dfs二叉树中的深搜(回溯、剪枝)--力扣129、814、230、257
目录
1.1题目链接:129.求根节点到叶结点数字之和
1.2题目描述:给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
1.3解法(dfs-前序遍历):
2.1题目链接:814.二叉树剪枝
2.2题目描述:
2.3解法(dfs-后序遍历):
3.1题目链接:98.验证二叉搜索树
3.2题目描述:
3.3解法(利用中序遍历)
4.1题目链接:230.二叉搜索树中第K小的元素
4.2题目描述:
4.3解法(中序遍历+计数器剪枝)
5.1题目链接:257.二叉树的所有路径
5.2题目描述:
5.3解法(回溯):
本文提供了四道关于二叉树的问题及它们的解法:
-
求根节点到叶结点数字之和:给定一个二叉树,树中每个节点存放一个0到9之间的数字,求从根节点到叶节点生成的所有数字之和。解法使用深度优先搜索(DFS)的前序遍历,整合父节点信息与当前节点信息计算当前节点数字,并递归向下传递,在叶子节点处返回结果。
-
二叉树剪枝:给定一个二叉树,节点值为0或1,返回移除所有不包含1的子树的原二叉树。解法使用DFS的后序遍历,逐步删除叶子节点,保证删除后节点仍满足条件。
-
验证二叉搜索树:判断给定二叉树是否是有效的二叉搜索树。解法利用中序遍历,递归判断左子树是否为BST,当前节点是否满足BST条件,以及右子树是否为BST。
-
二叉搜索树中第K小的元素:在二叉搜索树中查找第K小的元素。解法使用中序遍历配合计数器进行剪枝,当计数器等于0时找到第K小的元素。
此外,还提供了第5道题目二叉树的所有路径,返回所有从根节点到叶子节点的路径的解法,使用回溯法将路径存储在结果中。
1.1题目链接:129.求根节点到叶结点数字之和
1.2题目描述:
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字:
- 例如,从根节点到叶节点的路径
1 -> 2 -> 3表示数字123。
计算从根节点到叶节点生成的 所有数字之和 。
叶节点 是指没有子节点的节点。
示例 1:
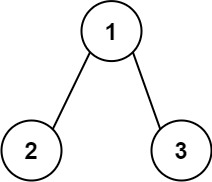
输入:root = [1,2,3] 输出:25 解释: 从根到叶子节点路径1->2代表数字12从根到叶子节点路径1->3代表数字13因此,数字总和 = 12 + 13 =25
示例 2:
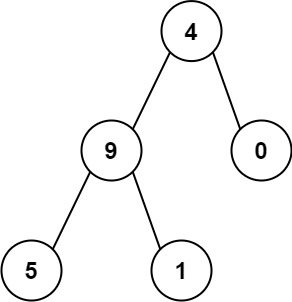
输入:root = [4,9,0,5,1] 输出:1026 解释: 从根到叶子节点路径4->9->5代表数字 495 从根到叶子节点路径4->9->1代表数字 491 从根到叶子节点路径4->0代表数字 40 因此,数字总和 = 495 + 491 + 40 =1026
提示:
- 树中节点的数目在范围
[1, 1000]内 0 <= Node.val <= 9- 树的深度不超过
10
1.3解法(dfs-前序遍历):
前序遍历按照根结点、左子树、右子树的顺序遍历二叉树的所有结点,通常用于子节点的状态依赖于父节点状态的题目。
算法思路:
在前序遍历的过程中,我们可以往左右子树传递信息,并且在回溯时得到左右子树的返回值。递归函数可以帮我们完成两件事:
- 将父节点的数字与当前结点的信息整合到一起,计算出当前结点的数字,然后传递到下一层进行递归;
- 当遇到叶子结点的时候,就不再向下传递信息,而是将整合的结果向上一直回溯到根节点。
当递归结束时,根结点需要返回的值也就被更新为了整棵数的数字和。
算法流程:
递归函数设计:int dfs(TreeNode* root, int num)
- 返回值:当前子树计算的结果(数字和);
- 参数num:递归过程中往下传递的信息(父结点的数字)
- 函数作用:整合父节点的信息与当前结点的信息计算当前结点数字,并向下传递,在回溯时返回当前子树(当前结点作为子树根结点)数字和
递归函数流程:
- 当遇到空节点的时候,说明这条路从根节点开始没有分支,返回0
- 结合父节点传下的信息以及当前节点的val,计算出当前节点数字sum
- 如果当前节点是叶子节点,直接返回整合后的结果sum
- 如果当前节点不是叶子节点,将sum传到左右子树中去,得到左右子树中节点路径的数字和,然后相加返回结果。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int sumNumbers(TreeNode* root) {return dfs(root,0);}int dfs(TreeNode* root, int sum){sum = sum*10 + root->val;if(root->left == nullptr && root->right == nullptr){return sum;}int ret = 0;if(root->left)ret += dfs(root->left, sum);if(root->right)ret += dfs(root->right, sum);return ret;}
};2.1题目链接:814.二叉树剪枝
2.2题目描述:
给你二叉树的根结点 root ,此外树的每个结点的值要么是 0 ,要么是 1 。
返回移除了所有不包含 1 的子树的原二叉树。
节点 node 的子树为 node 本身加上所有 node 的后代。
示例 1:

输入:root = [1,null,0,0,1] 输出:[1,null,0,null,1] 解释: 只有红色节点满足条件“所有不包含 1 的子树”。 右图为返回的答案。
示例 2:
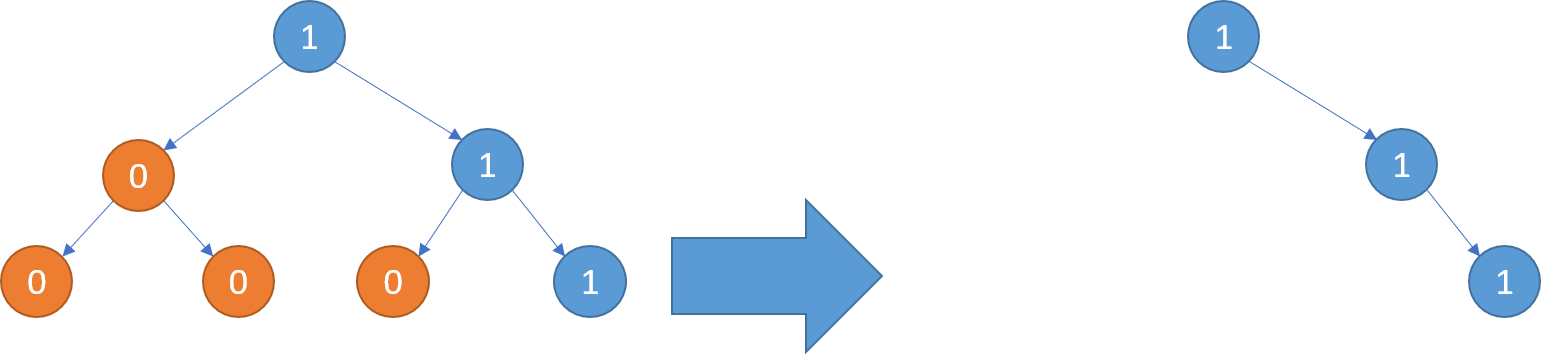
输入:root = [1,0,1,0,0,0,1] 输出:[1,null,1,null,1]
示例 3:
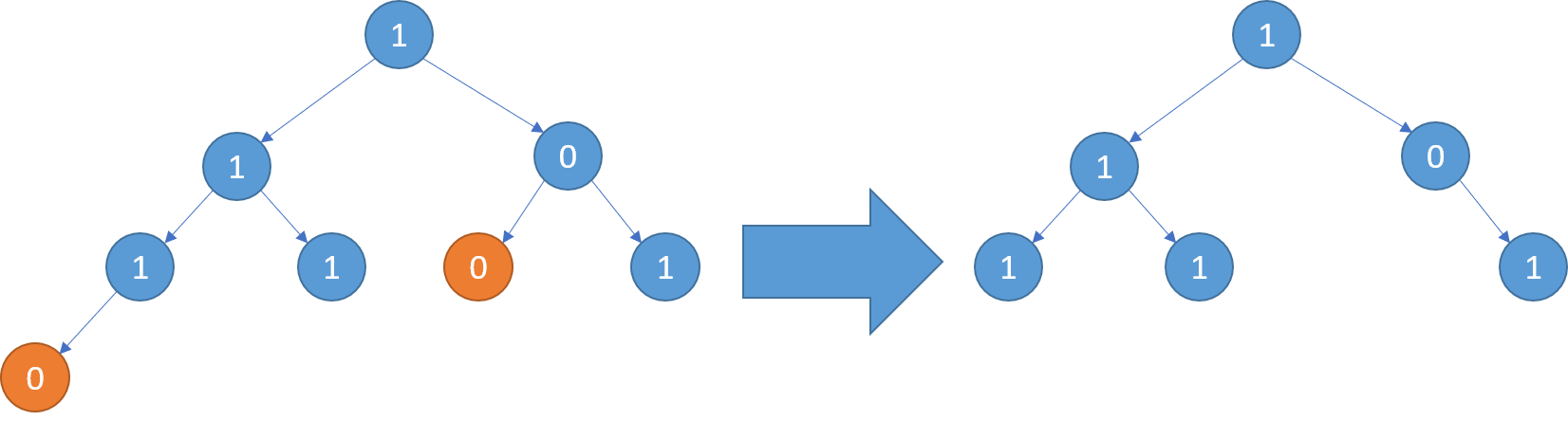
输入:root = [1,1,0,1,1,0,1,0] 输出:[1,1,0,1,1,null,1]
提示:
- 树中节点的数目在范围
[1, 200]内 Node.val为0或1
2.3解法(dfs-后序遍历):
后序遍历按照左子树、右子树、根节点的顺序遍历二叉树的所有结点,通常用于父节点的状态依赖于子结点状态的题目。
算法思路:
如果我们选择从上往下删除,我们需要收集左右子树的信息,这可能导致代码编写相对困难。然而,通过观察我们可以发现,如果我们先删除最底部的叶子结点,然后再处理删除后的结点,最终的结果并不会受到影响。
因此,我们可以采用后序遍历的方式来解决这个问题。在后序遍历中,我们先处理左子树,然后处理右子树,最后再处理当前节点。在处理当前节点时,我们可以判断其是否为叶子节点且其值是否为0,如果满足条件,我们可以删除当前节点。
- 需要注意的是,在删除叶子节点时,其父节点很可能会成为新的叶子节点。因此,在处理完子节点后,我们仍然需要处理当前节点。这也是为什么选择后序遍历的原因(后序遍历首先遍历到的一定是叶子节点)。
- 通过使用后序遍历,我们可以逐步删除叶子节点,并且保证删除后的节点仍然满足删除操作的要求。这样,我们可以较为方便地实现删除操作,而不会影响最终的结果。
- 若在处理结束后所有叶子节点的值均为1,则所有子树均包含1,此时可以返回。
算法流程:
递归函数设计:void dfs(TreeNode* root)
- 返回值:无;
- 参数:当前需要处理的节点
- 函数作用:判断当前节点是否需要删除,若需要删除,则删除当前节点。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:TreeNode* pruneTree(TreeNode* root) {if(root == nullptr) return nullptr;root->left = pruneTree(root->left);root->right = pruneTree(root->right);if(root->left == nullptr && root->right == nullptr && root->val == 0){delete root;//防止内存泄漏root = nullptr;}return root;}
};3.1题目链接:98.验证二叉搜索树
3.2题目描述:
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
- 节点的左子树只包含 小于 当前节点的数。
- 节点的右子树只包含 大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
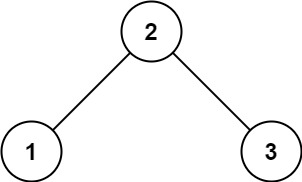
输入:root = [2,1,3] 输出:true
示例 2:
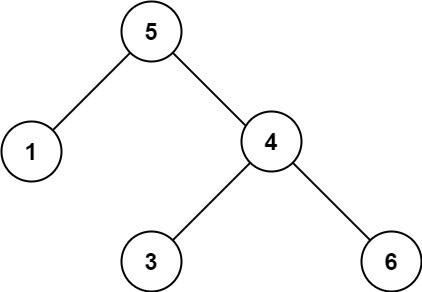
输入:root = [5,1,4,null,null,3,6] 输出:false 解释:根节点的值是 5 ,但是右子节点的值是 4 。
提示:
- 树中节点数目范围在
[1, 10^4]内 -2^31 <= Node.val <= 2^31 - 1
3.3解法(利用中序遍历)
后序遍历按照左子树、根节点、右子树的顺序遍历二叉树的所有节点,通常用于二叉搜索树相关题目。
算法思路:
如果一棵树是二叉搜索树,那么它的中序遍历的结果一定是一个严格递增的序列。
因此,我们可以初始化一个无穷小的全区变量,用来记录中序遍历过程中的前驱结点。那么就可以在中序遍历的过程中,先判断是否和前驱结点构成递增序列,然后修改前驱结点为当前结点,传入下一层的递归中。
算法流程:
1. 初始化一个全局的变量 prev,用来记录中序遍历过程中的前驱结点的val;
2. 中序遍历的递归函数中:
- 设置递归出口:root == nullptr的时候,返回true;
- 先递归判断左子树是否是二叉搜索树,用left标记
- 然后判断当前节点是否满足二叉搜索树,用cur标记 如果当前节点的val大于prev,说明满足条件,cur改为true 如果当前节点的val小于等于prev,说明不满足条件,cur改为false
- 最后递归判断右子树是否是二叉搜索树,用right标记
3.只有当left,cur,right都是true的时候,才返回true
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int prev;bool isValidBST(TreeNode* root) {if(root == nullptr)return true;bool left = isValidBST(root->left);//剪枝if(left == false)return false;bool cur = false;if(root->val > prev)cur = true;//剪枝if(cur == false)return false;prev = root->val; bool right = isValidBST(root->right);return left&&right&&cur;}
};4.1题目链接:230.二叉搜索树中第K小的元素
4.2题目描述:
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(从 1 开始计数)。
示例 1:
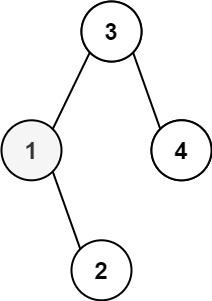
输入:root = [3,1,4,null,2], k = 1 输出:1
示例 2:
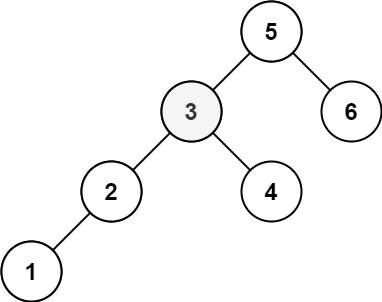
输入:root = [5,3,6,2,4,null,null,1], k = 3 输出:3
提示:
- 树中的节点数为
n。 1 <= k <= n <= 10^40 <= Node.val <= 10^4
4.3解法(中序遍历+计数器剪枝)
算法思路:
我们可以根据中序遍历的过程,只需扫描前k个结点即可。因此,我们可以创建一个全局的计数器count,将其初始化为k,每遍历一个节点就将count--。直到某次递归的时候,count 的值等于 1,说明此时的结点就是我们要找的结果。算法流程:
1. 定义一个全局的变量count,在主函数中初始化为k的值(不用全局也可以,当成参数传入递归过程中);递归函数的设计:int dfs(TreeNode* root):
• 返回值为第k个结点;
递归函数流程(中序遍历):
1. 递归出口:空节点直接返回-1,说明没有找到;
2. 去左子树上查找结果,记为 left:
a. 如果 left == -1,说明没找到,继续执行下面逻辑;
b. 如果 left != -1,说明找到了,直接返回结果,无需执行下面代码(剪枝)
3. 如果左子树没找到,判断当前结点是否符合:
a. 如果符合,直接返回结果
4.如果当前结点不符合,去右子树上寻找结果
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int count;int ret = 1;int kthSmallest(TreeNode* root, int k) {count = k;dfs(root);return ret;}void dfs(TreeNode* root){if(root == nullptr||count == 0)return;dfs(root->left);count--;if(count==0)ret = root->val;dfs(root->right);}
};5.1题目链接:257.二叉树的所有路径
5.2题目描述:
给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。
叶子节点 是指没有子节点的节点。
示例 1:
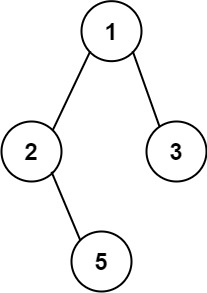
输入:root = [1,2,3,null,5] 输出:["1->2->5","1->3"]
示例 2:
输入:root = [1] 输出:["1"]
提示:
- 树中节点的数目在范围
[1, 100]内 -100 <= Node.val <= 100
5.3解法(回溯):
算法思路:
使用深度优先遍历(DFS)求解。
路径以字符串形式存储,从根节点开始遍历,每次遍历时将当前节点的值加入到路径中,如果该节点为叶子节点,将路径存储到结果中。否则,将"->”加入到路径中并递归遍历该节点的左右子树。
定义一个结果数组,进行递归。递归具体实现方法如下:
1. 如果当前节点不为空,就将当前节点的值加入路径 path 中,否则直接返回;
2. 判断当前节点是否为叶子节点,如果是,则将当前路径加入到所有路径的存储数组 paths 中;
3. 否则,将当前节点值加上“->"作为路径的分隔符,继续递归遍历当前节点的左右子节点。
4. 返回结果数组。
特别地,我们可以只使用一个字符串存储每个状态的字符串,在递归回溯的过程中,需要将路径中的当前节点移除,以回到上一个节点。
具体实现方法如下:
1.定义一个结果数组和一个路径数组。
2. 从根节点开始递归,递归函数的参数为当前节点、结果数组和路径数组。
a. 如果当前节点为空,返回
b. 将当前节点的值加入到路径数组中。
c.如果当前节点为叶子节点,将路径数组中的所有元素拼接成字符串,并将该字符串存储到结果数组中。
d. 递归遍历当前节点的左子树。
e. 递归遍历当前节点的右子树。
f.回溯,将路径数组中的最后一个元素移除。以返回到上一个节点3.返回结果数组
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:vector<string> ret;vector<string> binaryTreePaths(TreeNode* root) {dfs(root,"");return ret;}void dfs(TreeNode* root, string path){path += to_string(root->val);if(root->left == nullptr&&root->right == nullptr){ret.push_back(path);return;}path += "->";if(root->left)dfs(root->left,path);if(root->right)dfs(root->right,path);}
};相关文章:
--力扣129、814、230、257)
dfs二叉树中的深搜(回溯、剪枝)--力扣129、814、230、257
目录 1.1题目链接:129.求根节点到叶结点数字之和 1.2题目描述:给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。 1.3解法(dfs-前序遍历): 2.1题目链接:814.二叉树剪枝 2.2题目描述&…...

Python Selenium 一小时速通教程
Python Selenium 一小时速通教程 实战案例 一、环境配置(10分钟) 安装Python 确保已安装Python 3.x(官网下载)。 安装Selenium 在终端运行: pip install selenium下载浏览器驱动 Chrome:访问 ChromeDriv…...

通过GO后端项目实践理解DDD架构
最近在工作过程中重构的项目要求使用DDD架构,在网上查询资料发现教程五花八门,并且大部分内容都是长篇的概念讲解,晦涩难懂,笔者看了一些github上入门的使用DDD的GO项目,并结合自己开发中的经验,谈谈自己对…...

MybatisPlus最新版分页无法使用
在使用分页的时候发现分页拦截器关键API会报错,其实根本原因是在之前只需要导入一个mybatisplus依赖,而现在分页似乎被单独分离出来了,需要额外导入新依赖使其支持 <dependency><groupId>com.baomidou</groupId><art…...

【Android学习记录】工具使用
文章目录 一. 精准找视图资源ID1. 准备工作2. 使用 uiautomator 工具2.1. 获取设备的窗口内容2.2. Pull XML 文件2.3. 查看 XML 文件 3. 直接使用 ADB 命令4. 使用 Android Studio 的 Layout Inspector总结 二. adb shell dumpsys activity1. 如何使用 ADB 命令2. 输出内容解析…...

youtube视频和telegram视频加载原理差异分析
1. 客户侧缓存与流式播放机制 流式视频应用(如 Netflix、YouTube)通过边下载边播放实现流畅体验,其核心依赖以下技术: 缓存预加载:客户端在后台持续下载视频片段(如 DASH/HLS 协议的…...

在机器视觉检测中为何选择线阵工业相机?
线阵工业相机,顾名思义是成像传感器呈“线”状的。虽然也是二维图像,但极宽,几千个像素的宽度,而高度却只有几个像素的而已。一般在两种情况下使用这种相机: 1. 被测视野为细长的带状,多用于滚筒上检测的问…...

lwip记录
Index of /releases/lwip/ (gnu.org) 以太网(Ethernet)是互联网技术的一种,由于它是在组网技术中占的比例最高,很多人 直接把以太网理解为互联网。 以太网是指遵守 IEEE 802.3 标准组成的局域网,由 IEEE 802.3 标准规定的主要是位于 参考模…...

Redis清空缓存
尽管redis可以设置ttl过期时间进行指定key的定时删除,但是在某些场景下,比如: 测试时需要批量删除指定库下所有库下所有的数据,则会涉及到缓存清除的话题。 如下为具体的操作及说明: 场景类型操作指令清空当前库下所有…...

WPF 依赖注入启动的问题
原因是在App.xaml 设置了 StartupUri“MainWindow.xaml” 1.依赖注入后启动的主窗体存在无参构造 程序正常启动,但是主窗体界面会弹出2个窗体。 2.依赖注入后启动的主窗体存在有参构造 报错...
)
Arcgis经纬线标注设置(英文、刻度显示)
在arcgis软件中绘制地图边框,添加经纬度度时常常面临经纬度出现中文,如下图所示: 解决方法,设置一下Arcgis的语言 点击高级--确认 这样Arcgis就转为英文版了,此时在来看经纬线刻度的标注,自动变成英文...

【电子通识】案例:电缆的安装方式也会影响设备的可靠性?
背景 在日常生活中,我们常常会忽略一些看似微不足道的细节,但这些细节有时却能决定设备的寿命和安全性。比如,你知道吗?一根电缆的布置方式,可能会决定你的设备是否会因为冷凝水而损坏。 今天,我们就来聊聊…...

房屋装修费用预算表:45594 =未付14509 + 付清31085【时间:20250416】
文章目录 引言I 房屋装修费用预算表II 市场价参考防水搬运3000III 装修计划整体流程进度细节国补IV 付款凭证(销售单)伟星 PPR +PVC+太阳线+地漏=6500入户门设计通铺大板瓷砖 | 湿贴 3408(地)+3600(加)+5209(墙)=12217元门头铁空调引言 关注我,发送【装修记账】获取预…...

Python文件操作完全指南:从基础到高级应用
目录 一、文件基础概念 1.1 什么是文件? 1.2 文件的存储方式 文本文件 二进制文件 二、Python文件操作基础 2.1 文件操作三步曲 2.2 核心函数与方法 2.3 文件读取详解 基本读取示例 文件指针机制 2.4 文件打开模式 写入文件示例 2.5 高效读取大文件 三…...
-docker篇 Dockerfile镜像制作(jdk,jar)与jar包制作成docker容器方式)
03(总)-docker篇 Dockerfile镜像制作(jdk,jar)与jar包制作成docker容器方式
全文目录,一步到位 1.前言简介1.1 专栏传送门1.1.2 上文传送门 2. docker镜像制作一: jdk2.1 制作jdk镜像2.1.1 准备工作2.1.2 jdk镜像的Dockerfile2.1.3 基于Dockerfile构建镜像2.1.4 docker使用镜像运行容器2.1.5 进入jdk1.8容器内测试 3. docker镜像制作二: java镜像(jar包)…...

CUDA的安装
打开nvidia控制面板 找到组件 打开 CUDA Toolkit Archive | NVIDIA Developer 下载CUDA...

四六级听力调频广播有线传输无线覆盖系统:弥补单一发射系统安全缺陷,构建稳定可靠听力系统平台
四六级听力调频广播有线传输无线覆盖系统:弥补单一发射系统安全缺陷,构建稳定可靠听力系统平台 北京海特伟业科技有限公司任洪卓发布于2025年4月16日 随着英语四六级考试的规模不断扩大,听力考试部分的设备可靠性问题日益凸显。传统的无线发射系统存在…...

信创服务器-大国崛起,信创当道!
信创产业是数据安全、网络安全的基础,也是新基建的重要组成部分。在政策的推动下,2020-2022 年,中国信创服务器出货量整体呈现出快速增长的趋势,其中党政、电信、金融等领域采购频次高,单次采购量大,是中国…...

【仿Mudou库one thread per loop式并发服务器实现】SERVER服务器模块实现
SERVER服务器模块实现 1. Buffer模块2. Socket模块3. Channel模块4. Poller模块5. EventLoop模块5.1 TimerQueue模块5.2 TimeWheel整合到EventLoop5.1 EventLoop与线程结合5.2 EventLoop线程池 6. Connection模块7. Acceptor模块8. TcpServer模块 1. Buffer模块 Buffer模块&…...

冒泡与 qsort 排序策略集
今天我们要学习两种排序方法,分别是冒泡排序和qsort函数排序,冒泡排序相对qsort函数排序要简单一点,更易于理解。 1.冒泡排序 冒泡排序(Bubble Sort)是一种简单的排序算法,它通过重复遍历元素列并比较相邻元素来实现排…...

【Linux】第七章 控制对文件的访问
目录 1. 什么是文件系统权限?它是如何工作的?如何查看文件的权限? 2. 解释‘-rw-r--r--’这个字符串。 3. 使用什么命令可以更改文件和目录的权限?写出分别使用符号法和数值法将权限从 754 修改为 775 的命令。 4. 如何修改文…...

网站301搬家后谷歌一直不收录新页面怎么办?
当网站因更换域名或架构调整启用301重定向后,许多站长发现谷歌迟迟不收录新页面,甚至流量大幅下滑。 例如,301跳转设置错误可能导致权重传递失效,而新站内容与原站高度重复则可能被谷歌判定为“低价值页面”。 即使技术层面无误&a…...

socket 客户端和服务器通信
服务器 using BarrageGrab; using System; using System.Collections.Concurrent; using System.Linq; using System.Net; using System.Net.Sockets; using System.Text; using System.Threading;namespace Lyx {class Server{private TcpListener listener;private Concurre…...

C实现md5功能
md5在线验证: 在线MD5计算_ip33.com 代码如下: #include "md5.h" #include <string.h> #include "stdio.h"/** 32-bit integer manipulation macros (little endian)*/ #ifndef GET_ULONG_LE #define GET_ULONG_LE(n,b,i) …...

【项目】CherrySudio配置MCP服务器
CherrySudio配置MCP服务器 (一)Cherry Studio介绍(二)MCP服务环境搭建(1)环境准备(2)依赖组件安装<1> Bun和UV安装 (3)MCP服务器使用<1> 搜索MCP…...

第五节:React Hooks进阶篇-如何用useMemo/useCallback优化性能
反模式:滥用导致的内存开销React 19编译器自动Memoization原理 React Hooks 性能优化进阶:从手动到自动 Memoization (基于 React 18 及以下版本,结合 React 19 新特性分析) 一、useMemo/useCallback 的正确使用场景…...

【Qt】QWidget 核⼼属性详解
🍑个人主页:Jupiter. 🚀 所属专栏:QT 欢迎大家点赞收藏评论😊 目录 🏝 一.相关概念🎨二. 核⼼属性概览🍄2.1 enabled🥭2.2geometry🌸 2.3 windowTitle&#…...

如何知道raid 有问题了
在 Rocky Linux 8 上,你的服务器使用了 RAID5(根据 lsblk 输出,/dev/sda3、/dev/sdb1 和 /dev/sdc1 组成 md127 RAID5 阵列)。为了监控 RAID5 阵列中磁盘的健康状态,并及时发现某块磁盘损坏,可以通过以下方…...
)
操作系统之shell实现(上)
🌟 各位看官好,我是maomi_9526! 🌍 种一棵树最好是十年前,其次是现在! 🚀 今天来学习C语言的相关知识。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更…...
:用数据驱动企业发展的深度解析)
精益数据分析(3/126):用数据驱动企业发展的深度解析
精益数据分析(3/126):用数据驱动企业发展的深度解析 大家好!一直以来,我都坚信在当今竞争激烈的商业环境中,数据是企业获得竞争优势的关键。最近深入研究《精益数据分析》这本书,收获颇丰&…...

React 18/19 使用Ant Design全局弹窗message
react 18 及以上,拥有并发模式,不允许在渲染过程中直接触发副作用(如弹窗、网络请求等),应将其放至 useEffect 中,确保其在渲染完成后调用 useEffect(() > {message.success(操作成功!);}, …...

【spark3.2.4】--完全分布式集群搭建
一、spark-env.sh 文件配置(操作路径:$SPARK_HOME/conf/spark-env.sh) 如果还没创建: cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.sh然后编辑(比如用 vim): vim…...

Web3技术下数字资产数据保护的实践探索
在这个信息爆炸的时代,数字资产已经成为我们生活中不可或缺的一部分。随着Web3技术的兴起,它以其去中心化、透明性和安全性的特点,为数字资产的管理和保护提供了新的解决方案。本文将探讨Web3技术在数字资产数据保护方面的实践探索࿰…...
简介)
灰度共生矩阵(GLCM)简介
灰度共生矩阵(GLCM)简介 1. 基本概念 灰度共生矩阵(Gray-level Co-occurrence Matrix, GLCM)是一种用于分析图像纹理特征的统计方法。它通过计算图像中特定空间关系的像素对出现的频率,来描述纹理的规律性1。 核心思想:统计图像中相距为d、方向为θ的两个像素点,分别具…...

基于javaEE+jqueryEasyUi+eclipseLink+MySQL的课程设计客房管理信息系统
1. 系统概述 1.1 系统功能概述 1)客户管理。能够增加一个客户,包括:身份证号、客户名称、出生年月、性别、联系电话、邮箱、会员类别等信息,默认会员类别为空;能够修改和删除客户信息;能够根据客户名称、联系电话查询…...
)
3款本周高潜力开源AI工具(多模态集成_隐私本地化)
本周聚焦 AI 技术领域,为开发者精选 3 款兼具创新性与实用性的开源项目。这些项目覆盖图像生成、智能助手、大语言模型框架等方向,通过技术突破解决开发痛点,助力开发者高效构建智能应用。 更多精彩科技推荐请点击->:更多精彩科…...

第一期第10讲
Linux常用的压缩文件扩展名有 .tar, .tar.bz2, .tar.gz 使用gzip压缩和解压缩 对单个文件压缩: gzip a.c //压缩a.c为a.c.gz gzip -d a.c.gz //解压缩为a.c 对文件夹压缩: gzip -r test //对test文件夹里的文件进行压缩,不对test进行压缩…...

计算方法在单细胞数据分析中的应用及AI拓展
单细胞技术的出现彻底革新了我们对生物系统的理解,揭示了看似同质的细胞群体内部复杂的异质性。为了从这些技术产生的大量复杂数据中提取有意义的见解,精密的计算方法是不可或缺的。 AI拓展 单细胞数据分析的核心在于处理和解释高维度数据的能力&#…...

如何配置环境变量HADOOP_HOMEM、AVEN_HOME?不配置会怎么样
以下是在不同操作系统中配置 HADOOP_HOME 和 JAVA_HOME 环境变量的方法,以及不配置可能产生的后果: 配置 HADOOP_HOME - Windows系统:下载并解压Hadoop安装包,然后右键“此电脑”,选择“属性”,点击“高级…...

【现代深度学习技术】循环神经网络03:语言模型和数据集
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

【学习笔记】Taming 3DGS泛读
原文链接:https://arxiv.org/abs/2406.15643 代码链接:https://github.com/nullptr81/3dgs-accel 一、学习内容 1.研究背景 3DGS在新视角合成(NVS)中表现优异,但优化过程低效: 存在 1)资源需…...

SAP系统交货已完成标识
问题:交货已完成标识 现象:采购订单一直处于未完成交货状态,及交货完成标识处于非勾选状态 原因:采购订单交货完成标识勾会在两种情况下勾选, a.交货数量在容差范围内; b.手动勾选。 某些特殊情况…...

【正点原子STM32MP257连载】第四章 ATK-DLMP257B功能测试——音频测试 #ES8388 #录音测试
1)实验平台:正点原子ATK-DLMP257B开发板 2)浏览产品:https://www.alientek.com/Product_Details/135.html 3)全套实验源码手册视频下载:正点原子资料下载中心 文章目录 第四章 ATK-DLMP257B功能测试——音频…...

WPF 使用 DI EF CORE SQLITE
WPF 使用 DI EF CORE SQLITE 1.安装 nuget包 <PackageReference Include"Microsoft.EntityFrameworkCore.Sqlite" Version"9.0.4" />2.创建DbContext的实现类,创建有参构造函数 public XXContext(DbContextOptions<XXXContext> o…...

探索鸿蒙沉浸式:打造无界交互体验
一、鸿蒙沉浸式简介 在鸿蒙系统中,沉浸式是一种极具特色的设计理念,它致力于让用户在使用应用时能够全身心投入到内容本身,而尽可能减少被系统界面元素的干扰。通常来说,就是将应用的内容区巧妙地延伸到状态栏和导航栏所在的界面…...
在serverb上破解root密码)
Linux红帽:RHCSA认证知识讲解(十 三)在serverb上破解root密码
Linux红帽:RHCSA认证知识讲解(十 三)在serverb上破解root密码 前言操作步骤 前言 在红帽 Linux 系统的管理工作中,系统管理员可能会遇到需要重置 root 密码的情况。本文将详细介绍如何通过救援模式进入系统并重新设置 root 密码。…...
)
【网络安全】谁入侵了我的调制解调器?(一)
文章目录 我被黑了159.65.76.209,你是谁?黑客攻击黑客?交出证据三年后我被黑了 两年前,在我家里使用家庭网络远程办公时,遇到了一件非常诡异的事情。当时,我正在利用一个“盲 XXE 漏洞”,这个漏洞需要借助一个外部 HTTP 服务器来“走私”文件。为了实现这一点,我在 AW…...
)
阿里一面:Nacos配置中心交互模型是 push 还是 pull ?(原理+源码分析)
对于Nacos大家应该都不太陌生,出身阿里名声在外,能做动态服务发现、配置管理,非常好用的一个工具。然而这样的技术用的人越多面试被问的概率也就越大,如果只停留在使用层面,那面试可能要吃大亏。 比如我们今天要讨论的…...
)
MySQL 慢查询日志深入分析与工具实战(mysqldumpslow pt-query-digest)
🎯 学习目标 • ✅ 熟悉慢查询日志结构与核心字段 • ✅ 掌握日志开启与 SQL 记录机制 • ✅ 使用 pt-query-digest 工具进行分析 • ✅ 解读分析结果并提出优化建议 📂 基本概念 项目 内容说明 功能 记录执行时间超过阈值的 SQL 启动参数…...

JVM:垃圾回收
一、垃圾回收概述 (1)垃圾回收主要解决的问题 内存溢出:当程序在运行过程中,所需的内存超出了 JVM 被分配到的内存空间时,就会发生内存溢出。垃圾回收会将不再被引用的对象进行回收,释放内存空间…...