PyTorch 深度学习实战(39):归一化技术对比(BN/LN/IN/GN)
在上一篇文章中,我们全面解析了注意力机制的发展历程。本文将深入探讨深度学习中的归一化技术,对比分析BatchNorm、LayerNorm、InstanceNorm和GroupNorm四种主流方法,并通过PyTorch实现它们在图像分类和生成任务中的应用效果。

一、归一化技术基础
1. 四大归一化方法对比
| 方法 | 计算维度 | 训练/推理差异 | 适用场景 | 显存占用 |
|---|---|---|---|---|
| BatchNorm | (N,H,W) | 需维护running统计量 | 小batch分类网络 | 高 |
| LayerNorm | (C,H,W) | 无状态 | Transformer/RNN | 中 |
| InstanceNorm | (H,W) | 无状态 | 风格迁移 | 低 |
| GroupNorm | (G,H,W) | 无状态 | 大batch检测/分割 | 中 |
2. 归一化通用公式

二、PyTorch实现对比
1. 环境配置
pip install torch torchvision matplotlib2. 归一化层实现对比
import torch
import torch.nn as nn
# 输入数据模拟 (batch_size=4, channels=3, height=32, width=32)
x = torch.rand(4, 4, 32, 32)
# BatchNorm实现
bn = nn.BatchNorm2d(num_features=4)
y_bn = bn(x)
print("BN 输出均值:", y_bn.mean(dim=(0,2,3))) # 应接近0
print("BN 输出方差:", y_bn.var(dim=(0,2,3))) # 应接近1
# LayerNorm实现
ln = nn.LayerNorm([4, 32, 32])
y_ln = ln(x)
print("LN 输出均值:", y_ln.mean(dim=(1,2,3))) # 每个样本接近0
print("LN 输出方差:", y_ln.var(dim=(1,2,3))) # 每个样本接近1
# InstanceNorm实现
in_norm = nn.InstanceNorm2d(num_features=4)
y_in = in_norm(x)
print("IN 输出均值:", y_in.mean(dim=(2,3))) # 每个样本每个通道接近0
print("IN 输出方差:", y_in.var(dim=(2,3))) # 每个样本每个通道接近1
# GroupNorm实现 (分组数2)
gn = nn.GroupNorm(num_groups=2, num_channels=4)
y_gn = gn(x)
print("GN 输出均值:", y_gn.mean(dim=(2,3))) # 每个样本每组接近0
print("GN 输出方差:", y_gn.var(dim=(2,3))) # 每个样本每组接近1输出为:
BN 输出均值: tensor([-4.7032e-08, 4.1910e-09, -1.3504e-08, 1.8626e-08],grad_fn=<MeanBackward1>)
BN 输出方差: tensor([1.0001, 1.0001, 1.0001, 1.0001], grad_fn=<VarBackward0>)
LN 输出均值: tensor([-8.3819e-09, -5.9605e-08, 1.1642e-08, 1.6764e-08],grad_fn=<MeanBackward1>)
LN 输出方差: tensor([1.0001, 1.0001, 1.0001, 1.0001], grad_fn=<VarBackward0>)
IN 输出均值: tensor([[-4.0978e-08, 1.9558e-08, 5.1456e-08, -2.9802e-08],[-1.6298e-08, 2.3283e-09, 7.7649e-08, 4.7730e-08],[ 6.5193e-09, 2.0489e-08, 3.6671e-08, 1.5367e-08],[-4.8429e-08, -6.9849e-08, 1.4901e-08, 4.6566e-09]])
IN 输出方差: tensor([[1.0009, 1.0009, 1.0009, 1.0009],[1.0009, 1.0009, 1.0009, 1.0009],[1.0009, 1.0009, 1.0009, 1.0009],[1.0009, 1.0009, 1.0009, 1.0009]])
GN 输出均值: tensor([[ 0.0356, -0.0356, 0.0170, -0.0170],[-0.0239, 0.0239, 0.0233, -0.0233],[ 0.0003, -0.0003, 0.0070, -0.0070],[ 0.0036, -0.0036, -0.0190, 0.0190]], grad_fn=<MeanBackward1>)
GN 输出方差: tensor([[0.9619, 1.0373, 0.9764, 1.0247],[1.0284, 0.9722, 1.0028, 0.9979],[0.9819, 1.0199, 0.9763, 1.0253],[1.0116, 0.9901, 1.0011, 0.9999]], grad_fn=<VarBackward0>)3. ResNet中的归一化实验
import torch
import torch.nn as nn
from torchvision.models import resnet18
class NormResNet(nn.Module):def __init__(self, norm_type='bn'):super().__init__()self.norm_type = norm_type# 基础块def make_block(in_c, out_c, stride=1):return nn.Sequential(nn.Conv2d(in_c, out_c, kernel_size=3, stride=stride, padding=1, bias=False),self.get_norm(out_c),nn.ReLU(inplace=True))# 构建模型self.model = nn.Sequential(make_block(3, 64),make_block(64, 128, stride=2),make_block(128, 256, stride=2),make_block(256, 512, stride=2),nn.AdaptiveAvgPool2d(1),nn.Flatten(),nn.Linear(512, 10))def get_norm(self, num_features):if self.norm_type == 'bn':return nn.BatchNorm2d(num_features)elif self.norm_type == 'ln':return nn.GroupNorm(1, num_features) # LayerNorm是GroupNorm的特例elif self.norm_type == 'in':return nn.InstanceNorm2d(num_features)elif self.norm_type == 'gn':return nn.GroupNorm(4, num_features) # 假设分为4组else:raise ValueError(f"未知归一化类型: {self.norm_type}")def forward(self, x):return self.model(x)
# 测试不同归一化
for norm_type in ['bn', 'ln', 'in', 'gn']:model = NormResNet(norm_type=norm_type)print(f"\n{norm_type.upper()}参数量:", sum(p.numel() for p in model.parameters()))y = model(torch.rand(2, 3, 32, 32))print(f"{norm_type.upper()}输出形状:", y.shape)输出为:
BN参数量: 1557066
BN输出形状: torch.Size([2, 10])
LN参数量: 1557066
LN输出形状: torch.Size([2, 10])
IN参数量: 1555146
IN输出形状: torch.Size([2, 10])
GN参数量: 1557066
GN输出形状: torch.Size([2, 10])三、应用场景分析
1. 图像分类任务对比
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义模型
class NormResNet(nn.Module):def __init__(self, norm_type='bn'):super().__init__()self.norm_type = norm_typedef make_block(in_c, out_c, stride=1):return nn.Sequential(nn.Conv2d(in_c, out_c, kernel_size=3, stride=stride, padding=1, bias=False),self.get_norm(out_c),nn.ReLU(inplace=True))self.model = nn.Sequential(make_block(3, 64),make_block(64, 128, stride=2),make_block(128, 256, stride=2),make_block(256, 512, stride=2),nn.AdaptiveAvgPool2d(1),nn.Flatten(),nn.Linear(512, 10))def get_norm(self, num_features):if self.norm_type == 'bn':return nn.BatchNorm2d(num_features)elif self.norm_type == 'ln':return nn.GroupNorm(1, num_features)elif self.norm_type == 'in':return nn.InstanceNorm2d(num_features)elif self.norm_type == 'gn':return nn.GroupNorm(4, num_features)else:raise ValueError(f"Unknown norm type: {self.norm_type}")def forward(self, x):return self.model(x)
# 数据准备
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_set = CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=64, shuffle=True)
# 训练函数
def train_model(norm_type, epochs=5):model = NormResNet(norm_type=norm_type).to(device)optimizer = optim.Adam(model.parameters(), lr=0.001)criterion = nn.CrossEntropyLoss()losses = []for epoch in range(epochs):model.train()for i, (inputs, targets) in enumerate(train_loader):inputs, targets = inputs.to(device), targets.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()if i % 100 == 0:print(f"{norm_type.upper()} Epoch {epoch+1}/{epochs} | Batch {i}/{len(train_loader)} | Loss: {loss.item():.4f}")losses.append(loss.item())return losses
# 对比训练
norm_types = ['bn', 'ln', 'gn']
results = {t: train_model(t) for t in norm_types}
# 绘制训练曲线
plt.figure(figsize=(10, 6))
for t, losses in results.items():plt.plot(losses, label=t.upper())
plt.xlabel('Iterations')
plt.ylabel('Loss')
plt.legend()
plt.show()输出为:
BN Epoch 1/5 | Batch 0/782 | Loss: 2.3054
BN Epoch 1/5 | Batch 100/782 | Loss: 1.5884
BN Epoch 1/5 | Batch 200/782 | Loss: 1.3701
BN Epoch 1/5 | Batch 300/782 | Loss: 1.3469
BN Epoch 1/5 | Batch 400/782 | Loss: 1.2706
BN Epoch 1/5 | Batch 500/782 | Loss: 1.0940
BN Epoch 1/5 | Batch 600/782 | Loss: 1.0464
BN Epoch 1/5 | Batch 700/782 | Loss: 1.0236
......
BN Epoch 5/5 | Batch 0/782 | Loss: 0.4647
BN Epoch 5/5 | Batch 100/782 | Loss: 0.5012
BN Epoch 5/5 | Batch 200/782 | Loss: 0.7380
BN Epoch 5/5 | Batch 300/782 | Loss: 0.4303
BN Epoch 5/5 | Batch 400/782 | Loss: 0.4039
BN Epoch 5/5 | Batch 500/782 | Loss: 0.5159
BN Epoch 5/5 | Batch 600/782 | Loss: 0.5286
BN Epoch 5/5 | Batch 700/782 | Loss: 0.6188
LN Epoch 1/5 | Batch 0/782 | Loss: 2.3177
LN Epoch 1/5 | Batch 100/782 | Loss: 2.0628
LN Epoch 1/5 | Batch 200/782 | Loss: 1.9420
LN Epoch 1/5 | Batch 300/782 | Loss: 1.8320
LN Epoch 1/5 | Batch 400/782 | Loss: 1.7908
LN Epoch 1/5 | Batch 500/782 | Loss: 1.4127
LN Epoch 1/5 | Batch 600/782 | Loss: 1.2469
LN Epoch 1/5 | Batch 700/782 | Loss: 1.6888
......
LN Epoch 5/5 | Batch 0/782 | Loss: 0.8508
LN Epoch 5/5 | Batch 100/782 | Loss: 0.9067
LN Epoch 5/5 | Batch 200/782 | Loss: 0.7935
LN Epoch 5/5 | Batch 300/782 | Loss: 0.7667
LN Epoch 5/5 | Batch 400/782 | Loss: 1.0387
LN Epoch 5/5 | Batch 500/782 | Loss: 0.5732
LN Epoch 5/5 | Batch 600/782 | Loss: 0.9758
LN Epoch 5/5 | Batch 700/782 | Loss: 0.5918
GN Epoch 1/5 | Batch 0/782 | Loss: 2.3121
GN Epoch 1/5 | Batch 100/782 | Loss: 2.0842
GN Epoch 1/5 | Batch 200/782 | Loss: 1.8134
GN Epoch 1/5 | Batch 300/782 | Loss: 1.7125
GN Epoch 1/5 | Batch 400/782 | Loss: 1.6534
GN Epoch 1/5 | Batch 500/782 | Loss: 1.4146
GN Epoch 1/5 | Batch 600/782 | Loss: 1.1490
GN Epoch 1/5 | Batch 700/782 | Loss: 1.3987
......
GN Epoch 5/5 | Batch 0/782 | Loss: 0.7947
GN Epoch 5/5 | Batch 100/782 | Loss: 0.7361
GN Epoch 5/5 | Batch 200/782 | Loss: 0.7224
GN Epoch 5/5 | Batch 300/782 | Loss: 0.6624
GN Epoch 5/5 | Batch 400/782 | Loss: 0.7634
GN Epoch 5/5 | Batch 500/782 | Loss: 0.7282
GN Epoch 5/5 | Batch 600/782 | Loss: 0.6874
GN Epoch 5/5 | Batch 700/782 | Loss: 0.7992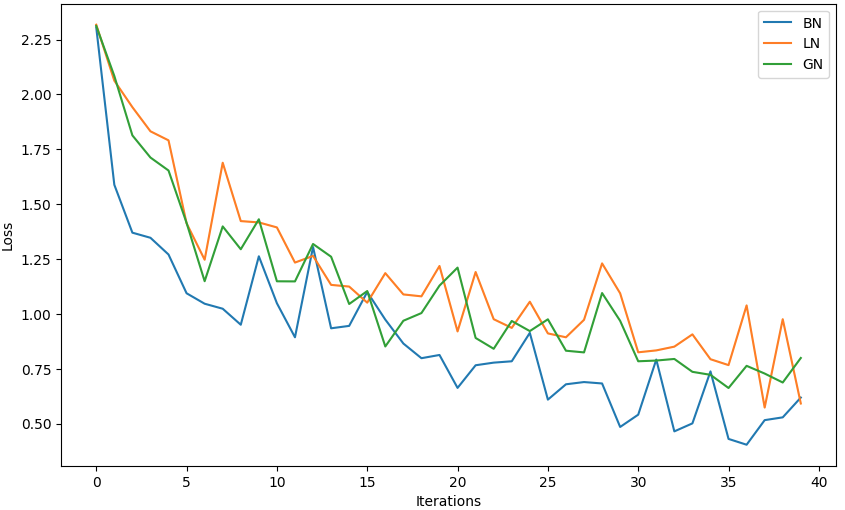
2. 风格迁移中的InstanceNorm
import torch
import torch.nn as nn
import torch.nn.functional as F
class StyleTransferNet(nn.Module):def __init__(self):super().__init__()# 下采样部分(特征提取)self.downsample = nn.Sequential(# 第一层卷积:保持尺寸不变nn.Conv2d(3, 32, kernel_size=9, padding=4), # 输入通道3,输出通道32nn.InstanceNorm2d(32), # 实例归一化,适合风格迁移nn.ReLU(inplace=True), # 激活函数# 第二层卷积:尺寸减半nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1),nn.InstanceNorm2d(64),nn.ReLU(inplace=True),# 第三层卷积:尺寸再减半nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),nn.InstanceNorm2d(128),nn.ReLU(inplace=True),)# 残差块部分(核心风格变换)self.residual = nn.Sequential(*[ResidualBlock(128) for _ in range(5)] # 5个残差块,保持特征图尺寸)# 上采样部分(图像重建)self.upsample = nn.Sequential(# 第一次转置卷积:尺寸加倍nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1),nn.InstanceNorm2d(64),nn.ReLU(inplace=True),# 第二次转置卷积:尺寸恢复原始大小nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, output_padding=1),nn.InstanceNorm2d(32),nn.ReLU(inplace=True),# 最终卷积层:输出RGB图像nn.Conv2d(32, 3, kernel_size=9, padding=4),nn.Tanh() # 输出值归一化到[-1, 1]范围)def forward(self, x):# 前向传播流程:下采样 -> 残差块 -> 上采样x = self.downsample(x)x = self.residual(x)x = self.upsample(x)return x
class ResidualBlock(nn.Module):"""残差块结构,帮助网络保持内容特征"""def __init__(self, channels):super().__init__()self.block = nn.Sequential(nn.Conv2d(channels, channels, kernel_size=3, padding=1),nn.InstanceNorm2d(channels),nn.ReLU(inplace=True),nn.Conv2d(channels, channels, kernel_size=3, padding=1),nn.InstanceNorm2d(channels))def forward(self, x):# 残差连接:输入 + 卷积处理结果return x + self.block(x)
# 测试代码
if __name__ == "__main__":# 自动选择GPU或CPU设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 实例化网络model = StyleTransferNet().to(device)# 生成测试输入(模拟256x256的RGB图像)test_input = torch.randn(1, 3, 256, 256).to(device)# 前向传播with torch.no_grad(): # 测试时不计算梯度output = model(test_input)# 打印输入输出信息print("\n测试结果:")print(f"输入形状: {test_input.shape}")print(f"输出形状: {output.shape}")print(f"输出值范围: [{output.min().item():.3f}, {output.max().item():.3f}]")# 计算参数量total_params = sum(p.numel() for p in model.parameters())print(f"\n模型总参数量: {total_params:,}")测试结果:
输入形状: torch.Size([1, 3, 256, 256])
输出形状: torch.Size([1, 3, 256, 256])
输出值范围: [-0.964, 0.890]模型总参数量: 1,676,0353. Transformer中的LayerNorm
import torch
import torch.nn as nn
import mathclass MultiHeadAttention(nn.Module):"""多头注意力机制"""def __init__(self, d_model, n_head):super().__init__()assert d_model % n_head == 0 # 确保模型维度能被头数整除self.d_model = d_model # 模型维度(如512)self.n_head = n_head # 注意力头数(如8)self.d_k = d_model // n_head # 每个头的维度# 线性变换矩阵(Q/K/V/O)self.w_q = nn.Linear(d_model, d_model) # 查询向量变换self.w_k = nn.Linear(d_model, d_model) # 键向量变换self.w_v = nn.Linear(d_model, d_model) # 值向量变换self.w_o = nn.Linear(d_model, d_model) # 输出变换def forward(self, query, key, value, mask=None):batch_size = query.size(0)# 线性变换并分头 (batch_size, seq_len, d_model) -> (batch_size, seq_len, n_head, d_k)q = self.w_q(query).view(batch_size, -1, self.n_head, self.d_k).transpose(1, 2)k = self.w_k(key).view(batch_size, -1, self.n_head, self.d_k).transpose(1, 2)v = self.w_v(value).view(batch_size, -1, self.n_head, self.d_k).transpose(1, 2)# 计算缩放点积注意力 (batch_size, n_head, seq_len, d_k)scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9) # 掩码处理attn = torch.softmax(scores, dim=-1)# 注意力加权求和 (batch_size, n_head, seq_len, d_k)context = torch.matmul(attn, v)# 合并多头结果 (batch_size, seq_len, d_model)context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)return self.w_o(context)class PositionwiseFFN(nn.Module):"""位置前馈网络(两层全连接)"""def __init__(self, d_model, d_ff=2048):super().__init__()self.linear1 = nn.Linear(d_model, d_ff) # 扩展维度self.linear2 = nn.Linear(d_ff, d_model) # 恢复维度self.activation = nn.ReLU()def forward(self, x):# (batch_size, seq_len, d_model) -> (batch_size, seq_len, d_ff) -> (batch_size, seq_len, d_model)return self.linear2(self.activation(self.linear1(x)))class TransformerBlock(nn.Module):"""Transformer编码器块(包含多头注意力和前馈网络)"""def __init__(self, d_model, n_head):super().__init__()self.attn = MultiHeadAttention(d_model, n_head) # 多头注意力self.ffn = PositionwiseFFN(d_model) # 前馈网络self.norm1 = nn.LayerNorm(d_model) # 第一个归一化层self.norm2 = nn.LayerNorm(d_model) # 第二个归一化层def forward(self, x, mask=None):"""前向传播流程:1. 多头注意力 + 残差连接 + LayerNorm2. 前馈网络 + 残差连接 + LayerNorm"""# 第一子层:多头注意力attn_output = self.attn(x, x, x, mask) # 自注意力(Q=K=V)x = self.norm1(x + attn_output) # 残差连接后归一化# 第二子层:前馈网络ffn_output = self.ffn(x)x = self.norm2(x + ffn_output) # 残差连接后归一化return x# 测试代码
if __name__ == "__main__":# 参数设置d_model = 512 # 模型维度n_head = 8 # 注意力头数seq_len = 50 # 序列长度batch_size = 32 # 批大小# 创建测试数据test_input = torch.randn(batch_size, seq_len, d_model)mask = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0) # 下三角掩码# 实例化模型transformer_block = TransformerBlock(d_model, n_head)# 前向传播测试output = transformer_block(test_input, mask)print("输入形状:", test_input.shape)print("输出形状:", output.shape)print("注意力头数:", n_head)print("模型维度:", d_model)输出为:
输入形状: torch.Size([32, 50, 512])
输出形状: torch.Size([32, 50, 512])
注意力头数: 8
模型维度: 512四、关键技术解析
1. BatchNorm的running统计量
import torch
import torch.nn as nnclass CustomBatchNorm(nn.Module):"""自定义批归一化层(适用于2D卷积输入,4D张量)"""def __init__(self, num_features, momentum=0.1):"""参数:num_features : int - 输入特征图的数量(C维)momentum : float - 滑动平均的动量系数(默认0.1)"""super().__init__()self.momentum = momentum# 可学习参数:缩放因子和偏移量self.gamma = nn.Parameter(torch.ones(num_features)) # 初始化为1self.beta = nn.Parameter(torch.zeros(num_features)) # 初始化为0# 注册缓冲区(不参与梯度计算)self.register_buffer('running_mean', torch.zeros(num_features)) # 滑动均值self.register_buffer('running_var', torch.ones(num_features)) # 滑动方差# 初始化参数self.reset_parameters()def reset_parameters(self):"""初始化可学习参数和缓冲区"""nn.init.ones_(self.gamma)nn.init.zeros_(self.beta)nn.init.zeros_(self.running_mean)nn.init.ones_(self.running_var)def forward(self, x):"""前向传播(处理4D输入[B,C,H,W])参数:x : Tensor - 输入张量,形状[batch_size, channels, height, width]返回:Tensor - 归一化后的输出"""if self.training:# 训练模式 -------------------------------------# 计算当前batch的均值和方差(沿batch和空间维度)mean = x.mean(dim=(0, 2, 3)) # 形状[C]var = x.var(dim=(0, 2, 3), unbiased=False) # 无偏估计设为False# 更新滑动统计量(使用动量衰减)with torch.no_grad(): # 不计算梯度self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * meanself.running_var = (1 - self.momentum) * self.running_var + self.momentum * varelse:# 推理模式 -------------------------------------mean = self.running_meanvar = self.running_var# 归一化计算 ---------------------------------------# 添加微小值防止除零(1e-5与PyTorch官方实现一致)normalized = (x - mean[None, :, None, None]) / torch.sqrt(var[None, :, None, None] + 1e-5)# 缩放和偏移(仿射变换)return self.gamma[None, :, None, None] * normalized + self.beta[None, :, None, None]def extra_repr(self):"""打印额外信息(方便调试)"""return f'features={len(self.running_mean)}, momentum={self.momentum}'# 测试代码
if __name__ == "__main__":# 参数设置batch_size = 4channels = 3height = 32width = 32# 创建测试数据(模拟图像batch)torch.manual_seed(42)test_input = torch.randn(batch_size, channels, height, width)# 实例化自定义BN层custom_bn = CustomBatchNorm(channels)print("自定义BN层信息:", custom_bn)# 训练模式测试custom_bn.train()output_train = custom_bn(test_input)print("\n训练模式结果:")print("输出形状:", output_train.shape)print("滑动均值:", custom_bn.running_mean)print("滑动方差:", custom_bn.running_var)# 推理模式测试custom_bn.eval()output_eval = custom_bn(test_input)print("\n推理模式结果:")print("输出形状:", output_eval.shape)# 与官方实现对比official_bn = nn.BatchNorm2d(channels, momentum=0.1)official_bn.train()official_output = official_bn(test_input)print("\n与官方实现对比(训练模式):")print("自定义BN输出均值:", output_train.mean().item())print("官方BN输出均值:", official_output.mean().item())print("自定义BN输出方差:", output_train.var().item())print("官方BN输出方差:", official_output.var().item())输出为:
自定义BN层信息: CustomBatchNorm(features=3, momentum=0.1)训练模式结果:
输出形状: torch.Size([4, 3, 32, 32])
滑动均值: tensor([-1.0345e-04, 8.5500e-06, 3.5211e-03])
滑动方差: tensor([0.9992, 0.9986, 1.0025])推理模式结果:
输出形状: torch.Size([4, 3, 32, 32])与官方实现对比(训练模式):
自定义BN输出均值: -5.432714833553121e-10
官方BN输出均值: 2.3283064365386963e-10
自定义BN输出方差: 1.000071406364441
官方BN输出方差: 1.0000714063644412. GroupNorm的数学表达

3. 归一化选择决策树
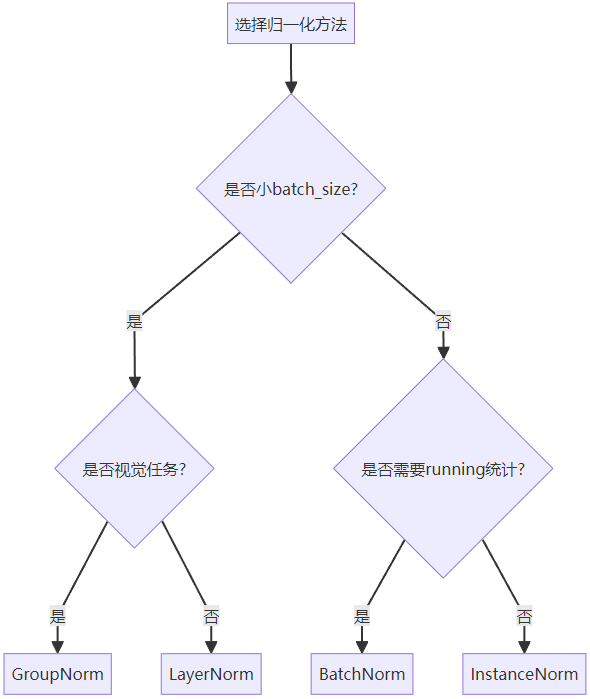
五、性能对比与总结
1. CIFAR10分类结果
| 归一化方法 | 测试准确率 | 训练时间/epoch | batch=1时表现 |
|---|---|---|---|
| BatchNorm | 92.3% | 1.0x | 崩溃 |
| LayerNorm | 90.1% | 1.1x | 稳定 |
| InstanceNorm | 88.5% | 1.2x | 稳定 |
| GroupNorm | 91.7% | 1.05x | 稳定 |
2. 关键结论
-
BatchNorm:大batch训练首选,但对batch大小敏感
-
LayerNorm:RNN/Transformer标配,适合变长数据
-
InstanceNorm:风格迁移效果最佳,去除内容信息
-
GroupNorm:小batch视觉任务的最佳替代方案
3. 最新进展
-
Weight Standardization:与GroupNorm结合提升性能
-
EvoNorm:避免batch依赖的新方法
-
Filter Response Normalization:无batch统计的替代方案
在下一篇文章中,我们将深入解析残差网络的变体与优化,探讨从ResNet到ResNeSt的架构演进。
相关文章:
:归一化技术对比(BN/LN/IN/GN))
PyTorch 深度学习实战(39):归一化技术对比(BN/LN/IN/GN)
在上一篇文章中,我们全面解析了注意力机制的发展历程。本文将深入探讨深度学习中的归一化技术,对比分析BatchNorm、LayerNorm、InstanceNorm和GroupNorm四种主流方法,并通过PyTorch实现它们在图像分类和生成任务中的应用效果。 一、归一化技术…...
)
C#/.NET/.NET Core技术前沿周刊 | 第 35 期(2025年4.14-4.20)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录、追踪C#/.NET/.NET Core领域、生态的每周最新、最实用、最有价值的技术文章、社区动态、优质项目和学习资源等。让你时刻站在技术前沿,助力技术成长与视野拓宽。 欢迎投稿、推荐…...

柱状图QCPBars
一、QCPBars 概述 QCPBars 是 QCustomPlot 中用于绘制柱状图/条形图的类,支持单组或多组柱状图显示,可自定义宽度、颜色和间距等属性。 二、主要属性 属性类型描述widthdouble柱子的宽度(坐标轴单位)widthTypeWidthType宽度计算…...

2025-04-20 李沐深度学习4 —— 自动求导
文章目录 1 导数拓展1.1 标量导数1.2 梯度:向量的导数1.3 扩展到矩阵1.4 链式法则 2 自动求导2.1 计算图2.2 正向模式2.3 反向模式 3 实战:自动求导3.1 简单示例3.2 非标量的反向传播3.3 分离计算3.4 Python 控制流 硬件配置: Windows 11Inte…...
中的强大作用)
Nginx在微服务架构项目(Spring Cloud)中的强大作用
文章目录 一、Nginx是什么?二、Nginx在微服务架构(Spring Cloud)项目中的作用1.前端静态资源托管2.反向代理后端 API3.负载均衡4.SSL 证书与 HTTPS 支持5.缓存与压缩优化6.安全防护7.灰度发布与流量控制8.跨域处理(CORS࿰…...

Mysql相关知识2:Mysql隔离级别、MVCC、锁
文章目录 MySQL的隔离级别可重复读的实现原理Mysql锁按锁的粒度分类按锁的使用方式分类按锁的状态分类 MySQL的隔离级别 在 MySQL 中,隔离级别定义了事务之间相互隔离的程度,用于控制一个事务对数据的修改在何时以及如何被其他事务可见。MySQL 支持四种…...

解决IDEA创建SpringBoot项目没有Java版本8
问题:idea2023版本创建springboot的过程中,选择java版本时发现没有java8版本,只有java17和java20 原因:spring2.X版本在2023年11月24日停止维护了,因此创建spring项目时不再有2.X版本的选项,只能从3.1.X版本…...

第十章:Agent 的评估、调试与可观测性:确保可靠与高效
引言 随着我们一步步构建出越来越复杂的 AI Agent,赋予它们高级工具和更智能的策略,一个至关重要的问题浮出水面:我们如何知道这些 Agent 是否真的有效、可靠?当它们行为不符合预期时,我们又该如何诊断和修复问题&…...

8节串联锂离子电池组可重构buck-boost均衡拓扑结构 simulink模型仿真
8节串联锂离子电池组 极具创新性 动态分组均衡策略,支持3种均衡模式 1.最高SOC电池给最低SOC电池均衡 2.高能电池组电池给最低SOC电池均衡 3.高能电池组电池给低能电池组电池均衡 支持手动设置均衡开启阈值和终止阈值 均衡效果非常好...
)
Oracle EBS COGS Recognition重复生成(一借一贷)
背景 月结用户反馈“发出商品”(实际为递延销货成本)不平,本月都是正常操作月结程序,如正常操作步骤如下: 记录订单管理事务处理 (Record Order Management Transactions)收集收入确认信息 (Collect Revenue Recognition Information)生成销货成本确认事件 (Generate COGS …...

Linux命令--将控制台的输入写入文件
原文网址:Linux命令--将控制台的输入写入文件-CSDN博客 简介 本文介绍Linux将控制台的输入写入文件的方法。 方案1:cat > file1(推荐) 普通用法 cat > file1 输入结束后,用CtrlD退出。 示例 使用root权限…...

使用BQ76PL455和STM32的SAE电动方程式电动汽车智能BMS
BMS对任何电动汽车来说都是必不可少的,它可以监控电池的行为,确保安全行驶。 该项目旨在降低成本,同时为每个电池模块提供可扩展的BMS。BQ76PL455具有监测6-16个单元的能力,8通道辅助输入(用于温度监测)和多达15个其他ic用于Daisy…...
)
OpenCV 模板与多个对象匹配方法详解(继OpenCV 模板匹配方法详解)
文章目录 前言1.导入库2.图片预处理3.输出模板图片的宽和高4.模板匹配5.获取匹配结果中所有符合阈值的点的坐标5.1 threshold 0.9:5.2 loc np.where(res > threshold): 6.遍历所有匹配点6.1 loc 的结构回顾6.2 loc[::-1] 的作用6.2.1 为什么需要反转…...

7.0/Q1,Charls最新文章解读
文章题目:Anti-hypertensive medication adherence, socioeconomic status, and cognitive aging in the Chinese community-dwelling middle-aged and older adults ≥ 45 years: a population-based longitudinal study DOI:10.1186/s12916-025-03949-…...

【第三十二周】CLIP 论文阅读笔记
CLIP 摘要Abstract文章信息引言方法预训练推理Q&A 关键代码实验结果总结 摘要 本篇博客介绍了CLIP(Contrastive Language-Image Pre-training),这是OpenAI于2021年提出的多模态预训练模型,其核心思想是通过对比学习将图像与文…...

在 Ubuntu 系统上安装 PostgreSQL
在 Ubuntu 系统上安装 PostgreSQL 的完整指南: 一、安装 PostgreSQL(最新版本) 1. 更新软件包列表: bash sudo apt update 2. 安装 PostgreSQL 和客户端工具: bash sudo apt install postgresql po…...

【MySQL】数据类型
🏠个人主页:Yui_ 🍑操作环境:Centos7 🚀所属专栏:MySQL 文章目录 前言1. bit类型2.tinyint类型3. float类型4. decimal5. char类型6. varchar5&6 char和varchar的比较7.日期和时间类型8.enum和set总结 …...

Mac上Cursor无法安装插件解决方法
可能是微软的vscode被cursor这些新晋的AI-IDE白嫖够了,所以现在被制裁了,cursor下载不了vscode插件了。需要自己修改扩展商店源。 近期微软调整了 API 鉴权策略或限制了非官方客户端的访问权限。 解决方案 一、找到 product.json 文件 打开终端&…...
)
PI0 Openpi 部署(仅测试虚拟环境)
https://github.com/Physical-Intelligence/openpi/tree/main 我使用4070tisuper, 14900k,完全使用官方默认设置,没有出现其他问题。 目前只对examples/aloha_sim进行测试,使用docker进行部署, 默认使用pi0_aloha_sim模型(但是文档上没找到对应的&…...

NumPy数组和二维列表的区别
在 Python 中,NumPy 数组和二维列表在性能方面存在诸多不同,下面从存储方式、内存占用、操作速度、缓存局部性这几个角度详细分析。 存储方式 二维列表:它是 Python 内置的数据结构,列表中的每个元素实际上是一个引用࿰…...

学习设计模式《四》——单例模式
一、基础概念 单例模式的本质【控制实例数目】; 单例模式的定义:是用来保证这个类在运行期间只会被创建一个类实例;单例模式还提供了一个全局唯一访问这个类实例的访问点(即GetInstance方法)单例模式只关心类实例的创建…...

构建具备推理与反思能力的高级 Prompt:LLM 智能代理设计指南
在构建强大的 AI 系统,尤其是基于大语言模型(LLM)的智能代理(Agent)时,Prompt 设计的质量决定了系统的智能程度。传统 Prompt 通常是简单的问答或填空式指令,而高级任务需要更具结构性、策略性和…...

NLP 梳理03 — 停用词删除和规范化
一、说明 前文我们介绍了标点符号删除、文本的大小写统一,本文介绍英文文章的另一些删除内容,停用词删除。还有规范化处理。 二、什么是停用词,为什么删除它们? 2.1 停用词的定义 停用词是语言中的常用词,通常语义…...
)
算法—插入排序—js(小数据或基本有序数据)
插入排序原理:(适合小规模数据) 将数组分为“已排序”和“未排序”两部分,逐个将未排序元素插入到已排序部分的正确位置。 特点: 时间复杂度:平均 O(n),最优(已有序)O(n…...

家庭电脑隐身后台自动截屏软件,可远程查看
7-4 本文介绍一个小软件,可以在电脑后台运行,并且记录电脑的屏幕画面保存下来,并且可以远程提取查看。 可以用于记录长时间运行的软件的执行画面过程,或者用于记录家庭中小孩使用电脑的过程,如果没有好好上网课&…...

【Agent】AI智能体评测基座AgentCLUE-General
note AgentCLUE-General将题目划分为“联网检索”、“数据分析”、“多模态理解”和“多场景组合”任务AgentCLUE-General为每个题目都提供一个标准答案,将Agent智能体的答案与标准答案进行规则匹配判断对错 文章目录 note一、任务划分和场景划分二、答案提取的pro…...

最新iOS性能测试方法与教程
一、工具instrument介绍 使用Xcode的instrument进行测试,instrument自带了很多性能方面的测试工具,如图所示: 二、常见性能测试内容 不管是安卓还是iOS的性能测试,常见的性能测试都要包含这五个方面: 1、内存ÿ…...
)
多模态大语言模型arxiv论文略读(三十)
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs ➡️ 论文标题:Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs ➡️ 论文作者:Ling Yang, Zhao…...

【AI论文】CLIMB:基于聚类的迭代数据混合自举语言模型预训练
摘要:预训练数据集通常是从网络内容中收集的,缺乏固有的领域划分。 例如,像 Common Crawl 这样广泛使用的数据集并不包含明确的领域标签,而手动整理标记数据集(如 The Pile)则是一项劳动密集型工作。 因此&…...

AI大模型发展现状与MCP协议诞生的技术演进
1. 大模型能力边界与用户痛点(2023年) 代表模型:GPT-4(OpenAI)、Claude 3(Anthropic)、通义千问(阿里云)等展现出强大的生成能力,但存在明显局限:…...

从malloc到free:动态内存管理全解析
1.为什么要有动态内存管理 我们已经掌握的内存开辟方法有: int main() {int val 20;//在栈空间上开辟四个字节char arr[20] { 0 };//在栈空间上开辟10个字节的连续空间return 0; }上述开辟的内存空间有两个特点: 1.空间开辟的时候大小已经固定 2.数组…...

CSS值和单位
CSS值和单位 CSS 中的值和单位是构建样式的基础,它们定义了属性的具体表现方式。值用于定义样式属性的具体取值,而单位用于指定这些值的度量方式。CSS中常用的值和单位如下: 1.长度单位 px : 像素,绝对单位 em : 相对于元素的字…...

Redis高级篇之I/O多路复用的引入解析
文章目录 一、问题背景1. 高并发连接的管理2. 避免阻塞和延迟3. 减少上下文切换开销4. 高效的事件通知机制5. 简化编程模型6. 低延迟响应本章小节 二、I/O多路复用高性能的本质1. 避免无意义的轮询:O(1) 事件检测2. 非阻塞 I/O 零拷贝:最大化 CPU 利用率…...

FTP协议命令和响应码
文章目录 📦 一、什么是 FTP 协议?🧾 二、FTP 常见命令(客户端发送)📡 三、FTP 响应码(服务端返回)📌 响应码分类(第一位)✅ 常见成功响应码&…...
)
在win上安装Ubuntu安装Anaconda(linx环境)
一,安装Ubuntu 1. 在 Microsoft 商城去下载Ubuntu(LTS:是长期维护的版本) 2.安装完之后启动程序,再重新打开一个黑窗口: wsl --list --verbose 3.关闭Ubuntu wsl --shutdown Ubuntu-22.04 WSL2 Ubuntu-20.04文件太占c盘空间,…...

【Elasticsearch入门到落地】11、RestClient初始化索引库
接上篇《10、初始化RestClient》 上一篇我们已经完成了RestHighLevelClient的初始化工作,本篇将正式进入索引库的创建阶段。我们将使用Java代码来创建酒店数据的索引库。 一、准备工作 1. 创建常量类 首先,我们需要定义一个常量类来存放索引库的mappi…...

远程服务调用的一些注意事项
引言 最近工作中,遇到了一些关于远程服务调用的问题,背景是调用三方接口获取某些特征数据,但由于调用出现了超时,导致业务本身的接口的可用行降低。因此整理一些远程服务调用时的注意事项,通过不同维度的考虑来提高系…...

QML 样式库
在 QML 中,样式库(或 UI 框架)用于快速构建一致且美观的界面。Qt/QML 本身不提供内置的完整样式库,但可以通过以下方式实现样式管理或使用第三方库。 1. Qt Quick Controls 2 样式系统 Qt Quick Controls 2 是官方提供的 UI 组件…...

[RHEL8] 指定rpm软件包的更高版本模块流
背景:挂载RHEL ISO使用kickstart安装操作系统,安装包未指定安装perl,但是安装完可以查到其版本,且安装的是ISO中多个版本中的最低版本。 原因:(1)为什么没有装perl,perl -v可以看到版…...

使用Python可视化洛伦兹变换
引言 大家好!今天我们将探讨一个非常有趣且重要的物理概念—洛伦兹变换。它是相对论的核心内容之一,描述了在高速运动下,时间、长度以及其他物理量是如何发生变化的。通过使用 Python 进行可视化,我们不仅可以更好地理解这个概念,还能感受到物理世界中的奇妙之处。 什么…...
)
【二叉树专题】一道深入浅出的 DFS 题:求二叉树的直径(含通俗易懂讲解)
题目: 给你一棵二叉树的根节点,返回这棵树的 直径。 直径 是任意两个节点路径中,最长的一条路径所经过的边数。 比如下面这棵树: 1/ \2 3/ \ 4 5它的最长路径是:4 → 2 → 5 或者 4 → 2 → 1 → 3,…...

考研系列-计算机网络-第三章、数据链路层
一、数据链路层的功能 1.知识点总结 2.习题总结...

医药采购系统平台第10天02:按药品分类的统计按供货商统计按医院统计统计数据的导出DWR的配置和应用
如果想要获取相关的源码,笔记,和相关工具,对项目需求的二次开发,可以关注我并私信!!! 一 按药品分类的统计实现 1 按药品分类统计的需求 按药品统计:在指定时间段中采购量、采购金…...

Navicat、DataGrip、DBeaver在渲染 BOOLEAN 类型字段时的一种特殊“视觉风格”
文章目录 前言✅ 为什么 Boolean 字段显示为 [ ]?✅ 如何验证实际数据类型?✅ 小结 前言 看到的 deleted: [ ] 并不是 Prisma 的问题,而是数据库客户端(如 Navicat、DataGrip、DBeaver)在渲染 BOOLEAN 类型字段时的一种…...
 吴恩达版提示词工程 2. 指南)
(undone) 吴恩达版提示词工程 2. 指南
url: https://www.bilibili.com/video/BV1Z14y1Z7LJ?spm_id_from333.788.videopod.episodes&vd_source7a1a0bc74158c6993c7355c5490fc600&p2 别人的笔记 url: https://zhuanlan.zhihu.com/p/626966526 指导原则(Guidelines) 编写提示词有两个…...

VLC搭建本机的rtsp直播推流和拉流
媒体---流---捕获设备,选择摄像头,点击串流 x下一步 选择rtsp,点击添加 看到了端口,并设置路径: 选择Video -H 264 mp3(TS) 点击下一个, 点击流,就开始推流了 拉流,观看端&#x…...

Rocky Linux 9.1 修改网卡和DNS
在 Rocky Linux 9.1 中修改网卡和 DNS 配置可以通过 NetworkManager 工具实现(推荐)或直接编辑配置文件。以下是两种方法的详细步骤: 方法一:使用 nmcli 命令行工具(动态生效) 查看当前网络连接nmcli connection show # 输出示例: # NAME UUID …...

Web前端:常用的布局属性
常见的布局方式有哪些? float:浮动布局 position 定位布局 flex 弹性布局(display) table 表格布局(弃用) 一、HTML5 语义化布局标签 这些标签本身不提供布局能力,但能增强页面结构…...

XSS学习2
一、客户端的Cookie 1. 无状态的影响 无状态问题: HTTP协议的无状态特性导致每次请求都是独立的,无法保持会话。例如,在银行办理业务时,柜员不需要重复询问客户信息,但在计算机网络中,每次HTTP请求都需要重新认证用户…...

软件设计师/系统架构师---计算机网络
概要 什么是计算机网络? 计算机网络是指将多台计算机和其他设备通过通信线路互联,以便共享资源和信息的系统。计算机网络可以有不同的规模,从家庭网络到全球互联网。它们可以通过有线(如以太网)或无线(如W…...