开源模型应用落地-Podcastfy-从文本到声音的智能跃迁-Gradio(一)
一、前言
在当今信息呈现方式越来越多样化的背景下,如何将文字、图片甚至视频高效转化为可听的音频体验,已经成为内容创作者、教育者和研究者们共同关注的重要话题。Podcastfy是一款基于Python的开源工具,它专注于将多种形式的内容智能转换成音频,正在引领一场“可听化”的创作新风潮。
通过结合生成式人工智能(GenAI)和先进的文本转语音(TTS)技术,Podcastfy能够将网页、PDF文件、图片甚至YouTube视频等多种输入,转变为自然流畅的多语言音频对话。
与传统的单一内容转化工具不同,Podcastfy支持从短小的2分钟精华片段到长达30分钟的深度播客生成,还允许用户在音频风格、语言结构和语音模型上进行高度自定义。并且,Podcastfy以其开源特性和程序化接口,为各种场景下的内容创作提供了灵活且专业的解决方案。这一工具的推出,不仅为信息的可及性带来了重要突破,还重新定义了“声音经济”时代的内容表达方式。
二、术语介绍
2.1.Podcastfy
是一款基于 Python 开发的开源多模态内容转换工具,其核心作用是通过生成式人工智能(GenAI)技术,将文本、图像、网页、PDF、YouTube 视频等多种形式的内容,智能转化为多语言音频对话,从而革新内容创作与传播方式。
技术定位与核心功能
1. 多模态输入兼容性
- Podcastfy 支持从网页、PDF、图像、YouTube 视频甚至用户输入的主题中提取内容,并自动生成对话式文本脚本。
2.多语言与音频定制化
- 工具内置多语言支持(包括中文、英语等),可生成不同语言版本的音频,并允许调整播客的风格、声音、时长(如 2-5 分钟短片或 30 分钟以上的长篇内容),甚至模拟自然对话的互动感。
3.技术架构与开源特性
- 生成式 AI 驱动:集成 100+ 主流语言模型(如 OpenAI、Anthropic、Google 等),支持本地运行 HuggingFace 上的 156+ 模型,兼顾生成质量与隐私控制。
- 高级 TTS 引擎:与 ElevenLabs、Microsoft Edge 等文本转语音平台无缝整合,生成拟人化语音效果。
- 开源可扩展:用户可自由修改代码,定制播客生成逻辑或集成私有模型,突破闭源工具(如 Google NotebookLM)的功能限制。
2.2.Gradio
是一个开源的 Python 库,专注于快速构建交互式 Web 应用程序,尤其适用于机器学习模型、API 或任意 Python 函数的可视化展示和用户交互。通过简单代码即可生成功能丰富的界面,无需前端开发经验。
2.3.nohup 命令
是类 Unix 系统中使用的一个工具,用于在后台运行程序并使其忽略挂起信号。在使用命令行运行程序时,通常如果你关闭终端或注销用户,正在运行的程序也会被终止。使用 nohup 可以避免这种情况,让程序在后台持续运行。
三、前置条件
3.1.基础环境及前置条件
1. 操作系统:无限制
3.2.安装依赖
conda create --name podcastfy-app python=3.12
conda activate podcastfy-apppip install gradio-client==1.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install gradio==5.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install podcastfy==0.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install python-dotenv==1.0.1 -i https://pypi.tuna.tsinghua.edu.cn/simple 四、技术实现
4.1.Gradio代码
# -*- coding:utf-8 -*-
import gradio as gr
import os
import tempfile
import logging
from podcastfy.client import generate_podcast
from dotenv import load_dotenv# Configure logging
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)# Load environment variables
load_dotenv()os.environ["GEMINI_API_KEY"] = 'xxxxxxxxxxxxxx-xxxxxxxx-xx'
os.environ["OPENAI_API_KEY"] = 'sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'def get_api_key(key_name, ui_value):return ui_value if ui_value else os.getenv(key_name)def process_inputs(text_input,urls_input,pdf_files,image_files,gemini_key,openai_key,elevenlabs_key,word_count,conversation_style,roles_person1,roles_person2,dialogue_structure,podcast_name,podcast_tagline,tts_model,creativity_level,user_instructions,longform
):try:logger.info("Starting podcast generation process")# API key handlinglogger.debug("Setting API keys")os.environ["GEMINI_API_KEY"] = get_api_key("GEMINI_API_KEY", gemini_key)if tts_model == "openai":logger.debug("Setting OpenAI API key")if not openai_key and not os.getenv("OPENAI_API_KEY"):raise ValueError("OpenAI API key is required when using OpenAI TTS model")os.environ["OPENAI_API_KEY"] = get_api_key("OPENAI_API_KEY", openai_key)if tts_model == "elevenlabs":logger.debug("Setting ElevenLabs API key")if not elevenlabs_key and not os.getenv("ELEVENLABS_API_KEY"):raise ValueError("ElevenLabs API key is required when using ElevenLabs TTS model")os.environ["ELEVENLABS_API_KEY"] = get_api_key("ELEVENLABS_API_KEY", elevenlabs_key)print(f'GEMINI_API_KEY: {os.environ["GEMINI_API_KEY"]},OPENAI_API_KEY: {os.environ["OPENAI_API_KEY"]}')# Process URLsurls = [url.strip() for url in urls_input.split('\n') if url.strip()]logger.debug(f"Processed URLs: {urls}")temp_files = []temp_dirs = []# Handle PDF filesif pdf_files is not None and len(pdf_files) > 0:logger.info(f"Processing {len(pdf_files)} PDF files")pdf_temp_dir = tempfile.mkdtemp()temp_dirs.append(pdf_temp_dir)for i, pdf_file in enumerate(pdf_files):pdf_path = os.path.join(pdf_temp_dir, f"input_pdf_{i}.pdf")temp_files.append(pdf_path)with open(pdf_path, 'wb') as f:f.write(pdf_file)urls.append(pdf_path)logger.debug(f"Saved PDF {i} to {pdf_path}")# Handle image filesimage_paths = []if image_files is not None and len(image_files) > 0:logger.info(f"Processing {len(image_files)} image files")img_temp_dir = tempfile.mkdtemp()temp_dirs.append(img_temp_dir)for i, img_file in enumerate(image_files):# Get file extension from the original name in the file tupleoriginal_name = img_file.orig_name if hasattr(img_file, 'orig_name') else f"image_{i}.jpg"extension = original_name.split('.')[-1]logger.debug(f"Processing image file {i}: {original_name}")img_path = os.path.join(img_temp_dir, f"input_image_{i}.{extension}")temp_files.append(img_path)try:# Write the bytes directly to the filewith open(img_path, 'wb') as f:if isinstance(img_file, (tuple, list)):f.write(img_file[1]) # Write the bytes contentelse:f.write(img_file) # Write the bytes directlyimage_paths.append(img_path)logger.debug(f"Saved image {i} to {img_path}")except Exception as e:logger.error(f"Error saving image {i}: {str(e)}")raise# Prepare conversation configlogger.debug("Preparing conversation config")conversation_config = {"word_count": word_count,"conversation_style": conversation_style.split(','),"roles_person1": roles_person1,"roles_person2": roles_person2,"dialogue_structure": dialogue_structure.split(','),"podcast_name": podcast_name,"podcast_tagline": podcast_tagline,"creativity": creativity_level,"user_instructions": user_instructions}# Generate podcastlogger.info("Calling generate_podcast function")logger.debug(f"URLs: {urls}")logger.debug(f"Image paths: {image_paths}")logger.debug(f"Text input present: {'Yes' if text_input else 'No'}")audio_file = generate_podcast(urls=urls if urls else None,text=text_input if text_input else None,image_paths=image_paths if image_paths else None,tts_model=tts_model,conversation_config=conversation_config,longform = eval(longform))logger.info("Podcast generation completed")# Cleanuplogger.debug("Cleaning up temporary files")for file_path in temp_files:if os.path.exists(file_path):os.unlink(file_path)logger.debug(f"Removed temp file: {file_path}")for dir_path in temp_dirs:if os.path.exists(dir_path):os.rmdir(dir_path)logger.debug(f"Removed temp directory: {dir_path}")return audio_fileexcept Exception as e:logger.error(f"Error in process_inputs: {str(e)}", exc_info=True)# Cleanup on errorfor file_path in temp_files:if os.path.exists(file_path):os.unlink(file_path)for dir_path in temp_dirs:if os.path.exists(dir_path):os.rmdir(dir_path)return str(e)# Create Gradio interface with updated theme
with gr.Blocks(title="Podcastfy.ai",theme=gr.themes.Base(primary_hue="blue",secondary_hue="slate",neutral_hue="slate"),css="""/* Move toggle arrow to left side */.gr-accordion {--accordion-arrow-size: 1.5em;}.gr-accordion > .label-wrap {flex-direction: row !important;justify-content: flex-start !important;gap: 1em;}.gr-accordion > .label-wrap > .icon {order: -1;}"""
) as demo:with gr.Tab("Content"):# API Keys Sectiongr.Markdown("""<h2 style='color: #2196F3; margin-bottom: 10px; padding: 10px 0;'>🔑 API Keys</h2>""",elem_classes=["section-header"])with gr.Accordion("Configure API Keys", open=False):gemini_key = gr.Textbox(label="Gemini API Key",type="password",value=os.getenv("GEMINI_API_KEY", ""),info="Required")openai_key = gr.Textbox(label="OpenAI API Key",type="password",value=os.getenv("OPENAI_API_KEY", ""),info="Required only if using OpenAI TTS model")elevenlabs_key = gr.Textbox(label="ElevenLabs API Key",type="password",value=os.getenv("ELEVENLABS_API_KEY", ""),info="Required only if using ElevenLabs TTS model [recommended]")# Content Input Sectiongr.Markdown("""<h2 style='color: #2196F3; margin-bottom: 10px; padding: 10px 0;'>📝 Input Content</h2>""",elem_classes=["section-header"])with gr.Accordion("Configure Input Content", open=False):with gr.Group():text_input = gr.Textbox(label="Text Input",placeholder="Enter or paste text here...",lines=3)urls_input = gr.Textbox(label="URLs",placeholder="Enter URLs (one per line) - supports websites and YouTube videos.",lines=3)# Place PDF and Image uploads side by sidewith gr.Row():with gr.Column():pdf_files = gr.Files( # Changed from gr.File to gr.Fileslabel="Upload PDFs", # Updated labelfile_types=[".pdf"],type="binary")gr.Markdown("*Upload one or more PDF files to generate podcast from*",elem_classes=["file-info"])with gr.Column():image_files = gr.Files(label="Upload Images",file_types=["image"],type="binary")gr.Markdown("*Upload one or more images to generate podcast from*", elem_classes=["file-info"])# Customization Sectiongr.Markdown("""<h2 style='color: #2196F3; margin-bottom: 10px; padding: 10px 0;'>⚙️ Customization Options</h2>""",elem_classes=["section-header"])with gr.Accordion("Configure Podcast Settings", open=False):# Basic Settingsgr.Markdown("""<h3 style='color: #1976D2; margin: 15px 0 10px 0;'>📊 Basic Settings</h3>""",)word_count = gr.Slider(minimum=500,maximum=5000,value=2000,step=100,label="Word Count",info="Target word count for the generated content")conversation_style = gr.Textbox(label="Conversation Style",value="engaging,fast-paced,enthusiastic",info="Comma-separated list of styles to apply to the conversation")# Roles and Structuregr.Markdown("""<h3 style='color: #1976D2; margin: 15px 0 10px 0;'>👥 Roles and Structure</h3>""",)roles_person1 = gr.Textbox(label="Role of First Speaker",value="main summarizer",info="Role of the first speaker in the conversation")roles_person2 = gr.Textbox(label="Role of Second Speaker",value="questioner/clarifier",info="Role of the second speaker in the conversation")dialogue_structure = gr.Textbox(label="Dialogue Structure",value="Introduction,Main Content Summary,Conclusion",info="Comma-separated list of dialogue sections")# Podcast Identitygr.Markdown("""<h3 style='color: #1976D2; margin: 15px 0 10px 0;'>🎙️ Podcast Identity</h3>""",)podcast_name = gr.Textbox(label="Podcast Name",value="PODCASTFY",info="Name of the podcast")podcast_tagline = gr.Textbox(label="Podcast Tagline",value="YOUR PERSONAL GenAI PODCAST",info="Tagline or subtitle for the podcast")# Voice Settingsgr.Markdown("""<h3 style='color: #1976D2; margin: 15px 0 10px 0;'>🗣️ Voice Settings</h3>""",)tts_model = gr.Radio(choices=["openai", "elevenlabs", "edge", "gemini", "geminimulti"],value="openai",label="Text-to-Speech Model",info="Choose the voice generation model (edge is free but of low quality, others are superior but require API keys)")# Advanced Settingsgr.Markdown("""<h3 style='color: #1976D2; margin: 15px 0 10px 0;'>🔧 Advanced Settings</h3>""",)creativity_level = gr.Slider(minimum=0,maximum=1,value=0.7,step=0.1,label="Creativity Level",info="Controls the creativity of the generated conversation (0 for focused/factual, 1 for more creative)")user_instructions = gr.Textbox(label="Custom Instructions",value="",lines=2,placeholder="Add any specific instructions to guide the conversation...",info="Optional instructions to guide the conversation focus and topics")longform = gr.Radio(choices=["True", "False"],value="False",label="Podcasts Generation Way",info="Choose the podcasts generation Content Length")# Output Sectiongr.Markdown("""<h2 style='color: #2196F3; margin-bottom: 10px; padding: 10px 0;'>🎵 Generated Output</h2>""",elem_classes=["section-header"])with gr.Group():generate_btn = gr.Button("🎙️ Generate Podcast", variant="primary")audio_output = gr.Audio(type="filepath",label="Generated Podcast")# Handle generationgenerate_btn.click(process_inputs,inputs=[text_input, urls_input, pdf_files, image_files,gemini_key, openai_key, elevenlabs_key,word_count, conversation_style,roles_person1, roles_person2,dialogue_structure, podcast_name,podcast_tagline, tts_model,creativity_level, user_instructions,longform],outputs=audio_output)DEFAULT_SERVER_NAME = '0.0.0.0'
DEFAULT_PORT = 8000
DEFAULT_USER = "zhangshan"
DEFAULT_PASSWORD = '123456'if __name__ == "__main__":demo.queue().launch(debug=False,share=False,inbrowser=False,server_port=DEFAULT_PORT,server_name=DEFAULT_SERVER_NAME,auth=(DEFAULT_USER, DEFAULT_PASSWORD) )4.2.测试
4.2.1.启动Gradio服务
nohup python /podcastfy-app/gradio-server.py > /logs/podcastfy-app.log 2>&1 &浏览器访问:http://IP:8000
输入账号:zhangshan/123456
4.2.2.测试文本输入
注意:需要具备科学上网的能力
PS:服务端输出的日志:
DEBUG:openai._base_client:HTTP Response: POST https://api.openai.com/v1/audio/speech "200 OK" Headers({'date': 'Wed, 16 Apr 2025 07:20:51 GMT', 'content-type': 'audio/mpeg', 'transfer-encoding': 'chunked', 'connection': 'keep-alive', 'access-control-expose-headers': 'X-Request-ID', 'openai-organization': 'everblessed-technology-inc', 'openai-processing-ms': '1334', 'openai-version': '2020-10-01', 'strict-transport-security': 'max-age=31536000; includeSubDomains; preload', 'via': 'envoy-router-84dd794555-brjjp', 'x-envoy-upstream-service-time': '1313', 'x-ratelimit-limit-requests': '10000', 'x-ratelimit-remaining-requests': '9999', 'x-ratelimit-reset-requests': '6ms', 'x-request-id': 'req_cc00076d234569e896d01ee281a07938', 'cf-cache-status': 'DYNAMIC', 'x-content-type-options': 'nosniff', 'server': 'cloudflare', 'cf-ray': '9311ec21cd46fb30-SJC', 'alt-svc': 'h3=":443"; ma=86400'})
DEBUG:openai._base_client:request_id: req_cc00076d234569e896d01ee281a07938
DEBUG:openai._base_client:Request options: {'method': 'post', 'url': '/audio/speech', 'headers': {'Accept': 'application/octet-stream'}, 'files': None, 'json_data': {'input': "Exactly! It's not just about the present moment. It's about envisioning a future, a forever, with this person. And that forever is clear, sharply defined.", 'model': 'tts-1-hd', 'voice': 'shimmer'}}
DEBUG:openai._base_client:Sending HTTP Request: POST https://api.openai.com/v1/audio/speech
DEBUG:httpcore.http11:send_request_headers.started request=<Request [b'POST']>
DEBUG:httpcore.http11:send_request_headers.complete
DEBUG:httpcore.http11:send_request_body.started request=<Request [b'POST']>
DEBUG:httpcore.http11:send_request_body.completeDEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/1_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/1_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/2_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/2_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/3_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/3_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/4_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/4_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/5_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/5_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/6_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/6_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/7_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/7_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
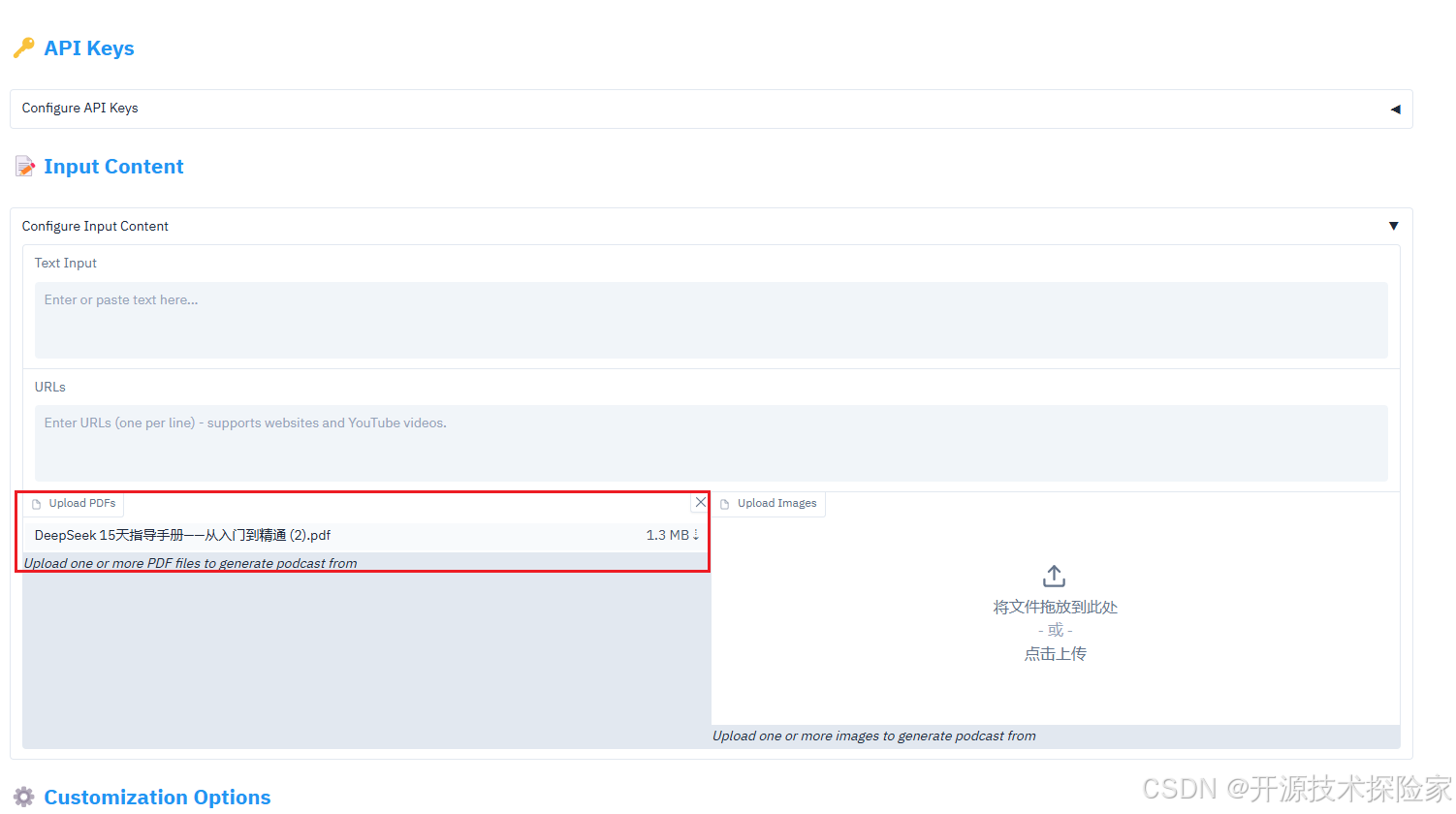
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'wav', '-i', '/tmp/tmpytxxw8ea', '-f', 'mp3', '/tmp/tmptv8lgkb9'])4.2.3.测试文件输入
注意:需要具备科学上网的能力

测试的PDF文件共25页,大小1.3M。
相关文章:
)
开源模型应用落地-Podcastfy-从文本到声音的智能跃迁-Gradio(一)
一、前言 在当今信息呈现方式越来越多样化的背景下,如何将文字、图片甚至视频高效转化为可听的音频体验,已经成为内容创作者、教育者和研究者们共同关注的重要话题。Podcastfy是一款基于Python的开源工具,它专注于将多种形式的内容智能转换成…...

【AI News | 20250416】每日AI进展
AI Repos 1、Tutorial-Codebase-Knowledge 自动分析 GitHub 仓库并生成适合初学者的通俗易懂教程,清晰解释代码如何运行,还能生成可视化内容来展示核心功能。爬取 GitHub 仓库并从代码中构建知识库;分析整个代码库以识别核心抽象概念及其交互…...

iOS内存管理中的强引用问题
iOS内存管理 关于强引用循环 强引用循环是 ARC 无法自动处理的常见问题。如果两个对象互相强引用对方,就会造成引用计数不为零,导致对象无法释放。典型的情况是在闭包中引用 self 时,self 和闭包之间可能会互相持有,形成强引用循…...

电脑一直不关机会怎么样?电脑长时间不关机的影响
现代生活中,许多人会让自己的电脑24小时不间断运行,无论是为了持续的工作、娱乐,还是出于忘记关机的习惯。然而,电脑长时间不关机,除了提供便利之外,也可能对设备的健康产生一系列影响。本文将为大家介绍电…...

openGauss DataVec + Dify,快速搭建你的智能助手平台
在当今数字化和智能化的时代,大语言模型(LLM)的应用正以前所未有的速度改变着各个领域的工作方式和用户体验。Dify 作为一个开源的大语言模型应用开发平台,为开发者们提供了便捷且强大的工具,助力构建从基础智能体到复…...

React 入门教程:构建第一个 React 应用
本教程将带你从零开始构建你的第一个 React 应用。我们将创建一个简单的计数器应用,涵盖 React 的基本概念和开发流程。 准备工作 在开始之前,请确保你的开发环境满足以下要求: Node.js (建议使用最新的 LTS 版本) npm 或 yarn (Node.js 安…...
)
【数字图像处理】数字图像空间域增强(3)
图像锐化 图像细节增强 图像轮廓:灰度值陡然变化的部分 空间变化:计算灰度变化程度 图像微分法:微分计算灰度梯度突变的速率 一阶微分:单向差值 二阶微分:双向插值 一阶微分滤波 1:梯度法 梯度࿱…...

mapstruct使用详解
一、背景:为什么需要 mapstruct 在 Java 开发中,对象之间的映射(如 DTO 转实体类、实体类转 VO)是一项高频且繁琐的任务。手动编写映射代码存在以下问题: 冗余代码多:每个类都需要重复编写 setter 和 get…...

Token与axios拦截器
目录 一、Token 详解 1. Token 的定义与作用 2. Token 的工作流程 3. Token 的优势 4. Token 的安全实践 5. JWT 结构示例 二、Axios 拦截器详解 1. 拦截器的作用 2. 请求拦截器 3. 响应拦截器 4. 拦截器常见场景 5. 移除拦截器 三、完整代码示例 四、总结 五、…...

windows上安装Jenkins
1. 下载windows版 jenkins安装包 2. 配置本地安全策略 在 Windows 11/10 上打开本地安全策略。 Secpol.msc 或本地安全策略编辑器是一个 Windows 管理工具,允许您在本地计算机上配置和管理与安全相关的策略。 安全设置-》本地策略-》用户权限分配-》作为服务登录…...
)
鸿蒙NEXT开发文件预览工具类(ArkTs)
import { uniformTypeDescriptor } from kit.ArkData; import { filePreview } from kit.PreviewKit; import { FileUtil } from ./FileUtil; import { AppUtil } from ./AppUtil; import { WantUtil } from ./WantUtil;/*** 文件预览工具类* 提供文件预览、加载、判断等功能。…...

【WPF-VisionMaster源代码】应用OpenCVSharp仿Vision Master页面开发的软件源代码
一、目的:开放WPF-VisionMaster源代码 二、简介 WPF-Vision Master 视觉处理软件源码 WPF-Vision Master是基于WPF-Control的UI框架与OpenCVSharp计算机视觉库联合,并参考Vision Master界面开发的视觉处理软件。该平台深度融合WPF强大的界面控制能力和Op…...

软件研发过程中的技术债
引言:数字时代的“技术利息” 在金融领域,债务是推动发展的杠杆;而在软件开发中,技术债(Technical Debt)却是一把双刃剑。据行业调查显示,70%的软件项目存在技术债,其中超过半数团队…...
开发篇2·Axios网络请求封装全流程解析)
鸿蒙应用(医院诊疗系统)开发篇2·Axios网络请求封装全流程解析
一、项目初始化与环境准备 1. 创建鸿蒙工程 src/main/ets/ ├── api/ │ ├── api.ets # 接口聚合入口 │ ├── login.ets # 登录模块接口 │ └── request.ets # 网络请求核心封装 └── pages/ └── login.ets # 登录页面逻辑…...

重新定义“边缘”:边缘计算如何重塑人类与数据的关系
在数字化浪潮中,云计算曾是科技界的宠儿,但如今,边缘计算正在悄然改变游戏规则。它不仅是一种技术进步,更是对人类与数据关系的一次深刻反思。本文将探讨边缘计算如何从“中心化”走向“分布式”,以及它如何在效率、隐…...

Flink CDC 出现错误码 1236 和 SQL 状态 HY000 的原因及解决方法
Flink CDC 出现错误码 1236 和 SQL 状态 HY000 的原因及解决方法 常见原因 server-id 冲突:当多个 Flink CDC 任务连接同一个 MySQL 实例,且使用了相同的 server-id 时,会导致该冲突。因为 MySQL 服务器通过 server-id 来区分不同的从服务器,如果多个 Flink CDC 任务使用相…...

如何解除Excel只读状态?4种方法全解析
在日常办公中,我们经常会遇到Excel文件被设置为只读模式的情况。只读模式可以防止文件被意外修改,但在需要编辑时,解除只读模式就显得尤为重要。下面小编分享退出Excel只读方式的4种方法,让你能够轻松编辑工作表。 方法1…...

深度学习与 Flask 应用常见问题解析
在深度学习和 Flask 应用开发过程中,我们常常会遇到一些关键的知识点和容易混淆的问题。下面我们就来对这些问题进行详细的解析。 一、卷积神经网络(CNN)常用层 在定义卷积神经网络时,有一些常用的层: Conv2D&#x…...

零浪费,最高效率:通往0%废品率的道路
在工业自动化领域,努力实现废品率为 0% 是最大的挑战之一。这意味着不生产任何有缺陷的产品 —— 从而减少浪费、降低成本,并提高客户满意度。尽管实现这一目标颇具雄心壮志,但企业可以采取几个步骤来改进自身流程,以达成这一目标…...

【c++深入系列】:new和delete运算符详解
🔥 本文专栏:c 🌸作者主页:努力努力再努力wz 💪 今日博客励志语录: “生活不会向你许诺什么,尤其不会向你许诺成功。它只会给你挣扎、痛苦和煎熬的过程。但只要你坚持下去,终有一天&…...
)
基础(测试用例:介绍,测试用例格式,案例)
目录 测试用例介绍 测试用例编写格式 案例 测试用例介绍 用例:用户使用软件的案例场景 测试用例:是为测试项目而设计的测试执行文档 测试用例的作用: 防止漏测是实施测试的标准可以作为测试工作量的评估 测试用例编写格式 用例编号 用例…...

MCP协议,.Net 使用示例
服务器端示例 基础服务器 以下是一个基础的 MCP 服务器示例,它使用标准输入输出(stdio)作为传输方式,并实现了一个简单的回显工具: using Microsoft.Extensions.DependencyInjection; using Microsoft.Extensions.H…...

Node.js 数据库 事务 项目示例
1、参考:JavaScript语言的事务管理_js 函数 事务性-CSDN博客 或者百度搜索:Nodejs控制事务, 2、实践 2.1、对于MySQL或MariaDB,你可以使用mysql或mysql2库,并结合Promise或async/await语法来控制事务。 使用 mysql2…...

【AI插件开发】Notepad++ AI插件开发实践:支持多平台多模型
引言 上篇文章我们的Notepad插件介绍到Dock窗口集成,本篇将继续完善插件功能,主要包括两个部分: 支持多平台、多模型支持多种授权验证、接口类型 一、多平台 原先的配置项很简单: // PluginConf.h class PlatformConf { publ…...

微信小程序数字滚动效果
效果图 .wxml <view class"container"><view class"container-num" wx:for"{{number}}" wx:key"index"><view class"num-container" style"--h:{{h}}px;--y:{{-item * h }}px;"><view wx:f…...

wx219基于ssm+vue+uniapp的教师管理系统小程序
开发语言:Java框架:ssmuniappJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:M…...

Python 注释进阶之Google风格
文章目录 1. Google 风格 Docstring 的核心特点2. Google 风格的基本结构3. 编写规则和注意事项4. 最常用的 Google 风格 Docstring 示例示例 1:普通函数 示例 2:带默认参数和可变参数的函数示例 3:类示例 4:生成器函数示例 5&…...

写测试文档时,需要的环境配置怎么查看
操作系统 cat /etc/os-releaseCPU信息 lscpu 内存 sudo dmidecode --type memory | grep -E "Size:|Type:|Speed:"硬盘 列出当前系统中 所有块设备(Block Devices) 的信息,并显示指定列(-o 参数) lsblk…...
actor-critic 方法)
强化学习的数学原理(十)actor-critic 方法
由于全文太长,只好分开发了。(已完结!在专栏查看本系列其他文章) 个人博客可以直接看全文~ 本系列为在学习赵世钰老师的“强化学习的数学原理” 课程后所作笔记。 课堂视频链接https://www.bilibili.com/video/BV1sd4y167NS/ 第十章 acto…...
)
多个定时器同时工作时,会出现哪些常见的bug ,如何解决??(定时任务未实时更新但刷新后正常的问题分析)
1. 定时器冲突与覆盖 问题:后设置的定时器可能覆盖先前的定时器,导致前一个定时器失效 原因:未正确管理定时器ID或未清除前一个定时器 2. 性能问题 内存泄漏:未清除不再需要的定时器会导致内存占用不断增加 CPU过载:…...
)
代码随想录算法训练营day5(哈希表)
华子目录 有效的字母异位词思路 有效的字母异位词 https://leetcode.cn/problems/valid-anagram/description/ 思路 使用哈希表,这里哈希表使用数组先申请一个26空间的大小的数组遍历第一个字符串,记录每个字符出现的次数1遍历第二个字符串,…...
Python字符编码完全指南:从存储原理到乱码终结实战)
Python(17)Python字符编码完全指南:从存储原理到乱码终结实战
目录 背景介绍一、字符编码核心原理1. 计算机存储本质2. Python3的编码革命3. 主流编码格式对比 二、编码转换核心方法1. 编码(Encode)过程2. 解码(Decode)过程3. 错误处理策略 三、文件操作编码实战1. 文本文件读写2. 二进制模式…...

Node.js 文件读取与复制相关内容
Node.js 文件读取与复制相关内容的系统总结,包括 同步读取、异步读取、流式读取、复制操作、两者对比及内存测试。 🧩 一、Node.js 文件读取方式总结 Node.js 使用 fs(文件系统)模块进行文件操作: 1. 同步读取&#…...

大数据面试问答-HBase/ClickHouse
1. HBase 1.1 概念 HBase是构建在Hadoop HDFS之上的分布式NoSQL数据库,采用列式存储模型,支持海量数据的实时读写和随机访问。适用于高吞吐、低延迟的场景,如实时日志处理、在线交易等。 RowKey(行键) 定义…...

jupyter 文件浏览器,加强版,超好用,免费exe
第一步:github搜索 lukairui的 jupyter-viewer-plus 仓库 第二步: git clone 到本地。 解压zip包 第三步: 进入压缩包,第一次双击打开jupyter-viewer-plus.exe运行,第一次运行后,界面上有一个“设为…...

【AI工具】用大模型生成脑图初试
刚试用了一下通过大模型生成脑图,非常简单,记录一下 一、用大模型生成脑图文件 关键:存在markdown文件 举例:使用Deepseek,输入问题:“针对大模型的后训练,生成一个开发计划,用ma…...

数据结构-树与二叉树
一、树的定义与基本术语 1.1 树的定义 树(Tree)是一种非线性的数据结构,它是由 n(n ≥ 0)个有限节点组成的集合。如果 n 0,称为空树;如果 n > 0,则: 有一个特定的节…...

STL_unordered_map_01_基本用法
👋 Hi, I’m liubo👀 I’m interested in harmony🌱 I’m currently learning harmony💞️ I’m looking to collaborate on …📫 How to reach me …📇 sssssdsdsdsdsdsdasd🎃 dsdsdsdsdsddfsg…...

ARCGIS国土超级工具集1.5更新说明
ARCGIS国土超级工具集V1.5版本更新说明:因作者近段时间工作比较忙及正在编写ARCGISPro国土超级工具集(截图附后)的原因,故本次更新为小更新(没有增加新功能,只更新了已有的工具)。本次更新主要修…...

主流物理仿真引擎和机器人/强化学习仿真平台对比
以下是当前主流的物理仿真引擎和机器人/强化学习仿真平台的特点和适用场景,方便根据需求选择: 🧠 NVIDIA 系列 ✅ Isaac Lab v1.4 / v2 特点: 基于 Omniverse Isaac Sim,属于高端视觉机器人仿真框架v2 更加模块化&a…...

STM32 HAL库内部 Flash 读写实现
一、STM32F407 内部 Flash 概述 1.1 Flash 存储器的基本概念 Flash 存储器是一种非易失性存储器,它可以在掉电的情况下保持数据。STM32F407 系列微控制器内部集成了一定容量的 Flash 存储器,用于存储程序代码和数据。Flash 存储器具有擦除和编程次数的…...

C++学习:六个月从基础到就业——面向对象编程:构造函数与析构函数
C学习:六个月从基础到就业——面向对象编程:构造函数与析构函数 本文是我C学习之旅系列的第十篇技术文章,主要讨论C中构造函数与析构函数的概念、特点和使用技巧。这些是C对象生命周期管理的关键组成部分。查看完整系列目录了解更多内容。 引…...
--力扣129、814、230、257)
dfs二叉树中的深搜(回溯、剪枝)--力扣129、814、230、257
目录 1.1题目链接:129.求根节点到叶结点数字之和 1.2题目描述:给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。 1.3解法(dfs-前序遍历): 2.1题目链接:814.二叉树剪枝 2.2题目描述&…...

Python Selenium 一小时速通教程
Python Selenium 一小时速通教程 实战案例 一、环境配置(10分钟) 安装Python 确保已安装Python 3.x(官网下载)。 安装Selenium 在终端运行: pip install selenium下载浏览器驱动 Chrome:访问 ChromeDriv…...

通过GO后端项目实践理解DDD架构
最近在工作过程中重构的项目要求使用DDD架构,在网上查询资料发现教程五花八门,并且大部分内容都是长篇的概念讲解,晦涩难懂,笔者看了一些github上入门的使用DDD的GO项目,并结合自己开发中的经验,谈谈自己对…...

MybatisPlus最新版分页无法使用
在使用分页的时候发现分页拦截器关键API会报错,其实根本原因是在之前只需要导入一个mybatisplus依赖,而现在分页似乎被单独分离出来了,需要额外导入新依赖使其支持 <dependency><groupId>com.baomidou</groupId><art…...

【Android学习记录】工具使用
文章目录 一. 精准找视图资源ID1. 准备工作2. 使用 uiautomator 工具2.1. 获取设备的窗口内容2.2. Pull XML 文件2.3. 查看 XML 文件 3. 直接使用 ADB 命令4. 使用 Android Studio 的 Layout Inspector总结 二. adb shell dumpsys activity1. 如何使用 ADB 命令2. 输出内容解析…...

youtube视频和telegram视频加载原理差异分析
1. 客户侧缓存与流式播放机制 流式视频应用(如 Netflix、YouTube)通过边下载边播放实现流畅体验,其核心依赖以下技术: 缓存预加载:客户端在后台持续下载视频片段(如 DASH/HLS 协议的…...

在机器视觉检测中为何选择线阵工业相机?
线阵工业相机,顾名思义是成像传感器呈“线”状的。虽然也是二维图像,但极宽,几千个像素的宽度,而高度却只有几个像素的而已。一般在两种情况下使用这种相机: 1. 被测视野为细长的带状,多用于滚筒上检测的问…...

lwip记录
Index of /releases/lwip/ (gnu.org) 以太网(Ethernet)是互联网技术的一种,由于它是在组网技术中占的比例最高,很多人 直接把以太网理解为互联网。 以太网是指遵守 IEEE 802.3 标准组成的局域网,由 IEEE 802.3 标准规定的主要是位于 参考模…...