Flink介绍——实时计算核心论文之Kafka论文总结
引入
大数据系统中的数据来源
在开始深入探讨Kafka之前,我们得先搞清楚一个问题:大数据系统中的数据究竟是从哪里来的呢?其实,这些数据大部分都是由各种应用系统或者业务系统产生的“日志”。 比如,互联网公司的广告和搜索业务,每次你浏览网页、点击广告或者进行搜索操作时,服务器上都会记录下相应的访问日志。
早期的时候,对于这些数据的处理需求主要还是通过MapReduce来进行批处理。所以,当时的首要任务就是要把每台应用服务器上的日志收集起来,放到Hadoop集群的HDFS上。最开始的时候,人们采用了一些比较简单的方法,比如直接把日志落地到服务器所在的本地硬盘上,然后按照时间定时分割出一个新文件,再通过像Linux下的cronjob这样的定时任务,把这个文件上传到HDFS上。
但是,这种方法存在着一个很明显的弊端,那就是在日志上传到HDFS之前,整个系统是没有灾备的。如果某一台服务器出现了硬件故障,那么就会有一段时间的日志文件丢失。为了解决这个问题,人们开始尝试直接通过HDFS提供的客户端,把日志文件往HDFS上写。这样,日志一旦写入到HDFS上,就可以有三份数据副本,避免了数据丢失的问题。
然而,这种做法又引发了新的问题。如果有很多应用服务器,那么就会有大量的客户端同时往HDFS上写入日志,给HDFS带来巨大的并发压力。而且,还要考虑是让所有的应用服务器各自写各自的日志文件,还是大家都往同一个日志文件里写。如果各自写各自的日志文件,就会产生大量的小文件,这不仅浪费存储空间,还会增加MapReduce处理数据的额外开销。而如果让很多个应用服务器往同一个HDFS的文件里写,又会遇到性能问题,因为HDFS对于单个文件,只适合一个客户端顺序大批量的写入。
日志收集系统的出现
为了解决这些问题,日志收集系统应运而生。Facebook推出了开源的Scribe,Cloudera推出了Flume。这些日志收集系统的架构相对简单,就是在各个应用服务器上部署一个日志收集器的客户端,多个客户端把日志发送到一个日志汇集的服务器里。多个日志汇集的服务器还可以再次用类似的方式进行汇集,通过一个多层树状的结构,最终只有几个日志汇集服务器会向HDFS写入数据。
这种方式既减少了并发写入请求到HDFS上,又充分发挥了HDFS顺序写入数据高吞吐量的优势。而且,这些系统本身也设计了各种容错机制,比如在网络传输中断的情况下,Scribe会先把数据写入到本地磁盘,等待网络恢复的时候再做“断点续传”。不过,在2011年这个时间节点,像Scribe这样的系统,仍然不是一个流式数据处理系统,而只是一个日志收集器。它并不是实时不断地向HDFS写入数据,而是定时地向HDFS上转存文件。
实时数据处理推动Kafka的诞生
随着业务的发展,每分钟运行一个MapReduce的任务显然不是一个高效的解决办法。而且,在这个机制下,日志传输的Scribe和进行数据分析的MapReduce任务之间,还有很多“隐式依赖”,使得实际的数据分析程序需要考虑对于Scribe这样的日志传输系统的“容错”问题。
比如说,数据分析程序往往想要分析最近一段时间的广告点击的数据,那么Scribe就需要按照一定的时间间隔生成一个新文件,放到HDFS上。而且,这个文件的文件名需要能够分辨出来是哪一分钟的日志。但是,Scribe里可能会出现网络中断、硬件故障等等的问题,很有可能在运行MapReduce任务去分析数据的时候,Scribe还没有把文件放到HDFS上。那么,MapReduce分析程序就需要对这种情况进行容错,比如下一分钟的时候,它需要去读取最近几分钟的数据,看看Scribe上传的新文件里是否有本该在上一分钟里读到的数据。
而这些机制,意味着下游的MapReduce任务需要去了解上游的日志收集器的实现机制,并且两边根据像文件名规则之类的隐式协议产生了依赖,这就使得数据分析程序写起来会很麻烦,维护起来也不轻松。这也就是为什么像Storm和Kafka这样的系统站上了历史舞台。
Kafka核心
Kafka的系统架构
Kafka可以看成是一个类似于Scribe这样的日志收集器。上游的应用服务器仍然会把日志发送给Kafka集群,但是在Kafka的下游,它不仅能把对应的数据作为文件上传到HDFS上。同时,像Storm这样的流式数据处理系统,它的Spout会直接从Kafka里获取数据,而不是从HDFS上去读文件。这个时候,Kafka其实变成了一个分布式的消息队列。如论文中的Kafka架构图所示:
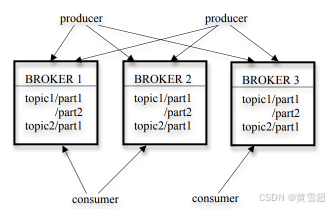
Kafka的整个系统架构是一个典型的生产者(Producer)-消费者(Consumer)模型。
在Kafka里,有这样几个角色:
-
Producer:也就是日志的生产者,通常它就是我们前面的应用服务器。应用服务器会生成日志,作为生产者,把日志发送给到Kafka系统中去。
-
Broker:也就是我们实际Kafka的服务进程。因为为了容错和高可用,Kafka是一个分布式的集群,所以会有很多台物理服务器,每台服务器上都会有对应的Broker的进程。Kafka会对所有的消息,进行两种类型的分组。第一种,是根据业务情况进行分组,对应的就是Topic(主题)这个概念。第二种,是进行数据分区,这个和我们见过的其他分布式系统进行分区的原因是一样的。一方面,分区可以帮助我们水平扩展系统的处理能力;同一个Topic的日志,可以平均分配到多台物理服务器上,确保系统可以并行处理。另一方面,这也是一个有效的“容错”机制,一旦有某一个Broker所在的物理服务器出现了硬件故障,那么上游的Producer,可以把日志发到其他的Broker上,来确保系统仍然可以正常运作。
-
Consumer:也就是实际去处理日志的消费者。我们去读取Kafka数据,把它放到HDFS上的程序,就是一个消费者。而我们去获取实时日志,进行分析的程序,也同样是一个消费者,比如一个已经提交运行的Storm Topology。Kafka对于它所处理的消息,是支持多个Consumer的,这个可以从两个层面来看:首先,是同样一条消息,可能有不同用途的应用程序都需要读取,它们都是Kafka的消费者。比如上传日志到HDFS是一个Consumer,Storm的Topology是另一个Consumer。其次,是同一个用途的应用程序,可以有多个并行的消费者,来同时并行处理数据,确保下游的Consumer有足够的吞吐量。为了区分这两种“多个消费者”代表的不同含义,Kafka把每一个用途的Consumer程序,称之为一个Consumer Group。
Kafka的独特设计
在遇到Kafka之前,人们通常会通过配置一下Scribe这样的日志收集器,来实现类似Kafka的功能。但是,传统的消息队列通常会通过一个message - id来唯一标识一条消息,只有当下游的所有订阅了这个消息的消费者,处理完成之后,消息队列就认为这条消息被处理完成了,可以从当前的消息队列里面删除掉了。但是,这个机制也就意味着,这个消息队列在下游数据分析完成之前,需要一直存储着这些消息,等待下游的响应,会消耗大量的资源。
而Kafka则采用了一个完全不同的方式来设计整个系统,简单来说,就是两点:
-
让所有的Consumer来“拉取”数据,而不是主动“推送”数据给到Consumer。并且,Consumer到底消费完了哪些数据,是由Consumer自己维护的,而不是由Kafka这个消息队列来进行维护。
-
采用了一个非常简单的追加文件写的方式 来直接作为我们的消息队列。在Kafka里,每一条消息并没有通过一个唯一的message - id,来标识或者维护。整个消息队列也没有维护什么复杂的内存里的数据结构。下游的消费者,只需要维护一个此时它处理到的日志,在这个日志文件中的偏移量(offset)就好了。
然后,基于这两个设计思路,Kafka做了一些简单的限制,那就是一个consumer总是顺序地去消费,来自一个特定分区(Partition)的消息。而一个Partition则是Kafka里面可以并行处理的最小单位,这就是说,一个Partition的数据,只会被一个consumer处理。
Kafka的单个Partition的读写实现
在实际的实现上,Kafka的每一个Topic会有很多个Partition,分布到不同的物理机器上。一个物理机上,可能会分配到多个Partition。实际存储的时候,我们的一个Partition是一个逻辑上的日志文件。在物理上,这个日志文件会给实现成一组大小基本相同的Segment文件,比如每个Segment是1GB大小。每当有新消息从Producer发过来的时候,Broker就会把消息追加写入到最后那个Segment文件里。
而为了性能考虑,Kafka支持我们自己设置,是每次写入到把数据刷新到硬盘里,还是在写入了一定数量的日志或者经过一个固定的时间的时候,才把文件刷新到硬盘里。
Broker会在内存里维护一个简单的索引,这个索引其实就是每个通过一个虚拟的偏移量,指向一个具体的Segment文件。那么在Consumer要消费数据的时候,就是根据Consumer本地维护的已经处理完的偏移量,在索引里找到实际的Segment文件,然后去读取数据就好了。
Kafka对Linux文件系统的利用
因为本质上,Kafka是直接使用本地的文件系统承担了消息队列持久化的功能,所以Kafka干脆没有实现任何缓存机制,而是直接依赖了Linux文件系统里的页缓存(Page Cache)。Kafka写入的数据,本质上都还是在Page Cache。而且因为我们是进行流式数据处理,读写的数据有很强的时间局部性,Broker刚刚写入的数据,几乎立刻会被下游的Consumer读取访问,所以大量的数据读写都会命中缓存。
而没有自己在内存里面实现缓存,也避免了两个问题。第一个是JVM里面的GC(垃圾回收)的开销。如果我们有大量的消息是缓存在内存里,那么处理完了之后,就需要通过GC销毁这些对象,腾出空间来容纳新的需要缓存的对象,而JVM的GC开销,可能会短时间大幅度影响Broker的性能。第二个是缓存的“冷启动问题”。如果我们的Broker进程挂掉了,重新启动了一个新的进程,那么此时,我们的内存里是没有任何缓存数据的,这个时候读取数据的性能,会比一个已经长时间运行、内存中缓存了很多数据的系统的性能,差上很多。这两点,都会导致系统本身的性能抖动。而通过直接利用文件系统本身的Page Cache,我们的JVM内除了基本的业务逻辑代码,没有其他的内存占用和GC开销。
除了利用文件系统之外,Kafka还利用了Linux下的 sendfile API,通过DMA直接将数据从文件系统传输到网络通道,所以它的网络数据传输开销也很小。
Kafka的分布式系统的实现
首先,Kafka系统并没有一个Master节点。每一个Kafka的Broker启动的时候,就会把自己注册到ZooKeeper上,注册信息自然是Broker的主机名和端口。在ZooKeeper上,Kafka还会记录,这个Broker里包含了哪些主题(Topic)和哪些分区(Partition)。
而ZooKeeper本身提供的接口,则和我们之前讲解过的Chubby类似,是一个分布式锁。每一个Kafka的Broker都会把自己的信息像一个文件一样,写在一个ZooKeeper的目录下。另外ZooKeeper本身,也提供了一个监听 - 通知的机制。
上游的Producer只需要监听Brokers的目录,就能知道下游有哪些Broker。那么,无论是随机发送,还是根据消息中的某些字段进行分区,上游都可以很容易地把消息发送到某一个Broker里。当然,Producer也可以无需关心ZooKeeper,而是直接把消息发送给一个负载均衡,由它去向下游的Broker进行数据分发。
Kafka的高可用机制
在Kafka最初的论文里,还没有包括Kafka的高可用机制。在这种情况下,一旦某个Broker节点挂了,它就会从ZooKeeper上消失,对应的分区也就不见了,自然数据我们也就没有办法访问了。
不过,在Kafka发布了0.8版本之后,它就支持了由多副本带来的高可用功能。在现实中,Kafka是这么做的:
-
首先,为了让Kafka能够高可用,我们需要对于每一个分区都有多个副本,和GFS一样,Kafka的默认参数选择了3个副本。
-
其次,这些副本中,有一个副本是Leader,其余的副本是Follower。我们的Producer写入数据的时候,只需要往Leader写入就好了。Leader自然也就是将对应的数据,写入到本地的日志文件里。
-
然后,每一个Follower都会从Leader去拉取最新的数据,一旦Follower拉到数据之后,会向Leader发送一个Ack的消息。
-
我们可以设定,有多少个Follower成功拉取数据之后,就能认为Producer写入完成了。这个可以通过在发送的消息里,设定一个acks的字段来决定。如果acks = 0,那就是Producer的消息发送到Broker之后,不管数据是否刷新到本地硬盘,我们都认为写入已经完成了;而如果设定acks = 2,意味着除了Leader之外,至少还有一个Follower也把数据写入完成,并且返回Leader一个Ack消息之后,消息才写入完成。我们可以通过调整acks这个参数,来在数据的可用性和性能之间取得一个平衡。
Kafka的负载均衡机制
Kafka的Consumer一样会把自己“注册”到ZooKeeper上。在同一个Consumer Group下,一个Partition只会被一个Consumer消费,这个Partition和Consumer的映射关系,也会被记录在ZooKeeper里。这部分信息,被称之为“所有权注册表”。
而Consumer会不断处理Partition的数据,一旦某一段的数据被处理完了,对应这个Partition被处理到了哪个Offset的位置,也会被记录到ZooKeeper上。这样,即使我们的Consumer挂掉,由别的Consumer来接手后续的消息处理,它也可以知道从哪里做起。
那么在这个机制下,一旦我们针对Broker或者Consumer进行增减,Kafka就会做一次数据“再平衡(Rebalance)”。所谓再平衡,就是把分区重新按照Consumer的数量进行分配,确保下游的负载是平均的。Kafka的算法也非常简单,就是每当有Broker或者Consumer的数量发生变化的时候,会再平均分配一次。
如果我们有X个分区和Y个Consumer,那么Kafka会计算出 N = X/Y,然后把0到N - 1的分区分配给第一个Consumer,N到2N - 1的分配给第二个Consumer,依此类推。而因为之前Partition的数据处理到了哪个Offset是有记录的,所以新的Consumer很容易就能知道从哪里开始处理消息。
Kafka的消息处理模式
本质上,Kafka对于消息的处理也是“至少一次”的。如果消息成功处理完了,那么我们会通过更新ZooKeeper上记录的Offset,来确认这一点。而如果在消息处理的过程中,Consumer出现了任何故障,我们都需要从上一个Offset重新开始处理。这样,我们自然也就避免不了重复处理消息。
如果你希望能够避免这一点,你需要在实际的消息体内,有类似message - id这样的字段,并且要通过其他的去重机制来解决,但是这并不容易做到。
不过,Kafka虽然有很强的性能,也在发布之后很快提供了基于多副本的高可用机制。但是Kafka本身,其实也是有很多限制的。
首先,是 Kafka很难提供针对单条消息的事务机制。因为我们在ZooKeeper上保存的,是最新处理完的消息的一个Offset,而不是哪些消息被处理完了、哪些消息没有被处理完这样的message - id = > status的映射关系。所以,Consumer没法说,我有一条新消息已经处理完了,但是还有一条旧消息还在处理中。而是只能按照消息在Partition中的偏移量,来顺序处理。
其次,是 Kafka里,对于消息是没有严格的“顺序”定义的。也就是我们无法保障,先从应用服务器发送出来的消息,会先被处理。因为下游是一个分布式的集群,所以先发送的消息X可能被负载均衡发送到Broker A,后发送的消息反而被负载均衡发送到Broker B。但是Broker B里的数据,可能会被下游的Consumer先处理,而Broker A里的数据后被处理。
不过,对于快速统计实时的搜索点击率这样的统计分析类的需求来说,这些问题都不是问题。而Kafka的应用场景也主要在这里,而不是用来作为传统的消息队列,完成业务系统之间的异步通信。
数据处理的Lambda架构和Kappa架构
有了Storm和Kafka这样的实时数据处理架构之后,另一个问题也就浮出了水面:既然我们已经可以获得分钟级别的统计数据,那我们还需要MapReduce这样的批处理程序吗?
答案当然还是需要的,因为在kafka出现的那个年代,在当时的框架下,我们的流式计算,还有几个问题没有处理好。首先,是我们的流式数据处理只能保障“至少一次(At Least Once)”的数据处理模式,而在批处理下,我们做到的是“正好一次(Exactly Once)”。也就意味着,批处理计算出来的数据是准确的,而流式处理计算的结果是有误差的。其次,是当数据处理程序需要做修改的时候,批处理程序很容易修改,而流式处理程序则没有那么容易。比如,增加一些数据分析的维度和指标。原先我们只计算点击率,现在可能还需要计算转化率;原先我们只需要有分国家的统计数据,现在还要有分省份和分城市的数据。
Lambda架构的基本思想是把大数据的批处理和实时数据结合在一起,变成一个统一的架构。它由批处理层、实时处理层和服务层组成。批处理层负责运行MapReduce任务,实时处理层运行Storm的Topology,服务层则是一个数据库,用于存储计算结果。批处理层的计算结果会不断替换实时处理层的计算结果,从而对最终计算的数据进行修正。对于外部用户来说,他们只需要查询服务层,而不需要关心底层的处理过程。
但是,Lambda架构有一个显著的缺点,那就是什么事情都需要做两遍。所有的视图,既需要在实时处理层计算一次,又要在批处理层计算一次。而且,所有的数据处理的程序,也需要撰写两遍。这就意味着,我们需要双倍的计算资源和开发资源。而且,由于批处理层和实时处理层的代码不同,我们还不得不解决两遍对于同样视图的理解不同,采用了不同的数据处理逻辑,引入新的Bug的问题。
Kappa架构则是Kafka的作者杰伊·克雷普斯(Jay Kreps)提出的一个新的数据计算框架。它在View = Query(Data)这个基本的抽象理念上,和Lambda架构没有变化。但是相比于Lambda架构,Kappa架构去掉了Lambda架构的批处理层,而是在实时处理层,支持了多个视图版本。如果要对Query进行修改,我们可以在实时处理层部署一个新版本的代码,然后对这个Topology进行对应日志的重放,在服务层生成一份新的数据结果表。一旦日志重放完成,新的Topology能够赶上进度,处理到最新产生的日志,那么我们就可以让查询切换到新的视图版本上来,旧的实时处理层的代码也就可以停掉了。
随着Kappa架构的提出,大数据处理开始迈入“流批一体”的新阶段。
总结
通过对Kafka的深入剖析,我们可以看到,它在大数据系统中扮演着一个极为关键的角色。从最早期的日志收集问题,到传统日志收集系统的局限性,再到Kafka的诞生及其独特的系统架构和设计,Kafka为我们提供了一种高效、可扩展的分布式消息处理方案。它通过创新的“拉取”数据模式和追加文件写的方式,极大地提高了数据处理的效率和系统的性能。同时,它利用Linux文件系统和ZooKeeper等技术,实现了高可用性和分布式协调。
Kafka的出现,不仅解决了传统日志收集系统中的许多痛点,还为实时数据处理和流式计算提供了强有力的支持。它极大的推动了数据处理架构从Lambda向Kappa的演变,让大数据处理进入了“流批一体”的新时代。
相关文章:

Flink介绍——实时计算核心论文之Kafka论文总结
引入 大数据系统中的数据来源 在开始深入探讨Kafka之前,我们得先搞清楚一个问题:大数据系统中的数据究竟是从哪里来的呢?其实,这些数据大部分都是由各种应用系统或者业务系统产生的“日志”。 比如,互联网公司的广告…...

模拟投资大师思维:AI对冲基金开源项目详解
这里写目录标题 引言项目概述核心功能详解多样化的AI投资智能体灵活的运行模式透明的决策过程 安装和使用教程环境要求安装步骤基本使用方法运行对冲基金模式运行回测模式 应用场景和实际价值教育和研究价值潜在的商业应用与现有解决方案的对比局限性与发展方向 结论 引言 随着…...

DAY4:数据库对象与高级查询深度解析:从视图到多表关联实战
一、数据库对象精要指南 1.1 视图(View)的进阶应用 视图是存储在数据库中的虚拟表,本质是预编译的SQL查询语句。通过视图可以简化复杂查询、实现数据安全隔离、保持业务逻辑一致性。 创建语法示例: CREATE VIEW sales_summary…...

【Matlab】中国东海阴影立体感地图
【Matlab】中国东海阴影立体感地图 【Matlab】中国东海阴影立体感地图 【Matlab】中国东海阴影图立体感画法 以前分享过一次,链接如下: 中国海域地形图 但是以前还是有些小问题,这次修改了。 另外,增加了新的画法: 另…...

python文件类操作:json/ini配置文件、logging日志统计、excel表格数据读写、os操作库
文章目录 一、with open文件操作二、csv表格数据读写三、Excel表格数据读写四、json配置文件读写五、ini配置文件读写六、logging日志统计七、os操作库(文件拼接、创建、判断等) 打开文件使用不同参数有着不同的含义,比如只读、只写、二进制读…...
)
VSCode安装与环境配置(Mac环境)
20250419 - 概述 大概是非常久之前了,装了VSCode,估计都得21的时候了,电脑上也没更新过。当时安装也直接装上就完事了。这次把版本更新一下,同时记录一下这个安装过程。 安装 mac下安装非常简单,直接从官网下载&am…...
)
【信息系统项目管理师】高分论文:论信息系统项目的采购管理(“营业工单系统”项目)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 论文1、规划采购管理2、实施采购3、控制采购论文 2018年1月,我参加了 XX运营商集团公司某省分公司的“营业工单系统”的信息化建设项目,我有幸担任项目经理。该项目投资1000万元人民币,建设工期为12个月。该…...

XCVU13P-2FHGA2104I Xilinx Virtex UltraScale+ FPGA
XCVU13P-2FHGA2104I 是 Xilinx(现为 AMD)Virtex UltraScale™ FPGA 系列中的高端 Premium 器件,基于 16nm FinFET 工艺并采用 3D IC 堆叠硅互连(SSI)技术,提供业内顶级的计算密度和带宽。该芯片集成约 3,…...

@Validated与@Valid的正确使用姿势
验证代码 Validated RestController public class A {PostMappingpublic void test(Min(value 1) Integer count) {} // 校验规则生效 }RestController public class A {PostMappingpublic void test(Validated Min(value 1) Integer count) {} // 校验规则不生效 }RestCont…...

Ubuntu20.04下Docker方案实现多平台SDK编译
0 前言 熟悉嵌入式平台Linux SDK编译流程的小伙伴都知道,假如平台a要求必须在Ubuntu18.04下编译,平台b要求要Ubuntu22.04的环境,那我只有Ubuntu20.04,或者说我的电脑硬件配置最高只能支持Ubuntu20.04怎么办?强行在Ubuntu20.04下编译,编又编不过,换到旧版本我又不愿意,…...
树莓派配置GPIO)
树莓派超全系列教程文档--(34)树莓派配置GPIO
配置GPIO GPIO控制gpio 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 GPIO控制 gpio 通过 gpio 指令,可以在启动时将 GPIO 引脚设置为特定模式和值,而以前需要自定义 dt-blob.bin 文件。每一行都对一组引脚应用相同的设…...
)
C语言 数组(下)
目录 1.二维数组的创建 2.二位数组的初始化 3.二维数组的使用 4.二维数组在内存中的储存 1.二维数组的创建 1.1二维数组的概念 前面学习的数组被称为一维数组,数组的元素都是内置类型的,如果我们把一维数组做为数组的元 素,这时候就是…...
)
opencv图像旋转(单点旋转的原理)
首先我们以最简单的一个点的旋转为例子,且以最简单的情况举例,令旋转中心为坐标系中心O(0,0),假设有一点P_{0}(x_{0},y_{0}),P_{0}离旋转中心O的距离为r,OP_{0}与坐标轴x轴的夹角为\…...

针对MCP认证考试中的常见技术难题进行实战分析与解决方案分享
一、身份与权限管理类难题 场景1:Active Directory组策略(GPO)不生效 问题现象:客户端计算机未应用新建的组策略。排查步骤: 检查GPO链接顺序:使用gpresult /r查看策略优先级,确保目标OU的GPO…...

systemctl管理指令
今天我们来继续学习服务管理指令,接下来才是重头戏-systemctl,那么话不多说,直接开始吧. systemctl管理指令 1.基本语法: systemctl [start | stop | restart | status]服务 注:systemctl指令管理的服务在/usr/lib/ systemd/system查看 2.systemctl设置服务的自…...

DataWhale AI春训营 问题汇总
1.没用下载训练集导致出错,爆错如下。 这个时候需要去比赛官网下载对应的初赛训练集 unzip -d /mnt/workspace/sais_third_new_energy_baseline/data /mnt/workspace/sais_third_new_energy_baseline/初赛训练集.zip 在命令行执行这个命令解压 2.没定义测试集 te…...

当算力遇上马拉松:一场科技与肉身的极限碰撞
目录 一、从"肉身苦修"到"科技修仙" 二、马拉松的"新大陆战争" 三、肉身会被算法"优化"吗? 马拉松的下一站是"人机共生"时代 当AI能预测你的马拉松成绩,算法能规划最佳补给方案,智能装备让训练效率翻倍——你还会用传…...

n8n 中文系列教程_02. 自动化平台深度解析:核心优势与场景适配指南
在低代码与AI技术深度融合的今天,n8n作为开源自动化平台正成为开发者提效的新利器。本文深度剖析其四大核心技术优势——极简部署、服务集成、AI工作流与混合开发模式,并基于真实场景测试数据,厘清其在C端高并发、多媒体处理等场景的边界。 一…...

Macvlan 网络类型详解:特点、优势与局限性
一、Macvlan 网络类型的基本概念 1. 什么是 Macvlan Macvlan 是 Linux 内核提供的一种网络虚拟化技术,允许在单个物理接口(例如 enp0s3)上创建多个虚拟网络接口。每个虚拟接口拥有独立的 MAC 地址,表现得像物理网络中的独立设备…...

tigase源码学习杂记-AbstractMessageReceiver
前言 废话,最近把工作中用的基于XMPP协议的经典开源框架又读了一遍,整理一下其优秀的源码学习记录。 概述 AbstractMessageReceiver是tigase核心组件MessageRouter、SessionManager的抽象父类,是tigase消息接收器的抽象。AbstractMessageR…...

C#.net core部署IIS
Windows IIS 部署 .NET 应用详细指南 本文档提供了在 Windows Server 上使用 IIS 部署 .NET 应用(包括 .NET Core 和传统 WebForms)的完整步骤和最佳实践。 目录 概述环境准备.NET Core 应用部署 应用准备发布应用在 IIS 中配置应用池配置高级配置 .N…...

sql学习
Name 列中选取唯一不同的值 插入 更新 删除 筛选固定的行数 模糊查询 包含 范围 name的别名是n 两个表交集 左边包含全部 右边包含全部 重复的展示一条 重复的都会展示 创建一个新表,把字段复制近期 创建数据库 约束 创建索引 删除 函数 聚合函数...

OSPF实验
实验要求: 1.R5为ISP,其上只能配置IP地址;R4作为企业边界路由器, 出口公网地址需要通过PPP协议获取,并进行chap认证 (上面这个不会做) 2.整个OSPF环境IP基于172.16.0.0/16划分; 3.所…...
)
洛谷题目:P8624 [蓝桥杯 2015 省 AB] 垒骰子 题解 (本题简)
题目传送门: P8624 [蓝桥杯 2015 省 AB] 垒骰子 - 洛谷 (luogu.com.cn) 前言: 这道题要求我们计算将 个骰子垒成柱体且满足某些面不能紧贴的不同垒骰字方式的数量,并且结果需要对 取模。下面小亦来带大家逐步分析解题思路: #基本概念理解: 1、骰子特性: 一直骰子的…...
)
简单线段树的讲解(一点点的心得体会)
目录 一、初识线段树 图例: 编辑 数组存储: 指针存储: 理由: build函数建树 二、线段树的区间修改维护 区间修改维护: 区间修改的操作: 递归更新过程: 区间修改update:…...

在 Node.js 中使用原生 `http` 模块,获取请求的各个部分:**请求行、请求头、请求体、请求路径、查询字符串** 等内容
在 Node.js 中使用原生 http 模块,可以通过 req 对象来获取请求的各个部分:请求行、请求头、请求体、请求路径、查询字符串 等内容。 ✅ 一、基础结构 const http require(http); const url require(url);const server http.createServer((req, res)…...

深度学习--mnist数据集实现卷积神经网络的手写数字识别
文章目录 一、卷积神经网络CNN1、什么是CNN2、核心3、构造 二、案例1、下载数据集(训练、测试集)并展示画布2、打包数据图片3、判断系统使用的是CPU还是GPU4、定义CNN神经网络5、训练和测试模型 一、卷积神经网络CNN 1、什么是CNN 卷积神经网络是一种深…...
)
python基础知识点(1)
python语句 一行写一条语句 一行内写多行语句,使用分号分隔建议每行写一句,且结束时不写分号写在[ ]、{ }内的跨行语句,被视为一行语句\ 是续行符,实现分行书写功能 反斜杠表示下一行和本行是同一行 代码块与缩进 代码块复合语句…...

详解反射型 XSS 的后续利用方式:从基础窃取到高级组合拳攻击链
在网络安全领域,反射型跨站脚本攻击(Reflected Cross-Site Scripting,简称反射型 XSS)因其短暂的生命周期和临时性,常被视为“低危”漏洞,威胁性不如存储型或 DOM 型 XSS。然而,这种看法低估了它…...

【问题笔记】解决python虚拟环境运行脚本无法激活问题
【问题笔记】解决python虚拟环境运行脚本无法激活问题 错误提示问题所在解决方法**方法 1:临时更改执行策略****方法 2:永久更改执行策略** **完整流程示例** 错误提示 PS F:\PythonProject\0419graphrag-local-ollama-main> venv1\Scripts\activate…...

CF148D Bag of mice
题目传送门 思路 状态设计 设 d p i , j dp_{i, j} dpi,j 表示袋中有 i i i 个白鼠和 j j j 个黑鼠时, A A A 能赢的概率。 状态转移 现在考虑抓鼠情况: A A A 抓到白鼠:直接判 A A A 赢,概率是 i i j \frac{i}{i j}…...
:深入理解精益分析的核心要点)
精益数据分析(6/126):深入理解精益分析的核心要点
精益数据分析(6/126):深入理解精益分析的核心要点 在创业和数据驱动的时代浪潮中,我们都在不断探索如何更好地利用数据推动业务发展。我希望通过和大家分享对《精益数据分析》的学习心得,一起在这个充满挑战和机遇的领…...

package.json ^、~、>、>=、* 详解
package.json ^、~、>、>、* 详解 在 Vue 项目中,package.json 文件的依赖项(dependencies)和开发依赖项(devDependencies)中,版本号前可能会带有一些特殊符号,例如 ^、~、>、<、&g…...

2025年赣教云智慧作业微课PPT模板
江西的老师们注意,2025年赣教云智慧作业微课PPT模版和往年不一样,千万不要搞错了,图上的才是正确的2025年的赣教云智慧作业微课PPT模版,赣教云智慧作业官网有问题,无法正确下载该模板,需要该模板的…...

Java PrintStream 类深度解析
Java PrintStream 类深度解析 便捷: 1.直接输出各种数据 2.自动刷新和自动换行(println方法) 3.支持字符串转义 4.自动编码(自动根据环境选择合适的编码方式) 1. 核心定位 PrintStream 是 FilterOutputStream 的子类,提供格式化输出能力,是标准输出 System.out 的…...

超简单的git学习教程
本博客仅用于记录学习和使用 前提声明全部内容全部来自下面廖雪峰网站,如果侵权联系我删除 1.小白学习看这篇,快速易懂入门,完整内容(半天完成学习本地和远程仓库建立) 简介 - Git教程 - 廖雪峰的官方网站 2.博客中…...

Yocto项目实战教程-第5章-5.1-5.2小节-BitBake的起源与源代码讲解
🔍 B站相应的视频教程: 📌 Yocto项目实战教程-第5章-5.1-5.2小节-BitBake的起源与源代码讲解 记得三连,标为原始粉丝。 📚 系列持续更新中,B站搜索 “嵌入式 Jerry”,系统学 Yocto 不迷路&#…...

SQL注入相关知识
一、布尔盲注 1、布尔盲简介 布尔盲注是一种SQL注入攻击技术,用于在无法直接获取数据库查询结果的情况下,通过页面的响应来判断注入语句的真假,从而获取数据库中的敏感信息 2、布尔盲注工作原理 布尔盲注的核心在于利用SQL语句的布尔逻辑…...

Linux网络编程 深入解析Linux TCP:TCP实操,三次握手和四次挥手的底层分析
知识点1【TCP编程概述】 1、TCP的概述 客户端:主动连接服务器,和服务器进行通信 服务器:被动被客户端连接,启动新的线程或进程,服务器客户端(并发服务器) 这里重复TCP和UDP特点 TCP&#x…...

实验4基于神经网络的模式识别实验
实验原理 1. BP学习算法是通过反向学习过程使误差最小,其算法过程从输出节点开始,反向地向第一隐含层(即最接近输入层的隐含层)传播由总误差引起的权值修正。BP网络不仅含有输入节点和输出节点,而且含有一层或多层隐(层)节点。输入信号先向前…...

Rust网络编程实战:全面掌握reqwest库的高级用法
一、开篇导引 1.1 对比Python Requests解释为何reqwest是Rust生态的标杆HTTP客户端 在Python生态中,Requests 库以其简洁易用的API成为了HTTP客户端的首选。它使得开发者能够轻松地发送各种HTTP请求,处理响应,而无需过多关注底层细节。然而…...
)
【漫话机器学习系列】211.驻点(Stationary Points)
驻点(Stationary Points):理解函数导数为零的关键位置 在数学分析、机器学习优化、物理建模等领域中,驻点(Stationary Points)是一个非常重要的概念。它们是函数图像中“停下来的点”,即导数为…...

图 - 最小生成树算法 - Kruskal - Prim
目录 前言 什么是最小生成树算法 Kruskal 克鲁斯卡尔 Prim 普利姆 结语 前言 在图中一共有两类算法,一种是最短路径,还有一种就是本篇要讲解的最小生成树算法了 其中,最短路径一共有三种,而最小生成树一共有两种ÿ…...

linux kernel irq相关函数详解
在Linux内核驱动开发中,处理中断涉及一系列关键函数,正确使用这些函数对确保驱动的稳定性和性能至关重要。以下是disable_irq、free_irq、platform_get_irq和request_irq等函数的详细解析,涵盖其功能、用法、注意事项及示例代码。 一、核心函…...

聊聊Doris的数据模型,如何用结构化设计解决实时分析难题
传统 OLAP 系统的局限 在大数据实时分析领域,数据模型设计直接决定了系统的查询性能、存储效率与业务适配性。Apache Doris作为新一代MPP分析型数据库,通过独创的多模型融合架构,在业内率先实现了"一份数据支持多种分析范式"的能力…...

[Swift]Xcode模拟器无法请求http接口问题
1.以前偷懒一直是这样设置 <key>NSAppTransportSecurity</key> <dict><key>NSAllowsArbitraryLoads</key><true/> </dict> 现在我在Xcode16.3上,这种设置方式在真机上能请求http(应该是设备开启了开发者模式…...

kafka认证部署
首先启动 zookeeper /home/kafka/bin/zookeeper-server-start.sh /home/kafka/config/zookeeper.properties 创建SCRAM证书 /home/kafka/bin/kafka-configs.sh --zookeeper localhost:2181 --alter --add-config SCRAM-SHA-256[iterations8192,passwordliebe],SCRAM-SHA-512[p…...

基于STM32中断讲解
基于STM32中断讲解 一、NVIC讲解 简介:当一个中断请求到达时,NVIC会确定其优先级并决定是否应该中断当前执行的程序,以便及时响应和处理该中断请求。这种设计有助于提高系统的响应速度和可靠性,特别是在需要处理大量中断请求的实…...
(以RPC 过程为例))
Java 动态代理教程(JDK 动态代理)(以RPC 过程为例)
1. 什么是动态代理 在运行时为指定的接口自动生成代理对象,并通过 invoke 方法增强了这些对象的功能 2. 两个核心组件 java.lang.reflect.Proxy类 这个类提供了方法:newProxyInstance()用来创建一个代理对象 public static Object newProxyInstance(…...

Linux Privilege Escalation: LD_PRELOAD
声明:本文所有操作需在授权环境下进行,严禁非法使用! 0x01 什么是 LD_PRELOAD? LD_PRELOAD 是 Linux 系统中一个特殊的环境变量,它允许用户在程序启动时优先加载自定义的动态链接库(.so 文件)&…...