C++漫溯键值的长河:map set
文章目录
- 1.关联式容器
- 2.set
- 2.1 find
- 2.2 lower_bound、upper_bound
- 3.multiset
- 3.1 count
- 3.2 equal_range
- 4.map
- 4.1 insert
- 4.2 operate->
- 4.3 operate[ ]
- 4.4 map的应用实践:随机链表的复制
- 5.multimap
- 希望读者们多多三连支持
- 小编会继续更新
- 你们的鼓励就是我前进的动力!
迄今为止,除了二叉搜索树以外的结构,我们学习到的顺序表,链表,栈和队列等都属于这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身
1.关联式容器
根据应用场景的不同,
STL总共实现了两种不同结构的管理式容器:树型结构与哈希结构。树型结构的关联式容器主要有四种:map、set、multimap、multiset。这四种容器的共同点是:使用平衡搜索树(即红黑树)作为其底层结果,容器中的元素是一个有序的序列
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高
键对值中的 key 表示键值,value 表示与 key 对应的信息
SGI-STL中关于键值对的定义:
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair() : first(T1()), second(T2()){}pair(const T1& a, const T2& b) : first(a), second(b){}
};
2.set

set 的主要特征可总结为:
set是按照一定次序存储元素的容器- 在
set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们 - 在内部,
set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行排序 set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对子集进行直接迭代set在底层是用二叉搜索树(红黑树)实现的
🔥值得注意的是:
- 与
map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是由<value, value>构成的键值对(后面底层的博客会解释) set中插入元素时,只需要插入value即可,不需要构造键值对set中的元素不可以重复(因此可以使用set进行去重)。- 使用
set的迭代器遍历set中的元素,可以得到有序序列 set中的元素默认按照小于来比较,即1、2、3…的顺序set中查找某个元素,时间复杂度为: l o g 2 n log_2 n log2nset中的元素不允许修改set中的底层使用二叉搜索树(红黑树)来实现
2.1 find

由于 set 的基本功能,像 insert、erase、迭代器等都和 string、vector 等差不多,这里就不过多解释,详细的可以自行查看官方文档,本文将针对部分特殊的函数进行解析
find 简单来说,就是寻找特定的键值,那么可以提出一个问题:
set<int> s;
s.insert(3);
s.insert(2);
s.insert(4);
s.insert(5);
s.insert(1);
s.insert(5);
s.insert(2)
s.insert(5);auto pos = s.find(3);//第一种
auto pos = find(s.begin(), s.end(), 3);//第二种
s.erase(3);
哪一种 find 方式能更好的删除?显然是第一种
因为第一种是 set 里面的 find,会以平衡二叉搜索树的方式去查找,大的往左走,小的往右走,时间复杂度为 O(logN);第二种是 algorithm(算法头文件)中的 find,是以依次遍历的方式,即中序遍历的方式进行的,时间复杂度为 O(N)
2.2 lower_bound、upper_bound
set<int> myset;
set<int>::iterator itlow, itup;for (int i = 1; i < 10; i++) myset.insert(i * 10); // 10 20 30 40 50 60 70 80 90itlow = myset.lower_bound(30); // ^
itup = myset.upper_bound(65); // ^myset.erase(itlow, itup); // 10 20 70 80 90cout << "myset contains:";
for (set<int>::iterator it = myset.begin(); it != myset.end(); ++it)cout << ' ' << *it;
cout << '\n';
因为迭代器的区间遵循左闭右开原则,所以 lower_bound 用于查找第一个大于等于给定值 val 的元素位置,upper_bound 用于查找第一个大于给定值 val 的元素位置
3.multiset

multiset 的主要特征可总结为:
multiset是按照特定顺序存储元素的容器,其中元素是可以重复的- 在
multiset中,元素的value也会识别它(因为multiset中本身存储的就是<value, value>组成的键值对,因此value本身就是key,key就是value,类型为T),multiset元素的值不能在容器中进行修改(因为元素总是const的),但可以从容器中插入或删除 - 在内部,
multiset中的元素总是按照其内部比较规则(类型比较)所指示的特定严格弱排序准则进行排序 multiset容器通过key访问单个元素的速度通常比unordered_multiset容器慢,但当使用迭代器遍历时会得到一个有序序列multiset底层结构为二叉搜索树(红黑树)
🔥值得注意的是:
multiset中再底层中存储的是<value, value>的键值对multiset的插入接口中只需要插入即可- 与
set的区别是,multiset中的元素可以重复,set是中value是唯一的 - 使用迭代器对
multiset中的元素进行遍历,可以得到有序的序列 multiset中的元素不能修改- 在
multiset中找某个元素,时间复杂度为 O ( l o g 2 N ) O(log_2 N) O(log2N) multiset的作用:可以对元素进行排序
3.1 count

multiset 同样是这几个,但是 count 和 equal_range 可以说是专门给 multiset 打造的,虽然 set 里也可以用,但是没什么意义
count 用于统计容器中某个值出现的次数
3.2 equal_range
set<int> mySet = {1, 2, 3, 3, 4, 5};
auto result = mySet.equal_range(3);for (auto it = result.first; it != result.second; ++it)
{cout << *it << " ";
}
cout << endl;
equal_range 用于查找重复元素之间的区间,返回一个 pair 对象,该对象包含两个迭代器:
- 第一个迭代器指向
multiset中第一个等于value的元素(如果存在),或者指向第一个大于value的元素(如果不存在等于 value 的元素) - 第二个迭代器指向
set中最后一个等于value的元素的下一个位置(如果存在等于value的元素),或者与第一个迭代器相等(如果不存在等于value的元素)
4.map

map的主要特征可总结为:
map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素- 在
map中,键值key通常用于排序和唯一地标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型value_type绑定在一起,为其取别名称为pair : typedef pair<const key, T>value_type - 在内部,
map中的元素总是按照键值key进行比较排序的 map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)map支持下标访问符,即在[]中放入key,就可以找到与key对应的valuemap通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))
由于 map 的基本功能,像 insert、erase、迭代器等都和 string、vector 等差不多,这里就不过多解释,详细的可以自行查看官方文档,本文将针对部分函数进行解析
4.1 insert
map 中的 insert 插入的是一个 pair 结构对象,下面将列举多种插入方式:
🚩创建普通对象插入
pair<string, string> kv1("insert", "插入");
dict.insert(kv1);
🚩创建匿名对象插入
dict.insert(pair<string, string>("sort", "排序"));
🚩调用make_pair函数插入
dict.insert(make_pair("string", "字符串"));
调用 make_pair 省去了声明类型的过程
🚩隐式类型转换插入
dict.insert({ "string","字符串" });
通常 C++98 只支持单参数隐式类型转换,到 C++11 的时候就开始支持多参数隐式类型转换
有这么一个问题:为什么加上了引用反而要加const
pair<string, string> kv2 = { "insert", "插入" };
const pair<string, string>& kv2 = { "insert", "插入" };
无引用情况: 对于 pair<string, string> kv2 = { "string", "字符串" }; ,编译器可能会执行拷贝省略(也叫返回值优化 RVO 或命名返回值优化 NRVO )。比如在创建 kv2 时,直接在其存储位置构造对象,而不是先创建一个临时对象再拷贝 / 移动过去
加引用情况: 使用 const pair<string, string>& kv2 = { "string", "字符串" }; 时,这里 kv2 是引用,它绑定到一个临时对象(由大括号初始化列表创建 )。因为引用本身不持有对象,只是给对象取别名,所以不存在像非引用对象构造时那种在自身存储位置直接构造的情况。不过,这种引用绑定临时对象的方式,只要临时对象的生命周期延长到与引用一样长(C++ 规则规定,常量左值引用绑定临时对象时,临时对象生命周期延长 ),也不会额外增加拷贝 / 移动开销
4.2 operate->
map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{//it->first = "xxx";//it->second = "xxx";//cout << (*it).first << ":" << (*it).second << endl;cout << it->first << ":" << it->second << endl;++it;
}
cout << endl;
map 中并没有对 pair 进行流插入运算符重载,(*it).first 这样子的方式又不太简洁不好看,所以进行了 -> 运算符重载,返回的是 first 的地址,因此 (*it).first 等价于 it->->first,为了代码可读性,就省略一个 ->
4.3 operate[ ]
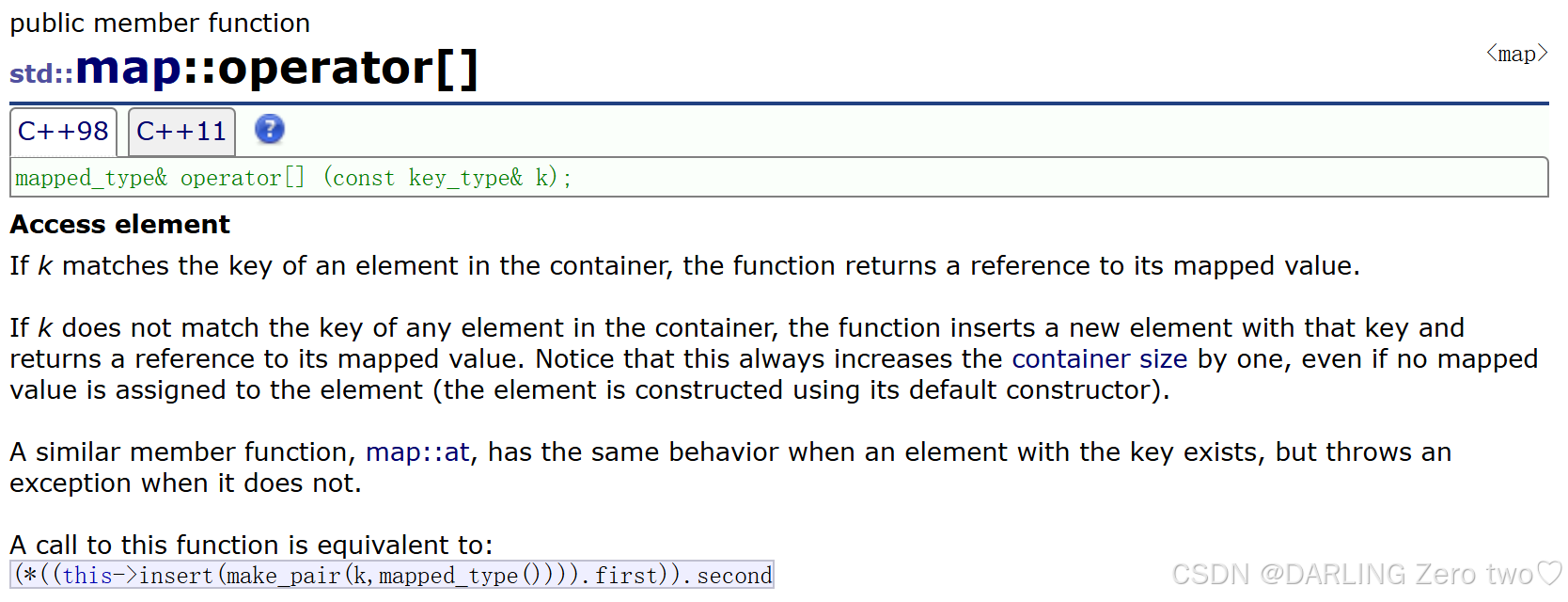
map 中提供了 [] 运算符重载,可以通过 key 来访问 value

首先我们知道 insert 的返回值 key 的部分是一个迭代器,value 的部分是个布尔值,文档中对该返回值的解释是:
key已经在树里面,返回pair<树里面key所在节点的iterator,false>,false表示不用插入了key不在树里面,返回pair<树里面key所在节点的iterator,true>,true表示需要插入新节点

再来看,左边是官方文档的原始定义,那么转化成右边的定义能够更直观理解其底层
这里 V 代表值类型,K 代表键类型 。operator[] 是操作符重载函数,接受一个常量引用类型的键 key ,返回值类型 V 的引用。这样设计是为了支持对容器内元素的读写操作。例如,可以通过 map[key] = newValue; 来修改值,或者通过 auto value = map[key]; 来读取值
然后通过 insert 判断是否插入新节点,最后返回指定节点的 value 值
4.4 map的应用实践:随机链表的复制
✏️题目描述:

✏️示例:
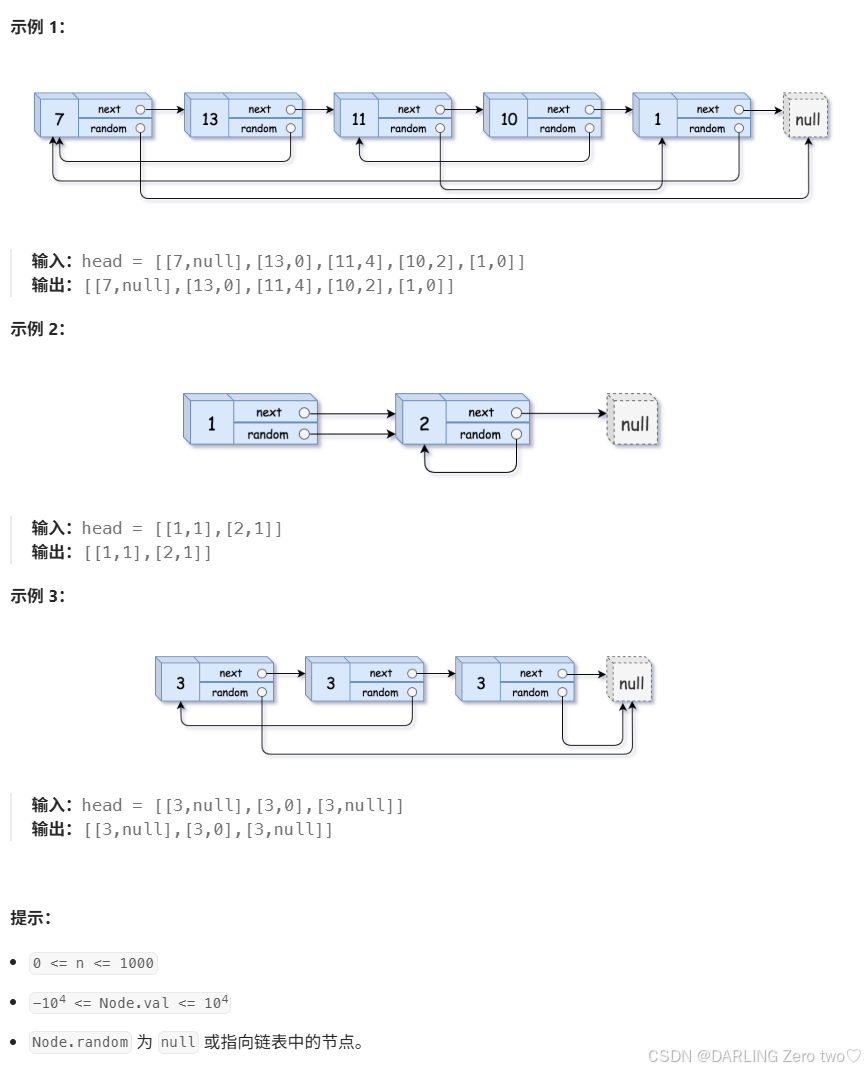
传送门: 随机链表的复制
题解:
利用 map 的映射机制,首先,在第一次遍历原链表时,为原链表的每个节点创建一个对应的新节点,并将原节点和新节点的映射关系存储在 map 中。然后,在第二次遍历原链表时,对于原链表中的每个节点 cur,我们可以通过 cur->random 找到其随机指针指向的原节点,再利用之前存储的映射关系,在 map 中查找该原节点对应的新节点,将这个新节点赋值给当前新节点 copynode 的随机指针 copynode->random
🔥值得注意的是:
记录的不是cur和newnode的关系吗,为什么可以通过cur->random找到newnode->random?
假设原链表有三个节点
A、B、C,节点A的随机指针指向节点C
建立映射阶段: 会为A、B、C分别创建对应的新节点A'、B'、C',并在nodeCopyMap中记录映射关系:{A->A',B->B',C->C'}。
设置随机指针阶段: 当处理节点A时,cur指向A,cur->random指向C。由于C作为键存在于nodeCopyMap中,通过nodeCopyMap[cur->random]也就是nodeCopyMap[C]可以找到C',接着把C'赋值给A'的随机指针A'->random,这样新链表中节点A'的随机指针就正确地指向了节点C',和原链表中节点A的随机指针指向C相对应
💻代码实现:
class Solution {
public:Node* copyRandomList(Node* head) {map<Node*, Node*> nodeCopyMap;Node* copyhead = nullptr;Node* copytail = nullptr;Node* cur = head;while (cur){Node* copynode = new Node(cur->val);if (copytail == nullptr){copyhead = copytail = copynode;}else{copytail->next = copynode;copytail = copynode;}nodeCopyMap[cur] = copynode;cur = cur->next;}Node* copy = copyhead;cur = head;while (cur){if (cur->random == nullptr){copy->random = nullptr;}else{copy->random = nodeCopyMap[cur->random];}cur = cur->next;copy = copy->next;}return copyhead;}
};
5.multimap
multimap的主要特征可总结为:
multimaps是关联式容器,它按照特定的顺序,存储由key和value映射成的键值对<key, value>,其中多个键值对之间的key是可以重复的。- 在
multimap中,通常按照key排序和惟一地标识元素,而映射的value存储与key关联的内容。key和value的类型可能不同,通过multimap内部的成员类型value_type组合在一起,value_type是组合key和value的键值对:typedef pair<const Key, T> value_type; - 在内部,
multimap中的元素总是通过其内部比较对象,按照指定的特定严格弱排序标准对key进行排序的。 multimap通过key访问单个元素的速度通常比unordered_multimap容器慢,但是使用迭代器直接遍历multimap中的元素可以得到关于key有序的序列multimap在底层用二叉搜索树(红黑树)来实现
注意:multimap 和 map 的唯一不同就是:map 中的 key 是唯一的,而 multimap 中key 是可以重复的
🔥值得注意的是:
multimap中的key是可以重复的multimap中的元素默认将key按照小于来比较multimap中没有重载operator[]操作,因为一个key对应多个value,不知道找哪个value- 使用时与
map包含的头文件相同
multimap 和 mutiset 是差不多的,而且在实际应用中用的不多,所以这里就不细讲了
希望读者们多多三连支持
小编会继续更新
你们的鼓励就是我前进的动力!

相关文章:

C++漫溯键值的长河:map set
文章目录 1.关联式容器2.set2.1 find2.2 lower_bound、upper_bound 3.multiset3.1 count3.2 equal_range 4.map4.1 insert4.2 operate->4.3 operate[ ]4.4 map的应用实践:随机链表的复制 5.multimap希望读者们多多三连支持小编会继续更新你们的鼓励就是我前进的动…...
(文末有下载方式))
西门子数字化研发设计制造一体化规划案例P87(87页PPT)(文末有下载方式)
资料解读:《西门子数字化研发设计制造一体化规划案例》 详细资料请看本解读文章的最后内容。 该文档围绕西门子为企业打造的智能化制造研发工艺生产一体化平台规划方案展开,全面阐述了从业务现状分析到项目实施及案例分享的整个过程。 业务现状与需求分析…...

Rust多线程性能优化:打破Arc+锁的瓶颈,效率提升10倍
一、引言 在 Rust 开发中,多线程编程是提升程序性能的重要手段。Arc(原子引用计数)和锁的组合是实现多线程数据共享的常见方式。然而,很多程序员在使用 Arc 和锁时会遇到性能瓶颈,导致程序运行效率低下。本文将深入剖…...

基于python的人工智能应用简述
基于Python的人工智能应用简述 Python已成为人工智能(AI)开发的首选语言,凭借其简洁性、丰富的库生态系统和强大的社区支持,广泛应用于各类AI应用场景。以下是Python在人工智能领域的主要应用领域和技术实现。 1. 机器学习(Machine Learning) Python通过Scikit-learn、Ten…...

《Android 应用开发基础教程》——第十章:使用 Gson 实现网络 JSON 数据解析与对象映射
目录 第十章:使用 Gson 实现网络 JSON 数据解析与对象映射 🔹 10.1 什么是 Gson? 🔸 10.2 添加依赖 🔸 10.3 基础使用 ✦ 示例 JSON 字符串: ✦ 定义对应的 Java 类: ✦ JSON ➜ 对象&am…...

【Android】四大组件之BroadcastReceiver
目录 一、什么是BroadcastReceiver 二、创建和使用BroadcastReceiver 三、跨应用广播接收权限 四、广播方式 五、广播类型与特性 六、BroadcasReceiver注册方式 七、BroadcasReceiver工作流程 你可以把广播接收器想象成一个“收音机”。它的作用是监听系统或应用发出的“…...

[UVM]寄存器模型的镜像值和期望值定义是什么?他们会保持一致吗?
寄存器模型的镜像值和期望值定义是什么?他们会保持一致吗? 摘要:在 UVM (Universal Verification Methodology) 寄存器模型中,镜像值 (mirrored value) 和期望值 (desired value) 是两个非常重要的概念,用于管理寄存器…...
 ---- VBO EBO VAO)
OpenGL-ES 学习(12) ---- VBO EBO VAO
目录 VBO 定义VBO 创建统一VertexData使用 VBO 绘制VAO VBO 定义 VBO(Vertex Buffer Object) 是指顶点缓冲区对象,而 EBO(Element Buffer Object)是指图元索引缓冲区对象,VBO 和 EBO实际上是同一类 buffer 按照用途的不同称呼 OpenGL-ES2.0 编程中&…...

【Redis分布式】主从复制
🔥个人主页: 中草药 🔥专栏:【中间件】企业级中间件剖析 一、主从复制 在分布式系统之中为了解决单点问题(1、可用性问题,该机器挂掉服务会停止2、性能支持的并发量是有限的)通常会把数据复制多…...

Node.js心得笔记
npm init 可用npm 来调试node项目 浏览器中的顶级对象时window <ref *1> Object [global] { global: [Circular *1], clearImmediate: [Function: clearImmediate], setImmediate: [Function: setImmediate] { [Symbol(nodejs.util.promisify.custom)]: [Getter] }, cl…...

多智能体空域协同中的伦理博弈与系统调停
在多智能体系统(MAS)广泛应用于低空飞行调度、应急响应与城市管理的背景下,AI之间的“协同”不仅是算法效率问题,更是伦理角色之间的权责动态博弈。尤其在高频互动、任务冲突、资源抢占等复杂场景中,智能体不再是“工具…...

面试中系统化地解答系统设计题:通用方法论
目录 一、明确需求(Clarify Requirements) (一)理解业务背景 (二)功能性需求(Functional Requirements) 1. 分析目标 2. 功能需求分类 A. 用户交互类功能 B. 数据处理类功能 C. 管理与运维类功能 D. 外部系统交互类功能 示例场景详解 3. 捕捉隐藏需求的技巧…...

kotlin中 热流 vs 冷流 的本质区别
🔥 冷流(Cold Flow) vs 热流(Hot Flow)区别 特性冷流(Cold Flow)热流(Hot Flow)数据生产时机每次 collect 才开始执行启动时就开始生产、始终运行生命周期与 collect 者…...

机器视觉开发-打开摄像头
以下是使用Python和OpenCV打开摄像头的最简单实现: import cv2# 打开默认摄像头(通常是0) cap cv2.VideoCapture(0)# 检查摄像头是否成功打开 if not cap.isOpened():print("无法打开摄像头")exit()print("摄像头已打开 - 按…...

Rerank详解
疑惑一 我对rag的流程理解是。后端首先建立embedding后的向量数据库,用户提问使用相同的embedding模型进行向量化,使用阈值控制相似度找出前topk个数据。然后rerank,将rerank的结果打包成prompt返回给大模型进行解答。我对于rerank的过程不是…...

深度探索DeepSeek:从架构设计到性能优化的实战指南
深度解码DeepSeek:从架构设计到工业级部署的全链路优化实践 引言:大模型时代的工程挑战 在人工智能技术进入工业化落地阶段的今天,大模型训练与推理的工程化能力已成为衡量企业技术实力的重要标尺。DeepSeek作为当前业界领先的超大规模语言…...

d202551
目录 一、175. 组合两个表 - 力扣(LeetCode) 二、511. 游戏玩法分析 I - 力扣(LeetCode) 三、1204. 最后一个能进入巴士的人 - 力扣(LeetCode) 一、175. 组合两个表 - 力扣(LeetCode…...
2025年第二十二届五一数学建模竞赛(五一杯/五一赛)解题思路|完整代码论文集合)
(C题|社交媒体平台用户分析问题)2025年第二十二届五一数学建模竞赛(五一杯/五一赛)解题思路|完整代码论文集合
我是Tina表姐,毕业于中国人民大学,对数学建模的热爱让我在这一领域深耕多年。我的建模思路已经帮助了百余位学习者和参赛者在数学建模的道路上取得了显著的进步和成就。现在,我将这份宝贵的经验和知识凝练成一份全面的解题思路与代码论文集合…...

计网_PPP协议
2024.10.15:beokayy计算机网络学习笔记 PPP协议 PPP协议的特点PPP协议应满足的需求(了解)PPP协议的组成(PPP协议有三个组成部分) PPP协议的帧格式PPP协议的工作状态 ISP指的是运营商,比如中国联通、中国电信…...

Mem0.ai研究团队开发的全新记忆架构系统“Mem0”正式发布
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

二叉树删除结点详细代码
#include<stdio.h> #include<stdlib.h> #include<string.h> #include<time.h>typedef int data_t; typedef struct _node {data_t data;struct _node* left;struct _node* right; }node_t;int bst_create(node_t**, data_t);//函数声明BST创建 int bst…...

PyTorch线性代数操作详解:点积、矩阵乘法、范数与轴求和
本文通过代码示例详细讲解PyTorch中常用的线性代数操作,包括点积、矩阵乘法、范数计算以及按轴求和等操作,帮助读者掌握张量运算的核心方法。 1. 点积运算 点积(Dot Product)是两个向量对应元素相乘后求和的结果。 实现代码&…...
——类和对象)
Java SE(6)——类和对象
1.初始面向对象 1.1 什么是面向对象 Java是一门纯面向对象的编程语言(Object Oriented Program,简称OOP),在面向对象的世界里,一切皆为对象。面向对象是解决问题的一种思想,主要依靠对象之间的交换来完成一件事情 1.2 面向过程…...
的API Server 组件原理与结合生产实战教程)
Kubernetes(k8s)的API Server 组件原理与结合生产实战教程
一、API Server 架构深度解析 1. 核心架构设计 二、生产环境安全加固实战 1. 认证(Authentication) 2. 授权(Authorization) 3. 准入控制(Admission Control) 三、性能优化与调参 1. 关键启动参数 四…...
)
Java面试高频问题(31-33)
三十一、服务网格:东西向流量治理与故障注入 服务网格架构分层 mermaid graph BT subgraph Control Plane APilot --> BEnvoy Sidecar CMixer --> B DCitadel --> B end subgraph Data Plane B --> E服务A B --> F服务B B --> G服务C end 核心能…...
)
VSCode开发调试Python入门实践(Windows10)
我的Windows10上的python环境是免安装直接解压的Python3.8.x老版本,可参见《Windows下Python3.8环境快速安装部署。 1. 安装VSCode 在Windows 10系统上安装Visual Studio Code(VS Code)是一个简单的过程,以下是详细的安装方法与…...
)
C++——入门基础(2)
文章目录 一、前言二、C入门2.1 缺省参数2.2 函数重载2.2.1 参数类型不同2.2.1.1 整体参数类型不同2.2.1.2 参数类型顺序不同 2.2.2 参数个数不同2.2.3 避坑注意2.2.3.1无参与有参2.2.3.2 返回值不同 2.3 引用2.3.1 引用的概念2.3.2引用的结构2.3.3 引用的特点2.3.4引用的作用2…...

【MySQL】复合查询与内外连接
目录 一、复合查询 1、基本查询回顾: 2、多表查询: 3、自连接: 4、子查询: 单列子查询 多行子查询: 多列子查询: 在from语句中使用子查询: 5、合并查询: union࿱…...

第3篇:请求参数处理与数据校验
在 Web 开发中,请求参数处理与数据校验是保障系统稳定性的第一道防线。本文将深入探讨 Egg.js 框架中参数处理的完整解决方案,涵盖常规参数获取、高效校验方案、文件流处理等核心功能,并分享企业级项目中的最佳实践。 一、多场景参数获取策略…...

Android JIT编译:adb shell cmd package compile选项
Android JIT编译:adb shell cmd package compile选项 例如: adb shell cmd package compile -m speed -f --full 包名 配置参数指令说明: compile [-r COMPILATION_REASON] [-m COMPILER_FILTER] [-p PRIORITY] [-f] [--primary-dex] …...

排序算法——冒泡排序
一、介绍 「冒泡排序bubblesort」通过连续地比较与交换相邻元素实现排序。这个过程就像气泡从底部升到顶部一样,因此得名冒泡排序。 冒泡过程可以利用元素交换操作来模拟:从数组最左端开始向右遍历,依次比较相邻元素大小,如果“左…...
)
文献阅读篇#5:5月一区好文阅读,BFA-YOLO,用于建筑信息建模!(上)
期刊简介:《Advanced Engineering Informatics》创刊于2002年,由Elsevier Ltd出版商出版,出版周期Quarterly。该刊已被SCIE数据库收录,在中科院最新升级版分区表中,该刊分区信息为大类学科工程技术1区,2023…...

工行手机银行安全吗?在应用商店下载工商银行安全吗?
现在很多的人都会用手机银行,其中工行的使用几率也是比较高的,但大家在使用的过程中就会比较关心使用工行手机银行是否安全。如果直接在应用商店下载,是否有安全保障? 工行的手机银行会拥有较高的保障,从技术到服务都可…...

python如何word转pdf
在Python中,将Word文档(.docx或.doc)转换为PDF可以通过多种库实现。以下是几种常见的方法及详细步骤: 方法1:使用 python-docx comtypes(仅Windows,需安装Word) 适用于Windows系统…...

在阿里云 Ubuntu 24.04 上部署 RabbitMQ:一篇实战指南
前言 RabbitMQ 是业界常用的开源消息中间件,支持 AMQP 协议,易于部署、高可用、插件丰富。本文以阿里云 ECS 上运行的 Ubuntu 24.04 LTS 为例,手把手带你完成 RabbitMQ 从仓库配置到运行的全流程,并分享在国内环境下常见的坑与对应解决方案。 环境概况 操作系统:Ubuntu …...
的实现机制)
Linux Shell 重定向与管道符号(>, >>, |)的实现机制
文章目录 Linux Shell 重定向与管道符号(>, >>, |)的实现机制一、重定向基础:dup2() 的核心作用二、输出重定向的实现原理>(覆盖重定向)>>(追加重定向) 三、| 管道符的实现原…...
)
GitHub 趋势日报 (2025年04月30日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1hacksider/Deep-Live-Camreal time face swap and one-click video deepfake with only a single image⭐ 1686⭐ 54925Python2Qwe…...

计算机操作系统知识集合
主要来自小林coding 硬件结构 cpu位宽 如果用 32 位 CPU 去加和两个 64 位大小的数字,就需要把这 2 个 64 位的数字分成 2 个低位 32 位数字和 2 个高位 32 位数字来计算,先加个两个低位的 32 位数字,算出进位,然后加和两个高位…...

PostgreSQL数据类型
数据类型 数值类型 整数类型 SMALLINT 小范围整数,取值范围:-32768 ~ 32767 INT(INTEGER) 普通大小整数,取值范围:-2147483648 ~ 2147483647 浮点数类型 REAL 6位十进制数字精度 NUMERIC(m, n) 任意精度…...

在Linux中,KVM和Docker在Linux虚拟化中的区别是什么?
KVM(Kernel-based Virtual Machine)和Docker是Linux环境中两种不同的虚拟化技术,它们在实现原理、资源隔离程度、应用场景等方面存在显著区别: 实现原理与技术层级 KVM:KVM是一种基于硬件辅助虚拟化的全虚拟化技术&a…...

【docker学习笔记】如何删除镜像启动默认命令
一些镜像会在它打镜像时,加入一些默认的启动命令,可以通过docker inspect \<image id\>来查看Entrypoint。如下图,docker run启动时,会默认执行 "python3 -m vllm.entrypoints.openai.api_server" 如果不想执行&…...

c语言 39.0625转为16进制
c语言 39.0625转为16进制 寄存器的4~15对应整数部分 39为整数部分 39 (10进制) 0x27(16进制) 寄存器的0~3对应小数部分 0.0625为小数部分 0.0626 1/16 则0~3位十六进制值应为 0x1 39.06250…...

【阿里云大模型高级工程师ACP习题集】2.8 部署模型
习题集: 以下关于直接调用模型(无需部署)的说法,错误的是?【单选题】 A. 无需部署模型,只需简单调用API B. 按token量计费,无需担心模型部署的资源消耗 C. 可随意调用,没有任何限制 D. 适合业务初期或中小规模场景 使用vLLM部署模型时,若出现端口被占用的情况,以下做…...

【进阶】--函数栈帧的创建和销毁详解
目录 一.函数栈帧的概念 二.理解函数栈帧能让我们解决什么问题 三.相关寄存器和汇编指令知识点补充 四.函数栈帧的创建和销毁 4.1.调用堆栈 4.2.函数栈帧的创建 4.3 函数栈帧的销毁 一.函数栈帧的概念 --在C语言中,函数栈帧是指在函数调用过程中,…...

猫,为什么是猫?
英语单词 cat,意为猫: cat n.猫 根据首字母象形原则,通常我们喜欢将首字母C,解释为猫爪,C的形象,通常可解释为字母K的右侧的中间凹陷部分,K | <,也就是 C 和 < 相通&#…...
(文末有下载方式))
数字智慧方案6169丨智慧医院后勤管理解决方案(58页PPT)(文末有下载方式)
资料解读:智慧医院后勤管理解决方案 详细资料请看本解读文章的最后内容。 在当今万物互联的时代,传统医院后勤管理模式逐渐暴露出诸多弊端,已难以适应医院集团化发展的需求。这份智慧医院后勤管理解决方案资料,深入剖析了传统管理…...

经济学和奥地利学派的起源
(一)经济学和奥地利学派的起源: 早期思想: 亚当斯密被认为是现代经济学的鼻祖,但早期的亚里士多德、柏拉图以及中国的《管子》等著作也包含经济学思想,但更偏向财政学。 亚当斯密之前的学者: 坎…...

Linux安全清理删除目录bash脚本
直接写清除目录命令可能会因为一时手抖导致删除重要目录 rm -rf是个危险的命令,我写了bash脚本,放在环境变量目录下可以当系统命令来用 这里是单线程的,如果需要更高的性能,需要加入多线程的支持。 1.实现功能 清理目录的子内容…...
)
C++/SDL 进阶游戏开发 —— 双人塔防(代号:村庄保卫战 17)
🎁个人主页:工藤新一 🔍系列专栏:C面向对象(类和对象篇) 🌟心中的天空之城,终会照亮我前方的路 🎉欢迎大家点赞👍评论📝收藏⭐文章 文章目录 二…...

Lucene并不是只有倒排索引一种数据结构,支持多种数据结构
Lucene 的核心机制确实以**倒排索引(Inverted Index)**为核心,但它并不是“全部”都依赖倒排索引。Lucene 的索引结构中还包含其他辅助数据结构,用于支持不同的查询场景。以下是详细的解释: 1. 核心机制:倒…...