MATLAB人工大猩猩部队GTO优化CNN-LSTM多变量时间序列预测
本博客来源于CSDN机器鱼,未同意任何人转载。
更多内容,欢迎点击本专栏目录,查看更多内容。
目录
0 引言
1 数据准备
2 CNN-LSTM模型搭建
3 GTO超参数优化
3.1 GTO函数极值寻优
3.2 GTO优化CNN-LSTM超参数
3.3 主程序
4 结语
0 引言
基于MATLAB2020b的深度学习框架,提出了一种基于CNN-LSTM的多变量电力负荷预测方法,该方法将历史负荷与气象的多变量时间序列数据作为输入,以当天的96个时刻负荷值为输出,建模学习特征内部动态变化规律,即多变量输入多输出模型。同时,针对该模型超参数选择困难的问题,提出利用人工大猩猩部队GTO算法实现该模型超参数的优化选择。
1 数据准备
数据为2016电工杯的电力负荷数据,数据可以在【这里】下载得到。数据包含20140101到20250110的375天多变量数据。每天含96个时刻的负荷数据,即每间隔15分钟采集一次;以及当天的最高温度℃、最低温度℃、平均温度℃、相对湿度(平均)、降雨量(mm),即一天101个数据。
我们做时间序列预测,采用的是滚动序列建模,即采用1到n天的n*101个值为输入,第n+1天的96个负荷做输出,然后第2到n+1天的n*101个值为输入,第n+2天的96个负荷值为输出,这样进行滚动序列建模。数据划分的代码如下,我先区分了负荷数据与气象数据,然后分别归一化再划分数据集,其实应该先划分数据,再对训练集归一化,然后用训练集的参数对测试集(验证集)做归一化,这个就不要纠结了,想改的自己改一下:
clc;clear;close all;
%%
data=xlsread('电荷数据.csv','B2:CX376');
%负荷数据--每天96个负荷值,气象数据 最高温度℃ 最低温度℃ 平均温度℃ 相对湿度(平均) 降雨量(mm)
power=data(:,1:96);
weather=data(:,97:end);
% 归一化 或者 标准化 看哪个效果好
method=@mapminmax;% mapstd mapminmax
[x1,mappingx1]=method(power');
[x2,mappingx2]=method(weather');
data=[x1' x2'];
% 前steps天steps*101 为输入,来预测未来一天的96负荷值 为输出
steps=10;
samples=size(data,1)-steps;%样本数
for i=1:samplesinput{i,:}=data(i:i+steps-1,:);output(i,:)=data(i+steps,1:96);
end
%% 数据划分 8:1:1划分训练集、验证集、测试集
n_samples=size(input,1);
n=1:n_samples;%顺序划分用这个n
m1=round(0.8*n_samples);
m2=round(0.9*n_samples);Train_X=input(n(1:m1));
Train_Y=output(n(1:m1),:);Val_X=input(n(m1+1:m2));
Val_Y=output(n(m1+1:m2),:);Ttest_X=input(n(m2+1:end));
Ttest_Y=output(n(m2+1:end),:);2 CNN-LSTM模型搭建
MATLAB2020b自带的深度学习框架,其中会用到convolution2dLayer,sequenceFoldingLayer,reluLayer,averagePooling2dLayer,lstmLayer,fullyConnectedLayer等。需要的函数主要参考【这里】,据此我们建立CNN-LSTM模型如下:
clc;clear;close all;
%%
data=xlsread('电荷数据.csv','B2:CX376');
%负荷数据--每天96各负荷值,气象数据 最高温度℃ 最低温度℃ 平均温度℃ 相对湿度(平均) 降雨量(mm)
power=data(:,1:96);
weather=data(:,97:end);
% 归一化 或者 标准化 看哪个效果好
method=@mapminmax;% mapstd mapminmax
[x1,mappingx1]=method(power');
[x2,mappingx2]=method(weather');
data=[x1' x2'];
% 前steps天steps*101 为输入,来预测未来一天的96负荷值 为输出
steps=10;
samples=size(data,1)-steps;%样本数
for i=1:samplesinput{i,:}=data(i:i+steps-1,:);output(i,:)=data(i+steps,1:96);
end
%% 数据划分 8:1:1划分训练集、验证集、测试集
n_samples=size(input,1);
n=1:n_samples;%顺序划分用这个n
m1=round(0.8*n_samples);
m2=round(0.9*n_samples);Train_X=input(n(1:m1));
Train_Y=output(n(1:m1),:);Val_X=input(n(m1+1:m2));
Val_Y=output(n(m1+1:m2),:);Ttest_X=input(n(m2+1:end));
Ttest_Y=output(n(m2+1:end),:);%% 网络搭建
lr=0.001;
epochs=100;
miniBatchSize = 32;
kernel1_num=8;
kernel1_size=3;
pool1_size=2;
kernel2_num=16;
kernel2_size=3;
pool2_size=2;
lstm_node=20;
fc_node=100;rng(0)
input_size=[size(Train_X{1}) 1];
output_size=size(Train_Y,2);
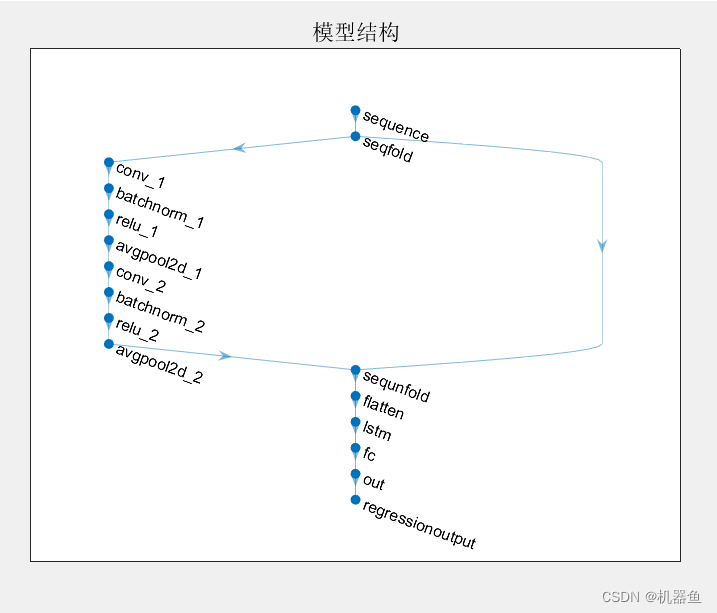
layers = [sequenceInputLayer(input_size,"Name","sequence")sequenceFoldingLayer("Name","seqfold")convolution2dLayer([kernel1_size kernel1_size],kernel1_num,"Name","conv_1","Padding","same")reluLayer("Name","relu_1")averagePooling2dLayer([1 pool1_size],"Name","avgpool2d_1")convolution2dLayer([kernel2_size kernel2_size],kernel2_num,"Name","conv_2","Padding","same")reluLayer("Name","relu_2")averagePooling2dLayer([1 pool2_size],"Name","avgpool2d_2")sequenceUnfoldingLayer("Name","sequnfold")flattenLayer("Name","flatten")lstmLayer(lstm_node,"Name","lstm",'OutputMode','last')fullyConnectedLayer(fc_node,"Name","fc")reluLayer("Name","relu_3")fullyConnectedLayer(output_size,"Name","out")regressionLayer("Name","regressionoutput")];
lgraph = layerGraph(layers);
lgraph = connectLayers(lgraph,"seqfold/miniBatchSize","sequnfold/miniBatchSize");
figure
plot(lgraph)
title("模型结构")options = trainingOptions('adam', ...'MiniBatchSize',miniBatchSize, ...'MaxEpochs',epochs, ...'InitialLearnRate',lr,...'LearnRateSchedule','piecewise',...'LearnRateDropFactor',1,...'Shuffle','every-epoch', ...'ValidationData',{Val_X,Val_Y}, ...'Verbose',1);train_again=1;% 为1就代码重新训练模型,为0就是调用训练好的网络
if train_again==1[net,traininfo] = trainNetwork(Train_X,Train_Y,lgraph,options);save result/cnn_lstm_net net traininfo
elseload result/cnn_lstm_net
endfigure
plot(traininfo.TrainingLoss);
grid on
title('CNN-LSTM');
xlabel('训练次数');
ylabel('损失值');%% 预测,
YPred1=predict(net,Ttest_X);
YPred1=method('reverse',YPred1',mappingx1);
Ytest1=method('reverse',Ttest_Y',mappingx1);
[m,n]=size(Ytest1);
real=reshape(Ytest1,[1,m*n]);
pred=reshape(YPred1,[1,m*n]);
result(real,pred,'CNN-LSTM')
save result/cnn_lstm_result real pred
figure
plot(real)
hold on;grid on
plot(pred)
legend('真实值','预测值')function result(true_value,predict_value,type)
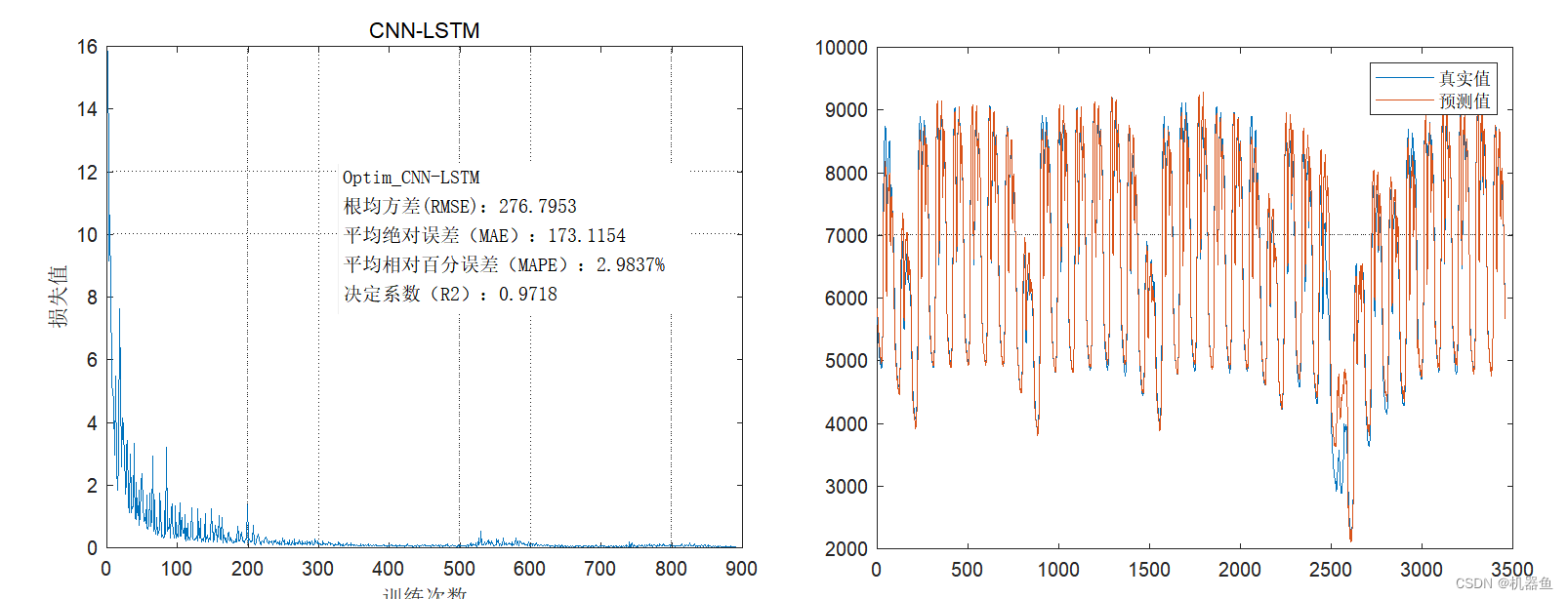
disp(type)
rmse=sqrt(mean((true_value-predict_value).^2));
disp(['根均方差(RMSE):',num2str(rmse)])
mae=mean(abs(true_value-predict_value));
disp(['平均绝对误差(MAE):',num2str(mae)])
mape=mean(abs((true_value-predict_value)./true_value));
disp(['平均相对百分误差(MAPE):',num2str(mape*100),'%'])R2 = 1 - norm(true_value-predict_value)^2/norm(true_value - mean(true_value))^2;disp(['决定系数(R2):',num2str(R2)])fprintf('\n')我们输入的是[batchsize steps 101],MATLAB的这个convolution2dLayer是2d卷积,不符合我们输入结构,好在提供了sequenceInputLayer,sequenceFoldingLayer,sequenceUnfoldingLayer这几个函数,专门用来接收这样的数据以便于连接conv2d与lstm。
与此同时,观察模型搭建那里,我们发现有很多参数需要进行手动设置,这个参数直接影响最后的结果,而设置这些参数我们是没有指导方法的,因此需要采用某些智能算法来优化选择。
lr=0.001;
epochs=100;
miniBatchSize = 32;
kernel1_num=8;
kernel1_size=3;
pool1_size=2;
kernel2_num=16;
kernel2_size=3;
pool2_size=2;
lstm_node=20;
fc_node=100;3 GTO超参数优化
3.1 GTO函数极值寻优
首先贴一下网上找的GTO函数极值寻优代码,如下:
function [Silverback_Score,Silverback,convergence_curve]=GTO(pop_size,max_iter,lower_bound,upper_bound,variables_no,fobj)% initialize Silverback
Silverback=[];
Silverback_Score=inf;%Initialize the first random population of Gorilla
X=initialization(pop_size,variables_no,upper_bound,lower_bound);convergence_curve=zeros(max_iter,1);for i=1:pop_sizePop_Fit(i)=fobj(X(i,:));%#okif Pop_Fit(i)<Silverback_ScoreSilverback_Score=Pop_Fit(i);Silverback=X(i,:);end
endGX=X(:,:);
lb=ones(1,variables_no).*lower_bound;
ub=ones(1,variables_no).*upper_bound;%% Controlling parameterp=0.03;
Beta=3;
w=0.8;%%Main loop
for It=1:max_itera=(cos(2*rand)+1)*(1-It/max_iter);C=a*(2*rand-1);%% Exploration:for i=1:pop_sizeif rand<pGX(i,:) =(ub-lb)*rand+lb;elseif rand>=0.5Z = unifrnd(-a,a,1,variables_no);H=Z.*X(i,:);GX(i,:)=(rand-a)*X(randi([1,pop_size]),:)+C.*H;elseGX(i,:)=X(i,:)-C.*(C*(X(i,:)- GX(randi([1,pop_size]),:))+rand*(X(i,:)-GX(randi([1,pop_size]),:))); %ok okendendendGX = boundaryCheck(GX, lower_bound, upper_bound);% Group formation operationfor i=1:pop_sizeNew_Fit= fobj(GX(i,:));if New_Fit<Pop_Fit(i)Pop_Fit(i)=New_Fit;X(i,:)=GX(i,:);endif New_Fit<Silverback_ScoreSilverback_Score=New_Fit;Silverback=GX(i,:);endend%% Exploitation:for i=1:pop_sizeif a>=wg=2^C;delta= (abs(mean(GX)).^g).^(1/g);GX(i,:)=C*delta.*(X(i,:)-Silverback)+X(i,:);elseif rand>=0.5h=randn(1,variables_no);elseh=randn(1,1);endr1=rand;GX(i,:)= Silverback-(Silverback*(2*r1-1)-X(i,:)*(2*r1-1)).*(Beta*h);endendGX = boundaryCheck(GX, lower_bound, upper_bound);% Group formation operationfor i=1:pop_sizeNew_Fit= fobj(GX(i,:));if New_Fit<Pop_Fit(i)Pop_Fit(i)=New_Fit;X(i,:)=GX(i,:);endif New_Fit<Silverback_ScoreSilverback_Score=New_Fit;Silverback=GX(i,:);endendconvergence_curve(It)=Silverback_Score;end
end% This function initialize the first population of search agents
function Positions=initialization(SearchAgents_no,dim,ub,lb)Boundary_no= size(ub,2); % numnber of boundaries% If the boundaries of all variables are equal and user enter a signle
% number for both ub and lb
if Boundary_no==1Positions=rand(SearchAgents_no,dim).*(ub-lb)+lb;
end% If each variable has a different lb and ub
if Boundary_no>1for i=1:dimub_i=ub(i);lb_i=lb(i);Positions(:,i)=rand(SearchAgents_no,1).*(ub_i-lb_i)+lb_i;end
end
end
function [ X ] = boundaryCheck(X, lb, ub)for i=1:size(X,1)FU=X(i,:)>ub;FL=X(i,:)<lb;X(i,:)=(X(i,:).*(~(FU+FL)))+ub.*FU+lb.*FL;
end
end% This function draw the benchmark functionsfunction func_plot(func_name)[lb,ub,dim,fobj]=Get_Functions_details(func_name);switch func_name case 'F1' x=-100:2:100; y=x; %[-100,100]case 'F2' x=-100:2:100; y=x; %[-10,10]case 'F3' x=-100:2:100; y=x; %[-100,100]case 'F4' x=-100:2:100; y=x; %[-100,100]case 'F5' x=-200:2:200; y=x; %[-5,5]case 'F6' x=-100:2:100; y=x; %[-100,100]case 'F7' x=-1:0.03:1; y=x %[-1,1]case 'F8' x=-500:10:500;y=x; %[-500,500]case 'F9' x=-5:0.1:5; y=x; %[-5,5] case 'F10' x=-20:0.5:20; y=x;%[-500,500]case 'F11' x=-500:10:500; y=x;%[-0.5,0.5]case 'F12' x=-10:0.1:10; y=x;%[-pi,pi]case 'F13' x=-5:0.08:5; y=x;%[-3,1]case 'F14' x=-100:2:100; y=x;%[-100,100]case 'F15' x=-5:0.1:5; y=x;%[-5,5]case 'F16' x=-1:0.01:1; y=x;%[-5,5]case 'F17' x=-5:0.1:5; y=x;%[-5,5]case 'F18' x=-5:0.06:5; y=x;%[-5,5]case 'F19' x=-5:0.1:5; y=x;%[-5,5]case 'F20' x=-5:0.1:5; y=x;%[-5,5] case 'F21' x=-5:0.1:5; y=x;%[-5,5]case 'F22' x=-5:0.1:5; y=x;%[-5,5] case 'F23' x=-5:0.1:5; y=x;%[-5,5]
end L=length(x);
f=[];for i=1:Lfor j=1:Lif strcmp(func_name,'F15')==0 && strcmp(func_name,'F19')==0 && strcmp(func_name,'F20')==0 && strcmp(func_name,'F21')==0 && strcmp(func_name,'F22')==0 && strcmp(func_name,'F23')==0f(i,j)=fobj([x(i),y(j)]);endif strcmp(func_name,'F15')==1f(i,j)=fobj([x(i),y(j),0,0]);endif strcmp(func_name,'F19')==1f(i,j)=fobj([x(i),y(j),0]);endif strcmp(func_name,'F20')==1f(i,j)=fobj([x(i),y(j),0,0,0,0]);end if strcmp(func_name,'F21')==1 || strcmp(func_name,'F22')==1 ||strcmp(func_name,'F23')==1f(i,j)=fobj([x(i),y(j),0,0]);end end
endsurfc(x,y,f,'LineStyle','none');end
% This function containts full information and implementations of the benchmark
% lb is the lower bound: lb=[lb_1,lb_2,...,lb_d]
% up is the uppper bound: ub=[ub_1,ub_2,...,ub_d]
% dim is the number of variables (dimension of the problem)function [lb,ub,dim,fobj] = Get_Functions_details(F)switch Fcase 'F1'fobj = @F1;lb=-100;ub=100;dim=30;case 'F2'fobj = @F2;lb=-10;ub=10;dim=30;case 'F3'fobj = @F3;lb=-100;ub=100;dim=30;case 'F4'fobj = @F4;lb=-100;ub=100;dim=30;case 'F5'fobj = @F5;lb=-30;ub=30;dim=30;case 'F6'fobj = @F6;lb=-100;ub=100;dim=30;case 'F7'fobj = @F7;lb=-1.28;ub=1.28;dim=30;case 'F8'fobj = @F8;lb=-500;ub=500;dim=30;case 'F9'fobj = @F9;lb=-5.12;ub=5.12;dim=30;case 'F10'fobj = @F10;lb=-32;ub=32;dim=30;case 'F11'fobj = @F11;lb=-600;ub=600;dim=30;case 'F12'fobj = @F12;lb=-50;ub=50;dim=30;case 'F13'fobj = @F13;lb=-50;ub=50;dim=30;case 'F14'fobj = @F14;lb=-65.536;ub=65.536;dim=2;case 'F15'fobj = @F15;lb=-5;ub=5;dim=4;case 'F16'fobj = @F16;lb=-5;ub=5;dim=2;case 'F17'fobj = @F17;lb=[-5,0];ub=[10,15];dim=2;case 'F18'fobj = @F18;lb=-2;ub=2;dim=2;case 'F19'fobj = @F19;lb=0;ub=1;dim=3;case 'F20'fobj = @F20;lb=0;ub=1;dim=6; case 'F21'fobj = @F21;lb=0;ub=10;dim=4; case 'F22'fobj = @F22;lb=0;ub=10;dim=4; case 'F23'fobj = @F23;lb=0;ub=10;dim=4;
endend% F1function o = F1(x)
o=sum(x.^2);
end% F2function o = F2(x)
o=sum(abs(x))+prod(abs(x));
end% F3function o = F3(x)
dim=size(x,2);
o=0;
for i=1:dimo=o+sum(x(1:i))^2;
end
end% F4function o = F4(x)
o=max(abs(x));
end% F5function o = F5(x)
dim=size(x,2);
o=sum(100*(x(2:dim)-(x(1:dim-1).^2)).^2+(x(1:dim-1)-1).^2);
end% F6function o = F6(x)
o=sum(abs((x+.5)).^2);
end% F7function o = F7(x)
dim=size(x,2);
o=sum([1:dim].*(x.^4))+rand;
end% F8function o = F8(x)
o=sum(-x.*sin(sqrt(abs(x))));
end% F9function o = F9(x)
dim=size(x,2);
o=sum(x.^2-10*cos(2*pi.*x))+10*dim;
end% F10function o = F10(x)
dim=size(x,2);
o=-20*exp(-.2*sqrt(sum(x.^2)/dim))-exp(sum(cos(2*pi.*x))/dim)+20+exp(1);
end% F11function o = F11(x)
dim=size(x,2);
o=sum(x.^2)/4000-prod(cos(x./sqrt([1:dim])))+1;
end% F12function o = F12(x)
dim=size(x,2);
o=(pi/dim)*(10*((sin(pi*(1+(x(1)+1)/4)))^2)+sum((((x(1:dim-1)+1)./4).^2).*...
(1+10.*((sin(pi.*(1+(x(2:dim)+1)./4)))).^2))+((x(dim)+1)/4)^2)+sum(Ufun(x,10,100,4));
end% F13function o = F13(x)
dim=size(x,2);
o=.1*((sin(3*pi*x(1)))^2+sum((x(1:dim-1)-1).^2.*(1+(sin(3.*pi.*x(2:dim))).^2))+...
((x(dim)-1)^2)*(1+(sin(2*pi*x(dim)))^2))+sum(Ufun(x,5,100,4));
end% F14function o = F14(x)
aS=[-32 -16 0 16 32 -32 -16 0 16 32 -32 -16 0 16 32 -32 -16 0 16 32 -32 -16 0 16 32;,...
-32 -32 -32 -32 -32 -16 -16 -16 -16 -16 0 0 0 0 0 16 16 16 16 16 32 32 32 32 32];for j=1:25bS(j)=sum((x'-aS(:,j)).^6);
end
o=(1/500+sum(1./([1:25]+bS))).^(-1);
end% F15function o = F15(x)
aK=[.1957 .1947 .1735 .16 .0844 .0627 .0456 .0342 .0323 .0235 .0246];
bK=[.25 .5 1 2 4 6 8 10 12 14 16];bK=1./bK;
o=sum((aK-((x(1).*(bK.^2+x(2).*bK))./(bK.^2+x(3).*bK+x(4)))).^2);
end% F16function o = F16(x)
o=4*(x(1)^2)-2.1*(x(1)^4)+(x(1)^6)/3+x(1)*x(2)-4*(x(2)^2)+4*(x(2)^4);
end% F17function o = F17(x)
o=(x(2)-(x(1)^2)*5.1/(4*(pi^2))+5/pi*x(1)-6)^2+10*(1-1/(8*pi))*cos(x(1))+10;
end% F18function o = F18(x)
o=(1+(x(1)+x(2)+1)^2*(19-14*x(1)+3*(x(1)^2)-14*x(2)+6*x(1)*x(2)+3*x(2)^2))*...(30+(2*x(1)-3*x(2))^2*(18-32*x(1)+12*(x(1)^2)+48*x(2)-36*x(1)*x(2)+27*(x(2)^2)));
end% F19function o = F19(x)
aH=[3 10 30;.1 10 35;3 10 30;.1 10 35];cH=[1 1.2 3 3.2];
pH=[.3689 .117 .2673;.4699 .4387 .747;.1091 .8732 .5547;.03815 .5743 .8828];
o=0;
for i=1:4o=o-cH(i)*exp(-(sum(aH(i,:).*((x-pH(i,:)).^2))));
end
end% F20function o = F20(x)
aH=[10 3 17 3.5 1.7 8;.05 10 17 .1 8 14;3 3.5 1.7 10 17 8;17 8 .05 10 .1 14];
cH=[1 1.2 3 3.2];
pH=[.1312 .1696 .5569 .0124 .8283 .5886;.2329 .4135 .8307 .3736 .1004 .9991;...
.2348 .1415 .3522 .2883 .3047 .6650;.4047 .8828 .8732 .5743 .1091 .0381];
o=0;
for i=1:4o=o-cH(i)*exp(-(sum(aH(i,:).*((x-pH(i,:)).^2))));
end
end% F21function o = F21(x)
aSH=[4 4 4 4;1 1 1 1;8 8 8 8;6 6 6 6;3 7 3 7;2 9 2 9;5 5 3 3;8 1 8 1;6 2 6 2;7 3.6 7 3.6];
cSH=[.1 .2 .2 .4 .4 .6 .3 .7 .5 .5];o=0;
for i=1:5o=o-((x-aSH(i,:))*(x-aSH(i,:))'+cSH(i))^(-1);
end
end% F22function o = F22(x)
aSH=[4 4 4 4;1 1 1 1;8 8 8 8;6 6 6 6;3 7 3 7;2 9 2 9;5 5 3 3;8 1 8 1;6 2 6 2;7 3.6 7 3.6];
cSH=[.1 .2 .2 .4 .4 .6 .3 .7 .5 .5];o=0;
for i=1:7o=o-((x-aSH(i,:))*(x-aSH(i,:))'+cSH(i))^(-1);
end
end% F23function o = F23(x)
aSH=[4 4 4 4;1 1 1 1;8 8 8 8;6 6 6 6;3 7 3 7;2 9 2 9;5 5 3 3;8 1 8 1;6 2 6 2;7 3.6 7 3.6];
cSH=[.1 .2 .2 .4 .4 .6 .3 .7 .5 .5];o=0;
for i=1:10o=o-((x-aSH(i,:))*(x-aSH(i,:))'+cSH(i))^(-1);
end
endfunction o=Ufun(x,a,k,m)
o=k.*((x-a).^m).*(x>a)+k.*((-x-a).^m).*(x<(-a));
end主函数如下所示,将上面几个函数复制进matlab保存成m文件,然后运行下面这个主函数即可:
clear ;close all;clc;format compact
%% 人工大猩猩部队优化算法
N=30; % Number of search agents
T=500; % Maximum number of iterations
Function_name='F4'; % Name of the test function that can be from F1 to F23 (Table 1,2,3 in the paper) 设定适应度函数
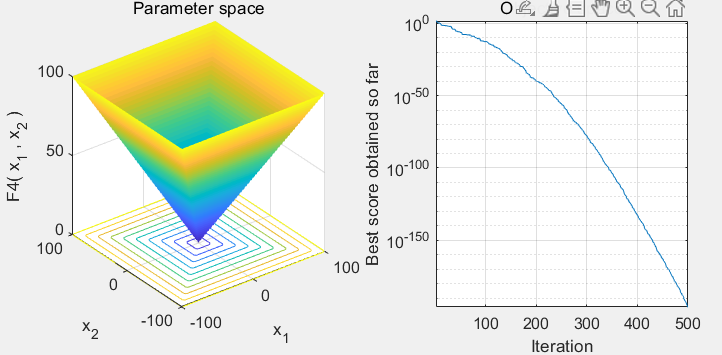
[lb,ub,dim,fobj]=Get_Functions_details(Function_name); %设定边界以及优化函数[BestF,BestP,Convergence_curve]=GTO(N,T,lb,ub,dim,fobj);figure('Position',[269 240 660 290])
subplot(1,2,1);
func_plot(Function_name);
title('Parameter space')
xlabel('x_1');
ylabel('x_2');
zlabel([Function_name,'( x_1 , x_2 )'])subplot(1,2,2);
semilogy(Convergence_curve)
hold on;title('Objective space')
xlabel('Iteration');
ylabel('Best score obtained so far');
axis tight
grid on
box on
3.2 GTO优化CNN-LSTM超参数
看过我之前的博客都知道,任意优化算法来做超参数寻优是不需要懂优化算法的原理的,看3.1可知我们下载的这份GTO代码是用来做极小值寻优的就行。然后遵循以下步骤进行代码修改:
步骤1:知道要优化的参数与优化范围。显然就是第2节提到的11个参数。代码如下,首先改写lb与ub,然后初始化的时候注意除了学习率,其他的都是整数。并将原来里面的边界判断,改成了Bounds函数,方便在计算适应度函数值的时候转化成整数与小数。如果学习率的位置不在最后,而是在其他位置,就需要改随机初始化位置和Bounds函数与fitness函数里对应的地方,具体怎么改就不说了,很简单。
%% 人工大猩猩部队优化算法
function [Silverback,convergence_curve,process]=GTO(P_train,P_valid,T_train,T_valid)
%% 参数设置
%lb ub为寻优范围 第一列是学习率[0.0001-0.01]
%然后分别是训练次数 batchsize 卷积层1的卷积核数量、大小 池化层1的大小
%卷积层2的卷积核数量、大小 池化层1的大小 lstm层的节点数 全连接层的节点数
lb=[1e-4 10 8 1 1 1 1 1 1 1 1];
ub=[1e-2 100 64 20 10 5 20 10 5 50 200];
variables_no=length(lb);
pop_size=5;%种群数量
max_iter=10;%寻优代数% initialize Silverback
Silverback=[];
Silverback_Score=inf;%Initialize the first random population of Gorilla
for i=1:pop_size%随机初始化速度,随机初始化位置for j=1:variables_noX( i, j ) = (ub(j)-lb(j))*rand+lb(j);end
endconvergence_curve=zeros(max_iter,1);for i=1:pop_sizeX(i,:) = Bounds( X(i,:), lb, ub );Pop_Fit(i)=fitness(X(i,:),P_train,P_valid,T_train,T_valid);if Pop_Fit(i)<Silverback_ScoreSilverback_Score=Pop_Fit(i);Silverback=X(i,:);end
endGX=X(:,:);%% Controlling parameterp=0.03;
Beta=3;
w=0.8;%%Main loop
for It=1:max_itera=(cos(2*rand)+1)*(1-It/max_iter);C=a*(2*rand-1);%% Exploration:for i=1:pop_sizeif rand<pGX(i,:) =(ub-lb).*rand(1,variables_no)+ub;elseif rand>=0.5Z = unifrnd(-a,a,1,variables_no);H=Z.*X(i,:);GX(i,:)=(rand-a)*X(randi([1,pop_size]),:)+C.*H;elseGX(i,:)=X(i,:)-C.*(C*(X(i,:)- GX(randi([1,pop_size]),:))+rand*(X(i,:)-GX(randi([1,pop_size]),:))); %ok okendendend% Group formation operationfor i=1:pop_sizeGX(i,:) = Bounds( GX(i,:), lb, ub );New_Fit= fitness(GX(i,:),P_train,P_valid,T_train,T_valid);if New_Fit<Pop_Fit(i)Pop_Fit(i)=New_Fit;X(i,:)=GX(i,:);endif New_Fit<Silverback_ScoreSilverback_Score=New_Fit;Silverback=GX(i,:);endend%% Exploitation:for i=1:pop_sizeif a>=wg=2^C;delta= (abs(mean(GX)).^g).^(1/g);GX(i,:)=C*delta.*(X(i,:)-Silverback)+X(i,:);elseif rand>=0.5h=randn(1,variables_no);elseh=randn(1,1);endr1=rand;GX(i,:)= Silverback-(Silverback*(2*r1-1)-X(i,:)*(2*r1-1)).*(Beta*h);endend% Group formation operationfor i=1:pop_sizeGX(i,:) = Bounds( GX(i,:), lb, ub );New_Fit= fitness(GX(i,:),P_train,P_valid,T_train,T_valid);if New_Fit<Pop_Fit(i)Pop_Fit(i)=New_Fit;X(i,:)=GX(i,:);endif New_Fit<Silverback_ScoreSilverback_Score=New_Fit;Silverback=GX(i,:);endendIt,Silverback_Score,Silverbackconvergence_curve(It)=Silverback_Score;process(It,:)= Silverback;
end
endfunction s = Bounds( s, Lb, Ub)
temp = s;
for i=1:length(s)if temp(:,i)>Ub(i) || temp(:,i)<Lb(i)temp(:,i) =rand*(Ub(i)-Lb(i))+Lb(i);endif i>1temp(:,i)=round(temp(:,i));%除了学习率 其他的都是整数end
end
s = temp;
end
步骤2:知道优化的目标。优化的目标是提高的网络的准确率,而GTO代码我们这个代码是最小值优化的,所以我们的目标可以是最小化CNN-LSTM的预测误差。预测误差具体是,测试集(或验证集)的预测值与真实值之间的均方差。
步骤3:构建适应度函数。通过步骤2我们已经知道优化的目标,即采用GTO去找11个值,用这11个值构建的CNN-LSTM网络,具备误差最小化。观察下面的代码,首先我们将GTO的值传进来,然后转成需要的11个值,然后构建网络,训练集训练、测试集预测,计算预测值与真实值的mse,将mse作为结果传出去作为适应度值。
function fit=fitness(x,P_train,P_valid,T_train,T_valid)
lr=x(1);
epochs=x(2);
miniBatchSize = x(3);
kernel1_num=x(4);
kernel1_size=x(5);
pool1_size=x(6);
kernel2_num=x(7);
kernel2_size=x(8);
pool2_size=x(9);
lstm_node=x(10);
fc_node=x(11);rng(0)
input_size=[size(P_train{1}) 1];
output_size=size(T_train,2);
layers = [sequenceInputLayer(input_size,"Name","sequence")sequenceFoldingLayer("Name","seqfold")convolution2dLayer([kernel1_size kernel1_size],kernel1_num,"Name","conv_1","Padding","same")reluLayer("Name","relu_1")averagePooling2dLayer([1 pool1_size],"Name","avgpool2d_1")convolution2dLayer([kernel2_size kernel2_size],kernel2_num,"Name","conv_2","Padding","same")reluLayer("Name","relu_2")averagePooling2dLayer([1 pool2_size],"Name","avgpool2d_2")sequenceUnfoldingLayer("Name","sequnfold")flattenLayer("Name","flatten")lstmLayer(lstm_node,"Name","lstm",'OutputMode','last')fullyConnectedLayer(fc_node,"Name","fc")reluLayer("Name","relu_3")fullyConnectedLayer(output_size,"Name","out")regressionLayer("Name","regressionoutput")];
lgraph = layerGraph(layers);
lgraph = connectLayers(lgraph,"seqfold/miniBatchSize","sequnfold/miniBatchSize");options = trainingOptions('adam', ...'MiniBatchSize',miniBatchSize, ...'MaxEpochs',epochs, ...'InitialLearnRate',lr,...'LearnRateSchedule','piecewise',...'LearnRateDropFactor',1,...'Shuffle','every-epoch', ...'Verbose',0);[net,~] = trainNetwork(P_train,T_train,lgraph,options);
YPred1=predict(net,P_valid);
[m,n]=size(T_valid);
real=reshape(T_valid,[1,m*n]);
pred=reshape(YPred1,[1,m*n]);
fit =mse(real-pred);% 以mse为适应度函数,优化算法目的就是找到一组超参数 使网络的mse最低
rng((100*sum(clock)))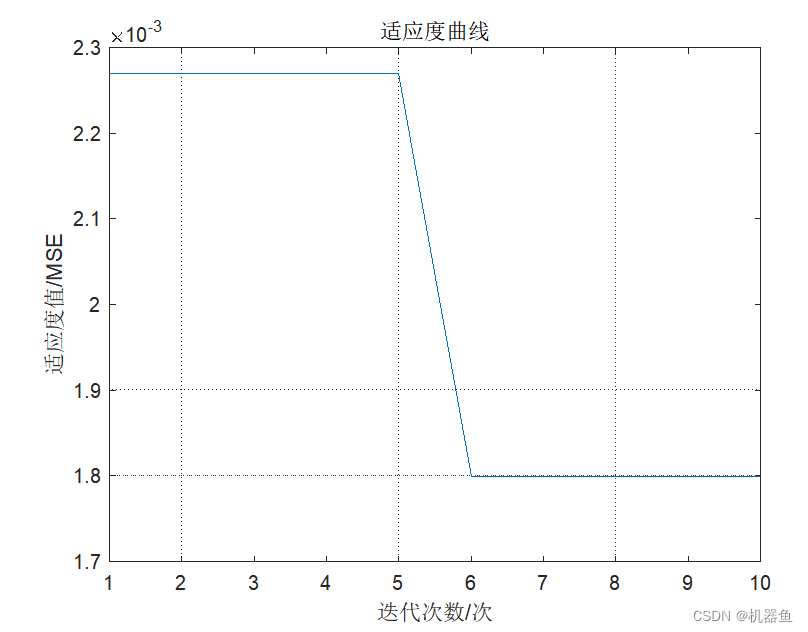
3.3 主程序
以下是调用上面这个优化算法的主程序,如下:
clc;clear;close all;format compact;format short
%%
data=xlsread('电荷数据.csv','B2:CX376');
%负荷数据--每天96各负荷值,气象数据 最高温度℃ 最低温度℃ 平均温度℃ 相对湿度(平均) 降雨量(mm)
power=data(:,1:96);
weather=data(:,97:end);
% 归一化 或者 标准化 看哪个效果好
method=@mapminmax;% mapstd mapminmax
[x1,mappingx1]=method(power');
[x2,mappingx2]=method(weather');
data=[x1' x2'];
% 前steps天steps*101 为输入,来预测未来一天的96负荷值 为输出
steps=10;
samples=size(data,1)-steps;%样本数
for i=1:samplesinput{i,:}=data(i:i+steps-1,:);output(i,:)=data(i+steps,1:96);
end
%% 数据划分 8:1:1划分训练集、验证集、测试集
n_samples=size(input,1);
n=1:n_samples;
m1=round(0.8*n_samples);
m2=round(0.9*n_samples);Train_X=input(n(1:m1));
Train_Y=output(n(1:m1),:);Val_X=input(n(m1+1:m2));
Val_Y=output(n(m1+1:m2),:);Ttest_X=input(n(m2+1:end));
Ttest_Y=output(n(m2+1:end),:);
%% 参数优化
optimization=0;%是否重新优化
if optimization==1[x ,fit_gen,process]=GTO(Train_X,Val_X,Train_Y,Val_Y);save result/optim_result x fit_gen process
elseload result/optim_result
end
figure
plot(fit_gen)
grid on
title('适应度曲线')
xlabel('迭代次数/次')
ylabel('适应度值/MSE')
%% 网络搭建
lr=x(1)
epochs=x(2)
miniBatchSize = x(3)
kernel1_num=x(4)
kernel1_size=x(5)
pool1_size=x(6)
kernel2_num=x(7)
kernel2_size=x(8)
pool2_size=x(9)
lstm_node=x(10)
fc_node=x(11)rng(0)
input_size=[size(Train_X{1}) 1];
output_size=size(Train_Y,2);
layers = [sequenceInputLayer(input_size,"Name","sequence")sequenceFoldingLayer("Name","seqfold")convolution2dLayer([kernel1_size kernel1_size],kernel1_num,"Name","conv_1","Padding","same")reluLayer("Name","relu_1")averagePooling2dLayer([1 pool1_size],"Name","avgpool2d_1")convolution2dLayer([kernel2_size kernel2_size],kernel2_num,"Name","conv_2","Padding","same")reluLayer("Name","relu_2")averagePooling2dLayer([1 pool2_size],"Name","avgpool2d_2")sequenceUnfoldingLayer("Name","sequnfold")flattenLayer("Name","flatten")lstmLayer(lstm_node,"Name","lstm",'OutputMode','las')fullyConnectedLayer(fc_node,"Name","fc")reluLayer("Name","relu_3")fullyConnectedLayer(output_size,"Name","out")regressionLayer("Name","regressionoutput")];
lgraph = layerGraph(layers);
lgraph = connectLayers(lgraph,"seqfold/miniBatchSize","sequnfold/miniBatchSize");
figure
plot(lgraph)
title("模型结构")
options = trainingOptions('adam', ...'MiniBatchSize',miniBatchSize, ...'MaxEpochs',epochs, ...'InitialLearnRate',lr,...'LearnRateSchedule','piecewise',...'LearnRateDropFactor',1,...'Shuffle','every-epoch', ...'ValidationData',{Val_X,Val_Y}, ...'Verbose',1);train_again=0;% 为1就代码重新训练模型,为0就是调用训练好的网络
if train_again==1[net,traininfo] = trainNetwork(Train_X,Train_Y,lgraph,options);save result/cnn_lstm_net2 net traininfo
elseload result/cnn_lstm_net2
endfigure
plot(traininfo.TrainingLoss);
grid on
title('CNN-LSTM');
xlabel('训练次数');
ylabel('损失值');%% 预测,
YPred1=predict(net,Ttest_X);
YPred1=method('reverse',YPred1',mappingx1);
Ytest1=method('reverse',Ttest_Y',mappingx1);
[m,n]=size(Ytest1);
real=reshape(Ytest1,[1,m*n]);
pred=reshape(YPred1,[1,m*n]);
result(real,pred,'Optim_CNN-LSTM')
save result/optim_cnn_lstm_result real pred
figure
plot(real)
hold on;grid on
plot(pred)
legend('真实值','预测值')4 结语
优化网络超参数的格式都是这样的!只要会改一种,那么随便拿一份能跑通的优化算法,在不管原理的情况下,都能用来优化网络的超参数。
更多内容【点击专栏】目录,您的点赞、关注、收藏是我更新【MATLAB神经网络1000个案例分析】的动力。
相关文章:

MATLAB人工大猩猩部队GTO优化CNN-LSTM多变量时间序列预测
本博客来源于CSDN机器鱼,未同意任何人转载。 更多内容,欢迎点击本专栏目录,查看更多内容。 目录 0 引言 1 数据准备 2 CNN-LSTM模型搭建 3 GTO超参数优化 3.1 GTO函数极值寻优 3.2 GTO优化CNN-LSTM超参数 3.3 主程序 4 结语 0 引言…...
: 连接设备到开发机)
android-ndk开发(3): 连接设备到开发机
android-ndk开发(3): 连接设备到开发机 2025/05/05 1. 术语解释 用来写代码的电脑, 我叫做开发机。 我打心底认为 Windows, Linux, macOS 都是 PC, 但是有些人不这么认为, 那就还是叫开发机。 android 手机能运行 app(众所周知…...

谷歌最新推出的Gemini 2.5 Flash人工智能模型因其安全性能相较前代产品出现下滑
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
-节点排错)
Kubernetes排错(七)-节点排错
1、节点 Crash 与 Vmcore 分析 kdump 介绍 目前大多 Linux 发新版都会默认开启 kdump 服务,以方便在内核崩溃的时候, 可以通过 kdump 服务提供的 kexec 机制快速的启用保留在内存中的第二个内核来收集并转储内核崩溃的日志信息(vmcore 等文件), 这种机制需要服务…...

《架构安全原则》解锁架构安全新密码
The Open Group最新发布的《架构安全原则》标准中文版为企业架构、技术架构、解决方案架构以及安全架构领域的专业人员提供了一套系统化、可落地的安全设计准则。这一权威文件旨在帮助组织在数字化转型的复杂环境中构建既安全又敏捷的架构体系,其内容与TOGAF标准、N…...
)
生物化学笔记:神经生物学概论10 运动节律的控制 运动时脑内活动 运动系统疾病及其治疗(帕金森、亨廷顿)
运动节律的控制 运动时脑内活动 运动系统疾病及其治疗 口服多巴胺无法穿越“血脑屏障”,进不到脑子里去,其前体(原材料)能进入血脑屏障。一直吃药,机体会偷懒。另一方面,会影响脑子其他部分。 损毁也只能暂时解决,黑质…...

DDR在PCB布局布线时的注意事项及设计要点
一、布局注意事项 控制器与DDR颗粒的布局 靠近原则:控制器与DDR颗粒应尽量靠近,缩短时钟(CLK)、地址/控制线(CA)、数据线(DQ/DQS)的走线长度,减少信号延迟差异。 分组隔…...

Paramiko源码深入解析
Paramiko是一个基于Python的SSHv2协议实现库,支持远程命令执行、文件传输(SFTP)和安全隧道功能。以下是对其源码的深入解析,涵盖核心模块、关键流程及实现细节。 1. 核心模块与结构 Paramiko的源码结构围绕SSH协议的各个层次设计…...

音频感知动画新纪元:Sonic让你的作品更生动
前言 在现代肖像动画领域,如何精准地控制画面中的焦点,确保声音和画面完美契合,已成为了一个十分值得探索的话题。于是,Sonic 方法应运而生,这种创新的音频感知技术,旨在让肖像动画中的焦点能够与音频内容同步,从而提升整体的沉浸感和表现力。在ComfyUI 中实现这一功能…...

uniapp开发06-视频组件video的使用注意事项
uniapp开发-视频组件video的使用注意事项!实际项目开发中,经常会遇到视频播放的业务需求。下面简单讲解一下,uniapp官方提供的视频播放组件video的常见参数和实际效果。 1:先看代码: <!--视频组件的使用展示-->…...

英伟达语音识别模型论文速读:Fast Conformer
Fast Conformer:一种具有线性可扩展注意力的高效语音识别模型 一、引言 Conformer 模型因其结合了深度可分离卷积层和自注意力层的优势,在语音处理任务中取得了出色的性能表现。然而,Conformer 模型存在计算和内存消耗大的问题,…...

利用jQuery 实现多选标签下拉框,提升表单交互体验
在 Web 开发中,表单设计常常需要支持用户选择多个选项的场景。传统的多选框或下拉菜单在处理大量选项时,可能会影响界面美观和操作便捷性。这时,多选标签下拉框就成为了一种优雅的解决方案。本文将详细介绍如何通过 HTML、CSS 和 jQuery 实现…...

基于 HTML 和 CSS 实现的 3D 翻转卡片效果
一、引言 在网页设计中,为了增加用户的交互体验和视觉吸引力,常常会运用一些独特的效果。本文将详细介绍一个基于 HTML 和 CSS 实现的 3D 翻转卡片效果,通过对代码的剖析,让你了解如何创建一个具有立体感的卡片,在鼠标…...
)
【阿里云大模型高级工程师ACP学习笔记】2.9 大模型应用生产实践 (下篇)
特别说明:由于这一章节是2025年3月官方重点更新的部分,新增内容非常多,因此我不得不整理成上、下两篇,方便大家参考。 学习目标 备考阿里云大模型高级工程师ACP认证的这部分内容,旨在深入理解大模型应用在安全合规方面的要求,掌握模型部署相关要点,提升实际操作和应对复…...

MVC、MVP、MVVM三大架构区别
1、MVC架构 M(Model):主要处理数据的存储、获取、解析。 V(View):即Fragement、Activity、View等XML文件 C(Controller):主要功能为控制View层数据的显示,…...

期末代码Python
以下是 学生信息管理系统 的简化版代码示例(控制台版本,使用文件存储数据),包含核心功能: 1. 定义学生类 class Student: def __init__(self, sid, name, score): self.sid sid # 学号 self.name name # 姓名 self.s…...

ecat总线6000段定义
1ecat总线 不适合新手学习,我复习用的。 can和ecat是一家的,就跟C和C的关系。 参考CIA402定义 2 PDOr⬇️ 主站发送到终端伺服。 有4组,0x1600 3 PDOt⬆️ 伺服驱动器发送到主站。 我记得有4组,但这款伺服只有2组。 4 速度模…...
全面解析:标准深度剖析与实践创新)
数据管理能力成熟度评估模型(DCMM)全面解析:标准深度剖析与实践创新
文章目录 一、DCMM模型的战略价值与理论基础1.1 DCMM的本质与战略定位1.2 DCMM的理论基础与创新点 二、DCMM模型的系统解构与逻辑分析2.1 八大能力域的有机关联与系统架构2.2 五级成熟度模型的内在逻辑与演进规律 三、DCMM八大能力域的深度解析与实践创新3.1 数据战略ÿ…...

Python精进系列:random.uniform 函数的用法详解
目录 🔍 一、引言📌 二、函数定义与参数说明✅ 函数定义⚙️ 参数说明 🧪 三、使用示例1️⃣ 生成单个随机数2️⃣ 生成多个随机数3️⃣ 生成二维坐标 🎯 四、应用场景🧪 模拟实验📊 数据采样🎮…...
)
观察者模式(Observer Pattern)
🧠 观察者模式(Observer Pattern) 观察者模式是一种行为型设计模式。它定义了一种一对多的依赖关系,使得当一个对象的状态发生变化时,所有依赖于它的对象都会得到通知并自动更新。通常用于事件驱动的编程场景中。 &am…...

【论文阅读】Joint Deep Modeling of Users and Items Using Reviews for Recommendation
Joint Deep Modeling of Users and Items Using Reviews for Recommendation 题目翻译:利用评论对用户和项目进行联合深度建模进行推荐 原文地址:点这里 关键词: DeepCoNN、推荐系统、卷积神经网络、评论建模、协同建模、评分预测、联合建模…...

webpack 的工作流程
Webpack 的工作流程可以分为以下几个核心步骤,我将结合代码示例详细说明每个阶段的工作原理: 1. 初始化配置 Webpack 首先会读取配置文件(默认 webpack.config.js),合并命令行参数和默认配置。 // webpack.config.js…...

Linux 常用指令详解
Linux 操作系统中有大量强大的命令行工具,下面我将分类介绍一些最常用的指令及其用法。 ## 文件与目录操作 ### 1. ls - 列出目录内容 ls [选项] [目录名] 常用选项: - -l:长格式显示(详细信息) - -a:显…...

DXFViewer进行中 : ->封装OpenGL -> 解析DXF直线
DXFViewer进行中,目标造一个dxf看图工具。. 目标1:封装OpenGL,实现正交相机及平移缩放功能 Application.h #pragma once #include <string> #include <glad/glad.h> #include <GLFW/glfw3.h> #include "../Core/TimeStamp.h" #includ…...

多序列比对软件MAFFT介绍
MAFFT(Multiple Alignment using Fast Fourier Transform)是一款广泛使用且高效的多序列比对软件,由日本京都大学的Katoh Kazutaka等人开发,最早发布于2002年,并持续迭代优化至今。 它支持从几十条到上万条核酸或蛋白质序列的快速比对,同时在准确率和计算效率之间提供灵…...

基于 HTML5 Canvas 实现图片旋转与下载功能
一、引言 在 Web 开发中,经常会遇到需要对图片进行处理并提供下载功能的需求。本文将深入剖析一段基于 HTML5 Canvas 的代码,该代码实现了图片的旋转(90 度和 180 度)以及旋转后图片的下载功能。通过对代码的解读,我们…...
)
学习路线(机器人系统)
机器人软件/系统学习路线(从初级到专家) 初级阶段(6-12个月)基础数学编程基础机器人基础概念推荐资源 中级阶段(1-2年)机器人运动学机器人动力学控制系统感知系统推荐资源 高级阶段(2-3年&#…...
)
基于EFISH-SCB-RK3576工控机/SAIL-RK3576核心板的网络安全防火墙技术方案(国产化替代J1900的全栈技术解析)
基于EFISH-SCB-RK3576/SAIL-RK3576的网络安全防火墙技术方案 (国产化替代J1900的全栈技术解析) 一、硬件架构设计 流量处理核心模块 多核异构架构: 四核Cortex-A72(2.3GHz):处理深度…...

基于 jQuery 实现复选框全选与选中项查询功能
在 Web 开发中,复选框是常见的交互元素,尤其是在涉及批量操作、数据筛选等场景时,全选功能和选中项查询功能显得尤为重要。本文将介绍如何使用 HTML、CSS 和 jQuery 实现一个具备全选、反选以及选中项查询功能的复选框组,帮助开发…...

Python中的JSON库,详细介绍与代码示例
目录 1. 前言 2. json 库基本概念 3. json 的适应场景 4. json 库的基本用法 4.1 导 json入 模块 4.2 将 Python 对象转换为 JSON 字符串 4.3 将 JSON 字符串转换为 Python 对象 4.4 将 Python 对象写入 JSON 文件 4.5 从 JSON 文件读取数据 4.6 json 的其他方法 5.…...

tensorflow 调试
tensorflow 调试 tf.config.experimental_run_functions_eagerly(True) 是 TensorFlow 中的一个配置函数,它的作用是: 让 tf.function 装饰的函数以 Eager 模式(即时执行)运行,而不是被编译成图(Graph&…...

iptables的基本选项及概念
目录 1.按保护范围划分: 2.iptables 的基础概念 4个规则表: 5个规则链: 3.iptables的基础选项 4.实验 1.按保护范围划分: 主机防火墙:服务范围为当前一台主机 input output 网络防火墙:服务范围为防…...

使用AI 将文本转成视频 工具 介绍
🎬 文字生成视频工具 一款为自媒体创作者设计的 全自动视频生成工具,输入文本即可输出高质量视频,大幅提升内容创作效率。视频演示:https://leeseean.github.io/Text2Video/?t23 ✨ 功能亮点 功能模块说明📝 智能分…...

Python生活手册-NumPy数组创建:从快递分拣到智能家居的数据容器
一、快递分拣系统(列表/元组转换) 1. 快递单号录入(np.array()) import numpy as np快递单号入库系统 快递单列表 ["SF123", "JD456", "EMS789"] 快递数组 np.array(快递单列表) print(f"…...

Cmake编译wxWidgets3.2.8
一、下载库源代码 去wxWidgets - Browse /v3.2.8 at SourceForge.net下载wxWidgets-3.2.8.7z 二、建立目录结构 1、在d:\codeblocks目录里新建wxWidgets_Src目录 2、把文件解压到该目录 3、建立 CB目录,并在该目录下分别建立 Debug 和 Release目录 三、使用Cmake…...

2.在Openharmony写hello world
原文链接:https://kashima19960.github.io/2025/03/21/openharmony/2.在Openharmony写hello%20world/ 前言 Openharmony 的第一个官方例程的是教你在Hi3861上编写hello world程序,这个例程相当简单编写 Hello World”程序,而且步骤也很省略&…...

「OC」源码学习——对象的底层探索
「OC」源码学习——对象的底层探索 前言 上次我们说到了源码里面的调用顺序,现在我们继续了解我们上一篇文章没有讲完的关于对象的内容函数,完整了解对象的产生对于isa赋值以及内存申请的内容 函数内容 先把_objc_rootAllocWithZone函数的内容先贴上…...

从0开始学习大模型--Day01--大模型是什么
初识大模型 在平时遇到问题时,我们总是习惯性地去运用各种搜索引擎如百度、知乎、CSDN等平台去搜索答案,但由于搜索到的内容质量参差不齐,检索到的内容只是单纯地根据关键字给出内容,往往看了几个网页都找不到答案;而…...

202533 | SpringBoot集成RocketMQ
SpringBoot集成RocketMQ极简入门 一、基础配置(3步完成) 添加依赖 <!-- pom.xml --> <dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version&g…...

大模型学习专栏-导航页
概要 本专栏是小编系统性调研大模型过程中沉淀的知识结晶,涵盖技术原理、实践应用、前沿动态等多维度内容。为助力读者高效学习,特整理此导航页,以清晰脉络串联核心知识点,搭建起系统的大模型学习框架,助您循序渐进掌握…...

互联网大厂Java面试:从Java SE到微服务的全栈挑战
场景概述 在这场面试中,谢飞机,一个搞笑但有些水的程序员,面对的是一位严肃的大厂面试官李严。面试官的目的是考察谢飞机在Java全栈开发,特别是微服务架构中的技术能力。面试场景设定在内容社区与UGC领域,模拟一个社交…...

2024年408真题及答案
2024年计算机408真题 2024年计算机408答案 2024 408真题下载链接 2024 408答案下载链接...

【datawhaleAI春训营】楼道图像分类
目录 图像分类任务的一般处理流程为什么使用深度学习迁移学习 加载实操环境的库加载数据集,默认data文件夹存储数据将图像类别进行编码自定义数据读取加载预训练模型模型训练,验证和预测划分验证集并训练模型 修改baseline处理输入数据选择合适的模型Ale…...
与持续检测键盘按键(Input.GetKey))
Unity:输入系统(Input System)与持续检测键盘按键(Input.GetKey)
目录 Unity 的两套输入系统: 🔍 Input.GetKey 详解 🎯 对比:常用的输入检测方法 技术底层原理(简化版) 示例:角色移动 为什么会被“新输入系统”替代? Unity 的两套输入系统&…...

day04_计算机常识丶基本数据类型转换
计算机常识 计算机如何存储数据 计算机底层只能识别二进制。计算机底层只识别二进制是因为计算机内部的电子元件只能识别两种状态,即开和关,或者高电平和低电平。二进制正好可以用两种状态来表示数字和字符,因此成为了计算机最基本的表示方…...
)
rvalue引用()
一、先确定基础:左值(Lvalue)和右值(Rvalue) 理解Rvalue引用,首先得搞清楚左值和右值的概念。 左值(Lvalue):有明确内存地址的表达式,可以取地址。比如变量名、引用等。 复制代码 int a = 10; // a是左值 int& ref = a; // ref也是左值右值(Rval…...

【Web3】上市公司利用RWA模式融资和促进业务发展案例
香港典型案例 朗新科技(充电桩RWA融资) 案例概述:2024年8月,朗新科技与蚂蚁数科合作,通过香港金管局“Ensemble沙盒”完成首单新能源充电桩资产代币化融资,募资1亿元人民币。技术实现:蚂蚁链提供…...

什么是IIC通信
IIC(Inter-Integrated Circuit),即IC,是一种串行通信总线,由飞利浦公司在1980年代开发,主要用于连接主板、嵌入式系统或手机中的低速外围设备1。IIC协议采用多主从架构,允许多个主设备和从设备连接在同一总线上进行通信。 IIC协议的工作原理: IIC协议使用两根信号线进…...

网络原理 TCP/IP
1.应用层 1.1自定义协议 客户端和服务器之间往往进行交互的是“结构化”数据,网络传输的数据是“字符串”“二进制bit流”,约定协议的过程就是把结构化”数据转成“字符串”或“二进制bit流”的过程. 序列化:把结构化”数据转成“字符串”…...

掌纹图像识别:解锁人类掌纹/生物识别的未来——技术解析与前沿数据集探索
概述 掌纹识别是一种利用手掌表面独特的线条、纹理和褶皱模式进行身份认证的生物识别技术。它具有非侵入性、高准确性和难以伪造的特点,被广泛应用于安全认证领域。以下将结合提供的链接,详细介绍掌纹识别的技术背景、数据集和研究进展。 提供的链接分析 香港理工大学掌纹数…...