数据结构之排序
排序
- 一.比较排序
- 1.插入排序
- 基本思想
- 1.1直接插入排序
- 1.2希尔排序
- 2.选择排序
- 直接选择排序
- 堆排序
- 3.交换排序
- 冒泡排序
- 快速排序
- hoare版本
- 挖坑法
- lomuto前后指针
- 非递归版本
- 4.归并排序
- 非递归的归并排序
- 非比较排序
- 1.计数排序
- 排序算法复杂度及稳定性分析

一.比较排序
1.插入排序
基本思想
直接插⼊排序是⼀种简单的插⼊排序法,其基本思想是:把待排序的记录按其关键码值的⼤⼩逐个插⼊到⼀个已经排好序的有序序列中,直到所有的记录插⼊完为⽌,得到⼀个新的有序序列。
1.1直接插入排序
内层循环从已排序部分的最后一个元素开始,向前遍历。
如果当前元素 a[end] 大于 tmp,则将 a[end] 向后移动一位(即 a[end + 1] = a[end]),并将 end 减 1,继续比较前一个元素。如此就会使最大的数放置在最后一位,如此反复。
如果遇到一个不大于 tmp 的元素,或者已经遍历到数组的开头(end < 0),则退出循环。
void InsertSort(int* a, int n)
{for (int i = 0; i < n- 1;i++){int end = i;int tmp = a[end + 1];while (end >= 0){if (a[end] > tmp){a[end+1] = a[end];end--;}elsebreak;}a[end + 1] = tmp;}
}
直接插⼊排序的特性总结
-
元素集合越接近有序,直接插⼊排序算法的时间效率越⾼
-
时间复杂度:O(N^2)
-
空间复杂度:O(1)
1.2希尔排序
希尔排序可以看作是直接插入排序的优化版,希尔排序法⼜称缩⼩增量法。希尔排序法的基本思想是:先选定⼀个整数(通常是gap=n/3+1),把待排序⽂件所有记录分成各组,所有的距离相等的记录分在同⼀组内,并对每⼀组内的记录进⾏排序,然后gap=gap/3+1得到下⼀个整数,再将数组分成各组,进⾏插⼊排序,当gap=1时,就相当于直接插⼊排序。
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;for (int i = 0;i < n-gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end = end - gap;}elsebreak;}a[end + gap] = tmp;}}
}希尔排序的特性总结
-
希尔排序是对直接插⼊排序的优化。
-
当 gap > 1 时都是预排序,⽬的是让数组更接近于有序。当 gap == 1 时,数组已经接近有序的了,这样就会很快。这样整体⽽⾔,可以达到优化的效果。
-
关于希尔排序的时间复杂度:

2.选择排序
选择排序的基本思想:
每⼀次从待排序的数据元素中选出最⼩(或最⼤)的⼀个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
直接选择排序
void SelectSort(int* a, int n)
{int begin = 0;int end = n - 1;while (begin < end){int max = end;int min = begin;for (int i = begin; i <= end;i++){if (a[i] > max)max = i;if (a[i] < min)min = i;}if (max == begin){max = min;}swap(&a[begin], &a[min]);swap(&a[end], &a[max]);begin++;end--;}
}
设立两个下标,分别表示最大和最小,遍历数组,并且记录下该数组最大数下标和最小数的下标。遍历完之后,将最小的数据换到最前,最大的换到最后。
但要注意的是,有一种情况,就是begin == max ,end == min 的情况,这时如若不经过特殊处理,将会换两次,导致方法失效,所以进行判断,将max = min 这样就能正确使用。(注意两次交换不能颠倒)
直接选择排序的特性总结:
-
时间复杂度:O(N的平方 )
-
空间复杂度:O(1)
堆排序
void AdjustDwon(int* a, int n, int root)
{int parent = root;int child = parent * 2 + 1;while (child < n){if (child + 1 < n && a[child] < a[child + 1])child++;if (a[parent] < a[child])swap(&a[parent], &a[child]);elsebreak;parent = child;child = parent * 2 + 1;}
}
void HeapSort(int* a, int n)
{for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDwon(a, n, i);}int end = n - 1;while (end > 0){swap(&a[0], &a[end]);AdjustDwon(a, end, 0);end--;}
}
堆排序用到了adjust down函数,主要有建堆和排序两个步骤,具体操作请看堆排序。
3.交换排序
- 交换排序基本思想:
所谓交换,就是根据序列中两个记录键值的⽐较结果来对换这两个记录在序列中的位置 - 交换排序的特点是:
将键值较⼤的记录向序列的尾部移动,键值较⼩的记录向序列的前部移动
冒泡排序
由于冒泡排序较为基础,这里不做过多赘述。
冒泡排序通过重复遍历待排序的数组,比较每对相邻元素,如果它们的顺序错误(即前一个元素大于后一个元素),就将它们交换。这个过程会不断重复,直到数组完全有序。
每一轮遍历都会将当前未排序部分的最大值“冒泡”到数组的末尾,因此数组的有序部分会逐渐增长,而未排序部分会逐渐缩短。
void bubblesort(int* a, int n)
{for (int i = 0;i < n;i++){for (int j = 0;j < n - i - 1;j++){if (a[j] > a[j + 1])swap(&a[j], &a[j + 1]);}}
}
快速排序
快速排序是Hoare于1962年提出的⼀种⼆叉树结构的交换排序⽅法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两⼦序列,左⼦序列中所有元素均⼩于基准值,右⼦序列中所有元素均⼤于基准值,然后最左右⼦序列重复该过程,直到所有元素都排列在相应位置上为⽌。
快速排序框架:
//快速排序 void QuickSort(int* a, int left, int right)
{if (left >= right) {return;}//_QuickSort⽤于按照基准值将区间[left,right)中的元素进⾏划分 int meet = _QuickSort(a, left, right);QuickSort(a, left, meet - 1);QuickSort(a, meet + 1, right);
}
我们要具体实现的是_QuickSort函数。
hoare版本
算法思路:
1)创建左右指针,确定基准值
2)从右向左找出⽐基准值⼩的数据,从左向右找出⽐基准值⼤的数据,左右指针数据交换,进⼊下次循环
int _QuickSort(int* a, int left, int right)
{int key = left;left++;while (left <= right){while (left <= right && a[right] > a[key]){right--;}while (left <= right && a[left] < a[key]){left++;}if(left<=right)swap(&a[left++], &a[right--]);}swap(&a[key], &a[right]);return right;
}
挖坑法
创建左右指针。⾸先从右向左找出⽐基准⼩的数据,找到后⽴即放⼊左边坑中,当前位置变为新的"坑",然后从左向右找出⽐基准⼤的数据,找到后⽴即放⼊右边坑中,当前位置变为新的"坑",结束循环后将最开始存储的分界值放⼊当的"坑"中,返回当前"坑"下标(即分界值下标)
int _QuickSort(int* a, int left, int right)
{int hole = left;int key = a[hole];while (left < right){while (left < right && a[right] > key){right--;}a[hole] = a[right];hole = right;while (left < right && a[left] < key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}
lomuto前后指针
创建前后指针,从左往右找⽐基准值⼩的进⾏交换,使得⼩的都排在基准值的左边。
- 定义两个指针,cur 和prev cur 作为探路指针,找比基准值小的数据。
- 若找到了prev++ ,交换数据 cur++(++prev != cur 是用于避免无用的操作)
- 若未找到则cur++。
- 现在prev及左边的数,都要比基准值小,右边的数据都比基准值大。
- 循环结束后,将基准值与prev的数据交换,返回prev。
int _QuickSort(int* a, int left, int right)
{int prev = left;int cur = left + 1;int key = left;while (cur <= right){if (a[cur] < a[key] && ++prev != cur){swap(&a[prev], &a[cur]);}cur++;}swap(&a[key], &a[prev]);return prev;
}
快速排序特性总结:
-
时间复杂度:O(nlogn)
-
空间复杂度:O(logn)
非递归版本
⾮递归版本的快速排序需要借助数据结构:栈。
基本算法思路可以参考lomuto前后指针法。
- 先将数组的最左和最右的数据入栈,进入循环后依次取栈顶,删除栈的操作,得到了我们所处理数据的begin 和end
- 依旧创建prev 和 cur ,cur作探路指针
- 得到最后的基准值,再次将新划分的数据入栈。重复循环操作,就实现了排序算法。
void QuicSortNoR(int* arr, int left, int right)
{ST st;StackInit(&st);StackPush(&st, left);StackPush(&st, right);while (!StackEmpty(&st)){//取栈顶两次int end = StackTop(&st);StackPop(&st);int begin = StackTop(&st);StackPop(&st);//[begin,end]找基准值int keyi = begin;int prev = begin, cur = prev + 1;while (cur <= end){if (arr[cur] < arr[keyi] && ++prev != cur){Swap(&arr[prev], &arr[cur]);}cur++;}Swap(&arr[keyi], &arr[prev]);keyi = prev;//begin keyi end//左序列:[begin,keyi-1] 右序列:[keyi+1,end];if (keyi + 1 < end){StackPush(&st, keyi + 1);StackPush(&st, end);}if (begin < keyi - 1){StackPush(&st, begin);StackPush(&st, keyi - 1);}}StackDestroy(&st);
}
4.归并排序
归并排序算法思想:
归并排序(MERGE-SORT)是建⽴在归并操作上的⼀种有效的排序算法,该算法是采⽤分治法(Divideand Conquer)的⼀个⾮常典型的应⽤。将已有序的⼦序列合并,得到完全有序的序列;即先使每个⼦序列有序,再使⼦序列段间有序。若将两个有序表合并成⼀个有序表,称为⼆路归并。归并排序核⼼步骤: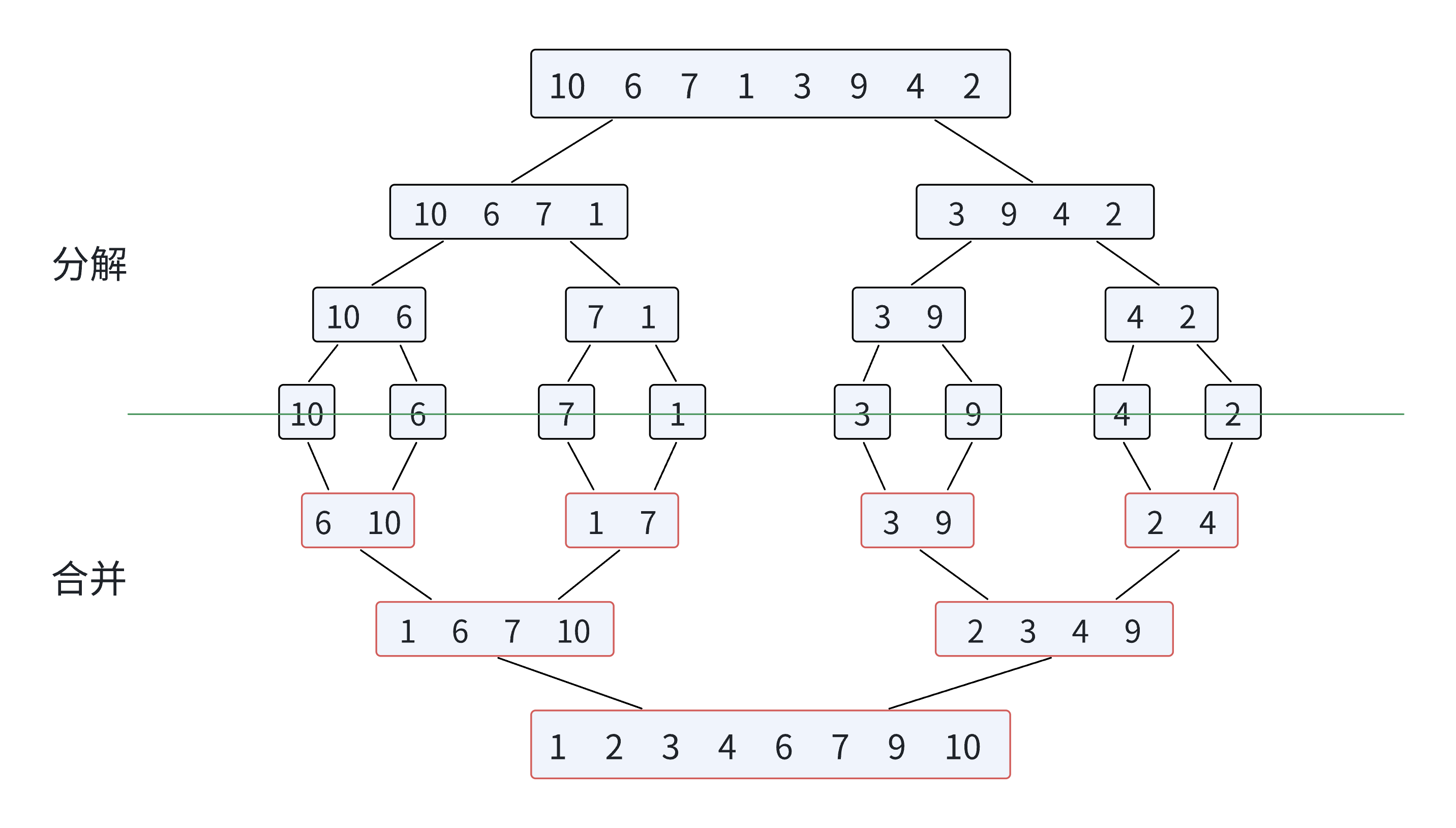
- 思路是将数据分成一个一个的数组,然后将这一个个的数组重新排序组合。赋值给tmp数组之中,最后将有序的数组重新传给a数组,实现排序的算法.
- 代码涉及到了合并两个有序数组。
void _MergeSort(int* arr, int left, int right, int* tmp)
{if (left >= right)return;int mid = (left + right) / 2;_MergeSort(arr, left, mid, tmp);_MergeSort(arr, mid + 1, right, tmp);int begin1 = left; int end1 = mid;int begin2 = mid + 1;int end2 = right;int index = left;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){tmp[index++] = arr[begin1++];}else{tmp[index++] = arr[begin2++];}}while (begin1 <= end1){tmp[index++] = arr[begin1++];}while (begin2 <= end2){tmp[index++] = arr[begin2++];}for (int i = left;i < right;i++){arr[i] = tmp[i];}
}// 归并排序递归实现
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);_MergeSort(a, 0, n - 1, tmp);free(tmp);tmp == NULL;
}
归并排序特性总结:
-
时间复杂度:O(nlogn)
-
空间复杂度:O(n)
非递归的归并排序
非递归归并排序的核心思想是逐步增加归并的子数组大小,从最小的子数组开始逐步合并,直到整个数组被排序。具体步骤如下:
初始化:将数组分成若干个大小为 1 的子数组。
逐步合并:每次迭代中,将相邻的两个子数组合并成一个有序的子数组,子数组的大小逐步翻倍。
重复上述过程:直到所有子数组合并成一个完整的有序数组。
void MergeSortNonR(int* arr, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);int gap = 1;while (gap < n){for (int i = 0;i <n;i = i+2*gap){int begin1 = i;int end1 = i + gap - 1;int begin2 = i + gap; int end2 = i + 2 * gap - 1;int index = i;if (begin2 >= n)break;if (end2 >= n){end2 = n - 1;}while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){tmp[index++] = arr[begin1++];}else{tmp[index++] = arr[begin2++];}}while (begin1 <= end1){tmp[index++] = arr[begin1++];}while (begin2 <= end2){tmp[index++] = arr[begin2++];}memcpy(arr + i, tmp + i, sizeof(int) * 2*gap);}gap *= 2;}}
详细步骤
假设数组长度为 n,以下是详细的实现步骤:
- 步骤1:初始化
创建一个临时数组 tmp,大小与原数组 arr 相同,用于存储归并后的结果。
初始化子数组大小 gap 为 1。 - 步骤2:逐步归并
使用一个 while 循环,条件是 gap < n,表示还有未排序的部分。
在每次迭代中,使用一个 for 循环,以 2 * gap 为步长遍历数组,将相邻的两个子数组合并。
确定每个子数组的起始和结束索引。
使用双指针方法将两个子数组合并到临时数组 tmp 中。
如果某个子数组已经遍历完,将另一个子数组的剩余部分复制到 tmp 中。
将临时数组 tmp 中的有序部分复制回原数组 arr。
将子数组大小 gap 翻倍。 - 步骤3:重复上述过程
重复步骤2,直到 gap >= n,此时整个数组已经排序完成。
非比较排序
1.计数排序
计数排序⼜称为鸽巢原理,是对哈希直接定址法的变形应⽤。
操作步骤:
1)统计相同元素出现次数
2)根据统计的结果将序列回收到原来的序列中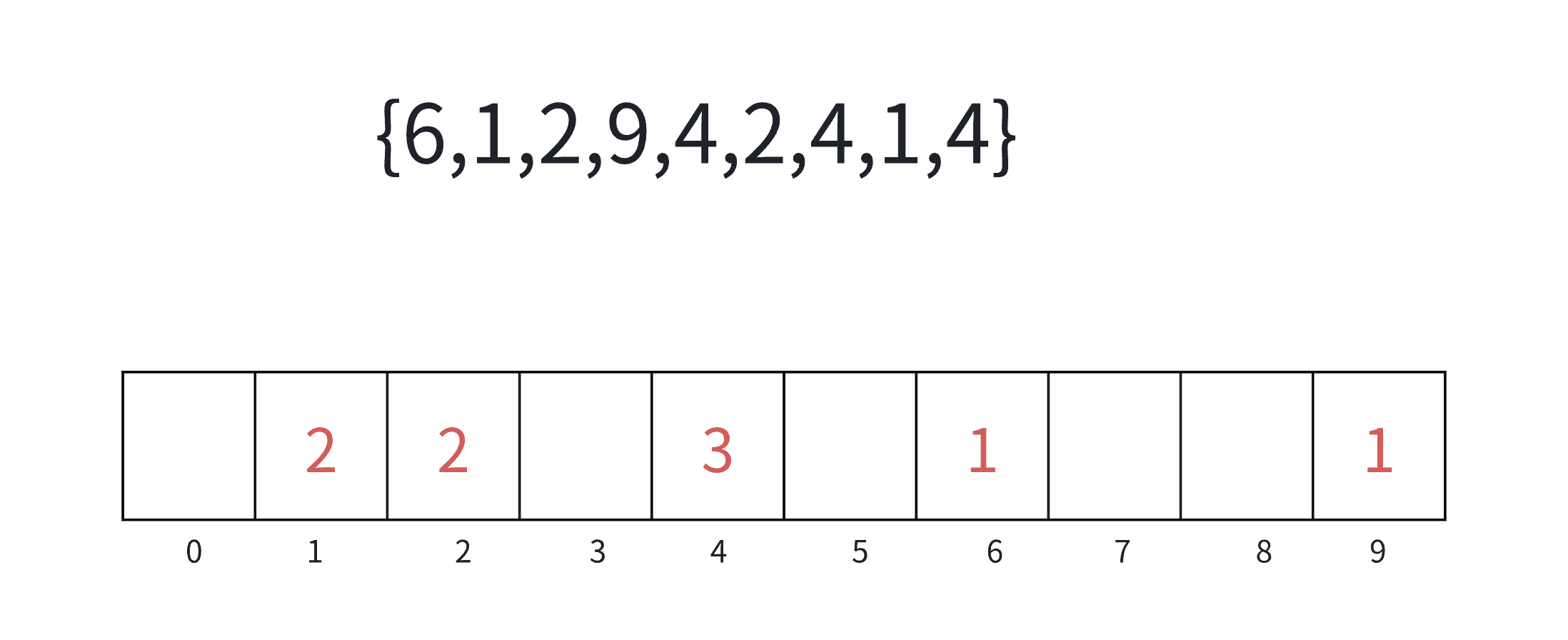
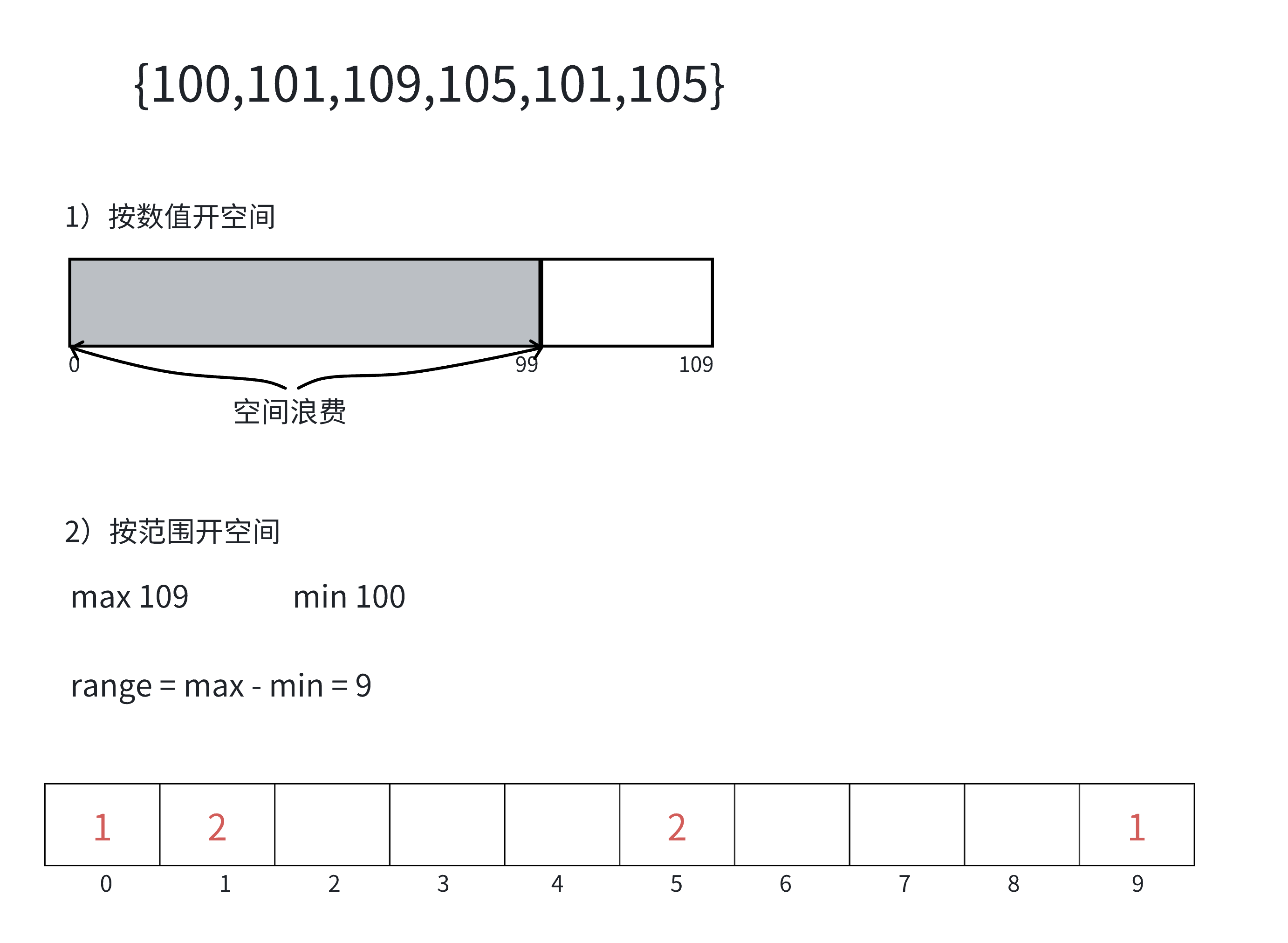
计数排序的特性:
计数排序在数据范围集中时,效率很⾼,但是适⽤范围及场景有限。
时间复杂度:O(N + range)
空间复杂度:O(range)
稳定性:稳定
void CountSort(int* a, int n)
{int min = a[0];int max = a[0];for (int i = 0;i < n;i++){if (a[i] < min)min = a[i];if (a[i] > max)max = a[i];}int range = max - min + 1;int* count = (int*)calloc(0,sizeof(int) * range);for (int i = 0;i < n;i++){count[a[i] - min]++;}int index = 0;for (int i = 0;i < range;i++){while (count[i]--)a[index++] = i+min;}
}
排序算法复杂度及稳定性分析
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的
相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,⽽在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
- 稳定的排序算法:冒泡排序,直接插入排序,归并排序。
- 不稳定的排序算法:直接选择排序,希尔排序,堆排序,快速排序。
相关文章:

数据结构之排序
排序 一.比较排序1.插入排序基本思想1.1直接插入排序1.2希尔排序 2.选择排序直接选择排序堆排序 3.交换排序冒泡排序快速排序hoare版本挖坑法lomuto前后指针非递归版本 4.归并排序非递归的归并排序 非比较排序1.计数排序 排序算法复杂度及稳定性分析 一.比较排序 1.插入排序 …...

cgroup sched_cfs_bandwidth_slice参数的作用及效果
一、背景 cgroup是一个非常重要的功能,其中cgroup cpu这块有不少功能,在之前的博客 CFS及RT调度整体介绍_rt调度器-CSDN博客 里,我们分析了cfs的组调度也就是cgroup cpu的这块内核逻辑的细节侧重于调度逻辑这块,在之前的博客 cgr…...

【C++指南】告别C字符串陷阱:如何实现封装string?
🌟 各位看官好,我是egoist2023! 🌍 种一棵树最好是十年前,其次是现在! 💬 注意:本章节只详讲string中常用接口及实现,有其他需求查阅文档介绍。 🚀 今天通过了…...
)
液体神经网络LNN-Attention创新结合——基于液体神经网络的时间序列预测(PyTorch框架)
1.数据集介绍 ETT(电变压器温度):由两个小时级数据集(ETTh)和两个 15 分钟级数据集(ETTm)组成。它们中的每一个都包含 2016 年 7 月至 2018 年 7 月的七种石油和电力变压器的负载特征。 traffic(交通) :描…...

kafka和Spark-Streaming2
Kafka 工作流程及文件存储机制 Kafka 中消息是以topic 进行分类的,生产者生产消息,消费者消费消息,都是面向topic 的。 “.log”文件存储大量的数据,“.index”文件存储偏移量索引信息,“.timeindex”存储时间戳索引文…...
)
MySQL日期函数的详细教程(包含常用函数及其示例)
概述 以下是一个关于MySQL日期函数的详细教程,包含常用函数及其示例内容以转换为PDF电子书,喜欢的朋友可以转存慢慢享用:https://pan.quark.cn/s/57d2e491bbbe 1. 获取当前日期和时间 • CURDATE() / CURRENT_DATE() 返回当前日期…...

P4017 最大食物链计数-拓扑排序
P4017 最大食物链计数 题目来源-洛谷 题意 要求最长食物链的数量。按照题意,最长食物链就是指有向无环图DAG中入度为0到出度为0的不同路径的数量(链数) 思路 在计算时,明显:一个被捕食者所…...

C语言——字串处理
C语言——字串处理 一、问题描述二、格式要求1.输入形式2.输出形式3.样例 三、实验代码 一、问题描述 现有两个字符串s1和s2,它们最多都只能包含255个字符。编写程序,将字符串s1中所有出现在字符串s2中的字符删去,然后输出s1。 二、格式要求…...

工业排风轴流风机:强劲动力与节能设计的完美融合
在工业生产中,通风换气是保障作业环境安全、维持设备正常运行的关键环节。工业排风轴流风机凭借其独特的设计,将强劲动力与节能特性完美融合,成为众多工业场景的首选通风设备,为企业高效生产与绿色发展提供了可靠支持。 工业排风…...

【Test】单例模式❗
文章目录 1. 单例模式2. 单例模式简单示例3. 懒汉模式4. 饿汉模式5. 懒汉式和饿汉式的区别 1. 单例模式 🐧定义:保证一个类仅有一个实例,并提供一个访问它的全局访问点。 单例模式是一种常用的软件设计模式,在它的核心结构中只包…...

3.3 Spring Boot文件上传
在 Spring Boot 项目中实现文件上传功能,首先创建项目并添加依赖,包括 Commons IO 用于文件操作。接着,创建文件上传控制器 FileUploadController,定义上传目录并实现文件上传逻辑,通过生成唯一文件名避免文件冲突。创…...
使用gstreamer)
【玩泰山派】7、玩linux桌面环境xfce - (4)使用gstreamer
文章目录 前言gstreamergstreamer概述基本概念主要功能应用场景开发方式 安装gstreamer使用gstreamer使用gstreamer播放视频 前言 玩一下gstreamer,使用gstreamer去播放下音视频 gstreamer gstreamer概述 GStreamer是一个用于构建多媒体应用程序的开源库和框架&…...

cpu性能统计
cpu负载 top中avg,/proc/loadavg, 包括cpu密集型任务io型任务 统计流程 每cpu scheduler_tick ----calc_global_load_tick : 当前瞬时 cpu::this_rq:: nr_runningnr_inunterrupt->calc_load_tasks(全局变量) 全局 do_timer ----calc_global_load&a…...

Java对接企业微信实战笔记
Java对接企业微信实战笔记 微信开发文档 有关企业微信的服务商的一些配置参考企业微信创建的服务商配置信息 一 流程图 只要企业安装应用后,就可以获取到企业的信息 二 创建应用获取suite_ticket 1.创建应用 微信开发平台得是服务商角色才能进入服务商后台创建一…...

HashMap的源码解析
HashMap基于哈希表的Map接口实现,是以key-value存储形式存在,即主要用来存放键值对。HashMap的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。 JDK1.8 之前 HashMap由数…...

【金仓数据库征文】金仓数据库KingbaseES:在技术与人文交织中开拓信创未来
🎁个人主页:User_芊芊君子 🎉欢迎大家点赞👍评论📝收藏⭐文章 🔍系列专栏:AI 【引言】 在信息技术应用创新(信创)的浪潮下,数据库作为数字经济的基石…...

【AI】[特殊字符]生产规模的向量数据库 Pinecone 使用指南
一、Pinecone 的介绍 Pinecone是一个完全托管的向量数据库服务,专为大规模机器学习应用设计。它允许开发者轻松存储、搜索和管理高维向量数据,为推荐系统、语义搜索、异常检测等应用提供强大的基础设施支持。 1.1 Pinecone的核心特性 1. 高性能向量搜…...

OpenHarmony之电源模式定制开发指导
OpenHarmony之电源模式定制开发指导 概述 简介 OpenHarmony默认提供了电源模式(如正常模式、性能模式、省电模式、极致省电模式)的特性。但由于不同产品的部件存在差异,导致在同样场景下电源模式的配置需要也存在差异,为此&…...

Jsp技术入门指南【十】IDEA 开发环境下实现 MySQL 数据在 JSP 页面的可视化展示,实现前后端交互
Jsp技术入门指南【十】IDEA 开发环境下实现 MySQL 数据在 JSP 页面的可视化展示,实现前后端交互 前言一、JDBC 核心接口和类:数据库连接的“工具箱”1. 常用的 2 个“关键类”2. 必须掌握的 5 个“核心接口” 二、创建 JDBC 程序的步骤1. 第一步…...

JDBC之ORM思想及SQL注入
目录 一. ORM编程思想 1. 简介 2. 实操ORM思想 a. Students实体类 b. ORM映射 二. SQL注入 1. 简介 2. 解决SQL注入 三. 总结 前言 本文来讲解ORM编程思想和SQL注入,旨在帮助大家更容易的理解和掌握 个人主页:艺杯羹 系列专栏:JDBC …...

UniApp学习笔记
在uniapp中使用View标签来代替div标签,使用rpx来取代px,rpx动态适配屏幕宽度750rpx100vw H5端不支持*的css选择器 body的元素选择器请改为page div和ul和li等改为view、 span和font改为text a改为navigator img改为image scoped:非H5端默认并未启…...

统计术语学习
基期、现期 作为对比参照的时期称为基期,而相对于基期的称为现期。 描述具体数值时我们称之为基期量和现期量。 【例 1】2017 年比 2016 年第三产业 GDP 增长 6.8%, (2016)为基期,(2017) 为现…...

认识 Linux 内存构成:Linux 内存调优之页表、TLB、缺页异常、大页认知
写在前面 博文内容涉及 Linux 内存中 多级页表,缺页异常,TLB,以及大页相关基本认知理解不足小伙伴帮忙指正对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是…...

Java File 类的常用方法详解
Java File 类的常用方法详解 File 类是 Java 中用于操作文件和目录的核心类,位于 java.io 包。它提供了丰富的方法来管理文件系统,包括创建、删除、重命名、查询属性、遍历目录等操作。 1. 构造方法 File 类提供多种构造方法,用于创建文件或…...

【AIGC】基础篇:VS Code 配置 Python 命令行参数调试debug超详细教程
文章目录 前言一、安装必要的扩展二、安装 debugpy三、创建 launch.json 配置文件四、配置调试环境五、开始调试六、命令行调试七、远程调试八、调试技巧九、常见问题及解决方法 前言 在 Python 开发过程中,调试是必不可少的环节。VS Code 提供了强大的调试功能&am…...

【金仓数据库征文】金仓数据库KingbaseES:千行百业国产化征程中的璀璨之星
🎁个人主页:User_芊芊君子 🎉欢迎大家点赞👍评论📝收藏⭐文章 🔍系列专栏:AI 【引言】 在数字化转型浪潮奔涌向前的时代,数据库作为数据存储与管理的核心枢纽,其重要性不…...

Linux进程学习【基本认知】
🌼🌼前言:前言理解冯诺依曼体系结构与操作系统原理 在计算机科学的基础理论中,冯诺依曼体系结构和操作系统是两个关键概念,它们共同构成了现代计算机的运行基础。本文将从这两个方面入手,简要讲解它们的基本…...

电子工厂POE交换机端口数量选择与部署策略
引言 在电子工厂的智能化升级过程中,POE(Power over Ethernet)交换机凭借其“供电数据传输”一体化功能,成为构建工业物联网的核心设备。与传统工业交换机相比,POE交换机通过单根网线实现设备供电与数据交互ÿ…...
 A-D)
Codeforces Round 1020 (Div. 3) A-D
A. Dr. TC https://codeforces.com/contest/2106/problem/A 题目大意: 对输入字符串每个位置字符依次翻转(1->0 , 0->1) 比如: 101 001 翻转位置1 111 2 100 3 题解: 观察数学特征:ansn…...
)
电子病历高质量语料库构建方法与架构项目(提示词设计篇)
电子病历人工智能提示词工程是医疗AI应用中的关键技术环节,它直接影响大语言模型在医疗场景下的输出质量和可靠性。随着大语言模型在电子病历生成、质控、数据提取等领域的广泛应用,如何通过编程实现高效、精准的提示词工程成为医疗信息化建设的重要课题。本文将系统介绍电子…...

蓝桥杯 4. 卡片换位
卡片换位 原题目链接 题目描述 你玩过华容道的游戏吗? 这是一个类似的,但更简单的游戏。 看下面的 3 2 格子: --------- | A | * | * | --------- | B | | * | ---------在其中放置了 5 张牌,其中: A 表示关…...

用python进行OCR识别
原文链接:https://www.bilibili.com/opus/1036675560501149699 我担心原作者删除,所以重新拷贝了一遍 1.下载tesseract 链接:https://github.com/UB-Mannheim/tesseract/wiki 这里示例安装最新版本 点击下载tesseract安装包 2.安装tess…...
在工业缺陷检测领域的应用)
【大语言模型】大语言模型(LLMs)在工业缺陷检测领域的应用
大语言模型(LLMs)在工业缺陷检测领域的应用场景正在快速扩展,结合其多模态理解、文本生成和逻辑推理能力,为传统检测方法提供了新的技术路径。以下是该领域的主要应用场景及相关技术进展: 1. 多模态缺陷检测与解释 视…...

202531读书笔记|《天上大风:良宽俳句·短歌·汉诗400》——我别无他物款待君,除了山中冬日寂寥,陶然共一醉,不知是与非,一饱百情足,一酣万事休
202531读书笔记|《天上大风:良宽俳句短歌汉诗400》——我别无他物款待君,除了山中冬日寂寥,陶然共一醉,不知是与非,一饱百情足,一酣万事休 《天上大风:良宽俳句短歌汉诗400》良宽是公认与松尾芭…...

HTMLCSS模板实现水滴动画效果
.container 类:定义了页面的容器样式。 display: flex:使容器成为弹性容器,方便对其子元素进行布局。justify-content: center 和 align-items: center:分别使子元素在水平和垂直方向上居中对齐。min-height: 100vh:设…...
静态页面抓取实战:requests库请求头配置与反反爬策略详解)
Python爬虫(5)静态页面抓取实战:requests库请求头配置与反反爬策略详解
目录 一、背景与需求二、静态页面抓取的核心流程三、requests库基础与请求头配置3.1 安装与基本请求3.2 请求头核心参数解析3.3 自定义请求头实战 四、实战案例:抓取豆瓣读书Top2501. 目标2. 代码实现3. 技术要点 五、高阶技巧与反反爬策略5.1 动态…...
)
电子病历高质量语料库构建方法与架构项目(数据遗忘篇)
引言 在人工智能与医疗健康的深度融合时代,医疗数据的价值与风险并存。跨机构和平台的医疗数据共享对于推动医学研究、提高诊断精度和实现个性化治疗至关重要,但同时也带来了前所未有的隐私挑战。先进的AI技术可以从理论上去标识化的医疗扫描中重新识别个人身份,例如从MRI数…...

需求开发向设计规划的转化-从需求到设计和编码
需求和设计之间存在差别,但尽量使你的规格说明的具体实现无倾向性。理想情况是:在设计上的考虑不应该歪曲对预期系统的描述( Jackson 1995)。需求开发和规格说明应该强调对预期系统外部行为的理解和描述。让设计者和开发者参与需求…...

browser-use:AI驱动的浏览器自动化工具使用指南
AI驱动浏览器自动化 browser-use下载项目创建Python环境安装依赖配置环境运行WebUI简单使用Deep Research使用本地浏览器免登录 browser-use browser-use是一个基于 Python 的开源库,旨在简化 AI 代理与浏览器之间的交互。它将先进的AI功能与强大的浏览器自动化功能…...
之旅——JavaSE终篇(异常))
Java从入门到“放弃”(精通)之旅——JavaSE终篇(异常)
Java从入门到“放弃”(精通)之旅🚀——JavaSE终篇(异常) 一、异常的概念与体系结构 1.1 什么是异常? 在生活中,当一个人表情痛苦时,我们可能会关心地问:"你是不是生…...

TCP协议理解
文章目录 TCP协议理解理论基础TCP首部结构图示字段逐项解析 TCP是面向连接(Connection-Oriented)面向连接的核心表现TCP 面向连接的核心特性TCP 与UDP对比 TCP是一个可靠的(reliable)序号与确认机制(Sequencing & Acknowledgment…...

NS3-虚拟网络与物理网络的交互-1 仿真概述
NS3-虚拟网络与物理网络的交互-1 仿真概述 目录 1. 仿真概述1.1 Testbed 仿真示例-FdNetDevice1.2 模拟通道示例-TapDevice 1. 仿真概述 NS-3 专为集成到 TestBed 和虚拟机中而设计 环境。我们通过提供两种网络设备来满足这一需求。 第一种设备是文件描述符 net 设备 &#x…...

晶振老化:不可忽视的隐患与预防策略
在电子设备的世界里,晶振如同精准的时钟,为电路系统提供稳定的频率信号。然而,随着时间推移,晶振会不可避免地出现老化现象。这个看似细微的变化,却可能引发设备性能下降、数据传输错误等一系列问题。晶振老化究竟藏着…...

企业为何要禁止“片断引用开源软件代码”?一文看透!
开篇故事:一段“开源代码”引发的百亿级灾难 某电商平台为快速上线新功能,从GitHub复制了一段“高性能加密算法”代码到支付系统中。 半年后,黑客通过该代码中的隐藏后门,盗取百万用户信用卡信息。 事后调查:这段代…...

测试模版x
本篇技术博文摘要 🌟 引言 📘 在这个变幻莫测、快速发展的技术时代,与时俱进是每个IT工程师的必修课。我是盛透侧视攻城狮,一名什么都会一丢丢的网络安全工程师,也是众多技术社区的活跃成员以及多家大厂官方认可人员&a…...

deepseek-r1-671B满血版,全栈式智能创作平台 - 多模态大模型赋能未来创作
引领AI创作新纪元 比象AI全栈式智能创作平台是基于全球领先的多模态大模型技术构建的新一代AI创作引擎,集成了前沿的BeyondLM-7B认知计算框架、BeyondDiffusion-XL视觉生成系统和BeyondSynth音视频合成技术,打造从内容构思到成品输出的完整智能创作闭环…...

Promethues 普罗米修斯
Prometheus 并非传统意义上的数据库,而是一个开源的系统监控和报警工具包,但它的核心组件之一是时间序列数据库,用于存储监控指标数据。以下是对 Prometheus 及其时间序列数据库功能的详细介绍: 1. Prometheus 概述 目标定位&a…...

Web 服务架构与技术组件概述
目录 web服务流程图 Web 服务流程图描述了客户端与服务器之间的交互。首先,用户通过浏览器发送请求到 Web 服务器。如果请求的是静态资源(如 HTML、CSS、图片),Web 服务器直接返回响应;如果是动态资源,We…...

华硕NUC产品闪耀第31届中国国际广播电视信息网络展览会
2025年4月22日,第31届中国国际广播电视信息网络展览会在北京国家会议中心盛大开幕。作为一年一度的行业盛会,展会汇聚了来自全球各地的顶尖技术与设备厂商。在这片科技与创新交织的海洋中,华硕NUC以其卓越性能、小巧体积和创新技术十分引人注…...
:动态交互、三维可视化与性能优化)
Matplotlib高阶技术全景解析(续):动态交互、三维可视化与性能优化
目录 编辑 一、动态可视化:实时数据流与动画生成 1. 实时数据流可视化 2. 复杂动画控制 二、三维可视化:科学计算与工程建模 1. 基础三维绘图 2. 高级三维渲染优化 三、交互式可视化:GUI集成与Web部署 1. Tkinter/PyQt嵌入式开发 …...