数据保留策略,其核心原理是保留每个key的最新有效记录。以下是关键原理分点说明: 1. 键值保留机制 通过扫描所有消息的key,仅保留每个key对应的最新value值。例如&#…...
·内存管理机制、优先级继承机制以及优先级翻转)
嵌入式面试八股文(十四)·内存管理机制、优先级继承机制以及优先级翻转
目录 1. 内存管理算法(五种内存管理机制) 1.1 heap_1.c 1.2 heap_2.c 1.3 heap_3.c 1.4 heap_4.c 1.5 heap_5.c 1.6 总结 2. STM32通知寄存器有哪些? 2.1 核心寄存器组(Cortex-M) 2.2 特殊功能寄存…...

深度剖析:可视化如何重塑驾驶舱信息交互模式
为什么你开车时总觉得“信息太多却抓不住重点”? 今天的汽车早已不是单纯的交通工具,而是一个高度集成的信息终端。从导航、油耗、胎压到自动驾驶提示,各种数据不断涌进驾驶舱。 但问题也随之而来: 关键信息被淹没在一堆图标里…...

app根据蓝牙名字不同,匹配不同的产品型号,显示对应的UI界面
在开发一个 App 时,如果希望根据蓝牙设备名称(Bluetooth Name)的不同,自动匹配不同的产品型号,并显示对应的 UI 界面,可以按照以下思路来实现: ✅ 功能目标 扫描并连接蓝牙设备;获取…...

数据结构 --- 栈
1.栈的初始化 2.入栈 3.出栈 4.取出栈顶元素 5.获取栈中有效元素个数 6.栈的销毁 栈:⼀种特殊的线性表,其只允许在固定的⼀端进⾏插⼊和删除元素操作。进⾏数据插⼊和删除操作 的⼀端称为栈顶,另⼀端称为栈底。栈中的数据元素遵守后进先…...
-第三十七天)
37-算法打卡-栈与队列-滑动窗口最大值-leetcode(239)-第三十七天
1 题目地址 239. 滑动窗口最大值 - 力扣(LeetCode)239. 滑动窗口最大值 - 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。返回 滑…...

【原创分享】魔音变声器内含超多语音包实时变声
魔音变声器,一款专业的调音变声器软件 亲测可使用所有功能[真棒] 去除所有广告 ————————————【下 载 地 址】———————————— 【获取方法1】:https://pan.xunlei.com/s/VOP_TXtKNlevTgYvIlxmmJquA1?pwd8vpi# ————————————【下 …...
——线性表的顺序表示和实现)
数据结构(一)——线性表的顺序表示和实现
一、线性表的定义 由n(n>0)个数据特性相同的元素构成的有限序列称为线性表,(n0)的时候被称为空表。 一个数据元素可以是简单的一个数据,一个符号,也可以是复杂的若干个数据项的组合。 二、线性表的类型定义 s线性表是由n(n≥0)个相同类…...
)
Winform(12.控件讲解)
ChildForm窗口: ChildForm代码: using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms; namespac…...
》)
Python 10天冲刺 《元编程(Meta-programming)》
Python 的元编程(Meta-programming)是指在程序运行期间动态生成、修改或操作代码的技术。它允许开发者通过代码控制代码的行为,从而实现灵活、可扩展和抽象化的编程模式。Python 提供了多种元编程工具,包括装饰器、元类、动态导入…...

Android开发-创建、运行、调试App工程
在移动应用开发的世界里,Android平台凭借其开放性和广泛的设备支持,成为了许多开发者的选择。而要成为一名合格的Android开发者,掌握如何创建、运行以及调试应用程序是必不可少的基础技能。本文将详细介绍如何使用Android Studio完成这些任务…...
:通过读取PE文件获取EXE或者DLL的依赖)
系统级编程(二):通过读取PE文件获取EXE或者DLL的依赖
PE文件 Windows的PE文件(Portable Executable)是一种专为Windows操作系统设计的标准可执行文件格式,用于存储和管理可执行程序、动态链接库(DLL)、驱动程序等二进制文件。PE文件格式自Windows NT 3.1引入以来,已成为Windows平台上所有可执行文件的标准格式,并广泛应用于…...

Linux主机时间设置操作指南及时间异常影响
一、Linux主机时间设置命令操作指南 1. 查看当前系统时间与时区 查看当前时间与时区:timedatectl # 显示详细时间与时区信息(systemd系统适用) date # 查看当前系统时间 hwclock --show # 查看硬件时…...

GPS定位方案
目录 一、常用的GPS定位方案包括: 二、主流品牌及热销型号 三、常用GPS算法及核心逻辑: 一、基础定位算法 二、高精度算法 三、辅助优化算法 四、信号处理底层算法 四、基本原理(想自己写算法的琢磨一下原理) 一、常用的GP…...

应对联网汽车带来的网络安全挑战
数字化加速正在彻底改变全球各行各业,而汽车行业更是走在了前列。目前,全球自动驾驶汽车保有量约为4860万辆,预计到2024年将增长至5420万辆。 智能汽车的崛起无疑令人兴奋,但也带来了一系列问题。为了保护客户免受新的威胁,汽车行业必须做出一系列考量:针对自动驾驶、网…...

人工智能与生命科学的深度融合:破解生物医学难题,引领未来科技革命
引言 随着人工智能技术的飞速发展,生命科学领域迎来了前所未有的变革。从药物研发到疾病预测,从个性化医疗到基因组学,AI的深度融入不仅加速了生物医学的进步,还在多个领域打破了传统科学研究的局限,开创了新的医学前沿…...
:4326和3857两种坐标系有什么区别?各自用途是什么?)
DeepSeek智能时空数据分析(七):4326和3857两种坐标系有什么区别?各自用途是什么?
序言:时空数据分析很有用,但是GIS/时空数据库技术门槛太高 时空数据分析在优化业务运营中至关重要,然而,三大挑战仍制约其发展:技术门槛高,需融合GIS理论、SQL开发与时空数据库等多领域知识;空…...

Qt/C++面试【速通笔记七】—Qt中为什么new QWidget不需要手动调用delete?
在Qt的开发中,管理内存是一个非常重要的话题,特别是在使用QWidget这类窗口组件时,很多开发者会遇到一个问题:“为什么我使用new QWidget创建的窗口对象不需要手动调用delete进行销毁?”。 1. 父子关系机制:…...

Super-vlan
Super VLAN(VLAN聚合)的理论与配置 1. 基本概念 Super VLAN(超级VLAN)是一种VLAN聚合技术,主要用于解决传统VLAN划分中IP地址浪费的问题。其核心思想是将多个Sub VLAN(子VLAN)聚合到一个Super …...

C——函数
一、函数的概念 数学中我们其实就⻅过函数的概念,⽐如:⼀次函数 y kx b ,k和b都是常数,给⼀个任意的 x,就得到⼀个y值。 其实在C语⾔也引⼊函数(function)的概念,有些翻译为&…...

5.6刷题并查集
P1551 亲戚 #include<bits/stdc.h> using namespace std; const int N 5010; int f[N]; int find(int x){if(f[x] x)return x;return f[x] find(f[x]); } void solve(){int n, m, p; cin >> n >> m >> p;for(int i 1; i < n; i)f[i] i;for(in…...