数据结构初阶:排序
概述:本篇博客主要介绍关于排序的算法。
目录
1.排序概念及应用
1.1 概念
1.2 运用
1.3 常见的排序算法
2. 实现常见排序算法
2.1 插入排序
2.1.1 直接插入排序
2.1.2 希尔排序
2.2 选择排序
2.2.1 直接选择排序
2.2.2 堆排序
2.3 交换排序
2.3.1 冒泡排序
2.3.2 快速排序
2.3.2.1 hoare版本
2.3.3.2 挖坑法
2.3 归并排序
3. 非比较排序 --计数排序
4. 总结

1.排序概念及应用
1.1 概念
排序: 所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作
1.2 运用
在生活中我们也会有用到各种各样的排序,譬如:在网上购物商店中根据某个商品进行排序。

譬如:高等院校之间的排名

1.3 常见的排序算法
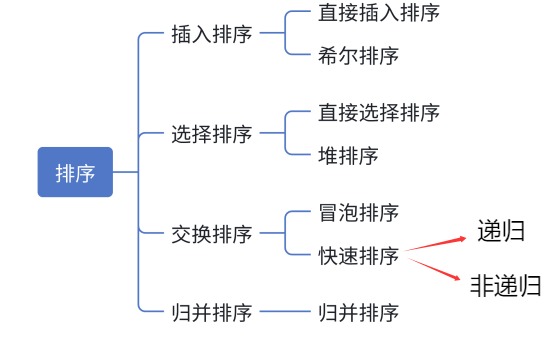
2. 实现常见排序算法
以该序列为例子:5,3,9,6,2,4,7,1,8
2.1 插入排序
- 基本思想 : 直接插入排序是一种简单的插入排序法,其基本思想是:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列

实际中我们玩扑克牌,就使用了插入排序的思想。
2.1.1 直接插入排序
当插入第i(i>=1)个元素时,前面的 array[0], array[1], …, array[i - 1]已经排好序,此时用 array[i]的排序码与 array[i - 1], array[i - 2], … 的排序码顺序进行比较,找到插入位置即将 array[i]插入,原来位置上的元素顺序后移。
代码实现:
//直接插入排序
void InsertSort(int* arr, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = arr[end + 1];while (end >= 0){if (arr[end] > tmp){arr[end + 1] = arr[end];end--;}else {break;}}arr[end + 1] = tmp;}
}逻辑概述:
直接插入排序的函数
InsertSort,用于对整数数组进行排序。函数的参数为整数数组
arr和数组的长度n。在函数内部,通过一个循环遍历数组的前
n - 1个元素。对于每个元素,设置一个变量end初始值为当前循环的索引i,并将下一个元素arr[end + 1]的值赋给变量tmp。然后,通过一个
while循环,只要end大于或等于0,并且当前end位置的元素arr[end]大于tmp,就将arr[end]的值向后移动一位(即arr[end + 1] = arr[end]),并将end减1。当找到一个位置,使得arr[end]小于或等于tmp时,循环结束。最后,将
tmp的值插入到end + 1的位置,完成一次插入操作。这样,通过每次将未排序的元素插入到已排序的部分,逐步完成整个数组的排序。
2.1.2 希尔排序
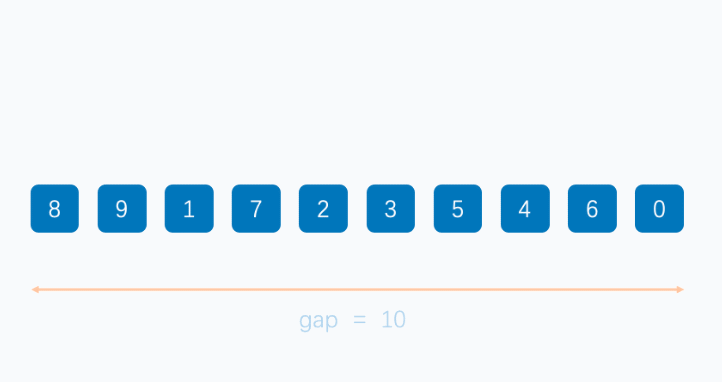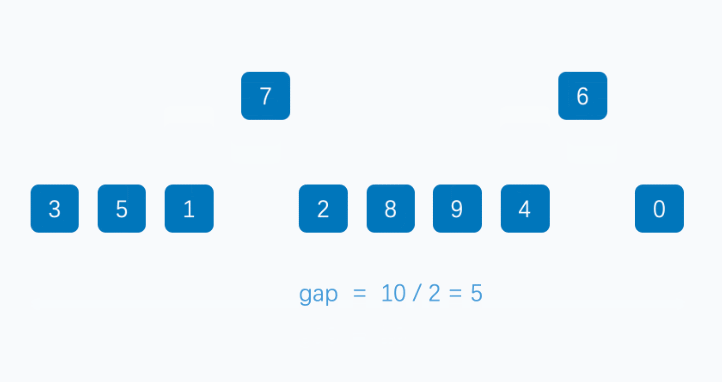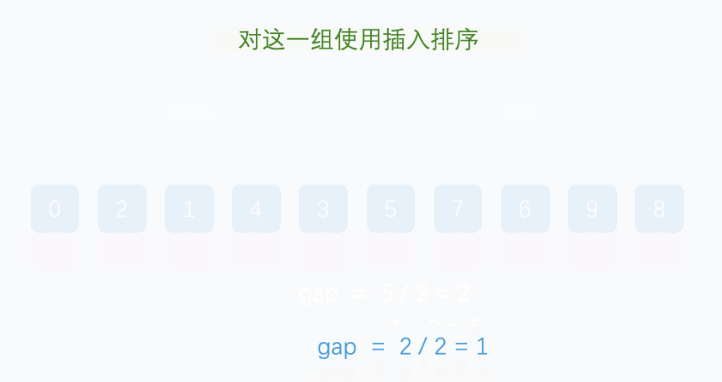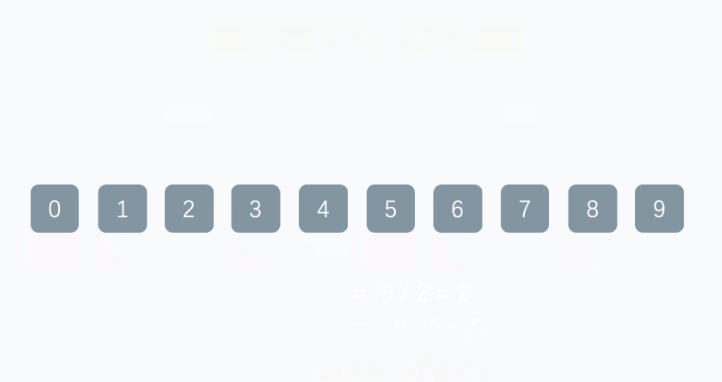
希尔排序法又称缩小增量法。其基本思想是:先选定一个整数(通常是 gap = n / 3 + 1),把待排序文件所有记录分成各组,所有距离相等的记录分在同一组内,并对每一组内的记录进行排序,然后 gap = gap / 3 + 1 得到下一个整数,再将数组分成各组,进行插入排序,当 gap = 1 时,就相当于直接插入排序。
希尔排序是在直接插入排序算法的基础上进行改进的一种高效的排序算法,也称“缩小增量排序”。它通过使用一个逐渐减小的增量序列,将数组分成若干个子序列,并对每个子序列进行插入排序。随着增量逐渐减小,每组包含的元素越来越多,当增量减至 1 时,对整个数组进行一次完整的插入排序,确保数组完全有序。
代码实现:
//希尔排序
void ShellSort(int* arr, int n)
{int gap = n;while (gap > 1){//5 2 1gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++){int end = i;int tmp = arr[end + gap];while (end >= 0){if (arr[end] > tmp){arr[end + gap] = arr[end];end -= gap;}else {break;}}arr[end + gap] = tmp;}}
}逻辑概述:
这段 C 语言代码实现了希尔排序的算法。希尔排序是一种插入排序的改进算法,通过按照一定的间隔(初始为数组长度)进行分组插入排序,逐步缩小间隔,直到间隔为 1 时完成整个数组的排序。
具体逻辑如下:
- 首先设定初始间隔
gap为数组长度n。- 在每次循环中,通过
gap = gap / 3 + 1计算新的间隔,直到gap小于等于 1。- 对于每个间隔
gap,进行插入排序。从数组的第gap个元素开始,将当前元素与前面间隔为gap的元素进行比较,如果前面的元素大于当前元素,则将前面的元素后移gap位,直到找到合适的位置插入当前元素。

2.2 选择排序
- 选择排序的基本思想: 每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
2.2.1 直接选择排序
1. 在元素集合 array[i]--array[n-1] 中选择关键码最⼤(小)的数据元素
2. 若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后⼀个(第⼀个)元素 交换
3. 在剩余的 array[i]--array[n-2](array[i+1]--array[n-1]) 集合中,重复上述步 骤,直到集合剩余 1 个元素
代码实现:
//直接选择排序
void SelectSort(int* arr, int n)
{int begin = 0, end = n - 1;while (begin < end){int mini = begin, maxi = begin;for (int i = begin + 1; i <= end; i++){if (arr[i] < arr[mini]){mini = i;}if (arr[i] > arr[maxi]){maxi = i;}}//mini begin//maxi endSwap(&arr[mini], &arr[begin]);Swap(&arr[maxi], &arr[end]);begin++;end--;}
}逻辑概述:
这段 C 语言代码实现了直接选择排序的算法。其逻辑概述如下:
- 定义两个指针
begin和end,分别指向数组的起始位置和末尾位置。- 在每次循环中,通过遍历从
begin + 1到end的元素,找到最小元素的索引mini和最大元素的索引maxi。- 将最小元素与
begin位置的元素交换,将最大元素与end位置的元素交换。- 然后将
begin指针向后移动一位,end指针向前移动一位,继续下一轮的选择和交换,直到begin大于等于end,完成整个数组的排序。
2.2.2 堆排序
堆排序由博主的上篇博客有详细介绍,这里不过多赘述。
https://blog.csdn.net/2401_87194328/article/details/147310043?spm=1001.2014.3001.5502
2.3 交换排序
- 基本思想: 所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置 。
- 特点: 将键值较大的记录序列的尾部移动,键值较小的记录向序列的前部移动。
2.3.1 冒泡排序
基本思想:重复地走访要排序的数列,一次比较两个数据元素,如果顺序不对则进行交换,并一直重复这样的走访操作,直到没有要交换的数据元素为止。
具体来说,对相邻的元素进行两两比较,顺序相反则进行交换,并一直重复这样的过程。每一轮比较都会将当前未排序部分的最大(或最小)元素“浮”到未排序部分的末尾(或开头)。经过若干轮比较后,整个数列就会变得有序。
代码实现:
void BubbleSort(int* arr, int n)
{for (int i = 0; i < n; i++){int exchange = 0;for (int j = 0; j < n - i - 1; j++){if (arr[j] > arr[j + 1]){exchange = 1;Swap(&arr[j], &arr[j + 1]);}}if (exchange == 0){break;}}
}逻辑概述:
这段 C 语言代码实现了冒泡排序的算法:
- 外层循环控制排序的轮数,共进行
n轮。- 内层循环用于每一轮的比较和交换操作。在每一轮中,从数组的第一个元素开始,依次比较相邻的两个元素,如果前一个元素大于后一个元素,则进行交换。每一轮结束后,最大的元素会“浮”到数组的末尾。
- 在内层循环中,设置一个标志变量
exchange,用于判断在本轮循环中是否进行了交换操作。如果没有进行交换,说明数组已经是有序的,此时可以提前结束排序。
2.3.2 快速排序
快速排序(Quick Sort)是 Hoare 于 1962 年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后对左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
2.3.2.1 hoare版本

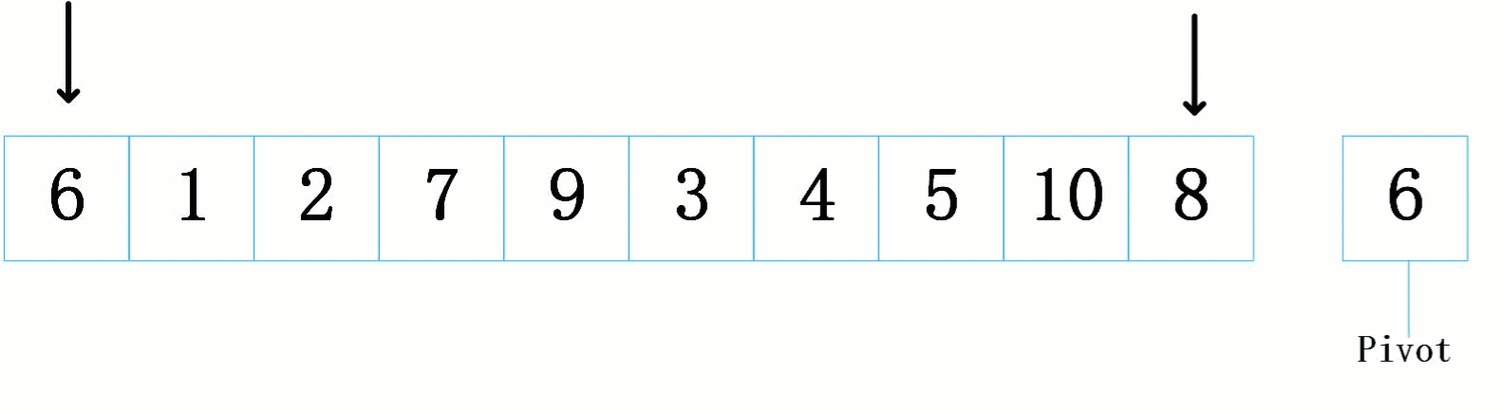
int _QuickSort(int* arr, int left, int right)
{int keyi = left;++left;while (left <= right){//right:从右往左找比基准值要小的数据while (left <= right && arr[right] > arr[keyi]){--right;}//left:从左往右找比基准值要大的数据while (left <= right && arr[left] < arr[keyi]){++left;}//left和right交换if (left <= right){Swap(&arr[left++], &arr[right--]);}}Swap(&arr[keyi], &arr[right]);return right;
}逻辑概述:
该代码实现了快速排序的一个函数
_QuickSort。快速排序的基本思想是分治和递归。在这个函数中,首先选择一个基准元素
arr[keyi],然后通过两个指针left和right从待排序序列的两端向中间扫描。对于右指针
right,从右往左找比基准值小的数据;对于左指针left,从左往右找比基准值大的数据。当找到这样的数据且left小于等于right时,交换这两个元素的位置。当
left和right相遇后,将基准元素与right指针所在位置的元素交换。最后,函数返回
right指针的位置,并对基准元素左边和右边的子序列分别进行快速排序,直至子序列长度为1(已经有序)。
2.3.3.2 挖坑法
思路: 创建左右指针。首先从右向左找出比基准值小的数据,找到后立即放入左边坑中,当前位置变为新的“坑”,然后从左到右找出比基准值大的数据,找到后立即放入右边坑中,当前位置变为新的“坑”,结束循环后将住开始存储的分界值放入当前的“坑”中,返回当前“坑”下标(即分界值下标)。
代码实现:
//快速排序法 挖坑法
void QuickSort1(int* arr, int begin, int end)
{if (begin >= end)return;int left = begin,right = end;int key = arr[begin];while (begin < end){//找小while (arr[end] >= key && begin < end){--end;}//小的放到左边的坑里arr[begin] = arr[end];//找大while (arr[begin] <= key && begin < end){++begin;}//大的放到右边的坑里arr[end] = arr[begin];}arr[begin] = key;int keyi = begin;//[left,keyi-1]keyi[keyi+1,right]QuickSort1(arr, left, keyi - 1);QuickSort1(arr, keyi + 1, right);
}逻辑概述 :
该代码实现了快速排序的一种方法——挖坑法。函数
QuickSort1用于对给定的整数数组进行快速排序。首先,进行边界条件判断,如果起始索引
begin大于或等于结束索引end,则直接返回。然后,设置左右指针
left和right,分别指向起始索引begin和结束索引end,并选取arr[begin]作为基准值key。接下来,通过两个循环进行元素的交换和调整。在第一个循环中,从右往左找到比基准值小的元素,将其放到左边的“坑”(当前
begin位置)中;在第二个循环中,从左往右找到比基准值大的元素,将其放到右边的“坑”(当前end位置)中。当begin和end相遇时,将基准值放入该位置。最后,以基准值所在位置
keyi为界,对左右子序列分别递归调用QuickSort1函数进行排序。
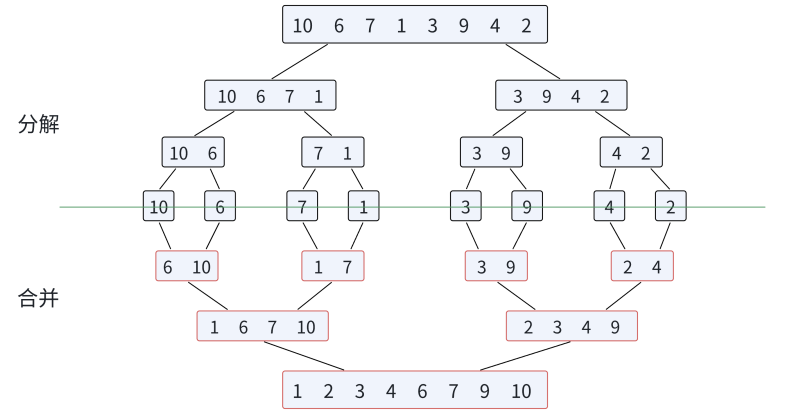
2.3 归并排序
- 算法思想: 归并排序(MERGE-SORT)是建立在归并操作上的⼀种有效的排序算法,该算法是采用分治法(Divide and Conquer)的⼀个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个 子序列有序,再使子序列段间有序。若将两个有序表合并成⼀个有序表,称为二路归并。归并排序核心步骤:
代码实现:
void _MergeSort(int* arr, int left, int right, int* tmp)
{//分解if (left >= right){return;}int mid = (left + right) / 2;//根据mid划分左右两个序列:[left,mid] [mid + 1,right]_MergeSort(arr, left, mid, tmp);_MergeSort(arr, mid + 1, right, tmp);//合并两个序列:[left,mid] [mid + 1,right]int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;int index = begin1;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){tmp[index++] = arr[begin1++];}else{tmp[index++] = arr[begin2++];}}//左序列数据没有全部放到tmp数组中//右序列数据没有全部放到tmp数组中while (begin1 <= end1){tmp[index++] = arr[begin1++];}while (begin2 <= end2){tmp[index++] = arr[begin2++];}//tmp中有序的数据导入到原数组for (int i = left; i <= right; i++){arr[i] = tmp[i];}
}
//归并排序
void MergeSort(int* arr, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);_MergeSort(arr, 0, n - 1, tmp);free(tmp);tmp = NULL;
}逻辑概述:
这段代码是一个使用归并排序算法对整数数组进行排序的 C 语言实现。以下是对代码的详细解释:
_MergeSort函数:
- 这是归并排序的核心函数,用于对数组的特定子区间进行排序和合并。
- 如果子区间的左边界大于或等于右边界,函数直接返回,这是递归的终止条件。
- 通过计算中间索引
mid,将数组划分为两个子区间:[left, mid]和[mid + 1, right],然后对这两个子区间分别进行递归调用_MergeSort进行排序。- 接下来,将两个已排序的子区间合并到一个临时数组
tmp中。通过两个指针begin1和begin2分别遍历两个子区间,将较小的元素依次放入tmp数组中。当其中一个子区间遍历完后,将另一个子区间剩余的元素全部放入tmp数组中。- 最后,将
tmp数组中的有序数据复制回原数组arr。MergeSort函数:
- 这个函数用于启动整个归并排序过程。
- 首先,分配一个与原数组大小相同的临时数组
tmp。- 然后,调用
_MergeSort函数对整个数组进行排序和合并。- 排序完成后,释放临时数组的内存,并将其指针置为
NULL。

3. 非比较排序 --计数排序
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。操作步骤:
1.)统计相同元素出现次数。 2.)根据统计的结果将序列回收到原来的序列。
代码实现:
//非比较排序 -- 计数排序
void CountSort(int* arr, int n)
{int min = arr[0], max = arr[0];for (int i = 1; i < n; i++){if (arr[i] < min){min = arr[i];}if (arr[i] > max){max = arr[i];}}//max minint range = max - min + 1;int* count = (int*)malloc(sizeof(int) * range);if (count == NULL){perror("malloc fail!");}memset(count, 0, sizeof(int) * range);//直接用calloc也是可以的for (int i = 0; i < n; i++){count[arr[i] - min]++;}//将次数还原到原数组中int index = 0;for (int i = 0; i < range; i++){//数据出现的次数count[i]//下标———源数据 i+minwhile (count[i]--){arr[index++] = i + min;}}
}逻辑概述:
这段代码是一个使用计数排序算法对整数数组进行排序的函数
CountSort。
- 首先,函数通过遍历数组找到数组中的最小值
min和最大值max。- 然后,计算数组值的范围
range,并使用malloc函数分配一个大小为range的整数数组count,用于记录每个值出现的次数。如果malloc分配内存失败,会输出错误信息。- 接下来,通过遍历原始数组,将每个值出现的次数记录在
count数组中。- 最后,通过遍历
count数组,将每个值按照出现的次数还原到原始数组中,从而实现排序。

4. 总结
以上便是本篇博客的所有内容,如果大家学到了知识,还请给博主点点赞!!!

相关文章:

数据结构初阶:排序
概述:本篇博客主要介绍关于排序的算法。 目录 1.排序概念及应用 1.1 概念 1.2 运用 1.3 常见的排序算法 2. 实现常见排序算法 2.1 插入排序 2.1.1 直接插入排序 2.1.2 希尔排序 2.2 选择排序 2.2.1 直接选择排序 2.2.2 堆排序 2.3 交换排序 2.3.1 冒泡排序…...

openwrt查询网关的命令
方法一:route -n 方法二:ip route show...

优化非线性复杂系统的参数
非线性项组合的系统 对于系统中的每一个复杂拟合,即每一个残差函数,都能表示为非线性方程的趋势,例如较为复杂的系统函数组, from optimtool.base import sp, np x sp.symbols("x1:5") res1 0.5*x[0] 0.2*x[1] 1.…...

【QQMusic项目界面开发复习笔记】第二章
🌹 作者: 云小逸 🤟 个人主页: 云小逸的主页 🤟 motto: 要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前,其次就是现在&…...

并发编程【深度解剖】
并发介绍 谈到并发,随之而来的就是那几个问题。并发 并行 线程 进程 注意!!!本篇文章更多用诙谐的语调讲解,为保证易于理解,不够官方正式,所以可以结合AI读本篇文章,并且本文是以 g…...

前端如何连接tcp 服务,接收数据
在传统的浏览器前端环境中,由于浏览器的同源策略和安全限制,无法直接建立 TCP 连接。不过,可以通过 WebSocket 或者使用 WebRTC 来间接实现与 TCP 服务的通信,另外在 Node.js 环境中可以直接使用 net 模块建立 TCP 连接。下面分别…...

用C语言实现——一个中缀表达式的计算器。支持用户输入和动画演示过程。
一、思路概要和知识回顾 1.思路概要 ①中缀表达式计算: 需要处理运算符的优先级,可能需要用到栈结构。 ❗❗如何将中缀表达式转换为后缀表达式?或者直接计算? 通常,中缀转后缀(逆波兰式)再…...

使用 Pandas 进行多格式数据整合:从 Excel、JSON 到 HTML 的处理实战
前言 在数据处理与分析的实际场景中,我们经常需要整合不同格式的数据,例如 Excel 表格、JSON 配置文件、HTML 报表等。本文以一个具体任务(蓝桥杯模拟练习题)为例,详细讲解如何使用 Python 的 Pandas 库结合其他工具&…...

常见游戏引擎介绍与对比
Unreal Engine (UE4/UE5) 主语言:C Unreal Engine 主要使用 C 作为开发语言。C 提供了高性能的底层控制,适用于需要精细调优的 AAA 级游戏。C 在 Unreal 中用于开发核心游戏逻辑、物理引擎等性能要求较高的部分。 脚本语言:蓝图(B…...
 成就系统(Steam/本地) 多语言支持)
第十一天 主菜单/设置界面 过场动画(Timeline) 成就系统(Steam/本地) 多语言支持
前言 对于刚接触Unity的新手开发者来说,构建完整的游戏系统往往充满挑战。本文将手把手教你实现游戏开发中最常见的四大核心系统:主菜单界面、过场动画、成就系统和多语言支持。每个模块都将结合完整代码示例,使用Unity 2022 LTS版本进行演示…...

vue3 使用 vite 管理多个项目,实现各子项目独立运行,独立打包
场景: 之前写过一篇 vite vue2 的配置,但是现在项目使用 vue3 较多,再更新一下 vue脚手架初始化之后的项目,每个项目都是独立的,导致项目多了之后,node依赖包过多,占用内存较多。想实现的效果…...
 — zookeeper集群部署(亲和性、污点与容忍测试))
k8s(9) — zookeeper集群部署(亲和性、污点与容忍测试)
一、部署思路 1、前期设想 zookeeper集群至少需要运行3个pod集群才能够正常运行,考虑到节点会有故障的风险这个3个pod最好分别运行在3个不同的节点上(为了实现这一需要用到亲和性和反亲和性概念),在部署的时候对zookeeper运行的pod打标签加…...

Linux操作系统复习
Linux操作系统复习 一. Linux的权限和shell原理1. Linux从广义上讲是什么 从狭义上讲是什么?2. shell是什么?3. 为什么要设置一个shell外壳而不是直接和linux 内核沟通4. shell的原理是什么5. Linux中权限的概念6. 如何提升当前操作的权限7. 文件访问者的…...

深入解析 Linux 中动静态库的加载机制:从原理到实践
引言 在 Linux 开发中,动静态库是代码复用的核心工具。静态库(.a)和动态库(.so)的加载方式差异显著,直接影响程序的性能、灵活性和维护性。本文将深入剖析两者的加载机制,结合实例演示和底层原…...

总账主数据——Part 2 科目-1
本文主要介绍在S4 HANA OP中 总账主数据的后台配置及前台操作。 目录 1. 准备 1.1 科目表的定义(OB13) 1.2 给公司代码分配科目表(OB62) 1.3 定义科目组(OBD4) 1.4 定义留存收益科目(OB53) 1.5 维护科目表层“文本标识” (OBT6) 1.6 维护公司代码层“文本标识” (OBT…...

借助内核逻辑锁pagecache到内存
一、背景 内存管理是一个永恒的主题,尤其在内存紧张触发内存回收的时候。系统在通过磁盘获取磁盘上的文件的内容时,若不开启O_DIRECT方式进行读写,磁盘上的任何东西都会被缓存到系统里,我们称之为page cache。可以想象࿰…...

✨ Apifox:这玩意儿是接口界的“瑞士军刀”吧![特殊字符][特殊字符]
——全网最皮最全测评,打工人看了直呼“真香” 📢 友情提醒 还在用 Postman 测接口、Swagger 写文档、Mock.js 造假数据、脑细胞搞团队协作? 停! 你仿佛在玩《工具人环游记》,而隔壁同事已经用 Apifox 「一杆清台」了…...

《普通逻辑》学习记录——性质命题及其推理
目录 一、性质命题概述 二、性质命题的种类 2.1、性质命题按质的分类 2.2、性质命题按量的分类 2.3、性质命题按质和量结合的分类 2.4、性质命题的基本形式归纳 三、四种命题的真假关系 3.1、性质命题与对象关系 3.2、四种命题的真假判定 3.3、四种命题的对当关系 四、四种命题…...
接入华为云iotDA平台的路径元素有哪些不同?)
设备接入与APP(应用程序)接入华为云iotDA平台的路径元素有哪些不同?
目录 壹、设备接入华为云iotDA 🏢 形象比喻:设备 员工,IoTDA 平台 安保森严的总部大楼 一、📍 平台接入地址 总部大楼地址 二、🧾 接入凭证 出入证 / 门禁卡 / 工牌 1. 设备密钥或证书 2. 预置接入凭证密钥&a…...

【git#4】分支管理 -- 知识补充
一、bug 分支 假如我们现在正在 dev2 分支上进行开发,开发到一半,突然发现 master 分支上面有 bug,需要解决。 在Git中,每个 bug 都可以通过一个新的临时分支来修复,修复后,合并分支,然后将临…...

AXOP34062: 40V双通道运算放大器
AXOP34062是一款通用型高压双通道运算放大器,产品的工作电压为2.5V至40V,具有25MHz的带宽,压摆率为10V/μs,静态电流为650A。较高的耐压和带宽使其可以胜任绝大多数的高压应用场景。 主要特性 轨到轨的输入输出范围低输入失调电…...
——光流估计)
OpenCv高阶(十)——光流估计
文章目录 前言一、光流估计二、使用步骤1、导库读取视频、随机初始化颜色2、初始化光流跟踪3、视频帧处理循环4、光流计算与可视化5、循环控制与资源释放完整代码 总结 前言 在计算机视觉领域,光流估计是捕捉图像序列中像素点运动信息的核心技术。它描述了图像中每…...

BS客户端的单点登录
1、参数类似于“XXXXX://?userIdsystem&time1696830378038&token38a8ea526537766f01ded33a6cdfa5bd” 2、在config里加一个LoginSecret参数可随意指定一个字符串 3、BS登录代码里会对“LoginSecret的参数值用户ID时间戳”进行MD5加密形成token,与传过来的…...
)
通讯录完善版本(详细讲解+源码)
目录 前言 一、使通讯可以动态更新内存 1、contact.h 2、contact.c 存信息: 删除联系人,并试一个不存在的人的信息,看看会不会把其他人删了 编辑 修改: 编辑 排序: 编辑 销毁: 编辑 …...

第3讲:ggplot2完美入门与美化细节打磨——从基础绘制到专业级润色
目录 1. 为什么选择ggplot2? 2. 快速了解ggplot2绘图核心逻辑 3. 基础绘图示范:柱状图、折线图、散点图 (1)简单柱状图 (2)折线图示范 (3)高级散点图 + 拟合线 4. 精细美化:细节打磨决定专业感 5. 推荐的美化小插件(可选进阶) 6. 小练习:快速上手一幅美化…...

带宽?增益带宽积?压摆率?
一、带宽(Bandwidth) 1.科学定义: 带宽指信号或系统能够有效通过的频率范围,通常定义为信号功率下降到中频值的一半(即 - 3dB)时的最高频率与最低频率之差。对于运算放大器(Op-Amp)…...

为什么栈内存比堆内存速度快?
博主介绍:程序喵大人 35- 资深C/C/Rust/Android/iOS客户端开发10年大厂工作经验嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手《C20高级编程》《C23高级编程》等多本书籍著译者更多原创精品文章,首发gzh,见文末👇…...

什么是非关系型数据库
什么是非关系型数据库? 引言 随着互联网应用的快速发展,传统的基于表格的关系型数据库(如 MySQL、Oracle 等)已经不能完全满足现代应用程序的需求。在这种背景下,非关系型数据库(NoSQL 数据库)…...

制作一个简单的操作系统9
自定义 myprintf 函数实现解析 探索如何实现一个自定义的 printf 函数来处理任意 %d 和 %s 组合 (说实话,想不用任何库函数和头文件,纯C实现太难了,我放弃了,弄了一个简陋版本 对付用) 运行效果: Hello 123 World 456 Coding这样参数传递:(最多支持5个参数,按顺序…...

华为Pura X的智控键:让折叠机体验更上一层楼的设计
还记得Mate 70系列刚出那会,我体验了下智控键,那时候就觉得这个“把快捷方式做进电源键”的交互方式非常惊艳,没想到在Pura X上,这种便捷体验感更上了一层楼。 智控键:折叠屏手机的天选快捷方式? 传统折叠…...

打造高功率、高电流和高可靠性电路板的厚铜PCB生产
厚铜PCB生产是指制作一种具有较厚铜层的PCB(Printed Circuit Board,印刷电路板)。这种PCB通常用于高功率、高电流和高可靠性的电子设备中。厚铜PCB的生产过程包括以下几个 主要步骤: 1. 基材准备 厚铜PCB的基材通常采用FR4或CEM-…...
---程序调用AI大模型的四种方式(SpringAI+LangChain4j+SDK+HTTP))
AI超级智能体教程(三)---程序调用AI大模型的四种方式(SpringAI+LangChain4j+SDK+HTTP)
文章目录 1.安装SDK(查看文档)2.创建API-key3.项目引入灵积大模型4.HTTP接入的方式5.SpringAI引入5.1添加依赖5.2添加配置5.3测试代码 6.LangChain4j引入6.1依赖引入6.2测试提问 1.安装SDK(查看文档) 安装阿里云百炼SDK_大模型服…...

JDBC连接数据库
一、查询 sqlserver数据库 private List<Map<String, String>> getPathList(String id) throws Exception {String driverName "com.microsoft.sqlserver.jdbc.SQLServerDriver";String dataBaseurl "jdbc:sqlserver://localhost:1433;SelectMeth…...
的区别与实现)
常见缓存淘汰算法(LRU、LFU、FIFO)的区别与实现
一、前言 缓存淘汰算法主要用于在内存资源有限的情况下,优化缓存空间的使用效率。以确保缓存系统在容量不足时能够智能地选择需要移除的数据。 二、LRU(Least Recently Used) 核心思想:淘汰最久未被访问的数据。实现方式&#x…...

深度学习--循环神经网络RNN
文章目录 前言一、RNN介绍1、传统神经网络存在的问题2、RNN的核心思想3、 RNN的局限性 二、RNN基本结构1、RNN基本结构2、推导3、注意4、循环的由来5、再谈RNN的局限 总结 前言 循环神经网络(RNN)的起源可以追溯到1982年,由Saratha Sathasiv…...

大学IP广播系统解决方案:构建数字化智慧化大学校园IP广播平台
大学IP广播系统解决方案:构建数字化智慧化大学校园IP广播平台 北京海特伟业科技有限公司任洪卓于2025年4月24日发布 随着教育信息化建设的深入推进,传统的模拟广播系统已无法满足现代化校园对智能化、场景化、融合化的管理需求。为此,海特伟业提出构建…...

#ifndef #else #endif条件编译
目录 一、#ifdef 1. 基本用法 2. 查看头文件 3. 目的 4. 常见用途 4. 取消定义 5.小结 二、#ifndef和#ifdef区别 1. #ifdef 2. #ifndef 3.结论 一、#ifdef 宏定义 #define H_PWM_L_ON 的作用是创建一个名为 H_PWM_L_ON 的宏。以下是这个宏定义的一些关键点ÿ…...

SystemVerilog语法之typedef与自定义结构
1.7 使用typedef创建新的类型 在Verilog中,你可以为操作数的位宽或者类型分别定义一个宏,但是你并没有创建新的数据类型,而是进行了文本的替换。在SystemVerilog中,可以使用typedef创建新的类型。可以将parameter和typedef语句放…...

【防火墙 pfsense】2配置
(1)接口配置和接口 IP 地址分配 ->配置广域网(WAN)和局域网(LAN)接口,分配设备标识符,如 eth0、eth1 等; ->如将WAN 接口将被分配到 eth0,而 LAN 接口将…...

数据结构之排序
排序 一.比较排序1.插入排序基本思想1.1直接插入排序1.2希尔排序 2.选择排序直接选择排序堆排序 3.交换排序冒泡排序快速排序hoare版本挖坑法lomuto前后指针非递归版本 4.归并排序非递归的归并排序 非比较排序1.计数排序 排序算法复杂度及稳定性分析 一.比较排序 1.插入排序 …...

cgroup sched_cfs_bandwidth_slice参数的作用及效果
一、背景 cgroup是一个非常重要的功能,其中cgroup cpu这块有不少功能,在之前的博客 CFS及RT调度整体介绍_rt调度器-CSDN博客 里,我们分析了cfs的组调度也就是cgroup cpu的这块内核逻辑的细节侧重于调度逻辑这块,在之前的博客 cgr…...

【C++指南】告别C字符串陷阱:如何实现封装string?
🌟 各位看官好,我是egoist2023! 🌍 种一棵树最好是十年前,其次是现在! 💬 注意:本章节只详讲string中常用接口及实现,有其他需求查阅文档介绍。 🚀 今天通过了…...
)
液体神经网络LNN-Attention创新结合——基于液体神经网络的时间序列预测(PyTorch框架)
1.数据集介绍 ETT(电变压器温度):由两个小时级数据集(ETTh)和两个 15 分钟级数据集(ETTm)组成。它们中的每一个都包含 2016 年 7 月至 2018 年 7 月的七种石油和电力变压器的负载特征。 traffic(交通) :描…...

kafka和Spark-Streaming2
Kafka 工作流程及文件存储机制 Kafka 中消息是以topic 进行分类的,生产者生产消息,消费者消费消息,都是面向topic 的。 “.log”文件存储大量的数据,“.index”文件存储偏移量索引信息,“.timeindex”存储时间戳索引文…...
)
MySQL日期函数的详细教程(包含常用函数及其示例)
概述 以下是一个关于MySQL日期函数的详细教程,包含常用函数及其示例内容以转换为PDF电子书,喜欢的朋友可以转存慢慢享用:https://pan.quark.cn/s/57d2e491bbbe 1. 获取当前日期和时间 • CURDATE() / CURRENT_DATE() 返回当前日期…...

P4017 最大食物链计数-拓扑排序
P4017 最大食物链计数 题目来源-洛谷 题意 要求最长食物链的数量。按照题意,最长食物链就是指有向无环图DAG中入度为0到出度为0的不同路径的数量(链数) 思路 在计算时,明显:一个被捕食者所…...

C语言——字串处理
C语言——字串处理 一、问题描述二、格式要求1.输入形式2.输出形式3.样例 三、实验代码 一、问题描述 现有两个字符串s1和s2,它们最多都只能包含255个字符。编写程序,将字符串s1中所有出现在字符串s2中的字符删去,然后输出s1。 二、格式要求…...

工业排风轴流风机:强劲动力与节能设计的完美融合
在工业生产中,通风换气是保障作业环境安全、维持设备正常运行的关键环节。工业排风轴流风机凭借其独特的设计,将强劲动力与节能特性完美融合,成为众多工业场景的首选通风设备,为企业高效生产与绿色发展提供了可靠支持。 工业排风…...

【Test】单例模式❗
文章目录 1. 单例模式2. 单例模式简单示例3. 懒汉模式4. 饿汉模式5. 懒汉式和饿汉式的区别 1. 单例模式 🐧定义:保证一个类仅有一个实例,并提供一个访问它的全局访问点。 单例模式是一种常用的软件设计模式,在它的核心结构中只包…...

3.3 Spring Boot文件上传
在 Spring Boot 项目中实现文件上传功能,首先创建项目并添加依赖,包括 Commons IO 用于文件操作。接着,创建文件上传控制器 FileUploadController,定义上传目录并实现文件上传逻辑,通过生成唯一文件名避免文件冲突。创…...