开源项目:optimum-quanto库介绍
项目地址:https://github.com/huggingface/optimum-quanto
官网介绍:https://huggingface.co/blog/quanto-introduction
量化是一种技术,通过使用低精度数据类型(如 8 位整数 (int8))而不是通常的 32 位浮点 (float32) 来表示深度学习模型的权重和激活,从而降低评估深度学习模型的计算和内存成本。
减少位数意味着生成的模型需要更少的内存存储,这对于在消费类设备上部署大型语言模型至关重要。 它还支持对较低位宽数据类型的特定优化,例如 CUDA 设备上的矩阵乘法, int8, float8.
许多开源库可用于量化 pytorch 深度学习模型,每个模型都提供非常强大的功能,但通常仅限于特定的模型配置和设备。
此外,尽管它们基于相同的设计原则,但不幸的是,它们经常彼此不兼容。
今天,我们很高兴地推出 quanto,这是 Optimum 的 PyTorch 量化后端。
它的设计考虑了多功能性和简单性:
- 所有功能在 EAGER 模式下可用(适用于不可追踪的模型),
- 量化模型可以放置在任何设备上(包括 CUDA 和 MPS),
- 自动插入量化和去量化存根,
- 自动插入量化的函数运算,
- 自动插入量化模块(请参阅下面的支持模块列表),
- 提供从 float 模型到 dynamic 到 static 量化模型的无缝工作流程,
- 与 PyTorch 和 🤗 Safetensors 兼容的序列化,weight_only
- CUDA 设备上的加速矩阵乘法(int8-int8、fp16-int4、bf16-int8、bf16-int4)、
- 支持 int2、int4、int8 和 float8 权重,
- 支持 int8 和 float8 激活。
最近的量化方法似乎专注于量化大型语言模型 (LLM),而 quanto 旨在为适用于任何模态的简单量化方案(线性量化、每组量化)提供极其简单的量化基元。
安装命令:
pip install optimum-quanto1、量化Hugging Face models
1.1 量化效果
基于官网发布的性能数据,综合评估可以发现量化前,bf16的性能与延时才是最佳的
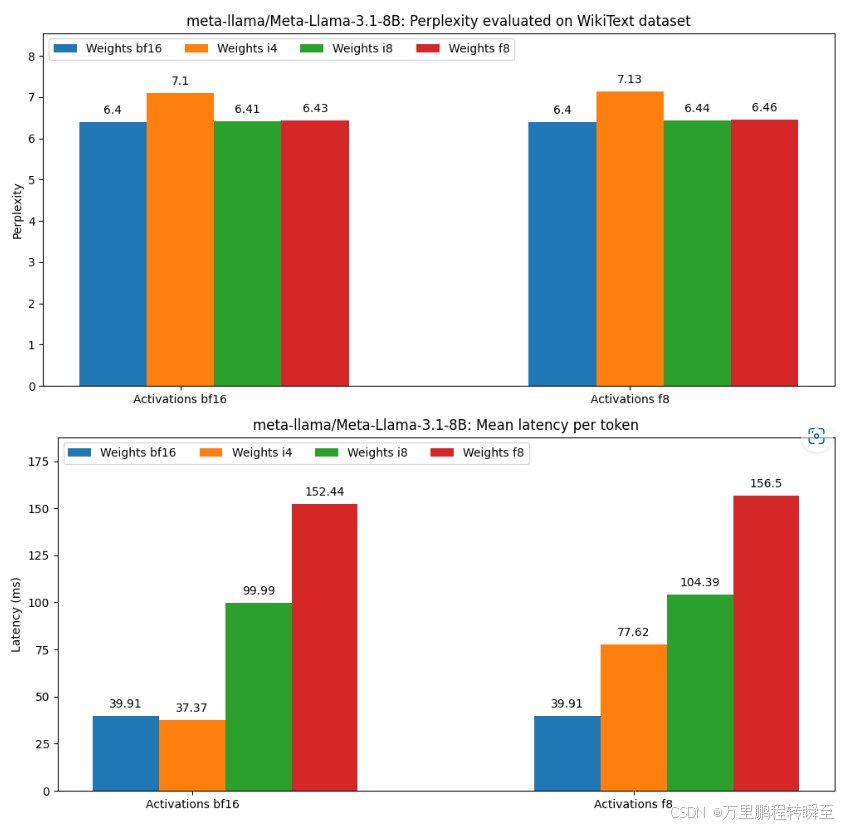
上图显示了在 NVIDIA A10 GPU 上测得的每个令牌的延迟,基于optimum-quanto得到的i4、i8量化模型并没有降低首token延时。只是在理论上降低了显存需求。
1.2 在transformers 库中使用
Quanto 无缝集成在 Hugging Face transformers 库中。您可以通过将 添加quantization_config配置项调用optimum-quanto库。 具体如下使用
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfigmodel_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)quantization_config = QuantoConfig(weights="int8")quantized_model = AutoModelForCausalLM.from_pretrained(model_id,quantization_config= quantization_config
)目前,您需要使用最新版本的 accelerate 以确保集成完全兼容。更多信息可以参考:https://huggingface.co/blog/quanto-introduction
2.1 量化常规模型
2.1 常规api
量化常规的torch模型有以下步骤:
第一步 量化
将标准浮点模型转换为动态量化模型。
from optimum.quanto import quantize, qint8quantize(model, weights=qint8, activations=qint8)
在此阶段,仅修改模型的推理以动态量化权重。
第二步 校准
校准(如果激活未量化,则可选)
Quanto 支持校准模式,该模式允许记录激活范围,同时通过量化模型传递代表性样本。
from optimum.quanto import Calibrationwith Calibration(momentum=0.9):model(samples)
这会自动激活量化模块中激活的量化。
第三步 Quantization-Aware-Training
import torchmodel.train()
for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data).dequantize()loss = torch.nn.functional.nll_loss(output, target)loss.backward()optimizer.step()第四步 冻结整数权重
冻结模型时,其浮点权重将替换为量化权重。*
from optimum.quanto import freezefreeze(model)第五步 序列化量化模型
量化模型的权重可以序列化为 ,并保存到文件中。 和 (recommended) 均受支持。
为了重新加载这些权重,还需要存储量化的 模型量化图。
from safetensors.torch import save_file
import jsonsave_file(model.state_dict(), 'model.safetensors')from optimum.quanto import quantization_map
with open('quantization_map.json', w) as f:json.dump(quantization_map(model))
第六步 重新加载量化模型
import jsonfrom safetensors.torch import load_file
state_dict = load_file('model.safetensors')
with open('quantization_map.json', r) as f:quantization_map = json.load(f)# Create an empty model from your modeling code and requantize it
with torch.device('meta'):new_model = """创建一个模型结构"""
requantize(new_model, state_dict, quantization_map, device=torch.device('cuda'))2.2 官方案例
https://github.com/huggingface/optimum-quanto/blob/main/examples/vision/image-classification/mnist/quantize_mnist_model.py
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.import argparse
import time
from tempfile import NamedTemporaryFileimport torch
import torch.nn.functional as F
from accelerate import init_empty_weights
from safetensors.torch import load_file, save_file
from torchvision import datasets, transforms
from transformers import AutoConfig, AutoModelfrom optimum.quanto import (Calibration,QTensor,freeze,qfloat8,qint4,qint8,quantization_map,quantize,requantize,
)def test(model, device, test_loader):model.to(device)model.eval()test_loss = 0correct = 0with torch.no_grad():start = time.time()for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)if isinstance(output, QTensor):output = output.dequantize()test_loss += F.nll_loss(output, target, reduction="sum").item() # sum up batch losspred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probabilitycorrect += pred.eq(target.view_as(pred)).sum().item()end = time.time()test_loss /= len(test_loader.dataset)print("\nTest set evaluated in {:.2f} s: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n".format(end - start, test_loss, correct, len(test_loader.dataset), 100.0 * correct / len(test_loader.dataset)))def train(log_interval, model, device, train_loader, optimizer, epoch):model.to(device)model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)if isinstance(output, QTensor):output = output.dequantize()loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % log_interval == 0:print("Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(epoch,batch_idx * len(data),len(train_loader.dataset),100.0 * batch_idx / len(train_loader),loss.item(),))def keyword_to_itype(k):return {"none": None, "int4": qint4, "int8": qint8, "float8": qfloat8}[k]def main():# Training settingsparser = argparse.ArgumentParser(description="PyTorch MNIST Example")parser.add_argument("--batch-size", type=int, default=250, metavar="N", help="input batch size for testing (default: 250)")parser.add_argument("--seed", type=int, default=1, metavar="S", help="random seed (default: 1)")parser.add_argument("--model", type=str, default="dacorvo/mnist-mlp", help="The name of the trained Model.")parser.add_argument("--weights", type=str, default="int8", choices=["int4", "int8", "float8"])parser.add_argument("--activations", type=str, default="int8", choices=["none", "int8", "float8"])parser.add_argument("--device", type=str, default=None, help="The device to use for evaluation.")args = parser.parse_args()torch.manual_seed(args.seed)if args.device is None:if torch.cuda.is_available():device = torch.device("cuda")elif torch.backends.mps.is_available():device = torch.device("mps")elif torch.xpu.is_available():device = torch.device("xpu")else:device = torch.device("cpu")else:device = torch.device(args.device)dataset_kwargs = {"batch_size": args.batch_size}if torch.cuda.is_available() or torch.xpu.is_available():backend_kwargs = {"num_workers": 1, "pin_memory": True, "shuffle": True}dataset_kwargs.update(backend_kwargs)transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,)),transforms.Lambda(lambda x: torch.flatten(x)),])dataset1 = datasets.MNIST("./data", train=True, download=True, transform=transform)train_loader = torch.utils.data.DataLoader(dataset1, **dataset_kwargs)dataset2 = datasets.MNIST("./data", train=False, download=True, transform=transform)test_loader = torch.utils.data.DataLoader(dataset2, **dataset_kwargs)model = AutoModel.from_pretrained(args.model, trust_remote_code=True)model.eval()print("Float model")test(model, device, test_loader)weights = keyword_to_itype(args.weights)activations = keyword_to_itype(args.activations)quantize(model, weights=weights, activations=activations)if activations is not None:print("Calibrating ...")with Calibration():test(model, device, test_loader)print(f"Quantized model (w: {args.weights}, a: {args.activations})")test(model, device, test_loader)print("Tuning quantized model for one epoch")optimizer = torch.optim.Adadelta(model.parameters(), lr=0.5)train(50, model, device, train_loader, optimizer, 1)print("Quantized tuned model")test(model, device, test_loader)print("Quantized frozen model")freeze(model)test(model, device, test_loader)# Serialize model to a state_dict, save it to disk and reload itwith NamedTemporaryFile() as tmp_file:save_file(model.state_dict(), tmp_file.name)state_dict = load_file(tmp_file.name)model_reloaded = AutoModel.from_pretrained(args.model, trust_remote_code=True)# Create an empty modelconfig = AutoConfig.from_pretrained(args.model, trust_remote_code=True)with init_empty_weights():model_reloaded = AutoModel.from_config(config, trust_remote_code=True)# Requantize it using the serialized state_dictrequantize(model_reloaded, state_dict, quantization_map(model), device)print("Serialized quantized model")test(model_reloaded, device, test_loader)if __name__ == "__main__":main()
2.3 博主实测
import torch
import torchvision
from torch import nn, optim
from torchvision import transforms, models
from torch.autograd import Variable
from torch.utils.data import DataLoader
import timm
from torchvision.transforms import transforms
from tqdm import tqdm
from torch.amp import GradScaler
from torch.amp import autocast
from copy import deepcopy
def train(model):train_loss = 0.train_acc = 0.n=0d_len=0pbar= tqdm(total=len(train_loader),desc='Train: ')for batch_x, batch_y in train_loader:batch_x, batch_y = Variable(batch_x).to(device), Variable(batch_y).to(device)# print(batch_x.shape,batch_y.shape)optimizer.zero_grad() # 梯度置0d_len+=batch_x.shape[0]if train_amp:#混合精度运算作用域with autocast(device_type='cuda'):out = model(batch_x) # 前向传播loss = loss_func(out, batch_y) # 计算loss#将梯度进行相应的缩放scaler.scale(loss).backward() # 返向传播#设置优化器计步scaler.step(optimizer)#更新尺度scaler.update()else:out = model(batch_x) # 前向传播loss = loss_func(out, batch_y) # 计算loss loss.backward()optimizer.step()# ------计算loss,acctrain_loss += loss.item()# torch.max(out, 1) 指第一维最大值,返回[最大值,最大值索引]pred = torch.max(out, 1)[1]train_correct = (pred == batch_y).sum()train_acc += train_correct.item()n += batch_y.shape[0]pbar.update(1)pbar.set_postfix({'loss': '%.4f' % (train_loss / n),'train acc': '%.3f' % (train_acc / n),'dlen':d_len})pbar.close()print('Train Loss: {:.6f}, Acc: {:.6f}'.format(train_loss / (len(train_data)), train_acc / (len(train_data))) ,batch_x.shape)def eval(model):model.eval()eval_loss = 0.eval_acc = 0.n=0d_len=0pbar= tqdm(total=len(test_loader),desc='Test: ')for batch_x, batch_y in test_loader:# 测试阶段不需要保存梯度信息with torch.no_grad():batch_x, batch_y = Variable(batch_x).to(device), Variable(batch_y).to(device)if train_amp:with autocast(device_type='cuda'):out = model(batch_x)loss = loss_func(out, batch_y)else:out = model(batch_x)loss = loss_func(out, batch_y)eval_loss += loss.item()pred = torch.max(out, 1)[1]num_correct = (pred == batch_y).sum()eval_acc += num_correct.item()d_len+=batch_x.shape[0]n+=1pbar.update(1)pbar.set_postfix({'loss': '%.4f' % (eval_loss / n),'eval acc': '%.3f' % (eval_acc / d_len),'dlen':d_len})pbar.close()print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(test_data)), eval_acc / (len(test_data))))transform_train=transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225))])# 数据预处理
transform_test = transforms.Compose([transforms.Resize(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])# 加载CIFAR-100数据集
train_data = torchvision.datasets.CIFAR100(root=r'D:/datasets/CIFAR-100', train=True, download=True, transform=transform_train)
train_loader = DataLoader(train_data, batch_size=200, shuffle=True)
test_data = torchvision.datasets.CIFAR100(root=r'D:/datasets/CIFAR-100', train=False, download=True, transform=transform_test)
test_loader = DataLoader(test_data, batch_size=200, shuffle=False)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = timm.create_model('resnet18', pretrained=True, num_classes=100).to(device)
#model = Net().to(device)from optimum.quanto import quantize, qint8,qint4,qint2,Calibration,freeze
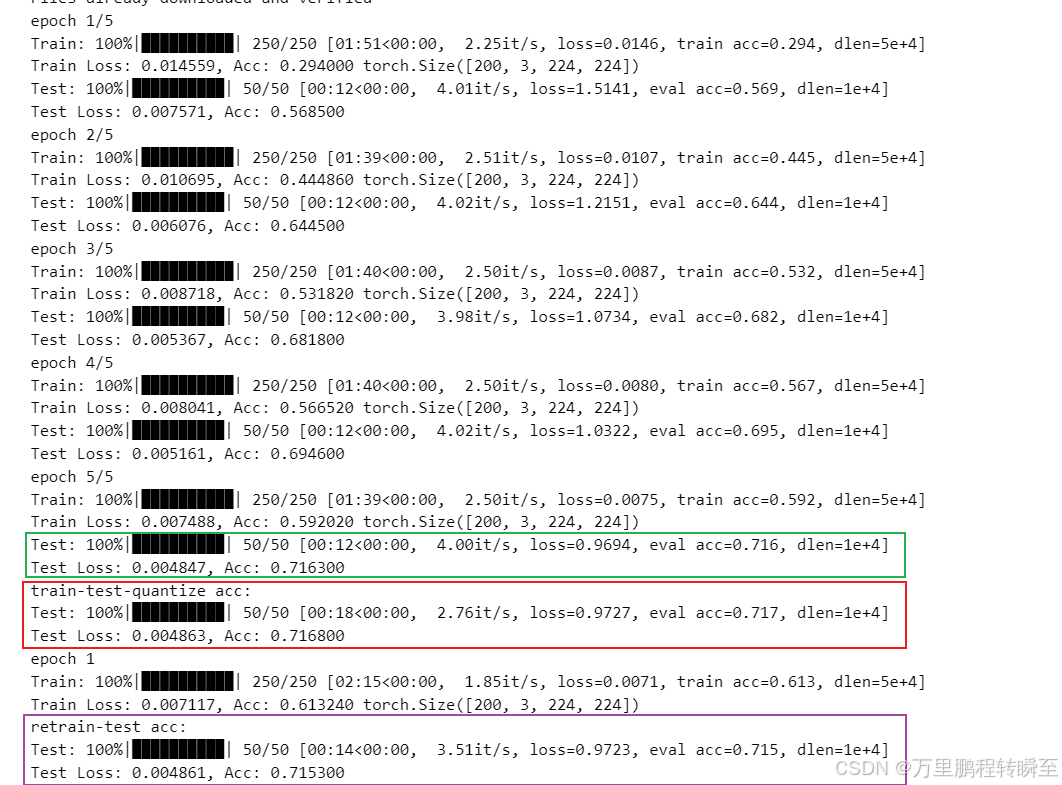
if __name__=="__main__":train_amp = True # EPOCH = 5optimizer = torch.optim.Adam(filter(lambda p : p.requires_grad, model.parameters()),lr=0.001)loss_func = torch.nn.CrossEntropyLoss()scaler = GradScaler()for epoch in range(EPOCH):print('epoch {}/{}'.format(epoch + 1,EPOCH))# training-----------------------------train(model)# evaluation--------------------------------eval(model)keys=list(model.state_dict().keys())key=keys[0]#print('train:',model.state_dict()[key].dtype,model.state_dict()[key][:,0,0,0])model4qat=deepcopy(model)#量化后的模型不支持amp训练train_amp = False # #将模型进行量化quantize(model4qat, weights=qint8, activations=qint8)print('train-test-quantize acc:')with Calibration(momentum=0.9):eval(model4qat)for epoch in range(1):print('epoch {}'.format(epoch + 1))# training-----------------------------train(model4qat)print('retrain-test acc:')eval(model4qat)from optimum.quanto import freezemodel_qat4freeze=deepcopy(model4qat)freeze(model_qat4freeze)# 参数key name发生了变化keys=list(model_qat4freeze.state_dict().keys())key=keys[0]print(model_qat4freeze)print('freeze-test acc:')eval(model_qat4freeze) #Test Loss: 0.004861, Acc: 0.715300
常规训练后量化后的模型精度如红框所示,为71.68%与量化前的71.63%基本一样。同时为了防止量化后模型精度下降,还进行了一个epoch的训练,虽然训练精度有所上升,但测试精度有轻微下降

量化后的模型结构如下所示,可以看到conv、linear相关的layer被替换为optimum-quanto库中的层
ResNet((conv1): QConv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act1): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): BasicBlock((conv1): QConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(drop_block): Identity()(act1): ReLU(inplace=True)(aa): Identity()(conv2): QConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act2): ReLU(inplace=True))(1): BasicBlock((conv1): QConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(drop_block): Identity()(act1): ReLU(inplace=True)(aa): Identity()(conv2): QConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
...(global_pool): SelectAdaptivePool2d(pool_type=avg, flatten=Flatten(start_dim=1, end_dim=-1))(fc): QLinear(in_features=512, out_features=100, bias=True)
)
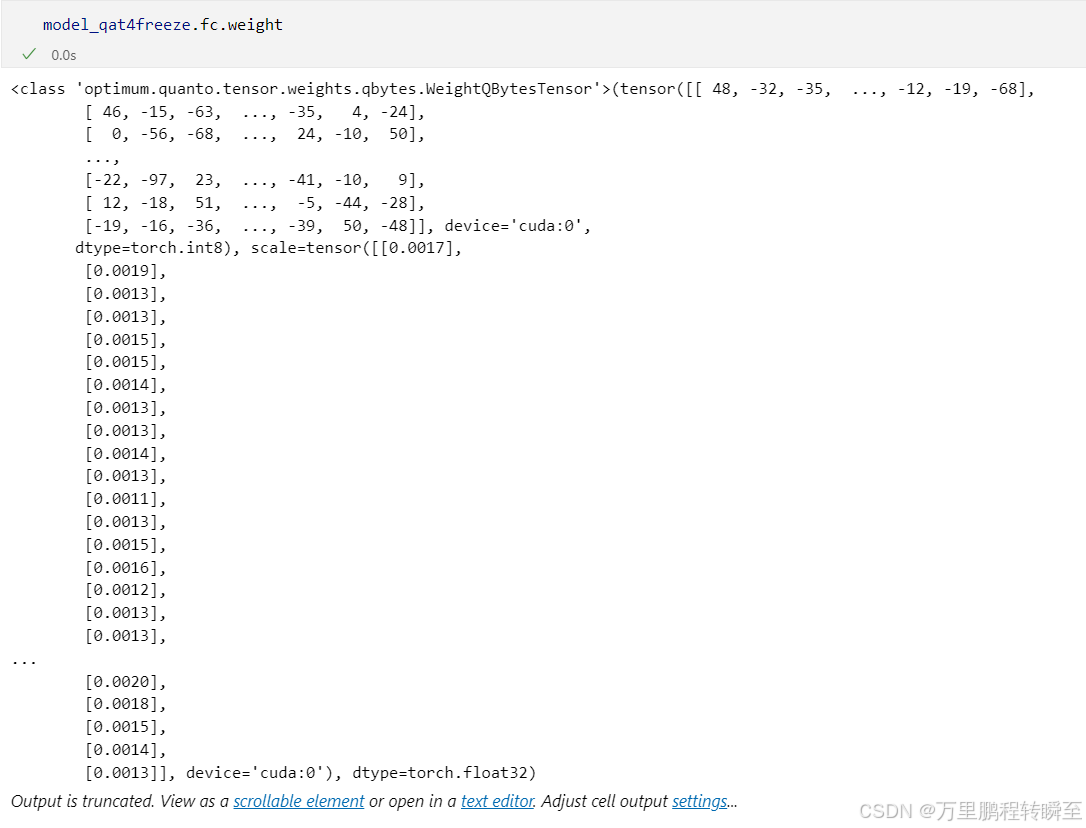
对模型权重进行输出测试,可以发现是int8格式的权重,scale是float
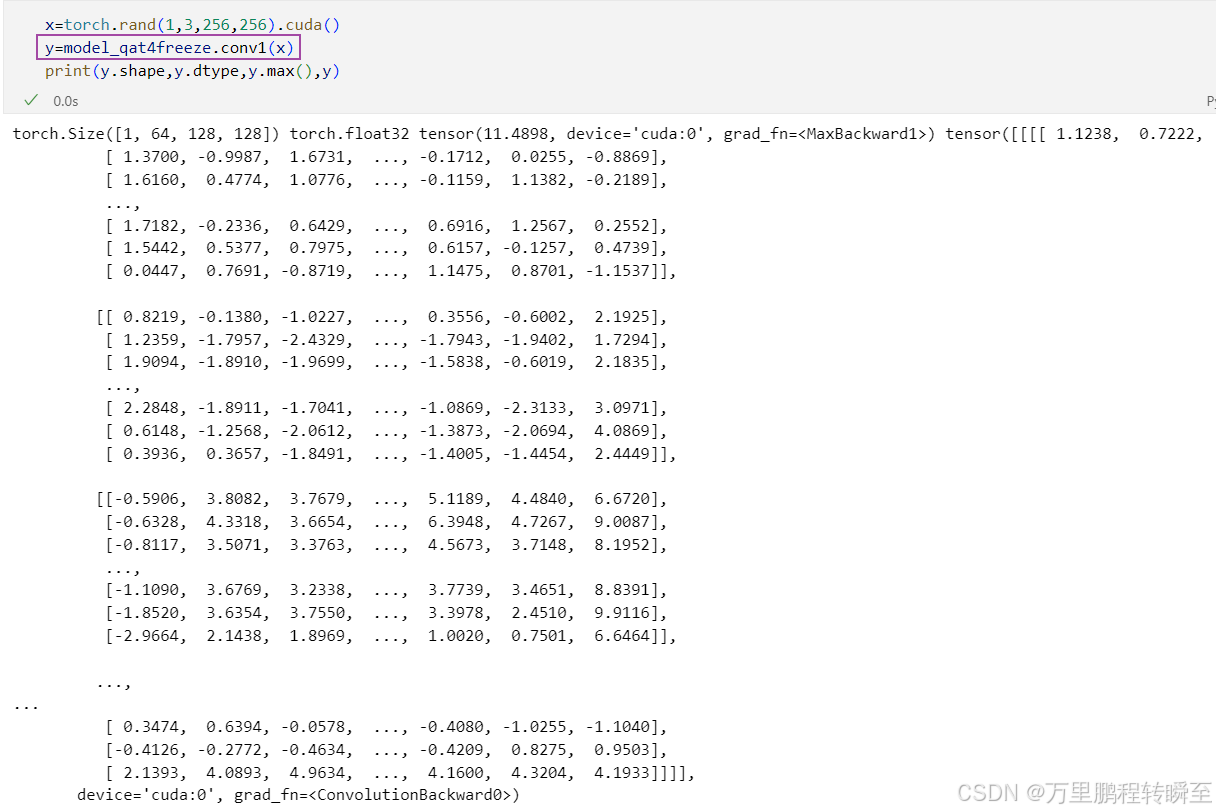
取模型中单独layer进行forward,可以发现输出的是flaot类型。
3、代码深入
在optimum.quanto库中,模型量化以quantize(model, weights=qint8, activations=qint8)为入口,自动将可量化训练layer替换为Qlayer(含量化与反量化操作)
3.1 量化操作链
在quantize=》_quantize_submodule=》quantize_module
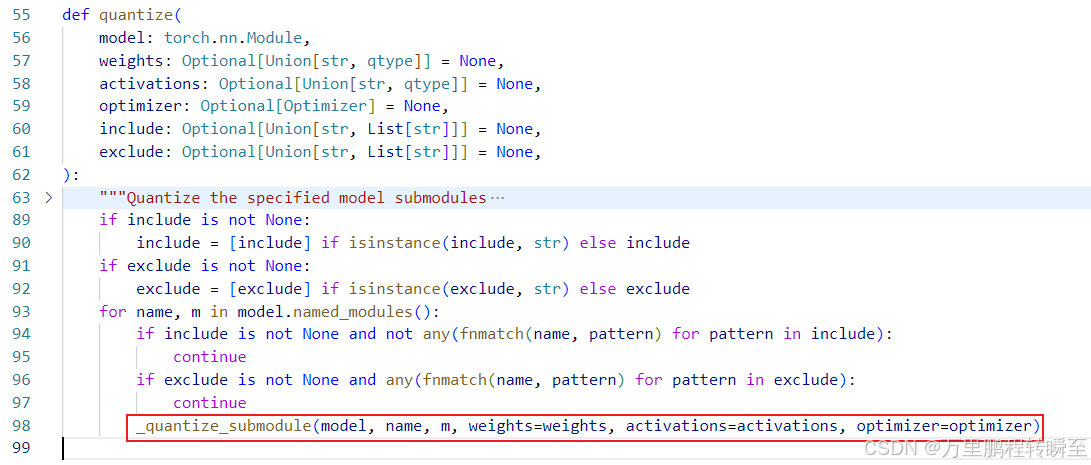
最终在quantize_module函数中,调用 qcls.from_module将原始layer替换为qlayer
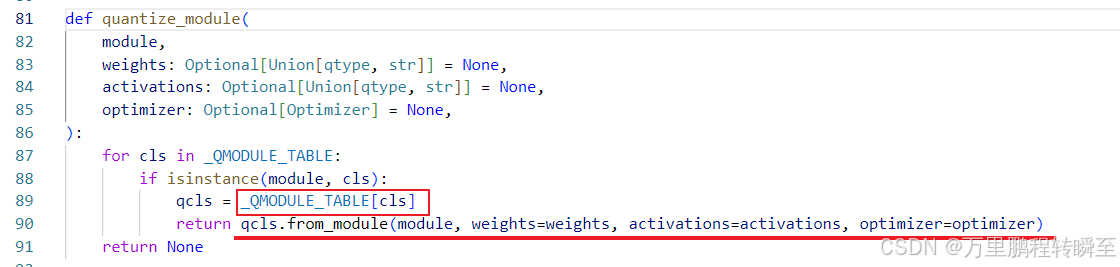
通过对源码追溯,可以发现支持对conv2d、Layernorm、linear的量化

3.2 QModuleMixin
在optimum-quanto中的实现,所有的qlayer均继承自QModuleMixin, torch.nn.Conv2d,基于qcreate属性完成属性初始化。
@register_qmodule(torch.nn.Conv2d)
class QConv2d(QModuleMixin, torch.nn.Conv2d):@classmethoddef qcreate(cls,module,weights: qtype,activations: Optional[qtype] = None,optimizer: Optional[Optimizer] = None,device: Optional[torch.device] = None,):return cls(in_channels=module.in_channels,out_channels=module.out_channels,kernel_size=module.kernel_size,stride=module.stride,padding=module.padding,dilation=module.dilation,groups=module.groups,bias=module.bias is not None,padding_mode=module.padding_mode,dtype=module.weight.dtype,device=device,weights=weights,activations=activations,optimizer=optimizer,)def forward(self, input: torch.Tensor) -> torch.Tensor:return self._conv_forward(input, self.qweight, self.bias)
在QModuleMixin中,可以跟量化直接相关的属性weight_qtype、activation_qtype、input_scale、output_scale。同时可以发现,关于输入输出的量化是基于hook实现的。此外,可以发现weight_group_size的值默认为最大值128,根据输入通道的变化,控制为32的倍数(只针对非int8量化有效)。
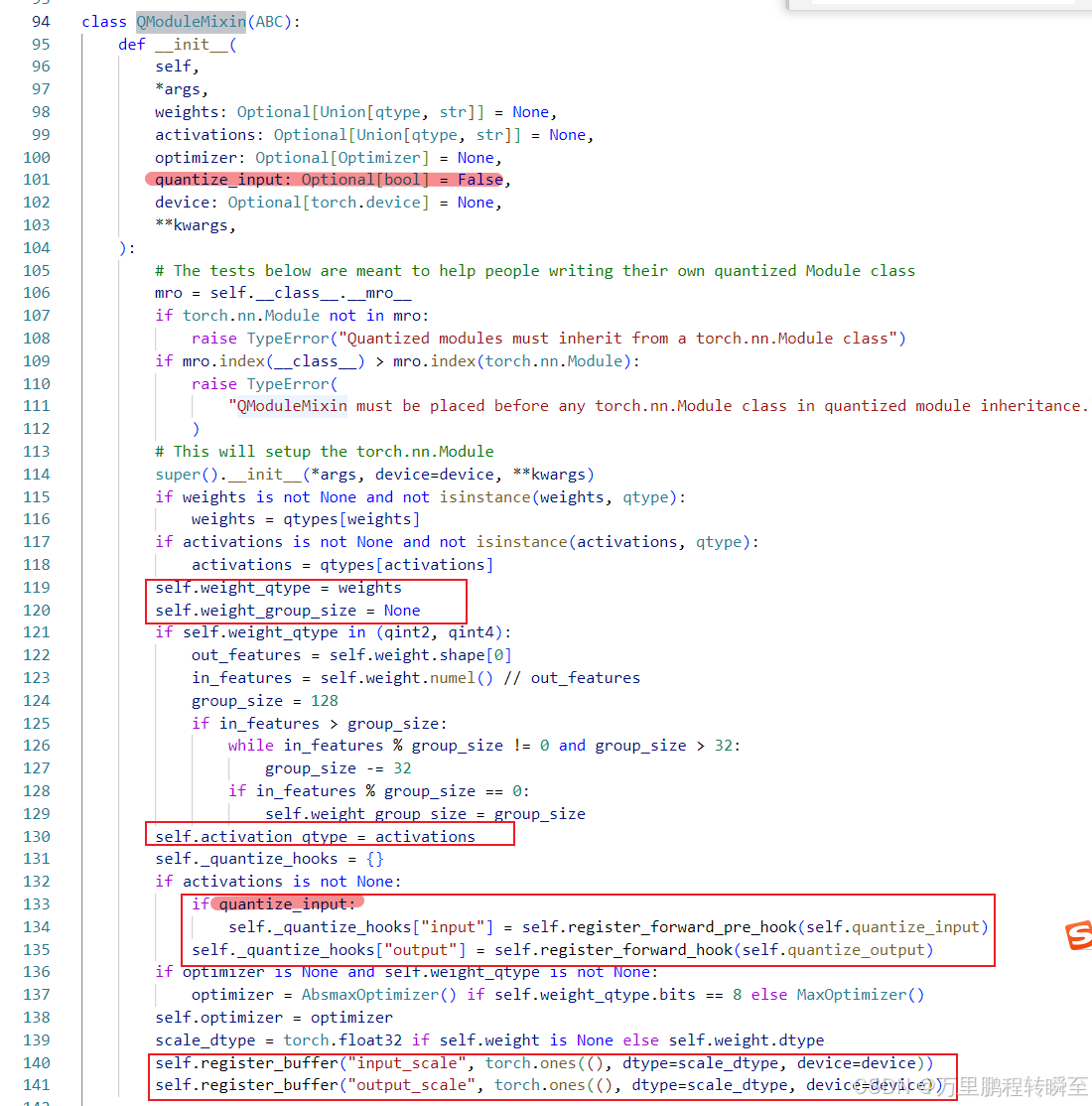
输入输出的量化 均基于quantize_activation函数实现
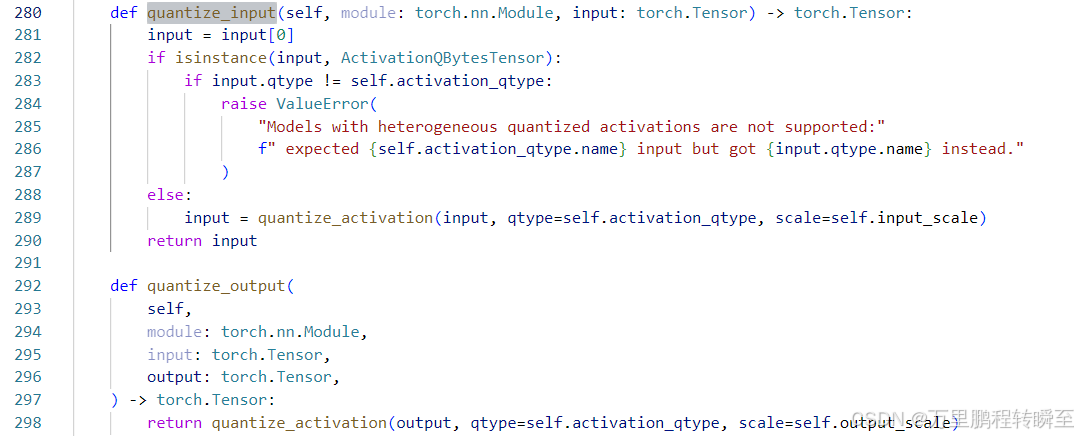
通过追溯可以定位到是基于torch.ops.quanto.quantize_symmetric函数实现量化
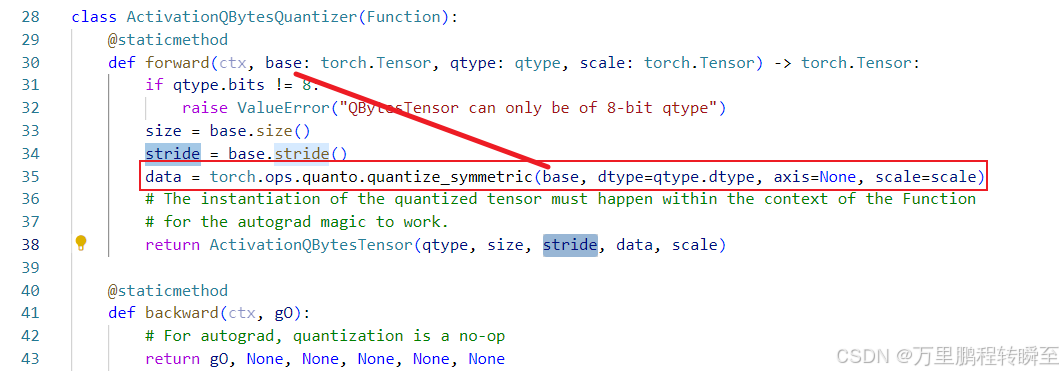
权重的量化 基于qweight属性调用self.optimizer与quantize_weight进行实现。如AbsmaxOptimizer用于计算出数据的scale。 如果是MaxOptimizer的话,会返回scale与zero_point
# zero_point为none
class AbsmaxOptimizer(SymmetricOptimizer): def optimize(self, base: torch.Tensor, qtype: qtype, axis: Optional[int] = None) -> Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]:base = torch.abs(base)if axis is None:rmax = torch.max(base)else:dim = list(range(1, base.ndim)) if (axis == 0) else list(range(0, base.ndim - 1))rmax = torch.amax(torch.abs(base), dim=dim, keepdim=True)return rmax / qtype.qmaxclass MaxOptimizer(AffineOptimizer):def optimize(self, base: torch.Tensor, qtype: qtype, axis: int) -> Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]:dim = list(range(1, base.ndim)) if (axis == 0) else list(range(0, base.ndim - 1))rmin = torch.amin(base, dim=dim, keepdim=True)rmax = torch.amax(base, dim=dim, keepdim=True)qmin = -(2 ** (qtype.bits - 1))qmax = 2 ** (qtype.bits - 1) - 1scale = (rmax - rmin) / (qmax - qmin)shift = -rminreturn scale, shift
quantize_weight在底层基于WeightsQBitsQuantizer类实现权重量化,核心操作为torch.ops.quanto.quantize_affine函数,具体如下。其中shift为量化后数据的0点。
class WeightsQBitsQuantizer(Function):@staticmethoddef forward(ctx,base: torch.Tensor,qtype: qtype,axis: int,group_size: int,scale: torch.Tensor,shift: torch.Tensor,optimized: bool,):if qtype not in (qint2, qint4):raise ValueError("WeightQBitsTensor can only be of qint2 or qint4 qtype")if axis not in (0, -1):raise ValueError("WeightQBitsTensor axis parameter must be 0 (first axis) or -1 (last axis)")size = base.size()stride = base.stride()data = torch.ops.quanto.quantize_affine(base, bits=qtype.bits, axis=axis, group_size=group_size, scale=scale, shift=shift)if optimized:return WeightQBitsTensor.create(qtype, axis, group_size, size, stride, data, scale, shift)return WeightQBitsTensor(qtype, axis, group_size, size, stride, data, scale, shift)@staticmethoddef backward(ctx, gO):# For autograd, quantization is a no-opreturn gO, None, None, None, None, None, None
相关文章:

开源项目:optimum-quanto库介绍
项目地址:https://github.com/huggingface/optimum-quanto 官网介绍:https://huggingface.co/blog/quanto-introduction 量化是一种技术,通过使用低精度数据类型(如 8 位整数 (int8))而不是通常…...

C++学习:六个月从基础到就业——C++11/14:lambda表达式
C学习:六个月从基础到就业——C11/14:lambda表达式 本文是我C学习之旅系列的第四十篇技术文章,也是第三阶段"现代C特性"的第二篇,主要介绍C11/14中引入的lambda表达式。查看完整系列目录了解更多内容。 引言 Lambda表达…...

cesium基础设置
在上节新建的程序中,我们会看到有一行小字: 原因为我们没有输入token,想要让这行小字消失的方法很简单,前往cesium的官网注册账号申请token.然后在App.vue中如下方式添加token 保存后即可发现小字消失. 如果连logo都想去掉呢? 在源代码中,我们初始化了一个viwer,即查看器窗口…...

一些好玩的东西
🚀 终极挑战:用 curl 玩《星球大战》 telnet towel.blinkenlights.nl # 其实不是 curl,但太经典了! 效果:在终端播放 ASCII 版《星球大战》电影!(如果 telnet 不可用,可以试…...
)
ActiveMQ 与其他 MQ 的对比分析:Kafka/RocketMQ 的选型参考(二)
ActiveMQ、Kafka 和 RocketMQ 详细对比 性能对比 在性能方面,Kafka 和 RocketMQ 通常在高吞吐量场景下表现出色,而 ActiveMQ 则相对较弱。根据相关测试数据表明,Kafka 在处理大规模日志数据时,单机吞吐量可以达到每秒数十万条甚…...
)
HTML学习笔记(7)
一、什么是jQuery jQuery 是一个 JavaScript 库。他实现了JavaScript的一些功能,并封装起来,对外提供接口。 例子实现一个点击消失的功能,用JavaScript实现 <!DOCTYPE html> <html lang"en"> <head><meta …...

Jenkis安装、配置及账号权限分配保姆级教程
Jenkis安装、配置及账号权限分配保姆级教程 安装Jenkins下载Jenkins启动Jenkins配置Jenkins入门Jenkins配置配置中文配置前端自动化任务流新建任务拉取代码打包上传云服务并运行配置后端自动化任务流新建任务拉取代码打包上传云服务并运行账号权限分配创建用户分配视图权限安装…...
是什么?)
面向对象编程(Object-Oriented Programming, OOP)是什么?
李升伟 编译 简介 如果你已经接触过软件开发领域的话,你肯定听说过"面向对象编程"(Object-Oriented Programming, OOP)这个术语。但你知道什么是OOP吗?为什么它如此重要?在这篇文章中我们将深入解析OOP的基…...
:单细胞转录组识别信息基因(和基因模块))
Hotspot分析(1):单细胞转录组识别信息基因(和基因模块)
这一期我们介绍一个常见的,高分文章引用很高的一个单细胞转录组分析工具Hotspot,它可针对单细胞转录组数据识别有意义基因或者基因module,类似于聚类模块。所谓的”informative "的基因是那些在给定度量中相邻的细胞之间以相似的方式表达…...

从图文到声纹:DeepSeek 多模态技术的深度解析与实战应用
目录 一、引言二、DeepSeek 技术基础2.1 架构与原理2.2 多模态能力概述 三、文本与图像关联应用3.1 图文跨模态对齐技术3.1.1 技术原理3.1.2 DeepSeek 的独特方法 3.2 图像生成与文本描述3.2.1 应用案例3.2.2 技术实现 3.3 多模态检索系统中的应用3.3.1 系统搭建流程3.3.2 实际…...

cuDNN 9.9.0 便捷安装-Windows
#工作记录 从 CUDA12.6.3 和 cuDNN9.6.0 版本起,开启了使用 exe 安装包直接进行安装升级的支持模式,彻底改变了以往那种繁琐的安装流程。 在这两个版本之前,开发者在安装 CUDA 和 cuDNN 时,不得不手动下载 cuDNN 压缩包…...

profile软件开发中的性能剖析与内存分析
在软件开发中,“Profile”(性能剖析/性能分析)指的是通过工具详细监控程序运行时的各种性能指标,帮助开发者定位代码中的效率瓶颈或资源问题。当有人建议你 “profile 一下内存问题” 时,本质上是让你用专业工具动态分…...

0.0973585?探究ts_rank的score为什么这么低
最近在使用postgres利用ts_rank进行排序找到最符合关键词要求得内容时发现: 即使是相似的内容,得分也是非常非常得低(其中一个case是0.0973585)。看起来很奇怪,非常不可行。于是我又做了一个简单测的测试: SELECT ts_rank(to_tsvector(english, skirt), to_tsquery(skirt)…...

架构思维:利用全量缓存架构构建毫秒级的读服务
文章目录 一、引言二、全量缓存架构概述三、基于 Binlog 的缓存同步方案1. Binlog 原理2. 同步中间件3. 架构整合核心收益 四、Binlog 全量缓存的优缺点与优化优点缺点与取舍优化策略 五、其他进阶优化点六、总结 一、引言 架构思维:使用简洁的架构实现高性能读服务…...

永磁同步电机控制算法--基于PI的位置伺服控制
一、原理介绍 永磁同步伺服系统是包含了电流环、速度环和位置环的三环控制系统。 伺服系统通过电流检测电路和光电编码器检测电动机三相绕组电流和转子位置θ,通过坐标变换,计算出转矩电流分量iq和励磁电流分量id。 位置信号指令与实际转子位置信号的差…...

P1603 斯诺登密码详解
这个题目,我详细讲题解的两种方法,洛谷里面的题解,我是觉得大部分的时候是差了点意思的,不是看不懂,就是新知识没人详细讲解,我也是经常破防 先看题目: 题目是什么意思: 1…...

计算方法实验六 数值积分
【实验性质】综合性实验。 【实验目的】理解插值型积分法;掌握复化积分法算法。 【实验内容】 1对 ,用复化梯形积分和变步长梯形积分求值(截断误差不超过)。 【理论基础】 积分在工程中有重要的应用,数值积分…...

avx指令实现FFT
avx指令实现FFT 参考代码实现的难点补充的avx指令fft_avx256实现可继续优化的点 C语言实现FFT变换参考的代码是参考大模型生成的代码,很明显其使用的是位反转和蝶形变换的方法实现的FFT变换。但是大模型无法正确的生成用avx指令写的FFT变换的算法,所以这…...

Nginx 核心功能之正反代理
目录 一、Nginx 二、正向代理 三、反向代理 四、Nginx 缓存 1. 缓存功能的核心原理和缓存类型 2. 代理缓存功能设置 五、Nginx rewrite和正则 (1)Nginx 正则 (2)nginx location (3)Rewrite &…...

function包装器的意义
一:function包装器的概念 function包装器 也叫作适配器。C中的function本质是一个类模板,也是一个包装器。 二:需要function包装器的场景 那么我们来看看,我们为什么需要function呢? 一个需要包装器的场景:…...

【ThinkBook 16+ 电脑重做系统type-c接口部分功能失效解决方案】
ThinkBook 16 电脑重做系统type-c接口部分功能失效解决方案 问题回顾:重做电脑后,type-c接口部分功能失效,充电正常,连接外置硬盘正常,无法连接外拓显示器,显示usbc无信号(不同设备可能显示不同…...

【言语理解】中心理解题目之选项分析
front:中心理解题目之结构分析 4.1两出处六有误 两出处 背景、例子、分析论证中提炼的选项出处有误,一般不选但是和因此之前、不是而是 的不是部分、被指代部分提炼的选项出处有误,一般不选。 六有误 片面:原文并列谈论两方面,只…...
:[macOS 64bit App开发]: [1]如何加载动态链接库, 并无缝支持原生底层开发?)
[原创](现代Delphi 12指南):[macOS 64bit App开发]: [1]如何加载动态链接库, 并无缝支持原生底层开发?
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C++、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、…...

VTK入门指南
什么是VTK VTK (Visualization Toolkit) 是一个开源的、跨平台的计算机图形学、图像处理和可视化系统。它提供了丰富的算法和高级工具,用于3D计算机图形学、图像处理和可视化。 安装VTK Windows平台 下载预编译版本: 从VTK官网或GitHub发布页面下载 …...

开始一个vue项目-day2
这次新增的功能有: 1、使用cookie存储token 参考网站:https://vueuse.org/ 安装包: npm i vueuse/integrations npm i universal-cookie^7 2、cookie的设置读取和删除,代码:composables/auth.js import { useCookies } from …...

Baklib驱动企业知识管理AI升级
Baklib如何实现知识AI化 Baklib通过构建企业级知识中台的核心能力,将人工智能技术深度融入知识管理的全生命周期。其底层架构采用自然语言处理(NLP)与机器学习算法,实现对企业文档的智能分类与语义解析。例如,系统可自…...

Linux线程同步机制深度解析:信号量、互斥锁、条件变量与读写锁
Linux线程同步机制深度解析:信号量、互斥锁、条件变量与读写锁 一、线程同步基础 在多线程编程中,多个线程共享进程资源(如全局变量、文件描述符)时,若对共享资源的访问不加控制,会导致数据不一致或竞态条…...

js逆向绕过指纹识别
一、兼容性说明 官方支持 curl_cffi 明确支持 Windows 平台,并提供了预编译的安装包。其核心功能(如浏览器指纹模拟、HTTP/2 支持)在 Windows 上与 Linux/macOS 表现一致。 版本要求 • Python 3.8 及以上版本(推荐 Pyth…...

笔记整理六----OSPF协议
OSPF 动态路由的分类: 1.基于网络范围进行划分--将网络本身划分为一个个AS(自治系统---方便管理和维护) 内部网关协议---负责AS内部用户之间互相访问使用的协议 IGP--RIP EIGRP ISIS OSPF 外部网关协议--负责AS之间(整个互联网&…...

USB Type-C是不是全方位优于其他USB接口?
首先,USB TypeC接口内部引脚呈中心对称分布,正插、反插都能用,所以可以肓插,使用起来非常方便顺手。 其次,USB TypeC接口体积很小,特别是很薄,几乎适用于所有设备。而USB TypeA就是因为不方便应…...
)
信息系统监理师第二版教材模拟题第一组(含解析)
信息系统监理基础 信息系统监理的核心目标是( ) A. 降低项目成本 B. 确保项目按合同要求完成 C. 提高开发人员技术水平 D. 缩短项目周期答案:B 解析:信息系统监理的核心目标是确保信息系统工程项目按照合同要求、技术标准和规范完成,保障项目质量、进度和投资控制。 下列哪…...

NPP库中libnppist模块介绍
1. libnppist 模块简介 libnppist 是 NPP 库中专注于 图像统计分析与直方图计算 的模块,提供 GPU 加速的统计操作,适用于计算机视觉和图像处理中的特征提取与分析。 核心功能包括: 直方图计算(支持单通道/多通道) 统…...

k230摄像头初始化配置函数解析
通过 csi id 和图像传感器类型构建 Sensor 对象。 在图像处理应用中,用户通常需要首先创建一个 Sensor 对象。CanMV K230 软件可以自动检测内置的图像传感器,无需用户手动指定具体型号,只需设置传感器的最大输出分辨率和帧率。有关支持的图像…...

Spring的循环依赖问题
文章目录 一、什么是循环依赖?二、Spring 是如何解决循环依赖的?1.三级缓存2.解决循环依赖的流程 三、三级缓存机制可以解决所有的循环依赖问题吗?1. 为什么三级缓存在这里无效?2. 如何解决构造器循环依赖? 四、循环依…...

华为鸿蒙PC:开启国产操作系统自主化新纪元
——全栈自研、生态重构与未来挑战 2025年5月,一个值得中国科技界铭记的时间点。华为正式推出首款搭载鸿蒙操作系统(HarmonyOS)的PC产品。乍一听这像是又一款新电脑的发布,但它背后的意义远比表面更深远——这是中国首次推出从操…...

【LeetCode Hot100】动态规划篇
前言 本文用于整理LeetCode Hot100中题目解答,因题目比较简单且更多是为了面试快速写出正确思路,只做简单题意解读和一句话题解方便记忆。但代码会全部给出,方便大家整理代码思路。 70. 爬楼梯 一句话题意 每次爬1or2,问爬到n的路…...

【Java JUnit单元测试框架-60】深入理解JUnit:Java单元测试的艺术与实践
在当今快节奏的软件开发环境中,保证代码质量的同时又要快速交付成为了开发者面临的主要挑战。单元测试作为软件测试金字塔的基石,为我们提供了一种高效的解决方案。而在Java生态系统中,JUnit无疑是单元测试框架的代名词。本文将全面探讨JUnit…...

Java运算符学习笔记
运算符 -运算符介绍 运算符是一种特殊的符号,用以表示数据的运算、赋值和比较等。 算数运算符赋值运算符关系运算符[比较运算符]逻辑运算符位运算符[需要二进制基础]三元运算符 -算数运算符 介绍 算数运算符是对数值类型的变量进行运算的,在Java程…...
)
shell编程补充内容(Linux课程实验3)
一、求前五个偶数的和 1.这里先介绍要用到的expr 1. 整数计算 # 加法(注意运算符两侧空格) $ expr 10 20 30# 带括号的运算(需要转义) $ expr \( 10 20 \) \* 2 60# 取模运算 $ expr 15 % 4 注意:仅支持整数&…...

iview table组件 自定义表头
在实际项目开发中,我们经常会用到各种各样的表格,比如在表格表头中填加按钮,下拉菜单,图标等等,在网上搜了一段时间发现比较少,所以写好之后就想着分享出来给有需要的人参考参考,例如下面这种表…...

二叉搜索树实现删除功能 Java
在开始编写删除功能之前,先要编写好searchParent()(寻找父节点)和min()(查找树中最小值)两个函数,后期会在删除功能中使用到。 searchParent()的编写 /*** * param value* return Node*/public Node searchParent(int value){if(rootnull) return null;…...

Android Framework学习三:zygote剖析
文章目录 Zygote工作内容起始点初始化步骤启动 ZygoteInitZygoteInit.main () 函数内部操作 Zygote如何启动SystemServer参与的类和文件流程步骤进程创建完成后的处理 Framework学习之系列文章 在 Android 系统中,Zygote 是一个非常关键的进程,有 “App …...
)
LLM-Based Agent及其框架学习的学习(三)
文章目录 摘要Abstract1. 引言2. 推理与规划2.1 推理2.2 规划2.2.1 计划指定2.2.2 计划反思 3. 迁移与泛化3.1 未知任务的泛化3.2 情景学习3.3 持续学习 4. 学习Crewai和LangGraph4.1 Crewai4.2 LangGraph 参考总结 摘要 本文系统阐述了基于大语言模型的智能体在认知架构中的核…...

修复笔记:获取 torch._dynamo 的详细日志信息
一、问题描述 在运行项目时,遇到与 torch._dynamo 相关的报错,并且希望获取更详细的日志信息以便于进一步诊断问题。 二、相关环境变量设置 通过设置环境变量,可以获得更详细的日志信息: set TORCH_LOGSdynamo set TORCHDYNAM…...
)
阿里云服务器全栈技术指导手册(2025版)
阿里云服务器全栈技术指导手册(2025版) 一、基础配置与核心架构设计 1. 精准实例选型策略 • 通用计算场景:选择ECS通用型(如ecs.g7)实例,搭载第三代Intel Xeon处理器,适合Web应用、中小型数…...

llfc项目笔记客户端TCP
一、整体架构流程图(简洁版) 复制代码 【客户端启动】 |--- 初始化TcpMgr(单例)|--- 连接信号初始化:连接成功、断开、错误、发数据| 【用户操作:登录成功】|--- 触发发起跳转:发起连接(sig_connect_tcp)| 【TcpMgr收到连接请求】|--- 连接到服务器(connectToHost)…...

基于python的task--时间片轮询
目录 前言 utf-8 chinese GB2312 utf-8 排除task.c chinese GB2312 排除task.c 运行结果 前言 建议是把能正常工作的单个功能函数放到一起(就和放while函数里的程序一样),程序会按顺序自动配置。 不同的格式已经对应给出。 utf-8 impo…...

《前端秘籍:SCSS阴影效果全兼容指南》
在前端开发的旅程中,为网页元素添上阴影效果,就像为一幅画作点缀光影,能让页面瞬间生动起来,赋予元素层次感与立体感。可当我们满心欢喜地在SCSS中写下阴影代码,满心期待着在各种浏览器中都呈现出完美效果时࿰…...

强化学习机器人模拟器——RobotApp:一个交互式强化学习模拟器
RobotApp 是一个基于 Python 和 Tkinter 的交互式强化学习(Reinforcement Learning, RL)模拟器,集成了 GridWorld 环境和 QAgent 智能体,支持 Q-learning、SARSA 和 SARSA(λ) 算法。本博客将详细解析 robot_app.py 的功能、架构和使用方法,展示其如何通过直观的 GUI 界面…...

2025-04-26-利用奇异值重构矩阵-美团
2025-04-26-利用奇异值重构矩阵-美团 题目内容 在一家致力于图像处理的科技公司,你被分配到一个新项目,目标是开发一种图像压缩算法,以减少存储空间并加速传输。团队决定使用奇异值分解( S V D SVD SVD)对图像进行降…...