自动驾驶系列—GLane3D: Detecting Lanes with Graph of 3D Keypoints
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 —— 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
- 1. 背景介绍
- 2. 相关工作
- 2.1. 二维车道检测
- 2.2. 三维车道检测
- 3. 方法
- 3.1 模型概述
- 3.2 特殊几何下的 PV 到 BEV 投影
- 3.3 多关键点估计
- 3.4 关键点连接预测
- 3.5 匹配与损失函数
- 3.6 从图中提取车道线
- 4. 实验
- 4.1 数据集
- 4.2 评估指标
- 4.3 实现细节
- 4.4 消融实验
- 4.5 OpenLane 结果
- 4.6 Apollo 结果
- 4.7 跨数据集评估
- 5. 结论
1. 背景介绍
Öztürk H İ, Kalfaoğlu M E, Kilinc O. GLane3D: Detecting Lanes with Graph of 3D Keypoints[J]. arXiv preprint arXiv:2503.23882, 2025.
🚀以上学术论文翻译由ChatGPT辅助。
在三维空间中实现准确且高效的车道线检测,对于自动驾驶系统至关重要,其中鲁棒的泛化能力是 3D 车道检测算法的首要要求。
考虑到全球车道结构的巨大差异,要实现高度的泛化能力尤其具有挑战性,因为算法必须能够准确识别各种不同的车道线模式。
传统的自顶向下方法严重依赖于从训练数据集中学习车道特征,往往难以应对具有未见属性的车道结构。
为了解决这一泛化能力的局限,我们提出了一种方法,首先检测车道的关键点,然后预测它们之间的顺序连接,以构建完整的三维车道线。
每个关键点对于维持车道连续性都是关键的,我们通过允许相邻网格使用偏移机制预测同一个关键点,从而对每个关键点生成多个候选提议。
我们引入 PointNMS 来去除重复的候选关键点,减少 BEV(鸟瞰图)图中的冗余,从而降低连接预测带来的计算开销。
我们的模型在 Apollo 和 OpenLane 数据集上均超越了之前的最新方法,展现了更高的 F1 分数。
尤其是当使用 OpenLane 数据集训练的模型在 Apollo 数据集上评估时,展示出相比以往方法更强的泛化能力。
稳健的 3D 车道线检测对于自动驾驶中的多种关键功能至关重要,例如车道保持、车道偏离预警和轨迹规划。
然而,车道检测方法在复杂场景下常常表现不佳。尽管部分系统采用了 LiDAR 或多传感器配置,但由于成本效益,纯视觉方案(仅使用摄像头)在车道线检测中越来越受到青睐。
目前的一大挑战在于如何准确检测 3D 车道边界,这对于安全导航至关重要,并为路径规划和车辆控制提供了关键信息。
从历史上看,车道线检测主要依赖于二维方法,包括基于分割的 [4, 6, 13, 25, 26, 29, 44, 49, 52],基于锚点的 [10, 15, 34, 36, 43, 50],以及基于关键点的方法 [9, 12, 32, 41, 45]。
为了将这些 2D 检测扩展到 3D 空间,研究者尝试了逆投影的方法;但这种方式由于缺乏深度信息,难以准确表示车道线的真实三维结构。
另一种变通方法 [46] 是在投影前进行深度估计,但这需要极其精确的深度数据和完美的二维分割结果。
最近,一些端到端的 3D 车道检测方法 [2, 5, 22, 28] 出现,使用前视摄像头图像作为输入,成为一种有前景的解决方案。
这些方法通常通过逆透视映射(IPM)或 Lift-Splat-Shoot(LSS)方法将透视视角的特征投影到鸟瞰图(BEV)。
另一类方法则将 3D 车道锚点投影到透视图中,预测必要的偏移后再进行重投影。
无论是二维还是三维空间中的车道检测,主要有两种思路:
- 自顶向下的基于实例的方法 [2, 16, 22, 28, 37, 50],直接预测完整的车道实例;
- 自底向上的方法,检测每个车道组件(如关键点),随后通过后处理将其组合成完整车道线 [32, 41, 42]。
将像素分割为车道和背景通常比直接预测复杂参数的整条车道线更容易。
这种差异增强了自底向上方法的泛化能力,使其在面对未见过的场景时依然能检测出车道片段,而自顶向下方法在面对新型车道类型时则可能表现不佳。
但另一方面,自底向上方法在如何将检测到的关键点聚合为连贯车道方面存在挑战。
例如,[42] 采用基于关键点特征的聚类进行后处理;[41] 则基于关键点指向公共车道起点的方向来进行分组;而 [32] 使用迭代的关键点关联逐步构建车道。
为简化关键点在后处理阶段的聚合问题,我们与其他自底向上方法不同地将车道检测形式化为:
- 在预测的有向图中定位关键点,并
- 预测它们之间的顺序连接,
从而可通过最短路径算法在起点和终点关键点之间提取完整车道。
准确检测每个车道关键点至关重要,漏检关键点将导致车道线断裂。为应对这一问题,我们为每个车道上的目标关键点在 d x dx dx 范围内生成多个候选关键点,并施加微小偏移来精确其位置。
引入冗余关键点虽降低了漏检概率,但同时也带来了计算成本的增加。为控制这一权衡,我们引入了 PointNMS 操作,仅保留最强的关键点,消除冗余。
我们的主要贡献如下:
-
我们提出了 GLane3D,一种基于关键点的 3D 车道检测方法。
它通过关键点之间的有向连接预测来实现高效的车道提取。
通过生成多个关键点候选,我们提高了检测召回率。
PointNMS 算法选择最强候选点,减少了歧义和计算开销。 -
使用逆透视映射(IPM)结合自定义的 BEV 位置,在前视图中计算采样点,
替代使用均匀分布的 BEV 位置,减少了自车附近区域的稀疏性,
缓解了远处区域的饱和问题。 -
得益于其创新的设计,GLane3D 展现出极强的泛化能力。
我们在跨数据集测试中验证了这一点:在 OpenLane[2] 上训练的模型在 Apollo[5] 上表现良好,
展示了 GLane3D 相比以往方法更强的泛化能力。 -
仅使用摄像头的 GLane3D 方法在 OpenLane[2] 和 Apollo[5] 两个数据集上都超过了当前最先进方法,
在 OpenLane 所有测试类别中均表现出色。
GLane3D 在摄像头+激光雷达融合设置下也取得了最高的 F1 得分。
此外,它在帧率(FPS)上也优于其他模型。
2. 相关工作
2.1. 二维车道检测
尽管二维车道检测已经取得了显著进展,但二维检测结果与现实应用中所需的精确三维位置之间,仍存在明显的差距。
二维车道检测方法大致可分为以下四类:
-
基于分割的方法 [4, 6, 13, 25, 26, 29, 44, 49, 52]:
通过在透视图中分割出车道线区域,然后经过后处理来获得完整车道实例。 -
基于锚点的方法 [10, 15, 34, 36, 43, 50]:
使用预定义的锚点(如线段锚点)来回归与目标之间的相对偏移量。
另一类锚点方法是基于行的锚点(row-based anchors) [17, 30, 31, 48],按行将像素分类为不同的车道。 -
基于曲线的方法 [3, 18, 20, 38–40]:
预测多项式参数来拟合车道曲线,利用车道的先验知识来提升预测精度。 -
基于关键点的方法 [9, 12, 32, 41, 45]:
先估计车道关键点的位置,再将这些点聚合成完整车道线,建模更加灵活。
聚合方式有多种:如使用全局点预测 [41],或结合全局和局部预测 [45],也有方法根据几何关系预测邻近点 [32]。
这些方法通常还包含一个额外步骤,如热图提取,以便更有效地匹配关键点。
2.2. 三维车道检测
为了获取精确的三维车道位置信息,三维车道检测方法通常从前视图(Front View, FV)图像中进行估计。
将前视图特征投影到鸟瞰图(Bird’s Eye View, BEV)空间,使得三维车道检测成为可能,如 [2, 5, 14, 27, 28] 所示。
三维车道检测中的投影方式主要分为两类:
-
基于 Lift-Splat-Shoot(LSS)方法 [21, 28]:
从前视图中直接学习深度估计,部分工作中使用监督深度估计 [21, 28]。 -
基于逆透视映射(IPM)方法 [2, 5, 14]:
将前视图投影到 BEV 空间后进行处理。
另外,也有方法无需特征投影,直接从前视图中预测 3D 车道点位置 [22, 23],其思想类似于 PETR [19] 中的车道和点查询机制。
此外,还有方法将锚点车道线投影到三维空间中,然后回归偏移量,无需进行特征投影 [8]。
一些方法尝试隐式学习 3D 投影过程,而不是显式的 FV 到 BEV 的转换,但在摄像头位置变化时往往表现不佳。
三维车道信息也可通过结合二维车道预测与密集深度估计获取 [46],或通过直接将二维预测投影到三维空间实现 [5]。
将前视图特征投影到 BEV 空间,使得可以利用已有的二维方法来进行三维车道检测:
-
基于锚点的方法 [2, 14, 21]:
从锚点车道线回归横向偏移量,以获得目标车道线。 -
基于曲线的方法 [1, 11, 27, 28]:
直接预测曲线的参数进行拟合,LaneCPP [28] 更是引入物理先验来调控学习到的参数。 -
基于关键点的方法:
BEVLaneDet [42] 使用以 BEV 网格中心为锚点的关键点,通过回归目标车道,再结合学习到的嵌入进行关键点分组。
将车道检测视为多点目标检测会限制模型的泛化能力,因为模型可能在遇到未见过的车道布局时表现不佳。
相比之下,关键点方法将车道检测视为局部结构的检测与组装,能有效提升泛化能力。
无论是 2D 还是 3D 空间中的关键点方法,通常都通过以下方式实现聚合:
- 基于聚类的后处理,
- 基于局部几何偏移的预测,
- 或两者结合。
GLane3D 方法在此基础上更进一步:
- 通过估计关键点之间的顺序连接关系,
- 并应用 PointNMS 来去除冗余关键点,
- 以实现高效且结构清晰的车道线组装。
3. 方法
GLane3D 检测三维关键点 k i ∈ K k_i \in K ki∈K,其中 k i = ( x i , y i , z i ) k_i = (x_i, y_i, z_i) ki=(xi,yi,zi), i = 1 , 2 , … , S i = 1, 2, \dots, S i=1,2,…,S,并预测一个邻接矩阵 A ∈ R S × S A \in \mathbb{R}^{S \times S} A∈RS×S,其中 A [ i ] [ j ] A[i][j] A[i][j] 表示关键点 k i k_i ki 和 k j k_j kj 之间存在连接的概率。
我们根据由公式 (1) 提取出的有向连接集合 C C C 构建有向图 G G G,其中预测关键点集合 K K K 来自模型输出。
通过这个有向图 G G G,车道实例可以被简单地提取出来。
C = { ( k i , k j ) ∣ A [ i ] [ j ] > t a } . (1) C = \{(k_i, k_j) \mid A[i][j] > t_a\}. \tag{1} C={(ki,kj)∣A[i][j]>ta}.(1)
预测过程基于将前视图(Frontal View, FV)特征 F F V F_{FV} FFV 投影到鸟瞰图(BEV)空间后的特征图 F B E V ∈ R c × H b × W b F_{BEV} \in \mathbb{R}^{c \times H_b \times W_b} FBEV∈Rc×Hb×Wb,该特征图通过逆透视映射(IPM)从输入图像 I ∈ R 3 × H × W I \in \mathbb{R}^{3 \times H \times W} I∈R3×H×W 提取。
3.1 模型概述
该模型使用锚点 a i , j ∈ R H b × W b × 2 a_{i,j} \in \mathbb{R}^{H_b \times W_b \times 2} ai,j∈RHb×Wb×2,其中 a i , j = ( x i , j , y i , j ) a_{i,j} = (x_{i,j}, y_{i,j}) ai,j=(xi,j,yi,j),每个锚点 a i , j a_{i,j} ai,j 对应特征 f i , j = F B E V [ i , j ] f_{i,j} = F_{BEV}[i, j] fi,j=FBEV[i,j],如图 1 所示。
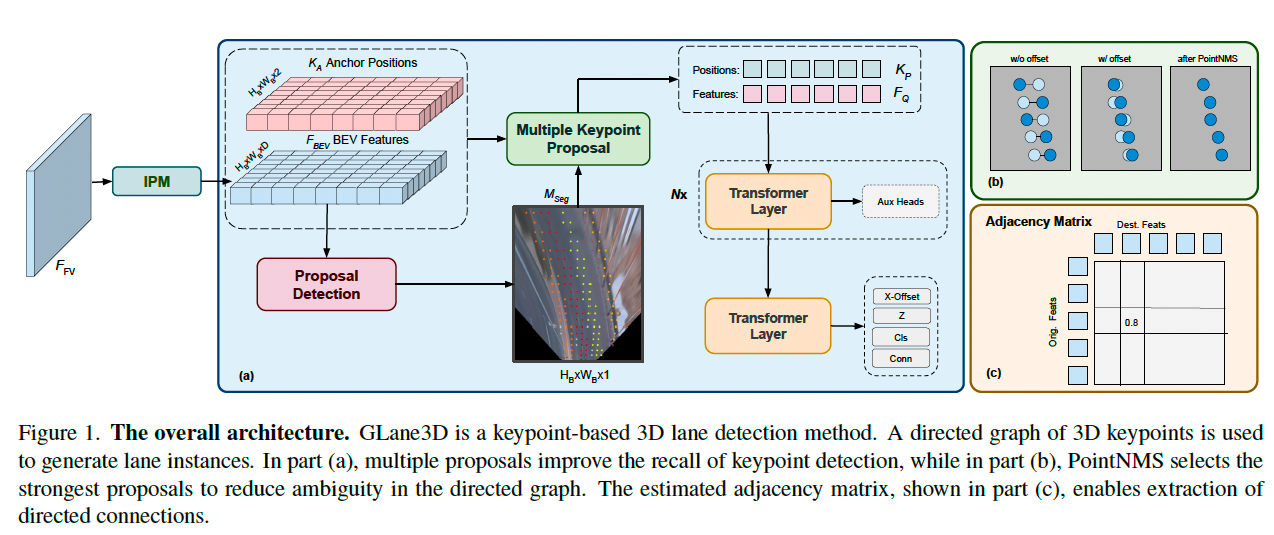
模型初始步骤中预测前景/背景分割图 M s e g ∈ R H b × W b × 1 M_{seg} \in \mathbb{R}^{H_b \times W_b \times 1} Mseg∈RHb×Wb×1。提议检测模块从中选出前 N N N 个得分最高的锚点作为候选关键点集合 K P K_P KP。
在自底向上的方法中,关键点对车道预测至关重要,若缺失某个关键点,可能导致车道线被断裂。
为避免此问题,GLane3D 中的提议检测模块会从锚点中选择多个候选关键点,如图 2a 所示,候选点在目标车道线的左右 d x d_x dx 范围内。
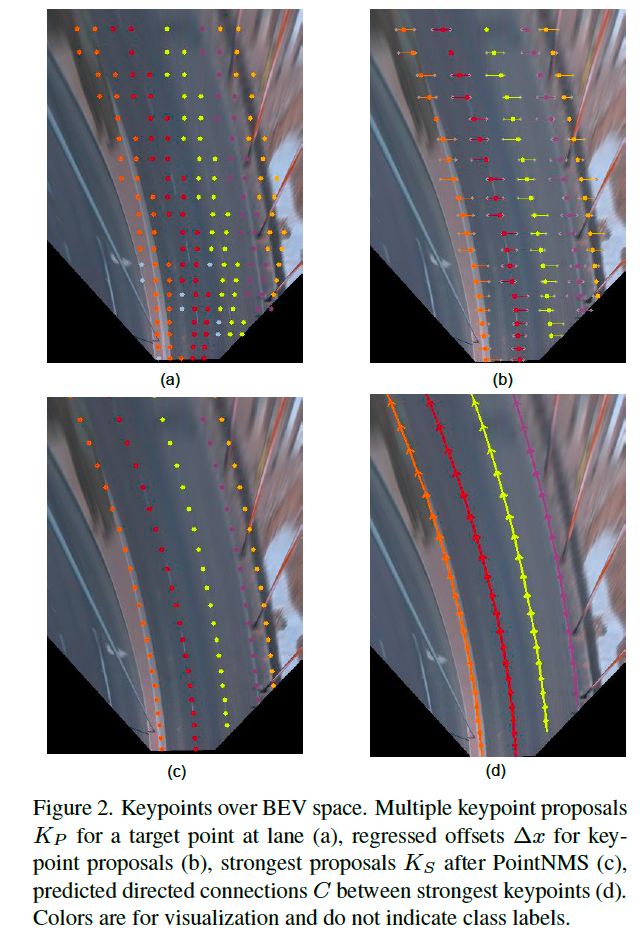
通过预测多个候选点,可显著减少漏检关键点的可能性。这些候选关键点随后会通过预测的横向偏移 Δ x \Delta x Δx 对齐到目标车道线,如图 2b 所示。
由于每个关键点是独立预测的,因此还需额外预测关键点之间的有向连接来形成车道线。在后处理阶段,通过追踪这些连接来提取完整车道。
为减少连接预测的计算开销,使用 PointNMS 操作,从 N N N 个候选点中保留 S S S 个置信度最高的关键点,其他低置信度的被丢弃。
连接头(relation head)在这 S S S 个关键点上运行,并输出邻接矩阵 A A A。
3.2 特殊几何下的 PV 到 BEV 投影
逆透视映射(IPM)将前视图特征 F P V F_{PV} FPV 投影到 BEV 空间,即将 BEV 空间的位置投影回 FV 空间,通过投影矩阵确定对应采样位置。
GLane3D 使用在 BEV 空间中的锚点位置 K A H b × W b × 2 K^{H_b \times W_b \times 2}_A KAHb×Wb×2 来计算其在前视图中的对应位置。
若 BEV 中锚点是等距均匀分布的,则在投影至 FV 时,近距离区域的投影点稀疏,而远处则密集,如图 3a 所示。
为使近距离区域在前视图中具有更密集的点,我们自定义锚点分布方式,使得越靠近 ego 车的区域,其锚点间距越小,且每一行锚点数量固定,得到如图 3c 的效果。
更多几何设计细节详见补充材料。

3.3 多关键点估计
GLane3D 会为车道线上的每个目标关键点预测多个候选点,如图 2a。
将被选中的锚点对应的特征向量组成 F Q F_Q FQ,如下式所示:
F Q = F B E V [ x i , y i ] , k i ∈ K P N × 2 . (2) F_Q = F_{BEV}[x_i, y_i], \quad k_i \in K^{N \times 2}_P. \tag{2} FQ=FBEV[xi,yi],ki∈KPN×2.(2)
这些查询特征 F Q F_Q FQ 被送入 Transformer 块,包含自注意力和交叉注意力层。交叉注意力中的 memory 输入为 F B E V F_{BEV} FBEV。
为提升效率,在交叉注意力中使用 deformable attention 机制。
我们使用 4 个 MLPs 来分别预测:
- 分类得分 S C L S S_{CLS} SCLS
- 横向偏移 Δ x \Delta x Δx
- 高度 z z z
- 连接特征向量 f c f_c fc
每个候选点 k i ∈ K P k_i \in K_P ki∈KP 都会产生以上预测结果。
训练过程中还加入辅助头,对 Transformer 中间层的特征进行额外监督,以增强稳定性。
应用横向偏移 Δ x \Delta x Δx 后,候选点会被对齐至目标关键点,如图 2b。
为了去除冗余且保持高召回率,我们使用 PointNMS 操作:在相距 d x d_x dx 范围内的候选点中,仅保留分类得分最大的点:
max ( s i ) , s i ∈ S C L S \max(s_i), \quad s_i \in S_{CLS} max(si),si∈SCLS
最终得到去重后的关键点集合 K S K_S KS,如图 2c 所示。
3.4 关键点连接预测
我们从邻接矩阵 A A A 中提取关键点之间的有向连接集合 C C C,如公式 (1),用于车道提取。
关键点的位置信息对连接预测至关重要,因此将位置编码 P E PE PE 和特征向量拼接,如下:
p e i = P E ( x i + Δ x , y i ) (3) pe_i = PE(x_i + \Delta x, y_i) \tag{3} pei=PE(xi+Δx,yi)(3)
f c ′ = concat ( p e i , f c ) (4) f'_c = \text{concat}(pe_i, f_c) \tag{4} fc′=concat(pei,fc)(4)
然后对所有特征 F C = ( f c ′ 0 , . . . , f c ′ S ) FC = (f'_c0, ..., f'_cS) FC=(fc′0,...,fc′S) 输入两个 MLP,分别生成:
- 起始点特征 F o r i g ∈ R S × d F_{orig} \in \mathbb{R}^{S \times d} Forig∈RS×d
- 终止点特征 F d e s t ∈ R S × d F_{dest} \in \mathbb{R}^{S \times d} Fdest∈RS×d
我们将 F o r i g F_{orig} Forig reshape 成 F o r i g ′ ∈ R S × 1 × d F'_{orig} \in \mathbb{R}^{S \times 1 \times d} Forig′∈RS×1×d, F d e s t F_{dest} Fdest reshape 成 F d e s t ′ ∈ R 1 × S × d F'_{dest} \in \mathbb{R}^{1 \times S \times d} Fdest′∈R1×S×d。
两者逐元素乘法后得到形状为 R S × S × d \mathbb{R}^{S \times S \times d} RS×S×d 的张量,随后通过一个线性层和 sigmoid 激活函数得到邻接矩阵 A A A:
C = σ ( F C ( F s r c ′ ⊙ F t g t ′ ) ) (5) C = \sigma(F_C(F'_{src} \odot F'_{tgt})) \tag{5} C=σ(FC(Fsrc′⊙Ftgt′))(5)
3.5 匹配与损失函数
我们使用 Hungarian 算法将预测关键点与真实关键点进行匹配。
由于不是所有 K P K_P KP 中的点都会参与连接预测,因此需两次应用该算法:
- 第一次用于所有候选关键点 K P K_P KP
- 第二次用于 PointNMS 后的强关键点 K S K_S KS
匹配过程考虑了关键点之间的距离和分类概率的相似度。
我们还设置限制,禁止匹配纵向 y y y 坐标差距过大的点对。
对于 K P K_P KP,我们复制真实关键点 n n n 次以确保匹配充足;而对于去重后的 K S K_S KS,无需复制。
整体损失函数如下:
L t o t a l = w k p L k p + w r L r + w c n L c n + w c L c (6) L_{total} = w_{kp} L_{kp} + w_r L_r + w_{cn} L_{cn} + w_c L_c \tag{6} Ltotal=wkpLkp+wrLr+wcnLcn+wcLc(6)
其中:
- L c n L_{cn} Lcn 是连接头的 Focal Loss
- L r L_r Lr 是偏移 Δ x \Delta x Δx 和高度 z z z 的 L1 损失
- L k p L_{kp} Lkp 是关键点提议的二元交叉熵
- L c L_c Lc 是分类损失
损失权重 w ∗ w_* w∗ 由模型学习,如 [7] 所提出。
3.6 从图中提取车道线
我们从预测关键点 K S = ( k 0 , … , k S ) K_S = (k_0, \dots, k_S) KS=(k0,…,kS) 中提取车道,每个关键点 k i = ( x i , Δ x , y i , z ) k_i = (x_i, \Delta x, y_i, z) ki=(xi,Δx,yi,z)。
首先识别起始点和终止点:
- 起始点:无入边,有出边
- 终止点:有入边,无出边
判断条件如下:
∑ j = 1 S C j i = 0 且 ∑ j = 1 S C i j > 0 (7) \sum_{j=1}^{S} C_{ji} = 0 \quad \text{且} \quad \sum_{j=1}^{S} C_{ij} > 0 \tag{7} j=1∑SCji=0且j=1∑SCij>0(7)
∑ j = 1 S C j i > 0 且 ∑ j = 1 S C i j = 0 (8) \sum_{j=1}^{S} C_{ji} > 0 \quad \text{且} \quad \sum_{j=1}^{S} C_{ij} = 0 \tag{8} j=1∑SCji>0且j=1∑SCij=0(8)
车道提取过程就是在起点和终点之间寻找路径。
我们采用 Dijkstra 最短路径算法,以 1 − A 1 - A 1−A 作为边权引导路径选择。由于已应用 PointNMS 去除重复关键点,提取复杂度大幅降低。
最后,车道类别和置信度通过关键点的分类得分确定。
4. 实验
我们在两个不同的数据集上评估模型:现实世界数据集 OpenLane 和合成数据集 Apollo。这两个数据集都提供了三维空间中的车道线真值标注和相机参数。
4.1 数据集
OpenLane [2] 是一个从 Waymo Open Dataset [35] 构建的大规模数据集,共包含 20 万帧图像,其中 15 万帧用于训练集,5 万帧用于测试集,采样自 1000 个场景。该数据集包含 88 万条车道标注,全部位于三维空间中。测试集的场景被划分为八个不同类别:上下坡、弯道、极端天气、夜间、交叉口、合并与分裂等。一个包含 300 个场景的子集,称为 Lane300,专用于消融实验。
Apollo [5] 是一个较小的合成数据集,包含 10,500 帧图像,来自高速公路、城市和乡村环境。数据集分为三个子集:标准场景、稀有场景和视觉变化场景。
4.2 评估指标
我们采用 Gen-LaneNet [5] 提出的评估指标,适用于两个三维数据集。这些指标计算纵向 y y y 轴方向上 0–100 米范围内等间距点的欧几里得距离。
一条预测车道与真值车道之间的匹配成功定义为:在纵向 y y y 方向上至少有 75% 的点落在指定距离阈值范围内。默认距离阈值为 1.5 米;由于该阈值相对较大,我们还使用了 0.5 米阈值作为补充评估。
4.3 实现细节
对于 Lite 和 Base 模型,我们使用 384 × 720 384 \times 720 384×720 的输入尺寸;Large 模型使用 512 × 960 512 \times 960 512×960 的输入尺寸。
BEV 投影的尺寸分别为 56 × 32 56 \times 32 56×32、 56 × 64 56 \times 64 56×64 和 72 × 128 72 \times 128 72×128。
最大提议关键点数 S S S 为 Lite 和 Base 模型设为 256,重复次数 n = 2 n=2 n=2;Large 模型设为 384,重复次数 n = 4 n=4 n=4。
我们使用 Adam 优化器,学习率为 3 × 1 0 − 4 3 \times 10^{-4} 3×10−4,采用 warm-up 和 cosine annealing 策略。
训练在 OpenLane v1.2 上进行 24 个 epoch,在 Apollo 上训练 300 个 epoch,batch size 为 16。
4.4 消融实验
如表 2 所示,单独使用 PointNMS 可提升性能;但仅使用多关键点提议反而会降低 F1 分数。
然而,当 PointNMS 与多关键点提议方法联合使用时,检测性能得到了提升。
仅使用多关键点提议造成性能下降的原因是连接图中的歧义性:因为 GLane3D 要求每个关键点仅有一个前驱和一个后继,在相同位置存在多个关键点会引入歧义。
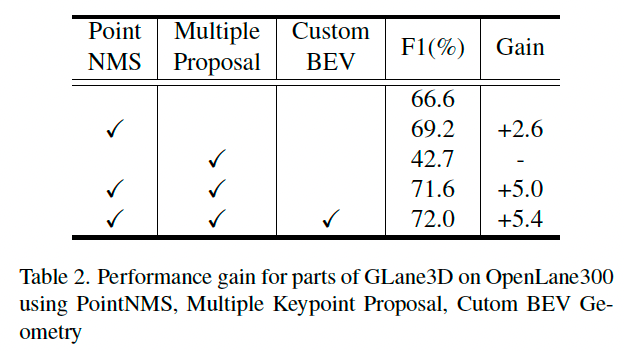
PointNMS 能解决这一问题,并减少计算开销。使用 IPM 中的自定义 BEV 几何也提升了性能,特别是在靠近 ego 车的位置提升了点密度。
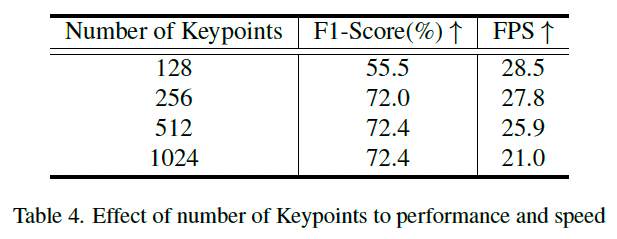
表 4 显示,增加关键点数量 S S S 的性能提升在超过 256 个节点后趋于饱和。超过这个最优点后,性能增益变小,但额外的关键点会增加计算量并降低 FPS。
这表明关键点提议头中前景/背景分离模块对模型速度有显著影响。
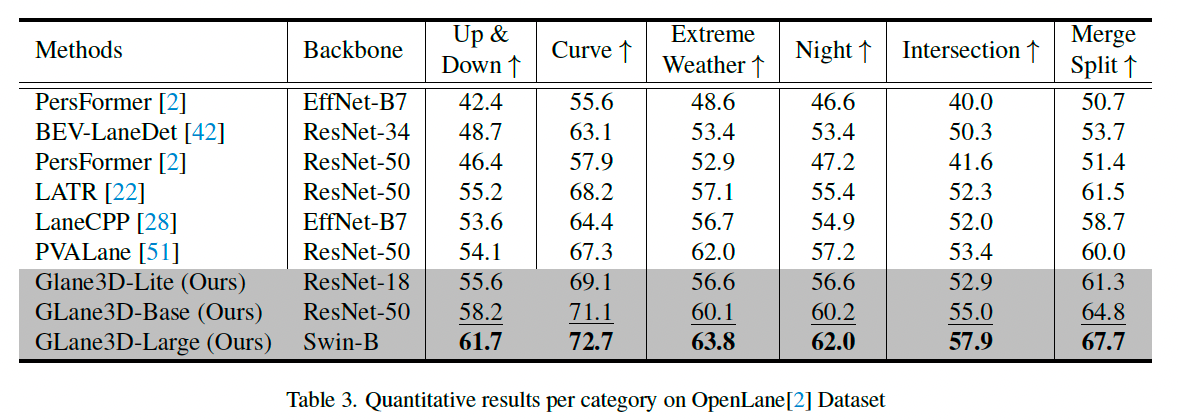
4.5 OpenLane 结果
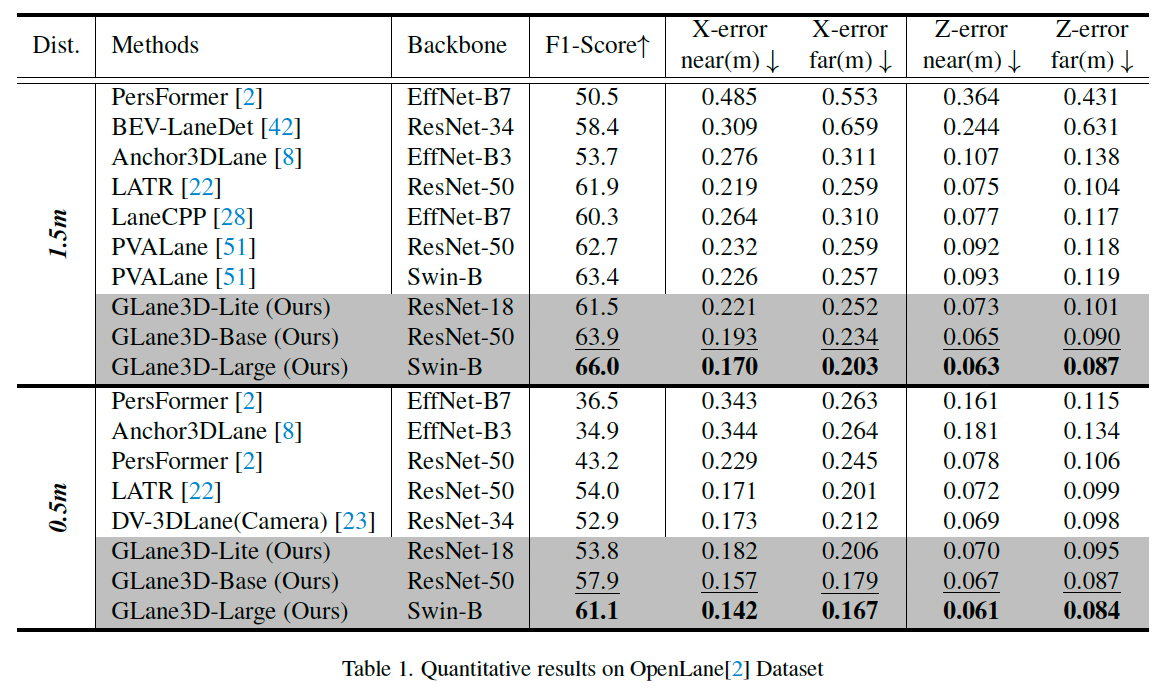
如表 1 所示,GLane3D 模型在 F1 分数方面持续优于此前的最先进方法(SoTA)。
使用 ResNet-50 主干时,相比于基线提升了 1.2%;使用 Swin-B 主干时,GLane3D 相比 PVALane 提升了 2.6%。
在定位精度方面,GLane3D 在 x x x 和 z z z 维度上都具有更高精度。
即使在严格的 0.5 米匹配阈值下,GLane3D 仍表现出色,展现出强鲁棒性。
从表 3 的类别分析中可以看出,GLane3D 在所有场景类别上均优于 SoTA 方法。
例如,在上下坡场景中,IPM 投影有助于模型学习非平坦路面,提高了对不同地形的适应性。
关键点表示方法的灵活性也使 GLane3D 在预测弯道方面提升了 3.8%,在合并分裂和交叉口场景分别提升了 4.8% 和 1.6%。
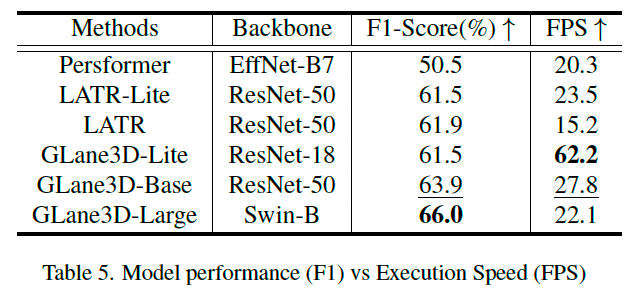
此外,GLane3D 在精度和效率之间也实现了良好平衡。
GLane3D-Lite 模型达到 62.2 FPS,F1 分数超过大多数模型,非常适合实时应用(见表 5)。
同时,GLane3D-Base 相比 LATR-Lite 提高了 2.4% 的 F1 分数,帧率相近。
该效率降低了车载部署的计算成本,提高了汽车应用的普适性和可达性。
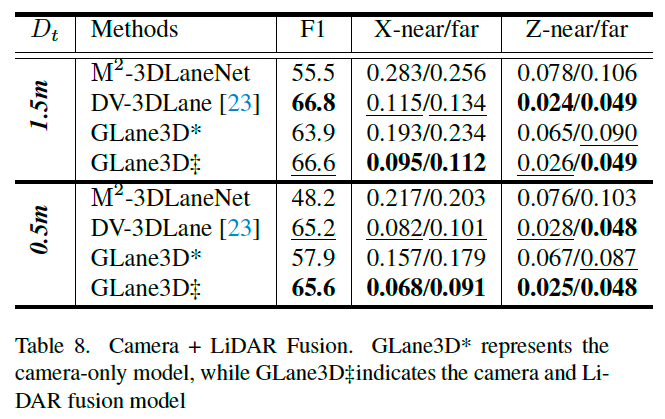
尽管近年来激光雷达成本下降,但仍远高于摄像头。因此,GLane3D 更侧重于基于摄像头的处理,而非复杂的融合方式。
我们也训练和评估了融合摄像头+雷达输入的 GLane3D 版本,以展示其适应性。
在雷达处理方面,使用了 SECOND [47] 作为雷达特征提取器,并将其与 IPM 特征结合。
尽管未采用先进融合技术,GLane3D 仍在 F1 分数上略优于先前模型(表 8),说明其在不同输入配置下的强鲁棒性和通用性。
4.6 Apollo 结果
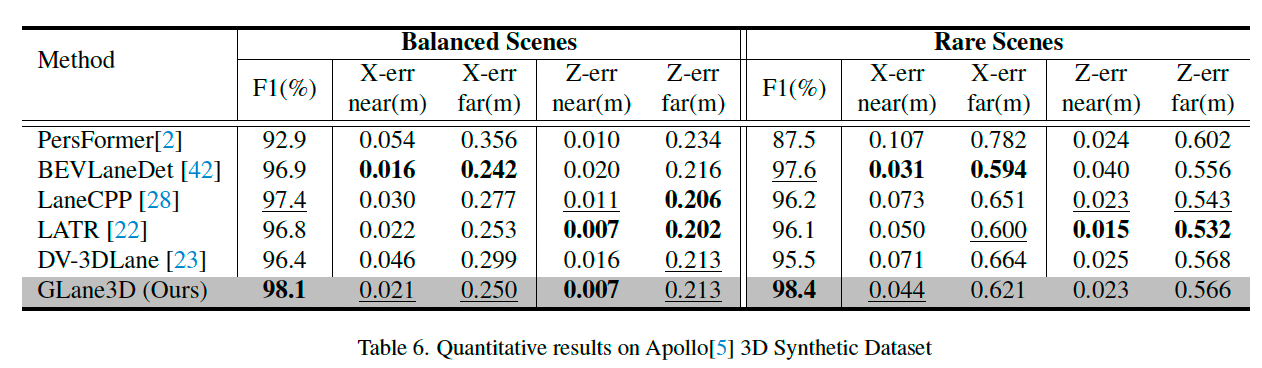
表 6 展示了在 Apollo 数据集上的量化结果。
GLane3D 在标准场景和稀有场景中 F1 分数均优于其他方法。
尽管定位误差趋于饱和,但 GLane3D 在大多数场景中定位误差仍更低。
更多详细结果见补充材料。
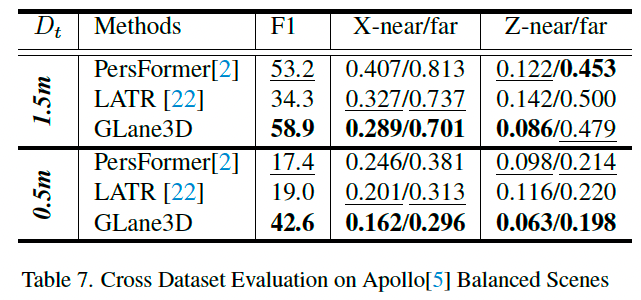
4.7 跨数据集评估
为评估模型的泛化能力,我们在 OpenLane 上训练模型,并在 Apollo 上测试。
这种方法可以验证模型在不同相机位置(俯仰、横滚、偏航及 x , y , z x,y,z x,y,z 位置)和未知环境中的推理能力,尤其是在未见过的车道结构下。
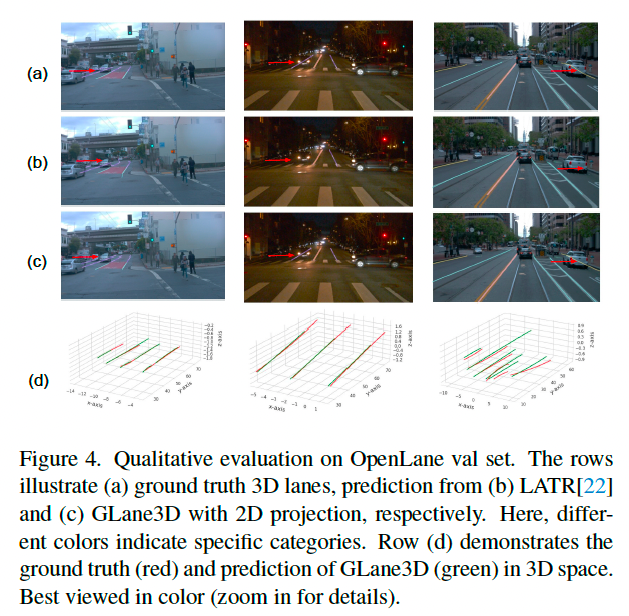
如表 7 所示,GLane3D 的泛化性能(包括 F1 分数和定位误差)明显优于其他方法。
与 LATR 相比,GLane3D 的车道预测更加平滑,表明自上而下方法在泛化能力上不如本方法(见图 5)。
另一个原因是 LATR 缺乏显式的 FV 到 BEV 投影模块。
PersFormer 在跨数据集推理中缺乏定位精度,尤其是在近距离区域。
由于 F1 分数计算使用的是 1.5 米阈值,因此表 7 中的性能并未受到严重影响。

5. 结论
本文提出了 GLane3D,一种基于关键点的三维车道检测方法,采用有向连接估计进行高效车道提取。
通过多提议关键点和 PointNMS 增强检测,减少了计算开销。
我们采用自定义的 BEV 锚点结合逆透视映射(IPM),提升了靠近 ego 车位置的采样密度,缓解远距离区域的稀疏问题。
跨数据集评估验证了 GLane3D 的强泛化能力。
GLane3D 在 OpenLane 和 Apollo 数据集上均超越当前最先进方法,在摄像头+雷达融合设置下也取得了最高 F1 分数。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 “Stay Hungry, Stay Foolish” —— 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!

相关文章:

自动驾驶系列—GLane3D: Detecting Lanes with Graph of 3D Keypoints
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...

【Amazon 工具】在MacOS本地安装 AWS CLI、kubectl、eksctl工具
文章目录 安装 AWS CLI安装 kubectl安装 eksctl参考链接 安装 AWS CLI 创建访问密钥安装或更新 AWS CLI curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg AWSCLIV2.pkg -target /要验证 Shell 是否可以在 $PAT…...

基于GTID的主从复制
MySQL主从复制实战指南(基于二进制日志)-CSDN博客 二、基于GTID的主从复制 基于 GTID 方式:全局事务标示符,自mysql5.6版本开启的新型复制方式。 GTID的组成:server_uuid:序列号 UUID:每个m…...
程编程——(8)多进程的冲突问题)
linux多线(进)程编程——(8)多进程的冲突问题
前言 随着时间的推移,共享内存已经在修真界已经沦为禁术。因为使用这种方式沟通的两人往往会陷入到走火入魔的状态,思维扭曲。进程君父子见到这种情况,连忙开始专研起来,终于它们发现了共享内存存在的问题: 进程间冲…...

数据结构——八大排序算法
排序在生活中应用很多,对数据排序有按成绩,商品价格,评论数量等标准来排序。 数据结构中有八大排序,插入、选择、快速、归并四类排序。 目录 插入排序 直接插入排序 希尔排序 选择排序 堆排序 冒泡排序 快速排序 hoare…...

线性代数 | 知识点整理 Ref 1
注:本文为 “线性代数 | 知识点整理” 相关文章合辑。 因 csdn 篇幅合并超限分篇连载,本篇为 Ref 1。 略作重排,未整理去重。 图片清晰度限于引文原状。 如有内容异常,请看原文。 线性代数知识汇总 Arrow 于 2016-11-27 16:27:5…...

Docker 设置镜像源后仍无法拉取镜像问题排查
#记录工作 Windows系统 在使用 Docker 的过程中,许多用户会碰到设置了国内镜像源后,依旧无法拉取镜像的情况。接下来,记录了操作要点以及问题排查方法,帮助我们顺利解决这类问题。 Microsoft Windows [Version 10.0.27823.1000…...
 多项式回归 (Polynomial Regression))
线性回归 (Linear Regression) 多项式回归 (Polynomial Regression)
目录 线性回归 (Linear Regression)单变量线性回归 (Univariate linear regression)代价函数 (Cost function)梯度下降 (gradient descent) 及公式由来梯度下降的变体Quiz多类特征 (Multiple features)多元线性回归 (Multiple linear regression)向量化 (Vectorization)正规方程…...

AI在能源消耗管理及能源效率提升中的核心应用场景及技术实现
以下是 AI在能源消耗管理及能源效率提升中的核心应用场景及技术实现,分领域详细说明: 1. 实时能源监测与异常检测 AI技术应用: 物联网(IoT) 传感器数据采集:实时收集设备、建筑或工厂的能耗数据ÿ…...

dumpsys--音频服务状态信息
Audio相关的信息获取指令: dumpsys media.audio_flinger dumpsys media.audio_policy dumpsys audio media.audio_flinger dumpsys media.audio_flinger 用于获取 AudioFlinger 服务的详细状态信息。 1. 命令作用 该命令输出当前系统的 音频设备状态、活跃音频流…...

JavaScript模块化开发:CommonJS、AMD到ES模块
引言 在Web开发的早期阶段,JavaScript代码通常被编写在一个庞大的文件中或分散在多个脚本标签里,这种方式导致了全局变量污染、依赖关系难以管理、代码复用困难等问题。随着Web应用日益复杂,模块化编程成为了解决这些问题的关键。本文将带您…...

面试情景题:企业内部系统如何做微前端拆分,如何通信?
在前端开发领域,技术的演进总是伴随着业务需求的复杂化与规模化而不断向前推进。近年来,微前端(Micro Frontends)作为一种全新的架构理念,逐渐成为解决大型前端应用复杂性的重要手段。与传统的单体前端应用不同&#x…...
:相机预览功能(ArkTS))
OpenHarmony Camera开发指导(五):相机预览功能(ArkTS)
预览是在相机启动后实时显示场景画面,通常在拍照和录像前执行。 开发步骤 创建预览Surface 如果想在屏幕上显示预览画面,一般由XComponent组件为预览流提供Surface(通过XComponent的getXcomponentSurfaceId方法获取surfaceid)&…...

鸿蒙API15 “一多开发”适配:解锁黄金三角法则,开启高效开发新旅程
一、引言 在万物互联的时代浪潮中,鸿蒙操作系统以其独特的 “一多开发” 理念,为开发者打开了一扇通往全场景应用开发的新大门。“一多开发”,即一次开发,多端部署 ,旨在让开发者通过一套代码工程,就能高效…...
、ReAct(推理与行动) 和 多模态AI 的详细解析,包括三者的定义、工作原理、应用场景及协同关系)
RAG(检索增强生成)、ReAct(推理与行动) 和 多模态AI 的详细解析,包括三者的定义、工作原理、应用场景及协同关系
以下是 RAG(检索增强生成)、ReAct(推理与行动) 和 多模态AI 的详细解析,包括三者的定义、工作原理、应用场景及协同关系: 一、RAG(Retrieval-Augmented Generation) 1. 核心原理 …...

网络安全知识点2
1.虚拟专用网VPN:VPN用户在此虚拟网络中传输私网流量,在不改变网络现状的情况下实现安全,可靠的连接 2.VPN技术的基本原理是利用隧道技术,对传输报文进行封装,利用VPN骨干网建立专用数据传输通道,实现报文…...

DS-SLAM 运动一致性检测的源码解读
运动一致性检测是Frame.cc的Frame::ProcessMovingObject(const cv::Mat &imgray)函数。 对应DS-SLAM流程图Moving consistency check的部分 把这个函数单独摘出来,写了一下对两帧检测,查看效果的程序: #include <opencv2/opencv.hpp…...
)
VSTO幻灯片退出播放(C#模拟键盘鼠标的事件)
今天遇到了个问题,幻灯片放映到某一页时需要退出播放,没有找到对应的方法,所以想到了直接通过ESC键可以退出,所以模拟执行了一下ESC键,发现真的可以。在此记录一下。 C# 模拟键盘鼠标的事件整理 1、模拟键盘2、模拟鼠标…...
)
Echarts柱状图斜线环纹(图形的贴花图案)
单独设置 <!--此示例下载自 https://echarts.apache.org/examples/zh/editor.html?cbar-stack&codePYBwLglsB2AEC8sDeAoWszGAG0iAXMmuhgE4QDmFApqYQOQCGAHhAM70A0x6L7ACsAjQwtQqhIkwATxDUGbABaMAJsADu9HrAC-xHd3TZqNaCvEHiFcuaKTjAMzAMAzAFIu28hUXPY9ABYPQxIAI2AwTABbV…...

前端页面效果收集
文章目录 数字雨元素融化动画电子签名共享屏幕 数字雨 <canvas id"matrix"></canvas> <script>const canvas document.getElementById(matrix);const ctx canvas.getContext(2d);canvas.width window.innerWidth;canvas.height window.innerH…...

ASP.NET Core Web API 配置系统集成
文章目录 前言一、配置源与默认设置二、使用步骤1)创建项目并添加配置2)配置文件3)强类型配置类4)配置Program.cs5)控制器中使用配置6)配置优先级测试7)动态重载配置测试8)运行结果示…...

【hadoop】基于hive的B站用户行为大数据分析
1.需求分析 b站现在积累有用户数据和视频列表数据,为了配合市场部门做好用户运营工作,需要对b站的用户行为进行分析,其具体需求如下所示: 统计b站视频不同评分等级(行转列)的视频数。 统计上传b站视频最多的…...

如何搭建符号执行环境并跑通第一个测试样例
0.如题 我使用的是verilator和klee进行符号执行的学习,目前还处于起步阶段,起步阶段除了要了解符号执行的定义和作用之外就是环境的搭建了,没想到搭建环境这一步就浪费了很多时间,主要问题出在按照官方的步骤进行搭建的时候&…...

基于 Django 进行 Python 开发
基于 Django 进行 Python 开发涉及多个方面的知识点,以下为你详细介绍: 1. Django 基础 项目与应用创建 借助django-admin startproject project_name来创建新的 Django 项目。利用python manage.py startapp app_name创建新的应用。项目结构 理解项目各文件和目录的作用,像…...

【含文档+PPT+源码】基于微信小程序的非遗文化黄梅戏宣传平台的设计与实现
课程目标: 教你从零开始部署运行项目,学习环境搭建、项目导入及部署,含项目源码、文档、数据库、软件等资料 课程简介: 本课程演示的是一款基于微信小程序的非遗文化黄梅戏宣传平台的设计与实现,主要针对计算机相关…...
)
使用DDR4控制器实现多通道数据读写(八)
一、 本章概括 在之前的章节已经详细介绍了DDR4的AXI协议,并实现了对DDR4简单的读写操作。这一章节来建立单通道的256位数据的读写,并放出工程框架,说明整体设计思路。 二、 工程框架 三、 设计思路 DDR内存通常用于大容量数据存储…...
问题解析)
Oracle 处理“不允许长度为0的列”(ORA-01723)问题解析
错误原因 当使用 CREATE TABLE ... AS SELECT 或创建物化视图时,若查询结果中的某列值为空字符串()或隐式 NULL 且未显式指定数据类型,Oracle 无法推断该列的长度和类型,从而抛出 ORA-01723: zero-length columns…...

燕山大学计算机网络之Java实现TCP数据包结构设计与收发
觉得博主写的好,给博主点点免费的关注吧! 目录 摘要.................................................................................................................... 4 前言.............................................................…...

Linux操作系统学习之---进程状态
目录 明确进程的概念: Linux下的进程状态: 虚拟终端的概念: 见一见现象: 用途之一 : 结合指令来监控进程的状态: 和进程强相关的系统调用函数接口: getpid()和getppid(): fork(): fork函数创建子进程的分流逻辑: 进程之间具有独立性: 进程中存在的写时拷贝: 见一见进程状态…...

Oracle 12.1.0.2补丁安装全流程
第一步,先进行备份 tar -cvf u01.tar /u01 第二步,更新OPatch工具包 根据补丁包中readme信息汇总提示的信息,下载对应版本的OPatch工具包,本次下载的版本为: p6880880_122010_Linux-x86-64.zip opatch版本为最新的…...

第19章:基于efficientNet实现的视频内容识别系统
目录 1.efficientNet 网络 2. 猫和老鼠 3. QT推理 4. 项目 1.efficientNet 网络 本章做了一个视频内容识别的系统 本文选用的模型是efficientNet b0版本 EfficientNet 是 Google 团队在 2019 年提出的一系列高效卷积神经网络模型,其核心思想是通过复合缩放&…...

【Java面试系列】Spring Cloud微服务架构中的分布式事务解决方案与Seata框架实现原理详解 - 3-5年Java开发必备知识
【Java面试系列】Spring Cloud微服务架构中的分布式事务解决方案与Seata框架实现原理详解 - 3-5年Java开发必备知识 引言 在微服务架构中,分布式事务是一个不可避免的挑战。随着业务复杂度的提升,如何保证跨服务的数据一致性成为了面试中的高频问题。本…...
和view(微信小程序专用组件)的主要区别体)
div(HTML标准元素)和view(微信小程序专用组件)的主要区别体
div(HTML标准元素)和view(微信小程序专用组件)的主要区别体现在以下方面: 一、应用场景与开发框架 适用平台不同 div是HTML/CSS开发中通用的块级元素,用于Web页面布局;view是微信小程序专…...

AI在多Agent协同领域的核心概念、技术方法、应用场景及挑战 的详细解析
以下是 AI在多Agent协同领域的核心概念、技术方法、应用场景及挑战 的详细解析: 1. 多Agent协同的定义与核心目标 多Agent系统(MAS, Multi-Agent System): 由多个独立或协作的智能体(Agent)组成ÿ…...

03_Americanas精益管理项目_StarRocks
文章目录 03_StarRocks(一)StarRocks简介1、什么是StarRocks【理解】1)概述2)适用场景2、系统架构【理解】1)系统架构图2)数据管理3、使用【熟悉】(二)表设计4、StarRocks表设计【理解】1)列式存储2)索引3)加速处理5、数据模型【掌握】5-1 明细模型1)适用场景2)创…...
)
CSS进度条带斑马纹动画(有效果图)
效果图 .wxml <view class"tb"><view class"tb-line" style"transform:translateX({{w%}})" /> </view> <button bind:tap"updateLine">增加进度</button>.js Page({data: {w:0,},updateLine(){this.…...

C++ static的使用方法及不同作用
在 C 里,static 是一个用途广泛的关键字,在不同场景下有不同含义,下面为你详细介绍: 1. 全局变量前的 static 当 static 用在全局变量前时,它会改变变量的链接属性。 默认全局变量:默认的全局变量具有外…...
)
CSS 美化页面(四)
一、浮动float属性 属性值描述适用场景left元素向左浮动,腾出右侧空间供其他元素使用,其他内容会围绕在其右侧。横向排列元素(如导航菜单)、图文混排布局。right元素向右浮动,腾出左侧空间供其他元素使…...

驱动-原子操作
前面 对并发与竞争进行了实验, 两个 app 应用程序之间对共享资源的竞争访问引起了数据传输错误, 而在 Linux 内核中, 提供了四种处理并发与竞争的常见方法: 分别是原子操作、 自旋锁、 信号量、 互斥体, 这里了解下原子…...

Flutter ListView 详解
ListView 是 Flutter 中用于构建滚动列表的核心组件,支持垂直、水平滚动以及复杂的动态布局。本文将深入解析其核心用法、性能优化策略和高级功能实现,助你打造流畅高效的列表界面。 一、基础篇:快速构建各类列表 1. 垂直列表(默…...

关于视频的一些算法内容,不包含代码等
视频算法: 视频降噪, 去除视频中的噪音,提高图像质量 工作原理: 时域降噪:利用相邻帧之间的相似性,通过平均或滤波来减少随机噪声。 空域降噪:在单帧内使用滤波器(高斯滤波器&am…...
颜色空间转换-----将 BGR 图像转换为 LUV 色彩空间函数BGR2LUV())
OpenCV 图形API(43)颜色空间转换-----将 BGR 图像转换为 LUV 色彩空间函数BGR2LUV()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将图像从BGR色彩空间转换为LUV色彩空间。 该函数将输入图像从BGR色彩空间转换为LUV。B、G和R通道值的传统范围是0到255。 输出图像必须是8位无符…...
: error: #67: expected a “}“)
keil报错 ..\..\Libraries\CMSIS\stm32f10x.h(298): error: #67: expected a “}“
报错原因: 通常是由于启动文件、头文件定义或驱动选择不一致导致的。以下是一些具体的解决方案,可以帮助你解决这个问题: 检查步骤: 1. 检查启动文件 确保你的启动文件与你的芯片型号相匹配。例如,如果你的芯片是S…...

图像预处理-添加水印
一.ROI切割 类似裁剪图片,但是原理是基于Numpy数组的切片操作(ROI数组切片是会修改原图数据的),也就是说这个“裁剪”不是为了保存“裁剪”部分,而是为了方便修改等处理。 import cv2 as cv import numpy as npimg cv.imread(../images/dem…...

扩展欧几里得算法【Exgcd】的内容与题目应用
1.简介 exgcd的目的是表示出二元一次不定方程的通解。 形式化地,exgcd算法就是输入a,b,c的值,返回一组x,y,满足 a x b y c axbyc axbyc。 2.1方程无整数解的情况 当 c 不能被 a ,b最小公倍…...

OpenCV day5
函数内容接上文:OpenCV day4-CSDN博客 目录 9.cv2.adaptiveThreshold(): 10.cv2.split(): 11.cv2.merge(): 12.cv2.add(): 13.cv2.subtract(): 14.cv2.multiply(): 15.cv2.divide(): 1…...

Spring DI 详解
学习过 IoC 后,就知道我们可以将对象交给 Spring 进行管理,但是我们在一个类会有若干属性,也就是这个类依赖于这若干个属性,那么我们就可以将交给 Spring 管理的对象注入到这个类中,这也就是依赖注入。 依赖注入有三种…...
)
解锁动态规划的奥秘:从零到精通的创新思维解析(9)
前言: 小编在前几日写了关于动态规划中的多状态dp的问题,此时小编将会讲述一个动态规划我们常常会遇到的一类问题——股票问题,股票问题就类似小编上一篇所讲述的粉刷房子的问题,可以通过一个二维的dp表来代替多个一维的dp表。买卖…...

redis 配置日志和数据存储位置
Redis配置日志和数据存储位置 介绍 Redis是一个开源的高性能键值存储数据库,常用于缓存、消息队列和实时分析等场景。在使用Redis时,我们需要配置日志和数据存储位置,以便更好地管理和监控Redis的运行状态。本文将介绍如何配置Redis的日志和数…...

STL详解 - stack与queue的模拟实现
目录 一、容器适配器 1. 什么是适配器模式 2. stack与queue的底层结构 3. deque的原理与缺陷 3.1 deque的原理 3.2 deque的缺陷 4. 为何选择deque作为默认底层容器 二、stack与queue的模拟实现 1. stack的实现 2. queue的实现 一、容器适配器 1. 什么是适配器模式 适…...