【datawhaleAI春训营】楼道图像分类
目录
- 图像分类任务的一般处理流程
- 为什么使用深度学习
- 迁移学习
- 加载实操环境的库
- 加载数据集,默认data文件夹存储数据
- 将图像类别进行编码
- 自定义数据读取
- 加载预训练模型
- 模型训练,验证和预测
- 划分验证集并训练模型
- 修改baseline
- 处理输入数据
- 选择合适的模型
- AlexNet
- GoogLeNet(Inception)
- ResNet
- EfficientNet模型
- 我们可以如何在已有的数据集上做文章呢?(数据增强)
- 还可以如何提升分类效果
- Focal Loss
- 还有哪些进阶方法?
没有看清楚教程。一开始选择了第一种cpu方式运行,发现不行。然后使用了方式二可以运行
# !unzip -n data/A.zip -d data/ # -n 不覆盖已存在的文件
# !unzip -n data/train.zip -d data/!pip install -r requirements.txtimport numpy as np
import cv2
import os
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image
import time
from datetime import datetimeimport torch
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Datasetfrom sklearn.model_selection import StratifiedKFoldtrain_df = pd.read_csv("data/train.txt", sep="\t", header=None)
train_df[0] = 'data/train/' + train_df[0]
train_dfdef is_valid_image(image_path):if not os.path.exists(image_path):return Falseimage = cv2.imread(image_path)return image is not Nonetrain_df = train_df[train_df[0].apply(is_valid_image)]train_dffor lbl in train_df[1].value_counts().index:img = cv2.imread(train_df[train_df[1] == lbl][0].sample(1).values[0])img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)plt.figure()plt.imshow(img)mapping_dict = {'高风险': 0,'中风险': 1,'低风险': 2,'无风险': 3,'非楼道': 4
}train_df[1] = train_df[1].map(mapping_dict)class GalaxyDataset(Dataset):def __init__(self, images, labels, transform=None):self.images = imagesself.labels = labelsif transform is not None:self.transform = transformelse:self.transform = Nonedef __getitem__(self, index):start_time = time.time()img = Image.open(self.images[index]).convert('RGB')if self.transform is not None:img = self.transform(img)return img,torch.from_numpy(np.array(self.labels[index]))def __len__(self):return len(self.labels)def get_model1():model = models.resnet18(True)model.fc = nn.Linear(512, 5)return modeldef get_model3():models.efficientnet_b0(True)model.fc = nn.Linear(512, 5)return modeldef validate(val_loader, model, criterion):# switch to evaluate modemodel.eval()total_acc = 0with torch.no_grad():end = time.time()for i, (input, target) in enumerate(val_loader):input = input.cuda()target = target.cuda()# compute outputoutput = model(input)loss = criterion(output, target)# measure accuracy and record losstotal_acc += (output.argmax(1).long() == target.long()).sum().item()return total_acc / len(val_loader.dataset)def train(train_loader, model, criterion, optimizer, epoch):# switch to train modemodel.train()end = time.time()for i, (input, target) in enumerate(train_loader):input = input.cuda(non_blocking=True)target = target.cuda(non_blocking=True)# compute outputoutput = model(input)loss = criterion(output, target)acc1 = (output.argmax(1).long() == target.long()).sum().item()# compute gradient and do SGD stepoptimizer.zero_grad()loss.backward()optimizer.step()if i % 100 == 0:print(datetime.now(), loss.item(), acc1 / input.size(0))skf = StratifiedKFold(n_splits=5, random_state=233, shuffle=True)
for _, (train_idx, val_idx) in enumerate(skf.split(train_df[0].values, train_df[1].values)):breaktrain_loader = torch.utils.data.DataLoader(GalaxyDataset(train_df[0].iloc[train_idx].values, train_df[1].iloc[train_idx].values,transforms.Compose([transforms.Resize((256, 256)),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])), batch_size=20, shuffle=True, num_workers=20, pin_memory=True
)val_loader = torch.utils.data.DataLoader(GalaxyDataset(train_df[0].iloc[val_idx].values, train_df[1].iloc[val_idx].values,transforms.Compose([transforms.Resize((256, 256)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])), batch_size=20, shuffle=False, num_workers=10, pin_memory=True
)model = get_model1().cuda()
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adam(model.parameters(), 0.005)
best_acc = 0.0
for epoch in range(5):print('Epoch: ', epoch)train(train_loader, model, criterion, optimizer, epoch)val_acc = validate(val_loader, model, criterion)print("Val acc", val_acc)model = get_model3().cuda()
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adam(model.parameters(), 0.003)
best_acc = 0.0
for epoch in range(5):print('Epoch: ', epoch)train(train_loader, model, criterion, optimizer, epoch)val_acc = validate(val_loader, model, criterion)print("Val acc", val_acc)def predict(test_loader, model):# switch to evaluate modemodel.eval()pred = [] with torch.no_grad():end = time.time()for i, (input, target) in enumerate(test_loader):input = input.cuda()target = target.cuda()# compute outputoutput = model(input)loss = criterion(output, target)pred += list(output.argmax(1).long().cpu().numpy())return predtest_df = pd.read_csv("data/A.txt", sep="\t", header=None)
test_df["path"] = 'data/A/' + test_df[0]
test_df["label"] = 1test_loader = torch.utils.data.DataLoader(GalaxyDataset(test_df["path"].values, test_df["label"].values,transforms.Compose([transforms.Resize((256, 256)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])), batch_size=20, shuffle=False, num_workers=10, pin_memory=True
)
pred = predict(test_loader, model)
pred = np.stack(pred)inverse_mapping_dict = {v: k for k, v in mapping_dict.items()}
inverse_transform = np.vectorize(inverse_mapping_dict.get)
test_df["label"] = inverse_transform(pred)test_df[[0, "label"]].to_csv("submit.txt", index=None, sep="\t", header=None)
import torchprint(torch.cuda.is_available())#查看是否可以使用pytorch
图像分类是计算机视觉中最基础的任务之一。它的目标是从输入的图像中判断出图像的类别(在这个赛题中,是判断场景是“楼道”还是“非楼道”)。这种任务相对简单,容易理解和实现,是入门计算机视觉的绝佳起点。
数据集的特点如下:
多样性:图片内容丰富,包含楼道、街道、室内其他区域等。
复杂性:楼道场景中可能存在各种消防隐患,如堆积物、电动车、飞线充电等。
标注信息(也是我们要分类预测的结果) :每张图片都有标注信息,说明其场景类别(楼道/非楼道)以及隐患等级(无隐患、低风险、中等风险、高风险)。

图像分类任务的一般处理流程
图像分类模型的训练和推理过程相对简单,不需要复杂的网络结构或大量的计算资源。这使得我们可以在短时间内完成模型的初步训练和评估,快速迭代和优化,一般需要做如下工作:
-
选择合适的网络架构 :对于图像分类任务,可以选择经典的卷积神经网络(CNN)架构,如 ResNet、VGG 或 MobileNet。这些架构已经被广泛验证,具有良好的性能和可扩展性。
-
选择 预训练模型 :利用预训练模型(如在 ImageNet 数据集上预训练的模型)可以大大减少训练时间和计算资源。通过迁移学习,将预训练模型的权重迁移到我们的任务上,并对最后几层进行微调,可以快速提升模型的性能。
-
设计 损失函数 :对于多分类任务,通常使用交叉熵损失函数(Cross-Entropy Loss)。它能够衡量模型输出的概率分布与真实标签之间的差异。
-
选择 优化器 :选择合适的优化器(如 Adam 或 SGD)来更新模型的权重。Adam 优化器由于其自适应学习率的特性,通常在训练初期表现较好。
-
调整 学习率 :在训练过程中,可以使用学习率调整策略(如学习率衰减或学习率预热),以加快收敛速度并提高模型的最终性能。
为什么使用深度学习
图像数据通常是高维度的(例如,一张256×256像素的RGB图像有196,608个特征值)。这些特征之间存在复杂的非线性关系,传统的机器学习方法(如支持向量机、决策树等)很难有效地捕捉这些关系。
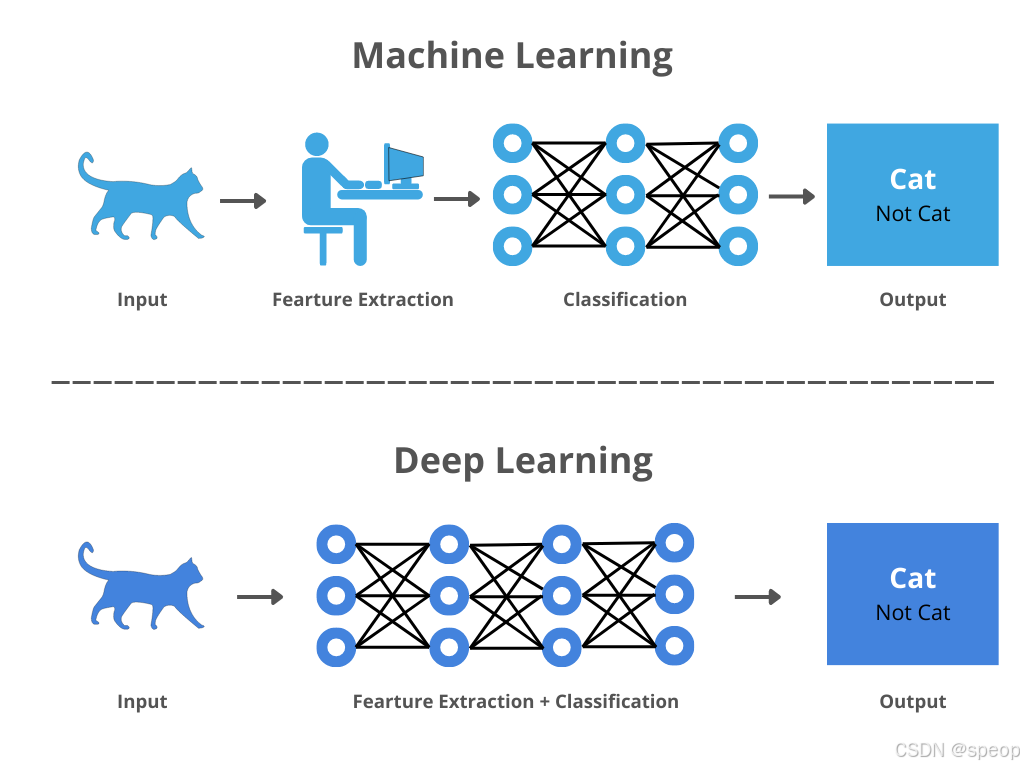
深度学习模型,尤其是CNN,通过多层神经网络结构,能够自动学习图像中的层次化特征表示。从低层次的边缘和纹理,到高层次的物体形状和场景结构,CNN可以逐步提取出对分类任务有用的特征。
赛题中的数据集包含多种场景(如楼道、街道、室内等),并且每个场景中可能存在多种消防隐患(如堆积物、电动车、飞线充电等)。这种多样性和复杂性要求模型能够泛化到不同的场景和情况。
深度学习模型通过大量的训练数据学习通用的特征表示,能够更好地适应数据集的多样性。通过数据增强技术(如旋转、翻转、裁剪等),还可以进一步提高模型的泛化能力。
迁移学习
在实际应用中,尤其是特定领域的任务(如消防隐患检测),很难收集到足够多的标注数据。深度学习模型通常需要大量的数据来学习有效的特征表示,数据量不足会导致模型过拟合,泛化能力差。
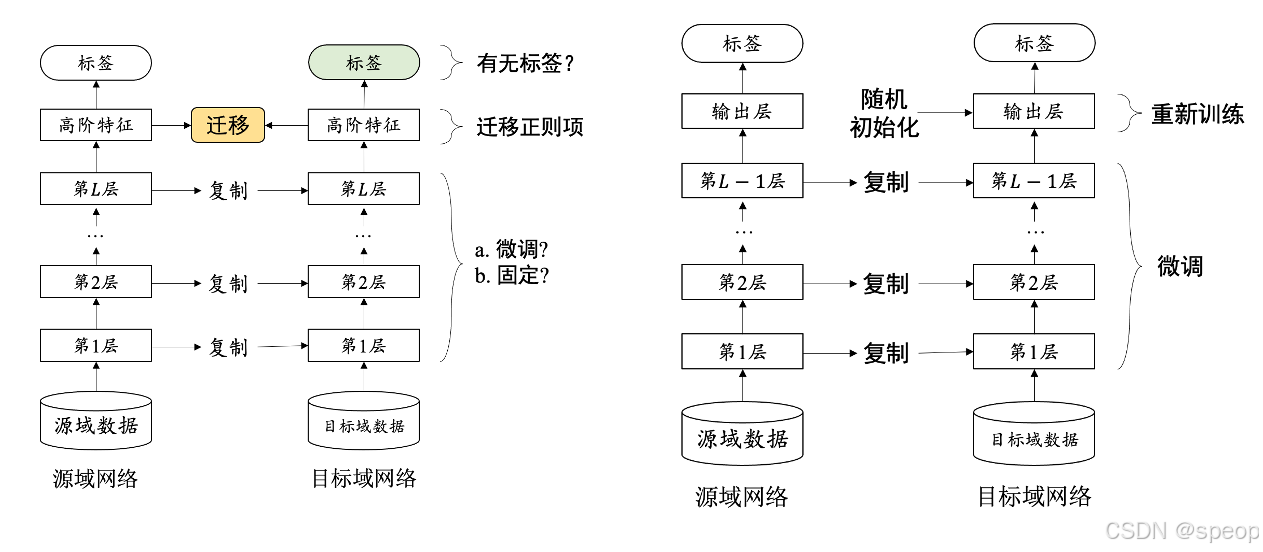
迁移学习通过在大规模通用数据集(如ImageNet)上预训练模型,学习到通用的图像特征表示。然后,将这些预训练模型迁移到特定任务上,并在有限的数据集上进行微调。这样可以充分利用预训练模型在大规模数据上学到的知识,弥补特定任务数据量不足的问题。
从头开始训练一个深度学习模型需要大量的计算资源和时间,尤其是对于复杂的网络结构(如ResNet、EfficientNet等)。训练过程可能需要数天甚至数周的时间,这对于快速迭代和优化模型非常不利。
baseline的大体情况如下:
- 分数区间:2.3分左右(具体分数可能因随机性略有波动)。
- 任务目标:对拍摄的照片内容进行识别,实时判断照片内场景是否存在消防安全隐患以及隐患的危险程度。
- 输入:蓝骑士拍摄的照片,内容包括楼道、街道、室内等场景。
- 输出:隐患等级(高风险、中风险、低风险、无风险、非楼道)。
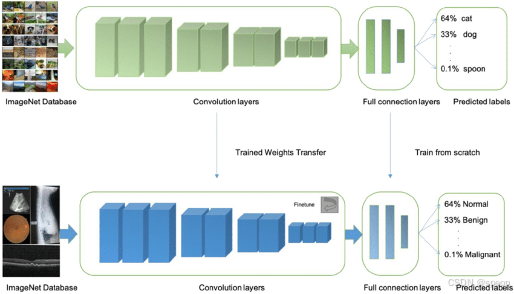
主要进行了以下工作:
- 数据预处理:加载数据集,过滤无效图片,对图片进行归一化和数据增强。
- 模型构建:加载预训练的ResNet18模型,修改最后的全连接层以适应5个分类类别。
- 模型训练:使用训练集进行模型训练,使用验证集进行模型验证,记录最佳模型。
- 模型评估:计算模型在验证集上的准确率,评估模型性能。
加载实操环境的库
import numpy as np
import cv2
import os
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image
import time
from datetime import datetimeimport torch
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Datasetfrom sklearn.model_selection import StratifiedKFold
加载数据集,默认data文件夹存储数据
train_df = pd.read_csv("data/train.txt", sep="\t", header=None)
train_df[0] = 'data/train/' + train_df[0]def is_valid_image(image_path):if not os.path.exists(image_path):return Falseimage = cv2.imread(image_path)return image is not Nonetrain_df = train_df[train_df[0].apply(is_valid_image)]
将图像类别进行编码
mapping_dict = {'高风险': 0,'中风险': 1,'低风险': 2,'无风险': 3,'非楼道': 4
}train_df[1] = train_df[1].map(mapping_dict)
自定义数据读取
class GalaxyDataset(Dataset):def __init__(self, images, labels, transform=None):self.images = imagesself.labels = labelsif transform is not None:self.transform = transformelse:self.transform = Nonedef __getitem__(self, index):start_time = time.time()img = Image.open(self.images[index]).convert('RGB')if self.transform is not None:img = self.transform(img)return img,torch.from_numpy(np.array(self.labels[index]))def __len__(self):return len(self.labels)
加载预训练模型
def get_model1():model = models.resnet18(True)model.fc = nn.Linear(512, 5)return modeldef get_model3():models.efficientnet_b0(True)model.fc = nn.Linear(512, 5)return model
模型训练,验证和预测
def validate(val_loader, model, criterion):# switch to evaluate modemodel.eval()total_acc = 0with torch.no_grad():end = time.time()for i, (input, target) in enumerate(val_loader):input = input.cuda()target = target.cuda()# compute outputoutput = model(input)loss = criterion(output, target)# measure accuracy and record losstotal_acc += (output.argmax(1).long() == target.long()).sum().item()return total_acc / len(val_loader.dataset)def train(train_loader, model, criterion, optimizer, epoch):# switch to train modemodel.train()end = time.time()for i, (input, target) in enumerate(train_loader):input = input.cuda(non_blocking=True)target = target.cuda(non_blocking=True)# compute outputoutput = model(input)loss = criterion(output, target)acc1 = (output.argmax(1).long() == target.long()).sum().item()# compute gradient and do SGD stepoptimizer.zero_grad()loss.backward()optimizer.step()if i % 100 == 0:print(datetime.now(), loss.item(), acc1 / input.size(0))def predict(test_loader, model):# switch to evaluate modemodel.eval()pred = [] with torch.no_grad():end = time.time()for i, (input, target) in enumerate(test_loader):input = input.cuda()target = target.cuda()# compute outputoutput = model(input)loss = criterion(output, target)pred += list(output.argmax(1).long().cpu().numpy())return pred
划分验证集并训练模型
train_loader = torch.utils.data.DataLoader(GalaxyDataset(train_df[0].iloc[train_idx].values, train_df[1].iloc[train_idx].values,transforms.Compose([transforms.Resize((256, 256)),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])), batch_size=20, shuffle=True, num_workers=20, pin_memory=True
)val_loader = torch.utils.data.DataLoader(GalaxyDataset(train_df[0].iloc[val_idx].values, train_df[1].iloc[val_idx].values,transforms.Compose([transforms.Resize((256, 256)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])), batch_size=20, shuffle=False, num_workers=10, pin_memory=True
)model = get_model1().cuda()
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adam(model.parameters(), 0.005)
best_acc = 0.0
for epoch in range(5):print('Epoch: ', epoch)train(train_loader, model, criterion, optimizer, epoch)val_acc = validate(val_loader, model, criterion)print("Val acc", val_acc)
修改baseline
处理输入数据
在PyTorch中,自定义数据集是一个常见的需求,特别是在处理非标准数据或需要特定预处理步骤时。在PyTorch中,你需要继承 torch.utils.data.Dataset 类来创建自定义数据集。这个类需要实现三个方法: init , len , 和 getitem 。
class GalaxyDataset(Dataset):def __init__(self, images, labels, transform=None):self.images = imagesself.labels = labelsif transform is not None:self.transform = transformelse:self.transform = Nonedef __getitem__(self, index):start_time = time.time()img = Image.open(self.images[index]).convert('RGB')if self.transform is not None:img = self.transform(img)return img,torch.from_numpy(np.array(self.labels[index]))def __len__(self):return len(self.labels)
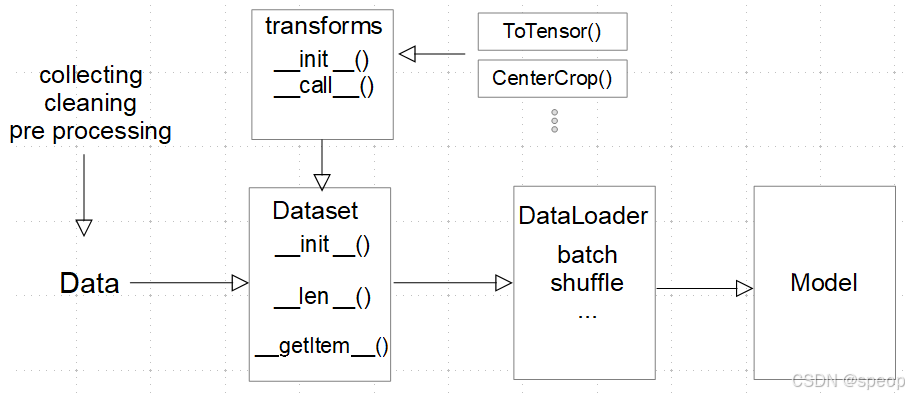
DataLoader 是PyTorch中用于加载数据集的一个类,它提供了批处理、打乱数据和多进程加载数据的功能。最后,你可以使用 DataLoader 在训练循环中加载数据,并将数据输入到你的模型中进行训练。
选择合适的模型
对于模型选择,可以从ImageNet的排行榜选择选择。但模型的选择需要根据具体的任务需求、数据量和计算资源来综合考虑。并不是越大的模型就一定越好。我们可以多参考开源社区分享的测评和经验贴:
参考网站2paperswithcode
参考网站1github
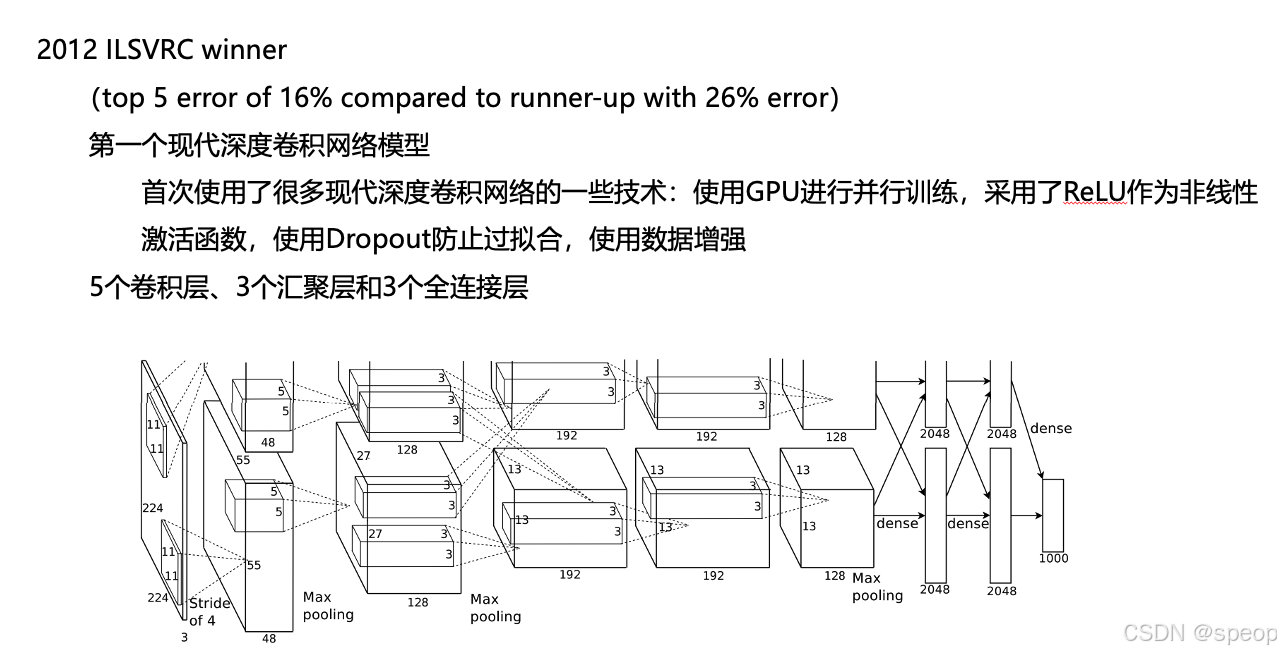
AlexNet
在ImageNet竞赛中取得突破性成果,使用ReLU激活函数和Dropout技术减少过拟合,开启了深度学习在图像分类领域的应用
GoogLeNet(Inception)
引入了Inception模块,通过并行的卷积和池化操作来增加网络宽度,同时控制参数数量。

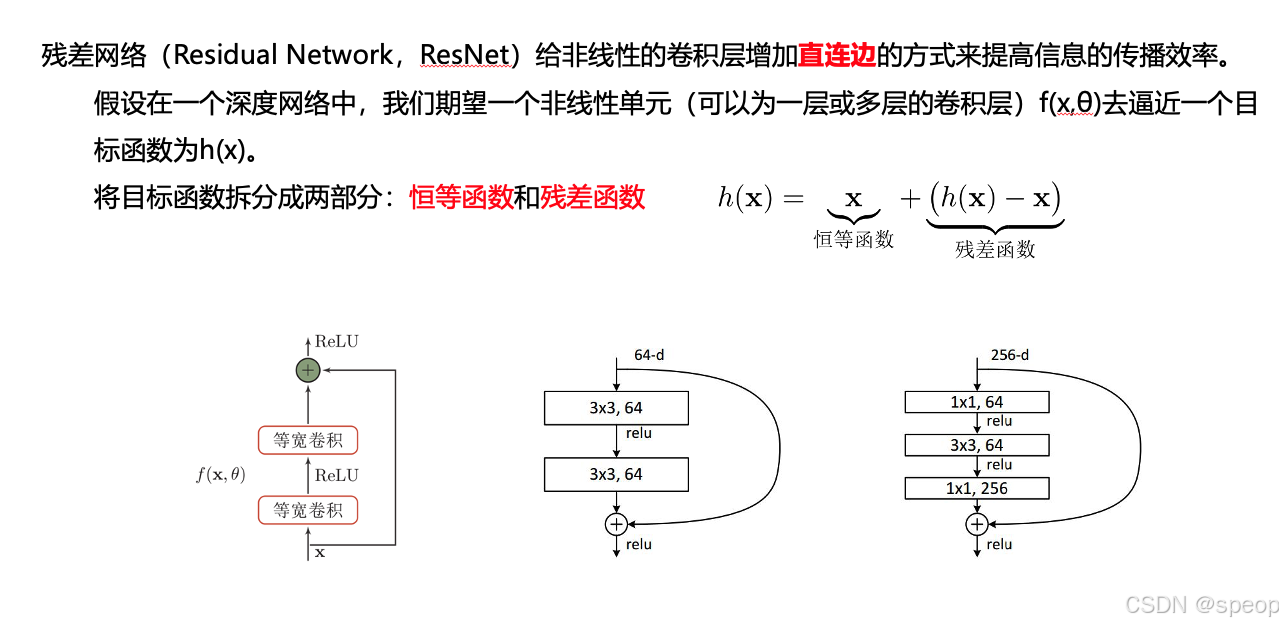
ResNet
引入了残差连接(Residual Connection),解决了深层网络训练中的退化问题,使得训练更深的网络成为可能。
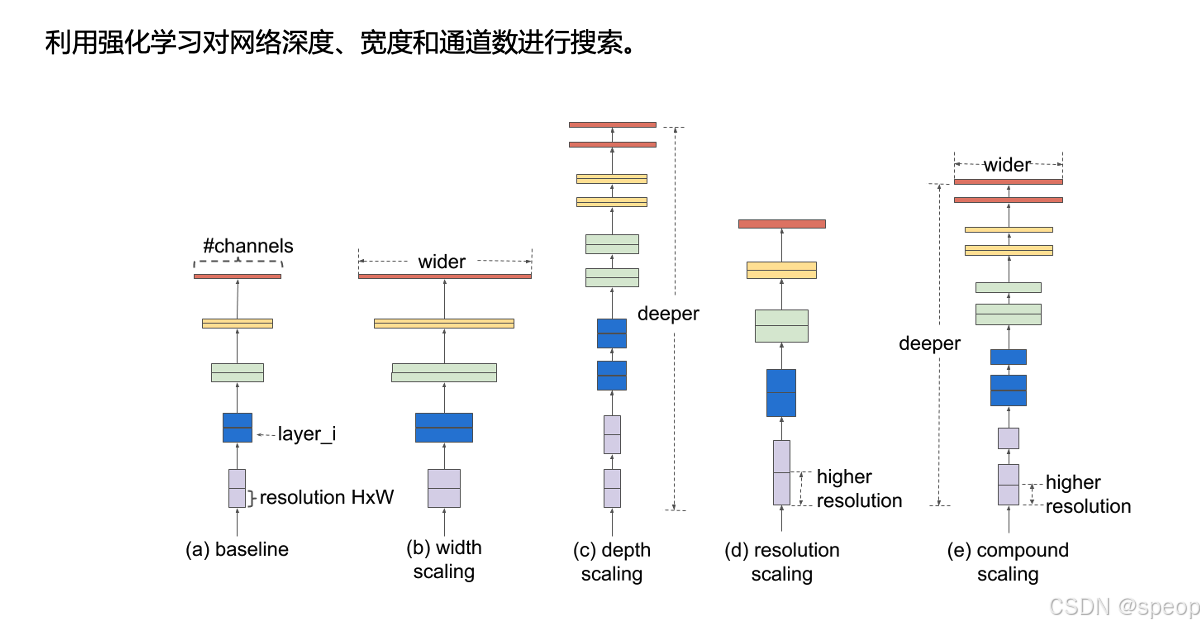
EfficientNet模型
通过复合缩放方法(同时扩展深度、宽度和分辨率)来提高网络性能,同时保持较低的计算成本。
我们可以如何在已有的数据集上做文章呢?(数据增强)
数据增强是图像分类任务中常用的技术,旨在通过对原始图像进行一系列随机变换来增加数据集的多样性,从而提高模型的泛化能力。

Mixup 是一种数据增强技术,通过将两张图像及其标签进行线性插值来生成新的训练样本。例如,给定两张图像 I 1 I_1 I1和 I 2 I_2 I2及其对应的标签 y 1 y _1 y1和 y 2 y_2 y2,Mixup生成新的图像和标签为:
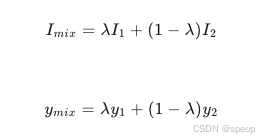
CutMix 是Mixup的变体,它不是对整个图像进行混合,而是在图像之间交换矩形区域。具体来说,随机选择一个矩形区域,将该区域从一张图像“剪切”并“粘贴”到另一张图像上,同时标签也按照区域面积比例进行混合。这种方法可以鼓励模型关注图像的局部特征,提高模型的鲁棒性。
这一部分的资料可以参考:
- https://albumentations.ai/docs/3-basic-usage/image-classification/
- https://pytorch.org/vision/main/transforms.html
还可以如何提升分类效果
Focal Loss
当类别分布不均匀时,模型可能会偏向于多数类,导致对少数类的识别性能较差。为了解决这个问题,可以采用多种策略,其中之一就是使用Focal Loss。
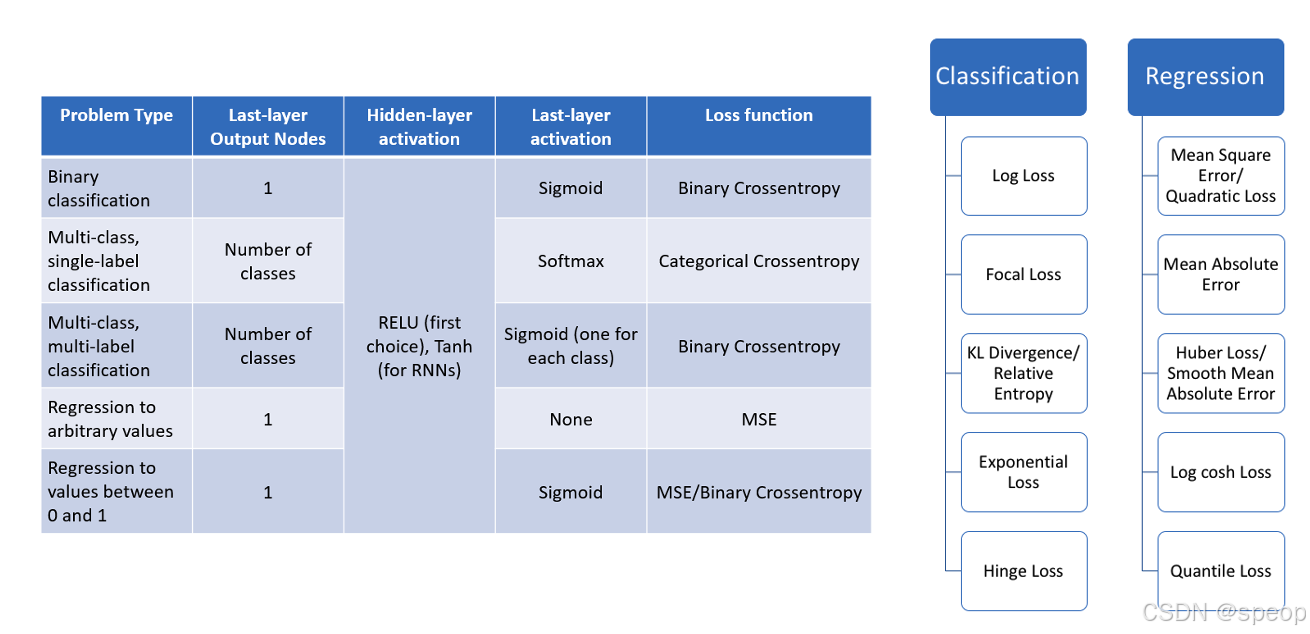
Focal Loss的优点
- 提高少数类识别性能:通过增加少数类样本的损失贡献,Focal Loss有助于提高模型对少数类的识别性能。
- 减少易分类样本的影响:通过减少易分类样本的损失贡献,Focal Loss有助于模型关注难以分类的样本,从而提高整体性能。
- 灵活性:Focal Loss的参数( α 和 γ )可以根据具体任务进行调整,以获得最佳性能。
还有哪些进阶方法?
在图像分类任务中,尤其是针对消防隐患识别这样的具体应用场景,除了基本的图像分类方法外,还有多种进阶方法可以帮助提升模型的性能和准确性。
-
高风险:楼道中出现电动车、电瓶、飞线充电等可能起火的元素。
-
中风险:楼道中存在大量堆积物严重影响通行或堆放大量纸箱、木质家具等能造成火势蔓延的堵塞物。
-
低风险:存在楼道堆物现象但不严重。
-
无风险:楼道干净,无堆放物品。
-
非楼道:一些与楼道无关的图片。
待选的思路如下: -
使用物体检测模型(如YOLO、Faster R-CNN等)来识别图像中的具体物体,如电动车、电瓶、堆积物等。
-
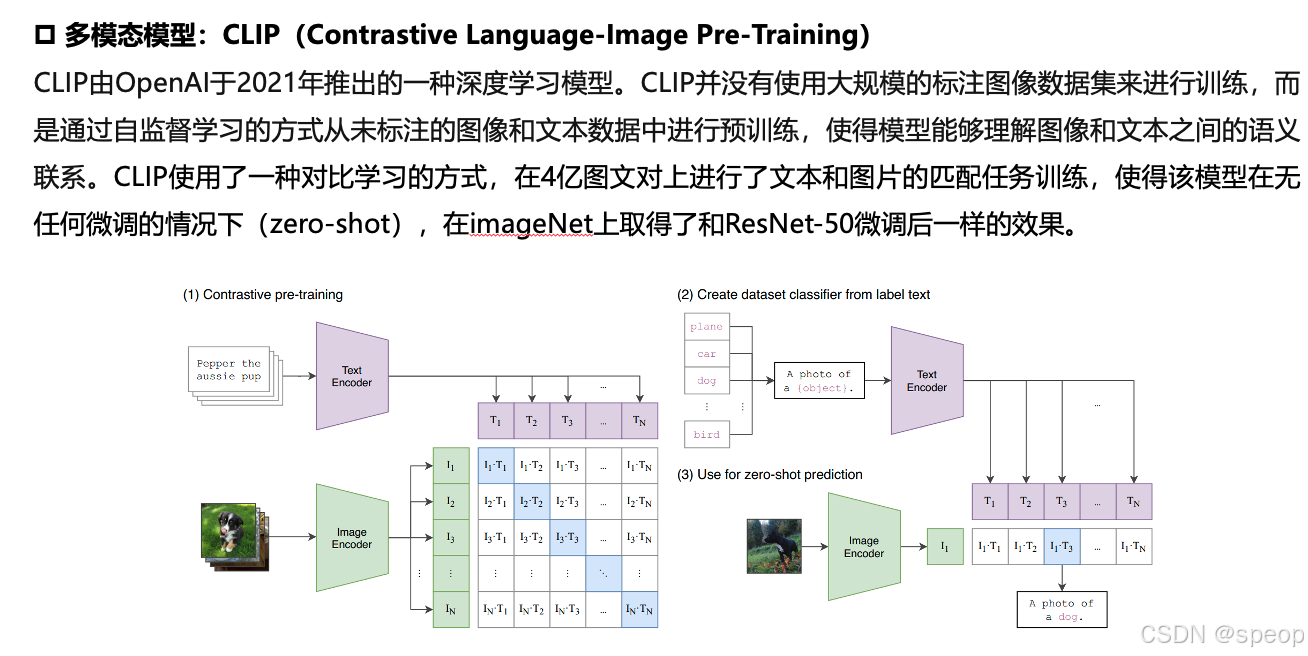
CLIP(Contrastive Language-Image Pre-training)模型能够将图像和文本映射到同一个嵌入空间,从而实现跨模态的匹配。
-
利用多模态大模型(如ViLT、ALIGN等),这些模型能够同时处理图像和文本信息。
相关文章:

【datawhaleAI春训营】楼道图像分类
目录 图像分类任务的一般处理流程为什么使用深度学习迁移学习 加载实操环境的库加载数据集,默认data文件夹存储数据将图像类别进行编码自定义数据读取加载预训练模型模型训练,验证和预测划分验证集并训练模型 修改baseline处理输入数据选择合适的模型Ale…...
与持续检测键盘按键(Input.GetKey))
Unity:输入系统(Input System)与持续检测键盘按键(Input.GetKey)
目录 Unity 的两套输入系统: 🔍 Input.GetKey 详解 🎯 对比:常用的输入检测方法 技术底层原理(简化版) 示例:角色移动 为什么会被“新输入系统”替代? Unity 的两套输入系统&…...

day04_计算机常识丶基本数据类型转换
计算机常识 计算机如何存储数据 计算机底层只能识别二进制。计算机底层只识别二进制是因为计算机内部的电子元件只能识别两种状态,即开和关,或者高电平和低电平。二进制正好可以用两种状态来表示数字和字符,因此成为了计算机最基本的表示方…...
)
rvalue引用()
一、先确定基础:左值(Lvalue)和右值(Rvalue) 理解Rvalue引用,首先得搞清楚左值和右值的概念。 左值(Lvalue):有明确内存地址的表达式,可以取地址。比如变量名、引用等。 复制代码 int a = 10; // a是左值 int& ref = a; // ref也是左值右值(Rval…...

【Web3】上市公司利用RWA模式融资和促进业务发展案例
香港典型案例 朗新科技(充电桩RWA融资) 案例概述:2024年8月,朗新科技与蚂蚁数科合作,通过香港金管局“Ensemble沙盒”完成首单新能源充电桩资产代币化融资,募资1亿元人民币。技术实现:蚂蚁链提供…...

什么是IIC通信
IIC(Inter-Integrated Circuit),即IC,是一种串行通信总线,由飞利浦公司在1980年代开发,主要用于连接主板、嵌入式系统或手机中的低速外围设备1。IIC协议采用多主从架构,允许多个主设备和从设备连接在同一总线上进行通信。 IIC协议的工作原理: IIC协议使用两根信号线进…...

网络原理 TCP/IP
1.应用层 1.1自定义协议 客户端和服务器之间往往进行交互的是“结构化”数据,网络传输的数据是“字符串”“二进制bit流”,约定协议的过程就是把结构化”数据转成“字符串”或“二进制bit流”的过程. 序列化:把结构化”数据转成“字符串”…...

掌纹图像识别:解锁人类掌纹/生物识别的未来——技术解析与前沿数据集探索
概述 掌纹识别是一种利用手掌表面独特的线条、纹理和褶皱模式进行身份认证的生物识别技术。它具有非侵入性、高准确性和难以伪造的特点,被广泛应用于安全认证领域。以下将结合提供的链接,详细介绍掌纹识别的技术背景、数据集和研究进展。 提供的链接分析 香港理工大学掌纹数…...

【FPGA开发】Xilinx DSP48E2 slice 一个周期能做几次int8乘法或者加法?如何计算FPGA芯片的GOPS性能?
Xilinx DSP48E2 slice 在一个时钟周期内处理 INT8(8 位整数)运算的能力。 核心能力概述 一个 DSP48E2 slice 包含几个关键计算单元: 预加器 (Pre-Adder): 可以执行 A D 或 A - D 操作,其中 A 是 30 位,D 是 27 位。…...

APP 设计中的色彩心理学:如何用色彩提升用户体验
在数字化时代,APP 已成为人们日常生活中不可或缺的一部分。用户在打开一个 APP 的瞬间,首先映入眼帘的便是其色彩搭配,而这些色彩并非只是视觉上的装饰,它们蕴含着强大的心理暗示力量,能够潜移默化地影响用户的情绪、行…...

残差网络实战:基于MNIST数据集的手写数字识别
残差网络实战:基于MNIST数据集的手写数字识别 在深度学习的广阔领域中,卷积神经网络(CNN)一直是处理图像任务的主力军。随着研究的深入,网络层数的增加虽然理论上能提升模型的表达能力,但却面临梯度消失、…...

科学养生,开启健康生活新篇章
在快节奏的现代生活中,健康养生成为人们关注的焦点。科学合理的养生方式,能帮助我们远离疾病,提升生活质量,无需依赖传统中医理念,也能找到适合自己的养生之道。 饮食是养生的基础。遵循均衡饮食原则,每…...

如何扫描系统漏洞?漏洞扫描的原理是什么?
如何扫描系统漏洞?漏洞扫描的原理是什么? 漏洞扫描是网络安全中识别系统潜在风险的关键步骤,其核心原理是通过主动探测和自动化分析发现系统的安全弱点。以下是详细解答: 一、漏洞扫描的核心原理 主动探测技术 通过模拟攻击者的行为…...

Scrapy分布式爬虫实战:高效抓取的进阶之旅
引言 在2025年的数据狂潮中,单机爬虫如孤舟难敌巨浪,Scrapy分布式爬虫宛若战舰编队,扬帆远航,掠夺信息珍宝!继“动态网页”“登录网站”“经验总结”后,本篇献上Scrapy-Redis分布式爬虫实战,基于Quotes to Scrape,从单机到多机协同,代码简洁可运行,适合新手到老兵。…...
)
开元类双端互动组件部署实战全流程教程(第1部分:环境与搭建)
作者:一个曾在“组件卡死”里悟道的搬砖程序员 在面对一个看似华丽的开元类互动组件时,很多人以为“套个皮、配个资源”就能跑通。实际上,光是搞定环境配置、组件解析、控制端响应、前后端互联这些流程,已经足够让新手懵3天、老鸟…...

【实验笔记】Kylin-Desktop-V10-SP1麒麟系统知识 —— 开机自启Ollama
提示: 分享麒麟Kylin-Desktop-V10-SP1系统 离线部署Deepseek后,实现开机自动启动 Ollama 工具 的详细操作步骤 说明:离线安装ollama后,每次开机都需要手动启动,并且需要保持命令终端不能关闭;通过文档操作方法能实现开机自动后台启动 Ollama 工具 一、前期准备 1、离…...

Redis:现代服务端开发的缓存基石与电商实践-优雅草卓伊凡
Redis:现代服务端开发的缓存基石与电商实践-优雅草卓伊凡 一、Redis的本质与核心价值 1.1 Redis的技术定位 Redis(Remote Dictionary Server)是一个开源的内存数据结构存储系统,由Salvatore Sanfilippo于2009年创建。它不同于传…...
协议以及它的作用和影响)
认识并理解什么是链路层Frame-Relay(帧中继)协议以及它的作用和影响
帧中继(Frame Relay)是一种高效的数据链路层协议,主要用于广域网(WAN)中实现多节点之间的数据通信。它通过**虚电路(Virtual Circuit)**和统计复用技术,优化了传统分组交换网络(如X.25)的性能,特别适合带宽需求高、时延敏感的场景。 一、帧中继的核心设计目标 简化协…...
)
Python基本语法(类和实例)
类和实例 类和对象是面向对象编程的两个主要方面。类创建一个新类型,而对象是这个 类的实例,类使用class关键字创建。类的域和方法被列在一个缩进块中,一般函数 也可以被叫作方法。 (1)类的变量:甴一个类…...

Netty的内存池机制怎样设计的?
大家好,我是锋哥。今天分享关于【Netty的内存池机制怎样设计的?】面试题。希望对大家有帮助; Netty的内存池机制怎样设计的? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Netty的内存池机制是为了提高性能ÿ…...
-绘画and动画)
Python学习之路(七)-绘画and动画
Python 虽然不是专为图形设计或动画开发的语言,但凭借其丰富的第三方库,依然可以实现 2D/3D 绘画、交互式绘图、动画制作、游戏开发 等功能。以下是 Python 在绘画和动画方面的主流支持方式及推荐库。建议前端web端展示还是用其他语言好╮(╯▽╰)╭ 一、Python 绘画支持(2D…...

【HarmonyOS 5】鸿蒙应用数据安全详解
【HarmonyOS 5】鸿蒙应用数据安全详解 一、前言 大家平时用手机、智能手表的时候,最担心什么?肯定是自己的隐私数据会不会泄露!今天就和大家唠唠HarmonyOS是怎么把应用安全这块“盾牌”打造得明明白白的,从里到外保护我们的信息…...

动态指令参数:根据组件状态调整指令行为
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》 🍚 蓝桥云课签约作者、…...

Linux:权限的理解
目录 引言:为何Linux需要权限? 一、用户分类与切换 1.1、用户角色 1.2、用户切换命令 二、权限的基础概念 2.1、文件属性 三、权限的管理指令 3.1、chmod:修改文件权限 3.2、chown与chgro:修改拥有者与所属组 四、粘滞位…...

/etc/kdump.conf 配置详解
/etc/kdump.conf 是 Linux kdump 机制的核心配置文件,用于定义内核崩溃转储(vmcore)的生成规则、存储位置、过滤条件及触发后的自定义操作。以下是对其配置项的详细解析及常见用法示例: 一、配置文件结构 文件通常位于 /etc/kdu…...
的深入解析)
Redis 中简单动态字符串(SDS)的深入解析
在 Redis 中,简单动态字符串(Simple Dynamic String,SDS)是一种非常重要的数据结构,它在 Redis 的底层实现中扮演着关键角色。本文将详细介绍 SDS 的结构、Redis 使用 SDS 的原因以及 SDS 的主要 API 及其源码解析。 …...

GPIO引脚的上拉下拉以及转换速度到底怎么选
【摘要】本文讲述在进行单片机开发当中,新手小白常常为GPIO端口的种种设置感到迷惑,例如到底设置什么模式?它们之间的区别是什么?到底是设置上拉还是下拉电阻,有什么讲究?端口的输出速度又该如何设置&#…...

day16 numpy和shap深入理解
NumPy数组的创建 NumPy数组是Python中用于存储和操作大型多维数组和矩阵的主要工具。NumPy数组的创建非常灵活,可以接受各种“序列型”对象作为输入参数来创建数组。这意味着你可以将Python的列表(List)、元组(Tuple)…...

深入探索 51 单片机:从入门到实践的全面指南
深入探索 51 单片机:从入门到实践的全面指南 一、引言 在嵌入式系统发展的漫长历程中,51 单片机犹如一颗璀璨的明星,虽然诞生已有数十年,但至今仍在众多领域发挥着重要作用。它以结构简单、易于学习、成本低廉等优势,…...

架构思维:构建高并发读服务_热点数据查询的架构设计与性能调优
文章目录 一、引言二、热点查询定义与场景三、主从复制——垂直扩容四、应用内前置缓存4.1 容量上限与淘汰策略4.2 延迟刷新:定期 vs. 实时4.3 逃逸流量控制4.4 热点发现:被动 vs. 主动 五、降级与限流兜底六、前端/接入层其他应对七、模拟压…...

时间同步服务核心知识笔记:原理、配置与故障排除
一、时间同步服务 在 Linux 系统中,准确的时间至关重要。对于服务器集群,时间同步确保各节点间数据处理和交互的一致性,避免因时间差异导致的事务处理错误、日志记录混乱等问题。在分布式系统中,时间同步有助于协调任务调度、数据…...
拉伸模拟方法对比)
三种石墨烯(Graphene)拉伸模拟方法对比
免责声明:个人理解,仅供参考,若有问题欢迎讨论! 一、原理解释 1、fix deform 法——整体拉伸的理想模型 📌 模拟逻辑: 使用 fix deform 指令,对模拟盒子整体在 x 方向均匀伸长; 同时施加 npt 控制,使 y 和 z 方向维持零压状态(自由弛豫); 整个石墨烯结构在形变…...
)
Linux系统编程--基础指令(!!详细讲解+知识拓展)
第一讲 基础指令 我们现如今自己使用的电脑大部分是用的都是windows或者macOS,并配合上由微软和苹果开发的图形化界面,所以使用鼠标再屏幕上进行点击即可完成许多任务。但是作为操作系统的学习者,在linux的基础上不再使用图形化界进行操作…...

Python10天冲刺《Pydantic 是一个用于数据验证和设置管理的 Python 库》
Pydantic 是一个用于数据验证和设置管理的 Python 库,其核心功能围绕 数据验证、类型检查 和 模型配置 展开。以下是 Pydantic 的主要功能分类及其简要说明和示例: 1. 数据验证与类型检查 Pydantic 的核心功能是自动验证数据的类型、格式和约束条件。 …...

【工具】adverSCarial评估单细胞 RNA 测序分类器抵御对抗性攻击的脆弱性
文章目录 介绍代码参考 介绍 针对单细胞 RNA 测序(scRNA-seq)数据中健康细胞类型与病变细胞类型的检测,已有多项机器学习(ML)算法被提出用于医学研究目的。这引发了人们对于这些算法易受对抗性攻击的担忧,…...

机场围界报警系统的研究与应用
机场围界报警系统的研究与应用 摘要 本论文围绕机场围界报警系统展开深入研究,阐述了机场围界报警系统的重要性,对当前主流的机场围界报警技术原理、特点及应用场景进行详细分析,并探讨了现有系统存在的问题,最后对未来发展趋势进行了展望。研究表明,机场围界报警系统对…...

嵌入式操作系统
嵌入式操作系统是一种用途广泛的系统软件,通常包括与硬件相关的底层驱动软件、系统内核、设备驱动接口、通信协议、图形界面、标准化浏览器等。嵌入式操作系统负责嵌入式系统的全部 软、硬件资源的分配、任务调度,控制、协调并发活动。 嵌入式实时…...

预测性维护与传统维护成本对比:基于技术架构的量化分析
在工业 4.0 的技术演进浪潮中,设备维护模式正经历从经验驱动向数据驱动的变革。传统维护模式依赖固定周期巡检与故障后抢修,犹如 “蒙眼驾车”;而预测性维护借助物联网(IoT)、机器学习(ML)等技术…...

定位理论第一法则在医疗AI编程中的应用
引言 定位理论的核心在于通过明确目标、界定边界和建立差异化优势来占据用户心智中的独特位置。在医疗AI领域,定位理论的应用尤为重要,尤其是在医疗AI编程中,如何通过科学的定位确保技术与医疗本质的深度协同,而非技术主导的颠覆,是一个需要深入探讨的课题。本研究将深入剖…...

【macOS常用快捷键】
以下是 macOS 最常用快捷键列表,按使用频率由高到低分类整理,涵盖日常操作、效率工具及系统控制,助你快速提升使用效率: 一、基础高频操作 快捷键功能说明Command C复制选中内容Command V粘贴Command X剪切Command Z撤销上一…...
)
【Flask】ORM模型以及数据库迁移的两种方法(flask-migrate、Alembic)
ORM模型 在Flask中,ORM(Object-Relational Mapping,对象关系映射)模型是指使用面向对象的方式来操作数据库的编程技术。它允许开发者使用Python类和对象来操作数据库,而不需要直接编写SQL语句。 核心概念 1. ORM模型…...

信息安全导论 第八章 入侵检测技术
目录 一、入侵检测系统概述 二、入侵检测技术 三、入侵检测系统实例 1. Snort简介 2. Snort架构 3. Snort规则示例 4. 检测流程 四、入侵防御系统 1. IPS vs. IDS 2. IPS分类 3. IPS核心技术 4. IPS优势 5.总结 一、入侵检测系统概述 定义 检测、识别和隔离对系统…...
)
每日c/c++题 备战蓝桥杯(P1886 滑动窗口 /【模板】单调队列)
洛谷P1886 滑动窗口【模板】单调队列详解 题目描述 给定一个长度为n的整数序列,要求输出所有长度为k的连续子数组的: 最小值(第一部分输出)最大值(第二部分输出) 数据范围: 1 ≤ k ≤ n ≤…...
:测试gstreamer/v4l2+sdl2/v4l2+QtOpengl打摄像头延迟和内存)
GStreamer开发笔记(三):测试gstreamer/v4l2+sdl2/v4l2+QtOpengl打摄像头延迟和内存
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://blog.csdn.net/qq21497936/article/details/147714800 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、O…...

Level DB --- MergingIterator
MergingIterator 是 Level DB中重要的类,在某一个level做多个file数据Compaction的时候,这多个file之间数据如何高效的组织和比较,这个时候用到了MergingIterator。 关键member & member function MergingIterator继承了Iterator&#…...
)
第六章 流量特征分析-蚁剑流量分析(玄机靶场系列)
先分享几个在Wireshark中好用的几个指令: 显示 POST 请求:http.request.method "POST",用于显示所有 POST 请求的 HTTP 数据包。显示 GET 请求:http.request.method "GET",仅显示包含 GET 请求…...

Redis数据结构ZipList,QuickList,SkipList
目录 1.ZipList 1.2.解析Entry: 1.3Encoding编码 1.4.ZipList连锁更新问题 2.QuickList SkipList跳表 RedisObject 五种数据类型 1.ZipList redis中的ZipList是一种紧凑的内存储存结构,主要可以节省内存空间储存小规模数据。是一种特殊的双端链表…...

Cordova开发自定义插件的方法
Cordova开发自定义插件的方法 文章目录 Cordova开发自定义插件的方法[TOC](文章目录) 一、自定义插件二、android下的自定义插件开发(一)步骤1、建立cordova工程2、建立自定义插件(1) 安装plugman(2) 用plu…...

Dify框架面试内容整理-如何评估基于Dify开发的AI应用的效果?
评估基于 Dify 开发的 AI 应用效果,需要从 用户体验、技术性能 与 业务价值 三个层面综合衡量。以下是详细的评估框架,涵盖三个关键点: 用户反馈与满意度...

基于python的哈希查表搜索特定文件
Python有hashlib库,支持多种哈希算法,比如MD5、SHA1、SHA256等。通常SHA256比较安全,但MD5更快,但可能存在碰撞风险,得根据自己需求决定。下面以SHA256做例。 import hashlib import os from typing import Dict, Lis…...