强化学习--2.数学
强化学习--数学
- 1、概率统计知识
- 1.1 随机变量与观测值
- 1.2 概率密度函数(PDF)
- 1.3 期望
- 1.4 随机抽样
- 2、数据期望E
- 3、正态分布
- 4、条件概率
- 1. **与多个条件相关**(依赖所有前置条件)
- 2. **仅与上一个条件相关**(马尔可夫性质)
- 5、马尔可夫
- 1、马尔可夫链
- 2、n 阶马尔可夫链
- 3、马尔可夫奖励过程/决策过程
- 4、隐马尔可夫
- 隐马尔可夫模型(HMM)
- 三个基本问题
- 前向算法、后向算法、Viterbi算法
- 6、KL散度(相对熵)
- 1、相对熵(KL散度)
- 2、交叉熵
- 7、贝尔曼方程
- **1. 定义问题**
- **2. 贝尔曼方程的推导**
- **状态值函数的贝尔曼方程**
- **动作值函数的贝尔曼方程**
- **3. 贝尔曼最优方程**
- **4. 关键思想**
- **总结**
- 8、强化学习知识点
1、概率统计知识
强化学习数学基础详解与示例
参考:https://blog.csdn.net/CltCj/article/details/119445005
1.1 随机变量与观测值
定义
随机变量是描述随机事件结果的变量,其取值具有不确定性;观测值则是随机事件实际发生后记录的具体结果。
示例:
假设抛一枚硬币,定义随机变量 X X X 表示抛硬币结果:正面记为 X = 1 X=1 X=1,反面记为 X = 0 X=0 X=0。抛硬币前, X X X 的取值是未知的,但概率分布已知( P ( X = 1 ) = 0.5 P(X=1)=0.5 P(X=1)=0.5, P ( X = 0 ) = 0.5 P(X=0)=0.5 P(X=0)=0.5)。若连续抛4次硬币,得到观测值序列 x 1 = 1 , x 2 = 0 , x 3 = 1 , x 4 = 1 x_1=1, x_2=0, x_3=1, x_4=1 x1=1,x2=0,x3=1,x4=1,这些具体数值即为观测值。
1.2 概率密度函数(PDF)
定义
概率密度函数描述随机变量在某一取值附近的相对可能性。
• 连续型分布:如高斯分布 N ( μ , σ 2 ) \mathcal{N}(\mu, \sigma^2) N(μ,σ2),其概率密度函数为:
p ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 p(x) = \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{(x-\mu)^2}{2\sigma^2}} p(x)=2πσ1e−2σ2(x−μ)2
该函数表明随机变量在均值 μ \mu μ 附近取值的概率较高。
• 离散型分布:例如随机变量 X X X 的取值为 {1, 3, 7},对应的概率密度函数为:
P ( X = 1 ) = 0.2 , P ( X = 3 ) = 0.5 , P ( X = 7 ) = 0.3 P(X=1)=0.2, \quad P(X=3)=0.5, \quad P(X=7)=0.3 P(X=1)=0.2,P(X=3)=0.5,P(X=7)=0.3
所有可能取值的概率之和为1。
1.3 期望
定义
期望是随机变量所有可能取值的概率加权平均,反映其长期平均结果。
• 连续型期望:
E [ f ( X ) ] = ∫ − ∞ ∞ f ( x ) p ( x ) d x \mathbb{E}[f(X)] = \int_{-\infty}^{\infty} f(x) p(x) \, dx E[f(X)]=∫−∞∞f(x)p(x)dx
例如,高斯分布 X ∼ N ( 0 , 1 ) X \sim \mathcal{N}(0, 1) X∼N(0,1) 的期望为 μ = 0 \mu=0 μ=0 。
• 离散型期望:
E [ f ( X ) ] = ∑ x ∈ X f ( x ) P ( X = x ) \mathbb{E}[f(X)] = \sum_{x \in \mathcal{X}} f(x) P(X=x) E[f(X)]=x∈X∑f(x)P(X=x)
以离散分布 P ( X = 1 ) = 0.2 , P ( X = 3 ) = 0.5 , P ( X = 7 ) = 0.3 P(X=1)=0.2, P(X=3)=0.5, P(X=7)=0.3 P(X=1)=0.2,P(X=3)=0.5,P(X=7)=0.3 为例,其期望为:
E [ X ] = 1 × 0.2 + 3 × 0.5 + 7 × 0.3 = 3.8 \mathbb{E}[X] = 1 \times 0.2 + 3 \times 0.5 + 7 \times 0.3 = 3.8 E[X]=1×0.2+3×0.5+7×0.3=3.8
。
1.4 随机抽样
定义
随机抽样是从概率分布中生成观测值的过程,用于近似理论分布。
示例:
假设一个箱子中有红球(20%)、绿球(50%)、蓝球(30%),每次随机抽取一个球并记录颜色。重复多次后,观测值的分布会趋近理论概率。通过Python代码实现:
import numpy as np
samples = np.random.choice(['R', 'G', 'B'], size=100, p=[0.2, 0.5, 0.3])
结果可能为 ['G', 'B', 'R', 'G', ...],其中红球占比接近20%,绿球50%,蓝球30%。
强化学习中的关联应用
- 策略函数中的动作选择:策略 π ( a ∣ s ) \pi(a|s) π(a∣s) 可视为动作空间的概率密度函数,例如在状态 s s s 下,动作 a 1 a_1 a1 的概率为0.7, a 2 a_2 a2 为0.3,通过随机抽样决定实际动作。
- 状态转移的随机性:环境的状态转移概率 P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a) 类似条件概率密度函数,例如智能体执行动作后,环境可能以80%概率转移到状态 s 1 s_1 s1,20%概率到 s 2 s_2 s2 。
- 蒙特卡洛方法:通过随机抽样轨迹估计状态价值函数,例如多次模拟游戏过程,计算平均回报以近似期望值。
2、数据期望E
https://zhuanlan.zhihu.com/p/481760712
离散型随机变量的一切可能的取值与对应的概率乘积之和称为该离散型随机变量的数学期望 [2](若该求和绝对收敛),记为E(x)




3、正态分布
https://baike.baidu.com/item/%E6%AD%A3%E6%80%81%E5%88%86%E5%B8%83/829892
正态分布(Normal distribution),又称为常态分布或高斯分布,通常记作X~N(μ ,σ2)。其中, μ是正态分布的数学期望(均值), σ2是正态分布的方差。μ = 0,σ = 1的正态分布被称为标准正态分布 [1]。


4、条件概率
https://baike.baidu.com/item/%E6%9D%A1%E4%BB%B6%E6%A6%82%E7%8E%87/4475278
- 条件概率
条件概率是指事件A在事件B发生的条件下发生的概率。条件概率表示为:P(A|B),读作“A在B发生的条件下发生的概率”。若只有两个事件A,B,那么,。 - 联合概率
表示两个事件共同发生的概率。A与B的联合概率表示为 P(AB) 或者P(A,B),或者P(A∩B)。 [2] - 边缘概率
是某个事件发生的概率,而与其它事件无关。边缘概率是这样得到的:在联合概率中,把最终结果中不需要的那些事件合并成其事件的全概率而消失(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率)。这称为边缘化(marginalization)。A的边缘概率表示为P(A),B的边缘概率表示为P(B)。
条件概率,多条件Xn,与多个条件相关和只与上一个条件相关:
当事件序列 X 1 , X 2 , … , X n X_1, X_2, \dots, X_n X1,X2,…,Xn 的条件概率依赖关系不同时,联合概率的计算方式也会不同。
1. 与多个条件相关(依赖所有前置条件)
• 定义:每个事件 X i X_i Xi 的条件概率依赖于之前所有事件 X 1 , X 2 , … , X i − 1 X_1, X_2, \dots, X_{i-1} X1,X2,…,Xi−1 的发生。
• 链式法则:
联合概率可分解为一系列条件概率的乘积,公式为:
P ( X 1 , X 2 , … , X n ) = P ( X 1 ) ⋅ P ( X 2 ∣ X 1 ) ⋅ P ( X 3 ∣ X 1 , X 2 ) ⋅ ⋯ ⋅ P ( X n ∣ X 1 , … , X n − 1 ) P(X_1, X_2, \dots, X_n) = P(X_1) \cdot P(X_2|X_1) \cdot P(X_3|X_1,X_2) \cdot \dots \cdot P(X_n|X_1,\dots,X_{n-1}) P(X1,X2,…,Xn)=P(X1)⋅P(X2∣X1)⋅P(X3∣X1,X2)⋅⋯⋅P(Xn∣X1,…,Xn−1)
- 概率计算:在这种情况下,计算事件 A 发生的概率 P(A|B,C,D) 可以用联合概率除以边缘概率的方法,即 P(A|B,C,D) = P(A,B,C,D)/P(B,C,D),其中 P(B,C,D) > 0。联合概率 P(A,B,C,D) 表示事件 A、B、C、D 同时发生的概率,边缘概率 P(B,C,D) 表示事件 B、C、D 同时发生的概率。
2. 仅与上一个条件相关(马尔可夫性质)
• 定义:每个事件 X i X_i Xi 的条件概率仅依赖于前一个事件 X i − 1 X_{i-1} Xi−1,即 P ( X i ∣ X 1 , … , X i − 1 ) = P ( X i ∣ X i − 1 ) P(X_i|X_1,\dots,X_{i-1}) = P(X_i|X_{i-1}) P(Xi∣X1,…,Xi−1)=P(Xi∣Xi−1)。
• 简化形式:
联合概率可简化为:
P ( X 1 , X 2 , … , X n ) = P ( X 1 ) ⋅ P ( X 2 ∣ X 1 ) ⋅ P ( X 3 ∣ X 2 ) ⋅ ⋯ ⋅ P ( X n ∣ X n − 1 ) P(X_1, X_2, \dots, X_n) = P(X_1) \cdot P(X_2|X_1) \cdot P(X_3|X_2) \cdot \dots \cdot P(X_n|X_{n-1}) P(X1,X2,…,Xn)=P(X1)⋅P(X2∣X1)⋅P(X3∣X2)⋅⋯⋅P(Xn∣Xn−1)
这种形式常见于时序模型(如马尔可夫链),例如网页 6 提到的股票价格预测中,当前价格可能仅依赖前一时段的价格。
- 概率计算:在这种情况下,条件概率可以简化为 P(A|B),而不必考虑更前面的条件。例如,在一个二阶马尔可夫链中,事件 A 发生的概率只与前两个事件有关,即 P(A|B,C),但与更早的事件无关。不过,对于一阶马尔可夫链,就只考虑前一个事件,即 P(A|B)。
5、马尔可夫
https://zhuanlan.zhihu.com/p/489239366
https://zhuanlan.zhihu.com/p/448575579
1、马尔可夫链
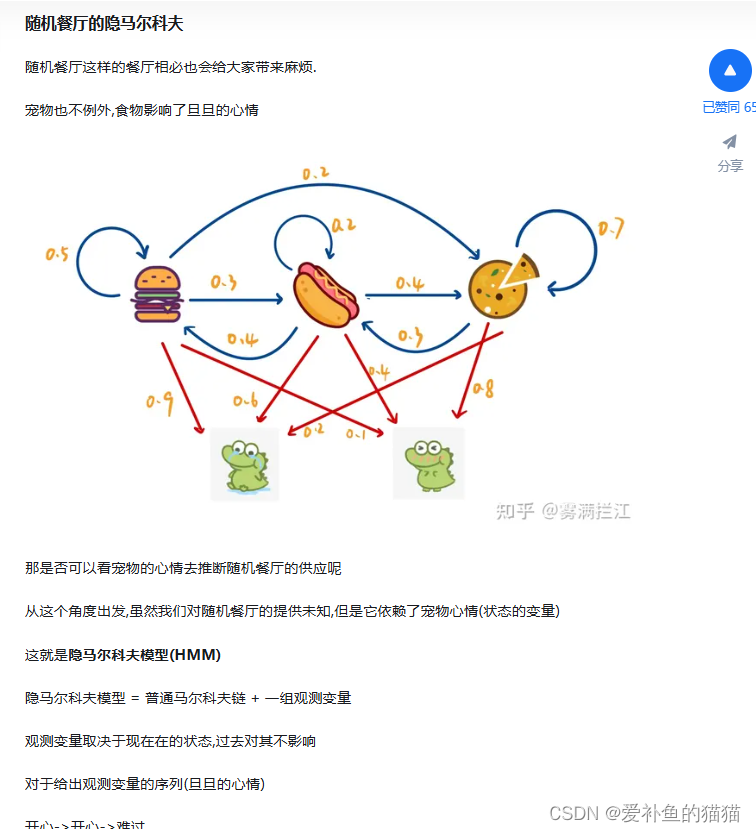
俄国数学家 Andrey Andreyevich Markov 研究并提出一个用数学方法就能解释自然变化的一般规律模型,被命名为马尔科夫链(Markov Chain)。马尔科夫链为状态空间中经过从一个状态到另一个状态的转换的随机过程,该过程要求具备“无记忆性 ”,即下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。这种特定类型的“无记忆性 ”称作马尔可夫性质。
状态转移矩阵的稳定性:
状态转移矩阵有一个非常重要的特性,经过一定有限次数序列的转换,最终一定可以得到一个稳定的概率分布 ,且与初始状态概率分布无关。
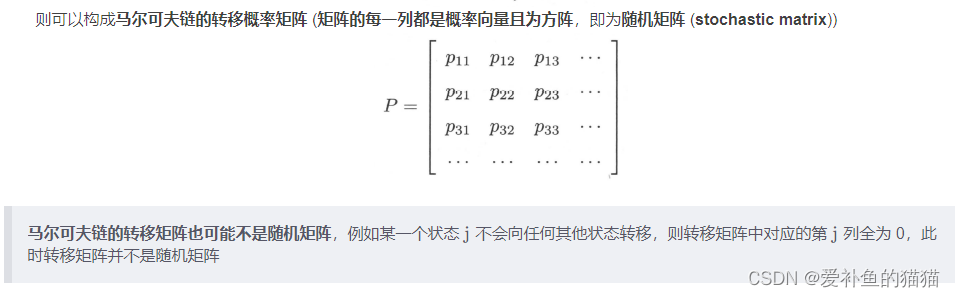
马尔科夫链(Markov Chain)-随机餐厅
https://zhuanlan.zhihu.com/p/489239366

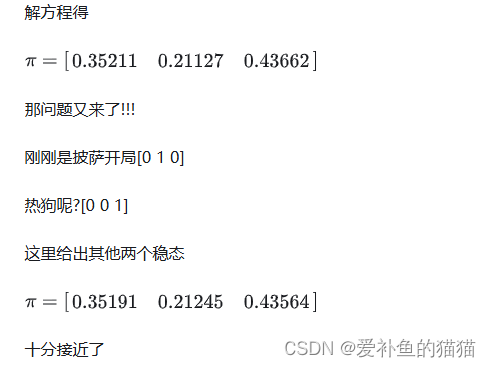
2、n 阶马尔可夫链
http://www.mselab.cn/media/files/B03.%E9%A9%AC%E5%B0%94%E5%8F%AF%E5%A4%AB%E6%A8%A1%E5%9E%8B.pdf
马尔科夫过程是指过程中的状态的转移依赖于之前的状态,当影响转移状态的数目是n时,这个过程被称为 n阶马尔科夫模型.

N-Gram最简单有效,所以应用的也最广泛。它基于独立输入假设:第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。
应用:
让机器“听懂”人类的语言,两个马尔科夫模型就解决了:
声学模型:利用HMM建模(隐马尔可夫模型),HMM是指这一马尔可夫模型的内部状态外界不可见,外界只能看到各个时刻的输出值。对语音识别系统,输出值通常就是从各个帧计算而得的声学特征。
语言模型:N-Gram最简单有效,所以应用的也最广泛。它基于独立输入假设:第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。

3、马尔可夫奖励过程/决策过程
https://www.cnblogs.com/jsfantasy/p/jsfantasy.html
https://blog.csdn.net/qq_33302004/article/details/115027798
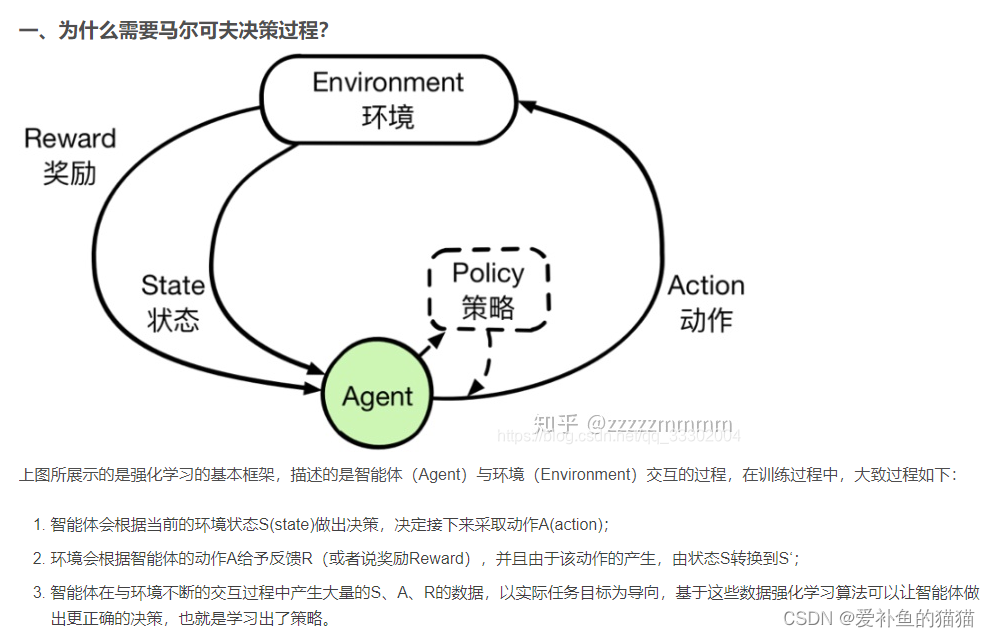
马尔科夫过程又叫做马尔科夫链(Markov Chain),它是一个无记忆的随机过程,可以用一个元组<S, P>表示。(上节回顾)。



马尔科夫奖励过程: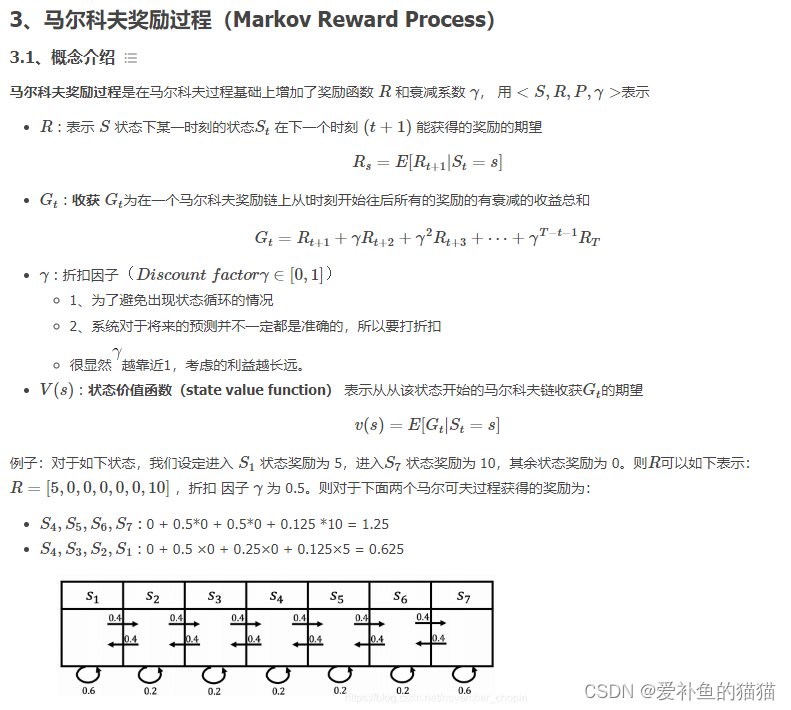
通过贝尔曼方程,可以看到价值函数有两部分组成,一个是当前获得的奖励的期望,另一个是下一时刻的状态期望,即下一时刻 可能的状态能获得奖励期望与对应状态转移概率乘积的和,最后在加上折扣。

马尔科夫决策过程(Markov Decision Process),马尔科夫决策过程是在马尔科夫奖励过程的基础上加了 Decision 过程,相当于多了一个动作集合。最优价值函数
解决强化学习问题意味着要寻找一个最优的策略让个体在与环境交互过程中获得始终比其它策略都要多的收获,这个最优策略我们可以用 π 表示。一旦找到这个最优策略π ,那么我们就解决了这个强化学习问题。一般来说,比较难去找到一个最优策略,但是可以通过比较若干不同策略的优劣来确定一个较好的策略,也就是局部最优解。

4、隐马尔可夫
https://zhuanlan.zhihu.com/p/35651762
https://zhuanlan.zhihu.com/p/151011287
https://zhuanlan.zhihu.com/p/547259609
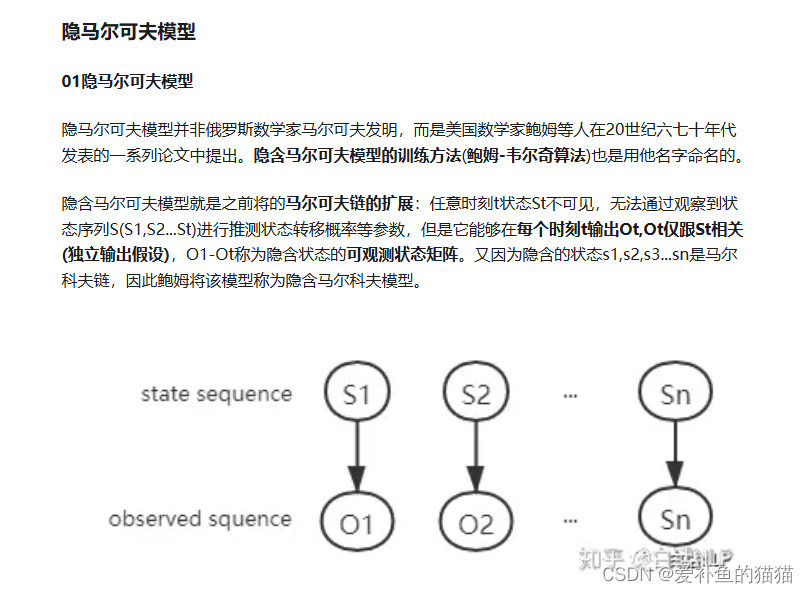
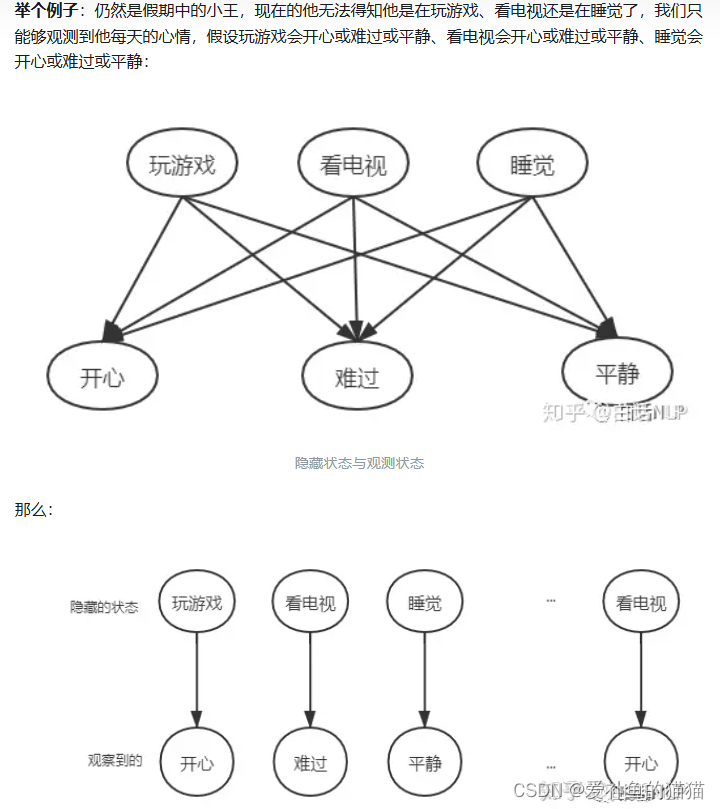
隐马尔可夫模型(HMM)
隐马尔可夫模型(Hidden Markov Model,HMM)是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言应用领域。经过长期发展,尤其在语音识别中成功应用,使它成为一种通用的统计工具。

三个基本问题
https://blog.csdn.net/qq_52785580/article/details/135746941
https://zhuanlan.zhihu.com/p/151011287
https://zhuanlan.zhihu.com/p/88362664

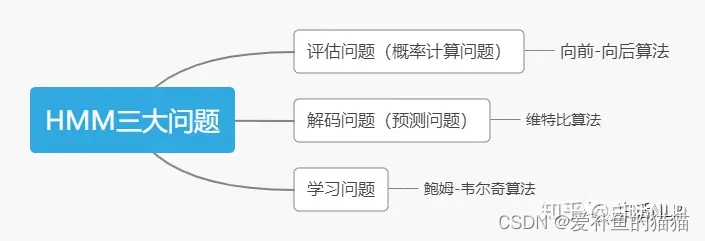

前向算法、后向算法、Viterbi算法
https://zhuanlan.zhihu.com/p/35651762
https://zhuanlan.zhihu.com/p/547259609
https://zhuanlan.zhihu.com/p/29938926






6、KL散度(相对熵)
https://blog.csdn.net/Rocky6688/article/details/103470437
https://zhuanlan.zhihu.com/p/74075915
信息量、熵、相对熵(KL散度)、交叉熵、JS散度、推土机理论、Wasserstein距离、WGAN中对JS散度,KL散度和推土机距离的描述
1、相对熵(KL散度)
相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异。
在机器学习中,P往往用来表示样本的真实分布,Q用来表示模型所预测的分布,那么KL散度就可以计算两个分布的差异,也就是Loss损失值。
从KL散度公式中可以看到Q的分布越接近P(Q分布越拟合P),那么散度值越小,即损失值越小。
因为对数函数是凸函数,所以KL散度的值为非负数。
有时会将KL散度称为KL距离,但它并不满足距离的性质:
KL散度不是对称的;
KL散度不满足三角不等式。

2、交叉熵

7、贝尔曼方程
贝尔曼方程,又叫动态规划方程,是以Richard Bellman命名的,表示动态规划问题中相邻状态关系的方程。某些决策问题可以按照时间或空间分成多个阶段,每个阶段做出决策从而使整个过程取得效果最优的多阶段决策问题,可以用动态规划方法求解。某一阶段最优决策的问题,通过贝尔曼方程转化为下一阶段最优决策的子问题,从而初始状态的最优决策可以由终状态的最优决策(一般易解)问题逐步迭代求解。存在某种形式的贝尔曼方程,是动态规划方法能得到最优解的必要条件。绝大多数可以用最优控制理论解决的问题,都可以通过构造合适的贝尔曼方程来求解。
贝尔曼方程是强化学习中描述状态值函数(或动作值函数)递归关系的核心方程,其推导基于马尔科夫决策过程(MDP)和全期望公式。以下是关键步骤和逻辑:
1. 定义问题
- 状态值函数 V π ( s ) V^\pi(s) Vπ(s):在策略 π \pi π 下,从状态 s s s 开始的期望累积回报:
V π ( s ) = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] V^\pi(s) = \mathbb{E}_\pi\left[ \sum_{k=0}^\infty \gamma^k R_{t+k+1} \mid S_t = s \right] Vπ(s)=Eπ[k=0∑∞γkRt+k+1∣St=s]
其中 γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1] 是折扣因子, R t + k + 1 R_{t+k+1} Rt+k+1 是未来奖励。 - 动作值函数 Q π ( s , a ) Q^\pi(s,a) Qπ(s,a):在状态 s s s 执行动作 a a a 后,遵循策略 π \pi π 的期望累积回报:
Q π ( s , a ) = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s , A t = a ] Q^\pi(s,a) = \mathbb{E}_\pi\left[ \sum_{k=0}^\infty \gamma^k R_{t+k+1} \mid S_t = s, A_t = a \right] Qπ(s,a)=Eπ[k=0∑∞γkRt+k+1∣St=s,At=a]

2. 贝尔曼方程的推导
状态值函数的贝尔曼方程
- 分解回报:将累积回报拆分为即时奖励和未来奖励:
V π ( s ) = E π [ R t + 1 + γ ∑ k = 1 ∞ γ k − 1 R t + k + 1 ∣ S t = s ] V^\pi(s) = \mathbb{E}_\pi\left[ R_{t+1} + \gamma \sum_{k=1}^\infty \gamma^{k-1} R_{t+k+1} \mid S_t = s \right] Vπ(s)=Eπ[Rt+1+γk=1∑∞γk−1Rt+k+1∣St=s] - 利用马尔科夫性质:下一状态 s ′ s' s′ 的转移概率仅依赖当前状态 s s s 和动作 a a a,即 P ( s ′ ∣ s , a ) P(s' \mid s, a) P(s′∣s,a),且策略 π ( a ∣ s ) \pi(a \mid s) π(a∣s) 决定动作选择。
- 全期望公式展开:
V π ( s ) = ∑ a π ( a ∣ s ) [ R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) V π ( s ′ ) ] V^\pi(s) = \sum_{a} \pi(a \mid s) \left[ R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) V^\pi(s') \right] Vπ(s)=a∑π(a∣s)[R(s,a)+γs′∑P(s′∣s,a)Vπ(s′)]
其中 R ( s , a ) = E [ R t + 1 ∣ S t = s , A t = a ] R(s,a) = \mathbb{E}[R_{t+1} \mid S_t=s, A_t=a] R(s,a)=E[Rt+1∣St=s,At=a] 是即时奖励期望 。
动作值函数的贝尔曼方程
- 类似地,对 Q π ( s , a ) Q^\pi(s,a) Qπ(s,a) 进行分解:
Q π ( s , a ) = R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) ∑ a ′ π ( a ′ ∣ s ′ ) Q π ( s ′ , a ′ ) Q^\pi(s,a) = R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) \sum_{a'} \pi(a' \mid s') Q^\pi(s',a') Qπ(s,a)=R(s,a)+γs′∑P(s′∣s,a)a′∑π(a′∣s′)Qπ(s′,a′)
即当前动作 a a a 的价值等于即时奖励加上未来动作价值的期望 。
3. 贝尔曼最优方程
若策略 π \pi π 是最优策略 π ∗ \pi^* π∗,则值函数满足贝尔曼最优方程:
V ∗ ( s ) = max a [ R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) V ∗ ( s ′ ) ] V^*(s) = \max_a \left[ R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) V^*(s') \right] V∗(s)=amax[R(s,a)+γs′∑P(s′∣s,a)V∗(s′)]
Q ∗ ( s , a ) = R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) max a ′ Q ∗ ( s ′ , a ′ ) Q^*(s,a) = R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) \max_{a'} Q^*(s',a') Q∗(s,a)=R(s,a)+γs′∑P(s′∣s,a)a′maxQ∗(s′,a′)
最优方程通过最大化未来价值,体现了“贪心”策略的选择 。
4. 关键思想
- 递归关系:当前状态的价值由即时奖励和未来状态的价值共同决定,形成递归结构 。
- 动态规划基础:贝尔曼方程是动态规划求解最优策略的核心,通过迭代更新值函数逼近最优解 。
- 折扣因子 γ \gamma γ:控制未来奖励的重要性, γ = 0 \gamma=0 γ=0 时仅关注即时奖励, γ = 1 \gamma=1 γ=1 时完全考虑长期回报 。
总结
贝尔曼方程通过将复杂的时间序列问题转化为递归形式,为强化学习提供了数学基础。其推导依赖于MDP的马尔科夫性、全期望公式和最优性原理 。
8、强化学习知识点
强化学习知识点链接
相关文章:

强化学习--2.数学
强化学习--数学 1、概率统计知识1.1 随机变量与观测值1.2 概率密度函数(PDF)1.3 期望1.4 随机抽样 2、数据期望E3、正态分布4、条件概率1. **与多个条件相关**(依赖所有前置条件)2. **仅与上一个条件相关**(马尔可夫性…...

rails 8 CSS不起效问题解决
很久没用rails了,最近打算重新复习一下。在配置好环境后,创建了项目,通过脚手架创建了数据库表,和相关的文件。但我发现却没有生成相应的CSS文件,可能是rails8 取消了吧。于是自己手动创建了相应的css文件。但是刷新页…...
)
双指针算法详解(含力扣和蓝桥杯例题)
目录 一、双指针算法核心概念 二、常用的双指针类型: 2.1 对撞指针 例题1:盛最多水的容器 例题2:神奇的数组 2.2 快慢指针: 例题1:移动零 例题2:美丽的区间(蓝桥OJ1372) 3.总…...

C 语言字符输入:掌握 getchar 和 scanf 的用法与陷阱
各类资料学习下载合集 https://pan.quark.cn/s/8c91ccb5a474 C 语言字符输入:掌握 getchar 和 scanf 的用法与陷阱 你好!在 C 语言编程中,与用户进行交互最基本的方式就是通过标准输入和标准输出。我们之前探讨了如何使用 printf 和 putchar 进行…...

算法笔记。质数筛算法
题目: 给定一个正整数 n,请你求出 1∼n 中质数的个数。 输入格式 共一行,包含整数 n。 输出格式 共一行,包含一个整数,表示 1∼n 中质数的个数。 数据范围 1≤n≤106 输入样例: 8输出样例…...

C语言中memmove和memcpy
1、memmove()函数 void *memmove(void *str1, const void *str2, size_t n); 将str2所指向的存储区的前n个字节复制到str1所指向的存储区。 memmove()允许“str1和str2所指向的存储区重叠”。通过检查地址关系,自动选择复制方向(从前往后或从后往前&a…...
空间跳跃))
GESP2024年6月认证C++八级( 第三部分编程题(2)空间跳跃)
参考程序: #include <cstdio> #include <vector> #include <queue> #include <utility> #include <cstring> using namespace std;// 定义一个结构体,用于 Dijkstra 优先队列中的节点 struct Node {int v, w; // v 表示图…...

使用DeepSeek定制Python小游戏——以“俄罗斯方块”为例
前言 本来想再发几个小游戏后在整理一下流程的,但是今天试了一下这个俄罗斯方块的游戏结果发现本来修改的好好的的,结果后面越改越乱,前面的版本也没保存,根据AI修改他是在几个版本改来改去,想着要求还是不能这么高。…...

Linux中安装mysql8,转载及注意事项
一、先前往官网下载mysql8 下载地址: https://dev.mysql.com/downloads/选择Linux 二、删除Linux中的mysql(如果有的话),上传安装包 1、先查看mysql是否存在,命令如下: rpm -qa|grep -i mysql如果使用这…...

网站即时备份,网站即时备份的方法有哪些
网站数据的安全性与业务连续性直接关系到企业的核心竞争力。无论是因硬件故障、人为误操作、网络攻击还是自然灾害,数据丢失或服务中断都可能带来难以估量的损失。因此,网站即时备份成为保障业务稳定性的关键技术手段。 一、核心即时备份技术方案 云服…...

LVM扩容小计
文章目录 [toc]当前磁盘使用问题分析关键问题定位推荐解决方案方案一:扩展根分区(LVM 动态扩容)方案二:清理磁盘空间(紧急临时处理) 当前磁盘使用问题分析 根据你的磁盘信息,根文件系统 (/) 已…...
)
【2025软考高级架构师】——案例分析总结(13)
摘要 本文对2025年软考高级架构师的考纲及案例分析进行了总结。内容涵盖系统规划、架构设计、系统建模、安全架构、可靠性分析、大数据架构等多方面知识点,还涉及软件质量特性、系统流程图与数据流图、嵌入式系统架构、分布式系统设计等考查内容,详细列…...

Redis ⑨-Jedis | Spring Redis
Jedis 通过 Jedis 可以连接 Redis 服务器。 通过 Maven 引入 Jedis 依赖。 <!-- https://mvnrepository.com/artifact/redis.clients/jedis --> <dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><versi…...

aidermacs开源程序使用 Aider 在 Emacs 中进行 AI 配对编程
一、软件介绍 文末提供程序和源码下载 Aidermacs 通过集成 Aider(最强大的开源 AI 配对编程工具之一)为 Emacs 带来了 AI 驱动的开发。如果您缺少 Cursor,但更喜欢生活在 Emacs 中,Aidermacs 提供了类似的 AI 功能,同…...
)
HarmonyOS NEXT——DevEco Studio的使用(还没写完)
一、IDE环境的搭建 Windows环境 运行环境要求 为保证DevEco Studio正常运行,建议电脑配置满足如下要求: 操作系统:Windows10 64位、Windows11 64位 内存:16GB及以上 硬盘:100GB及以上 分辨率:1280*8…...
)
使用PageHelper实现分页查询(详细)
一:需求分析与设计 1.1 产品原型 (1)分页展示,每页展示10条数据,根据员工姓名进行搜索 (2)业务规则 1.2 接口设计 (1)操作:查询,请求方式…...

神经网络基础-从零开始搭建一个神经网络
一、什么是神经网络 人工神经网络(Articial Neural Network,简写为ANN)也称为神经网络(NN),是一种模仿生物神经网络和功能的计算模型,人脑可以看做是一个生物神经网络,由众多的神经元连接而成,…...

数据库原理与应用实验二 题目七
利用sql建立教材数据库,并定义以下基本表: 学生(学号,年龄,性别,系名) 教材(编号,书名,出版社编号,价格) 订购(学号,书号,数量) 出版社(编号,名称,地址) 1定义主码、外码、和价格、数量的取值范围。 2 在三个表中输入若干记录,注意如果输入违反完整…...

如何在 CentOS 7 命令行连接 Wi-Fi?如何在 Linux 命令行连接 Wi-Fi?
如何在 CentOS 7 命令行连接 Wi-Fi?如何在 Linux 命令行连接 Wi-Fi? 摘要 本教程覆盖如何在多种 Linux 发行版下通过命令行连接 Wi-Fi,包括: CentOS 7、Ubuntu、Debian、Arch Linux、Fedora、Alpine Linux、Kali Linux、OpenSU…...

【学习笔记】 强化学习:实用方法论
作者选择了由 Ian Goodfellow、Yoshua Bengio 和 Aaron Courville 三位大佬撰写的《Deep Learning》(人工智能领域的经典教程,深度学习领域研究生必读教材),开始深度学习领域学习,深入全面的理解深度学习的理论知识。 之前的文章参考下面的链接…...
:字段膨胀(Mapping 爆炸)问题的解决思路)
ElasticSearch深入解析(十):字段膨胀(Mapping 爆炸)问题的解决思路
文章目录 一、核心原理:动态映射的双刃剑1. 动态映射的工作机制2. 映射爆炸的触发条件3. 底层性能损耗 二、典型场景与案例分析1. 日志系统:动态标签引发的灾难2. 物联网数据:设备属性的无序扩展 三、系统性解决方案1. 架构层优化2. 配置层控…...

react18基础速成
1、项目搭建 npx create-react-app my-react-app(项目名) cd 项目名进入项目目录 终端输入 npm start 启动项目 浏览器查看 项目搭建成功 2、JSX JavaScript语法和HTML语法写在一起就是JSX语法 jsx只能返回一个根元素,即最外层的div&a…...

18、状态库:中央魔法仓库——React 19 Zustand集成
一、量子熔炉的诞生 "Zustand是记忆水晶的量子纠缠体,让状态流无需魔杖驱动即可自洽!"霍格沃茨炼金术研究院的工程师挥动魔杖,Zustand 的原子化状态流在空中交织成星轨矩阵。 ——基于《魔法国会》第2025号协议,Zustan…...

PyCharm中全局搜索无效
发现是因为与搜狗快捷键冲突了,把框选的那个勾选去掉或设置为其他键就好了...

【Hive入门】Hive与Spark SQL深度集成:执行引擎性能全面对比与调优分析
目录 引言 1 Hive执行引擎架构演进 1.1 Hive执行引擎发展历程 1.2 执行引擎架构对比 1.2.1 MapReduce引擎架构 1.2.2 Tez引擎架构 1.2.3 Spark引擎架构 2 执行引擎切换与配置指南 2.1 引擎切换配置方法 2.1.1 全局配置 2.1.2 会话级配置 2.2 资源管理配置 2.2.1 T…...

【算法基础】快速排序算法 - JAVA
一、算法基础 1.1 什么是快速排序 快速排序(Quick Sort)是一种高效的分治排序算法,由英国计算机科学家Tony Hoare于1960年提出。它的核心思想是: 选择一个基准元素(pivot)将数组分成两部分:小…...

Ubuntu 24.04 通过 update-alternatives 切换GCC版本
在 Ubuntu 中编译项目, 会遇到项目依赖于某个特定版本 GCC 的情况, 例如 Ubuntu 24.04 的默认 GCC 版本是 13, 但是有一些项目需要 GCC11才能正常编译, 在 Ubuntu 24.04 默认的环境下编译会报错. 这时候可以通过 update-alternatives 切换GCC版本. all 展示全部 用--all参数会…...

Linux中的时间同步
一、时间同步服务扩展总结 1. 时间同步的重要性 多主机协作需求:在分布式系统、集群、微服务架构中,时间一致性是日志排序、事务顺序、数据一致性的基础。 安全协议依赖:TLS/SSL证书、Kerberos认证等依赖时间有效性,时间偏差可能…...
——质量管理——时效性原则)
数据赋能(209)——质量管理——时效性原则
概述 数据时效性原则在数据收集、处理、分析和应用的过程中确保数据在特定时间范围内保持其有效性和相关性,为决策提供准确、及时的依据。在快速变化的市场环境中,数据时效性对于企业的竞争力和决策效率具有决定性的影响。 原则定义 数据时效性原则&a…...

AnimateCC教学:照片旋转飞舞并爆炸....
1.核心代码: <!DOCTYPE html> <html><head><meta charset="UTF-8" /><title>旋转照片演示</title><script src="https://code.createjs.com/1.0.0/createjs.min.js"></script><script src="http…...

腾讯混元-DiT 文生图
1 混元-DiT所需的模型大小一共是41G https://huggingface.co/Tencent-Hunyuan/HunyuanDiT https://colab.research.google.com/ HunyuanDiT_jupyter.ipynb %cd /content !GIT_LFS_SKIP_SMUDGE1 git clone -b dev https://github.com/camenduru/HunyuanDiT %cd /content/Hun…...

优化高搜索量还是低竞争关键词?SEO策略解析
在2025年的SEO环境中,关键词研究仍然是优化网站排名的基石。然而,一个常见的问题困扰着SEO从业者:在使用谷歌关键词规划师(Google Keyword Planner)进行关键词研究时,是否应该优先选择月搜索量较高的关键词…...

对比表格:数字签名方案、密钥交换协议、密码学协议、后量子密码学——密码学基础
文章目录 一、数字签名方案1.1 ECDSA:基于椭圆曲线的数字签名算法1.2 EdDSA:Edwards曲线数字签名算法1.3 RSA-PSS:带有概率签名方案的RSA1.4 数字签名方案对比 二、密钥交换协议2.1 Diffie-Hellman密钥交换2.2 ECDH:椭圆曲线Diffi…...

在MySQL中建索引时需要注意哪些事项?
在 MySQL 中建立索引是优化查询性能的重要手段,但不当的索引设计可能导致资源浪费、性能下降甚至拖慢写入速度。 所以我们我们首先要判断对于一个字段或者一些字段要不要建立索引。 适合建立索引的字段通常是: 主键字段:MySQL 会自动为主键…...

dstack 是 Kubernetes 和 Slurm 的开源替代方案,旨在简化 ML 团队跨顶级云、本地集群和加速器的 GPU 分配和 AI 工作负载编排
一、软件介绍 文末提供程序和源码下载 dstack 是 Kubernetes 和 Slurm 的开源替代方案,旨在简化顶级云和本地集群中 ML 团队的 GPU 分配和 AI 工作负载编排。 二、Accelerators 加速器 dstack 支持 NVIDIA 开箱即用的 、 AMD 、 Google TPU 和 Intel Gaudi 加速器…...

Linux 的 epoll 与 Windows 的 IOCP 详解
如果你在搞网络编程或者高性能服务器,一定要搞懂这两个模型——它们都是用来解决“多路复用”问题的工具,让你同时处理大量的网络连接变得高效又可控。 一、什么是“多路复用”? 简单说,就是你手里有很多任务(比如很多客户端的请求),但系统的核心(线程或者进程)资源…...
)
C# 方法(控制流和方法调用)
本章内容: 方法的结构 方法体内部的代码执行 局部变量 局部常量 控制流 方法调用 返回值 返回语句和void方法 局部函数 参数 值参数 引用参数 引用类型作为值参数和引用参数 输出参数 参数数组 参数类型总结 方法重载 命名参数 可选参数 栈帧 递归 控制流 方法包含了组成程序的…...

Webug4.0靶场通关笔记11- 第15关任意文件下载与第16关MySQL配置文件下载
目录 一、文件下载 二、第15关 任意文件下载 1.打开靶场 2.源码分析 3.渗透实战 三、第16关 MySQL配置文件下载 1.打开靶场 2.源码分析 3.渗透实战 (1)Windows系统 (2)Linux系统 四、渗透防御 一、文件下载 本文通过…...

More Effective C++学习笔记
条款1 指针与引用的区别 条款2 尽量使用C风格的类型转换 条款3 不要对数组使用多态 条款4 避免无用的缺省构造函数 条款5 谨慎定义类型转换函数 条款6 自增(increment)、自减(decrement)操作符前缀形式与后缀形式的区别 条款7 不要重载“&&”,“||”, 或“,” 条款8 理…...

如何设计抗Crosstalk能力强的PCB镀穿孔
一个高速PCB通道通常包含芯片SerDes IP、走线、穿层Via、连接器和Cable。 其中内层走线对于Crosstalk影响甚微(请参考什么? Stripline的FEXT为0! Why? ),而Via与连接器由于其参考路径较差的关系,…...

多线程系列三:这就是线程的状态?
1.认识线程的状态 NEW:Thread对象已经创建好了,但还没有调用start方法在系统中创建线程 RUNNABLE:就绪状态,表示这个线程正在CPU上执行,或准备就绪,随时可以去CPU上执行 BLOCKED:表示由于锁竞争…...
)
生成对抗网络(GAN, Generative Adversarial Network)
定义:一种通过对抗训练让两个神经网络(生成器与判别器)相互博弈的深度学习模型,用于生成逼真的数据(如图像、音频、文本等)。 一、核心思想:对抗博弈 GAN的核心是让两个神…...

用可视化学习逆置法
1.逆置法思路 目标:将这个彩色数组向右旋转3步 🔴1 → 🟠2 → 🟡3 → 🟢4 → 🔵5 → 🟣6 → ⚪7我们希望得到 🔵5 → 🟣6 → ⚪7 → 🔴1 → 🟠…...

家用服务器 Ubuntu 服务器配置与 Cloudflare Tunnel 部署指南
Ubuntu 服务器配置与 Cloudflare Tunnel 部署指南 本文档总结了我们讨论的所有内容,包括 Ubuntu 服务器配置、硬盘扩容、静态 IP 设置以及 Cloudflare Tunnel 的部署步骤。 目录 硬盘分区与扩容设置静态 IPCloudflare Tunnel 部署SSH 通过 Cloudflare Tunnel常见…...
)
【C++篇】类和对象(上)
目录 类的定义格式: 内敛函数: 类与struct的区别: 类的访问权限: 类域: 类的实例化: 对象大小: 计算对象的大小时,也存在内存对齐(与结构体一样)&…...

ES6/ES11知识点 续一
模板字符串 在 ECMAScript(ES)中,模板字符串(Template Literals)是一种非常强大的字符串表示方式,它为我们提供了比传统字符串更灵活的功能,尤其是在处理动态内容时。模板字符串通过反引号&…...

ES6入门---第二单元 模块二:关于数组新增
一、扩展运算符。。。 1、可以把ul li转变为数组 <script>window.onloadfunction (){let aLi document.querySelectorAll(ul li);let arrLi [...aLi];arrLi.pop();arrLi.push(asfasdf);console.log(arrLi);};</script> </head> <body><ul><…...

使用python加edge-tts实现文字转语音
文章目录 使用python加edge-tts实现文字转语音1. 使用 Python 安装 Edge-TTS2. 进一步优化3. 使用说明3.1 查看语音列表3.2 单语音转换3.3 批量生成所有语音3.4 改进亮点4. 使用教程最终代码文章创作不易使用python加edge-tts实现文字转语音 Edge-TTS(edge-tts Python 模块)本…...

如何用CSS实现HTML元素的旋转效果:从基础到高阶应用
在网页设计中,元素的动态效果能显著提升用户体验,而旋转效果是其中最常用的交互方式之一。CSS的transform属性提供了强大的旋转功能,结合动画(animation)和过渡(transition),开发者可…...

轻量级RTSP服务模块:跨平台低延迟嵌入即用的流媒体引擎
在音视频流媒体系统中,RTSP(Real-Time Streaming Protocol)服务模块通常扮演着“视频分发中心”的角色,它将编码后的音视频内容转为标准的流媒体格式,供客户端(播放器、云端平台、AI模块等)拉流…...