spark总结
文章目录
- 一 spark简介
- 1.1 什么是spark
- 1.2 spark运行过程
- 1.2.1 组成
- 1.2.2 过程
- 1.2.3 事例(词频统计WordCount程序)
- 1.3 spark运行模式
- 1.4 pyspark
- 二 SparkCore
- 2.1 RDD介绍
- 2.2 RDD编写
- 2.3 RDD算子
- 2.4 RDD的持久化
- 2.4.1 为什么需要缓存和检查点机制?
- 2.4.2 缓存
- 2.4.3 检查点机制(CheckPoint)
- 2.4.4 缓存和CheckPoint的对比
- 2.4.5 注意
- 2.5 RDD的共享变量
- 2.5.1 广播变量
- 2.5.2 累加器
- 2.6 Spark的内核调度(重点)
- 2.6.1 DAG(有向无环图)
- 2.6.2 DAG的宽窄依赖和阶段划分
- 2.6.3 内存迭代计算
- 2.6.4 Spark并行度
- 2.6.5 Spark任务调度
- 三 SparkSql
- 3.1 SparkSQL概述
- 3.2 DataFrame
- 3.2.1 DataFrame组成
- 3.2.2 两种编程风格DSL\SQL
- 3.2.3 全局表和临时表
- 3.3 SparkSQL函数定义
- 3.3.1 三种类型:UDF\UDAF\UDTF
- 3.3.2 两种定义方式
- 3.3.3 开窗函数
- 3.4 SparkSQL的执行流程
- 3.4.1 CataLyst优化器
- 3.5 SparkSQL整合Hive
视频链接: 【黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程】 https://www.bilibili.com/video/BV1Jq4y1z7VP/?p=41&share_source=copy_web&vd_source=8f9078186b93d9eee26026fd26e8a6ed
一 spark简介
1.1 什么是spark
-
spark定义
spark是一种分布式计算分析引擎,借鉴MapReduce思想发展而来,保留了分布式计算的优点并改进了MapReduce的缺点,让中间数据存储在内存中提高了运行速度,提供了丰富的数据处理的API,提高了开发速度 -
spark的作用:
可以处理结构化数据、半结构化数据、非结构化数据,支持python,sql,scala,R,java语言,底层语言使用scala写的 -
与Hadoop框架的区别
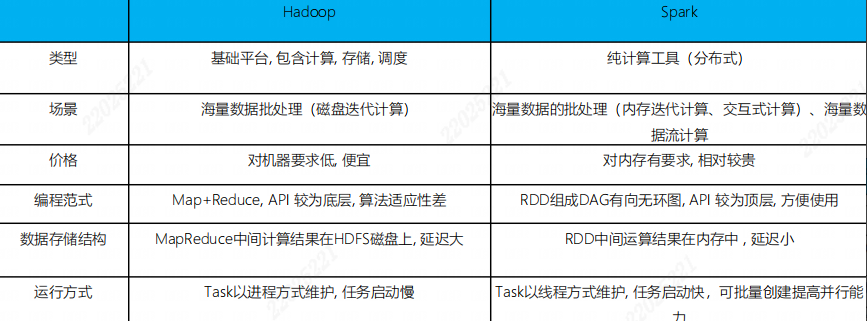
-
spark的特点:速度快、易使用、通用性强、支持多种运行方式
-
spark组成
- Sparkcore
- Sparkcore是spark的核心,数据抽象是RDD,可以编程进行海量离线数据批量处理
- 可以处理结构化和非结构化数据
- Sparksql
- Sparksql是基于Sparkcore,数据抽象是DataFrame,使用sql语言进行离线数据开发,针对流式计算,其提供StructuredStreaming模块,以sparksql为基础,进行流式计算
- 有两种模式DSL和SQL,DSL可以处理结构化和非结构化数据,SQL可以处理结构化数据
- Sparkstreaming
- 是以sparkcore为基础,提供流式处理
- SparkMLlib
- 是以sparkcore为基础,进行机器学习计算,内置大量机器学习库
- SparkGraphX
- Apache Spark 生态系统中的图计算框架,主要用于大规模图数据的处理和分析,用于大规模图数据处理;图分析;图可视化;图机器学习
- Sparkcore
1.2 spark运行过程
1.2.1 组成
spark架构的组成与Yarn很相似,也是采用主从架构,Yarn是由ResouseManager、NodeManager、ApplicationMaster、Container组成,类比到spark也是由4部分组成:Master、Worker、Driver、Executor
- Master:集群大管家, 整个集群的资源管理和分配
- Worker:单个机器的管家,负责在单个服务器上提供运行容器,管理当前机器的资源
- driver:单个Spark任务的管理者,管理Executor的任务执行和任务分解分配, 类似YARN的ApplicationMaster;
- excutor:具体干活的进程, Spark的工作任务(Task)都由Executor来负责执行
1.2.2 过程
-
用户程序创建sparkcontext,sparkcontext连接到clustermanager,clustermanager根据所需的内存、cpu等信息分配资源,启动executor
-
driver将用户程序划分为不同的执行阶段stage,每一阶段stage由一组相同的task组成,每一个task即为一个线程,每一个task分处在不同的分区。在stage和task创建完成后,driver会向executor发送task
-
executor在接受到task后,会下载task的运行时依赖,在准备好task执行环境后,执行task,然后将task的执行状态汇报给driver
-
driver根据接收到的task运行状态处理不同的状态更新。task分为两种,一种是shuffle map task,一种是result task,前一种负责数据重新洗牌,洗牌的结果保存到executor节点的文件系统中,后一种是负责生成结果数据
-
driver会不断地调用task,将task发送到executor执行,在所有的task都正确执行或者超过执行次数限制仍然没有执行成功时停止
1.2.3 事例(词频统计WordCount程序)
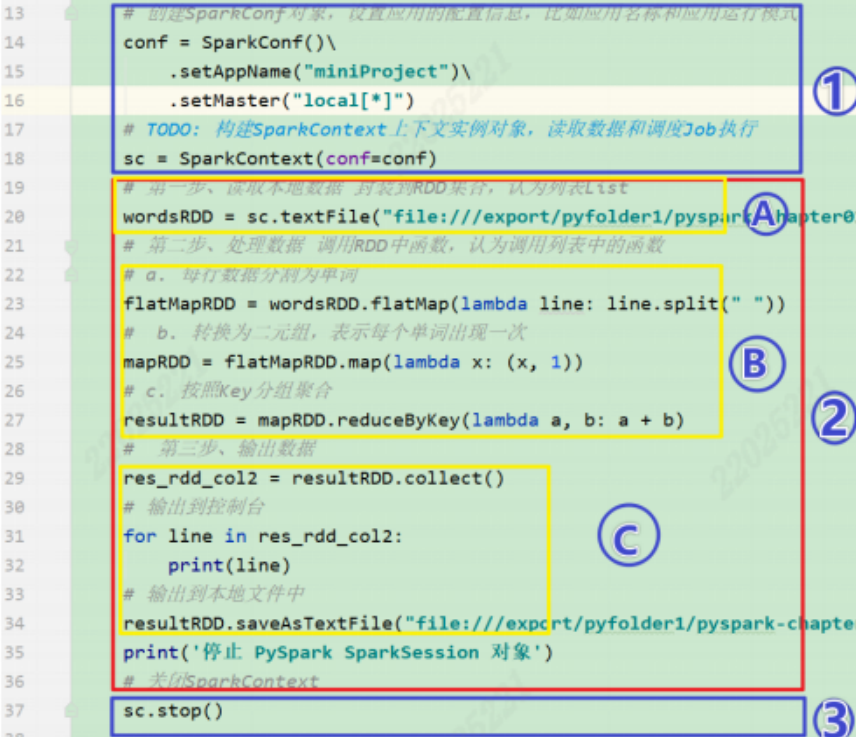
-
①和③是在driver上执行,提交和关闭sparkcontext资源,将所需要的cpu、内存等资源提交给Master
-
②过程都在Executors上执行,其中A是数据加载,B是处理数据,C是保存数据,这是一个job
1.3 spark运行模式
主要介绍两种
-
StandAlone HA模式
为什么需要StandAlone HA模式:
在主从模式的(master-slaves)集群下,存在着Master单点故障(SPOF)的问题,StandAlone HA模式就是为了解决这个问题基于zookeeper实现HA,zookeeper使用Leader Elective机制,利用其可以保证虽然集群存在多个Master,但是只有一个Active的,其他都是Standby,当active的master出现故障,Standby Master会被选举出来。由于集群的信息(Worker、Driver、Application的信息)都已经持久化到文件系统中,因此在切换过程中只会影响新的Job提交,对于正在进行的Job没有任何的影响。
-
SparkOnYarn模式
- 为什么需要SparkOnYarn模式:
因为在企业中主流的数据管理用的Hadoop集群,如果再搭建一个Spark StandAlone HA集群,产生了资源浪费(提高资源利用率),所以在企业中,多数场景下,会将Spark运行到Yarn集群中,这样的话,只需要找一台服务器充当Spark客户端即可,将任务提交到Yarn集群中运行 - SparkOnYarn本质:
master:yarn中的resourcemanager替代
worker:yarn中的nodemanager替代
driver角色运行在yarn容器内,或提交任务的客户端进程中,真正干活的executor在yarn容器内 - SparkOnYarn需要啥:
-
- yarn集群
-
- spark客户端:将spark程序提交到yarn中运行
-
- 需要被提交的代码程序(我们自己写)
-
- 两种运行模式(Cluster和Client)
- Cluster模式即: Driver运行在YARN容器内部, 和ApplicationMaster在同一个容器内
- Client模式即: Driver运行在客户端进程中, 比如Driver运行在spark-submit程序的进程中
- 区别:
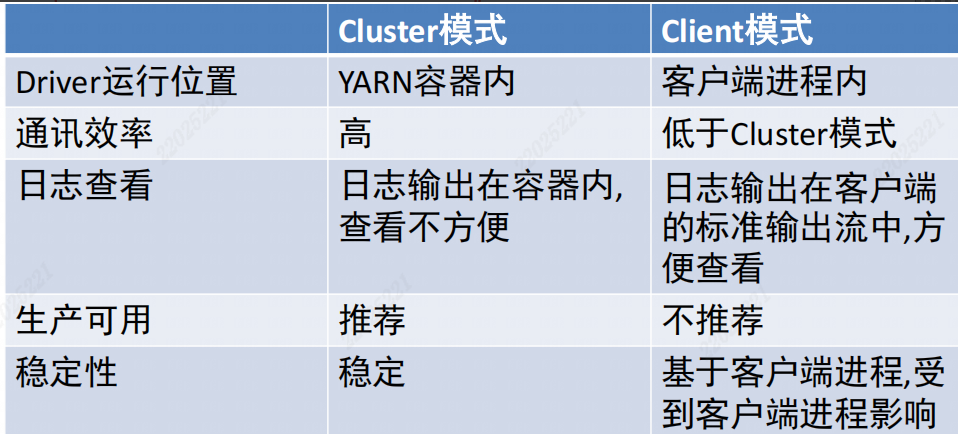
- 为什么需要SparkOnYarn模式:
1.4 pyspark
-
什么是pyspark:是使用python语言应用spark框架的类库,内置了完全的spark api,可以通过pyspark类库来编写spark程序
-
pyspark与标准spark框架的对比
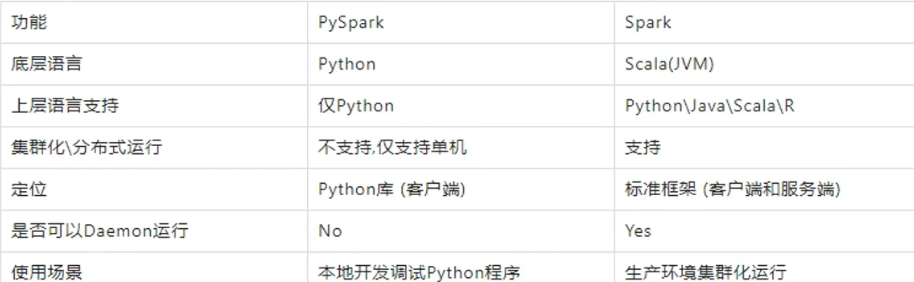
-
python on spark的执行原理
pyspark宗旨是在不破坏spark已有运行架构基础上,在spark架构外层包装一层python API,借助pyj4实现python和java的交互,进行实现python编写spark的应用程序
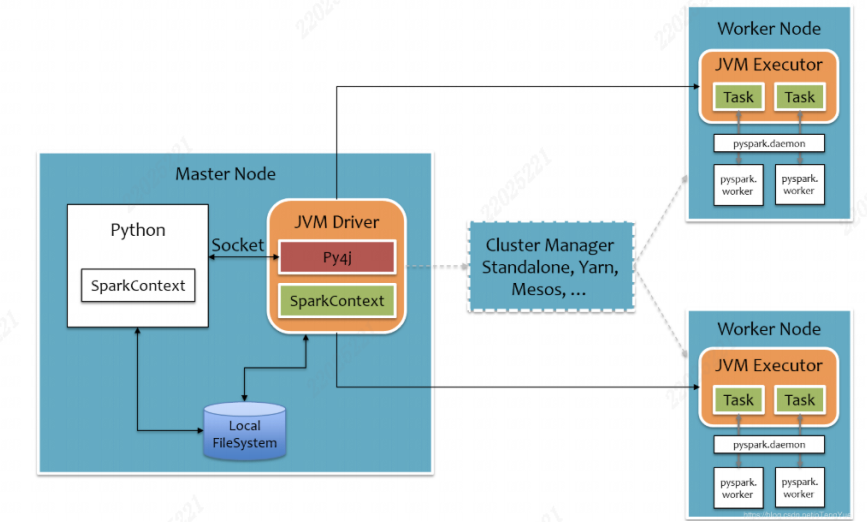
在driver端,python的driver代码会翻译成JVM代码,由py4j模块完成,再执行JVM driver运行,转化后的代码传到worker,但由于使用java语言所能使用的算子太少,不好翻译,于是使用pyspark.daemon守护进程做一个中转站,在底层的executor执行,执行的是python语言。
即python–>JVM代码–>JVM Driver–>调度JVM Eexcutor–>pyspark中转–>python executor进程
二 SparkCore
2.1 RDD介绍
-
为什么需要RDD:
分布式计算需要分区控制、Shuffle控制、数据存储\序列化、数据计算API等一些列功能,而python中的本地集合对象(如list、set等)不能满足,所以在分布式框架中,需要一个数据抽象对象,实现分布式计算所需功能,这数据抽象就是RDD -
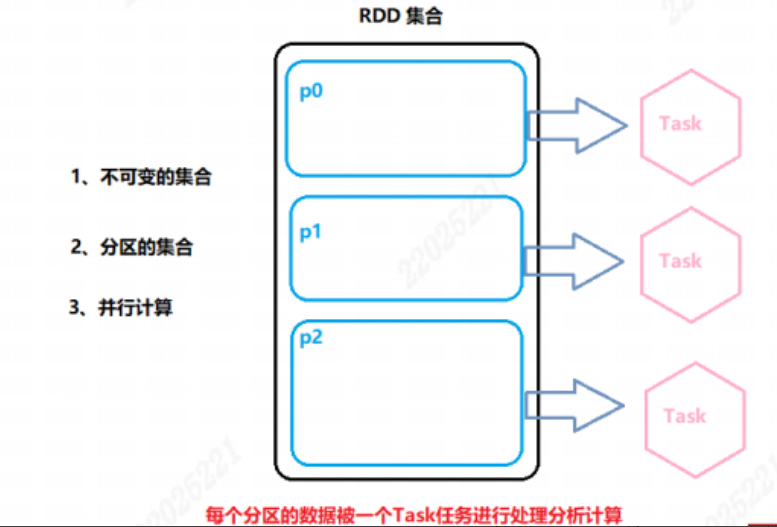
RDD(Resilient Distributed Dataset,弹性分布式数据集)是Spark中最基本的数据抽象,代表一个不可变、可分区、可并行计算的集合
- Dataset:一个数据集合,用于存放数据的。
Distributed:RDD中的数据是分布式存储的,可用于分布式计算。
Resilient:RDD中的数据可以存储在内存中或者磁盘中
- Dataset:一个数据集合,用于存放数据的。
-
RDD的五大特性
- RDD是有分区的
- RDD的方法会作用到所有分区上
- RDD之间是有相互依赖关系的(RDD有血缘关系)
- Key-Value型的RDD可以有分区器
- RDD的分区规划,会尽量靠近数据所在的服务器上
2.2 RDD编写
-
程序入口SparkContext对象
RDD编程的程序入口对象是SparkContext,基于它才能调用API
-
RDD创建(两种方式)
- 通过并行化集合创建,rdd = sc.parallelize()
- 读取外部数据源, rdd = sc.textFile();rdd=sc.wholeTextFile()
-
算子
分布式集合对象上的API,叫做算子,分为两类:transformation算子、action算子,transformation算子是懒加载的,如果没有action算子启动,它是不工作的。transformation算子相当于在构建执行计划,action是一个指令,让这个计划开始工作- transformation算子
- action算子
- 学习地址: https://spark.apache.org/docs/latest/api/python/reference/pyspark.html
2.3 RDD算子
https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.RDD.html
2.4 RDD的持久化
RDD数据是过程数据,一旦处理完成,就会清理,这特性是为了最大化利用资源,给后续计算腾出资源
2.4.1 为什么需要缓存和检查点机制?
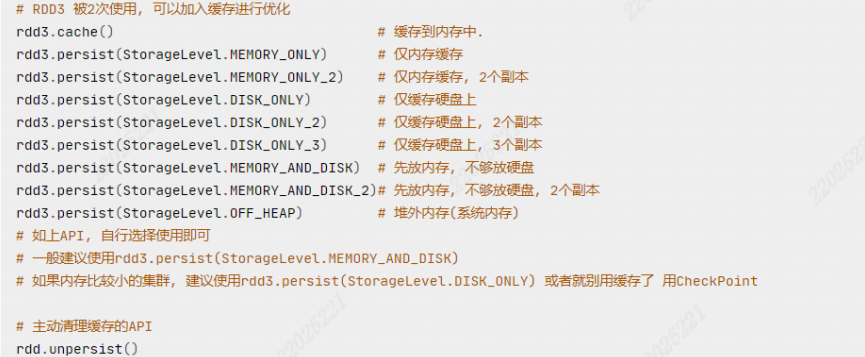
如果在后续过程中还应用到计算过rdd数据,对其缓存,实现多次利用,这样就不用再重新计算。如果不进行缓存,RDD会依据血缘关系重新计算,耗费了时间
2.4.2 缓存
特点:
- 缓存技术可以将过程RDD数据,持久化保存到内存或者硬盘上
- 这个保存在设定上是认为不安全的,认为有丢失的风险
- 缓存保留RDD之间的血缘关系,缓存一旦丢失,可基于血缘关系,重新计算RDD的数据
缓存如何丢失:
- 断电、计算任务内存不足,把缓存清理给计算让路
- 硬盘损坏也可能造成丢失
缓存是如何保存的:每个分区自行将其数据保存在其所在的Executor内存和硬盘上,即分散存储
2.4.3 检查点机制(CheckPoint)
- 也是保存RDD数据,仅支持硬盘存储
- 它被设计认为是安全的,不保留血缘关系
- CheckPoint存储RDD数据,是集中收集各个分区数据进行存储,存储在HDFS上

2.4.4 缓存和CheckPoint的对比
- CheckPoint不管多少分区,风险是一样的,缓存分区越多,风险越大
- CheckPoint支持写入HDFS,缓存不行,HDFS是高可靠存储,所以CheckPoint被认为是安全的
- CheckPoint不支持内存,缓存可以,缓存是写入内存,性能比CheckPoint要好一些
- CheckPoint因为设计上认为是安全的,所以不保留血缘关系,而缓存因为设计上认为是不安全的,所以保留
2.4.5 注意
- CheckPoint是一种重量级的使用,也就是RDD的重新计算成本很高的时候,或者数据量很大,采用它比较合适,如果数据量小,计算快,就没有必要了,直接使用缓存就行
- cache和checkpoint两个API都不是Action类型,所以想要其工作,需要后面接上Action,这样做的目的是为了让RDD有数据
2.5 RDD的共享变量
2.5.1 广播变量
为什么使用广播变量?
A表是一张维度表,B表是一张明细表,是RDD对象,两表做关联,A需要被发送到每个分区的处理线程上使用,如果在一个executor内,也就是一个进程中,有多个线程,因为executor是进程,进程内资源共享,进程中只保留一个表A即可,也就是说没必要每个线程上都有表A(这样会造成内存浪费),广播变量就是为了这个问题

使用方式

2.5.2 累加器
-
需求:想要对map算子计算中的数据,进行计数累加,得到全部数据计算完后的累加结果
-
累加器对象架构方式:sc.accumulator(初始值)构建,这个对象可以从各个Executor中收集他们的执行结果,作用回自己身上
-
需要注意的是:使用累加器时,要注意,因为rdd是过程数据,如果rdd被多次使用,可能会重建此rdd,如果累加器累加代码在重新构建的步骤中,累加器累加代码就可能被多次执行
2.6 Spark的内核调度(重点)
2.6.1 DAG(有向无环图)
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心的重要一环,管理任务调度,就是如何组织任务去处理RDD每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效完成任务计算
- 1个Action=1个DAG=1个JOB
- 层级关系:(一个代码运行起来,就是一个application)
1个Application,可以有多个JOB,每一个JOB内含一个DAG,同时每一个JOB都是由一个Action产生
2.6.2 DAG的宽窄依赖和阶段划分
- 宽依赖:父RDD的一个分区,全部数据发送给子RDD的一个分区
- 窄依赖(即shuffle):父RDD的一个分区,将数据发送给子RDD的多个分区
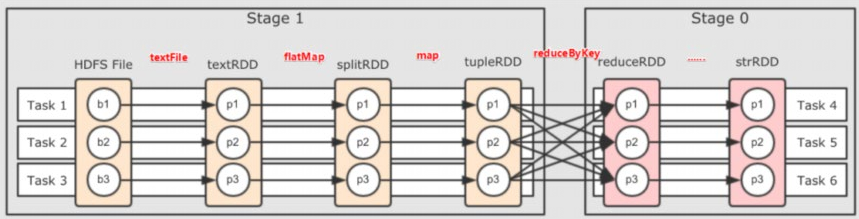
按照宽依赖,划分不同的DAG阶段,从后向前,遇到宽依赖就划分出一个阶段stage,stage内部一定都是窄依赖
2.6.3 内存迭代计算
-
spark默认受全局并行度的限制,除了个别算子的特殊分区情况,大部分的算子,都会遵循全局并行度的要求,来规划自己的分区数
-
Spark为什么比MapReduce快:
- spark的算子丰富,而mapreduce缺乏算子,使其很难处理复杂任务
- spark可以执行内存迭代,算子之间形成DAG,基于依赖划分阶段,在阶段内形成迭代管道,而mapreduce的map和reduce之间交互式通过硬盘交互的
2.6.4 Spark并行度
- 在同一时间内,有多少个task在同时进行
- 全局并行度配置:spark.default.parallelism 全局并行度是推荐设置,不要针对RDD改分区,可能会影响内存迭代管道的构建,或者会产生额外的shuffle
- 如何在集群中规划并行度:设置为CPU总核心的2-10倍
2.6.5 Spark任务调度

- DAG调度器:将逻辑的DAG图进行处理,最终得到逻辑上的Task划分
- Task调度器:基于DAG Scheduler的产出,来规划这些逻辑的task,应该在那些物理的executor上运行,以及监督管理它们的运行
三 SparkSql
3.1 SparkSQL概述
-
SparkSQL用于处理大规模结构化数据的计算引擎,在企业中广泛应用,性能极好
-
支持SQL语言\性能强\可以自动优化\API简单\兼容HIVE等等
-
应用场景:离线开发、数仓搭建、科学计算、数据分析
-
特点
- 融合性:SQL可以无缝集成在代码中,随时用SQL处理数据
- 统一数据访问:一套标准API可读写不同数据源
- HIVE兼容:spark直接计算生成hive数据表
- 支持标准的JDBC\ODBC连接,方便各种数据库进行交互
-
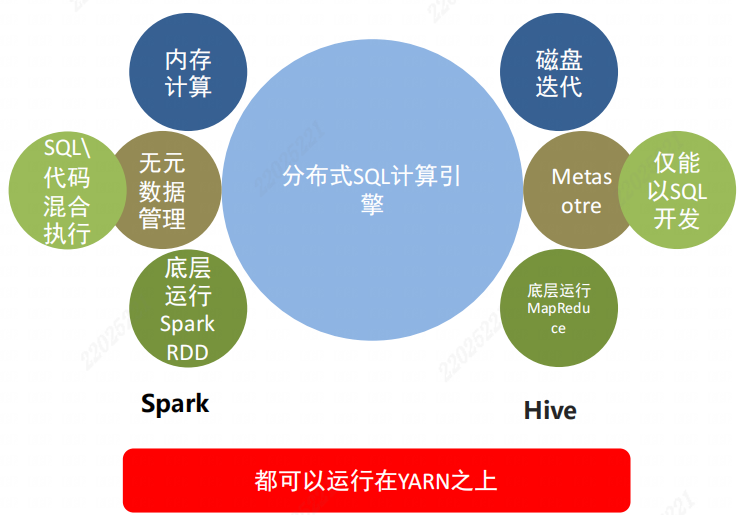
SparkSQL和Hive的不同
3.2 DataFrame
- DataFrame是SparkSQL的数据抽象,存储的是二维表结构数据
- DataFrame和RDD比较:
rdd可以存储任意结构的数据,dataframe存储二维表结构化数据
dataframe和rdd是:弹性的,分布式的,数据集
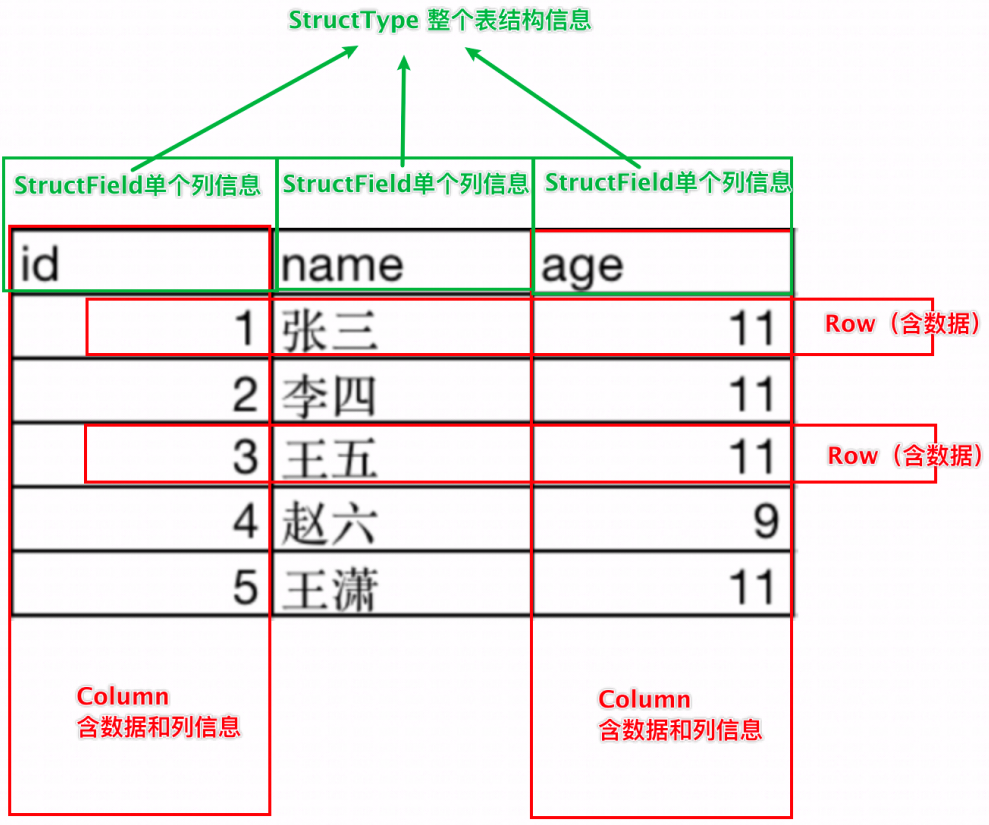
3.2.1 DataFrame组成
-
dataframe是二维表结构,离不开行、列、表结构描述
-
表结构层面:
- StructType对象:描述整个DataFrame的表结构
- StructField对象:描述一个列的信息
-
数据层面:
- Row对象:记录一行数据
- Column对象:记录一列数据并包含列的信息
将RDD转换为DataFrame:因为RDD和dataframe都是分布式数据集,只需要转换一下内部存储结构,转换为二维表结构,有三种转换方式
3.2.2 两种编程风格DSL\SQL
- 两种编程风格(DSL\SQL):DSL处理数据的灵活性更强,可以通过自定义函数处理非结构化数据;SQL使用sql语句只能处理结构化数据
官方文档: https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/index.html
3.2.3 全局表和临时表
-
跨SparkSession对象使用,一个程序内多个SparkSession中均可使用,查询前带上前缀 global_temp.
-
临时表:只在当前SparkSession中可用
3.3 SparkSQL函数定义
3.3.1 三种类型:UDF\UDAF\UDTF
-
udf:一对一的关系,输入一个值经过函数以后输出一个值;在hive中继续udf类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法
-
udaf:聚合函数,多对一的关系,输入过个值输出一个值,通常与groupBy联合使用
-
udtf:一对多的关系,输入一个值输出多个值(一行变多行);用户自定义生成函数,有点像flatMap
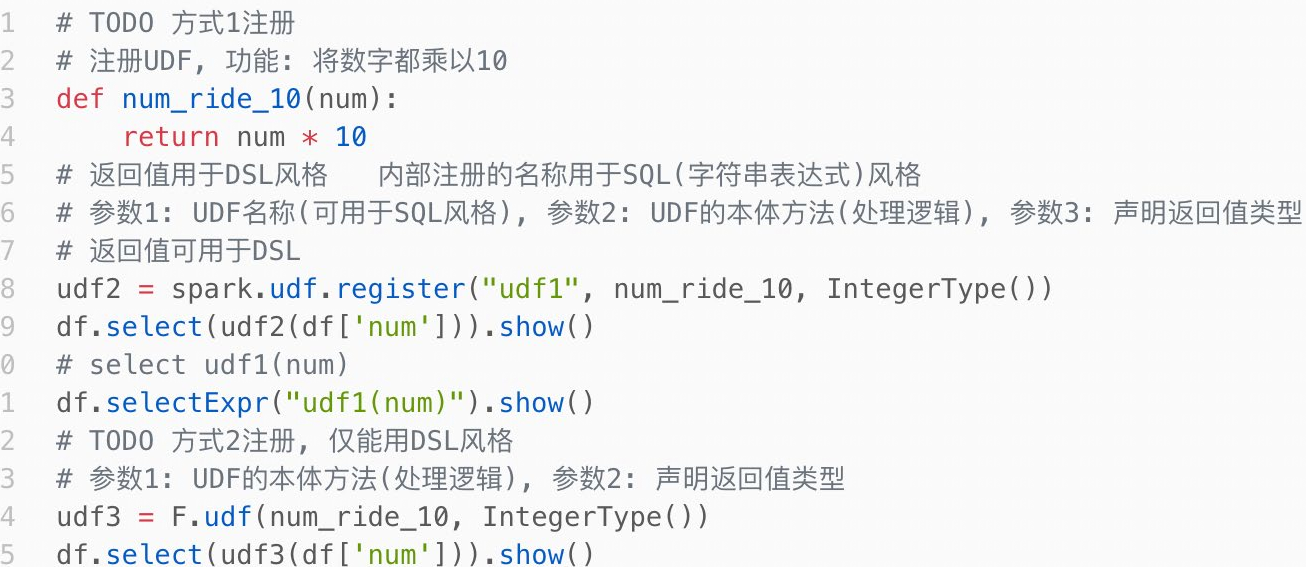
3.3.2 两种定义方式
-
sparksession.udf.register()
注册的udf可以用于DSL和SQL,返回值用于DSL风格,传参内给的名字用于SQL风格 -
pyspark.sql.funcations.udf
仅能用于DSL风格
3.3.3 开窗函数

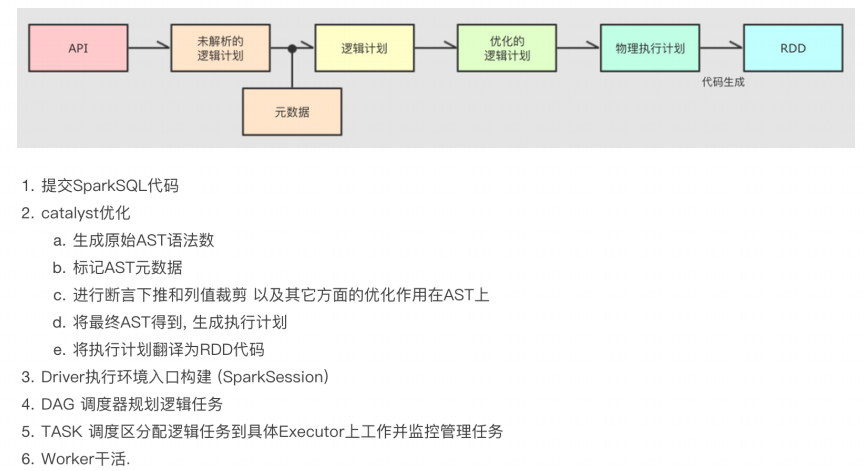
3.4 SparkSQL的执行流程
-
RDD执行流程回顾
- RDD(代码)–>DAG调度器逻辑任务–>Task调度器任务分配和管理监控–>worker干活
-
SparkSQL自动优化
- RDD的运行会完全按照开发者的代码执行,如果开发者水平有限,RDD的执行效率也会受到影响,而SparkSQL会对写完的代码,执行“自动优化”,以提升代码运行效率,避免开发这水平影响到代码执行效率
-
为什么SparkSQL可以自动优化,而RDD不可以
- RDD:内含数据类型不限格式和结构,难以形成统一
- DataFrame:100%是二维表结构,可以被针对
-
SparkSQL的自动优化:依赖于CataLyst优化器
3.4.1 CataLyst优化器

- CataLyst是为了解决过多依赖hive的问题,具体流程:
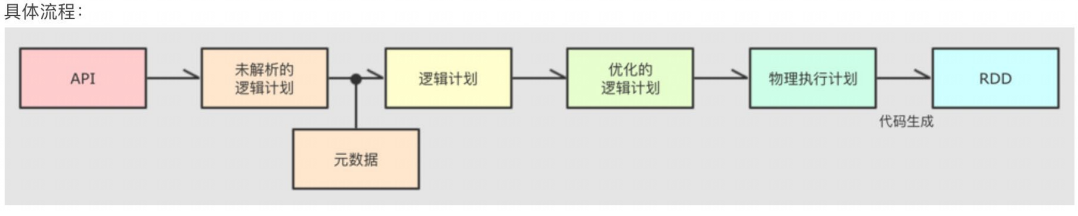
- 优化方向:断言下推(行过滤,提前where),列值裁剪(列过滤,提前规划select的字段数量)
- SparkSQL执行流程
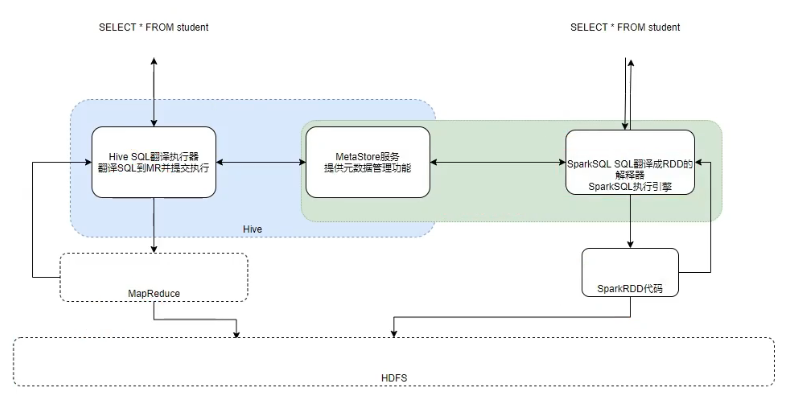
3.5 SparkSQL整合Hive
本质上sparksql借助hive的元数据管理功能,实现对表结构的读取,然后通过执行RDD代码执行读取HDFS的数据,所以说spark连接上hive的MateStore即可
相关文章:

spark总结
文章目录 一 spark简介1.1 什么是spark1.2 spark运行过程1.2.1 组成1.2.2 过程1.2.3 事例(词频统计WordCount程序) 1.3 spark运行模式1.4 pyspark 二 SparkCore2.1 RDD介绍2.2 RDD编写2.3 RDD算子2.4 RDD的持久化2.4.1 为什么需要缓存和检查点机制&#…...

【随笔】地理探测器原理与运用
文章目录 一、作者与下载1.1 软件作者1.2 软件下载 二、原理简述2.1 空间分异性与地理探测器的提出2.2 地理探测器的数学模型2.21 分异及因子探测2.22 交互作用探测2.23 风险区与生态探测 三、使用:excel 一、作者与下载 1.1 软件作者 作者: DOI: 10.…...

补码底层逻辑探讨
在计算机里面以二进制进行存储,二进制并不能区分正负数 为了处理负数,人们想了很多办法 1.原码 首先,很直观的区分方法就是设置一个flag 在二进制前面加一个符号位,0是正、1是负 但是在电路里面处理这样的信号却很复杂&#…...

第二大脑-个人知识库
原文链接:https://i68.ltd/notes/posts/20250407-llm-person-kb/ Quivr-第二大脑一样的个人助手,利用AI技术增强个人生产力 将 GenAI 集成到您的应用程序中的个性化 RAG,专注于您的产品而非 RAG项目仓库:https://github.com/QuivrHQ/quivr Star:37.7k官网:https:/…...
)
泰勒展开概念解释(图优化SLAM中非线性系统的线性处理)
1. 泰勒展开 泰勒展开是一种用多项式近似复杂函数的数学方法,其核心思想是通过函数在某一点的各阶导数信息,构建一个多项式来逼近原函数,即通过函数在某一点x0的各阶导数值,构造一个多项式 P(x),使得该多项式在 x0 附近与原函数 f(x) 的值及其导数尽可能匹配,数学形式为…...

CANape与MATLAB数据接口技术详解
目录 CANape与MATLAB数据接口技术详解 一、数据互操作背景与意义 1.1 汽车电子开发中的测量需求 1.2 技术标准演进分析 二、CANape数据导出深度解析 2.1 MDF文件结构说明 2.2 转换流程优化建议 三、MATLAB数据处理进阶技术 3.1 数据质量评估脚本 3.2 数据可视化增强方…...

per-task affinity 是什么?
Per-Task Affinity(任务级CPU亲和性)详解 Per-Task Affinity 是 Linux 调度器提供的一种机制,允许将单个任务(进程/线程)绑定到特定的 CPU 核心(或核心集合)上运行,从而优化性能、减…...

基于先进MCU的机器人运动控制系统设计:理论、实践与前沿技术
摘要:随着机器人技术的飞速发展,对运动控制系统的性能要求日益严苛。本文聚焦于基于先进MCU(微控制单元)的机器人运动控制系统设计,深入剖析其理论基础、实践方法与前沿技术。以国科安芯的MCU芯片AS32A601为例…...

Network.framework 的引入,不是为了取代 URLSession
Network.framework 的引入,不是为了取代 URLSession 如果你感觉 Network.framework 的引入, 可能是为了取代 URLSession, 那你就大错特错了!这里需要非常准确地区分一下: 🔵 Network.framework 不是为了取代 URLSession。 &…...

gradle-缓存、依赖、初始化脚本、仓库配置目录详解
1.启用init.gradle文件的方法 在命令置顶文件,例如gradle --init-script yourdir/init.gradle -q taskName,你可以多次输入此命令来制定多个init文件把init.gradle文件放到USER_HOME/.gradle/目录下把以.gradle结尾的文件放到USER_HOME/.gradle/.init.d/目录下把以…...

提示词的神奇魔力——如何通过它改变AI的输出
一、引言:初识AI的惊艳与迷茫 最近这段时间,我像很多人一样,一头扎进了生成式AI的世界,尝试使用各种工具,从文字助手到图像生成器。一开始,我被它们的能力深深震撼,感觉就像突然拥有了一个无所…...
:Scikit-learn 机器学习初步 - 让数据预测未来!)
零基础上手Python数据分析 (24):Scikit-learn 机器学习初步 - 让数据预测未来!
写在前面 在前面的学习中,我们已经掌握了使用 Python、Pandas、NumPy、Matplotlib 和 Seaborn 进行数据处理、分析和可视化的全套核心技能。我们学会了如何从数据中提取信息、清洗数据、整合数据、探索数据模式并将其可视化呈现。 现在,我们站在了一个新的起点。数据分析不仅…...

React 与 Vue 虚拟 DOM 实现原理深度对比:从理论到实践
在现代前端开发中,React 和 Vue 作为最流行的两大框架,都采用了虚拟 DOM(Virtual DOM) 技术来优化渲染性能。虚拟 DOM 的核心思想是通过 JavaScript 对象模拟真实 DOM,减少直接操作 DOM 的开销,从而提高页面…...

结合五层网络结构讲一下用户在浏览器输入一个网址并按下回车后到底发生了什么?
文章目录 实际应用第一步:用户在浏览器输入 www.baidu.com 并按下回车1. 浏览器触发域名解析(DNS查询) 第二步:DNS请求的逐层封装与传输1. 应用层(DNS协议)2. 传输层(UDP协议)3. 网络…...

关于Code_流苏:商务合作、产品开发、计算机科普、自媒体运营,一起见证科技与艺术的交融!
Code_流苏 🌿 名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 🌟 欢迎来到Code_流苏的CSDN主页 —— 与我一起&…...

Webpack模块打包工具
1. 认识webpack的基本用法步骤创建项目->下载webpack webpack-cli -> npm init -y -> package.json的scripts中配置webpack默认打包入口:src/index.js默认打包出口: dist/main.js2. 认识webpack.config.js的基本配置loader -> 打包css,less…...

crossOriginLoading使用说明
1. 说明 此配置用于控制 Webpack 动态加载的代码块(chunk)(例如代码分割或懒加载的模块)在跨域(不同域名)加载时的行为。它通过为动态生成的 <script>标签添加 crossorigin 属性,确保符合…...

Linux系统性能调优技巧分享
在数字化时代,Linux 系统以其开源、稳定、高效的特性,成为服务器、云计算、物联网等领域的核心支撑。然而,随着业务规模的扩大和负载的增加,系统性能问题逐渐凸显。掌握 Linux 系统性能调优技巧,不仅能提升系统运行效率,还能降低运维成本。下面从多个方面介绍实用的性能调…...
,方法同样适用于其它绝大部分Git服务)
在Windows11中配置Git+SSH环境,本此实践使用Gitee(码云),方法同样适用于其它绝大部分Git服务
1.下载并安装Git 进入官网下载 Git - Downloading Package 选择下载Standalone Installer安装包,看自己电脑是64-bit还是32-bit(一般都是64-bit) 双击安装包进行安装,Next 这里可以自定义安装路径 这里可以勾选添加桌面快捷方式…...

【软考-架构】14、软件可靠性基础
✨资料&文章更新✨ GitHub地址:https://github.com/tyronczt/system_architect 文章目录 软件可靠性基本概念软件可靠性建模软件可靠性管理软件可靠性设计N版本程序设计恢复块设计(动态冗余)双机容错技术、集群技术负载均衡软件可靠性测试…...

怎样理解ceph?
Ceph 是一个开源的、高度可扩展的 分布式存储系统,设计用于提供高性能、高可靠性的对象存储(Object)、块存储(Block)和文件存储(File)服务。它的核心思想是通过去中心化的架构和智能的数据分布策…...

《AI大模型趣味实战》智能Agent和MCP协议的应用实例:搭建一个能阅读DOC文件并实时显示润色改写过程的Python Flask应用
智能Agent和MCP协议的应用实例:搭建一个能阅读DOC文件并实时显示润色改写过程的Python Flask应用 引言 随着人工智能技术的飞速发展,智能Agent与模型上下文协议(MCP)的应用场景越来越广泛。本报告将详细介绍如何基于Python Flask框架构建一个智能应用&…...

Pygame字体与UI:打造游戏菜单和HUD界面
Pygame字体与UI:打造游戏菜单和HUD界面 在现代游戏中,用户界面(UI)是玩家与游戏互动的重要桥梁。一个精心设计的UI不仅能够提升游戏的视觉效果,还能增强玩家的游戏体验。Pygame作为一个强大的游戏开发库,提供了丰富的工具和方法来创建和管理UI元素。本文将详细介绍如何使…...

游戏引擎学习第246天:将 Worker 上下文移到主线程创建
回顾并为今天的工作做准备 关于GPU驱动bug的问题,目前本地机器上没有复现。如果有问题,昨天的测试就应该已经暴露出来了。当前演示的是游戏的过场动画,运行正常,使用的是硬件渲染。 之前使用软件渲染时没有遇到太多问题ÿ…...
—Redis—消息队列—数据库—熔限降)
系统设计(2)—Redis—消息队列—数据库—熔限降
Redis 缓存设计 在高并发系统中,缓存是提升性能、减轻后端负载的杀手锏。Redis 作为内存级的高性能缓存数据库,被广泛应用于各类系统设计中。利用 Redis,将热点数据存储在内存中,可以加速读写并大幅降低对后端关系型数据库的直接…...

第十六届蓝桥杯大赛软件赛省赛第二场 C/C++ 大学 A 组
比赛还没有开始,竟然忘记写using namespace std; //debug半天没看明白 (平时cv多了 然后就是忘记那个编译参数,(好惨的开局 编译参数-stdc11 以下都是赛时所写代码,赛时无聊时把思路都打上去了(除了倒数第二题&#…...
插件)
HiSpark Studio如何使用Trae(Marscode)插件
引言 我现在非常喜欢使用编程辅助插件,用的最多的是Trae(以前叫Marscode)。以前华为的DevEco Device Tools是基于VSCode的,直接使用官方的插件市场就可以安装了。现在海思提供了自己的HiSpark Studio,比原来的Device …...

Netmiko连接池与长连接优化
背景与原理 在网络自动化中,频繁创建和断开 SSH 连接会带来以下问题: 性能损耗:每次连接需经历 TCP 握手、SSH 协商、用户认证等流程,耗时约 1~3 秒。资源浪费:设备端可能限制并发连接数,频繁连接易触发阈…...

10:00面试,10:08就出来了,面试问的问题太。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40%,这…...

从基础到实战的量化交易全流程学习:1.2 金融市场基础
从基础到实战的量化交易全流程学习:1.2 金融市场基础 在量化交易领域,扎实的金融市场基础是策略开发与风险控制的核心支撑。本文将从交易品种、市场机制、监管合规三方面展开,结合市场特性、真实数据案例及实践要点进行系统化解析,…...

游戏状态管理:用Pygame实现场景切换与暂停功能
游戏状态管理:用Pygame实现场景切换与暂停功能 在开发游戏时,管理游戏的不同状态(如主菜单、游戏进行中、暂停等)是非常重要的。这不仅有助于提升玩家的游戏体验,还能使代码结构更加清晰。本文将通过一个简单的示例,展示如何使用Pygame库来实现游戏中的场景切换和暂停功…...

数据资产价值及其实现路径-简答题回顾
1. 简述数据资产的定义及其特征。 答案:数据资产是指企业或组织所拥有的、具有经济价值的数据资源。它具有以下特征:可复制性(数据可以多次使用)、价值潜力(数据经过处理、分析可以创造经济价值)、流动性&…...

Docker化HBase排错实录:从Master hflush启动失败到Snappy算法未支持解决
前言 在容器化时代,使用 Docker 部署像 HBase 这样复杂的分布式系统也比较方便。社区也提供了许多方便的 HBase Docker 镜像,没有找到官方的 apache的,但有包含许多大数据工具的 harisekhon/hbase 或用于学习目的的 bigdatauniversity/hbase…...

端到端自动驾驶的数据规模化定律
25年4月来自Nvidia、多伦多大学、NYU和斯坦福大学的论文“Data Scaling Laws for End-to-End Autonomous Driving”。 自动驾驶汽车 (AV) 栈传统上依赖于分解方法,使用单独的模块处理感知、预测和规划。然而,这种设计在模块间通信期间会引入信息丢失&am…...

桌面端开发技术栈选型:开启高效开发之旅
在数字化浪潮中,桌面端应用依然占据重要地位,而选择合适的技术栈是打造优质桌面端应用的关键一步。以下是多种主流桌面端开发技术栈的介绍与对比,希望能为大家提供有价值的参考。 基于 Web 技术的跨平台框架 • Electron: • 特…...

C++模拟Java C#的 finally
在 Java 和 C# 中,finally 是一个与异常处理(try-catch)配合使用的关键字,用于确保一段代码无论是否发生异常都会被执行。它通常用于释放资源(如文件句柄、数据库连接、锁等),避免内存泄漏或状态…...

Spring Boot安装指南
🔖 Spring Boot安装指南 🌱 Spring Boot支持两种使用方式: 1️⃣ 可作为常规Java开发工具使用 2️⃣ 可作为命令行工具安装 ⚠️ 安装前提: 📌 系统需安装 Java SDK 17 或更高版本 🔍 建议先运行检查命令…...

zephyr架构下Bluetooth advertising接口
目录 概述 1 函数接口 2 主要函数介绍 2.1 bt_le_adv_start函数 2.1.1 函数功能介绍 2.1.2 典型使用示例 2.1.3 广播间隔 2.1.4 注意事项 2.2 bt_le_adv_stop 函数 2.2.1 函数功能 2.2.2 使用方法介绍 2.2.3 实际应用示例 2.2.4 关键注意事项 2.2.5 常见问题解决 …...

Oracle官宣 MySQL+APEX+AI三认证限时免费
1 MySQL8 OCP 考试代码 1Z0-908 免费时间:2025年4月20日至7月31日 https://education.oracle.com/mysql-promo 2 APEX云开发专家 考试代码 1Z0-771 免费时间:2025年5月15日截止! https://mylearn.oracle.com/ou/learning-path/become…...

深入理解N皇后问题:从DFS到对角线优化
N皇后问题是一个经典的算法问题,要求在NN的棋盘上放置N个皇后,使得它们互不攻击。本文将全面解析该问题的解法,特别聚焦于DFS算法和对角线优化的数学原理。 问题描述 在NN的国际象棋棋盘上放置N个皇后,要求: 任意两个…...

1软考系统架构设计师:第一章系统架构概述 - 超简记忆要点、知识体系全解、考点深度解析、真题训练附答案及解析
超简记忆要点 一、考试大纲 目标:架构设计能力(需求→架构)能力:技术/方法/行业科目:综合(选择)、案例(问答)、论文(论述) 二、架构核心 定义…...

MuJoCo 关节角速度记录与可视化,监控机械臂运动状态
视频讲解: MuJoCo 关节角速度记录与可视化,监控机械臂运动状态 代码仓库:GitHub - LitchiCheng/mujoco-learning 关节空间的轨迹优化,实际上是对于角速度起到加减速规划的控制,故一般来说具有该效果的速度变化会显得丝…...

如何打包python程序为可执行文件
将 Python 程序打包为可执行文件是一个常见需求,尤其是在希望将应用程序分享给不具备 Python 环境的用户时。以下是使用 PyInstaller 工具将 Python 程序打包为可执行文件的步骤。 步骤 1:安装 PyInstaller 如果您还没有安装 PyInstaller,请…...

产销协同是什么?产销协同流程有哪些?
目录 一、产销协同是什么 1.从市场需求的角度来看 2.企业内部运营的角度来看 3.从供应链的角度来看 二、实现产销协同的八大步骤 1. 市场需求预测 2. 销售计划制定 3. 生产能力评估 4. 生产计划制定 5. 库存管理 6. 信息共享与沟通 7. 订单执行与跟踪 8. 绩效评估…...

SQL 查询进阶:WHERE 子句与连接查询详解
SQL(Structured Query Language)是管理关系型数据库的核心语言,熟练掌握其查询功能对于数据处理至关重要。本文将深入探讨 SQL 中的两个关键概念:WHERE 子句和连接查询。我们将详细讲解 WHERE 子句中的模糊查询、IS NULL、IS NOT …...

【计算机视觉】CV实战项目- DFace: 基于深度学习的高性能人脸识别
图:MTCNN的三阶段网络结构(P-Net、R-Net、O-Net) DFace深度解析:基于深度学习的高性能人脸识别 深度解析DFace:基于PyTorch的实时人脸检测与识别系统技术背景与项目概述核心功能与特点实战部署指南环境准备硬件要求软…...

基于Docker、Kubernetes和Jenkins的百节点部署架构图及信息流描述
以下是基于Docker、Kubernetes和Jenkins的百节点部署架构图及信息流描述,使用文本和Mermaid语法表示: 架构图(Mermaid语法) #mermaid-svg-WWCAqL1oWjvRywVJ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-WWCAq…...

百度搜索AI开放计划:让应用连接精准流量的秘诀
引言 在人工智能技术深刻改变各行各业的今天,每天都有许多AI应用诞生。然而无论是开发者还是用户依然会感到自己的应用鲜有人使用或是需求没有被充分满足。这种情况正说明了为什么我们需要SEO流量,而一个能够与AI应用直接相关的SEO平台更是呼之欲出。百度…...

Redis数据结构SDS,IntSet,Dict
1.字符串:SDS SDS的底层是C语言编写的构建的一种简单动态字符串 简称SDS,是redis比较常见的数据结构。 由于以下几种缺点,Redis并没有直接采用C语言的字符串。 1.获取长度需要计算 2.非二进制安全 :中间不能有 \0,…...

leetcode201.数字范围按位与
找到公共前缀部分,然后后面的部分全0 class Solution {public int rangeBitwiseAnd(int left, int right) {int offset 0;while (left ! right) {offset;left left >> 1;right right >> 1;}return right << offset;} }...