【昇腾】PaddleOCR转om推理
文章目录
- 1. 使用Paddle框架推理
- 1.1 安装
- 1.2 推理
- 2. paddle 转 ONNX
- 3. 转om
- 4. Ais_bench 命令推理
- 5. Ais_bench 编写推理代码
概要:
PyTorch官方提供了昇腾插件包,安装后虽然可以支持PytorchOCR和PaddlePaddle的推理任务,但性能通常低于GPU。
为了充分发挥昇腾硬件的潜力,可以采用离线推理方案:
模型转换:将Paddle模型转换为昇腾专用的OM格式;
高效推理:通过昇腾 ACL 框架运行,显著提升性能。
这种方案通过硬件深度优化,能大幅提升推理速度。
1. 使用Paddle框架推理
1.1 安装
# 先安装飞桨 CPU 安装包
python -m pip install paddlepaddle==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/# 再安装飞桨 NPU 插件包
python -m pip install paddle-custom-npu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/npu/如果失败,使用源码编译安装(确实会有安装失败的情况)
# 下载 PaddleCustomDevice 源码
git clone https://github.com/PaddlePaddle/PaddleCustomDevice -b release/3.0.0# 进入硬件后端(昇腾 NPU)目录
cd PaddleCustomDevice/backends/npu# 先安装飞桨 CPU 安装包
python -m pip install paddlepaddle==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/# 执行编译脚本 - submodule 在编译时会按需下载
bash tools/compile.sh# 飞桨 NPU 插件包在 build/dist 路径下,使用 pip 安装即可
python -m pip install build/dist/paddle_custom_npu*.whl健康检查:
# 检查当前安装版本
python -c "import paddle_custom_device; paddle_custom_device.npu.version()"
# 飞桨基础健康检查
python -c "import paddle; paddle.utils.run_check()"
1.2 推理
设置环境变量:
推理时有算子触发
jit编译,会导致推理很慢。所以需要设置环境变量来禁止。
export FLAGS_npu_jit_compile=0
export FLAGS_use_stride_kernel=0
推理代码:
添加参数:use_npu=True
from paddleocr import PaddleOCR
PaddleOCR(show_log=True,use_npu=True,# 其他参数)
2. paddle 转 ONNX
参考文档
下载模型
wget -nc -P ./inference https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_det_infer.tar
cd ./inference && tar xf ch_PP-OCRv4_det_infer.tar && cd ..wget -nc -P ./inference https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_infer.tar
cd ./inference && tar xf ch_PP-OCRv4_rec_infer.tar && cd ..
转ONNX
paddle2onnx --model_dir ./inference/ch_PP-OCRv4_det_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file ./inference/det_onnx/model.onnx \
--opset_version 11 \
--enable_onnx_checker Truepaddle2onnx --model_dir ./inference/ch_PP-OCRv4_rec_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file ./inference/rec_onnx/model.onnx \
--opset_version 11 \
--enable_onnx_checker True
3. 转om
请保证昇腾环境已安装,文档
我的场景下只需要这两个模型:rec、det。即文本识别、文本检测。
对于shape需要观察paddle模型的结构,根据输入shape和我们的业务需求来做配置,在线查看模型结构网站:https://netron.app
rec
其原有模型结构为:(x:-1,3,48,-1) 。batch 和 宽度是动态的,那么正常来说ATC转换时也根据这个来配置就好了,但我测试了多次,如果按照(x:-1,3,48,-1) 会报错,或者转换不保存推理时报错。档位直接-1也会报错。所以我选择了(x:-1,3,48,320),并设置了动态batch分档。
当然如果没有动态shape的需求,会更简单,固定即可,大概率是ok的。
det
其原有模型结构为:(x:-1,3,-1,-1) 。可以正常去做动态shape。
atc --model=./inference/rec_onnx/model.onnx \
--framework=5 \
--output=./d_n_recfix \
--input_format=NCHW \
--input_shape="x:-1,3,48,320" \
--dynamic_batch_size="1,2,3,4,5,6" \
--soc_version=Ascend910B3atc --model=./inference/det_onnx/model.onnx \
--framework=5 \
--output=./d_n_decfix \
--input_format=NCHW \
--input_shape="x:-1,3,-1,-1" \
--soc_version=Ascend910B3
4. Ais_bench 命令推理
Ais_bench 是昇腾测试 om 模型性能的工具。功能可以这样理解:快速验证om模型是否正常、快速编写推理代码。
最开始说我们要使用ACL来做推理,直接编写ACL是很麻烦的,设计到数据内存设计、内存申请、释放、数据搬入搬出等等操作,Ais_bench是更上层的测试工具,我们可以暂时使用Ais_bench来做推理测试和代码编写。Ais_bench即有命令行工具也提供python包。
ais_bench推理工具使用指南。请先根据文档下载whl包。
python3 -m ais_bench --model d_n_recfix.om --dymBatch 6
如果有本地的bin文件,可以添加参数:--input=/rec/bin
bin文件:可以将数据预处理后的tensor保存为bin文件,再用ais_bench推理bin文件可以输出一个bin,再用输出的bin接入后处理,可以快速验证推理的正确性
5. Ais_bench 编写推理代码
Ais_bench接口文档
代码中 muti_infer_det、infer_rec、infer_det 函数需要实例AisBenchInfer后使用。
下面两部分主要是用于测试om模型是否正常和他们的精度,可以删除:
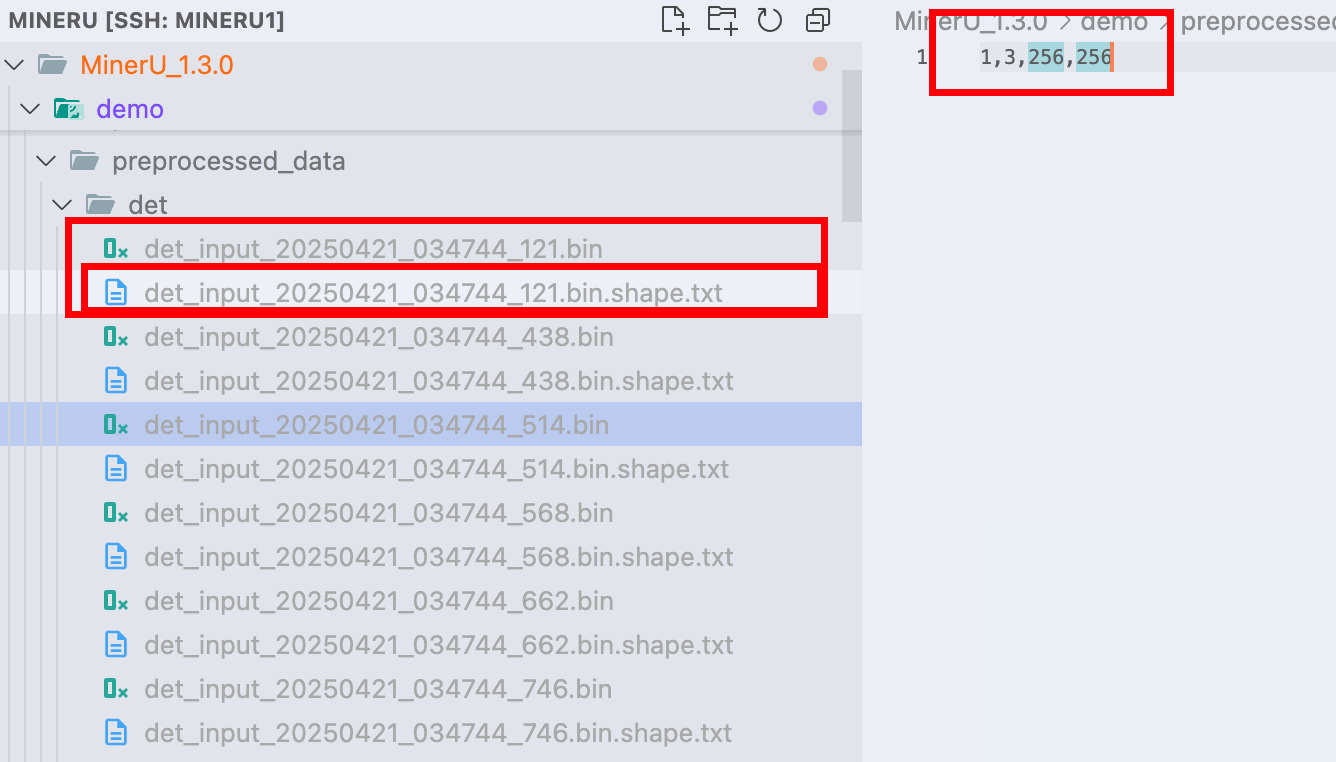
infer_with_file、infer_with_file_det 为推理单张图片bin文件/bin文件夹 使用。因为bin只是tensor数据,没有shape,所以需要重塑shape为正常形状
infer_folder_det、infer_folder_rec 推理整个文件夹,每个bin都有一个相应的记录shape的txt,每次都读取bin和shape的txt文件,用于重塑shape为正常形状
样例文件:
其他说明:
rec推理没有问题,只是只能batch为动态,宽度固定。
det推理单张图片没有问题,推理多张图片会出现错误,大概率和Ais_bench中的session创建有关系。有一个不是好方案的方案,使用MultiDeviceSession,多线程调用,每次调用时创建一个session,即推理多张图片每次都需要初始化,所以会很慢。
毕竟Ais_bench是ACL的上层封装,或许在某些场景确实有问题,有可能使用ACL编写代码会避免,但ACL有一定的学习成本,大家如果有测试的可以发出来一起讨论。
import os
import time
import numpy as npfrom ais_bench.infer.interface import InferSession,MultiDeviceSession
from ais_bench.infer.common.utils import logger_printmodel_path_rec = "/home/aicc/mineru/model/d_n_recfix.om"
model_path_det = "/home/aicc/mineru/model/d_n_decfix_linux_aarch64.om"
class AisBenchInfer:_instance = None # 单例模式的类变量def __new__(cls, device_id=1):# 单例模式实现:如果实例不存在则创建,否则返回已有实例if cls._instance is None:cls._instance = super(AisBenchInfer, cls).__new__(cls)cls._instance._initialized = False # 标记是否已经初始化return cls._instancedef __init__(self, device_id=1):"""初始化推理模型Args:device_id: 设备IDmodel_path: 模型路径"""# 只在第一次初始化时执行if not self._initialized:self.device_id = device_idself.model_path_rec = model_path_recself.session_rec = InferSession(device_id, self.model_path_rec)self.model_path_det = model_path_det# self.session_det = InferSession(device_id, self.model_path_det)self.multi_session_det = MultiDeviceSession(self.model_path_det)# self.session_det.set_staticbatch()print("初始化完成:")self._initialized = True # 标记为已初始化def muti_infer_det(self, norm_img_batch: np.ndarray):"""执行推理Args:norm_img_batch: 输入的图像批次数据Returns:推理输出结果"""outputs = self.multi_session_det.infer({self.device_id: [[norm_img_batch]]}, mode='dymshape', custom_sizes=1000000)print("推理成功")# print(outputs)return outputsdef infer_rec(self, norm_img_batch: np.ndarray):"""执行推理Args:norm_img_batch: 输入的图像批次数据Returns:推理输出结果"""outputs = self.session_rec.infer([norm_img_batch], mode='dymbatch')print("推理成功")return outputsdef infer_det(self, norm_img_batch: np.ndarray):"""执行推理Args:norm_img_batch: 输入的图像批次数据Returns:推理输出结果"""# model_path_det = "/home/aicc/mineru/model/d_n_decfix_linux_aarch64.om"# session_det = InferSession(self.device_id, model_path_det)outputs = self.session_det.infer([norm_img_batch], mode='dymshape')print("type(outputs):", type(outputs)) # 应输出 <class 'list'>print("type(outputs[0]):", type(outputs[0])) # 应输出 <class 'numpy.ndarray'>print("outputs[0].dtype:", outputs[0].dtype) # 应输出 float32print("outputs[0].shape:", outputs[0].shape) # 例如 (6, 25, 6625)print("outputs:", outputs) # 例如 (6, 25, 6625)print(len(outputs)) # 例如 (6, 25, 6625)print("推理成功")# outputs = self.session_det.infer([norm_img_batch], mode='dymshape')# print("推理成功")# session_det.free_resource()return outputsdef free_resource(self):"""释放模型资源"""if hasattr(self, 'session'):self.session.free_resource()@staticmethoddef infer_with_file(bin_file_path, device_id=0, model_path='/home/aicc/mineru/model/d_model_rec_linux_aarch64.om'):"""使用文件执行动态批量推理Args:bin_file_path: 二进制输入文件路径device_id: 设备IDmodel_path: 模型路径Returns:推理输出结果"""session = InferSession(device_id, model_path)# 读取数据ndata = np.fromfile(bin_file_path, dtype=np.float32)print("ndata shape:", ndata.shape)print("ndata元素数量:", ndata.size)print("ndata数据类型:", ndata.dtype)# 重塑数据ndata = ndata.reshape(6, 3, 48, 320)print("重塑后的ndata shape:", ndata.shape)# 执行推理outputs = session.infer([ndata], mode='dymshape')# 打印输出信息print(type(outputs)) # 应输出 <class 'list'>print(type(outputs[0])) # 应输出 <class 'numpy.ndarray'>print(outputs[0].dtype) # 应输出 float32print(outputs[0].shape) # 例如 (6, 25, 6625)# 释放资源session.free_resource()return outputs@staticmethoddef infer_with_file_det(bin_file_path, device_id=0, model_path='/home/aicc/mineru/model/d_n_decfix_linux_aarch64.om'):"""使用文件执行动态批量推理Args:bin_file_path: 二进制输入文件路径device_id: 设备IDmodel_path: 模型路径Returns:推理输出结果"""session = InferSession(device_id, model_path)# 读取数据ndata = np.fromfile(bin_file_path, dtype=np.float32)print("ndata shape:", ndata.shape) print("ndata元素数量:", ndata.size)print("ndata数据类型:", ndata.dtype)# 重塑数据ndata = ndata.reshape(1, 3, 800, 704)print("重塑后的ndata shape:", ndata.shape)# 执行推理outputs = session.infer([ndata], mode='dymshape')# 打印输出信息print(type(outputs)) # 应输出 <class 'list'>print(type(outputs[0])) # 应输出 <class 'numpy.ndarray'>print(outputs[0].dtype) # 应输出 float32print(outputs[0].shape) # 例如 (6, 25, 6625)# 释放资源session.free_resource()return outputs@staticmethoddef infer_folder_det(folder_path, device_id=0, model_path='/home/aicc/mineru/model/d_n_decfix_linux_aarch64.om'):"""处理文件夹中的所有bin文件进行检测推理Args:folder_path: 包含bin文件和shape.txt文件的文件夹路径device_id: 设备IDmodel_path: 模型路径Returns:所有bin文件的推理结果字典,键为bin文件名,值为推理输出"""session = MultiDeviceSession( model_path)# session.set_staticbatch()results = {}# 获取文件夹中所有bin文件bin_files = [f for f in os.listdir(folder_path) if f.endswith('.bin') and not f.endswith('.shape.txt')]for bin_file in bin_files:bin_file_path = os.path.join(folder_path, bin_file)shape_file_path = bin_file_path + '.shape.txt'# 检查shape文件是否存在if not os.path.exists(shape_file_path):print(f"跳过 {bin_file}: 找不到shape文件")continue# 读取shape数据with open(shape_file_path, 'r') as f:shape_str = f.read().strip()# 解析shape数据shape = tuple(map(int, shape_str.split(',')))# 读取bin数据ndata = np.fromfile(bin_file_path, dtype=np.float32)print(f"处理 {bin_file}")print(f"原始数据shape: {ndata.shape}")print(f"从shape文件读取的形状: {shape}")# 重塑数据try:ndata = ndata.reshape(shape)print(f"重塑后的数据shape: {ndata.shape}")# 执行推理outputs = session.infer({device_id: [[ndata]]}, mode='dymshape', custom_sizes=10000000)print(f"{bin_file} 推理成功")# 记录结果results[bin_file] = outputsexcept Exception as e:print(f"处理 {bin_file} 时出错: {e}")# 释放资源# session.free_resource()return results@staticmethoddef infer_folder_rec(folder_path, device_id=0, model_path='/home/aicc/mineru/model/d1001_n_recfix_linux_aarch64.om'):"""处理文件夹中的所有bin文件进行识别推理Args:folder_path: 包含bin文件和shape.txt文件的文件夹路径device_id: 设备IDmodel_path: 模型路径Returns:所有bin文件的推理结果字典,键为bin文件名,值为推理输出"""session = InferSession(device_id, model_path)results = {}# 获取文件夹中所有bin文件bin_files = [f for f in os.listdir(folder_path) if f.endswith('.bin') and not f.endswith('.shape.txt')]for bin_file in bin_files:bin_file_path = os.path.join(folder_path, bin_file)shape_file_path = bin_file_path + '.shape.txt'# 检查shape文件是否存在if not os.path.exists(shape_file_path):print(f"跳过 {bin_file}: 找不到shape文件")continue# 读取shape数据with open(shape_file_path, 'r') as f:shape_str = f.read().strip()# 解析shape数据shape = tuple(map(int, shape_str.split(',')))# 读取bin数据ndata = np.fromfile(bin_file_path, dtype=np.float32)print(f"处理 {bin_file}")print(f"原始数据shape: {ndata.shape}")print(f"从shape文件读取的形状: {shape}")# 重塑数据try:ndata = ndata.reshape(shape)print(f"重塑后的数据shape: {ndata.shape}")# 执行推理outputs = session.infer([ndata], mode='dymbatch')print(f"{bin_file} 推理成功")# 记录结果results[bin_file] = outputsexcept Exception as e:print(f"处理 {bin_file} 时出错: {e}")# 释放资源session.free_resource()return results# 使用示例:# import acl# infer_model = AisBenchInfer()
# result = infer_model.infer_det(np.zeros((1, 3, 608, 704), dtype=np.float32))
# result = infer_model.infer_det(np.zeros((1, 3, 608, 704), dtype=np.float32))# 使用 muti 推理多个 ,muti每次都会创建InferSession。 使用推理接口时才会在指定的几个devices的每个进程中新建一个InferSession。
# result = infer_model.muti_infer_det(np.zeros((1, 3, 800, 704), dtype=np.float32))
# result = infer_model.muti_infer_det(np.zeros((1, 3, 608, 704), dtype=np.float32))# infer_model.free_resource()# 或者直接使用静态方法:
# result = AisBenchInfer.infer_with_file('/home/aicc/mineru/MinerU_1.3.0/demo/preprocessed_data/rec/rec_input_batch_0_20250421_091529_142.bin')
# result = AisBenchInfer.infer_with_file_det('/home/aicc/mineru/MinerU_1.3.0/demo/preprocessed_data/det/det_input_20250421_034746_105.bin')# results = AisBenchInfer.infer_folder_det('/home/aicc/mineru/MinerU_1.3.0/demo/preprocessed_data/det')
# results = AisBenchInfer.infer_folder_rec('/home/aicc/mineru/MinerU_1.3.0/demo/preprocessed_data/rec')
# print("检测推理结果:", results)相关文章:

【昇腾】PaddleOCR转om推理
文章目录 1. 使用Paddle框架推理1.1 安装1.2 推理 2. paddle 转 ONNX3. 转om4. Ais_bench 命令推理5. Ais_bench 编写推理代码 概要: PyTorch官方提供了昇腾插件包,安装后虽然可以支持PytorchOCR和PaddlePaddle的推理任务,但性能通常低于GPU。…...

【数据融合】基于拓展卡尔曼滤波实现雷达与红外的异步融合附matlab代码
一、问题分析与技术难点 1. 传感器特性对比 传感器测量维度优势局限性噪声模型雷达距离 $ r $、方位角 $ \theta $、速度 $ v $测距精度高、全天候工作角度分辨率低、易受多径干扰高斯噪声,协方差矩阵 $ R_r \text{diag}(\sigma_r^2, \sigma_\theta^2, \sigma_v^…...

第一部分:网页的骨架 —— HTML
这目录 前言1. 初识 HTML:搭建地基和框架1.1 小例子: 创建一个最简单的 HTML 页面,包含 "Hello World"。1.2 练习 2. 常用文本与内容标签:填充墙体和房间2.1 小例子: 创建一个包含个人简介(使用标…...

RTMP 协议解析 1
介绍 📖 什么是 RTMP? RTMP协议(Real-Time Messaging Protocol,实时消息传输协议)是由Adobe公司(最初由Macromedia开发)设计的一种用于实时传输音频、视频和数据流的网络协议,主要…...

c++初始化数组
1.前言 话说数组是n年前的事了,我为啥现在又提到它呢?因为很多人不会初始化数组,所以今天我来教教大家 2.初始化数组 初始化数组就是定义数组,就像这样 int a[5]{0}; 这样是a[0]到a[5]全都等于0 如果要输出这个数组…...

支持Win和Mac的批量图片压缩方法
软件介绍 如果你的图片太大,传输或上传总是卡壳,那就需要一款好用的图片压缩工具了。今天推荐的这款工具支持Windows和Mac双系统,简直是图片压缩界的"变形金刚"! 图压(图片压缩双系统版) …...
环境下载git-lfs等工具及使用)
autodl(linux)环境下载git-lfs等工具及使用
一、git-lfs工具下载 #初始化git.lfs命令 curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash sudo apt-get install git-lfs git lfs install 二、 huggingface-cli工具下载及使用 Linux设置huggingface的镜像: ex…...

云原生--核心组件-容器篇-3-Docker核心之-镜像
1、定义与作用 定义: Docker镜像是一个只读的模板,包含运行应用程序所需的所有内容,包括代码、依赖库、环境变量、配置文件等。简单来说,Docker镜像是一个轻量级、独立、可执行的软件包,它包含了运行某个软件所需的所有…...

Dify与n8n深度对比:AI应用开发与自动化工作流的双轨选择
Dify与n8n深度对比:AI应用开发与自动化工作流的双轨选择 在数字化转型加速的2025年,Dify和n8n作为两大主流工具,分别代表了AI应用开发与自动化工作流领域的顶尖解决方案。本文将从核心定位、功能特性、使用场景等维度展开对比,为…...

AI算法优化建筑形态与能耗管理 实现方案和技术架构
以下是基于AI算法优化建筑形态与能耗管理的实现方案与技术架构,结合行业实践与前沿技术趋势,分层次解析核心要素及实施路径: 一、技术架构设计 1. 数据采集与感知层 多源数据融合 传感器网络:部署温湿度、CO₂浓度、光照、人流密度等传感器,构建实时数据采集体系(如北京…...

【互联网架构解析】从物理层到应用层的全栈组成
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比 二、实战演示环境配置要求核心代码实现(Python网络请求)运行结果验证 三、性能对比测试方法论量化数据对比结果分…...

Redis和MQ的区别
redis是一个高性能的key-value数据库,支持消息推送功能,可以当做一个轻量级的队列服务器使用。 redis只是提供一个高性能的、原子操作内存键值队,具有高速访问能力,虽然可以做消息队列的存储,但不具备消息队列的任何功…...

多系统安装经验,移动硬盘,ubuntu grub修改/etc/fstab 移动硬盘需要改成nfts格式才能放steam游戏
笔记本一个系统,移动硬盘两个系统,当前系统sda4.jpg 移动硬盘需要再装一个linux会有boot/efi,启动的时候grub界面才能识别,单linux没有efi别的电脑识别不到 没efi甚至启动不了grub 按下f6.jpg 看看笔记本grub能不能识别得到移动硬…...

4.26学习——web刷题
把攻防世界的web做了20道左右,挑了几道学到东西的题目记录一下 攻防世界warmup 进到环境中读取源代码发先有个提示:source.php,进去看看 <?phphighlight_file(__FILE__);class emmm{public static function checkFile(&$page){$wh…...

Go 语言中的实时交互式编程环境
在 Go 语言中,确实有几种方法可以实现类似 Python REPL 的实时交互式编程体验,让你可以实时编写代码并查看输出,而无需每次都编译运行整个程序。 但是需要注意的是,由于 Go 是编译型语言,完全的实时交互体验不如解释型…...
详解)
动态规划求解leetcode300.最长递增子序列(LIS)详解
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。 示例 1&#…...

冯·诺依曼和哈佛架构两种架构的总线组成及核心特点
在计算机体系结构中,哈佛架构和冯诺依曼架构是两种不同的存储与总线设计范式,它们的总线组成和访问方式有显著差异。以下是两种架构的总线组成及核心特点的详细分析: 1. 冯诺依曼架构(Von Neumann Architecture) 核心…...
-进度(p75-P80))
7.学习笔记-Maven进阶(P75-P89)-进度(p75-P80)
1.MAVEN-01-分模块开发的意义 (一)分模块开发意义 模块可以按功能划分,也可以按团队划分,所以把domain的方法抽取出来,进行共享,从而提高开发 的效率。 (1)分模块开发的意义…...

Java——令牌技术
目录 一、何为令牌 JWT令牌 介绍 JWT组成 二、JWT用于验证用户登录 三、JWT令牌生成和校验 简单用法 1.创建生成密钥的方法 2.接着添加过期时间,密钥,BASE64解码密钥的属性以及生成token的方法,合并上面生成密钥的方法,下面…...

【含文档+PPT+源码】基于Python校园跑腿管理系统设计与实现
项目介绍 本课程演示的是一款基于Python校园跑腿管理系统设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Python学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本套系统 3.…...

Spring AI Alibaba - Milvus 初体验,实现知识库效果
先看效果 数据被存储在 milvus 中,包括原始数据和向量数据。 大模型使用向量化数据的回答: 环境准备 安装 milvus Milvus 是一款专为向量相似性搜索设计的高性能开源数据库。 本地测试环境可以直接 Standalone 模式安装,需要用到 docke…...

arcpy列表函数的应用
arcpy.ListDatasets() 该函数用于列出指定工作空间中的所有数据集(如要素数据集、栅格数据集等)。 语法: python arcpy.ListDatasets(wild_cardNone, feature_typeNone) • wild_card:用于筛选数据集名称的通配符。 • feat…...

上位机知识篇---时钟分频
文章目录 前言 前言 本文简单介绍了一下时钟分频。时钟分频(Clock Division)是数字电路设计中常见的技术,用于将高频时钟信号转换为较低频率的时钟信号,以满足不同模块的时序需求。它在处理器、FPGA、SoC(片上系统&am…...

Redis的两种持久化方式:RDB和AOF
Redis持久化概述 Redis作为内存数据库,数据存储在内存中。为了保证数据在服务器重启或宕机时不丢失,Redis提供了两种持久化方案: RDB(Redis Database):定时生成内存快照 AOF(Append Only File&…...

1位的推理框架bitnet.cpp
源码:https://github.com/microsoft/BitNet bitnet.cpp 技术解析 bitnet.cpp 是专为 低精度大语言模型(如 BitNet b1.58) 设计的官方推理框架,其核心特性如下: 一、架构优势 全栈优化引擎 提供高度优化…...

教育领域的AIGC革命:构建多模态智能教学系统
一、智能教育系统技术架构 1.1 教育场景技术需求 教学环节 传统痛点 AIGC解决方案 课程设计 耗时耗力,创新不足 跨学科教案自动生成 课堂互动 单向传授,参与度低 多模态交互式虚拟教师 作业批改 重复劳动,反馈延迟 全自动批改与个性化评语 学…...

Simulink 数据存储机制:Base Workspace、Model Workspace 与 Data Dictionary 的核心区别
1. 核心定位与设计目标 存储方式本质核心设计目标Base WorkspaceMATLAB全局内存空间临时数据交互,快速原型开发Model Workspace模型私有数据容器模型数据隔离,防止命名冲突Data Dictionary专业数据管理文件(.sldd)复杂系统数据治理,支持团队…...

TI---UART通信
一、SysConfig 中 UART 配置的核心参数与生成逻辑 1. 基础参数配置(图形化界面) 配置项功能说明生成代码影响模式选择主机模式(Master)/ 从机模式(仅部分芯片支持,如 UART 作为 I2C 桥接)生成…...

spark总结
文章目录 一 spark简介1.1 什么是spark1.2 spark运行过程1.2.1 组成1.2.2 过程1.2.3 事例(词频统计WordCount程序) 1.3 spark运行模式1.4 pyspark 二 SparkCore2.1 RDD介绍2.2 RDD编写2.3 RDD算子2.4 RDD的持久化2.4.1 为什么需要缓存和检查点机制&#…...

【随笔】地理探测器原理与运用
文章目录 一、作者与下载1.1 软件作者1.2 软件下载 二、原理简述2.1 空间分异性与地理探测器的提出2.2 地理探测器的数学模型2.21 分异及因子探测2.22 交互作用探测2.23 风险区与生态探测 三、使用:excel 一、作者与下载 1.1 软件作者 作者: DOI: 10.…...

补码底层逻辑探讨
在计算机里面以二进制进行存储,二进制并不能区分正负数 为了处理负数,人们想了很多办法 1.原码 首先,很直观的区分方法就是设置一个flag 在二进制前面加一个符号位,0是正、1是负 但是在电路里面处理这样的信号却很复杂&#…...

第二大脑-个人知识库
原文链接:https://i68.ltd/notes/posts/20250407-llm-person-kb/ Quivr-第二大脑一样的个人助手,利用AI技术增强个人生产力 将 GenAI 集成到您的应用程序中的个性化 RAG,专注于您的产品而非 RAG项目仓库:https://github.com/QuivrHQ/quivr Star:37.7k官网:https:/…...
)
泰勒展开概念解释(图优化SLAM中非线性系统的线性处理)
1. 泰勒展开 泰勒展开是一种用多项式近似复杂函数的数学方法,其核心思想是通过函数在某一点的各阶导数信息,构建一个多项式来逼近原函数,即通过函数在某一点x0的各阶导数值,构造一个多项式 P(x),使得该多项式在 x0 附近与原函数 f(x) 的值及其导数尽可能匹配,数学形式为…...

CANape与MATLAB数据接口技术详解
目录 CANape与MATLAB数据接口技术详解 一、数据互操作背景与意义 1.1 汽车电子开发中的测量需求 1.2 技术标准演进分析 二、CANape数据导出深度解析 2.1 MDF文件结构说明 2.2 转换流程优化建议 三、MATLAB数据处理进阶技术 3.1 数据质量评估脚本 3.2 数据可视化增强方…...

per-task affinity 是什么?
Per-Task Affinity(任务级CPU亲和性)详解 Per-Task Affinity 是 Linux 调度器提供的一种机制,允许将单个任务(进程/线程)绑定到特定的 CPU 核心(或核心集合)上运行,从而优化性能、减…...

基于先进MCU的机器人运动控制系统设计:理论、实践与前沿技术
摘要:随着机器人技术的飞速发展,对运动控制系统的性能要求日益严苛。本文聚焦于基于先进MCU(微控制单元)的机器人运动控制系统设计,深入剖析其理论基础、实践方法与前沿技术。以国科安芯的MCU芯片AS32A601为例…...

Network.framework 的引入,不是为了取代 URLSession
Network.framework 的引入,不是为了取代 URLSession 如果你感觉 Network.framework 的引入, 可能是为了取代 URLSession, 那你就大错特错了!这里需要非常准确地区分一下: 🔵 Network.framework 不是为了取代 URLSession。 &…...

gradle-缓存、依赖、初始化脚本、仓库配置目录详解
1.启用init.gradle文件的方法 在命令置顶文件,例如gradle --init-script yourdir/init.gradle -q taskName,你可以多次输入此命令来制定多个init文件把init.gradle文件放到USER_HOME/.gradle/目录下把以.gradle结尾的文件放到USER_HOME/.gradle/.init.d/目录下把以…...

提示词的神奇魔力——如何通过它改变AI的输出
一、引言:初识AI的惊艳与迷茫 最近这段时间,我像很多人一样,一头扎进了生成式AI的世界,尝试使用各种工具,从文字助手到图像生成器。一开始,我被它们的能力深深震撼,感觉就像突然拥有了一个无所…...
:Scikit-learn 机器学习初步 - 让数据预测未来!)
零基础上手Python数据分析 (24):Scikit-learn 机器学习初步 - 让数据预测未来!
写在前面 在前面的学习中,我们已经掌握了使用 Python、Pandas、NumPy、Matplotlib 和 Seaborn 进行数据处理、分析和可视化的全套核心技能。我们学会了如何从数据中提取信息、清洗数据、整合数据、探索数据模式并将其可视化呈现。 现在,我们站在了一个新的起点。数据分析不仅…...

React 与 Vue 虚拟 DOM 实现原理深度对比:从理论到实践
在现代前端开发中,React 和 Vue 作为最流行的两大框架,都采用了虚拟 DOM(Virtual DOM) 技术来优化渲染性能。虚拟 DOM 的核心思想是通过 JavaScript 对象模拟真实 DOM,减少直接操作 DOM 的开销,从而提高页面…...

结合五层网络结构讲一下用户在浏览器输入一个网址并按下回车后到底发生了什么?
文章目录 实际应用第一步:用户在浏览器输入 www.baidu.com 并按下回车1. 浏览器触发域名解析(DNS查询) 第二步:DNS请求的逐层封装与传输1. 应用层(DNS协议)2. 传输层(UDP协议)3. 网络…...

关于Code_流苏:商务合作、产品开发、计算机科普、自媒体运营,一起见证科技与艺术的交融!
Code_流苏 🌿 名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 🌟 欢迎来到Code_流苏的CSDN主页 —— 与我一起&…...

Webpack模块打包工具
1. 认识webpack的基本用法步骤创建项目->下载webpack webpack-cli -> npm init -y -> package.json的scripts中配置webpack默认打包入口:src/index.js默认打包出口: dist/main.js2. 认识webpack.config.js的基本配置loader -> 打包css,less…...

crossOriginLoading使用说明
1. 说明 此配置用于控制 Webpack 动态加载的代码块(chunk)(例如代码分割或懒加载的模块)在跨域(不同域名)加载时的行为。它通过为动态生成的 <script>标签添加 crossorigin 属性,确保符合…...

Linux系统性能调优技巧分享
在数字化时代,Linux 系统以其开源、稳定、高效的特性,成为服务器、云计算、物联网等领域的核心支撑。然而,随着业务规模的扩大和负载的增加,系统性能问题逐渐凸显。掌握 Linux 系统性能调优技巧,不仅能提升系统运行效率,还能降低运维成本。下面从多个方面介绍实用的性能调…...
,方法同样适用于其它绝大部分Git服务)
在Windows11中配置Git+SSH环境,本此实践使用Gitee(码云),方法同样适用于其它绝大部分Git服务
1.下载并安装Git 进入官网下载 Git - Downloading Package 选择下载Standalone Installer安装包,看自己电脑是64-bit还是32-bit(一般都是64-bit) 双击安装包进行安装,Next 这里可以自定义安装路径 这里可以勾选添加桌面快捷方式…...

【软考-架构】14、软件可靠性基础
✨资料&文章更新✨ GitHub地址:https://github.com/tyronczt/system_architect 文章目录 软件可靠性基本概念软件可靠性建模软件可靠性管理软件可靠性设计N版本程序设计恢复块设计(动态冗余)双机容错技术、集群技术负载均衡软件可靠性测试…...

怎样理解ceph?
Ceph 是一个开源的、高度可扩展的 分布式存储系统,设计用于提供高性能、高可靠性的对象存储(Object)、块存储(Block)和文件存储(File)服务。它的核心思想是通过去中心化的架构和智能的数据分布策…...

《AI大模型趣味实战》智能Agent和MCP协议的应用实例:搭建一个能阅读DOC文件并实时显示润色改写过程的Python Flask应用
智能Agent和MCP协议的应用实例:搭建一个能阅读DOC文件并实时显示润色改写过程的Python Flask应用 引言 随着人工智能技术的飞速发展,智能Agent与模型上下文协议(MCP)的应用场景越来越广泛。本报告将详细介绍如何基于Python Flask框架构建一个智能应用&…...