NLP 梳理03 — 停用词删除和规范化
一、说明
前文我们介绍了标点符号删除、文本的大小写统一,本文介绍英文文章的另一些删除内容,停用词删除。还有规范化处理。
二、什么是停用词,为什么删除它们?
2.1 停用词的定义
停用词是语言中的常用词,通常语义意义不大,但经常使用。英文中的例子包括 “the”、“is”、“in”、“and”、“to” 等。
2.2 为什么要删除停用词?
删除停用词,有以下考虑:
- 1 从增强模型性能上考虑
停用词可能会在分析中引入噪声。
删除它们使模型能够专注于有意义的单词,从而提高准确性。 - 2 降维目的
停用词会添加不必要的标记,从而增加数据集的大小。
通过删除非索引字,可以降低特征空间的维数,从而提高模型的效率。
example_text = "The cat is sitting in the garden."
important_words = ["cat", "sitting", "garden"] # Stopwords removed
三、归一化技术简介
文本处理中的规范化是将文本转换为一致的标准格式以减少可变性的过程。
3.1 归一化技术
1 删除多余的空格
单词之间的多个空格可能会导致分析过程中出现问题。规范化会删除这些多余的空格。
2. 将文本转换为一致的格式
将文本小写可确保一致性。
替换缩写(例如,将 “don’t” 替换为 “do not”)。
3.2 标准化的重要性
维护数据的完整性。
减少由文本格式变化引起的歧义。
example_text = " This is an example text! "
normalized_text = "this is an example text"
四、使用 NLTK、spaCy 或自定义列表删除停用词
4.1 使用 NLTK 删除非索引字
I:下载 NLTK 资源
import nltk # Download necessary NLTK resources
nltk.download('stopwords')
nltk.download('punkt')
II:文本处理
from nltk.corpus import stopwords text = "The quick brown fox jumps over the lazy dog."
words = nltk.word_tokenize(text) # Tokenize the input text
stop_words = set(stopwords.words('english')) # Get the set of English stopwords # Filter out stopwords from the tokenized words
filtered_words = [word for word in words if word.lower() not in stop_words] print("Original:", words)
print("Filtered:", filtered_words)
输出:
Original: [‘The’, ‘quick’, ‘brown’, ‘fox’, ‘jumps’, ‘over’, ‘the’, ‘lazy’, ‘dog’, ‘.’]
Filtered: [‘quick’, ‘brown’, ‘fox’, ‘jumps’, ‘lazy’, ‘dog’, ‘.’]
4.2.使用 spaCy 删除停用词
import spacynlp = spacy.load("en_core_web_sm")text = "The quick brown fox jumps over the lazy dog."
doc = nlp(text)
filtered_words = [token.text for token in doc if not token.is_stop]print("Original:", [token.text for token in doc])
print("Filtered:", filtered_words)
输出:
Original: [‘The’, ‘quick’, ‘brown’, ‘fox’, ‘jumps’, ‘over’, ‘the’, ‘lazy’, ‘dog’, ‘.’]
Filtered: [‘quick’, ‘brown’, ‘fox’, ‘jumps’, ‘lazy’, ‘dog’, ‘.’]
示例 1:在数据集中实施停用词删除并规范化文本
在自然语言处理 (NLP) 中,预处理对于在分析之前提高文本数据的质量至关重要。本教程重点介绍如何使用 Python 和 NLTK 库实现非索引字删除和文本规范化。
- 设置和导入
首先,确保导入必要的库并下载所需的 NLTK 数据。
import re
import nltk
from nltk.corpus import stopwords # Download necessary NLTK resources
nltk.download('stopwords')
nltk.download('punkt')
- 文本清理功能
定义一个函数,该函数对文本执行多个预处理步骤:转换为小写、删除标点符号、分词和筛选出非索引字。
import string
import nltkdef remove_punctuation(text):return "".join(char for char in text if char not in string.punctuation)def clean_text(text, stop_words):# Convert to lowercasetext = text.lower()# Remove punctuation text = remove_punctuation(text)# Remove punctuation # text = re.sub(r'[\W_]+', ' ', text)# Tokenize textwords = nltk.word_tokenize(text)# Remove stopwordsfiltered_words = [word for word in words if word not in stop_words]return " ".join(filtered_words)
五、删除停用词并规范化文本示例(1)
使用 NLTK 设置英文停用词,并将清理功能应用于每个示例文本。打印清理后的结果以进行比较。
sample_texts = [ "The quick brown fox jumps over the lazy dog.", "This is an example of text preprocessing!", "Stopword removal and normalization are essential steps in NLP."
]stop_words = set(stopwords.words('english')) for text in sample_texts: cleaned_text = clean_text(text, stop_words) print("Original:", text) print("Cleaned:", cleaned_text) print()
- 输出
当您运行上述代码时,您将看到原始文本及其清理后的版本,展示了停用词删除和文本规范化的有效性。
Original: The quick brown fox jumps over the lazy dog.
Cleaned: quick brown fox jumps lazy dogOriginal: This is an example of text preprocessing!
Cleaned: example text preprocessingOriginal: Stopword removal and normalization are essential steps in NLP.
Cleaned: stopword removal normalization essential steps nlp
结果分析
观察如何删除 “the”、“is” 和 “and” 等非索引字。
请注意规范化的影响,例如一致的小写和删除标点符号。
五、删除停用词并规范化文本示例(2)
示例 2:试验 spaCy 的 Property属性is_stop
利用 spaCy 的内置功能来识别非索引字,深入了解文本预处理。
- 设置
在开始之前,请确保您已安装 spaCy 并下载了英语模型。您可以在终端中使用以下命令执行此作:
pip install spacy
python -m spacy download en_core_web_sm
设置 spaCy 后,您可以导入库并加载英文模型:
import spacy # Load the English NLP model
nlp = spacy.load("en_core_web_sm")
- 文本分析
定义一个函数,该函数处理输入文本并利用 spaCy 的属性is_stop来标识非索引字和非非停用词。
def identify_stopwords(text): # Process the input text with spaCy doc = nlp(text) stopwords = [token.text for token in doc if token.is_stop] non_stopwords = [token.text for token in doc if not token.is_stop] return stopwords, non_stopwords
接下来,创建一个要分析的示例句子列表:
sample_sentences = [ "The quick brown fox jumps over the lazy dog.", "This is another example for testing purposes.", "Natural Language Processing is fascinating and powerful."
] # Analyze each sentence for stopwords
for sentence in sample_sentences: stopwords, non_stopwords = identify_stopwords(sentence) print(f"Original Sentence: {sentence}") print(f"Stopwords: {stopwords}") print(f"Non-Stopwords: {non_stopwords}") print()
示例输出
当您运行代码时,输出将显示原始句子以及识别的停用词和非停用词,从而深入了解其重要性。
Original Sentence: The quick brown fox jumps over the lazy dog.
Stopwords: ['The', 'over', 'the']
Non-Stopwords: ['quick', 'brown', 'fox', 'jumps', 'lazy', 'dog', '.']Original Sentence: This is another example for testing purposes.
Stopwords: ['This', 'is', 'another', 'for']
Non-Stopwords: ['example', 'testing', 'purposes', '.']Original Sentence: Natural Language Processing is fascinating and powerful.
Stopwords: ['is', 'and']
Non-Stopwords: ['Natural', 'Language', 'Processing', 'fascinating', 'powerful', '.']
六、删除停用词并规范化文本示例(3)
示例 3:使用 spaCy 进行分词和语言分析
此 Python 脚本演示了使用 spaCy(一个强大的语言分析库)进行自然语言处理 (NLP)。该脚本执行标记化并从给定句子中提取各种语言特征。
加载 spaCy 的英语语言模型
nlp = spacy.load(“en_core_web_sm”)
加载小型英语模型 (en_core_web_sm),该模型提供预先训练的单词嵌入、POS 标记、依赖项解析等。
2. 处理文本
doc = nlp(“Big Brother is watching…probably on his new OLED TV.”)
函数nlp()处理文本并创建一个包含结构化语言数据的对象Doc。
3. 迭代标记并提取特征(使用适当的表格显示打印)
from tabulate import tabulate # Install via: pip install tabulate# Prepare data for tabulation
data = []
headers = ["Token", "Lemma", "POS", "Tag", "Dep", "Shape", "Alpha", "Stopword"]for token in doc:data.append([token.text, token.lemma_, token.pos_, token.tag_, token.dep_,token.shape_, token.is_alpha, token.is_stop])# Print as a table
print(tabulate(data, headers=headers, tablefmt="fancy_grid"))
输出:
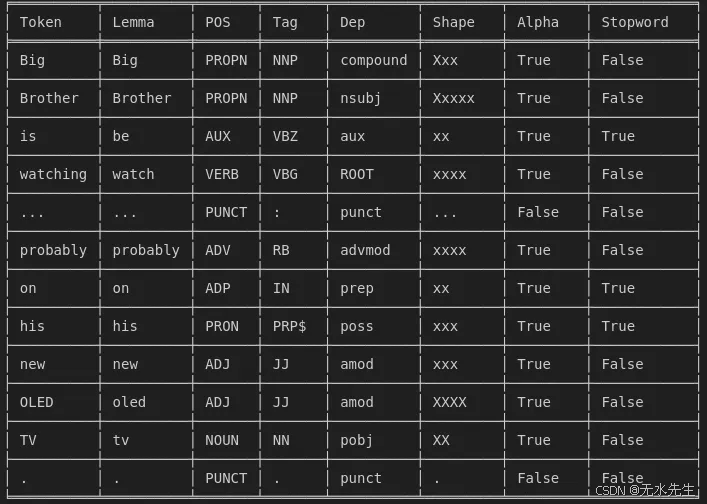
循环迭代文本中的每个标记(单词或标点符号)并打印以下属性:
token.text→ 原词
token.lemma_→ 单词 (lemma) 的基本形式
token.pos_→ 词性 (POS)
token.tag_→ 详细的 POS 标签
token.dep_→ 与根词的依赖关系
token.shape_→ Word 形状(例如,“Xxxx”代表“Apple”)
token.is_alpha→ 令牌是字母 ( 还是TrueFalse)
token.is_stop→ 令牌是停用词 ( 或TrueFalse)
七、结论
本教程介绍了停用词删除和规范化在文本预处理中的重要性。使用 NLTK 和 spaCy 等库,我们实施了实用的解决方案来清理和准备 NLP 任务的文本。
相关文章:

NLP 梳理03 — 停用词删除和规范化
一、说明 前文我们介绍了标点符号删除、文本的大小写统一,本文介绍英文文章的另一些删除内容,停用词删除。还有规范化处理。 二、什么是停用词,为什么删除它们? 2.1 停用词的定义 停用词是语言中的常用词,通常语义…...
)
算法—插入排序—js(小数据或基本有序数据)
插入排序原理:(适合小规模数据) 将数组分为“已排序”和“未排序”两部分,逐个将未排序元素插入到已排序部分的正确位置。 特点: 时间复杂度:平均 O(n),最优(已有序)O(n…...

家庭电脑隐身后台自动截屏软件,可远程查看
7-4 本文介绍一个小软件,可以在电脑后台运行,并且记录电脑的屏幕画面保存下来,并且可以远程提取查看。 可以用于记录长时间运行的软件的执行画面过程,或者用于记录家庭中小孩使用电脑的过程,如果没有好好上网课&…...

【Agent】AI智能体评测基座AgentCLUE-General
note AgentCLUE-General将题目划分为“联网检索”、“数据分析”、“多模态理解”和“多场景组合”任务AgentCLUE-General为每个题目都提供一个标准答案,将Agent智能体的答案与标准答案进行规则匹配判断对错 文章目录 note一、任务划分和场景划分二、答案提取的pro…...

最新iOS性能测试方法与教程
一、工具instrument介绍 使用Xcode的instrument进行测试,instrument自带了很多性能方面的测试工具,如图所示: 二、常见性能测试内容 不管是安卓还是iOS的性能测试,常见的性能测试都要包含这五个方面: 1、内存ÿ…...
)
多模态大语言模型arxiv论文略读(三十)
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs ➡️ 论文标题:Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs ➡️ 论文作者:Ling Yang, Zhao…...

【AI论文】CLIMB:基于聚类的迭代数据混合自举语言模型预训练
摘要:预训练数据集通常是从网络内容中收集的,缺乏固有的领域划分。 例如,像 Common Crawl 这样广泛使用的数据集并不包含明确的领域标签,而手动整理标记数据集(如 The Pile)则是一项劳动密集型工作。 因此&…...

AI大模型发展现状与MCP协议诞生的技术演进
1. 大模型能力边界与用户痛点(2023年) 代表模型:GPT-4(OpenAI)、Claude 3(Anthropic)、通义千问(阿里云)等展现出强大的生成能力,但存在明显局限:…...

从malloc到free:动态内存管理全解析
1.为什么要有动态内存管理 我们已经掌握的内存开辟方法有: int main() {int val 20;//在栈空间上开辟四个字节char arr[20] { 0 };//在栈空间上开辟10个字节的连续空间return 0; }上述开辟的内存空间有两个特点: 1.空间开辟的时候大小已经固定 2.数组…...

CSS值和单位
CSS值和单位 CSS 中的值和单位是构建样式的基础,它们定义了属性的具体表现方式。值用于定义样式属性的具体取值,而单位用于指定这些值的度量方式。CSS中常用的值和单位如下: 1.长度单位 px : 像素,绝对单位 em : 相对于元素的字…...

Redis高级篇之I/O多路复用的引入解析
文章目录 一、问题背景1. 高并发连接的管理2. 避免阻塞和延迟3. 减少上下文切换开销4. 高效的事件通知机制5. 简化编程模型6. 低延迟响应本章小节 二、I/O多路复用高性能的本质1. 避免无意义的轮询:O(1) 事件检测2. 非阻塞 I/O 零拷贝:最大化 CPU 利用率…...

FTP协议命令和响应码
文章目录 📦 一、什么是 FTP 协议?🧾 二、FTP 常见命令(客户端发送)📡 三、FTP 响应码(服务端返回)📌 响应码分类(第一位)✅ 常见成功响应码&…...
)
在win上安装Ubuntu安装Anaconda(linx环境)
一,安装Ubuntu 1. 在 Microsoft 商城去下载Ubuntu(LTS:是长期维护的版本) 2.安装完之后启动程序,再重新打开一个黑窗口: wsl --list --verbose 3.关闭Ubuntu wsl --shutdown Ubuntu-22.04 WSL2 Ubuntu-20.04文件太占c盘空间,…...

【Elasticsearch入门到落地】11、RestClient初始化索引库
接上篇《10、初始化RestClient》 上一篇我们已经完成了RestHighLevelClient的初始化工作,本篇将正式进入索引库的创建阶段。我们将使用Java代码来创建酒店数据的索引库。 一、准备工作 1. 创建常量类 首先,我们需要定义一个常量类来存放索引库的mappi…...

远程服务调用的一些注意事项
引言 最近工作中,遇到了一些关于远程服务调用的问题,背景是调用三方接口获取某些特征数据,但由于调用出现了超时,导致业务本身的接口的可用行降低。因此整理一些远程服务调用时的注意事项,通过不同维度的考虑来提高系…...

QML 样式库
在 QML 中,样式库(或 UI 框架)用于快速构建一致且美观的界面。Qt/QML 本身不提供内置的完整样式库,但可以通过以下方式实现样式管理或使用第三方库。 1. Qt Quick Controls 2 样式系统 Qt Quick Controls 2 是官方提供的 UI 组件…...

[RHEL8] 指定rpm软件包的更高版本模块流
背景:挂载RHEL ISO使用kickstart安装操作系统,安装包未指定安装perl,但是安装完可以查到其版本,且安装的是ISO中多个版本中的最低版本。 原因:(1)为什么没有装perl,perl -v可以看到版…...

使用Python可视化洛伦兹变换
引言 大家好!今天我们将探讨一个非常有趣且重要的物理概念—洛伦兹变换。它是相对论的核心内容之一,描述了在高速运动下,时间、长度以及其他物理量是如何发生变化的。通过使用 Python 进行可视化,我们不仅可以更好地理解这个概念,还能感受到物理世界中的奇妙之处。 什么…...
)
【二叉树专题】一道深入浅出的 DFS 题:求二叉树的直径(含通俗易懂讲解)
题目: 给你一棵二叉树的根节点,返回这棵树的 直径。 直径 是任意两个节点路径中,最长的一条路径所经过的边数。 比如下面这棵树: 1/ \2 3/ \ 4 5它的最长路径是:4 → 2 → 5 或者 4 → 2 → 1 → 3,…...

考研系列-计算机网络-第三章、数据链路层
一、数据链路层的功能 1.知识点总结 2.习题总结...

医药采购系统平台第10天02:按药品分类的统计按供货商统计按医院统计统计数据的导出DWR的配置和应用
如果想要获取相关的源码,笔记,和相关工具,对项目需求的二次开发,可以关注我并私信!!! 一 按药品分类的统计实现 1 按药品分类统计的需求 按药品统计:在指定时间段中采购量、采购金…...

Navicat、DataGrip、DBeaver在渲染 BOOLEAN 类型字段时的一种特殊“视觉风格”
文章目录 前言✅ 为什么 Boolean 字段显示为 [ ]?✅ 如何验证实际数据类型?✅ 小结 前言 看到的 deleted: [ ] 并不是 Prisma 的问题,而是数据库客户端(如 Navicat、DataGrip、DBeaver)在渲染 BOOLEAN 类型字段时的一种…...
 吴恩达版提示词工程 2. 指南)
(undone) 吴恩达版提示词工程 2. 指南
url: https://www.bilibili.com/video/BV1Z14y1Z7LJ?spm_id_from333.788.videopod.episodes&vd_source7a1a0bc74158c6993c7355c5490fc600&p2 别人的笔记 url: https://zhuanlan.zhihu.com/p/626966526 指导原则(Guidelines) 编写提示词有两个…...

VLC搭建本机的rtsp直播推流和拉流
媒体---流---捕获设备,选择摄像头,点击串流 x下一步 选择rtsp,点击添加 看到了端口,并设置路径: 选择Video -H 264 mp3(TS) 点击下一个, 点击流,就开始推流了 拉流,观看端&#x…...

Rocky Linux 9.1 修改网卡和DNS
在 Rocky Linux 9.1 中修改网卡和 DNS 配置可以通过 NetworkManager 工具实现(推荐)或直接编辑配置文件。以下是两种方法的详细步骤: 方法一:使用 nmcli 命令行工具(动态生效) 查看当前网络连接nmcli connection show # 输出示例: # NAME UUID …...

Web前端:常用的布局属性
常见的布局方式有哪些? float:浮动布局 position 定位布局 flex 弹性布局(display) table 表格布局(弃用) 一、HTML5 语义化布局标签 这些标签本身不提供布局能力,但能增强页面结构…...

XSS学习2
一、客户端的Cookie 1. 无状态的影响 无状态问题: HTTP协议的无状态特性导致每次请求都是独立的,无法保持会话。例如,在银行办理业务时,柜员不需要重复询问客户信息,但在计算机网络中,每次HTTP请求都需要重新认证用户…...

软件设计师/系统架构师---计算机网络
概要 什么是计算机网络? 计算机网络是指将多台计算机和其他设备通过通信线路互联,以便共享资源和信息的系统。计算机网络可以有不同的规模,从家庭网络到全球互联网。它们可以通过有线(如以太网)或无线(如W…...
学习笔记(二)--k8s 集群安装)
Kubernetes(k8s)学习笔记(二)--k8s 集群安装
1、kubeadm kubeadm 是官方社区推出的一个用于快速部署 kubernetes 集群的工具。这个工具能通过两条指令完成一个 kubernetes 集群的部署: 1.1 创建一个 Master 节点$ kubeadm init 1.2 将一个 Node 节点加入到当前集群中$ kubeadm join <Master 节点的 IP 和…...
)
线性DP:最长上升子序列(子序列可不连续,子数组必须连续)
目录 Q1:简单遍历 Q2:变式(加大数据量) Q1:简单遍历 Dp问题 状态表示 f(i,j) 集合所有以第i个数结尾的上升子序列集合-f(i,j)的值存的是什么序列长度最大值max- 状态计算 (其实质是集合的划分)…...

SpringBoot 基本原理
SpringBoot 为我们做的自动配置,确实方便快捷,但一直搞不明白它的内部启动原理,这次就来一步步解开 SpringBoot 的神秘面纱,让它不再神秘。 目录 SpringBootApplication 背后的秘密 Configuration ComponentScan EnableAutoC…...

LeetCode第158题_用Read4读取N个字符 II
LeetCode 第158题:用Read4读取N个字符 II 题目描述 给你一个文件,并且该文件只能通过给定的 read4 方法来读取,请实现一个方法来读取 n 个字符。 read4 方法: API read4 可以从文件中读取 4 个连续的字符,并且将它…...

webgl入门实例-矩阵在图形学中的作用
矩阵在图形学中扮演着核心角色,几乎所有图形变换、投影和空间转换都依赖矩阵运算来实现高效计算。以下是矩阵在图形学中的主要作用及具体应用: 1. 几何变换 矩阵乘法可以高效表示物体的平移、旋转、缩放等基本变换,并通过矩阵连乘实现复合变…...

基于Matlab求解矩阵电容等效容值
1需求 仿真测试8*10阶举证电容等效容值。 2模型搭建 2.1打开simscape 在打开simulink之后打开simscape库,Simscape库位置如下 2.2搭建模型 在库中寻找需要的元件搭建电路。 2.2.1基本元件 电阻电容电感等基础器件,搭建电路之后需要对其进行幅值&…...

铅酸电池充电器方案EG1253+EG4321
参考: 基于EG1253EG4321铅酸电池(48V20AH)三段式充电器 屹晶微高性价比的电瓶车充电器方案——EG1253 电瓶电压 48V电瓶锂电池,其充满约为55V~56V,因此充电器输出电压为55V~56V; 若是48V铅酸电池,标称电压为48V&…...
:less)
每天学一个 Linux 命令(26):less
可访问网站查看,视觉品味拉满: http://www.616vip.cn/26/index.html less 是 Linux 中一个强大的文件内容查看工具,用于分页显示文件内容,支持快速搜索、滚动浏览、跳转等操作。相比 more,less 功能更丰富且支持向前和向后翻页,适合查看大文件或日志。 命令格式 les…...

【网络】数据链路层知识梳理
全是通俗易懂的讲解,如果你本节之前的知识都掌握清楚,那就速速来看我的笔记吧~ 自己写自己的八股!让未来的自己看懂! (全文手敲,受益良多) 数据链路层 我们来重新理解一下这个图:…...

2.2 BackgroundWorker的使用介绍
BackgroundWorker 是 .NET Framework 中一个简化异步操作的组件,它位于 System.ComponentModel 命名空间下。它为开发人员提供了一种简单的方式在后台执行耗时操作,同时保持与 UI 线程的交互 主要属性以及任务如下: DoWork 事件:…...
之旅——类和对象全面解析⑦)
Java从入门到“放弃”(精通)之旅——类和对象全面解析⑦
Java从入门到“放弃”(精通)之旅🚀——类和对象全面解析⑦ 一、面向对象初探 1.1 什么是面向对象? Java是一门纯面向对象的语言(OOP),在面向对象的世界里,一切皆为对象。面向对象是解决问题的一种思想&a…...

无回显RCE
在CTF和实战渗透中,不是每一个命令执行点都有回显,有时我们审了半天代码,却发现好不容易找到的命令执行没有回显,但是这并不代表这段代码不能被我们利用,在无回显的情况下也是可以利用的 首先我们来写一个最简单的php…...

DQN在Gym的MountainCar环境的实现
DQN on MountainCar 引言 在本次实验里,我构建了DQN和Dueling DQN,并在Gymnasium库的MountainCar环境中对它们展开测试。我通过调整训练任务的超参数,同时设计不同的奖励函数及其对应参数,致力于获取更优的训练效果。最后&#…...

typescript判断是否为空
1 判断数据类型 1.1 基础数据类型 比如number,string,boolean,使用typeof,返回值是string类型: 例如: if("number" typeof(item)) {egret.log("item的类型是number"); } else if(&…...
)
JavaScript forEach介绍(JS forEach、JS for循环)
文章目录 JavaScript forEach 方法全面解析基本概念语法详解参数说明 工作原理与其他循环方法的比较forEach vs for循环forEach vs map 实际应用场景DOM元素批量操作数据处理 性能考量常见陷阱与解决方案无法中断循环异步操作问题 高级技巧链式调用(不使用 forEach …...

C语言之图像文件的属性
🌟 嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 图像文件属性提取系统设计与实现 目录 设计题目设计内容系统分析总体设计详细设计程序实现…...

Java链表反转方法详解
一、理解链表结构 假设链表节点定义为: class ListNode {int val;ListNode next;ListNode(int x) { val x; } } 二、迭代法反转链表 核心思路 逐步反转每个节点的指针方向,最终使整个链表反向。 步骤拆解 初始化三个指针: prev…...

lmm-r1开源程序是扩展 OpenRLHF 以支持 LMM RL 训练,用于在多模态任务上重现 DeepSeek-R1
一、软件介绍 文末提供程序和源码下载学习 lmm-r1开源程序是扩展 OpenRLHF 以支持 LMM RL 训练,用于在多模态任务上重现 DeepSeek-R1。 二、简介 小型 3B 大型多模态模型(LMMs)由于参数容量有限以及将视觉感知与逻辑推理相结合的固有复杂性…...
)
Java学习笔记(数组,方法)
一,数组 1.数组初始化 1.1动态初始化 格式:数据类型[] 数组名 new 数据类型[数组长度]; int[] arr new int[3]; // 定义长度为3的int数组,元素默认值为0 double[] scores new double[5]; // 长度5,元素默认0.0 String[…...
)
嵌入式---零点漂移(Zero Drift)
一、零点漂移的定义与本质 零点漂移(简称“零漂”)指传感器在输入信号为零(或理论上应输出固定零值)时,输出信号随时间、温度、环境等因素变化而偏离初始零点的现象。 核心特征:无输入时输出非零且缓慢变…...
含万字详细文档)
健身房管理系统设计与实现(springboot+ssm+vue+mysql)含万字详细文档
健身房管理系统设计与实现(springbootssmvuemysql)含万字详细文档 健身房管理系统是一个全面的解决方案,旨在帮助健身房高效管理日常运营。系统主要功能模块包括个人中心、会员管理、员工管理、会员卡管理、会员卡类型管理、教练信息管理、解聘管理、健身项目管理、…...

C语言if
一、题目引入 如果从键盘输入58,则以下程序输出的结果是多少? 二、运行结果 三、题目分析 因为这道题中的多个if是并列结构 所以只要条件满足都会执行 这一题58满足所有的条件 所以可以运行出来 也就是说每个if里面的条件都满足 所以都会打印出来 而下面的这种情况就是 if e…...