手撕LLM(四):从源码出发,探索大模型的预训练(pretrain)过程

前面我们基于Minimind项目介绍了大模型的推理、LoRa加载、Moe结构, 大家对大模型的整体结构应该有一个比较清晰的认识;从该篇博客开始,我们通过代码剖析大模型的训练过程,今天的主题是大模型的预训练。
那大模型的预训练是一个什么阶段呢?其实就是大模型从零开始学习的一个阶段,就像是一个刚出生的婴儿,虽然有一个结构复杂的大脑,但是还没有经过任何数据的训练,对这个世界的认识、框架的构建还处于一个空白的状态,需要通过数据集去学习普遍的知识、社会关系、物理定理等。
训练一个模型最重要的几个点包括:模型结构的搭建、训练集的准备、Loss函数的定义和优化器的定义;前面我们已经介绍了模型的框架,接下来我们就从训练集构建出发,探索整个大模型的预训练过程。
一、源码分析
1.1 整体介绍
还是基于Minimind项目,它的预训练代码在./train_pretrain.py,如下所示,通过代码,我们可以看到整个代码就分为模型和分词器加载、训练集预处理、模型训练、梯度更新四部分;
# train_pretrain.pyimport os
import platform
import argparse
import time
import math
import warnings
import pandas as pd
import torch
import torch.distributed as dist
from torch import optim, nn
from torch.nn.parallel import DistributedDataParallel
from torch.optim.lr_scheduler import CosineAnnealingLR
from torch.utils.data import DataLoader, DistributedSampler
from contextlib import nullcontextfrom transformers import AutoTokenizerfrom model.model import MiniMindLM
from model.LMConfig import LMConfig
from model.dataset import PretrainDatasetwarnings.filterwarnings('ignore')def Logger(content):if not ddp or dist.get_rank() == 0:print(content)def get_lr(current_step, total_steps, lr):return lr / 10 + 0.5 * lr * (1 + math.cos(math.pi * current_step / total_steps))def train_epoch(epoch, wandb):loss_fct = nn.CrossEntropyLoss(reduction='none')start_time = time.time()for step, (X, Y, loss_mask) in enumerate(train_loader):X = X.to(args.device)Y = Y.to(args.device)loss_mask = loss_mask.to(args.device)lr = get_lr(epoch * iter_per_epoch + step, args.epochs * iter_per_epoch, args.learning_rate)for param_group in optimizer.param_groups:param_group['lr'] = lrwith ctx:res = model(X)loss = loss_fct(res.logits.view(-1, res.logits.size(-1)),Y.view(-1)).view(Y.size())loss = (loss * loss_mask).sum() / loss_mask.sum()loss += res.aux_lossloss = loss / args.accumulation_stepsscaler.scale(loss).backward()if (step + 1) % args.accumulation_steps == 0:scaler.unscale_(optimizer)torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)scaler.step(optimizer)scaler.update()optimizer.zero_grad(set_to_none=True)if step % args.log_interval == 0:spend_time = time.time() - start_timeLogger('Epoch:[{}/{}]({}/{}) loss:{:.3f} lr:{:.12f} epoch_Time:{}min:'.format(epoch + 1,args.epochs,step,iter_per_epoch,loss.item() * args.accumulation_steps,optimizer.param_groups[-1]['lr'],spend_time / (step + 1) * iter_per_epoch // 60 - spend_time // 60))if (wandb is not None) and (not ddp or dist.get_rank() == 0):wandb.log({"loss": loss.item() * args.accumulation_steps,"lr": optimizer.param_groups[-1]['lr'],"epoch_Time": spend_time / (step + 1) * iter_per_epoch // 60 - spend_time // 60})if (step + 1) % args.save_interval == 0 and (not ddp or dist.get_rank() == 0):model.eval()moe_path = '_moe' if lm_config.use_moe else ''ckp = f'{args.save_dir}/pretrain_{lm_config.dim}{moe_path}.pth'if isinstance(model, torch.nn.parallel.DistributedDataParallel):state_dict = model.module.state_dict()else:state_dict = model.state_dict()torch.save(state_dict, ckp)model.train()def init_model(lm_config):tokenizer = AutoTokenizer.from_pretrained('./model/minimind_tokenizer')model = MiniMindLM(lm_config).to(args.device)Logger(f'LLM总参数量:{sum(p.numel() for p in model.parameters() if p.requires_grad) / 1e6:.3f} 百万')return model, tokenizerdef init_distributed_mode():if not ddp: returnglobal ddp_local_rank, DEVICEdist.init_process_group(backend="nccl")ddp_rank = int(os.environ["RANK"])ddp_local_rank = int(os.environ["LOCAL_RANK"])ddp_world_size = int(os.environ["WORLD_SIZE"])DEVICE = f"cuda:{ddp_local_rank}"torch.cuda.set_device(DEVICE)# torchrun --nproc_per_node 2 1-pretrain.py
if __name__ == "__main__":parser = argparse.ArgumentParser(description="MiniMind Pretraining")parser.add_argument("--out_dir", type=str, default="out")# 若要以最快速度实现zero则epochs设置为1轮;否则应当利用有限的数据训练2~6个epochs。parser.add_argument("--epochs", type=int, default=1)parser.add_argument("--batch_size", type=int, default=32)parser.add_argument("--learning_rate", type=float, default=5e-4)parser.add_argument("--device", type=str, default="cuda:0" if torch.cuda.is_available() else "cpu")parser.add_argument("--dtype", type=str, default="bfloat16")parser.add_argument("--use_wandb", action="store_true")parser.add_argument("--wandb_project", type=str, default="MiniMind-Pretrain")parser.add_argument("--num_workers", type=int, default=1)parser.add_argument("--ddp", action="store_true")parser.add_argument("--accumulation_steps", type=int, default=8)parser.add_argument("--grad_clip", type=float, default=1.0)parser.add_argument("--warmup_iters", type=int, default=0)parser.add_argument("--log_interval", type=int, default=100)parser.add_argument("--save_interval", type=int, default=100)parser.add_argument('--local_rank', type=int, default=-1)parser.add_argument('--dim', default=512, type=int)parser.add_argument('--n_layers', default=8, type=int)parser.add_argument('--max_seq_len', default=512, type=int)parser.add_argument('--use_moe', default=False, type=bool)parser.add_argument("--data_path", type=str, default="./dataset/pretrain_hq.jsonl")args = parser.parse_args()lm_config = LMConfig(dim=args.dim, n_layers=args.n_layers, max_seq_len=args.max_seq_len, use_moe=args.use_moe)args.save_dir = os.path.join(args.out_dir)os.makedirs(args.save_dir, exist_ok=True)os.makedirs(args.out_dir, exist_ok=True)tokens_per_iter = args.batch_size * lm_config.max_seq_lendevice_type = "cuda" if "cuda" in args.device else "cpu"args.wandb_run_name = f"MiniMind-Pretrain-Epoch-{args.epochs}-BatchSize-{args.batch_size}-LearningRate-{args.learning_rate}"ctx = nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast()ddp = int(os.environ.get("RANK", -1)) != -1 # is this a ddp run?ddp_local_rank, DEVICE = 0, "cuda:0"base_seed = 1337torch.manual_seed(base_seed)torch.cuda.manual_seed(base_seed)if ddp:init_distributed_mode()args.device = torch.device(DEVICE)rank = dist.get_rank()torch.manual_seed(base_seed + rank)# 同时设置 CUDA 的随机种子torch.cuda.manual_seed(base_seed + rank)if args.use_wandb and (not ddp or ddp_local_rank == 0):import wandbwandb.init(project=args.wandb_project, name=args.wandb_run_name)else:wandb = Nonemodel, tokenizer = init_model(lm_config)train_ds = PretrainDataset(args.data_path, tokenizer, max_length=lm_config.max_seq_len)train_sampler = DistributedSampler(train_ds) if ddp else Nonetrain_loader = DataLoader(train_ds,batch_size=args.batch_size,pin_memory=True,drop_last=False,shuffle=False,num_workers=args.num_workers,sampler=train_sampler)scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype in ['float16', 'bfloat16']))optimizer = optim.AdamW(model.parameters(), lr=args.learning_rate)if ddp:model._ddp_params_and_buffers_to_ignore = {"pos_cis"}model = DistributedDataParallel(model, device_ids=[ddp_local_rank])iter_per_epoch = len(train_loader)for epoch in range(args.epochs):train_epoch(epoch, wandb)
1.2 代码分析
和之前一样,依然在train_pretrain.py同级目录创建一个jujupyterNotebook文件;
1.2.1 导包
代码:
import os
import platform
import argparse
import time
import math
import warnings
import pandas as pd
import torch
import torch.distributed as dist
from torch import optim, nn
from torch.nn.parallel import DistributedDataParallel
from torch.optim.lr_scheduler import CosineAnnealingLR
from torch.utils.data import DataLoader, DistributedSampler
from contextlib import nullcontextfrom transformers import AutoTokenizerfrom model.model import MiniMindLM
from model.LMConfig import LMConfig
from model.dataset import PretrainDatasetwarnings.filterwarnings('ignore')1.2.2 加载模型和分词器
这些在前面模型推理部分已经做过详细的代码解释,这里不再赘述,到此我们就获得了模型对象和分词器对象;
代码:
lm_config = LMConfig(dim=512, n_layers=8, max_seq_len=512, use_moe=False)def init_model(lm_config):tokenizer = AutoTokenizer.from_pretrained('./model/minimind_tokenizer')model = MiniMindLM(lm_config).to('cpu')# Logger(f'LLM总参数量:{sum(p.numel() for p in model.parameters() if p.requires_grad) / 1e6:.3f} 百万')return model, tokenizermodel, tokenizer = init_model(lm_config)1.2.3 超参解释
代码:
parser = argparse.ArgumentParser(description="MiniMind Pretraining")
parser.add_argument("--out_dir", type=str, default="out")
parser.add_argument("--epochs", type=int, default=1)
parser.add_argument("--batch_size", type=int, default=32)
parser.add_argument("--learning_rate", type=float, default=5e-4)
parser.add_argument("--device", type=str, default="cuda:0" if torch.cuda.is_available() else "cpu")
parser.add_argument("--dtype", type=str, default="bfloat16")
parser.add_argument("--use_wandb", action="store_true")
parser.add_argument("--wandb_project", type=str, default="MiniMind-Pretrain")
parser.add_argument("--num_workers", type=int, default=1)
parser.add_argument("--ddp", action="store_true")
parser.add_argument("--accumulation_steps", type=int, default=8)
parser.add_argument("--grad_clip", type=float, default=1.0)
parser.add_argument("--warmup_iters", type=int, default=0)
parser.add_argument("--log_interval", type=int, default=100)
parser.add_argument("--save_interval", type=int, default=100)
parser.add_argument('--local_rank', type=int, default=-1)
parser.add_argument('--dim', default=512, type=int)
parser.add_argument('--n_layers', default=8, type=int)
parser.add_argument('--max_seq_len', default=512, type=int)
parser.add_argument('--use_moe', default=False, type=bool)
parser.add_argument("--data_path", type=str, default="./dataset/pretrain_hq.jsonl")
- --out_dir:输出路径;
--epochs:训练轮数;
--batch_size:单次训练批次数;
--learning_rate:学习率;
--device:运算硬件;
--dtype:运算精度;
--accumulation_steps:梯度累积数;
--grad_clip:最大梯度范数(max norm),用于梯度裁剪中限制梯度的大小;
--data_path:训练集json文件本地路径;
1.2.4 拆解训练集
1.2.4.1 加载训练集
代码1:
def load_data(path):samples = []with open(path, 'r', encoding='utf-8') as f:for line_num, line in enumerate(f, 1):data = json.loads(line.strip())samples.append(data)return samples代码2:
samples = load_data('./dataset/pretrain_hq.jsonl')
print(type(samples))
print(len(samples))
print(samples[0])输出结果2:
通过输出结果可以看出,samples是一个列表,里面包含了1413103个文本字典,每个字典有一个‘text’Key值,对应的是一段文本信息;
<class 'list'>
1413103
{'text': '<s>鉴别一组中文文章的风格和特点,例如官方、口语、文言等。需要提供样例文章才能准确鉴别不同的风格和特点。</s> <s>好的,现在帮我查一下今天的天气怎么样?今天的天气依据地区而异。请问你需要我帮你查询哪个地区的天气呢?</s> <s>打开闹钟功能,定一个明天早上七点的闹钟。好的,我已经帮您打开闹钟功能,闹钟将在明天早上七点准时响起。</s> <s>为以下场景写一句话描述:一个孤独的老人坐在公园长椅上看着远处。一位孤独的老人坐在公园长椅上凝视远方。</s> <s>非常感谢你的回答。请告诉我,这些数据是关于什么主题的?这些数据是关于不同年龄段的男女人口比例分布的。</s> <s>帮我想一个有趣的标题。这个挺有趣的:"如何成为一名成功的魔术师" 调皮的标题往往会吸引读者的注意力。</s> <s>回答一个问题,地球的半径是多少?地球的平均半径约为6371公里,这是地球自赤道到两极的距离的平均值。</s> <s>识别文本中的语气,并将其分类为喜悦、悲伤、惊异等。\n文本:“今天是我的生日!”这个文本的语气是喜悦。</s>'}1.2.4.2 数据处理(getitem)
源码中数据加载和数据处理是通过继承dataset类实现的,这里我们将其拆解,看一下它是如何对数据进行加工处理的;
代码1:
sample = samples[0]
print(sample)输出结果1:
{'text': '<s>鉴别一组中文文章的风格和特点,例如官方、口语、文言等。需要提供样例文章才能准确鉴别不同的风格和特点。</s> <s>好的,现在帮我查一下今天的天气怎么样?今天的天气依据地区而异。请问你需要我帮你查询哪个地区的天气呢?</s> <s>打开闹钟功能,定一个明天早上七点的闹钟。好的,我已经帮您打开闹钟功能,闹钟将在明天早上七点准时响起。</s> <s>为以下场景写一句话描述:一个孤独的老人坐在公园长椅上看着远处。一位孤独的老人坐在公园长椅上凝视远方。</s> <s>非常感谢你的回答。请告诉我,这些数据是关于什么主题的?这些数据是关于不同年龄段的男女人口比例分布的。</s> <s>帮我想一个有趣的标题。这个挺有趣的:"如何成为一名成功的魔术师" 调皮的标题往往会吸引读者的注意力。</s> <s>回答一个问题,地球的半径是多少?地球的平均半径约为6371公里,这是地球自赤道到两极的距离的平均值。</s> <s>识别文本中的语气,并将其分类为喜悦、悲伤、惊异等。\n文本:“今天是我的生日!”这个文本的语气是喜悦。</s>'}代码2:
# 构建输入文本
text = f"{tokenizer.bos_token}{str(sample['text'])}{tokenizer.eos_token}"
print(text)输出结果2:
<s><s>鉴别一组中文文章的风格和特点,例如官方、口语、文言等。需要提供样例文章才能准确鉴别不同的风格和特点。</s> <s>好的,现在帮我查一下今天的天气怎么样?今天的天气依据地区而异。请问你需要我帮你查询哪个地区的天气呢?</s> <s>打开闹钟功能,定一个明天早上七点的闹钟。好的,我已经帮您打开闹钟功能,闹钟将在明天早上七点准时响起。</s> <s>为以下场景写一句话描述:一个孤独的老人坐在公园长椅上看着远处。一位孤独的老人坐在公园长椅上凝视远方。</s> <s>非常感谢你的回答。请告诉我,这些数据是关于什么主题的?这些数据是关于不同年龄段的男女人口比例分布的。</s> <s>帮我想一个有趣的标题。这个挺有趣的:"如何成为一名成功的魔术师" 调皮的标题往往会吸引读者的注意力。</s> <s>回答一个问题,地球的半径是多少?地球的平均半径约为6371公里,这是地球自赤道到两极的距离的平均值。</s> <s>识别文本中的语气,并将其分类为喜悦、悲伤、惊异等。
文本:“今天是我的生日!”这个文本的语气是喜悦。</s></s>代码3:
encoding = tokenizer(text,max_length=512,padding='max_length',truncation=True,return_tensors='pt')
print(encoding.keys())
输出结果3:
dict_keys(['input_ids', 'token_type_ids', 'attention_mask'])这里需要解释一下,在对单个文本进行分词时,通过tokenizer实现,其中:
- text——表示需要进行分词的文本信息;
- max_length——表示token序列的最大长度;
- padding——表示按照最大长度填充;
- truncation——表示超过最大长度的部分是否舍弃;
- return_tensors——表示返回数据类型为pytorch张量;
返回结果是一个字典,包含三个键值对,其中:
- input_ids——表示转换后的tokenID;
- token_type_ids——表示每一个tokenID所属分句索引;
- attention_mask——表示对应token ID是否为填充项;
代码4:
input_ids = encoding.input_ids.squeeze()
print(input_ids.shape)输出结果4:
torch.Size([512])代码5:
loss_mask = (input_ids != tokenizer.pad_token_id)
print(loss_mask.shape)
loss_mask = torch.tensor(loss_mask[1:], dtype=torch.long)
print(loss_mask.shape)输出结果5:
torch.Size([512])
torch.Size([511])loss_mask 是一个与输入序列等长的二进制掩码(通常为 0 或 1),用于指示哪些 token 的预测损失需要被计算。 1: 表示该位置的 loss 需要被计算。 0: 表示该位置的 loss 被忽略(即不参与梯度更新)。 作用: 屏蔽无效 token: 忽略填充(padding)部分或其他不需要计算 loss 的 token。 任务特定控制: 在某些任务中,只关注特定部分的预测结果,而不是整个序列。
代码6:
X = torch.tensor(input_ids[:-1], dtype=torch.long)
print(X.shape)输出结果6:
torch.Size([511])代码7:
Y = torch.tensor(input_ids[1:], dtype=torch.long)
print(Y.shape)输出结果7:
torch.Size([511])通过对单个数据样本的处理,可以看出整个流程是将文本转为tokenID,然后进行填充对齐,X表示训练样本,Y表示对应标签,loss_msk表示计算损失的数据区域;X每个元素对应Y里面的值是X中该元素的下一个元素,所以预训练过程是一个无监督学习的过程。
1.2.4.3 批量数据加载
代码:
train_loader = DataLoader(train_ds,batch_size=2,pin_memory=False, # 是否将数据加载到 CUDA 固定内存中,加速 GPU 训练drop_last=True, # 如果数据集大小不能被 batch_size 整除,是否丢弃最后一个不完整的批次shuffle=False, # 是否在每个 epoch 开始时打乱数据顺序num_workers=1, # 用于数据加载的子进程数量sampler=None # 自定义采样器,用于指定数据加载顺序)
print(len(train_loader))输出结果:
7065511.2.5 混合精度处理
代码:
scaler = torch.cuda.amp.GradScaler(enabled=True)torch.cuda.amp.GradScaler 是 PyTorch 中用于处理混合精度训练的核心工具之一,其主要功能包括:
- 放大损失值: 在反向传播之前,将损失值乘以一个缩放因子(scale factor),以避免 float16 梯度下溢。
- 反向传播后缩小梯度: 在完成反向传播后,将梯度除以相同的缩放因子,恢复到原始范围。
- 动态调整缩放因子: 根据是否发生梯度溢出(NaN 或 Inf),动态调整缩放因子的大小,确保训练过程稳定。
1.2.6 优化器加载
代码:
optimizer = optim.AdamW(model.parameters(), lr=5e-4)
- 这里使用的是带有动量的adam优化器;
- model.parameters() 是 PyTorch 中用于访问模型中所有可训练参数(即需要优化的参数)的方法;
1.2.7 模型训练
代码:
def train_epoch(epoch, wandb):# 1loss_fct = nn.CrossEntropyLoss(reduction='none')start_time = time.time()# 2for step, (X, Y, loss_mask) in enumerate(train_loader):# 2.1X = X.to('cpu')Y = Y.to('cpu')loss_mask = loss_mask.to('cpu')# 2.2lr = get_lr(epoch * iter_per_epoch + step, 2 * iter_per_epoch, 5e-4)# 2.3for param_group in optimizer.param_groups:param_group['lr'] = lrwith ctx:# 2.4res = model(X)# 2.5loss = loss_fct(res.logits.view(-1, res.logits.size(-1)),Y.view(-1)).view(Y.size())# 2.6loss = (loss * loss_mask).sum() / loss_mask.sum()# 2.7loss += res.aux_loss# 2.8loss = loss / 2# 3scaler.scale(loss).backward()# 4if (step + 1) % 2 == 0:scaler.unscale_(optimizer)# 4.1torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # 梯度裁剪# 4.2scaler.step(optimizer)scaler.update()# 4.3optimizer.zero_grad(set_to_none=True)
- 1——定义损失函数,
nn.CrossEntropyLoss是 PyTorch 中用于分类任务的常用损失函数,特别是在多分类问题中。它结合了 LogSoftmax 和 NLLLoss(负对数似然损失),提供了一种简洁的方式来计算分类任务中的损失;- 2——遍历批量训练集;
- 2.1——张量设备转移;
- 2.2——通常被称为 余弦退火(Cosine Annealing)。它的作用是根据训练的进度动态调整学习率,从而在训练过程中更好地控制模型的收敛速度和稳定性;
- 2.3——动态调整优化器(
optimizer)中每个参数组的学习率(lr)。具体来说,它会将优化器中所有参数组的学习率更新为指定的值lr;2.4——前向推理;2.5——计算损失值;2.6——去除填充token的损失值影响;2.7——添加aux_loss到总的loss中,aux_loss用于均衡门控专家,在MoE模型中才有;2.8——将计算得到的loss值除以梯度更新批次数;3——梯度回传,更新梯度图;4——达到权重更新批次后通过梯度值更新权重值;4.1——梯度裁剪,计算梯度向量的L2范数,如果大于指定阈值就等比例缩小到阈值范围内,主要用于防止过拟合;4.2——更新权重值;4.3——梯度清零,进行下一轮梯度计算;
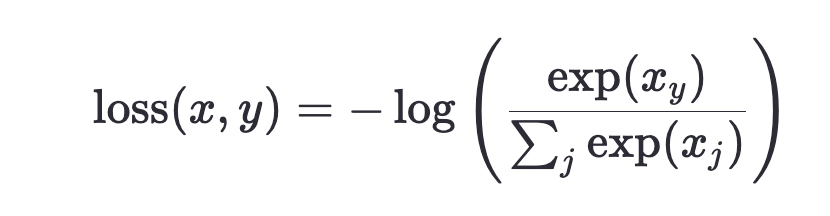
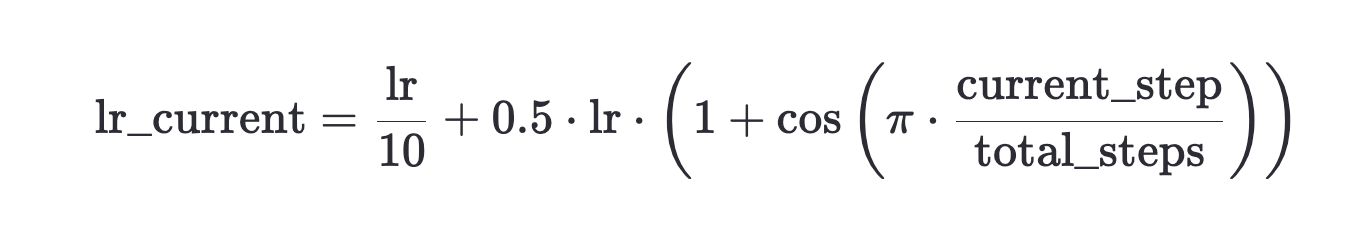
二、总结
大模型的预训练是一种无监督学习训练, 训练集中当前token的标签是下一个token;损失函数采用CrossEntropyLoss,它是一种类似于交叉熵损失函数结构的一种函数,结合了 LogSoftmax 和 NLLLoss(负对数似然损失),用于解决多分类问题;优化器采用AdamW,AdamW 将权重衰减视为 L2 正则化的一部分,在梯度计算前应用;
相关文章:
:从源码出发,探索大模型的预训练(pretrain)过程)
手撕LLM(四):从源码出发,探索大模型的预训练(pretrain)过程
前面我们基于Minimind项目介绍了大模型的推理、LoRa加载、Moe结构, 大家对大模型的整体结构应该有一个比较清晰的认识;从该篇博客开始,我们通过代码剖析大模型的训练过程,今天的主题是大模型的预训练。 那大模型的预训练是一个什么…...
)
Linux系统:进程终止的概念与相关接口函数(_exit,exit,atexit)
本节目标 理解进程终止的概念理解退出状态码的概念以及使用方法掌握_exit与exit函数的用法以及区别atexit函数注册终止时执行的函数相关宏 一、进程终止 进程终止(Process Termination)是指操作系统结束一个进程的执行,回收其占用的资源&a…...

keil5 µVision 升级为V5.40.0.0:增加了对STM32CubeMX作为全局生成器的支持,主要有哪些好处?
在Keil5 μVision V5.40.0.0版本中,增加了对STM32CubeMX作为全局生成器的支持,这一更新主要带来了以下三方面的提升: 开发流程整合STM32CubeMX原本就支持生成Keil项目代码,但新版本将这一集成升级为“全局生成器”级别,意味着STM32CubeMX生成的代码能直接成为Keil项目的核…...

C 语言联合与枚举:自定义类型的核心解析
上篇博客中,我们通过学习了解了C语言中一种自定义类型结构体的相关知识,那么该语言中是否还拥有相似的自定义类型呢?这将是我们今天学习的目标。 1.联合体 联合体其实跟结构体类似,也是由一个或多个成员构成,这些成员…...

P1113 杂务-拓扑排序
拓扑排序 P1113 杂务 题目来源-洛谷 题意 求出完成所有任务的最短时间 思路 要求完成所有任务的最短时间,即每个任务尽可能最短,所以再求完成所有任务中的最大值(需要最长时间的任务都完成了才叫全部完成) 问题化解…...

Flink介绍——实时计算核心论文之Kafka论文总结
引入 大数据系统中的数据来源 在开始深入探讨Kafka之前,我们得先搞清楚一个问题:大数据系统中的数据究竟是从哪里来的呢?其实,这些数据大部分都是由各种应用系统或者业务系统产生的“日志”。 比如,互联网公司的广告…...

模拟投资大师思维:AI对冲基金开源项目详解
这里写目录标题 引言项目概述核心功能详解多样化的AI投资智能体灵活的运行模式透明的决策过程 安装和使用教程环境要求安装步骤基本使用方法运行对冲基金模式运行回测模式 应用场景和实际价值教育和研究价值潜在的商业应用与现有解决方案的对比局限性与发展方向 结论 引言 随着…...

DAY4:数据库对象与高级查询深度解析:从视图到多表关联实战
一、数据库对象精要指南 1.1 视图(View)的进阶应用 视图是存储在数据库中的虚拟表,本质是预编译的SQL查询语句。通过视图可以简化复杂查询、实现数据安全隔离、保持业务逻辑一致性。 创建语法示例: CREATE VIEW sales_summary…...

【Matlab】中国东海阴影立体感地图
【Matlab】中国东海阴影立体感地图 【Matlab】中国东海阴影立体感地图 【Matlab】中国东海阴影图立体感画法 以前分享过一次,链接如下: 中国海域地形图 但是以前还是有些小问题,这次修改了。 另外,增加了新的画法: 另…...

python文件类操作:json/ini配置文件、logging日志统计、excel表格数据读写、os操作库
文章目录 一、with open文件操作二、csv表格数据读写三、Excel表格数据读写四、json配置文件读写五、ini配置文件读写六、logging日志统计七、os操作库(文件拼接、创建、判断等) 打开文件使用不同参数有着不同的含义,比如只读、只写、二进制读…...
)
VSCode安装与环境配置(Mac环境)
20250419 - 概述 大概是非常久之前了,装了VSCode,估计都得21的时候了,电脑上也没更新过。当时安装也直接装上就完事了。这次把版本更新一下,同时记录一下这个安装过程。 安装 mac下安装非常简单,直接从官网下载&am…...
)
【信息系统项目管理师】高分论文:论信息系统项目的采购管理(“营业工单系统”项目)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 论文1、规划采购管理2、实施采购3、控制采购论文 2018年1月,我参加了 XX运营商集团公司某省分公司的“营业工单系统”的信息化建设项目,我有幸担任项目经理。该项目投资1000万元人民币,建设工期为12个月。该…...

XCVU13P-2FHGA2104I Xilinx Virtex UltraScale+ FPGA
XCVU13P-2FHGA2104I 是 Xilinx(现为 AMD)Virtex UltraScale™ FPGA 系列中的高端 Premium 器件,基于 16nm FinFET 工艺并采用 3D IC 堆叠硅互连(SSI)技术,提供业内顶级的计算密度和带宽。该芯片集成约 3,…...

@Validated与@Valid的正确使用姿势
验证代码 Validated RestController public class A {PostMappingpublic void test(Min(value 1) Integer count) {} // 校验规则生效 }RestController public class A {PostMappingpublic void test(Validated Min(value 1) Integer count) {} // 校验规则不生效 }RestCont…...

Ubuntu20.04下Docker方案实现多平台SDK编译
0 前言 熟悉嵌入式平台Linux SDK编译流程的小伙伴都知道,假如平台a要求必须在Ubuntu18.04下编译,平台b要求要Ubuntu22.04的环境,那我只有Ubuntu20.04,或者说我的电脑硬件配置最高只能支持Ubuntu20.04怎么办?强行在Ubuntu20.04下编译,编又编不过,换到旧版本我又不愿意,…...
树莓派配置GPIO)
树莓派超全系列教程文档--(34)树莓派配置GPIO
配置GPIO GPIO控制gpio 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 GPIO控制 gpio 通过 gpio 指令,可以在启动时将 GPIO 引脚设置为特定模式和值,而以前需要自定义 dt-blob.bin 文件。每一行都对一组引脚应用相同的设…...
)
C语言 数组(下)
目录 1.二维数组的创建 2.二位数组的初始化 3.二维数组的使用 4.二维数组在内存中的储存 1.二维数组的创建 1.1二维数组的概念 前面学习的数组被称为一维数组,数组的元素都是内置类型的,如果我们把一维数组做为数组的元 素,这时候就是…...
)
opencv图像旋转(单点旋转的原理)
首先我们以最简单的一个点的旋转为例子,且以最简单的情况举例,令旋转中心为坐标系中心O(0,0),假设有一点P_{0}(x_{0},y_{0}),P_{0}离旋转中心O的距离为r,OP_{0}与坐标轴x轴的夹角为\…...

针对MCP认证考试中的常见技术难题进行实战分析与解决方案分享
一、身份与权限管理类难题 场景1:Active Directory组策略(GPO)不生效 问题现象:客户端计算机未应用新建的组策略。排查步骤: 检查GPO链接顺序:使用gpresult /r查看策略优先级,确保目标OU的GPO…...

systemctl管理指令
今天我们来继续学习服务管理指令,接下来才是重头戏-systemctl,那么话不多说,直接开始吧. systemctl管理指令 1.基本语法: systemctl [start | stop | restart | status]服务 注:systemctl指令管理的服务在/usr/lib/ systemd/system查看 2.systemctl设置服务的自…...

DataWhale AI春训营 问题汇总
1.没用下载训练集导致出错,爆错如下。 这个时候需要去比赛官网下载对应的初赛训练集 unzip -d /mnt/workspace/sais_third_new_energy_baseline/data /mnt/workspace/sais_third_new_energy_baseline/初赛训练集.zip 在命令行执行这个命令解压 2.没定义测试集 te…...

当算力遇上马拉松:一场科技与肉身的极限碰撞
目录 一、从"肉身苦修"到"科技修仙" 二、马拉松的"新大陆战争" 三、肉身会被算法"优化"吗? 马拉松的下一站是"人机共生"时代 当AI能预测你的马拉松成绩,算法能规划最佳补给方案,智能装备让训练效率翻倍——你还会用传…...

n8n 中文系列教程_02. 自动化平台深度解析:核心优势与场景适配指南
在低代码与AI技术深度融合的今天,n8n作为开源自动化平台正成为开发者提效的新利器。本文深度剖析其四大核心技术优势——极简部署、服务集成、AI工作流与混合开发模式,并基于真实场景测试数据,厘清其在C端高并发、多媒体处理等场景的边界。 一…...

Macvlan 网络类型详解:特点、优势与局限性
一、Macvlan 网络类型的基本概念 1. 什么是 Macvlan Macvlan 是 Linux 内核提供的一种网络虚拟化技术,允许在单个物理接口(例如 enp0s3)上创建多个虚拟网络接口。每个虚拟接口拥有独立的 MAC 地址,表现得像物理网络中的独立设备…...

tigase源码学习杂记-AbstractMessageReceiver
前言 废话,最近把工作中用的基于XMPP协议的经典开源框架又读了一遍,整理一下其优秀的源码学习记录。 概述 AbstractMessageReceiver是tigase核心组件MessageRouter、SessionManager的抽象父类,是tigase消息接收器的抽象。AbstractMessageR…...

C#.net core部署IIS
Windows IIS 部署 .NET 应用详细指南 本文档提供了在 Windows Server 上使用 IIS 部署 .NET 应用(包括 .NET Core 和传统 WebForms)的完整步骤和最佳实践。 目录 概述环境准备.NET Core 应用部署 应用准备发布应用在 IIS 中配置应用池配置高级配置 .N…...

sql学习
Name 列中选取唯一不同的值 插入 更新 删除 筛选固定的行数 模糊查询 包含 范围 name的别名是n 两个表交集 左边包含全部 右边包含全部 重复的展示一条 重复的都会展示 创建一个新表,把字段复制近期 创建数据库 约束 创建索引 删除 函数 聚合函数...

OSPF实验
实验要求: 1.R5为ISP,其上只能配置IP地址;R4作为企业边界路由器, 出口公网地址需要通过PPP协议获取,并进行chap认证 (上面这个不会做) 2.整个OSPF环境IP基于172.16.0.0/16划分; 3.所…...
)
洛谷题目:P8624 [蓝桥杯 2015 省 AB] 垒骰子 题解 (本题简)
题目传送门: P8624 [蓝桥杯 2015 省 AB] 垒骰子 - 洛谷 (luogu.com.cn) 前言: 这道题要求我们计算将 个骰子垒成柱体且满足某些面不能紧贴的不同垒骰字方式的数量,并且结果需要对 取模。下面小亦来带大家逐步分析解题思路: #基本概念理解: 1、骰子特性: 一直骰子的…...
)
简单线段树的讲解(一点点的心得体会)
目录 一、初识线段树 图例: 编辑 数组存储: 指针存储: 理由: build函数建树 二、线段树的区间修改维护 区间修改维护: 区间修改的操作: 递归更新过程: 区间修改update:…...

在 Node.js 中使用原生 `http` 模块,获取请求的各个部分:**请求行、请求头、请求体、请求路径、查询字符串** 等内容
在 Node.js 中使用原生 http 模块,可以通过 req 对象来获取请求的各个部分:请求行、请求头、请求体、请求路径、查询字符串 等内容。 ✅ 一、基础结构 const http require(http); const url require(url);const server http.createServer((req, res)…...

深度学习--mnist数据集实现卷积神经网络的手写数字识别
文章目录 一、卷积神经网络CNN1、什么是CNN2、核心3、构造 二、案例1、下载数据集(训练、测试集)并展示画布2、打包数据图片3、判断系统使用的是CPU还是GPU4、定义CNN神经网络5、训练和测试模型 一、卷积神经网络CNN 1、什么是CNN 卷积神经网络是一种深…...
)
python基础知识点(1)
python语句 一行写一条语句 一行内写多行语句,使用分号分隔建议每行写一句,且结束时不写分号写在[ ]、{ }内的跨行语句,被视为一行语句\ 是续行符,实现分行书写功能 反斜杠表示下一行和本行是同一行 代码块与缩进 代码块复合语句…...

详解反射型 XSS 的后续利用方式:从基础窃取到高级组合拳攻击链
在网络安全领域,反射型跨站脚本攻击(Reflected Cross-Site Scripting,简称反射型 XSS)因其短暂的生命周期和临时性,常被视为“低危”漏洞,威胁性不如存储型或 DOM 型 XSS。然而,这种看法低估了它…...

【问题笔记】解决python虚拟环境运行脚本无法激活问题
【问题笔记】解决python虚拟环境运行脚本无法激活问题 错误提示问题所在解决方法**方法 1:临时更改执行策略****方法 2:永久更改执行策略** **完整流程示例** 错误提示 PS F:\PythonProject\0419graphrag-local-ollama-main> venv1\Scripts\activate…...

CF148D Bag of mice
题目传送门 思路 状态设计 设 d p i , j dp_{i, j} dpi,j 表示袋中有 i i i 个白鼠和 j j j 个黑鼠时, A A A 能赢的概率。 状态转移 现在考虑抓鼠情况: A A A 抓到白鼠:直接判 A A A 赢,概率是 i i j \frac{i}{i j}…...
:深入理解精益分析的核心要点)
精益数据分析(6/126):深入理解精益分析的核心要点
精益数据分析(6/126):深入理解精益分析的核心要点 在创业和数据驱动的时代浪潮中,我们都在不断探索如何更好地利用数据推动业务发展。我希望通过和大家分享对《精益数据分析》的学习心得,一起在这个充满挑战和机遇的领…...

package.json ^、~、>、>=、* 详解
package.json ^、~、>、>、* 详解 在 Vue 项目中,package.json 文件的依赖项(dependencies)和开发依赖项(devDependencies)中,版本号前可能会带有一些特殊符号,例如 ^、~、>、<、&g…...

2025年赣教云智慧作业微课PPT模板
江西的老师们注意,2025年赣教云智慧作业微课PPT模版和往年不一样,千万不要搞错了,图上的才是正确的2025年的赣教云智慧作业微课PPT模版,赣教云智慧作业官网有问题,无法正确下载该模板,需要该模板的…...

Java PrintStream 类深度解析
Java PrintStream 类深度解析 便捷: 1.直接输出各种数据 2.自动刷新和自动换行(println方法) 3.支持字符串转义 4.自动编码(自动根据环境选择合适的编码方式) 1. 核心定位 PrintStream 是 FilterOutputStream 的子类,提供格式化输出能力,是标准输出 System.out 的…...

超简单的git学习教程
本博客仅用于记录学习和使用 前提声明全部内容全部来自下面廖雪峰网站,如果侵权联系我删除 1.小白学习看这篇,快速易懂入门,完整内容(半天完成学习本地和远程仓库建立) 简介 - Git教程 - 廖雪峰的官方网站 2.博客中…...

Yocto项目实战教程-第5章-5.1-5.2小节-BitBake的起源与源代码讲解
🔍 B站相应的视频教程: 📌 Yocto项目实战教程-第5章-5.1-5.2小节-BitBake的起源与源代码讲解 记得三连,标为原始粉丝。 📚 系列持续更新中,B站搜索 “嵌入式 Jerry”,系统学 Yocto 不迷路&#…...

SQL注入相关知识
一、布尔盲注 1、布尔盲简介 布尔盲注是一种SQL注入攻击技术,用于在无法直接获取数据库查询结果的情况下,通过页面的响应来判断注入语句的真假,从而获取数据库中的敏感信息 2、布尔盲注工作原理 布尔盲注的核心在于利用SQL语句的布尔逻辑…...

Linux网络编程 深入解析Linux TCP:TCP实操,三次握手和四次挥手的底层分析
知识点1【TCP编程概述】 1、TCP的概述 客户端:主动连接服务器,和服务器进行通信 服务器:被动被客户端连接,启动新的线程或进程,服务器客户端(并发服务器) 这里重复TCP和UDP特点 TCP&#x…...

实验4基于神经网络的模式识别实验
实验原理 1. BP学习算法是通过反向学习过程使误差最小,其算法过程从输出节点开始,反向地向第一隐含层(即最接近输入层的隐含层)传播由总误差引起的权值修正。BP网络不仅含有输入节点和输出节点,而且含有一层或多层隐(层)节点。输入信号先向前…...

Rust网络编程实战:全面掌握reqwest库的高级用法
一、开篇导引 1.1 对比Python Requests解释为何reqwest是Rust生态的标杆HTTP客户端 在Python生态中,Requests 库以其简洁易用的API成为了HTTP客户端的首选。它使得开发者能够轻松地发送各种HTTP请求,处理响应,而无需过多关注底层细节。然而…...
)
【漫话机器学习系列】211.驻点(Stationary Points)
驻点(Stationary Points):理解函数导数为零的关键位置 在数学分析、机器学习优化、物理建模等领域中,驻点(Stationary Points)是一个非常重要的概念。它们是函数图像中“停下来的点”,即导数为…...

图 - 最小生成树算法 - Kruskal - Prim
目录 前言 什么是最小生成树算法 Kruskal 克鲁斯卡尔 Prim 普利姆 结语 前言 在图中一共有两类算法,一种是最短路径,还有一种就是本篇要讲解的最小生成树算法了 其中,最短路径一共有三种,而最小生成树一共有两种ÿ…...

linux kernel irq相关函数详解
在Linux内核驱动开发中,处理中断涉及一系列关键函数,正确使用这些函数对确保驱动的稳定性和性能至关重要。以下是disable_irq、free_irq、platform_get_irq和request_irq等函数的详细解析,涵盖其功能、用法、注意事项及示例代码。 一、核心函…...

聊聊Doris的数据模型,如何用结构化设计解决实时分析难题
传统 OLAP 系统的局限 在大数据实时分析领域,数据模型设计直接决定了系统的查询性能、存储效率与业务适配性。Apache Doris作为新一代MPP分析型数据库,通过独创的多模型融合架构,在业内率先实现了"一份数据支持多种分析范式"的能力…...