庙算兵棋推演AI开发初探(7-神经网络训练与评估概述)
前面我们提取了特征做了数据集、设计并实现了处理数据集的神经网络,接下来我们需要训练神经网络了,就是把数据对接好灌进去,训练后查看预测的和实际的结果是否一致——也就是训练与评估。
数据解析提取
数据编码为数据集
设计神经网络
-->>神经网络训练与评估
神经网络一个重要指标是收敛 ,就是用可以逼近任意函数的神经网络是否可以逼近你数据集中隐含的模式。
再重复一遍【特征工程】与【神经网络】的区别:
前者就像人发现了牛顿第二定律F=ma,显式的找到公式并处理数据得到m和a,然后输入得到F;
后者是把包含多余的各种参数都放到神经网络中,然后人为的把F作为标签-对应那些参数的数据集中,经过训练得到隐含关系,用到时候把各种参数都输入到神经网络后得到F。
一、神经网络
nn的实现方式使得我一个编码人员看不懂了,根本看不到函数调用的模式了,在初期接触时还以为是之前的人写错了……
(1)神经网络nn
nn.Module 是一切的基础
在 torch.nn 中,所有神经网络的组成部分(比如一层线性变换、一个激活函数、一个完整的模型)都是一个类,这个类要继承自 nn.Module。
比如你定义一个自己的神经网络层:
import torch
import torch.nn as nnclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.linear = nn.Linear(10, 5) # 线性层:输入10维,输出5维def forward(self, x):x = self.linear(x)return x
-
__init__里初始化网络的各种层。 -
forward定义了前向传播过程。
(2)前向传递函数forword
注意: 你自己不会直接调用 forward(),而是直接让对象“像函数一样”去调用,比如:
model = MyModel()
output = model(input_data) # 这里实际上是自动调用 model.forward(input_data)
这一点跟 Python 普通类的调用规则有点不一样。
PyTorch 在 nn.Module 里重载了 __call__() 方法:当你 model(input_data) 时,它实际上内部做了
def __call__(self, *args, **kwargs):# 还有别的一些操作return self.forward(*args, **kwargs)
所以你只写 forward(),调用的时候直接用 (),很自然。
nn模块里有很多“层”和“工具”
比如:
nn.Linear(in_features, out_features):全连接层(线性变换)
nn.Conv2d(in_channels, out_channels, kernel_size):卷积层
nn.ReLU()、nn.Sigmoid():常用激活函数
nn.CrossEntropyLoss():损失函数
nn.Sequential(...):顺序搭建一堆层...
这些都是封装好的,你拿来直接用。
管理参数:所有 nn.Module 都自动帮你管理它的参数,比如 model.parameters() 可以拿到里面所有需要训练的权重。
(3)张量tensor和“层”的输入(训练中经常需要注意的形状tensor.shape() )
这种图是经常在神经网络的学习中会提到的:
.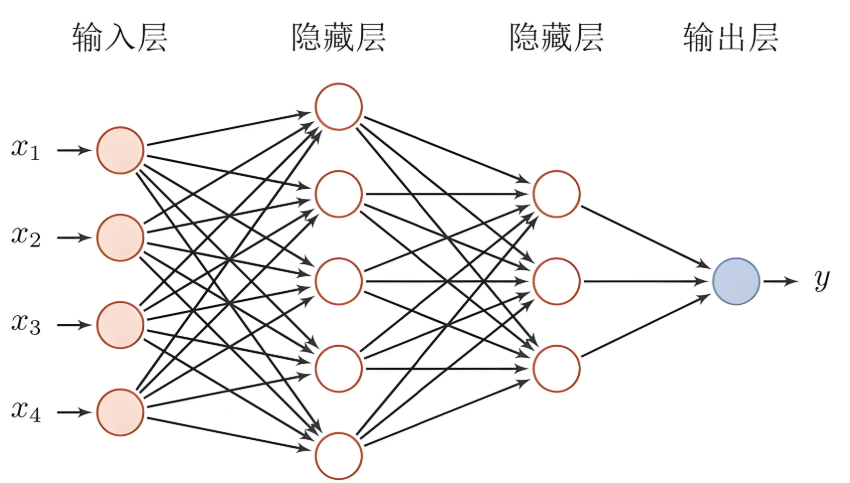
刚刚提到的“层的输入”in_features, out_features 就是输出特征数, 输入特征数 而继承了nn.Module 的类,就都会自动调用forward函数。
最简版 nn.Linear 实现
self.weight是一个 (输出特征数, 输入特征数) 的矩阵;
self.bias是一个 (输出特征数, ) 的向量;
nn.Parameter包了一下,让这两个变量能被自动识别为需要优化的参数;
forward里用的是:
x @ self.weight.t():表示矩阵乘法(这里需要对weight做转置.t(),因为 PyTorch标准是(out_features, in_features)存的)
+ self.bias:加上偏置。
import torch
import torch.nn as nnclass MyLinear(nn.Module):def __init__(self, in_features, out_features):super(MyLinear, self).__init__()# 初始化权重和偏置self.weight = nn.Parameter(torch.randn(out_features, in_features)) # (out, in)self.bias = nn.Parameter(torch.randn(out_features)) # (out, )def forward(self, x):# 线性变换:y = x @ W^T + breturn x @ self.weight.t() + self.bias
x @ self.weight.t():表示矩阵乘法(这里需要对 weight 做转置 .t(),因为 PyTorch标准是(out_features, in_features)存的)
二、梯度更新
import torch
import torch.nn as nn
import torch.optim as optim# 定义一个简单的模型
model = nn.Linear(10, 2) # 输入维度为10,输出维度为2
criterion = nn.CrossEntropyLoss() # 损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01) # 使用随机梯度下降优化器# 模拟输入数据和标签
inputs = torch.randn(5, 10) # batch size 为 5,输入维度为 10
labels = torch.tensor([0, 1, 0, 1, 0]) # 对应的标签# 前向传播
outputs = model(inputs) # 计算模型输出
loss = criterion(outputs, labels) # 计算损失# 反向传播
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
optimizer.step() # 更新模型参数# 打印损失值
print(f"Loss: {loss.item()}")(1)loss 损失函数-反向传播
在机器学习/深度学习中,损失(loss)的作用是:
衡量模型输出 和 真实标签 之间的差距有多大。
差距越大,loss越大,训练目标就是让loss变小。
这部分是继承自torch.nn的,继承了在反向传播时就可以自动执行了——loss 是一个函数,它根据模型的输出(预测)和真实答案(标签)算出“错了多少”。而且——PyTorch 已经帮你写好了很多常见的损失函数,所以可以自动计算损失值!
举例:
outputs = torch.tensor([[0.8], [0.2]]) # 模型预测
targets = torch.tensor([[1.0], [0.0]]) # 真实答案loss_fn = nn.MSELoss()
loss = loss_fn(outputs, targets)
print(loss)
用 MSELoss(均方误差),计算出来的是:
PyTorch中,常见的 loss 都是封装成了一个类,比如 nn.MSELoss、n.CrossEntropyLoss,使用起来就像调用一个函数一样。
| 损失函数 | 适用情况 | 计算公式(简略版) |
|---|---|---|
nn.MSELoss | 回归问题 | 均方误差 (初中学的方差) |
nn.CrossEntropyLoss | 多分类问题 | 交叉熵 |
nn.BCELoss | 二分类问题(sigmoid后输出) | 二元交叉熵 |
nn.L1Loss | 有时用于回归,鲁棒性更好 | 绝对值误差 |
(2)optimizer 优化器-反向传播
Optimizer 是用来:
-
根据梯度(.grad)调整模型参数,让模型的损失 (loss) 变小。
也就是说:优化器就是根据 .grad 去真正“更新”权重的人。
在 PyTorch 里,常见的优化器有:
torch.optim.SGD(随机梯度下降)
torch.optim.Adam(自适应动量优化)
torch.optim.RMSprop(更适合处理稀疏数据)等等等等
举例:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)意思是:
用随机梯度下降法(SGD)
学习率
lr=0.01优化
model里面所有可以训练的参数。
套路——每一轮训练时需要:
loss.backward() # 计算梯度,填到 param.grad
optimizer.step() # 用 param.grad 来更新 param
optimizer.zero_grad()# 清空梯度,准备下一轮
小结比较一下自动化调用
| 步骤 | 说明 | 自动吗? |
|---|---|---|
| 1 | 前向传播 (forward) 计算输出 | ✅ |
| 2 | 计算损失 (loss) | ✅ |
| 3 | 反向传播 (loss.backward()) 计算梯度 | 你需要手动调用 .backward() |
| 4 | 用优化器 (optimizer.step()) 更新参数 | 你需要手动调用 .step() |
(3)scheduler 学习率调度器
Scheduler 是用来:
-
动态调整学习率 (learning rate) 的。(scheduler是用来让学习率“聪明变化”的。)
因为:
-
一开始训练时需要大学习率快速接近目标;
-
后面训练细节时需要小学习率慢慢收敛到最优。
PyTorch提供了各种学习率调度器(scheduler),比如:
StepLR(每隔几步降低一次)
ExponentialLR(指数下降)
ReduceLROnPlateau(如果验证集loss不下降,就降低学习率)
CosineAnnealingLR(余弦退火,非常热门)
用法举例:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
意思是:
-
用SGD,初始学习率是0.1
-
每30个epoch,学习率乘0.1(变成原来的十分之一)
训练套路:
for epoch in range(100):train() # 自己定义的训练过程validate() # 验证scheduler.step() # 记得每个epoch后,scheduler自己去调整学习率
三、训练模式与评估模式
所以,最后所谓保存的“模型”是什么?就是各种权重的一个字典,包括了继承自torch的那些【nn、loss、optimizer】
训练的时候是【修改梯度】的,就像人学新东西时要保持接受的状态。
评估的时候是【禁止修改梯度】的,就像人考试的时候一样,知识不能再根据考卷摇摆。
import torch
import torch.nn as nn# 定义一个简单的模型
model = nn.Linear(2, 1) # 输入维度为2,输出维度为1
criterion = nn.MSELoss() # 损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 模拟训练数据
train_inputs = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
train_targets = torch.tensor([[5.0], [7.0]])# 模拟评估数据
eval_inputs = torch.tensor([[5.0, 6.0]])
eval_targets = torch.tensor([[11.0]])# 训练模式
model.train() # 切换到训练模式
for epoch in range(10):optimizer.zero_grad()outputs = model(train_inputs)loss = criterion(outputs, train_targets)loss.backward()optimizer.step()print(f"Epoch {epoch+1}, Loss: {loss.item()}")# 评估模式
model.eval() # 切换到评估模式
with torch.no_grad(): # 禁用梯度计算eval_outputs = model(eval_inputs)eval_loss = criterion(eval_outputs, eval_targets)print(f"Evaluation Loss: {eval_loss.item()}")-
model.train():- 启用训练模式。
- 影响某些层(如
Dropout和BatchNorm),使它们在训练时正常工作。
-
model.eval():- 启用评估模式。
- 禁用
Dropout和固定BatchNorm的均值和方差,使模型在评估时表现稳定。
-
torch.no_grad():- 在评估模式下,禁用梯度计算以节省内存和加速推理。
总结流程:
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()→ 计算出每个参数的.grad
optimizer.step()→ 根据.grad更新参数
optimizer.zero_grad()→ 清空上一次的梯度
相关文章:
)
庙算兵棋推演AI开发初探(7-神经网络训练与评估概述)
前面我们提取了特征做了数据集、设计并实现了处理数据集的神经网络,接下来我们需要训练神经网络了,就是把数据对接好灌进去,训练后查看预测的和实际的结果是否一致——也就是训练与评估。 数据解析提取 数据编码为数据集 设计神经网络 -->…...
)
[实战] IRIG-B协议详解及Verilog实现(完整代码)
目录 IRIG-B(B码)协议详解及Verilog实现一、IRIG-B协议概述二、帧格式详细解析1. 码元类型与索引计数2. 时间编码字段3. 控制功能码元(CF)4. 纯二进制秒码(SBS) 三、编码与信号特性四、时间编码实现1. 时间参数转换2. 帧数据填充规…...

从传统制造到智能工厂:MES如何重塑电子制造业?
在“中国制造2025”战略的引领下,电子制造业正经历深刻变革。多品种小批量、工艺复杂度高、质量追溯严苛等需求日益凸显。由此,如何通过数字化手段实现生产透明化、质量可追溯和资源高效协同,成为行业转型的关键命题。 一、电子制造业转型痛…...

使用Curl进行本地MinIO的操作
前言 最近在做相关的项目中关于本地服务搭建和访问的技术验证,打进来最基本的数据访问,使用了C。可以进行:服务器的可用性检查、Bucket的创建、文件夹的创建、文件的上传、文件的下载、文件夹和Bucket的存在性检查等基本接口,对自…...

uniswap getTickAtSqrtPrice 方法解析
先上代码: function getTickAtSqrtPrice(uint160 sqrtPriceX96) internal pure returns (int24 tick) {unchecked {// Equivalent: if (sqrtPriceX96 < MIN_SQRT_PRICE || sqrtPriceX96 > MAX_SQRT_PRICE) revert InvalidSqrtPrice();// second inequality mu…...
 -- qemu-user使用)
qemu(3) -- qemu-user使用
1. 前言 qemu中有很多的特技,此处记录下qemu-arm的使用方式,简单来说qemu-system-xx用于虚拟整个设备,包括操作系统的运行环境,而qemu-xx仅虚拟Linux应用程序的环境,不涉及操作系统,应用程序的系统调用有宿…...

CMCC RAX3000M使用Tftpd刷写OpenWrt固件的救砖方法
有时候,我们在玩运行 OpenWrt 的 CMCC RAX3000M ,因为一些操作不当,导致无法进入路由器系统,无法正常刷机。此时,如果我们已经刷写了uboot,则可以在uboot模式下通过Tftpd刷写新的OpenWrt固件,实…...
_计算属性)
Vue基础(7)_计算属性
计算属性(computed) 一、使用方式: 1.定义计算属性: 在Vue组件中,通过在 computed 对象中定义计算属性名称及对应的计算函数来创建计算属性。计算函数会返回计算属性的值。 2.在模板中使用计算属性: 在Vue的模板中,您…...

1.9多元函数积分学
引言 多元函数积分学是考研数学一的核心内容,涵盖三重积分、曲线积分、曲面积分及空间曲线积分。本文系统梳理4大考点,结合公式速查与典型示例,助你高效攻克积分难题! 考点一:三重积分计算与应用 1️⃣ 对称性 (1) …...

【LINUX操作系统】线程操作
了解了线程的基本原理之后,我们来学习线程在C语言官方库中的写法与用法。 1. 常见pthread接口及其背后逻辑 1.1 pthread_create 与线程有关的函数构成了⼀个完整的系列,绝⼤多数函数的名字都是以“pthread_”打头的 • 要使⽤这些函数库,…...

web技术与nginx网站环境部署
一:web基础 1.域名和DNS 1.1域名的概念 网络是基于TCP/IP协议进行通信和连接的,每一台主机都有一个唯一的标识(固定的IP地址),用以区别在网络上成千上万个用户和计算机。网络在区分所有与之相连的网络和主机时,均采用一种唯一、通用的地址…...

多元复合函数求导的三种情况
1. 一元函数与多元函数复合 1.1 变量关系 1.2 求导公式 因为根据链式法则,先对z求导,z是二元函数,所以说是偏导;再对里面求导,u、v是一元函数,所以说是全导。 2. 多元函数与多元函数复合 2.1 变量关系…...
 —— 多令牌预测(Multi Token Prediction))
全面解析DeepSeek算法细节(2) —— 多令牌预测(Multi Token Prediction)
概述 多令牌预测(MTP)技术使DeepSeek-R1能够并行预测多个令牌,显著提升推理速度。 关键特性 并行多令牌预测:DeepSeek-R1通过同时预测多个令牌而非按顺序预测,提升了推理速度。这减少了解码延迟,在不影响…...

如何从大规模点集中筛选出距离不小于指定值的点
一、背景:当点集处理遇见效率挑战 在数字化浪潮席卷各行各业的今天,点集数据处理已成为地理信息系统(GIS)、计算机视觉、粒子物理仿真等领域的核心需求。以自动驾驶场景为例,激光雷达每秒可产生超过10万个点云数据&am…...

单片机-89C51部分:6、数码管
飞书文档https://x509p6c8to.feishu.cn/wiki/WRNLwDd0iiG8OWkyatOcom6knHf 一、数码管简介 通俗解释: 一个数码管等于八个LED组合在一起,想要显示什么形状,就点亮对应LED即可。 一般数码管分为共阴极数码管和共阳极数码管。 共阳极接法&…...
:让机器决策透明化)
可解释人工智能(XAI):让机器决策透明化
在人工智能(AI)技术飞速发展的今天,AI 系统已经广泛应用于金融、医疗、交通等多个关键领域。然而,随着 AI 系统的复杂性不断增加,尤其是深度学习模型的广泛应用,AI 的“黑箱”问题逐渐凸显。AI 系统的决策过…...

深入理解网络原理:TCP协议详解
在现代计算机网络中,传输控制协议(TCP,Transmission Control Protocol)是最常用的传输层协议之一。TCP被广泛应用于互联网中的许多关键应用,如网页浏览、电子邮件和文件传输等。作为一种面向连接的协议,TCP…...

二极管钳位电路——Multisim电路仿真
目录 二极管钳位电路 2.1 二极管正向钳位电路 二极管压降测试 2.1.1 二极管正向钳位电路图 2.1.2 二极管正向钳位工作原理 2.2 二极管负向钳位电路 2.2.1 二极管负向钳位电路图 2.2.2 二极管负向钳位工作原理 二极管正向反向钳位仿真电路实验结果 2.3 二极管顶部钳位…...
)
【更新】LLM Interview (2)
字数溢出,不解释 前文:llm interview (1) 文章目录 强化学习专题1 什么是RL?2 RL和监督、非监督、深度学习的区别3 RL中所谓的损失函数与深度学习中的损失函数有何区别?4 RL历史5 RL分类5.1 分类图示5.2 根据智能体动作选取方式分…...

第二节:文件系统
理论知识 文件系统的基本概念:文件系统是操作系统中负责管理持久数据的子系统,它将数据组织成文件和目录的形式,方便用户存储和访问数据。Linux文件系统的类型:常见的 Linux 文件系统类型有 Ext2、Ext3、Ext4、XFS、Btrfs 等。Ex…...

astrbot_plugin_composting_bucket开源程序是一个用于降低AstrBot的deepseek api调用费用的插件
一、软件介绍 文末提供程序和源码下载 astrbot_plugin_composting_bucket开源程序是一个用于降低AstrBot的deepseek api调用费用的插件,让deepseek api调用费用更低! 本插件功能已集成到 AstrBot ,您可以移除此插件,在 AstrBot…...

8.Three.js中的 StereoCamera 立体相机详解+示例代码
✨ 运行效果 👀 左边一幅图、右边一幅图,略微偏移,形成立体感~ (戴上VR眼镜或红蓝3D眼镜体验更明显哦~) 🔥 小球或方块旋转中,左右略微不同步,立体感更强&am…...

MYSQL——时间字段映射Java类型
在 Java 中查询数据库中的【时间字段】时,可以使用以下几种类型来处理: 1. java.sql.Date 适用场景:当数据库中的时间字段是 date 类型时,使用 java.sql.Date 是最合适的选择。示例代码:ResultSet rs statement.exe…...

搭建speak yarn集群:从零开始的详细指南
在大数据处理领域,Apache Spark 是一个高性能的分布式计算框架,而 YARN(Yet Another Resource Negotiator)是 Hadoop 的资源管理器。将 Spark 集成到 YARN 中,不仅可以充分利用 Hadoop 的资源管理能力,还能…...

第十三章-PHP MySQL扩展
第十三章-PHP与MySQL 一,连接数据库 1. 使用 MySQLi(面向对象方式) <?php // 数据库参数 $host localhost; $username root; $password ; $database test_db;// 创建连接 $conn new mysqli($host, $username, $password, $databa…...

在服务器中,搭建FusionCompute,实现集群管理
序:需要自备一台服务器,并安装部署好KVM,自行下载镜像,将所需的CNA和VRM镜像放到服务器中,小编所用的进项版本如下,读者可自行根据需求下载其它版本的镜像。 CNA镜像:FusionCompute_CNA-8.3.0-…...

嵌入式开发学习日志Day11
一、函数的递归调用 在调用一个函数的过程中,又出现直接或者间接的调用函数本身,称之为函数的递归调用; 函数的递归调用是使用大量的内存空间完成程序进行的; 1.间接调用 2.直接调用 注意: 上图仅为示意,…...

【线性规划】对偶问题的实际意义与重要性质 学习笔记
【线性规划】对偶问题的实际意义与重要性质_哔哩哔哩_bilibili...

代码随想录第30天:动态规划3
一、01背包理论基础(Kama coder 46) “01背包”:有n件物品和一个最多能背重量为w 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。 1. 确…...

DSP48E2 的 MAC模式功能仿真
DSP48E2 仿真代码: 测试的功能为 P i ( A D ) ∗ B P i − 1 P_{i} (AD) * B P_{i-1} Pi(AD)∗BPi−1 timescale 1ns / 1nsmodule dsp_tb;// 输入reg CLK;reg CE;reg SCLR;reg signed [26:0] A, D;reg signed [17:0] B;// 输出wire signed [47:0] P;par…...

【环境配置】Mac电脑安装运行R语言教程 2025年
一、安装 Xcode Command Line Tools 打开终端,输入如下命令: xcode-select --install安装完成后,输入如下命令,能看见版本号说明安装成功 gcc --version二、下载安装R语言 https://mirrors.tuna.tsinghua.edu.cn/CRAN/ 点开后…...

常见算法的总结与实现思路
前言 hello,我是Maybe。昨天和今天花了两天左右的时间。把常见的排序算法都学完了,自己也实现了一遍。感觉收获满满,但是过程是艰辛的。下面我将分享代码和思维导图,希望可以帮助到大家。 思维导图(含注意事项,实现思…...

Ethan独立开发产品日报 | 2025-04-27
1. CreateWise AI 旨在提升你工作效率的AI播客编辑器 人工智能播客编辑器,让你的播客制作速度提升10倍!它可以自动去除口头语和沉默,生成节目笔记和精彩片段,还能一键制作适合社交媒体分享的短视频——所有这些功能都只需一次点…...

5G与边缘计算:协同发展,开启智慧世界新篇章
**5G与边缘计算:协同发展,开启智慧世界新篇章 ** 大家好,我是Echo_Wish。今天我们来探讨一个备受关注的技术话题——5G与边缘计算的协同发展。随着5G网络的逐步普及以及边缘计算技术的快速发展,二者的结合为我们带来了前所未有的创…...

AcWing 885:求组合数 I ← 杨辉三角
【题目来源】 https://www.acwing.com/problem/content/887/ 【题目描述】 给定 n 组询问,每组询问给定两个整数 a,b,请你输出 C(a,b) mod (10^97) 的值。 【输入格式】 第一行包含整数 n。 接下来 n 行,每行包含一组 a 和 b。 …...

Python3:Jupyterlab 安装和配置
Python3:Jupyterlab 安装和配置 Jupyter源于Ipython Notebook项目,是使用Python(也有R、Julia、Node等其他语言的内核)进行代码演示、数据分析、机器学习、可视化、教学的非常好的工具。 最新的基于web的交互式开发环境,适用于n…...

如何搭建spark yarn模式的集合集群
一、环境准备 在搭建 Spark on YARN 集群之前,需要确保以下环境已经准备就绪: 操作系统:推荐使用 CentOS、Ubuntu 等 Linux 发行版。 Java 环境:确保安装了 JDK 1.8 或更高版本。 Hadoop 集群:已经搭建并运行的 Had…...

智能座舱架构中芯片算力评估
在智能座舱(Intelligent Cockpit)领域,芯片的算力是决定系统性能、响应速度以及用户体验的关键因素之一。 随着汽车智能化程度的不断提高,智能座舱对芯片的算力、功耗、集成度以及安全性提出了更高的要求。 智能座舱架构中芯片算…...

STM32完整内存地址空间分配详解
在STM32这类基于ARM Cortex-M的32位微控制器中,整个4GB的地址空间(从0x00000000到0xFFFFFFFF)有着非常系统化的分配方案,每个区域都有其特定的用途。下面我将详细介绍这些地址区域的分配及其功能: STM32完整内存地址空间分配详解(0x00000000…...

叉车司机N1考试的实操部分有哪些注意事项?
叉车司机 N1 考试实操部分分为场地考试和场内道路考试,以下是一些注意事项: 场地考试 起步:检查车辆仪表和个人仪容,穿好工作服、戴安全帽,不穿拖鞋等不符规定的鞋。同时检查换挡和换向操纵杆在空档位置,…...

【行业特化篇2】金融行业简历特化指南:合规性要求与风险控制能力的艺术化呈现
写在最前 作为一个中古程序猿,我有很多自己想做的事情,比如埋头苦干手搓一个低代码数据库设计平台(目前只针对写java的朋友),比如很喜欢帮身边的朋友看看简历,讲讲面试技巧,毕竟工作这么多年,也做到过高管,有很多面人经历,意见还算有用,大家基本都能拿到想要的offe…...

Linux 定时备份到windows 方案比较
1 传输协议比较 特性SCPRSYNCSFTP基本功能文件传输(本地与远程)文件和目录的同步与传输文件管理(上传、下载、删除等)增量传输不支持增量传输支持增量传输不支持增量传输性能传输速度较慢,效率低高效,适合…...

【网络编程】TCP/IP四层模型、MAC和IP
1. TCP/IP的四层模型 网络模型的目的:规范通信标准,确保不同设备和系统之间能够有效通信 对比OSI模型与TCP/IP模型: OSI模型的七层架构(物理层、数据链路层、网络层、传输层、会话层、表示层、应用层)TCP/IP模型的四…...

Java学习手册: IoC 容器与依赖注入
一、IoC 容器概述 IoC(Inversion of Control,控制反转)容器是 Spring 框架的核心组件之一。它负责创建对象、管理对象的生命周期以及对象之间的依赖关系。通过将对象的创建和管理交给 IoC 容器,开发者可以实现代码的松耦合&#…...

Web 基础与Nginx访问统计
目录 Web基础 域名与DNS 域名的结构 网页与HTML 网页概述 HTML 概述 HTML基本标签 1、HTML 语法规则 2、HTML 文件结构 静态网页和动态网页 HTTP协议概述 HTTP方法 HTTP状态码 Nginx访问状态统计 Web基础 域名与DNS 网络是基于 TCP/IP 协议进行通信和连接的,每一台主机都有一…...
)
了解Android studio 初学者零基础推荐(1)
线上学习课程链接 开发Andorid App 使用的语言有很多,包括java, kotlin,C,等,首先让我们了解kotlin这个热门语言。 kotlin 程序 fun main() {println("hello,xu") } kotlin中的函数定义语法:函数名称在fun关键字后面࿰…...

Android Studio 2024版,前进返回按钮丢失解决
最近升级完AS最新系统后,顶部的前进和返回按钮默认隐藏了 解决方案: 1. 打开settings 2. 找到左侧 Appearance & Behavior 下面点击 Menus and Toolbars 3. 点击 Main Toolar 4. 点击Left,右键选择 Add Actions 5. 弹框中选择 Main Me…...

详解UnityWebRequest类
什么是UnityWebRequest类 UnityWebRequest 是 Unity 引擎中用于处理网络请求的一个强大类,它可以让你在 Unity 项目里方便地与网络资源进行交互,像发送 HTTP 请求、下载文件等操作都能实现。下面会详细介绍 UnityWebRequest 的相关内容。 UnityWebRequ…...

安装qt4.8.7
QT4.8.7安装详细教程(MinGW 4.8.2和QTCreator4.2.0)_qtcreater482-CSDN博客 QT4.8.7安装详细教程(MinGW 4.8.2和QTCreator4.2.0) 1、下载 1)下载QT4.8.7 http://download.qt.io/archive/ 名称:qt-opensource-windows-x86-mingw482…...

2025系统架构师---管道/过滤器架构风格
引言 在分布式系统与数据密集型应用主导技术演进的今天,管道/过滤器架构风格(Pipes and Filters Architecture Style)凭借其数据流驱动、组件解耦与并行处理能力,成为处理复杂数据转换任务的核心范式。从Unix命令…...