交我算使用保姆教程:在计算中心利用singularity容器训练深度学习模型
文章目录
- 准备工作
- 步骤
- 如何封装和使用容器
- 安装
- 创建 Singularity 容器
- 编写 def 文件
- 构建容器
- 查看构建容器的 python 版本
- 本地测试挂载数据集和代码
- 如何上传数据
- windows 系统
- Linux 系统
- 如何设置作业
- 任务脚本的结构
- 常用的 Slurm 参数
- 一份完整的 slurm 作业示例
- 如何在 debug 队列测试
- 如何提交作业
- 检查作业的状态
- 其它学习资源
准备工作
- 在交我办app上检索“交我算”,申请交我算主账号(有教职的才能申请主账号),然后让主账号申请子账号(都需要答题,可以重复提交,要100分才行)
- 开通账号之后获取账号和密码
步骤
- 准备作业,在本地调通,确定没有 bug
- 在本地封装环境为镜像,本地测试,镜像没有问题
- 将镜像、数据、代码全部上传(要通过数据节点上传,不然被封号)
- 在 debug 队列测试,确实可以运行
- ARM 作业在 ARM 的登录节点或计算节点提交;思源一号配备单独的登录节点,思源一号作业在思源一号的登录节点或计算节点提交;
需要注意的是:
- 上传 1T 以下的数据,用数据节点(节点名称一般包含 data 字样),不能在登录节点上上传(节点名称一般包含 login 字样);登录到数据节点上传数据(Windows 用 WinSCP 软件;linux 用 sftp);登录到登录节点提交任务(Windows用 Mobaxterm 软件模拟 terminal,linux 直接在 terminal 里面用 ssh)。上传 1T 以上的数据,直接用硬盘去网络中心拷。
- 登录到数据节点或者登录节点之后,都是直接进入自己的 home 目录下,如果
.sh或者.slurm文件在 home 目录下,那么你的工作目录就是 home 目录 - 登录到登录节点之后,就和本地使用 linux 一样的体验;但是不要在这里运行计算任务,而是包装成任务提交系统,让系统调度资源帮你运行
如何封装和使用容器
简单说,容器可以提供一个和本地相同的运行环境。在交我算上,没有root权限,很多东西安装不了,你可以把环境打包到容器里面,把容器上传到服务器,然后在容器里运行程序。
镜像和容器的关系:通过镜像生成容器
- 镜像:像预制好的房间设计图纸(包含家具、电路等)。
- 容器:根据图纸实际建造的房间实例,可快速复制多个相同的房间。
实际上我感觉这俩词混用也问题不大(?可以吗)
Docker 是最简单的容器技术,但是不足够用,这里得用 Singularity(因为我们没有 root 权限,Docker 默认是以 root 用户运行的)
Singularity 使用 .sif(Singularity Image Format)文件作为容器镜像
安装
注意版本,可以自己去官网找一个版本
# 下载 Singularity
wget https://github.com/sylabs/singularity/releases/download/v3.9.0/singularity-ce-3.9.0.tar.gz# 解压
tar -xzf singularity-ce-3.9.0.tar.gz# 进入解压后的目录
cd singularity-ce-3.9.0# 编译和安装
./mconfig
make -C builddir
sudo make -C builddir install
创建 Singularity 容器
首先,要编辑 .def 文件,这个文件表明你希望如何打包容器。然后,使用 singularity build container.sif container.def 命令从 Singularity 定义文件(.def 文件)或 Docker 镜像创建 Singularity 镜像。因为我们要用 pytorch 还有 cuda,官方有提供已经打包了 cuda 和 torch 的 docker 容器,我们直接在该基础上打包。
singularity 容器一旦打包完成,就不可以再修改了,如果代码要小改一下,就得重新打包,非常不方便。还有数据集,非常大,不能直接打包到容器里。所以我们在容器里只打包运行程序需要的包,也就是只打包环境,然后在运行的过程中,再通过参数说明我们的代码和数据集的位置(这种方式叫做“挂载”)
编写 def 文件
一份 .def 文件示例如下:
Bootstrap: docker
From: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/pytorch/pytorch:2.3.1-cuda11.8-cudnn8-runtime%post# 使用 Conda 安装 mpi4pyconda install -y mpi4py# 安装其他依赖pip install --no-cache-dir \tensorboard \transformers \accelerate>=0.26.0 \decord \tqdm \safetensors%environmentexport PATH=/usr/local/bin:$PATHexport LD_LIBRARY_PATH=/usr/lib/x86_64-linux-gnu/openmpi/lib:$LD_LIBRARY_PATH%runscript# 默认运行命令(可选)echo "Singularity 镜像已启动!"
前两行:
Bootstrap: docker这行指定了 Singularity 使用 docker 作为构建容器的引导方式。Singularity 支持多种引导方式(如 library、shub、localimage 等),这里选择 docker 表示 Singularity 会从 Docker 镜像构建容器。From: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/pytorch/pytorch:2.3.1-cuda11.8-cudnn8-runtime这行指定了 Singularity 使用的 Docker 镜像的来源。查找 torch 和 cuda docker(国内镜像):https://docker.aityp.com/r/docker.io/pytorch/pytorch
这个基础容器有说法;库里有 pytorch:2.3.1-cuda11.8-cudnn8-runtime 还有这种 pytorch:2.2.1-cuda11.8-cudnn8-devel ,除了版本区别以外,这两种的区别在于一个是 runtime 一个是 devel,runtime 这个文件比 devel 小很多。runtime 表示这是一个运行时镜像,通常用于部署和运行 PyTorch 应用,而不是用于开发。devel 表示这是一个开发镜像,通常包含了构建和开发 PyTorch 应用所需的工具和库。runtime 包含 cuda 运行需要的库,但是 nvcc 命令是不起用的,有些情况代码可以运行,有些情况会说找不到 cuda,就老实换成 devel 版本吧
在 Singularity 定义文件(.def 文件)中,% 用于表示不同的区块(sections),每个区块定义了容器构建过程中的不同部分。以下是一些常见的区块及其作用:
%help提供容器的帮助信息,用户在运行容器时可以通过singularity help <容器名>查看此信息。%labels用于为容器添加元数据(metadata),例如版本号、作者信息等。%files用于将主机上的文件或目录复制到容器中。例如:
%files
/path/on/host/file.txt /path/in/container/file.txt
但是在示例的文件没有用这个区块,因为数据集太大了,打包进去不方便;代码可能还需要修改,不要直接打包进去,而是通过挂载的方式,可以修改。
有一些包,需要联网下载,但是无法访问,可以先下载到本地,然后在 %files 段中把这个文件挂载到容器里,然后在 %post 段读取这个文件并安装。
%environment用于设置容器的环境变量,这些变量会在容器运行时生效。例如:
%environment
export PATH=/usr/local/cuda/bin:$PATH
%post这个命令就是在构建容器的时候会执行的命令(注意区分,不是在运行容器,而是在构建容器);这里一般写上需要在容器里安装的包。在这个示例中,安装 mpy4pi 用的是 conda 而不是 pip,因为 pip 装不上总是报错,没办法了,只能用 conda。torch不用写了,docker里面有。%runscript定义容器运行时默认执行的命令。当用户直接运行容器时,会执行此区块中的命令。如果把代码打包进容器了,那在这里写上运行代码的命令,到时候直接运行容器,就会执行代码了。
构建容器
写好 .def 文件之后,在terminal执行命令:sudo singularity build my_container.sif my_container.def 然后等待,完成之后会打印:
...
INFO: Adding environment to container
INFO: Adding runscript
INFO: Creating SIF file...
INFO: Build complete: my_container.sif
查看构建容器的 python 版本
singularity exec my_container.sif python --version
本地测试挂载数据集和代码
你可以把容器理解为一个独立的文件系统,存放逻辑和linux系统是一致的。假设你的数据集在本地存放的地址是 /home/you/datasets/my_dataset ,你可以把数据集挂载到容器的任何位置,例如我想挂载到容器的 /datasets/my_dataset 地址下,那么,容器里的 code 访问数据集的时候都是通过 /datasets/my_dataset 去访问的。所以在代码里面,你要把数据集地址修改为 /datasets/my_dataset ,不然程序访问不到,就会报错。
把代码里的地址改好,然后准备在本地测试容器是否可以正常使用。假设你本地运行代码使用的命令是这样:
torchrun --nnodes=1 --nproc_per_node=2 --master_port=29500;
那么你要让程序在容器里运行,你需要这样(其中 /code/train.py 是代码文件挂载到容器中的地址):
singularity exec vidAidImage.sif torchrun --nnodes=1 --nproc_per_node=2 --master_port=29500 /code/train.py
但是这样还是会报错,因为你忘记挂载代码和数据集地址了。当然,我这里还用到了预训练参数,所以预训练参数的文件地址也要挂载的(代码里读取的地址也要一起修改为挂载后的地址)
挂载的方法是:--bind 原地址:挂载地址 (原地址就是实际存放在运行程序的电脑里的地址,如果是在本地测试容器是否能用,那就是文件在你的电脑里的地址;如果是在交我算上运行,那就是文件在交我算上放的位置)
例如,我要挂载下面三个地址:
| 本地地址 | 想要挂载的地址 |
|---|---|
/media/gao/hardD1/eye_help_data/singularity/code | /code |
/media/gao/hardD1/pretrained_checkpoint | /pretrained |
/media/gao/hardD1/datasets/videoHelpDatasets/dataset-use | /datasets |
运行程序的命令是:
singularity exec --bind /media/gao/hardD1/eye_help_data/singularity/code:/code,/media/gao/hardD1/pretrained_checkpoint:/pretrained,/media/gao/hardD1/datasets/videoHelpDatasets/dataset-use:/datasets vidAidImage.sif torchrun --nnodes=1 --nproc_per_node=2 --master_port=29500 /code/train.py
但是,这样还是会报错。因为程序要用到 GPU,容器识别不到驱动。这时候只需要加上参数 --nv 就可以了,所以最后可以执行的命令就是:
singularity exec --nv --bind /media/gao/hardD1/eye_help_data/singularity/code:/code,/media/gao/hardD1/pretrained_checkpoint:/pretrained,/media/gao/hardD1/datasets/videoHelpDatasets/dataset-use:/datasets vidAidImage.sif torchrun --nnodes=1 --nproc_per_node=2 --master_port=29500 /code/train.py
另外,如果在代码中有相对路径,那可能也会报错,没有办法读到正确的地址。这时候你需要设置一下当前的工作目录,把代码变成这样:
singularity exec --nv --bind /media/gao/hardD1/eye_help_data/singularity/code:/code,/media/gao/hardD1/pretrained_checkpoint:/pretrained,/media/gao/hardD1/datasets/videoHelpDatasets/dataset-use:/datasets vidAidImage.sif bash -c "cd /code && torchrun --nnodes=1 --nproc_per_node=2 --master_port=29500 /code/train.py"
如果本地运行没有错误,就可以把文件都传到交我算上,在 debug 队列里测试一下,也没有问题的话就可以跑起来了。
如何上传数据
登录节点是可以访问到文件存储系统的,但是,不要在登录节点上传大量数据,会被封号的,请通过数据节点传输。(区分“登录”行为和“登录节点”这个节点)
首先要弄清数据应该上传到哪里,π2.0/AI/ARM集群及思源一号集群使用两个独立的存储系统。如果要用 A100 显卡,那是在思源一号集群,得登录到思源一号的传输节点传输。传输节点地址如下:
- 思源一号传输节点地址为
sydata.hpc.sjtu.edu.cn - π 2.0/AI/ARM 集群传输节点地址为
data.hpc.sjtu.edu.cn
windows 系统
下载 WinSCP 应用程序,在登陆会话框中,文件协议选择 SFTP;主机名称填写:sydata.hpc.sjtu.edu.cn
(这个是数据节点,登陆这个节点上传数据是允许的,不会被封号)
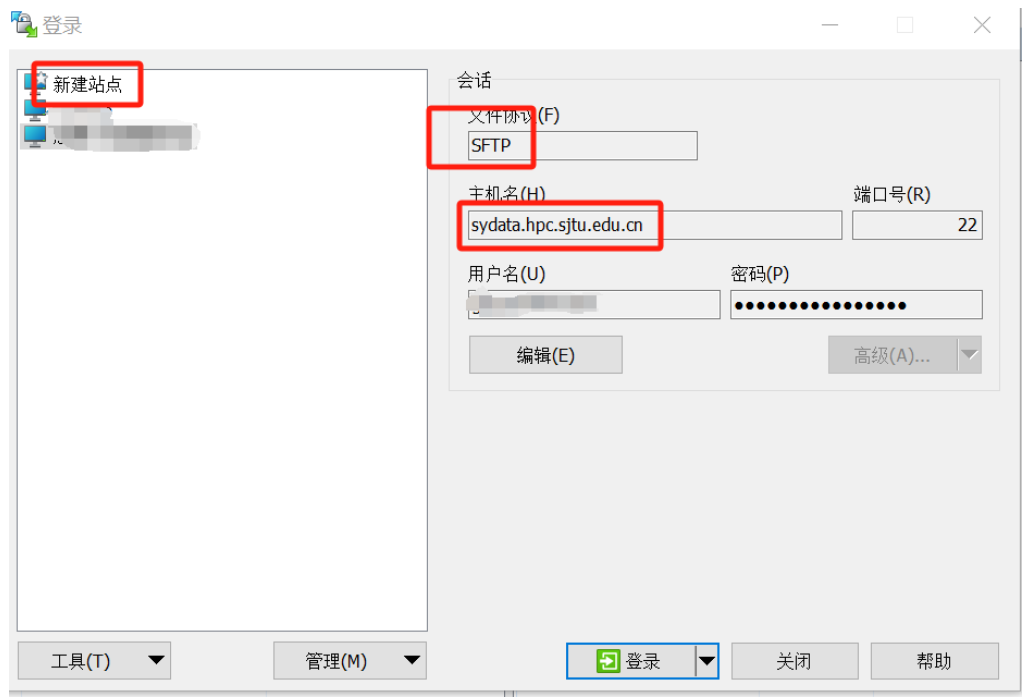
登陆之后自动进去你账号下的 home 目录,这里是你的地盘,可以任意操作(新建文件夹、上传数据)
Linux 系统
一般已经安装了,检查是否安装 sftp:
sftp -V
如果没安装,安装命令(Ubuntu):
sudo apt-get install openssh-server openssh-client
- 登陆:
sftp username@remote_name
username 是账号名,remote_name这里就是 sydata.hpc.sjtu.edu.cn;回车之后会让输入密码 - 上传文件
put local_file remote_file - 下载文件
get remote_file local_file
如何设置作业
代码写好后,在本地运行,只需要一行 python train.py 即可,但是如果直接在登录节点上运行这一行,是不可以的。
你必须要写一个“作业”,说明你需要多少资源、要运行哪个程序,然后把这个“作业”提交,Slurm 作业调度系统会根据目前系统硬件资源的繁忙情况,给你分配资源之后帮你运行。
作业其实就是一个 .sh 脚本;用代码 sbatch my_job.sh 提交任务;在交我算的文档里给的示例是 sbatch my_job.slurm 这个只是文件命名的区别,无所谓用哪一种,关键是文件内容正确即可。
任务脚本的结构
- Shebang 行
就是第一行,指定脚本使用的解释器(通常是 Bash)
#!/bin/bash
-
Slurm 参数(以
#SBATCH开头)
这些参数用于指定作业的资源需求和运行方式。常用的参数介绍见后文。 -
加载模块(可选)
在计算中心,通常需要加载一些软件模块以使用特定工具或库。但是我们在容器里运行,一般要什么容器里都有,所以这个可以不填。 -
设置环境变量(可选)
定义一些环境变量,方便脚本中使用。例如:
export DATA_DIR="/path/to/data"
export OUTPUT_DIR="/path/to/output"
- 运行命令
这是脚本的核心部分,指定需要执行的命令。例如:
python train.py --data_dir $DATA_DIR --output_dir $OUTPUT_DIR
常用的 Slurm 参数
- 作业基本信息
#SBATCH --job-name=my_job # 作业名称
#SBATCH --output=output_%j.out # 标准输出文件(%j 会被替换为作业ID)
#SBATCH --error=error_%j.err # 标准错误文件
标准输出文件是什么内容?
- 代码里的 print、命令行的输出、还有 slurm 调度的时候的一些信息,会输出到“标准输出文件”。
标准输出文件会存放在哪里?
- 如果你按照上面那么写,也就是相对路径,那么当前工作文件夹就是这个
.sh或者.slurm文件所在的位置;如果写绝对路径,那就会放在绝对路径的位置
- 资源需求
#SBATCH --ntasks=1 # 任务数量
#SBATCH --cpus-per-task=4 # 每个任务使用的 CPU 核心数
#SBATCH --gres=gpu:2 # 使用的 GPU 数量
#SBATCH --mem=32G # 内存需求
#SBATCH --time=01:00:00 # 任务最长运行时间(格式:HH:MM:SS)
- 分区和约束
#SBATCH --partition=? # 分区名称(根据计算中心的配置填写)
partition 参数这样填:
| 队列 | 参数 |
|---|---|
| 思源一号cpu | 64c512g |
| 思源一号gpu | a100 |
| ARM 节点 | arm128c256g |
| debuga100队列 | debuga100 |
| dgx2队列 | dgx2 |
- 其他选项
#SBATCH --mail-type=END,FAIL # 任务结束时发送邮件
#SBATCH --mail-user=your_email@example.com # 接收邮件的邮箱
一份完整的 slurm 作业示例
#!/bin/bash
#SBATCH --job-name=videoLLaMA2_finetune # 作业名称
#SBATCH --output=outputs/videoLLaMA2/finetune_%j.out # 标准输出文件
#SBATCH --error=outputs/videoLLaMA2/finetune_%j.err # 标准错误文件
#SBATCH --ntasks=1 # 任务数量
#SBATCH --cpus-per-task=16 # 每个任务使用的CPU核心数
#SBATCH --gres=gpu:4 # 使用的GPU数量
#SBATCH --time=2-00:00:00 # 任务最长运行时间(2天)
#SBATCH --partition=a100 # 分区名称(思源1号)
#SBATCH --mem=128G # 内存需求# 加载必要的模块(根据计算中心的配置填写)
module load singularity# 定义变量
SIF_FILE="/dssg/home/xx/xx/containers/torch2_2.sif" # Singularity容器路径;我用的是思源一号,所以这个存储系统是在 /dssg 下面的,用的不是思源一号,就不是这个目录
CODE_DIR="/dssg/home/xx/xx/code/VideoLLaMA2" # 代码目录
PRETRAINED_DIR="/dssg/home/xxg/xx/pretrained" # 预训练模型目录
OUTPUT_DIR="/dssg/home/xx/xx/outputs/videoLLaMA2" # 输出目录
DATASET_DIR="/dssg/home/xx/xx/datasets" # 数据集目录# 执行命令
singularity exec --nv --bind ${CODE_DIR}:/code/VideoLLaMA2,${PRETRAINED_DIR}:/pretrained,${OUTPUT_DIR}:/output/videoLLaMA2,${DATASET_DIR}:/datasets ${SIF_FILE} bash -c "cd /dssg/home/xx/xx/code/VideoLLaMA2 && /dssg/home/xx/xx/code/VideoLLaMA2/my_finetune.sh 1 4"
如何在 debug 队列测试
提交 debug A100 队列作业使用思源一号登录节点 sylogin.hpc.sjtu.edu.cn
登录方法:在终端运行 ssh 命令,ssh username@登录节点地址 回车之后会让输入密码。
debuga100队列是调试用的队列 ,目前只提供1节点,因此只能投递单节点作业。调试节点将4块a100物理卡虚拟成 4*7=28 块gpu卡,每卡拥有5G独立显存;节点CPU资源依然为64核,请在作业参数中合理指定gpu与cpu的配比。
投放到此队列的作业 运行时间最长为20分钟 ,超时后会被终止。
测试的时候,数据集用一个很小的,让它快速走完一个流程,保证 checkpoint 是可以保存的,以免跑了很久发现参数没有存下来……
测试的时候,与正式版的需要修改:
- 队列名称:
partition=debuga100 - 时间,不能超过 20min,不然会报错;它不是超过 20min 自动停,而是你设置的时候就不能超过 20min
- 资源,按理来说可以申请不超过这个队列的资源;但是这种情况系统直接给 cancel 了;我测试只申请
cpus-per-task=1; gres=gpu:1; mem=4G可以继续往下运行;不过一般这个体量跑不了模型,只能看报错是 run out of memory 然后就直接提交正式任务了
提交任务:sbatch my_task.sh
提交任务之后系统会返回给你一串字符,例如:Submitted batch job 111111
你要看这个任务的状态,使用命令:scontrol show job 111111
这个命令系统会给你返回如下信息,例如:
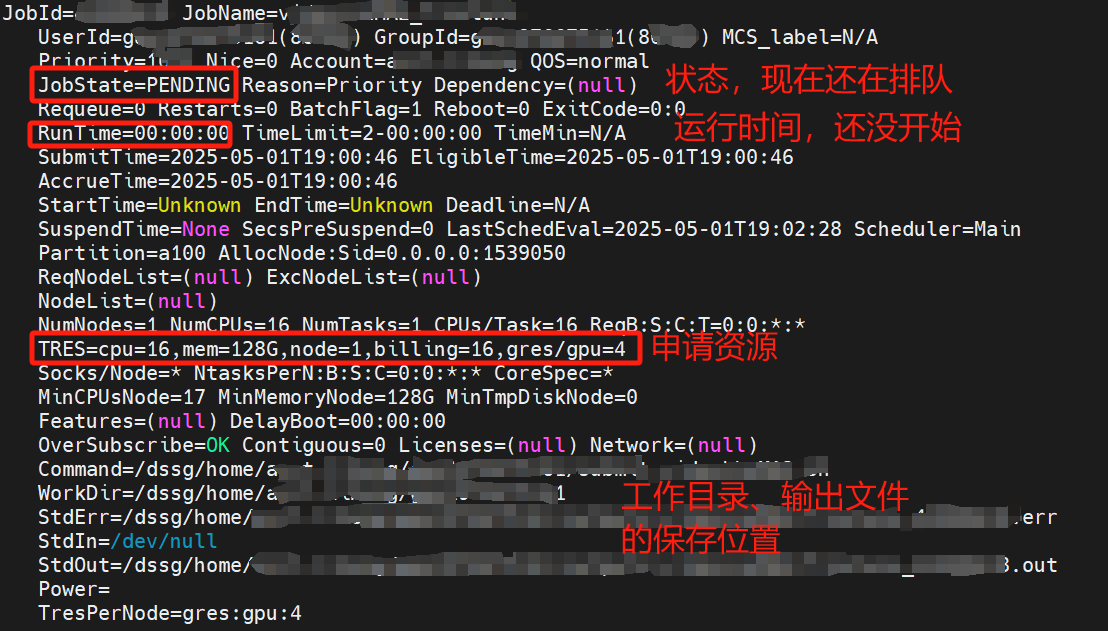
如何提交作业
- 提交a100队列作业请使用 思源一号登录节点。
- 提交dgx2队列作业请使用 π 2.0 集群登录节点。
登录方法:在终端运行 ssh 命令,ssh username@登录节点地址 回车之后会让输入密码。
检查作业的状态
查看自己账号下的作业:squeue -u your_username

作业状态包括R(正在运行),PD(正在排队),CG(即将完成),CD(已完成)。
查看作业的详细信息:scontrol show job 作业id
常用命令:

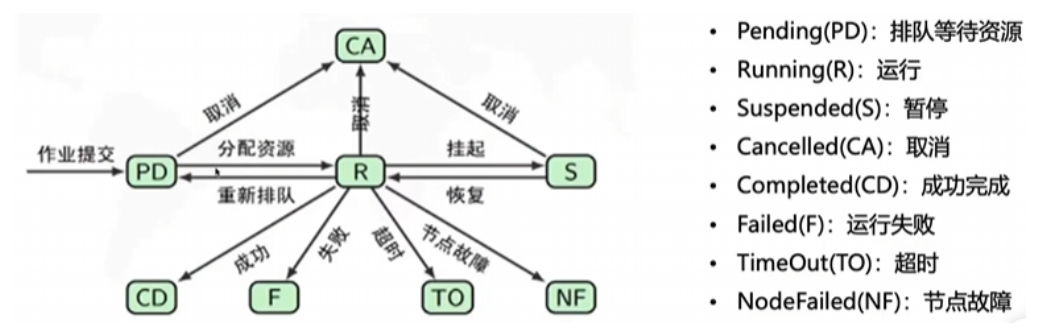
其它学习资源
b站官方视频
官方使用手册
相关文章:

交我算使用保姆教程:在计算中心利用singularity容器训练深度学习模型
文章目录 准备工作步骤如何封装和使用容器安装创建 Singularity 容器编写 def 文件构建容器查看构建容器的 python 版本本地测试挂载数据集和代码 如何上传数据windows 系统Linux 系统 如何设置作业任务脚本的结构常用的 Slurm 参数一份完整的 slurm 作业示例 如何在 debug 队列…...

CMake中强制启用option定义变量的方法
在CMake中,若要在另一个CMake文件中强制启用由option()定义的变量,可使用set(... FORCE)覆盖缓存变量。具体步骤如下: 使用set命令强制覆盖缓存: 在需要强制启用选项的CMake文件中,使用set命令并指定CACHE和FORCE参数。…...

图解 Git 工作流:理解 Rebase、Merge 与 Pull Request 的区别
图解 Git 工作流:理解 Rebase、Merge 与 Pull Request 的区别 在多人协作开发中,选择合适的 Git 分支管理策略至关重要。Merge、Rebase 和 Pull Request 是最常见的三种方式,它们本质不同,使用场景也不同。 本文将通过流程图&am…...

图与网络模型
目录 图的基本概念 例题:比赛的安排 MATLAB作图 最短路径模型 Dijkstra算法步骤 最短路径的Dijkstra算法示例 Dijkstra算法的Matlab函数 最短路径的Floyd算法模型 最短路径的Floyd算法步骤 Floyd算法的Matlab函数 图的基本概念 图G是一个二重组: …...

连接linux虚拟机并运行C++【从0开始】
连接linux虚拟机并运行C【从0开始】 NetSarang安装后两个,其实更加常用的 安装VMware安装Ubuntu 的 ISO 镜像VMWare--TipsUbuntu快捷键,可以在设置里面修改 连接Linux运行cwhy剪不断,理还乱操作 因为好多判题系统,后台都是Linux环…...

多线程系列二:Thread类
Thread类是jvm用来管理线程的一个类,换句话说,每个线程都有一个唯一的Thread对象与之关联 1.Thread常见构造方法 Thread():创建线程对象Thread(Runnable target):使用Runnable对象创建线程对象Thread(String name):创…...

2025五一杯数学建模C题:社交媒体平台用户分析问题,完整第一问模型与求解+代码
完整代码模型请见文末名片 • 问题1分析: – 来龙去脉和与其他问题的内在联系: • 来龙去脉:社交媒体平台为了评估博主的价值,合理分配资源和优化内容推荐,需要准确预测博主的新增关注数。新增关注数是衡量博主影响…...

开源飞控软件:推动无人机技术进步的引擎
在过去的二十年里,众多开源自动驾驶仪项目极大地推动了无人机技术的发展。像 MatrixPilot、Baseflight、TauLabs、OpenPilot、Cleanflight、MultiWii 和 dRonin 等一些开源自动驾驶仪项目已经停止开发,然而,Ardupilot/APM、Pixhawk/PX4、Papa…...

Pinia: vue3状态管理
一、Pinia 的相关介绍 1. 什么是 Pinia Pinia 是一个专门配合 vue.js 使用的状态管理, 从而实现跨组建通信或实现多个组件共享数据的一种技术 2. 使用 Pinia 的目的 我们的vuejs有俩个特性: 1> 数据驱动视图. 2> 组件化开发 基于这俩个特性, 我们引出pinia的使用目的 …...

初学Vue之记事本案例
初学Vue之记事本案例 案例功能需求相关Vue知识案例实现1.实现方法及代码2.演示 案例收获与总结 案例功能需求 基于Vue实现记事功能(不通过原生JS实现) 1.点击保存按钮将文本框的内容显示在特定位置,且清空文本框内容 2.点击清空按钮&#x…...

中国发布Web3计划:区块链列为核心基础技术,不排除发展加密资产应用!
在全球数字化浪潮汹涌、Web3概念方兴未艾之际,中国政府再次展现了其在区块链技术领域的雄心与布局。近日,北京市多个核心政府部门联合发布了一项名为《北京市区块链创新应用发展行动计划(2025–2027年)》的重要政策文件࿰…...
:两阶段终止(Two-Phase Termination))
并发设计模式实战系列(11):两阶段终止(Two-Phase Termination)
🌟 大家好,我是摘星! 🌟 今天为大家带来的是并发设计模式实战系列,第十一章两阶段终止(Two-Phase Termination),废话不多说直接开始~ 目录 一、核心原理深度拆解 1. 两阶段终止流…...

科学养生,解锁健康生活密码
健康是生命的基石,养生并非高深的学问,而是通过科学的生活方式,为身体构筑持久的健康防线。在现代快节奏生活中,掌握正确的养生方法,能有效提升生活质量,预防疾病侵袭。 均衡饮食是养生的核心。日常饮食应遵…...

计算机视觉——基于树莓派的YOLO11模型优化与实时目标检测、跟踪及计数的实践
概述 设想一下,你在多地拥有多个仓库,要同时监控每个仓库的实时状况,这对于时间和精力而言,都构成了一项艰巨挑战。从成本和可靠性的层面考量,大规模部署计算设备也并非可行之策。一方面,大量计算设备的购…...

初识 Java
文章目录 一、背景知识二、技术体系 一、背景知识 Java 是美国 sun(Stanford University Network)公司(2009 年被 Oracle 公司收购)在 1995 年推出的一门计算机高级编程语言 二、技术体系 Java SE(Java Standard Edition):标准版,Java 技术的核心和基…...

彩带飘落效果
文章目录 彩带效果适应场景HTML版本Vue3版本 彩带效果 彩带特效组件 适应场景 完成小结、版本升级等场景。提供HTM、Vue3版本。 HTML版本 <!doctype html> <html lang"zh-CN"><head><meta charset"UTF-8" /><meta name"…...

统计模式识别理论与方法
我们在前文《模式识别的基本概念与理论体系》中就已经提及“模式分类”。 具体内容看我的CSDN文章:模式识别的基本概念与理论体系-CSDN博客 模式的识别方法主要有统计模式识别方法和结构模式识别方法两大类。统计模式识别方法提出得较早,理论也较成熟…...

Ubuntu 安装 Cursor
Cursor 目前只有 Windows 和 Mac 版本,那么如何在 Ubuntu 上运行呢? 本质上是一个如何在 Ubuntu 运行 .appimage 的问题。 1. 下载 Cursor Linux 首先找到 Cursor 官网,下载 x64 安装包,如果你是 arm 架构,就下载 ar…...

前端八股 7
垃圾回收机制 系统周期性地找出暂时不再使用的变量的机制,释放其内存的机制 方法:古老引用计数法 创建一张引用表记录各种资源被引用的次数,当引用次数为0就回收 问题:当有两个对象互相引用时会造成内存泄漏 比如:…...

二、HTML
2.1 介绍 HTML(HyperText Markup Language,超文本标记语言) HTML是网页的骨架,用于定义网页的结构和内容。通过各种标签(如<div>、<p>、<a>、<img>等)来组织文本、图片、表格、表…...

EBO的使用
EBO 其实就是个索引,绑定在相应的VAO中,用来描述绘制顺序。比如在OpenGL绘制三角形的时候,假设有四个顶点,我称他们分别为1,2,3,4号顶点,常规绘制三角形函数是按三个点为一组&#x…...

AI大模型基础设施:NVIDIA的用于AI大语言模型训练和推理的几款主流显卡
英伟达(NVIDIA)在AI大语言模型(LLM)的训练和推理领域占据主导地位,其GPU因强大的并行计算能力和专为深度学习优化的架构而广受青睐。以下介绍几款主流的NVIDIA GPU,适用于AI大语言模型的训练和推理…...

面试手撕——迭代法中序遍历二叉树
思路 访问顺序和处理顺序不一致导致迭代法难写,体现在总要先遍历根节点,才能访问左右孩子,用null标记,null标记的节点表示已经访问过了,下一次可以处理,所以在当前栈顶节点不是null的时候,都要…...

SQL注入与简单实战
Example1 谁从小还没有一个当黑帽子的梦想呢,所以就来讲讲SQL💉🩸吧… 环境要求 sqlmap命令行工具使用Go语言安装包:waybackruls (需要在自己的电脑上部署) 寻找目标 url 对目标网站使用: echo https://xxx | wayb…...

ffmpeg 元数据
ffmpeg 元数据 1. 解释什么是ffmpeg元数据 ffmpeg元数据是指与音视频文件相关的附加信息,这些信息不直接影响音视频内容的播放,但提供了关于文件内容、创作者、版权、播放参数等的有用信息。元数据在音视频文件的处理、管理和共享中起着重要作用。 2.…...

Qwen3 正式发布
2025 年 4 月 29 日,阿里巴巴正式发布新一代通义千问模型 Qwen31。此次发布的 Qwen3 包含多种模型版本,具体如下: MoE 模型:有 Qwen3-235B-A22B(总参数 2350 亿,激活参数 220 亿)和 Qwen3-30B-A…...

[操作系统] 线程互斥
文章目录 背景概念线程互斥的引出互斥量锁的操作初始化 (Initialization)静态初始化动态初始化 加锁 (Locking)阻塞式加锁非阻塞式加锁 (尝试加锁/一般不考虑) 解锁 (Unlocking)销毁 (Destruction)设置属性 (Setting Attributes - 通过 pthread_mutex_init) 锁本身的保护互斥锁…...
时间序列(Time Series)论文总结)
KDD 2025 | (8月轮)时间序列(Time Series)论文总结
KDD 2025将在2025年8月3号到7号在加拿大多伦多举行,本文总结了KDD 2025(August Cycle)有关时间序列(Time Series)相关文章,共计11篇,其中1-10为Research Track,11为ADS Track。如有疏漏,欢迎补充…...

Spring MVC @PathVariable 注解怎么用?
我们来详细分析 Spring MVC 中的 PathVariable 注解。 PathVariable 注解的作用 PathVariable 注解用于从 URI 模板(URI Template)中提取值,并将这些值绑定到 Controller 方法的参数上。URI 模板是一种包含占位符的 URL 路径,这…...

PostgreSQL运算符
运算符 算数运算符 运算符描述示例加法SELECT 2 3; 结果为 5-减法SELECT 5 - 2; 结果为 3*乘法SELECT 2 * 3; 结果为 6/除法(对于整数相除,会截断小数部分)SELECT 5 / 2; 结果为 2 ,若要得到精确结果,可使用浮点数 …...
)
Ocelot与.NETcore7.0部署(基于腾讯云)
资料链接:https://download.csdn.net/download/ly1h1/90731290 1.效果 基于Ocelot,实现对3个微服务的轮询调用,实现不停机更新,无缝更新; 2.环境要求 1.部署环境:腾讯云的轻量化应用服务器 2.系统环境&…...
)
Umi-OCR项目(1)
最近接触到了一个项目,我在想能不能做出点东西出来。 目标:识别一张带表格的图片,要求非表格内容和表格内容都要识别得很好,并且可视化输出为word文档。 下面是第一步的测试代码,测试是否能够调用ocr能力。 import re…...

前端面试常问问题[From CV]
作为前端面试官,我会针对简历中的技术栈、项目经历和技能细节提出以下20个问题,并附上参考答案: 技术基础类问题 Q:请解释JavaScript事件循环机制,结合宏任务/微任务说明代码执行顺序 A:事件循环分为调用栈…...

C语言学习之动态内存的管理
学完前面的C语言内容后,我们之前给内存开辟空间的方式是这样的。 int val20; char arr[10]{0}; 我们发现这个方式有两个弊端:空间是固定的;同时在声明的时候必须指定数组的长度,一旦确定了大小就不能调整的。 而实际应用的过程中…...

CMake中的“包管理“模块FetchContent
背景介绍 C的包管理工具,好像除了微软家的vcpkg外,并没有一个特别有名的包管理器。 CMake其实也提供了基础的包管理功能。使用 FetchContent 模块系列命令可以下载项目依赖的源代码或者其他文件。 基本用法 FetchContent_Declare命令定义我们下载的内…...

python3基础
Python3 基础教程 1. Python简介 Python是一种高级、解释型、通用的编程语言,由Guido van Rossum于1989年底发明。Python的设计哲学强调代码的可读性和简洁性,其核心理念体现在"Python之禅"中: 优美胜于丑陋(Beautiful is better than ugly) 显式胜于隐式(E…...
,使用无迹卡尔曼滤波(UKF)的非线性滤波算法,MATLAB实现)
课题推荐——通信信号处理中的非线性系统状态估计(如信号跟踪、相位恢复等场景),使用无迹卡尔曼滤波(UKF)的非线性滤波算法,MATLAB实现
给出一个基于无迹卡尔曼滤波(UKF)的非线性滤波算法及其MATLAB实现,适用于通信信号处理中的非线性系统状态估计(如信号跟踪、相位恢复等场景)。该算法结合了非线性动态模型和观测模型,并通过UT变换避免雅可比…...
优化器nestloop参数化路径评估不准问题分析)
Postgresql源码(145)优化器nestloop参数化路径评估不准问题分析
相关 《Postgresql源码(133)优化器动态规划生成连接路径的实例分析》 1 问题 最近遇到一个问题,评估行数和真实行数存在较大差距,导致计划不准的问题。 nestloop内表评估是根据外表的参数来的。因为外表驱动表每取一条ÿ…...

【深度学习新浪潮】小米MiMo-7B报告内容浅析
一段话总结 该报告介绍了专为推理任务设计的大语言模型MiMo-7B,其在预训练阶段通过优化数据预处理、采用三阶段数据混合策略(处理约25万亿token)和引入MultiToken Prediction(MTP)目标提升推理潜力;后训练阶段构建13万可验证数学和编程问题数据集,结合测试难度驱动奖励…...

使用Python和Pandas实现的Snowflake权限检查与SQL生成用于IT审计
import snowflake.connector import pandas as pddef get_snowflake_permissions():# 连接Snowflake(需要替换实际凭证)conn snowflake.connector.connect(user<USER>,password<PASSWORD>,account<ACCOUNT>,warehouse<WAREHOUSE&g…...

spring 从application.properties中获取参数的四种方式
在Spring Boot中,自定义一个Starter时,从application.properties中获取参数主要有以下几种方法: 使用Value注解 这是最常用的方法之一,通过Value注解可以直接将application.properties中的属性值注入到Spring管理的Bean中。 imp…...

react学习笔记2——基于React脚手架与ajax
使用create-react-app创建react应用 react脚手架 xxx脚手架: 用来帮助程序员快速创建一个基于xxx库的模板项目 包含了所有需要的配置(语法检查、jsx编译、devServer…)下载好了所有相关的依赖可以直接运行一个简单效果 react提供了一个用于创建react项…...

nim模块教程
导入一个模块 如果我们想要导入一个模块,并且和它的所有函数,我们要做的是写import <moduleName>在我们的文件里,这通常是在文件顶部进行的,这样我们就可以很容易地看到我们的代码使用了什么。 创建一个模块 first.nim …...

雅马哈SMT贴片机高效精密制造解析
内容概要 作为电子制造领域的核心装备,雅马哈SMT贴片机通过集成高速运动控制、智能视觉识别与模块化供料三大技术体系,构建了精密电子元件贴装的工业化解决方案。其YSM系列设备在5G通讯模组、汽车电子控制器及智能穿戴设备等场景中,实现了每…...

审计专员简历模板
模板信息 简历范文名称:审计专员简历模板,所属行业:其他 | 职位,模板编号:KSJYVR 专业的个人简历模板,逻辑清晰,排版简洁美观,让你的个人简历显得更专业,找到好工作。希…...
(指由宿主环境提供的依赖))
npm宿主依赖、宿主环境依赖(peerDependencies)(指由宿主环境提供的依赖)
文章目录 宿主环境依赖详解基本概念工作原理应用场景插件开发UI组件库 与其他依赖类型对比npm不同版本处理差异npm v3-v6npm v7 实际应用示例React插件开发 解决宿主依赖问题 宿主环境依赖详解 基本概念 宿主环境依赖(peerDependencies)是指包声明自身…...
 全攻略)
Android Kotlin 项目集成 Firebase Cloud Messaging (FCM) 全攻略
Firebase Cloud Messaging (FCM) 是 Google 提供的跨平台消息推送解决方案。以下是在 Android Kotlin 项目中集成 FCM 的详细步骤。 一、前期准备 1. 创建 Firebase 项目 访问 Firebase 控制台点击"添加项目",按照向导创建新项目项目创建完成后&#x…...

游戏引擎学习第252天:允许编辑调试值
回顾并为今天的工作设定目标 我们处理了调试值(debug value)的编辑功能。我们希望实现可以在调试界面中编辑某些值,为此还需要做一些额外的工作。 我们的问题在于:当某个调试值被编辑时,我们需要把这个“编辑”的操作…...

支持selenium的chrome driver更新到136.0.7103.49
最近chrome释放新版本:136.0.7103.49 如果运行selenium自动化测试出现以下问题,是需要升级chromedriver才可以解决的。 selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only su…...

cPanelWHM 的 AutoSSL
在 cPanel&WHM 的第58版本中,开始增加了AutoSSL,这是一项非常棒的新功能。 什么是 AutoSSL? AutoSSL 是为了解决每个使用 cPanel&WHM 用户的最大难题:SSL 证书的安装和续期。有了 AutoSSL,这个问题就不再是问…...