vLLM技术解析:大语言模型推理服务的性能革新引擎
vLLM大模型
vLLM(Vectorized Large Language Model Serving System)是由加州大学伯克利分校计算机系统研究团队开发的下一代大语言模型推理服务系统。作为专为现代化AI部署设计的开源框架,该系统通过突破性的内存架构创新和计算流程优化,成功实现了大模型服务在吞吐量、响应速度和资源利用率三个维度的协同提升,现已成为工业界优化LLM推理成本的关键技术方案。

核心技术优势
分布式推理架构
采用动态请求调度和零拷贝并行技术,支持跨多GPU/TPU设备的细粒度负载均衡。通过流水线并行与张量并行的混合策略,可线性扩展至数百张加速卡,实现每秒数万token的集群处理能力。
显存革命性优化
首创PagedAttention内存管理机制,将操作系统的虚拟内存分页理念引入注意力计算领域。该技术通过分块管理注意力键值张量(KV Cache),使显存碎片率降低83%,单卡可承载的并发请求量提升24倍,显著降低大模型服务门槛。
全场景覆盖能力
• 在线服务:支持动态批处理(Dynamic Batching)和连续批处理(Continuous Batching),在100ms级延迟约束下实现90%+的硬件利用率
• 边缘计算:通过量化感知服务(Quantization-Aware Serving)和自适应模型切分,可在消费级显卡部署百亿参数模型
• 模型微调:提供与训练框架无缝衔接的LoRA适配模块,支持实时热更新模型参数
该框架已成功应用于ChatGPT、Claude等知名AI产品的推理优化,在同等硬件条件下相比传统方案可实现5-10倍吞吐量提升。其创新的内存管理思想更被纳入PyTorch 2.3核心特性,持续推动大模型服务技术的演进。
vLLM vs Ollama:对比分析
在LLM推理引擎的选择上,vLLM和Ollama是两个常见的选项。对比如下:
| 对比维度 | Ollama | vLLM | 备注 |
|---|---|---|---|
| 量化与压缩策略 | 默认采用4-bit/8-bit量化,显存占用降至25%-50% | 默认使用FP16/BF16精度,保留完整参数精度 | Ollama 牺牲精度换显存,vLLM 牺牲显存换计算效率 |
| 优化目标 | 轻量化和本地部署,动态加载模型分块,按需使用显存 | 高吞吐量、低延迟,预加载完整模型到显存,支持高并发 | Ollama 适合单任务,vLLM 适合批量推理 |
| 显存管理机制 | 分块加载 + 动态缓存,仅保留必要参数和激活值 | PagedAttention + 全量预加载,保留完整参数和中间激活值 | vLLM 显存占用为 Ollama 的 2-5 倍 |
| 硬件适配 | 针对消费级GPU(如RTX 3060)优化,显存需求低 | 依赖专业级GPU(如A100/H100),需多卡并行或分布式部署 | Ollama 可在 24GB 显存运行 32B 模型,vLLM 需至少 64GB |
| 性能与资源平衡 | 显存占用低,但推理速度较慢(适合轻量级应用) | 显存占用高,但吞吐量高(适合企业级服务) | 量化后 Ollama 速度可提升,但仍低于 vLLM |
| 适用场景 | 个人开发、本地测试、轻量级应用 | 企业级API服务、高并发推理、大规模部署 | 根据显存和性能需求选择框架 |
总结:Ollama更适合个人开发和轻量级应用,而vLLM则更适合企业级服务和高并发场景。
DeepSeek-R1-Distill-Qwen-32B模型对比
DeepSeek-R1-Distill-Qwen-32B模型在Ollama和vLLM框架下的显存占用、存储需求及性能对比
| 指标 | Ollama (4-bit) | vLLM (FP16) | 说明 |
|---|---|---|---|
| 显存占用 | 19-24 GB | 64-96 GB | Ollama通过4-bit量化压缩参数,vLLM需保留完整FP16参数和激活值 |
| 存储空间 | 20 GB | 64 GB | Ollama存储量化后模型,vLLM存储原始FP16精度模型 |
| 推理速度 | 较低(5-15 tokens/s) | 中高(30-60 tokens/s) | Ollama因量化计算效率降低,vLLM通过批处理和并行优化提升吞吐量 |
| 硬件门槛 | 高端消费级GPU(≥24GB) | 多卡专业级GPU(如2×A100 80GB) | Ollama勉强单卡运行,vLLM需多卡并行或分布式部署 |
ModelScope:开源模型即服务(MaaS)平台
ModelScope是由阿里巴巴集团推出的开源模型即服务(MaaS)平台,旨在简化模型应用的过程,为AI开发者提供灵活、易用、低成本的一站式模型服务产品。
核心功能:
- 汇集多种最先进的机器学习模型,涵盖NLP、CV、语音识别等领域。
- 提供丰富的API接口和工具,方便开发人员集成和使用模型。
- 支持模型的下载、部署和推理,降低开发门槛。
安装与使用:
-
下载DeepSeek模型
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple -
创建模型存放目录
mkdir -p /data/deepseek-ai/models/deepseek-70b -
下载DeepSeek-R1-Distill-Llama-70B模型
modelscope download --local_dir /data/deepseek-ai/models/deepseek-70b --model deepseek-ai/DeepSeek-R1-Distill-Llama-70B
docker部署
下载 Docker 二进制包
Docker 官方网站下载二进制包文件
wget https://download.docker.com/linux/static/stable/x86_64/docker-26.1.4.tgz
解压 Docker 压缩包
tar -zxvf docker-26.1.4.tgz
移动二进制文件到系统目录
mv docker/* /usr/bin/
创建 Docker 用户和组
-
创建 Docker 组
groupadd docker -
创建 Docker 用户,并将其添加到 Docker 组
useradd -s /sbin/nologin -M -g docker docker
配置 Docker 服务
创建并配置 docker.service 文件
-
打开或创建
docker.service文件vim /usr/lib/systemd/system/docker.service -
添加以下内容:
[Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target firewalld.service Wants=network-online.target[Service] Type=notify ExecStart=/usr/bin/dockerd ExecReload=/bin/kill -s HUP $MAINPID LimitNOFILE=infinity LimitNPROC=infinity TimeoutStartSec=0 Delegate=yes KillMode=process Restart=on-failure StartLimitBurst=3 StartLimitInterval=60s[Install] WantedBy=multi-user.target
配置国内 Docker 镜像加速
-
创建 Docker 配置目录:
mkdir -p /etc/docker -
打开或创建
daemon.json文件:vim /etc/docker/daemon.json -
添加以下内容:
{ "registry-mirrors": ["https://docker.rainbond.cc"] }
启动 Docker 服务
-
启动 Docker 服务
systemctl start docker -
设置 Docker 服务开机启动
systemctl enable docker
验证 Docker 安装
-
查看 Docker 版本
docker -v
vLLM容器化部署指南
环境准备
-
更新软件包列表并安装NVIDIA容器工具包
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit -
配置NVIDIA容器运行时
sudo nvidia-ctk runtime configure --runtime=docker -
重加载系统服务并重启Docker
sudo systemctl daemon-reload sudo systemctl restart docker -
下载vllm/vllm-openai容器
docker pull vllm/vllm-openai -
查看vllm/vllm-openai容器
docker images
启动vLLM容器
docker run -itd --restart=always --name vllm_ds70 \
-v /data/deepseek-ai:/data \
-p 18005:8000 \
--gpus all \
--ipc=host \
vllm/vllm-openai:latest \
--dtype bfloat16 \
--served-model-name DeepSeek-R1-Distill-Llama-70B \
--model "/data/models/deepseek-70b" \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 8 \
--max-model-len 30000 \
--api-key token-abc123参数解释:
-
--restart=always
:容器退出后自动重启,除非显式停止或dockerd服务重启。
-
--name vllm_ds70
为容器指定一个名称,便于后续管理和操作。
-
-v /data/deepseek-ai:/data
将主机上的/data/deepseek-ai目录挂载到容器的/data目录,用于存储模型文件和数据。
-
-p 18005:8000
将容器的8000端口映射到主机的18005端口,用于通过主机端口访问容器内的服务。
-
-itd
命令选项组合,-i和-t、-d,保持容器在后台运行,同时允许用户通过Docker logs或attach命令查看输出。
-
--gpus all
:允许容器使用宿主机的所有GPU资源。
-
--dtype bfloat16
-
--dtype {auto,half,float16,bfloat16,float,float32}
:指定数据类型,优化内存使用和计算效率。auto模式会根据模型类型自动选择精度,而half或float16则常用于半精度计算以节省显存。
-
--tensor-parallel-size 8
:设置张量并行的大小,通过将模型分割到多个GPU上进行并行计算,提升模型推理的速度和效率。
-
--ipc=host
:配置容器的IPC(Inter-Process Communication)模式,允许容器与宿主机或其他容器共享共享内存,提升模型并行性能。
-
--served-model-name DeepSeek-R1-Distill-Llama-70B
:指定服务的模型名称,标识当前服务的模型,便于管理和路由
-
--model "/data/models/deepseek-70b"
指定模型文件的路径,告诉服务从哪里加载模型权重和配置文件,确保模型能够正确加载。
-
--gpu-memory-utilization 0.95
设置GPU内存使用率,限制模型使用的GPU内存占比,避免因内存不足导致服务崩溃。
-
--tensor-parallel-size 8
设置张量并行的大小,通过将模型分割到多个GPU上进行并行计算,提升模型推理的速度和效率。
-
--max-model-len 30000
设置模型的最大上下文长度,限制模型在一次推理中能处理的最大输入长度,避免因过长输入导致性能问题。
-
--api-key token-abc123
指定API密钥,用于身份验证和授权,确保只有有权限的用户才能访问服务。
查看vLLM容器日志
docker logs -f b05b9c3646ec
访问vLLM容器
docker exec -it b05b9c3646ec /bin/bash
vLLM API 调用测试
curl http://192.168.1.34:18005/v1/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer token-abc123" \-d '{"model": "DeepSeek-R1-Distill-Llama-70B","prompt": "北京的著名景点有哪些","max_tokens": 1000,"temperature": 0.3}'
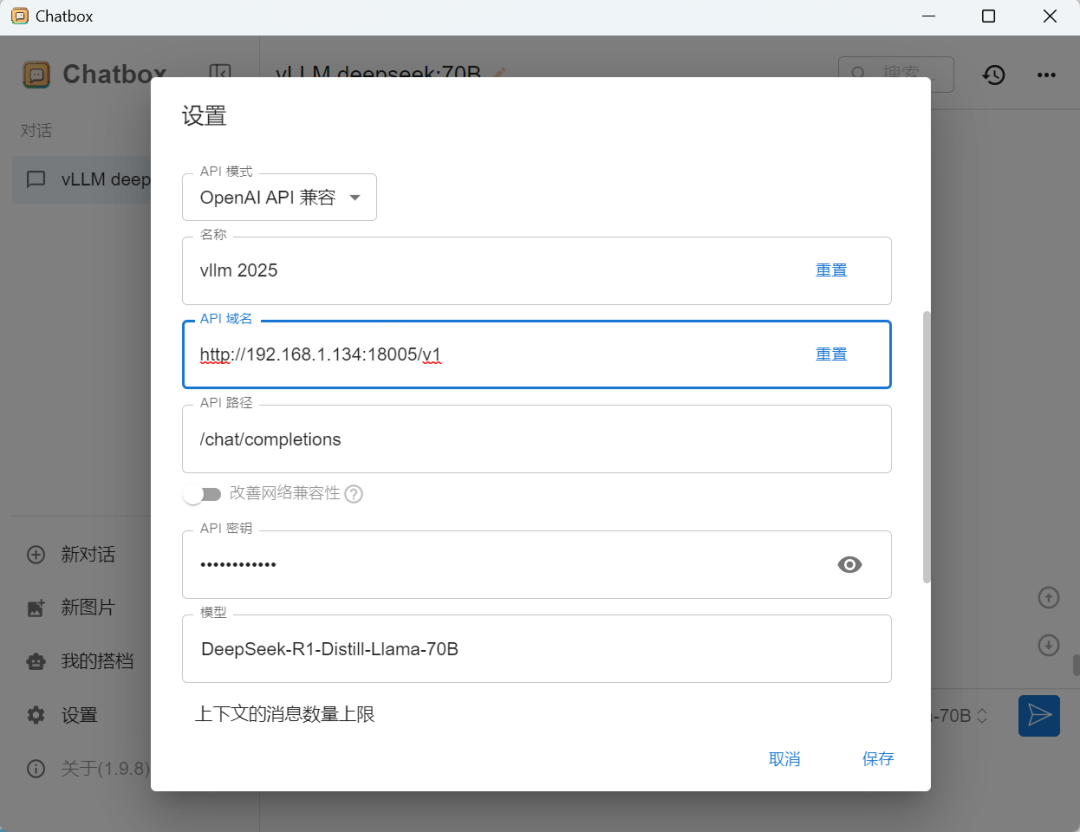
Chatbox设置
DeepSeek-R1 模型 Ollama VS vLLM 占用显存对比
| Model | Base Model | Ollama | vLLM |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | 1.1GB | 3-6 GB |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | 4.7GB | 14-21 GB |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 4.9GB | 16-24 GB |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 9.0GB | 28-42 GB |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 20GB | 64-96 GB |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 43GB | 140-210 GB |
| DeepSeek-R1-671B | DeepSeek-R1-671B | 404GB | 1342-2013 GB |
PyTorch、cuDNN、CUDA、NVIDIA驱动和NVIDIA GPU之间的关系
- PyTorch
作为应用层,调用cuDNN和CUDA提供的接口来加速计算。
- cuDNN
作为加速库层,依赖于CUDA提供的GPU计算能力,优化了深度学习任务。
- CUDA
作为计算平台层,依赖于NVIDIA驱动与GPU硬件通信,提供了通用的GPU计算接口。
- NVIDIA驱动
作为驱动层,管理着NVIDIA GPU的硬件资源,允许上层软件与GPU进行交互。
- NVIDIA GPU
作为硬件层,执行实际的计算任务,提供了强大的并行计算能力。
相关文章:

vLLM技术解析:大语言模型推理服务的性能革新引擎
vLLM大模型 vLLM(Vectorized Large Language Model Serving System)是由加州大学伯克利分校计算机系统研究团队开发的下一代大语言模型推理服务系统。作为专为现代化AI部署设计的开源框架,该系统通过突破性的内存架构创新和计算流程优化&…...

《无刷空心杯电机减速机选型及行业发展趋势》
无刷空心杯电机作为高精度驱动系统的核心部件,通常需搭配减速机以实现低转速、高扭矩输出。以下是当前主流的减速机类型、市场占比、参数对比及优劣势分析,结合行业数据与典型应用场景展开说明: 一、主流减速机类型及市场占比 1. 行星减速机 市场占比:约 45%-55%(工业自…...

Java锁的升级流程详解:无锁、偏向锁、轻量级锁、重量级锁
在Java中,为了在多线程并发场景下既保证线程安全,又尽可能提高性能,JVM针对synchronized实现了锁的优化升级机制。 锁可以从无锁逐步升级到偏向锁、轻量级锁,最后是重量级锁。 话不多说,发车! 一、无锁&am…...

terraform local-exec与remote-exec详解
在 Terraform 中,local-exec 和 remote-exec 是两种常用的 provisioner(资源调配器),用于在资源创建前后执行脚本或命令。它们的核心区别在于执行位置:local-exec 在运行 Terraform 的本地机器上执行命令,而…...

武装Burp Suite工具:APIKit插件_接口安全扫描.
武装Burp Suite工具:APIKit插件_接口安全扫描. API安全是指通过技术手段和管理措施保护应用程序接口(API)免受未授权访问、数据泄露或恶意攻击的防护体系,核心措施包括身份认证(如OAuth2.0/JWT)、权限控制…...

数据库系统概论|第三章:关系数据库标准语言SQL—课程笔记6
前言 经过前面几篇文章的介绍,已经完成了对于数据查询操作的介绍,接下来,本篇文章将介绍数据更新这一板块,包括插入数据、修改数据以及删除数据三种操作方法。 注:本文中所涉及的数据库前文中已经介绍(指…...

如何在idea中写spark程序
1. 安装配置 Java 和 Scala Java:确保已安装合适版本的 Java Development Kit(JDK),并配置好 JAVA_HOME 环境变量。Scala:由于 Spark 常用 Scala 语言编写,需安装 Scala 开发环境。可在 IDEA 中通过 Se…...

Linux428 chmod 0xxx 1xxx 2xxx 4xxx;umask;chown 属主属组 软件包rpm
sudo: 账户过期,或 PAM 配置缺少 sudo 使用的“account”节,联系您的系统管理员 这样子有没有用嘞 不行 为什么使用caozx26用户sudo修改了shop文件夹强制位,shop文件夹权限中不显示 成功了?真奇怪 查看文件夹权限用 -ld ch…...

基于强化学习的用于非刚性图像配准的引导式超声采集|文献速递-深度学习医疗AI最新文献
Title 题目 Guided ultrasound acquisition for nonrigid image registration usingreinforcement learning 基于强化学习的用于非刚性图像配准的引导式超声采集 01 文献速递介绍 超声成像通常用于引导手术和其他医疗程序,在这些过程中,临床医生会持…...

Shell脚本-嵌套循环应用案例
在Shell脚本编程中,嵌套循环是一种强大的工具,可以用于处理复杂的任务和数据结构。通过在一个循环内部再嵌套另一个循环,我们可以实现对多维数组、矩阵操作、文件处理等多种高级功能。本文将通过几个实际的应用案例来展示如何使用嵌套循环解决…...

QTableView复选框居中
目录 方法一:QSS方法2:自定义复选框委托类一、构造函数 CheckBoxDelegate()二、paint() 方法三、editorEvent() 方法四、关键设计要点五、扩展应用场景六、代码示例(补充) 方法一:QSS QTableView::indicator {position: relative…...
:C 语言共用体详解)
C语言教程(十八):C 语言共用体详解
一、共用体的定义 共用体的定义和结构体类似,使用 union 关键字,其基本语法如下: union 共用体名 { 数据类型 成员1; 数据类型 成员2; // 可以有更多成员 }; 以下是一个简单的共用体定义示例: union Data {int i;float f;char …...

企业办公系统开发如何重塑现代工作方式?
随着工作方式的革新,企业办公软件开发已成为提升组织效率的核心驱动力。从基础的文档处理到复杂的协同办公平台开发,现代办公系统正在彻底改变传统工作模式。本文将深入解析办公类软件的关键技术与发展趋势。 一、企业级办公系统开发的核心模块 专业的O…...

springboot 实现敏感信息脱敏
记录于2025年4月28号晚上--梧州少帅 1. 定义枚举类: public enum DesensitizeType {NAME, EMAIL } 2. 创建自定义注解: 用于标记需要脱敏的字段及其类型。 Retention(RetentionPolicy.RUNTIME) JacksonAnnotationsInside JsonSerialize(using Desen…...

JavaWeb学习打卡-Day5-Spring事务管理、SpringAOP
Spring事务管理 Transactional注解 位置:业务层(Service)的方法上、类上、接口上。作用:将当前方法交给spring进行事务管理,方法执行前,开启事务;成功执行完毕,提交事务࿱…...

项目立项管理
项目立项管理是对拟规划和实施的项目技术上的先进性、适用性,经济上的合理性、效益性,实施上的可能性、风险性以及社会价值的有效性、可持续性等进行全面科学的综合分析,为项目决策提供客观依据的一种技术经济研究活动。 一般包括项目建议与…...

一文梳理业财融合在财务管理中的运用!
目录 一、业财融合在财务管理中的运用概括 二、促进财务决策科学化 1. 传统财务决策的局限性 2. 业财融合助力财务决策科学化 三、加强成本控制 1. 传统成本控制的不足 2. 业财融合实现精准成本管控 四、优化资金管理 1. 传统资金管理的问题 2. 业财融合优化资金配置…...

C#核心知识
委托 如何声明一个委托:通过 【delegate 返回值类型 委托名称】 的格式来定义 如何使用一个委托:使用new关键字,并传入和声明委托的构造相同的方法名,比如:new 委托名称(与委托的参数和返回值相同的一个方法名) 如何…...

[多彩数据结构] 笛卡尔树
[多彩数据结构] 笛卡尔树 定义 笛卡尔树,就是一棵树(废话)中存两个信息,为 ( w , i ) (w,i) (w,i)。其中 k w e i g h t , i i d kweight,iid kweight,iid。 即 w w w 存的是节点的值, i i i 存的是编号。 每…...

【Spark入门】Spark RDD基础:转换与动作操作深度解析
目录 1 RDD编程模型概述 1.1 RDD操作分类 2 常用转换操作详解 2.1 基本转换操作 2.2 键值对转换操作 2.3 复杂转换操作 3 动作操作触发机制 3.1 常见动作操作 3.2 动作操作性能对比 4 RDD执行机制深度解析 4.1 惰性求值原理 4.2 任务生成过程 5 性能优化实践 5.1 …...
)
一文了解 模型上下文协议(MCP)
MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司于2024年11月推出的一项开放标准协议,旨在解决大型语言模型(LLM)与外部数据源和工具之间的通信问题。其核心目标是通过提供一个标准化的接口&…...

每日算法-250428
每日算法 - 2024年4月28日 记录今天完成的几道 LeetCode 算法题。 1877. 数组中最大数对和的最小值 题目描述: 思路 贪心策略。 解题过程 为了最小化所有数对和中的最大值,直观的想法是避免让两个较大的数相加。因此,最优策略是将数组中最小的元素…...

【“星瑞” O6 评测】 — CPU llama.cpp不同优化速度对比
前言 随着大模型应用场景的不断拓展,arm cpu 凭借其独特优势在大模型推理领域的重要性日益凸显。它在性能、功耗、架构适配等多方面发挥关键作用,推动大模型在不同场景落地 1. Kleidi AI 简介 Arm Kleidi 成为解决这些挑战的理想方案,它能…...

Redis 常见问题深度剖析与全方位解决方案指南
Redis 是一款广泛使用的开源内存数据库,在实际应用中常会遇到以下一些常见问题: 1.内存占用问题 问题描述:随着数据量的不断增加,Redis 占用的内存可能会超出预期,导致服务器内存不足,影响系统的稳定性和…...
和边(Edge)的定义与功能的区别)
在g2o图优化框架中,顶点(Vertex)和边(Edge)的定义与功能的区别
在g2o图优化框架中,顶点(Vertex)和边(Edge)是构建优化问题的核心组件,两者的定义与功能存在以下关键区别: 1. 作用与本质差异 顶点(Vertex) 代表待优化的变量,例如: 位姿(如VertexSE3Expmap表示3D位姿,包含平移和旋转)空间点坐标(如VertexPointXYZ表示3D点)参数…...
 阅读资料手册)
stm32wb55rg (2) 阅读资料手册
阅读资料是嵌入式开发的必备技能,能够从资料中找到自己想要的技术信息,才是最为核心的技术能力。 nucleowb55rg板子的MCU为stm32wb55rg,这块板子的资料有很多,但有些内容可以边用边读,有些内容有必要预先掌握下。 下面…...

基于Python的携程国际机票价格抓取与分析
一、项目背景与目标 携程作为中国领先的在线旅行服务平台,提供了丰富的机票预订服务。其国际机票价格受多种因素影响,包括季节、节假日、航班时刻等。通过抓取携程国际机票价格数据,我们可以进行价格趋势分析、性价比评估以及旅行规划建议等…...

【LLM开发】Unigram算法
Unigram算法 参考:Unigram算法解释 参考书籍:How Can We Make Language Models Better at Handling the Diversity and Variability of Natural Languages Unigram 算法是一种基于概率的子词分词方法,与BPE算法、WordPiece算法不同ÿ…...
单片机IAP(在应用编程)详解及实战源码)
GD32F407单片机开发入门(十六)单片机IAP(在应用编程)详解及实战源码
文章目录 一.概要二.GD32F407VET6单片机IAP介绍1.GD32F407VET6单片机IAP基本原理2.GD32F407VET6单片机IAP基本流程3.Ymodem协议 三.配置一个BOOT工程四.配置一个APP工程五.工程源代码下载六.小结 一.概要 单片机上电或系统复位后,ARM Cortex-M4处理器先从0x0000 00…...
)
庙算兵棋推演AI开发初探(7-神经网络训练与评估概述)
前面我们提取了特征做了数据集、设计并实现了处理数据集的神经网络,接下来我们需要训练神经网络了,就是把数据对接好灌进去,训练后查看预测的和实际的结果是否一致——也就是训练与评估。 数据解析提取 数据编码为数据集 设计神经网络 -->…...
)
[实战] IRIG-B协议详解及Verilog实现(完整代码)
目录 IRIG-B(B码)协议详解及Verilog实现一、IRIG-B协议概述二、帧格式详细解析1. 码元类型与索引计数2. 时间编码字段3. 控制功能码元(CF)4. 纯二进制秒码(SBS) 三、编码与信号特性四、时间编码实现1. 时间参数转换2. 帧数据填充规…...

从传统制造到智能工厂:MES如何重塑电子制造业?
在“中国制造2025”战略的引领下,电子制造业正经历深刻变革。多品种小批量、工艺复杂度高、质量追溯严苛等需求日益凸显。由此,如何通过数字化手段实现生产透明化、质量可追溯和资源高效协同,成为行业转型的关键命题。 一、电子制造业转型痛…...

使用Curl进行本地MinIO的操作
前言 最近在做相关的项目中关于本地服务搭建和访问的技术验证,打进来最基本的数据访问,使用了C。可以进行:服务器的可用性检查、Bucket的创建、文件夹的创建、文件的上传、文件的下载、文件夹和Bucket的存在性检查等基本接口,对自…...

uniswap getTickAtSqrtPrice 方法解析
先上代码: function getTickAtSqrtPrice(uint160 sqrtPriceX96) internal pure returns (int24 tick) {unchecked {// Equivalent: if (sqrtPriceX96 < MIN_SQRT_PRICE || sqrtPriceX96 > MAX_SQRT_PRICE) revert InvalidSqrtPrice();// second inequality mu…...
 -- qemu-user使用)
qemu(3) -- qemu-user使用
1. 前言 qemu中有很多的特技,此处记录下qemu-arm的使用方式,简单来说qemu-system-xx用于虚拟整个设备,包括操作系统的运行环境,而qemu-xx仅虚拟Linux应用程序的环境,不涉及操作系统,应用程序的系统调用有宿…...

CMCC RAX3000M使用Tftpd刷写OpenWrt固件的救砖方法
有时候,我们在玩运行 OpenWrt 的 CMCC RAX3000M ,因为一些操作不当,导致无法进入路由器系统,无法正常刷机。此时,如果我们已经刷写了uboot,则可以在uboot模式下通过Tftpd刷写新的OpenWrt固件,实…...
_计算属性)
Vue基础(7)_计算属性
计算属性(computed) 一、使用方式: 1.定义计算属性: 在Vue组件中,通过在 computed 对象中定义计算属性名称及对应的计算函数来创建计算属性。计算函数会返回计算属性的值。 2.在模板中使用计算属性: 在Vue的模板中,您…...

1.9多元函数积分学
引言 多元函数积分学是考研数学一的核心内容,涵盖三重积分、曲线积分、曲面积分及空间曲线积分。本文系统梳理4大考点,结合公式速查与典型示例,助你高效攻克积分难题! 考点一:三重积分计算与应用 1️⃣ 对称性 (1) …...

【LINUX操作系统】线程操作
了解了线程的基本原理之后,我们来学习线程在C语言官方库中的写法与用法。 1. 常见pthread接口及其背后逻辑 1.1 pthread_create 与线程有关的函数构成了⼀个完整的系列,绝⼤多数函数的名字都是以“pthread_”打头的 • 要使⽤这些函数库,…...

web技术与nginx网站环境部署
一:web基础 1.域名和DNS 1.1域名的概念 网络是基于TCP/IP协议进行通信和连接的,每一台主机都有一个唯一的标识(固定的IP地址),用以区别在网络上成千上万个用户和计算机。网络在区分所有与之相连的网络和主机时,均采用一种唯一、通用的地址…...

多元复合函数求导的三种情况
1. 一元函数与多元函数复合 1.1 变量关系 1.2 求导公式 因为根据链式法则,先对z求导,z是二元函数,所以说是偏导;再对里面求导,u、v是一元函数,所以说是全导。 2. 多元函数与多元函数复合 2.1 变量关系…...
 —— 多令牌预测(Multi Token Prediction))
全面解析DeepSeek算法细节(2) —— 多令牌预测(Multi Token Prediction)
概述 多令牌预测(MTP)技术使DeepSeek-R1能够并行预测多个令牌,显著提升推理速度。 关键特性 并行多令牌预测:DeepSeek-R1通过同时预测多个令牌而非按顺序预测,提升了推理速度。这减少了解码延迟,在不影响…...

如何从大规模点集中筛选出距离不小于指定值的点
一、背景:当点集处理遇见效率挑战 在数字化浪潮席卷各行各业的今天,点集数据处理已成为地理信息系统(GIS)、计算机视觉、粒子物理仿真等领域的核心需求。以自动驾驶场景为例,激光雷达每秒可产生超过10万个点云数据&am…...

单片机-89C51部分:6、数码管
飞书文档https://x509p6c8to.feishu.cn/wiki/WRNLwDd0iiG8OWkyatOcom6knHf 一、数码管简介 通俗解释: 一个数码管等于八个LED组合在一起,想要显示什么形状,就点亮对应LED即可。 一般数码管分为共阴极数码管和共阳极数码管。 共阳极接法&…...
:让机器决策透明化)
可解释人工智能(XAI):让机器决策透明化
在人工智能(AI)技术飞速发展的今天,AI 系统已经广泛应用于金融、医疗、交通等多个关键领域。然而,随着 AI 系统的复杂性不断增加,尤其是深度学习模型的广泛应用,AI 的“黑箱”问题逐渐凸显。AI 系统的决策过…...

深入理解网络原理:TCP协议详解
在现代计算机网络中,传输控制协议(TCP,Transmission Control Protocol)是最常用的传输层协议之一。TCP被广泛应用于互联网中的许多关键应用,如网页浏览、电子邮件和文件传输等。作为一种面向连接的协议,TCP…...

二极管钳位电路——Multisim电路仿真
目录 二极管钳位电路 2.1 二极管正向钳位电路 二极管压降测试 2.1.1 二极管正向钳位电路图 2.1.2 二极管正向钳位工作原理 2.2 二极管负向钳位电路 2.2.1 二极管负向钳位电路图 2.2.2 二极管负向钳位工作原理 二极管正向反向钳位仿真电路实验结果 2.3 二极管顶部钳位…...
)
【更新】LLM Interview (2)
字数溢出,不解释 前文:llm interview (1) 文章目录 强化学习专题1 什么是RL?2 RL和监督、非监督、深度学习的区别3 RL中所谓的损失函数与深度学习中的损失函数有何区别?4 RL历史5 RL分类5.1 分类图示5.2 根据智能体动作选取方式分…...

第二节:文件系统
理论知识 文件系统的基本概念:文件系统是操作系统中负责管理持久数据的子系统,它将数据组织成文件和目录的形式,方便用户存储和访问数据。Linux文件系统的类型:常见的 Linux 文件系统类型有 Ext2、Ext3、Ext4、XFS、Btrfs 等。Ex…...

astrbot_plugin_composting_bucket开源程序是一个用于降低AstrBot的deepseek api调用费用的插件
一、软件介绍 文末提供程序和源码下载 astrbot_plugin_composting_bucket开源程序是一个用于降低AstrBot的deepseek api调用费用的插件,让deepseek api调用费用更低! 本插件功能已集成到 AstrBot ,您可以移除此插件,在 AstrBot…...