【论文阅读】Joint Deep Modeling of Users and Items Using Reviews for Recommendation
Joint Deep Modeling of Users and Items Using Reviews for Recommendation
题目翻译:利用评论对用户和项目进行联合深度建模进行推荐
原文地址:点这里
关键词: DeepCoNN、推荐系统、卷积神经网络、评论建模、协同建模、评分预测、联合建模
摘要
用户撰写的大量评论包含着丰富的信息,而目前的大多数推荐系统忽视了这部分资源。本文提出了一个深度模型,名为 DeepCoNN,用于从评论中同时学习商品属性和用户行为。该模型由两个并行神经网络组成,分别利用用户撰写的评论和商品收到的评论进行建模,最终在顶部的共享层将二者耦合。这个共享层允许用户和商品的隐变量交互,类似因子分解模型的方式。实验表明,DeepCoNN 在多个数据集上显著优于所有的基线模型
一、前言
在过去十年里,商品和服务的种类和数量显著增加,虽然这为用户提供了更多选择,但也使他们更难做出决策。推荐系统应运而生,它们通过分析用户的偏好、需求和历史行为,向用户推荐可能感兴趣的商品,如网购、阅读文章、观看电影等场景中广泛使用。
当前主流的推荐系统方法主要基于 协同过滤(Collaborative Filtering, CF),尤其是基于 矩阵分解(Matrix Factorization) 的方法,它通过发现用户和商品之间的潜在因子(如电影的类型、演员等)来预测评分。这些方法虽然在多个应用中取得了成功,但也存在一个关键问题——稀疏性问题:用户评分(显式)过少,导致模型难以准确建模。
为了解决评分数据不足的问题,有研究尝试引入用户评论信息。用户在撰写评论时会表达对商品的看法,这些评论中包含了对评分背后的解释和情感信息,是评分矩阵之外的重要信息源。然而,大多数现有方法仍然忽视了这部分内容,仅基于评分建模用户和商品。
为此,本文提出了一个新的基于深度神经网络的模型,名为 DeepCoNN(Deep Cooperative Neural Networks),该模型从评论文本中联合建模用户行为和商品属性,从而提高评分预测的准确性。其核心思想如下:
- 使用两个并行神经网络分别对用户和商品进行建模;
- 每个网络的输入是该用户或该商品的所有评论;
- 顶部引入一个共享层,让用户和商品的潜在特征能够交互,类似于矩阵分解方法;
- 采用预训练词向量(如Word2Vec) 表示评论,提升语义建模效果。
论文的实验表明,DeepCoNN 在多个真实世界的数据集上(如 Yelp、Amazon、Beer)表现出显著优于现有方法的准确性,特别是在应对用户和商品评分稀缺的情况下,更能有效缓解稀疏性问题。
二、方法
表一:符号总结
| 符号 | 定义与描述 |
|---|---|
| d u 1 : n d_u^{1:n} du1:n | 用户或物品 u u u 的评论文本,由 n n n 个单词组成 |
| V u 1 : n V_u^{1:n} Vu1:n | 用户或物品 u u u 的词向量矩阵 |
| w u i w_{ui} wui | 用户 u u u 对物品 i i i 所写的评论文本 |
| o j o_j oj | 第 j j j 个卷积层神经元的输出 |
| n i n_i ni | 第 i i i 层神经元的数量 |
| K j K_j Kj | 第 j j j 个卷积核(Kernel) |
| b j b_j bj | 第 j j j 个卷积核的偏置项 |
| g g g | 全连接层的偏置项 |
| z j z_j zj | 第 j j j 个卷积特征图(Feature Map) |
| W W W | 全连接层的权重矩阵 |
| t t t | 卷积核的窗口大小(即卷积覆盖的词数) |
| c c c | 词向量的维度(例如 Word2Vec 常为 300) |
| x u x_u xu | 用户网络 Net u _u u 的输出向量 |
| y i y_i yi | 物品网络 Net i _i i 的输出向量 |
| λ \lambda λ | 学习 |
图1
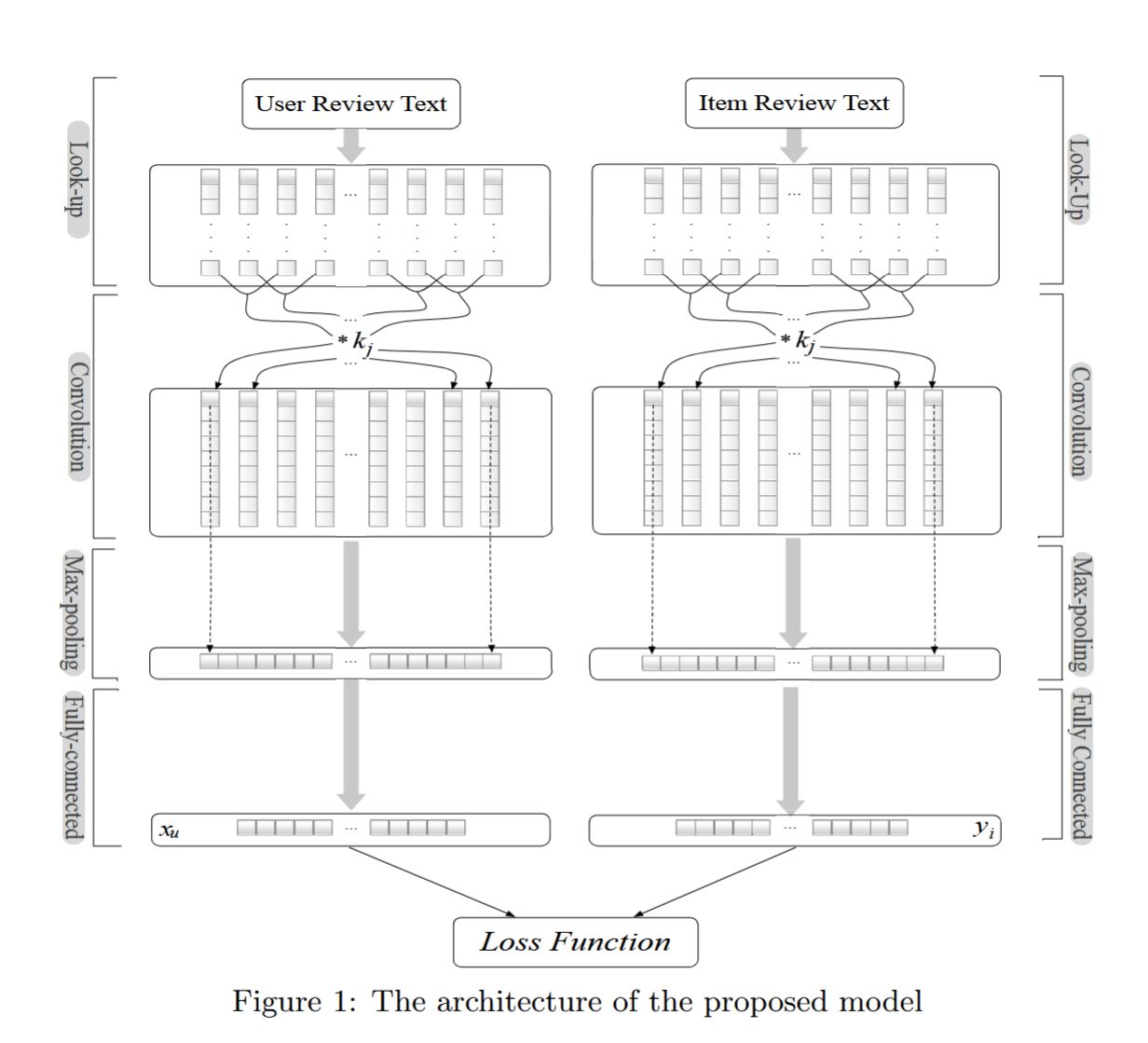
2.2 模型架构
评分预测任务中所提出模型的结构如图1所示。该模型由两个并行的神经网络构成,在最后一层进行耦合:一个网络用于用户建模(记作 Net u _u u),另一个用于商品建模(记作 Net i _i i)。用户撰写的评论和商品收到的评论分别作为输入传递给 Net u _u u 和 Net i _i i,最终输出预测评分。
模型的第一层被称为 查找层(look-up layer),它将评论文本转化为词嵌入矩阵(word embedding matrices),以提取评论中的语义信息。接下来的几层则是 CNN 中常用的结构,用于提取用户和商品的多层次特征,包括:
- 卷积层(convolution layer)、
- 最大池化层(max pooling layer)、
- 全连接层(fully connected layer)。
在两个网络的顶端,模型引入了一个 共享层(top shared layer),用于让用户和商品的隐向量进行交互。该层通过 Net u _u u 和 Net i _i i 输出的隐变量计算预测评分误差,即优化目标函数。
2.3 词嵌入表示
词嵌入是一种将单词映射为向量的参数化函数,记作 f : M → R n f : M \rightarrow \mathbb{R}^n f:M→Rn,其中 M M M 表示词汇表,函数 f f f 将每个单词映射为一个 n n n 维的分布式向量。近年来,这种表示方式在许多自然语言处理(NLP)任务中显著提升了性能【参考文献12, 7】。
在 DeepCoNN 模型中,采用这种表示技术来挖掘评论文本中的语义信息。在模型的第一层,即查找层(look-up layer),评论被表示为一个词嵌入矩阵,以提取其中的语义特征。
具体做法是:将用户 u u u 撰写的所有评论合并为一个整体文档,记作 d u 1 : n d_u^{1:n} du1:n,该文档由总共 n n n 个单词组成。随后,为用户 u u u 构建其对应的词向量矩阵 V u 1 : n V_u^{1:n} Vu1:n,公式如下:
V u 1 : n = ϕ ( d u 1 ) ⊕ ϕ ( d u 2 ) ⊕ ϕ ( d u 3 ) ⊕ ⋯ ⊕ ϕ ( d u n ) V_u^{1:n} = \phi(d_u^1) \oplus \phi(d_u^2) \oplus \phi(d_u^3) \oplus \cdots \oplus \phi(d_u^n) Vu1:n=ϕ(du1)⊕ϕ(du2)⊕ϕ(du3)⊕⋯⊕ϕ(dun)
其中, d u k d_u^k duk 表示文档 d u 1 : n d_u^{1:n} du1:n 中的第 k k k 个单词,查找函数 ϕ ( d u k ) \phi(d_u^k) ϕ(duk) 返回该单词对应的 c c c 维词向量,符号 ⊕ \oplus ⊕ 表示向量拼接操作。
需要特别指出的是,这种表示方法保留了词语的顺序信息,这是它相较于传统的“词袋模型(bag-of-words)”方法的一大优势。
2.4 卷积神经网络层
接下来的几层包括 卷积层(convolution layer)、最大池化层(max pooling) 和 全连接层(fully connected layer),这些结构遵循文献 [7] 中提出的 CNN 模型设计。
- 卷积层 由 m m m 个神经元组成,每个神经元通过在用户 u u u 的词向量矩阵 V u 1 : n V_u^{1:n} Vu1:n 上应用卷积操作来提取新的特征。
- 每个卷积神经元 j j j 使用一个大小为 c × t c \times t c×t 的卷积核 K j K_j Kj,在长度为 t t t 的词窗口上滑动进行计算。
- 卷积操作的结果如下式所示:
z j = f ( V u 1 : n ∗ K j + b j ) (2) z_j = f(V_u^{1:n} * K_j + b_j) \tag{2} zj=f(Vu1:n∗Kj+bj)(2)
其中:
- ∗ * ∗ 表示卷积操作符;
- b j b_j bj 是该卷积核的偏置项;
- f f f 是激活函数。
在本模型中,我们使用 ReLU(修正线性单元) 作为激活函数,其定义如下:
f ( x ) = max { 0 , x } (3) f(x) = \max\{0, x\} \tag{3} f(x)=max{0,x}(3)
使用 ReLU 的深度卷积神经网络相比使用 tanh 单元的网络训练速度更快【参考文献14】。
- 接下来,按照文献 [7] 的方法,我们在每个卷积特征图上执行 最大池化操作(max pooling),并取最大值作为该卷积核提取的代表性特征:
o j = max { z 1 , z 2 , … , z n − t + 1 } (4) o_j = \max\{z_1, z_2, \dots, z_{n-t+1}\} \tag{4} oj=max{z1,z2,…,zn−t+1}(4)
此方法可以自然地应对评论文本长度不一的问题。最大池化之后,卷积结果被压缩成一个固定大小的向量。
- 上述过程描述了一个卷积核提取一个特征的流程。实际模型中使用多个卷积核来提取不同的特征,其卷积层输出向量为:
O = { o 1 , o 2 , o 3 , … , o n 1 } (5) O = \{o_1, o_2, o_3, \dots, o_{n_1}\} \tag{5} O={o1,o2,o3,…,on1}(5)
其中, n 1 n_1 n1 表示卷积层中卷积核的数量。
- 然后,将最大池化层的输出 O O O 输入到一个全连接层,使用权重矩阵 W W W 和偏置 g g g 进行线性变换并激活,得到用户 u u u 的特征向量 x u x_u xu:
x u = f ( W × O + g ) (6) x_u = f(W \times O + g) \tag{6} xu=f(W×O+g)(6)
最终,我们可以分别获得用户端 CNN 的输出 x u x_u xu 和物品端 CNN 的输出 y i y_i yi,作为后续评分预测的输入。
2.5 共享层
尽管用户和物品的输出向量 x u x_u xu 和 y i y_i yi 可以被视为各自的特征表示,但它们可能处于不同的特征空间,因此彼此之间不可直接比较或交互。
为了解决这个问题,本文在两个神经网络的顶部引入了一个共享层(shared layer),用于将 Net u _u u 和 Net i _i i 的输出耦合在一起。
具体做法是,将用户和物品的向量拼接成一个新的向量:
z ^ = ( x u , y i ) \hat{z} = (x_u, y_i) z^=(xu,yi)
为了建模该拼接向量 z ^ \hat{z} z^ 中所有特征之间的高阶交互关系,我们引入了 因子分解机(Factorization Machine, FM)【参考文献24】作为评分预测的估计器。
因此,给定一个包含 N N N 个训练样本的批次 T T T,我们定义其损失函数(代价函数)如下:
J = w ^ 0 + ∑ i = 1 ∣ z ^ ∣ w ^ i z ^ i + ∑ i = 1 ∣ z ^ ∣ ∑ j = i + 1 ∣ z ^ ∣ ⟨ v ^ i , v ^ j ⟩ z ^ i z ^ j (7) J = \hat{w}_0 + \sum_{i=1}^{|\hat{z}|} \hat{w}_i \hat{z}_i + \sum_{i=1}^{|\hat{z}|} \sum_{j=i+1}^{|\hat{z}|} \langle \hat{v}_i, \hat{v}_j \rangle \hat{z}_i \hat{z}_j \tag{7} J=w^0+i=1∑∣z^∣w^iz^i+i=1∑∣z^∣j=i+1∑∣z^∣⟨v^i,v^j⟩z^iz^j(7)
其中:
- w ^ 0 \hat{w}_0 w^0 是全局偏置项;
- w ^ i \hat{w}_i w^i 表示 z ^ \hat{z} z^ 中第 i i i 个变量的权重;
- ⟨ v ^ i , v ^ j ⟩ \langle \hat{v}_i, \hat{v}_j \rangle ⟨v^i,v^j⟩ 表示变量 i i i 和 j j j 的二阶交互项,定义为向量内积:
⟨ v ^ i , v ^ j ⟩ = ∑ f = 1 ∣ z ^ ∣ v ^ i , f ⋅ v ^ j , f \langle \hat{v}_i, \hat{v}_j \rangle = \sum_{f=1}^{|\hat{z}|} \hat{v}_{i,f} \cdot \hat{v}_{j,f} ⟨v^i,v^j⟩=f=1∑∣z^∣v^i,f⋅v^j,f
x和y处于不同的特征空间,不能直接比较,采用耦合
2.6 网络训练(Network Training)
我们的模型通过最小化公式(7)所表示的损失函数 J J J 来进行训练。对该函数关于 z ^ i \hat{z}_i z^i 求导后,得到如下导数表达式(公式8):
∂ J ∂ z ^ i = w ^ i + ∑ j = i + 1 ∣ z ^ ∣ ⟨ v ^ i , v ^ j ⟩ z ^ j (8) \frac{\partial J}{\partial \hat{z}_i} = \hat{w}_i + \sum_{j=i+1}^{|\hat{z}|} \langle \hat{v}_i, \hat{v}_j \rangle \hat{z}_j \tag{8} ∂z^i∂J=w^i+j=i+1∑∣z^∣⟨v^i,v^j⟩z^j(8)
对于网络中其他层的参数,其梯度可以通过链式法则(chain rule)进一步求得。
给定一个包含 N N N 个样本元组的训练集 T T T,我们采用 RMSprop 优化器【参考文献30】在随机打乱后的小批量(mini-batches)上进行模型优化。
RMSprop 是一种自适应版本的梯度下降算法,它根据梯度的绝对值动态调整学习率。其做法是:用当前梯度的平方值对历史梯度进行加权平均,从而缩放每个权重参数的更新量。
其参数 θ \theta θ 的更新规则如下:
r t ← 0.9 ( ∂ J ∂ θ ) 2 + 0.1 ⋅ r t − 1 (9) r_t \leftarrow 0.9 \left( \frac{\partial J}{\partial \theta} \right)^2 + 0.1 \cdot r_{t-1} \tag{9} rt←0.9(∂θ∂J)2+0.1⋅rt−1(9)
θ ← θ − ( λ r t + ε ) ⋅ ∂ J ∂ θ (10) \theta \leftarrow \theta - \left( \frac{\lambda}{\sqrt{r_t} + \varepsilon} \right) \cdot \frac{\partial J}{\partial \theta} \tag{10} θ←θ−(rt+ελ)⋅∂θ∂J(10)
其中:
- λ \lambda λ 是学习率;
- ε \varepsilon ε 是为避免数值不稳定性而加入的一个很小的常数。
此外,为了防止过拟合,在两个神经网络的全连接层中还使用了 dropout 策略【参考文献28】。
思考
1. DeepCoNN模型解决一个什么问题
显示评分数据少且评论信息为利用
2. DeepCoNN模型怎么解决这个问题
-
联合建模评论文本
- 对每个用户与每个物品分别汇总其所有评论,输入到两条并行的卷积神经网络(Netₙᵤ 和 Netᵢₜₑₘ),自动抽取深层语义特征。
-
词嵌入 + CNN 提取特征
- 使用预训练的词向量保留评论的语义与词序;
- 通过卷积层 + 最大池化获得固定维度的特征向量,捕捉局部 n-gram 信息。
-
共享交互层
- 将用户向量 x u x_u xu 与物品向量 y i y_i yi 拼接,输入因子分解机(FM),同时建模一阶偏置项和二阶交互项,输出评分预测。
3. DeepCoNN模型在当时创新点是什么
- 首个深度联合模型:将用户和物品的评论文本放入两条并行 CNN,同时学习并耦合二者的隐向量,用于评分预测;
- 语义与词序保留:通过预训练词嵌入和卷积操作,克服了 Bag‑of‑Words/主题模型忽视词序与词语语义多样性的局限;
- 与经典矩阵分解融合:在顶层采用因子分解机(FM)建模高阶交互,将深度特征与协同过滤思想有机结合;
和二阶交互项,输出评分预测。
3. DeepCoNN模型在当时创新点是什么
- 首个深度联合模型:将用户和物品的评论文本放入两条并行 CNN,同时学习并耦合二者的隐向量,用于评分预测;
- 语义与词序保留:通过预训练词嵌入和卷积操作,克服了 Bag‑of‑Words/主题模型忽视词序与词语语义多样性的局限;
- 与经典矩阵分解融合:在顶层采用因子分解机(FM)建模高阶交互,将深度特征与协同过滤思想有机结合;
- 缓解稀疏与冷启动:实验证明,在用户或物品评分极少(甚至仅一条评论)时,DeepCoNN 仍能显著降低预测误差。
相关文章:

【论文阅读】Joint Deep Modeling of Users and Items Using Reviews for Recommendation
Joint Deep Modeling of Users and Items Using Reviews for Recommendation 题目翻译:利用评论对用户和项目进行联合深度建模进行推荐 原文地址:点这里 关键词: DeepCoNN、推荐系统、卷积神经网络、评论建模、协同建模、评分预测、联合建模…...

webpack 的工作流程
Webpack 的工作流程可以分为以下几个核心步骤,我将结合代码示例详细说明每个阶段的工作原理: 1. 初始化配置 Webpack 首先会读取配置文件(默认 webpack.config.js),合并命令行参数和默认配置。 // webpack.config.js…...

Linux 常用指令详解
Linux 操作系统中有大量强大的命令行工具,下面我将分类介绍一些最常用的指令及其用法。 ## 文件与目录操作 ### 1. ls - 列出目录内容 ls [选项] [目录名] 常用选项: - -l:长格式显示(详细信息) - -a:显…...

DXFViewer进行中 : ->封装OpenGL -> 解析DXF直线
DXFViewer进行中,目标造一个dxf看图工具。. 目标1:封装OpenGL,实现正交相机及平移缩放功能 Application.h #pragma once #include <string> #include <glad/glad.h> #include <GLFW/glfw3.h> #include "../Core/TimeStamp.h" #includ…...

多序列比对软件MAFFT介绍
MAFFT(Multiple Alignment using Fast Fourier Transform)是一款广泛使用且高效的多序列比对软件,由日本京都大学的Katoh Kazutaka等人开发,最早发布于2002年,并持续迭代优化至今。 它支持从几十条到上万条核酸或蛋白质序列的快速比对,同时在准确率和计算效率之间提供灵…...

基于 HTML5 Canvas 实现图片旋转与下载功能
一、引言 在 Web 开发中,经常会遇到需要对图片进行处理并提供下载功能的需求。本文将深入剖析一段基于 HTML5 Canvas 的代码,该代码实现了图片的旋转(90 度和 180 度)以及旋转后图片的下载功能。通过对代码的解读,我们…...
)
学习路线(机器人系统)
机器人软件/系统学习路线(从初级到专家) 初级阶段(6-12个月)基础数学编程基础机器人基础概念推荐资源 中级阶段(1-2年)机器人运动学机器人动力学控制系统感知系统推荐资源 高级阶段(2-3年&#…...
)
基于EFISH-SCB-RK3576工控机/SAIL-RK3576核心板的网络安全防火墙技术方案(国产化替代J1900的全栈技术解析)
基于EFISH-SCB-RK3576/SAIL-RK3576的网络安全防火墙技术方案 (国产化替代J1900的全栈技术解析) 一、硬件架构设计 流量处理核心模块 多核异构架构: 四核Cortex-A72(2.3GHz):处理深度…...

基于 jQuery 实现复选框全选与选中项查询功能
在 Web 开发中,复选框是常见的交互元素,尤其是在涉及批量操作、数据筛选等场景时,全选功能和选中项查询功能显得尤为重要。本文将介绍如何使用 HTML、CSS 和 jQuery 实现一个具备全选、反选以及选中项查询功能的复选框组,帮助开发…...

Python中的JSON库,详细介绍与代码示例
目录 1. 前言 2. json 库基本概念 3. json 的适应场景 4. json 库的基本用法 4.1 导 json入 模块 4.2 将 Python 对象转换为 JSON 字符串 4.3 将 JSON 字符串转换为 Python 对象 4.4 将 Python 对象写入 JSON 文件 4.5 从 JSON 文件读取数据 4.6 json 的其他方法 5.…...

tensorflow 调试
tensorflow 调试 tf.config.experimental_run_functions_eagerly(True) 是 TensorFlow 中的一个配置函数,它的作用是: 让 tf.function 装饰的函数以 Eager 模式(即时执行)运行,而不是被编译成图(Graph&…...

iptables的基本选项及概念
目录 1.按保护范围划分: 2.iptables 的基础概念 4个规则表: 5个规则链: 3.iptables的基础选项 4.实验 1.按保护范围划分: 主机防火墙:服务范围为当前一台主机 input output 网络防火墙:服务范围为防…...

使用AI 将文本转成视频 工具 介绍
🎬 文字生成视频工具 一款为自媒体创作者设计的 全自动视频生成工具,输入文本即可输出高质量视频,大幅提升内容创作效率。视频演示:https://leeseean.github.io/Text2Video/?t23 ✨ 功能亮点 功能模块说明📝 智能分…...

Python生活手册-NumPy数组创建:从快递分拣到智能家居的数据容器
一、快递分拣系统(列表/元组转换) 1. 快递单号录入(np.array()) import numpy as np快递单号入库系统 快递单列表 ["SF123", "JD456", "EMS789"] 快递数组 np.array(快递单列表) print(f"…...

Cmake编译wxWidgets3.2.8
一、下载库源代码 去wxWidgets - Browse /v3.2.8 at SourceForge.net下载wxWidgets-3.2.8.7z 二、建立目录结构 1、在d:\codeblocks目录里新建wxWidgets_Src目录 2、把文件解压到该目录 3、建立 CB目录,并在该目录下分别建立 Debug 和 Release目录 三、使用Cmake…...

2.在Openharmony写hello world
原文链接:https://kashima19960.github.io/2025/03/21/openharmony/2.在Openharmony写hello%20world/ 前言 Openharmony 的第一个官方例程的是教你在Hi3861上编写hello world程序,这个例程相当简单编写 Hello World”程序,而且步骤也很省略&…...

「OC」源码学习——对象的底层探索
「OC」源码学习——对象的底层探索 前言 上次我们说到了源码里面的调用顺序,现在我们继续了解我们上一篇文章没有讲完的关于对象的内容函数,完整了解对象的产生对于isa赋值以及内存申请的内容 函数内容 先把_objc_rootAllocWithZone函数的内容先贴上…...

从0开始学习大模型--Day01--大模型是什么
初识大模型 在平时遇到问题时,我们总是习惯性地去运用各种搜索引擎如百度、知乎、CSDN等平台去搜索答案,但由于搜索到的内容质量参差不齐,检索到的内容只是单纯地根据关键字给出内容,往往看了几个网页都找不到答案;而…...

202533 | SpringBoot集成RocketMQ
SpringBoot集成RocketMQ极简入门 一、基础配置(3步完成) 添加依赖 <!-- pom.xml --> <dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version&g…...

大模型学习专栏-导航页
概要 本专栏是小编系统性调研大模型过程中沉淀的知识结晶,涵盖技术原理、实践应用、前沿动态等多维度内容。为助力读者高效学习,特整理此导航页,以清晰脉络串联核心知识点,搭建起系统的大模型学习框架,助您循序渐进掌握…...

互联网大厂Java面试:从Java SE到微服务的全栈挑战
场景概述 在这场面试中,谢飞机,一个搞笑但有些水的程序员,面对的是一位严肃的大厂面试官李严。面试官的目的是考察谢飞机在Java全栈开发,特别是微服务架构中的技术能力。面试场景设定在内容社区与UGC领域,模拟一个社交…...

2024年408真题及答案
2024年计算机408真题 2024年计算机408答案 2024 408真题下载链接 2024 408答案下载链接...

【datawhaleAI春训营】楼道图像分类
目录 图像分类任务的一般处理流程为什么使用深度学习迁移学习 加载实操环境的库加载数据集,默认data文件夹存储数据将图像类别进行编码自定义数据读取加载预训练模型模型训练,验证和预测划分验证集并训练模型 修改baseline处理输入数据选择合适的模型Ale…...
与持续检测键盘按键(Input.GetKey))
Unity:输入系统(Input System)与持续检测键盘按键(Input.GetKey)
目录 Unity 的两套输入系统: 🔍 Input.GetKey 详解 🎯 对比:常用的输入检测方法 技术底层原理(简化版) 示例:角色移动 为什么会被“新输入系统”替代? Unity 的两套输入系统&…...

day04_计算机常识丶基本数据类型转换
计算机常识 计算机如何存储数据 计算机底层只能识别二进制。计算机底层只识别二进制是因为计算机内部的电子元件只能识别两种状态,即开和关,或者高电平和低电平。二进制正好可以用两种状态来表示数字和字符,因此成为了计算机最基本的表示方…...
)
rvalue引用()
一、先确定基础:左值(Lvalue)和右值(Rvalue) 理解Rvalue引用,首先得搞清楚左值和右值的概念。 左值(Lvalue):有明确内存地址的表达式,可以取地址。比如变量名、引用等。 复制代码 int a = 10; // a是左值 int& ref = a; // ref也是左值右值(Rval…...

【Web3】上市公司利用RWA模式融资和促进业务发展案例
香港典型案例 朗新科技(充电桩RWA融资) 案例概述:2024年8月,朗新科技与蚂蚁数科合作,通过香港金管局“Ensemble沙盒”完成首单新能源充电桩资产代币化融资,募资1亿元人民币。技术实现:蚂蚁链提供…...

什么是IIC通信
IIC(Inter-Integrated Circuit),即IC,是一种串行通信总线,由飞利浦公司在1980年代开发,主要用于连接主板、嵌入式系统或手机中的低速外围设备1。IIC协议采用多主从架构,允许多个主设备和从设备连接在同一总线上进行通信。 IIC协议的工作原理: IIC协议使用两根信号线进…...

网络原理 TCP/IP
1.应用层 1.1自定义协议 客户端和服务器之间往往进行交互的是“结构化”数据,网络传输的数据是“字符串”“二进制bit流”,约定协议的过程就是把结构化”数据转成“字符串”或“二进制bit流”的过程. 序列化:把结构化”数据转成“字符串”…...

掌纹图像识别:解锁人类掌纹/生物识别的未来——技术解析与前沿数据集探索
概述 掌纹识别是一种利用手掌表面独特的线条、纹理和褶皱模式进行身份认证的生物识别技术。它具有非侵入性、高准确性和难以伪造的特点,被广泛应用于安全认证领域。以下将结合提供的链接,详细介绍掌纹识别的技术背景、数据集和研究进展。 提供的链接分析 香港理工大学掌纹数…...

【FPGA开发】Xilinx DSP48E2 slice 一个周期能做几次int8乘法或者加法?如何计算FPGA芯片的GOPS性能?
Xilinx DSP48E2 slice 在一个时钟周期内处理 INT8(8 位整数)运算的能力。 核心能力概述 一个 DSP48E2 slice 包含几个关键计算单元: 预加器 (Pre-Adder): 可以执行 A D 或 A - D 操作,其中 A 是 30 位,D 是 27 位。…...

APP 设计中的色彩心理学:如何用色彩提升用户体验
在数字化时代,APP 已成为人们日常生活中不可或缺的一部分。用户在打开一个 APP 的瞬间,首先映入眼帘的便是其色彩搭配,而这些色彩并非只是视觉上的装饰,它们蕴含着强大的心理暗示力量,能够潜移默化地影响用户的情绪、行…...

残差网络实战:基于MNIST数据集的手写数字识别
残差网络实战:基于MNIST数据集的手写数字识别 在深度学习的广阔领域中,卷积神经网络(CNN)一直是处理图像任务的主力军。随着研究的深入,网络层数的增加虽然理论上能提升模型的表达能力,但却面临梯度消失、…...

科学养生,开启健康生活新篇章
在快节奏的现代生活中,健康养生成为人们关注的焦点。科学合理的养生方式,能帮助我们远离疾病,提升生活质量,无需依赖传统中医理念,也能找到适合自己的养生之道。 饮食是养生的基础。遵循均衡饮食原则,每…...

如何扫描系统漏洞?漏洞扫描的原理是什么?
如何扫描系统漏洞?漏洞扫描的原理是什么? 漏洞扫描是网络安全中识别系统潜在风险的关键步骤,其核心原理是通过主动探测和自动化分析发现系统的安全弱点。以下是详细解答: 一、漏洞扫描的核心原理 主动探测技术 通过模拟攻击者的行为…...

Scrapy分布式爬虫实战:高效抓取的进阶之旅
引言 在2025年的数据狂潮中,单机爬虫如孤舟难敌巨浪,Scrapy分布式爬虫宛若战舰编队,扬帆远航,掠夺信息珍宝!继“动态网页”“登录网站”“经验总结”后,本篇献上Scrapy-Redis分布式爬虫实战,基于Quotes to Scrape,从单机到多机协同,代码简洁可运行,适合新手到老兵。…...
)
开元类双端互动组件部署实战全流程教程(第1部分:环境与搭建)
作者:一个曾在“组件卡死”里悟道的搬砖程序员 在面对一个看似华丽的开元类互动组件时,很多人以为“套个皮、配个资源”就能跑通。实际上,光是搞定环境配置、组件解析、控制端响应、前后端互联这些流程,已经足够让新手懵3天、老鸟…...

【实验笔记】Kylin-Desktop-V10-SP1麒麟系统知识 —— 开机自启Ollama
提示: 分享麒麟Kylin-Desktop-V10-SP1系统 离线部署Deepseek后,实现开机自动启动 Ollama 工具 的详细操作步骤 说明:离线安装ollama后,每次开机都需要手动启动,并且需要保持命令终端不能关闭;通过文档操作方法能实现开机自动后台启动 Ollama 工具 一、前期准备 1、离…...

Redis:现代服务端开发的缓存基石与电商实践-优雅草卓伊凡
Redis:现代服务端开发的缓存基石与电商实践-优雅草卓伊凡 一、Redis的本质与核心价值 1.1 Redis的技术定位 Redis(Remote Dictionary Server)是一个开源的内存数据结构存储系统,由Salvatore Sanfilippo于2009年创建。它不同于传…...
协议以及它的作用和影响)
认识并理解什么是链路层Frame-Relay(帧中继)协议以及它的作用和影响
帧中继(Frame Relay)是一种高效的数据链路层协议,主要用于广域网(WAN)中实现多节点之间的数据通信。它通过**虚电路(Virtual Circuit)**和统计复用技术,优化了传统分组交换网络(如X.25)的性能,特别适合带宽需求高、时延敏感的场景。 一、帧中继的核心设计目标 简化协…...
)
Python基本语法(类和实例)
类和实例 类和对象是面向对象编程的两个主要方面。类创建一个新类型,而对象是这个 类的实例,类使用class关键字创建。类的域和方法被列在一个缩进块中,一般函数 也可以被叫作方法。 (1)类的变量:甴一个类…...

Netty的内存池机制怎样设计的?
大家好,我是锋哥。今天分享关于【Netty的内存池机制怎样设计的?】面试题。希望对大家有帮助; Netty的内存池机制怎样设计的? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Netty的内存池机制是为了提高性能ÿ…...
-绘画and动画)
Python学习之路(七)-绘画and动画
Python 虽然不是专为图形设计或动画开发的语言,但凭借其丰富的第三方库,依然可以实现 2D/3D 绘画、交互式绘图、动画制作、游戏开发 等功能。以下是 Python 在绘画和动画方面的主流支持方式及推荐库。建议前端web端展示还是用其他语言好╮(╯▽╰)╭ 一、Python 绘画支持(2D…...

【HarmonyOS 5】鸿蒙应用数据安全详解
【HarmonyOS 5】鸿蒙应用数据安全详解 一、前言 大家平时用手机、智能手表的时候,最担心什么?肯定是自己的隐私数据会不会泄露!今天就和大家唠唠HarmonyOS是怎么把应用安全这块“盾牌”打造得明明白白的,从里到外保护我们的信息…...

动态指令参数:根据组件状态调整指令行为
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》 🍚 蓝桥云课签约作者、…...

Linux:权限的理解
目录 引言:为何Linux需要权限? 一、用户分类与切换 1.1、用户角色 1.2、用户切换命令 二、权限的基础概念 2.1、文件属性 三、权限的管理指令 3.1、chmod:修改文件权限 3.2、chown与chgro:修改拥有者与所属组 四、粘滞位…...

/etc/kdump.conf 配置详解
/etc/kdump.conf 是 Linux kdump 机制的核心配置文件,用于定义内核崩溃转储(vmcore)的生成规则、存储位置、过滤条件及触发后的自定义操作。以下是对其配置项的详细解析及常见用法示例: 一、配置文件结构 文件通常位于 /etc/kdu…...
的深入解析)
Redis 中简单动态字符串(SDS)的深入解析
在 Redis 中,简单动态字符串(Simple Dynamic String,SDS)是一种非常重要的数据结构,它在 Redis 的底层实现中扮演着关键角色。本文将详细介绍 SDS 的结构、Redis 使用 SDS 的原因以及 SDS 的主要 API 及其源码解析。 …...

GPIO引脚的上拉下拉以及转换速度到底怎么选
【摘要】本文讲述在进行单片机开发当中,新手小白常常为GPIO端口的种种设置感到迷惑,例如到底设置什么模式?它们之间的区别是什么?到底是设置上拉还是下拉电阻,有什么讲究?端口的输出速度又该如何设置&#…...

day16 numpy和shap深入理解
NumPy数组的创建 NumPy数组是Python中用于存储和操作大型多维数组和矩阵的主要工具。NumPy数组的创建非常灵活,可以接受各种“序列型”对象作为输入参数来创建数组。这意味着你可以将Python的列表(List)、元组(Tuple)…...