k8s(9) — zookeeper集群部署(亲和性、污点与容忍测试)
一、部署思路
1、前期设想
zookeeper集群至少需要运行3个pod集群才能够正常运行,考虑到节点会有故障的风险这个3个pod最好分别运行在3个不同的节点上(为了实现这一需要用到亲和性和反亲和性概念),在部署的时候对zookeeper运行的pod打标签加入app=zk,那么假设当zookeeper-1在node1节点上运行,那么zookeeper-2部署的时候发现node1节点上已经存在app=zk标签就不会在再node1节点上运行(这里可能会用到硬策略 +亲和性(NotIn)或者硬策略+反亲和性(In))来实现。3个pod至少需要3台机器而实验环境只用3台机器(一台master节点和2台node节点),因为污点原因master节点不参与集群节点的调度工作,所以为了完成部署可能需要引入污点与容忍概念。
2、实现思路
1、创建一个service类型的无头服务zk-headless(因为zookeeper集群服务可能会进行销毁创建IP不固定,所以zookeeper配置文件中不能配置IP,所以要创建一个clusterIP: None的service表示不分配ip,通过域名进行访问)
产生的域名格式:<pod-name>.<service-name>.<namespace>.svc.cluster.local。
2、要创建一个zookeeper集群配置清单(将上述的生成的域名写入到配置中)。
3、创建PodDisruptionBudget确保集群正常可用。
4、创建StatefulSet有状态服务(绑定上述的无头服务serviceName: zk-headless)配置亲和性或污点容忍策略。
5、创建一个NodePort类型的service用于外部连接测试使用。
二、部署 zookeeper集群
(一)、zookeeper pod部署
1、将master上的污点设置为:PreferNoSchedule
表示 k8s 将尽量避免将 Pod 调度到具有该污点的 Node 上
#将污点设置为PreferNoSchedule表示 k8s 将尽量避免将 Pod 调度到具有该污点的 Node 上
kubectl taint node master node-role.kubernetes.io/master:PreferNoSchedule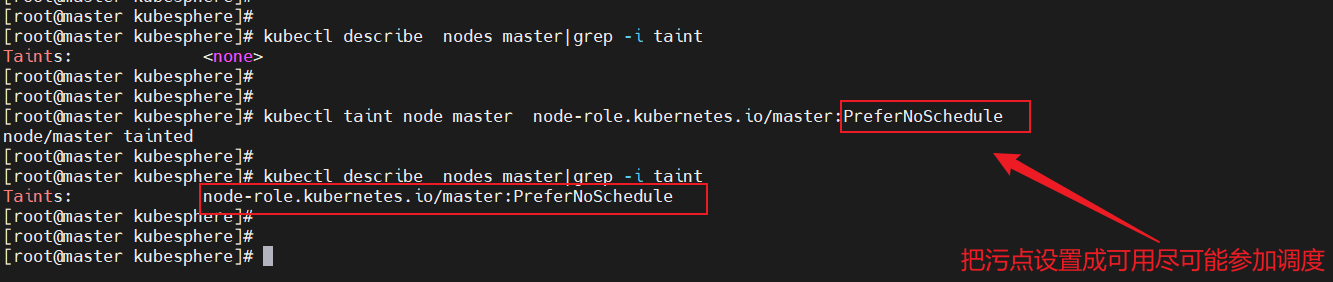
2、创建PodDisruptionBudget资源对象
2.1、PodDisruptionBudget资源对象简介
在 Kubernetes(K8s)里,
PodDisruptionBudget(PDB)是一种非常重要的资源对象,它主要用于保障应用的高可用性,避免因计划内的中断(比如节点维护、集群升级等)而导致过多的 Pod 同时被终止。下面为你详细介绍PodDisruptionBudget。2.1.1、核心作用
在 Kubernetes 集群中,计划内的中断事件是难以避免的,像节点维护、节点升级、节点驱逐等操作都可能导致 Pod 被终止。
PodDisruptionBudget的作用就是对这些计划内中断进行管控,确保在任何时候都有足够数量的 Pod 处于运行状态,从而保障应用的正常运行和服务的稳定性。2.1.2、关键概念
minAvailable:该参数规定了在计划内中断期间,必须保持运行的最小 Pod 数量或者比例。例如,设置minAvailable: 3表示至少要有 3 个 Pod 处于运行状态;设置minAvailable: 50%则意味着至少要有一半的 Pod 保持运行。maxUnavailable:此参数定义了在计划内中断期间,允许不可用的最大 Pod 数量或者比例。例如,设置maxUnavailable: 2表示最多允许 2 个 Pod 不可用;设置maxUnavailable: 25%则表示最多允许 25% 的 Pod 不可用。2.1.3、配置示例
以下是一个
PodDisruptionBudget的 YAML 配置示例:pod-disruption-budget-examplePodDisruptionBudget 配置示例
V1
生成 pod-disruption-budget.yaml
2.1.4、配置解释
apiVersion:指定使用的 Kubernetes API 版本,这里使用的是policy/v1。kind:表明资源对象的类型为PodDisruptionBudget。metadata:包含资源对象的元数据,name为该PodDisruptionBudget的名称。spec:定义了PodDisruptionBudget的具体规格。
minAvailable:设置为 2,表示在计划内中断期间,至少要有 2 个带有app: my-app标签的 Pod 保持运行状态。selector:用于筛选要应用该PodDisruptionBudget的 Pod,这里通过matchLabels选择带有app: my-app标签的 Pod。2.1.5、工作机制
当计划内中断事件发生时,Kubernetes 会检查
PodDisruptionBudget的规则。如果中断操作会导致不符合minAvailable或maxUnavailable的要求,那么该操作将会被阻止,直到满足PodDisruptionBudget的条件为止。2.1.6、使用场景
- 关键业务应用:对于像数据库、缓存服务这类关键业务应用,使用
PodDisruptionBudget可以确保在集群维护或升级期间,有足够数量的 Pod 继续运行,避免服务中断。- 多副本应用:对于运行多个副本的应用,
PodDisruptionBudget可以防止过多的副本同时被终止,保证服务的稳定性和可用性。通过使用
PodDisruptionBudget,你可以在 Kubernetes 集群中更好地管理计划内中断,保障应用的高可用性。分享
如何创建一个PodDisruptionBudget?
查看PodDisruptionBudget的详细信息。
如何调整PodDisruptionBudget的配置?
2.2、怎样查看PodDisruptionBudget的apiVersion需要填什么
kubectl explain poddisruptionbudget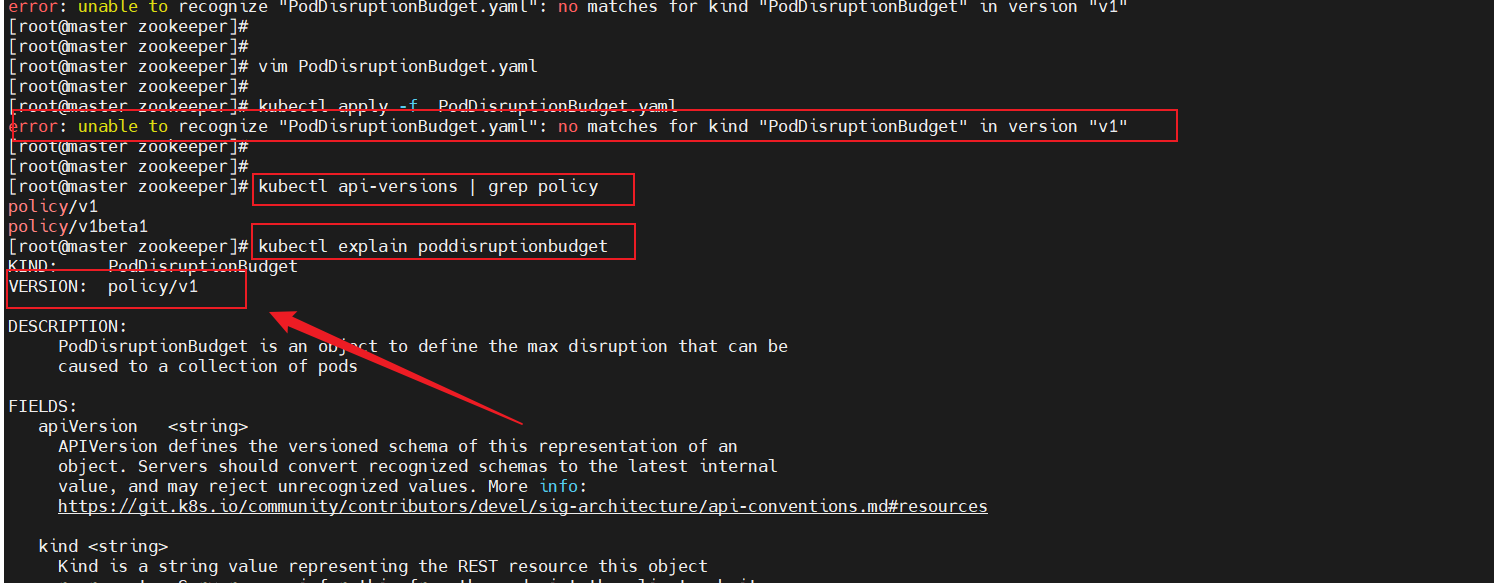
2.3、创建PodDisruptionBudget
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:name: zookeepernamespace: kafka
spec:minAvailable: 2selector:matchLabels:app: zookeeper3、创建无头服务
创建一个名为zk-headless(因为zookeeper集群服务可能会进行销毁创建IP不固定,所以zookeeper配置文件中不能配置IP,要创建一个clusterIP: None的service表示不分配ip,通过域名进行访问)。
产生的域名格式:<pod-name>.<service-name>.<namespace>.svc.cluster.local。
apiVersion: v1
kind: Service
metadata:name: zk-headlessnamespace: kafka
spec:clusterIP: None # Headless Service,不分配IPselector:app: zookeeperports:- name: clientport: 2181targetPort: 2181- name: peer-electionport: 3888targetPort: 3888- name: peer-communicationport: 2888targetPort: 28884、创建一个zookeeper集群配置清单
apiVersion: v1
kind: ConfigMap
metadata:name: zoo-confnamespace: kafka
data:zoo.cfg: |tickTime=2000dataDir=/var/lib/zookeeper/datadataLogDir=/var/lib/zookeeper/logclientPort=2181initLimit=5syncLimit=2# 动态生成集群节点(如3节点)server.0=zk-0.zk-headless.kafka.svc.cluster.local:2888:3888server.1=zk-1.zk-headless.kafka.svc.cluster.local:2888:3888server.2=zk-2.zk-headless.kafka.svc.cluster.local:2888:3888
后边部署的pod名称是zk是所以这里填入zk-0、zk-1、zk-2 。
5、创建StatefulSet有状态服务
apiVersion: apps/v1
kind: StatefulSet #部署服务的类型
metadata:name: zknamespace: kafka
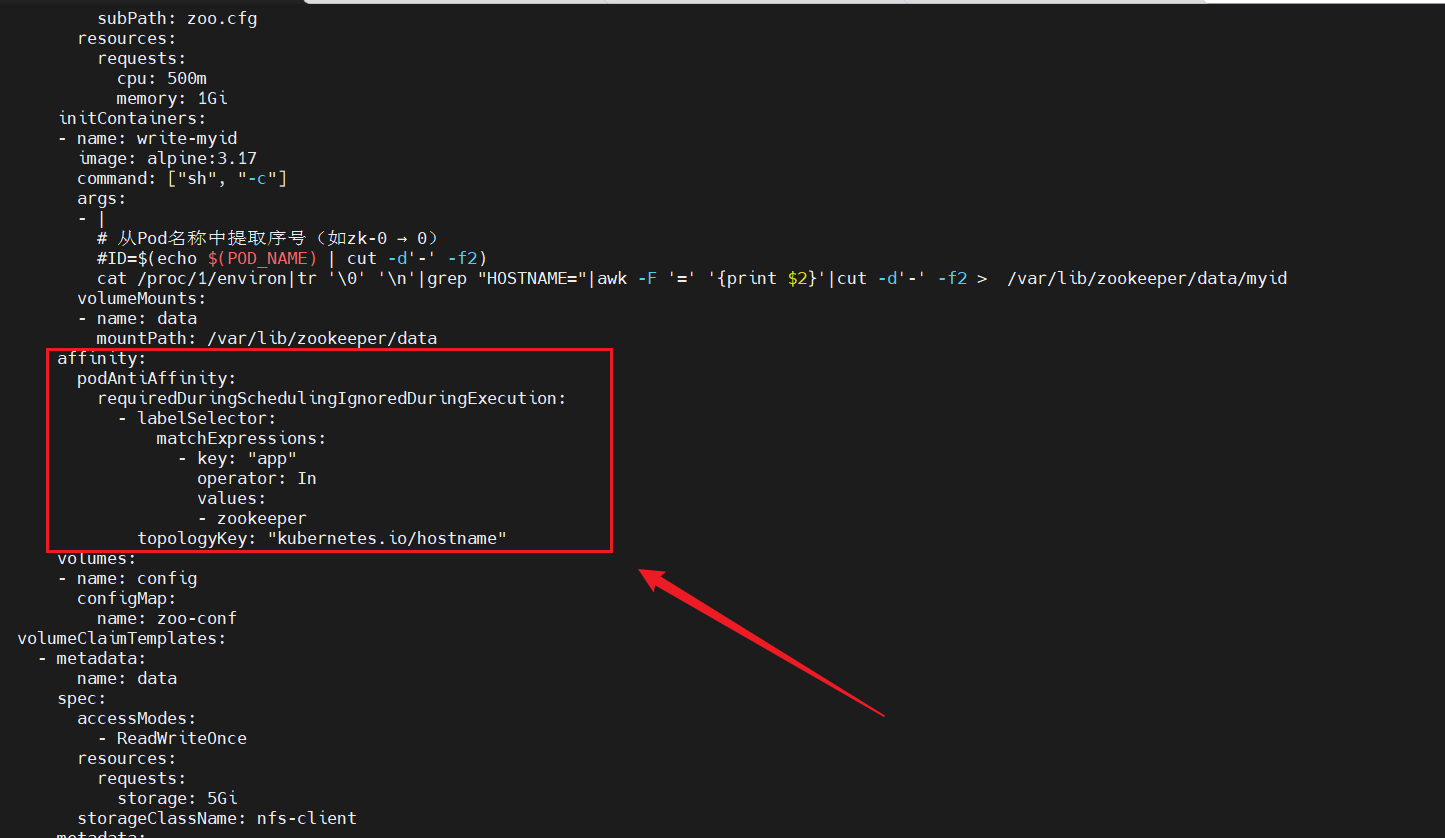
spec:replicas: 3 # 集群节点数selector:matchLabels:app: zookeeperserviceName: zk-headless #绑定的无头服务名称template:metadata:labels:app: zookeeperspec:containers:- name: zookeeperimage: zookeeper:3.8.0 # 官方镜像ports:- containerPort: 2181name: client- containerPort: 3888name: zk-leader- containerPort: 2888name: zk-serverenv:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name # 获取Pod名称(如zk-0)volumeMounts:- name: datamountPath: /var/lib/zookeeper/data- name: logmountPath: /var/lib/zookeeper/log- name: configmountPath: /conf/zoo.cfgsubPath: zoo.cfgresources:requests:cpu: 500mmemory: 1GiinitContainers:- name: write-myidimage: alpine:3.17command: ["sh", "-c"]args:- |# 从Pod名称中提取序号(如zk-0 → 0)#ID=$(echo $(POD_NAME) | cut -d'-' -f2)cat /proc/1/environ|tr '\0' '\n'|grep "HOSTNAME="|awk -F '=' '{print $2}'|cut -d'-' -f2 > /var/lib/zookeeper/data/myidvolumeMounts:- name: datamountPath: /var/lib/zookeeper/dataaffinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: "app"operator: Invalues:- zookeepertopologyKey: "kubernetes.io/hostname"volumes:- name: configconfigMap:name: zoo-confvolumeClaimTemplates:- metadata:name: dataspec:accessModes:- ReadWriteOnceresources:requests:storage: 5GistorageClassName: nfs-client- metadata:name: logspec:accessModes:- ReadWriteOnceresources:requests:storage: 5GistorageClassName: nfs-client
5.1、配置亲和性策略
affinity:podAntiAffinity: #反亲和requiredDuringSchedulingIgnoredDuringExecution: #硬策略- labelSelector:matchExpressions:- key: "app" #指定key是appoperator: In values:- zookeeper #即匹配app=zookeeper的标签topologyKey: "kubernetes.io/hostname"
6、创建一个NodePort类型的service用于外部连接测试使用
apiVersion: v1
kind: Service
metadata:name: zk-clientnamespace: kafka
spec:selector:app: zookeeperports:- name: clientport: 2181targetPort: 2181type: NodePort # 如需外部访问,可改为NodePort或LoadBalancer(二)、部署过程问题排查
1、pod节点没有创建因为变量命名规则大于15个字符导致报错问题处理
#查看描述
kubectl get statefulset -n zookeeper
kubectl describe statefulset -n zookeeper zk-cluster | tail -n 10

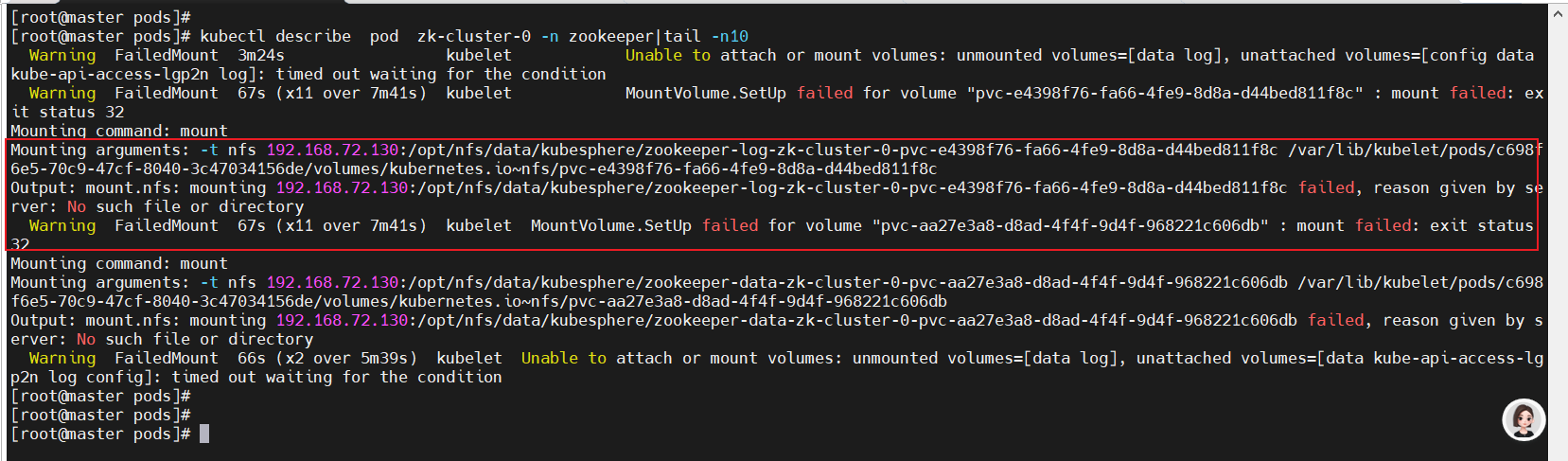
2、配置文件名称不一致问题处理
kubectl get pod -n zookeeper -w
kubectl describe pod zk-cluster-0 -n zookeeper|tail -n10
kubectl logs zk-cluster-0 -n zookeeper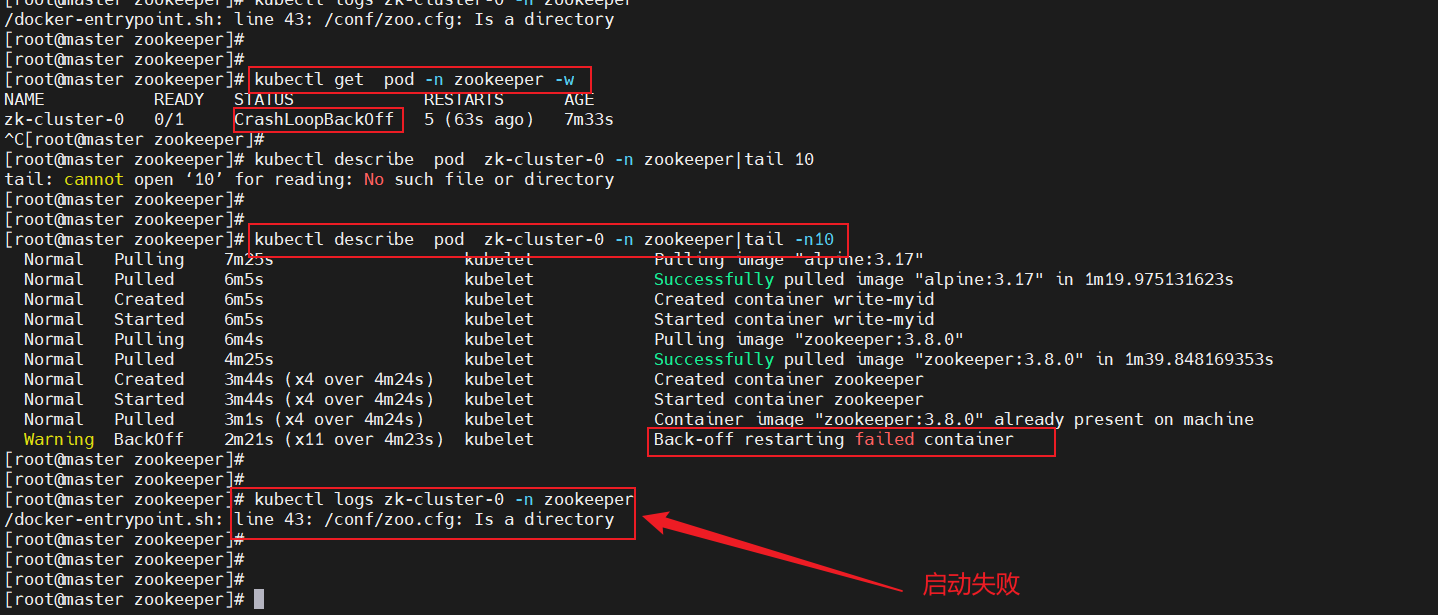
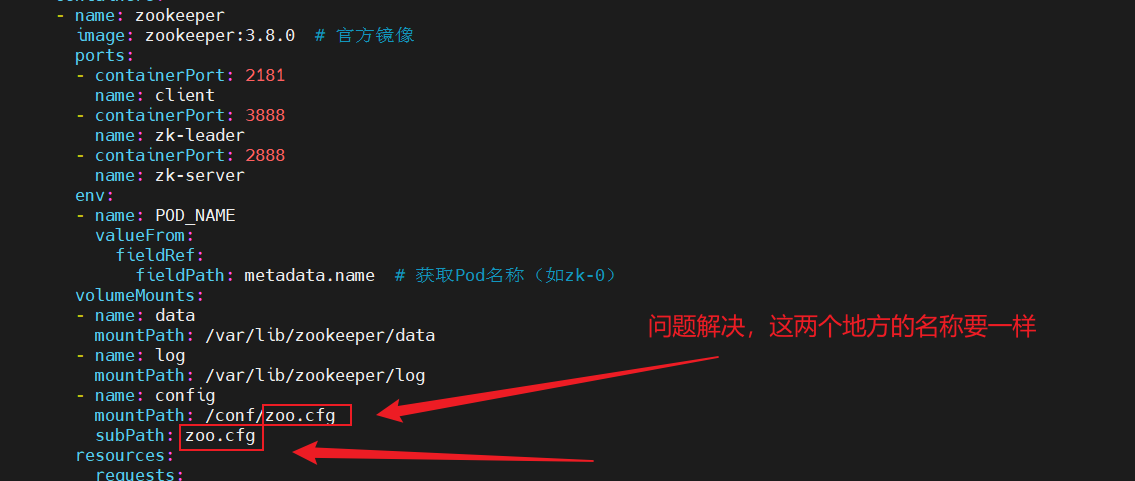
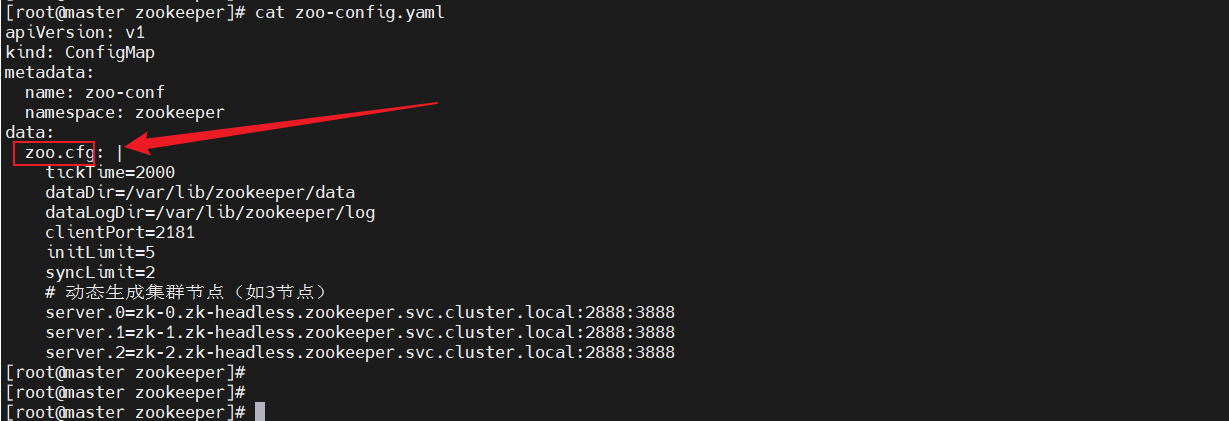
3、statefulset服务将pod信息存储在/var/lib/kubelet/pods中删除动态卷下的数据会导致再次部署的时候发生报错。
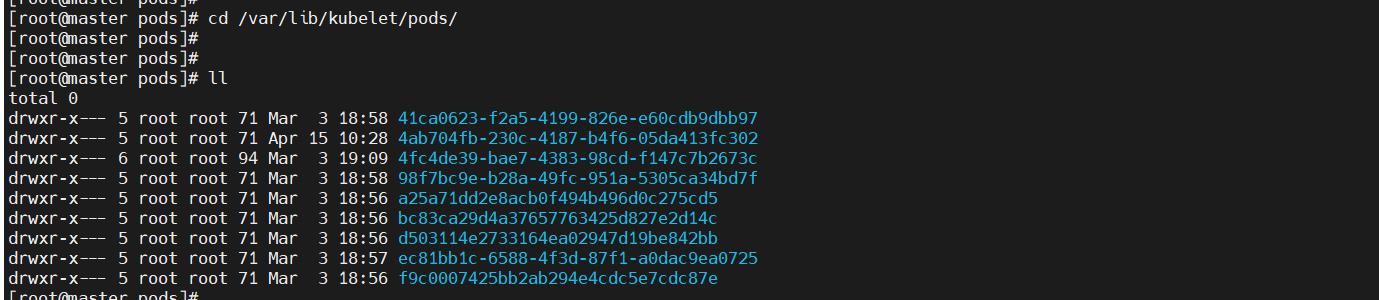
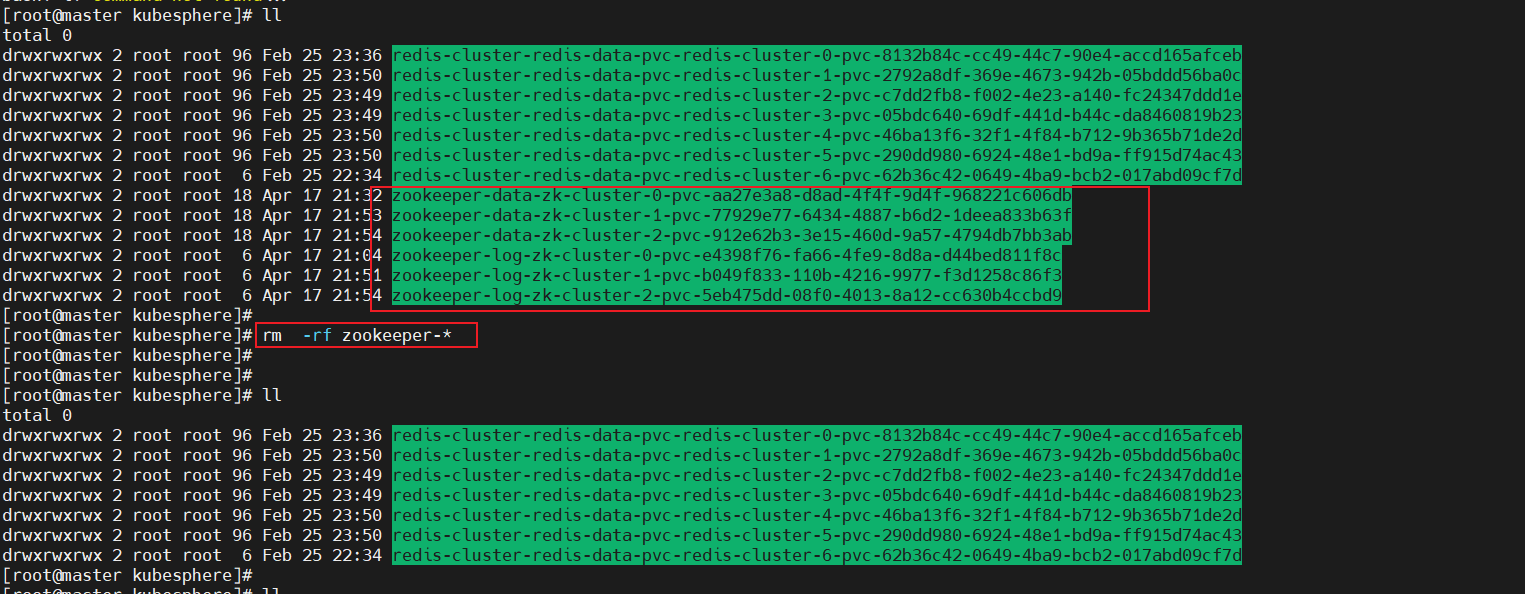 报错:
报错:
解决:执行kubectl delete -f *yaml 将之前部署到所有yaml清单全部删除。
4、POD_NAME变量获取不到问题处理
在部署zookeeper集群时,需要在每个zookeeper节点的myid中填入对应的值,这里直接将POD_NAME变量名后的数字写入,但是在部署的过程中发现metadata.name值无法获取,所以在这里使用shell获取pod名称编号写入myid,方法如下:
#在实验中POD_NAME变量的名称获取不到env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name # 获取Pod名称(如zk-0)#解决方法使用如下命令获取pod的名称cat /proc/1/environ|tr '\0' '\n'|grep "HOSTNAME="|awk -F '=' '{print $2}'|cut -d'-' -f2 > /var/lib/zookeeper/data/myid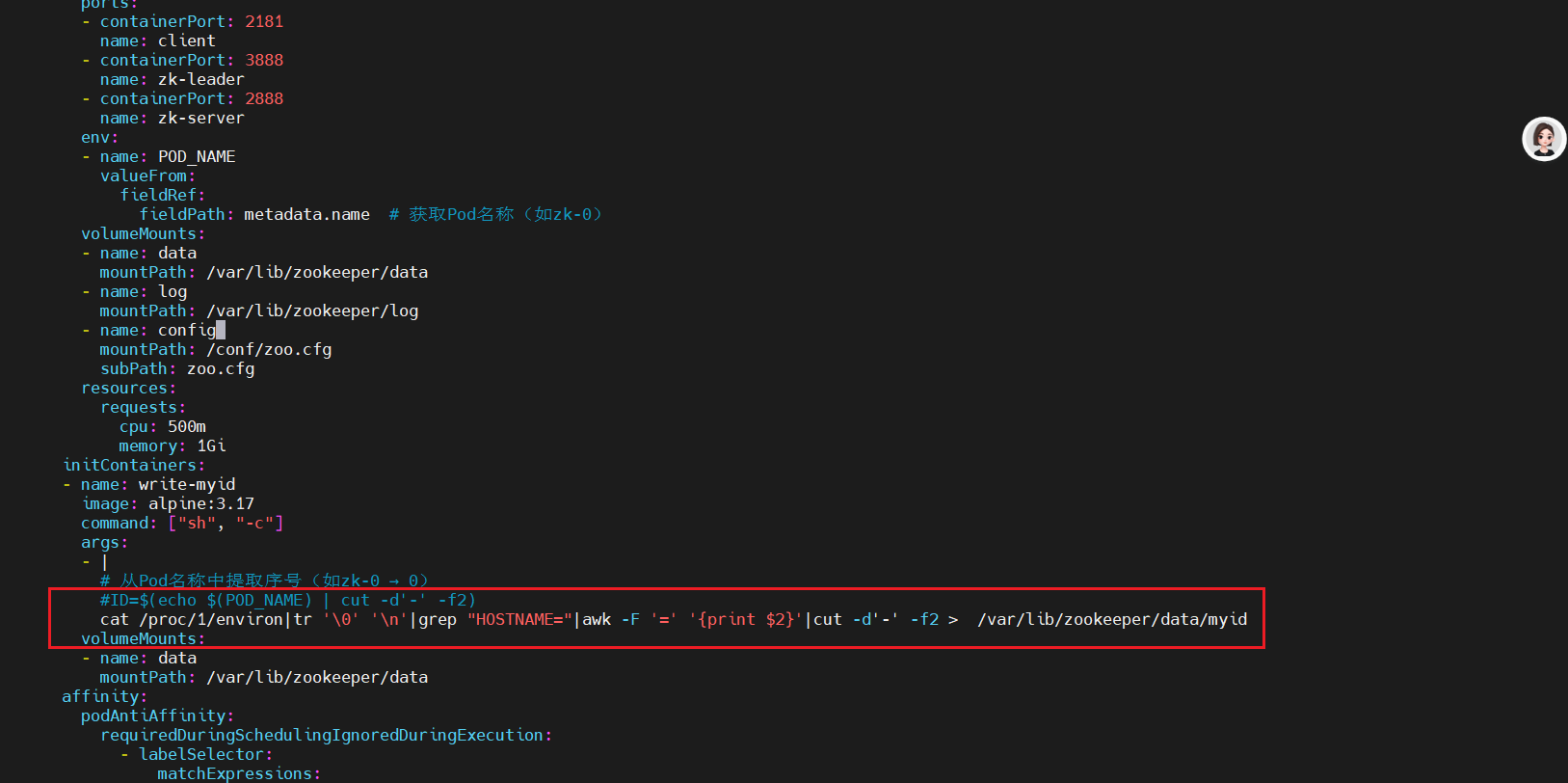
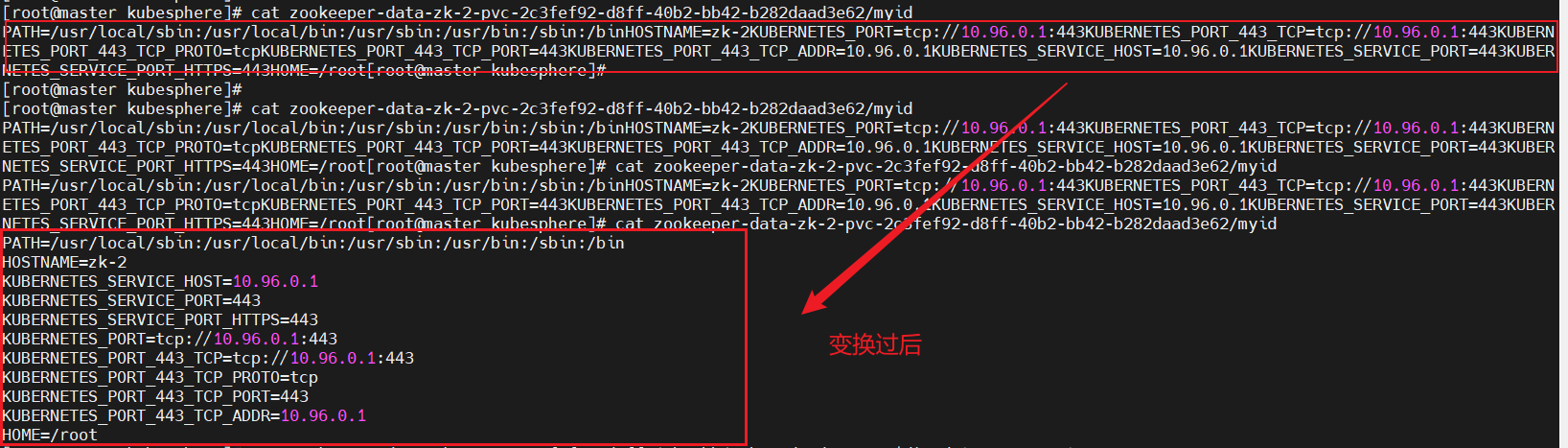
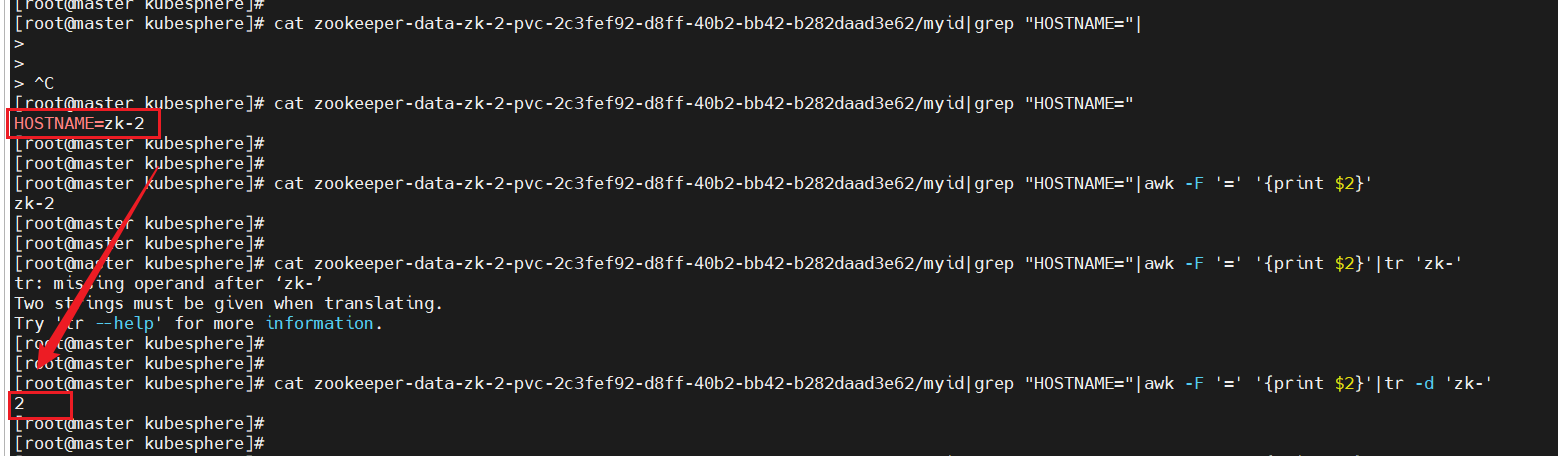 :
:
(三)、完整的zookeeper集群部署流程清单
#创建配置apiVersion: v1
kind: ConfigMap
metadata:name: zoo-confnamespace: zookeeper
data:zoo.cfg: |tickTime=2000dataDir=/var/lib/zookeeper/datadataLogDir=/var/lib/zookeeper/logclientPort=2181initLimit=5syncLimit=2# 动态生成集群节点(如3节点)server.0=zk-0.zk-headless.zookeeper.svc.cluster.local:2888:3888server.1=zk-1.zk-headless.zookeeper.svc.cluster.local:2888:3888server.2=zk-2.zk-headless.zookeeper.svc.cluster.local:2888:3888---
#创建PodDisruptionBudgetapiVersion: policy/v1
kind: PodDisruptionBudget
metadata:name: zookeepernamespace: zookeeper
spec:minAvailable: 2selector:matchLabels:app: zookeeper---
apiVersion: v1
kind: Service
metadata:name: zk-clientnamespace: zookeeper
spec:selector:app: zookeeperports:- name: clientport: 2181targetPort: 2181type: ClusterIP # 如需外部访问,可改为NodePort或LoadBalancer---#创建无头服务
apiVersion: v1
kind: Service
metadata:name: zk-headlessnamespace: zookeeper
spec:clusterIP: None # Headless Service,不分配IPselector:app: zookeeperports:- name: clientport: 2181targetPort: 2181- name: peer-electionport: 3888targetPort: 3888- name: peer-communicationport: 2888targetPort: 2888---#创建有状态副本集apiVersion: apps/v1
kind: StatefulSet
metadata:name: zknamespace: zookeeper
spec:replicas: 3 # 集群节点数selector:matchLabels:app: zookeeperserviceName: zk-headlesstemplate:metadata:labels:app: zookeeperspec:containers:- name: zookeeperimage: zookeeper:3.8.0 # 官方镜像ports:- containerPort: 2181name: client- containerPort: 3888name: zk-leader- containerPort: 2888name: zk-serverenv:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name # 获取Pod名称(如zk-0)volumeMounts:- name: datamountPath: /var/lib/zookeeper/data- name: logmountPath: /var/lib/zookeeper/log- name: configmountPath: /conf/zoo.cfgsubPath: zoo.cfgresources:requests:cpu: 500mmemory: 1GiinitContainers:- name: write-myidimage: alpine:3.17command: ["sh", "-c"]args:- |# 从Pod名称中提取序号(如zk-0 → 0)#ID=$(echo $(POD_NAME) | cut -d'-' -f2)cat /proc/1/environ|tr '\0' '\n'|grep "HOSTNAME="|awk -F '=' '{print $2}'|cut -d'-' -f2 > /var/lib/zookeeper/data/myidvolumeMounts:- name: datamountPath: /var/lib/zookeeper/dataaffinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: "app"operator: Invalues:- zookeepertopologyKey: "kubernetes.io/hostname"volumes:- name: configconfigMap:name: zoo-confvolumeClaimTemplates:- metadata:name: dataspec:accessModes:- ReadWriteOnceresources:requests:storage: 5GistorageClassName: nfs-client- metadata:name: logspec:accessModes:- ReadWriteOnceresources:requests:storage: 5GistorageClassName: nfs-client---
#创建与外部连接的serviceapiVersion: v1
kind: Service
metadata:name: zk-clientnamespace: zookeeper
spec:selector:app: zookeeperports:- name: clientport: 2181targetPort: 2181type: ClusterIP # 如需外部访问,可改为NodePort或LoadBalancer
[root@master zookeeper]#
(四)、集群访问测试
1、查看集群状态是否正常
#进入集群内部
kubectl exec -it zk-0 -n kafka -- /bin/bash#查看zk-0的状态
echo srvr|nc zk-0.zk-headless.kafka.svc.cluster.local 2181#查看zk-1的状态
echo srvr|nc zk-1.zk-headless.kafka.svc.cluster.local 2181#查看zk-2的状态
echo srvr|nc zk-2.zk-headless.kafka.svc.cluster.local 2181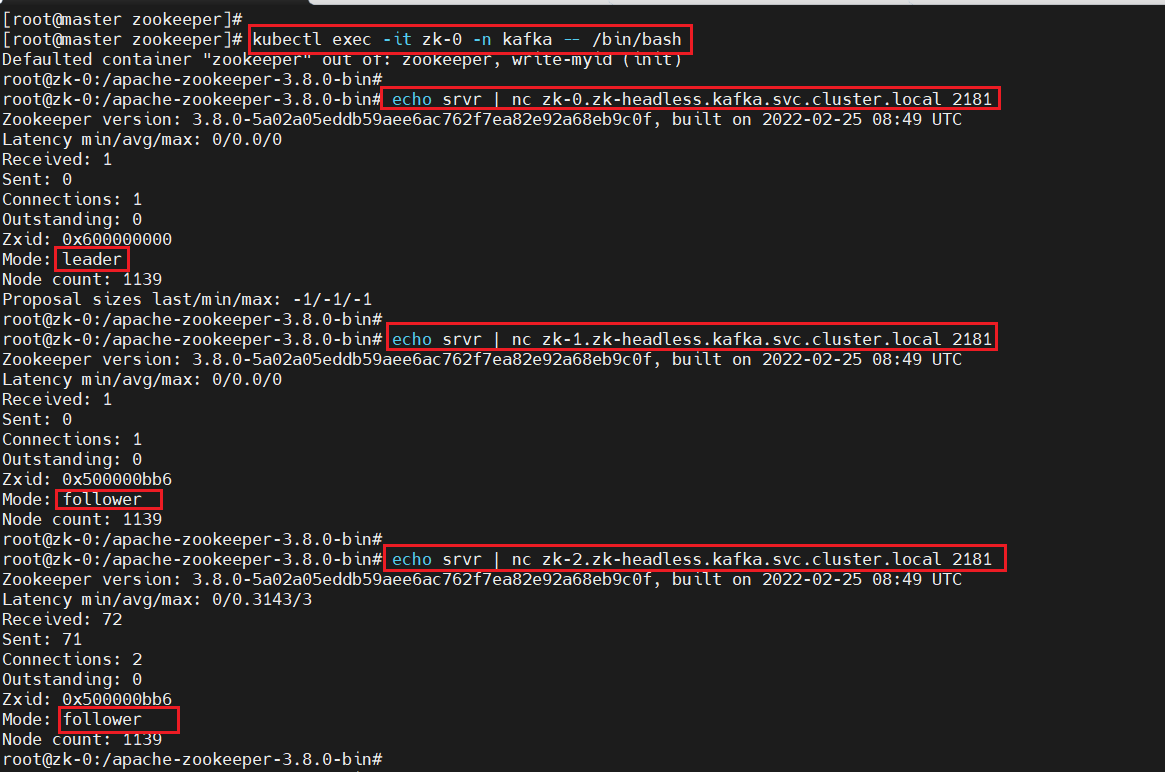
2、在zookeeper集群中写入数据
编写python代码往zookeeper集群中写入1000个数据
from kazoo.client import KazooClientdef xixi(path, data):hosts = "192.168.72.130:30459"# 创建 KazooClient 实例zk = KazooClient(hosts=hosts)try:# 连接到 ZooKeeper 集群zk.start()print("成功连接到 ZooKeeper 集群")# 要写入的路径# path = "/test_node"# # 要写入的数据# data = b"Hello, ZooKeeper!"# 检查路径是否存在,如果不存在则创建if not zk.exists(path):zk.create(path, data)print(f"成功在路径 {path} 创建节点并写入数据")else:# 如果节点已存在,更新数据zk.set(path, data)print(f"成功更新路径 {path} 下的数据")except Exception as e:print(f"发生错误: {e}")finally:# 关闭连接if zk.connected:zk.stop()print("已断开与 ZooKeeper 集群的连接")if __name__ == '__main__':# ZooKeeper 集群地址hosts = "192.168.72.130:30459"# 创建 KazooClient 实例zk = KazooClient(hosts=hosts)for i in range(1,1000):print(i)path = f"/test_{i}"data_1 = f'zookeeper-{i}'data = data_1.encode('utf-8')xixi(path, data)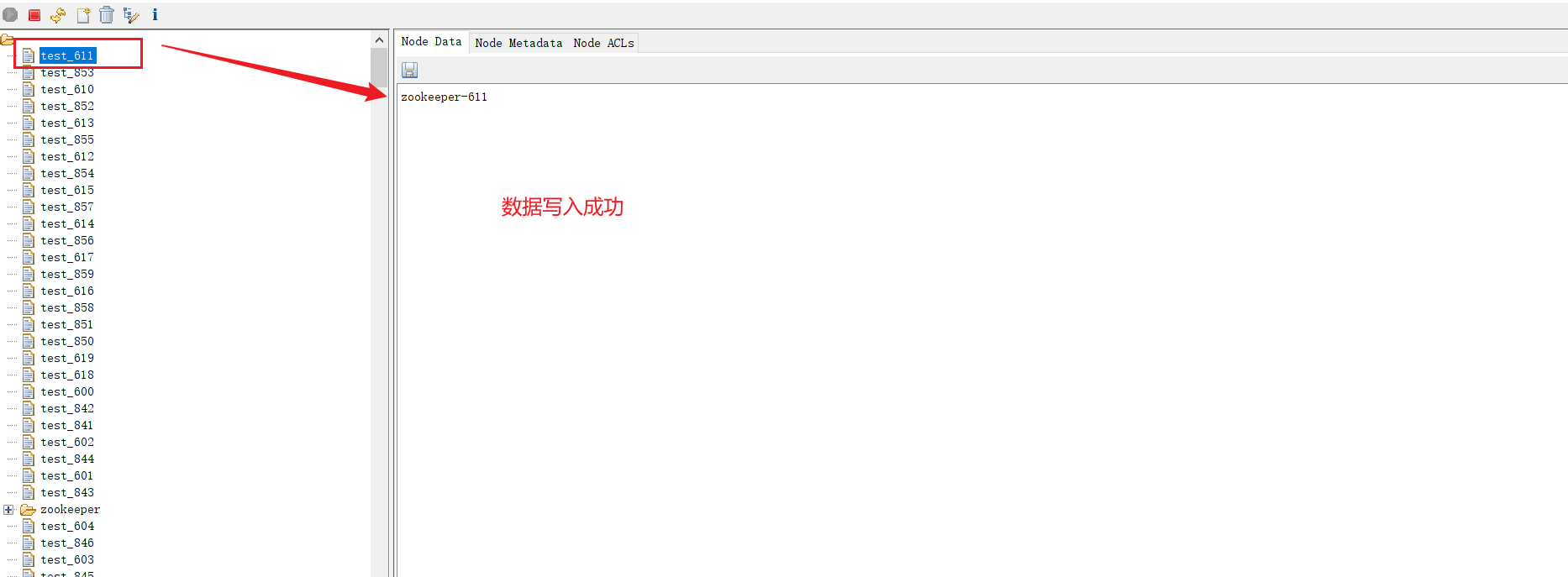
三、污点与容忍
(一)、不设置污点容忍master节点无法参与调度
将master主节点上的污点修改成NoSchedule (修改之后zookeeper pod将不能再调度到master节点上,这意味着剩下两个节点中的有一个节点要运行两个pod,而我们在yaml中配置了亲和性所以已经存在zookeeper标签的节点不能再运行,因此3个副本中只有两个副本是正常的,还有一个处于异常状态)
为了验证上述的说法,我开始以下测试
步骤一:将之前部署的zookeeper集群删除掉(环境清理)
执行脚本: sh deploy.sh delete
deploy.sh脚本内容如下:
##创建命名空间
#kubectl create namespace zookeeper
#
##根据配置文件创建configmapx
#kubectl create configmap zoo.cfg --from-file=zoo.conf
#
##创建PodDisruptionBudget只能指定集群运行节点的最小数
#kubectl apply -f podDisruptionBudget.yaml
#
##创建一个service使得pod之间产生一个可用互相访问的域名用于 StatefulSet 的稳定 DNS 解析,格式为 pod-name.service-name.namespace.svc.cluster.local
#
apply ()
{kubectl apply -f podDisruptionBudget.yamlkubectl apply -f zk-client-service.yamlkubectl apply -f zk-headless-service.yamlkubectl apply -f zoo-config.yamlkubectl apply -f zk-statefulset.yaml
}delete ()
{kubectl delete -f podDisruptionBudget.yamlkubectl delete -f zk-client-service.yamlkubectl delete -f zk-headless-service.yamlkubectl delete -f zoo-config.yamlkubectl delete -f zk-statefulset.yaml
}main ()
{case $1 inapply)apply;;delete)deleteesac
}main $1步骤二:将master污点设置成:NoSchedule
#将污点设置为:NoSchedule
kubectl taint node master node-role.kubernetes.io/master:NoSchedule#查看污点是否设置成功
kubectl describe nodes master|grep -i taint
步骤三:执行脚本sh deploy.sh apply (重新部署zookeeper集群)
测试结果:master节点无法参与调度
只有两个pod成功运行,一个pod处于Pending状态
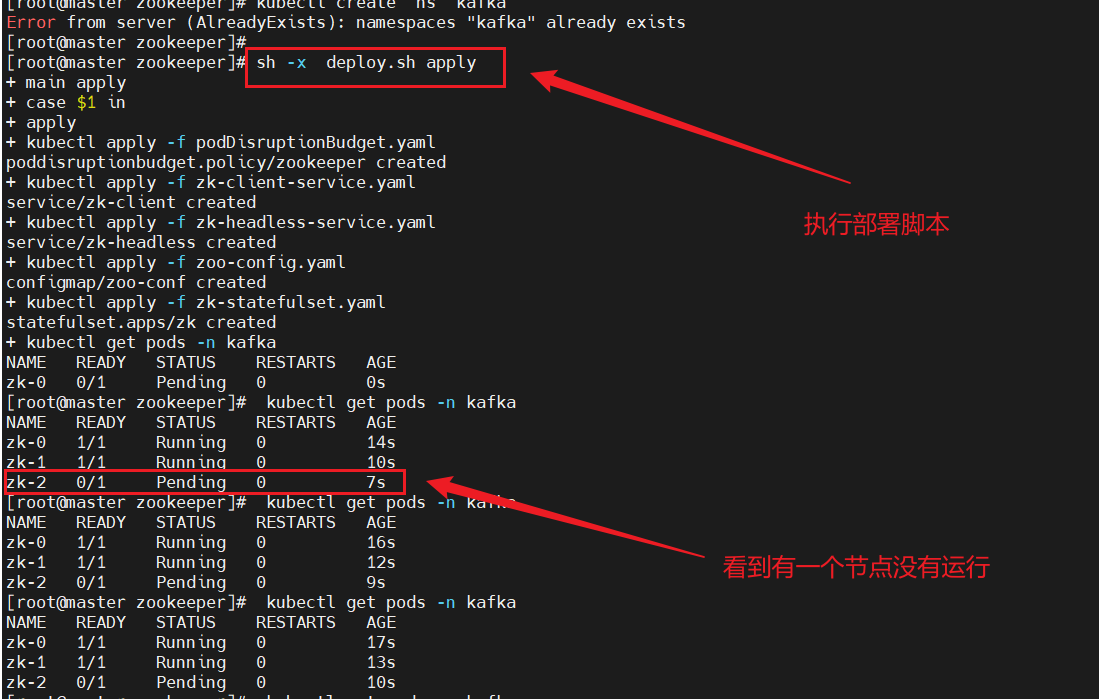
报错信息与设想的结果一致
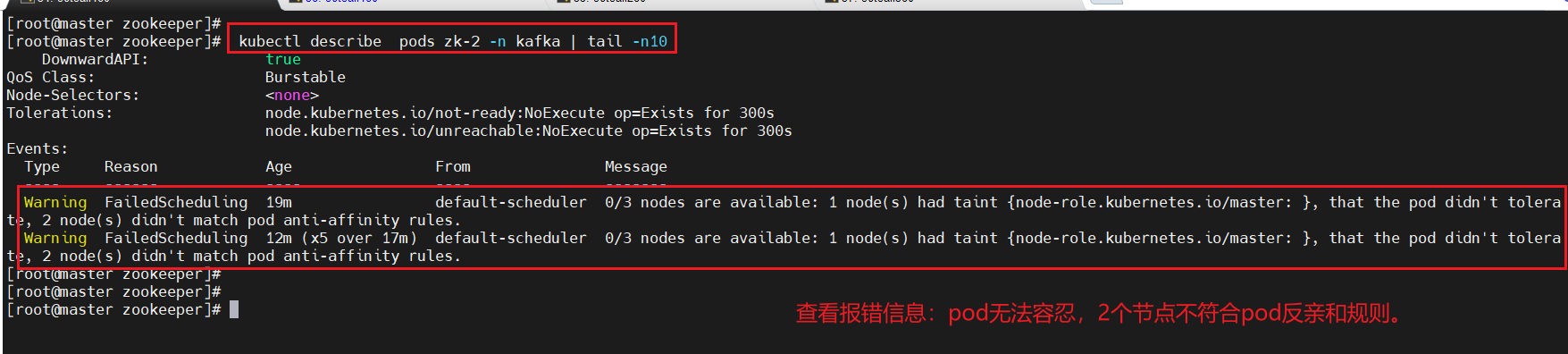

(二)、设置污点容忍master上可以参与调度
假设将zookeeper集群的yaml文件中配置污点容忍,那么master节点也可以参与调度(之前3个副本只能运行两个,如果添加了污点容忍那么master节点上也可以参与调度,即3个pod都能正常运行)
1、污点容忍配置
在 Kubernetes(k8s)里,污点(Taints)和容忍度(Tolerations)是用来控制 Pod 调度到特定节点的机制。污点应用于节点,而容忍度则设置在 Pod 上,允许 Pod 调度到带有特定污点的节点。下面详细介绍如何设置污点和容忍度。
1.1. 设置节点污点
可以使用
kubectl taint命令为节点添加污点。污点的格式为key=value:effect,其中effect有三种类型:
NoSchedule:新的 Pod 不会被调度到带有该污点的节点,但已在该节点上运行的 Pod 不受影响。PreferNoSchedule:系统会尽量避免将新的 Pod 调度到带有该污点的节点,但不是强制的。NoExecute:新的 Pod 不会被调度到带有该污点的节点,并且如果已在该节点上运行的 Pod 没有相应的容忍度,它们会被驱逐。以下是添加污点的示例命令:
# 添加一个 NoSchedule 类型的污点 kubectl taint nodes <node-name> key1=value1:NoSchedule# 添加一个 PreferNoSchedule 类型的污点 kubectl taint nodes <node-name> key2=value2:PreferNoSchedule# 添加一个 NoExecute 类型的污点 kubectl taint nodes <node-name> key3=value3:NoExecute要将
<node-name>替换成实际的节点名称。1.2. 删除节点污点
若要删除节点上的污点,可以使用以下命令:
kubectl taint nodes <node-name> key1:NoSchedule-这里的
-表示删除该污点。1.3. 设置 Pod 容忍度
在 Pod 的 YAML 文件中添加容忍度设置,以下是一个示例:
pod-with-tolerations带有容忍度设置的 Pod YAML 文件
生成 pod-with-tolerations.yaml
apiVersion: v1 kind: Pod metadata:name: pod-with-tolerations spec:containers:- name: nginximage: nginx:1.14.2ports:- containerPort: 80tolerations:- key: "key1"operator: "Equal"value: "value1"effect: "NoSchedule"- key: "key2"operator: "Equal"value: "value2"effect: "PreferNoSchedule"- key: "key3"operator: "Equal"value: "value3"effect: "NoExecute"tolerationSeconds: 3600 # 表示在节点添加该污点后,Pod 还能继续运行 3600 秒在这个示例中:
key:对应节点上污点的键。operator:有Equal和Exists两种取值。Equal表示容忍度的key和value必须与污点的key和value完全匹配;Exists表示只要节点上存在该key的污点,不管value是什么,都能容忍。value:对应节点上污点的值。effect:对应节点上污点的效果。tolerationSeconds:仅在effect为NoExecute时有效,表示在节点添加该污点后,Pod 还能继续运行的时间。1.4. 部署带有容忍度的 Pod
将上述 YAML 文件保存为
pod-with-tolerations.yaml,然后使用以下命令部署 Pod:kubectl apply -f pod-with-tolerations.yaml通过上述步骤,你就可以设置节点的污点和 Pod 的容忍度,从而控制 Pod 的调度。
2、在zookeeper部署的yaml中配置污点容忍
步骤一:查看污点所对应的key值
#查看污点所对应的key
kubectl get nodes master -o yaml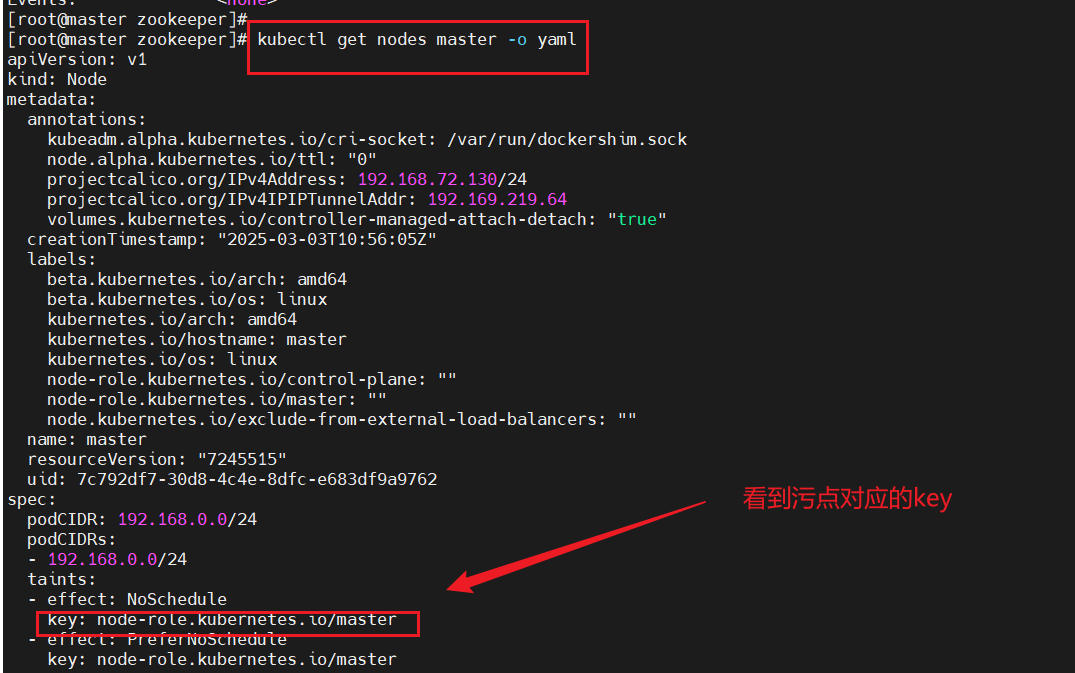
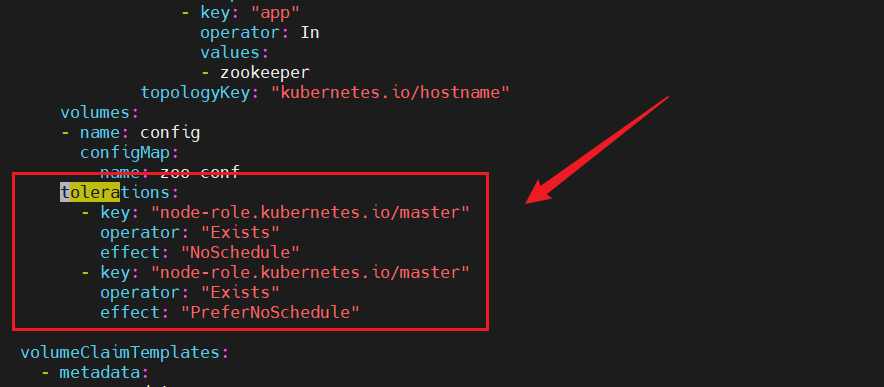
步骤二:在yaml中加入污点容忍
#在pod的spec下加入tolerations:- key: "node-role.kubernetes.io/master"operator: "Exists"effect: "NoSchedule"- key: "node-role.kubernetes.io/master"operator: "Exists"effect: "PreferNoSchedule"
步骤三:部署3个pod的zookeeper集群
sh -x deploy.sh apply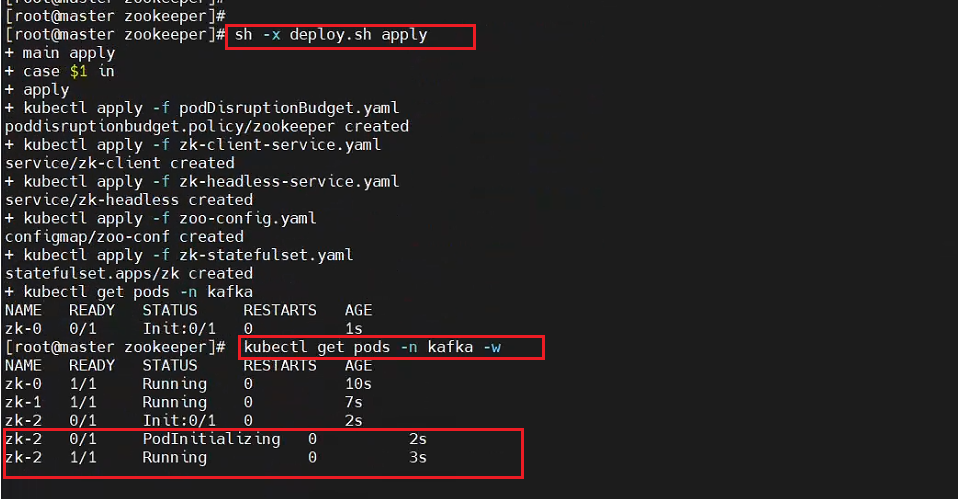
测试结果:master节点参与调度,污点容忍策略生效

参考博客链接:k8s设置容器环境变量&service服务无法获取到环境变量的解决方法_yaml <podname> 变量-CSDN博客
相关文章:
 — zookeeper集群部署(亲和性、污点与容忍测试))
k8s(9) — zookeeper集群部署(亲和性、污点与容忍测试)
一、部署思路 1、前期设想 zookeeper集群至少需要运行3个pod集群才能够正常运行,考虑到节点会有故障的风险这个3个pod最好分别运行在3个不同的节点上(为了实现这一需要用到亲和性和反亲和性概念),在部署的时候对zookeeper运行的pod打标签加…...

Linux操作系统复习
Linux操作系统复习 一. Linux的权限和shell原理1. Linux从广义上讲是什么 从狭义上讲是什么?2. shell是什么?3. 为什么要设置一个shell外壳而不是直接和linux 内核沟通4. shell的原理是什么5. Linux中权限的概念6. 如何提升当前操作的权限7. 文件访问者的…...

深入解析 Linux 中动静态库的加载机制:从原理到实践
引言 在 Linux 开发中,动静态库是代码复用的核心工具。静态库(.a)和动态库(.so)的加载方式差异显著,直接影响程序的性能、灵活性和维护性。本文将深入剖析两者的加载机制,结合实例演示和底层原…...

总账主数据——Part 2 科目-1
本文主要介绍在S4 HANA OP中 总账主数据的后台配置及前台操作。 目录 1. 准备 1.1 科目表的定义(OB13) 1.2 给公司代码分配科目表(OB62) 1.3 定义科目组(OBD4) 1.4 定义留存收益科目(OB53) 1.5 维护科目表层“文本标识” (OBT6) 1.6 维护公司代码层“文本标识” (OBT…...

借助内核逻辑锁pagecache到内存
一、背景 内存管理是一个永恒的主题,尤其在内存紧张触发内存回收的时候。系统在通过磁盘获取磁盘上的文件的内容时,若不开启O_DIRECT方式进行读写,磁盘上的任何东西都会被缓存到系统里,我们称之为page cache。可以想象࿰…...

✨ Apifox:这玩意儿是接口界的“瑞士军刀”吧![特殊字符][特殊字符]
——全网最皮最全测评,打工人看了直呼“真香” 📢 友情提醒 还在用 Postman 测接口、Swagger 写文档、Mock.js 造假数据、脑细胞搞团队协作? 停! 你仿佛在玩《工具人环游记》,而隔壁同事已经用 Apifox 「一杆清台」了…...

《普通逻辑》学习记录——性质命题及其推理
目录 一、性质命题概述 二、性质命题的种类 2.1、性质命题按质的分类 2.2、性质命题按量的分类 2.3、性质命题按质和量结合的分类 2.4、性质命题的基本形式归纳 三、四种命题的真假关系 3.1、性质命题与对象关系 3.2、四种命题的真假判定 3.3、四种命题的对当关系 四、四种命题…...
接入华为云iotDA平台的路径元素有哪些不同?)
设备接入与APP(应用程序)接入华为云iotDA平台的路径元素有哪些不同?
目录 壹、设备接入华为云iotDA 🏢 形象比喻:设备 员工,IoTDA 平台 安保森严的总部大楼 一、📍 平台接入地址 总部大楼地址 二、🧾 接入凭证 出入证 / 门禁卡 / 工牌 1. 设备密钥或证书 2. 预置接入凭证密钥&a…...

【git#4】分支管理 -- 知识补充
一、bug 分支 假如我们现在正在 dev2 分支上进行开发,开发到一半,突然发现 master 分支上面有 bug,需要解决。 在Git中,每个 bug 都可以通过一个新的临时分支来修复,修复后,合并分支,然后将临…...

AXOP34062: 40V双通道运算放大器
AXOP34062是一款通用型高压双通道运算放大器,产品的工作电压为2.5V至40V,具有25MHz的带宽,压摆率为10V/μs,静态电流为650A。较高的耐压和带宽使其可以胜任绝大多数的高压应用场景。 主要特性 轨到轨的输入输出范围低输入失调电…...
——光流估计)
OpenCv高阶(十)——光流估计
文章目录 前言一、光流估计二、使用步骤1、导库读取视频、随机初始化颜色2、初始化光流跟踪3、视频帧处理循环4、光流计算与可视化5、循环控制与资源释放完整代码 总结 前言 在计算机视觉领域,光流估计是捕捉图像序列中像素点运动信息的核心技术。它描述了图像中每…...

BS客户端的单点登录
1、参数类似于“XXXXX://?userIdsystem&time1696830378038&token38a8ea526537766f01ded33a6cdfa5bd” 2、在config里加一个LoginSecret参数可随意指定一个字符串 3、BS登录代码里会对“LoginSecret的参数值用户ID时间戳”进行MD5加密形成token,与传过来的…...
)
通讯录完善版本(详细讲解+源码)
目录 前言 一、使通讯可以动态更新内存 1、contact.h 2、contact.c 存信息: 删除联系人,并试一个不存在的人的信息,看看会不会把其他人删了 编辑 修改: 编辑 排序: 编辑 销毁: 编辑 …...

第3讲:ggplot2完美入门与美化细节打磨——从基础绘制到专业级润色
目录 1. 为什么选择ggplot2? 2. 快速了解ggplot2绘图核心逻辑 3. 基础绘图示范:柱状图、折线图、散点图 (1)简单柱状图 (2)折线图示范 (3)高级散点图 + 拟合线 4. 精细美化:细节打磨决定专业感 5. 推荐的美化小插件(可选进阶) 6. 小练习:快速上手一幅美化…...

带宽?增益带宽积?压摆率?
一、带宽(Bandwidth) 1.科学定义: 带宽指信号或系统能够有效通过的频率范围,通常定义为信号功率下降到中频值的一半(即 - 3dB)时的最高频率与最低频率之差。对于运算放大器(Op-Amp)…...

为什么栈内存比堆内存速度快?
博主介绍:程序喵大人 35- 资深C/C/Rust/Android/iOS客户端开发10年大厂工作经验嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手《C20高级编程》《C23高级编程》等多本书籍著译者更多原创精品文章,首发gzh,见文末👇…...

什么是非关系型数据库
什么是非关系型数据库? 引言 随着互联网应用的快速发展,传统的基于表格的关系型数据库(如 MySQL、Oracle 等)已经不能完全满足现代应用程序的需求。在这种背景下,非关系型数据库(NoSQL 数据库)…...

制作一个简单的操作系统9
自定义 myprintf 函数实现解析 探索如何实现一个自定义的 printf 函数来处理任意 %d 和 %s 组合 (说实话,想不用任何库函数和头文件,纯C实现太难了,我放弃了,弄了一个简陋版本 对付用) 运行效果: Hello 123 World 456 Coding这样参数传递:(最多支持5个参数,按顺序…...

华为Pura X的智控键:让折叠机体验更上一层楼的设计
还记得Mate 70系列刚出那会,我体验了下智控键,那时候就觉得这个“把快捷方式做进电源键”的交互方式非常惊艳,没想到在Pura X上,这种便捷体验感更上了一层楼。 智控键:折叠屏手机的天选快捷方式? 传统折叠…...

打造高功率、高电流和高可靠性电路板的厚铜PCB生产
厚铜PCB生产是指制作一种具有较厚铜层的PCB(Printed Circuit Board,印刷电路板)。这种PCB通常用于高功率、高电流和高可靠性的电子设备中。厚铜PCB的生产过程包括以下几个 主要步骤: 1. 基材准备 厚铜PCB的基材通常采用FR4或CEM-…...
---程序调用AI大模型的四种方式(SpringAI+LangChain4j+SDK+HTTP))
AI超级智能体教程(三)---程序调用AI大模型的四种方式(SpringAI+LangChain4j+SDK+HTTP)
文章目录 1.安装SDK(查看文档)2.创建API-key3.项目引入灵积大模型4.HTTP接入的方式5.SpringAI引入5.1添加依赖5.2添加配置5.3测试代码 6.LangChain4j引入6.1依赖引入6.2测试提问 1.安装SDK(查看文档) 安装阿里云百炼SDK_大模型服…...

JDBC连接数据库
一、查询 sqlserver数据库 private List<Map<String, String>> getPathList(String id) throws Exception {String driverName "com.microsoft.sqlserver.jdbc.SQLServerDriver";String dataBaseurl "jdbc:sqlserver://localhost:1433;SelectMeth…...
的区别与实现)
常见缓存淘汰算法(LRU、LFU、FIFO)的区别与实现
一、前言 缓存淘汰算法主要用于在内存资源有限的情况下,优化缓存空间的使用效率。以确保缓存系统在容量不足时能够智能地选择需要移除的数据。 二、LRU(Least Recently Used) 核心思想:淘汰最久未被访问的数据。实现方式&#x…...

深度学习--循环神经网络RNN
文章目录 前言一、RNN介绍1、传统神经网络存在的问题2、RNN的核心思想3、 RNN的局限性 二、RNN基本结构1、RNN基本结构2、推导3、注意4、循环的由来5、再谈RNN的局限 总结 前言 循环神经网络(RNN)的起源可以追溯到1982年,由Saratha Sathasiv…...

大学IP广播系统解决方案:构建数字化智慧化大学校园IP广播平台
大学IP广播系统解决方案:构建数字化智慧化大学校园IP广播平台 北京海特伟业科技有限公司任洪卓于2025年4月24日发布 随着教育信息化建设的深入推进,传统的模拟广播系统已无法满足现代化校园对智能化、场景化、融合化的管理需求。为此,海特伟业提出构建…...

#ifndef #else #endif条件编译
目录 一、#ifdef 1. 基本用法 2. 查看头文件 3. 目的 4. 常见用途 4. 取消定义 5.小结 二、#ifndef和#ifdef区别 1. #ifdef 2. #ifndef 3.结论 一、#ifdef 宏定义 #define H_PWM_L_ON 的作用是创建一个名为 H_PWM_L_ON 的宏。以下是这个宏定义的一些关键点ÿ…...

SystemVerilog语法之typedef与自定义结构
1.7 使用typedef创建新的类型 在Verilog中,你可以为操作数的位宽或者类型分别定义一个宏,但是你并没有创建新的数据类型,而是进行了文本的替换。在SystemVerilog中,可以使用typedef创建新的类型。可以将parameter和typedef语句放…...

【防火墙 pfsense】2配置
(1)接口配置和接口 IP 地址分配 ->配置广域网(WAN)和局域网(LAN)接口,分配设备标识符,如 eth0、eth1 等; ->如将WAN 接口将被分配到 eth0,而 LAN 接口将…...

数据结构之排序
排序 一.比较排序1.插入排序基本思想1.1直接插入排序1.2希尔排序 2.选择排序直接选择排序堆排序 3.交换排序冒泡排序快速排序hoare版本挖坑法lomuto前后指针非递归版本 4.归并排序非递归的归并排序 非比较排序1.计数排序 排序算法复杂度及稳定性分析 一.比较排序 1.插入排序 …...

cgroup sched_cfs_bandwidth_slice参数的作用及效果
一、背景 cgroup是一个非常重要的功能,其中cgroup cpu这块有不少功能,在之前的博客 CFS及RT调度整体介绍_rt调度器-CSDN博客 里,我们分析了cfs的组调度也就是cgroup cpu的这块内核逻辑的细节侧重于调度逻辑这块,在之前的博客 cgr…...

【C++指南】告别C字符串陷阱:如何实现封装string?
🌟 各位看官好,我是egoist2023! 🌍 种一棵树最好是十年前,其次是现在! 💬 注意:本章节只详讲string中常用接口及实现,有其他需求查阅文档介绍。 🚀 今天通过了…...
)
液体神经网络LNN-Attention创新结合——基于液体神经网络的时间序列预测(PyTorch框架)
1.数据集介绍 ETT(电变压器温度):由两个小时级数据集(ETTh)和两个 15 分钟级数据集(ETTm)组成。它们中的每一个都包含 2016 年 7 月至 2018 年 7 月的七种石油和电力变压器的负载特征。 traffic(交通) :描…...

kafka和Spark-Streaming2
Kafka 工作流程及文件存储机制 Kafka 中消息是以topic 进行分类的,生产者生产消息,消费者消费消息,都是面向topic 的。 “.log”文件存储大量的数据,“.index”文件存储偏移量索引信息,“.timeindex”存储时间戳索引文…...
)
MySQL日期函数的详细教程(包含常用函数及其示例)
概述 以下是一个关于MySQL日期函数的详细教程,包含常用函数及其示例内容以转换为PDF电子书,喜欢的朋友可以转存慢慢享用:https://pan.quark.cn/s/57d2e491bbbe 1. 获取当前日期和时间 • CURDATE() / CURRENT_DATE() 返回当前日期…...

P4017 最大食物链计数-拓扑排序
P4017 最大食物链计数 题目来源-洛谷 题意 要求最长食物链的数量。按照题意,最长食物链就是指有向无环图DAG中入度为0到出度为0的不同路径的数量(链数) 思路 在计算时,明显:一个被捕食者所…...

C语言——字串处理
C语言——字串处理 一、问题描述二、格式要求1.输入形式2.输出形式3.样例 三、实验代码 一、问题描述 现有两个字符串s1和s2,它们最多都只能包含255个字符。编写程序,将字符串s1中所有出现在字符串s2中的字符删去,然后输出s1。 二、格式要求…...

工业排风轴流风机:强劲动力与节能设计的完美融合
在工业生产中,通风换气是保障作业环境安全、维持设备正常运行的关键环节。工业排风轴流风机凭借其独特的设计,将强劲动力与节能特性完美融合,成为众多工业场景的首选通风设备,为企业高效生产与绿色发展提供了可靠支持。 工业排风…...

【Test】单例模式❗
文章目录 1. 单例模式2. 单例模式简单示例3. 懒汉模式4. 饿汉模式5. 懒汉式和饿汉式的区别 1. 单例模式 🐧定义:保证一个类仅有一个实例,并提供一个访问它的全局访问点。 单例模式是一种常用的软件设计模式,在它的核心结构中只包…...

3.3 Spring Boot文件上传
在 Spring Boot 项目中实现文件上传功能,首先创建项目并添加依赖,包括 Commons IO 用于文件操作。接着,创建文件上传控制器 FileUploadController,定义上传目录并实现文件上传逻辑,通过生成唯一文件名避免文件冲突。创…...
使用gstreamer)
【玩泰山派】7、玩linux桌面环境xfce - (4)使用gstreamer
文章目录 前言gstreamergstreamer概述基本概念主要功能应用场景开发方式 安装gstreamer使用gstreamer使用gstreamer播放视频 前言 玩一下gstreamer,使用gstreamer去播放下音视频 gstreamer gstreamer概述 GStreamer是一个用于构建多媒体应用程序的开源库和框架&…...

cpu性能统计
cpu负载 top中avg,/proc/loadavg, 包括cpu密集型任务io型任务 统计流程 每cpu scheduler_tick ----calc_global_load_tick : 当前瞬时 cpu::this_rq:: nr_runningnr_inunterrupt->calc_load_tasks(全局变量) 全局 do_timer ----calc_global_load&a…...

Java对接企业微信实战笔记
Java对接企业微信实战笔记 微信开发文档 有关企业微信的服务商的一些配置参考企业微信创建的服务商配置信息 一 流程图 只要企业安装应用后,就可以获取到企业的信息 二 创建应用获取suite_ticket 1.创建应用 微信开发平台得是服务商角色才能进入服务商后台创建一…...

HashMap的源码解析
HashMap基于哈希表的Map接口实现,是以key-value存储形式存在,即主要用来存放键值对。HashMap的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。 JDK1.8 之前 HashMap由数…...

【金仓数据库征文】金仓数据库KingbaseES:在技术与人文交织中开拓信创未来
🎁个人主页:User_芊芊君子 🎉欢迎大家点赞👍评论📝收藏⭐文章 🔍系列专栏:AI 【引言】 在信息技术应用创新(信创)的浪潮下,数据库作为数字经济的基石…...

【AI】[特殊字符]生产规模的向量数据库 Pinecone 使用指南
一、Pinecone 的介绍 Pinecone是一个完全托管的向量数据库服务,专为大规模机器学习应用设计。它允许开发者轻松存储、搜索和管理高维向量数据,为推荐系统、语义搜索、异常检测等应用提供强大的基础设施支持。 1.1 Pinecone的核心特性 1. 高性能向量搜…...

OpenHarmony之电源模式定制开发指导
OpenHarmony之电源模式定制开发指导 概述 简介 OpenHarmony默认提供了电源模式(如正常模式、性能模式、省电模式、极致省电模式)的特性。但由于不同产品的部件存在差异,导致在同样场景下电源模式的配置需要也存在差异,为此&…...

Jsp技术入门指南【十】IDEA 开发环境下实现 MySQL 数据在 JSP 页面的可视化展示,实现前后端交互
Jsp技术入门指南【十】IDEA 开发环境下实现 MySQL 数据在 JSP 页面的可视化展示,实现前后端交互 前言一、JDBC 核心接口和类:数据库连接的“工具箱”1. 常用的 2 个“关键类”2. 必须掌握的 5 个“核心接口” 二、创建 JDBC 程序的步骤1. 第一步…...

JDBC之ORM思想及SQL注入
目录 一. ORM编程思想 1. 简介 2. 实操ORM思想 a. Students实体类 b. ORM映射 二. SQL注入 1. 简介 2. 解决SQL注入 三. 总结 前言 本文来讲解ORM编程思想和SQL注入,旨在帮助大家更容易的理解和掌握 个人主页:艺杯羹 系列专栏:JDBC …...

UniApp学习笔记
在uniapp中使用View标签来代替div标签,使用rpx来取代px,rpx动态适配屏幕宽度750rpx100vw H5端不支持*的css选择器 body的元素选择器请改为page div和ul和li等改为view、 span和font改为text a改为navigator img改为image scoped:非H5端默认并未启…...

统计术语学习
基期、现期 作为对比参照的时期称为基期,而相对于基期的称为现期。 描述具体数值时我们称之为基期量和现期量。 【例 1】2017 年比 2016 年第三产业 GDP 增长 6.8%, (2016)为基期,(2017) 为现…...