03_Americanas精益管理项目_StarRocks
文章目录
- 03_StarRocks
- (一)StarRocks简介
- 1、什么是StarRocks【理解】
- 1)概述
- 2)适用场景
- 2、系统架构【理解】
- 1)系统架构图
- 2)数据管理
- 3、使用【熟悉】
- (二)表设计
- 4、StarRocks表设计【理解】
- 1)列式存储
- 2)索引
- 3)加速处理
- 5、数据模型【掌握】
- 5-1 明细模型
- 1)适用场景
- 2)创建表
- 3)使用说明
- 5-2 聚合模型
- 1)适用场景
- 2)原理
- 3)创建表
- 4)使用说明
- 5-3 更新模型
- 1)适用场景
- 2)原理
- 3)创建表
- 4)使用说明
- 5-4 主键模型
- 1)适用场景
- 2)原理
- 3)创建表
- 4)使用说明
- 6、数据分布【熟悉】
- 6-1 StarRocks的数据分布方式
- 6-2 分区
- 1)时间函数表达式
- 2)列表达式分区(自v3.1)
- 6-3 分桶
- 如何选择分桶键
- 7、数据压缩【了解】
- 1)选择数据压缩算法
- 2)设置数据压缩算法
- 8、排序键和前缀索引【理解】
- 1)排序原理
- 2)选择排序列
- (三)查询数据湖(联邦查询)
- 9、Catalog【理解】
- 1)基本概念
- 2)案例
- (四)查询及优化
- 10、查询与优化【了解】
- (五)物化视图
- 11、同步物化视图【掌握】
- 12、异步物化视图【掌握】
- (六)数仓场景:即席查询案例
- 13、数仓场景:即席查询案例【实现】
- 1)场景介绍
- 2)方案架构
- 3)方案特点
- 4)操作流程
- 步骤一:创建MySQL源数据表
- 步骤二:创建StarRocks表
- 步骤三:将MySQL数据写入StarRocks
- 步骤四:验证数据
03_StarRocks
(一)StarRocks简介
1、什么是StarRocks【理解】
1)概述
StarRocks 是新一代极速全场景 MPP (Massively Parallel Processing) 数据库。
MPP,即大规模并行处理。MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总到一起得到最终的结果(跟Hadoop相似)。具有可伸缩性强、高可用、高性能等优势。
特点:
(1)MPP、向量化引擎、CBO优化器、物化视图,使查询速度遥遥领先
(2)支持实时数据分析
(3)StarRocks兼容MySQL协议,支持标准SQL语法
2)适用场景
StarRocks 可以满足企业级用户的多种分析需求,包括 OLAP多维分析、实时数据仓库、高并发查询、统一分析(联邦查询)。
2、系统架构【理解】
1)系统架构图
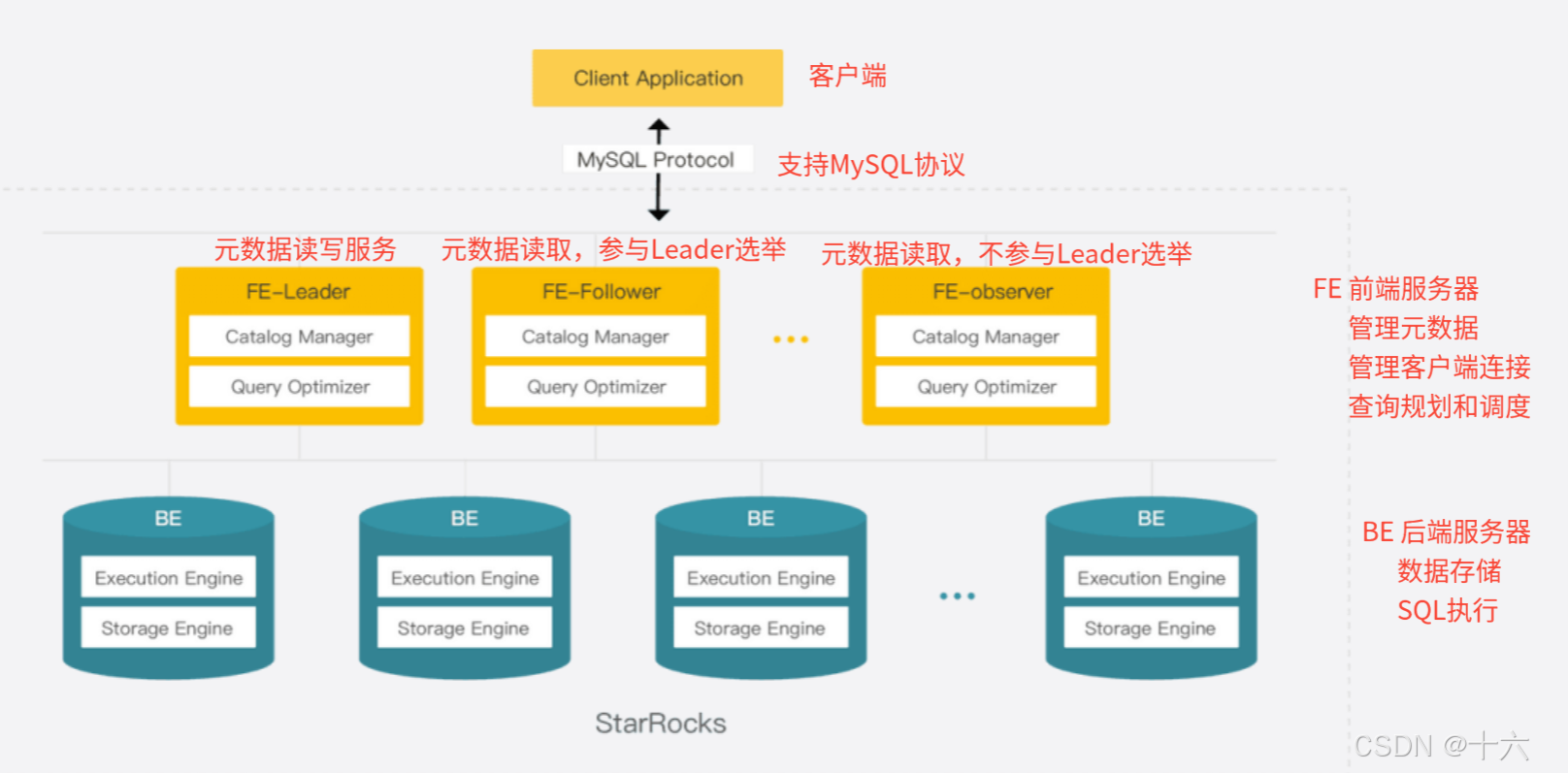
2)数据管理
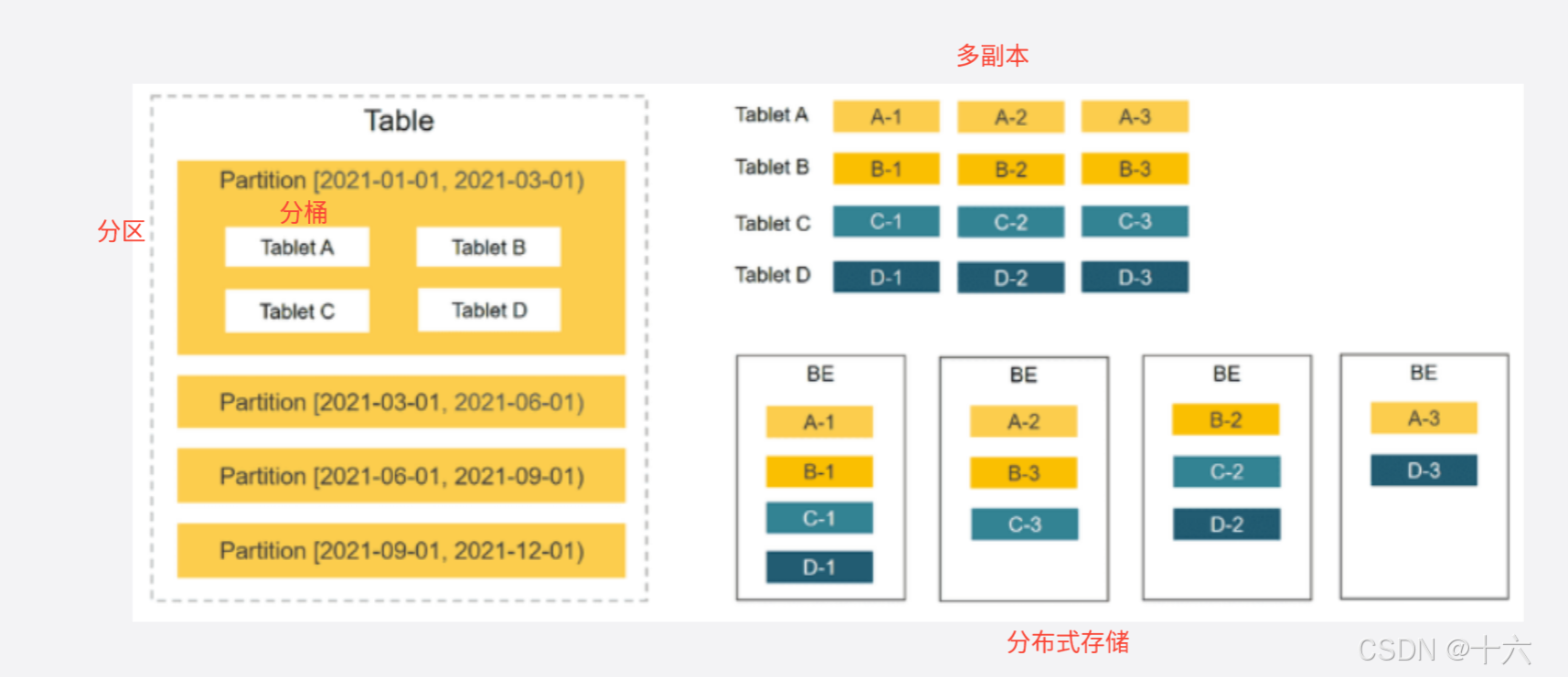
StarRocks 使用列式存储,采用分区分桶机制进行数据管理。
Tablet 是 StarRocks 中最小的数据管理单元。多个分桶可以增加数据读写的效率,扩展系统支持高并发的能力。
StarRocks可以做到无需停止服务,自动完成节点的增减
每个 Tablet 都会以多副本 (replica) 的形式存储在不同的 BE 节点中。多副本能够保证数据存储的高可靠以及服务的高可用【在具体工作中,一般保留2副本即可】
3、使用【熟悉】
启动:
cd /export/server/starrocks
./fe/bin/start_fe.sh --daemoncd /export/server/starrocks
./be/bin/start_be.sh --daemon
停止:
cd /export/server/starrocks
sh ./fe/bin/stop_fe.sh --daemoncd /export/server/starrocks
sh ./be/bin/stop_be.sh --daemon
web访问:
Starrocks-WebUI登入:192.168.88.161:8130
Starrocks-WebUI登入:用户名:root 密码:123456
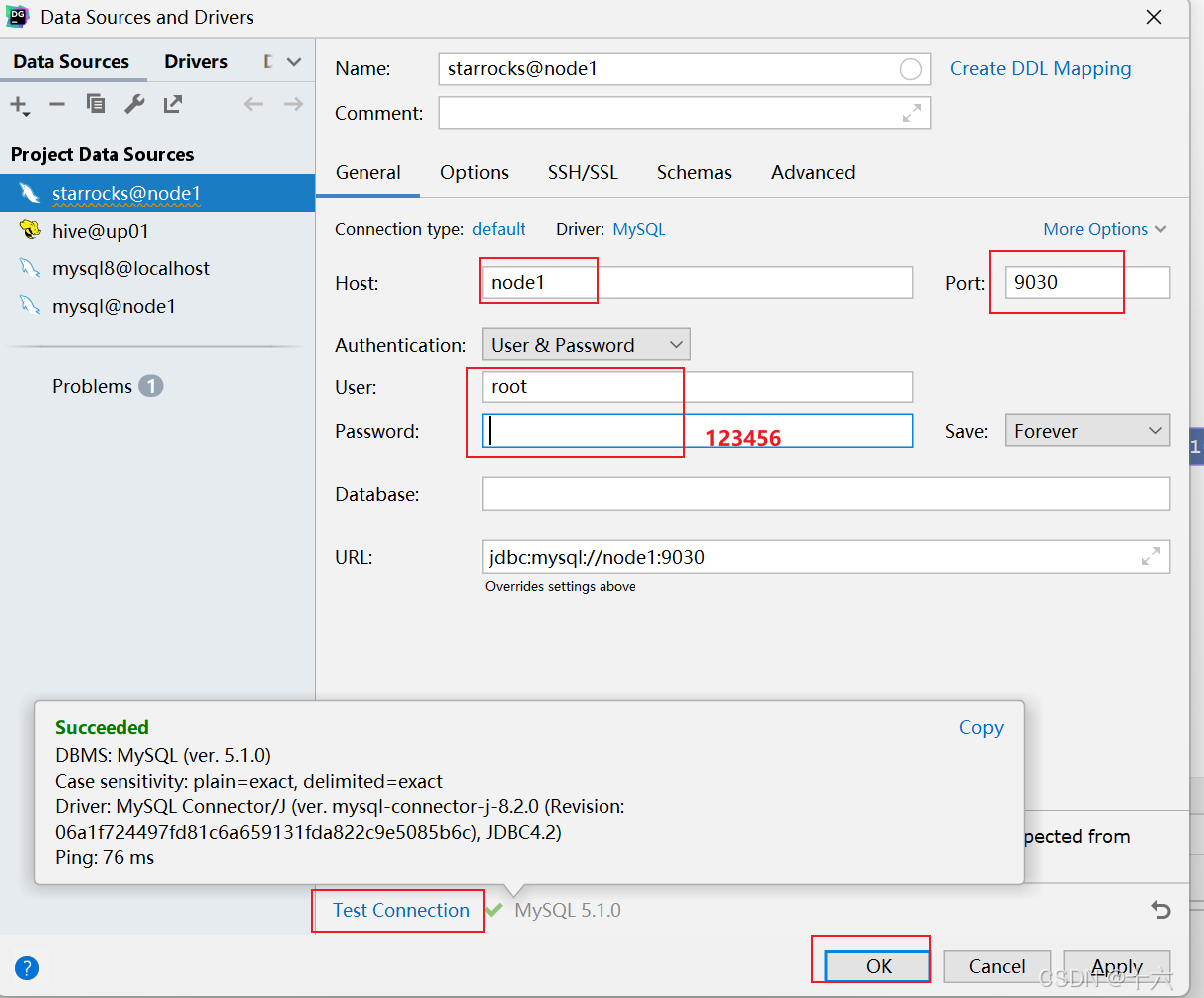
客户端访问:
mysql -h node1 -P9030 -uroot -p
123456
可以使用DataGrip等进行连接:
(二)表设计
4、StarRocks表设计【理解】
1)列式存储
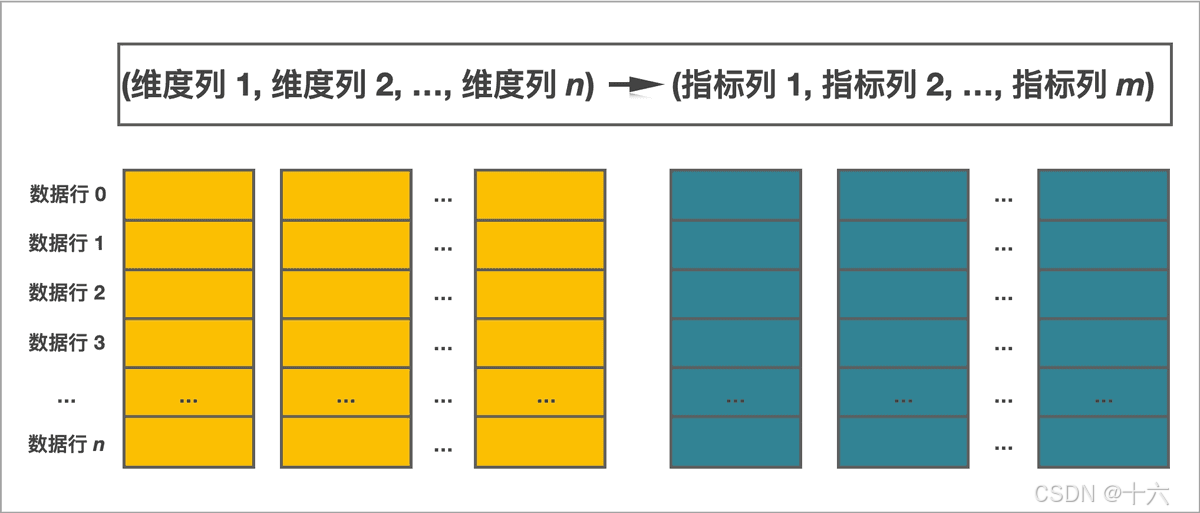
StarRocks 中的表由行和列构成。
在 StarRocks 中,表数据按列存储。
在 StarRocks 中,一张表的列可以分为维度列(也称为 Key 列)和指标列(也称为 Value 列)。
2)索引
StarRocks 通过前缀索引 (Prefix Index) 和列级索引,能够快速找到目标行所在数据块的起始行号。
StarRocks 表设计原理如下图所示。
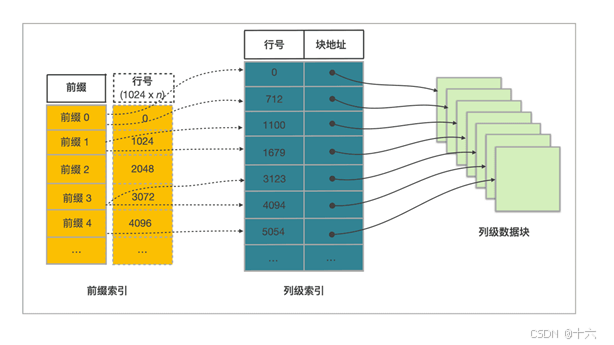
通过某行数据的维度列所构成的前缀查找该行数据的过程包含以下五个步骤:
- 先查找前缀索引表,获得逻辑数据块的起始行号。
- 查找维度列的行号索引,定位到维度列的数据块。
- 读取数据块。
- 解压、解码数据块。
- 从数据块中找到维度列前缀对应的数据项。
3)加速处理
- 聚合模型可以预先聚合value列
- 使用分区分桶切分数据
- 使用物化视图构建索引,加快查询效率
- 多种列级索引支持,加快查询
5、数据模型【掌握】
5-1 明细模型
明细模型是默认的建表模型,可以保留所有明细数据。
1)适用场景
- 适用于存储原始数据
- 查询方式灵活
- 数据不更新,只有追加
2)创建表
使用DUPLICATE KEY来指定排序键。
创建表时,支持定义排序键,使用DUPLICATE KEY指定。
示例:
例如,需要分析某时间范围的某一类事件的数据,则可以将事件时间(event_time)和事件类型(event_type)作为排序键。
CREATE TABLE IF NOT EXISTS test.detail (event_time DATETIME NOT NULL COMMENT "事件时间",event_type INT NOT NULL COMMENT "事件类型",user_id INT COMMENT "用户ID",device_code INT COMMENT "设备编码",channel INT COMMENT ""
)
DUPLICATE KEY(event_time, event_type)
DISTRIBUTED BY HASH(user_id)
PROPERTIES (
"replication_num" = "1"
);
注意
建表时必须使用 DISTRIBUTED BY HASH 子句指定分桶键,否则建表失败。
自 2.5.7 版本起,StarRocks 支持在建表和新增分区时自动设置分桶数量 (BUCKETS),无需手动设置分桶数量。
3)使用说明
- 排序键的相关说明:
- 在建表语句中,排序键必须定义在其他列之前。
- 排序键可以通过 DUPLICATE KEY 显式定义。本示例中排序键为 event_time 和 event_type。如果未指定,则默认选择表的前三列作为排序键。
- 明细模型中的排序键可以为部分或全部维度列。
5-2 聚合模型
==建表时,支持定义排序键和指标列,并为指标列指定聚合函数。当多条数据具有相同的排序键时,指标列会进行聚合。==在分析统计和汇总数据时,聚合模型能够减少查询时所需要处理的数据,提升查询效率。
1)适用场景
适用于分析统计和汇总数据。
在这些场景中,数据查询和导入,具有以下特点:
- 多为汇总类查询,比如 SUM、MAX、MIN等类型的查询。
- 不需要查询原始的明细数据。
- 旧数据更新不频繁,只会追加新的数据。
2)原理
从数据导入至数据查询阶段,聚合模型内部同一排序键的数据会多次聚合,最终返回合并后的数据。
例如,导入如下数据至聚合模型中,排序键为 Date、Country:
| Date | Country | PV |
|---|---|---|
| 2020.05.01 | CHN | 1 |
| 2020.05.01 | CHN | 2 |
| 2020.05.01 | USA | 3 |
| 2020.05.01 | USA | 4 |
在聚合模型中,以上四条数据会聚合为两条数据。这样在后续查询处理的时候,处理的数据量就会显著降低。
| Date | Country | PV |
|---|---|---|
| 2020.05.01 | CHN | 3 |
| 2020.05.01 | USA | 7 |
3)创建表
例如需要分析某一段时间内,来自不同城市的用户,访问不同网页的总次数。则可以将网页地址 site_id、日期 date 和城市代码 city_code 作为排序键,将访问次数 pv 作为指标列,并为指标列 pv 指定聚合函数为 SUM。
在该业务场景下,建表语句如下:
CREATE TABLE IF NOT EXISTS test.aggregate_tbl (site_id LARGEINT NOT NULL COMMENT "id of site",date DATE NOT NULL COMMENT "time of event",city_code VARCHAR(20) COMMENT "city_code of user",pv BIGINT SUM DEFAULT "0" COMMENT "total page views"
)
AGGREGATE KEY(site_id, date, city_code)
DISTRIBUTED BY HASH(site_id)
PROPERTIES (
"replication_num" = "1"
);
4)使用说明
-
排序键的相关说明:
-
在建表语句中,排序键必须定义在其他列之前。
-
排序键可以通过 AGGREGATE KEY 显式定义。
如果 AGGREGATE KEY 未包含全部维度列(除指标列之外的列),则建表会失败。
如果不通过 AGGREGATE KEY 显示定义排序键,则默认除指标列之外的列均为排序键。
-
排序键必须满足唯一性约束,必须包含全部维度列,并且列的值不会更新。
-
建议将频繁使用的过滤字段作为排序键
-
-
指标列:通过在列名后指定聚合函数,定义该列为指标列。一般为需要汇总统计的数据。
-
聚合函数:指标列使用的聚合函数。聚合模型支持的聚合函数,请参见 CREATE TABLE。常见的有SUM、MAX、MIN、REPLACE。
5-3 更新模型
建表时,支持定义主键和指标列,查询时返回主键相同的一组数据中的最新数据。能够更好地支撑实时和频繁更新的场景。
1)适用场景
实时和频繁更新的业务场景。不需要保留明细数据,也不需要进行预聚合,只需要保留最新的数据
2)原理
更新模型可以视为聚合模型的特殊情况,指标列指定的聚合函数为 REPLACE,返回具有相同主键的一组数据中的最新数据。
3)创建表
在电商订单分析场景中,经常按照日期对订单状态进行统计分析,则可以将经常使用的过滤字段订单创建时间 create_time、订单编号 order_id 作为主键,其余列订单状态 order_state 和订单总价 total_price 作为指标列。这样既能够满足实时更新订单状态的需求,又能够在查询中进行快速过滤。
在该业务场景下,建表语句如下:
CREATE TABLE IF NOT EXISTS test.update_orders (create_time DATE NOT NULL COMMENT "create time of an order",order_id BIGINT NOT NULL COMMENT "id of an order",order_state INT COMMENT "state of an order",total_price BIGINT COMMENT "price of an order"
)
UNIQUE KEY(create_time, order_id)
DISTRIBUTED BY HASH(order_id)
PROPERTIES (
"replication_num" = "1"
);
4)使用说明
- 主键的相关说明:
- 在建表语句中,主键必须定义在其他列之前。
- 主键通过 UNIQUE KEY 定义。
- 主键必须满足唯一性约束,且列的值不会修改。
- 设置合理的主键。
- 可以把经常过滤的字段作为unique key
- 在聚合操作中group by里的字段作为unique key
5-4 主键模型
主键模型支持分别定义主键和排序键。数据导入至主键模型的表时先按照排序键排序后存储。查询时返回主键相同的一组数据中的最新数据。
1)适用场景
主键模型适用于实时和频繁更新的场景。
不需要保留明细数据,也不需要进行预聚合,只需要保留最新的数据
2)原理
相比于更新模型,主键模型的元数据组织、读取、写入方式完全不同,不需要执行聚合操作,并且支持谓词和索引下推,极大地提高了查询性能。
更新模型使用 Merge-On-Read策略,而主键模型使用Delete+Insert策略。
区别:主键模型适合写少读多的场景【数据写入的同时,就做Delete+Insert操作了,所以写入效率相对较低,但是提前把数据处理好了,所以读的效率更高】。
更新模型适合写多读少的场景【数据都先写进来,我定期或在你读取的时候再合并,所以写的效率高】。
3)创建表
例如,需要按地域、最近活跃时间实时分析用户情况,则可以将表示用户 ID 的 user_id 列作为主键,表示地域的 address 列和表示最近活跃时间的 last_active 列作为排序键。建表语句如下:
CREATE TABLE IF NOT EXISTS test.primary_users (user_id bigint NOT NULL,name string NOT NULL,email string NULL,address string NULL,age tinyint NULL,sex tinyint NULL,last_active datetime,property0 tinyint NOT NULL,property1 tinyint NOT NULL,property2 tinyint NOT NULL,property3 tinyint NOT NULL
) PRIMARY KEY (user_id)
DISTRIBUTED BY HASH(user_id)
ORDER BY(`address`,`last_active`)
PROPERTIES ("replication_num" = "1","enable_persistent_index" = "true"
);
4)使用说明
-
主键相关的说明:
- 在建表语句中,主键必须定义在其他列之前。
- 主键通过 PRIMARY KEY 定义。
- 主键必须满足唯一性约束,且列的值不会修改。本示例中主键为 dt、order_id。
- 主键支持以下数据类型:BOOLEAN、TINYINT、SMALLINT、INT、BIGINT、LARGEINT、DATE、DATETIME、VARCHAR/STRING。并且不允许为 NULL。
- 分区列和分桶列必须在主键中。
-
通过 ORDER BY 关键字指定排序键,可指定为任意列的排列组合。
注意:如果指定了排序键,就根据排序键构建前缀索引;如果没指定排序键,就根据主键构建前缀索引。
- 支持使用 ALTER TABLE 进行表结构变更,但是存在如下注意事项:
- 不支持修改主键。
- 对于排序键,支持通过 ALTER TABLE … ORDER BY … 重新指定排序键。不支持删除排序键,不支持修改排序键中列的数据类型。
- 不支持调整列顺序。
总结:
| 模型类型 | 应用场景 | 建表方式 | 原理 |
|---|---|---|---|
| 明细模型 | 存储所有明细数据 | DUPLICATE KEY() | |
| 聚合模型 | 分析统计或汇总数据(只需要保留聚合之后的结果) | AGGREGATE KEY() | 相同key的数据进行聚合 |
| 更新模型 | 实时和频繁更新的业务场景,保留最新的数据==【写多读少】== | UNIQUE KEY() | Merge-on-Read的策略 |
| 主键模型 | 实时和频繁更新的业务场景,保留最新的数据==【写少读多】== | PRIMARY KEY() | Delete+Insert的策略 |
6、数据分布【熟悉】
6-1 StarRocks的数据分布方式
StarRocks 支持单独和组合使用数据分布方式。
| **说明:**除了常见的分布方式外, StarRocks 还支持了 Random 分布,可以简化分桶设置。 |
|---|
并且 StarRocks 通过设置分区 + 分桶的方式来实现数据分布。
- 第一层为分区:在一张表中,可以进行分区,支持的分区方式有表达式分区、Range 分区和 List 分区,或者不分区(即全表只有一个分区)。
- 第二层为分桶:在一个分区中,必须进行分桶。支持的分桶方式有哈希分桶和随机分桶。
| 数据分布方式 | 分区和分桶方式 | 说明 |
|---|---|---|
| Random 分布 | 随机分桶 | 一张表为一个分区,表中数据随机分布至不同分桶。该方式为默认数据分布方式。 |
| Hash 分布 | 哈希分桶 | 一张表为一个分区,对表中数据的分桶键值使用哈希函数进行计算后,得出其哈希值,分布到对应分桶。 |
| Range+Random 分布 | 表达式分区或者 Range 分区 + 随机分桶 | 表的数据根据分区列值所属范围,分布至对应分区。 同一分区的数据随机分布至不同分桶。 |
| Range+Hash 分布 | 表达式分区或者 Range 分区 + 哈希分桶 | 表的数据根据分区列值所属范围,分布至对应分区。 对同一分区的数据的分桶键值使用哈希函数进行计算,得出其哈希值,分布到对应分桶。 |
| List+Random 分布 | 表达式分区或者 List 分区 + 随机分桶 | 表的数据根据分区列值所属枚举值列表,分布至对应分区。 同一分区的数据随机分布至不同分桶。 |
| List+ Hash 分布 | 表达式分区或者 List 分区+ 哈希分桶 | 表的数据根据分区列值所属枚举值列表,分布至对应分区。 对同一分区的数据的分桶键值使用哈希函数进行计算,得出其哈希值,分布到对应分桶。 |
6-2 分区
分区用于将数据划分成不同的区间。分区的主要作用是将一张表按照分区键拆分成不同的管理单元,针对每一个管理单元选择相应的存储策略,比如分桶数、冷热策略、存储介质、副本数等。
| 分区方式 | 适用场景 | 分区创建方式 |
|---|---|---|
| 表达式分区(推荐) | 原称自动创建分区,适用大多数场景,并且灵活易用。适用于按照连续日期范围或者枚举值来查询和管理数据。 | 导入时自动创建 |
| Range 分区 | 典型的场景是数据简单有序,并且通常按照连续日期/数值范围来查询和管理数据。再如一些特殊场景,比如历史数据需要按月划分分区,而最近数据需要按天划分分区。 | 动态、批量或者手动创建 |
| List 分区 | 典型的场景是按照枚举值来查询和管理数据,并且一个分区中需要包含各分区列的多值。比如经常按照国家和城市来查询和管理数据,则可以使用该方式,选择分区列为 city,一个分区包含属于一个国家的多个城市的数据。 | 手动创建 |
注意:
如果需要自动创建分区,就使用表达式分区即可。
如果需要手动创建分区,则使用Range分区和List分区。Range分区适用于分区的字段是一个连续值,而List分区适用于分区的字段是一个枚举值。
选择分区列和分区粒度
- 一般按照时间列结合数据量进行分区
1)时间函数表达式
自 v3.0 起,StarRocks 支持表达式分区(原称自动创建分区),可以使用时间函数表达式或列表达式来创建。
(一)语法
PARTITION BY expression
...
[ PROPERTIES( 'partition_live_number' = 'xxx' ) ]expression ::={ date_trunc ( <time_unit> , <partition_column> ) |time_slice ( <partition_column> , INTERVAL <N> <time_unit> [ , boundary ] ) }(二)参数解释
| 参数 | 是否必填 | 说明 |
|---|---|---|
| expression | 是 | 目前仅支持 date_trunc 和 time_slice 函数。并且如果使用 time_slice 函数,则可以不传入参数 boundary,因为在该场景中该参数默认且仅支持为 floor,不支持为 ceil。 |
| time_unit | 是 | 分区粒度,目前仅支持为 hour、day、month 或 year,暂时不支持为 week。如果分区粒度为 hour,则仅支持分区列为 DATETIME 类型,不支持为 DATE 类型。 |
| partition_column | 是 | 分区列 仅支持为日期类型(DATE 或 DATETIME),不支持为其它类型。如果使用 date_trunc 函数,则分区列支持为 DATE 或 DATETIME 类型。如果使用 time_slice 函数,则分区列仅支持为 DATETIME 类型。分区列的值支持为 NULL。 如果分区列是 DATE 类型,则范围支持为 [0000-01-01 ~ 9999-12-31]。如果分区列是 DATETIME 类型,则范围支持为 [0000-01-01 01:01:01 ~ 9999-12-31 23:59:59]。 目前仅支持指定一个分区列,不支持指定多个分区列。 |
| partition_live_number | 否 | 保留最近多少数量的分区。 |
注意:StarRocks 自动创建分区数量上限默认为 4096,由 FE 配置参数 max_automatic_partition_number 决定。该参数可以防止由于误操作而创建大量分区。
(三)示例
假设经常按天查询数据,则建表时可以使用分区表达式 date_trunc() ,并且设置分区列为 event_day ,分区粒度为 day,实现导入数据时自动按照数据所属日期划分分区。将同一天的数据存储在一个分区中,利用分区裁剪可以显著提高查询效率。
CREATE TABLE test.site_express1 (event_day DATETIME NOT NULL,site_id INT DEFAULT '10',city_code VARCHAR(100),user_name VARCHAR(32) DEFAULT '',pv BIGINT DEFAULT '0'
)
DUPLICATE KEY(event_day, site_id, city_code, user_name)
PARTITION BY date_trunc('day', event_day)
DISTRIBUTED BY HASH(event_day, site_id)
PROPERTIES (
"replication_num" = "1"
);导入如下两行数据,则 StarRocks 会根据导入数据的日期范围自动创建两个分区 p20230226、p20230227,范围分别为 [2023-02-26 00:00:00,2023-02-27 00:00:00)、[2023-02-27 00:00:00,2023-02-28 00:00:00)。如果后续导入数据的日期属于这两个范围,则都会自动划分至对应分区。
-- 导入两行数据
相关文章:

03_Americanas精益管理项目_StarRocks
文章目录 03_StarRocks(一)StarRocks简介1、什么是StarRocks【理解】1)概述2)适用场景2、系统架构【理解】1)系统架构图2)数据管理3、使用【熟悉】(二)表设计4、StarRocks表设计【理解】1)列式存储2)索引3)加速处理5、数据模型【掌握】5-1 明细模型1)适用场景2)创…...
)
CSS进度条带斑马纹动画(有效果图)
效果图 .wxml <view class"tb"><view class"tb-line" style"transform:translateX({{w%}})" /> </view> <button bind:tap"updateLine">增加进度</button>.js Page({data: {w:0,},updateLine(){this.…...

C++ static的使用方法及不同作用
在 C 里,static 是一个用途广泛的关键字,在不同场景下有不同含义,下面为你详细介绍: 1. 全局变量前的 static 当 static 用在全局变量前时,它会改变变量的链接属性。 默认全局变量:默认的全局变量具有外…...
)
CSS 美化页面(四)
一、浮动float属性 属性值描述适用场景left元素向左浮动,腾出右侧空间供其他元素使用,其他内容会围绕在其右侧。横向排列元素(如导航菜单)、图文混排布局。right元素向右浮动,腾出左侧空间供其他元素使…...

驱动-原子操作
前面 对并发与竞争进行了实验, 两个 app 应用程序之间对共享资源的竞争访问引起了数据传输错误, 而在 Linux 内核中, 提供了四种处理并发与竞争的常见方法: 分别是原子操作、 自旋锁、 信号量、 互斥体, 这里了解下原子…...

Flutter ListView 详解
ListView 是 Flutter 中用于构建滚动列表的核心组件,支持垂直、水平滚动以及复杂的动态布局。本文将深入解析其核心用法、性能优化策略和高级功能实现,助你打造流畅高效的列表界面。 一、基础篇:快速构建各类列表 1. 垂直列表(默…...

关于视频的一些算法内容,不包含代码等
视频算法: 视频降噪, 去除视频中的噪音,提高图像质量 工作原理: 时域降噪:利用相邻帧之间的相似性,通过平均或滤波来减少随机噪声。 空域降噪:在单帧内使用滤波器(高斯滤波器&am…...
颜色空间转换-----将 BGR 图像转换为 LUV 色彩空间函数BGR2LUV())
OpenCV 图形API(43)颜色空间转换-----将 BGR 图像转换为 LUV 色彩空间函数BGR2LUV()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将图像从BGR色彩空间转换为LUV色彩空间。 该函数将输入图像从BGR色彩空间转换为LUV。B、G和R通道值的传统范围是0到255。 输出图像必须是8位无符…...
: error: #67: expected a “}“)
keil报错 ..\..\Libraries\CMSIS\stm32f10x.h(298): error: #67: expected a “}“
报错原因: 通常是由于启动文件、头文件定义或驱动选择不一致导致的。以下是一些具体的解决方案,可以帮助你解决这个问题: 检查步骤: 1. 检查启动文件 确保你的启动文件与你的芯片型号相匹配。例如,如果你的芯片是S…...

图像预处理-添加水印
一.ROI切割 类似裁剪图片,但是原理是基于Numpy数组的切片操作(ROI数组切片是会修改原图数据的),也就是说这个“裁剪”不是为了保存“裁剪”部分,而是为了方便修改等处理。 import cv2 as cv import numpy as npimg cv.imread(../images/dem…...

扩展欧几里得算法【Exgcd】的内容与题目应用
1.简介 exgcd的目的是表示出二元一次不定方程的通解。 形式化地,exgcd算法就是输入a,b,c的值,返回一组x,y,满足 a x b y c axbyc axbyc。 2.1方程无整数解的情况 当 c 不能被 a ,b最小公倍…...

OpenCV day5
函数内容接上文:OpenCV day4-CSDN博客 目录 9.cv2.adaptiveThreshold(): 10.cv2.split(): 11.cv2.merge(): 12.cv2.add(): 13.cv2.subtract(): 14.cv2.multiply(): 15.cv2.divide(): 1…...

Spring DI 详解
学习过 IoC 后,就知道我们可以将对象交给 Spring 进行管理,但是我们在一个类会有若干属性,也就是这个类依赖于这若干个属性,那么我们就可以将交给 Spring 管理的对象注入到这个类中,这也就是依赖注入。 依赖注入有三种…...
)
解锁动态规划的奥秘:从零到精通的创新思维解析(9)
前言: 小编在前几日写了关于动态规划中的多状态dp的问题,此时小编将会讲述一个动态规划我们常常会遇到的一类问题——股票问题,股票问题就类似小编上一篇所讲述的粉刷房子的问题,可以通过一个二维的dp表来代替多个一维的dp表。买卖…...

redis 配置日志和数据存储位置
Redis配置日志和数据存储位置 介绍 Redis是一个开源的高性能键值存储数据库,常用于缓存、消息队列和实时分析等场景。在使用Redis时,我们需要配置日志和数据存储位置,以便更好地管理和监控Redis的运行状态。本文将介绍如何配置Redis的日志和数…...

STL详解 - stack与queue的模拟实现
目录 一、容器适配器 1. 什么是适配器模式 2. stack与queue的底层结构 3. deque的原理与缺陷 3.1 deque的原理 3.2 deque的缺陷 4. 为何选择deque作为默认底层容器 二、stack与queue的模拟实现 1. stack的实现 2. queue的实现 一、容器适配器 1. 什么是适配器模式 适…...
)
Chromium 134 编译指南 macOS篇:获取源代码(四)
1. 引言 在Chromium 134的开发之旅中,获取源代码是一个至关重要的里程碑。本文将引导您完成这一关键步骤,为后续的编译和开发工作奠定坚实的基础。无论您是出于学习目的,还是计划开发自己的浏览器项目,掌握获取Chromium源码的方法…...

关于 IntelliJ IDEA 中频繁出现的 Kotlin 及其核心作用
关于 IntelliJ IDEA 中频繁出现的 Kotlin 及其核心作用 1. Kotlin 是什么? Kotlin 是由 JetBrains(IntelliJ IDEA 的开发商)设计的一种现代化编程语言,2016年正式发布,2017年被 Google 指定为 Android 官方开发语言。…...
Happy Number(快乐数)(超快解法:图论思想解题))
MYOJ_11700(UVA10591)Happy Number(快乐数)(超快解法:图论思想解题)
原题(English) Let the sum of the square of the digits of a positive integer S0S0 be represented by S1S1. In a similar way, let the sum of the squares of the digits of S1S1 be represented by S2S2 and so on. If Si1Si1 for some i≥1i≥1, then the or…...

2843. 统计对称整数的数目
2843. 统计对称整数的数目 题目链接:2843. 统计对称整数的数目 代码如下: class Solution { public:int countSymmetricIntegers(int low, int high) {int res 0;for (int i low;i < high;i) {string s to_string(i);int n s.size();if (n % 2 …...

【模块化拆解与多视角信息6】自我评价:人设构建的黄金50字——从无效堆砌到精准狙击的认知升级
写在最前 作为一个中古程序猿,我有很多自己想做的事情,比如埋头苦干手搓一个低代码数据库设计平台(目前只针对写java的朋友),比如很喜欢帮身边的朋友看看简历,讲讲面试技巧,毕竟工作这么多年,也做到过高管,有很多面人经历,意见还算有用,大家基本都能拿到想要的offe…...

ServletRequestAttributeListener 的用法笔记250417
ServletRequestAttributeListener 的用法笔记250417 以下是关于 ServletRequestAttributeListener 的用法详解,涵盖核心方法、实现步骤、典型应用场景及注意事项,帮助您有效监听请求级别属性(ServletRequest 中的属性)的变化&…...

大模型在胃十二指肠溃疡预测及诊疗方案制定中的应用研究
目录 一、引言 1.1 研究背景与目的 1.2 国内外研究现状 1.3 研究方法和创新点 二、大模型相关理论基础 2.1 大模型的基本原理 2.2 适用于医疗领域的大模型类型 2.3 大模型在医疗领域的应用现状和潜力 三、胃十二指肠溃疡的疾病特征 3.1 疾病概述 3.2 诊断方法 3.3 …...

第九节:React HooksReact 18+新特性-React 19的use钩子如何简化异步操作?
对比:useEffect vs use处理Promise 代码题:用use改写数据请求逻辑 React 19 use 钩子:异步操作革命性简化方案(附完整代码对比) 一、useEffect vs use 处理 Promise 核心差异对比 对比维度useEffect 方案use 钩子方案…...

【React】项目的搭建
create-react-app 搭建vite 搭建相关下载 在Vue中搭建项目的步骤:1.首先安装脚手架的环境,2.通过脚手架的指令创建项目 在React中有两种方式去搭建项目:1.和Vue一样,先安装脚手架然后通过脚手架指令搭建;2.npx create-…...

方案精读:华为数字化转型实践案例合集【附全文阅读】
华为数字化转型旨在通过数字化变革实现全连接的智能华为,成为行业标杆,提升客户满意度和运营效率。其以客户为中心,基于 “双轮驱动” 理念,从转意识、方法、文化、组织、模式等方面入手,构建数字化平台,推进数据治理,保障安全,开展业务重构。通过合同 360、产品设计与…...
)
VScode使用Pyside6(环境篇)
Pyside6的环境搭建: cmd命令窗口输入:pip install pyside6 使用everthing进行查找:(非常好用的一款搜索工具 ) 进入PySide6文件夹中,点击designer.exe,查看是否能够点开。 VScode环境搭建: 下…...

智能云图库-12-DDD重构
本节重点 之前我们已经完成了本项目的功能开发。由于本项目功能丰富、代码量大,如果是在企业中维护开发的项目,传统的 MVC 架构可能会让后续的开发协作越来越困难。所以本节鱼皮要从 0 带大家学习一种新的架构设计模式 —— DDD 领域驱动设计。 大纲…...

Linux 网络配置
文章目录 网络基础知识IP地址子网掩码DNS Linux操作系统网络配置 网络基础知识 IP地址 IP地址是用于区分同一个网络中的不同主机的唯一标识。 Internet中的主机要与其他机器通信必须具有一个IP地址,因为网络中传输的数据包必须携带目的IP地址和源IP地址ÿ…...

05-DevOps-Jenkins自动拉取构建代码2
通过前面的操作,已经成功完成了源代码的打包工作,具体操作参见下面的文章: 05-DevOps-Jenkins自动拉取构建代码-CSDN博客 验证打包文件 验证打包后的文件是否存在,进入到Jenkins的工作目录中,找到对应的jar包&#x…...
)
ESP32之OTA固件升级流程,基于VSCode环境下的ESP-IDF开发,基于阿里云物联网平台MQTT-TLS连接通信(附源码)
目录 1.创建产品和设备 2.准备工作 2.1 获取基础工程 2.2 基本知识概述 2.2.1 OTA升级流程 2.2.2 主题和数据格式 (1)设备上报版本号 ①请求主题(设备 -> 阿里云): ②响应主题(阿里云->设备…...
:拾遗 - imgproc 基础操作(下))
【秣厉科技】LabVIEW工具包——OpenCV 教程(20):拾遗 - imgproc 基础操作(下)
文章目录 前言imgproc 基础操作(下)8. 霍夫检测9. 滤波与模糊10. 拟合与包围 总结 前言 需要下载安装OpenCV工具包的朋友,请前往 此处 ;系统要求:Windows系统,LabVIEW>2018,兼容32位和64位。…...

kafka发送消息,同时支持消息压缩和不压缩
1、生产者配置 nacos中增加配置,和公共spring-kafka配置字段有区分 需要发送压缩消息时,使用该配置类发送即可 import org.apache.kafka.clients.producer.ProducerConfig; import org.springframework.beans.factory.annotation.Autowired; import or…...

AOSP世界时间的更新
在 AOSP(Android Open Source Project)中,世界时间的更新主要涉及设备时区数据的管理和更新,以确保设备能够正确显示全球各地的时间。AOSP 依赖 IANA 时区数据库(也称为 tzdata)来提供时区规则和世界时间数…...

Python + 链上数据可视化:让区块链数据“看得懂、用得上”
Python + 链上数据可视化:让区块链数据“看得懂、用得上” 区块链技术的透明性和去中心化特性,使得链上数据成为金融、供应链、NFT 以及 DeFi 领域的关键参考。可是,对于普通用户而言,链上数据往往晦涩难懂,难以直接利用。那么,如何利用 Python 提取、分析并直观展示链上…...

方德桌面操作系统V5.0-G23 vim无法复制粘贴内容
1.修改 Vim 配置文件 rootyuhua-virtualmachine:/etc/docker# sudo vim /usr/share/vim/vim82/defaults.vim 2.在第82行找到set mousea行,将其为set mouse-a。如果文件中没有set mousea,则修改添加set mouse-a。 3.保存文件并退出 Vim: 4…...

[linux] vim 乱码
1. 确保终端支持中文 设置终端编码为 UTF-8,运行: echo $LANG如果不是 UTF-8(如 en_US.UTF-8),你可以设置为: export LANG=zh_CN.UTF-8 export LC_ALL=zh_CN.UTF-8 2. 确保 Vim 使用 UTF-8 编码 打开 .vimrc 或输入以下命令: :set encoding=utf-8 :set fileencodin…...

天洑参加人工智能校企产学研及人才对接活动——走进南京大学人工智能学院
4月15日,人工智能校企产学研及人才对接——走进南京大学人工智能学院活动在南京大学成功举办。此次活动由江苏省人工智能学会、南京大学人工智能学院主办,江苏省工业和信息化厅党组成员、副厅长池宇,南京大学副校长周志华出席。江苏省工业和信…...

33、单元测试实战练习题
以下是三个练习题的具体实现方案,包含完整代码示例和详细说明: 练习题1:TDD实现博客评论功能 步骤1:编写失败测试 # tests/test_blog.py import unittest from blog import BlogPost, Comment, InvalidCommentErrorclass TestBl…...
设计与优化)
《AI大模型应知应会100篇》第22篇:系统提示词(System Prompt)设计与优化
第22篇:系统提示词(System Prompt)设计与优化 摘要 在大语言模型(LLM)应用中,系统提示词(System Prompt)是控制模型行为的核心工具之一。它不仅定义了模型的身份、角色和行为规范,还直接影响输…...

【KWDB 创作者计划】_深度学习篇---松科AI加速棒
文章目录 前言一、简介二、安装与配置硬件连接驱动安装软件环境配置三、使用步骤初始化设备调用SDK接口检测设备状态:集成到AI项目四、注意事项兼容性散热固件更新安全移除五、硬件架构与技术规格核心芯片专用AI处理器内存配置接口类型物理接口虚拟接口能效比散热设计六、软件…...

【Quest开发】在虚拟世界设置具有遮挡关系的透视窗口
软件:Unity 2022.3.51f1c1、vscode、Meta XR All in One SDK V72 硬件:Meta Quest3 仅针对urp管线 参考了YY老师这篇,可以先看他的再看这个可能更好理解一些:Unity Meta Quest MR 开发(七):使…...

Spark on K8s 在vivo大数据平台的混部实战
作者:vivo 互联网大数据团队- Qin Yehai 在离线混部可以提高整体的资源利用率,不过离线Spark任务部署到混部容器集群需要做一定的改造,本文将从在离线混部中的离线任务的角度,讲述离线任务是如何进行容器化、平台上的离线任务如何…...

Mac配置Java的环境变量
刚拿到手的Mac mini M4如何去设置java的环境变量? 第一步: 首先,你先下载好intelliJ IDEA,然后在里面自带的jdk列表里选择你自己想要使用的jdk的版本以及供应商。 下面是我自己使用的jdk版本以及供应商: 第二步&am…...

RPCRT4!OSF_CCONNECTION::OSF_CCONNECTION函数分析之创建一个RPCRT4!OSF_CCALL--RPC源代码分析
RPCRT4!OSF_CCONNECTION::OSF_CCONNECTION函数分析之创建一个RPCRT4!OSF_CCALL 第一部分: 1: kd> p RPCRT4!OSF_CCONNECTION::OSF_CCONNECTION0x167: 001b:77bf6957 393dec35c877 cmp dword ptr [RPCRT4!gfRPCVerifierEnabled (77c835ec)],edi 1: kd> …...

6、事件处理法典:魔杖交互艺术——React 19 交互实现
一、魔杖启灵:交互魔法的本质 "记住,巫师们!魔杖的每一次挥动都是与魔法世界的对话,"麦格教授的魔杖在空中划出金色事件流,"React 19的useTransition如同时间转换器,让麻瓜设备也能感知魔杖…...

.net C# 使用Epplus库将Datatable导出到Excel合并首列
最近处理大量数据,需单独导出到首列名称一致的excel,Epplus免费,效率spire高,在Nuget添加Epplus。因为特殊原因,不能使用数据库,只能由数据源导出到excel;最终处理39万行输出到单独的excel文件时间2分钟。 一、EPPlus 基础介绍 EPPlus 是一个开源的 .NET 库(适用…...

【gpt生成-总览】怎样才算开发了一门编程语言,需要通过什么测试
开发一门真正的编程语言需要经历完整的设计、实现和验证过程,并通过系统的测试体系验证其完备性。以下是分阶段开发标准及测试方法: 一、语言开发核心阶段 1. 语言规范设计(ISO/IEC 标准级别) 语法规范:BNF/…...

网络417 路由转发2 防火墙
路由器临时开启路由转发功能 查看节点a网关ip 节点b网关 1.开启路由器路由转发功能。 2.配置到节点a 节点b的网络。 节点a因为和节点b不在同一网段,计划通过网关直达 网关就是中间节点路由器的ip地址 再Ping另一个 计划节点bping节点c ping不通 是因为 修改了…...

HttpSessionAttributeListener 的用法笔记250417
HttpSessionAttributeListener 的用法笔记250417 以下是关于 HttpSessionAttributeListener 的用法详解,涵盖核心方法、应用场景、实现步骤及关键注意事项,帮助您有效监听会话(HttpSession)中属性的动态变化: 1. 核心功…...