Postgresql源码(145)优化器nestloop参数化路径评估不准问题分析
相关
《Postgresql源码(133)优化器动态规划生成连接路径的实例分析》
1 问题
最近遇到一个问题,评估行数和真实行数存在较大差距,导致计划不准的问题。
nestloop内表评估是根据外表的参数来的。因为外表驱动表每取一条,内表才能做查询。所以这里外表的一条数据对内表来说就是参数。内表使用参数化路径来评估行数。
本篇针对这个实例对参数化路径行数评估做一些分析。
postgres=# explain analyze select * from iii, mmm where iii.poid = mmm.poid;QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------Nested Loop (cost=0.43..125.97 rows=17 width=27) (actual time=0.063..6.031 rows=1000 loops=1)-> Seq Scan on mmm (cost=0.00..1.10 rows=10 width=13) (actual time=0.005..0.010 rows=10 loops=1)-> Index Scan using idx_iii_poid on iii (cost=0.43..12.47 rows=2 width=14) (actual time=0.022..0.563 rows=100 loops=10)Index Cond: (poid = mmm.poid)Planning Time: 0.351 msExecution Time: 6.138 ms
(6 rows)
2 全文总结(便于查询)
文章结论
- get_parameterized_baserel_size计算参数化路径的选择率,本例中并没有看到任何特殊的评估方法,完全是按照poid的选择率来评估的。
clauselist_selectivity = 1.7108151058814915e-07
rel->tuples = 10000001nrows = rel->tuples * clauselist_selectivity = 2
- pg_statistic记录的poid列唯一值个数占比
-0.58516644 - pg_class记录行数为
10000001条,所以评估poid列的唯一值个数为10000001*0.58516644=5845167(实际9901001)。这里有一半的偏差,但不是主要原因。 2行=10000001*1.71e-07,在一个均匀分布的数据集中,每一个唯一值出现的概率是1.71e-07。所以如果有1千万行数据,随便给一个poid,能选出来两行不一样的。- 如果唯一值非常少,那么选择率会变大,趋近于1,则
10000001行=10000001*1。随便给一个poid,能选出来会非常多。 - 如果唯一值非常多,那么选择率会变小,趋近于0,则
0行=10000001*0。随便给一个poid,能选出来会非常少。
- 如果唯一值非常少,那么选择率会变大,趋近于1,则
- 评估两行但实际是100行的原因是,数据不均匀但统计信息平均采样,导致pg_statistic中stadistinct不准,进一步导致选择率不准,导致计算出现偏差。
分析思路整理
- standard_join_search逐层规划连接顺序,找到参数化path节点。
1.1.1 PATH 1:用索引参数化路径,评估2行 - create_index_path在make_one_rel→set_base_rel_pathlists中一共调用6次,其中一次是参数化路径,特点是入参required_outer有值,可能拿到外表信息。
- 进一步分析create_index_path参数化成本计算,create_index_path→get_baserel_parampathinfo函数生成ParamPathInfo,ParamPathInfo中ppi_rows记录估算函数。
- 进一步分析ppi_rows的计算,在create_index_path→get_baserel_parampathinfo中处理,get_baserel_parampathinfo用行数1千万乘以选择率得到行数。
- 进一步分析选择率的计算
- clauselist_selectivity → clause_selectivity_ext → restriction_selectivity → eqsel_internal → var_eq_non_const
- 使用
stadistinct = stats->stadistinct = -0.58516644(来自pg_statistic表) - 使用
ntuples = vardata->rel->tuples = 10000001(来自relation结构,来自pg_class表) - 计算唯一行数:
clamp_row_est(-stadistinct * ntuples = 5845167.024516644) = 5845167 - 进而得到选择率selec = selec / ndistinct = 1 / 5845167 = 1.7108151058814915e-07
实例
-
计划二:优化器认为驱动表每一行,内表有2行能连接上,实际有100行能连接上。为什么差距大?
-
(cost=0.43..12.47 rows=2 width=14) (actual time=0.022..0.563 rows=100 loops=10)评估不准的原因是什么?
-- 计划二
drop table iii;
CREATE TABLE iii (poid INT NOT NULL, value NUMERIC, status int);
-- 可以和mmm表连上
INSERT INTO iii SELECT t%1000, t, 0 FROM generate_series(1, 100000) t order by random();
-- 干扰数据,占比高担都和mmm表连不上
INSERT INTO iii SELECT t, t, 0 FROM generate_series(100000, 10000000) t order by random();
CREATE INDEX idx_iii_poid ON iii(poid);
analyze iii;drop table mmm;
CREATE TABLE mmm (poid INT NOT NULL, value NUMERIC, status int);
INSERT INTO mmm SELECT t, t, 0 FROM generate_series(1, 10) t order by random();
CREATE INDEX idx_mmm_poid ON mmm(poid);
analyze mmm;set enable_hashjoin to off;
set enable_mergejoin to off;
set enable_bitmapscan to off;
explain analyze select * from iii, mmm where iii.poid = mmm.poid;postgres=# explain analyze select * from iii, mmm where iii.poid = mmm.poid;QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------Nested Loop (cost=0.43..125.97 rows=17 width=27) (actual time=0.063..6.031 rows=1000 loops=1)-> Seq Scan on mmm (cost=0.00..1.10 rows=10 width=13) (actual time=0.005..0.010 rows=10 loops=1)-> Index Scan using idx_iii_poid on iii (cost=0.43..12.47 rows=2 width=14) (actual time=0.022..0.563 rows=100 loops=10)Index Cond: (poid = mmm.poid)Planning Time: 0.351 msExecution Time: 6.138 ms
(6 rows)要分析这个问题需要从path生成开始看:
path生成
1 standard_join_search第一层
1.1 第一层第一个RelOptInfo(iii表)
p ((RelOptInfo*)root->join_rel_level[1].elements[0].ptr_value).pathlist
1.1.1 PATH 1:用索引参数化路径,评估2行,代价total_cost = 12.466928526553348
$53 = {path = {type = T_IndexPath,pathtype = T_IndexScan,parent = 0x1e91558,pathtarget = 0x1e697c8,param_info = 0x1e8d340,parallel_aware = false,parallel_safe = true,parallel_workers = 0,rows = 2,startup_cost = 0.435,total_cost = 12.466928526553348,pathkeys = 0x1e8cf90},indexinfo = 0x1e91768,indexclauses = 0x1e8cef0,indexorderbys = 0x0,indexorderbycols = 0x0,indexscandir = ForwardScanDirection,indextotalcost = 4.4499999999999993,indexselectivity = 1.7108151058814915e-07
}
param_info = 0x1e8d340 记录了什么?
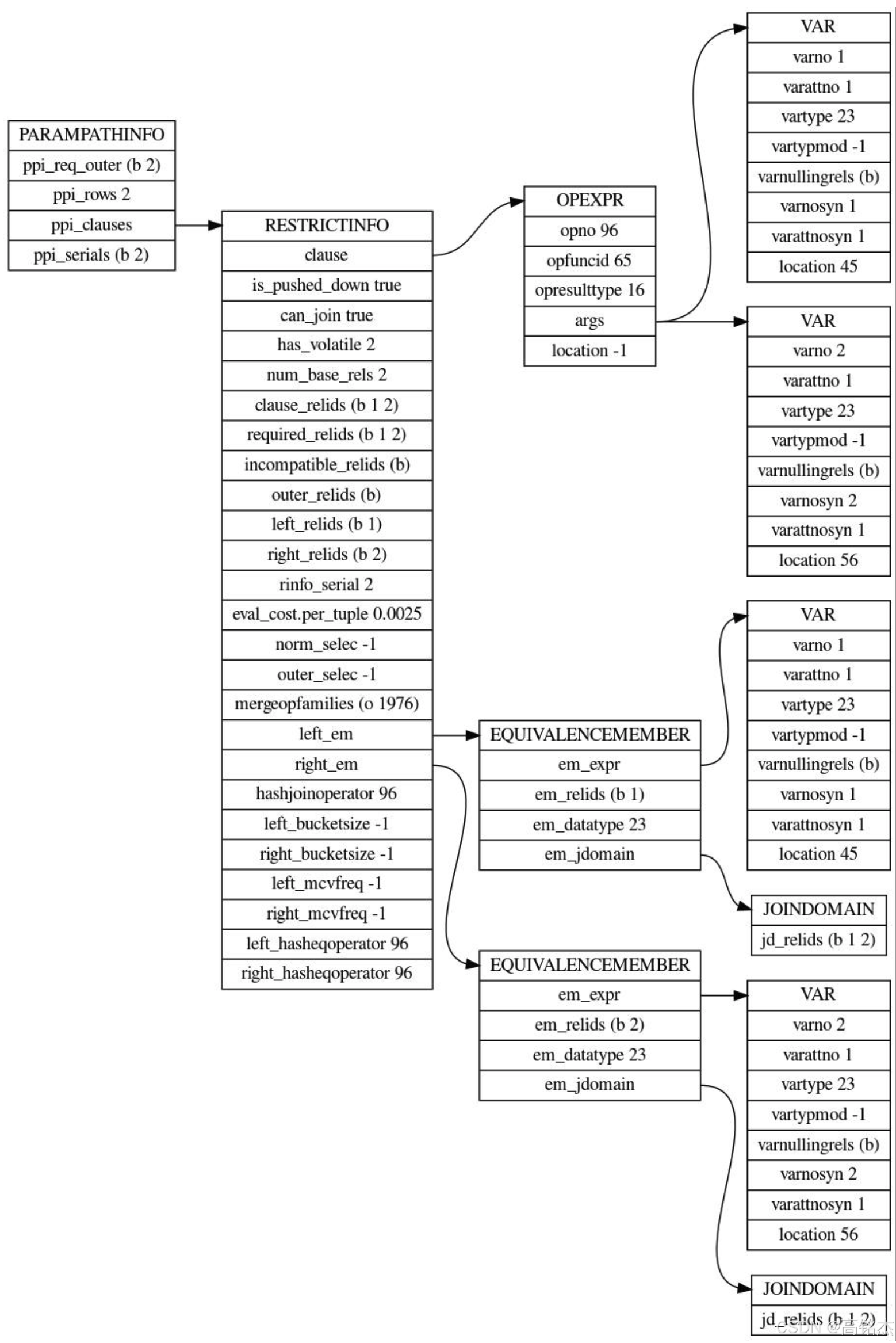
1.1.2 PATH 2:全表扫,代价total_cost = 154055.01000000001
(gdb) tr Path 0x1e8bbc0
$55 = {type = T_Path,pathtype = T_SeqScan,parent = 0x1e91558,pathtarget = 0x1e697c8,param_info = 0x0,parallel_aware = false,parallel_safe = true,parallel_workers = 0,rows = 10000001,startup_cost = 0,total_cost = 154055.01000000001,pathkeys = 0x0
}
1.1.3 PATH 3:用索引全表扫iii表,评估10000001行。代价total_cost = 475019.93093073595
$57 = {path = {type = T_IndexPath,pathtype = T_IndexScan,parent = 0x1e91558,pathtarget = 0x1e697c8,param_info = 0x0,parallel_aware = false,parallel_safe = true,parallel_workers = 0,rows = 10000001,startup_cost = 0.435,total_cost = 475019.93093073595,pathkeys = 0x1e8c7d0},indexinfo = 0x1e91768,indexclauses = 0x0,indexorderbys = 0x0,indexorderbycols = 0x0,indexscandir = ForwardScanDirection,indextotalcost = 158924.44,indexselectivity = 1
}
1.2 第一层第二个RelOptInfo(mmm表)
p ((RelOptInfo*)root->join_rel_level[1].elements[1].ptr_value).pathlist
1.2.1 PATH 1:用索引参数化路径,评估1行,代价total_cost = 0.15250119999987999
$70 = {path = {type = T_IndexPath,pathtype = T_IndexScan,parent = 0x1e90d28,pathtarget = 0x1e698f8,param_info = 0x1eac2d8,parallel_aware = false,parallel_safe = true,parallel_workers = 0,rows = 1,startup_cost = 0.13500000000000001,total_cost = 0.15250119999987999,pathkeys = 0x1eabfd8},indexinfo = 0x1e8b8c8,indexclauses = 0x1eabf38,indexorderbys = 0x0,indexorderbycols = 0x0,indexscandir = ForwardScanDirection,indextotalcost = 0.14250079999991999,indexselectivity = 0.10000000000000001
}
1.2.2 PATH 2:全表扫,评估10行,代价total_cost = 1.1000000000000001
$71 = {type = T_Path,pathtype = T_SeqScan,parent = 0x1e90d28,pathtarget = 0x1e698f8,param_info = 0x0,parallel_aware = false,parallel_safe = true,parallel_workers = 0,rows = 10,startup_cost = 0,total_cost = 1.1000000000000001,pathkeys = 0x0
}
1.2.3 PATH 3:索引全表扫,评估10行,代价otal_cost = 12.285
{path = {type = T_IndexPath,pathtype = T_IndexScan,parent = 0x1e90d28,pathtarget = 0x1e698f8,param_info = 0x0,parallel_aware = false,parallel_safe = true,parallel_workers = 0,rows = 10,startup_cost = 0.13500000000000001,total_cost = 12.285,pathkeys = 0x1eab998},indexinfo = 0x1e8b8c8,indexclauses = 0x0,indexorderbys = 0x0,indexorderbycols = 0x0,indexscandir = ForwardScanDirection,indextotalcost = 8.1850000000000005,indexselectivity = 1
}
2 standard_join_search第二层,只有一个RelOptInfo
p ((RelOptInfo*)root->join_rel_level[2].elements[0].ptr_value).pathlist
只有一个PATH
$91 = {jpath = {path = {type = T_NestPath,pathtype = T_NestLoop,parent = 0x1eacc28,pathtarget = 0x1eace58,param_info = 0x0,parallel_aware = false,parallel_safe = true,parallel_workers = 0,rows = 17,startup_cost = 0.435,total_cost = 125.96928526553347,pathkeys = 0x0},jointype = JOIN_INNER,inner_unique = false,outerjoinpath = 0x1e8d780, innerjoinpath = 0x1e8d020,joinrestrictinfo = 0x0}
}
- outerjoinpath = 0x1e8d780:选择了1.2.2 PATH 2:全表扫,评估10行,代价total_cost = 1.1000000000000001。
- innerjoinpath = 0x1e8d020:选择了1.1.1 PATH 1:用索引参数化路径,评估2行,代价total_cost = 12.466928526553348。
为什么iii表的索引参数化路径评估只有2行?
- 现阶段只有nestloop的内表需要参数化路径,因为内表评估行数时,无法确切知道能连上多少行,所以只能计算出一个行数。
- 在上文
1.1.1 PATH 1:用索引参数化路径,评估2行,代价total_cost = 12.466928526553348中,参数化node评估的行数是怎么计算出来的?
$53 = {path = {type = T_IndexPath,pathtype = T_IndexScan,parent = 0x1e91558,pathtarget = 0x1e697c8,param_info = 0x1e8d340,parallel_aware = false,parallel_safe = true,parallel_workers = 0,rows = 2,startup_cost = 0.435,total_cost = 12.466928526553348,pathkeys = 0x1e8cf90},indexinfo = 0x1e91768,indexclauses = 0x1e8cef0,indexorderbys = 0x0,indexorderbycols = 0x0,indexscandir = ForwardScanDirection,indextotalcost = 4.4499999999999993,indexselectivity = 1.7108151058814915e-07
}
create_index_path在make_one_rel→set_base_rel_pathlists中一共调用6次:
-- iii表的索引 idx_iii_poid,非参数化路径
create_index_path (root=0x1e68cb8, index=0x1e91768, indexclauses=0x0, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1e8c7d0, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x0, loop_count=1, partial_path=false)
-- iii表的索引 idx_iii_poid,非参数化路径
create_index_path (root=0x1e68cb8, index=0x1e91768, indexclauses=0x0, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1e8c7d0, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x0, loop_count=1, partial_path=true)
-- iii表的索引 idx_iii_poid,required_outer有值,计算参数化路径
create_index_path (root=0x1e68cb8, index=0x1e91768, indexclauses=0x1e8cef0, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1e8cf90, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x1e8cca0, loop_count=10, partial_path=false)-- mmm表的索引 idx_mmm_poid
create_index_path (root=0x1e68cb8, index=0x1e8b8c8, indexclauses=0x0, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1eab998, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x0, loop_count=1, partial_path=false)
create_index_path (root=0x1e68cb8, index=0x1e8b8c8, indexclauses=0x0, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1eab998, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x0, loop_count=1, partial_path=true)
create_index_path (root=0x1e68cb8, index=0x1e8b8c8, indexclauses=0x1eabf38, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1eabfd8, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x1e8d2d0, loop_count=10000001, partial_path=false)
- required_outer有值,表示参数化的indexpath:
-- iii表的索引 idx_iii_poid,required_outer有值,计算参数化路径
create_index_path (root=0x1e68cb8, index=0x1e91768, indexclauses=0x1e8cef0, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1e8cf90, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x1e8cca0, loop_count=10, partial_path=false)
参数化路径计算
create_index_path→get_baserel_parampathinfo函数生成ParamPathInfo
get_baserel_parampathinfo调用get_parameterized_baserel_size评估,当前节点是几行。例如评估出来2行。explain时内表看到的rows就是2行,含义是外表每一行过来,内表有两行能连上。
get_parameterized_baserel_size
double
get_parameterized_baserel_size(PlannerInfo *root, RelOptInfo *rel,List *param_clauses)
{List *allclauses;double nrows;allclauses = list_concat_copy(param_clauses, rel->baserestrictinfo);nrows = rel->tuples *clauselist_selectivity(root,allclauses,rel->relid, /* do not use 0! */JOIN_INNER,NULL);nrows = clamp_row_est(nrows);/* For safety, make sure result is not more than the base estimate */if (nrows > rel->rows)nrows = rel->rows;return nrows;
}
- allclauses合并param_clauses参数化条件和rel->baserestrictinfo当前表自身的约束条件,得到综合条件列表。
- 使用 clauselist_selectivity 函数计算这些条件的综合选择率,再乘以表的基数rel->tuples,最终得到参数化路径下的预估行数。
当前的allclauses表本身没有条件,只有外表提供的参数化条件:
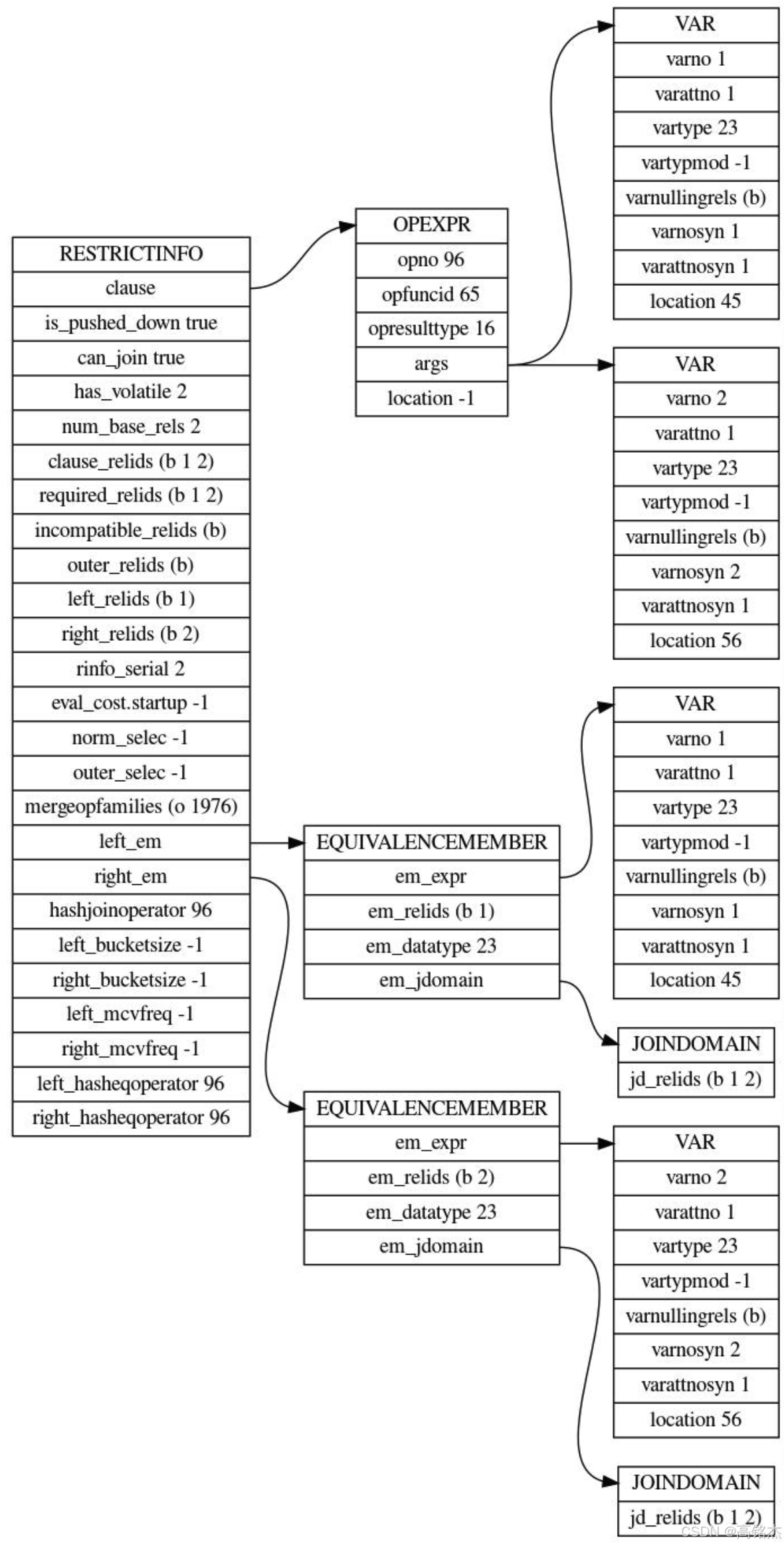
-
上图中opexpr是等号,指向varno=1、varno=2指向两个基表。
-
nrows = rel->tuples * clauselist_selectivity = 2
- clauselist_selectivity = 1.7108151058814915e-07
- rel->tuples = 10000001
clauselist_selectivity → clause_selectivity_ext的计算逻辑分支较多,这里只给出本例走到的分支:
clause_selectivity_ext......clause = (Node *) rinfo->clause;......else if (is_opclause(clause) || IsA(clause, DistinctExpr))......restriction_selectivity...
restriction_selectivity用于计算条件(where中过滤条件)的选择率:
Selectivity
restriction_selectivity(PlannerInfo *root,Oid operatorid,List *args,Oid inputcollid,int varRelid)
{
- 这里operatorid=96是等号。
- get_oprrest从系统表中拿到oprrest 字段,字段指向一个注册的选择率计算函数oid=101,eqsel函数。
RegProcedure oprrest = get_oprrest(operatorid);float8 result;/** if the oprrest procedure is missing for whatever reason, use a* selectivity of 0.5*/if (!oprrest)return (Selectivity) 0.5;result = DatumGetFloat8(OidFunctionCall4Coll(oprrest,inputcollid,PointerGetDatum(root),ObjectIdGetDatum(operatorid),PointerGetDatum(args),Int32GetDatum(varRelid)));if (result < 0.0 || result > 1.0)elog(ERROR, "invalid restriction selectivity: %f", result);return (Selectivity) result;
}
进入eqsel函数开始计算选择率,eqsel用于计算等值和不等值操作符的选择率,是优化器代价模型的核心组成部分。
- root:优化器上下文(包含统计信息、表元数据等)
- operator:操作符的 OID(如 = 或 <>)
- args:操作符的参数列表(如 a = 5 中的列 a 和常量 5)
- varRelid:关联的关系 ID(用于确定统计信息范围)
- collation:排序规则(影响字符串比较)
/** Common code for eqsel() and neqsel()*/
static double
eqsel_internal(PG_FUNCTION_ARGS, bool negate)
{PlannerInfo *root = (PlannerInfo *) PG_GETARG_POINTER(0);Oid operator = PG_GETARG_OID(1);List *args = (List *) PG_GETARG_POINTER(2);int varRelid = PG_GETARG_INT32(3);Oid collation = PG_GET_COLLATION();VariableStatData vardata;Node *other;bool varonleft;double selec;
negate表示不等值。
if (negate){operator = get_negator(operator);if (!OidIsValid(operator)){/* Use default selectivity (should we raise an error instead?) */return 1.0 - DEFAULT_EQ_SEL;}}
本例中的args:
- Var = {xpr = {type = T_Var}, varno = 1, varattno = 1, vartype = 23}
- Var = {xpr = {type = T_Var}, varno = 2, varattno = 1, vartype = 23}
- varRelid = 1
/** If expression is not variable = something or something = variable, then* punt and return a default estimate.*/if (!get_restriction_variable(root, args, varRelid,&vardata, &other, &varonleft))return negate ? (1.0 - DEFAULT_EQ_SEL) : DEFAULT_EQ_SEL;
get_restriction_variable将条件拆分为变量和常量或其他表达式。
- vardata
- {var = 0x1e6b2c0, rel = 0x1e8b8f8, statsTuple = 0x7f4874e75e08, freefunc = 0xb73cd6 , vartype = 23, atttype = 23, atttypmod = -1, isunique = false, acl_ok = true}
- var = {xpr = {type = T_Var}, varno = 1, varattno = 1, vartype = 23}
- statsTuple = pg_stat_statistic对应的行。
- {var = 0x1e6b2c0, rel = 0x1e8b8f8, statsTuple = 0x7f4874e75e08, freefunc = 0xb73cd6 , vartype = 23, atttype = 23, atttypmod = -1, isunique = false, acl_ok = true}
- other = {{xpr = {type = T_Var}, varno = 2, varattno = 1, vartype = 2}
- varonleft = true
开始计算选择率 var_eq_non_const
/** We can do a lot better if the something is a constant. (Note: the* Const might result from estimation rather than being a simple constant* in the query.)*/if (IsA(other, Const))selec = var_eq_const(&vardata, operator, collation,((Const *) other)->constvalue,((Const *) other)->constisnull,varonleft, negate);elseselec = var_eq_non_const(&vardata, operator, collation, other,varonleft, negate);ReleaseVariableStats(vardata);return selec;
}
var_eq_non_const用于计算变量与非常量表达式(如其他列或子查询结果)的等值条件(= 或 <>)的选择率,例如 a = b 或 x <> y。核心逻辑是基于统计信息(如唯一性约束、NULL值比例、不同值数量等),结合启发式规则估算满足条件的行数比例
- vardata:变量统计信息(如列 a 的直方图、MCV列表等)。
- oproid:操作符OID(如 = 或 <>)。
- other:非常量表达式(如另一列 b 或表达式 b + 1)。
- negate:不等。
/** var_eq_non_const --- eqsel for var = something-other-than-const case** This is exported so that some other estimation functions can use it.*/
double
var_eq_non_const(VariableStatData *vardata, Oid oproid, Oid collation,Node *other,bool varonleft, bool negate)
{double selec;double nullfrac = 0.0;bool isdefault;先拿到pg_statistic表对应的行。
if (HeapTupleIsValid(vardata->statsTuple)){Form_pg_statistic stats;stats = (Form_pg_statistic) GETSTRUCT(vardata->statsTuple);nullfrac = stats->stanullfrac;}...else if (HeapTupleIsValid(vardata->statsTuple)){double ndistinct;AttStatsSlot sslot;
基于统计信息估算:
- 计算非NULL值比例 1 - nullfrac。
- 通过 get_variable_numdistinct 获取变量不同值数量 ndistinct。
- 假设每个不同值均匀分布,选择率为 (1 - nullfrac) / ndistinct。
- 与MCV(最常见值)的最大频率比较,避免高估。
selec = 1.0 - nullfrac;ndistinct = get_variable_numdistinct(vardata, &isdefault);
get_variable_numdistinct计算结果:5845167
stadistinct = stats->stadistinct = -0.58516644(来自pg_statistic表)stanullfrac = 0ntuples = vardata->rel->tuples = 10000001(来自relation结构,来自pg_class表)- 计算结果:
clamp_row_est(-stadistinct * ntuples = 5845167.024516644) = 5845167
get_variable_numdistinct计算方法总结:pg_statistic表的stadistinct中取得选择率 乘以 评估行数,等于评估出来多少个唯一值。stadistinct含义:stadistinct > 0表示该列中非空唯一值的实际数量。stadistinct < 0表示非空唯一值的数量占总行数的比例。stadistinct = 0表示无法确定该列的非空唯一值数量。
if (ndistinct > 1)selec /= ndistinct;......return selec;
计算得到选择率
selec = selec / ndistinct = 1 / 5845167 = 1.7108151058814915e-07
回到最初的行数评估函数get_parameterized_baserel_size中:
- nrows = rel->tuples * clauselist_selectivity = 2
- clauselist_selectivity = 1.7108151058814915e-07
- rel->tuples = 10000001
总结:
- pg_statistic记录的poid列唯一值个数占比
-0.58516644 - pg_class记录行数为
10000001条,所以评估poid列的唯一值个数为10000001*0.58516644=5845167(实际9901001)。这里有一半的偏差,但不是主要原因。 2行=10000001*1.71e-07,在一个均匀分布的数据集中,每一个唯一值出现的概率是1.71e-07。所以如果有1千万行数据,随便给一个poid,能选出来两行不一样的。- 如果唯一值非常少,那么选择率会变大,趋近于1,则
10000001行=10000001*1。随便给一个poid,能选出来会非常多。 - 如果唯一值非常多,那么选择率会变小,趋近于0,则
0行=10000001*0。随便给一个poid,能选出来会非常少。
- 如果唯一值非常少,那么选择率会变大,趋近于1,则
- 评估两行但实际是100行的原因是,pg_statistic中stadistinct记录的连接条件poid列的唯一值。
create_index_path→cost_index计算参数化路径评估行数(从上一步的ParamPathInfo结果中取得)
- cost_index中如果发现参数化路径,会从ParamPathInfo中取评估行数
- 本例中path->path.param_info->ppi_rows=2。
- param_info存在表示当前索引扫描路径是参数化的,依赖外部循环(如嵌套循环连接的外层表)提供的参数值。
- 行数估算:ppi_rows 表示参数化路径的预估行数,这是优化器根据外层表(如嵌套循环中的驱动表)的约束条件和连接关系动态调整的结果,比如ppi_rows=2表示,优化器评估外表每一条,内表有两条能连得上。
void
cost_index(IndexPath *path, PlannerInfo *root, double loop_count,bool partial_path)......if (path->path.param_info){path->path.rows = path->path.param_info->ppi_rows;/* qpquals come from the rel's restriction clauses and ppi_clauses */qpquals = list_concat(extract_nonindex_conditions(path->indexinfo->indrestrictinfo,path->indexclauses),extract_nonindex_conditions(path->path.param_info->ppi_clauses,path->indexclauses));}else{path->path.rows = baserel->rows;/* qpquals come from just the rel's restriction clauses */qpquals = extract_nonindex_conditions(path->indexinfo->indrestrictinfo,path->indexclauses);}...
相关文章:
优化器nestloop参数化路径评估不准问题分析)
Postgresql源码(145)优化器nestloop参数化路径评估不准问题分析
相关 《Postgresql源码(133)优化器动态规划生成连接路径的实例分析》 1 问题 最近遇到一个问题,评估行数和真实行数存在较大差距,导致计划不准的问题。 nestloop内表评估是根据外表的参数来的。因为外表驱动表每取一条ÿ…...

【深度学习新浪潮】小米MiMo-7B报告内容浅析
一段话总结 该报告介绍了专为推理任务设计的大语言模型MiMo-7B,其在预训练阶段通过优化数据预处理、采用三阶段数据混合策略(处理约25万亿token)和引入MultiToken Prediction(MTP)目标提升推理潜力;后训练阶段构建13万可验证数学和编程问题数据集,结合测试难度驱动奖励…...

使用Python和Pandas实现的Snowflake权限检查与SQL生成用于IT审计
import snowflake.connector import pandas as pddef get_snowflake_permissions():# 连接Snowflake(需要替换实际凭证)conn snowflake.connector.connect(user<USER>,password<PASSWORD>,account<ACCOUNT>,warehouse<WAREHOUSE&g…...

spring 从application.properties中获取参数的四种方式
在Spring Boot中,自定义一个Starter时,从application.properties中获取参数主要有以下几种方法: 使用Value注解 这是最常用的方法之一,通过Value注解可以直接将application.properties中的属性值注入到Spring管理的Bean中。 imp…...

react学习笔记2——基于React脚手架与ajax
使用create-react-app创建react应用 react脚手架 xxx脚手架: 用来帮助程序员快速创建一个基于xxx库的模板项目 包含了所有需要的配置(语法检查、jsx编译、devServer…)下载好了所有相关的依赖可以直接运行一个简单效果 react提供了一个用于创建react项…...

nim模块教程
导入一个模块 如果我们想要导入一个模块,并且和它的所有函数,我们要做的是写import <moduleName>在我们的文件里,这通常是在文件顶部进行的,这样我们就可以很容易地看到我们的代码使用了什么。 创建一个模块 first.nim …...

雅马哈SMT贴片机高效精密制造解析
内容概要 作为电子制造领域的核心装备,雅马哈SMT贴片机通过集成高速运动控制、智能视觉识别与模块化供料三大技术体系,构建了精密电子元件贴装的工业化解决方案。其YSM系列设备在5G通讯模组、汽车电子控制器及智能穿戴设备等场景中,实现了每…...

审计专员简历模板
模板信息 简历范文名称:审计专员简历模板,所属行业:其他 | 职位,模板编号:KSJYVR 专业的个人简历模板,逻辑清晰,排版简洁美观,让你的个人简历显得更专业,找到好工作。希…...
(指由宿主环境提供的依赖))
npm宿主依赖、宿主环境依赖(peerDependencies)(指由宿主环境提供的依赖)
文章目录 宿主环境依赖详解基本概念工作原理应用场景插件开发UI组件库 与其他依赖类型对比npm不同版本处理差异npm v3-v6npm v7 实际应用示例React插件开发 解决宿主依赖问题 宿主环境依赖详解 基本概念 宿主环境依赖(peerDependencies)是指包声明自身…...
 全攻略)
Android Kotlin 项目集成 Firebase Cloud Messaging (FCM) 全攻略
Firebase Cloud Messaging (FCM) 是 Google 提供的跨平台消息推送解决方案。以下是在 Android Kotlin 项目中集成 FCM 的详细步骤。 一、前期准备 1. 创建 Firebase 项目 访问 Firebase 控制台点击"添加项目",按照向导创建新项目项目创建完成后&#x…...

游戏引擎学习第252天:允许编辑调试值
回顾并为今天的工作设定目标 我们处理了调试值(debug value)的编辑功能。我们希望实现可以在调试界面中编辑某些值,为此还需要做一些额外的工作。 我们的问题在于:当某个调试值被编辑时,我们需要把这个“编辑”的操作…...

支持selenium的chrome driver更新到136.0.7103.49
最近chrome释放新版本:136.0.7103.49 如果运行selenium自动化测试出现以下问题,是需要升级chromedriver才可以解决的。 selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only su…...

cPanelWHM 的 AutoSSL
在 cPanel&WHM 的第58版本中,开始增加了AutoSSL,这是一项非常棒的新功能。 什么是 AutoSSL? AutoSSL 是为了解决每个使用 cPanel&WHM 用户的最大难题:SSL 证书的安装和续期。有了 AutoSSL,这个问题就不再是问…...

MySQL数据同步之Canal讲解
文章目录 1 Canal搭建1.1 简介1.1.1 概述1.1.2 优点1.1.3 作用&核心组件 1.2 搭建 Canal1.2.1 准备工作1.2.1.1 检查配置1.2.1.2 MySQL配置 1.2.2 下载并安装 Canal1.2.3 配置 Canal Server1.2.3.1 全局配置1.2.3.2 实例配置1.2.3.3 配置目标系统1.2…...

完整迁移物理机Windows XP到PVE8
计划对2007年部署的windows_xp_professional _service_pack_2_x86系统主机,进行重新部署,由于确实环境包和软件包,无法从头部署,只能考虑带系统环境迁移。原主机年代台久远(1Ghz处理器,1G内存)G…...

量子加密通信:打造未来信息安全的“铜墙铁壁”
在数字化时代,信息安全已成为全球关注的焦点。随着量子计算技术的飞速发展,传统的加密算法面临着前所未有的挑战。量子计算机的强大计算能力能够轻易破解现有的加密体系,这使得信息安全领域急需一种全新的加密技术来应对未来的威胁。量子加密…...
 : 画廊问题)
11.多边形的三角剖分 (Triangulation) : 画廊问题
目录 1.Methodology 编辑2. Definition 3. Lower & Upper Bound 4.Hardness 5.Approximation & Classification 6. Necessity of floor(n/3) 1.Methodology 多边形三角剖分 点集三角剖分 2. Definition 假设存在一个艺术馆,里面存在很大艺术品需…...

[蓝桥杯 2023 国 Python B] 划分 Java
import java.util.*;public class Main {public static void main(String[] args) {Scanner sc new Scanner(System.in);int[] arr new int[41];int sum 0;for (int i 1; i < 40; i) {arr[i] sc.nextInt();sum arr[i];}sc.close();int target sum / 2; // 最接近的两…...

计算机网络——HTTP/IP 协议通俗入门详解
HTTP/IP 协议通俗入门详解 一、什么是 HTTP 协议?1. 基本定义2. HTTP 是怎么工作的? 二、HTTP 协议的特点三、HTTPS 是什么?它和 HTTP 有啥区别?1. HTTPS 概述2. HTTP vs HTTPS 四、HTTP 的通信过程步骤详解: 五、常见…...

渗透测试中的那些“水洞”:分析与防御
1. Nginx 版本泄露 风险分析: Nginx 默认会在响应头中返回 Server: nginx/x.x.x,攻击者可利用该信息匹配已知漏洞进行攻击。 防御措施: 修改 nginx.conf 配置文件,隐藏版本信息:server_tokens off;使用 WAF 进行信息…...

攻防世界 - Misc - Level 3 | 3-1
🌟 关注这个靶场的其它相关笔记:CTF 靶场笔记 —— 攻防世界(XCTF) 过关思路合集 0x01:考点速览 本题考察的是 Misc 中的流量分析题,想要通过此关,你需要具备以下技术: 会通过 010 …...

安装linux下的idea
1.有可能传不了文件 2.按这个包里的流程装 通过网盘分享的文件:idea旗下所有产品.txt 链接: https://pan.baidu.com/s/1kHHkW3DB3z3a6CG0qnMkWA?pwdgg3f 提取码: gg3f...

【音频】基础知识
1、原始数据 1)音频信号:声音是一种机械波,经过麦克风等设备转化为电信号,再经过模数转换(ADC)变成数字信号,这个数字信号就是音频信号。 2)音频信号的参数: 采样率:一秒钟内对音频的模拟信号采样的个数; 8000Hz:主要用于电话通信 、满足基本的语音通信需求,同时…...

系统思考:企业效率提升关键
最近在辅导一家企业时,我们一起画出了这张图。老板说:“我每天都在救火,员工效率不高,我只能不断加班加点,亲自盯、亲自跑、亲自上阵……” 但图画出来才发现,问题不是出在员工不够努力,也不是老…...

MySQL 查找指定表名的表的主键
原理 SELECT COLUMN_NAME FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE WHERE TABLE_NAME 表名 AND CONSTRAINT_NAME PRIMARY方法 public static String getPk(String tableName) {String sql "SELECT COLUMN_NAME FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE WHERE TA…...

华为eNSP:IS-IS认证
一、什么是IS-IS认证? 华为eNSP中的IS-IS认证 IS-IS认证是华为eNSP网络中用于保障中间系统到中间系统(IS-IS)协议通信安全性的核心机制,通过身份验证和数据完整性校验防止非法路由信息注入或篡改。其实现方式与关键特性如下&…...
 -- qemu-system-arm使用)
qemu(4) -- qemu-system-arm使用
1. 前言 参考网上的资料,使用qemu中的vexpress_a9板子,跑一下Linux环境。 2. 源码 2.1 u-boot 可以到U-Boot官网下载对应的源码,我下载的是u-boot-2025.04-rc5.tar.gz,大约24MB。 3.2 linux 可以到The Linux Kernel Archive…...

JavaScript基础-递增和递减运算符
在JavaScript编程中,递增()和递减(--)运算符是操作数值变量的快捷方式。它们能够简洁地对变量值进行加一或减一的操作。尽管看似简单,但正确理解这两种运算符的不同使用方式(前缀与后缀)对于编写高效且无误的代码至关重要。本文将…...

解决Win10虚拟机“网络连接不上”,“Ethernet0 网络电缆被拔出”的问题
一、情景引入 今天用Win10虚拟机打开浏览器发现: 很奇怪,平常都没有这个问题。 二、检查网络状态 点击更改适配器选项,发现如下: 三、解决问题 打开任务管理器,点击服务,搜索栏搜索:VM …...

【Redis】String详细介绍及其应用场景
文章目录 String类型存储方式set命令get命令mset命令mget命令setnx命令setex和psetex命令incr和decr命令系列append命令--raw选项让redis尝试将二进制数据翻译 getrange命令setrange命令strlen命令字符串类型命令小结string内部的编码方式string类型的典型应用场景1.RedisMySQL…...

C++负载均衡远程调用学习之消息路分发机制
目录 1.LARV0.5-TCP_server链接管理的功能实现及测试 2.LARV0.6 3.LARV0.6 4.LARV0.6 5.LARV0.6-tcp_server集成 6.LARV0.6-tcp_server集成消息路由分发机制总结 7.LARV0.6回顾 1.LARV0.5-TCP_server链接管理的功能实现及测试 ### 16.2 完成Lars Reactor V0.12开发 ###…...

实现了一个基于寄存器操作STM32F103C8t6的工程, 并实现对PA1,PA2接LED正极的点灯操作
#include "stm32f10x.h"// 基于寄存器开发的项目了 int main(){RCC->APB2ENR 0x00000004; // 开启时钟GPIOA->CRL 0x00003330; // 配置引脚 // 0011 0011 0000GPIOA->ODR 0x0000000E; // 1110while(1){} }...
详解:从创建到操作全掌握)
Python字典(dict)详解:从创建到操作全掌握
前言 字典是可变容器,可存储任意类型对象 字典以键(key)-值(value)对的形式进行映射,键值对用冒号分割,对之间用逗号分割 d {key1 : value1, key2 : value2, key3 : value3 } 字典的数据是无序的 字典的键只能用不可变类型,且…...

UDP数据包和TCP数据包的区别;网络编程套接字;不同协议的回显服务器
目录 一、UDP 数据包与 TCP 数据包的区别: 连接方面: 传输方面: 面向对象: 双工模式: 二、UDP 网络编程套接字;基于 UDP 协议的回显服务器: 1. UDP 数据报套接字核心类 DatagramSocket &…...

Python 应用异常追踪实战:如何集成 Sentry 进行高效错误监控
Python 应用异常追踪实战:如何集成 Sentry 进行高效错误监控 引言 在现代应用开发中,异常处理和错误监控至关重要。一个小的运行时错误可能会导致整个系统崩溃,而难以发现的逻辑漏洞可能长期影响用户体验。为了提升代码的稳定性,我们需要一个高效的异常监控机制,以便能够…...

【数据结构】--- 双向链表的增删查改
前言: 经过了几个月的漫长岁月,回头时年迈的小编发现,数据结构的内容还没有写博客,于是小编赶紧停下手头的活动,补上博客以洗清身上的罪孽 目录 前言: 概念: 双链表的初始化 双链表的判空 双链表…...

【C语言练习】014. 使用数组作为函数参数
014. 使用数组作为函数参数 014. 使用数组作为函数参数示例1:使用数组作为函数参数并修改数组元素函数定义输出结果 示例2:使用数组作为函数参数并计算数组的平均值函数定义输出结果 示例3:使用二维数组作为函数参数函数定义输出结果 示例4&a…...

本地服务器备份网站数据,本地服务器备份网站的操作步骤
本地服务器备份网站数据的完整操作指南 一、明确备份需求与目标 核心备份对象 网站文件: 上传的媒体文件(图片、视频、PDF等) 配置文件(如.htaccess、wp-config.php) 附加内容(根据需求选择ÿ…...

机器学习Day15 LightGBM算法
浅谈LightGBM算法:我们之前讲的集成学习算法分为三要素吧,就是形式,损失函数,优化方法,但是LightGBM算法并没有固定的形式,它主要是针对具体算法给出一些优化,它更像是前向分步算法一样,像一个框…...

算法查找目录
1. 基础数据结构 数组与链表 动态数组 实现与自动扩容机制均摊分析ArrayList/Vector实现 单向链表 基本操作(插入、删除、查找)链表反转环检测(Floyd判圈算法) 双向链表 插入删除操作优化双向遍历优势边界情况处理 循环链表 约瑟夫环问题单向循环链表双向循环链表 跳表 基本原…...

【HarmonyOS】作业三 UI
目录 一. 单选题(共10题,10分) 1. (单选题, 1分)关于Tabs组件页签的位置设置,下面描述错误的是 2. (单选题, 1分)下面哪个组件不能包含子组件? 3. (单选题, 1分)ArkTS语言的实现计数器功能的组件名称是以下哪个? 4. (单选题…...

2025五一杯数学建模B题:矿山数据处理问题,详细问题分析,思路模型
一、尊重原创:详细内容文末名片获取 二、数据文件解读 (一)数据文件 1:矿山监测一维数值样例数据.csv 想象一下,这就像是一本简单的记录册,里面记录着一组一维数值序列,每个数据点如同册子里的…...

ES6-Set-Map对象小记
Set 对象 添加元素 set.add(value)常用方法 方法描述has()判断 Set 对象中特定元素是否存在delete()从 Set 对象中删除指定元素clear()清空 Set 对象 遍历方法 很容易想到使用set.forEach(callBackFn, thisArg)方法来进行遍历,其中callBackFn回调的形式如下&am…...

WGCLOUD使用 - 如何监控RabbitMQ运行参数
WGCLOUD是一款开源免费的运维监控软件,开箱即用,实用轻量,高效简单。 RabbitMQ指标数据的采集工作是由server-backup来做的,所以我们需要部署server-backup,它是一个server的辅助工具,作用相当于agent Rabb…...

FreeSWITCH 发送 sip message 的 lua 程序
-- chat.lualocal from argv[1] local to argv[2] local body argv[3] local profile "internal" -- 改成自己的 sip_profileif not body thenstream:write("-ERR miss ie")return endlocal api freeswitch.API() local domain api:executeString(&q…...

安全学习基础入门5集
前言: 来源于b站小迪安全v2023第5天:基础入门-反弹SHELL&不回显带外&正反向连接&防火墙出入站&文件下载_哔哩哔哩_bilibili 环境准备: 通过网盘分享的文件:netcat-1.11 链接: https://pan.baidu.com/s/1zgyYvPf…...

Python结合QT进行开发
Python结合Qt进行开发指南 1. Qt for Python简介 Qt for Python(PySide/PyQt)是Python的官方Qt绑定,允许使用Python语言开发跨平台的GUI应用程序。PySide是Qt官方支持的Python绑定,而PyQt是Riverbank Computing提供的商业/开源版本。 主要特点: 跨平台支持(Windows/macOS…...

Python与深度学习:自动驾驶中的物体检测,如何让汽车“看懂”世界
Python与深度学习:自动驾驶中的物体检测,如何让汽车“看懂”世界 一、引言:自动驾驶的“眼睛”——物体检测 在自动驾驶技术的浪潮中,如何让汽车像人类一样“看懂”周围的环境,成为了最为关键的一环。汽车需要感知道路上的行人、障碍物、交通标志、其他车辆等信息,做出实…...

深度学习-神经网络参数优化的约束与迭代策略
文章目录 前言一、正则化惩罚1、权重正则化(Weight Regularization)2、结构正则化(Structural Regularization)3、其他正则化方法 二、梯度下降1、基本原理(1)梯度下降的计算(2) 算法…...

PyTorch 与 TensorFlow:深度学习框架的深度剖析与实战对比
PyTorch 与 TensorFlow:深度学习框架的深度剖析与实战对比 摘要 :本文深入对比 PyTorch 与 TensorFlow 两大深度学习框架,从核心架构、优缺点、适用场景等多维度剖析,结合实例讲解,帮助开发者清晰理解两者特性&#x…...