Android设备运行yolov8
放假这几天搞了一个基于uniapp+rk3588实现了一版yolo检测
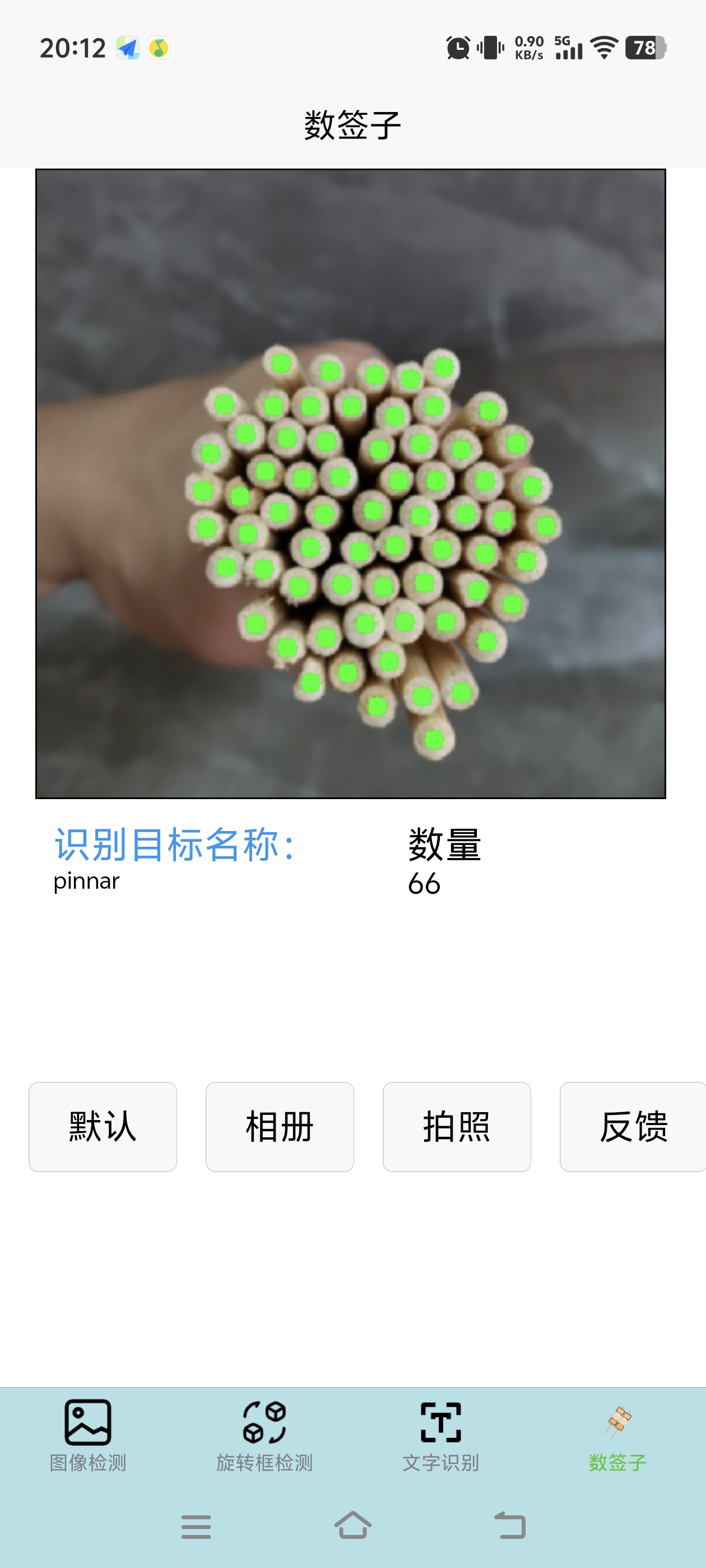
这个是基于前端调用后端api来实现,感觉还可以,但是需要有网络才能进行图像检测,网络不稳定就会出现等待时间会比较久的问题,然后有做了一个在做了一个Android版本的图像检测,我也是参考别人的实现来弄了。
记录一下大概步骤:
1.先安装Android Studio工具
2.下载检测代码yolov8安卓端识别代码
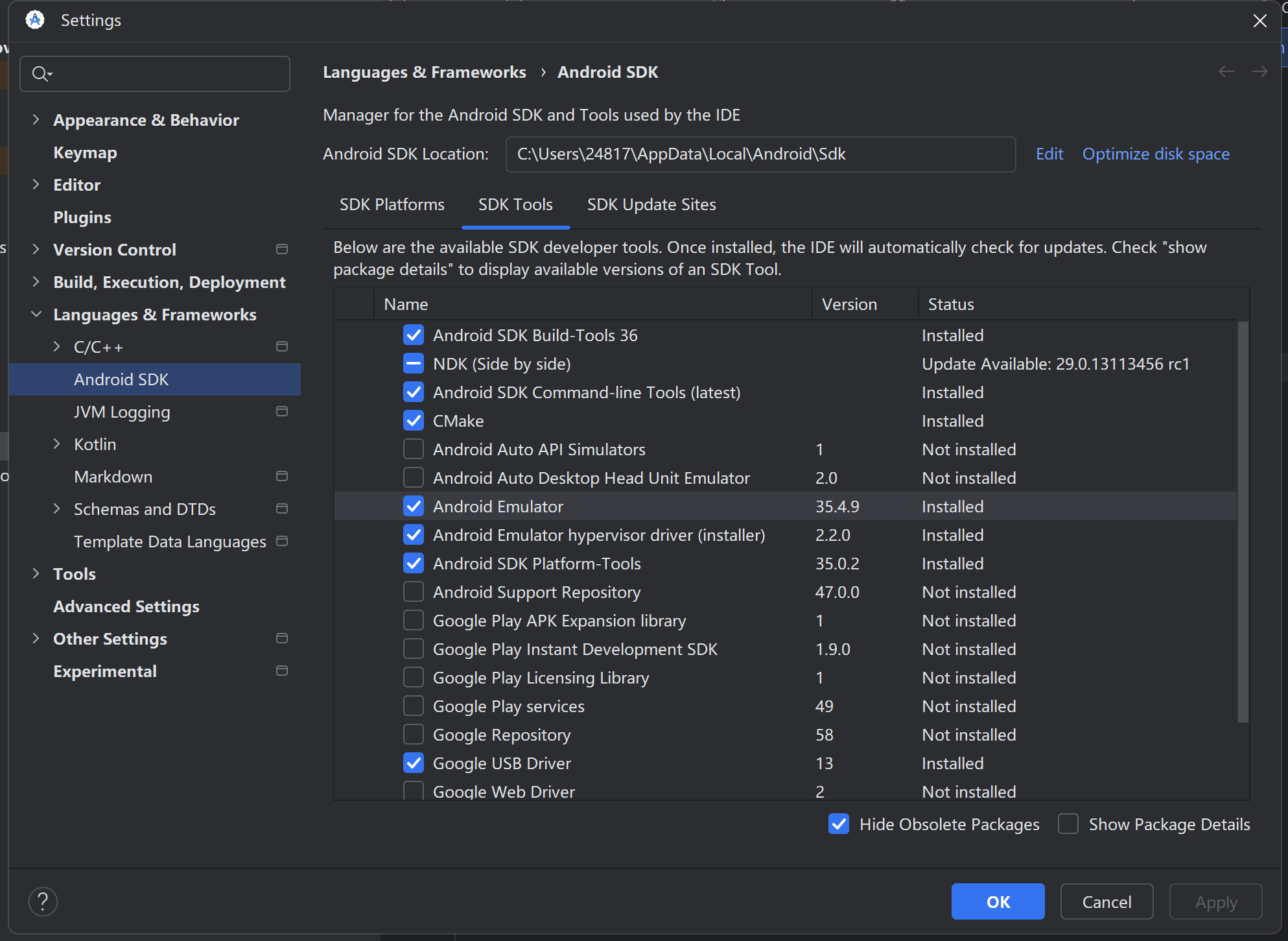
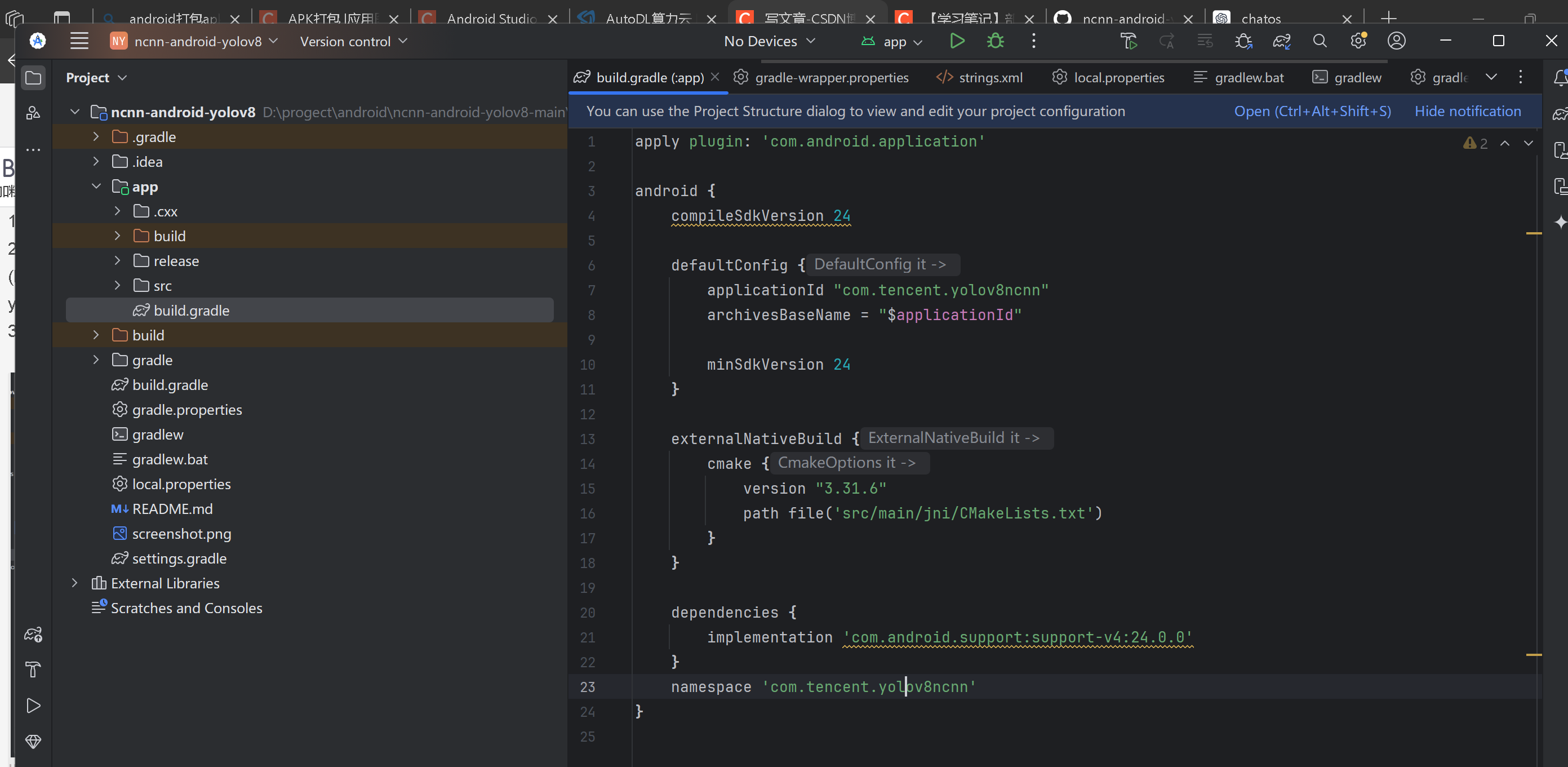
3.配置项目环境,项目下载下来只要环境配置好就可以运行,运行不起来不要怀疑是代码问题,大概下图中的都配置好没报错就可以连接手机,开始真机运行了

4.项目中默认运行项目中自带模型,如果想换其他模型,可以自己训练后转换进行替换
4.1替换默认模型大概步骤
先去拉取yolov8的训练代码 目前我使用yolov8-8.0.50版本,注意训练和导出onnx模型代码要分开,也就是说可以分成两套,下载好yolov8-8.0.50版本代码多复制一份出来,修改其中一套出来用于模型转换(pt转onnx)
具体修改:替换ultralytics-8.0.50\ultralytics-8.0.50\ultralytics\nn\modules.py中的内容,可以直接复制粘贴替换,替换完这个项目用于pt转onnx
转换还需要安装 onnx-simplifier
pip install onnx-simplifier #用于简化onnx模型
# Ultralytics YOLO 🚀, GPL-3.0 license
"""
Common modules
"""import mathimport torch
import torch.nn as nnfrom ultralytics.yolo.utils.tal import dist2bbox, make_anchorsdef autopad(k, p=None, d=1): # kernel, padding, dilation# Pad to 'same' shape outputsif d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))class DWConv(Conv):# Depth-wise convolutiondef __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activationsuper().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)class DWConvTranspose2d(nn.ConvTranspose2d):# Depth-wise transpose convolutiondef __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # ch_in, ch_out, kernel, stride, padding, padding_outsuper().__init__(c1, c2, k, s, p1, p2, groups=math.gcd(c1, c2))class ConvTranspose(nn.Module):# Convolution transpose 2d layerdefault_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=2, s=2, p=0, bn=True, act=True):super().__init__()self.conv_transpose = nn.ConvTranspose2d(c1, c2, k, s, p, bias=not bn)self.bn = nn.BatchNorm2d(c2) if bn else nn.Identity()self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv_transpose(x)))def forward_fuse(self, x):return self.act(self.conv_transpose(x))class DFL(nn.Module):# Integral module of Distribution Focal Loss (DFL) proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391def __init__(self, c1=16):super().__init__()self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)x = torch.arange(c1, dtype=torch.float)self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))self.c1 = c1def forward(self, x):b, c, a = x.shape # batch, channels, anchorsreturn self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)class TransformerLayer(nn.Module):# Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)def __init__(self, c, num_heads):super().__init__()self.q = nn.Linear(c, c, bias=False)self.k = nn.Linear(c, c, bias=False)self.v = nn.Linear(c, c, bias=False)self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)self.fc1 = nn.Linear(c, c, bias=False)self.fc2 = nn.Linear(c, c, bias=False)def forward(self, x):x = self.ma(self.q(x), self.k(x), self.v(x))[0] + xx = self.fc2(self.fc1(x)) + xreturn xclass TransformerBlock(nn.Module):# Vision Transformer https://arxiv.org/abs/2010.11929def __init__(self, c1, c2, num_heads, num_layers):super().__init__()self.conv = Noneif c1 != c2:self.conv = Conv(c1, c2)self.linear = nn.Linear(c2, c2) # learnable position embeddingself.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))self.c2 = c2def forward(self, x):if self.conv is not None:x = self.conv(x)b, _, w, h = x.shapep = x.flatten(2).permute(2, 0, 1)return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expandsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = Conv(c_, c2, k[1], 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class BottleneckCSP(nn.Module):# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)self.cv4 = Conv(2 * c_, c2, 1, 1)self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)self.act = nn.SiLU()self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):y1 = self.cv3(self.m(self.cv1(x)))y2 = self.cv2(x)return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))class C3(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))class C2(nn.Module):# CSP Bottleneck with 2 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv(2 * self.c, c2, 1) # optional act=FReLU(c2)# self.attention = ChannelAttention(2 * self.c) # or SpatialAttention()self.m = nn.Sequential(*(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n)))def forward(self, x):a, b = self.cv1(x).chunk(2, 1)return self.cv2(torch.cat((self.m(a), b), 1))class C2f(nn.Module):# CSP Bottleneck with 2 convolutionsdef __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))def forward(self, x):# y = list(self.cv1(x).chunk(2, 1))# y.extend(m(y[-1]) for m in self.m)# return self.cv2(torch.cat(y, 1))print('forward C2f')x = self.cv1(x)x = [x, x[:, self.c:, ...]]x.extend(m(x[-1]) for m in self.m)x.pop(1)return self.cv2(torch.cat(x, 1))def forward_split(self, x):y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))class ChannelAttention(nn.Module):# Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdetdef __init__(self, channels: int) -> None:super().__init__()self.pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)self.act = nn.Sigmoid()def forward(self, x: torch.Tensor) -> torch.Tensor:return x * self.act(self.fc(self.pool(x)))class SpatialAttention(nn.Module):# Spatial-attention moduledef __init__(self, kernel_size=7):super().__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'padding = 3 if kernel_size == 7 else 1self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.act = nn.Sigmoid()def forward(self, x):return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))class CBAM(nn.Module):# Convolutional Block Attention Moduledef __init__(self, c1, kernel_size=7): # ch_in, kernelssuper().__init__()self.channel_attention = ChannelAttention(c1)self.spatial_attention = SpatialAttention(kernel_size)def forward(self, x):return self.spatial_attention(self.channel_attention(x))class C1(nn.Module):# CSP Bottleneck with 1 convolutiondef __init__(self, c1, c2, n=1): # ch_in, ch_out, numbersuper().__init__()self.cv1 = Conv(c1, c2, 1, 1)self.m = nn.Sequential(*(Conv(c2, c2, 3) for _ in range(n)))def forward(self, x):y = self.cv1(x)return self.m(y) + yclass C3x(C3):# C3 module with cross-convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__(c1, c2, n, shortcut, g, e)self.c_ = int(c2 * e)self.m = nn.Sequential(*(Bottleneck(self.c_, self.c_, shortcut, g, k=((1, 3), (3, 1)), e=1) for _ in range(n)))class C3TR(C3):# C3 module with TransformerBlock()def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e)self.m = TransformerBlock(c_, c_, 4, n)class C3Ghost(C3):# C3 module with GhostBottleneck()def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e) # hidden channelsself.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))class SPP(nn.Module):# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729def __init__(self, c1, c2, k=(5, 9, 13)):super().__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])def forward(self, x):x = self.cv1(x)return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))class SPPF(nn.Module):# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocherdef __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))super().__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * 4, c2, 1, 1)self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)def forward(self, x):x = self.cv1(x)y1 = self.m(x)y2 = self.m(y1)return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))class Focus(nn.Module):# Focus wh information into c-spacedef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)# self.contract = Contract(gain=2)def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))# return self.conv(self.contract(x))class GhostConv(nn.Module):# Ghost Convolution https://github.com/huawei-noah/ghostnetdef __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groupssuper().__init__()c_ = c2 // 2 # hidden channelsself.cv1 = Conv(c1, c_, k, s, None, g, act=act)self.cv2 = Conv(c_, c_, 5, 1, None, c_, act=act)def forward(self, x):y = self.cv1(x)return torch.cat((y, self.cv2(y)), 1)class GhostBottleneck(nn.Module):# Ghost Bottleneck https://github.com/huawei-noah/ghostnetdef __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stridesuper().__init__()c_ = c2 // 2self.conv = nn.Sequential(GhostConv(c1, c_, 1, 1), # pwDWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dwGhostConv(c_, c2, 1, 1, act=False)) # pw-linearself.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False), Conv(c1, c2, 1, 1,act=False)) if s == 2 else nn.Identity()def forward(self, x):return self.conv(x) + self.shortcut(x)class Concat(nn.Module):# Concatenate a list of tensors along dimensiondef __init__(self, dimension=1):super().__init__()self.d = dimensiondef forward(self, x):return torch.cat(x, self.d)class Proto(nn.Module):# YOLOv8 mask Proto module for segmentation modelsdef __init__(self, c1, c_=256, c2=32): # ch_in, number of protos, number of maskssuper().__init__()self.cv1 = Conv(c1, c_, k=3)self.upsample = nn.ConvTranspose2d(c_, c_, 2, 2, 0, bias=True) # nn.Upsample(scale_factor=2, mode='nearest')self.cv2 = Conv(c_, c_, k=3)self.cv3 = Conv(c_, c2)def forward(self, x):return self.cv3(self.cv2(self.upsample(self.cv1(x))))class Ensemble(nn.ModuleList):# Ensemble of modelsdef __init__(self):super().__init__()def forward(self, x, augment=False, profile=False, visualize=False):y = [module(x, augment, profile, visualize)[0] for module in self]# y = torch.stack(y).max(0)[0] # max ensemble# y = torch.stack(y).mean(0) # mean ensembley = torch.cat(y, 1) # nms ensemblereturn y, None # inference, train output# heads
class Detect(nn.Module):# YOLOv8 Detect head for detection modelsdynamic = False # force grid reconstructionexport = False # export modeshape = Noneanchors = torch.empty(0) # initstrides = torch.empty(0) # initdef __init__(self, nc=80, ch=()): # detection layersuper().__init__()self.nc = nc # number of classesself.nl = len(ch) # number of detection layersself.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)self.no = nc + self.reg_max * 4 # number of outputs per anchorself.stride = torch.zeros(self.nl) # strides computed during buildc2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], self.nc) # channelsself.cv2 = nn.ModuleList(nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()def forward(self, x):shape = x[0].shape # BCHWfor i in range(self.nl):x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)if self.training:return xelif self.dynamic or self.shape != shape:self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))self.shape = shape# if self.export and self.format == 'edgetpu': # FlexSplitV ops issue# x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)# box = x_cat[:, :self.reg_max * 4]# cls = x_cat[:, self.reg_max * 4:]# else:# box, cls = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2).split((self.reg_max * 4, self.nc), 1)# dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides# y = torch.cat((dbox, cls.sigmoid()), 1)# return y if self.export else (y, x)print('forward Detect')pred = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2).permute(0, 2, 1)return preddef bias_init(self):# Initialize Detect() biases, WARNING: requires stride availabilitym = self # self.model[-1] # Detect() module# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequencyfor a, b, s in zip(m.cv2, m.cv3, m.stride): # froma[-1].bias.data[:] = 1.0 # boxb[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)class Segment(Detect):# YOLOv8 Segment head for segmentation modelsdef __init__(self, nc=80, nm=32, npr=256, ch=()):super().__init__(nc, ch)self.nm = nm # number of masksself.npr = npr # number of protosself.proto = Proto(ch[0], self.npr, self.nm) # protosself.detect = Detect.forwardc4 = max(ch[0] // 4, self.nm)self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.nm, 1)) for x in ch)def forward(self, x):p = self.proto(x[0]) # mask protosbs = p.shape[0] # batch sizemc = torch.cat([self.cv4[i](x[i]).view(bs, self.nm, -1) for i in range(self.nl)], 2) # mask coefficientsx = self.detect(self, x)if self.training:return x, mc, preturn (torch.cat([x, mc], 1), p) if self.export else (torch.cat([x[0], mc], 1), (x[1], mc, p))class Classify(nn.Module):# YOLOv8 classification head, i.e. x(b,c1,20,20) to x(b,c2)def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()c_ = 1280 # efficientnet_b0 sizeself.conv = Conv(c1, c_, k, s, autopad(k, p), g)self.pool = nn.AdaptiveAvgPool2d(1) # to x(b,c_,1,1)self.drop = nn.Dropout(p=0.0, inplace=True)self.linear = nn.Linear(c_, c2) # to x(b,c2)def forward(self, x):if isinstance(x, list):x = torch.cat(x, 1)x = self.linear(self.drop(self.pool(self.conv(x)).flatten(1)))return x if self.training else x.softmax(1)5.onnx转ncnn
去官网下载ncnn转换工具

下载完成后打开进入到ncnn-20241226-windows-vs2019\ncnn-20241226-windows-vs2019\x86\bin下面
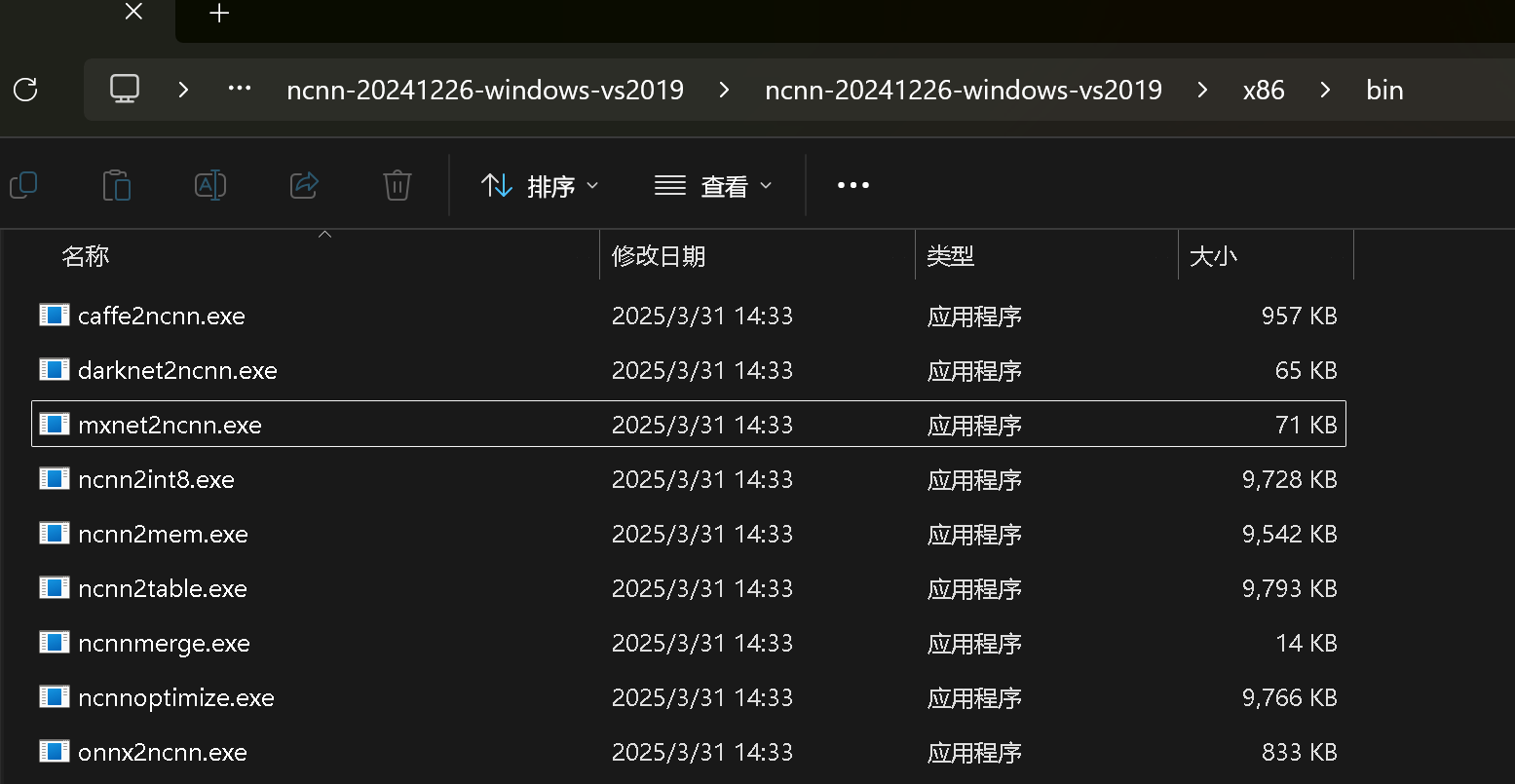
打开cmd终端执行下面命令 后面的onnx填自己转换的模型
onnx2ncnn.exe yolo.onnx

转换完后会产生两个 bin结尾和param结尾的文件
打开param文件修改最后一行,把output0改成output,这个里面的内容不一定要完全和ncnn-android-yolov8项目中的模型内容一样,刚开始我产生了误区是转换出来必须和项目中的模型内容一样,其实不一样也可以,修改完后就可以拿去替换项目中的模型了
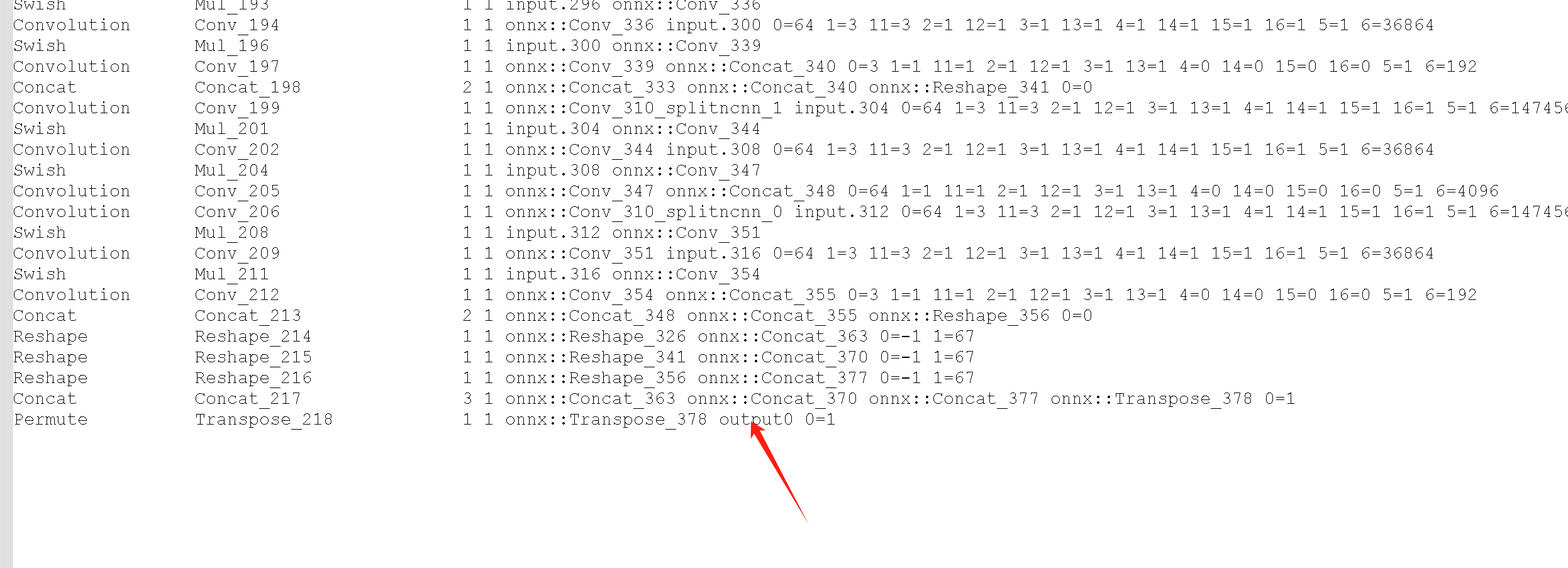
注意:项目中的模型默认是80类别的 如果替换会自己训练的模型一定要对应修改,类别数量
可以下载我上传的android-yolov8检测资源文件,已经测试过没问题
相关文章:

Android设备运行yolov8
放假这几天搞了一个基于uniapprk3588实现了一版yolo检测 这个是基于前端调用后端api来实现,感觉还可以,但是需要有网络才能进行图像检测,网络不稳定就会出现等待时间会比较久的问题,然后有做了一个在做了一个Android版本的图像检…...

Debezium MySqlValueConverters详解
Debezium MySqlValueConverters详解 1. 类的作用与功能 1.1 核心作用 MySqlValueConverters是Debezium中负责MySQL数据类型转换的核心类,主要功能包括: 数据类型映射:将MySQL的数据类型映射到Kafka Connect的Schema类型值转换:将MySQL的原始值转换为Kafka Connect可用的…...
)
Redis从入门到实战——实战篇(下)
四、达人探店 1. 发布探店笔记 探店笔记类似于点评网站的评价,往往是图文结合。对应的表有两个: tb_blog:探店笔记表,包含笔记中的标题、文字、图片等tb_blog_comments:其他用户对探店笔记的评价 步骤①࿱…...
)
算法中的数学:质数(素数)
1.质数 1.1定义 一个大于1的自然数,除了1和它自身外,不能被其他自然数整除,那么他就是质数,否则他就是合数。 注意:1既不是质数也不是合数 唯一的偶质数是2,其余所有质数都是奇质数 1.2质数判定求法 试除法…...

linux、window安装部署nacos
本文以nacos 2.2.0为例 文章目录 1.下载安装包2.按需修改配置配置单机模式配置内存 -Xms -Xmx -Xmn配置数据库为MySQL 3. 访问http://ip:8848/nacos4.常见问题找不到javac命令 1.下载安装包 打开官网,下载2.2.0版本 2.按需修改配置 配置单机模式 默认集群模式&…...

C++ 外观模式详解
外观模式(Facade Pattern)是一种结构型设计模式,它为复杂的子系统提供一个简化的接口。 概念解析 外观模式的核心思想是: 简化接口:为复杂的子系统提供一个更简单、更统一的接口 降低耦合:减少客户端与子…...
,一篇文章讲透彻)
42. 接雨水(相向双指针/前后缀分解),一篇文章讲透彻
给定一个数组,代表柱子的高度 求出下雨之后,能接的水有多少单位。我们将每一个柱子想象成一个水桶,看他能接多少水 以这个水桶为例,他所能接的水取决于左边的柱子的最大高度和右边柱子的最大高度,因为只有柱子高的时候…...

vue实现AI问答Markdown打字机效果
上线效果 功能清单 AI问答,文字输出跟随打字机效果格式化回答内容(markdown格式)停止回答,复制回答内容回答时自动向下滚动全屏切换历史问答查看 主要技术 vue 2.7.1markdown-it 14.1.0microsoft/fetch-event-source 2.0.1high…...

【QT】QT中的事件
QT中的事件 1.事件的定义和作用2.QT中事件产生和派发流程2.1 步骤2.2 图示示例代码:(event函数接收所有事件) 3.常见的事件3.1 鼠标事件示例代码:现象: 3.2 按键事件3.3 窗口大小改变事件 4.举例说明示例代码ÿ…...

【QT】QT中的软键盘设计
QT的软键盘设计 1.软键盘制作步骤2.介绍有关函数的使用3.出现的编译错误及解决办法示例代码1:按键事件实现软键盘现象:示例代码2:按键事件实现软键盘(加特殊按键)现象: 软键盘移植到新的工程的步骤…...

【Unity】一个AssetBundle热更新的使用小例子
1.新建两个预制体: Cube1:GameObject Material1:Material Cube1使用了Material1材质 之后设置打包配置 Cube1的打包配置为custom.ab Material1的打包配置为mat.ab 2.在Asset文件夹下创建Editor文件夹,并在Editor下创建BuildBundle…...
)
【Bootstrap V4系列】学习入门教程之 组件-按钮组(Button group)
Bootstrap V4系列 学习入门教程之 组件-按钮组(Button group) 按钮组(Button group)一、Basic example二、Button toolbar 按钮工具条三、Sizing 尺寸四、Nesting 嵌套五、Vertical variation 垂直变化 按钮组(Button …...

Linux进程间的通信
IPC 即 Inter-Process Communication,也就是进程间通信,它指的是在不同进程之间进行数据交换和协调同步的机制。在操作系统里,每个进程都有自己独立的内存空间,一般情况下不能直接访问其他进程的内存,所以需要借助 IPC…...

常用非对称加密算法的Python实现及详解
非对称加密算法(Asymmetric Encryption)使用公钥加密、私钥解密,解决了对称加密的密钥分发问题。本文将详细介绍 RSA、ECC、ElGamal、DSA、ECDSA、Ed25519 等非对称加密算法的原理,并提供Python实现代码及安全性分析。 1. 非对称加…...

【题解-洛谷】B4303 [蓝桥杯青少年组省赛 2024] 字母移位
题目:B4303 [蓝桥杯青少年组省赛 2024] 字母移位 题目描述 字母移位表示将字母按照字母表的顺序进行移动。 例如, b \texttt{b} b 向右移动一位是 c \texttt{c} c, f \texttt{f} f 向左移动两位是 d \texttt{d} d。 特别地,…...

详讲viewer查看器
将Python与Cesium结合起来,可以实现高效的数据处理与可视化展示。本文将详细介绍如何在Python环境中集成Cesium,以及实现数据可视化的具体方法。 我们可以通过在app.vue中的修改来更改我们查看器的显示方法 修改前 修改后 还可以进行各式各样的自定义操作…...

开关电源原理
开关电源原理 一、 开关电源的电路组成: 开关电源的主要电路是由输入电磁干扰滤波器(EMI)、整流滤波电路、功率变换电路、PWM控制器电路、输出整流滤波电路组成。辅助电路有输入过欠压保护电路、输出过欠压保护电路、输出过流保护电路、输出短…...

数据库的并发控制
并发控制 12.1 并发级别 问题:交错的读写 并发客户端可以随意进入和退出事务,并在中途请求读取和写入。为了简化分析,假设enter/exit/read/write是原子步骤,因此并发事务只是这些步骤的交错。 我们还将区分只读事务和读写事务…...

力扣第448场周赛
赛时成绩如下: 这应该是我力扣周赛的最好成绩了(虽然还是三题) 1. 两个数字的最大乘积 给定一个正整数 n。 返回 任意两位数字 相乘所得的 最大 乘积。 注意:如果某个数字在 n 中出现多次,你可以多次使用该数字。 示例 1: 输入࿱…...

关于Python:9. 深入理解Python运行机制
一、Python内存管理(引用计数、垃圾回收) Python(CPython)采用的是: “引用计数为主,垃圾回收为辅” 的内存管理机制。 也就是说: 引用计数机制:负责大部分内存释放,简…...

Cron表达式的用法
最近几天开发东西用到了定时脚本的问题,中间隔了一段时间没有用到,再次复习一下Cron表达式的用法。 Cron表达式是一种用于定义定时任务执行时间的字符串格式,广泛应用于Unix/Linux系统以及各种编程语言中。其主要用途是通过灵活的时间规则来…...

手机通过局域网访问网狐接口及管理后台网站
1.本地部署接口及后台网站 2.设置允许网站端口通过防火墙 3.查看网站服务器IP 4.手机连接到本地服务器同一局域网 5.手机访问本地服务器接口...
)
JavaSE核心知识点01基础语法01-01(关键字、标识符、变量)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 JavaSE核心知识点01基础语法01-01࿰…...
)
Sliding Window Attention(Longformer)
最简单的自注意力大家肯定都会啦。 但这种全连接的自注意力(即每个 token 需要 attend 到输入序列中的所有其他 token)计算与内存开销是 O ( n 2 ) O(n^2) O(n2) 。为了缓解这个问题,研究者们提出了 Sliding Window Attention。 Sliding W…...
)
ROS2 开发踩坑记录(持续更新...)
1. 从find_package(xxx REQUIRED)说起,如何引用其他package(包) 查看包的安装位置和include路径详细文件列表 例如,xxx包名为pluginlib # 查看 pluginlib 的安装位置 dpkg -L ros-${ROS_DISTRO}-pluginlib | grep include 这条指令的目的是…...

刷leetcodehot100返航版--哈希表5/5、5/6
回顾一下之前做的哈希,貌似只有用到 unordered_set:存储无序元素unordered_map:存储无序键值对 代码随想录 常用代码模板2——数据结构 - AcWing C知识回顾-CSDN博客 1.两数之和5/5【30min】 1. 两数之和 - 力扣(LeetCode&am…...

嵌入式开发学习日志Day13
第九章 预处理命令 前面加“#”的都为预处理命令; 预处理命令是无脑的文本替换; 一、宏定义 1、不带参数的宏定义 一般形式为: #define 标识符 字符串 (谷歌规定):所有的宏名均大写,便于…...

AI预测的艺术品走势靠谱吗?
首席数据官高鹏律师团队 AI预测艺术品价格走势:技术与法律的双重考量在当今数字化浪潮席卷全球的时代,人工智能(AI)技术正以前所未有的速度渗透到各个领域,艺术品市场也不例外。AI预测艺术品价格走势这一新兴事物&…...

AVL树 和 红黑树 的插入算法
1.AVL树 按照二叉搜索树的规则找到要插入的位置并插入,插入过后看是父节点的左还是右孩子,然后把父节点的平衡因子-1或1,调整后如果父节点的平衡因子是0,那就说明这颗子树的高度插入前后不变,上面的就不用调整平衡因子…...
)
【项目】基于ArkTS的网吧会员应用开发(1)
一、效果图展示 二、界面讲解 以上是基于ArkTS的鸿蒙应用网吧会员软件的引导页,使用滑动组件滑动页面,至最后一页时,点击立即体验,进入登录页面。 三、代码演示 import promptAction from ohos.promptAction; import router fr…...
)
命令模式(Command Pattern)
非常好!现在我们来深入讲解行为型设计模式之一 —— 命令模式(Command Pattern)。 我将通过: ✅ 定义解释 🎯 使用动机 🐍 Python 完整调用代码(含注释) 🧭 清晰类图 …...

CMake基础介绍
1、CMake 概述 CMake 是一个项目构建工具,并且是跨平台的;关于项目构建目前比较流行的还有 Makefile(通过 Make 命令进行项目的构建), 大多 IDE 软件都集成了 make,比如:VS 的 nmake、linux 下的 GNU make、Qt 的 qmake 等&…...

偷钱包行为检测数据集VOC+YOLO格式922张1类别有增强
有320张图片是原图剩余为增强图片 数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):922 标注数量(xml文件个数):922 标注数量…...

C 语言比较运算符:程序如何做出“判断”?
各类资料学习下载合集 https://pan.quark.cn/s/8c91ccb5a474 在编写程序时,我们经常需要根据不同的条件来执行不同的代码。比如,如果一个分数大于 60 分,就判断为及格;如果用户的年龄小于 18 岁,就禁止访问某个内容等等。这些“判断”的核心,就依赖于程序能够比…...
)
Webug4.0靶场通关笔记16- 第20关文件上传(截断上传)
目录 第20关 文件上传(截断上传) 1.打开靶场 2.源码分析 (1)右键查看前端源码 (2)服务端源码分析 (3)渗透思路 3.渗透实战 (1)构建脚本 (2)bp抓包 …...
增强方法)
10 种最新的思维链(Chain-of-Thought, CoT)增强方法
防御式链式思维(Chain-of-Defensive-Thought) 该方法通过引入结构化、防御性的推理示例,提高大语言模型在面对被污染或误导信息时的稳健性。 📄 论文链接:https://arxiv.org/abs/2504.20769 混合链式思维(…...

力扣119题解
记录 2025.5.5 题目: 思路: 代码: class Solution {public List<Integer> getRow(int rowIndex) {List<Integer> row new ArrayList<Integer>();row.add(1);for (int i 1; i < rowIndex; i) {row.add((int) ((long) row.get(i…...

NSOperation深入解析:从使用到底层原理
1. 基础概念与使用 1.1 NSOperation概述 NSOperation是Apple提供的一个面向对象的并发编程API,它基于GCD(Grand Central Dispatch)构建,但提供了更高层次的抽象和更丰富的功能。NSOperation允许开发者以面向对象的方式管理并发任…...
)
suna工具调用可视化界面实现原理分析(二)
这是一个基于React的浏览器操作可视化调试组件,主要用于在AI开发工具中展示网页自动化操作过程(如导航、点击、表单填写等)的执行状态和结果。以下是关键技术组件和功能亮点的解析: 一、核心功能模块 浏览器操作状态可视化 • 实时…...

【大模型面试每日一题】Day 9:BERT 的 MLM 和 GPT 的 Next Token Prediction 有什么区别?
【大模型面试每日一题】Day 9:BERT 的 MLM 和 GPT 的 Next Token Prediction 有什么区别? 📌 题目重现 🌟 面试官:预训练任务中,BERT 的 MLM(Masked Language Modeling)和 GPT 的 …...
,strtoul()和strtod()三个函数的功能)
分析strtol(),strtoul()和strtod()三个函数的功能
字符串转换为数值部分和子字符串首地址的函数有strtol(),strtoul()和strtod()三个函数。 1、strtol()函数 long int strtol(const char *str, char **endptr, int base) //当base0时,若字符串不是以"0","0x"和"0X"开头,则将数字部分按照10进制…...

Spring Boot 加载application.properties或application.yml配置文件的位置顺序。
我换一种更通俗易懂的方式,结合具体例子来解释 Spring Boot 加载application.properties或application.yml配置文件的位置顺序。 生活场景类比 想象你要找一本书,你有几个可能存放这本书的地方,你会按照一定顺序去这些地方找,直…...

C++进阶之——多态
1. 多态的概念 多态是用来描述这个世界的 多态的概念:通俗来说,就是多种形态,具体点就是去完成某个行为,当不同的对象去完成时会 产生出不同的状态。 这里就很厉害了,能够实现特殊处理,本文章就是来仔细…...

第13项三期,入组1123例:默沙东启动TROP2 ADC+PD-1子宫内膜癌头对头临床
Umabs DB作为目前全球最全面的抗体药物专业数据库,收录全球近10000个从临床前到商业化阶段抗体药物,涉及靶点1600,涉及疾病种类2400,研发机构2900,覆盖药物蛋白序列、专利和临床等多种专业信息。Umabs DB药物数据库已正…...

政务服务智能化改造方案和案例分析
政务服务智能化改造方案和案例分析 一、引言 在数字化时代浪潮的推动下,政务服务智能化改造已成为提升政府服务效能、优化营商环境、增强民众满意度的关键举措。传统政务服务模式存在流程繁琐、信息孤岛、办理效率低等问题,难以满足现代社会快节奏发展和…...

15.日志分析入门
日志分析入门 第一部分:日志分析基础第二部分:日志分析方法与工具第三部分:日志分析实践总结 目标: • 理解日志分析在网络安全中的作用 • 掌握日志的基本类型和分析方法 • 通过实践初步体验日志分析的过程 第一部分ÿ…...

EPSG:3857 和 EPSG:4326 的区别
EPSG:3857 和 EPSG:4326 是两种常用的空间参考系统,主要区别在于坐标表示方式和应用场景。以下是它们的核心差异: 1. 坐标系类型 EPSG:4326(WGS84) 地理坐标系(Geographic Coordinate System),基…...

Python Cookbook-7.2 使用 pickle 和 cPickle 模块序列化数据
任务 你想以某种可以接受的速度序列化和重建Python 数据结构,这些数据既包括基本Python 对象也包括类和实例。 解决方案 如果你不想假设你的数据完全由基本 Python 对象组成,或者需要在不同的 Python 版本之间移植,再或者需要将序列化后的…...

Java学习手册:Spring 多数据源配置与管理
在实际开发中,有时需要连接多个数据库,例如,一个系统可能需要从不同的数据库中读取和写入数据。Spring 提供了多种方式来配置和管理多数据源,以下将介绍常见的配置和管理方法。 一、多数据源配置 在 Spring 中,可以通…...

六、shell脚本--正则表达式:玩转文本匹配的“万能钥匙”
想象一下,你需要在一大堆文本(比如日志文件、配置文件、网页代码)里查找符合某种特定模式的字符串,而不是仅仅查找固定的单词。比如说: 找出所有的电子邮件地址 📧。找到所有看起来像电话号码 Ὅ…...