PyTorch 深度学习实战(37):分布式训练(DP/DDP/Deepspeed)实战
在上一篇文章中,我们探讨了混合精度训练与梯度缩放技术。本文将深入介绍分布式训练的三种主流方法:Data Parallel (DP)、Distributed Data Parallel (DDP) 和 DeepSpeed,帮助您掌握大规模模型训练的关键技术。我们将使用PyTorch在CIFAR-10分类任务上实现这三种方法,并进行性能对比。
一、分布式训练基础
1. 三种分布式方法对比
| 特性 | DataParallel (DP) | DistributedDataParallel (DDP) | DeepSpeed |
|---|---|---|---|
| 实现难度 | 简单 | 中等 | 复杂 |
| 多机支持 | 不支持 | 支持 | 支持 |
| 通信效率 | 低效(单进程) | 高效(NCCL) | 极高效(优化通信) |
| 显存优化 | 无 | 一般 | 优秀(ZeRO阶段1-3) |
| 适合场景 | 单机多卡 | 多机多卡 | 超大模型训练 |
2. 关键概念解析
class DistributedTerms:def __init__(self):self.world_size = "参与训练的进程总数"self.rank = "当前进程的全局ID"self.local_rank = "当前节点上的进程ID"self.backend = "通信后端(nccl/gloo/mpi)"self.init_method = "初始化方式(env/file/tcp)"二、DataParallel (DP) 实战
1. 基础DP实现
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
# 设备设置 (自动使用所有可用GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 模型定义
class ConvNet(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(3, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.fc1 = nn.Linear(64*6*6, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = F.relu(self.conv1(x))x = F.max_pool2d(x, 2)x = F.relu(self.conv2(x))x = F.max_pool2d(x, 2)x = x.view(-1, 64*6*6)x = F.relu(self.fc1(x))x = self.fc2(x)return x
# 数据准备
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
# 包装模型为DP
model = ConvNet().to(device)
if torch.cuda.device_count() > 1:print(f"使用 {torch.cuda.device_count()} 个GPU!")model = nn.DataParallel(model)
# 训练循环
train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
for epoch in range(10):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()if batch_idx % 100 == 0:print(f"Epoch: {epoch} | Batch: {batch_idx}/{len(train_loader)} | Loss: {loss.item():.4f}")输出为:
Epoch: 0 | Batch: 0/196 | Loss: 2.2991
Epoch: 0 | Batch: 100/196 | Loss: 1.4741
Epoch: 1 | Batch: 0/196 | Loss: 1.3207
Epoch: 1 | Batch: 100/196 | Loss: 1.1767
Epoch: 2 | Batch: 0/196 | Loss: 1.0995
Epoch: 2 | Batch: 100/196 | Loss: 1.0768
Epoch: 3 | Batch: 0/196 | Loss: 1.0013
Epoch: 3 | Batch: 100/196 | Loss: 0.8572
Epoch: 4 | Batch: 0/196 | Loss: 0.9214
Epoch: 4 | Batch: 100/196 | Loss: 0.8575
Epoch: 5 | Batch: 0/196 | Loss: 0.8531
Epoch: 5 | Batch: 100/196 | Loss: 0.9046
Epoch: 6 | Batch: 0/196 | Loss: 0.8146
Epoch: 6 | Batch: 100/196 | Loss: 0.6766
Epoch: 7 | Batch: 0/196 | Loss: 0.6395
Epoch: 7 | Batch: 100/196 | Loss: 0.6545
Epoch: 8 | Batch: 0/196 | Loss: 0.7298
Epoch: 8 | Batch: 100/196 | Loss: 0.7052
Epoch: 9 | Batch: 0/196 | Loss: 0.6747
Epoch: 9 | Batch: 100/196 | Loss: 0.60762. DP的局限性
class DPLimitations:def __init__(self):self.issues = ["单进程多线程导致GIL争用","梯度聚合在单一GPU(主卡)形成瓶颈","显存利用率不均衡(主卡OOM风险)","不支持多节点扩展"]self.solution = "使用DDP替代"三、DistributedDataParallel (DDP) 实战
1. 单机多卡DDP实现
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
import os
class ConvNet(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(3, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.fc1 = nn.Linear(64 * 6 * 6, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = F.relu(self.conv1(x))x = F.max_pool2d(x, 2)x = F.relu(self.conv2(x))x = F.max_pool2d(x, 2)x = x.view(-1, 64 * 6 * 6)x = F.relu(self.fc1(x))x = self.fc2(x)return x
def ddp_setup(rank, world_size):os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '12355'dist.init_process_group("nccl", rank=rank, world_size=world_size)torch.cuda.set_device(rank)
def cleanup():if dist.is_initialized():dist.destroy_process_group()
class DDPTrainer:def __init__(self, rank, world_size):self.rank = rankself.world_size = world_sizeself.model = ConvNet().to(rank)self.model = DDP(self.model, device_ids=[rank])self.optimizer = optim.Adam(self.model.parameters(), lr=0.001)self.criterion = nn.CrossEntropyLoss()self.train_loader = self._prepare_dataloader()def _prepare_dataloader(self):transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform)sampler = torch.utils.data.distributed.DistributedSampler(dataset,num_replicas=self.world_size,rank=self.rank,shuffle=True)return DataLoader(dataset,batch_size=256,sampler=sampler,num_workers=2,pin_memory=True)def train(self, total_epochs=10):for epoch in range(total_epochs):self.model.train()self.train_loader.sampler.set_epoch(epoch) # 确保每个epoch有不同的shufflefor batch_idx, (data, target) in enumerate(self.train_loader):data, target = data.to(self.rank), target.to(self.rank)self.optimizer.zero_grad()output = self.model(data)loss = self.criterion(output, target)loss.backward()self.optimizer.step()if batch_idx % 100 == 0 and self.rank == 0: # 仅主进程打印print(f"Epoch: {epoch} | Batch: {batch_idx}/{len(self.train_loader)} | Loss: {loss.item():.4f}")if self.rank == 0:torch.save(self.model.module.state_dict(), "ddp_model.pth")
def main_ddp(rank, world_size):ddp_setup(rank, world_size)trainer = DDPTrainer(rank, world_size)trainer.train()cleanup()
if __name__ == "__main__":world_size = torch.cuda.device_count()mp.spawn(main_ddp, args=(world_size,), nprocs=world_size)输出为:
Files already downloaded and verified
Epoch: 0 | Batch: 0/196 | Loss: 2.3034
Epoch: 0 | Batch: 100/196 | Loss: 1.4479
Epoch: 1 | Batch: 0/196 | Loss: 1.2776
Epoch: 1 | Batch: 100/196 | Loss: 1.3570
Epoch: 2 | Batch: 0/196 | Loss: 1.1137
Epoch: 2 | Batch: 100/196 | Loss: 0.9530
Epoch: 3 | Batch: 0/196 | Loss: 1.0887
Epoch: 3 | Batch: 100/196 | Loss: 0.8944
Epoch: 4 | Batch: 0/196 | Loss: 0.8131
Epoch: 4 | Batch: 100/196 | Loss: 0.9242
Epoch: 5 | Batch: 0/196 | Loss: 0.9026
Epoch: 5 | Batch: 100/196 | Loss: 1.0272
Epoch: 6 | Batch: 0/196 | Loss: 0.6772
Epoch: 6 | Batch: 100/196 | Loss: 0.8683
Epoch: 7 | Batch: 0/196 | Loss: 0.7747
Epoch: 7 | Batch: 100/196 | Loss: 0.7627
Epoch: 8 | Batch: 0/196 | Loss: 0.6991
Epoch: 8 | Batch: 100/196 | Loss: 0.7003
Epoch: 9 | Batch: 0/196 | Loss: 0.6409
Epoch: 9 | Batch: 100/196 | Loss: 0.66212. 多机DDP关键配置
def multi_machine_setup():config = {"init_method": "env://", # 使用环境变量初始化"environment_vars": {"MASTER_ADDR": "192.168.1.1", # 主节点IP"MASTER_PORT": "29500", # 开放端口"WORLD_SIZE": "8", # 总GPU数"RANK": "0-7" # 各节点rank},"per_machine_cmd": "python train.py --local_rank=$LOCAL_RANK","launcher": "torchrun" # 推荐使用torchrun替代mp.spawn}return config四、DeepSpeed 实战
1. DeepSpeed基础配置
# ds_config.json
{"train_batch_size": 32,"gradient_accumulation_steps": 1,"optimizer": {"type": "Adam","params": {"lr": 0.001,"betas": [0.8, 0.999],"eps": 1e-8,"weight_decay": 3e-7}},"fp16": {"enabled": true,"auto_cast": true,"loss_scale": 0,"loss_scale_window": 1000,"hysteresis": 2,"min_loss_scale": 1},"zero_optimization": {"stage": 2,"allgather_partitions": true,"allgather_bucket_size": 200000000,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": 200000000,"contiguous_gradients": true}}2. DeepSpeed训练实现
import deepspeed
import torch.nn as nn
from torchvision import datasets, transforms
import torch.nn.functional as F
import argparse
class ConvNet(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(3, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.fc1 = nn.Linear(64 * 6 * 6, 128)self.fc2 = nn.Linear(128, 10)
def forward(self, x):# Convert input to match model's dtype if neededif next(self.parameters()).dtype != x.dtype:x = x.to(next(self.parameters()).dtype)
x = F.relu(self.conv1(x))x = F.max_pool2d(x, 2)x = F.relu(self.conv2(x))x = F.max_pool2d(x, 2)x = x.view(-1, 64 * 6 * 6)x = F.relu(self.fc1(x))x = self.fc2(x)return x
def train_deepspeed(args):model = ConvNet()
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])dataset = datasets.CIFAR10(root='./data', train=True, download=True,transform=transform)
# Initialize DeepSpeedmodel_engine, optimizer, train_loader, _ = deepspeed.initialize(args=args,model=model,model_parameters=model.parameters(),training_data=dataset)
for epoch in range(args.epochs):model_engine.train()for batch_idx, (inputs, targets) in enumerate(train_loader):inputs = inputs.to(model_engine.device)targets = targets.to(model_engine.device)
# Ensure inputs match model dtypeif model_engine.fp16_enabled():inputs = inputs.half()
outputs = model_engine(inputs)loss = F.cross_entropy(outputs, targets)
model_engine.backward(loss)model_engine.step()
if batch_idx % 100 == 0 and model_engine.local_rank == 0:print(f"Epoch: {epoch} | Batch: {batch_idx} | Loss: {loss.item():.4f}")
def get_args():parser = argparse.ArgumentParser(description='DeepSpeed CIFAR10 Training')parser.add_argument('--epochs', type=int, default=10)parser.add_argument('--local_rank', type=int, default=-1)parser.add_argument('--deepspeed_config', type=str,default='ds_config.json',help='path to DeepSpeed config file')return parser.parse_args()
if __name__ == "__main__":args = get_args()train_deepspeed(args)# 运行脚本deepspeed --num_gpus=1 deepspeed_train.py --deepspeed_config ds_config.json,其中num_gpus指gpu数量
# 需要pip install deepspeed输出为:
[2025-04-05 03:34:29,680] [INFO] [real_accelerator.py:239:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2025-04-05 03:34:31,203] [WARNING] [runner.py:215:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
[2025-04-05 03:34:31,203] [INFO] [runner.py:605:main] cmd = /root/miniforge3/bin/python3.10 -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMF19 --master_addr=127.0.0.1 --master_port=29500 --enable_each_rank_log=None e38-3.py --deepspeed_config ds_config.json
[2025-04-05 03:34:32,803] [INFO] [real_accelerator.py:239:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2025-04-05 03:34:34,305] [INFO] [launch.py:139:main] 0 NV_LIBNCCL_DEV_PACKAGE=libnccl-dev=2.21.5-1+cuda12.4
[2025-04-05 03:34:34,305] [INFO] [launch.py:139:main] 0 NV_LIBNCCL_DEV_PACKAGE_VERSION=2.21.5-1
[2025-04-05 03:34:34,305] [INFO] [launch.py:139:main] 0 NCCL_VERSION=2.21.5-1
[2025-04-05 03:34:34,305] [INFO] [launch.py:139:main] 0 NV_LIBNCCL_DEV_PACKAGE_NAME=libnccl-dev
[2025-04-05 03:34:34,305] [INFO] [launch.py:139:main] 0 NV_LIBNCCL_PACKAGE=libnccl2=2.21.5-1+cuda12.4
[2025-04-05 03:34:34,305] [INFO] [launch.py:139:main] 0 NV_LIBNCCL_PACKAGE_NAME=libnccl2
[2025-04-05 03:34:34,305] [INFO] [launch.py:139:main] 0 NV_LIBNCCL_PACKAGE_VERSION=2.21.5-1
[2025-04-05 03:34:34,305] [INFO] [launch.py:146:main] WORLD INFO DICT: {'localhost': [0]}
[2025-04-05 03:34:34,305] [INFO] [launch.py:152:main] nnodes=1, num_local_procs=1, node_rank=0
[2025-04-05 03:34:34,305] [INFO] [launch.py:163:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0]})
[2025-04-05 03:34:34,305] [INFO] [launch.py:164:main] dist_world_size=1
[2025-04-05 03:34:34,305] [INFO] [launch.py:168:main] Setting CUDA_VISIBLE_DEVICES=0
[2025-04-05 03:34:34,306] [INFO] [launch.py:256:main] process 13722 spawned with command: ['/root/miniforge3/bin/python3.10', '-u', 'e38-3.py', '--local_rank=0', '--deepspeed_config', 'ds_config.json']
[2025-04-05 03:34:35,911] [INFO] [real_accelerator.py:239:get_accelerator] Setting ds_accelerator to cuda (auto detect)
Files already downloaded and verified
[2025-04-05 03:34:38,546] [INFO] [logging.py:107:log_dist] [Rank -1] DeepSpeed info: version=0.16.5, git-hash=unknown, git-branch=unknown
[2025-04-05 03:34:38,546] [INFO] [comm.py:658:init_distributed] cdb=None
[2025-04-05 03:34:38,546] [INFO] [comm.py:689:init_distributed] Initializing TorchBackend in DeepSpeed with backend nccl
[2025-04-05 03:34:38,549] [INFO] [config.py:734:__init__] Config mesh_device None world_size = 1
[2025-04-05 03:34:38,992] [INFO] [logging.py:107:log_dist] [Rank 0] DeepSpeed Flops Profiler Enabled: False
Using /root/.cache/torch_extensions/py310_cu124 as PyTorch extensions root...
Detected CUDA files, patching ldflags
Emitting ninja build file /root/.cache/torch_extensions/py310_cu124/fused_adam/build.ninja...
/root/miniforge3/lib/python3.10/site-packages/torch/utils/cpp_extension.py:1964: UserWarning: TORCH_CUDA_ARCH_LIST is not set, all archs for visible cards are included for compilation.
If this is not desired, please set os.environ['TORCH_CUDA_ARCH_LIST'].warnings.warn(
Building extension module fused_adam...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
ninja: no work to do.
Loading extension module fused_adam...
Time to load fused_adam op: 0.055249929428100586 seconds
[2025-04-05 03:34:39,049] [INFO] [logging.py:107:log_dist] [Rank 0] Using DeepSpeed Optimizer param name adam as basic optimizer
[2025-04-05 03:34:39,049] [INFO] [logging.py:107:log_dist] [Rank 0] Removing param_group that has no 'params' in the basic Optimizer
[2025-04-05 03:34:39,049] [INFO] [logging.py:107:log_dist] [Rank 0] DeepSpeed Basic Optimizer = FusedAdam
[2025-04-05 03:34:39,049] [INFO] [utils.py:59:is_zero_supported_optimizer] Checking ZeRO support for optimizer=FusedAdam type=<class 'deepspeed.ops.adam.fused_adam.FusedAdam'>
[2025-04-05 03:34:39,049] [INFO] [logging.py:107:log_dist] [Rank 0] Creating torch.float16 ZeRO stage 2 optimizer
[2025-04-05 03:34:39,049] [INFO] [stage_1_and_2.py:149:__init__] Reduce bucket size 200000000
[2025-04-05 03:34:39,049] [INFO] [stage_1_and_2.py:150:__init__] Allgather bucket size 200000000
[2025-04-05 03:34:39,050] [INFO] [stage_1_and_2.py:151:__init__] CPU Offload: False
[2025-04-05 03:34:39,050] [INFO] [stage_1_and_2.py:152:__init__] Round robin gradient partitioning: False
[2025-04-05 03:34:39,174] [INFO] [utils.py:781:see_memory_usage] Before initializing optimizer states
[2025-04-05 03:34:39,175] [INFO] [utils.py:782:see_memory_usage] MA 0.0 GB Max_MA 0.0 GB CA 0.02 GB Max_CA 0 GB
[2025-04-05 03:34:39,175] [INFO] [utils.py:789:see_memory_usage] CPU Virtual Memory: used = 3.37 GB, percent = 11.0%
[2025-04-05 03:34:39,285] [INFO] [utils.py:781:see_memory_usage] After initializing optimizer states
[2025-04-05 03:34:39,285] [INFO] [utils.py:782:see_memory_usage] MA 0.0 GB Max_MA 0.0 GB CA 0.02 GB Max_CA 0 GB
[2025-04-05 03:34:39,286] [INFO] [utils.py:789:see_memory_usage] CPU Virtual Memory: used = 3.37 GB, percent = 11.0%
[2025-04-05 03:34:39,286] [INFO] [stage_1_and_2.py:556:__init__] optimizer state initialized
[2025-04-05 03:34:39,380] [INFO] [utils.py:781:see_memory_usage] After initializing ZeRO optimizer
[2025-04-05 03:34:39,380] [INFO] [utils.py:782:see_memory_usage] MA 0.0 GB Max_MA 0.0 GB CA 0.02 GB Max_CA 0 GB
[2025-04-05 03:34:39,381] [INFO] [utils.py:789:see_memory_usage] CPU Virtual Memory: used = 3.37 GB, percent = 11.0%
[2025-04-05 03:34:39,381] [INFO] [logging.py:107:log_dist] [Rank 0] DeepSpeed Final Optimizer = DeepSpeedZeroOptimizer
[2025-04-05 03:34:39,381] [INFO] [logging.py:107:log_dist] [Rank 0] DeepSpeed using configured LR scheduler = None
[2025-04-05 03:34:39,381] [INFO] [logging.py:107:log_dist] [Rank 0] DeepSpeed LR Scheduler = None
[2025-04-05 03:34:39,381] [INFO] [logging.py:107:log_dist] [Rank 0] step=0, skipped=0, lr=[0.001], mom=[[0.8, 0.999]]
[2025-04-05 03:34:39,381] [INFO] [config.py:1000:print] DeepSpeedEngine configuration:
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] activation_checkpointing_config {"partition_activations": false, "contiguous_memory_optimization": false, "cpu_checkpointing": false, "number_checkpoints": null, "synchronize_checkpoint_boundary": false, "profile": false
}
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] aio_config ................... {'block_size': 1048576, 'queue_depth': 8, 'intra_op_parallelism': 1, 'single_submit': False, 'overlap_events': True, 'use_gds': False}
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] amp_enabled .................. False
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] amp_params ................... False
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] autotuning_config ............ {"enabled": false, "start_step": null, "end_step": null, "metric_path": null, "arg_mappings": null, "metric": "throughput", "model_info": null, "results_dir": "autotuning_results", "exps_dir": "autotuning_exps", "overwrite": true, "fast": true, "start_profile_step": 3, "end_profile_step": 5, "tuner_type": "gridsearch", "tuner_early_stopping": 5, "tuner_num_trials": 50, "model_info_path": null, "mp_size": 1, "max_train_batch_size": null, "min_train_batch_size": 1, "max_train_micro_batch_size_per_gpu": 1.024000e+03, "min_train_micro_batch_size_per_gpu": 1, "num_tuning_micro_batch_sizes": 3
}
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] bfloat16_enabled ............. False
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] bfloat16_immediate_grad_update False
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] checkpoint_parallel_write_pipeline False
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] checkpoint_tag_validation_enabled True
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] checkpoint_tag_validation_fail False
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] comms_config ................. <deepspeed.comm.config.DeepSpeedCommsConfig object at 0x7f7f620f2b30>
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] communication_data_type ...... None
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] compression_config ........... {'weight_quantization': {'shared_parameters': {'enabled': False, 'quantizer_kernel': False, 'schedule_offset': 0, 'quantize_groups': 1, 'quantize_verbose': False, 'quantization_type': 'symmetric', 'quantize_weight_in_forward': False, 'rounding': 'nearest', 'fp16_mixed_quantize': False, 'quantize_change_ratio': 0.001}, 'different_groups': {}}, 'activation_quantization': {'shared_parameters': {'enabled': False, 'quantization_type': 'symmetric', 'range_calibration': 'dynamic', 'schedule_offset': 1000}, 'different_groups': {}}, 'sparse_pruning': {'shared_parameters': {'enabled': False, 'method': 'l1', 'schedule_offset': 1000}, 'different_groups': {}}, 'row_pruning': {'shared_parameters': {'enabled': False, 'method': 'l1', 'schedule_offset': 1000}, 'different_groups': {}}, 'head_pruning': {'shared_parameters': {'enabled': False, 'method': 'topk', 'schedule_offset': 1000}, 'different_groups': {}}, 'channel_pruning': {'shared_parameters': {'enabled': False, 'method': 'l1', 'schedule_offset': 1000}, 'different_groups': {}}, 'layer_reduction': {'enabled': False}}
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] curriculum_enabled_legacy .... False
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] curriculum_params_legacy ..... False
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] data_efficiency_config ....... {'enabled': False, 'seed': 1234, 'data_sampling': {'enabled': False, 'num_epochs': 1000, 'num_workers': 0, 'pin_memory': False, 'curriculum_learning': {'enabled': False}, 'dynamic_batching': {'enabled': False, 'lr_scaling_method': 'linear', 'min_batch_size': 1, 'max_batch_size': None, 'sequence_picking_order': 'dataloader', 'verbose': False}}, 'data_routing': {'enabled': False, 'random_ltd': {'enabled': False, 'layer_token_lr_schedule': {'enabled': False}}}}
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] data_efficiency_enabled ...... False
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] dataloader_drop_last ......... False
[2025-04-05 03:34:39,382] [INFO] [config.py:1004:print] disable_allgather ............ False
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] dump_state ................... False
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] dynamic_loss_scale_args ...... {'init_scale': 65536, 'scale_window': 1000, 'delayed_shift': 2, 'consecutive_hysteresis': False, 'min_scale': 1}
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] eigenvalue_enabled ........... False
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] eigenvalue_gas_boundary_resolution 1
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] eigenvalue_layer_name ........ bert.encoder.layer
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] eigenvalue_layer_num ......... 0
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] eigenvalue_max_iter .......... 100
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] eigenvalue_stability ......... 1e-06
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] eigenvalue_tol ............... 0.01
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] eigenvalue_verbose ........... False
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] elasticity_enabled ........... False
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] flops_profiler_config ........ {"enabled": false, "recompute_fwd_factor": 0.0, "profile_step": 1, "module_depth": -1, "top_modules": 1, "detailed": true, "output_file": null
}
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] fp16_auto_cast ............... True
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] fp16_enabled ................. True
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] fp16_master_weights_and_gradients False
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] global_rank .................. 0
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] grad_accum_dtype ............. None
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] gradient_accumulation_steps .. 1
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] gradient_clipping ............ 0.0
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] gradient_predivide_factor .... 1.0
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] graph_harvesting ............. False
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] hybrid_engine ................ enabled=False max_out_tokens=512 inference_tp_size=1 release_inference_cache=False pin_parameters=True tp_gather_partition_size=8
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] initial_dynamic_scale ........ 65536
[2025-04-05 03:34:39,383] [INFO] [config.py:1004:print] load_universal_checkpoint .... False
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] loss_scale ................... 0
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] memory_breakdown ............. False
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] mics_hierarchial_params_gather False
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] mics_shard_size .............. -1
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] monitor_config ............... tensorboard=TensorBoardConfig(enabled=False, output_path='', job_name='DeepSpeedJobName') comet=CometConfig(enabled=False, samples_log_interval=100, project=None, workspace=None, api_key=None, experiment_name=None, experiment_key=None, online=None, mode=None) wandb=WandbConfig(enabled=False, group=None, team=None, project='deepspeed') csv_monitor=CSVConfig(enabled=False, output_path='', job_name='DeepSpeedJobName')
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] nebula_config ................ {"enabled": false, "persistent_storage_path": null, "persistent_time_interval": 100, "num_of_version_in_retention": 2, "enable_nebula_load": true, "load_path": null
}
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] optimizer_legacy_fusion ...... False
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] optimizer_name ............... adam
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] optimizer_params ............. {'lr': 0.001, 'betas': [0.8, 0.999], 'eps': 1e-08, 'weight_decay': 3e-07}
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0, 'pipe_partitioned': True, 'grad_partitioned': True}
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] pld_enabled .................. False
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] pld_params ................... False
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] prescale_gradients ........... False
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] scheduler_name ............... None
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] scheduler_params ............. None
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] seq_parallel_communication_data_type torch.float32
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] sparse_attention ............. None
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] sparse_gradients_enabled ..... False
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] steps_per_print .............. None
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] tensor_parallel_config ....... dtype=torch.float16 autotp_size=0 tensor_parallel=TPConfig(tp_size=1, tp_grain_size=1, mpu=None, tp_group=None) injection_policy_tuple=None keep_module_on_host=False replace_with_kernel_inject=False
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] timers_config ................ enabled=True synchronized=True
[2025-04-05 03:34:39,384] [INFO] [config.py:1004:print] train_batch_size ............. 32
[2025-04-05 03:34:39,385] [INFO] [config.py:1004:print] train_micro_batch_size_per_gpu 32
[2025-04-05 03:34:39,385] [INFO] [config.py:1004:print] use_data_before_expert_parallel_ False
[2025-04-05 03:34:39,385] [INFO] [config.py:1004:print] use_node_local_storage ....... False
[2025-04-05 03:34:39,385] [INFO] [config.py:1004:print] wall_clock_breakdown ......... False
[2025-04-05 03:34:39,385] [INFO] [config.py:1004:print] weight_quantization_config ... None
[2025-04-05 03:34:39,385] [INFO] [config.py:1004:print] world_size ................... 1
[2025-04-05 03:34:39,385] [INFO] [config.py:1004:print] zero_allow_untested_optimizer False
[2025-04-05 03:34:39,385] [INFO] [config.py:1004:print] zero_config .................. stage=2 contiguous_gradients=True reduce_scatter=True reduce_bucket_size=200000000 use_multi_rank_bucket_allreduce=True allgather_partitions=True allgather_bucket_size=200000000 overlap_comm=True load_from_fp32_weights=True elastic_checkpoint=False offload_param=None offload_optimizer=None sub_group_size=1000000000 cpu_offload_param=None cpu_offload_use_pin_memory=None cpu_offload=None prefetch_bucket_size=50000000 param_persistence_threshold=100000 model_persistence_threshold=9223372036854775807 max_live_parameters=1000000000 max_reuse_distance=1000000000 gather_16bit_weights_on_model_save=False module_granularity_threshold=0 use_all_reduce_for_fetch_params=False stage3_gather_fp16_weights_on_model_save=False ignore_unused_parameters=True legacy_stage1=False round_robin_gradients=False zero_hpz_partition_size=1 zero_quantized_weights=False zero_quantized_nontrainable_weights=False zero_quantized_gradients=False zeropp_loco_param=None mics_shard_size=-1 mics_hierarchical_params_gather=False memory_efficient_linear=True pipeline_loading_checkpoint=False override_module_apply=True log_trace_cache_warnings=False
[2025-04-05 03:34:39,385] [INFO] [config.py:1004:print] zero_enabled ................. True
[2025-04-05 03:34:39,385] [INFO] [config.py:1004:print] zero_force_ds_cpu_optimizer .. True
[2025-04-05 03:34:39,385] [INFO] [config.py:1004:print] zero_optimization_stage ...... 2
[2025-04-05 03:34:39,385] [INFO] [config.py:990:print_user_config] json = {"train_batch_size": 32, "gradient_accumulation_steps": 1, "optimizer": {"type": "Adam", "params": {"lr": 0.001, "betas": [0.8, 0.999], "eps": 1e-08, "weight_decay": 3e-07}}, "fp16": {"enabled": true, "auto_cast": true, "loss_scale": 0, "loss_scale_window": 1000, "hysteresis": 2, "min_loss_scale": 1}, "zero_optimization": {"stage": 2, "allgather_partitions": true, "allgather_bucket_size": 2.000000e+08, "overlap_comm": true, "reduce_scatter": true, "reduce_bucket_size": 2.000000e+08, "contiguous_gradients": true}
}
[2025-04-05 03:34:40,640] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
Epoch: 0 | Batch: 0 | Loss: 2.3125
[2025-04-05 03:34:40,646] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 0 | Batch: 100 | Loss: 1.8994
Epoch: 0 | Batch: 200 | Loss: 1.5488
Epoch: 0 | Batch: 300 | Loss: 1.7979
Epoch: 0 | Batch: 400 | Loss: 1.5400
Epoch: 0 | Batch: 500 | Loss: 1.3965
Epoch: 0 | Batch: 600 | Loss: 1.6631
Epoch: 0 | Batch: 700 | Loss: 1.4385
Epoch: 0 | Batch: 800 | Loss: 1.1826
Epoch: 0 | Batch: 900 | Loss: 1.2168
Epoch: 0 | Batch: 1000 | Loss: 1.3877
[2025-04-05 03:34:47,610] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:34:47,617] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 0 | Batch: 1100 | Loss: 1.2227
Epoch: 0 | Batch: 1200 | Loss: 1.3486
Epoch: 0 | Batch: 1300 | Loss: 1.4824
Epoch: 0 | Batch: 1400 | Loss: 1.2939
Epoch: 0 | Batch: 1500 | Loss: 1.3477
Epoch: 1 | Batch: 0 | Loss: 1.0166
Epoch: 1 | Batch: 100 | Loss: 1.3037
Epoch: 1 | Batch: 200 | Loss: 0.9531
Epoch: 1 | Batch: 300 | Loss: 1.2051
Epoch: 1 | Batch: 400 | Loss: 1.1250
[2025-04-05 03:34:54,593] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:34:54,599] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 1 | Batch: 500 | Loss: 1.0322
Epoch: 1 | Batch: 600 | Loss: 1.1992
Epoch: 1 | Batch: 700 | Loss: 0.9302
Epoch: 1 | Batch: 800 | Loss: 1.0225
Epoch: 1 | Batch: 900 | Loss: 0.9985
Epoch: 1 | Batch: 1000 | Loss: 1.0186
Epoch: 1 | Batch: 1100 | Loss: 0.7178
Epoch: 1 | Batch: 1200 | Loss: 1.0322
Epoch: 1 | Batch: 1300 | Loss: 1.3174
Epoch: 1 | Batch: 1400 | Loss: 1.0762
[2025-04-05 03:35:01,555] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:35:01,560] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 1 | Batch: 1500 | Loss: 1.0664
Epoch: 2 | Batch: 0 | Loss: 0.7202
Epoch: 2 | Batch: 100 | Loss: 1.1133
Epoch: 2 | Batch: 200 | Loss: 0.7842
Epoch: 2 | Batch: 300 | Loss: 1.0312
Epoch: 2 | Batch: 400 | Loss: 0.8369
Epoch: 2 | Batch: 500 | Loss: 0.8916
Epoch: 2 | Batch: 600 | Loss: 0.8364
Epoch: 2 | Batch: 700 | Loss: 0.8110
Epoch: 2 | Batch: 800 | Loss: 0.8823
[2025-04-05 03:35:08,718] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:35:08,725] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 2 | Batch: 900 | Loss: 0.9097
Epoch: 2 | Batch: 1000 | Loss: 0.7773
Epoch: 2 | Batch: 1100 | Loss: 0.6465
Epoch: 2 | Batch: 1200 | Loss: 0.8125
Epoch: 2 | Batch: 1300 | Loss: 1.2598
Epoch: 2 | Batch: 1400 | Loss: 0.9136
Epoch: 2 | Batch: 1500 | Loss: 0.9321
Epoch: 3 | Batch: 0 | Loss: 0.5562
Epoch: 3 | Batch: 100 | Loss: 0.9727
Epoch: 3 | Batch: 200 | Loss: 0.6489
Epoch: 3 | Batch: 300 | Loss: 0.8125
[2025-04-05 03:35:15,595] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:35:15,600] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 3 | Batch: 400 | Loss: 0.6260
Epoch: 3 | Batch: 500 | Loss: 0.7510
Epoch: 3 | Batch: 600 | Loss: 0.6504
Epoch: 3 | Batch: 700 | Loss: 0.7002
Epoch: 3 | Batch: 800 | Loss: 0.9238
Epoch: 3 | Batch: 900 | Loss: 0.8267
Epoch: 3 | Batch: 1000 | Loss: 0.5518
Epoch: 3 | Batch: 1100 | Loss: 0.6138
Epoch: 3 | Batch: 1200 | Loss: 0.6401
Epoch: 3 | Batch: 1300 | Loss: 1.0996
[2025-04-05 03:35:22,512] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:35:22,518] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 3 | Batch: 1400 | Loss: 0.7559
Epoch: 3 | Batch: 1500 | Loss: 0.8115
Epoch: 4 | Batch: 0 | Loss: 0.4153
Epoch: 4 | Batch: 100 | Loss: 0.8018
Epoch: 4 | Batch: 200 | Loss: 0.5034
Epoch: 4 | Batch: 300 | Loss: 0.7324
Epoch: 4 | Batch: 400 | Loss: 0.5508
Epoch: 4 | Batch: 500 | Loss: 0.6274
Epoch: 4 | Batch: 600 | Loss: 0.4768
Epoch: 4 | Batch: 700 | Loss: 0.6201
[2025-04-05 03:35:29,241] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:35:29,247] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 4 | Batch: 800 | Loss: 0.9185
Epoch: 4 | Batch: 900 | Loss: 0.7114
Epoch: 4 | Batch: 1000 | Loss: 0.4934
Epoch: 4 | Batch: 1100 | Loss: 0.5396
Epoch: 4 | Batch: 1200 | Loss: 0.5234
Epoch: 4 | Batch: 1300 | Loss: 1.0225
Epoch: 4 | Batch: 1400 | Loss: 0.6353
Epoch: 4 | Batch: 1500 | Loss: 0.6787
Epoch: 5 | Batch: 0 | Loss: 0.3416
Epoch: 5 | Batch: 100 | Loss: 0.6562
Epoch: 5 | Batch: 200 | Loss: 0.3862
[2025-04-05 03:35:35,900] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:35:35,905] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 5 | Batch: 300 | Loss: 0.6436
Epoch: 5 | Batch: 400 | Loss: 0.5190
Epoch: 5 | Batch: 500 | Loss: 0.4709
Epoch: 5 | Batch: 600 | Loss: 0.3555
Epoch: 5 | Batch: 700 | Loss: 0.5088
Epoch: 5 | Batch: 800 | Loss: 0.8574
Epoch: 5 | Batch: 900 | Loss: 0.5903
Epoch: 5 | Batch: 1000 | Loss: 0.4016
Epoch: 5 | Batch: 1100 | Loss: 0.4583
Epoch: 5 | Batch: 1200 | Loss: 0.4756
[2025-04-05 03:35:42,493] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:35:42,499] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 5 | Batch: 1300 | Loss: 0.8867
Epoch: 5 | Batch: 1400 | Loss: 0.4451
Epoch: 5 | Batch: 1500 | Loss: 0.5991
Epoch: 6 | Batch: 0 | Loss: 0.3013
Epoch: 6 | Batch: 100 | Loss: 0.5547
Epoch: 6 | Batch: 200 | Loss: 0.4202
Epoch: 6 | Batch: 300 | Loss: 0.5542
Epoch: 6 | Batch: 400 | Loss: 0.5361
Epoch: 6 | Batch: 500 | Loss: 0.4175
Epoch: 6 | Batch: 600 | Loss: 0.2228
[2025-04-05 03:35:49,174] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:35:49,179] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 6 | Batch: 700 | Loss: 0.4939
Epoch: 6 | Batch: 800 | Loss: 0.7461
Epoch: 6 | Batch: 900 | Loss: 0.4568
Epoch: 6 | Batch: 1000 | Loss: 0.3052
Epoch: 6 | Batch: 1100 | Loss: 0.3608
Epoch: 6 | Batch: 1200 | Loss: 0.3230
Epoch: 6 | Batch: 1300 | Loss: 0.7437
Epoch: 6 | Batch: 1400 | Loss: 0.3889
Epoch: 6 | Batch: 1500 | Loss: 0.4861
Epoch: 7 | Batch: 0 | Loss: 0.2820
[2025-04-05 03:35:56,089] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:35:56,095] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 7 | Batch: 100 | Loss: 0.4968
Epoch: 7 | Batch: 200 | Loss: 0.4492
Epoch: 7 | Batch: 300 | Loss: 0.4956
Epoch: 7 | Batch: 400 | Loss: 0.4265
Epoch: 7 | Batch: 500 | Loss: 0.3296
Epoch: 7 | Batch: 600 | Loss: 0.2382
Epoch: 7 | Batch: 700 | Loss: 0.3796
Epoch: 7 | Batch: 800 | Loss: 0.7739
Epoch: 7 | Batch: 900 | Loss: 0.3135
Epoch: 7 | Batch: 1000 | Loss: 0.3032
[2025-04-05 03:36:02,665] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:36:02,672] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 7 | Batch: 1100 | Loss: 0.3655
Epoch: 7 | Batch: 1200 | Loss: 0.2328
Epoch: 7 | Batch: 1300 | Loss: 0.5957
Epoch: 7 | Batch: 1400 | Loss: 0.3350
Epoch: 7 | Batch: 1500 | Loss: 0.3853
Epoch: 8 | Batch: 0 | Loss: 0.1986
Epoch: 8 | Batch: 100 | Loss: 0.3679
Epoch: 8 | Batch: 200 | Loss: 0.4087
Epoch: 8 | Batch: 300 | Loss: 0.4595
Epoch: 8 | Batch: 400 | Loss: 0.3025
Epoch: 8 | Batch: 500 | Loss: 0.2805
[2025-04-05 03:36:09,754] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:36:09,761] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 8 | Batch: 600 | Loss: 0.1461
Epoch: 8 | Batch: 700 | Loss: 0.2495
Epoch: 8 | Batch: 800 | Loss: 0.7319
Epoch: 8 | Batch: 900 | Loss: 0.2815
Epoch: 8 | Batch: 1000 | Loss: 0.2094
Epoch: 8 | Batch: 1100 | Loss: 0.2241
Epoch: 8 | Batch: 1200 | Loss: 0.2345
Epoch: 8 | Batch: 1300 | Loss: 0.5073
Epoch: 8 | Batch: 1400 | Loss: 0.3091
Epoch: 8 | Batch: 1500 | Loss: 0.3027
[2025-04-05 03:36:16,435] [INFO] [loss_scaler.py:190:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, but hysteresis is 2. Reducing hysteresis to 1
[2025-04-05 03:36:16,440] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768
Epoch: 9 | Batch: 0 | Loss: 0.2148
Epoch: 9 | Batch: 100 | Loss: 0.2515
Epoch: 9 | Batch: 200 | Loss: 0.3958
Epoch: 9 | Batch: 300 | Loss: 0.3501
[2025-04-05 03:36:19,196] [INFO] [loss_scaler.py:183:update_scale] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 32768, reducing to 16384
Epoch: 9 | Batch: 400 | Loss: 0.3362
Epoch: 9 | Batch: 500 | Loss: 0.2739
Epoch: 9 | Batch: 600 | Loss: 0.2272
Epoch: 9 | Batch: 700 | Loss: 0.2355
Epoch: 9 | Batch: 800 | Loss: 0.5708
Epoch: 9 | Batch: 900 | Loss: 0.1432
Epoch: 9 | Batch: 1000 | Loss: 0.2303
Epoch: 9 | Batch: 1100 | Loss: 0.2595
Epoch: 9 | Batch: 1200 | Loss: 0.1442
Epoch: 9 | Batch: 1300 | Loss: 0.4683
Epoch: 9 | Batch: 1400 | Loss: 0.2491
Epoch: 9 | Batch: 1500 | Loss: 0.2827
[rank0]:[W405 03:36:27.708658550 ProcessGroupNCCL.cpp:1250] Warning: WARNING: process group has NOT been destroyed before we destruct ProcessGroupNCCL. On normal program exit, the application should call destroy_process_group to ensure that any pending NCCL operations have finished in this process. In rare cases this process can exit before this point and block the progress of another member of the process group. This constraint has always been present, but this warning has only been added since PyTorch 2.4 (function operator())
[2025-04-05 03:36:28,420] [INFO] [launch.py:351:main] Process 13722 exits successfully.3. ZeRO阶段对比
| ZeRO阶段 | 显存优化 | 通信量 | 适用场景 |
|---|---|---|---|
| 阶段0 | 无 | 正常 | 基线对比 |
| 阶段1 | 优化器状态分区 | 低 | 中等规模模型 |
| 阶段2 | +梯度分区 | 中 | 大规模模型 |
| 阶段3 | +参数分区 | 高 | 超大规模模型 |
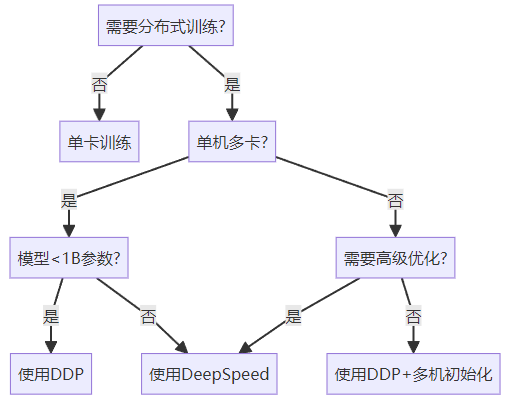
五、选择指南
六、总结与展望
本文全面介绍了三种分布式训练方法:
-
DP:适合快速原型开发,但存在明显瓶颈
-
DDP:生产环境首选,支持多机多卡
-
DeepSpeed:专为超大模型设计,提供ZeRO优化
典型使用场景:
-
单机4卡以下:DDP
-
多机训练:DDP + torchrun
-
10B+参数模型:DeepSpeed + ZeRO-3
在下一篇文章中,我们将深入解析注意力机制,从Seq2Seq到Transformer的完整演进历程,揭示现代深度学习架构的核心思想。
相关文章:
:分布式训练(DP/DDP/Deepspeed)实战)
PyTorch 深度学习实战(37):分布式训练(DP/DDP/Deepspeed)实战
在上一篇文章中,我们探讨了混合精度训练与梯度缩放技术。本文将深入介绍分布式训练的三种主流方法:Data Parallel (DP)、Distributed Data Parallel (DDP) 和 DeepSpeed,帮助您掌握大规模模型训练的关键技术。我们将使用PyTorch在CIFAR-10分类…...

MCP系列之架构篇:深入理解MCP的设计架构
前言 在上一篇《MCP系列之基础篇》中,我们初步了解了MCP(模型上下文协议)的基本概念和价值。本篇文章将深入探讨MCP的技术架构,帮助开发者和技术爱好者更全面地理解这一协议的内部工作机制。我们将剖析MCP的核心组件、通信模型和工作流程,解析Host、Client和Server三者之…...

RT-Thread RTThread studio 初使用
RT-Thread Studio 下载 https://www.rt-thread.org/studio.html 安装使用 https://bbs.elecfans.com/jishu_2425653_1_1.html 4 编译问题解决 问题一:error: unknown type name clock_t 具体的类型值是在sys/_types.h中定义的,需要包含sys/_types.h 这个…...

设计模式 --- 外观模式
外观模式是一种结构型设计模式,为复杂子系统提供统一的高层接口,通过定义一个外观类来简化客户端与子系统的交互,降低系统耦合度。这种模式隐藏了子系统的复杂性,将客户端与子系统的实现细节隔离开来,…...

第十二节:原理深挖-React Fiber架构核心思想
链表结构、时间切片(Time Slicing) 优先级调度实现(如用户输入>网络请求) React Fiber架构深度解析:从链表到优先级调度的革命性升级 一、Fiber架构核心设计思想 React Fiber是React 16的底层协调算法重构&#x…...

利用DeepSeek设计一个HTML批量转换工具设计
需求词:需要设计一个能够批量转换HTML文件格式的网页在线工具,界面简洁易用 功能概述 设计一个网页在线工具,允许用户批量上传HTML文件并进行格式转换,包括: HTML美化/格式化 HTML压缩/最小化 HTML到XHTML转换 HT…...
)
TypeScript 从入门到精通:完整教程与实战应用(一)
1. TypeScript 简介 什么是 TypeScript? TypeScript 是 JavaScript 的超集,添加了静态类型系统,由微软开发并开源。它编译成纯 JavaScript 运行在任何 JavaScript 环境中。 为什么使用 TypeScript? 类型安全:在编译时…...

什么是Python单例模式
什么是Python单例模式 Python单例模式是一种创建型设计模式,目的是确保一个类仅有一个实例,并提供一个全局访问点来获取该实例。以下从作用和示例进行介绍: 作用 控制资源使用:避免对系统资源的重复消耗,像数据库连接、文件句柄等稀缺资源,只创建一个实例来管理使用,防…...

PHP8.2.9NTS版本使用composer报错,扩展找不到的问题处理
使用composer install时报错: The openssl extension is required for SSL/TLS protection but is not available. If you can not enable the openssl extension, you can disable this error, at y our own risk, by setting the ‘disable-tls’ option to true.…...

memcache使用
Memcache 是一款高性能的分布式内存对象缓存系统,以下是其使用方法: 安装与配置 • 安装 Memcached :在 CentOS 7 系统中,可使用命令sudo yum install memcached进行安装,也可从源码编译安装,如下载 memca…...
)
旅游资源网站登录(jsp+ssm+mysql5.x)
旅游资源网站登录(jspssmmysql5.x) 旅游资源网站是一个为旅游爱好者提供全面服务的平台。网站登录界面简洁明了,用户可以选择以管理员或普通用户身份登录。成功登录后,用户可以访问个人中心,进行修改密码和个人信息管理。用户管理模块允许管…...

Nacos 中使用了哪些缓存?缓存的目的是什么?是如何实现的?
Nacos 在服务端和客户端都广泛的使用了缓存机制,下面着重介绍一下。 一、 Nacos 服务端缓存 (Server-Side Caching) Nacos 服务端缓存的主要目的是提高读取性能、降低对底层存储(数据库或磁盘文件)的压力,并加速对客户端请求的响…...

「GitHub热榜」AIGC系统源码:AI问答+绘画+PPT+音乐生成一站式
—零门槛搭建私有化AI内容工厂,源码开放商业落地指南 为什么全栈AIGC系统成为企业刚需? 1. 传统方案的致命缺陷 痛点 使用ChatGPTMidjourneyCanva 本全栈方案 工具割裂 需切换5平台 一个系统全搞定 成本 年费50万 一次部署永久免费 数据安全 …...
)
Dify LLM大模型参数(一)
深入了解大语言模型(LLM)的参数设置 模型的参数对模型的输出效果有着至关重要的影响。不同的模型会拥有不同的参数,而这些参数的设置将直接影响模型的生成结果。以下是 DeepSeek 模型参数的详细介绍: 温度(Tempera…...

快速使用工具Cursor
Cursor 是一款面向开发者的集成开发环境,用途如下: 代码编写:支持多语言,有语法高亮、智能补全与格式化功能。代码生成:能依据自然语言描述生成代码。协作开发:支持多人实时协作编辑项目。调试程序&#x…...

JVM之经典垃圾回收器
一、垃圾回收算法 1. 标记-清除(Mark-Sweep) 步骤: 标记:遍历对象图,标记所有存活对象。清除:回收未被标记的垃圾对象。 特点:简单,但会产生内存碎片。 2. 标记-复制(…...

【“星瑞” O6 评测】—NPU 部署 face parser 模型
前言 瑞莎星睿 O6 (Radxa Orion O6) 拥有高达 28.8TOPs NPU (Neural Processing Unit) 算力,支持 INT4 / INT8 / INT16 / FP16 / BF16 和 TF32 类型的加速。这里通过通过官方的工具链进行FaceParsingBiSeNet的部署 1. FaceParsingBiSeNet onnx 推理 首先从百度网盘…...

hadoop的三大结构及其各自的作用
Hadoop 主要有三大核心组件,分别是 HDFS(Hadoop Distributed File System)、MapReduce 和 YARN,以下是它们各自的作用: HDFS(Hadoop Distributed File System) 存储数据:HDFS 是一个…...
)
免费将静态网站部署到服务器方法(仅支持HTML,CSS,JS)
原视频链接:把HTML免费部署到网站上,实现别人也能访问的教程来啦QAQ_哔哩哔哩_bilibili 注意:仅支持HTML、CSS、JS。不支持Vue等框架。 1.打开网站www.wordpress.org 点击红框按钮 点击红框按钮下载wordpress模板文件并解压。 将自己编写的…...

2、SpringAI接入ChatGPT与微服务整合
2、SpringAI接入ChatGPT与微服务整合 小薛博客AI 大模型资料 1、SpringAI简介 https://spring.io/projects/spring-ai Spring AI是一个人工智能工程的应用框架。其目标是将Spring生态系统的设计原则(如可移植性和模块化设计)应用于人工智能领域&#…...
)
6.7.图的深度优先遍历(英文缩写DFS)
树是特殊的图,没有回路的图就是树 BFS与DFS的区别在于,BFS使用了队列,DFS使用了栈 一.深度优先遍历: 1.树的深度优先遍历: 树的深度优先遍历分为先根遍历和后根遍历。 以树的先根遍历为例: 上述图片里…...

若依同步企业微信架构及ACTIVITI
企业微信配置 1.进入企业微信后台管理应用管理,新建应用 2.配置网页授权及JS-SDK 将验证文件下载到项目的pubilc下 启动项目 npm run dev 然后验证域名归属 3.配置企业可信IP 公网IP地址即可,仅此IP的服务可调用企业微信接口信息 4.构造域名回调域&a…...
)
PyTorch分布式训练调试方法(跟踪调用过程)
PyTorch分布式训练调试方法(跟踪调用过程) 背景 在分布式深度学习训练场景中,通信操作(如AllReduce、Send/Recv)和CUDA操作的时序问题往往难以调试。本工具通过以下方式提供调试支持: 拦截所有PyTorch张量操作并记录调用栈监控分布式通信操作的完整生命周期自动生成带时间…...

跟我学C++中级篇——内存异常的分析
一、内存问题引发的现象 在实际使用电脑过程中,经常会遇到电脑卡住了,鼠标和键盘也没反应。这时候儿会怎么办?其实此时打开任务管理器,就可以发现,有几种情况:一是CPU占用过高;二是IO占用过高&…...

HTML新标签与核心 API 实战
HTML5 新标签与核心 API 实战 引言 今天咱们来看看HTML5 新标签以及一些核心 API。 HTML5 的引入彻底改变了 Web 前端开发格局,尤其是其新增的多媒体和交互能力标签。对于前端开发者而言,理解并掌握 <video>、<audio>、<canvas> 和…...

vscode 红色波浪线问题
VSCode 红色波浪线问题终极解决方案 问题描述 在编写 C 项目时,CMake 编译通过但代码出现红色波浪线,常见问题: #include 提示找不到头文件枚举或类型名未定义成员函数或变量无法识别 这些是 VSCode 的 IntelliSense 配置问题,…...

类型补充,scan 和数据库管理命令
Redis 数据类型 stream stream 就是一个队列(阻塞队列) Redis 作为一个消息队列的重要支撑,属于是 list 中 blpop 和 brpop 的升级版本 geospatial 主要用于存储地理位置信息,并对存储的信息进行操作 存储一些点后,…...
 -Data Agent(数据分析智能体)开源资源汇总)
AI Agent系列(十) -Data Agent(数据分析智能体)开源资源汇总
AI Agent系列【十】 前言一、 Open Interpreter1.1 Open Interpreter的特点1.2 Open Interpreter的优势1.3 Open Interpreter的应用场景 二、DB-GPT2.1 核心能力2.2关键特性:2.3 系统架构 三、DeepBI3.1 特点 前言 DataAgent的能力本质上比较依赖大模型的自然语言转API/SQL/代…...

Vue3 + TypeScript中provide和inject的用法示例
基础写法(类型安全) typescript // parent.component.vue import { provide, ref } from vue import type { InjectionKey } from vue// 1. 定义类型化的 InjectionKey const COUNTER_KEY Symbol() as InjectionKey<number> const USER_KEY Sy…...

【国家能源集团生态协作平台-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

不确定与非单调推理的基本概念
前文我们讨论了建立在经典逻辑基础上的确定性推理,这是一种运用确定性知识进行的精确推理。同时,它又是一种单调性推理,即随着新知识的加人,推出的结论或证明了的命题将单调地增加。但是,人们通常是在信息不完善、不精确的情况下运用不确定性知识进行思维、求解问题的,推…...
高效记忆要点、知识体系、考点详解、、练习题并提供答案与解析)
系统架构设计师:计算机组成与体系结构(如CPU、存储系统、I/O系统)高效记忆要点、知识体系、考点详解、、练习题并提供答案与解析
计算机组成与体系结构高效记忆要点 从CPU、存储系统、I/O系统三大模块展开,结合高频考点与记忆技巧,有助于系统化掌握核心知识点。 一、CPU结构与工作原理 1. CPU的组成 核心组件: 运算器(ALU) :负责算术…...
操作)
FreeSWITCH中SIP网关(Gateway)操作
freeswitch是一款简单好用的VOIP开源软交换平台。 以下是一篇关于FreeSWITCH中SIP网关(Gateway)操作的技术指南,基于提供的官方文档内容整理: 一、网关生命周期管理 1. 创建新SIP Profile并启动 FreeSWITCH支持多SIP Profile&…...

构建自动翻译工作流:技术与实践
一、引言 制药行业客户迫切需要一种翻译解决方案,以解决公司内部多样化的翻译难题。他们需要的不仅是提升翻译效率和准确性的工具,更希望能够保持文档的原始格式。我们观察到客户的需求广泛,包括多语言办公文件、研究文档和药品报批文件等&a…...
)
在pycharm中搭建yolo11分类检测系统--PyQt5学习(二)
第二部分 测试本地pycharm通过程序连接远程服务器autodl 模型的推理需要借助远程服务器autodl,但是界面的运行是在pycharm中,我的设想是按钮调用一个py文件就好了。 1. 本地运行PyQt5界面。 2. 当需要载入权重时,通过SSH连接到AutodL服务…...

汽车行驶工况特征参数:从“速度曲线”到“驾驶DNA”的硬核解码
作为新能源汽车行业的从业者,你是否曾困惑于这些问题: 为什么同一款电动车,不同用户的实际续航差异高达30%?如何精准量化驾驶行为对电池寿命的影响?车企标定的“NEDC续航”与真实路况差距的根源是什么? 这…...

dify本地部署,docker-plugin_daemon-1启动不了,一直报错
解决办法,修改这两个配置,然后重启 进入源代码目录,docker文件夹下 docker compose down docker compose up -d https://github.com/langgenius/dify/issues/17677...

2025 年第十五届 MathorCup 数学应用挑战赛 A 题:汽车风阻预测
A 题:汽车风阻预测 在空气动力学领域,空气阻力对汽车以及航空航天工业中载具的 性能和效率有着至关重要的影响。以往的研究表明,预测这种阻力需 要借助先进的工业仿真软件进行大规模流体力学模拟仿真,而该模拟 过程不仅算法复杂…...

AI Agents系列之AI代理架构体系
1. 引言 智能体架构是定义智能体组件如何组织和交互的蓝图,使智能体能够感知其环境、推理并采取行动。本质上,它就像是智能体的数字大脑——集成了“眼睛”(传感器)、“大脑”(决策逻辑)和“手”(执行器),用于处理信息并采取行动。 选择正确的架构对于构建有效的智能…...

使用Java动态数据生成PDF报告:简化您的报告导出流程
在当今的数据驱动世界中,能够快速且有效地将数据转化为可视化的报告是一项宝贵的技能。无论是商业分析、项目管理还是学术研究,PDF报告都是分享和存档信息的理想格式。在这篇博客中,我们将探讨如何使用Java编程语言结合iText库来动态生成包含…...

Sqlite3交叉编译全过程
Sqlite3交叉编译全过程 一、概述二、下载三、解压四、配置五、编译六、安装七、验证文件类型八、移植8.1、头文件sqlite3.h8.2、动态链接库移植8.3、静态态链接库移植 九、验证使用9.1. 关键函数说明 十、触发器使用十一、sqlite表清空且恢复id值十二、全文总结 一、概述 SQLi…...

Qt QThread 两种线程管理方法
在 Qt 中,QThread 有两种常见的用法,分别对应不同的线程管理模型。这两种方法各有优缺点,适用于不同的场景: 1. 子类化 QThread(继承 QThread,重写 run() 方法) 这是传统的线程用法,类似于 Java 或 C++ 标准库中的线程模型。通过继承 QThread 并重写 run() 方法,将需…...

React 中如何获取 DOM:用 useRef 操作非受控组件
📌 场景说明 在写 React 的时候,通常我们是通过“受控组件”来管理表单元素,比如用 useState 控制 <input> 的值。 但有些时候,控制的需求只是临时性的,或者完全不需要重新渲染组件,这时候直接访问…...

GoogleCodeUtil.java
Google动态验证码实现 GoogleCodeUtil.java package zwf;import java.io.UnsupportedEncodingException; import java.net.URLEncoder; import java.nio.charset.StandardCharsets; import java.security.SecureRandom;/** https://mvnrepository.com/artifact/commons-codec/…...

Hutool之DateUtil:让Java日期处理变得更加简单
前言 在Java开发中,日期和时间的处理是一个常见问题。为了简化这个过程,许多开发者会使用第三方工具包,如Hutool。Hutool是一个Java工具包,提供了许多实用的功能,其中之一就是日期处理。日期时间工具类是Hutool的核心包…...

解锁古籍中的气候密码,探索GPT/BERT在历史灾害研究中的前沿应用;气候史 文本挖掘 防灾减灾;台风案例、干旱案例、暴雨案例
历史灾害文献分析方法论的研究,是连接过去与未来的关键桥梁。通过对古籍、方志、档案等非结构化文本的系统性挖掘与量化分析,不仅能够重建千年尺度的灾害事件序列(如台风、洪旱等),弥补仪器观测数据的时空局限性&#…...

DeepSeek-R3、GPT-4o 与 Claude-3.5-Sonnet 全面对比:性能、应用场景与技术解析
随着大模型技术的迅猛发展,国产模型正逐渐崭露头角,尤其是DeepSeek-R3的发布,更是在AI技术社区中引起广泛关注。而与此同时,国际领先的GPT-4o和Claude-3.5-Sonnet也在不断迭代升级,持续刷新业界对AI能力的认知。下文将…...

智能翻译播放器,让无字幕视频不再难懂
打工人们你们好!这里是摸鱼 特供版~ 今天给大家带来一款超牛的黑科技——Splayer,完全免费的智能翻译播放器,让你轻松看懂无字幕视频! 推荐指数:★★★★★ 软件简介 Splayer 是一款完全免费的智能翻译播放器&#…...

快手本地生活2024年GMV同增200%,“新线城市+AI”将成增长引擎
4月17日,“新线大市场,AI新机遇”快手本地生活2025聚力大会在沈阳召开。 会上,快手高级副总裁、本地生活事业部负责人笑古在聚力大会上表示,“新线城市AI”将成为快手本地生活的增长引擎。 据「TMT星球」了解,2024年…...

第七篇:系统分析师第三遍——1、2章
目录 一、目标二、计划三、完成情况四、意外之喜(最少2点)1.计划内的明确认知和思想的提升标志2.计划外的具体事情提升内容和标志 五、总结 一、目标 通过参加考试,训练学习能力,而非单纯以拿证为目的。 1.在复习过程中,训练快速阅读能力、掌…...