气泡图、桑基图的绘制
1、气泡图
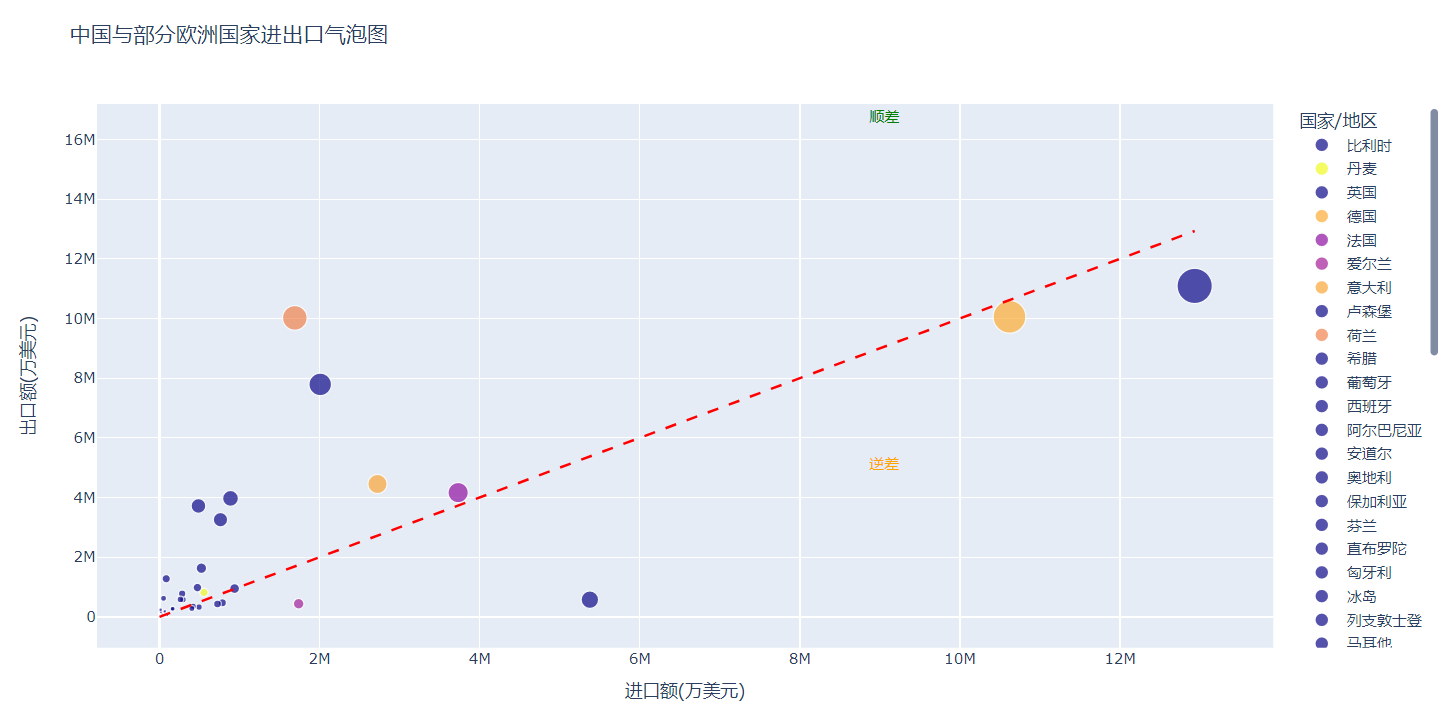
使用气泡图分析某一年中国同欧洲各国之间的贸易情况。
气泡图分析的三个维度:
• 进口额:横轴
• 出口额:纵轴
• 进出口总额:气泡大小
数据来源:链接: 国家统计局数据
数据概览(进出口总额,进口总额和出口总额数据格式与总额类似)
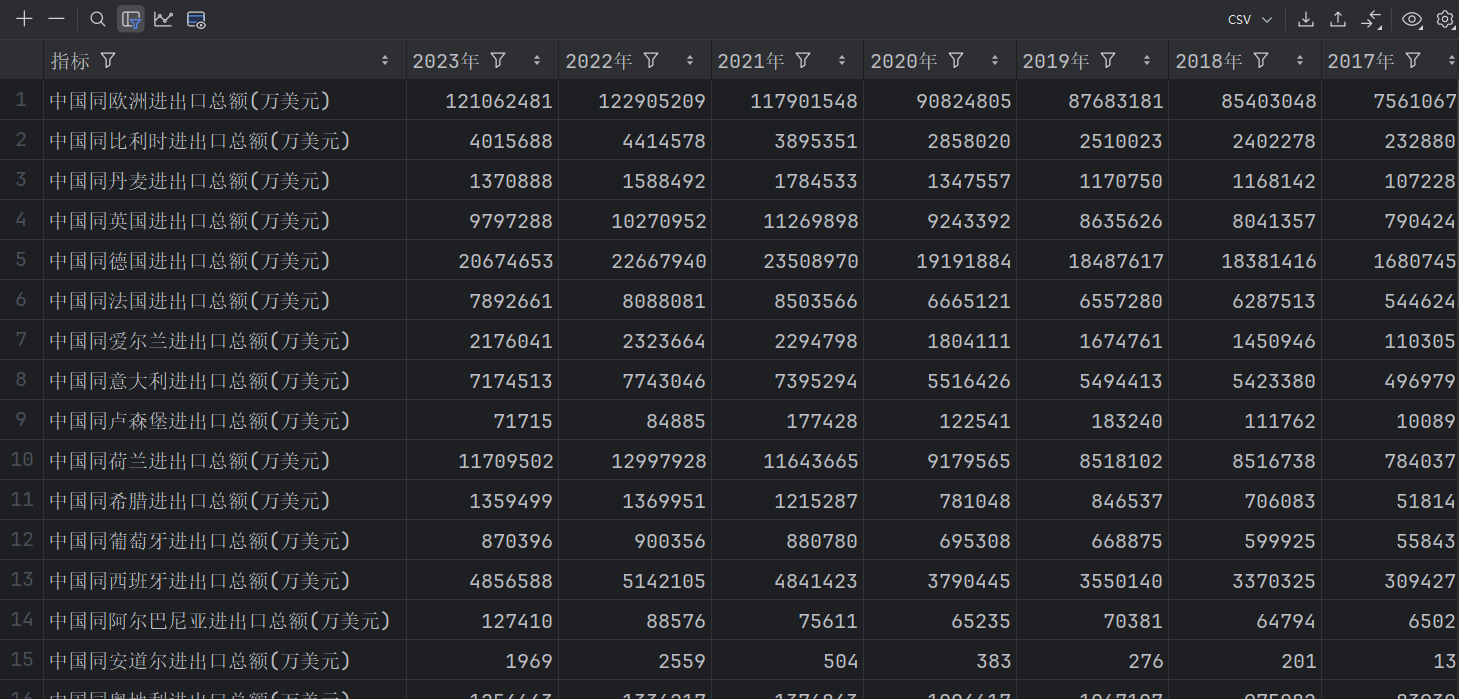
(1)数据预处理
1. 知识点:
- 通过 .str 来调用字符串处理方法
- extract 方法的作用是根据指定的正则表达式模式,从字符串中提取出符合模式的部分。它会返回一个新的 DataFrame 或者 Series
- 正则表达式 r’同(.*?)进出口总额’:整体意思是捕获 “同” 后面直到遇到 “进出口总额” 之前的任意字符内容。
2. 代码:
#数据预处理:填充缺失值、提取国家名称
# 提取国家名称替换 country 列
df['country'] = df['country'].str.extract(r'同(.*?)进出口总额')
# 将 input 列中的缺失值用 0 填充
df['input'] = df['input'].fillna(0)
# 将结果保存为 Excel 文件
df.to_excel('/初始数据_2023_预处理.xlsx', index=False)
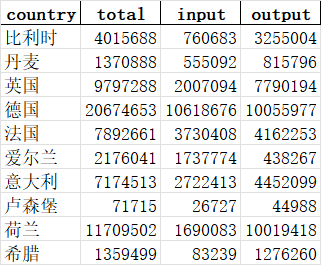
3. 结果:
备注:删除 “欧洲” 这样一行数据,避免造成数据量级差别较大造成的不美观
(2)可视化
1. 知识点:
- plt.cm.tab20:cm 是 matplotlib 中颜色映射(colormap)模块。tab20 是 matplotlib 内置的一种颜色映射表,它包含 20 种不同的颜色 ,这些颜色在视觉上有较好的区分度,适用于区分多个类别。
- linspace 函数用于在指定的区间内生成均匀间隔的数值序列。
- 使用plotly.express绘制气泡图并添加悬停提示
2. 代码:
import pandas as pd
import plotly.express as px
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import numpy as np# 读取Excel文件数据
df = pd.read_excel('初始数据_2023_预处理.xlsx', engine='openpyxl')# 使用seaborn设置风格
sns.set_style("whitegrid")# 自定义颜色映射
colors = plt.cm.tab20(np.linspace(0, 5, len(df)))
cmap = ListedColormap(colors)# 使用plotly.express绘制气泡图并添加悬停提示
fig = px.scatter(df, x='input', y='output', size='total',color='country',color_discrete_sequence=cmap.colors,labels={'input': '进口额(万美元)', 'output': '出口额(万美元)', 'total': '进出口总额(万美元)','country': '国家/地区'},title='中国与部分欧洲国家进出口气泡图')
# 更新标记点为圆形
fig.update_traces(marker=dict(symbol='circle'))# 添加进出口平衡辅助线
fig.add_shape(type="line",x0=df['input'].min(), # 辅助线起点x坐标为进口额最小值y0=df['input'].min(), # 辅助线起点y坐标(与进口额相等,保证在平衡线上 )x1=df['input'].max(), # 辅助线终点x坐标为进口额最大值y1=df['input'].max(), # 辅助线终点y坐标(与进口额相等,保证在平衡线上 )line=dict(color="red", # 辅助线颜色设为红色width=2,dash="dash" # 辅助线样式设为虚线)
)# 为顺差区域添加注释
fig.add_annotation(xref="x",yref="y",x=df['input'].max() * 0.7, # 注释x坐标位置y=df['input'].max() * 1.3, # 注释y坐标位置text="顺差", # 注释文本font=dict(size=12,color="green" # 注释文字颜色),showarrow=False # 不显示箭头
)# 为逆差区域添加注释
fig.add_annotation(xref="x",yref="y",x=df['input'].max() * 0.7,y=df['input'].max() * 0.4,text="逆差",font=dict(size=12,color="orange"),showarrow=False
)# 显示图形
fig.show()
3. 结果:
2、动态气泡图:
(1)数据预处理
1. 知识点:
- melt 函数用于将数据从宽格式转换为长格式
- id_vars=[‘指标’] :指定在重塑过程中保持不变的列,这里 ‘指标’ 列的内容会被保留。
- var_name=‘年份’ :将原来宽格式数据中的列名(除 id_vars 列外)转换为长格式中的一列,并将该列命名为 ‘年份’ 。
- value_name=‘进出口总额’ :将原来宽格式数据中对应的值转换为长格式中的一列,并将该列命名为 ‘进出口总额’ 。通过这一步,数据的结构变得更便于后续分析。
- 提取年份中的数字并转换类型
- df_total[‘年份’].str.extract(‘(\d+)’) :使用 str.extract 方法,结合正则表达式 (\d+) 从 ‘年份’ 列的字符串中提取连续的数字部分。(\d+) 表示捕获一个或多个数字。
- .astype(int) :将提取出的数字字符串转换为整数类型,这样 ‘年份’ 列的数据类型就变为整数,方便后续进行数值相关的操作或分析。
- dropna 函数用于删除包含缺失值的行。subset=[‘国家’] 表示只检查 ‘国家’ 这一列,如果这一列存在缺失值(NaN ),则删除对应的行。这样可以保证数据集中的 ‘国家’ 列没有缺失值,使后续基于该列的分析更加可靠。
2. 代码:
import pandas as pdpd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
# 读取数据
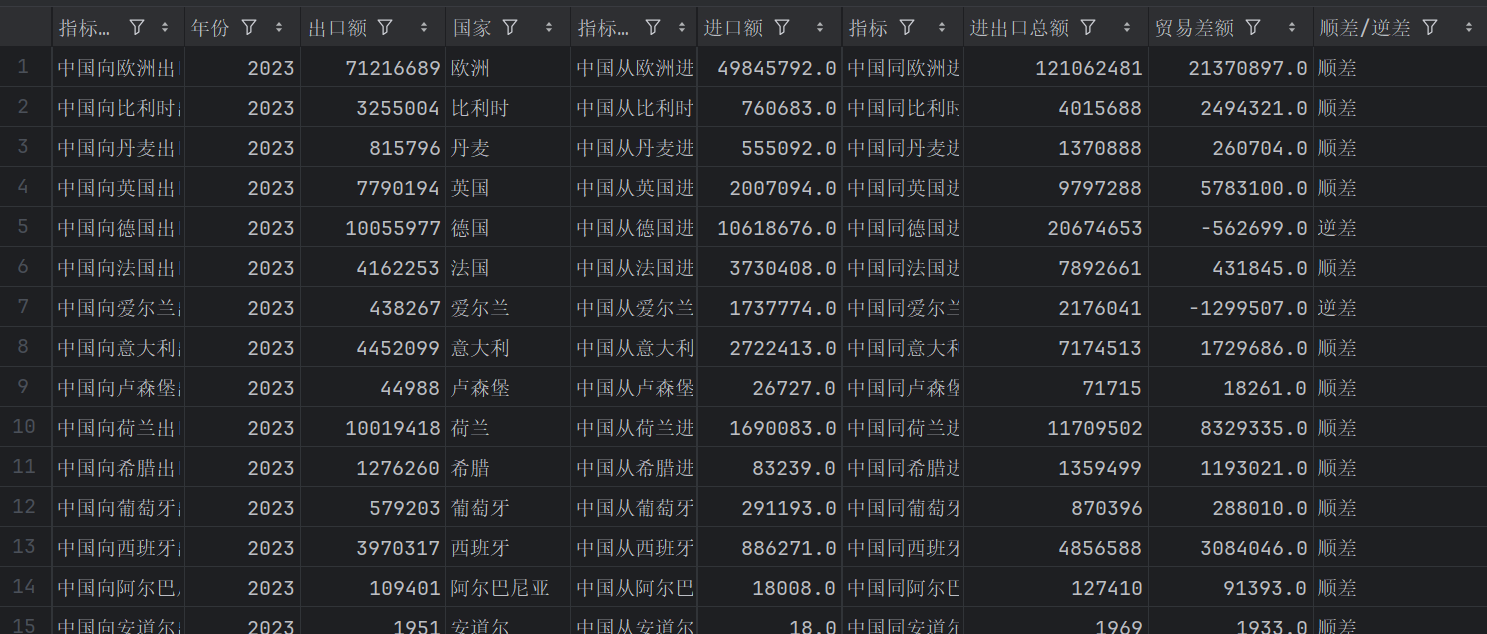
def read_data():# 读取出口数据df_export = pd.read_csv('年度数据(1).csv', encoding='utf-8')df_export = df_export.melt(id_vars=['指标'], var_name='年份', value_name='出口额')df_export['年份'] = df_export['年份'].str.extract('(\d+)').astype(int)df_export['国家'] = df_export['指标'].str.extract('中国向(.*?)出口总额')df_export = df_export.dropna(subset=['国家'])# 读取进口数据df_import = pd.read_csv('年度数据(2).csv', encoding='utf-8')df_import = df_import.melt(id_vars=['指标'], var_name='年份', value_name='进口额')df_import['年份'] = df_import['年份'].str.extract('(\d+)').astype(int)df_import['国家'] = df_import['指标'].str.extract('中国从(.*?)进口总额')df_import = df_import.dropna(subset=['国家'])# 读取进出口总额数据df_total = pd.read_csv('年度数据.csv', encoding='utf-8')df_total = df_total.melt(id_vars=['指标'], var_name='年份', value_name='进出口总额')df_total['年份'] = df_total['年份'].str.extract('(\d+)').astype(int)df_total['国家'] = df_total['指标'].str.extract('中国同(.*?)进出口总额')df_total = df_total.dropna(subset=['国家'])# 合并数据df = pd.merge(df_export, df_import, on=['国家', '年份'])df = pd.merge(df, df_total, on=['国家', '年份'])# 计算贸易差额df['贸易差额'] = df['出口额'] - df['进口额']df['顺差/逆差'] = df['贸易差额'].apply(lambda x: '顺差' if x > 0 else '逆差')return df# 读取数据
df = read_data()# 将 DataFrame 存储为 CSV 文件
df.to_csv('中国进出口贸易数据.csv', index=False, encoding='utf-8-sig') # utf-8-sig 支持 Excel 中文显示
print("\n数据已保存到 '中国进出口贸易数据.csv'")
3. 结果:
(2)可视化V1 —— 展示贸易顺差/逆差随着年份的变化
1. 实现步骤
a. 数据分组:
函数 create_bubble_chart 接受一个 DataFrame 对象 df 作为输入。
使用 groupby 方法按 ‘年份’ 和 ‘国家’ 对数据进行分组,然后使用 agg 方法对分组后的数据进行聚合操作:
‘出口额’、‘进口额’、‘进出口总额’ 和 ‘贸易差额’ 列使用 ‘sum’ 方法进行求和。
‘顺差/逆差’ 列使用 ‘first’ 方法,即取每组中的第一个值(假设每组中该值是相同的)。
最后使用 reset_index 方法重置索引,使分组的 ‘年份’ 和 ‘国家’ 变为普通列。
df_grouped = df.groupby(['年份', '国家']).agg({'出口额': 'sum','进口额': 'sum','进出口总额': 'sum','贸易差额': 'sum','顺差/逆差': 'first'}).reset_index()
b. 创建气泡图
使用 plotly.express 库的 scatter 函数创建一个散点图(气泡图):
x 和 y 分别指定为 ‘进口额’ 和 ‘出口额’ 列。
size 指定为 ‘进出口总额’ 列,用于表示气泡的大小。
color 指定为 ‘顺差/逆差’ 列,用于根据贸易状况给气泡上色。
hover_name 指定为 ‘国家’ 列,当鼠标悬停在气泡上时显示国家名称。
animation_frame 指定为 ‘年份’ 列,使图表按年份进行动态变化。
animation_group 指定为 ‘国家’ 列,确保每个国家的数据在动画中保持一致。
size_max 设置气泡的最大大小为 60。
range_x 和 range_y 设置 x 轴和 y 轴的范围,分别为进口额和出口额最大值的 1.1 倍。
labels 字典用于自定义图表中各轴和图例的标签。
title 设置图表的标题。
color_discrete_map 字典指定了 ‘顺差’ 和 ‘逆差’ 对应的颜色。
fig = px.scatter(df_grouped,x="进口额",y="出口额",size="进出口总额",color="顺差/逆差",hover_name="国家",animation_frame="年份",animation_group="国家",size_max=60,range_x=[0, df_grouped['进口额'].max() * 1.1],range_y=[0, df_grouped['出口额'].max() * 1.1],labels={"进口额": "进口额 (万美元)","出口额": "出口额 (万美元)","进出口总额": "进出口总额","顺差/逆差": "贸易状况"},title="中国与欧洲各国贸易情况 (2014-2023)",color_discrete_map={"顺差": "blue","逆差": "red"})
c. 添加辅助线
for frame in fig.frames::这是一个循环,遍历 fig(即创建的气泡图对象)中的每一个 frame(帧)。因为这个气泡图是动态的,按年份作为动画帧展示数据变化,所以这里要对每一个帧都添加辅助线,以保证在动画的每一帧中都能显示平衡线。
frame.data += (…):frame.data 表示每一帧中的数据集合,这里使用 += 操作符向每一帧的数据集合中添加一个新的 go.Scatter 对象。
go.Scatter 对象用于创建一个散点图(在这里用于创建一条线):
x=[0, max_value] 和 y=[0, max_value]:指定了这条线的起点 (0, 0) 和终点 (max_value, max_value),这样就形成了 y = x 的直线。
mode=‘lines’:表示这个 go.Scatter 对象的模式是绘制线。
line=dict(color=‘gray’, dash=‘dash’):设置线的属性,颜色为灰色,样式为虚线。
name=‘平衡线 (出口=进口)’:给这条线命名为 ‘平衡线 (出口=进口)’,用于标识这条线的含义。
showlegend=False:设置这条线不显示在图例中,因为这条辅助线主要是为了视觉上的参考,不需要在图例中占据空间。
# 获取最大值的110%用于辅助线 这样可以确保所有的数据点都在辅助线所界定的区域内显示,使图表更加完整和美观
max_value = max(df_grouped['进口额'].max(), df_grouped['出口额'].max()) * 1.1# 添加辅助线 (y = x)
for frame in fig.frames:frame.data += (go.Scatter(x=[0, max_value],y=[0, max_value],mode='lines',line=dict(color='gray', dash='dash'),name='平衡线 (出口=进口)',showlegend=False
d. 更新布局
- hovermode 用于设置当鼠标悬停在图形上时的交互模式。这里设置为 “closest”,表示当鼠标悬停在图表上时,会显示离鼠标位置最近的数据点的详细信息(例如国家名称、进口额、出口额等,这些信息是在创建气泡图时通过 hover_name 等参数设置的)。
- updatemenus 用于在图形中添加一些交互按钮或菜单。这里创建了一个类型为 “buttons” 的 updatemenus,即添加按钮。
buttons 是一个列表,用于定义按钮的具体属性。这里列表中只有一个按钮,通过 dict 来设置按钮的属性。
label=“播放” 设置按钮的显示文本为 “播放”。
method=“animate” 表示当点击这个按钮时,执行的操作是启动动画。
args 是传递给 animate 方法的参数。[None, {“frame”: {“duration”: 1000, “redraw”: True}, “fromcurrent”: True}] 中,None 表示不指定特定的帧序列来播放动画;{“frame”: {“duration”: 1000, “redraw”: True}, “fromcurrent”: True} 表示设置动画帧的持续时间为 1000 毫秒,并且在播放动画时重新绘制图形(redraw": True),同时从当前帧开始播放动画(“fromcurrent”: True)。
fig.update_layout(xaxis_title="进口额 (万美元)",yaxis_title="出口额 (万美元)",legend_title="贸易状况",hovermode="closest",transition={'duration': 1000},updatemenus=[dict(type="buttons",buttons=[dict(label="播放",method="animate",args=[None, {"frame": {"duration": 1000, "redraw": True}, "fromcurrent": True}]),dict(label="暂停",method="animate",args=[[None], {"frame": {"duration": 0, "redraw": False}, "mode": "immediate","transition": {"duration": 0}}])])])
e. 添加初始辅助线
fig.add_trace(…):
fig 是 plotly 里的图形对象,代表了整个图表。add_trace 方法的作用是往图表里添加一个新的绘图轨迹(trace)。绘图轨迹可以理解成图表中的一个独立绘图元素,例如散点图、折线图等。这里添加的是一条直线。
fig.add_trace(go.Scatter(x=[0, max_value],y=[0, max_value],mode='lines',line=dict(color='gray', dash='dash'),name='平衡线 (出口=进口)'))
3. 结果
图片:
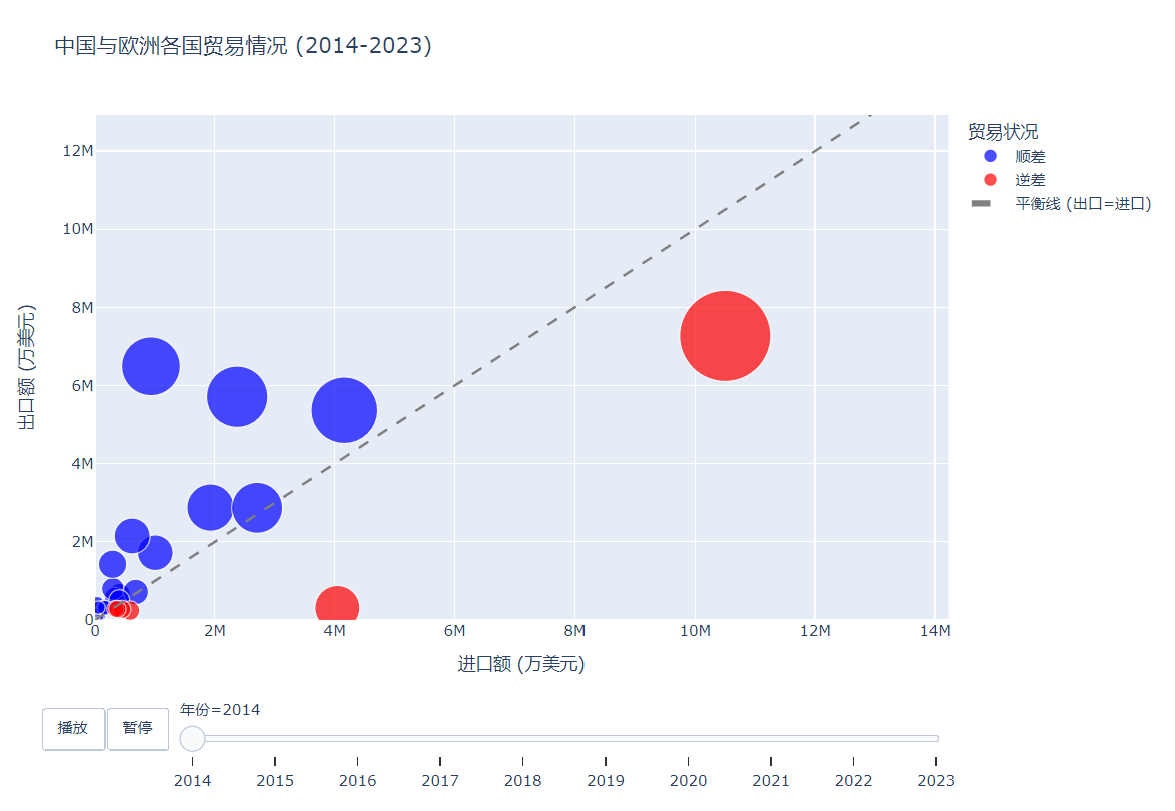
视频:
动态气泡图_顺逆差
(3)可视化V1
1. 改进
体现具体国家而不仅仅是顺逆差
2. 结果
动态气泡图_彩色
3、桑基图 Sankey diagram:分析与可视化不同因素之间的关系,借助绘制桑基图来呈现这些因素之间的关联和流动情况
(1)桑基图简介
- 组成要素
- 节点:代表不同的类别或状态,通常用矩形或其他形状表示。例如,在能源流动的桑基图中,节点可以是不同的能源来源(如煤炭、石油、天然气)和能源使用部门(如工业、交通、居民生活)。
- 边或流线:连接节点的线条,用于表示数据的流动方向和数量。边的宽度与所代表的数据量成正比,因此可以直观地看出不同路径上数据的相对大小。
- 特点
- 可视化数据流动:能够清晰地展示数据从一个状态或类别到另一个状态或类别的流动过程,使复杂的流程和关系变得直观易懂。
- 定量展示:通过边的宽度准确地展示数据的数量,让观众可以直观地比较不同部分的数据大小,了解各部分在整体中所占的比例。
- 整体守恒:桑基图中所有流入节点的流量总和等于所有流出节点的流量总和,体现了数据在整个系统中的守恒关系,有助于分析数据在各个环节的分配和转化情况。
(2)数据集
- credit_record.csv
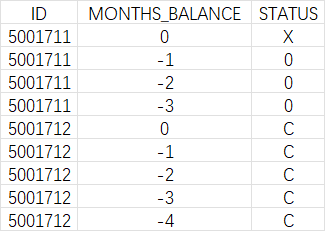
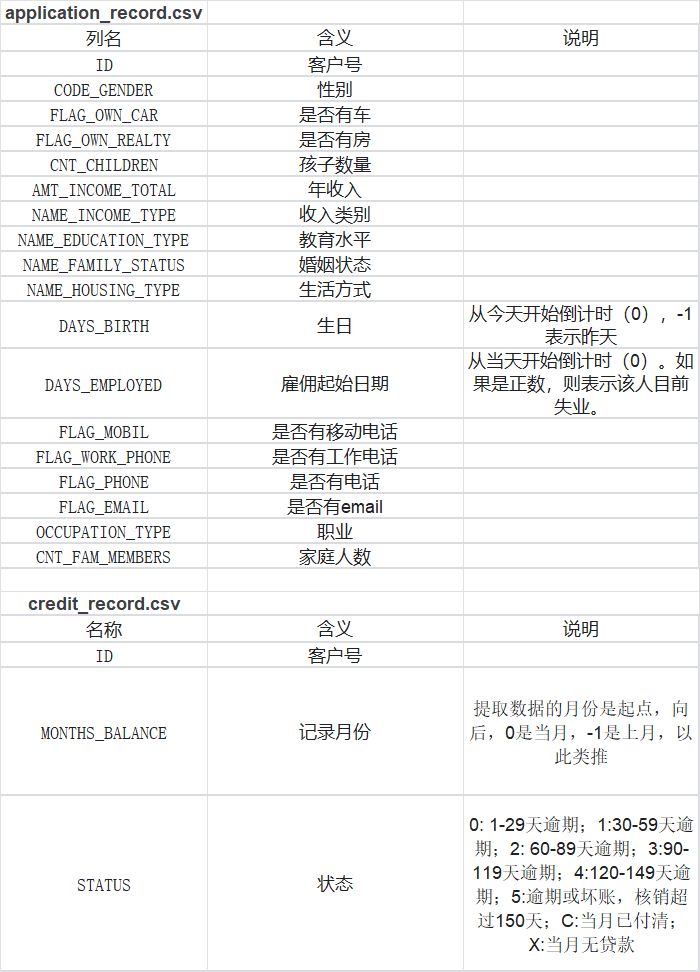
- application_record.csv:

- 数据说明:
(3)实现步骤
1.导入包、读取数据
import pandas as pd
import plotly.graph_objects as go# 读取数据
app = pd.read_csv("application_record.csv")
credit = pd.read_csv("credit_record.csv")
2.定义函数用于信用状态分类——优先考虑逾期情况最严重的状态
- 如果列表中有多种状态,首先使用 any(s in [‘1’, ‘2’, ‘3’, ‘4’, ‘5’] for s in status_list) 判断列表中是否存在逾期状态(‘1’ 到 ‘5’)。any() 函数用于判断可迭代对象中是否有任何一个元素满足条件。
- 如果存在逾期状态,优先考虑逾期最严重的情况,按照逾期天数从多到少的顺序进行判断,返回对应的信用状态分类描述
- 如果列表中不存在逾期状态,使用 all(s in [‘C’, ‘0’] for s in status_list) 判断列表中的所有状态是否都为 ‘C’(本月已还清)或 ‘0’(逾期 1 - 29 天)。
- all() 函数用于判断可迭代对象中的所有元素是否都满足条件。 如果是,则返回 ‘Paid off’ 表示已还清。
- credit.groupby(‘ID’) 按照用户 ID 对信用记录数据 credit 进行分组。
.apply(classify_credit_status) 对每个分组应用 classify_credit_status 函数,得到每个用户的信用状态分类结果。
.reset_index() 重置索引,将结果转换为一个数据框。
credit_status.columns = [‘ID’, ‘CREDIT_STATUS’] 为数据框的列设置名称,分别为 ‘ID’ 和 ‘CREDIT_STATUS’。
f classify_credit_status(group):status_list = group['STATUS'].tolist()# 如果列表中只有一种状态,直接返回该状态对应的分类if len(set(status_list)) == 1:status = status_list[0]if status == '0':return '1-29 days due'elif status == '1':return '30-59 days due'elif status == '2':return '60-89 days due'elif status == '3':return '90-119 days due'elif status == '4':return '120-149 days due'elif status == '5':return 'Over 150 days due or bad debt'elif status == 'C':return 'Paid off this month'elif status == 'X':return 'No loan this month'# 如果列表中有多种状态,需要根据规则判断else:if any(s in ['1', '2', '3', '4', '5'] for s in status_list):# 优先考虑逾期严重的情况if '5' in status_list:return 'Over 150 days due or bad debt'elif '4' in status_list:return '120-149 days due'elif '3' in status_list:return '90-119 days due'elif '2' in status_list:return '60-89 days due'elif '1' in status_list:return '30-59 days due'elif all(s in ['C', '0'] for s in status_list):return 'Paid off'elif 'X' in status_list:return 'No loan this month'else:return 'Complex status'credit_status = credit.groupby('ID').apply(classify_credit_status).reset_index()
credit_status.columns = ['ID', 'CREDIT_STATUS']3.合并数据
merged = pd.merge(app, credit_status, on='ID')
4.创建字段
依据 FLAG_OWN_REALTY 列创建新列 OWN_REALTY,将 Y 映射为 Yes Property,N 映射为 No Property。
merged['OWN_REALTY'] = merged['FLAG_OWN_REALTY'].map({'Y': 'Yes Property', 'N': 'No Property'})
5.选取需要的字段
df = merged[['NAME_HOUSING_TYPE', 'NAME_INCOME_TYPE', 'OWN_REALTY', 'CREDIT_STATUS']]
6.汇总数据
按照 NAME_HOUSING_TYPE、NAME_INCOME_TYPE、OWN_REALTY 和 CREDIT_STATUS 进行分组,统计每组的数量,将结果保存到 count 列。
df_grouped = df.groupby(['NAME_HOUSING_TYPE', 'NAME_INCOME_TYPE', 'OWN_REALTY', 'CREDIT_STATUS']).size().reset_index(name='count')
7.设置标签和映射
labels:将所有可能的标签(房屋类型、收入类型、是否拥有房产、信用状态)合并,去除重复项后转换为列表。
label_index:创建一个字典,将每个标签映射到一个唯一的索引。
labels = pd.concat([df_grouped['NAME_HOUSING_TYPE'], df_grouped['NAME_INCOME_TYPE'],df_grouped['OWN_REALTY'], df_grouped['CREDIT_STATUS']]).unique().tolist()
label_index = {label: i for i, label in enumerate(labels)}
8.构建链接
source、target 和 value:分别代表桑基图中链接的起始节点索引、结束节点索引和链接的值(即每组的数量)。
通过三次循环构建三组链接:房屋类型到收入类型、收入类型到是否拥有房产、是否拥有房产到信用状态。
source = []
target = []
value = []# Housing ➝ Income Type
for _, row in df_grouped.iterrows():source.append(label_index[row['NAME_HOUSING_TYPE']])target.append(label_index[row['NAME_INCOME_TYPE']])value.append(row['count'])# Income Type ➝ Own Realty
for _, row in df_grouped.iterrows():source.append(label_index[row['NAME_INCOME_TYPE']])target.append(label_index[row['OWN_REALTY']])value.append(row['count'])# Own Realty ➝ Credit Status
for _, row in df_grouped.iterrows():source.append(label_index[row['OWN_REALTY']])target.append(label_index[row['CREDIT_STATUS']])value.append(row['count'])
9.绘制桑基图
go.Sankey:创建一个桑基图对象。
node:设置节点的属性,如节点间距、厚度、线条颜色和宽度、标签等。
link:设置链接的属性,如起始节点索引、结束节点索引和链接的值。
fig.update_layout:更新图表的布局,设置标题和字体大小。
fig.show():显示桑基图。
fig = go.Figure(data=[go.Sankey(node=dict(pad=15,thickness=20,line=dict(color="black", width=0.5),label=labels),link=dict(source=source,target=target,value=value))])fig.update_layout(title_text="House Type ➝ Income Type ➝ Owns Property ➝ Credit Status", font_size=12)
fig.show()
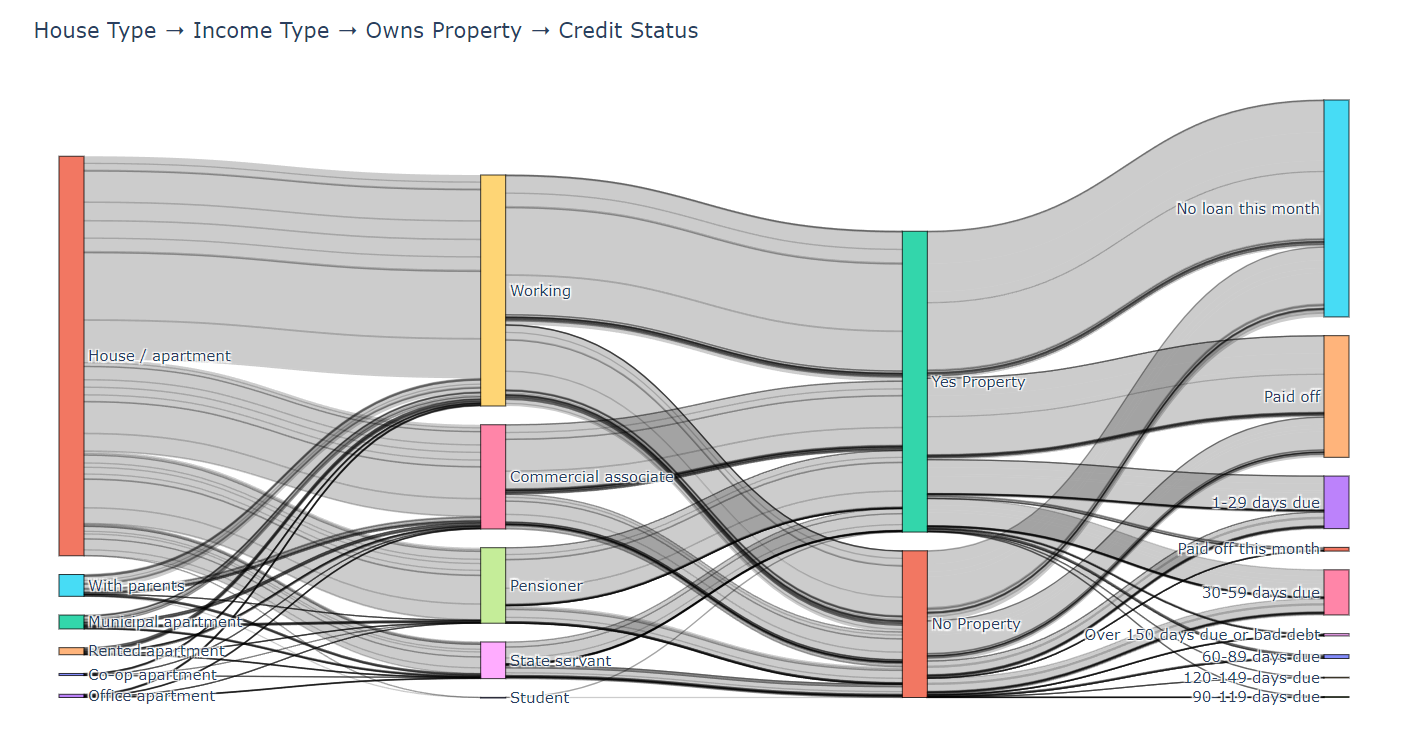
(4)结果
- House Type → Income Type → Owns Property → Credit Status
4、桑基图2
同理根据以下代码绘制结果如图
import pandas as pd
import plotly.graph_objects as go# 读取数据
app = pd.read_csv("application_record.csv")
credit = pd.read_csv("credit_record.csv")# 一、处理收入分组
def map_income_level(income):if income < 50000:return "Very Low income"elif income < 100000:return "Low income"elif income < 150000:return "Lower - middle income"elif income < 200000:return "Middle income"elif income < 300000:return "Upper - middle income"elif income < 400000:return "Moderate - high income"elif income < 600000:return "High income"else:return "Very High income"app["INCOME_LEVEL"] = app["AMT_INCOME_TOTAL"].apply(map_income_level)# 二、处理信用记录中的月收支平衡时间段
def map_month_balance(group):earliest = group['MONTHS_BALANCE'].min()if earliest >= -6:return "Within 6 months"elif earliest >= -12:return "6 - 12 months ago"elif earliest >= -24:return "1 - 2 years ago"elif earliest >= -36:return "2 - 3 years ago"elif earliest >= -48:return "3 - 4 years ago"elif earliest >= -60:return "4 - 5 years ago"else:return "Over 5 years ago"credit_time = credit.groupby('ID').apply(map_month_balance).reset_index()
credit_time.columns = ['ID', 'MONTH_BALANCE_GROUP']# 三、合并数据
merged = pd.merge(app, credit_time, on='ID')# 四、选取需要的字段
df = merged[['CODE_GENDER', 'INCOME_LEVEL', 'NAME_EDUCATION_TYPE', 'NAME_FAMILY_STATUS', 'MONTH_BALANCE_GROUP']]# 五、分组统计
df_grouped = df.groupby(['CODE_GENDER', 'INCOME_LEVEL', 'NAME_EDUCATION_TYPE', 'NAME_FAMILY_STATUS', 'MONTH_BALANCE_GROUP']).size().reset_index(name='count')# 六、构建节点标签及索引映射
labels = pd.concat([df_grouped['CODE_GENDER'],df_grouped['INCOME_LEVEL'],df_grouped['NAME_EDUCATION_TYPE'],df_grouped['NAME_FAMILY_STATUS'],df_grouped['MONTH_BALANCE_GROUP']
]).unique().tolist()label_index = {label: i for i, label in enumerate(labels)}# 七、构建桑基图的 source、target、value
source, target, value = [], [], []# Gender ➝ Income Level
for _, row in df_grouped.iterrows():source.append(label_index[row['CODE_GENDER']])target.append(label_index[row['INCOME_LEVEL']])value.append(row['count'])# Income Level ➝ Education Level
for _, row in df_grouped.iterrows():source.append(label_index[row['INCOME_LEVEL']])target.append(label_index[row['NAME_EDUCATION_TYPE']])value.append(row['count'])# Education Level ➝ Marital Status
for _, row in df_grouped.iterrows():source.append(label_index[row['NAME_EDUCATION_TYPE']])target.append(label_index[row['NAME_FAMILY_STATUS']])value.append(row['count'])# Marital Status ➝ Month Balance
for _, row in df_grouped.iterrows():source.append(label_index[row['NAME_FAMILY_STATUS']])target.append(label_index[row['MONTH_BALANCE_GROUP']])value.append(row['count'])# 八、绘制桑基图
fig = go.Figure(data=[go.Sankey(node=dict(pad=15,thickness=20,line=dict(color="black", width=0.5),label=labels),link=dict(source=source,target=target,value=value))])fig.update_layout(title_text="Gender / Income Level / Education Level / Marital Status / Month Balance",font_size=12,height=700
)
fig.show()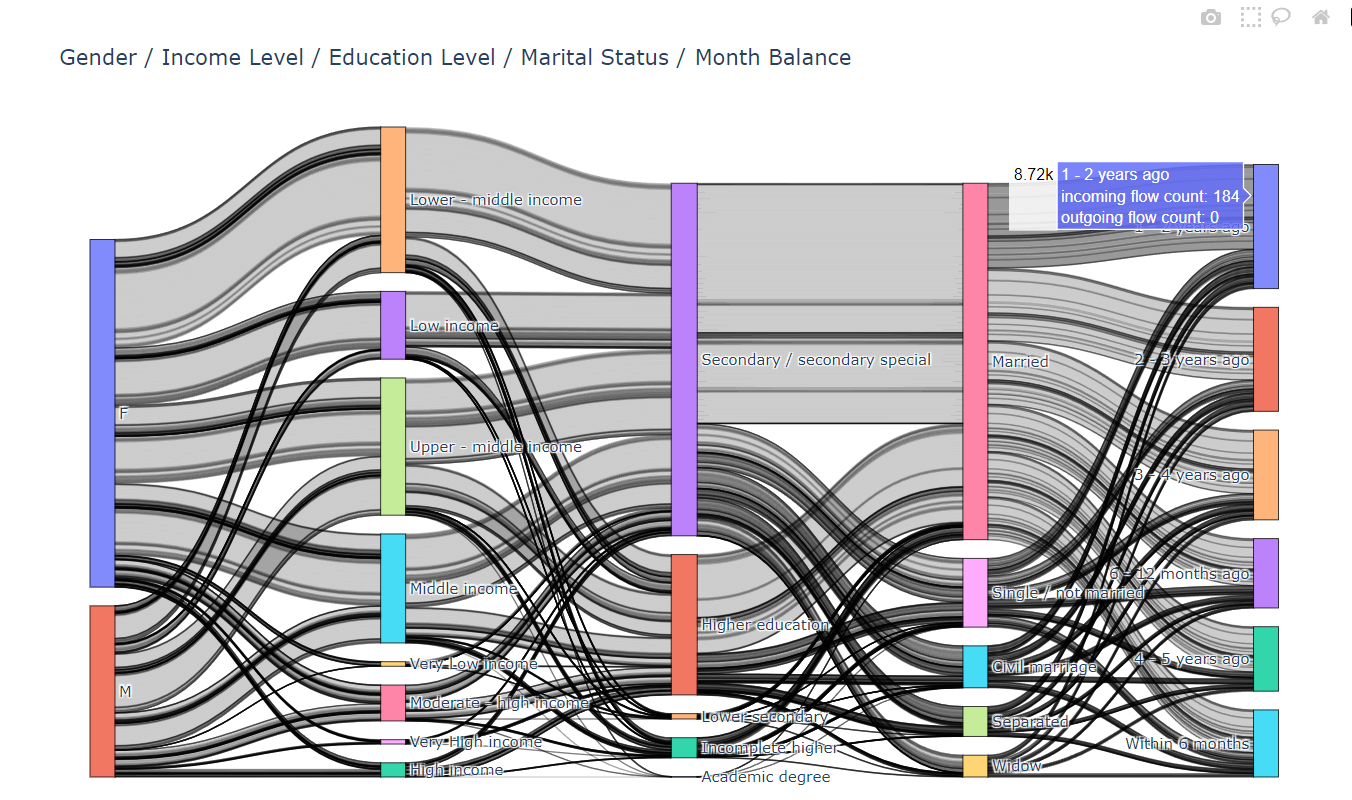
5、存在的问题——信用状态的判断
-
最近一个月的信用状态?
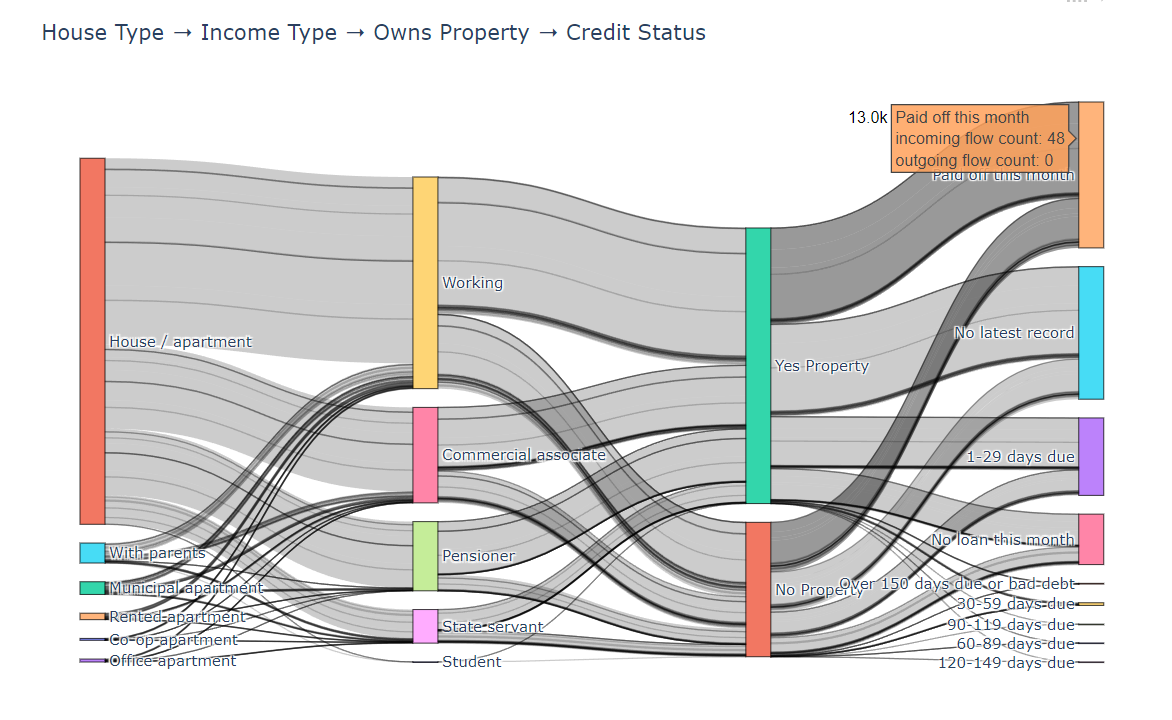
-
逾期最严重的信用状态?
# 图2 House Type → Income Type → Owns Property → Credit Statusimport pandas as pd
import plotly.graph_objects as go# 读取数据
app = pd.read_csv("application_record.csv")
credit = pd.read_csv("credit_record.csv")# 信用状态分类
def classify_credit_status(group):status_list = group['STATUS'].tolist()# 如果列表中只有一种状态,直接返回该状态对应的分类if len(set(status_list)) == 1:status = status_list[0]if status == '0':return '1-29 days due'elif status == '1':return '30-59 days due'elif status == '2':return '60-89 days due'elif status == '3':return '90-119 days due'elif status == '4':return '120-149 days due'elif status == '5':return 'Over 150 days due or bad debt'elif status == 'C':return 'Paid off this month'elif status == 'X':return 'No loan this month'# 如果列表中有多种状态,需要根据规则判断else:if any(s in ['1', '2', '3', '4', '5'] for s in status_list):# 优先考虑逾期严重的情况if '5' in status_list:return 'Over 150 days due or bad debt'elif '4' in status_list:return '120-149 days due'elif '3' in status_list:return '90-119 days due'elif '2' in status_list:return '60-89 days due'elif '1' in status_list:return '30-59 days due'elif all(s in ['C', '0'] for s in status_list):return 'Paid off'elif 'X' in status_list:return 'No loan this month'else:return 'Complex status'credit_status = credit.groupby('ID').apply(classify_credit_status).reset_index()
credit_status.columns = ['ID', 'CREDIT_STATUS']# 合并
merged = pd.merge(app, credit_status, on='ID')# 创建字段
merged['OWN_REALTY'] = merged['FLAG_OWN_REALTY'].map({'Y': 'Yes Property', 'N': 'No Property'})df = merged[['NAME_HOUSING_TYPE', 'NAME_INCOME_TYPE', 'OWN_REALTY', 'CREDIT_STATUS']]# 汇总
df_grouped = df.groupby(['NAME_HOUSING_TYPE', 'NAME_INCOME_TYPE', 'OWN_REALTY', 'CREDIT_STATUS']).size().reset_index(name='count')# 标签和映射
labels = pd.concat([df_grouped['NAME_HOUSING_TYPE'], df_grouped['NAME_INCOME_TYPE'],df_grouped['OWN_REALTY'], df_grouped['CREDIT_STATUS']]).unique().tolist()
label_index = {label: i for i, label in enumerate(labels)}# 构建链接
source = []
target = []
value = []# Housing ➝ Income Type
for _, row in df_grouped.iterrows():source.append(label_index[row['NAME_HOUSING_TYPE']])target.append(label_index[row['NAME_INCOME_TYPE']])value.append(row['count'])# Income Type ➝ Own Realty
for _, row in df_grouped.iterrows():source.append(label_index[row['NAME_INCOME_TYPE']])target.append(label_index[row['OWN_REALTY']])value.append(row['count'])# Own Realty ➝ Credit Status
for _, row in df_grouped.iterrows():source.append(label_index[row['OWN_REALTY']])target.append(label_index[row['CREDIT_STATUS']])value.append(row['count'])# 绘制桑基图
fig = go.Figure(data=[go.Sankey(node=dict(pad=15,thickness=20,line=dict(color="black", width=0.5),label=labels),link=dict(source=source,target=target,value=value))])fig.update_layout(title_text="House Type ➝ Income Type ➝ Owns Property ➝ Credit Status", font_size=12)
fig.show()- 所有的信用状态全部考虑的数据流向和流量是否准确(因为会把重复的用户计入)
import pandas as pd
import plotly.graph_objects as go# 读取数据
app = pd.read_csv("application_record.csv")
credit = pd.read_csv("credit_record.csv")# 按 ID 合并数据集
merged = pd.merge(app, credit, on='ID')# 创建新字段 OWN_REALTY
merged['OWN_REALTY'] = merged['FLAG_OWN_REALTY'].map({'Y': 'Yes Property', 'N': 'No Property'})# 定义状态映射字典
status_mapping = {'0': '1-29 days due','1': '30-59 days due','2': '60-89 days due','3': '90-119 days due','4': '120-149 days due','5': 'Over 150 days due or bad debt','C': 'Paid off this month','X': 'No loan this month'
}# 将 STATUS 列映射为描述性状态
merged['CREDIT_STATUS'] = merged['STATUS'].map(status_mapping)# 选择用于绘制桑基图的列
columns = ['NAME_HOUSING_TYPE', 'NAME_INCOME_TYPE', 'OWN_REALTY', 'CREDIT_STATUS']# 分组统计每个组合的数量
df_grouped = merged.groupby(columns).size().reset_index(name='count')# 生成所有唯一的标签
labels = pd.concat([df_grouped[col] for col in columns]).unique().tolist()
# 为每个标签分配一个索引
label_index = {label: i for i, label in enumerate(labels)}# 初始化存储链接信息的列表
source = []
target = []
value = []# 构建所有可能的链接
for i in range(len(columns) - 1):for _, row in df_grouped.iterrows():source.append(label_index[row[columns[i]]])target.append(label_index[row[columns[i + 1]]])value.append(row['count'])# 创建桑基图对象
fig = go.Figure(data=[go.Sankey(node=dict(pad=15,thickness=20,line=dict(color="black", width=0.5),label=labels),link=dict(source=source,target=target,value=value))])# 更新图表布局,设置标题和字体大小
fig.update_layout(title_text="House Type ➝ Income Type ➝ Owns Property ➝ Credit Status", font_size=12)
# 显示桑基图
fig.show()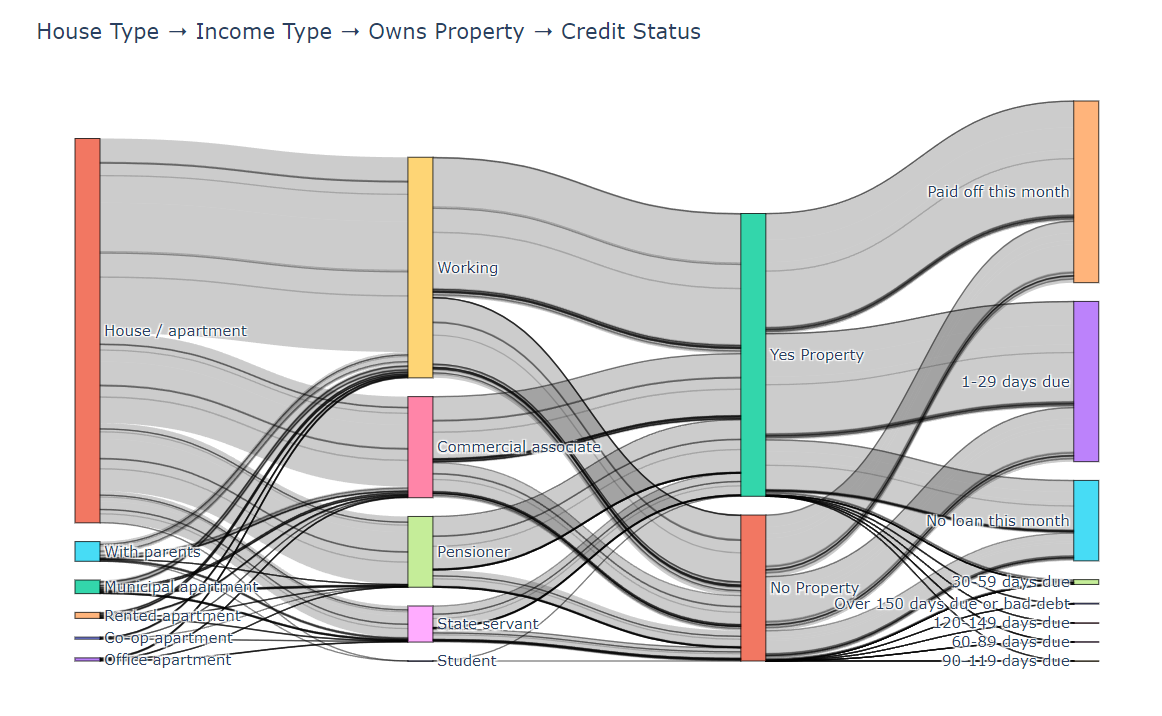
6、相关资料:
链接1: 桑基图
链接2: plotly 基本操作手册
相关文章:

气泡图、桑基图的绘制
1、气泡图 使用气泡图分析某一年中国同欧洲各国之间的贸易情况。 气泡图分析的三个维度: • 进口额:横轴 • 出口额:纵轴 • 进出口总额:气泡大小 数据来源:链接: 国家统计局数据 数据概览(进出口总额&…...

数据库Mysql_联合查询
或许自己的不完美才是最完美的地方,那些让自己感到不安的瑕疵,最终都会变成自己的特色。 ----------陳長生. 1.介绍 1.1.为什么要进行联合查询 在数据设计的时候,由于范式的需求,会被分为多个表,但是当我们要查询数据…...

数字孪生:解码智慧城市的 “数字神经系统”
当城市规模以惊人速度扩张,传统管理模式在交通拥堵、能源浪费、应急响应滞后等问题面前渐显乏力。数字孪生技术正以 “数字镜像” 重构城市运作逻辑,为智慧城市装上一套高效、智能的 “数字神经系统”。通过将物理世界的城市映射到虚拟空间,实…...

开源项目:optimum-quanto库介绍
项目地址:https://github.com/huggingface/optimum-quanto 官网介绍:https://huggingface.co/blog/quanto-introduction 量化是一种技术,通过使用低精度数据类型(如 8 位整数 (int8))而不是通常…...

C++学习:六个月从基础到就业——C++11/14:lambda表达式
C学习:六个月从基础到就业——C11/14:lambda表达式 本文是我C学习之旅系列的第四十篇技术文章,也是第三阶段"现代C特性"的第二篇,主要介绍C11/14中引入的lambda表达式。查看完整系列目录了解更多内容。 引言 Lambda表达…...

cesium基础设置
在上节新建的程序中,我们会看到有一行小字: 原因为我们没有输入token,想要让这行小字消失的方法很简单,前往cesium的官网注册账号申请token.然后在App.vue中如下方式添加token 保存后即可发现小字消失. 如果连logo都想去掉呢? 在源代码中,我们初始化了一个viwer,即查看器窗口…...

一些好玩的东西
🚀 终极挑战:用 curl 玩《星球大战》 telnet towel.blinkenlights.nl # 其实不是 curl,但太经典了! 效果:在终端播放 ASCII 版《星球大战》电影!(如果 telnet 不可用,可以试…...
)
ActiveMQ 与其他 MQ 的对比分析:Kafka/RocketMQ 的选型参考(二)
ActiveMQ、Kafka 和 RocketMQ 详细对比 性能对比 在性能方面,Kafka 和 RocketMQ 通常在高吞吐量场景下表现出色,而 ActiveMQ 则相对较弱。根据相关测试数据表明,Kafka 在处理大规模日志数据时,单机吞吐量可以达到每秒数十万条甚…...
)
HTML学习笔记(7)
一、什么是jQuery jQuery 是一个 JavaScript 库。他实现了JavaScript的一些功能,并封装起来,对外提供接口。 例子实现一个点击消失的功能,用JavaScript实现 <!DOCTYPE html> <html lang"en"> <head><meta …...

Jenkis安装、配置及账号权限分配保姆级教程
Jenkis安装、配置及账号权限分配保姆级教程 安装Jenkins下载Jenkins启动Jenkins配置Jenkins入门Jenkins配置配置中文配置前端自动化任务流新建任务拉取代码打包上传云服务并运行配置后端自动化任务流新建任务拉取代码打包上传云服务并运行账号权限分配创建用户分配视图权限安装…...
是什么?)
面向对象编程(Object-Oriented Programming, OOP)是什么?
李升伟 编译 简介 如果你已经接触过软件开发领域的话,你肯定听说过"面向对象编程"(Object-Oriented Programming, OOP)这个术语。但你知道什么是OOP吗?为什么它如此重要?在这篇文章中我们将深入解析OOP的基…...
:单细胞转录组识别信息基因(和基因模块))
Hotspot分析(1):单细胞转录组识别信息基因(和基因模块)
这一期我们介绍一个常见的,高分文章引用很高的一个单细胞转录组分析工具Hotspot,它可针对单细胞转录组数据识别有意义基因或者基因module,类似于聚类模块。所谓的”informative "的基因是那些在给定度量中相邻的细胞之间以相似的方式表达…...

从图文到声纹:DeepSeek 多模态技术的深度解析与实战应用
目录 一、引言二、DeepSeek 技术基础2.1 架构与原理2.2 多模态能力概述 三、文本与图像关联应用3.1 图文跨模态对齐技术3.1.1 技术原理3.1.2 DeepSeek 的独特方法 3.2 图像生成与文本描述3.2.1 应用案例3.2.2 技术实现 3.3 多模态检索系统中的应用3.3.1 系统搭建流程3.3.2 实际…...

cuDNN 9.9.0 便捷安装-Windows
#工作记录 从 CUDA12.6.3 和 cuDNN9.6.0 版本起,开启了使用 exe 安装包直接进行安装升级的支持模式,彻底改变了以往那种繁琐的安装流程。 在这两个版本之前,开发者在安装 CUDA 和 cuDNN 时,不得不手动下载 cuDNN 压缩包…...

profile软件开发中的性能剖析与内存分析
在软件开发中,“Profile”(性能剖析/性能分析)指的是通过工具详细监控程序运行时的各种性能指标,帮助开发者定位代码中的效率瓶颈或资源问题。当有人建议你 “profile 一下内存问题” 时,本质上是让你用专业工具动态分…...

0.0973585?探究ts_rank的score为什么这么低
最近在使用postgres利用ts_rank进行排序找到最符合关键词要求得内容时发现: 即使是相似的内容,得分也是非常非常得低(其中一个case是0.0973585)。看起来很奇怪,非常不可行。于是我又做了一个简单测的测试: SELECT ts_rank(to_tsvector(english, skirt), to_tsquery(skirt)…...

架构思维:利用全量缓存架构构建毫秒级的读服务
文章目录 一、引言二、全量缓存架构概述三、基于 Binlog 的缓存同步方案1. Binlog 原理2. 同步中间件3. 架构整合核心收益 四、Binlog 全量缓存的优缺点与优化优点缺点与取舍优化策略 五、其他进阶优化点六、总结 一、引言 架构思维:使用简洁的架构实现高性能读服务…...

永磁同步电机控制算法--基于PI的位置伺服控制
一、原理介绍 永磁同步伺服系统是包含了电流环、速度环和位置环的三环控制系统。 伺服系统通过电流检测电路和光电编码器检测电动机三相绕组电流和转子位置θ,通过坐标变换,计算出转矩电流分量iq和励磁电流分量id。 位置信号指令与实际转子位置信号的差…...

P1603 斯诺登密码详解
这个题目,我详细讲题解的两种方法,洛谷里面的题解,我是觉得大部分的时候是差了点意思的,不是看不懂,就是新知识没人详细讲解,我也是经常破防 先看题目: 题目是什么意思: 1…...

计算方法实验六 数值积分
【实验性质】综合性实验。 【实验目的】理解插值型积分法;掌握复化积分法算法。 【实验内容】 1对 ,用复化梯形积分和变步长梯形积分求值(截断误差不超过)。 【理论基础】 积分在工程中有重要的应用,数值积分…...

avx指令实现FFT
avx指令实现FFT 参考代码实现的难点补充的avx指令fft_avx256实现可继续优化的点 C语言实现FFT变换参考的代码是参考大模型生成的代码,很明显其使用的是位反转和蝶形变换的方法实现的FFT变换。但是大模型无法正确的生成用avx指令写的FFT变换的算法,所以这…...

Nginx 核心功能之正反代理
目录 一、Nginx 二、正向代理 三、反向代理 四、Nginx 缓存 1. 缓存功能的核心原理和缓存类型 2. 代理缓存功能设置 五、Nginx rewrite和正则 (1)Nginx 正则 (2)nginx location (3)Rewrite &…...

function包装器的意义
一:function包装器的概念 function包装器 也叫作适配器。C中的function本质是一个类模板,也是一个包装器。 二:需要function包装器的场景 那么我们来看看,我们为什么需要function呢? 一个需要包装器的场景:…...

【ThinkBook 16+ 电脑重做系统type-c接口部分功能失效解决方案】
ThinkBook 16 电脑重做系统type-c接口部分功能失效解决方案 问题回顾:重做电脑后,type-c接口部分功能失效,充电正常,连接外置硬盘正常,无法连接外拓显示器,显示usbc无信号(不同设备可能显示不同…...

【言语理解】中心理解题目之选项分析
front:中心理解题目之结构分析 4.1两出处六有误 两出处 背景、例子、分析论证中提炼的选项出处有误,一般不选但是和因此之前、不是而是 的不是部分、被指代部分提炼的选项出处有误,一般不选。 六有误 片面:原文并列谈论两方面,只…...
:[macOS 64bit App开发]: [1]如何加载动态链接库, 并无缝支持原生底层开发?)
[原创](现代Delphi 12指南):[macOS 64bit App开发]: [1]如何加载动态链接库, 并无缝支持原生底层开发?
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C++、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、…...

VTK入门指南
什么是VTK VTK (Visualization Toolkit) 是一个开源的、跨平台的计算机图形学、图像处理和可视化系统。它提供了丰富的算法和高级工具,用于3D计算机图形学、图像处理和可视化。 安装VTK Windows平台 下载预编译版本: 从VTK官网或GitHub发布页面下载 …...

开始一个vue项目-day2
这次新增的功能有: 1、使用cookie存储token 参考网站:https://vueuse.org/ 安装包: npm i vueuse/integrations npm i universal-cookie^7 2、cookie的设置读取和删除,代码:composables/auth.js import { useCookies } from …...

Baklib驱动企业知识管理AI升级
Baklib如何实现知识AI化 Baklib通过构建企业级知识中台的核心能力,将人工智能技术深度融入知识管理的全生命周期。其底层架构采用自然语言处理(NLP)与机器学习算法,实现对企业文档的智能分类与语义解析。例如,系统可自…...

Linux线程同步机制深度解析:信号量、互斥锁、条件变量与读写锁
Linux线程同步机制深度解析:信号量、互斥锁、条件变量与读写锁 一、线程同步基础 在多线程编程中,多个线程共享进程资源(如全局变量、文件描述符)时,若对共享资源的访问不加控制,会导致数据不一致或竞态条…...

js逆向绕过指纹识别
一、兼容性说明 官方支持 curl_cffi 明确支持 Windows 平台,并提供了预编译的安装包。其核心功能(如浏览器指纹模拟、HTTP/2 支持)在 Windows 上与 Linux/macOS 表现一致。 版本要求 • Python 3.8 及以上版本(推荐 Pyth…...

笔记整理六----OSPF协议
OSPF 动态路由的分类: 1.基于网络范围进行划分--将网络本身划分为一个个AS(自治系统---方便管理和维护) 内部网关协议---负责AS内部用户之间互相访问使用的协议 IGP--RIP EIGRP ISIS OSPF 外部网关协议--负责AS之间(整个互联网&…...

USB Type-C是不是全方位优于其他USB接口?
首先,USB TypeC接口内部引脚呈中心对称分布,正插、反插都能用,所以可以肓插,使用起来非常方便顺手。 其次,USB TypeC接口体积很小,特别是很薄,几乎适用于所有设备。而USB TypeA就是因为不方便应…...
)
信息系统监理师第二版教材模拟题第一组(含解析)
信息系统监理基础 信息系统监理的核心目标是( ) A. 降低项目成本 B. 确保项目按合同要求完成 C. 提高开发人员技术水平 D. 缩短项目周期答案:B 解析:信息系统监理的核心目标是确保信息系统工程项目按照合同要求、技术标准和规范完成,保障项目质量、进度和投资控制。 下列哪…...

NPP库中libnppist模块介绍
1. libnppist 模块简介 libnppist 是 NPP 库中专注于 图像统计分析与直方图计算 的模块,提供 GPU 加速的统计操作,适用于计算机视觉和图像处理中的特征提取与分析。 核心功能包括: 直方图计算(支持单通道/多通道) 统…...

k230摄像头初始化配置函数解析
通过 csi id 和图像传感器类型构建 Sensor 对象。 在图像处理应用中,用户通常需要首先创建一个 Sensor 对象。CanMV K230 软件可以自动检测内置的图像传感器,无需用户手动指定具体型号,只需设置传感器的最大输出分辨率和帧率。有关支持的图像…...

Spring的循环依赖问题
文章目录 一、什么是循环依赖?二、Spring 是如何解决循环依赖的?1.三级缓存2.解决循环依赖的流程 三、三级缓存机制可以解决所有的循环依赖问题吗?1. 为什么三级缓存在这里无效?2. 如何解决构造器循环依赖? 四、循环依…...

华为鸿蒙PC:开启国产操作系统自主化新纪元
——全栈自研、生态重构与未来挑战 2025年5月,一个值得中国科技界铭记的时间点。华为正式推出首款搭载鸿蒙操作系统(HarmonyOS)的PC产品。乍一听这像是又一款新电脑的发布,但它背后的意义远比表面更深远——这是中国首次推出从操…...

【LeetCode Hot100】动态规划篇
前言 本文用于整理LeetCode Hot100中题目解答,因题目比较简单且更多是为了面试快速写出正确思路,只做简单题意解读和一句话题解方便记忆。但代码会全部给出,方便大家整理代码思路。 70. 爬楼梯 一句话题意 每次爬1or2,问爬到n的路…...

【Java JUnit单元测试框架-60】深入理解JUnit:Java单元测试的艺术与实践
在当今快节奏的软件开发环境中,保证代码质量的同时又要快速交付成为了开发者面临的主要挑战。单元测试作为软件测试金字塔的基石,为我们提供了一种高效的解决方案。而在Java生态系统中,JUnit无疑是单元测试框架的代名词。本文将全面探讨JUnit…...

Java运算符学习笔记
运算符 -运算符介绍 运算符是一种特殊的符号,用以表示数据的运算、赋值和比较等。 算数运算符赋值运算符关系运算符[比较运算符]逻辑运算符位运算符[需要二进制基础]三元运算符 -算数运算符 介绍 算数运算符是对数值类型的变量进行运算的,在Java程…...
)
shell编程补充内容(Linux课程实验3)
一、求前五个偶数的和 1.这里先介绍要用到的expr 1. 整数计算 # 加法(注意运算符两侧空格) $ expr 10 20 30# 带括号的运算(需要转义) $ expr \( 10 20 \) \* 2 60# 取模运算 $ expr 15 % 4 注意:仅支持整数&…...

iview table组件 自定义表头
在实际项目开发中,我们经常会用到各种各样的表格,比如在表格表头中填加按钮,下拉菜单,图标等等,在网上搜了一段时间发现比较少,所以写好之后就想着分享出来给有需要的人参考参考,例如下面这种表…...

二叉搜索树实现删除功能 Java
在开始编写删除功能之前,先要编写好searchParent()(寻找父节点)和min()(查找树中最小值)两个函数,后期会在删除功能中使用到。 searchParent()的编写 /*** * param value* return Node*/public Node searchParent(int value){if(rootnull) return null;…...

Android Framework学习三:zygote剖析
文章目录 Zygote工作内容起始点初始化步骤启动 ZygoteInitZygoteInit.main () 函数内部操作 Zygote如何启动SystemServer参与的类和文件流程步骤进程创建完成后的处理 Framework学习之系列文章 在 Android 系统中,Zygote 是一个非常关键的进程,有 “App …...
)
LLM-Based Agent及其框架学习的学习(三)
文章目录 摘要Abstract1. 引言2. 推理与规划2.1 推理2.2 规划2.2.1 计划指定2.2.2 计划反思 3. 迁移与泛化3.1 未知任务的泛化3.2 情景学习3.3 持续学习 4. 学习Crewai和LangGraph4.1 Crewai4.2 LangGraph 参考总结 摘要 本文系统阐述了基于大语言模型的智能体在认知架构中的核…...

修复笔记:获取 torch._dynamo 的详细日志信息
一、问题描述 在运行项目时,遇到与 torch._dynamo 相关的报错,并且希望获取更详细的日志信息以便于进一步诊断问题。 二、相关环境变量设置 通过设置环境变量,可以获得更详细的日志信息: set TORCH_LOGSdynamo set TORCHDYNAM…...
)
阿里云服务器全栈技术指导手册(2025版)
阿里云服务器全栈技术指导手册(2025版) 一、基础配置与核心架构设计 1. 精准实例选型策略 • 通用计算场景:选择ECS通用型(如ecs.g7)实例,搭载第三代Intel Xeon处理器,适合Web应用、中小型数…...

llfc项目笔记客户端TCP
一、整体架构流程图(简洁版) 复制代码 【客户端启动】 |--- 初始化TcpMgr(单例)|--- 连接信号初始化:连接成功、断开、错误、发数据| 【用户操作:登录成功】|--- 触发发起跳转:发起连接(sig_connect_tcp)| 【TcpMgr收到连接请求】|--- 连接到服务器(connectToHost)…...

基于python的task--时间片轮询
目录 前言 utf-8 chinese GB2312 utf-8 排除task.c chinese GB2312 排除task.c 运行结果 前言 建议是把能正常工作的单个功能函数放到一起(就和放while函数里的程序一样),程序会按顺序自动配置。 不同的格式已经对应给出。 utf-8 impo…...