[论文阅读]Deep Cross Network for Ad Click Predictions
摘要
特征工程是许多预测模型成功的关键。然而,这个过程是困难的,甚至需要手动特征工程或穷举搜索。DNN能够自动学习特征交互;然而,它们隐式地生成所有的交互,并且不一定有效地学习所有类型的交叉特征。在本文中,我们提出了深度交叉网络(Deep & Cross Network, DCN),它保留了DNN模型的优点,并在此基础上引入了一种新的交叉网络,该网络在学习确定的有界度特征时效率更高。特别地,DCN明确地在每一层应用特征交叉,不需要手动特征工程,并且相比DNN模型增加微不足道的额外复杂性。我们的实验结果表明,在CTR预测数据集和密集分类数据集上,该算法在模型精度和内存使用方面都优于目前最先进的算法。
1. 介绍
点击率(CTR)预测是一个大规模的问题,对数十亿美元的在线广告行业至关重要。在广告行业,广告商付钱给出版商,让他们在出版商的网站上展示自己的广告。一种流行的付费模式是按点击付费(CPC)模式,即只有当点击发生时才向广告商收费。因此,发行商的收益很大程度上依赖于准确预测点击率的能力。
识别频繁预测的特征,同时探索未见或罕见的交叉特征是做出良好预测的关键。然而,web尺度的推荐系统的数据大多是离散的和分类的,这导致了一个大而稀疏的特征空间,这对特征探索是一个挑战。这使得大多数大规模系统被限制为线性模型,如逻辑回归。
线性模型简单,可解释,易于缩放;然而,他们的表达能力是有限的。另一方面,交叉特征已被证明在提高模型的表达能力方面具有重要意义。不幸的是,它通常需要手动特征工程或详尽搜索来识别这些特征;进一步地,推广到未知的特征交互是困难的。
在本文中,我们旨在通过引入一种新的神经网络结构——交叉网络,来避免特定于任务的特征工程,而是以自动的方式显式地应用特性交叉。交叉网络由多层组成,其中最高程度的相互作用可证明由层深度决定。每一层产生基于现有交互的高阶交互,并保持来自前一层的交互。我们与深度神经网络(DNN)联合训练交叉网络。深度神经网络有望捕获特征之间非常复杂的相互作用;然而,与我们的交叉网络相比,它需要近一个数量级的参数,无法明确地形成交叉特征,并且可能无法有效地学习某些类型的特征交互。然而,联合训练交叉和DNN组件可以有效地捕获预测特征交互,并在Criteo CTR数据集上提供最先进的性能。
1.1 相关工作
由于数据集的大小和维数的急剧增加,已经提出了许多方法来避免广泛的任务特定特征工程,主要基于嵌入技术和神经网络。
因子分解机(FMs)[11,12]将稀疏特征投影到低维密集向量上,并从向量内积中学习特征交互。Field因子分解机(FFM)[7,8]进一步允许每个特征学习多个向量,其中每个向量与一个字段相关联。令人遗憾的是,FMs和FFMs的浅结构限制了它们的表现能力。已经有工作将FMs扩展到更高阶[1,18],但一个缺点在于它们的大量参数会产生不可计的计算成本。由于嵌入向量和非线性激活函数,深度神经网络(DNN)能够学习非平凡的高阶特征相互作用。残余网络[5]最近的成功使非常深度的网络训练成为可能。深交叉[15]扩展残差网络,通过叠加所有类型的输入实现自动特征学习。
深度学习的显著成功引发了对其表达能力的理论分析。有研究[16,17]表明dnn能够在给定足够多的隐藏单元或隐藏层的情况下,在一定的平滑假设下以任意精度逼近任意函数。此外,在实践中,已经发现深度神经网络在可行的参数数量下工作良好。一个关键的原因是,大多数具有实际意义的函数都不是任意的。
然而剩下的一个问题是,dnn是否真的是最有效的代表这些实际意义的函数。在Kaggle竞赛中,许多获胜的解决方案中手工生成的特征程度低,格式明确,效果好。另一方面,dnn学习的特征是隐式的和高度非线性的。这阐明了如何设计一个模型,该模型能够比通用深度神经网络更有效、更明确地学习有界度特征相互作用。
宽而深就是这种精神的典范。它将交叉特征作为线性模型的输入,并与DNN模型联合训练线性模型。然而,宽深融合的成功取决于交叉特征的正确选择,这是一个指数问题,目前还没有明确的有效方法。
1.2主要贡献
在本文中,我们提出了深度交叉网络(DCN)模型,该模型可以在稀疏和密集输入下实现web规模的自动特征学习。DCN能有效捕获有界度的有效特征交互,学习高度非线性的相互作用,不需要人工特征工程或穷举搜索,计算成本低。论文的主要贡献包括:
- 我们提出了一种新的交叉网络,它明确地在每一层应用特征交叉,有效地学习有界度的预测交叉特征,并且不需要人工特征工程或穷举搜索。
- 交叉网络简单而有效。根据设计,最高多项式次数在每一层增加,并由层深度决定。该网络由最高阶的所有交叉项组成,它们的系数都不同。
- 交叉网络内存效率高,易于实现。
- 我们的实验结果表明,在交叉网络中,DCN的logloss比DNN的参数量少了近一个数量级。
论文组织如下:第2节描述了深度和交叉网络的体系结构。第三部分详细分析了交叉网络。第4节给出了实验结果。
2. DCN
在本节中,我们将描述深度与交叉网络(DCN)模型的体系结构。DCN模型从嵌入堆叠层开始,然后是并行的交叉网络和深度网络。这些的最后的组合层,它将两个网络的输出组合在一起。完整的
DCN模型如图1所示。
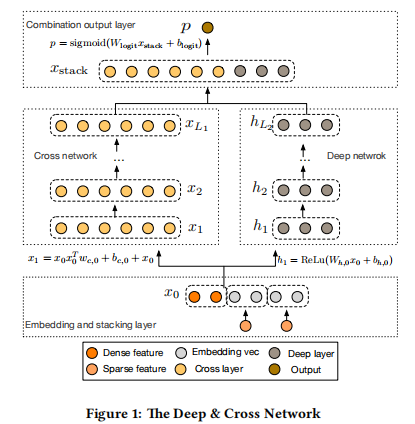
2.1 嵌入堆叠层
我们考虑具有稀疏和密集特征的输入数据。在Web尺度的推荐系统(如CTR预测)中,输入主要是分类特征,例如:“国家=美国”。这些特征通常被编码为独热向量,例如“(0,1,0)”;然而,对于大型词汇表,这可能会导致过于高维的特征空间。(如果涉及的特征特别多,那么维度也会随之线性增加)。为了降低维数,我们采用嵌入过程将这些二值特征转换为实值的密集向量(通常称为嵌入向量)。
x e m b e d , i = W e m b e d , i x i x_{embed,i}=W_{embed,i}x_i xembed,i=Wembed,ixi
其中, x e m b e d , i x_{embed,i} xembed,i是嵌入向量, x i x_i xi是第i类的二值输入,而 W e m b e d , i ∈ R n e × n v W_{embed,i} \in \mathbb R^{n_e \times n_v} Wembed,i∈Rne×nv 是将与网络中其他参数一起优化的相应的嵌入矩阵, n e , n v n_e,n_v ne,nv分别表示嵌入大小和词汇表大小。
最后,我们将嵌入向量与标准化的密集特征 x d e n s e x_{dense} xdense叠加成一个向量:
x 0 = [ x e m b e d , 1 T , . . . , x e m b e d , k T , x d e n s e T ] x_0=[x^T_{embed,1},...,x^T_{embed,k},x^T_{dense}] x0=[xembed,1T,...,xembed,kT,xdenseT]
然后将 x 0 x_0 x0作为网络输入。
2.2 交叉网络
我们的新型交叉网络的关键思想是以有效的方式应用显式特征交叉。交叉网络由交叉层组成,每层有如下公式:
x l + 1 = x 0 x l T w l + b l + x l = f ( x l , w l , b l ) + x l x_{l+1}=x_0x^T_lw_l+b_l+x_l=f(x_l,w_l,b_l)+x_l xl+1=x0xlTwl+bl+xl=f(xl,wl,bl)+xl
其中 x l x_l xl, x l + 1 ∈ R d x_{l+1}∈\mathbb R^d xl+1∈Rd为列向量,分别表示第l和第(l +1)的交叉层的输出; w l , b l ∈ R d w_l,b_l \in \mathbb R^d wl,bl∈Rd是第l层的权重和偏置参数。每个交叉层在经过一个特征交叉f后将其输入加回,其映射函数 f : R d → R d f: R^d→R^d f:Rd→Rd拟合 x l + 1 − x l x_{l+1} - x_l xl+1−xl的残差。一个交叉层的可视化如图2所示。
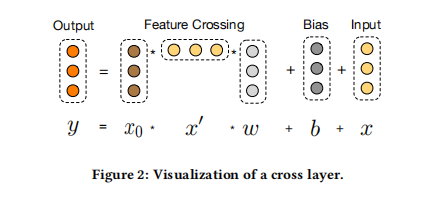
特征之间的高度交互交叉网络的特殊结构使交叉特征的维度随层深而增大。l层交叉网络的最高多项式次数为l +1。实际上,交叉网络包含所有的交叉项 x 1 α 1 x 2 α 2 . . . x d α d x_1^{\alpha_1}x_2^{\alpha_2}...x_d^{\alpha_d} x1α1x2α2...xdαd次从1到1 + 1。详细分析见第3节。
复杂度分析设 L c L_c Lc表示交叉层数,d表示输入维数。那么交叉网络中涉及的参数个数为
d × L c × 2 d \times L_c \times 2 d×Lc×2
交叉网络的时间和空间复杂度在输入维上是线性的。因此,与深度网络相比,交叉网络引入的复杂性可以忽略不计,使DCN的整体复杂性保持在与传统DNN相同的水平。
它的效率得益于 x 0 x l T x_0x_l^T x0xlT的一阶属性,这使我们能够生成所有的交叉项,而不需要计算或存储整个矩阵。
交叉网络的参数数量少,限制了模型的容量。为了捕捉高度非线性的相互作用,我们引入了一个并行的深度网络
2.3 深度网络
深度网络是一个全连接的前馈神经网络,每个深层具有以下公式:
h l + 1 = f ( W l h l + b l ) h_{l+1}=f(W_lh_l+b_l) hl+1=f(Wlhl+bl)
其中, h l ∈ R n l , h l + 1 ∈ R n l + 1 h_l\in \mathbb R^{n_l},h_{l+1}\in \mathbb R^{n_{l+1}} hl∈Rnl,hl+1∈Rnl+1分别是第l和第l+1隐藏层; W l ∈ R n l + 1 × n l , b l ∈ R n l + 1 W_l\in \mathbb R^{n_{l+1}\times n_l},b_l \in \mathbb R^{n_{l+1}} Wl∈Rnl+1×nl,bl∈Rnl+1是第l深度层的参数,f(.)是ReLU函数。
复杂度分析为简单起见,我们假设所有深度层的大小相等。令 L d L_d Ld表示深度层的数量,m表示深度层的大小。则深度网络中的参数个数为
d × m + m + ( m 2 + m ) × ( L d − 1 ) d\times m+m+(m^2+m)\times(L_d-1) d×m+m+(m2+m)×(Ld−1)
2.4 组合层
组合层连接来自两个网络的输出,并将连接的向量馈送到标准logits层。
下面是一个两分类问题的公式:
p = σ ( [ x L T , h L 2 T ] w l o g i t s ) p=\sigma([x_L^T,h_{L_2}^T]w_{logits}) p=σ([xLT,hL2T]wlogits)
其中, x L 1 ∈ R d , h L 2 ∈ R m x_{L_1} \in \mathbb R^d,h_{L_2}\in R^m xL1∈Rd,hL2∈Rm分别表示,交叉网络和深度网络的输出, w l o g i t s ∈ R ( d + m ) w_{logits}\in \mathbb R^{(d+m)} wlogits∈R(d+m)是组合层的权重向量, σ \sigma σ表示1/(1+exp(-x))。
损失函数是带正则化项的对数损失,
l o s s = − 1 N ∑ i = 1 N y i l o g ( p i ) + ( 1 − y i ) l o g ( 1 − p i ) + λ ∑ l ∣ ∣ w l ∣ ∣ 2 loss=-\frac1N\sum^N_{i=1}y_ilog(p_i)+(1-y_i)log(1-p_i)+\lambda\sum_l||w_l||^2 loss=−N1i=1∑Nyilog(pi)+(1−yi)log(1−pi)+λl∑∣∣wl∣∣2
其中,p为由式(5)计算的概率, y i y_i yi为真值标签,N为输入总数,λ为L2正则化参数。
我们联合训练这两个网络,因为这允许每个单独的网络在训练过程中了解其他网络。
3.交叉网络分析
在本节中,我们分析DCN的交叉网络,以了解其有效性。我们提供了三种观点:多项式近似、对FMs的泛化和有效投影。为简单起见,我们假设bi = 0。
符号。 设向量 w j w_j wj中的第i个元素是 w j ( i ) w^{(i)}_j wj(i).对于多维索引 α = [ α 1 , . . . , α d ] ∈ N d \alpha=[\alpha_1,...,\alpha_d]\in \mathbb N^d α=[α1,...,αd]∈Nd和 x = [ x 1 , . . . , x d ] ∈ R d x=[x_1,...,x_d] \in \mathbb R^d x=[x1,...,xd]∈Rd我们定义 ∣ α ∣ = ∑ i = 1 d α i |\alpha|=\sum^d_{i=1}\alpha_i ∣α∣=∑i=1dαi
术语。 交叉项的次(单项) x 1 α 1 x 2 α 2 . . . x d α d x_1^{\alpha_1}x_2^{\alpha_2}...x_d^{\alpha_d} x1α1x2α2...xdαd被定义为 ∣ α ∣ |\alpha| ∣α∣.多项式的次是由多项式项的最高次来定义的。
3.1 多项式近似
通过Weierstrass近似定理,在一定的平滑性假设下,任何函数都可以用多项式逼近到任意精度。因此,我们从多项式近似的角度来分析交叉网络。特别是,交叉网络以一种高效、富有表现力的方式近似相同程度的多项式类,并将其推广到现实世界的数据集。我们详细地研究了交叉网络对同次多项式类的逼近。我们用 P n ( x ) P_n(x) Pn(x)表示n次的多元多项式类:
P n ( x ) = { ∑ α w α x 1 α 1 x 2 α 2 . . . x d α d ∣ 0 ≤ ∣ α ∣ ≤ n , α ∈ N d } P_n(x)=\{\sum_\alpha w_\alpha x^{\alpha1}_1x^{\alpha2}_2...x^{\alpha d}_d|0 \leq|\alpha|\leq n,\alpha \in \mathbb N^d\} Pn(x)={α∑wαx1α1x2α2...xdαd∣0≤∣α∣≤n,α∈Nd}
这类中的每个多项式都有 o ( d n ) o (d^n) o(dn)系数.我们证明,在只有O (d)个参数的情况下,交叉网络包含了所有出现在同一次多项式中的交叉项,并且每个项的系数彼此不同.
定理 3.1设一个l层交叉网络,其第 i + 1 i+1 i+1 层定义为 x i + 1 = x 0 x i ⊤ w i + x i . \mathbf{x}_{i+1} = \mathbf{x}_0 \mathbf{x}_i^\top \mathbf{w}_i + \mathbf{x}_i. xi+1=x0xi⊤wi+xi.令网络的输入为 x 0 = [ x 1 , x 2 , … , x d ] ⊤ \mathbf{x}_0 = [x_1, x_2, \dots, x_d]^\top x0=[x1,x2,…,xd]⊤,输出定义为 g l ( x 0 ) = x l ⊤ w l , g_l(\mathbf{x}_0) = \mathbf{x}_l^\top \mathbf{w}_l, gl(x0)=xl⊤wl,参数为 w i , b i ∈ R d \mathbf{w}_i, \mathbf{b}_i \in \mathbb{R}^d wi,bi∈Rd。则多变量多项式 g l ( x 0 ) g_l(\mathbf{x}_0) gl(x0) 可重构出如下形式的多项式类:
{ ∑ α c α ( w 0 , … , w l ) x 1 α 1 x 2 α 2 ⋯ x d α d | 0 ≤ ∣ α ∣ ≤ l + 1 , α ∈ N d } \left\{ \sum_{\boldsymbol{\alpha}} c_{\boldsymbol{\alpha}}(\mathbf{w}_0, \dots, \mathbf{w}_l) x_1^{\alpha_1} x_2^{\alpha_2} \cdots x_d^{\alpha_d} \;\middle|\; 0 \leq |\boldsymbol{\alpha}| \leq l+1, \boldsymbol{\alpha} \in \mathbb{N}^d \right\} {α∑cα(w0,…,wl)x1α1x2α2⋯xdαd 0≤∣α∣≤l+1,α∈Nd}
其中,系数 c α c_{\boldsymbol{\alpha}} cα 定义如下 c α = M α ∑ i ∈ B α ∑ j ∈ P α ∏ k = 1 ∣ α ∣ w i k ( j k ) c_{\boldsymbol{\alpha}} = M_{\boldsymbol{\alpha}} \sum_{\mathbf{i} \in B_{\boldsymbol{\alpha}}} \sum_{\mathbf{j} \in P_{\mathbf{\alpha}}} \prod_{k=1}^{|\boldsymbol{\alpha}|} w_{i_k}^{(j_k)} cα=Mα∑i∈Bα∑j∈Pα∏k=1∣α∣wik(jk), M α M_{\boldsymbol{\alpha}} Mα 是一个与 w i \mathbf{w}_i wi 无关的常数; i = [ i 1 , … , i ∣ α ∣ ] \mathbf{i} = [i_1, \dots, i_{|\boldsymbol{\alpha}|}] i=[i1,…,i∣α∣], j = [ j 1 , … , j ∣ α ∣ ] \mathbf{j} = [j_1, \dots, j_{|\boldsymbol{\alpha}|}] j=[j1,…,j∣α∣] 为多重索引; B α = { y ∈ { 0 , 1 , … , l } ∣ α ∣ | y k ≤ j k ∧ j k ∈ { 0 , … , l } } B_{\boldsymbol{\alpha}} = \left\{ \mathbf{y} \in \{0, 1, \dots, l\}^{|\boldsymbol{\alpha}|} \;\middle|\; y_k \leq j_k \land j_k \in \{0, \dots, l\} \right\} Bα={y∈{0,1,…,l}∣α∣ yk≤jk∧jk∈{0,…,l}}; P α P_{\boldsymbol{\alpha}} Pα 是对索引 ( 1 , … , 1 , … , d , … , d ) (1, \dots, 1, \dots, d, \dots, d) (1,…,1,…,d,…,d) 的所有排列的集合,其中每个变量 x j x_j xj 重复 α j \alpha_j αj 次。
考虑定理 3.1 的证明(详见附录)。我们给出一个示例。设 α = ( 1 , 1 , 1 , 0 , … , 0 ) \boldsymbol{\alpha} = (1, 1, 1, 0, \dots, 0) α=(1,1,1,0,…,0),即对应于单项式 x 1 x 2 x 3 x_1 x_2 x_3 x1x2x3 的系数 c α c_{\boldsymbol{\alpha}} cα。在忽略某个常数因子的前提下:当 l = 2 l = 2 l=2 时,有 c α = ∑ i , j , k ∈ P α w 0 ( i ) w 1 ( j ) w 2 ( k ) . c_{\boldsymbol{\alpha}} = \sum_{i,j,k \in P_{\boldsymbol{\alpha}}} w_0^{(i)} w_1^{(j)} w_2^{(k)}. cα=∑i,j,k∈Pαw0(i)w1(j)w2(k).也可以具体写为 w 0 ( i ) w 1 ( j ) w 2 ( k ) + w 0 ( j ) w 1 ( i ) w 2 ( k ) w_0^{(i)} w_1^{(j)} w_2^{(k)} + w_0^{(j)} w_1^{(i)} w_2^{(k)} w0(i)w1(j)w2(k)+w0(j)w1(i)w2(k)当 l = 3 l = 3 l=3 时,有 c α = ∑ i , j , k ∈ P α w 0 ( i ) w 1 ( j ) w 2 ( k ) w 3 ( k ) + w 0 ( i ) w 1 ( k ) w 2 ( j ) w 3 ( k ) + w 0 ( j ) w 1 ( i ) w 2 ( k ) w 3 ( k ) . c_{\boldsymbol{\alpha}} = \sum_{i,j,k \in P_{\boldsymbol{\alpha}}} w_0^{(i)} w_1^{(j)} w_2^{(k)} w_3^{(k)} + w_0^{(i)} w_1^{(k)} w_2^{(j)} w_3^{(k)} + w_0^{(j)} w_1^{(i)} w_2^{(k)} w_3^{(k)}. cα=∑i,j,k∈Pαw0(i)w1(j)w2(k)w3(k)+w0(i)w1(k)w2(j)w3(k)+w0(j)w1(i)w2(k)w3(k).
3.2 因子分解机的推广
交叉网络继承了FM模型的参数共享精神,并将其进一步扩展到更深层次的结构。
在 FM(因子分解机)模型中,特征 x i x_i xi 对应一个权重向量 v i \mathbf{v}_i vi,交叉项 x i x j x_i x_j xixj 的权重通过 ⟨ v i , v j ⟩ \langle \mathbf{v}_i, \mathbf{v}_j \rangle ⟨vi,vj⟩ 计算得出。而在 DCN(深度交叉网络)中,特征 x i x_i xi 对应一组标量 { w k ( i ) } k = 1 l \{w_k^{(i)}\}_{k=1}^l {wk(i)}k=1l,而交叉项 x i x j x_i x_j xixj 的权重由 { w k ( i ) } k = 0 l \{w_k^{(i)}\}_{k=0}^l {wk(i)}k=0l 与 { w k ( j ) } k = 0 l \{w_k^{(j)}\}_{k=0}^l {wk(j)}k=0l 两组参数乘积组成。两种模型都在不同层次上学习到一部分跨特征共享的参数,而交叉项的权重是这些对应参数的特定组合。
这种参数共享机制不仅提高了模型效率,还使模型具备了对未见过的特征组合进行泛化的能力,并且对噪声更具鲁棒性。例如,对于稀疏数据集,如果两个特征 x i x_i xi 和 x j x_j xj 在训练数据中几乎从未同时出现(即 x i ⋅ x j = 0 x_i \cdot x_j = 0 xi⋅xj=0),那么 FM 中学到的交叉项 x i x j x_i x_j xixj 的权重对于预测是没有意义的。
FM 是一种浅层结构,主要用于表示二阶交叉项(即 x i x j x_i x_j xixj)。而 DCN 则可以构造所有满足 ∣ α ∣ ≤ l |\boldsymbol{\alpha}| \leq l ∣α∣≤l 的高阶交叉项 x 1 α 1 x 2 α 2 ⋯ x d α d x_1^{\alpha_1} x_2^{\alpha_2} \cdots x_d^{\alpha_d} x1α1x2α2⋯xdαd,其中 l l l 是网络深度,具体如定理 3.1 所示。因此,交叉网络实现了参数在多层之间的共享,从而更高效地建模高阶交叉项。不同于传统高阶 FM 模型,交叉网络中的参数数量仅以输入维度线性增长。
3.3 高效投影
每一层交叉层都将输入向量 x 0 \mathbf{x}_0 x0 与 x 1 \mathbf{x}_1 x1 之间的所有两两交互项(pairwise interactions),以一种高效的方式重新投影回输入的维度。
考虑将 x ~ ∈ R d \tilde{\mathbf{x}} \in \mathbb{R}^d x~∈Rd 作为输入送入交叉层。交叉层首先隐式构造所有 d 2 d^2 d2 个交互项 x i x ~ j x_i \tilde{x}_j xix~j,然后以内存高效的方式将其投影回维度 d d d。而如果直接显式构造这些交互项,则需要立方级别的计算成本。
我们的交叉层提供了一种高效的方式,将计算成本降至关于输入维度 d d d 的线性级别。设:
x p = x 0 x ~ ⊤ w , \mathbf{x}_p = \mathbf{x}_0 \tilde{\mathbf{x}}^\top \mathbf{w}, xp=x0x~⊤w,
这实际上等价于:
x p ⊤ = [ x 1 x ~ 1 ⋯ x 1 x ~ d ⋯ x d x ~ 1 ⋯ x d x ~ d ] [ w 0 0 ⋯ 0 w 0 ⋯ 0 0 w ⋯ ⋮ ⋮ ⋮ ⋱ ] (8) \mathbf{x}_p^\top = \begin{bmatrix} x_1 \tilde{x}_1 & \cdots & x_1 \tilde{x}_d & \cdots & x_d \tilde{x}_1 & \cdots & x_d \tilde{x}_d \end{bmatrix} \begin{bmatrix} w & 0 & 0 & \cdots \\ 0 & w & 0 & \cdots \\ 0 & 0 & w & \cdots \\ \vdots & \vdots & \vdots & \ddots \end{bmatrix} \tag{8} xp⊤=[x1x~1⋯x1x~d⋯xdx~1⋯xdx~d] w00⋮0w0⋮00w⋮⋯⋯⋯⋱ (8)
其中,行向量包含所有 d 2 d^2 d2 个交叉项 x i x ~ j x_i \tilde{x}_j xix~j,而投影矩阵是一个块对角结构,每个块为 w ∈ R d \mathbf{w} \in \mathbb{R}^d w∈Rd 的列向量。
4. 实验结果
在本节中,我们评估了DCN在一些流行的分类数据集上的性能。
4.1 Criteo Display Ads 数据
Criteo Display Ads² 数据集用于预测广告的点击率(click-through rate, CTR)。该数据集包含:13 个整数特征,26 个类别特征,其中每个类别具有很高的基数(即类别种类很多)。对于该数据集来说,logloss 提高 0.001 就被视为具有实际意义的改进。原因在于:当面对庞大的用户群时,即便是微小的预测精度提升,也可能为企业带来可观的收入增长。数据详情如下:总数据量为 11 GB(约 4100 万条用户日志记录),覆盖 7 天的用户行为。使用前 6 天的数据作为训练集;第 7 天的数据被随机分为验证集和测试集,各占一半。
4.2 实现细节
DCN 是在 TensorFlow 上实现的,下面简要介绍一些训练时的实现细节:
*数据处理与嵌入:*对实值特征进行了对数变换以实现归一化。对于类别特征,我们将其嵌入到维度为6 ×(类别基数)^¼ 的稠密向量中。所有嵌入拼接后的总维度为 1026。
*优化:*我们使用 Adam 优化器进行小批量随机梯度下降(SGD)。批大小设为 512。对深度网络应用了批归一化,并将梯度裁剪阈值设置为 100。
*正则化:*我们采用了早停策略,因为发现 L2 正则化和 Dropout 并未有效提升性能。
*超参数设置:*我们在以下超参数上进行网格搜索:隐藏层数2 到 5 层;每层的隐藏单元数32 到 1024;学习率;交叉层数:1 到 6 层初始学习率 的搜索范围是 0.0001 到 0.001,步长为 0.0001。所有实验在训练达到第 150,000 步时应用早停,因为之后开始出现过拟合。
4.3 比较模型
我们将DCN与五种模型进行比较:无交叉网络的DCN模型(DNN),逻辑回归(LR),分解机
(FMs),宽深模型(W&D)和深交叉(DC)。
DNN(深度神经网络):嵌入层、输出层以及超参数调优过程与 DCN 相同。唯一的区别是 DNN 模型中不包含交叉层(cross layers)。
LR(逻辑回归):我们使用了 Sibyl [2] —— 一个大规模的分布式逻辑回归系统。整数特征通过对数刻度进行离散化。交叉特征由一个复杂的特征选择工具选出。所有的单特征(原始特征)均被使用。
FM。我们使用了带有专有细节的基于fm的模型。
W&D。与DCN不同的是,它的宽分量以原始稀疏特征为输入,依靠穷举搜索和领域知识来选择预测交叉特征。我们跳过了比较,因为没有好的方法来选择交叉特征。
DC。与DCN相比,DC没有形成明确的交叉特征。它主要依靠堆叠和剩余单元来创建隐式交叉。我们应用了与DCN相同的嵌入(堆叠)层,然后是另一个ReLu层来生成残差单元序列的输入。残留单元数从1调至5,输入维数和交叉维数从100调至1026。
4.4 模型表现
在本节中,我们首先列出了logloss下不同模型的最佳性能,然后我们详细比较了DCN和DNN,也就是说,我们进一步研究了交叉网络引入的影响。
不同模型的性能: 不同模型在测试集上的最佳 logloss 如表 1 所示。最优的超参数配置为:DCN 模型使用了 2 层深度网络(每层大小为 1024)和 6 层交叉网络;DNN 使用了 5 层深度网络(每层大小为 1024);DC 模型使用了 5 个残差单元(输入维度为 424,交叉维度为 537);LR 模型使用了 42 个交叉特征。在具有最深交叉结构时获得最佳性能,说明来自交叉网络的高阶特征交互是有价值的。正如我们所见,DCN 的表现显著优于所有其他模型。特别是,它优于最先进的 DNN 模型,但仅使用了后者 40% 的内存。

对于每个模型的最优超参数配置,我们还报告了在 10 次独立运行中测试 logloss 的均值和标准差,结果如下:DCN:0.4422 ± 9 × 10⁻⁵,DNN:0.4430 ± 3.7 × 10⁻⁴,DC:0.4430 ± 4.3 × 10⁻⁴,如上所示,DCN 的表现始终显著优于其他模型。
DCN 与 DNN 的对比:考虑到交叉网络仅引入了 O ( d ) O(d) O(d) 数量级的额外参数,我们将 DCN 与其深层网络(即传统的 DNN)进行对比,并在不同的内存预算和损失容忍度条件下展示实验结果。
在下文中,对于某一特定参数数量,我们报告的是所有学习速率和模型结构中验证集上的最佳损失值。由于嵌入层参数对两个模型完全一致,因此未将其计入参数总数。
表2报告了实现所需logloss阈值所需的最小参数数量。从表2中我们可以看到由于交叉网络能够更有效地学习有界度特征交互,DCN的内存效率比单个DNN高近一个数量级。

表 3 对比了在固定内存预算下各神经网络模型的性能。可以看出,DCN 的表现始终优于 DNN。在参数较少的情形下,交叉网络中的参数数量与深度网络相当,而性能上的明显提升说明:交叉网络在学习有效的特征交互方面更加高效。在参数较多的情形下,DNN 的性能有所追赶,但 DCN 仍显著优于 DNN,说明它能够高效地学习某些有意义的特征交互类型,即便是体量巨大的 DNN 模型也难以做到。
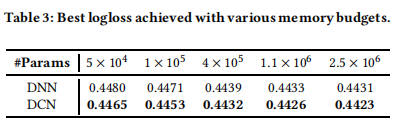
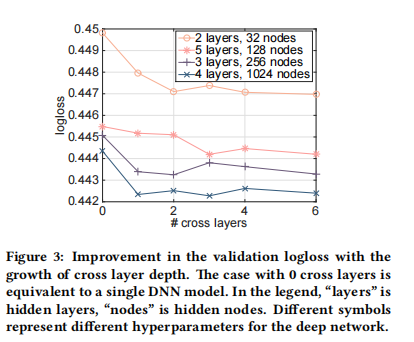
我们通过更细致的分析来探讨 DCN 的效果,具体展示在给定 DNN 模型的基础上引入交叉网络所带来的影响。我们首先比较在相同层数和每层大小的条件下,DNN 与 DCN 的最佳性能表现;然后,在每组设置下,我们展示随着交叉层数的增加,验证集上的 logloss 如何变化。表 4 展示了 DCN 与 DNN 模型在 logloss 上的差异。即使在相同的实验设置下,DCN 模型的最佳 logloss 始终优于结构相同的单一 DNN 模型。此外,这种提升在所有超参数组合中都表现一致,说明其改进效果已显著减少了来自初始化与随机优化过程的影响。
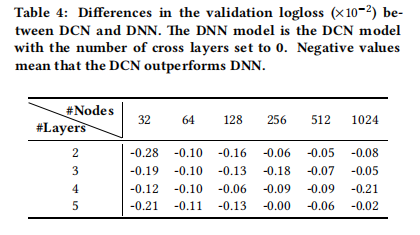
图 3 展示了在随机选择的设置下,随着交叉层数量的增加,模型性能的提升情况。对于图 3 中的深度网络,在模型中加入一个交叉层时,性能有明显提升。随着更多交叉层的引入,对于某些设置,logloss 持续下降,说明新增的交叉项对预测是有效的;而对于其他设置,logloss 开始波动甚至略微上升,表明所引入的高阶特征交互并未带来帮助。
4.5 Non-CTR数据集
我们展示了 DCN 在非点击率(CTR)预测问题上也有良好的表现。我们使用了 UCI 数据集中 forest covertype(包含 581012 个样本和 54 个特征)和 Higgs(包含 1100 万个样本和 28 个特征)这两个数据集。数据集被随机划分为训练集(90%)和测试集(10%)。我们对超参数进行了网格搜索。深度网络层数从 1 到 10,单层规模从 50 到 300。交叉层的层数从 4 到 10。残差单元的层数从 1 到 5,其输入维度和交叉维度从 50 到 300 不等。对于 DCN,输入向量被直接传入交叉网络。
在 forest covertype 数据集上,DCN 在内存消耗最少的情况下取得了最高的准确率 0.9740。DNN 和 DC 都达到了 0.9737。最优的超参数设置为:DCN 使用了 8 层交叉层(单层规模为 54)和 6 层深度层(单层规模为 292),DNN 使用了 7 层深度层(单层规模为 292),而 DC 使用了 4 个残差单元(输入维度为 271,交叉维度为 287)。
在 Higgs 数据集上,DCN 取得了最佳的 logloss 为 0.4494,而 DNN 的 logloss 为 0.4506。最优的超参数设置为:DCN 使用了 4 层交叉层(单层规模为 28)和 4 层深度层(单层规模为 209),DNN 使用了 10 层深度层(单层规模为 196)。DCN 仅使用 DNN 一半的内存就实现了更优表现。
5. 结论及未来发展方向
识别有效的特征相互作用是许多预测模型成功的关键。遗憾的是,这个过程需要手动特征提取和穷举搜索。dnn在自动特征学习中很受欢迎;然而,学习到的特征是隐式的和高度非线性的,在学习某些特征时,网络可能会变得不必要的庞大和低效。本文提出的深度交叉网络可以处理大量的稀疏和密集特征,并与传统的深度表示联合学习有界度的显式交叉特征。交叉特征度在每个交叉层增加1。我们的实验结果证明了它在稀疏和密集数据集上优于最先进的算法,在模型精度和内存使用方面都是如此。
我们希望进一步探索在其他模型中使用交叉层作为构建块,实现更深层次交叉网络的有效训练,研究多项式近似下交叉网络的效率,并在优化过程中进一步了解其与深度网络的相互作用
相关文章:

[论文阅读]Deep Cross Network for Ad Click Predictions
摘要 特征工程是许多预测模型成功的关键。然而,这个过程是困难的,甚至需要手动特征工程或穷举搜索。DNN能够自动学习特征交互;然而,它们隐式地生成所有的交互,并且不一定有效地学习所有类型的交叉特征。在本文中&…...

薪技术|0到1学会性能测试第45课-apache调优技术
前面的推文我们掌握了apache监控技术,今天我们继续来看下apache调优技术,究竟是怎么做性能调优???后续文章都会系统分享干货,带大家从0到1学会性能测试。 Apache调优技术 Apache最近的版本是2.2版,Apache2.2是一个多用途的web服务器,其设计在灵活性、可移植性和性能中…...
)
Linux之基础开发工具二(makefile,git,gdb)
目录 一、自动化构建-make/makefile 1.1、背景 1.2、基本使用 1.3、推导过程 1.4、语法拓展 二、进度条小程序 2.1、回车与换行 2.2、行缓冲区 2.3、练手-倒计时程序 2.4、进度条程序 三、版本控制器-Git 3.1、版本控制器 3.2、gitee的使用 3.2.1、如何创建仓库 …...

cesium之自定义地图与地图叠加
在appvue中,cesium支持更换不同的地图资源,代码如下 <template><div id"cesiumContainer" ref"cesiumContainer"></div> </template><script setup> import * as Cesium from cesium; import "./Widgets/widgets.css&…...

链表结构深度解析:从单向无头到双向循环的实现全指南
上篇博客实现动态顺序表时,我们会发现它存在许多弊端,如: • 中间/头部的插⼊删除,时间复杂度为O(N) • 增容需要申请新空间,拷⻉数据,释放旧空间。会有不⼩的消耗。 • 增容⼀般是呈2倍的增⻓,…...

Apache Velocity代码生成简要介绍
Apache Velocity 概述 Apache Velocity 是一个基于 Java 的模板引擎,它允许将 Java 代码与 HTML、XML 或其他文本格式分离,实现视图与数据的解耦。在 Web 开发中,Velocity 常用于生成动态网页内容;在其他场景下,也可用…...
!)
阿里云前端Nginx部署完,用ip地址访问却总访问不到,为什么?检查安全组是否设置u为Http(80)!
根据你的描述,Ping测试显示数据包无丢失但无法通过公网IP访问服务,说明网络基础层(ICMP协议)是通畅的,但更高层(如TCP/UDP协议或服务配置)存在问题。以下是系统性排查与解决方案: 一…...

【Hive入门】Hive行级安全:基于Apache Ranger的细粒度访问控制深度解析
引言 在大数据时代,数据安全与隐私保护已成为企业不可忽视的核心需求。传统表级权限控制已无法满足"同一张表不同用户看到不同数据"的业务场景,行级安全(Row-Level Security)成为数据仓库系统的必备能力。 1 行级安全概述 1.1 什么是行级安全…...

Marin说PCB之1000-BASE-T1的PCB设计总结--04
另外一路的1000-BASE-T1 Circuit:千兆以太网的仿真电路原理图的连接搭建方式如下: (共模电感的连接需要特别注意一下PIN序别搞错了) 这一路1000-BASE-T1 Circuit是做了兼容设计的: 其中电容C2099和C2100是百兆以太网的…...
)
两数之和(暴力+哈希查找)
目录 一.题目 二.解题过程 题目解析 方法一(暴力求解) 思路 代码 提交结果 方法二(哈希查找) 思路 代码 提交结果 作者的个人gitee 作者的算法讲解主页▶️ 每日一言:“愿你纵踩淤泥,也要…...

Qt项目——天气预报
目录 前言结果预览工程文件窗体无状态栏窗口跟随移动HTTP基本概念JSON数据QT解析JSON数据结语 前言 通过对之前Qt的学习其实我们就已经有一点经验了,做天气预报只需要了解以下内容: stylesheet界面美化 Json数据解析 HTTP通信 自定义控件绘制温度 结果预…...

智能推理DeepSeek-R1+Word深度整合业级智能办公构建
前引: 当我们将DeepSeek-R1深度集成到Word时,实际上是在构建智能办公的"数字神经系统"。这个系统不仅理解文字内容,更能感知用户意图,在恰当的时刻提供精准的智能辅助。随着RAG(检索增强生成)技术…...

【C++ Qt】常用输入类下:Combo Box/Spin Box/DataTimeEdit/Dial/Slide
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 在Qt开发框架中,UI组件是构建用户交互界面的基石。本章将详细探讨Qt中常用的UI组件,包括下拉框(QComboBoxÿ…...
)
基于Piecewise Jerk Speed Optimizer的速度规划算法(附ROS C++/Python仿真)
目录 1 时空解耦运动规划2 PJSO速度规划原理2.1 优化变量2.2 代价函数2.3 约束条件2.4 二次规划形式 3 算法仿真3.1 ROS C仿真3.2 Python仿真 1 时空解耦运动规划 在自主移动系统的运动规划体系中,时空解耦的递进式架构因其高效性与工程可实现性被广泛采用。这一架…...

K8s 常用命令、对象名称缩写汇总
K8s 常用命令、对象名称缩写汇总 前言 在之前的文章中已经陆续介绍过 Kubernetes 的部分命令,本文将专题介绍 Kubernetes 的常用命令,处理日常工作基本够用了。 集群相关 1、查看集群信息 kubectl cluster-info # 输出信息Kubernetes master is run…...

C++编程语言:从高效系统开发到现代编程范式的演进之路
目录 前言一、c简介1.1 起源1.2 c的特点 二、开发环境搭建 2.1. 安装 Qt 开发工具2.2 修改编码环境 2.3创建第一个 Qt 项目2.4 c的编译过程2.5 代码示例 2.6 qt疑难杂症 2.6.1 遇到无法删除代码,一点击光标就变成小黑块2.6.2 遇到运行不弹出终端 编辑 2.6.3 遇到…...

OpenCV进阶操作:角点检测
文章目录 一、角点检测1、定义2、检测流程1)输入图像2)图像预处理3)特征提取4)角点检测5)角点定位和标记6)角点筛选或后处理(可选)7)输出结果 二、Harris 角点检测&#…...

广州华锐视点邀您参与2025广交会VRAR展【5月10-12日】
2025 广交会数字显示与元宇宙生态博览会暨第 9 届世界 VR&AR 展将在广州盛大举行 。时间:2025 年 5 月 10 日至 12 日,广州华锐视点作为一家深耕 VR、AR、AI、元宇宙内容制作领域的企业,也将携旗下众多创新产品和解决方案闪耀登场&#x…...

mac m2 安装 hbase
默认安装好了 homebrew。 1. 终端先更新下 homebrew brew upgrade再安装 hbase brew install hbase 安装完会有如下图的内容 2. 按照提示启动 hbase brew services start hbase返回启动成功 3. 访问 http://localhost:16010 检验一下 启动成功 4. 在启动 hbase shell之…...

k8s node 报IPVS no destination available
在 Kubernetes 集群中,IPVS no destination available 错误通常表示 kube-proxy(IPVS 模式)无法为 Service 找到可用的后端 Pod。这会导致流量无法正确转发,影响服务可用性。以下是详细的排查和解决方法: 一、错误原因…...
 的用法详解)
MySQL 中 EXISTS (SELECT 1 FROM ...) 的用法详解
EXISTS (SELECT 1 FROM ...) 是 MySQL 中用于存在性检查的核心语法,其核心逻辑是判断子查询是否返回至少一行数据。以下从作用原理、使用场景、性能优化等方面展开解析,并结合具体示例说明。 1. 基本语法与作用原理 语法结构: SELECT 列名 F…...
)
荣耀A8互动娱乐组件部署实录(第3部分:控制端结构与房间通信协议)
作者:曾在 WebSocket 超时里泡了七天七夜的苦命人 一、控制端总体架构概述 荣耀A8控制端主要承担的是“运营支点”功能,也就是开发与运营之间的桥梁。它既不直接参与玩家行为,又控制着玩家的行为逻辑和游戏规则触发机制。控制端的主要职责包…...

前端-HTML+CSS+JavaScript+Vue+Ajax概述
HTML(超文本标记语言)常见标签 <html><head> <title>这是标题的内容,显示在浏览器的头部</title></head><body><!-- 这里面的内容在浏览器显示给用户看 --><!-- h1 -> h6 : 标题从大到小 …...

20250506格式化NanoPi NEO开发板使用Ubuntu core16.04系统的TF启动卡
https://www.sdcard.org/downloads/formatter/eula_windows/SDCardFormatterv5_WinEN.zip 20250506使用SDCardFormatter工具格式化NanoPi NEO开发板使用Ubuntu core16.04系统的TF启动卡 2025/5/6 20:04 缘起:使用友善之臂的NanoPi NEO开发板,制作了Ubunt…...

信息时代的政治重构:网络空间与主权的未来
一、网络空间:暴力垄断的终结 无边界主权的崛起 网络空间作为“第五阶段”的暴力竞争场域,打破传统领土垄断。政府无法像控制物理世界那样垄断网络暴力,类似公海的法律真空状态。 边区类比:中世纪的安道尔(法西共管避…...

Kotlin重构Android项目实践
以下是使用 Kotlin 重构 Android 项目的 5 个常见场景实践,通过对比 Java 实现方式,展示 Kotlin 的简洁性和现代特性: 场景 1:数据类替代 Java POJO Java 传统实现: public class User {private String name;private…...

Vue + Element UI 表单弹窗输入法卡顿问题解决方案
Vue Element UI 表单弹窗输入法卡顿问题解决方案 前言 在使用 Vue 和 Element UI 开发后台管理系统时,经常会遇到 el-dialog 弹出表单对话框的场景。然而,很多开发者可能会遇到一个棘手的问题:当调用 resetFields() 方法重置表单时&#x…...

ubantu安装CUDA
想要通过llama.cpp的方式跑deepseek R1模型。在按照https://huggingface.co/unsloth/DeepSeek-R1-GGUF教程去配环境时报错了。具体如下: (base) oemcore:~/Desktop/deepseek_llama.cpp$ sudo cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBSOFF -DGGM…...

Python生活手册-Numpy多维数组构建:从快递分拣到智能家居的数据变形术
一、快递分拣系统(基础构建) 1. 电子面单生成(列表转数组) import numpy as np手工录入的快递单号 纸质单号 [["SF123", "JD456", "EMS789"],["YT012", "ZT345", "YZ6…...

数据库的范围查询
范围查询 B树迭代器 迭代器接口 B树的基本操作包括用于范围查询的查找和迭代。B树的位置由状态化的迭代器 BIter 表示。 // 查找小于或等于输入键的最近位置 func (tree *BTree) SeekLE(key []byte) *BIter// 获取当前键值对 func (iter *BIter) Deref() ([]byte, []byte)/…...

JS DAY4 日期对象与节点
一日期对象 日期对象:用来表示时间的对象 作用:可以得到当前系统时间 1.实例化 在代码中发现了 new 关键字时,一般将这个操作称为实例化 创建一个时间对象并获取时间 时间必须实例化 获得当前时间 const date new Date() 获得指定时间 const date new Date(…...

【Leetcode 每日一题 - 补卡】1007. 行相等的最少多米诺旋转
问题背景 在一排多米诺骨牌中, t o p s [ i ] tops[i] tops[i] 和 b o t t o m s [ i ] bottoms[i] bottoms[i] 分别代表第 i i i 个多米诺骨牌的上半部分和下半部分。(一个多米诺是两个从 1 1 1 到 6 6 6 的数字同列平铺形成的 —— 该平铺的每一半…...

Android设备运行yolov8
放假这几天搞了一个基于uniapprk3588实现了一版yolo检测 这个是基于前端调用后端api来实现,感觉还可以,但是需要有网络才能进行图像检测,网络不稳定就会出现等待时间会比较久的问题,然后有做了一个在做了一个Android版本的图像检…...

Debezium MySqlValueConverters详解
Debezium MySqlValueConverters详解 1. 类的作用与功能 1.1 核心作用 MySqlValueConverters是Debezium中负责MySQL数据类型转换的核心类,主要功能包括: 数据类型映射:将MySQL的数据类型映射到Kafka Connect的Schema类型值转换:将MySQL的原始值转换为Kafka Connect可用的…...
)
Redis从入门到实战——实战篇(下)
四、达人探店 1. 发布探店笔记 探店笔记类似于点评网站的评价,往往是图文结合。对应的表有两个: tb_blog:探店笔记表,包含笔记中的标题、文字、图片等tb_blog_comments:其他用户对探店笔记的评价 步骤①࿱…...
)
算法中的数学:质数(素数)
1.质数 1.1定义 一个大于1的自然数,除了1和它自身外,不能被其他自然数整除,那么他就是质数,否则他就是合数。 注意:1既不是质数也不是合数 唯一的偶质数是2,其余所有质数都是奇质数 1.2质数判定求法 试除法…...

linux、window安装部署nacos
本文以nacos 2.2.0为例 文章目录 1.下载安装包2.按需修改配置配置单机模式配置内存 -Xms -Xmx -Xmn配置数据库为MySQL 3. 访问http://ip:8848/nacos4.常见问题找不到javac命令 1.下载安装包 打开官网,下载2.2.0版本 2.按需修改配置 配置单机模式 默认集群模式&…...

C++ 外观模式详解
外观模式(Facade Pattern)是一种结构型设计模式,它为复杂的子系统提供一个简化的接口。 概念解析 外观模式的核心思想是: 简化接口:为复杂的子系统提供一个更简单、更统一的接口 降低耦合:减少客户端与子…...
,一篇文章讲透彻)
42. 接雨水(相向双指针/前后缀分解),一篇文章讲透彻
给定一个数组,代表柱子的高度 求出下雨之后,能接的水有多少单位。我们将每一个柱子想象成一个水桶,看他能接多少水 以这个水桶为例,他所能接的水取决于左边的柱子的最大高度和右边柱子的最大高度,因为只有柱子高的时候…...

vue实现AI问答Markdown打字机效果
上线效果 功能清单 AI问答,文字输出跟随打字机效果格式化回答内容(markdown格式)停止回答,复制回答内容回答时自动向下滚动全屏切换历史问答查看 主要技术 vue 2.7.1markdown-it 14.1.0microsoft/fetch-event-source 2.0.1high…...

【QT】QT中的事件
QT中的事件 1.事件的定义和作用2.QT中事件产生和派发流程2.1 步骤2.2 图示示例代码:(event函数接收所有事件) 3.常见的事件3.1 鼠标事件示例代码:现象: 3.2 按键事件3.3 窗口大小改变事件 4.举例说明示例代码ÿ…...

【QT】QT中的软键盘设计
QT的软键盘设计 1.软键盘制作步骤2.介绍有关函数的使用3.出现的编译错误及解决办法示例代码1:按键事件实现软键盘现象:示例代码2:按键事件实现软键盘(加特殊按键)现象: 软键盘移植到新的工程的步骤…...

【Unity】一个AssetBundle热更新的使用小例子
1.新建两个预制体: Cube1:GameObject Material1:Material Cube1使用了Material1材质 之后设置打包配置 Cube1的打包配置为custom.ab Material1的打包配置为mat.ab 2.在Asset文件夹下创建Editor文件夹,并在Editor下创建BuildBundle…...
)
【Bootstrap V4系列】学习入门教程之 组件-按钮组(Button group)
Bootstrap V4系列 学习入门教程之 组件-按钮组(Button group) 按钮组(Button group)一、Basic example二、Button toolbar 按钮工具条三、Sizing 尺寸四、Nesting 嵌套五、Vertical variation 垂直变化 按钮组(Button …...

Linux进程间的通信
IPC 即 Inter-Process Communication,也就是进程间通信,它指的是在不同进程之间进行数据交换和协调同步的机制。在操作系统里,每个进程都有自己独立的内存空间,一般情况下不能直接访问其他进程的内存,所以需要借助 IPC…...

常用非对称加密算法的Python实现及详解
非对称加密算法(Asymmetric Encryption)使用公钥加密、私钥解密,解决了对称加密的密钥分发问题。本文将详细介绍 RSA、ECC、ElGamal、DSA、ECDSA、Ed25519 等非对称加密算法的原理,并提供Python实现代码及安全性分析。 1. 非对称加…...

【题解-洛谷】B4303 [蓝桥杯青少年组省赛 2024] 字母移位
题目:B4303 [蓝桥杯青少年组省赛 2024] 字母移位 题目描述 字母移位表示将字母按照字母表的顺序进行移动。 例如, b \texttt{b} b 向右移动一位是 c \texttt{c} c, f \texttt{f} f 向左移动两位是 d \texttt{d} d。 特别地,…...

详讲viewer查看器
将Python与Cesium结合起来,可以实现高效的数据处理与可视化展示。本文将详细介绍如何在Python环境中集成Cesium,以及实现数据可视化的具体方法。 我们可以通过在app.vue中的修改来更改我们查看器的显示方法 修改前 修改后 还可以进行各式各样的自定义操作…...

开关电源原理
开关电源原理 一、 开关电源的电路组成: 开关电源的主要电路是由输入电磁干扰滤波器(EMI)、整流滤波电路、功率变换电路、PWM控制器电路、输出整流滤波电路组成。辅助电路有输入过欠压保护电路、输出过欠压保护电路、输出过流保护电路、输出短…...

数据库的并发控制
并发控制 12.1 并发级别 问题:交错的读写 并发客户端可以随意进入和退出事务,并在中途请求读取和写入。为了简化分析,假设enter/exit/read/write是原子步骤,因此并发事务只是这些步骤的交错。 我们还将区分只读事务和读写事务…...