第十章:Agent 的评估、调试与可观测性:确保可靠与高效
引言
随着我们一步步构建出越来越复杂的 AI Agent,赋予它们高级工具和更智能的策略,一个至关重要的问题浮出水面:我们如何知道这些 Agent 是否真的有效、可靠?当它们行为不符合预期时,我们又该如何诊断和修复问题?在 Agent 被部署到真实世界后,我们又该如何持续监控它们的表现?本章,我们将深入探讨 Agent 开发与运维生命周期中不可或缺的三个支柱:评估 (Evaluation)、调试 (Debugging) 和 可观测性 (Observability)。掌握这些方法、工具和实践,是确保我们构建的 Agent 不仅功能强大,而且稳定、可信、高效的关键。
10.1 Agent 评估的挑战与复杂性
首先,我们需要认识到评估 AI Agent 并非易事。其挑战源于 Agent 的固有特性:
- 开放域任务: 许多 Agent 需要在无法预先穷举所有情况的开放环境中工作。
- 多步骤交互: Agent 的决策通常涉及一系列相互依赖的思考、行动和观察步骤,单一指标难以衡量整体效果。
- 对环境的依赖性: Agent 的表现可能高度依赖于其与之交互的外部工具、API 或动态变化的在线环境。
- 结果的多样性与非确定性: 对于同一个任务,可能有多种可接受的解决方案路径和最终结果,且 LLM 的输出本身就带有一定的随机性。
这些复杂性意味着我们需要一套更全面、更细致的评估方法论。
10.2 设计有效的评估策略
面对评估的复杂性,仅仅罗列指标是不够的,我们需要制定清晰的评估策略:
- 评估目标设定: 评估的第一步是明确:对于这个特定的 Agent,什么是“成功”? 是任务完成率?是用户满意度?是成本效率?还是安全性?需要根据 Agent 的应用场景和预期目标,定义清晰、可衡量的成功标准。
- 方法组合选择: 没有万能的评估方法。一个有效的策略通常需要组合使用多种方法:
- 早期开发阶段: 可以利用自动化基准(10.4)进行快速迭代和比较不同设计的效果。
- 接近部署阶段: 人工评估(10.5)变得至关重要,以捕捉自动化指标无法衡量的细微差别,如结果质量、交互自然度、安全性等。
- 上线后: 在线 A/B 测试和持续的可观测性数据(10.7)可以提供最真实的性能反馈。
- 成本与效益权衡: 评估是有成本的——需要时间、人力、计算资源,甚至 API 调用费用。我们需要在评估的覆盖度、深度与可行性、成本之间做出明智的权衡。
10.3 核心评估指标体系
一个全面的评估体系应涵盖多个维度:
- 任务完成度:
- 成功率 (Success Rate): Agent 成功完成指定任务的比例。
- 目标达成度 (Goal Achievement): 衡量 Agent 最终输出在多大程度上满足了初始目标。
- 结果质量 (Quality Score): 对 Agent 输出结果的质量进行评分(通常需要人工评估)。
- 效率指标:
- 步数 (Number of Steps): 完成任务所需的思考-行动循环次数。
- 时间消耗 (Latency): 端到端的响应时间或完成任务的总时间。
- LLM 调用次数 & Token 消耗: 直接关系到运行成本。
- 成本 (Cost): API 调用费用、计算资源费用等。
- 鲁棒性指标 (Robustness): Agent 在面对输入扰动、环境噪声或工具临时失效等情况下的表现稳定性。
- 安全性与对齐指标 (Safety & Alignment):
- 是否遵循了预设的指令和约束(Guardrails)。
- 是否避免了生成有害、不当或偏见性内容。
- 其行为和决策过程是否符合人类的价值观和预期。
- 工具使用与规划指标:
- 工具选择准确率: 是否选择了最合适的工具来完成子任务。
- 工具调用成功率: 工具执行是否成功,有无异常。
- 工具参数准确性: 传递给工具的参数是否正确。
- 规划合理性与效率: 生成的计划步骤是否逻辑清晰、有效且没有冗余。
10.4 自动化评估平台与基准:快速迭代与横向比较
为了实现快速、可重复的评估,并方便比较不同 Agent 或模型的效果,社区开发了多种自动化评估平台和基准。了解这些主流基准有助于我们选择合适的工具来衡量 Agent 的特定能力:
-
AgentBench: 一个由清华大学等机构推出的综合性评估框架,旨在全面评估 LLM 作为 Agent 在多种不同环境和任务中的表现。它涵盖了操作系统交互、数据库查询、知识图谱推理、数字卡牌游戏、网页浏览等多种复杂场景,是目前衡量 Agent 通用能力的重要基准之一。
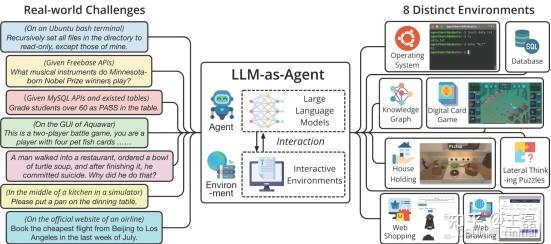
-
ToolBench: 同样来自清华大学等机构,专注于评估 Agent 使用真实世界 API 工具的能力。它构建了一个包含数千个真实 API 的庞大工具集,并设计了需要 Agent 进行复杂规划、选择合适 API 并正确调用以完成特定指令的任务。这对于需要与外部服务大量交互的 Agent 评估非常有价值。
-
WebArena: 一个基于真实网站构建的、可复现的 Web Agent 评估环境。Agent 需要在模拟浏览器环境中,与如购物网站、论坛、项目管理工具等真实网站进行交互,完成信息查找、内容创建、在线预订等贴近实际应用的复杂任务,是评估 Agent 网页自主导航和操作能力的有力工具。
-
SuperCLUE-Agent: 针对中文语言环境的 Agent 评估需求,SuperCLUE 推出了 SuperCLUE-Agent 榜单。它不仅评估模型的基础能力,更聚焦于 Agent 在中文语境下的规划、工具使用和任务解决能力。该榜单通常包含更贴合中文用户习惯和场景的任务,并提供公开排名,方便横向比较不同 Agent 在中文环境下的表现。
-
PaperBench: 这是一个专门为评估大型语言模型(LLMs)作为科学研究助手(Autonomous Agents for Scientific Literature)而设计的基准。它侧重于衡量 Agent 在处理科学文献方面的能力,例如:查找相关论文、总结论文核心贡献、比较不同论文的方法论、综合多篇论文的信息等。PaperBench 对于评估 Agent 在知识密集型、需要深度理解和信息综合能力的科研场景下的表现非常有意义。
选择与局限性:
选择哪个或哪些基准进行评估,取决于你最关心 Agent 的哪方面能力(通用性、工具使用、Web 交互、中文处理等)。需要注意的是,这些自动化基准虽然对于快速迭代、比较相对性能非常有用,但它们通常基于预设的任务和环境,可能无法完全反映 Agent 在真实、动态、开放世界中的全部表现。因此,自动化评估通常需要与人工评估(见下一节)相结合。
10.5 人工评估方法:弥补自动化之不足
由于 Agent 行为的复杂性和评估标准的主观性,人工评估是不可或缺的一环:
- 用户研究与可用性测试: 让真实用户与 Agent 交互,收集关于易用性、满意度、任务完成流畅度的反馈。
- 专家打分与评估: 由领域专家根据预定义的详细评估标准(Rubrics),对 Agent 的输出质量、推理过程、安全性等进行打分。
- A/B 测试与偏好判断: 将两个不同版本(例如,使用不同模型或 Prompt)的 Agent 同时呈现给用户,让用户选择更偏好的一个。
- 红队测试 (Red Teaming): 模拟恶意用户或极端场景,主动寻找 Agent 的漏洞、安全风险或可能产生有害输出的情况。
10.6 调试复杂 Agent 行为:工具、技术与思维
当 Agent 行为不符合预期时,调试是找出问题根源的关键。调试复杂 Agent 比调试传统软件更具挑战性。
可视化追踪工具:
像 LangSmith、Helicone、Phoenix/Arize 等工具是调试 Agent 的利器。它们能够帮助我们:
- 追踪完整的 Agent 执行轨迹: 清晰展示 Thought -> Action -> Observation 的每一步。
- 检查 LLM 调用详情: 查看发送给 LLM 的完整 Prompt、LLM 的原始响应、Token 消耗、耗时等。
- 监控工具使用: 查看 Agent 调用了哪个工具、传入了什么参数、工具返回了什么结果。
核心调试技术:
除了可视化工具,一些基础的调试技术仍然适用:
- 详细日志分析 (Logging): 在代码中记录关键信息点,用于事后分析。
- 中间步骤验证与断点: 检查 Agent 在关键步骤的内部状态或输出是否符合预期,模拟“断点”调试。
- 单元测试: 测试单个工具或 Agent 内部的某个模块(如 Prompt 生成逻辑)是否按预期工作。
- 集成测试: 测试 Agent 各个组件(LLM、工具、Memory)之间的交互是否顺畅。
调试工作流与思维模式:
掌握正确的调试思维同样重要:
- 回溯追踪 (Traceback): 从观察到的失败结果(如错误答案、异常行为)出发,利用追踪工具沿着执行链反向追溯,检查每一步的输入、输出和决策,定位问题首次出现的环节。
- 问题隔离 (Isolation): 有系统地缩小问题范围。问自己:是 LLM 理解错了指令吗? 是 Prompt 设计有歧义或引导错误吗? 是 工具本身出错了,还是 Agent 错误地使用了工具? 是 规划逻辑本身存在缺陷吗? 还是外部环境因素(如 API 不可用)导致的?尝试单独测试可疑组件。
- 复现与简化 (Reproduction & Simplification): 首先要能稳定地复现问题。然后,尝试简化导致问题的输入、环境或 Agent 配置,去除无关变量,更容易定位核心原因。
调试图相关行为的要点:
如果 Agent 使用了知识图谱工具,调试时需要特别关注:
- 检查生成的图查询语句的语法和意图是否正确。
- 验证知识图谱返回结果的准确性和相关性。
- 如果 Agent 基于图结构进行推理,需理解其图遍历或推理路径是否符合逻辑。
10.7 可观测性 (Observability) 实践:实时洞察 Agent 行为
可观测性关注的是在 Agent 运行时持续收集数据,以实时了解其状态、性能和行为,这对于生产环境中的 Agent 至关重要。它的目标是构建全面的监控系统,以实时了解 Agent 在运行时的表现、发现潜在问题并收集改进数据。这通常建立在三大支柱之上:
追踪 (Tracing):
- 记录完整的端到端任务执行链(用户输入 -> Thought -> Action -> Observation -> … -> 最终输出)。
- 包含每次 LLM 调用的详细信息(使用的模型、完整 Prompt、原始响应、耗时、Token 消耗)。
- 包含每次工具调用的详细信息(工具名称、输入参数、输出结果、耗时、成功/失败状态)。
- 记录 Agent 内部状态的关键变化(如 Memory 更新)。
日志 (Logging):
- 记录比追踪更细节、更灵活的信息。
- 例如:详细的 Prompt 构建过程、LLM 返回的原始文本(可能包含反思、中间思考)、工具执行的详细日志、遇到的各种错误(如 Prompt 格式错误、API 超时、输出解析失败)、自我反思步骤的具体内容等。
指标 (Metrics):
- 对追踪和日志数据进行聚合,形成可量化、可监控的指标。常见的关键指标包括:
- 业务指标: 任务成功率、特定目标的达成率、用户满意度评分(如果可收集)。
- 性能指标: 端到端请求延迟(平均值、P95、P99)、LLM 调用平均延迟、工具调用平均延迟。
- 成本指标: 平均 Token 消耗(Prompt Tokens + Completion Tokens)、单位任务的 API 调用费用。
- 错误率: Agent 执行失败率、工具调用失败率、输出解析错误率、特定类型异常(如幻觉、安全违规)的发生频率。
- 图相关指标: (若使用图)如图查询成功率、图查询平均延迟、返回结果的相关性或准确率(如果能建立自动判断机制)。
总结与展望
在本章中,我们系统地探讨了确保 AI Agent 可靠与高效的三大支柱:评估、调试与可观测性。我们了解了评估的挑战、策略、指标和方法(包括了 AgentBench, ToolBench, WebArena, SuperCLUE-Agent 等自动化基准以及 OpenAI 的评估实践);掌握了调试复杂 Agent 行为的工具、技术和思维模式;并学习了如何通过可观测性实践来实时洞察 Agent 的运行时表现。

理解这三者并非孤立存在,而是形成了一个持续改进的闭环至关重要。可观测性提供运行时的原始数据,这些数据用于评估 Agent 的实际表现和发现潜在问题;评估的结果(无论是自动化基准分数还是人工反馈)指明了需要调试的方向和优先级;调试修复问题后,又需要通过可观测性来监控改进效果,并进行新一轮的评估。正是这个闭环驱动着 Agent 不断迭代优化。
随着 Agent 技术的飞速发展,评估、调试和可观测性技术也在不断演进。未来,我们可以期待更智能、更自动化的评估基准;更强大的、能够理解 Agent 内部状态的可视化调试工具;以及对 Agent 安全性、对齐和伦理方面更深入、更细致的监控与评估方法。负责任地开发和部署 Agent,离不开在这些领域的持续投入和创新。
相关文章:

第十章:Agent 的评估、调试与可观测性:确保可靠与高效
引言 随着我们一步步构建出越来越复杂的 AI Agent,赋予它们高级工具和更智能的策略,一个至关重要的问题浮出水面:我们如何知道这些 Agent 是否真的有效、可靠?当它们行为不符合预期时,我们又该如何诊断和修复问题&…...

8节串联锂离子电池组可重构buck-boost均衡拓扑结构 simulink模型仿真
8节串联锂离子电池组 极具创新性 动态分组均衡策略,支持3种均衡模式 1.最高SOC电池给最低SOC电池均衡 2.高能电池组电池给最低SOC电池均衡 3.高能电池组电池给低能电池组电池均衡 支持手动设置均衡开启阈值和终止阈值 均衡效果非常好...
)
Oracle EBS COGS Recognition重复生成(一借一贷)
背景 月结用户反馈“发出商品”(实际为递延销货成本)不平,本月都是正常操作月结程序,如正常操作步骤如下: 记录订单管理事务处理 (Record Order Management Transactions)收集收入确认信息 (Collect Revenue Recognition Information)生成销货成本确认事件 (Generate COGS …...

Linux命令--将控制台的输入写入文件
原文网址:Linux命令--将控制台的输入写入文件-CSDN博客 简介 本文介绍Linux将控制台的输入写入文件的方法。 方案1:cat > file1(推荐) 普通用法 cat > file1 输入结束后,用CtrlD退出。 示例 使用root权限…...

使用BQ76PL455和STM32的SAE电动方程式电动汽车智能BMS
BMS对任何电动汽车来说都是必不可少的,它可以监控电池的行为,确保安全行驶。 该项目旨在降低成本,同时为每个电池模块提供可扩展的BMS。BQ76PL455具有监测6-16个单元的能力,8通道辅助输入(用于温度监测)和多达15个其他ic用于Daisy…...
)
OpenCV 模板与多个对象匹配方法详解(继OpenCV 模板匹配方法详解)
文章目录 前言1.导入库2.图片预处理3.输出模板图片的宽和高4.模板匹配5.获取匹配结果中所有符合阈值的点的坐标5.1 threshold 0.9:5.2 loc np.where(res > threshold): 6.遍历所有匹配点6.1 loc 的结构回顾6.2 loc[::-1] 的作用6.2.1 为什么需要反转…...

7.0/Q1,Charls最新文章解读
文章题目:Anti-hypertensive medication adherence, socioeconomic status, and cognitive aging in the Chinese community-dwelling middle-aged and older adults ≥ 45 years: a population-based longitudinal study DOI:10.1186/s12916-025-03949-…...

【第三十二周】CLIP 论文阅读笔记
CLIP 摘要Abstract文章信息引言方法预训练推理Q&A 关键代码实验结果总结 摘要 本篇博客介绍了CLIP(Contrastive Language-Image Pre-training),这是OpenAI于2021年提出的多模态预训练模型,其核心思想是通过对比学习将图像与文…...

在 Ubuntu 系统上安装 PostgreSQL
在 Ubuntu 系统上安装 PostgreSQL 的完整指南: 一、安装 PostgreSQL(最新版本) 1. 更新软件包列表: bash sudo apt update 2. 安装 PostgreSQL 和客户端工具: bash sudo apt install postgresql po…...

【MySQL】数据类型
🏠个人主页:Yui_ 🍑操作环境:Centos7 🚀所属专栏:MySQL 文章目录 前言1. bit类型2.tinyint类型3. float类型4. decimal5. char类型6. varchar5&6 char和varchar的比较7.日期和时间类型8.enum和set总结 …...

Mac上Cursor无法安装插件解决方法
可能是微软的vscode被cursor这些新晋的AI-IDE白嫖够了,所以现在被制裁了,cursor下载不了vscode插件了。需要自己修改扩展商店源。 近期微软调整了 API 鉴权策略或限制了非官方客户端的访问权限。 解决方案 一、找到 product.json 文件 打开终端&…...
)
PI0 Openpi 部署(仅测试虚拟环境)
https://github.com/Physical-Intelligence/openpi/tree/main 我使用4070tisuper, 14900k,完全使用官方默认设置,没有出现其他问题。 目前只对examples/aloha_sim进行测试,使用docker进行部署, 默认使用pi0_aloha_sim模型(但是文档上没找到对应的&…...

NumPy数组和二维列表的区别
在 Python 中,NumPy 数组和二维列表在性能方面存在诸多不同,下面从存储方式、内存占用、操作速度、缓存局部性这几个角度详细分析。 存储方式 二维列表:它是 Python 内置的数据结构,列表中的每个元素实际上是一个引用࿰…...

学习设计模式《四》——单例模式
一、基础概念 单例模式的本质【控制实例数目】; 单例模式的定义:是用来保证这个类在运行期间只会被创建一个类实例;单例模式还提供了一个全局唯一访问这个类实例的访问点(即GetInstance方法)单例模式只关心类实例的创建…...

构建具备推理与反思能力的高级 Prompt:LLM 智能代理设计指南
在构建强大的 AI 系统,尤其是基于大语言模型(LLM)的智能代理(Agent)时,Prompt 设计的质量决定了系统的智能程度。传统 Prompt 通常是简单的问答或填空式指令,而高级任务需要更具结构性、策略性和…...

NLP 梳理03 — 停用词删除和规范化
一、说明 前文我们介绍了标点符号删除、文本的大小写统一,本文介绍英文文章的另一些删除内容,停用词删除。还有规范化处理。 二、什么是停用词,为什么删除它们? 2.1 停用词的定义 停用词是语言中的常用词,通常语义…...
)
算法—插入排序—js(小数据或基本有序数据)
插入排序原理:(适合小规模数据) 将数组分为“已排序”和“未排序”两部分,逐个将未排序元素插入到已排序部分的正确位置。 特点: 时间复杂度:平均 O(n),最优(已有序)O(n…...

家庭电脑隐身后台自动截屏软件,可远程查看
7-4 本文介绍一个小软件,可以在电脑后台运行,并且记录电脑的屏幕画面保存下来,并且可以远程提取查看。 可以用于记录长时间运行的软件的执行画面过程,或者用于记录家庭中小孩使用电脑的过程,如果没有好好上网课&…...

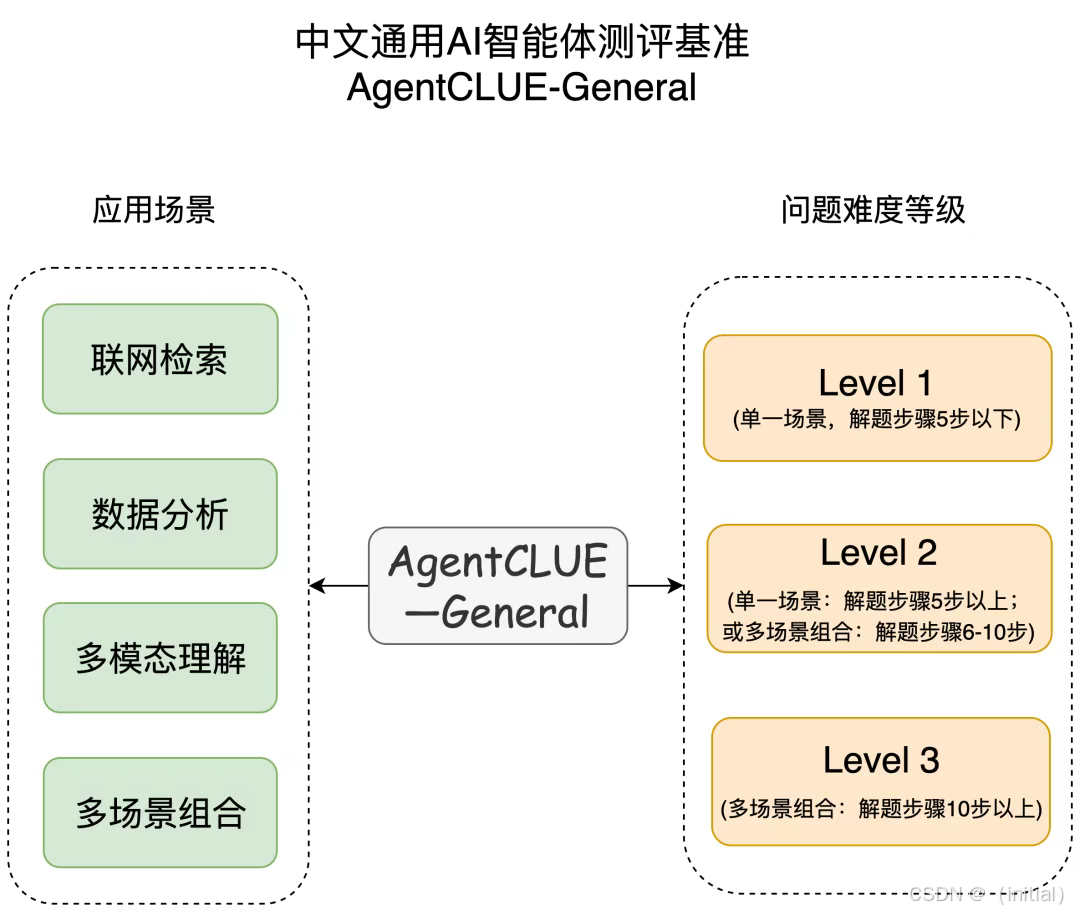
【Agent】AI智能体评测基座AgentCLUE-General
note AgentCLUE-General将题目划分为“联网检索”、“数据分析”、“多模态理解”和“多场景组合”任务AgentCLUE-General为每个题目都提供一个标准答案,将Agent智能体的答案与标准答案进行规则匹配判断对错 文章目录 note一、任务划分和场景划分二、答案提取的pro…...

最新iOS性能测试方法与教程
一、工具instrument介绍 使用Xcode的instrument进行测试,instrument自带了很多性能方面的测试工具,如图所示: 二、常见性能测试内容 不管是安卓还是iOS的性能测试,常见的性能测试都要包含这五个方面: 1、内存ÿ…...
)
多模态大语言模型arxiv论文略读(三十)
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs ➡️ 论文标题:Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs ➡️ 论文作者:Ling Yang, Zhao…...

【AI论文】CLIMB:基于聚类的迭代数据混合自举语言模型预训练
摘要:预训练数据集通常是从网络内容中收集的,缺乏固有的领域划分。 例如,像 Common Crawl 这样广泛使用的数据集并不包含明确的领域标签,而手动整理标记数据集(如 The Pile)则是一项劳动密集型工作。 因此&…...

AI大模型发展现状与MCP协议诞生的技术演进
1. 大模型能力边界与用户痛点(2023年) 代表模型:GPT-4(OpenAI)、Claude 3(Anthropic)、通义千问(阿里云)等展现出强大的生成能力,但存在明显局限:…...

从malloc到free:动态内存管理全解析
1.为什么要有动态内存管理 我们已经掌握的内存开辟方法有: int main() {int val 20;//在栈空间上开辟四个字节char arr[20] { 0 };//在栈空间上开辟10个字节的连续空间return 0; }上述开辟的内存空间有两个特点: 1.空间开辟的时候大小已经固定 2.数组…...

CSS值和单位
CSS值和单位 CSS 中的值和单位是构建样式的基础,它们定义了属性的具体表现方式。值用于定义样式属性的具体取值,而单位用于指定这些值的度量方式。CSS中常用的值和单位如下: 1.长度单位 px : 像素,绝对单位 em : 相对于元素的字…...

Redis高级篇之I/O多路复用的引入解析
文章目录 一、问题背景1. 高并发连接的管理2. 避免阻塞和延迟3. 减少上下文切换开销4. 高效的事件通知机制5. 简化编程模型6. 低延迟响应本章小节 二、I/O多路复用高性能的本质1. 避免无意义的轮询:O(1) 事件检测2. 非阻塞 I/O 零拷贝:最大化 CPU 利用率…...

FTP协议命令和响应码
文章目录 📦 一、什么是 FTP 协议?🧾 二、FTP 常见命令(客户端发送)📡 三、FTP 响应码(服务端返回)📌 响应码分类(第一位)✅ 常见成功响应码&…...
)
在win上安装Ubuntu安装Anaconda(linx环境)
一,安装Ubuntu 1. 在 Microsoft 商城去下载Ubuntu(LTS:是长期维护的版本) 2.安装完之后启动程序,再重新打开一个黑窗口: wsl --list --verbose 3.关闭Ubuntu wsl --shutdown Ubuntu-22.04 WSL2 Ubuntu-20.04文件太占c盘空间,…...

【Elasticsearch入门到落地】11、RestClient初始化索引库
接上篇《10、初始化RestClient》 上一篇我们已经完成了RestHighLevelClient的初始化工作,本篇将正式进入索引库的创建阶段。我们将使用Java代码来创建酒店数据的索引库。 一、准备工作 1. 创建常量类 首先,我们需要定义一个常量类来存放索引库的mappi…...

远程服务调用的一些注意事项
引言 最近工作中,遇到了一些关于远程服务调用的问题,背景是调用三方接口获取某些特征数据,但由于调用出现了超时,导致业务本身的接口的可用行降低。因此整理一些远程服务调用时的注意事项,通过不同维度的考虑来提高系…...

QML 样式库
在 QML 中,样式库(或 UI 框架)用于快速构建一致且美观的界面。Qt/QML 本身不提供内置的完整样式库,但可以通过以下方式实现样式管理或使用第三方库。 1. Qt Quick Controls 2 样式系统 Qt Quick Controls 2 是官方提供的 UI 组件…...

[RHEL8] 指定rpm软件包的更高版本模块流
背景:挂载RHEL ISO使用kickstart安装操作系统,安装包未指定安装perl,但是安装完可以查到其版本,且安装的是ISO中多个版本中的最低版本。 原因:(1)为什么没有装perl,perl -v可以看到版…...

使用Python可视化洛伦兹变换
引言 大家好!今天我们将探讨一个非常有趣且重要的物理概念—洛伦兹变换。它是相对论的核心内容之一,描述了在高速运动下,时间、长度以及其他物理量是如何发生变化的。通过使用 Python 进行可视化,我们不仅可以更好地理解这个概念,还能感受到物理世界中的奇妙之处。 什么…...
)
【二叉树专题】一道深入浅出的 DFS 题:求二叉树的直径(含通俗易懂讲解)
题目: 给你一棵二叉树的根节点,返回这棵树的 直径。 直径 是任意两个节点路径中,最长的一条路径所经过的边数。 比如下面这棵树: 1/ \2 3/ \ 4 5它的最长路径是:4 → 2 → 5 或者 4 → 2 → 1 → 3,…...

考研系列-计算机网络-第三章、数据链路层
一、数据链路层的功能 1.知识点总结 2.习题总结...

医药采购系统平台第10天02:按药品分类的统计按供货商统计按医院统计统计数据的导出DWR的配置和应用
如果想要获取相关的源码,笔记,和相关工具,对项目需求的二次开发,可以关注我并私信!!! 一 按药品分类的统计实现 1 按药品分类统计的需求 按药品统计:在指定时间段中采购量、采购金…...

Navicat、DataGrip、DBeaver在渲染 BOOLEAN 类型字段时的一种特殊“视觉风格”
文章目录 前言✅ 为什么 Boolean 字段显示为 [ ]?✅ 如何验证实际数据类型?✅ 小结 前言 看到的 deleted: [ ] 并不是 Prisma 的问题,而是数据库客户端(如 Navicat、DataGrip、DBeaver)在渲染 BOOLEAN 类型字段时的一种…...
 吴恩达版提示词工程 2. 指南)
(undone) 吴恩达版提示词工程 2. 指南
url: https://www.bilibili.com/video/BV1Z14y1Z7LJ?spm_id_from333.788.videopod.episodes&vd_source7a1a0bc74158c6993c7355c5490fc600&p2 别人的笔记 url: https://zhuanlan.zhihu.com/p/626966526 指导原则(Guidelines) 编写提示词有两个…...

VLC搭建本机的rtsp直播推流和拉流
媒体---流---捕获设备,选择摄像头,点击串流 x下一步 选择rtsp,点击添加 看到了端口,并设置路径: 选择Video -H 264 mp3(TS) 点击下一个, 点击流,就开始推流了 拉流,观看端&#x…...

Rocky Linux 9.1 修改网卡和DNS
在 Rocky Linux 9.1 中修改网卡和 DNS 配置可以通过 NetworkManager 工具实现(推荐)或直接编辑配置文件。以下是两种方法的详细步骤: 方法一:使用 nmcli 命令行工具(动态生效) 查看当前网络连接nmcli connection show # 输出示例: # NAME UUID …...

Web前端:常用的布局属性
常见的布局方式有哪些? float:浮动布局 position 定位布局 flex 弹性布局(display) table 表格布局(弃用) 一、HTML5 语义化布局标签 这些标签本身不提供布局能力,但能增强页面结构…...

XSS学习2
一、客户端的Cookie 1. 无状态的影响 无状态问题: HTTP协议的无状态特性导致每次请求都是独立的,无法保持会话。例如,在银行办理业务时,柜员不需要重复询问客户信息,但在计算机网络中,每次HTTP请求都需要重新认证用户…...

软件设计师/系统架构师---计算机网络
概要 什么是计算机网络? 计算机网络是指将多台计算机和其他设备通过通信线路互联,以便共享资源和信息的系统。计算机网络可以有不同的规模,从家庭网络到全球互联网。它们可以通过有线(如以太网)或无线(如W…...
学习笔记(二)--k8s 集群安装)
Kubernetes(k8s)学习笔记(二)--k8s 集群安装
1、kubeadm kubeadm 是官方社区推出的一个用于快速部署 kubernetes 集群的工具。这个工具能通过两条指令完成一个 kubernetes 集群的部署: 1.1 创建一个 Master 节点$ kubeadm init 1.2 将一个 Node 节点加入到当前集群中$ kubeadm join <Master 节点的 IP 和…...
)
线性DP:最长上升子序列(子序列可不连续,子数组必须连续)
目录 Q1:简单遍历 Q2:变式(加大数据量) Q1:简单遍历 Dp问题 状态表示 f(i,j) 集合所有以第i个数结尾的上升子序列集合-f(i,j)的值存的是什么序列长度最大值max- 状态计算 (其实质是集合的划分)…...

SpringBoot 基本原理
SpringBoot 为我们做的自动配置,确实方便快捷,但一直搞不明白它的内部启动原理,这次就来一步步解开 SpringBoot 的神秘面纱,让它不再神秘。 目录 SpringBootApplication 背后的秘密 Configuration ComponentScan EnableAutoC…...

LeetCode第158题_用Read4读取N个字符 II
LeetCode 第158题:用Read4读取N个字符 II 题目描述 给你一个文件,并且该文件只能通过给定的 read4 方法来读取,请实现一个方法来读取 n 个字符。 read4 方法: API read4 可以从文件中读取 4 个连续的字符,并且将它…...

webgl入门实例-矩阵在图形学中的作用
矩阵在图形学中扮演着核心角色,几乎所有图形变换、投影和空间转换都依赖矩阵运算来实现高效计算。以下是矩阵在图形学中的主要作用及具体应用: 1. 几何变换 矩阵乘法可以高效表示物体的平移、旋转、缩放等基本变换,并通过矩阵连乘实现复合变…...

基于Matlab求解矩阵电容等效容值
1需求 仿真测试8*10阶举证电容等效容值。 2模型搭建 2.1打开simscape 在打开simulink之后打开simscape库,Simscape库位置如下 2.2搭建模型 在库中寻找需要的元件搭建电路。 2.2.1基本元件 电阻电容电感等基础器件,搭建电路之后需要对其进行幅值&…...

铅酸电池充电器方案EG1253+EG4321
参考: 基于EG1253EG4321铅酸电池(48V20AH)三段式充电器 屹晶微高性价比的电瓶车充电器方案——EG1253 电瓶电压 48V电瓶锂电池,其充满约为55V~56V,因此充电器输出电压为55V~56V; 若是48V铅酸电池,标称电压为48V&…...