Milvus(12):分析器
1 分析器概述
在文本处理中,分析器是将原始文本转换为结构化可搜索格式的关键组件。每个分析器通常由两个核心部件组成:标记器和过滤器。它们共同将输入文本转换为标记,完善这些标记,并为高效索引和检索做好准备。
在 Milvus 中,创建 Collections 时,将VARCHAR 字段添加到 Collections Schema 时,会对分析器进行配置。分析器生成的标记可用于建立关键字匹配索引,或转换为稀疏嵌入以进行全文检索。
使用分析器可能会影响性能:
-
全文搜索:对于全文搜索,数据节点和查询节点通道消耗数据的速度更慢,因为它们必须等待标记化完成。因此,新输入的数据需要更长的时间才能用于搜索。
-
关键词匹配:对于关键字匹配,索引创建速度也较慢,因为标记化需要在索引建立之前完成。
1.1 分析器剖析
Milvus 的分析器由一个标记化器和零个或多个过滤器组成。
-
标记化器:标记器将输入文本分解为称为标记的离散单元。根据标记符类型的不同,这些标记符可以是单词或短语。
-
过滤器:可以对标记符进行过滤,进一步细化标记符,例如将标记符变成小写或删除常用词。
标记符仅支持 UTF-8 格式。未来版本将增加对其他格式的支持。下面的工作流程显示了分析器如何处理文本。
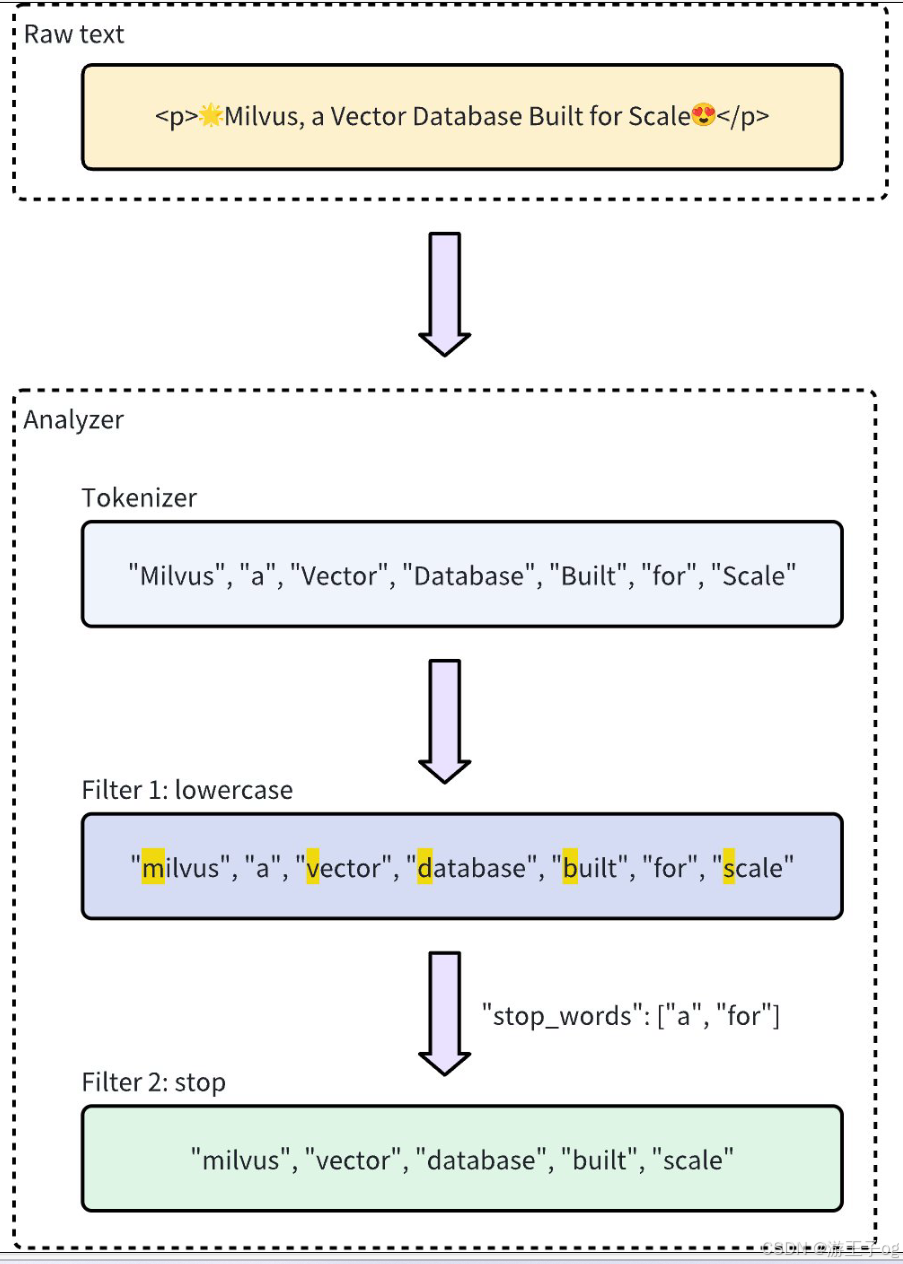
1.2 分析器类型
Milvus 提供两种类型的分析器,以满足不同的文本处理需求:
-
内置分析器:这些是预定义配置,只需最少的设置即可完成常见的文本处理任务。内置分析器不需要复杂的配置,是通用搜索的理想选择。
-
自定义分析器:对于更高级的需求,自定义分析器允许你通过指定标记器和零个或多个过滤器来定义自己的配置。这种自定义级别对于需要精确控制文本处理的特殊用例尤其有用。
如果在创建 Collections 时省略了分析器配置,Milvus 默认使用standard 分析器进行所有文本处理。
1.2.1 内置分析器
Milvus 中的内置分析器预先配置了特定的标记符号化器和过滤器,使你可以立即使用它们,而无需自己定义这些组件。每个内置分析器都是一个模板,包括预设的标记化器和过滤器,以及用于自定义的可选参数。
例如,要使用standard 内置分析器,只需将其名称standard 指定为type ,并可选择包含该分析器类型特有的额外配置,如stop_words :
analyzer_params = {"type": "standard", # 使用标准的内置分析器"stop_words": ["a", "an", "for"] # 定义要从标记化中排除的常用单词(停止词)列表
} 上述standard 内置分析器的配置等同于使用以下参数设置自定义分析器,其中tokenizer 和filter 选项是为实现类似功能而明确定义的:
analyzer_params = {"tokenizer": "standard","filter": ["lowercase",{"type": "stop","stop_words": ["a", "an", "for"]}]
}
Milvus 提供以下内置分析器,每个分析器都是为特定文本处理需求而设计的:
standard:适用于通用文本处理,应用标准标记化和小写过滤。english:针对英语文本进行了优化,支持英语停止词。chinese:专门用于处理中文文本,包括针对中文语言结构的标记化。
1.2.2 自定义分析器
对于更高级的文本处理,Milvus 中的自定义分析器允许您通过指定标记化器和过滤器来构建定制的文本处理管道。这种设置非常适合需要精确控制的特殊用例。
标记化器是自定义分析器的必备组件,它通过将输入文本分解为离散单元或标记来启动分析器管道。标记化遵循特定的规则,例如根据标记化器的类型用空白或标点符号分割。这一过程可以更精确、更独立地处理每个单词或短语。
例如,标记化器会将文本"Vector Database Built for Scale" 转换为单独的标记:
["Vector", "Database", "Built", "for", "Scale"]指定标记符的示例:
analyzer_params = {"tokenizer": "whitespace",
} 过滤器是可选组件,用于处理标记化器生成的标记,并根据需要对其进行转换或细化。例如,在对标记化术语["Vector", "Database", "Built", "for", "Scale"] 应用lowercase 过滤器后,结果可能是:
["vector", "database", "built", "for", "scale"]自定义分析器中的过滤器可以是内置的,也可以是自定义的,具体取决于配置需求。
-
内置过滤器:由 Milvus 预先配置,只需最少的设置。您只需指定过滤器的名称,就能立即使用这些过滤器。以下是可直接使用的内置过滤器:
-
lowercase:将文本转换为小写,确保不区分大小写进行匹配。 -
asciifolding:将非 ASCII 字符转换为 ASCII 对应字符,简化多语言文本处理。 -
alphanumonly:只保留字母数字字符,删除其他字符。 -
cnalphanumonly:删除包含除汉字、英文字母或数字以外的任何字符的标记。 -
cncharonly:删除包含任何非汉字的标记。
-
使用内置过滤器的示例:
analyzer_params = {"tokenizer": "standard", # 必选:指定标记器"filter": ["lowercase"], # 可选:内置过滤器,将文本转换为小写
} 自定义过滤器:自定义过滤器允许进行专门配置。您可以通过选择有效的过滤器类型 (filter.type) 并为每种过滤器类型添加特定设置来定义自定义过滤器。支持自定义的过滤器类型示例:
-
stop:通过设置停止词列表(如"stop_words": ["of", "to"])删除指定的常用词。 -
length:根据长度标准(如设置最大标记长度)排除标记。 -
stemmer:将单词还原为词根形式,以便更灵活地进行匹配。
配置自定义过滤器的示例:
analyzer_params = {"tokenizer": "standard", # 必选:指定标记器"filter": [{"type": "stop", # 指定‘stop’作为过滤器类型"stop_words": ["of", "to"], # 指定‘stop’作为过滤器类型}]
}1.3 使用示例
在本示例中,您将创建一个 Collections Schema,其中包括:
-
一个用于嵌入的向量字段。
-
两个
VARCHAR字段,用于文本处理:-
一个字段使用内置分析器。
-
其他使用自定义分析器。
-
1.3.1 初始化 MilvusClient 并创建 Schema
首先设置 Milvus 客户端并创建新的 Schema。
from pymilvus import MilvusClient, DataType# 设置一个Milvus客户端
client = MilvusClient(uri="http://localhost:19530")# 创建一个新模式
schema = client.create_schema(auto_id=True, enable_dynamic_field=False)1.3.2 定义和验证分析仪配置
配置并验证内置分析器(english):定义内置英文分析器的分析器参数。
# 内置分析器配置,用于英文文本处理
analyzer_params_built_in = {"type": "english"
}配置并验证自定义分析器:定义自定义分析器,该分析器使用标准标记符号生成器、内置小写过滤器以及标记符号长度和停用词自定义过滤器。
# 自定义分析器配置与标准标记器和自定义过滤器
analyzer_params_custom = {"tokenizer": "standard","filter": ["lowercase", # 内置过滤器:将令牌转换为小写{"type": "length", # 自定义过滤器:限制令牌长度"max": 40},{"type": "stop", # 自定义过滤:删除指定的停止词"stop_words": ["of", "for"]}]
}
1.3.3 向 Schema 添加字段
在验证了分析器配置后,请将其添加到 Schema 字段中:
# 使用内置分析器配置添加VARCHAR字段‘title_en’
schema.add_field(field_name='title_en',datatype=DataType.VARCHAR,max_length=1000,enable_analyzer=True,analyzer_params=analyzer_params_built_in,enable_match=True,
)# 使用自定义分析器配置添加VARCHAR字段“title”
schema.add_field(field_name='title',datatype=DataType.VARCHAR,max_length=1000,enable_analyzer=True,analyzer_params=analyzer_params_custom,enable_match=True,
)# 为嵌入添加矢量场
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)# 添加主键字段
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)1.3.4 准备索引参数并创建 Collections
# 为矢量场设置索引参数
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")# 使用已定义的模式和索引参数创建集合
client.create_collection(collection_name="my_collection",schema=schema,index_params=index_params
)2 内置分析器
2.1 标准
standard 分析器是 Milvus 的默认分析器,如果没有指定分析器,它将自动应用于文本字段。它使用基于语法的标记化,对大多数语言都很有效。
2.1.1 定义
standard 分析器包括
- 标记化器:使用
standard标记符号化器,根据语法规则将文本分割成离散的单词单位。 - 过滤器:使用
lowercase过滤器将所有标记转换为小写,从而实现不区分大小写的搜索。
standard 分析器的功能相当于以下自定义分析器配置:
analyzer_params = {"tokenizer": "standard","filter": ["lowercase"]
}2.1.2 配置
要将standard 分析器应用到一个字段,只需在analyzer_params 中将type 设置为standard ,并根据需要加入可选参数即可。
analyzer_params = {"type": "standard", # 指定标准分析器类型
} standard 分析器接受以下可选参数:
| 参数 | 说明 |
|---|---|
|
| 一个数组,包含将从标记化中删除的停用词列表。默认为 |
自定义停止词配置示例:
analyzer_params = {"type": "standard", # 指定标准分析器类型"stop_words", ["of"] # 可选:要从标记化中排除的单词列表analyzerParams = map[string]any{"type": "standard", "stop_words": []string{"of"}} 定义analyzer_params 后,您可以在定义 Collections Schema 时将其应用到VARCHAR 字段。这样,Milvus 就能使用指定的分析器处理该字段中的文本,从而实现高效的标记化和过滤。
2.1.3 示例
分析器配置
analyzer_params = {"type": "standard", # 标准分析仪配置"stop_words": ["for"] # 可选:自定义停止词参数
}预期输出
Standard analyzer output: ['the', 'milvus', 'vector', 'database', 'is', 'built', 'scale']2.2 英语
Milvus 中的english 分析器旨在处理英文文本,应用特定语言规则进行标记化和过滤。
2.2.1 定义
english 分析器使用以下组件:
-
标记化器:使用
standard标记化器将文本分割成离散的单词单位。 -
过滤器:包括多个过滤器,用于全面处理文本:
-
lowercase:将所有标记转换为小写,从而实现不区分大小写的搜索。 -
stemmer:将单词还原为词根形式,以支持更广泛的匹配(例如,"running "变为 "run")。 -
stop_words:删除常见的英文停止词,以便集中搜索文本中的关键词语。
-
english 分析器的功能相当于以下自定义分析器配置:
analyzer_params = {"tokenizer": "standard","filter": ["lowercase",{"type": "stemmer","language": "english"}, {"type": "stop","stop_words": "_english_"}]
}2.2.2 配置
要将english 分析器应用到一个字段,只需在analyzer_params 中将type 设置为english ,并根据需要加入可选参数即可。
analyzer_params = {"type": "english",
} english 分析器接受以下可选参数:
| 参数 | 说明 |
|---|---|
|
| 一个数组,包含将从标记化中删除的停用词列表。默认为 |
自定义停止词配置示例:
analyzer_params = {"type": "english","stop_words": ["a", "an", "the"]
} 定义analyzer_params 后,您可以在定义 Collections Schema 时将其应用到VARCHAR 字段。这样,Milvus 就能使用指定的分析器处理该字段中的文本,以实现高效的标记化和过滤。
2.2.3 示例
分析器配置
analyzer_params = {"type": "english","stop_words": ["a", "an", "the"]
}预期输出
English analyzer output: ['milvus', 'vector', 'databas', 'built', 'scale']2.3 中文
chinese 分析器专为处理中文文本而设计,提供有效的分段和标记化功能。
2.3.1 定义
chinese 分析器包括
- 标记化器:使用
jieba标记化器,根据词汇和上下文将中文文本分割成标记。 - 过滤器:使用
cnalphanumonly过滤器删除包含任何非汉字的标记。
chinese 分析器的功能相当于以下自定义分析器配置:
analyzer_params = {"tokenizer": "jieba","filter": ["cnalphanumonly"]
}2.3.2 配置
要将chinese 分析器应用到一个字段,只需在analyzer_params 中将type 设置为chinese 即可。chinese 分析器不接受任何可选参数。
analyzer_params = {"type": "chinese",
}2.3.3 示例
分析器配置
analyzer_params = {"type": "chinese",
}预期输出
Chinese analyzer output: ['Milvus', '是', '一个', '高性', '性能', '高性能', '可', '扩展', '的', '向量', '数据', '据库', '数据库']相关文章:
:分析器)
Milvus(12):分析器
1 分析器概述 在文本处理中,分析器是将原始文本转换为结构化可搜索格式的关键组件。每个分析器通常由两个核心部件组成:标记器和过滤器。它们共同将输入文本转换为标记,完善这些标记,并为高效索引和检索做好准备。 在 Milvus 中&a…...
)
小程序滚动条隐藏(uniapp版本)
单独指定页面隐藏(找到对应的scroll-view) <style> /* 全局隐藏滚动条样式 */ ::-webkit-scrollbar { display: none; width: 0; height: 0; color: transparent; background: transparent; } /* 确保scroll-view组件也隐藏滚动条 */ …...

在 Trae CN IDE 中配置 Python 3.11的指南
在 Trae CN IDE 中配置 Python 3.11的指南 下载 python 3.11 安装 Python 3.11 首先,我们需要确保安装了 Python 3.11。可以从Python 官方网站下载适合你操作系统的版本。 链接 如果你已经安装了 Python 3.11,可以通过以下命令确认: 文…...
)
AI 大模型常见面试题(及内容解析)
大模型领域包含许多专业术语,以下是一些关键术语的解释: 人工智能(AI):是指使计算机系统能够模拟人类智能行为,以执行任务、解决问题和学习的科学和技术。 大型语言模型(LLM)&#…...
)
QT —— QWidget(1)
QT —— QWidget(1) QWidget是啥通俗解释:QWidget 是什么?1. QWidget 能干什么?2. 举个栗子 🌰3. QWidget 的特点4. 和“控件”是什么关系?5. 什么时候用 QWidget?6. 总结 QWidget 核…...

with的用法
Python SQLite 操作详解 本文档详细解释了使用 Python 操作 SQLite 数据库时涉及的关键概念和代码实践,包括 with 语句、事务处理、批量插入以及相关的优化建议。 一、with 语句的作用(自动关门的保险库) with sqlite3.connect(city_1301.d…...
)
Go反射-通过反射调用结构体的方法(带入参)
使用反射前,我们需要提前做好映射配置 papckage_struct_relationship.go package reflectcommonimport (api "template/api" )// 包名到包对象的映射 var structMap map[string]func() interface{}{"template/api": func() interface{} { re…...
)
C++/SDL 进阶游戏开发 —— 双人塔防(代号:村庄保卫战 19)
🎁个人主页:工藤新一 🔍系列专栏:C面向对象(类和对象篇) 🌟心中的天空之城,终会照亮我前方的路 🎉欢迎大家点赞👍评论📝收藏⭐文章 文章目录 二…...

使用 Selenium 爬取动态网页数据 —— 实战与坑点详解
本文记录了笔者在爬取网页数据过程中遇到的各种技术挑战,包括页面动态渲染、JavaScript 注入等问题,并最终给出一个可运行的完整方案。 文章目录 网页获取不到数据🚀 尝试用 Selenium 渲染页面 网页获取不到数据 某网页数据依赖大量 JavaSc…...

强化学习--2.数学
强化学习--数学 1、概率统计知识1.1 随机变量与观测值1.2 概率密度函数(PDF)1.3 期望1.4 随机抽样 2、数据期望E3、正态分布4、条件概率1. **与多个条件相关**(依赖所有前置条件)2. **仅与上一个条件相关**(马尔可夫性…...

rails 8 CSS不起效问题解决
很久没用rails了,最近打算重新复习一下。在配置好环境后,创建了项目,通过脚手架创建了数据库表,和相关的文件。但我发现却没有生成相应的CSS文件,可能是rails8 取消了吧。于是自己手动创建了相应的css文件。但是刷新页…...
)
双指针算法详解(含力扣和蓝桥杯例题)
目录 一、双指针算法核心概念 二、常用的双指针类型: 2.1 对撞指针 例题1:盛最多水的容器 例题2:神奇的数组 2.2 快慢指针: 例题1:移动零 例题2:美丽的区间(蓝桥OJ1372) 3.总…...

C 语言字符输入:掌握 getchar 和 scanf 的用法与陷阱
各类资料学习下载合集 https://pan.quark.cn/s/8c91ccb5a474 C 语言字符输入:掌握 getchar 和 scanf 的用法与陷阱 你好!在 C 语言编程中,与用户进行交互最基本的方式就是通过标准输入和标准输出。我们之前探讨了如何使用 printf 和 putchar 进行…...

算法笔记。质数筛算法
题目: 给定一个正整数 n,请你求出 1∼n 中质数的个数。 输入格式 共一行,包含整数 n。 输出格式 共一行,包含一个整数,表示 1∼n 中质数的个数。 数据范围 1≤n≤106 输入样例: 8输出样例…...

C语言中memmove和memcpy
1、memmove()函数 void *memmove(void *str1, const void *str2, size_t n); 将str2所指向的存储区的前n个字节复制到str1所指向的存储区。 memmove()允许“str1和str2所指向的存储区重叠”。通过检查地址关系,自动选择复制方向(从前往后或从后往前&a…...
空间跳跃))
GESP2024年6月认证C++八级( 第三部分编程题(2)空间跳跃)
参考程序: #include <cstdio> #include <vector> #include <queue> #include <utility> #include <cstring> using namespace std;// 定义一个结构体,用于 Dijkstra 优先队列中的节点 struct Node {int v, w; // v 表示图…...

使用DeepSeek定制Python小游戏——以“俄罗斯方块”为例
前言 本来想再发几个小游戏后在整理一下流程的,但是今天试了一下这个俄罗斯方块的游戏结果发现本来修改的好好的的,结果后面越改越乱,前面的版本也没保存,根据AI修改他是在几个版本改来改去,想着要求还是不能这么高。…...

Linux中安装mysql8,转载及注意事项
一、先前往官网下载mysql8 下载地址: https://dev.mysql.com/downloads/选择Linux 二、删除Linux中的mysql(如果有的话),上传安装包 1、先查看mysql是否存在,命令如下: rpm -qa|grep -i mysql如果使用这…...

网站即时备份,网站即时备份的方法有哪些
网站数据的安全性与业务连续性直接关系到企业的核心竞争力。无论是因硬件故障、人为误操作、网络攻击还是自然灾害,数据丢失或服务中断都可能带来难以估量的损失。因此,网站即时备份成为保障业务稳定性的关键技术手段。 一、核心即时备份技术方案 云服…...

LVM扩容小计
文章目录 [toc]当前磁盘使用问题分析关键问题定位推荐解决方案方案一:扩展根分区(LVM 动态扩容)方案二:清理磁盘空间(紧急临时处理) 当前磁盘使用问题分析 根据你的磁盘信息,根文件系统 (/) 已…...
)
【2025软考高级架构师】——案例分析总结(13)
摘要 本文对2025年软考高级架构师的考纲及案例分析进行了总结。内容涵盖系统规划、架构设计、系统建模、安全架构、可靠性分析、大数据架构等多方面知识点,还涉及软件质量特性、系统流程图与数据流图、嵌入式系统架构、分布式系统设计等考查内容,详细列…...

Redis ⑨-Jedis | Spring Redis
Jedis 通过 Jedis 可以连接 Redis 服务器。 通过 Maven 引入 Jedis 依赖。 <!-- https://mvnrepository.com/artifact/redis.clients/jedis --> <dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><versi…...

aidermacs开源程序使用 Aider 在 Emacs 中进行 AI 配对编程
一、软件介绍 文末提供程序和源码下载 Aidermacs 通过集成 Aider(最强大的开源 AI 配对编程工具之一)为 Emacs 带来了 AI 驱动的开发。如果您缺少 Cursor,但更喜欢生活在 Emacs 中,Aidermacs 提供了类似的 AI 功能,同…...
)
HarmonyOS NEXT——DevEco Studio的使用(还没写完)
一、IDE环境的搭建 Windows环境 运行环境要求 为保证DevEco Studio正常运行,建议电脑配置满足如下要求: 操作系统:Windows10 64位、Windows11 64位 内存:16GB及以上 硬盘:100GB及以上 分辨率:1280*8…...
)
使用PageHelper实现分页查询(详细)
一:需求分析与设计 1.1 产品原型 (1)分页展示,每页展示10条数据,根据员工姓名进行搜索 (2)业务规则 1.2 接口设计 (1)操作:查询,请求方式…...

神经网络基础-从零开始搭建一个神经网络
一、什么是神经网络 人工神经网络(Articial Neural Network,简写为ANN)也称为神经网络(NN),是一种模仿生物神经网络和功能的计算模型,人脑可以看做是一个生物神经网络,由众多的神经元连接而成,…...

数据库原理与应用实验二 题目七
利用sql建立教材数据库,并定义以下基本表: 学生(学号,年龄,性别,系名) 教材(编号,书名,出版社编号,价格) 订购(学号,书号,数量) 出版社(编号,名称,地址) 1定义主码、外码、和价格、数量的取值范围。 2 在三个表中输入若干记录,注意如果输入违反完整…...

如何在 CentOS 7 命令行连接 Wi-Fi?如何在 Linux 命令行连接 Wi-Fi?
如何在 CentOS 7 命令行连接 Wi-Fi?如何在 Linux 命令行连接 Wi-Fi? 摘要 本教程覆盖如何在多种 Linux 发行版下通过命令行连接 Wi-Fi,包括: CentOS 7、Ubuntu、Debian、Arch Linux、Fedora、Alpine Linux、Kali Linux、OpenSU…...

【学习笔记】 强化学习:实用方法论
作者选择了由 Ian Goodfellow、Yoshua Bengio 和 Aaron Courville 三位大佬撰写的《Deep Learning》(人工智能领域的经典教程,深度学习领域研究生必读教材),开始深度学习领域学习,深入全面的理解深度学习的理论知识。 之前的文章参考下面的链接…...
:字段膨胀(Mapping 爆炸)问题的解决思路)
ElasticSearch深入解析(十):字段膨胀(Mapping 爆炸)问题的解决思路
文章目录 一、核心原理:动态映射的双刃剑1. 动态映射的工作机制2. 映射爆炸的触发条件3. 底层性能损耗 二、典型场景与案例分析1. 日志系统:动态标签引发的灾难2. 物联网数据:设备属性的无序扩展 三、系统性解决方案1. 架构层优化2. 配置层控…...

react18基础速成
1、项目搭建 npx create-react-app my-react-app(项目名) cd 项目名进入项目目录 终端输入 npm start 启动项目 浏览器查看 项目搭建成功 2、JSX JavaScript语法和HTML语法写在一起就是JSX语法 jsx只能返回一个根元素,即最外层的div&a…...

18、状态库:中央魔法仓库——React 19 Zustand集成
一、量子熔炉的诞生 "Zustand是记忆水晶的量子纠缠体,让状态流无需魔杖驱动即可自洽!"霍格沃茨炼金术研究院的工程师挥动魔杖,Zustand 的原子化状态流在空中交织成星轨矩阵。 ——基于《魔法国会》第2025号协议,Zustan…...

PyCharm中全局搜索无效
发现是因为与搜狗快捷键冲突了,把框选的那个勾选去掉或设置为其他键就好了...

【Hive入门】Hive与Spark SQL深度集成:执行引擎性能全面对比与调优分析
目录 引言 1 Hive执行引擎架构演进 1.1 Hive执行引擎发展历程 1.2 执行引擎架构对比 1.2.1 MapReduce引擎架构 1.2.2 Tez引擎架构 1.2.3 Spark引擎架构 2 执行引擎切换与配置指南 2.1 引擎切换配置方法 2.1.1 全局配置 2.1.2 会话级配置 2.2 资源管理配置 2.2.1 T…...

【算法基础】快速排序算法 - JAVA
一、算法基础 1.1 什么是快速排序 快速排序(Quick Sort)是一种高效的分治排序算法,由英国计算机科学家Tony Hoare于1960年提出。它的核心思想是: 选择一个基准元素(pivot)将数组分成两部分:小…...

Ubuntu 24.04 通过 update-alternatives 切换GCC版本
在 Ubuntu 中编译项目, 会遇到项目依赖于某个特定版本 GCC 的情况, 例如 Ubuntu 24.04 的默认 GCC 版本是 13, 但是有一些项目需要 GCC11才能正常编译, 在 Ubuntu 24.04 默认的环境下编译会报错. 这时候可以通过 update-alternatives 切换GCC版本. all 展示全部 用--all参数会…...

Linux中的时间同步
一、时间同步服务扩展总结 1. 时间同步的重要性 多主机协作需求:在分布式系统、集群、微服务架构中,时间一致性是日志排序、事务顺序、数据一致性的基础。 安全协议依赖:TLS/SSL证书、Kerberos认证等依赖时间有效性,时间偏差可能…...
——质量管理——时效性原则)
数据赋能(209)——质量管理——时效性原则
概述 数据时效性原则在数据收集、处理、分析和应用的过程中确保数据在特定时间范围内保持其有效性和相关性,为决策提供准确、及时的依据。在快速变化的市场环境中,数据时效性对于企业的竞争力和决策效率具有决定性的影响。 原则定义 数据时效性原则&a…...

AnimateCC教学:照片旋转飞舞并爆炸....
1.核心代码: <!DOCTYPE html> <html><head><meta charset="UTF-8" /><title>旋转照片演示</title><script src="https://code.createjs.com/1.0.0/createjs.min.js"></script><script src="http…...

腾讯混元-DiT 文生图
1 混元-DiT所需的模型大小一共是41G https://huggingface.co/Tencent-Hunyuan/HunyuanDiT https://colab.research.google.com/ HunyuanDiT_jupyter.ipynb %cd /content !GIT_LFS_SKIP_SMUDGE1 git clone -b dev https://github.com/camenduru/HunyuanDiT %cd /content/Hun…...

优化高搜索量还是低竞争关键词?SEO策略解析
在2025年的SEO环境中,关键词研究仍然是优化网站排名的基石。然而,一个常见的问题困扰着SEO从业者:在使用谷歌关键词规划师(Google Keyword Planner)进行关键词研究时,是否应该优先选择月搜索量较高的关键词…...

对比表格:数字签名方案、密钥交换协议、密码学协议、后量子密码学——密码学基础
文章目录 一、数字签名方案1.1 ECDSA:基于椭圆曲线的数字签名算法1.2 EdDSA:Edwards曲线数字签名算法1.3 RSA-PSS:带有概率签名方案的RSA1.4 数字签名方案对比 二、密钥交换协议2.1 Diffie-Hellman密钥交换2.2 ECDH:椭圆曲线Diffi…...

在MySQL中建索引时需要注意哪些事项?
在 MySQL 中建立索引是优化查询性能的重要手段,但不当的索引设计可能导致资源浪费、性能下降甚至拖慢写入速度。 所以我们我们首先要判断对于一个字段或者一些字段要不要建立索引。 适合建立索引的字段通常是: 主键字段:MySQL 会自动为主键…...

dstack 是 Kubernetes 和 Slurm 的开源替代方案,旨在简化 ML 团队跨顶级云、本地集群和加速器的 GPU 分配和 AI 工作负载编排
一、软件介绍 文末提供程序和源码下载 dstack 是 Kubernetes 和 Slurm 的开源替代方案,旨在简化顶级云和本地集群中 ML 团队的 GPU 分配和 AI 工作负载编排。 二、Accelerators 加速器 dstack 支持 NVIDIA 开箱即用的 、 AMD 、 Google TPU 和 Intel Gaudi 加速器…...

Linux 的 epoll 与 Windows 的 IOCP 详解
如果你在搞网络编程或者高性能服务器,一定要搞懂这两个模型——它们都是用来解决“多路复用”问题的工具,让你同时处理大量的网络连接变得高效又可控。 一、什么是“多路复用”? 简单说,就是你手里有很多任务(比如很多客户端的请求),但系统的核心(线程或者进程)资源…...
)
C# 方法(控制流和方法调用)
本章内容: 方法的结构 方法体内部的代码执行 局部变量 局部常量 控制流 方法调用 返回值 返回语句和void方法 局部函数 参数 值参数 引用参数 引用类型作为值参数和引用参数 输出参数 参数数组 参数类型总结 方法重载 命名参数 可选参数 栈帧 递归 控制流 方法包含了组成程序的…...

Webug4.0靶场通关笔记11- 第15关任意文件下载与第16关MySQL配置文件下载
目录 一、文件下载 二、第15关 任意文件下载 1.打开靶场 2.源码分析 3.渗透实战 三、第16关 MySQL配置文件下载 1.打开靶场 2.源码分析 3.渗透实战 (1)Windows系统 (2)Linux系统 四、渗透防御 一、文件下载 本文通过…...

More Effective C++学习笔记
条款1 指针与引用的区别 条款2 尽量使用C风格的类型转换 条款3 不要对数组使用多态 条款4 避免无用的缺省构造函数 条款5 谨慎定义类型转换函数 条款6 自增(increment)、自减(decrement)操作符前缀形式与后缀形式的区别 条款7 不要重载“&&”,“||”, 或“,” 条款8 理…...

如何设计抗Crosstalk能力强的PCB镀穿孔
一个高速PCB通道通常包含芯片SerDes IP、走线、穿层Via、连接器和Cable。 其中内层走线对于Crosstalk影响甚微(请参考什么? Stripline的FEXT为0! Why? ),而Via与连接器由于其参考路径较差的关系,…...

多线程系列三:这就是线程的状态?
1.认识线程的状态 NEW:Thread对象已经创建好了,但还没有调用start方法在系统中创建线程 RUNNABLE:就绪状态,表示这个线程正在CPU上执行,或准备就绪,随时可以去CPU上执行 BLOCKED:表示由于锁竞争…...