day17 天池新闻数据KMeans、DBSCAN 与层次聚类的对比
在数据分析中,聚类是一种常见的无监督学习方法,用于将数据划分为不同的组或簇。本文将通过news数据集(news.csv),使用 KMeans、DBSCAN 和层次聚类三种方法进行聚类分析,并对比它们的性能。
数据来源于天池 新闻推荐
数据准备
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, MiniBatchKMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 加载数据
data = pd.read_csv('news.csv') # 替换为你的数据文件路径# 提取特征
features = ['user_id', 'click_timestamp', 'click_environment', 'click_deviceGroup', 'click_os', 'click_country', 'click_region', 'click_referrer_type']
X = data[features]# 将时间戳转换为数值型特征(例如,提取小时数)
X['click_hour'] = pd.to_datetime(X['click_timestamp'], unit='ms').dt.hour# 删除原始时间戳列
X = X.drop(columns=['click_timestamp'])# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)k-means聚类
# 选择部分数据进行聚类
sample_size = 1000 # 选择 1000 个样本
X_scaled_sample = X_scaled[:sample_size]# 使用 PCA 降维
pca = PCA(n_components=5) # 保留 10 个主成分
X_scaled_pca = pca.fit_transform(X_scaled_sample)# 评估不同 k 值下的指标
k_range = range(2, 6) # 测试 k 从 2 到 5
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42)kmeans_labels = kmeans.fit_predict(X_scaled_pca)inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)silhouette = silhouette_score(X_scaled_pca, kmeans_labels) # 轮廓系数silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled_pca, kmeans_labels) # CH 指数ch_scores.append(ch)db = davies_bouldin_score(X_scaled_pca, kmeans_labels) # DB 指数db_scores.append(db)print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")# 绘制评估指标图
plt.figure(figsize=(15, 10))# 肘部法则图(Inertia)
plt.subplot(2, 2, 1)
plt.plot(k_range, inertia_values, marker='o')
plt.title('肘部法则确定最优聚类数 k(惯性,越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('惯性')
plt.grid(True)# 轮廓系数图
plt.subplot(2, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o', color='orange')
plt.title('轮廓系数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 3)
plt.plot(k_range, ch_scores, marker='o', color='green')
plt.title('Calinski-Harabasz 指数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 4)
plt.plot(k_range, db_scores, marker='o', color='red')
plt.title('Davies-Bouldin 指数确定最优聚类数 k(越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()k=2, 惯性: 3143.25, 轮廓系数: 0.635, CH 指数: 295.74, DB 指数: 0.539
k=3, 惯性: 2125.48, 轮廓系数: 0.513, CH 指数: 457.16, DB 指数: 0.800
k=4, 惯性: 1463.95, 轮廓系数: 0.461, CH 指数: 592.08, DB 指数: 0.757
k=5, 惯性: 974.44, 轮廓系数: 0.514, CH 指数: 791.42, DB 指数: 0.665
k=6, 惯性: 778.98, 轮廓系数: 0.545, CH 指数: 841.08, DB 指数: 0.733
k=7, 惯性: 696.43, 轮廓系数: 0.539, CH 指数: 802.81, DB 指数: 0.719
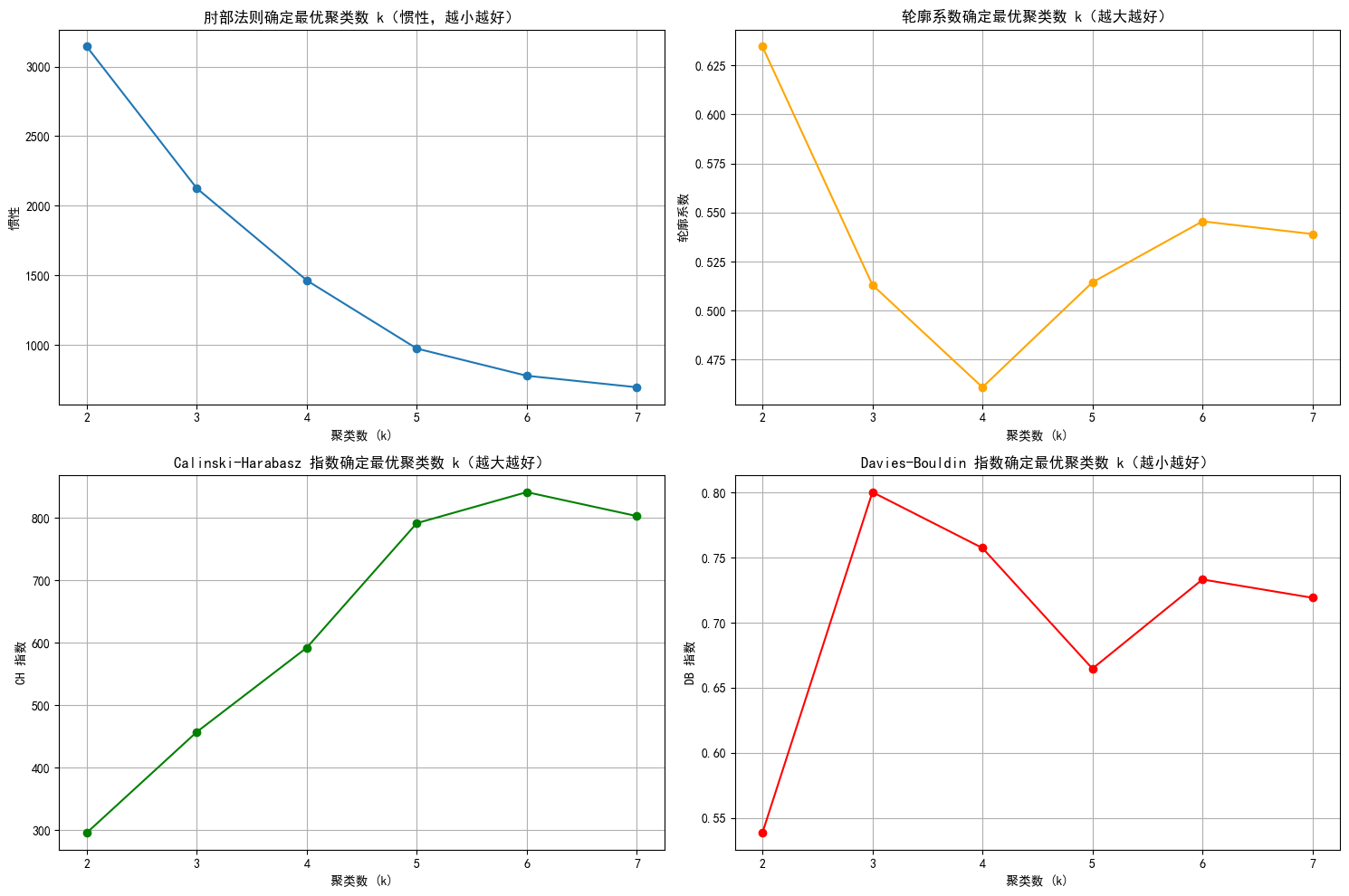
综上,选择3比较合适。
# 提示用户选择 k 值
selected_k =3# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())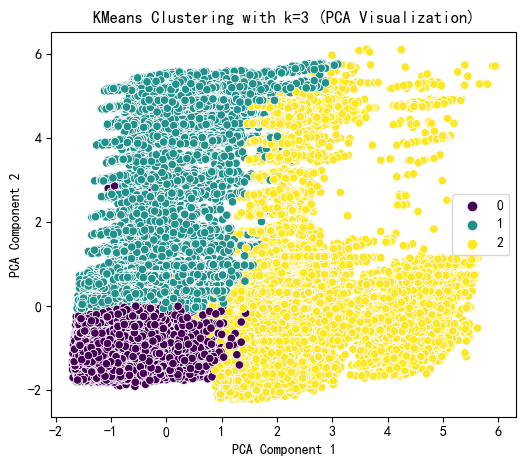
KMeans Cluster labels (k=3) added to X:
KMeans_Cluster
1 460706 0 327049
2 324868
Name: count,
dtype: int64
DBSCAN聚类
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 评估不同 eps 和 min_samples 下的指标
# eps这个参数表示邻域的半径,min_samples表示一个点被认为是核心点所需的最小样本数。
# min_samples这个参数表示一个核心点所需的最小样本数。eps_range = np.arange(0.3, 0.8, 0.1) # 测试 eps 从 0.3 到 0.7
min_samples_range = range(3, 8) # 测试 min_samples 从 3 到 7
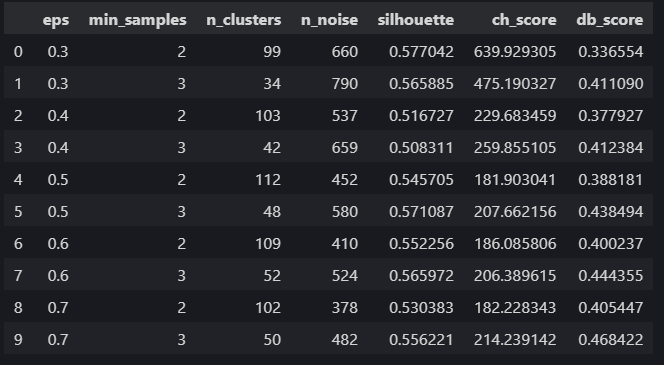
results = []for eps in eps_range:for min_samples in min_samples_range:dbscan = DBSCAN(eps=eps, min_samples=min_samples)dbscan_labels = dbscan.fit_predict(X_scaled)# 计算簇的数量(排除噪声点 -1)n_clusters = len(np.unique(dbscan_labels)) - (1 if -1 in dbscan_labels else 0)# 计算噪声点数量n_noise = list(dbscan_labels).count(-1)# 只有当簇数量大于 1 且有有效簇时才计算评估指标if n_clusters > 1:# 排除噪声点后计算评估指标mask = dbscan_labels != -1if mask.sum() > 0: # 确保有非噪声点silhouette = silhouette_score(X_scaled[mask], dbscan_labels[mask])ch = calinski_harabasz_score(X_scaled[mask], dbscan_labels[mask])db = davies_bouldin_score(X_scaled[mask], dbscan_labels[mask])results.append({'eps': eps,'min_samples': min_samples,'n_clusters': n_clusters,'n_noise': n_noise,'silhouette': silhouette,'ch_score': ch,'db_score': db})print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, "f"轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")else:print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, 无法计算评估指标")# 将结果转为 DataFrame 以便可视化和选择参数
results_df = pd.DataFrame(results)| eps | min\_samples | n\_clusters | n\_noise | silhouette | ch\_score | db\_score |
| --: | -----------: | ----------: | -------: | ---------: | --------: | --------: |
| 0.3 | 2 | 99 | 660 | 0.577 | 639.93 | 0.337 |
| 0.3 | 3 | 34 | 790 | 0.566 | 475.19 | 0.411 |
| 0.4 | 2 | 103 | 537 | 0.517 | 229.68 | 0.378 |
| 0.4 | 3 | 42 | 659 | 0.508 | 259.86 | 0.412 |
| 0.5 | 2 | 112 | 452 | 0.546 | 181.90 | 0.388 |
| 0.5 | 3 | 48 | 580 | 0.571 | 207.66 | 0.438 |
| 0.6 | 2 | 109 | 410 | 0.552 | 186.09 | 0.400 |
| 0.6 | 3 | 52 | 524 | 0.566 | 206.39 | 0.444 |
| 0.7 | 2 | 102 | 378 | 0.530 | 182.23 | 0.405 |
| 0.7 | 3 | 50 | 482 | 0.556 | 214.24 | 0.468 |
# 绘制评估指标图,增加点论文中的工作量
plt.figure(figsize=(15, 10))
# 轮廓系数图
plt.subplot(2, 2, 1)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples] # plt.plot(subset['eps'], subset['silhouette'], marker='o', label=f'min_samples={min_samples}')
plt.title('轮廓系数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('轮廓系数')
plt.legend()
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 2)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['ch_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Calinski-Harabasz 指数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('CH 指数')
plt.legend()
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 3)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['db_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Davies-Bouldin 指数确定最优参数(越小越好)')
plt.xlabel('eps')
plt.ylabel('DB 指数')
plt.legend()
plt.grid(True)# 簇数量图
plt.subplot(2, 2, 4)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['n_clusters'], marker='o', label=f'min_samples={min_samples}')
plt.title('簇数量变化')
plt.xlabel('eps')
plt.ylabel('簇数量')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.show()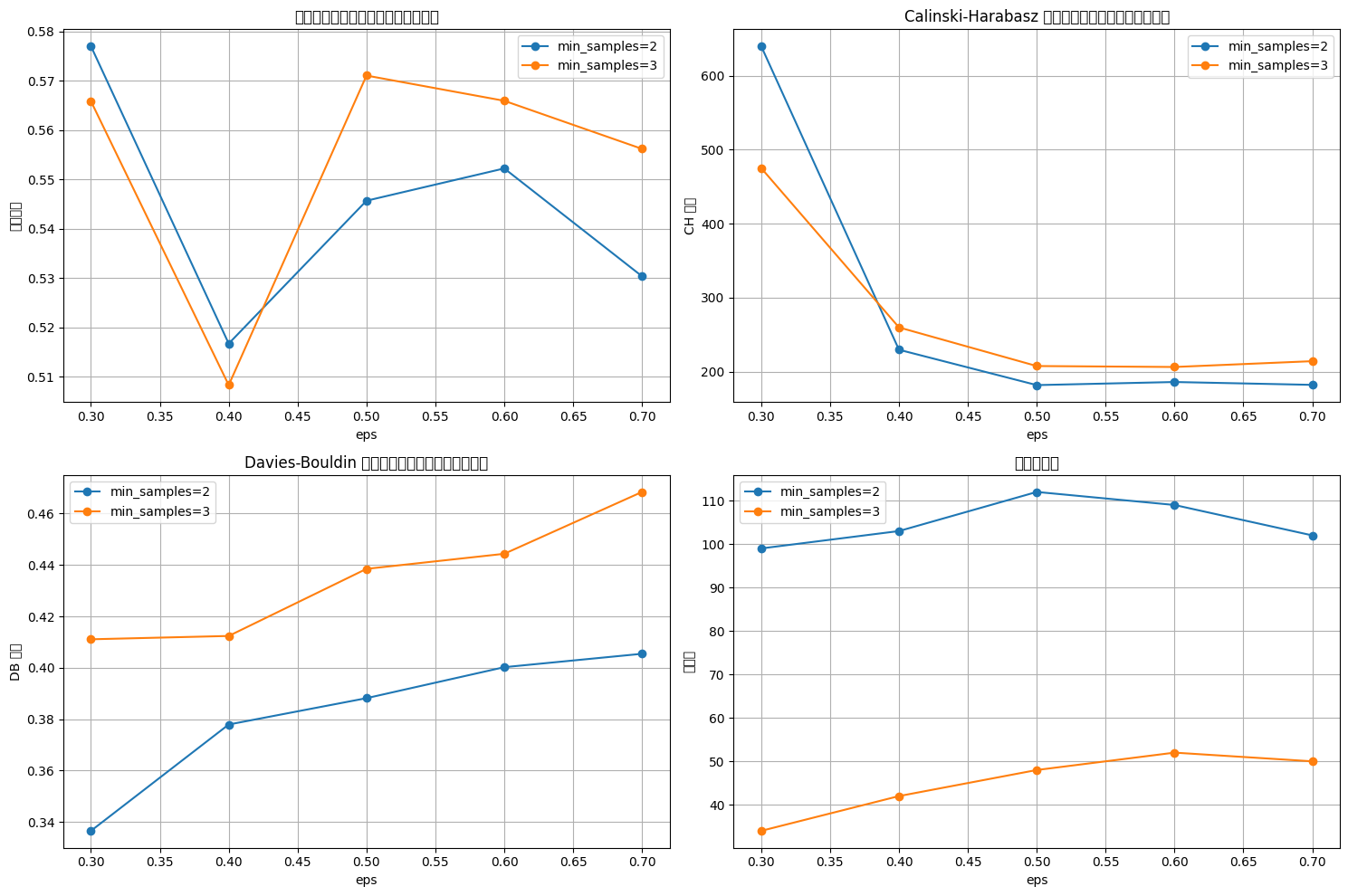
# 选择 eps 和 min_samples 值(根据图表选择最佳参数)
selected_eps = 0.6 # 根据图表调整
selected_min_samples = 6 # 根据图表调整# 使用选择的参数进行 DBSCAN 聚类
dbscan = DBSCAN(eps=selected_eps, min_samples=selected_min_samples)
dbscan_labels = dbscan.fit_predict(X_scaled)
X['DBSCAN_Cluster'] = dbscan_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# DBSCAN 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=dbscan_labels, palette='viridis')
plt.title(f'DBSCAN Clustering with eps={selected_eps}, min_samples={selected_min_samples} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 DBSCAN 聚类标签的分布
print(f"DBSCAN Cluster labels (eps={selected_eps}, min_samples={selected_min_samples}) added to X:")
print(X[['DBSCAN_Cluster']].value_counts())features = ['user_id', 'click_timestamp', 'click_environment', 'click_deviceGroup', 'click_os', 'click_country', 'click_region', 'click_referrer_type']
X = data[features]
# 选择 eps 和 min_samples 值(根据图表选择最佳参数)
selected_eps = 0.6 # 根据图表调整
selected_min_samples = 6 # 根据图表调整# 对数据进行采样,减少数据量
X_sampled, X_scaled_sampled = resample(X, X_scaled, n_samples=1000, random_state=42) # 根据需要调整采样数量# 使用选择的参数进行 DBSCAN 聚类
dbscan = DBSCAN(eps=selected_eps, min_samples=selected_min_samples)
dbscan_labels = dbscan.fit_predict(X_scaled_sampled)# 将聚类标签添加到采样后的数据中
X_sampled['DBSCAN_Cluster'] = dbscan_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled_sampled)# DBSCAN 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=dbscan_labels, palette='viridis')
plt.title(f'DBSCAN Clustering with eps={selected_eps}, min_samples={selected_min_samples} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 DBSCAN 聚类标签的分布
print(f"DBSCAN Cluster labels (eps={selected_eps}, min_samples={selected_min_samples}) added to X_sampled:")
print(X_sampled['DBSCAN_Cluster'].value_counts())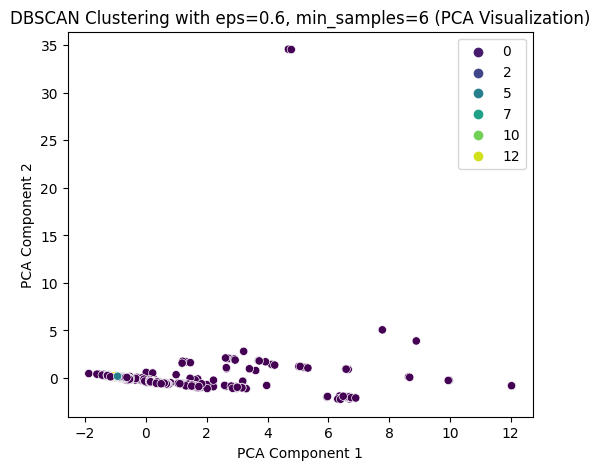
DBSCAN Cluster labels (eps=0.6, min_samples=6) added to X_sampled:
DBSCAN_Cluster
-1 707
1 78
2 62
3 31
5 25
8 17
0 14
10 13
9 12
4 9 7
8 12
7 6
6 13
6 11
5 Name: count,
dtype: int64
看起来效果不太好
层次聚类
import numpy as np
import pandas as pd
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
from sklearn.utils import resample
import matplotlib.pyplot as plt
import seaborn as sns# 假设 X 是原始数据的 DataFrame# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 对数据进行采样,减少数据量
X_sampled, X_scaled_sampled = resample(X, X_scaled, n_samples=1000, random_state=42) # 根据需要调整采样数量# 评估不同 n_clusters 下的指标
n_clusters_range = range(2, 11) # 测试簇数量从 2 到 10
silhouette_scores = []
ch_scores = []
db_scores = []for n_clusters in n_clusters_range:agglo = AgglomerativeClustering(n_clusters=n_clusters, linkage='ward') # 使用 Ward 准则合并簇agglo_labels = agglo.fit_predict(X_scaled_sampled)# 计算评估指标silhouette = silhouette_score(X_scaled_sampled, agglo_labels)ch = calinski_harabasz_score(X_scaled_sampled, agglo_labels)db = davies_bouldin_score(X_scaled_sampled, agglo_labels)silhouette_scores.append(silhouette)ch_scores.append(ch)db_scores.append(db)print(f"n_clusters={n_clusters}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")# 绘制评估指标图
plt.figure(figsize=(15, 5))# 轮廓系数图
plt.subplot(1, 3, 1)
plt.plot(n_clusters_range, silhouette_scores, marker='o')
plt.title('轮廓系数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(1, 3, 2)
plt.plot(n_clusters_range, ch_scores, marker='o')
plt.title('Calinski-Harabasz 指数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(1, 3, 3)
plt.plot(n_clusters_range, db_scores, marker='o')
plt.title('Davies-Bouldin 指数确定最优簇数(越小越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()n_clusters=2, 轮廓系数: 0.289, CH 指数: 201.78, DB 指数: 1.878 n_clusters=3, 轮廓系数: 0.267, CH 指数: 203.11, DB 指数: 1.445 n_clusters=4, 轮廓系数: 0.289, CH 指数: 225.13, DB 指数: 1.076 n_clusters=5, 轮廓系数: 0.331, CH 指数: 255.56, DB 指数: 1.055 n_clusters=6, 轮廓系数: 0.248, CH 指数: 269.20, DB 指数: 1.159 n_clusters=7, 轮廓系数: 0.278, CH 指数: 268.75, DB 指数: 1.161 n_clusters=8, 轮廓系数: 0.275, CH 指数: 264.39, DB 指数: 1.187 n_clusters=9, 轮廓系数: 0.263, CH 指数: 258.00, DB 指数: 1.202 n_clusters=10, 轮廓系数: 0.258, CH 指数: 251.18, DB 指数: 1.158
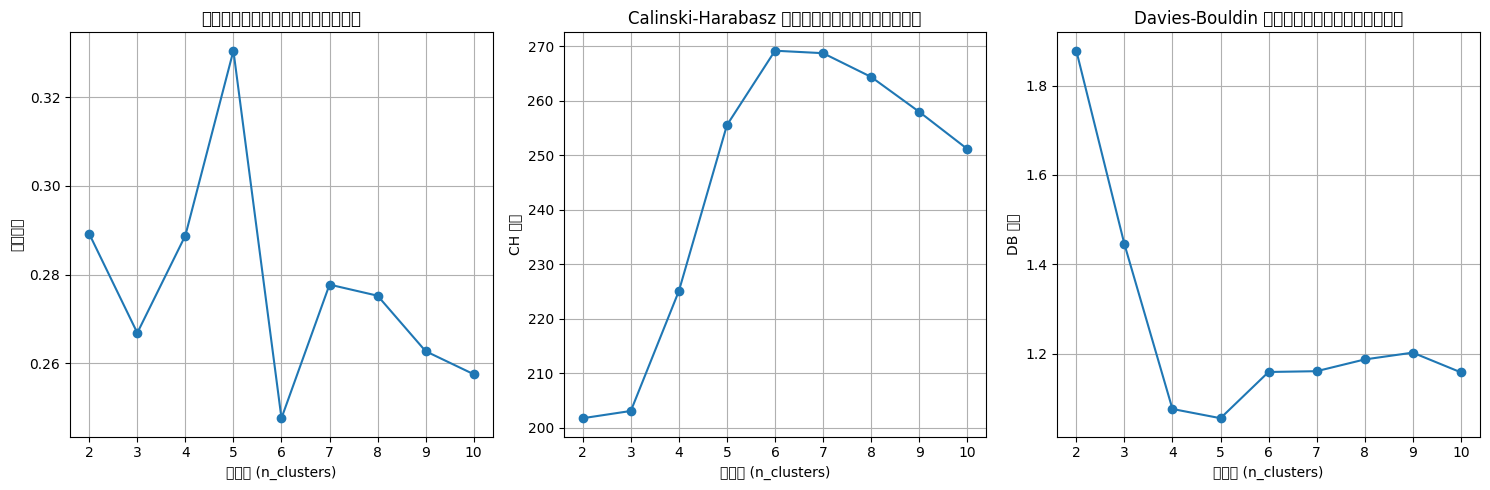
# 提示用户选择 n_clusters 值(这里可以根据图表选择最佳簇数)
selected_n_clusters = 10 # 示例值,根据图表调整# 使用选择的簇数进行 Agglomerative Clustering 聚类
agglo = AgglomerativeClustering(n_clusters=selected_n_clusters, linkage='ward')
agglo_labels = agglo.fit_predict(X_scaled)
X['Agglo_Cluster'] = agglo_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# Agglomerative Clustering 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=agglo_labels, palette='viridis')
plt.title(f'Agglomerative Clustering with n_clusters={selected_n_clusters} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 Agglomerative Clustering 聚类标签的分布
print(f"Agglomerative Cluster labels (n_clusters={selected_n_clusters}) added to X:")
print(X[['Agglo_Cluster']].value_counts())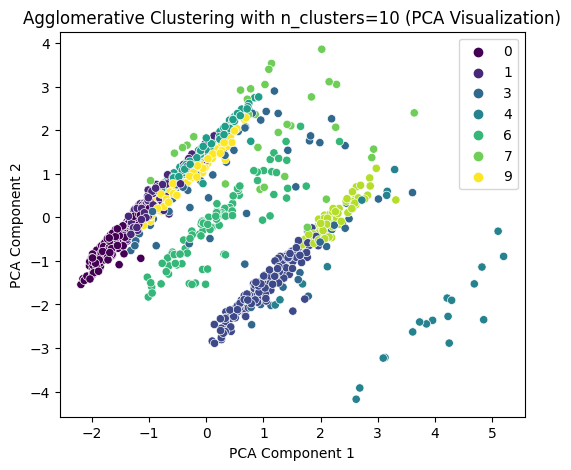
Agglomerative Cluster labels (n_clusters=10) added to X_sampled: Agglo_Cluster 0 206 2 153 1 130 5 126 9 95 6 87 3 78 8 68 7 32 4 25 Name: count, dtype: int64
from scipy.cluster import hierarchy
import matplotlib.pyplot as plt# 假设 X 是原始数据的 DataFrame# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 对数据进行采样,减少数据量
X_sampled, X_scaled_sampled = resample(X, X_scaled, n_samples=1000, random_state=42) # 根据需要调整采样数量# 计算层次聚类的链接矩阵
Z = hierarchy.linkage(X_scaled_sampled, method='ward') # 'ward' 是常用的合并准则# 绘制树状图
plt.figure(figsize=(10, 6))
hierarchy.dendrogram(Z, truncate_mode='level', p=3) # p 控制显示的层次深度
plt.title('Dendrogram for Agglomerative Clustering')
plt.xlabel('Sample Index')
plt.ylabel('Distance')
plt.show()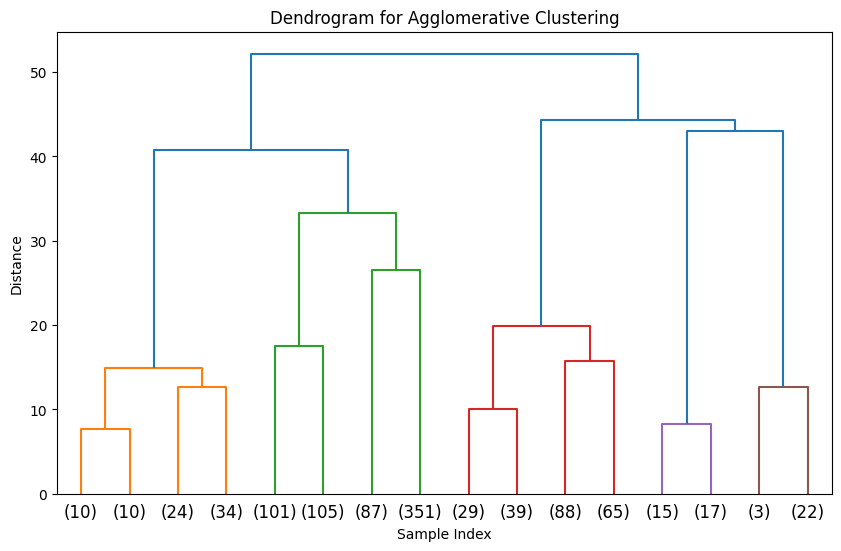
整一个流程下来,发现由于数据集的问题,导致Unable to allocate 4.50 TiB for an array with shape (618964413753,) and data type float64。可以说是维度爆炸,独热编码会为每个类别创建一个新的列,如果某个特征的类别数量非常多,就会导致生成大量的新列,从而显著增加数据的维度。这不仅会消耗大量内存,还可能导致计算速度变慢甚至崩溃。和我之前遇到的问题一样,后面通过代码将数据选择数量为1000得以解决。
# 标准化数据 scaler = StandardScaler() X_scaled = scaler.fit_transform(X)# 对数据进行采样,减少数据量 X_sampled, X_scaled_sampled = resample(X, X_scaled, n_samples=1000, random_state=42) # 根据需要调整采样数量
不同的数据集适合的算法不一样,选择合适的聚类算法,我得先看看我的数据是什么情况。如果数据点都挺规整的,像一个个圆球一样,那我就用 KMeans,这算法简单又快,特别适合这种场景。要是我的数据形状不规则,或者我怀疑里面有不少“杂点”,那我就试试 DBSCAN,它能很好地揪出这些杂点,还能处理各种奇怪形状的簇。要是数据量不大,我可能会考虑层次聚类,尤其是想看看聚类的过程,它能给我画个树状图,一目了然。但如果数据特别多,我就得用 MiniBatchKMeans 了,这样不会把电脑给“撑爆”。数据维度太高的话,我一般先用 PCA 降维,不然计算量太大,而且有时候高维度的数据也会让人看不清楚重点。我还会用一些评估指标,比如轮廓系数、CH 指数、DB 指数,来检查聚类效果怎么样。如果能画个图看看聚类结果就更好了,这样我能更直观地判断是不是符合我的预期。总之,选聚类算法就像挑工具,得看手头的活儿是个啥情况,选最顺手的那个。
@浙大疏锦行
相关文章:

day17 天池新闻数据KMeans、DBSCAN 与层次聚类的对比
在数据分析中,聚类是一种常见的无监督学习方法,用于将数据划分为不同的组或簇。本文将通过news数据集(news.csv),使用 KMeans、DBSCAN 和层次聚类三种方法进行聚类分析,并对比它们的性能。 数据来源于天池 …...

数学复习笔记 3
background music 《有人懂你》赵十三 前言 也别开始强化吧,复盘前面复习过的内容,可能是更稳的方式。 无穷级数 写无穷级数的例题。感觉自己真的学会了么,我生怕一写一个不吱声了。呜呜呜。这一章有 27 个例题。我从最后一个例题开始写…...
)
Navicat Premium 17 备份,还原数据库(PostGreSql)
目录 备份 还原备份 备份 1、点击数据库,点击备份 2、点击新建备份 3、点击备份,查看执行日志 还原备份 1、点击备份、右键还原备份从... 2、 选择文件目录,以及xxx.nb3文件,点击打开 3、点击还原 4、执行日志...

25_05_02Linux架构篇、第1章_03安装部署nginx
Linux_基础篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:安装部署nginx 版本号: 1.0,0 作者: 老王要学习 日期: 2025.05.02 适用环境: Centos7 文档说明 本文档聚焦于 CentOS 7 环境下 Nginx 的安装部…...

PostgreSQL存储过程“多态“实现:同一方法名支持不同参数
引言 在传统编程语言中,方法重载(同一方法名不同参数)是实现多态的重要手段。但当我们将目光转向PostgreSQL数据库时,是否也能在存储过程(函数)中实现类似的功能?本文将深入探讨PostgreSQL中如…...

Messenger.Default.Send 所有重载参数说明
Messenger.Default.Send 是 MVVM 框架中实现消息传递的核心方法,其重载参数主要用于控制消息的发送范围和接收条件。以下是其所有重载形式及参数说明: 1. 基本消息发送 Send<TMessage>(TMessage message) 参数说明: TMessage:消息类型(泛型参数),可以是任…...

java安全入门
文章目录 java基础知识this变量方法可变参数构造方法继承的关键字protected super阻止继承方法重载向上转型和向下转型多态抽象接口static静态字段default方法 包final内部类 java序列化与反序列化反射urldns链动态代理类加载器(ClassLoader)双亲委派模型…...

【开源深度解析】从零打造AI暗棋对战系统:Python实现中国象棋暗棋全攻略
🎲【开源深度解析】从零打造AI暗棋对战系统:Python实现中国象棋暗棋全攻略 🌈 个人主页:创客白泽 - CSDN博客 🔥 系列专栏:🐍《Python开源项目实战》 💡 热爱不止于代码,…...

UE5 Daz头发转Blender曲线再导出ABC成为Groom
先安装Daz to Blender Import插件 【神器】 --DAZ一键导入blender插件的详细安装和使用,自带骨骼绑定和控制器,多姿势动画,Importer桥接插件_哔哩哔哩_bilibili 然后安装DAZHairConverter插件 一分钟将DAZ头发转化成Blender粒子毛发_哔哩哔…...

【Java学习】反射
目录 反射类 一、泛型参数 二、反射类类型 三、实例化 1.实例化材料 2.结构信息可使用化 四、使用 1.Class —类完整结构信息 1.1Class<类>实例化 1.2Class<类>实例获取 1.2.1Class类静态获取: 1.2.2信息类静态获取 1.2.3信息类非静态获取 …...

SQLite数据类型
目录 1 SQLite的类型概述 1.1 存储类(Storage Classes) 1.2 类型亲和性(Type Affinity) 2 类型亲和性分配规则 3 数据类型详细说明 3.1 INTEGER类型 3.2 REAL类型 3.3 TEXT类型 3.4 BLOB类型 3.5 NULL类型 3.6 NUMERI…...

Django异步任务处理方式总结
在 Django 中实现异步任务处理是优化性能和用户体验的关键。以下是几种常见的异步任务处理方式及详细说明: 1. Celery(最主流方案) 适用场景:需要可靠、分布式、复杂任务队列的项目(如定时任务、重试机制、多节点部署…...

AI技术下研发体系重构
导语: 人工智能技术已发展70余年,经历了从逻辑符号主义向数据驱动范式的转变,目前正处于向多模态、通用化以及伦理化方向演化的阶段。在接下来的五年内,人工智能技术的商业化应用预计将迎来关键性的转变。大模型技术的突破、多模…...

UE5 使用插槽和物理约束对角色新增的饰品添加物理效果
这是一条项链,分为链部分和吊坠部分 新增物理碰撞资产,链部分在前面(作为固定),吊坠部分在后面(作为物理模拟) 链部分的Physics设置 连接部分的设置 吊坠部分 添加物理约束,在Constraint里面添加角色名和饰品名 在约束里面可以对特定骨骼约束,这里需要把链部分约束...

邂逅蓝耘元生代:ComfyUI 工作流与服务器虚拟化的诗意交织
往期推荐: 探秘蓝耘元生代:ComfyUI 工作流创建与网络安全的奇妙羁绊-CSDN博客 工作流 x 深度学习:揭秘蓝耘元生代如何用 ComfyUI 玩转 AI 开发-CSDN博客 探索元生代:ComfyUI 工作流与计算机视觉的奇妙邂逅-CSDN博客 解锁元生代&a…...

【Elasticsearch】在kibana中能获取已创建的api keys吗?
在 Kibana 中,目前没有直接的界面功能可以列出或查看已创建的 API 密钥(API keys)。API 密钥的管理和查看主要通过 Elasticsearch 的 REST API 来完成,而不是通过 Kibana 的管理界面。 在 Kibana 中使用 Dev Tools 查看 API 密钥…...

[论文阅读]Deep Cross Network for Ad Click Predictions
摘要 特征工程是许多预测模型成功的关键。然而,这个过程是困难的,甚至需要手动特征工程或穷举搜索。DNN能够自动学习特征交互;然而,它们隐式地生成所有的交互,并且不一定有效地学习所有类型的交叉特征。在本文中&…...

薪技术|0到1学会性能测试第45课-apache调优技术
前面的推文我们掌握了apache监控技术,今天我们继续来看下apache调优技术,究竟是怎么做性能调优???后续文章都会系统分享干货,带大家从0到1学会性能测试。 Apache调优技术 Apache最近的版本是2.2版,Apache2.2是一个多用途的web服务器,其设计在灵活性、可移植性和性能中…...
)
Linux之基础开发工具二(makefile,git,gdb)
目录 一、自动化构建-make/makefile 1.1、背景 1.2、基本使用 1.3、推导过程 1.4、语法拓展 二、进度条小程序 2.1、回车与换行 2.2、行缓冲区 2.3、练手-倒计时程序 2.4、进度条程序 三、版本控制器-Git 3.1、版本控制器 3.2、gitee的使用 3.2.1、如何创建仓库 …...

cesium之自定义地图与地图叠加
在appvue中,cesium支持更换不同的地图资源,代码如下 <template><div id"cesiumContainer" ref"cesiumContainer"></div> </template><script setup> import * as Cesium from cesium; import "./Widgets/widgets.css&…...

链表结构深度解析:从单向无头到双向循环的实现全指南
上篇博客实现动态顺序表时,我们会发现它存在许多弊端,如: • 中间/头部的插⼊删除,时间复杂度为O(N) • 增容需要申请新空间,拷⻉数据,释放旧空间。会有不⼩的消耗。 • 增容⼀般是呈2倍的增⻓,…...

Apache Velocity代码生成简要介绍
Apache Velocity 概述 Apache Velocity 是一个基于 Java 的模板引擎,它允许将 Java 代码与 HTML、XML 或其他文本格式分离,实现视图与数据的解耦。在 Web 开发中,Velocity 常用于生成动态网页内容;在其他场景下,也可用…...
!)
阿里云前端Nginx部署完,用ip地址访问却总访问不到,为什么?检查安全组是否设置u为Http(80)!
根据你的描述,Ping测试显示数据包无丢失但无法通过公网IP访问服务,说明网络基础层(ICMP协议)是通畅的,但更高层(如TCP/UDP协议或服务配置)存在问题。以下是系统性排查与解决方案: 一…...

【Hive入门】Hive行级安全:基于Apache Ranger的细粒度访问控制深度解析
引言 在大数据时代,数据安全与隐私保护已成为企业不可忽视的核心需求。传统表级权限控制已无法满足"同一张表不同用户看到不同数据"的业务场景,行级安全(Row-Level Security)成为数据仓库系统的必备能力。 1 行级安全概述 1.1 什么是行级安全…...

Marin说PCB之1000-BASE-T1的PCB设计总结--04
另外一路的1000-BASE-T1 Circuit:千兆以太网的仿真电路原理图的连接搭建方式如下: (共模电感的连接需要特别注意一下PIN序别搞错了) 这一路1000-BASE-T1 Circuit是做了兼容设计的: 其中电容C2099和C2100是百兆以太网的…...
)
两数之和(暴力+哈希查找)
目录 一.题目 二.解题过程 题目解析 方法一(暴力求解) 思路 代码 提交结果 方法二(哈希查找) 思路 代码 提交结果 作者的个人gitee 作者的算法讲解主页▶️ 每日一言:“愿你纵踩淤泥,也要…...

Qt项目——天气预报
目录 前言结果预览工程文件窗体无状态栏窗口跟随移动HTTP基本概念JSON数据QT解析JSON数据结语 前言 通过对之前Qt的学习其实我们就已经有一点经验了,做天气预报只需要了解以下内容: stylesheet界面美化 Json数据解析 HTTP通信 自定义控件绘制温度 结果预…...

智能推理DeepSeek-R1+Word深度整合业级智能办公构建
前引: 当我们将DeepSeek-R1深度集成到Word时,实际上是在构建智能办公的"数字神经系统"。这个系统不仅理解文字内容,更能感知用户意图,在恰当的时刻提供精准的智能辅助。随着RAG(检索增强生成)技术…...

【C++ Qt】常用输入类下:Combo Box/Spin Box/DataTimeEdit/Dial/Slide
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 在Qt开发框架中,UI组件是构建用户交互界面的基石。本章将详细探讨Qt中常用的UI组件,包括下拉框(QComboBoxÿ…...
)
基于Piecewise Jerk Speed Optimizer的速度规划算法(附ROS C++/Python仿真)
目录 1 时空解耦运动规划2 PJSO速度规划原理2.1 优化变量2.2 代价函数2.3 约束条件2.4 二次规划形式 3 算法仿真3.1 ROS C仿真3.2 Python仿真 1 时空解耦运动规划 在自主移动系统的运动规划体系中,时空解耦的递进式架构因其高效性与工程可实现性被广泛采用。这一架…...

K8s 常用命令、对象名称缩写汇总
K8s 常用命令、对象名称缩写汇总 前言 在之前的文章中已经陆续介绍过 Kubernetes 的部分命令,本文将专题介绍 Kubernetes 的常用命令,处理日常工作基本够用了。 集群相关 1、查看集群信息 kubectl cluster-info # 输出信息Kubernetes master is run…...

C++编程语言:从高效系统开发到现代编程范式的演进之路
目录 前言一、c简介1.1 起源1.2 c的特点 二、开发环境搭建 2.1. 安装 Qt 开发工具2.2 修改编码环境 2.3创建第一个 Qt 项目2.4 c的编译过程2.5 代码示例 2.6 qt疑难杂症 2.6.1 遇到无法删除代码,一点击光标就变成小黑块2.6.2 遇到运行不弹出终端 编辑 2.6.3 遇到…...

OpenCV进阶操作:角点检测
文章目录 一、角点检测1、定义2、检测流程1)输入图像2)图像预处理3)特征提取4)角点检测5)角点定位和标记6)角点筛选或后处理(可选)7)输出结果 二、Harris 角点检测&#…...

广州华锐视点邀您参与2025广交会VRAR展【5月10-12日】
2025 广交会数字显示与元宇宙生态博览会暨第 9 届世界 VR&AR 展将在广州盛大举行 。时间:2025 年 5 月 10 日至 12 日,广州华锐视点作为一家深耕 VR、AR、AI、元宇宙内容制作领域的企业,也将携旗下众多创新产品和解决方案闪耀登场&#x…...

mac m2 安装 hbase
默认安装好了 homebrew。 1. 终端先更新下 homebrew brew upgrade再安装 hbase brew install hbase 安装完会有如下图的内容 2. 按照提示启动 hbase brew services start hbase返回启动成功 3. 访问 http://localhost:16010 检验一下 启动成功 4. 在启动 hbase shell之…...

k8s node 报IPVS no destination available
在 Kubernetes 集群中,IPVS no destination available 错误通常表示 kube-proxy(IPVS 模式)无法为 Service 找到可用的后端 Pod。这会导致流量无法正确转发,影响服务可用性。以下是详细的排查和解决方法: 一、错误原因…...
 的用法详解)
MySQL 中 EXISTS (SELECT 1 FROM ...) 的用法详解
EXISTS (SELECT 1 FROM ...) 是 MySQL 中用于存在性检查的核心语法,其核心逻辑是判断子查询是否返回至少一行数据。以下从作用原理、使用场景、性能优化等方面展开解析,并结合具体示例说明。 1. 基本语法与作用原理 语法结构: SELECT 列名 F…...
)
荣耀A8互动娱乐组件部署实录(第3部分:控制端结构与房间通信协议)
作者:曾在 WebSocket 超时里泡了七天七夜的苦命人 一、控制端总体架构概述 荣耀A8控制端主要承担的是“运营支点”功能,也就是开发与运营之间的桥梁。它既不直接参与玩家行为,又控制着玩家的行为逻辑和游戏规则触发机制。控制端的主要职责包…...

前端-HTML+CSS+JavaScript+Vue+Ajax概述
HTML(超文本标记语言)常见标签 <html><head> <title>这是标题的内容,显示在浏览器的头部</title></head><body><!-- 这里面的内容在浏览器显示给用户看 --><!-- h1 -> h6 : 标题从大到小 …...

20250506格式化NanoPi NEO开发板使用Ubuntu core16.04系统的TF启动卡
https://www.sdcard.org/downloads/formatter/eula_windows/SDCardFormatterv5_WinEN.zip 20250506使用SDCardFormatter工具格式化NanoPi NEO开发板使用Ubuntu core16.04系统的TF启动卡 2025/5/6 20:04 缘起:使用友善之臂的NanoPi NEO开发板,制作了Ubunt…...

信息时代的政治重构:网络空间与主权的未来
一、网络空间:暴力垄断的终结 无边界主权的崛起 网络空间作为“第五阶段”的暴力竞争场域,打破传统领土垄断。政府无法像控制物理世界那样垄断网络暴力,类似公海的法律真空状态。 边区类比:中世纪的安道尔(法西共管避…...

Kotlin重构Android项目实践
以下是使用 Kotlin 重构 Android 项目的 5 个常见场景实践,通过对比 Java 实现方式,展示 Kotlin 的简洁性和现代特性: 场景 1:数据类替代 Java POJO Java 传统实现: public class User {private String name;private…...

Vue + Element UI 表单弹窗输入法卡顿问题解决方案
Vue Element UI 表单弹窗输入法卡顿问题解决方案 前言 在使用 Vue 和 Element UI 开发后台管理系统时,经常会遇到 el-dialog 弹出表单对话框的场景。然而,很多开发者可能会遇到一个棘手的问题:当调用 resetFields() 方法重置表单时&#x…...

ubantu安装CUDA
想要通过llama.cpp的方式跑deepseek R1模型。在按照https://huggingface.co/unsloth/DeepSeek-R1-GGUF教程去配环境时报错了。具体如下: (base) oemcore:~/Desktop/deepseek_llama.cpp$ sudo cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBSOFF -DGGM…...

Python生活手册-Numpy多维数组构建:从快递分拣到智能家居的数据变形术
一、快递分拣系统(基础构建) 1. 电子面单生成(列表转数组) import numpy as np手工录入的快递单号 纸质单号 [["SF123", "JD456", "EMS789"],["YT012", "ZT345", "YZ6…...

数据库的范围查询
范围查询 B树迭代器 迭代器接口 B树的基本操作包括用于范围查询的查找和迭代。B树的位置由状态化的迭代器 BIter 表示。 // 查找小于或等于输入键的最近位置 func (tree *BTree) SeekLE(key []byte) *BIter// 获取当前键值对 func (iter *BIter) Deref() ([]byte, []byte)/…...

JS DAY4 日期对象与节点
一日期对象 日期对象:用来表示时间的对象 作用:可以得到当前系统时间 1.实例化 在代码中发现了 new 关键字时,一般将这个操作称为实例化 创建一个时间对象并获取时间 时间必须实例化 获得当前时间 const date new Date() 获得指定时间 const date new Date(…...

【Leetcode 每日一题 - 补卡】1007. 行相等的最少多米诺旋转
问题背景 在一排多米诺骨牌中, t o p s [ i ] tops[i] tops[i] 和 b o t t o m s [ i ] bottoms[i] bottoms[i] 分别代表第 i i i 个多米诺骨牌的上半部分和下半部分。(一个多米诺是两个从 1 1 1 到 6 6 6 的数字同列平铺形成的 —— 该平铺的每一半…...

Android设备运行yolov8
放假这几天搞了一个基于uniapprk3588实现了一版yolo检测 这个是基于前端调用后端api来实现,感觉还可以,但是需要有网络才能进行图像检测,网络不稳定就会出现等待时间会比较久的问题,然后有做了一个在做了一个Android版本的图像检…...

Debezium MySqlValueConverters详解
Debezium MySqlValueConverters详解 1. 类的作用与功能 1.1 核心作用 MySqlValueConverters是Debezium中负责MySQL数据类型转换的核心类,主要功能包括: 数据类型映射:将MySQL的数据类型映射到Kafka Connect的Schema类型值转换:将MySQL的原始值转换为Kafka Connect可用的…...