基础学习:(6)nanoGPT
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 1 nanoGPT 浅尝
- 1.1 基础环境
- 1.2 prepare.py
- 1.2 train.py
- 1.3 sample.py
- 2 再探gpt
- 2.1 layer_norm
- 2.2 KQV 和 self attention
- 2.3 masked self-attention
- 2.4 调用构架
- 2.5 Pre-Ln
- 2.6 Encoder & Decoder
前言
看到一个很火的学习开源项目 nano gpt,换换思维,学习下nano gpt
这是我个人仓库,里面很多内容已经build 好,如果有不对的也欢迎大家指正.
我个人非常喜欢<斗破苍穹>, 因此用了土豆老师的斗破苍穹的小说作为训练样本(非商业用途),如有不敬书迷给你磕一个.

1 nanoGPT 浅尝
1.1 基础环境
(1) 仓库地址:https://github.com/MexWayne/mexwayne_nanoGPT
(2) 仓库环境: 见 transformer_env.txt
(3) 训练: python train.py config/train_doupocangqiong_char.py
(4) 推理: python sample.py --init_from=resume --start=“介绍小医仙” --num_samples=5 --max_new_tokens=200
(5) onnx 模型: 用 pt2onnx.py 生成
1.2 prepare.py
prepare.py 是为了将小说数据拆为训练数据和验证数据
(1) 将小说放到input.txt 中.
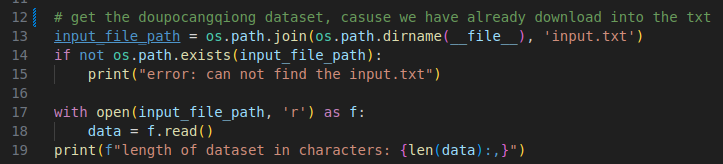
(2) 运行: python data/doupocangqiong_char/prepare.py
prepare过程会将文字进行编码

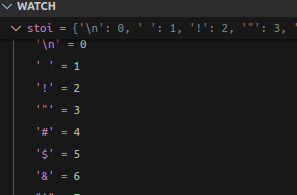
这里用了set 将重复的char 去掉, 得到字符集合
 真正的小说肯定没有乱字符,我这里因为是我网上爬的,所以先将就.这个字典信息会保留到 meta.pkl(pickle) 中.
真正的小说肯定没有乱字符,我这里因为是我网上爬的,所以先将就.这个字典信息会保留到 meta.pkl(pickle) 中.
(3) 将小说的0%-90% 将小说的90%-100%部分作为验证数据
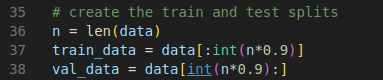
接着将小说的中欧给你的字符串根据set 进行编码.
 于是有
于是有
(3) encode 和 decode 函数
比较简陋

将训练集和测试集用encode转为网络认识的bin文件
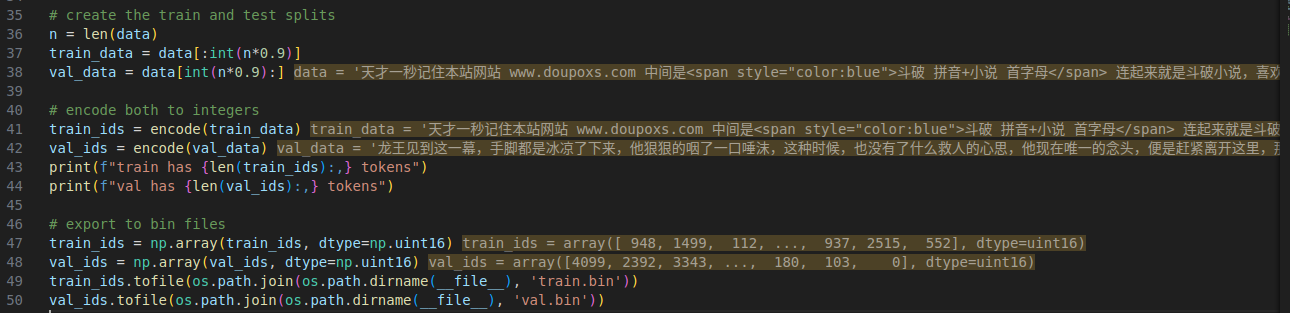
最终将其保存在 meta.pkl 中
1.2 train.py
(1) 这里有个默认的训练设置,scractch 是 从头, resume 是 继续上一次训练, gpt2 是基于gpt2

(2) wandb 很常见就是做可视化的,我这里用的默认

(3) nanogpt 这里很细节, 我们batch大小越大越好,我的实践经验是这样loss 下降的比较快,且训练的结果要强于batch 小的情况,但是我的 4070ti 就12g 显存, 一次读不下太大的batch 所以只能算一点一点算,然后积累到一个 batch 后,更新一次optimizer,这样看起来就像是用个大batch.
配置1个gradient_accumulation_steps 为40, batch size 为 12. block_size = 1024
相当于gradient_accumulation_steps * batch_size * block_size 大小的数据(也就是40 * 12 = 480 个样本)才更新一次

(4) 这里到了 配置 gpt 的模型

但是我这里将生成的模型保存后转为onnx 发现只有6层
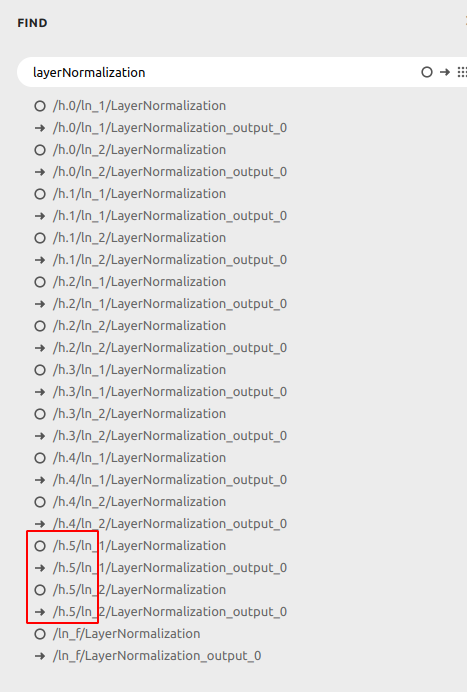
通过如下方式进行打印,也是只有6层,少了一半

看了下代码,发现这里会重写
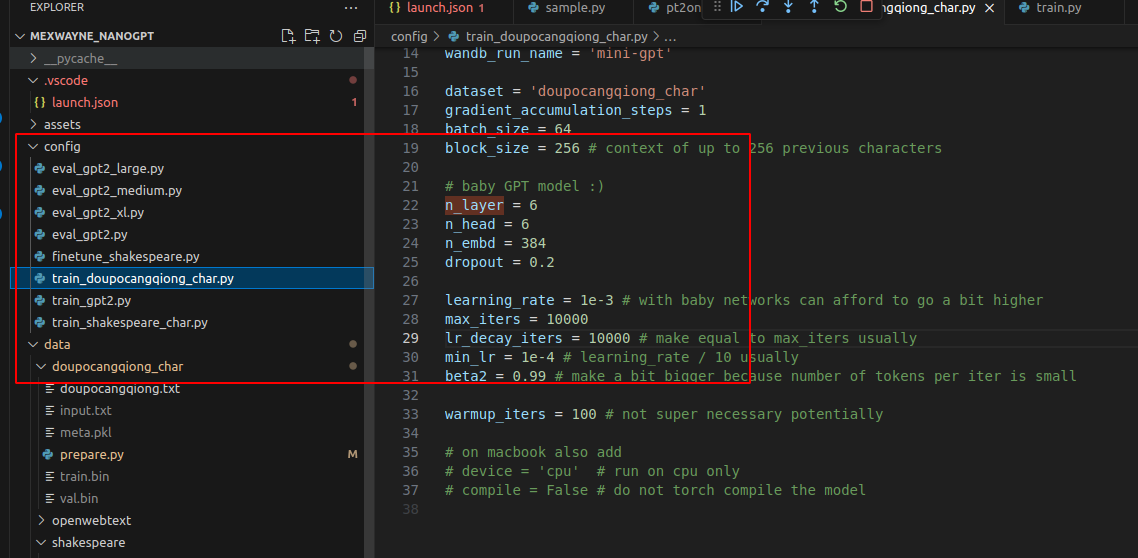
修改后键入: python train.py config/train_doupocangqiong_char.py
改了后就对了
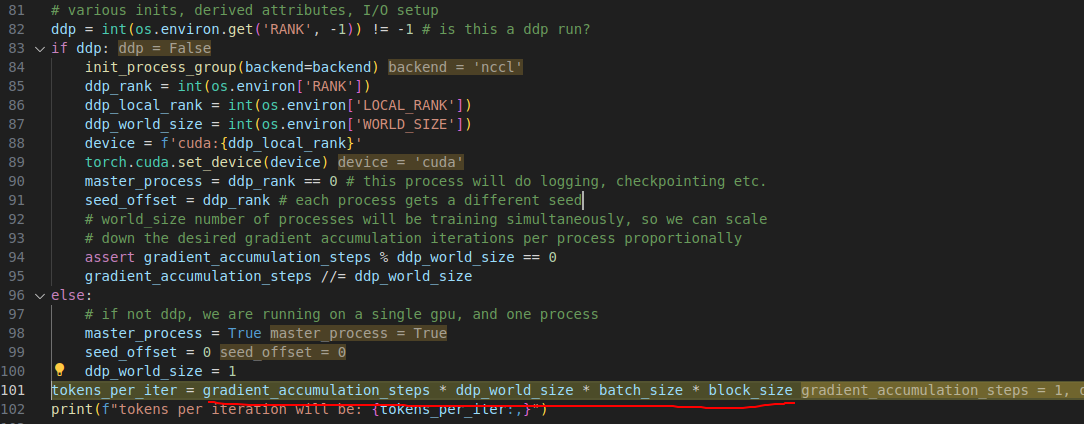
(4) DistributedDataParallel(DDP)
多卡多机训练为false因为我就一张卡.
这里的一个iter 训练大小也符合之前本文前面的公式
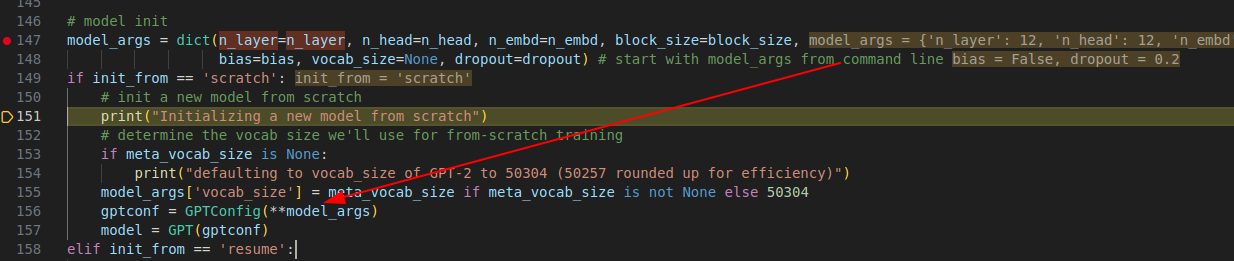
(5) build gpt 模型
这里也很制式化,就是设计好layernorm 等结构的参数,传入后训练即可
(6)model的size 大于模型的size 需要剪裁,最大就是1024,是我们配置好的

(7)混合精度训练—满满的细节

(8) 优化器

weight_decay L2 正则项系数(防止过拟合)
learning_rate 学习率,我一直理解为步长
(beta1, beta2) AdamW 的动量超参数 详见 adamw,我就不多说
device_type 设备类型, 这里是 cuda就是gpu
(9)开启图编译优化

这里不得不说下, 因为编译好的算子都是一个节点,进而将一个网络通过图论思想建立为一个有向或者无向图
根据当前任务,部分算子可以融合或者并行优化或者直接利用硬件加速,满满的细节.
(9) eval_loss
有之前配置,每250步算一次loss,每次计算loss 需要200个batch
这里也是满满的细节,我之前训练降噪,顶多是用指数下降,这里是先
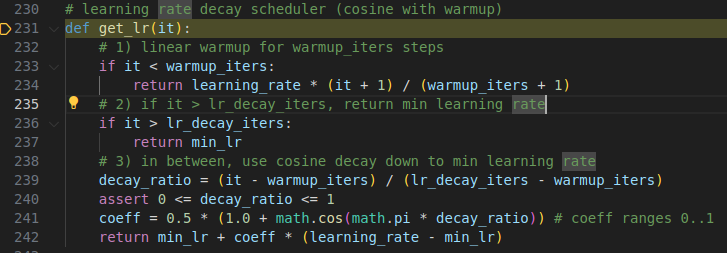
这里是分三段,地一段热身: 学习率线性上升. 第二阶段:中间cos 阶段,用 0~1来控制,最后一个阶段 decay,这个阶段就是最小学习率等步长走. 全是细节.看了下,先线性升高(warmup),再使用余弦函数平滑下降(cosine decay),最后保持最低值,Transformer 训练的标准做法。如下示意图
(10) train主体
注意这里有个细节
optimizer = torch.optim.AdamW([{'params': model.backbone.parameters(), 'lr': 1e-4},{'params': model.head.parameters(), 'lr': 5e-4},
])
每次计算完不同阶段的 loss rate 后喂给 backbone和head 的都是 相同 lr,其实不是,查了下网上,这里可以用相同的学习率 且不是 backbone 和 head 而是一组加 weight decay,另一组不加.
optimizer = AdamW([{"params": decay_params, "weight_decay": 0.1},{"params": no_decay_params, "weight_decay": 0.0}
], lr=6e-4)
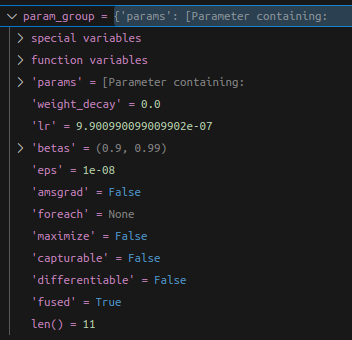
哪些情况下要用不一样的 lr?
- 使用预训练 + 微调(fine-tuning):
预训练层(backbone)设低 lr
微调新加的输出层(head)设高 lr - 做 multi-stage training / layer-wise lr decay
- 训练 GAN、diffusion 等复杂结构
(11) 40个小batch+前向传播 + 反向传播 + 梯度累积 + 梯度裁剪 + 参数更新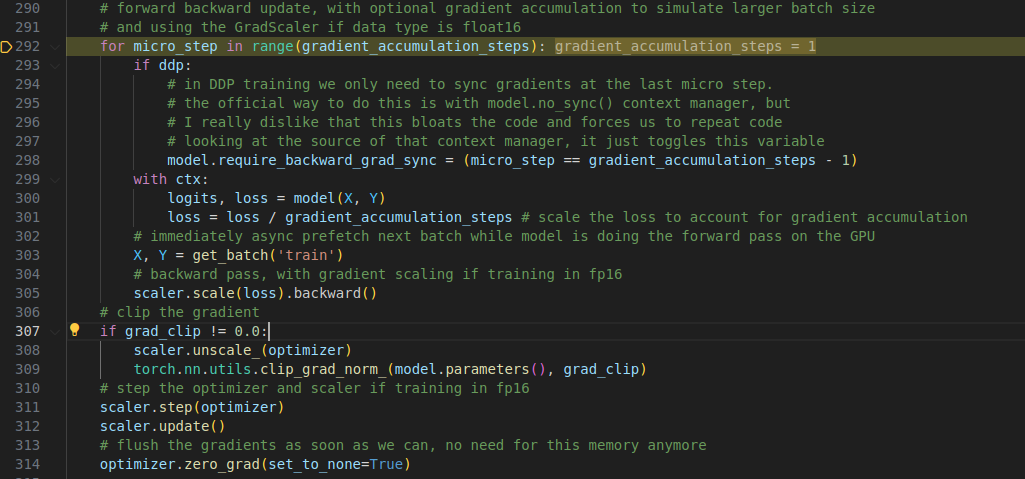
40个小batch
range(gradient_accumulation_steps): 这里gradient_accumulation_steps=40
用于 模拟大 batch(显存不够)
将多个小 batch 梯度累积后再更新参数
比如:你设置了 gradient_accumulation_steps = 40,那么每次训练就会累积 40 个 小batch后,再更新一次参数相当于更新了一次大batch.
ddp的训练按照 最后一次通信的计算— 这个是制式的,我每次照抄.
前向传播
前向传播是通过过了 model 得到的 loss 是40个小batch 中的一个,所以要除以gradient_accumulation_steps 才是正确的 loss
with ctx 是采用了混合精度.
预取
get_batch 是预取下一次batch, 类似优化常用的ping-pong 操作
反向传播
使用 AMP 训练(float16)时:
scaler.scale() 会把 loss 放大,避免梯度 underflow(过小变 0)然后 backward() 会传播放大后的梯度
40次循环结束后
梯度剪裁:
必须先 unscale_(),因为上一步的梯度是放大过的, 然后 执行 torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip) 进行梯度剪裁防止梯度爆炸大模型训练经常需要
梯度更新
略
(12)都是logging 略
1.3 sample.py
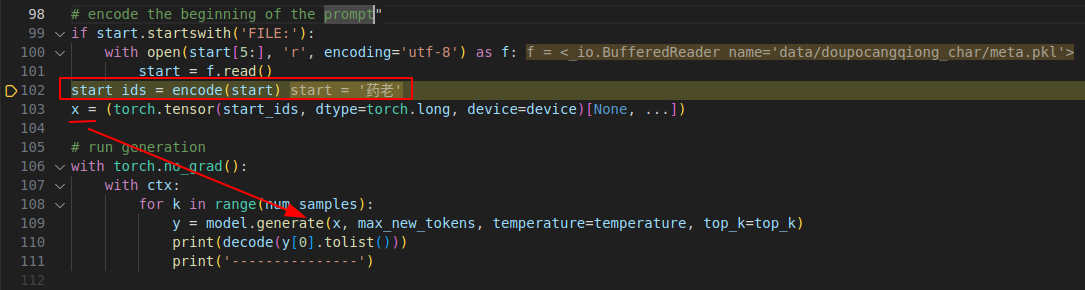
sample 其实就是 inference
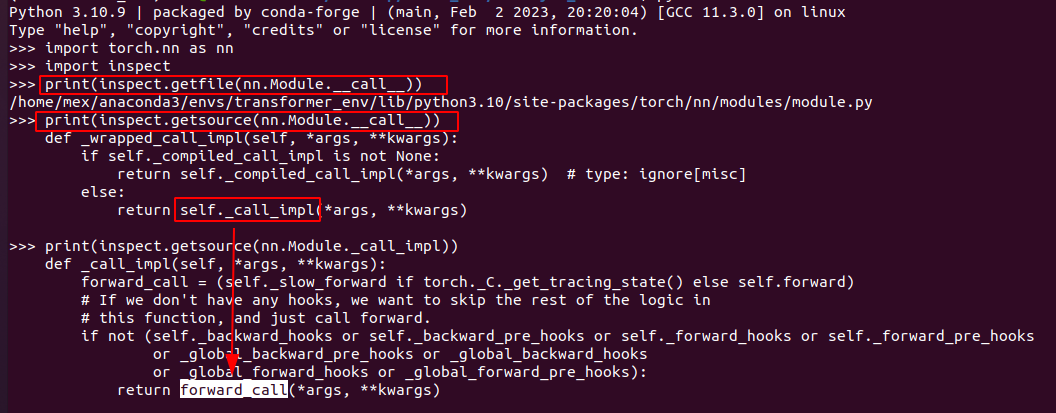
这里的 start 就是 q k v 的 query , 但需要 将其 encode 再经过embedding.

下图可以看到 送给 gpt 的 foward
2 再探gpt
上面第一章,摸清了基本运行代码,下面我们深入探究
2.1 layer_norm
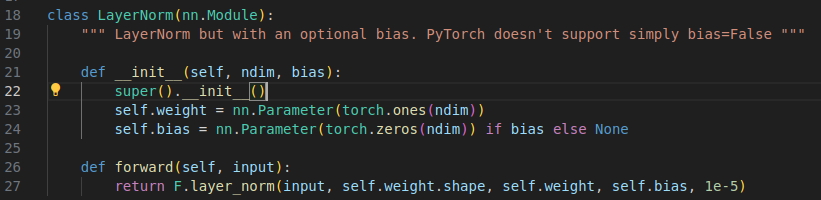
代码比较制式, 讲layer norm详细内容见:https://blog.csdn.net/mikhailbran/article/details/147249369?spm=1001.2014.3001.5501
2.2 KQV 和 self attention
这个 self attention是 gpt 的核心之一,网上讲解巨多无比,我这里列下公式,方便讲解.
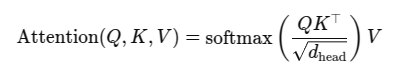
nanogpt也给出了标准过程
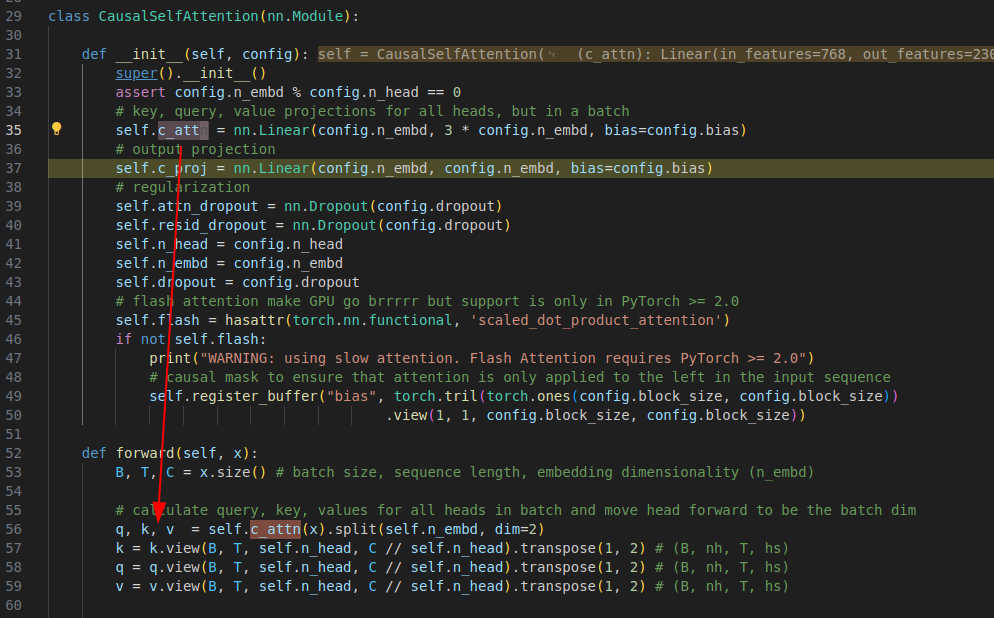
37行一次生成了 3 * n_embd 数据即 qkv 数据. 是为下图过程做准备,因为nn.Linear 就是计算 xw + b, b 是偏移,这里没有.所以就是 xw. 所以我们就的到 QKV.
45行是判断是否开启了 flash attention,详细见链接:https://blog.csdn.net/mikhailbran/article/details/140446863?spm=1001.2014.3001.5501
nanogpt 是开启的.
2.3 masked self-attention
这里有个 很细节的地方,因为我们默认开了 flash attention, 虽然没有 attn_mask, 但是有了casual_mask, 网上查了下这个是下三角mask
y = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout if self.training else 0, is_causal=True)
代码中的 is_causal 就是 mask
2.4 调用构架
这里代码非常清晰,结构关系如下图

注意这里有个小trick, 之前见过, 这里顺带看了下 gpt 也是一样的.
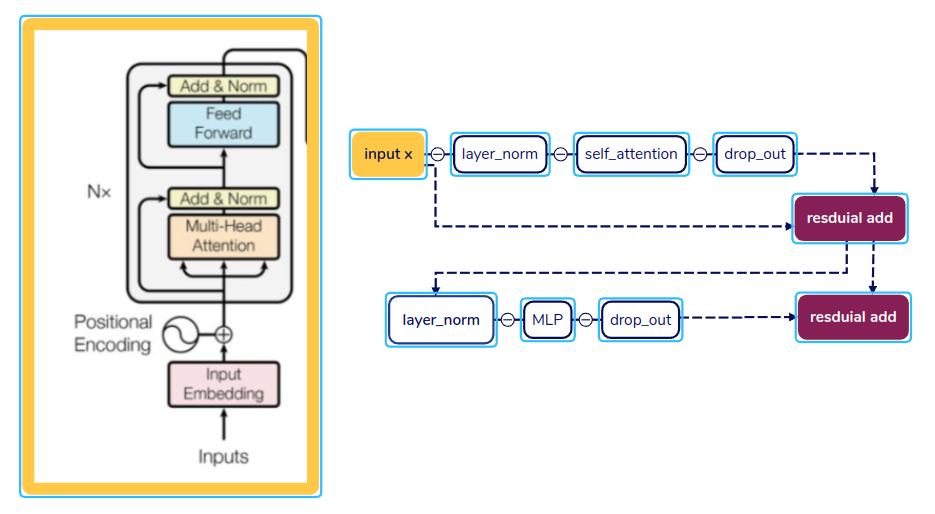
2.5 Pre-Ln
看到这里我还有点懵: nanogpt 是 input -> layerNorm-> atten->layer_norm->mlp->output. 论文里是:
input -> atten->layer_norm->mlp->layerNorm-> output. 后来查了下,nanogpt 是 Pre-LN 架构而 论文中是Post-LN.
Pre-LN 构架有如下优点:
(1)更稳定 在训练深层模型时,Pre-LN 不容易梯度爆炸或消失
(2) 更容易收敛 特别是在长序列或超大模型下(GPT-3、GPT-4 都用)
(3) 实现更优雅 结构更统一,不需要太多调参技巧
在《On Layer Normalization in the Transformer Architecture》(2020)以及 GPT-3 论文《Language Models are Few-Shot Learners》附录 B 以及《A Primer in BERTology: What we know about how BERT works》三个文章中 都 强调了 LayerNorm 的位置影响很大. 下图左侧是论文示意图,右边是nanogpt 示意图.
2.6 Encoder & Decoder
看论文的时候我们发现, 结构是 encoder 和 decoder. 但是nanogpt 中只有decoder.而且我在第一章的实践中,你不难发现 nanogpt 给一个输出,并给一段可能的后面链接的输出.你可看到我输入的问题, 其实我想要的是nanogpt读懂小说并回答我的问题, 说白了就是预测token 也就是一个 自回归语言模型(CLM)
| 模块 | 作用 | 用于什么任务? |
|---|---|---|
| Encoder | 编码输入信息(如一整段文字) | 翻译、问答、分类等 |
| Decoder | 一边看前文,一边逐步生成目标语言输出 | 生成任务,如翻译输出句子、对话、生成文本 |
结合之前我使用过的 bert, 再进行比较
| 模型类型 | Attention 类型 | Encoder 结构 | Decoder 结构 |
|---|---|---|---|
| 原始 Transformer | Self + Cross Attention | 有 | 有 |
| BERT | Self Attention | 有 | 没有 |
| GPT / GPT-2 / NanoGPT | Masked Self Attention | 没有 | 部分 |
至此, nanogpt 工程基本过了一遍
相关文章:
nanoGPT)
基础学习:(6)nanoGPT
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言1 nanoGPT 浅尝1.1 基础环境1.2 prepare.py1.2 train.py1.3 sample.py 2 再探gpt2.1 layer_norm2.2 KQV 和 self attention2.3 masked self-attention2.4 调用构…...

python支持自定义基准的相对误差计算
def is_within_tolerance_custom(a, b, tolerance0.1, reference“max”): “”" 支持自定义基准的相对误差计算。 参数:reference (str): 基准类型,可选 "max"(默认)、"min"、"mean"、"a"&am…...

力扣DAY52-54 | 热100 | 图论:腐烂的橘子、课程表、前缀树
前言 中等 √ 腐烂的橘子用层次遍历,课程表用俩哈希表,前缀树基本与题解一致。however不太规范。 腐烂的橘子 我的题解 层次遍历,先找出所有腐烂的橘子进入队列并记录数量,接着内层遍历第一层腐烂的橘子,上下左右四…...

java CountDownLatch用法简介
CountDownLatch倒计数锁存器 CountDownLatch:用于协同控制一个或多个线程等待在其他线程中执行的一组操作完成,然后再继续执行 CountDownLatch用法 构造方法:CountDownLatch(int count),count指定等待的条件数(任务…...

科技项目验收测试报告有哪些作用?需要多长时间和费用?
在当今快速发展的科技环境中,科技项目的有效验收至关重要。对于公司、开发团队以及客户来说,科技项目验收测试报告更是一个不可缺少的一项重要环节。 科技项目验收测试报告是对一个项目在开发完成后所进行的一系列测试结果的总结。这份报告不仅用于证明…...

网络原理面试题
1.如何理解 URI? URI, 全称为(Uniform Resource Identifier), 也就是统一资源标识符,它的作用很简单,就是区分互联网上不同的资源。但是,它并不是我们常说的网址, 网址指的是URL, 实际上URI包含了URN和URL两个部分,由于 URL 过于普及,就默认将 URI 视为 URL 了。 URI 的…...

专为路由器和嵌入式设备设计的OpenWrt是什么?
OpenWrt是一款基于Linux内核的开源嵌入式操作系统,专为路由器和嵌入式设备设计。自2004年诞生以来,它已成为替代商业固件的首选方案,凭借其高度可定制性、模块化架构和活跃的开发者社区,广泛应用于家庭网络、企业级设备、物联网(IoT)及安全领域。以下从多个维度展开详细介…...

NVIDIA RTX™ GPU 低成本启动零售 AI 场景开发
零售行业正在探索应用 AI 升级客户体验,同时优化内部流程。面对多重应用场景以及成本优化压力,团队可采用成本相对可控的方案,来应对多重场景的前期项目预演和落地,避免短期内大规模投入造成的资源浪费。 客户体验 AI 场景的研究…...

element-ui自定义主题
此处的element-ui为基于vue2.x的 由于https://element.eleme.cn/#/zh-CN/theme/preview(element的主题)报错503, 所以使用https://element.eleme.cn/#/zh-CN/component/custom-theme 自定义主题文档中,在项目中改变scss变量的方…...

PhotoShop学习10
1.画板功能的使用 使用画板功能可以轻松针对不同的设备和屏幕尺寸设计网页和 APP。画板是一种容器,类似于特殊图层组。画板中的图层在图层面板中,按画板进行分组。 使用画板,一个文档中可以有多个设计版面,这样可以在画板之间轻…...
的步骤——以激光微加工为例)
基于LLVM设计领域专用语言(DSL)的步骤——以激光微加工为例
1. 明确DSL的设计目标 在激光微加工领域,DSL需解决以下问题: • 工艺参数抽象化:激光功率、频率、扫描路径等需用高阶语法描述,而非底层G代码。 • 实时性要求:控制指令需低延迟编译为机器码(如FPGA或运动控…...

【MAUI】IOS保活
文章目录 概述sevice使用 概述 每种方法都是独立的,可以根据应用的需求单独使用。例如,如果应用的主要功能是跟踪用户的地理位置,则可以仅使用后台定位;若是为了保持应用在后台运行以完成特定任务(比如上传数据&#…...

shardingsphere-jdbc集成Seata分布式事务
1、导入相关依赖 <!-- shardingsphere-jdbc --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc</artifactId><version>5.5.1</version></dependency><!-- shardingspher…...

基于区块链的技术应用探索
文章目录 前言一、区块链技术的核心特性1.1 去中心化1.2 不可篡改性1.3 透明性与可追溯性1.4 智能合约机制 二、区块链的典型应用场景2.1 金融与支付2.2 溯源与供应链管理2.3 数字身份与数据隐私2.4 数字资产与NFT2.5 公共服务与政务透明 三、区块链的分类1.按权限管理方式分类…...
消息重复消费问题的全面解决方案)
MQ(RabbitMQ)消息重复消费问题的全面解决方案
MQ消息重复消费是分布式系统中的常见问题,主要由网络问题、消费者故障、消息重试机制等引起。以下是针对RabbitMQ的完整解决方案体系: 一、消息生产端解决方案 1. 消息幂等设计 全局唯一消息ID: MessageProperties props MessagePropert…...

windows Cursor 配置MCP的小坑
以高德地图MCP举例 按需求配置好以后,会提示 Client closed 解决方案, windows 需要更改一下 commandargs 新增一个npx保存后Cursor设置MCP页面Refresh一下即可,打开的终端不要关闭 最后贴一下文本代码,方便复制粘贴 {"m…...

探秘串口服务器厂家:背后的故事与应用
在科技飞速发展的今天,串口服务器作为连接串口设备与网络的桥梁,在工业自动化、智能交通、智能家居等众多领域发挥着关键作用。你是否好奇,那些生产串口服务器的厂家究竟有着怎样的故事?它们的产品背后又蕴含着怎样的原理呢&#…...
)
二叉树详细讲解(2/2)
4. 实现链式结构二叉树 ⽤链表来表⽰⼀棵⼆叉树,即⽤链来指⽰元素的逻辑关系。通常的⽅法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别⽤来给出该结点左孩⼦和右孩⼦所在的链结点的存储地址,其结构如下&#…...

SpringBoot整合Redis限流
通过一个完整的Spring Boot项目演示如何用Redis实现简单的API限流功能。我们将从零开始搭建项目。 一、环境准备 1.1 开发环境要求 JDK 1.8IntelliJ IDEA(推荐)Redis 5.0(本地安装)Postman(测试用) 1.2…...
自动驾驶仿真 设计驾驶场景、配置传感器并生成合成 数据)
(Matlab)自动驾驶仿真 设计驾驶场景、配置传感器并生成合成 数据
驾驶场景仿真平台核心功能 一、场景搭建与编辑 可视化场景构建 使用拖放界面创建道路网络和角色模型(车辆、行人等)支持欧洲新车评估计划(Euro NCAP)测试协议及其他预置场景模板 二、传感器配置 车载传感器系统 支持…...
-----------实战演练)
接口测试(get请求方法)-----------实战演练
1.最简单的get请求方法 eg:请求一个王者荣耀语音包的接口 接口文档如下: 2.把接口地址、请求方法、请求参数写到postman相应位置 3.填写请求参数的值,点击发送按钮,即可获得到返回参数...

【赵渝强老师】TiDB的列存引擎:TiFlash
TiDB的TiFlash提供列式存储,且拥有借助ClickHouse高效实现的协处理器层。除此以外,它与TiKV非常类似,依赖同样的Multi-Raft体系,以Region为单位进行数据复制和分散。TiFlash以低消耗不阻塞TiKV写入的方式,实时复制TiKV…...

《vue3学习手记3》
标签的ref属性 vue3和vue2中的ref属性: 用在普通DOM标签上,获取的是DOM节点 ref用在组件标签上,获取的是组件实例对象 区别在于: 1.vue3中person子组件中的数据父组件App不能直接使用,需要引入并使用defineExpose才可…...

【Vue】从 MVC 到 MVVM:前端架构演变与 Vue 的实践之路
个人博客:haichenyi.com。感谢关注 一. 目录 一–目录二–架构模式的演变背景三–MVC:经典的分层起点四–MVP:面向接口的解耦尝试五–MVVM:数据驱动的终极形态六–Vue:MVVM 的现代化实践 二. 架构模…...

Docker Compose 命令实现动态构建和部署
Docker Compose 命令实现动态构建和部署 一、编写支持动态版本号的 docker-compose.yml version: 3.8services:myapp:build: context: . # Dockerfile所在目录args:APP_VERSION: ${TAG:-latest} # 从环境变量获取版本号,默认latestimage: myapp:${TAG:-latest} …...

工厂模式实现案例
场景一:配置文件解析(工厂模式实现) 1. 定义解析器接口与具体实现 from abc import ABC, abstractmethod import json import yaml # 需要安装PyYAML库:pip install pyyamlclass ConfigParser(ABC):"""配置文件解…...
:其他全局设置项)
Vue3.5 企业级管理系统实战(十五):其他全局设置项
在设置面板中,除了主题颜色的选择设置,还可以添加其他全局配置选项,如 tagsView 导航栏,Logo 的显示隐藏配置等。 1 Settings 的 Pinia 配置 在 src/stores/settings.ts 中添加要持久存储的全局配置项,这里是 tagsVi…...

L2-052 吉利矩阵分
L2-052 吉利矩阵 - 团体程序设计天梯赛-练习集 所有元素为非负整数,且各行各列的元素和都等于 7 的 33 方阵称为“吉利矩阵”,因为这样的矩阵一共有 666 种。 本题就请你统计一下,把 7 换成任何一个 [2,9] 区间内的正整数 L,把矩…...
)
408 计算机网络 知识点记忆(9)
前言 本文基于王道考研课程与湖科大计算机网络课程教学内容,系统梳理核心知识记忆点和框架,既为个人复习沉淀思考,亦希望能与同行者互助共进。(PS:后续将持续迭代优化细节) 往期内容 408 计算机网络 知识…...

矩阵基础+矩阵转置+矩阵乘法+行列式与逆矩阵
GPU渲染过程 矩阵 什么是矩阵(Matrix) 向量 (3,9,88) 点乘:计算向量夹角 叉乘:计算两个向量构成平面的法向量。 矩阵 矩阵有3行,2列,所以表示为M32 获取固…...

如何在 .NET 环境中使用 Npgsql 驱动连接 KaiwuDB
在现代软件开发中,数据库连接和操作是任何应用程序的核心部分。本文将介绍如何在 .NET 环境下,使用 Npgsql 驱动连接 KaiwuDB,并执行基本的数据库操作,包括创建表、插入数据和查询操作。我们假设您已经安装并配置好了 KaiwuDB 数据…...
: 、)
【代理错误 django】Request error: HTTPSConnectionPool(host=‘‘, port=443): 、
❗问题 ❶:仍然是代理错误(ProxyError) 错误日志: Request error: HTTPSConnectionPool(hostxueshu.baidu.com, port443): Max retries exceeded ... Caused by ProxyError(Unable to connect to proxy, FileNotFoundError(2, N…...

5.9 《GPT-4调试+测试金字塔:构建高可靠系统的5大实战策略》
5.4 测试与调试:构建企业级质量的保障体系 关键词:测试金字塔模型、GPT-4调试助手、LangChain调试模式、异步任务验证 测试策略设计(测试金字塔实践) #mermaid-svg-RblGbJVMnCIShiCW {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill…...

Maven 多仓库和多镜像配置
Maven是一个流行的Java项目构建和管理工具。在Maven中,我们可以配置多个仓库源来下载和管理依赖项。同时,我们还可以使用repositories和mirrors进行配置,以满足特定的需求。 首先,让我们了解一下repositories和mirrors的作用。在M…...

案例驱动的 IT 团队管理:创新与突破之路:第五章 创新管理:从机制设计到文化养成-5.1 创新激励体系-5.1.3失败案例的价值转化机制
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 失败案例的价值转化机制:IT团队创新管理中的"黑天鹅"炼金术1. 认知重构:重新定义失败的价值1.1 传统失败管理的困境1.2 失败价值转化模型 …...

华为纯血 卓易通 使用记录
(1)我们在测试华为纯血的时候,发现了,使用咱们的基站上的wifi, wifi与手机终端是互相ping 通的, 手机可以发信号到基站,但基站收到信号后,也发出信号 ,但信号 不能到达手机。 这个是…...
-以及案例)
计算机网络中科大 - 第7章 网络安全(详细解析)-以及案例
目录 🛡️ 第8章:网络安全(Network Security)优化整合笔记📌 本章学习目标 一、网络安全概念二、加密技术(Encryption)1. 对称加密(Symmetric Key)2. 公钥加密࿰…...

初识Redis · set和zset
目录 前言: set 基本命令 交集并集差集 内部编码和应用场景 zset 基本命令 交集并集差集 内部编码和应用场景 应用场景(AI生成) 排行榜系统 应用背景 设计思路 热榜系统 应用背景 设计思路 热度计算方式 总结对比表 前言&a…...

Prometheus+Grafana+K8s构建监控告警系统
一、技术介绍 Prometheus、Grafana及K8S服务发现详解 Prometheus简介 Prometheus是一个开源的监控系统和时间序列数据库,最初由SoundCloud开发,现已成为CNCF(云原生计算基金会)的毕业项目。它专注于实时监控和告警,特别适合云原生和分布式…...

用 AI + 前端实现一个简易产品图生成器:上传商品标题 → 多场景展示图自动生成
文章目录 一、项目背景与功能概述核心功能: 二、技术选型与环境准备安装依赖与 API Key 配置 三、核心功能模块实现1. 商品图生成器核心逻辑2. 组件模板与 UI 结构 四、功能拓展与优化建议(附代码思路)✅ 1. 本地历史记录可视化✅ 3. 支持图片…...

实现高效灵活的模糊搜索:JavaScript中的多条件过滤实践
现代Web应用中,数据搜索功能是用户体验的关键部分。本文将深入探讨如何实现一个高效灵活的模糊搜索函数,支持多条件组合查询、精确匹配、模糊匹配以及时间范围筛选。 需求分析 我们需要一个通用的搜索函数,能够处理以下场景: 多…...

ChatterBot的JupyterLab实践指南,从零开始构建AI聊天机器人
从手机上的语音助手到电商平台的客服机器人,这些能理解人类语言的程序背后,都离不开自然语言处理(NLP)技术的支撑。本文将以JupyterLab为实验平台,带您亲手打造一个会对话的AI机器人。通过这个项目,您不仅能…...

《深度学习》课程之卷积神经网络原理与实践教学设计方案
《深度学习》课程之卷积神经网络原理与实践教学设计方案 一、教学目标设计 (一)知识目标 学生能够准确描述卷积神经网络(CNN)的基本定义,包括其核心组成部分(如卷积层、池化层、全连接层等)及…...

快手OneRec 重构推荐系统:从检索排序到生成统一的跃迁
文章目录 1. 背景2. 方法2.1 OneRec框架2.2 Preliminary2.3 生成会话列表2.4 利用奖励模型进行迭代偏好对齐2.4.1 训练奖励模型2.4.2 迭代偏好对齐 3. 总结 昨天面试的时候聊到了OneRec,但是由于上次看这篇文章已经是一个月之前,忘得差不多了,…...

算法——直接插入排序
目录 一、直接插入排序的定义 二、直接插入排序的原理 三、直接插入排序的特点 四、代码实现 一、直接插入排序的定义 直接插入排序是一种简单直观的排序算法,其基本思想是将一个元素插入到已经排好序的部分数组中,使得插入后的数组仍然保持有序。具…...

Linux 软件管理
文章目录 dpkg软件包管理工具APT软件包管理工具apt-get命令apt-cache Linux操作系统主要支持RPM和Deb两种软件包管理工具。 RPM(Redhat Package Manager)是一种用于互联网下载包的打包及安装工具。 其原始设计理念是开放的,不仅可以在Redhat平…...

电力实训中应注意以下安全事项
电力实训中应注意以下安全事项: 一、环境准备与设备检查 保持实训场地整洁通风,清除易燃物与杂物,确保操作空间充足。 电路容量需匹配设备功率,安装漏电保护器及空气开关。 非带电金属设备外壳应接地,定期检查线路…...

序列化-流量统计
新建文件夹及文件 编写流量统计的Bean对象 package com.root.mapreduce.writable; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; //1 继承Writable接口 public class FlowBean implements Writab…...

矩阵游戏--二分图的匈牙利算法
https://www.luogu.com.cn/problem/P1129 学习路线---https://blog.csdn.net/qq_39304630/article/details/108135381 1.二分图就是两个独立的两个集合,如这里是行和列 2.匈牙利匹配就是媒婆拉媒,没伴侣或者伴侣可以换就将当前的塞给她 3.最后true的…...

spring security解析
Spring Security 中文文档 :: Spring Security Reference 1. 密码存储 最早是明文存储,但是攻击者获得数据库的数据后就能得到用户密码。 于是将密码单向hash后存储,然后攻击者利用彩虹表(算法高级(23)-彩虹表&…...